

Battery and Hydrogen Energy Storage Control in a Smart Energy Network with Flexible Energy Demand Using Deep Reinforcement Learning


 ,
,
Abstract
:1. Introduction
1.1. Related Works
1.2. Contributions
- We formulate the SEN system cost minimisation problem, complete with a BESS, an HESS, flexible demand, and solar and wind generation, as well as dynamic energy pricing as a function of energy costs and carbon emissions cost. The system cost minimisation problem is then reformulated as a continuous action-based Markov game with unknown probability to adequately obtain the optimal energy control policies without explicitly estimating the underlying model of the SEN and relying on future information.
- A data-driven self-learning-based MADDPG algorithm that outperforms a model-based solution and other DRL-based algorithms used as a benchmark is proposed to solve the Markov game in real-time. This also includes the use of a novel real-world generation and consumption data set collected from the Smart Energy Network Demonstrator (SEND) project at Keele University [36].
- We conduct a simulation analysis of a SEN model for five different scenarios to demonstrate the benefits of integrating a hybrid of BESS and HESS and scheduling the energy demand in the network.
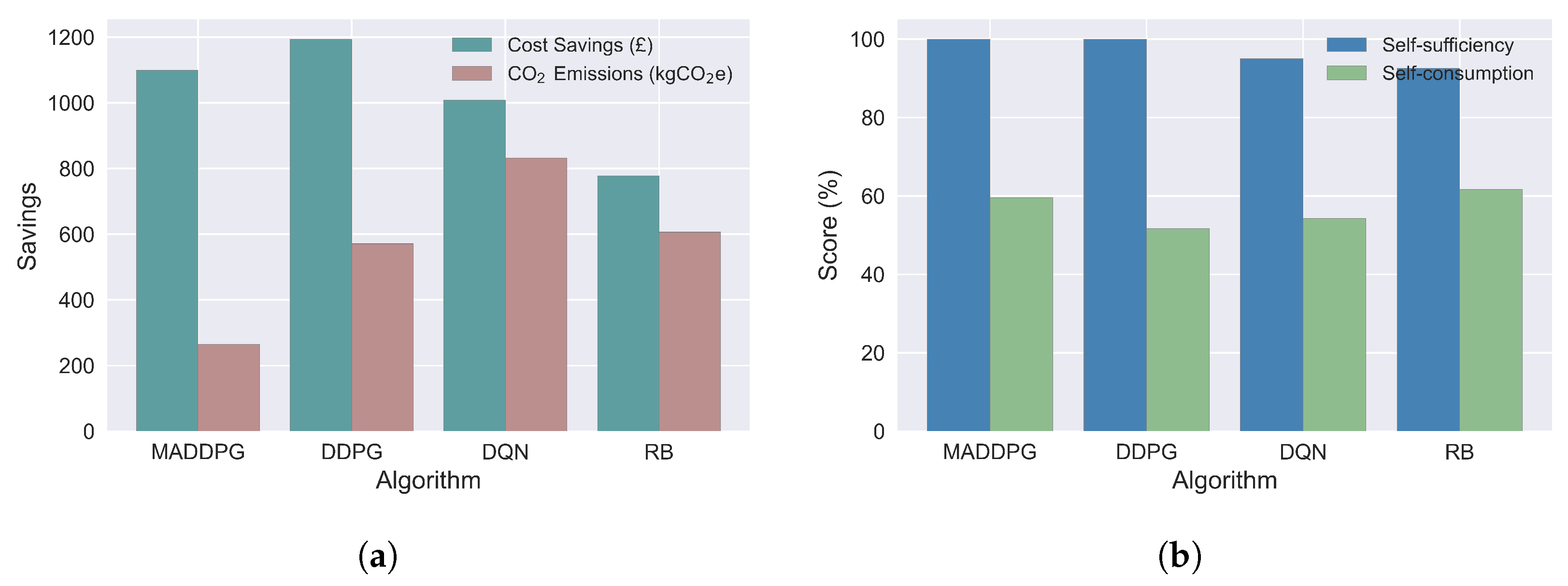
- Simulation results based on SEND data show that the proposed algorithm can increase cost savings and reduce carbon emissions by 41.33% and 56.3%, respectively, compared with other bench-marking algorithms and baseline models.
2. Smart Energy Network
2.1. PV and Wind Turbine Model
2.2. BESS Model
2.3. HESS Model
2.4. Load Model
2.5. SEN Energy Balance Model
3. Problem Formulation
3.1. Problem Formulation
3.2. Markov Game Formulation
3.2.1. State Space
3.2.2. Action Space
3.2.3. Reward Space
4. Reinforcement Learning
4.1. Background
4.2. Learning Algorithms
4.2.1. DQN
4.2.2. DDPG
4.3. The Proposed MADDPG Algorithm
| Algorithm 1 MADDPG-based Optimal Control of an SEN |
|
5. Simulation Results
5.1. Experimental Setup
5.2. Benchmarks
- Rule-based (RB) algorithm: This is a model-based algorithm that follows the standard practice of wanting to meet the energy demand of the SEN using the RES generation without guiding the operation of the BESS, HESS, and flexible demands towards periods of low/high electricity price to save energy costs. In the event that there is surplus energy generation, the surplus is first stored in the short-term BESS, followed by the long-term HESS, and any extra is sold to the main grid. If the energy demand exceeds RES generation, the deficit is first provided by the BESS followed by the HESS, and then the main grid.
- DQN algorithm: As discussed in Section 4, this is a value-based DRL algorithm, which intends to optimally schedule the operation of the BESS, HESS, and flexible demand using a single agent and a discretised action space.
- DDPG algorithm: This is a policy-based DRL algorithm, which intends to optimally schedule the operation of the BESS, HESS, and flexible demand using a single agent and a continuous action space, as discussed in Section 4.
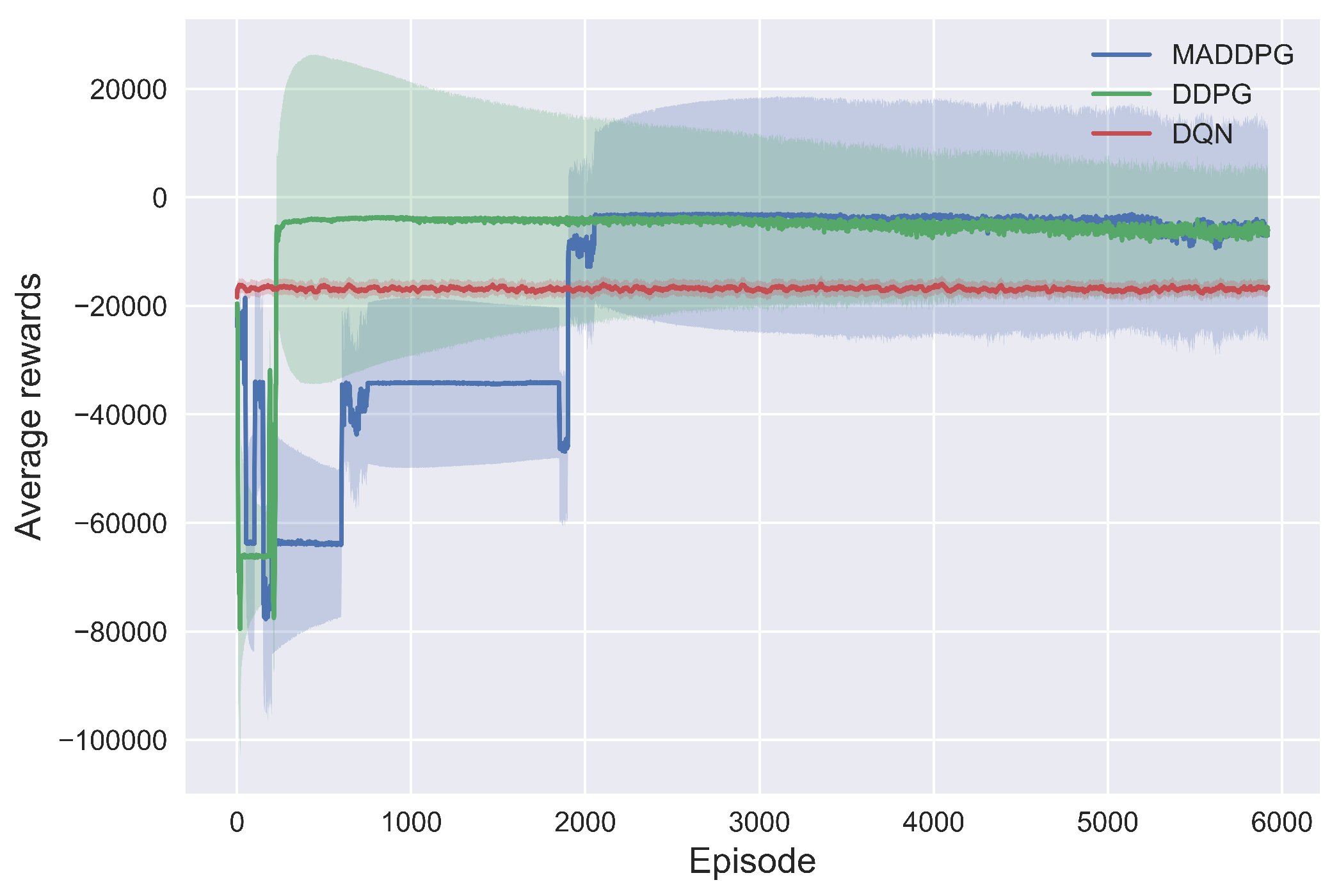
5.3. Algorithm Convergence
5.4. Algorithm Performance
5.5. Improvement in Cost Saving and Carbon Emission
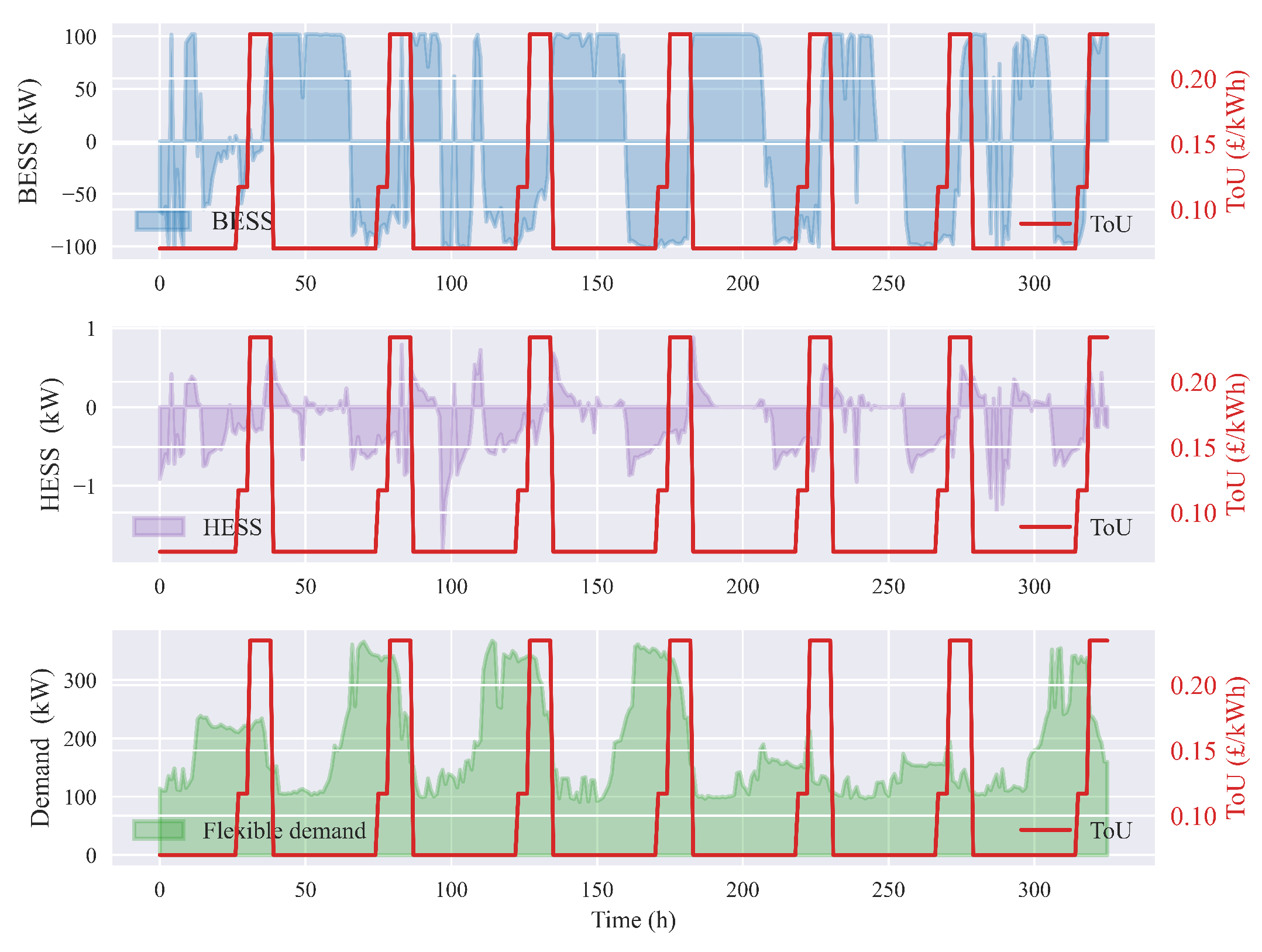
5.6. Improvement in RES Utilisation
5.7. Algorithm Evaluation
5.8. Sensitivity Analysis of Parameter
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ritchie, H.; Roser, M.; Rosado, P. Carbon Dioxide and Greenhouse Gas Emissions, Our World in Data. 2020. Available online: https://ourworldindata.org/co2-and-greenhouse-gas-emissions (accessed on 10 July 2023).
- Allen, M.R.; Babiker, M.; Chen, Y.; de Coninck, H.; Connors, S.; van Diemen, R.; Dube, O.P.; Ebi, K.L.; Engelbrecht, F.; Ferrat, M.; et al. Summary for policymakers. In Global Warming of 1.5: An IPCC Special Report on the Impacts of Global Warming of 1.5 °C above Pre-Industrial Levels and Related Global Greenhouse Gas Emission Pathways, in the Context of Strengthening the Global Response to the Threat of Climate Change, Sustainable Development, and Efforts to Eradicate Poverty; IPCC: Geneva, Switzerland, 2018. [Google Scholar]
- Fuller, A.; Fan, Z.; Day, C.; Barlow, C. Digital twin: Enabling technologies, challenges and open research. IEEE Access 2020, 8, 108952–108971. [Google Scholar] [CrossRef]
- Bouckaert, S.; Pales, A.F.; McGlade, C.; Remme, U.; Wanner, B.; Varro, L.; D’Ambrosio, D.; Spencer, T. Net Zero by 2050: A Roadmap for the Global Energy Sector; International Energy Agency: Paris, France, 2021.
- Paul, D.; Ela, E.; Kirby, B.; Milligan, M. The Role of Energy Storage with Renewable Electricity Generation; National Renewable Energy Laboratory: Golden, CO, USA, 2010.
- Harrold, D.J.; Cao, J.; Fan, Z. Renewable energy integration and microgrid energy trading using multi-agent deep reinforcement learning. Appl. Energy 2022, 318, 119151. [Google Scholar] [CrossRef]
- Arbabzadeh, M.; Sioshansi, R.; Johnson, J.X.; Keoleian, G.A. The role of energy storage in deep decarbonization of electricity production. Nature Commun. 2019, 10, 3414. [Google Scholar] [CrossRef]
- Desportes, L.; Fijalkow, I.; Andry, P. Deep reinforcement learning for hybrid energy storage systems: Balancing lead and hydrogen storage. Energies 2021, 14, 4706. [Google Scholar] [CrossRef]
- Qazi, U.Y. Future of hydrogen as an alternative fuel for next-generation industrial applications; challenges and expected opportunities. Energies 2022, 15, 4741. [Google Scholar] [CrossRef]
- Correa, G.; Muñoz, P.; Falaguerra, T.; Rodriguez, C. Performance comparison of conventional, hybrid, hydrogen and electric urban buses using well to wheel analysis. Energy 2017, 141, 537–549. [Google Scholar] [CrossRef]
- Harrold, D.J.; Cao, J.; Fan, Z. Battery control in a smart energy network using double dueling deep q-networks. In Proceedings of the 2020 IEEE PES Innovative Smart Grid Technologies Europe (ISGT-Europe), Virtual, 26–28 October 2020; pp. 106–110. [Google Scholar]
- Vivas, F.; Segura, F.; Andújar, J.; Caparrós, J. A suitable state-space model for renewable source-based microgrids with hydrogen as backup for the design of energy management systems. Energy Convers. Manag. 2020, 219, 113053. [Google Scholar] [CrossRef]
- Cau, G.; Cocco, D.; Petrollese, M.; Kær, S.K.; Milan, C. Energy management strategy based on short-term generation scheduling for a renewable microgrid using a hydrogen storage system. Energy Convers. Manag. 2014, 87, 820–831. [Google Scholar] [CrossRef]
- Enayati, M.; Derakhshan, G.; Hakimi, S.M. Optimal energy scheduling of storage-based residential energy hub considering smart participation of demand side. J. Energy Storage 2022, 49, 104062. [Google Scholar] [CrossRef]
- HassanzadehFard, H.; Tooryan, F.; Collins, E.R.; Jin, S.; Ramezani, B. Design and optimum energy management of a hybrid renewable energy system based on efficient various hydrogen production. Int. J. Hydrogen Energy 2020, 45, 30113–30128. [Google Scholar] [CrossRef]
- Castaneda, M.; Cano, A.; Jurado, F.; Sánchez, H.; Fernández, L.M. Sizing optimization, dynamic modeling and energy management strategies of a stand-alone pv/hydrogen/battery-based hybrid system. Int. J. Hydrogen Energy 2013, 38, 3830–3845. [Google Scholar] [CrossRef]
- Liu, J.; Xu, Z.; Wu, J.; Liu, K.; Guan, X. Optimal planning of distributed hydrogen-based multi-energy systems. Appl. Energy 2021, 281, 116107. [Google Scholar] [CrossRef]
- Pan, G.; Gu, W.; Lu, Y.; Qiu, H.; Lu, S.; Yao, S. Optimal planning for electricity-hydrogen integrated energy system considering power to hydrogen and heat and seasonal storage. IEEE Trans. Sustain. Energy 2020, 11, 2662–2676. [Google Scholar] [CrossRef]
- Tao, Y.; Qiu, J.; Lai, S.; Zhao, J. Integrated electricity and hydrogen energy sharing in coupled energy systems. IEEE Trans. Smart Grid 2020, 12, 1149–1162. [Google Scholar] [CrossRef]
- Nakabi, T.A.; Toivanen, P. Deep reinforcement learning for energy management in a microgrid with flexible demand. Sustain. Energy Grids Netw. 2021, 25, 100413. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Samende, C.; Cao, J.; Fan, Z. Multi-agent deep deterministic policy gradient algorithm for peer-to-peer energy trading considering distribution network constraints. Appl. Energy 2022, 317, 119123. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv Prep. 2015, arXiv:1509.02971. [Google Scholar]
- Wan, T.; Tao, Y.; Qiu, J.; Lai, S. Data-driven hierarchical optimal allocation of battery energy storage system. IEEE Trans. Sustain. Energy 2021, 12, 2097–2109. [Google Scholar] [CrossRef]
- Bui, V.-H.; Hussain, A.; Kim, H.-M. Double deep q -learning-based distributed operation of battery energy storage system considering uncertainties. IEEE Trans. Smart Grid 2020, 11, 457–469. [Google Scholar] [CrossRef]
- Sang, J.; Sun, H.; Kou, L. Deep reinforcement learning microgrid optimization strategy considering priority flexible demand side. Sensors 2022, 22, 2256. [Google Scholar] [CrossRef]
- Gao, S.; Xiang, C.; Yu, M.; Tan, K.T.; Lee, T.H. Online optimal power scheduling of a microgrid via imitation learning. IEEE Trans. Smart Grid 2022, 13, 861–876. [Google Scholar] [CrossRef]
- Mbuwir, B.V.; Geysen, D.; Spiessens, F.; Deconinck, G. Reinforcement learning for control of flexibility providers in a residential microgrid. IET Smart Grid 2020, 3, 98–107. [Google Scholar] [CrossRef]
- Chen, T.; Gao, C.; Song, Y. Optimal control strategy for solid oxide fuel cell-based hybrid energy system using deep reinforcement learning. IET Renew. Power Gener. 2022, 16, 912–921. [Google Scholar] [CrossRef]
- Zhu, Z.; Weng, Z.; Zheng, H. Optimal operation of a microgrid with hydrogen storage based on deep reinforcement learning. Electronics 2022, 11, 196. [Google Scholar] [CrossRef]
- Tomin, N.; Zhukov, A.; Domyshev, A. Deep reinforcement learning for energy microgrids management considering flexible energy sources. In EPJ Web of Conferences; EDP Sciences: Les Ulis, France, 2019; Volume 217, p. 01016. [Google Scholar]
- Yu, L.; Qin, S.; Xu, Z.; Guan, X.; Shen, C.; Yue, D. Optimal operation of a hydrogen-based building multi-energy system based on deep reinforcement learning. arXiv 2021, arXiv:2109.10754. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Abbeel, O.P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Wright, G. Delivering Net Zero: A Roadmap for the Role of Heat Pumps, HPA. Available online: https://www.heatpumps.org.uk/wp-content/uploads/2019/11/A-Roadmap-for-the-Role-of-Heat-Pumps.pdf (accessed on 26 May 2023).
- Keele University, The Smart Energy Network Demonstrator. Available online: https://www.keele.ac.uk/business/businesssupport/smartenergy/ (accessed on 19 September 2023).
- Samende, C.; Bhagavathy, S.M.; McCulloch, M. Distributed state of charge-based droop control algorithm for reducing power losses in multi-port converter-enabled solar dc nano-grids. IEEE Trans. Smart Grid 2021, 12, 4584–4594. [Google Scholar] [CrossRef]
- Samende, C.; Bhagavathy, S.M.; McCulloch, M. Power loss minimisation of off-grid solar dc nano-grids—Part ii: A quasi-consensus-based distributed control algorithm. IEEE Trans. Smart Grid 2022, 13, 38–46. [Google Scholar] [CrossRef]
- Han, S.; Han, S.; Aki, H. A practical battery wear model for electric vehicle charging applications. Appl. Energy 2014, 113, 1100–1108. [Google Scholar] [CrossRef]
- Dufo-Lopez, R.; Bernal-Agustín, J.L.; Contreras, J. Optimization of control strategies for stand-alone renewable energy systems with hydrogen storage. Renew. Energy 2007, 32, 1102–1126. [Google Scholar] [CrossRef]
- Uhlenbeck, G.E.; Ornstein, L.S. On the theory of the brownian motion. Phys. Rev. 1930, 36, 823. [Google Scholar] [CrossRef]
- RenSMART, UK CO2(eq) Emissions due to Electricity Generation. Available online: https://www.rensmart.com/Calculators/KWH-to-CO2 (accessed on 20 June 2023).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Luthander, R.; Widén, J.; Nilsson, D.; Palm, J. Photovoltaic self-consumption in buildings: A review. Appl. Energy 2015, 142, 80–94. [Google Scholar] [CrossRef]
- Long, C.; Wu, J.; Zhou, Y.; Jenkins, N. Peer-to-peer energy sharing through a two-stage aggregated battery control in a community microgrid. Appl. Energy 2018, 226, 261–276. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ESS | Parameter and Value |
|---|---|
| BESS | 2 MWh, kW, 80% |
| 0.1 MWh, 1.9 MWh, 3650 | |
| = £210,000, 98% | |
| HESS | 2 Nm, 10 Nm, 3 kW |
| 3 kW, 50%, 90% | |
| h, 0.23 Nm/kWh | |
| 1.32 kWh/Nm, = £0.174/h | |
| = £60,000, = £22,000 |
| Hyperparameter | Actor Network | Critic Network |
|---|---|---|
| Optimiser | Adam | Adam |
| Batch size | 256 | 256 |
| Discount factor | 0.95 | 0.95 |
| Learning rate | ||
| No. of hidden layers | 2 | 2 |
| No. of neurons | 500 | 500 |
| Models | Proposed | No BESS | No HESS | No Flex. Demand | No Assets |
|---|---|---|---|---|---|
| BESS | ✔ | × | ✔ | ✔ | × |
| HESS | ✔ | ✔ | × | ✔ | × |
| Flex. Demand | ✔ | ✔ | ✔ | × | × |
| Cost Saving (£) | 1099.60 | 890.36 | 1054.58 | 554.01 | 451.26 |
| Carbon Emission (kg COe) | 265.25 | 1244.70 | 521.92 | 1817.37 | 2175.66 |
| Models | Proposed | No BESS | No HESS | No Flex. Demand | No Assets |
|---|---|---|---|---|---|
| BESS | ✔ | × | ✔ | ✔ | × |
| HESS | ✔ | ✔ | × | ✔ | × |
| Flex. Demand | ✔ | ✔ | ✔ | × | × |
| Self-consumption | 59.6% | 48.0% | 39.2% | 46.0% | 50.0% |
| Self-sufficiency | 100% | 85.3% | 95.2% | 78.8% | 73.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samende, C.; Fan, Z.; Cao, J.; Fabián, R.; Baltas, G.N.; Rodriguez, P. Battery and Hydrogen Energy Storage Control in a Smart Energy Network with Flexible Energy Demand Using Deep Reinforcement Learning. Energies 2023, 16, 6770. https://doi.org/10.3390/en16196770
Samende C, Fan Z, Cao J, Fabián R, Baltas GN, Rodriguez P. Battery and Hydrogen Energy Storage Control in a Smart Energy Network with Flexible Energy Demand Using Deep Reinforcement Learning. Energies. 2023; 16(19):6770. https://doi.org/10.3390/en16196770
Chicago/Turabian StyleSamende, Cephas, Zhong Fan, Jun Cao, Renzo Fabián, Gregory N. Baltas, and Pedro Rodriguez. 2023. "Battery and Hydrogen Energy Storage Control in a Smart Energy Network with Flexible Energy Demand Using Deep Reinforcement Learning" Energies 16, no. 19: 6770. https://doi.org/10.3390/en16196770
APA StyleSamende, C., Fan, Z., Cao, J., Fabián, R., Baltas, G. N., & Rodriguez, P. (2023). Battery and Hydrogen Energy Storage Control in a Smart Energy Network with Flexible Energy Demand Using Deep Reinforcement Learning. Energies, 16(19), 6770. https://doi.org/10.3390/en16196770