
Data-Driven Modeling of Appliance Energy Usage


Abstract
:1. Introduction
2. Materials and Methods
3. Results
3.1. Data Preprocessing
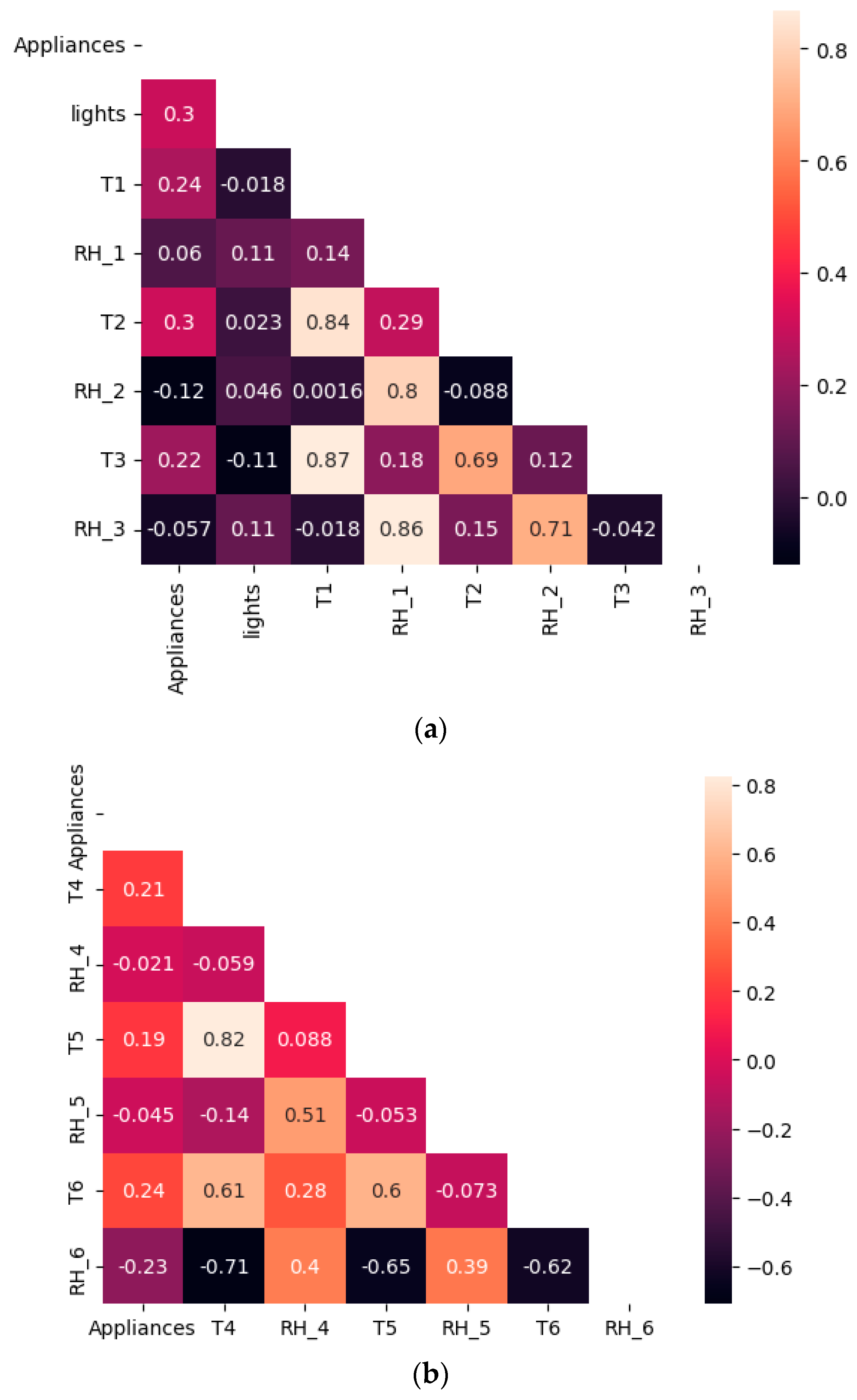
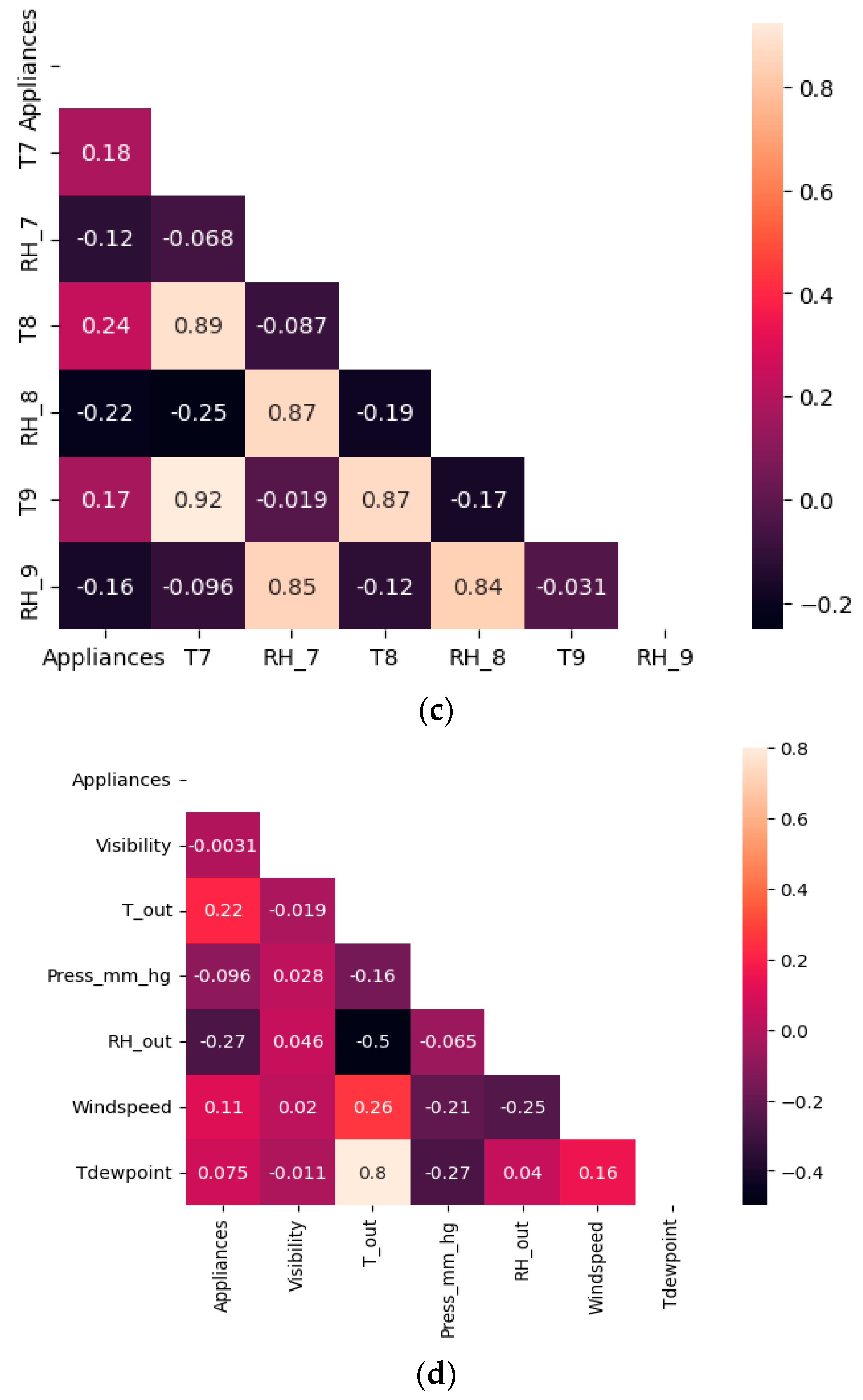
3.1.1. Correlation Analysis
3.1.2. Feature Engineering
3.2. Modeling
3.2.1. Training/Testing Procedure
3.2.2. Model Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yezioro, A.; Dong, B.; Leite, F. An Applied Artificial Intelligence Approach towards Assessing Building Performance Simulation Tools. Energy Build. 2008, 40, 612–620. [Google Scholar] [CrossRef]
- Candanedo, L.M.; Feldheim, V.; Deramaix, D. Data Driven Prediction Models of Energy Use of Appliances in a Low-Energy House. Energy Build. 2017, 140, 81–97. [Google Scholar] [CrossRef]
- Tsanas, A.; Xifara, A. Accurate Quantitative Estimation of Energy Performance of Residential Buildings Using Statistical Machine Learning Tools. Energy Build. 2012, 49, 560–567. [Google Scholar] [CrossRef]
- Dong, B.; Cao, C.; Lee, S.E. Applying Support Vector Machines to Predict Building Energy Consumption in Tropical Region. Energy Build. 2005, 37, 545–553. [Google Scholar] [CrossRef]
- Touzani, S.; Granderson, J.; Fernandes, S. Gradient Boosting Machine for Modeling the Energy Consumption of Commercial Buildings. Energy Build. 2018, 158, 1533–1543. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Y.; Zeng, R.; Srinivasan, R.S.; Ahrentzen, S. Random Forest Based Hourly Building Energy Prediction. Energy Build. 2018, 171, 11–25. [Google Scholar] [CrossRef]
- Fan, C.; Sun, Y.; Zhao, Y.; Song, M.; Wang, J. Deep Learning-Based Feature Engineering Methods for Improved Building Energy Prediction. Appl. Energy 2019, 240, 35–45. [Google Scholar] [CrossRef]
- Mo, Y.; Zhao, D. Effective Factors for Residential Building Energy Modeling Using Feature Engineering. J. Build. Eng. 2021, 44, 102891. [Google Scholar] [CrossRef]
- Wang, Z.; Xia, L.; Yuan, H.; Srinivasan, R.S.; Song, X. Principles, Research Status, and Prospects of Feature Engineering for Data-Driven Building Energy Prediction: A Comprehensive Review. J. Build. Eng. 2022, 58, 105028. [Google Scholar] [CrossRef]
- Zheng, J.; Zhu, J.; Xi, H. Short-Term Energy Consumption Prediction of Electric Vehicle Charging Station Using Attentional Feature Engineering and Multi-Sequence Stacked Gated Recurrent Unit. Comput. Electr. Eng. 2023, 108, 108694. [Google Scholar] [CrossRef]
- FathollahZadeh Aghdam, R.; Ahmad, N.; Naveed, A.; Berenjforoush Azar, B. On the Relationship between Energy and Development: A Comprehensive Note on Causation and Correlation. Energy Strategy Rev. 2023, 46, 101034. [Google Scholar] [CrossRef]
- Wang, X.; Li, J.; Ren, X.; Bu, R.; Jawadi, F. Economic Policy Uncertainty and Dynamic Correlations in Energy Markets: Assessment and Solutions. Energy Econ. 2023, 117, 106475. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, F. Research on Energy-Saving Coupling Correlation of New Energy Buildings Based on Carbon Emission Effect. Sustain. Energy Technol. Assess. 2023, 56, 103043. [Google Scholar] [CrossRef]
- Candelieri, A.; Giordani, I.; Archetti, F.; Barkalov, K.; Meyerov, I.; Polovinkin, A.; Sysoyev, A.; Zolotykh, N. Tuning Hyperparameters of a SVM-Based Water Demand Forecasting System through Parallel Global Optimization. Comput. Oper. Res. 2019, 106, 202–209. [Google Scholar] [CrossRef]
- Jiang, B.; Gong, H.; Qin, H.; Zhu, M. Attention-LSTM Architecture Combined with Bayesian Hyperparameter Optimization for Indoor Temperature Prediction. Build. Environ. 2022, 224, 109536. [Google Scholar] [CrossRef]
- Morteza, A.; Yahyaeian, A.A.; Mirzaeibonehkhater, M.; Sadeghi, S.; Mohaimeni, A.; Taheri, S. Deep Learning Hyperparameter Optimization: Application to Electricity and Heat Demand Prediction for Buildings. Energy Build. 2023, 289, 113036. [Google Scholar] [CrossRef]
- Kumar Panda, D.; Das, S.; Townley, S. Hyperparameter Optimized Classification Pipeline for Handling Unbalanced Urban and Rural Energy Consumption Patterns. Expert Syst. Appl. 2023, 214, 119127. [Google Scholar] [CrossRef]
- 18. Zulfiqar, M.H.; Kamran, M.A.; Rasheed, M.B.; Alquthami, T.; Milyani, A.H. Hyperparameter Optimization of Support Vector Machine Using Adaptive Differential Evolution for Electricity Load Forecasting. Energy Rep. 2022, 8, 13333–13352. [Google Scholar] [CrossRef]
- Catalina, T.; Virgone, J.; Blanco, E. Development and Validation of Regression Models to Predict Monthly Heating Demand for Residential Buildings. Energy Build. 2008, 40, 1825–1832. [Google Scholar] [CrossRef]
- Li, Q.; Meng, Q.; Cai, J.; Yoshino, H.; Mochida, A. Applying Support Vector Machine to Predict Hourly Cooling Load in the Building. Appl. Energy 2009, 86, 2249–2256. [Google Scholar] [CrossRef]
- Zhang, J.; Haghighat, F. Development of Artificial Neural Network Based Heat Convection Algorithm for Thermal Simulation of Large Rectangular Cross-Sectional Area Earth-To-Air Heat Exchangers. Energy Build. 2010, 42, 435–440. [Google Scholar] [CrossRef]
- Kwok, S.S.K.; Yuen, R.K.K.; Lee, E.W.M. An Intelligent Approach to Assessing the Effect of Building Occupancy on Building Cooling Load Prediction. Build. Environ. 2011, 46, 1681–1690. [Google Scholar] [CrossRef]
- Moldovan, D.; Slowik, A. Energy Consumption Prediction of Appliances Using Machine Learning and Multi-Objective Binary Grey Wolf Optimization for Feature Selection. Appl. Soft Comput. 2021, 111, 107745. [Google Scholar] [CrossRef]
- Lentzas, A.; Vrakas, D. Machine Learning Approaches for Non-Intrusive Home Absence Detection Based on Appliance Electrical Use. Expert Syst. Appl. 2022, 210, 118454. [Google Scholar] [CrossRef]
- Priyadarshini, I.; Sahu, S.; Kumar, R.; Taniar, D. A Machine-Learning Ensemble Model for Predicting Energy Consumption in Smart Homes. Internet Things 2022, 20, 100636. [Google Scholar] [CrossRef]
- 26. Ma, H.; Xu, L.; Javaheri, Z.; Moghadamnejad, N.; Abedi, M. Reducing the Consumption of Household Systems Using Hybrid Deep Learning Techniques. Sustain. Comput. Inform. Syst. 2023, 38, 100874. [Google Scholar] [CrossRef]
- Wang, B.; Wang, X.; Wang, N.; Javaheri, Z.; Moghadamnejad, N.; Abedi, M. Machine Learning Optimization Model for Reducing the Electricity Loads in Residential Energy Forecasting. Sustain. Comput. Inform. Syst. 2023, 38, 100876. [Google Scholar] [CrossRef]
- Perwez, U.; Yamaguchi, Y.; Ma, T.; Dai, Y.; Shimoda, Y. Multi-Scale GIS-Synthetic Hybrid Approach for the Development of Commercial Building Stock Energy Model. Appl. Energy 2022, 323, 119536. [Google Scholar] [CrossRef]
- Carneiro, T.; Medeiros Da Nobrega, R.V.; Nepomuceno, T.; Bian, G.-B.; De Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array Programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Mckinney, W. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython; O’reilly Uuuu-Uuuu: Sebastopol, CA, USA, 2011; ISBN 9781491957615. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. Available online: http://arxiv.org/abs/1201.0490 (accessed on 3 November 2023).
- Jolliffe, I.T.; Cadima, J. Principal Component Analysis: A Review and Recent Developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- Chowning, S. The Singular Value Decomposition; 2020. Available online: https://www.dam.brown.edu/drp/proposals/SamChowning.pdf (accessed on 3 November 2023).
- Heinen, A.; Valdesogo, A. Spearman Rank Correlation of the Bivariate Student T and Scale Mixtures of Normal Distributions. J. Multivar. Anal. 2020, 179, 104650. [Google Scholar] [CrossRef]
- Shah, D.; Xue, Z.; Aamodt, T.M. Label Encoding for Regression Networks. arXiv 2022, arXiv:2212.01927. [Google Scholar]
- Sharma, P.; Dinkar, S.K. A Linearly Adaptive Sine–Cosine Algorithm with Application in Deep Neural Network for Feature Optimization in Arrhythmia Classification Using ECG Signals. Knowl.-Based Syst. 2022, 242, 108411. [Google Scholar] [CrossRef]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support Vector Machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’16, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Yadav, S.; Shukla, S. Analysis of K-Fold Cross-Validation over Hold-out Validation on Colossal Datasets for Quality Classification. In Proceedings of the 2016 IEEE 6th International Conference on Advanced Computing (IACC), Bhimavaram, India, 27–28 February 2016. [Google Scholar] [CrossRef]
- Bergstra, J.; Ca, J.; Ca, Y. Random Search for Hyper-Parameter Optimization Yoshua Bengio. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]



{kind=link}
{kind=link}
| Variables | Units |
|---|---|
| Appliance energy consumption | Wh |
| Light energy consumption | Wh |
| T1-T9, Indoor temperatures | °C |
| RH1-RH9, Indoor humidities | % |
| To, Temperature outside | °C |
| Pressure | mm Hg |
| RHo, Humidity outside | % |
| Wind speed | m/s |
| Visibility * | km |
| Tdewpoint | °C |
| Number of seconds from midnight (NSM) | s |
| Week status (weekend or weekday) | Categorical |
| Day of week | Categorical |
| Date time stamp * | year-month-day |
| hour:min:s | |
| Month | month |
| Day | day |
| Hour | h |
| Hour_sin, hour sine transformation | - |
| Hour_cos, hour cosine transformation | - |
| Season (autumn, winter, spring, or summer) | Categorical |
| Model | RMSE | R2 | MAE | MAPE |
|---|---|---|---|---|
| LM | 91.52 | 0.2 | 51.61 | 58.89 |
| SVR | 68.31 | 0.55 | 30.61 | 28.66 |
| GB | 64.77 | 0.6 | 31.29 | 31.51 |
| RF | 62.96 | 0.62 | 29.09 | 28.19 |
| XGB | 63.86 | 0.61 | 30.24 | 29.78 |
| ET | 59.61 | 0.66 | 26.62 | 25.37 |
| Model | RMSE | R2 | MAE | MAPE |
|---|---|---|---|---|
| LM | −1.78 | 25.43 | −0.69 | −1.74 |
| SVR | −3.44 | 6.58 | −2.38 | −3.71 |
| GB | −2.82 | 5.12 | −11.16 | −17.70 |
| RF | −8.07 | 15.16 | −8.68 | −10.18 |
| XGB * | −4.18 | 7.02 | −3.56 | 0.08 |
| ET * | −10.56 | 15.94 | −15.10 | −14.77 |
| Average | −5.14 | 12.54 | −6.93 | −8.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Assadian, C.F.; Assadian, F. Data-Driven Modeling of Appliance Energy Usage. Energies 2023, 16, 7536. https://doi.org/10.3390/en16227536
Assadian CF, Assadian F. Data-Driven Modeling of Appliance Energy Usage. Energies. 2023; 16(22):7536. https://doi.org/10.3390/en16227536
Chicago/Turabian StyleAssadian, Cameron Francis, and Francis Assadian. 2023. "Data-Driven Modeling of Appliance Energy Usage" Energies 16, no. 22: 7536. https://doi.org/10.3390/en16227536
APA StyleAssadian, C. F., & Assadian, F. (2023). Data-Driven Modeling of Appliance Energy Usage. Energies, 16(22), 7536. https://doi.org/10.3390/en16227536