

Analysis of the Behavior Pattern of Energy Consumption through Online Clustering Techniques




Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions of the Paper
- We propose a framework to analyze the evolution of energy consumption patterns;
- We adjust two clustering techniques to carry out an online clustering process of energy consumption data.
2. Online Unsupervised Machine Learning Used
2.1. X-Means
- Assignment of points/individuals to the nearest centroid;
- Calculation of centroids.
2.2. LAMDA (Learning Algorithm for Multivariate Data Analysis)
3. Experiments
3.1. Data Preparation
3.2. Metrics
3.2.1. Silhouette
3.2.2. Davies-Bouldin
3.3. Modeling
3.3.1. X-Means
3.3.2. LAMDA
3.4. Comparison of Both Algorithms
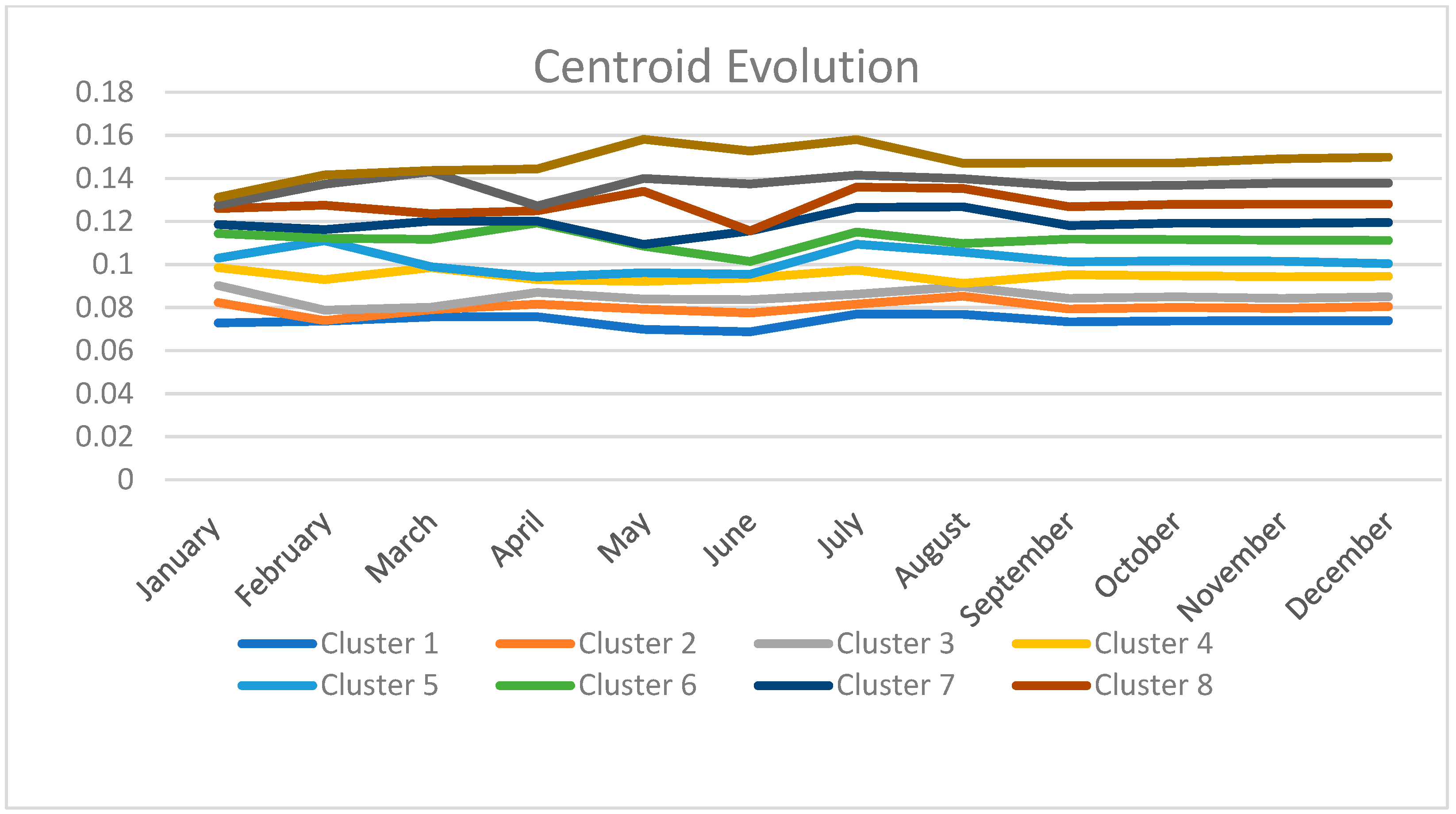
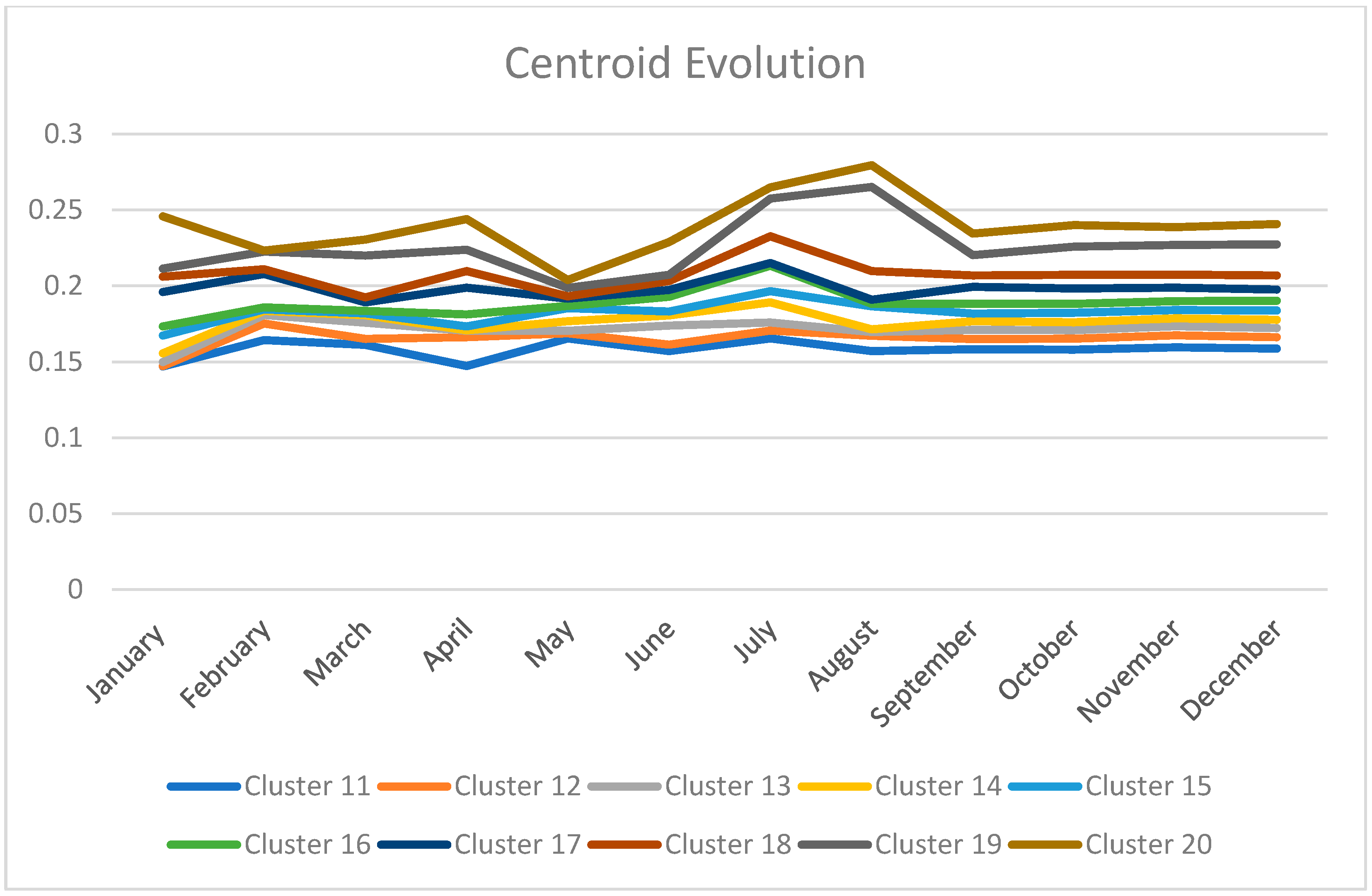
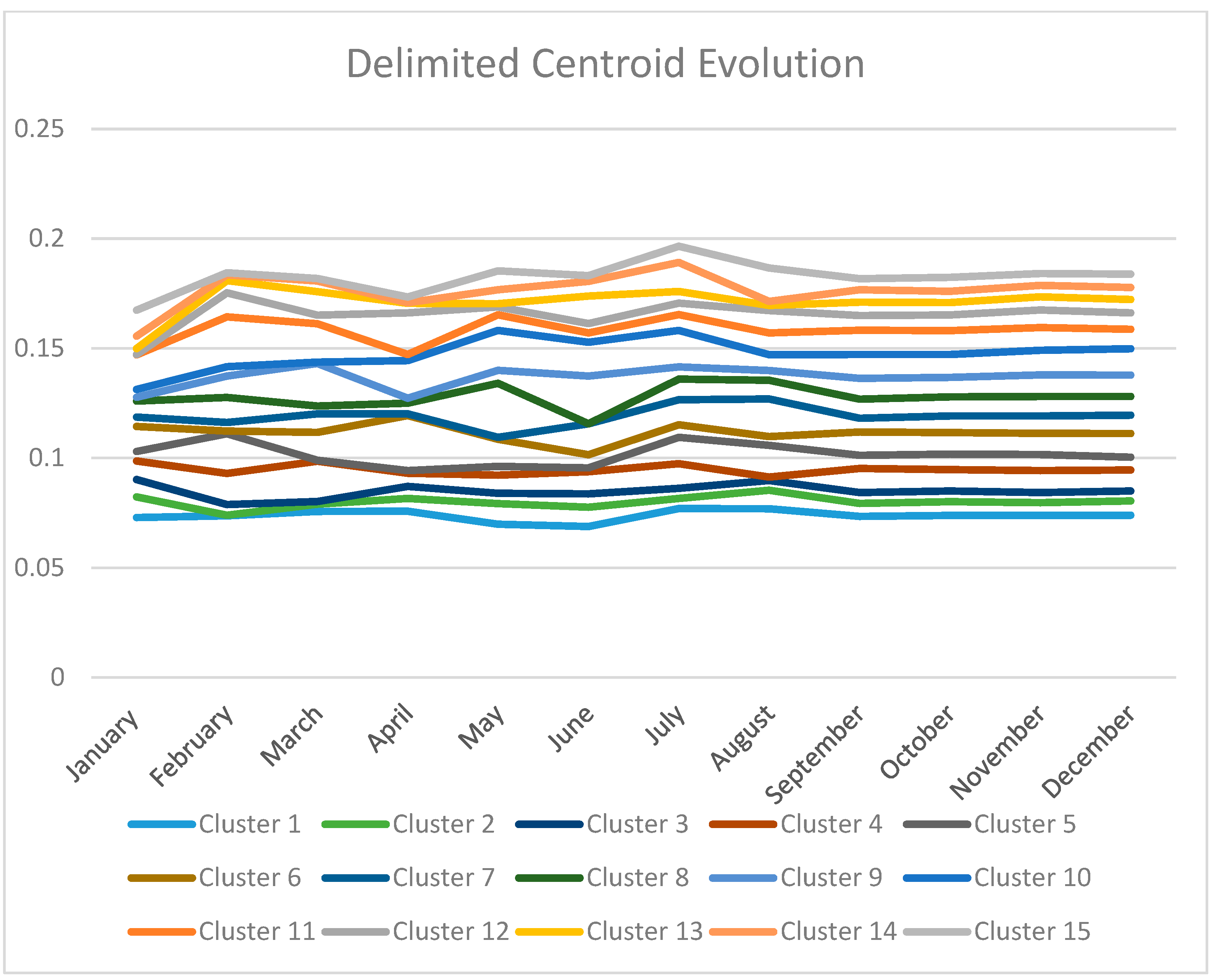
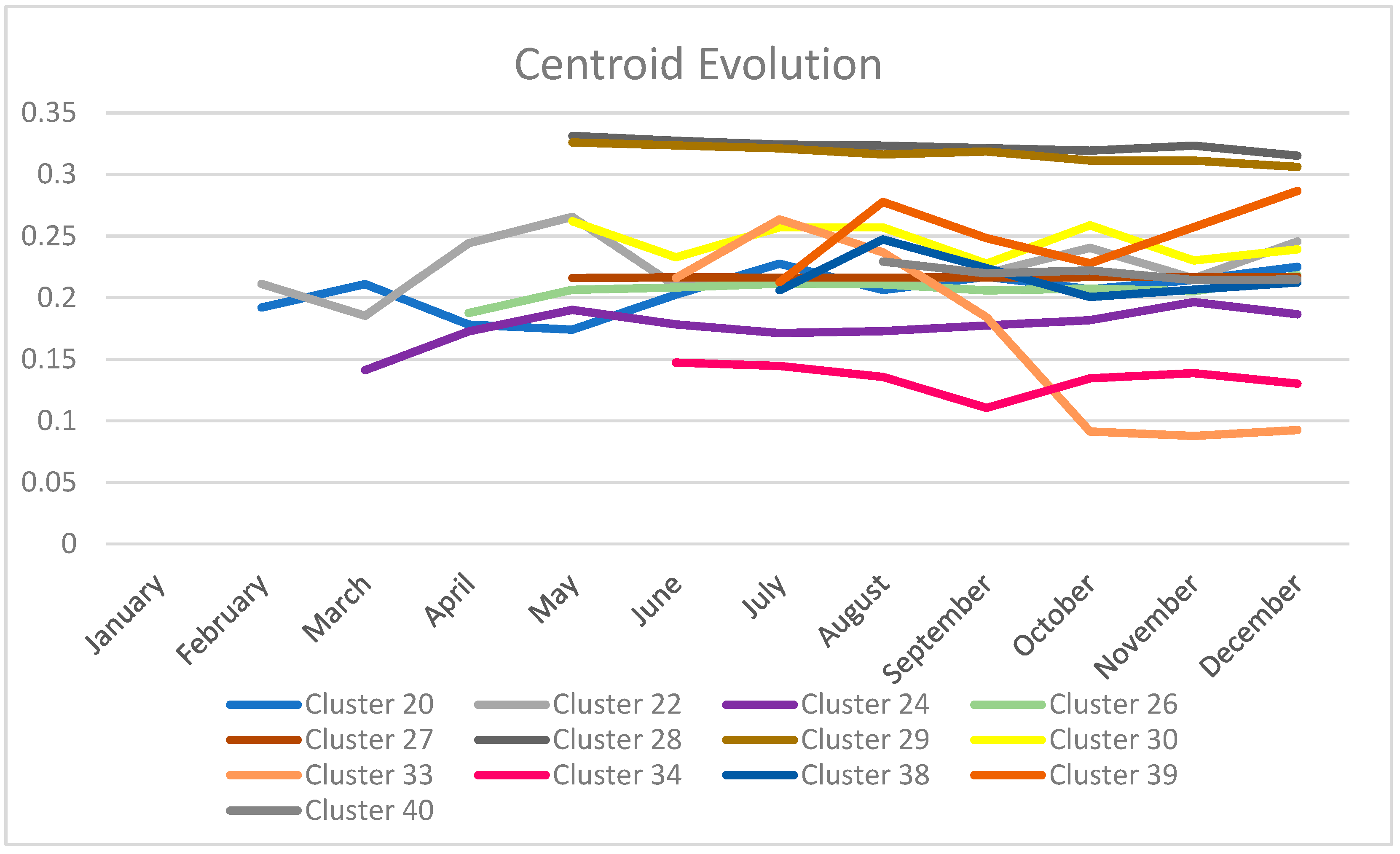
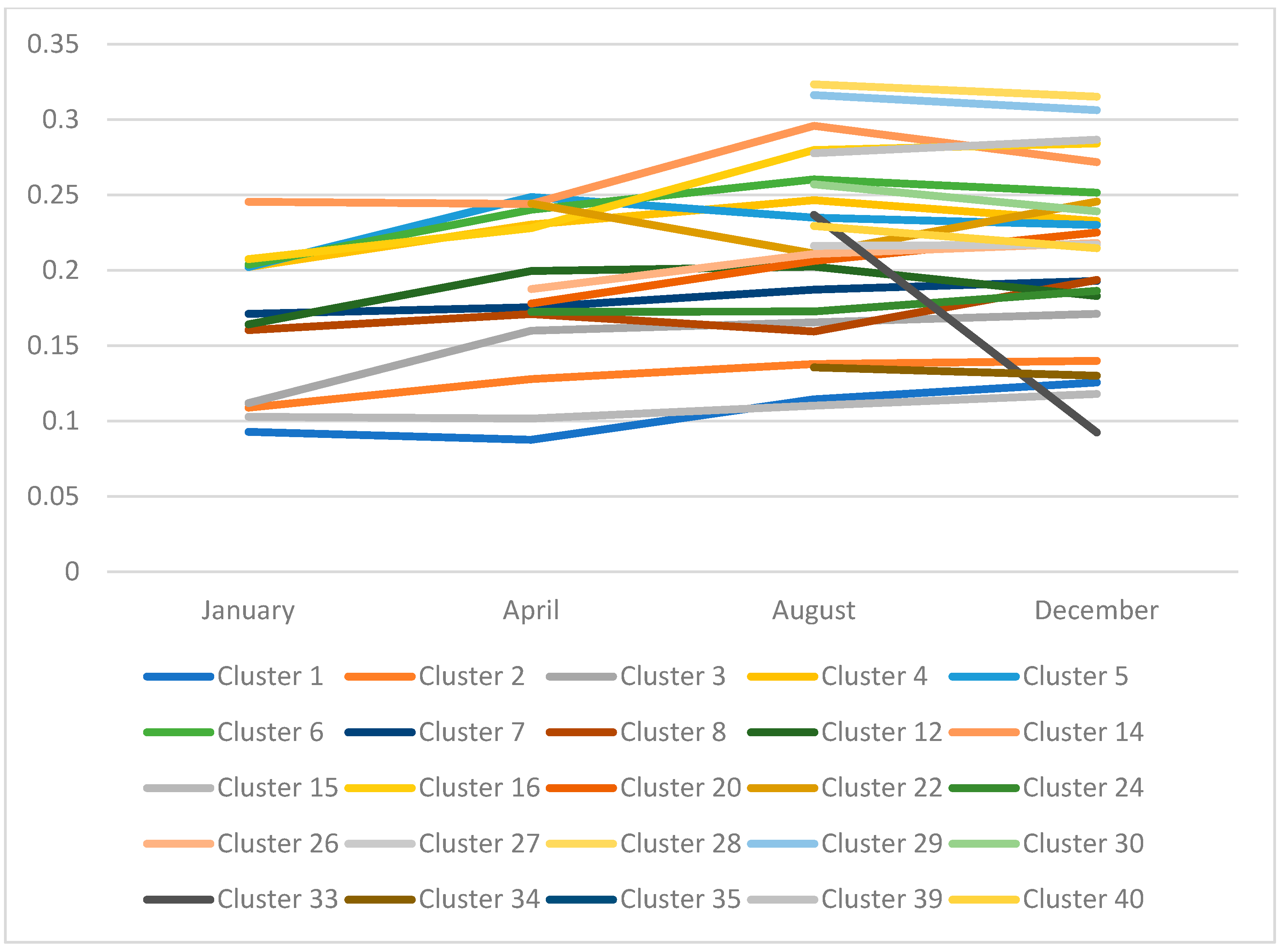
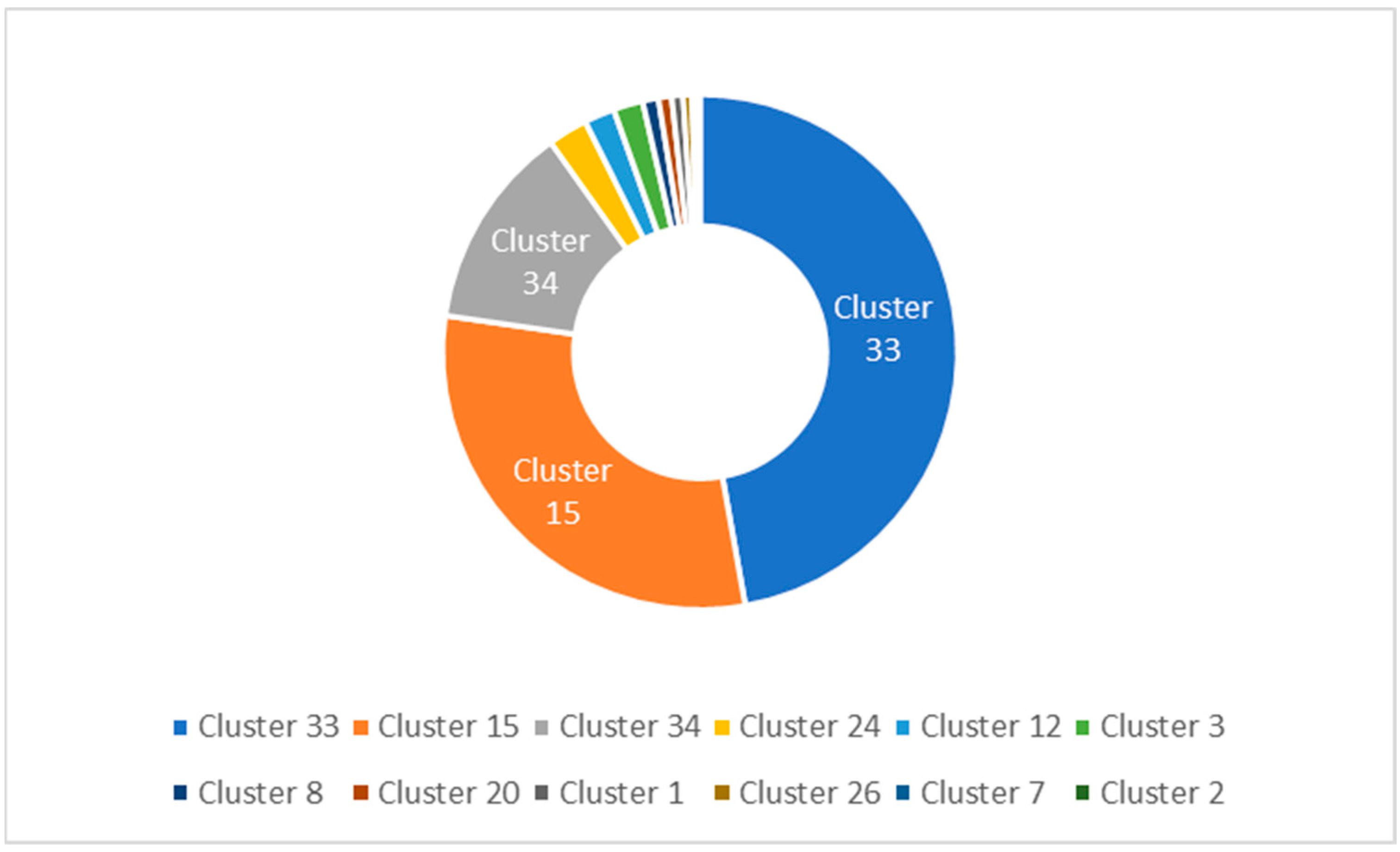
4. Analysis of the Evolution of Clusters
4.1. Initial Experiment
4.2. Quarterly Evolution Analysis
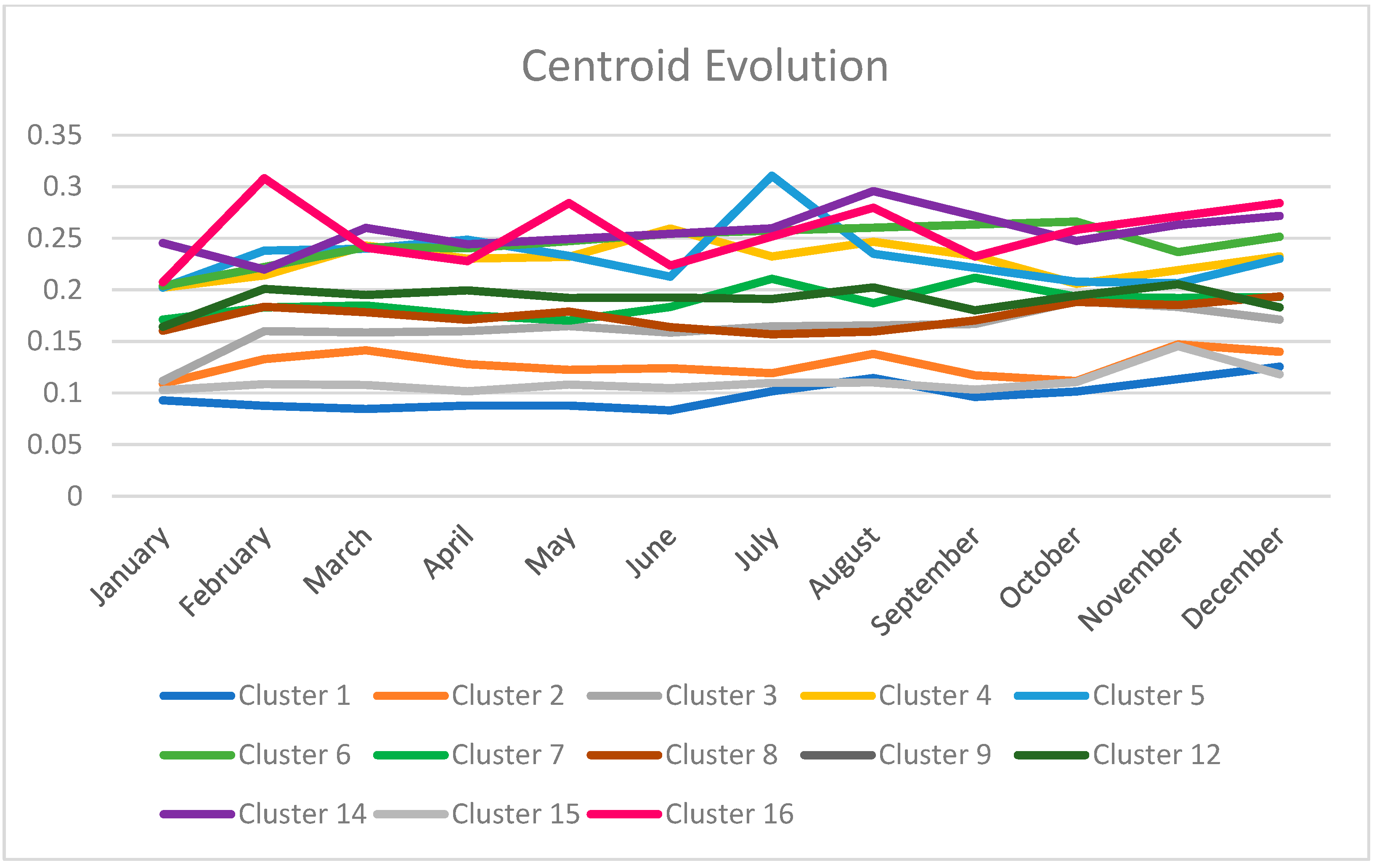
5. Comparison in Different Datasets
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Disclaimer
References
- Akkaya, K.; Guvenc, I.; Aygun, R.; Pala, N.; Kadri, A. IoT-based occupancy monitoring techniques for energy-efficient smart buildings. In Proceedings of the IEEE Wireless Communications and Networking Conference Workshops (WCNCW), New Orleans, LA, USA, 9–12 March 2015. [Google Scholar] [CrossRef]
- Patel, K.; Patel, S. Internet of Things-IOT: Definition, Characteristics, Architecture, Enabling Technologies, Application & Future Challenges. Int. J. Eng. Sci. Comput. 2016, 6, 6122–6131. [Google Scholar]
- Gray, C.; Ayre, R.; Hinton, K.; Campbell, L. ‘Smart’ Is Not Free: Energy Consumption of Consumer Home Automation Systems. IEEE Trans. Consum. Electron. 2020, 66, 87–95. [Google Scholar] [CrossRef]
- Yang, R.; Wang, L. Development of multi-agent system for building energy and comfort management based on occupant behaviors. Energy Build. 2013, 56, 1–7. [Google Scholar] [CrossRef]
- Fotopoulou, E.; Zafeiropoulos, A.; Terroso-Sáenz, F.; Şimşek, U.; González-Vidal, A.; Tsiolis, G.; Gouvas, P.; Liapis, P.; Fensel, A.; Skarmeta, A. Providing Personalized Energy Management and Awareness Services for Energy Efficiency in Smart Buildings. Sensors 2017, 17, 2054. [Google Scholar] [CrossRef]
- Aguilar, J.; Garces-Jimenez, A.; R-Moreno, M.; García, R. A systematic literature review on the use of artificial intelligence in energy self-management in smart buildings. Renew. Sustain. Energy Rev. 2021, 151, 111530. [Google Scholar] [CrossRef]
- Escobar, L.M.; Aguilar, J.; Garcés-Jiménez, A.; De Mesa, J.A.G.; Gomez-Pulido, J.M. Advanced Fuzzy-Logic-Based Context-Driven Control for HVAC Management Systems in Buildings. IEEE Access 2020, 8, 16111–16126. [Google Scholar] [CrossRef]
- Yoon, G.; Park, S.; Park, S.; Lee, T.; Kim, S.; Jang, H.; Lee, S.; Park, S. Prediction of machine learning base for efficient use of energy infrastructure in smart city. In Proceedings of the International Conference on Computing, Electronics & Communications Engineering (iCCECE), London, UK, 22–23 August 2019; pp. 32–35. [Google Scholar]
- Wu, Z.; Chu, W. Sampling strategy analysis of machine learning models for energy consumption prediction. In Proceedings of the IEEE 9th International Conference on Smart Energy Grid Engineering, Oshawa, ON, Canada, 11–13 August 2021; pp. 77–81. [Google Scholar] [CrossRef]
- Xiao, Q.; Li, C.; Tang, Y.; Chen, X. Energy Efficiency Modeling for Configuration-Dependent Machining via Machine Learning: A Comparative Study. Tase 2021, 18, 717–730. [Google Scholar] [CrossRef]
- Zhang, N.; Shetty, D. An effective LS-SVM-based approach for surface roughness prediction in machined surfaces. Neurocomputing 2016, 198, 35–39. [Google Scholar] [CrossRef]
- Abdulshahed, A.M.; Longstaff, A.; Fletcher, S.; Potdar, A. Thermal error modelling of a gantry-type 5-axis machine tool using a Grey Neural Network Model. J. Manuf. Syst. 2016, 41, 130–142. [Google Scholar] [CrossRef] [Green Version]
- Kong, D.; Chen, Y.; Li, N. Gaussian process regression for tool wear prediction. Mech. Syst. Signal Process. 2018, 104, 556–574. [Google Scholar] [CrossRef]
- Bashawyah, D.A.; Qaisar, S.M. Machine learning based short-term load forecasting for smart meter energy consumption data in london households. In Proceedings of the IEEE 12th International Conference on Electronics and Information Technologies, Lviv, Ukraine, 19–21 May 2021; pp. 99–102. [Google Scholar] [CrossRef]
- Olanrewaju, O.A. Predicting industrial sector’s energy consumption: Application of support vector machine. In Proceedings of the IEEE International Conference on Industrial Engineering and Engineering Management, Macao, China, 15–18 December 2019; pp. 1597–1600. [Google Scholar] [CrossRef]
- Chu, W.; Spinella, L.; Shirley, D.; Ho, P. Effects of wiring density and pillar structure on chip package interaction for advanced cu low-k chips. In Proceedings of the IEEE International Reliability Physics Symposium, Dallas, TX, USA, 28 April–30 May 2020. [Google Scholar] [CrossRef]
- Darlis, D.N.; Latip, M.A.; Zaini, N.; Norhazman, H. Random forest approach for energy consumption behavior analysis. In Proceedings of the IEEE Symposium on Industrial Electronics & Applications, Kuala Lumpur, Malaysia, 17–18 July 2020. [Google Scholar] [CrossRef]
- Aguilar, J.; Cerrada, M.; Hidrobo, F. A Methodology to Specify Multiagent Systems; Lecture Notes in Computer Science 4496; Springer: Berlin/Heidelberg, Germany, 2007; pp. 92–101. [Google Scholar] [CrossRef]
- Aguilar, J.; Salazar, C.; Velasco, H.; Monsalve-Pulido, J.; Montoya, E. Comparison and Evaluation of Different Methods for the Feature Extraction from Educational Contents. Computation 2020, 8, 30. [Google Scholar] [CrossRef]
- Aguilar, J. Definition of an energy function for the random neural to solve optimization problems. Neural Netw. 1998, 11, 731–737. [Google Scholar] [CrossRef]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2016. [Google Scholar]
- Bagirov, A.M.; Karmitsa, N.; Taheri, S. Partitional Clustering via Nonsmooth Optimization, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Camargo, E.; Aguilar, J.; Quintero, Y.; Rivas, F.; Ardila, D. An incremental learning approach to prediction models of SEIRD variables in the context of the COVID-19 pandemic. Health Technol. 2022, 12, 867–877. [Google Scholar] [CrossRef] [PubMed]
- Pelleg, D.; Moore, A. X-means: Extending K-means with Efficient Estimation of the Number of Clusters. Mach. Learn. 2002, 1, 727–734. [Google Scholar]
- Pham, D.; Dimov, S.; Nguyen, C. Selection of K in K -means clustering. Inst. Mech. Eng. Part C-J. Mech. Eng. Sci. 2005, 219, 103–119. [Google Scholar] [CrossRef] [Green Version]
- Morales, L.; Aguilar, J. An Automatic Merge Technique to Improve the Clustering Quality Performed by LAMDA. IEEE Access 2020, 8, 162917–162944. [Google Scholar] [CrossRef]
- Morales, L.; Ouedraogo, C.; Aguilar; Chassot, C.; Medjiah, S.; Drira, K. Experimental comparison of the diagnostic capabilities of classification and clustering algorithms for the QoS management in an autonomic IoT platform. Serv. Oriented Comput. Appl. 2019, 13, 199–219. [Google Scholar] [CrossRef]
- Mizumoto, M. Pictorial representations of fuzzy connectives, Part I: Cases of t-norms, t-conorms and averaging operators. Fuzzy Sets Syst. 1989, 31, 217–242. [Google Scholar] [CrossRef]
- Ruiz, F.A.; Isaza, C.V.; Agudelo, A.F.; Agudelo, J.R. A new criterion to validate and improve the classification process of LAMDA algorithm applied to diesel engines. Eng. Appl. Artif. Intell. 2017, 60, 117–127. [Google Scholar] [CrossRef]
- Bedoya, C.; Uribe, C.; Isaza, C. Unsupervised feature selection based on fuzzy clustering for fault detection of the Tennessee Eastman process. In Advances in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; pp. 350–360. [Google Scholar]
- Royapoor, M.; Pazhoohesh, M.; Davison, P.; Patsios, C.; Walker, S. Building as a virtual power plant, magnitude and persistence of deferrable loads and human comfort implications. Energy Build. 2020, 213, 109794. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef] [PubMed]
- Papaioannou, T.; Stamoulis, G. Teaming and competition for demand-side management in office buildings. In Proceedings of the IEEE International Conference on Smart Grid Communications (SmartGridComm), Dresden, Germany, 23–27 October 2017; pp. 332–337. [Google Scholar]
- Power Consumption Data of a Hotel Building. Available online: https://ieee-dataport.org/documents/power-consumption-data-hotel-building (accessed on 1 July 2022).
- Zhang, L.; Wen, J. Data for: A Systematic Feature Selection Procedure for Short-Term Data-Driven Building Energy Forecasting Model Development. Mendeley Data. Available online: https://data.mendeley.com/datasets/r532stprhv/1 (accessed on 1 July 2022).
- Zhang, L.; Wen, J. A systematic feature selection procedure for short-term data-driven building energy forecasting model development. Energy Build. 2019, 183, 428–442. [Google Scholar] [CrossRef]
- Pipattanasomporn, M.; Chitalia, G.; Songsiri, J.; Aswakul, C.; Pora, W.; Suwankawin, S.; Audomvongseree, K.; Hoonchareon, N. CU-BEMS, smart building electricity consumption and indoor environmental sensor datasets. Sci. Data 2020, 7, 241. [Google Scholar] [CrossRef]
- Long-Term Energy Consumption & Outdoor Air Temperature for 11 Commercial Buildings. Available online: https://trynthink.github.io/buildingsdatasets/show.html?title_id=long-term-energy-consumption-outdoor-air-temperature-for-11-commercial-buildings (accessed on 1 July 2022).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| X-Means | LAMDA | |||
|---|---|---|---|---|
| Silhouette | Davies-Boulding | Silhouette | Davies-Boulding | |
| January | 0.446 | 0.620 | 0.694 | 0.305 |
| February | 0.388 | 0.645 | 0.521 | 0.396 |
| March | 0.389 | 0.604 | 0.514 | 0.278 |
| April | 0.384 | 0.614 | 0.541 | 0.238 |
| May | 0.346 | 0.589 | 0.563 | 0.217 |
| June | 0.390 | 0.598 | 0.513 | 0.233 |
| July | 0.387 | 0.626 | 0.561 | 0.321 |
| August | 0.382 | 0.614 | 0.591 | 0.348 |
| September | 0.377 | 0.597 | 0.515 | 0.423 |
| October | 0.386 | 0.603 | 0.528 | 0.248 |
| November | 0.384 | 0.638 | 0.519 | 0.321 |
| December | 0.381 | 0.599 | 0.516 | 0.294 |
| Month | Id of Clusters Created | Total of Clusters | Comments |
|---|---|---|---|
| 1 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16 | 13 | 16 clusters formed and the next clusters are merged: 10, 11 and 13 |
| 2 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22 | 15 | 6 additional clusters are formed and the next clusters are merged: 17, 18, 19 and 21 |
| 3 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24 | 16 | 2 additional clusters are formed and the next cluster is generated: 23 |
| 4 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24, 26 | 17 | 2 additional clusters are formed and the next cluster is generated: 25 |
| 5 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24, 26, 27, 28, 29, 30 | 21 | 4 additional clusters are formed and there is no fusion |
| 6 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24, 26, 27,28, 29, 30, 33, 34 | 23 | Form 4 additional clusters and merge 31 and 32 |
| 7 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24, 26, 27, 28, 29, 30, 33, 34, 38, 39 | 25 | Form 5 additional clusters and merge: 35 36 and 37 |
| 8 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24, 26, 27, 28, 29, 30, 33, 34, 38, 39, 40 | 26 | 1 additional cluster is formed and there is no fusion |
| 9 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24, 26, 27, 28, 29, 30, 33, 34, 38, 39, 40 | 26 | No additional cluster formation |
| 10 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24, 26, 27, 28, 29, 30, 33, 34, 38, 39, 40 | 26 | No additional cluster formation |
| 11 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24, 26, 27, 28, 29, 30, 33, 34, 38, 39, 40 | 26 | No additional cluster formation |
| 12 | 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 14, 15, 16, 20, 22, 24, 26, 27, 28, 29, 30, 33, 34, 38, 39, 40 | 26 | No additional cluster formation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viera, J.; Aguilar, J.; Rodríguez-Moreno, M.; Quintero-Gull, C. Analysis of the Behavior Pattern of Energy Consumption through Online Clustering Techniques. Energies 2023, 16, 1649. https://doi.org/10.3390/en16041649
Viera J, Aguilar J, Rodríguez-Moreno M, Quintero-Gull C. Analysis of the Behavior Pattern of Energy Consumption through Online Clustering Techniques. Energies. 2023; 16(4):1649. https://doi.org/10.3390/en16041649
Chicago/Turabian StyleViera, Juan, Jose Aguilar, Maria Rodríguez-Moreno, and Carlos Quintero-Gull. 2023. "Analysis of the Behavior Pattern of Energy Consumption through Online Clustering Techniques" Energies 16, no. 4: 1649. https://doi.org/10.3390/en16041649
APA StyleViera, J., Aguilar, J., Rodríguez-Moreno, M., & Quintero-Gull, C. (2023). Analysis of the Behavior Pattern of Energy Consumption through Online Clustering Techniques. Energies, 16(4), 1649. https://doi.org/10.3390/en16041649