
Class Thresholds Pre-Definition by Clustering Techniques for Applications of ELECTRE TRI Method

 ,
,  , ,
, ,  , , ,
, , ,  and
and 
Abstract
:1. Introduction
2. Problem Statement
3. Theoretical Foundations and Related Works
3.1. Clustering Approach on MCDA Methods
3.2. MCDA Methods and Subjectivity
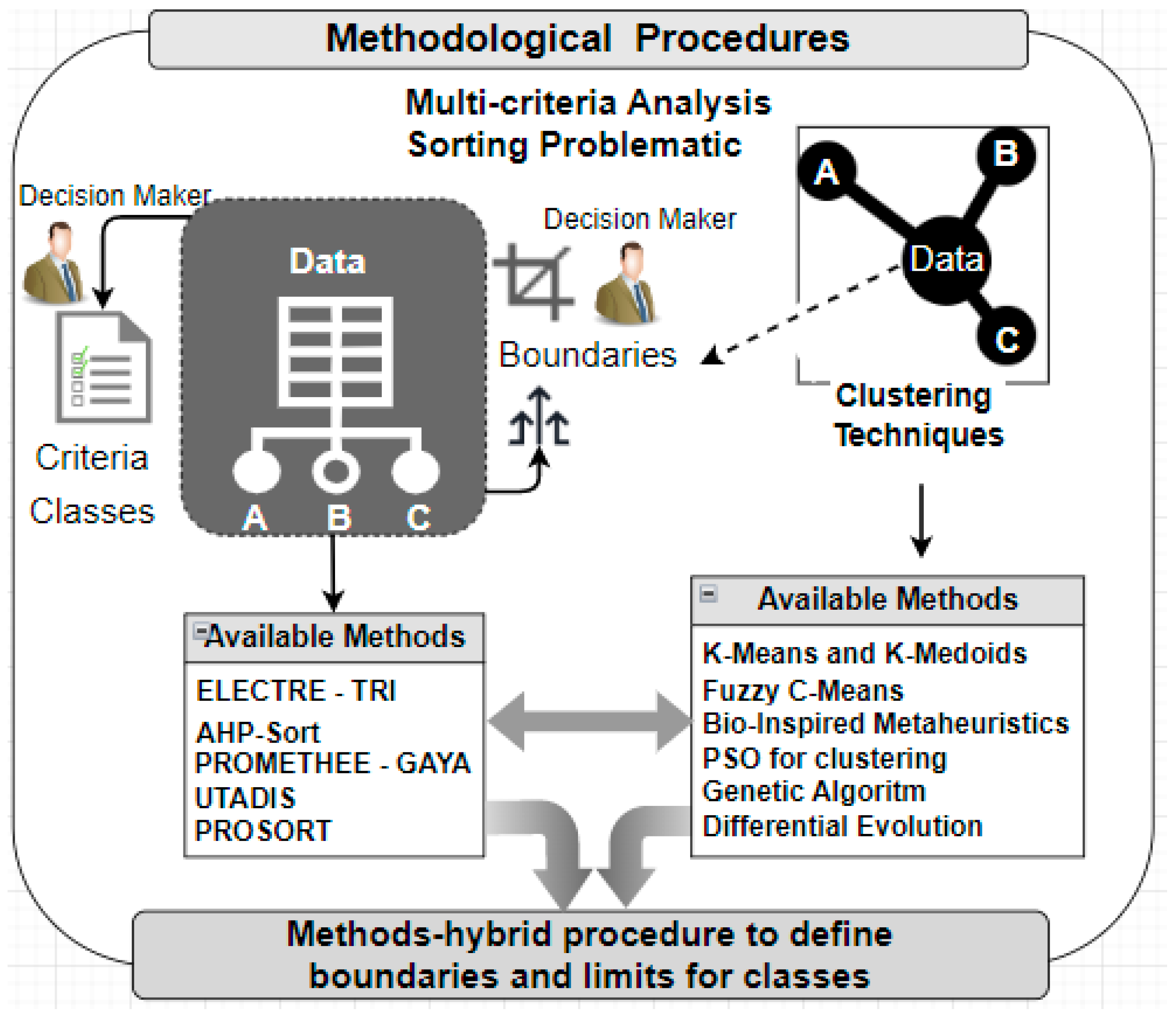
4. Methodology
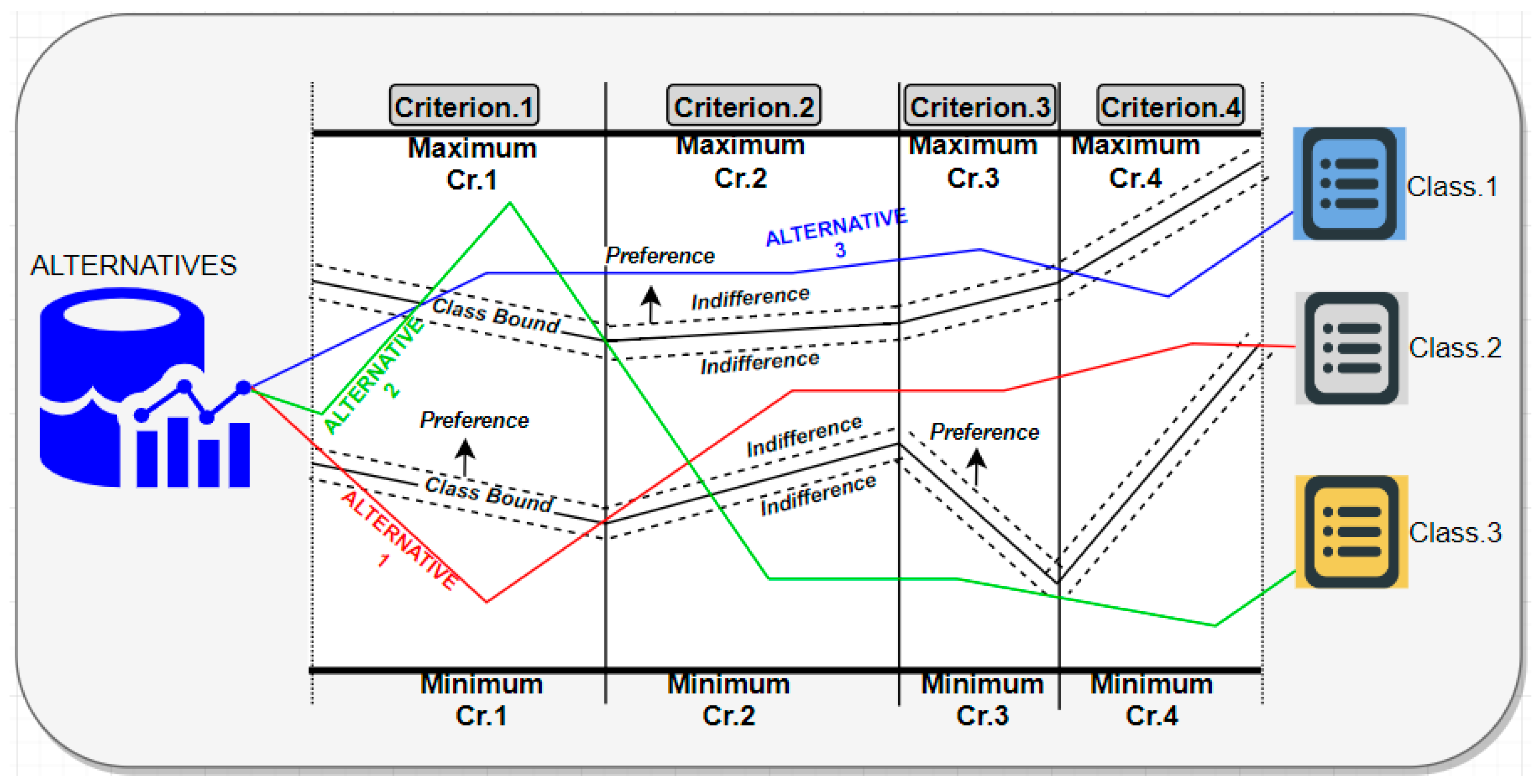
4.1. Multi-Criteria Outranking Sorting Method ELECTRE TRI
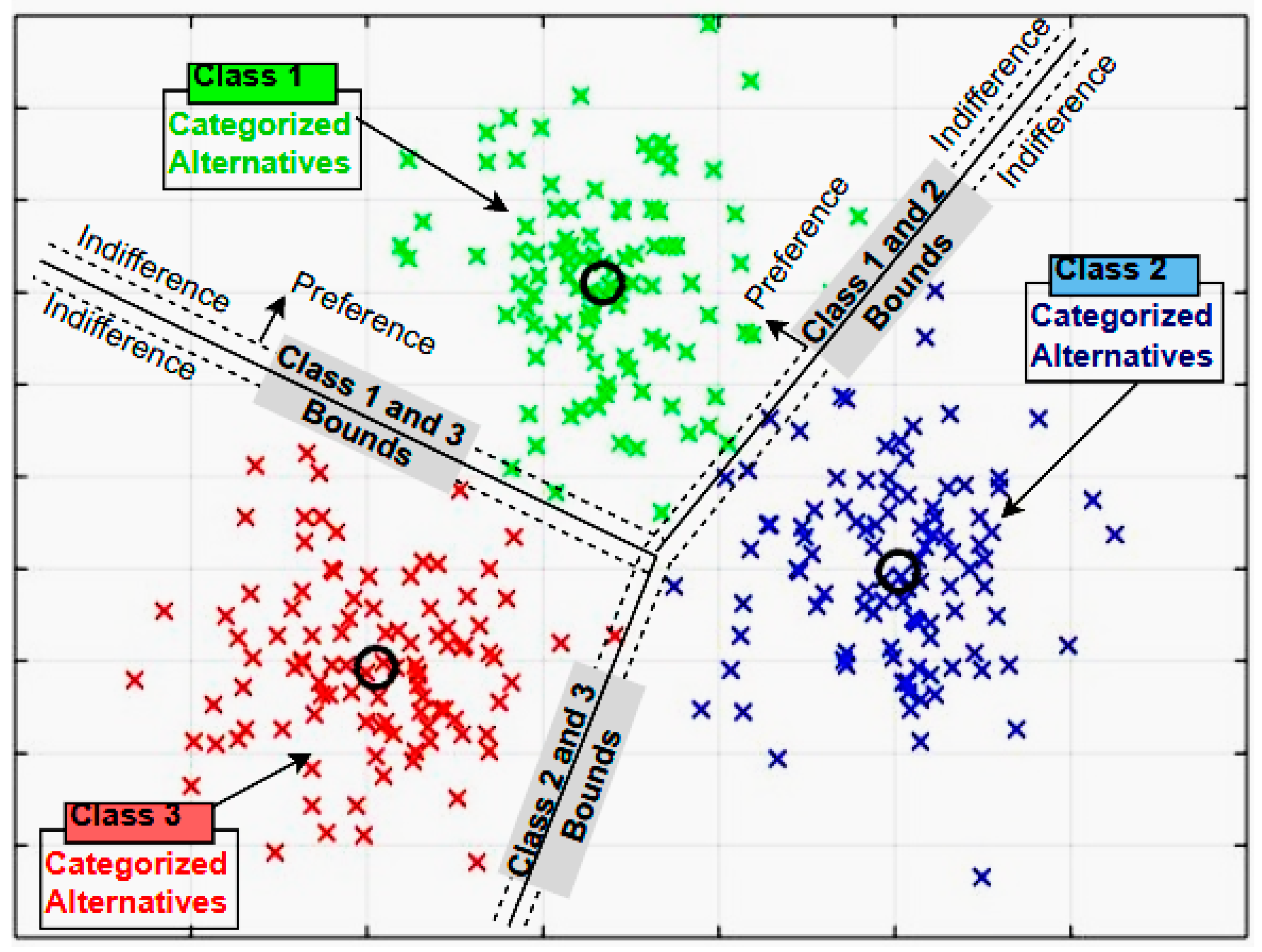
4.2. Clustering Techniques
4.3. K-Means and K-Medoids
4.4. Bio-Inspired Metaheuristics
4.5. PSO for Clustering
4.6. Genetic Algorithm for Clustering
4.7. Differential Evolution for Clustering
4.8. Fuzzy C-Means
4.9. Numerical Application
4.10. Sorting Areas into Three Categories
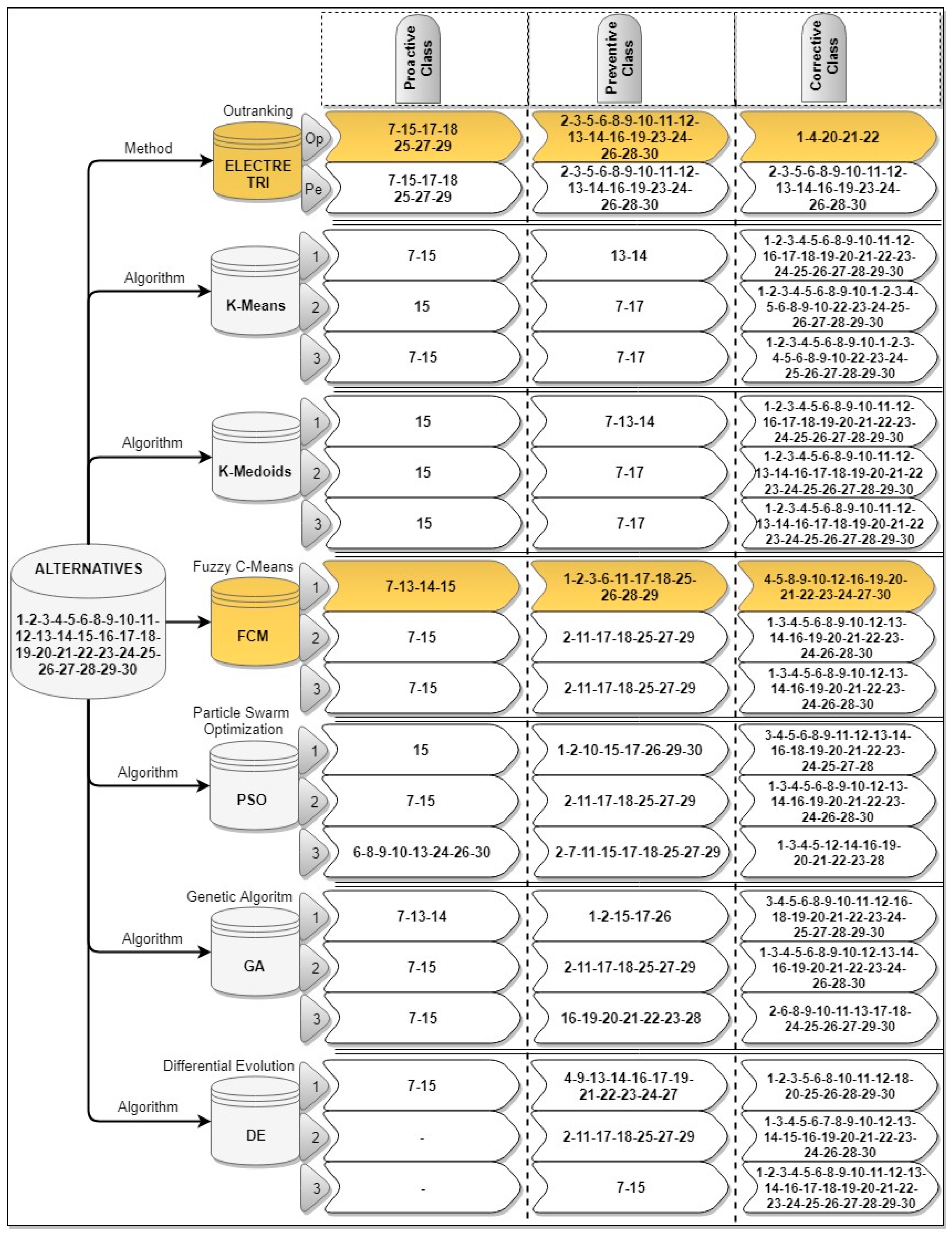
5. Results and Discussion
- K-Means and K-Medoids: 100 independent runs;
- PSO: population of 20 agents, 50 iterations, c1 = c2 = 2.05, ω with linear decay, 30 independent runs;
- GA: population of 20 agents, 50 iterations, 80% of crossover probability, 30% of mutation probability, 30 independent runs;
- DE: population of 20 agents, 50 iterations, 80% of crossover probability, F = 0.8, 30 independent runs;
- FCM: 100 independent runs.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Safarzadeh, S.; Khansefid, S.; Rasti-Barzoki, M. A group multi-criteria decision-making based on best-worst method. Comput. Ind. Eng. 2018, 126, 111–121. [Google Scholar] [CrossRef]
- Rivero Gutiérrez, L.; De Vicente Oliva, M.A.; Romero-Ania, A. Managing sustainable urban public transport systems: An AHP multicriteria decision model. Sustainability 2021, 13, 4614. [Google Scholar] [CrossRef]
- Pala, O. A mixed-integer linear programming model for aggregating multi–criteria decision making methods. Decis. Mak. Appl. Manag. Eng. 2022, 5, 260–286. [Google Scholar] [CrossRef]
- Karaaslan, F.; Özlü, Ş. Correlation coefficients of dual type-2 hesitant fuzzy sets and their applications in clustering analysis. Int. J. Intell. Syst. 2020, 35, 1200–1229. [Google Scholar] [CrossRef]
- Romero-Ania, A.; Rivero Gutiérrez, L.; De Vicente Oliva, M.A. Multiple criteria decision analysis of sustainable urban public transport systems. Mathematics 2021, 9, 1844. [Google Scholar] [CrossRef]
- Macedo, M.; Figueiredo, E.; Soares, F.; Siqueira, H.; Maciel, A.; Gokhale, A.; Bastos-Filho, C. Clustering Students Based on Grammatical Errors for On-line Education. Learn. Nonlinear Model. 2018, 16, 26–40. [Google Scholar] [CrossRef]
- Nanda, S.J.; Panda, G. A survey on nature inspired metaheuristic algorithms for partitional clustering. Swarm Evol. Comput. 2014, 16, 1–18. [Google Scholar] [CrossRef]
- Hruschka, E.R.; Campello, R.J.; Freitas, A.A. A survey of evolutionary algorithms for clustering. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2009, 39, 133–155. [Google Scholar] [CrossRef] [Green Version]
- Alam, S.; Dobbie, G.; Koh, Y.S.; Riddle, P.; Rehman, S.U. Research on particle swarm optimization based clustering: A systematic review of literature and techniques. Swarm Evol. Comput. 2014, 17, 1–13. [Google Scholar] [CrossRef]
- Figueiredo, E.; Macedo, M.; Siqueira, H.V.; Santana, C.J., Jr.; Gokhale, A.; Bastos-Filho, C.J. Swarm intelligence for clustering—A systematic review with new perspectives on data mining. Eng. Appl. Artif. Intell. 2019, 82, 313–329. [Google Scholar] [CrossRef]
- Guerreiro, M.T.; Guerreiro, E.M.A.; Barchi, T.M.; Biluca, J.; Alves, T.A.; de Souza Tadano, Y.; Trojan, F.; Siqueira, H.V. Anomaly Detection in Automotive Industry Using Clustering Methods—A Case Study. Appl. Sci. 2021, 11, 9868. [Google Scholar] [CrossRef]
- Mukhopadhyay, A.; Maulik, U.; Bandyopadhyay, S. A survey of multiobjective evolutionary clustering. ACM Comput. Surv. CSUR 2015, 47, 1–46. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA; Statistical Laboratory of the University of California: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Hancer, E.; Karaboga, D. A comprehensive survey of traditional, merge-split and evolutionary approaches proposed for determination of cluster number. Swarm Evol. Comput. 2017, 32, 49–67. [Google Scholar] [CrossRef]
- Van der Merwe, D.; Engelbrecht, A.P. Data clustering using particle swarm optimization. In Proceedings of the 2003 Congress on Evolutionary Computation, Canberra, Australia, 8–12 December 2003; Volume 1, pp. 215–220. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Bäck, T.; Fogel, D.B.; Michalewicz, Z. Evolutionary Computation 1: Basic Algorithms and Operators; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- De Souza Tadano, Y.; Siqueira, H.V.; Alves, T.A. Unorganized machines to predict hospital admissions for respiratory diseases. In Proceedings of the 2016 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Cartagena, Colombia, 2–4 November 2016; pp. 1–6. [Google Scholar]
- Kachba, Y.; Chiroli, D.M.d.G.; Belotti, J.T.; Antonini Alves, T.; de Souza Tadano, Y.; Siqueira, H. Artificial neural networks to estimate the influence of vehicular emission variables on morbidity and mortality in the largest metropolis in South America. Sustainability 2020, 12, 2621. [Google Scholar] [CrossRef] [Green Version]
- Trojan, F.; Morais, D.C. Maintenance management decision model for reduction of losses in water distribution networks. Water Resour. Manag. 2015, 29, 3459–3479. [Google Scholar] [CrossRef]
- Thesari, S.S.; Trojan, F.; Batistus, D.R. A decision model for municipal resources management. Manag. Decis. 2019, 57, 3015–3034. [Google Scholar] [CrossRef]
- Ma, L.C. A two-phase case-based distance approach for multiple-group classification problems. Comput. Ind. Eng. 2012, 63, 89–97. [Google Scholar] [CrossRef]
- Keeney, R.; Raiffa, H. Decisions with Multiple Objectives: Preferences and Value Tradeoffs; John Wiley & Sons: New York, NY, USA, 1976. [Google Scholar]
- De Almeida, A.T.; de Almeida, J.A.; Costa, A.P.C.S.; de Almeida-Filho, A.T. A new method for elicitation of criteria weights in additive models: Flexible and interactive tradeoff. Eur. J. Oper. Res. 2016, 250, 179–191. [Google Scholar] [CrossRef]
- Goodwin, P.; Wright, G. Book Selection-Decision Analysis for Management Judgement (2nd Ed.). J. Oper. Res. Soc. 1998, 49, 1107. [Google Scholar]
- Bana e Costa, C.A.; Vansnick, J.C. Applications of the MACBETH approach in the framework of an additive aggregation model. J. Multi-Criteria Decis. Anal. 1997, 6, 107–114. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision making with the analytic hierarchy process. Int. J. Serv. Sci. 2008, 1, 83–98. [Google Scholar] [CrossRef]
- Mousseau, V.; Slowinski, R. Inferring an ELECTRE TRI model from assignment examples. J. Glob. Optim. 1998, 12, 157–174. [Google Scholar] [CrossRef]
- Ishizaka, A.; Pearman, C.; Nemery, P. AHPSort: An AHP-based method for sorting problems. Int. J. Prod. Res. 2012, 50, 4767–4784. [Google Scholar] [CrossRef] [Green Version]
- Ramezanian, R. Estimation of the profiles in posteriori ELECTRE TRI: A mathematical programming model. Comput. Ind. Eng. 2019, 128, 47–59. [Google Scholar] [CrossRef]
- Costa, A.S.; Govindan, K.; Figueira, J.R. Supplier classification in emerging economies using the ELECTRE TRI-nC method: A case study considering sustainability aspects. J. Clean. Prod. 2018, 201, 925–947. [Google Scholar] [CrossRef]
- Galo, N.R.; Calache, L.D.D.R.; Carpinetti, L.C.R. A group decision approach for supplier categorization based on hesitant fuzzy and ELECTRE TRI. Int. J. Prod. Econ. 2018, 202, 182–196. [Google Scholar] [CrossRef]
- Sánchez-Lozano, J.; García-Cascales, M.S.; Lamata, M.T. Comparative TOPSIS-ELECTRE TRI methods for optimal sites for photovoltaic solar farms. Case study in Spain. J. Clean. Prod. 2016, 127, 387–398. [Google Scholar] [CrossRef]
- Bernardo, H.; Gaspar, A.; Antunes, C.H. An application of a multi-criteria decision support system to assess energy performance of school buildings. Energy Procedia 2017, 122, 667–672. [Google Scholar] [CrossRef]
- Certa, A.; Enea, M.; Galante, G.M.; La Fata, C.M. ELECTRE TRI-based approach to the failure modes classification on the basis of risk parameters: An alternative to the risk priority number. Comput. Ind. Eng. 2017, 108, 100–110. [Google Scholar] [CrossRef]
- Trojan, F.; Morais, D.C. Prioritising alternatives for maintenance of water distribution networks: A group decision approach. Water SA 2012, 38, 555–564. [Google Scholar] [CrossRef] [Green Version]
- Koca, E.; Yaman, H.; Aktürk, M.S. Stochastic lot sizing problem with controllable processing times. Omega 2015, 53, 1–10. [Google Scholar] [CrossRef]
- Hashemi, S.S.; Hajiagha, S.H.R.; Zavadskas, E.K.; Mahdiraji, H.A. Multicriteria group decision making with ELECTRE III method based on interval-valued intuitionistic fuzzy information. Appl. Math. Model. 2016, 40, 1554–1564. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, J.; Yuan, J.; Geng, S.; Zhang, H. Study of decision framework of offshore wind power station site selection based on ELECTRE-III under intuitionistic fuzzy environment: A case of China. Energy Convers. Manag. 2016, 113, 66–81. [Google Scholar] [CrossRef]
- Rivero Gutiérrez, L.; De Vicente Oliva, M.A.; Romero-Ania, A. Economic, Ecological and Social Analysis Based on DEA and MCDA for the Management of the Madrid Urban Public Transportation System. Mathematics 2022, 10, 172. [Google Scholar] [CrossRef]
- Romero-Ania, A.; De Vicente Oliva, M.A.; Rivero Gutiérrez, L. Economic Evaluation of the Urban Road Public Transport System Efficiency Based on Data Envelopment Analysis. Appl. Sci. 2021, 12, 57. [Google Scholar] [CrossRef]
- Zak, J.; Kruszyn’ ski, M. Application of AHP and ELECTRE III/IV methods to multiple level, multiple criteria evaluation of urban transportation projects. Transp. Res. Procedia 2015, 10, 820–830. [Google Scholar] [CrossRef] [Green Version]
- Zhou, M.; Liu, X.B.; Yang, J.B. Evidential reasoning-based nonlinear programming model for MCDA under fuzzy weights and utilities. Int. J. Intell. Syst. 2010, 25, 31–58. [Google Scholar] [CrossRef]
- Çali, S.; Balaman, Ş.Y. Improved decisions for marketing, supply and purchasing: Mining big data through an integration of sentiment analysis and intuitionistic fuzzy multi criteria assessment. Comput. Ind. Eng. 2019, 129, 315–332. [Google Scholar] [CrossRef]
- Aldouri, Y.K.; Al-Chalabi, H.; Zhang, L. Data clustering and imputing using a two-level multi-objective genetic algorithm (GA): A case study of maintenance cost data for tunnel fans. Cogent Eng. 2018, 5, 1513304. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, S.; Sun, S. Clustering and genetic algorithm based hybrid flowshop scheduling with multiple operations. Math. Probl. Eng. 2014, 2014, 167073. [Google Scholar] [CrossRef] [Green Version]
- Meirelles, G.; Brentan, B.; Izquierdo, J.; Ramos, H.; Luvizotto, E. Trunk network rehabilitation for resilience improvement and energy recovery in water distribution networks. Water 2018, 10, 693. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, S.; Shao, Z. Household monthly electricity consumption pattern mining: A fuzzy clustering-based model and a case study. J. Clean. Prod. 2017, 141, 900–908. [Google Scholar] [CrossRef]
- Peng, P.; Addam, O.; Elzohbi, M.; Özyer, S.T.; Elhajj, A.; Gao, S.; Liu, Y.; Özyer, T.; Kaya, M.; Ridley, M.; et al. Reporting and analyzing alternative clustering solutions by employing multi-objective genetic algorithm and conducting experiments on cancer data. Knowl.-Based Syst. 2014, 56, 108–122. [Google Scholar] [CrossRef]
- Dhalmahapatra, K.; Shingade, R.; Mahajan, H.; Verma, A.; Maiti, J. Decision support system for safety improvement: An approach using multiple correspondence analysis, t-SNE algorithm and K-means clustering. Comput. Ind. Eng. 2019, 128, 277–289. [Google Scholar] [CrossRef]
- Berbel, J.; Rodriguez-Ocana, A. An MCDM approach to production analysis: An application to irrigated farms in Southern Spain. Eur. J. Oper. Res. 1998, 107, 108–118. [Google Scholar] [CrossRef]
- Gómez-Limón, J.A.; Riesgo, L. Irrigation water pricing: Differential impacts on irrigated farms. Agric. Econ. 2004, 31, 47–66. [Google Scholar] [CrossRef]
- Azadnia, A.H.; Ghadimi, P.; Saman, M.Z.M.; Wong, K.Y.; Sharif, S. Supplier selection: A hybrid approach using ELECTRE and fuzzy clustering. In Proceedings of the International Conference on Informatics Engineering and Information Science, Kuala Lumpur, Malaysia, 12–14 November 2011; pp. 663–676. [Google Scholar]
- Chen, T.Y. Multiple criteria decision analysis under complex uncertainty: A Pearson-like correlation-based Pythagorean fuzzy compromise approach. Int. J. Intell. Syst. 2019, 34, 114–151. [Google Scholar] [CrossRef] [Green Version]
- Maghsoodi, A.I.; Kavian, A.; Khalilzadeh, M.; Brauers, W.K. CLUS-MCDA: A novel framework based on cluster analysis and multiple criteria decision theory in a supplier selection problem. Comput. Ind. Eng. 2018, 118, 409–422. [Google Scholar] [CrossRef]
- Ortiz-Barrios, M.; Miranda-De la Hoz, C.; López-Meza, P.; Petrillo, A.; De Felice, F. A case of food supply chain management with AHP, DEMATEL, and TOPSIS. J. Multi-Criteria Decis. Anal. 2020, 27, 104–128. [Google Scholar] [CrossRef]
- Alemi-Ardakani, M.; Milani, A.S.; Yannacopoulos, S.; Shokouhi, G. On the effect of subjective, objective and combinative weighting in multiple criteria decision making: A case study on impact optimization of composites. Expert Syst. Appl. 2016, 46, 426–438. [Google Scholar] [CrossRef]
- Ma, J.; Fan, Z.P.; Huang, L.H. A subjective and objective integrated approach to determine attribute weights. Eur. J. Oper. Res. 1999, 112, 397–404. [Google Scholar] [CrossRef]
- Wang, T.C.; Lee, H.D. Developing a fuzzy TOPSIS approach based on subjective weights and objective weights. Expert Syst. Appl. 2009, 36, 8980–8985. [Google Scholar] [CrossRef]
- Moghaddam, K.S. Fuzzy multi-objective model for supplier selection and order allocation in reverse logistics systems under supply and demand uncertainty. Expert Syst. Appl. 2015, 42, 6237–6254. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Z. Extension of TOPSIS to multiple criteria decision making with Pythagorean fuzzy sets. Int. J. Intell. Syst. 2014, 29, 1061–1078. [Google Scholar] [CrossRef]
- Yildirim, B.F.; Yıldırım, S.K. Evaluating the satisfaction level of citizens in municipality services by using picture fuzzy VIKOR method: 2014–2019 period analysis. Decis. Mak. Appl. Manag. Eng. 2022, 5, 50–66. [Google Scholar] [CrossRef]
- Yu, W. ELECTRE TRI(Aspects Méthodologiques et Manuel D’utilisation); Document; Université de Paris-Dauphine, LAMSADE: Paris, France, 1992. [Google Scholar]
- Mousseau, V.; Figueira, J.; Naux, J.P. Using assignment examples to infer weights for ELECTRE TRI method: Some experimental results. Eur. J. Oper. Res. 2001, 130, 263–275. [Google Scholar] [CrossRef] [Green Version]
- José-García, A.; Gómez-Flores, W. Automatic clustering using nature-inspired metaheuristics: A survey. Appl. Soft Comput. 2016, 41, 192–213. [Google Scholar] [CrossRef]
- De Mattos Neto, P.S.; Firmino, P.R.A.; Siqueira, H.; Tadano, Y.S.; Antonini Alves, T.; de Oliveira, J.F.L.; Marinho, M.H.; Madeiro, F.A. Neural-based ensembles for particulate matter forecasting. IEEE Access 2021, 9, 14470–14490. [Google Scholar] [CrossRef]
- Tan, H.; Li, Z.; Wang, Q.; Mohamed, M.A. A novel forecast scenario-based robust energy management method for integrated rural energy systems with greenhouses. Appl. Energy 2023, 330, 120343. [Google Scholar] [CrossRef]
- Siqueira, H.; Boccato, L.; Attux, R.; Filho, C.L. Echo state networks for seasonal streamflow series forecasting. In Proceedings of the Intelligent Data Engineering and Automated Learning-IDEAL 2012: 13th International Conference, Natal, Brazil, 29–31 August 2012; Volume 13, pp. 226–236. [Google Scholar]
- Santos, P.; Macedo, M.; Figueiredo, E.; Santana, C.J.; Soares, F.; Siqueira, H.; Maciel, A.; Gokhale, A.; Bastos-Filho, C.J. Application of PSO-based clustering algorithms on educational databases. In Proceedings of the 2017 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Arequipa, Peru, 8–10 November 2017; pp. 1–6. [Google Scholar]
- Dayalan, S.; Gul, S.S.; Rathinam, R.; Fernandez Savari, G.; Aleem, S.H.A.; Mohamed, M.A.; Ali, Z.M. Multi-Stage Incentive-Based Demand Response Using a Novel Stackelberg–Particle Swarm Optimization. Sustainability 2022, 14, 10985. [Google Scholar] [CrossRef]
- Ma, R.; Zeng, W.; Song, G.; Yin, Q.; Xu, Z. Pythagorean fuzzy C-means algorithm for image segmentation. Int. J. Intell. Syst. 2021, 36, 1223–1243. [Google Scholar] [CrossRef]
- Jahan, A.; Edwards, K.L. A state-of-the-art survey on the influence of normalization techniques in ranking: Improving the materials selection process in engineering design. Mater. Des. 2015, 65, 335–342. [Google Scholar] [CrossRef]
- Lizot, M.; Trojan, F.; Afonso, P. Combining Total Cost of Ownership and Multi-Criteria Decision Analysis to Improve Cost Management in Family Farming. Agriculture 2021, 11, 139. [Google Scholar] [CrossRef]
- Lizot, M.; Goffi, A.S.; Thesari, S.S.; Trojan, F.; Afonso, P.S.L.P.; Ferreira, P.F.V. Multi-criteria methodology for selection of wastewater treatment systems with economic, social, technical and environmental aspects. Environ. Dev. Sustain. 2021, 23, 9827–9851. [Google Scholar] [CrossRef]
- Oliveira Leme, M.; Trojan, F.; Francisco, A.C.; Paula Xavier, A.A. Digital Energy Management for Houses and Small Industries Based on a Low-cost Hardware. IEEE Lat. Am. Trans. 2016, 14, 4275–4278. [Google Scholar] [CrossRef]
- Wang, H.; Wang, B.; Luo, P.; Ma, F.; Zhou, Y.; Mohamed, M.A. State evaluation based-feature identification of measurement data for resilient power system. CSEE J. Power Energy Syst. 2021, 8, 983–992. [Google Scholar]
- Chen, J.; Li, X.; Mohamed, M.A.; Jin, T. An adaptive matrix pencil algorithm based-wavelet soft-threshold denoising for analysis of low frequency oscillation in power systems. IEEE Access 2020, 8, 7244–7255. [Google Scholar] [CrossRef]
- Alnowibet, K.; Annuk, A.; Dampage, U.; Mohamed, M.A. Effective energy management via false data detection scheme for the interconnected smart energy hub–microgrid system under stochastic framework. Sustainability 2021, 13, 11836. [Google Scholar] [CrossRef]
- Basílio, M.P.; Pereira, V.; Costa, H.G.; Santos, M.; Ghosh, A. A Systematic Review of the Applications of Multi-Criteria Decision Aid Methods (1977–2022). Electronics 2022, 11, 1720. [Google Scholar] [CrossRef]
- Mohamed, M.A. A relaxed consensus plus innovation based effective negotiation approach for energy cooperation between smart grid and microgrid. Energy 2022, 252, 123996. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
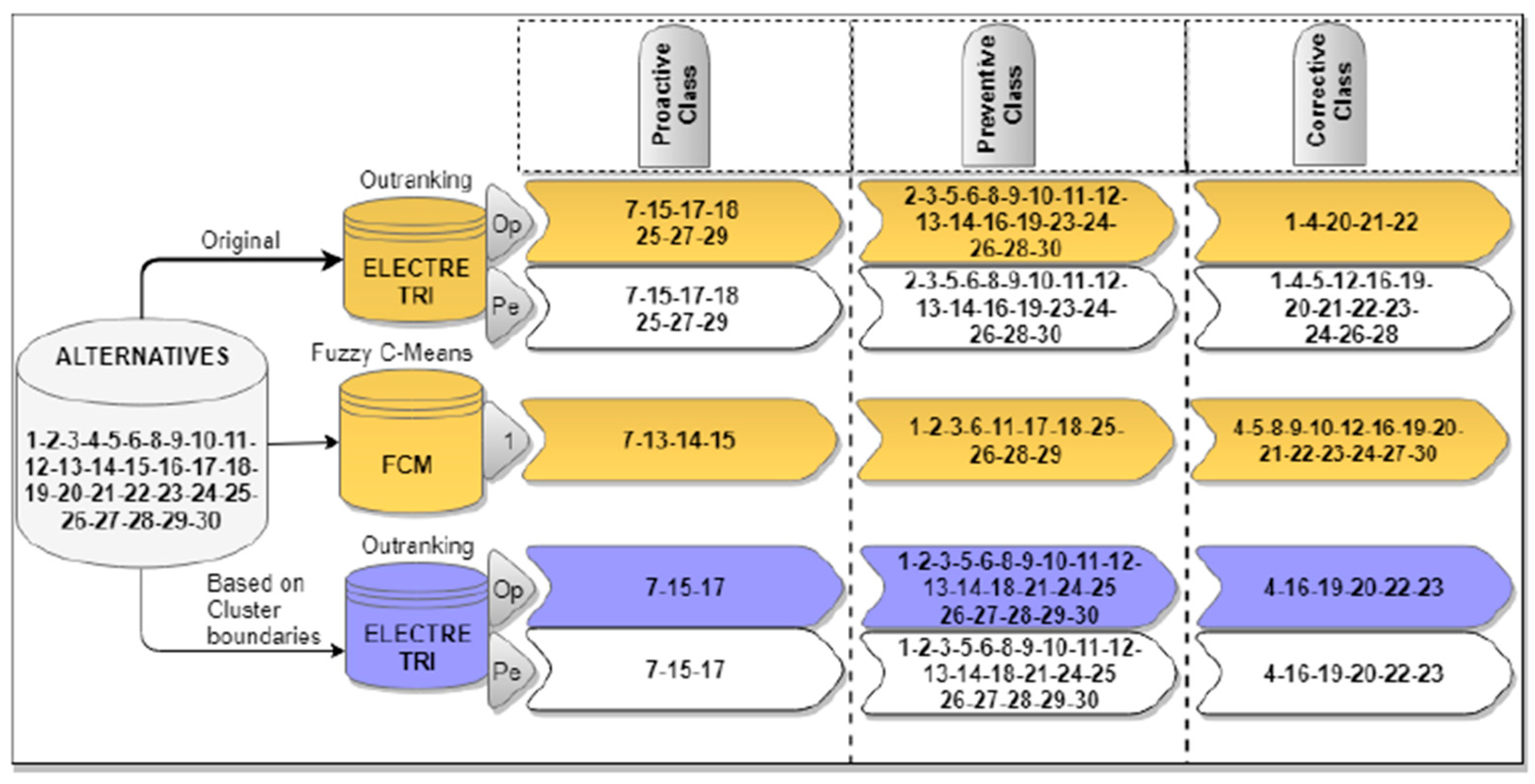{kind=link}
| Reference | Year | Approach |
|---|---|---|
| Multi-criteria concepts and methods | ||
| [35] | 2017 | Classification of equipment failure models |
| [36] | 2012 | Procedure to prioritize alternatives for maintenance on water distribution networks |
| [37] | 2015 | Selection of clients who will receive a joint research loan |
| [32] | 2018 | Fuzzy methodology is used in conjunction with ELECTRE TRI |
| [38] | 2016 | Decisions based on interval-valued intuitionistic fuzzy information |
| [39] | 2016 | Power station site selection under intuitionistic fuzzy environment |
| [42] | 2015 | Evaluation of urban transportation projects. |
| [43] | 2010 | Evidential reasoning-based nonlinear programming model for MCDA |
| [44] | 2019 | A new decision support system for product classification problems that integrate multi-criteria decision-making |
| [56] | 2020 | Supply chain management with AHP, DEMATEL, and TOPSIS |
| [57] | 2016 | Subjective, objective, and combinative weighting in multiple criteria decision making |
| [58] | 1999 | Determination of attribute weights |
| [59] | 2009 | Fuzzy TOPSIS based on subjective and objective weights |
| [60] | 2015 | Supplier selection and order allocation in reverse logistics systems |
| [61] | 2014 | TOPSIS to multiple criteria decision making with Pythagorean fuzzy sets |
| [2] | 2021 | Managing Sustainable Urban Public Transport Systems: an AHP Multicriteria Decision Model |
| [5] | 2021 | Multiple Criteria Decision Analysis of Sustainable Urban Public Transport Systems |
| [40] | 2022 | Economic, Ecological, and Social Analysis Based on DEA and MCDA for the Management of the Madrid Urban Public Transportation System |
| [41] | 2022 | Economic Evaluation of the Urban Road Public Transport System Efficiency Based on Data Envelopment Analysis |
| [3] | 2022 | A mixed-integer linear programming model for aggregating multi–criteria decision-making methods |
| [62] | 2021 | Evaluating the satisfaction level of citizens in municipality services by using picture fuzzy VIKOR method: 2014 2019 period analysis |
| Clustering | ||
| [10] | 2019 | Swarm intelligence for clustering |
| [45] | 2018 | An investigation that used genetic algorithms and Fuzzy C-means for evaluations of maintenance costs |
| [46] | 2014 | Clustering with a genetic algorithm to perform the sequencing of an aircraft manufacturing industry with a flow shop environment with multiple operations |
| [47] | 2018 | K-Means method for energy recovery in water distribution networks |
| [48] | 2017 | Fuzzy C-Means clustering for evaluation of household monthly electricity consumption |
| [49] | 2014 | Decision support system using the t-SNE algorithm and K-Means clustering to improve security using multiple matching analyses |
| [50] | 2019 | Clustering and genetic algorithm to group characteristics of individuals with cancer |
| Clustering and MCDA combined | ||
| [51] | 1998 | Developed a technique based on clustering and goal programming to analyze the decision-making process in irrigated farms |
| [52] | 2004 | Combined Clustering analysis and Multi-Attribute Utility Theory (MAUT) to verify the impact of water pricing on farms |
| [53] | 2011 | Fuzzy C-Means and ELECTRE II were combined to supplier selection problems in the automotive industry |
| [54,55] | 2019 | K-Means was combined with MULTIMOORA to improve the MCDA analyses |
| Criteria | |
|---|---|
| g1 | Number of connections (CN) |
| g2 | Measured Volume (MV) |
| g3 | Water Losses (WL) |
| g4 | Meters per connection (MC) |
| g5 | Population (POP) |
| g6 | Public Economies (PE) |
| Categories /Classes | Maintenance | Borders | Criteria | |||||
|---|---|---|---|---|---|---|---|---|
| (CN) g1 | (MV) g2 | (WL) g3 | (MC) g4 | (POP) g5 | (PE) g6 | |||
| CL1 | Proactive | b1 | 3500 | 37,000 | 93.00 | 27.00 | 12,000 | 15 |
| CL2 | Preventive | |||||||
| b2 | 1900 | 18,500 | 86.00 | 25.00 | 8000 | 5 | ||
| CL3 | Corrective | |||||||
| Weights | 23% | 10% | 20% | 15% | 12% | 20% | ||
| Direction of Preferences | ↑ up | ↑up | ↑up | ↑up | ↑up | ↑up | ||
| Benefit | Benefit | Cost | Cost | Benefit | Benefit | |
|---|---|---|---|---|---|---|
| Weights | 23% | 10% | 20% | 15% | 12% | 20% |
| Areas (flow sectors) an | Number of Connections (index) | Measured Volume (index) | Water Losses (index) | Meters of Network Per Connections (index) | Population (index) | Public Economies (index) |
| a1 | 883 | 12,404 | 41.50 | 14.49 | 3033 | 10 |
| a2 | 3255 | 57,729 | 39.18 | 15.81 | 14,960 | 5 |
| a3 | 1850 | 19,130 | 29.69 | 10.19 | 6470 | 5 |
| a4 | 1310 | 16,810 | 53.55 | 13.31 | 4267 | 2 |
| a5 | 1192 | 11,425 | 37.24 | 8.91 | 4059 | 2 |
| a6 | 2783 | 30,220 | 36.94 | 11.98 | 10,220 | 5 |
| a7 | 14,375 | 180,585 | 55.25 | 12.62 | 48,444 | 20 |
| a8 | 3397 | 32,938 | 51.11 | 10.01 | 11,574 | 6 |
| a9 | 2622 | 33,182 | 65.26 | 13.05 | 8837 | 5 |
| a10 | 2779 | 35,797 | 51.77 | 11.34 | 10,160 | 5 |
| a11 | 3286 | 45,784 | 39.63 | 11.70 | 11,750 | 7 |
| a12 | 2208 | 20,382 | 44.10 | 9.93 | 7647 | 3 |
| a13 | 3333 | 35,474 | 41.50 | 10.52 | 11,521 | 20 |
| a14 | 2685 | 26,499 | 38.90 | 10.17 | 9259 | 20 |
| a15 | 23,474 | 302,947 | 34.13 | 12.34 | 83,563 | 10 |
| a16 | 1830 | 22,472 | 66.49 | 12.24 | 6226 | 3 |
| a17 | 8667 | 92,686 | 46.94 | 10.76 | 29,887 | 10 |
| a18 | 5124 | 53,416 | 32.72 | 10.76 | 17,268 | 6 |
| a19 | 1705 | 19,250 | 61.68 | 11.29 | 5881 | 5 |
| a20 | 865 | 10,864 | 46.32 | 11.53 | 3077 | 5 |
| a21 | 974 | 9158 | 64.80 | 9.99 | 3289 | 5 |
| a22 | 727 | 7483 | 66.76 | 10.35 | 2520 | 3 |
| a23 | 1844 | 20,141 | 54.08 | 11.09 | 6362 | 5 |
| a24 | 2961 | 34,724 | 65.70 | 11.81 | 10,604 | 3 |
| a25 | 4586 | 51,197 | 39.39 | 10.44 | 15,729 | 4 |
| a26 | 2156 | 36,343 | 27.52 | 16.74 | 9074 | 4 |
| a27 | 4527 | 50,234 | 74.81 | 11.45 | 15,545 | 5 |
| a28 | 1876 | 23,153 | 37.07 | 12.04 | 6623 | 4 |
| a29 | 4651 | 56,296 | 52.43 | 11.98 | 16,290 | 9 |
| a30 | 2774 | 33,143 | 59.60 | 11.94 | 9668 | 8 |
| Benefit | Benefit | Benefit | Benefit | Benefit | Benefit | |
|---|---|---|---|---|---|---|
| Weights | 23% | 10% | 20% | 15% | 12% | 20% |
| Areas (flow sectors) an | Number of Connections (index) | Measured Volume (index) | Water Losses (index) | Meters of Network Per Connections (index) | Population (index) | Public Economies (index) |
| a1 | 0.16 | 0.17 | 11.70 | 4.31 | 0.08 | 8.89 |
| a2 | 2.56 | 1.70 | 12.16 | 1.78 | 1.84 | 3.33 |
| a3 | 1.14 | 0.39 | 14.06 | 12.55 | 0.58 | 3.33 |
| a4 | 0.59 | 0.32 | 9.29 | 6.57 | 0.26 | 0.00 |
| a5 | 0.47 | 0.13 | 12.55 | 15.00 | 0.23 | 0.00 |
| a6 | 2.08 | 0.77 | 12.61 | 9.12 | 1.14 | 3.33 |
| a7 | 13.80 | 5.86 | 8.95 | 7.89 | 6.80 | 20.00 |
| a8 | 2.70 | 0.86 | 9.78 | 12.89 | 1.34 | 4.44 |
| a9 | 1.92 | 0.87 | 6.95 | 7.07 | 0.94 | 3.33 |
| a10 | 2.07 | 0.96 | 9.65 | 10.34 | 1.13 | 3.33 |
| a11 | 2.59 | 1.30 | 12.07 | 9.66 | 1.37 | 5.56 |
| a12 | 1.50 | 0.44 | 11.18 | 13.05 | 0.76 | 1.11 |
| a13 | 2.63 | 0.95 | 11.70 | 11.92 | 1.33 | 20.00 |
| a14 | 1.98 | 0.64 | 12.22 | 12.59 | 1.00 | 20.00 |
| a15 | 23.00 | 10.00 | 13.17 | 8.43 | 12.00 | 8.89 |
| a16 | 1.12 | 0.51 | 6.70 | 8.62 | 0.55 | 1.11 |
| a17 | 8.03 | 2.88 | 10.61 | 11.46 | 4.05 | 8.89 |
| a18 | 4.45 | 1.55 | 13.46 | 11.46 | 2.18 | 4.44 |
| a19 | 0.99 | 0.40 | 7.66 | 10.44 | 0.50 | 3.33 |
| a20 | 0.14 | 0.11 | 10.74 | 9.98 | 0.08 | 3.33 |
| a21 | 0.25 | 0.06 | 7.04 | 12.93 | 0.11 | 3.33 |
| a22 | 0.00 | 0.00 | 6.65 | 12.24 | 0.00 | 1.11 |
| a23 | 1.13 | 0.43 | 9.18 | 10.82 | 0.57 | 3.33 |
| a24 | 2.26 | 0.92 | 6.86 | 9.44 | 1.20 | 1.11 |
| a25 | 3.90 | 1.48 | 12.12 | 12.07 | 1.96 | 2.22 |
| a26 | 1.44 | 0.98 | 14.50 | 0.00 | 0.97 | 2.22 |
| a27 | 3.84 | 1.45 | 5.04 | 10.13 | 1.93 | 3.33 |
| a28 | 1.16 | 0.53 | 12.59 | 9.00 | 0.61 | 2.22 |
| a29 | 3.97 | 1.65 | 9.51 | 9.12 | 2.04 | 7.78 |
| a30 | 2.07 | 0.87 | 8.08 | 9.20 | 1.06 | 6.67 |
| Benefit | Benefit | Benefit | Benefit | Benefit | Benefit | |
|---|---|---|---|---|---|---|
| Weights | 23% | 10% | 20% | 15% | 12% | 20% |
| Areas (flow sectors) an | Number of Connections | Measured Volume (m3/month) | Water Losses (%) | Meters of Network Per Connections (Index) | Population (Inhabitants) | Public Economies (Number) |
| a1 | 203 | 1240.4 | 58.5 | 0.069 | 363.9 | 2.0 |
| a2 | 748 | 5772.9 | 60.8 | 0.063 | 1795.2 | 1.0 |
| a3 | 425 | 1913.0 | 70.3 | 0.098 | 776.4 | 1.0 |
| a4 | 301 | 1681.0 | 46.4 | 0.075 | 512.0 | 0.4 |
| a5 | 274 | 1142.5 | 62.7 | 0.112 | 487.0 | 0.4 |
| a6 | 640 | 3022.0 | 63.0 | 0.083 | 1226.4 | 1.0 |
| a7 | 3306 | 18,058.5 | 44.7 | 0.079 | 5813.2 | 4.0 |
| a8 | 781 | 3293.8 | 48.8 | 0.100 | 1388.8 | 1.2 |
| a9 | 603 | 3318.2 | 34.7 | 0.077 | 1060.4 | 1.0 |
| a10 | 639 | 3579.7 | 48.2 | 0.088 | 1219.2 | 1.0 |
| a11 | 755 | 4578.4 | 60.3 | 0.085 | 1410.0 | 1.4 |
| a12 | 507 | 2038.2 | 55.9 | 0.101 | 917.6 | 0.6 |
| a13 | 766 | 3547.4 | 58.5 | 0.095 | 1382.5 | 4.0 |
| a14 | 617 | 2649.9 | 61.1 | 0.098 | 1111.0 | 4.0 |
| a15 | 5399 | 30,294.7 | 65.8 | 0.081 | 10,027.5 | 2.0 |
| a16 | 420 | 2247.2 | 33.5 | 0.082 | 747.1 | 0.6 |
| a17 | 1993 | 9268.6 | 53.0 | 0.093 | 3586.4 | 2.0 |
| a18 | 1178 | 5341.6 | 67.2 | 0.093 | 2072.1 | 1.2 |
| a19 | 392 | 1925.0 | 38.3 | 0.089 | 705.7 | 1.0 |
| a20 | 198 | 1086.4 | 53.6 | 0.087 | 369.2 | 1.0 |
| a21 | 224 | 915.8 | 35.2 | 0.100 | 394.6 | 1.0 |
| a22 | 167 | 748.3 | 33.2 | 0.097 | 302.4 | 0.6 |
| a23 | 424 | 2014.1 | 45.9 | 0.090 | 763.4 | 1.0 |
| a24 | 681 | 3472.4 | 34.3 | 0.085 | 1272.4 | 0.6 |
| a25 | 1054 | 5119.7 | 60.6 | 0.096 | 1887.4 | 0.8 |
| a26 | 495 | 3634.3 | 72.4 | 0.060 | 1088.8 | 0.8 |
| a27 | 1041 | 5023.4 | 25.1 | 0.087 | 1865.4 | 1.0 |
| a28 | 431 | 2315.3 | 62.9 | 0.083 | 794.7 | 0.8 |
| a29 | 1069 | 5629.6 | 47.5 | 0.083 | 1954.8 | 1.8 |
| a30 | 638 | 3314.3 | 40.4 | 0.084 | 1160.1 | 1.6 |
| Benefit | Benefit | Benefit | Benefit | Benefit | Benefit | |
|---|---|---|---|---|---|---|
| Weights | 23% | 10% | 20% | 15% | 12% | 20% |
| Areas (flow sectors) an | Number of Connections | Measured Volume (m3/month) | Water Losses (%) | Meters of Network Per Connections (Index) | Population (Inhabitants) | Public Economies (Number) |
| a1 | 883 | 12,404 | 58.50 | 18.99 | 3033 | 10 |
| a2 | 3255 | 57,729 | 60.82 | 17.67 | 14,960 | 5 |
| a3 | 1850 | 19,130 | 70.31 | 23.29 | 6470 | 5 |
| a4 | 1310 | 16,810 | 46.45 | 20.17 | 4267 | 2 |
| a5 | 1192 | 11,425 | 62.76 | 24.57 | 4059 | 2 |
| a6 | 2783 | 30,220 | 63.06 | 21.50 | 10,220 | 5 |
| a7 | 14,375 | 180,585 | 44.75 | 20.86 | 48,444 | 20 |
| a8 | 3397 | 32,938 | 48.89 | 23.47 | 11,574 | 6 |
| a9 | 2622 | 33,182 | 34.74 | 20.43 | 8837 | 5 |
| a10 | 2779 | 35,797 | 48.23 | 22.14 | 10,160 | 5 |
| a11 | 3286 | 45,784 | 60.37 | 21.78 | 11,750 | 7 |
| a12 | 2208 | 20,382 | 55.90 | 23.55 | 7647 | 3 |
| a13 | 3333 | 35,474 | 58.50 | 22.96 | 11,521 | 20 |
| a14 | 2685 | 26,499 | 61.10 | 23.31 | 9259 | 20 |
| a15 | 23,474 | 302,947 | 65.87 | 21.14 | 83,563 | 10 |
| a16 | 1830 | 22,472 | 33.51 | 21.24 | 6226 | 3 |
| a17 | 8667 | 92,686 | 53.06 | 22.72 | 29,887 | 10 |
| a18 | 5124 | 53,416 | 67.28 | 22.72 | 17,268 | 6 |
| a19 | 1705 | 19,250 | 38.32 | 22.19 | 5881 | 5 |
| a20 | 865 | 10,864 | 53.68 | 21.95 | 3077 | 5 |
| a21 | 974 | 9158 | 35.20 | 23.49 | 3289 | 5 |
| a22 | 727 | 7483 | 33.24 | 23.13 | 2520 | 3 |
| a23 | 1844 | 20,141 | 45.92 | 22.39 | 6362 | 5 |
| a24 | 2961 | 34,724 | 34.30 | 21.67 | 10,604 | 3 |
| a25 | 4586 | 51,197 | 60.61 | 23.04 | 15,729 | 4 |
| a26 | 2156 | 36,343 | 72.48 | 16.74 | 9074 | 4 |
| a27 | 4527 | 50,234 | 25.19 | 22.03 | 15,545 | 5 |
| a28 | 1876 | 23,153 | 62.93 | 21.44 | 6623 | 4 |
| a29 | 4651 | 56,296 | 47.57 | 21.50 | 16,290 | 9 |
| a30 | 2774 | 33,143 | 40.40 | 21.54 | 9668 | 8 |
| Benefit | Benefit | Benefit | Benefit | Benefit | Benefit | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Classes/Limits | an | Number of Connections | Measured Volume (m3/month) | Water Losses (%) | Meters of Network Per Connections (m/connections) | Population (Inhabitants) | Public Economies (Number) | |||
| High(Hi1) | a15 | 23,474 | 302,947 | 65.87 | 12.34 | 83,563 | 10 | |||
| Proactive Class | a7 | 14,375 | 180,585 | 44.75 | 12.62 | 48,444 | Max20 | |||
| a13 | 3333 | 35,474 | 58.50 | 10.52 | 11,521 |  | 20 | |||
| Low(Lo1) | a14 | Lo1 = 2685 | Lo1 = 26,499 | 38.90 | Lo1 = 10.17 | 9259 | 20 | |||
| Limits for Preventive/ Proactive | ||||||||||
| LIMIT VALUES | (8667 − 2685/2) + 2685 = 5676 | (92,686 − 26,499/2) + 26,499 = 59,592 | = 72.48 | (23.29 − 10.17/2) + 23.29 = 29.85 | (29,887 − 9259/2) + 9259 = 19,573 | = 20 | ||||
| High(Hi2) | a17 | Hi2 = 8667 | Hi2 = 92,686 |  | 53.06 | 10.76 | Hi2 =29,887 | 10 | ||
| Preventive Class | a2 | 3255 | 57,729 | 60.82 | 15.81 | 14,960 | 5 | |||
| a29 | 4651 | 56,296 | 47.57 | 11.98 | 16,290 | 9 | ||||
| a18 | 5124 | 53,416 | 67.28 | 22.72 | 17,268 | 6 | ||||
| a25 | 4586 | 51,197 | 60.61 | 23.04 | 15,729 | 4 | ||||
| a11 | 3286 | 45,784 | 60.37 | 21.78 | 11,750 | 7 | ||||
| a26 | 2156 | 36,343 | Max72.48 | 16.74 | 9074 | 4 | ||||
| a6 | 2783 | 30,220 | 63.06 | 21.50 | 10,220 | 5 | ||||
| a28 | 1876 | 23,153 | 62.93 | 21.44 | 6623 | Lo2 = 4 | ||||
| a3 | 1850 | 19,130 | 70.31 | Hi2 = 23.29 | 6470 | 5 | ||||
| Low(Lo2) | a1 | Lo2 = 883 | Lo2 = 12,404 | 58.50 | 18.99 | Lo2 = 3033 | 10 | |||
| Limits for Corrective/ Preventive | ||||||||||
| LIMIT VALUES | (4527 − 883/2) + 883 = 2705 | (50,234 − 12,404/2) + 12,404 = 31,319 | = 62.76 | = 24.57 | (15,545 − 3033/2) + 3033 = 9289 | (8 − 4/2) + 4 = 6 | ||||
| High(Hi3) | a27 | Hi3 = 4527 | Hi3 = 50,234 |  | 25.19 | | 22.03 | Hi3 = 15,545 | 5 | |
| Corrective Class | a10 | 2779 | 35,797 | 48.23 | 22.14 | 10,160 | 5 | |||
| a24 | 2961 | 34,724 | 34.30 | 21.67 | 10,604 | 3 | ||||
| a9 | 2622 | 33,182 | 34.74 | 20.43 | 8837 | 5 | ||||
| a30 | 2774 | 33,143 | 40.40 | 21.54 | 9668 | Hi3 = 8 | ||||
| a8 | 3397 | 32,938 | 48.89 | 23.47 | 11,574 | 6 | ||||
| a16 | 1830 | 22,472 | 33.51 | 21.24 | 6226 | 3 | ||||
| a12 | 2208 | 20,382 | 55.90 | 23.55 | 7647 | 3 | ||||
| a23 | 1844 | 20,141 | 45.92 | 22.39 | 6362 | 5 | ||||
| a19 | 1705 | 19,250 | 38.32 | 22.19 | 5881 | 5 | ||||
| a4 | 1310 | 16,810 | 46.45 | 20.17 | 4267 | 2 | ||||
| a5 | 1192 | 11,425 | Max62.76 | Hi3 = 24.57 | 4059 | 2 | ||||
| a20 | 865 | 10,864 | 53.68 | 21.95 | 3077 | 5 | ||||
| a21 | 974 | 9158 | 35.20 | 23.49 | 3289 | 5 | ||||
| Low(Lo3) | a22 | 727 | 7483 | 33.24 | 23.13 | 2.520 | 3 | |||
| Categories /Classes | Maintenance | Borders | Criteria | |||||
|---|---|---|---|---|---|---|---|---|
| (CN) g1 | (MV) g2 | (WL) g3 | (MC) g4 | (POP) g5 | (PE) g6 | |||
| CL1 | Proactive | b1 b1* | 3500 5676 | 37,000 59,592 | 93.00 72.48 | 27.00 29.85 | 12,000 19,573 | 15 20 |
| CL2 | Preventive | |||||||
| b2 b2* | 1900 2705 | 18,500 31,319 | 86.00 62.76 | 25.00 24.57 | 8000 9289 | 5 6 | ||
| CL3 | Corrective | |||||||
| Method | Average SSW | Average SSB | Average Silhouette |
|---|---|---|---|
| K-Means | 940.42 | 106.43 | 0.65 |
| K-Medoids | 945.20 | 140.81 | 0.80 |
| FCM | 630.53 | 80.01 | 0.53 |
| PSO | 145.76 | 89.18 | 0.41 |
| GA | 142.60 | 102.16 | 0.58 |
| DE | 145.07 | 108.62 | 0.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trojan, F.; Fernandez, P.I.R.; Guerreiro, M.; Biuk, L.; Mohamed, M.A.; Siano, P.; Filho, R.F.D.; Marinho, M.H.N.; Siqueira, H.V. Class Thresholds Pre-Definition by Clustering Techniques for Applications of ELECTRE TRI Method. Energies 2023, 16, 1936. https://doi.org/10.3390/en16041936
Trojan F, Fernandez PIR, Guerreiro M, Biuk L, Mohamed MA, Siano P, Filho RFD, Marinho MHN, Siqueira HV. Class Thresholds Pre-Definition by Clustering Techniques for Applications of ELECTRE TRI Method. Energies. 2023; 16(4):1936. https://doi.org/10.3390/en16041936
Chicago/Turabian StyleTrojan, Flavio, Pablo Isaias Rojas Fernandez, Marcio Guerreiro, Lucas Biuk, Mohamed A. Mohamed, Pierluigi Siano, Roberto F. Dias Filho, Manoel H. N. Marinho, and Hugo Valadares Siqueira. 2023. "Class Thresholds Pre-Definition by Clustering Techniques for Applications of ELECTRE TRI Method" Energies 16, no. 4: 1936. https://doi.org/10.3390/en16041936
APA StyleTrojan, F., Fernandez, P. I. R., Guerreiro, M., Biuk, L., Mohamed, M. A., Siano, P., Filho, R. F. D., Marinho, M. H. N., & Siqueira, H. V. (2023). Class Thresholds Pre-Definition by Clustering Techniques for Applications of ELECTRE TRI Method. Energies, 16(4), 1936. https://doi.org/10.3390/en16041936