
Research on Transformer Voiceprint Anomaly Detection Based on Data-Driven

Abstract
:1. Introduction
2. Acquisition and Analysis of Transformer Sound Signals
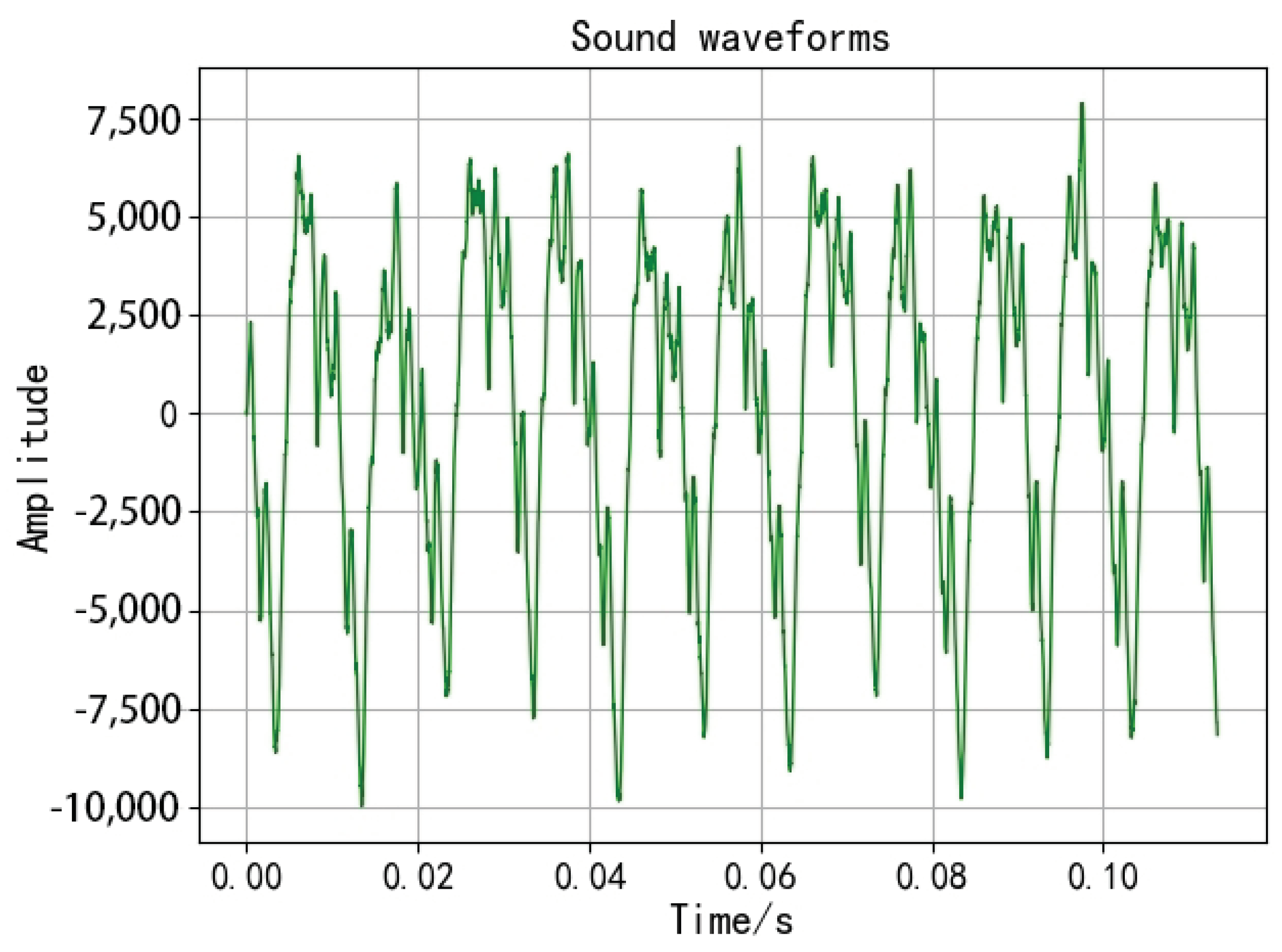
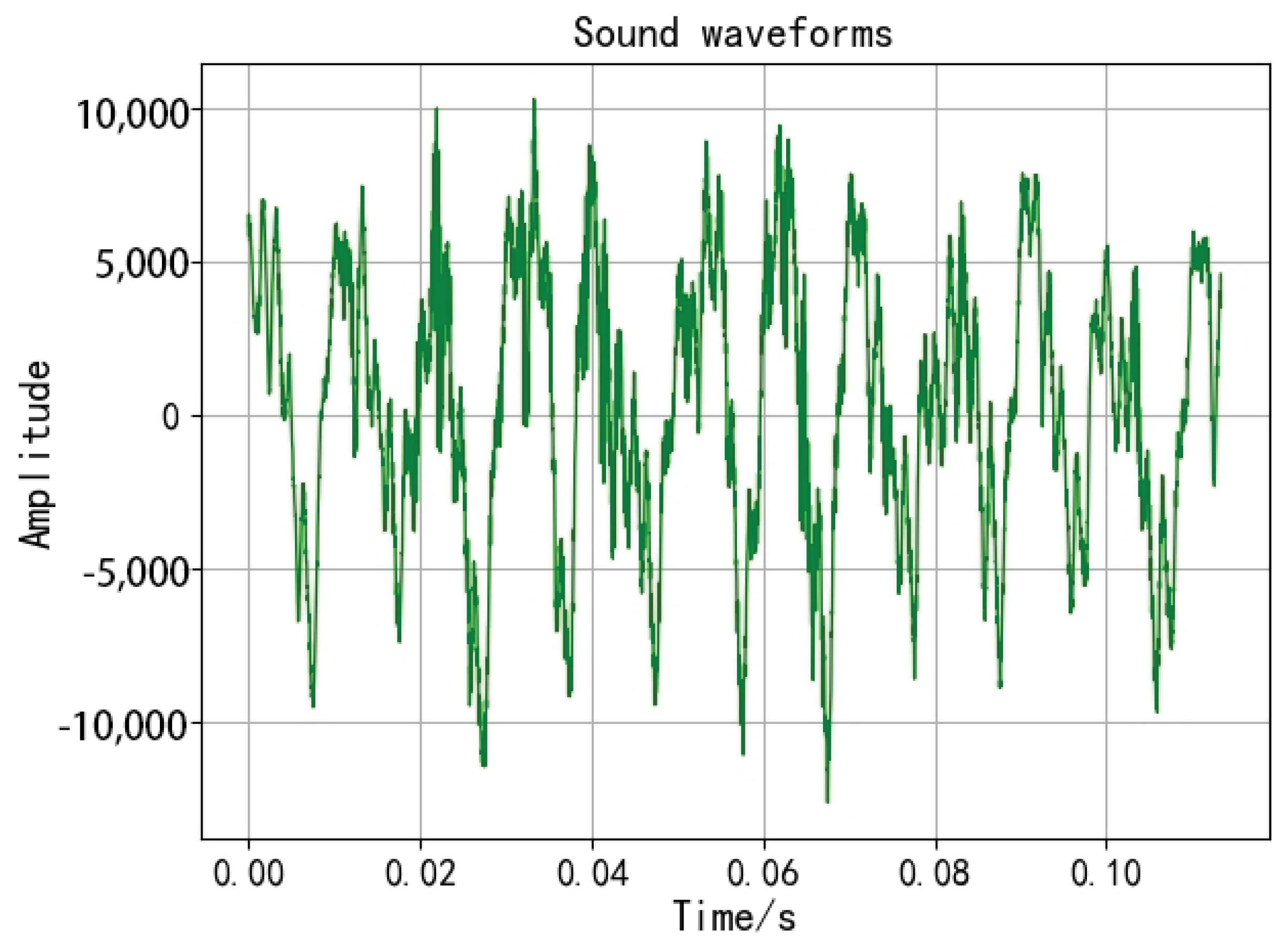
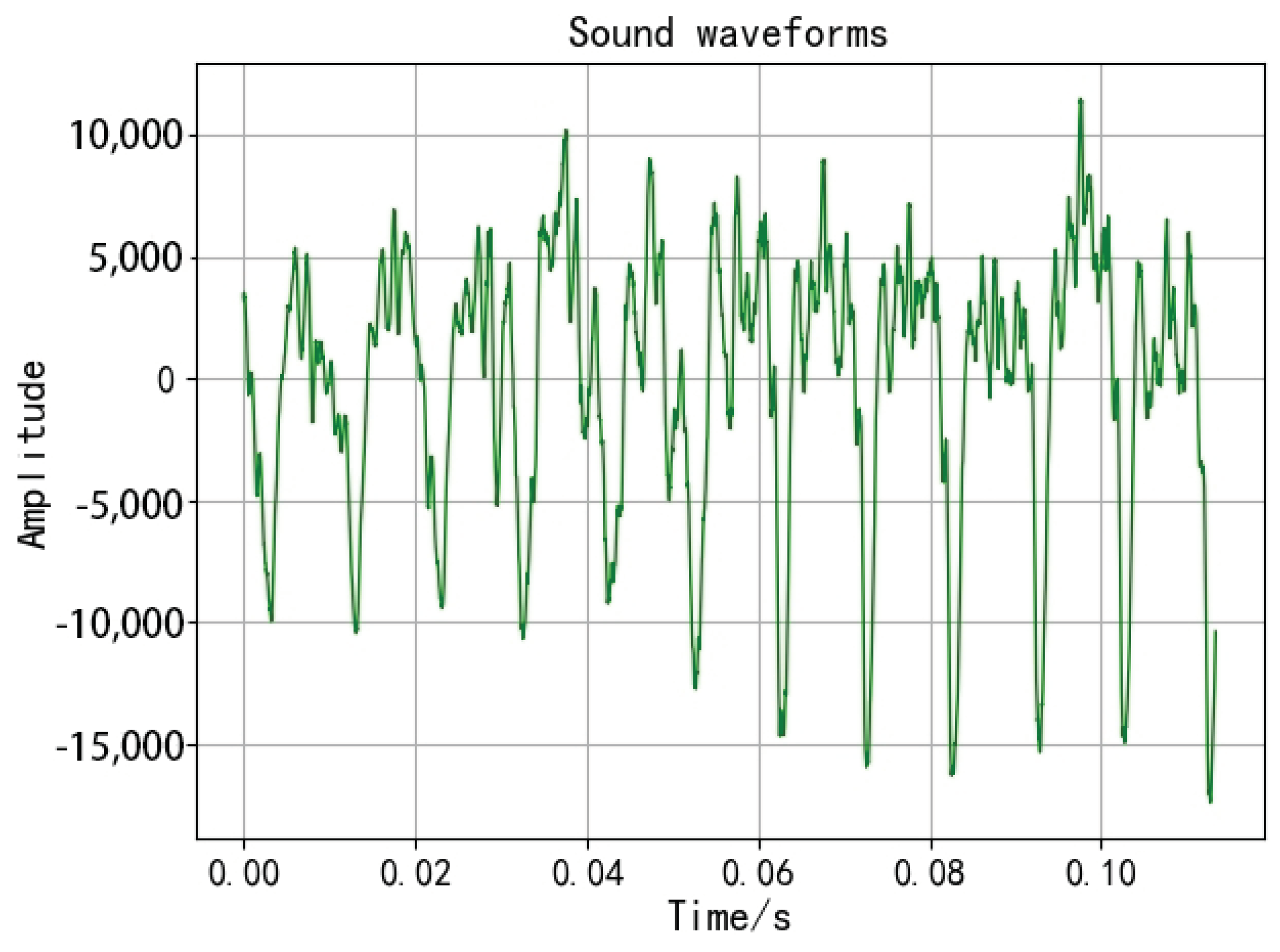
2.1. Time Domain Analysis
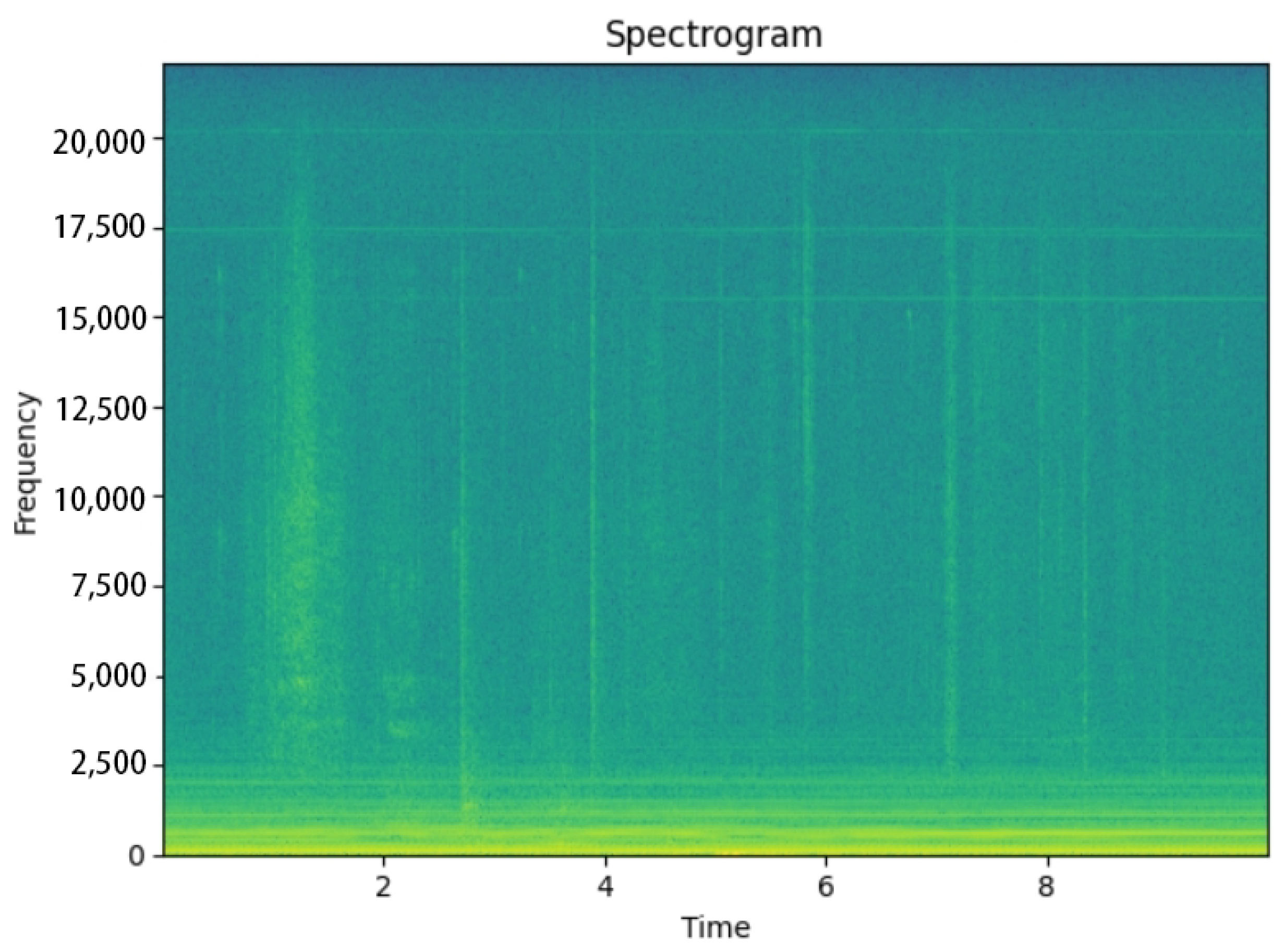
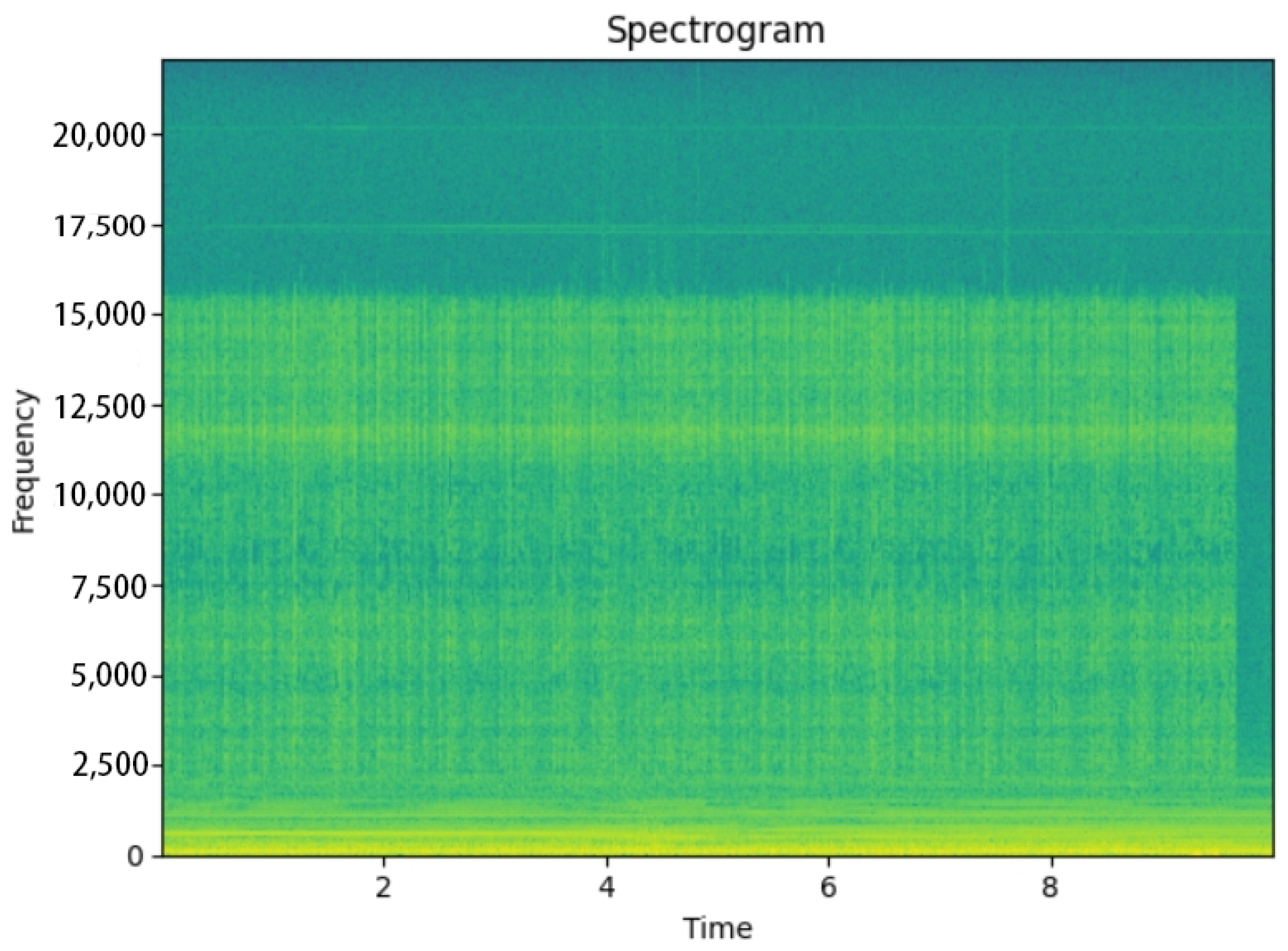
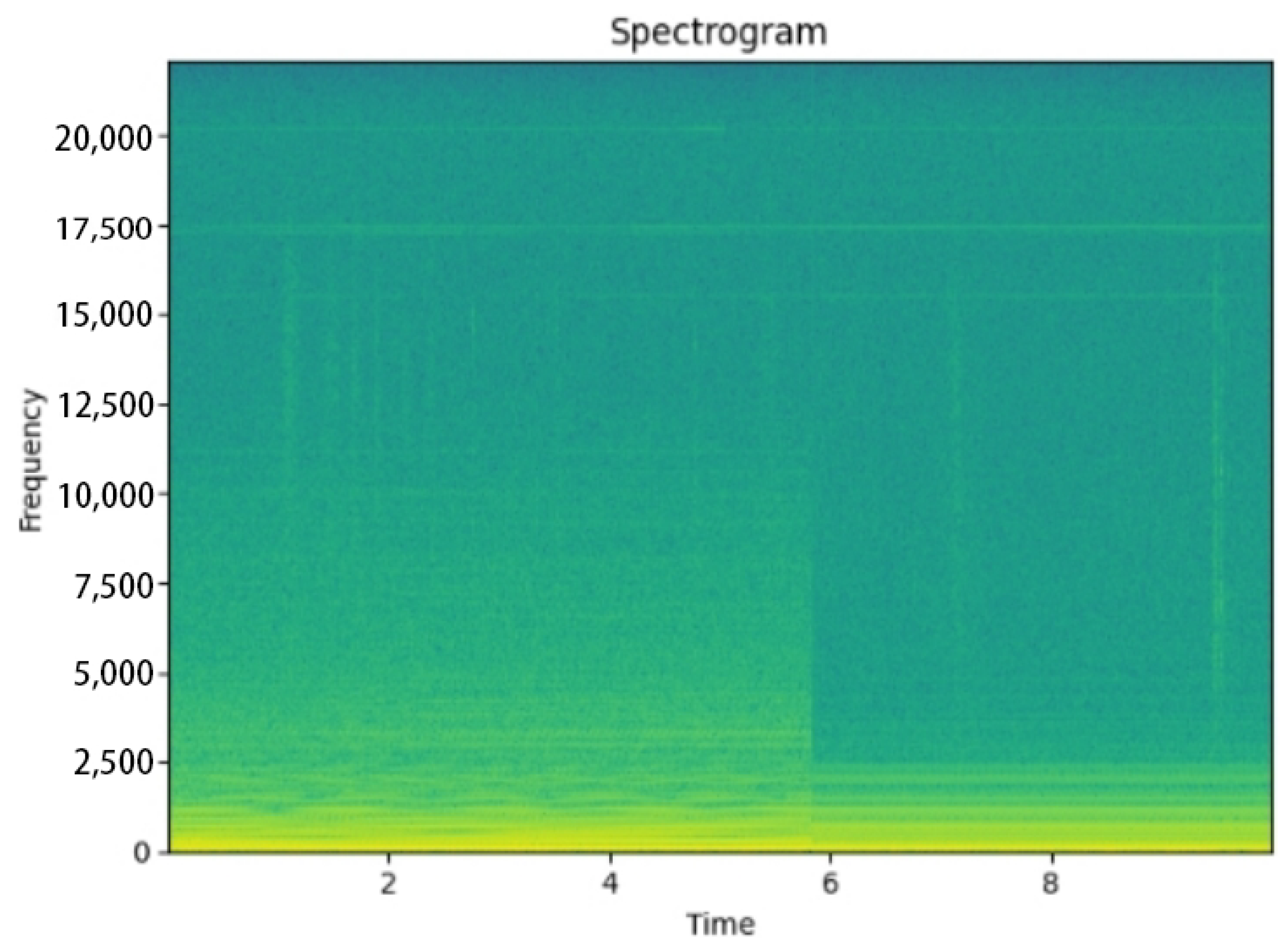
2.2. Grammatic Analysis
3. Preprocessing and Feature Extraction of Sound Signals
3.1. Preprocessing of Sound Signals
3.2. Feature Extraction of Sound Signals
4. Construction of CNN-LSTM Hybrid Model Based on Attention Mechanism
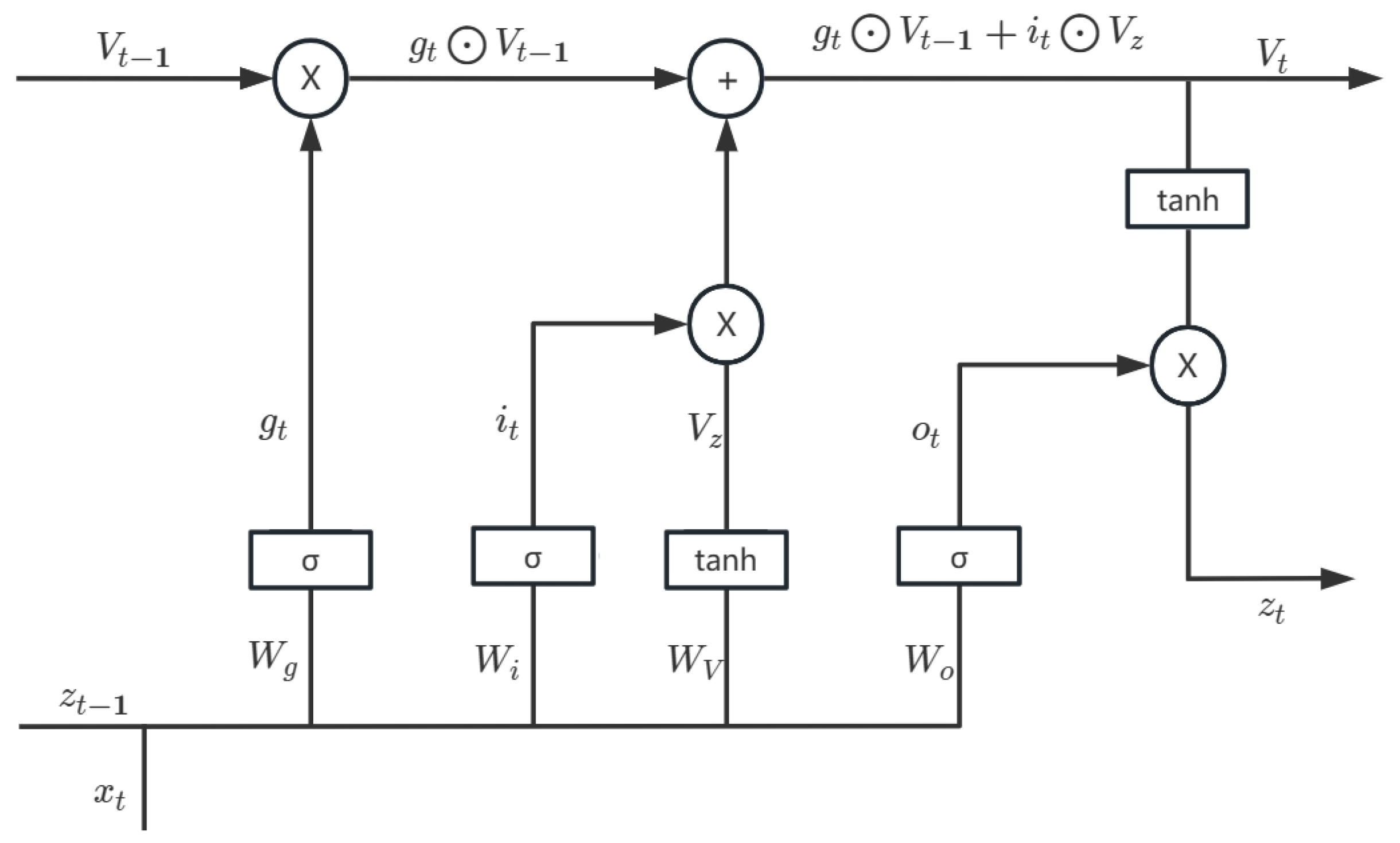
4.1. Long Short-Term Memory
4.2. Convolutional Neural Networks
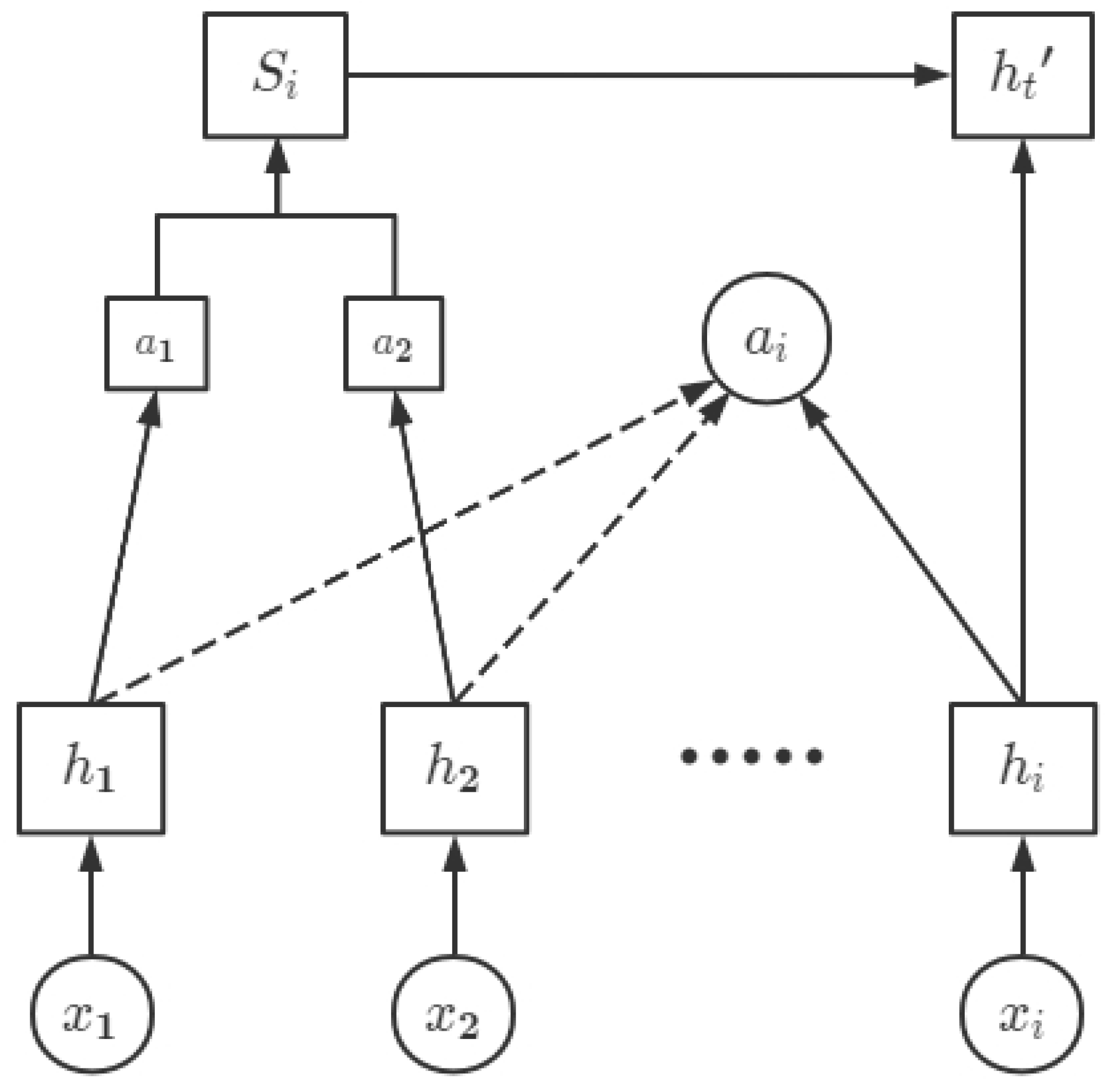
4.3. Attention Mechanism
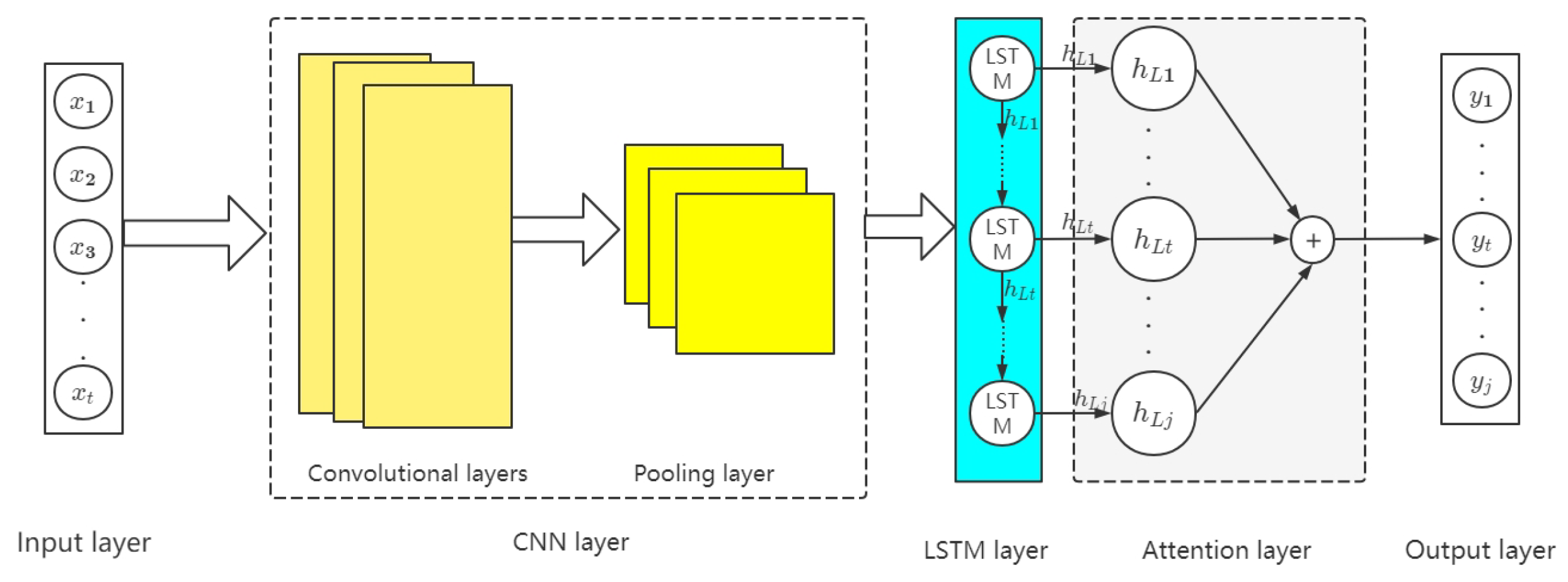
4.4. CNN-LSTM Hybrid Model Based on Attention Mechanism
- Input layer: The MFCC features of the sound samples after feature extraction is passed into the model through the input layer. If the input length is t, can be used to represent the input direction.
- CNN layer: The CNN layer mainly includes the convolutional layer and the pooling layer, which is to feature further extraction of the feature vector input of the input layer and extract and screen out the important feature vectors into the LSTM layer. According to the data structure of the voiceprint sample, this paper uses two-dimensional convolution, the convolution kernel is 9, and the activation function is ReLU. In order to retain more features, this paper uses the maximum pooling, and the pool size is 2. After the CNN layer processes the input vector, the incoming fully connected layer is transformed into a new feature vector (26). The output of the CNN layer is , and the calculation formula iswhere C is the convolutional layer’s output, and are the weights and biases of the convolutional layer, respectively, ⊗ is the convolution operator, P is the pooling layer’s output, is the maximum pooling mode, and is the bias of the pooling layer. The fully connected layer’s activation function is called f. The fully connected layer’s weights and biases are and .
- LSTM layer: To understand how the data feature time series are related, the CNN layer passes the extracted feature vectors onto the LSTM layer. In this paper, the LSTM structure of bidirectional transmission is adopted, and the number of hidden units in each layer is 120. The activation function is the RULE function, and the LSTM layer’s output vector is .
- Attention layer: In accordance with the weight distribution principle, we input the vector output of LSTM into the attention layer and assign distinct parameters to distinct characteristic parameters to create the ideal weight parameter matrix. The output of this layer is .
- Output layer:The output from the attention layer goes into the output layer, which then sends the status data for the transformer through the full connection layer. The output is Y, and the following formula calculates it aswhere and are the weights and biases of the output layer.
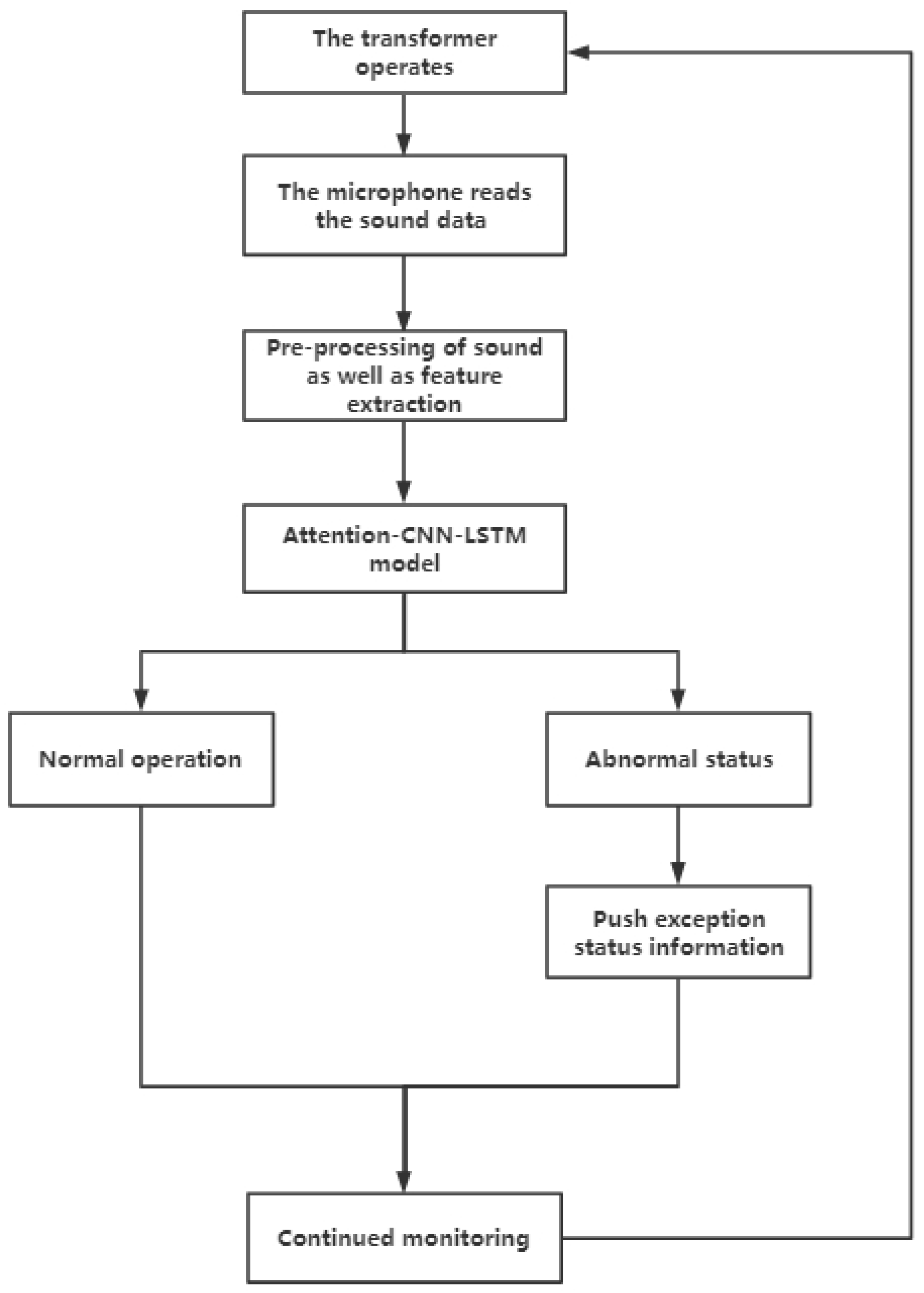
4.5. Real-Time Transformer Condition Monitoring Process
- The sound of the transformer operation is collected in real time through the microphone and converted into data.
- Preprocess the data collected by the microphone and extract MFCC features to form a feature vector.
- Input feature vectors into the trained Attention-CNN-LSTM model for discrimination.
- If the discrimination result is normal, continue monitoring. If the discrimination result is the abnormal state (discharge, overload), push the abnormal information and occurrence time, and continue monitoring.
5. Analysis of Experimental Results
5.1. Model Training Settings
5.1.1. Sample Settings
5.1.2. Evaluate the Performance Index Settings
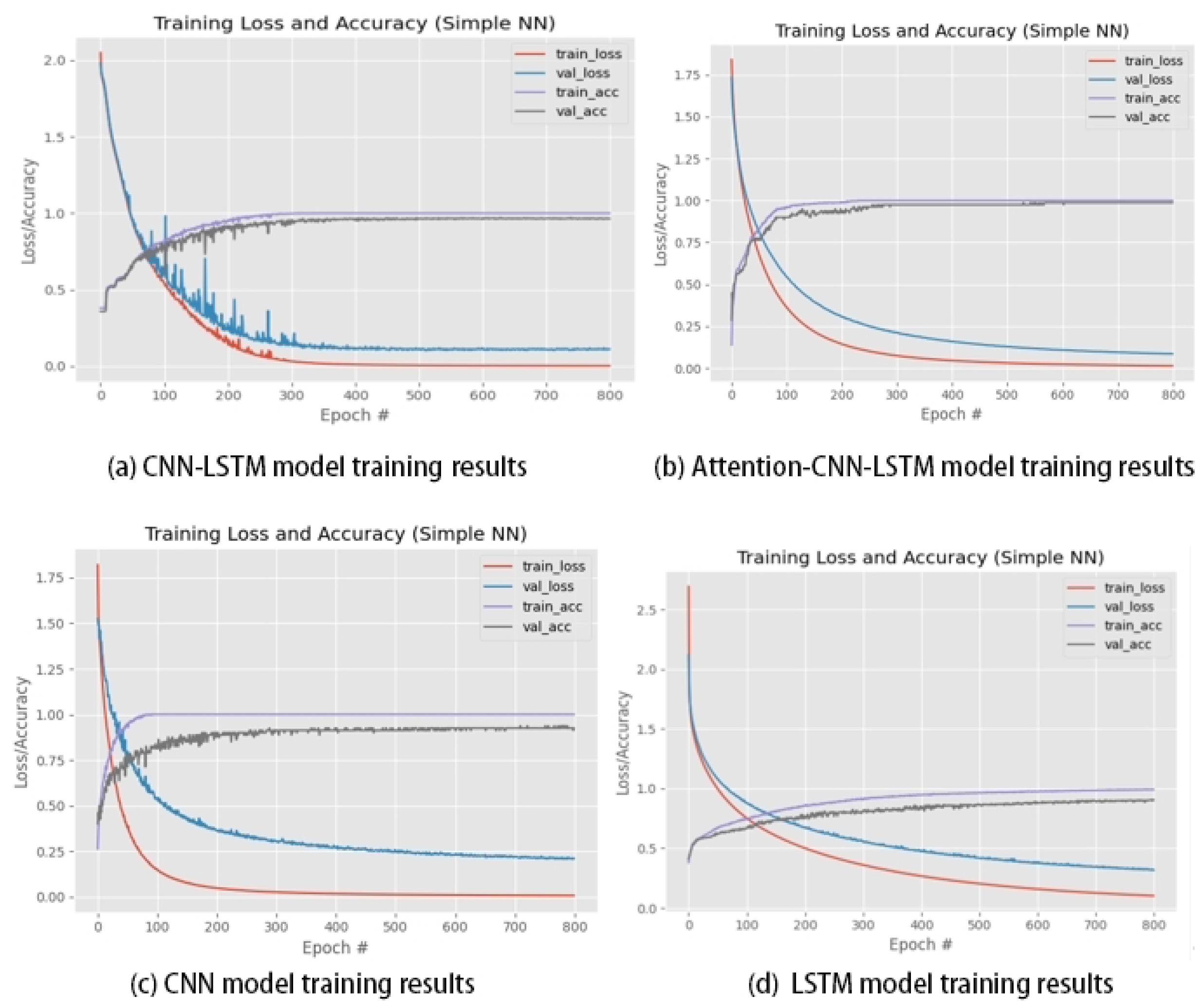
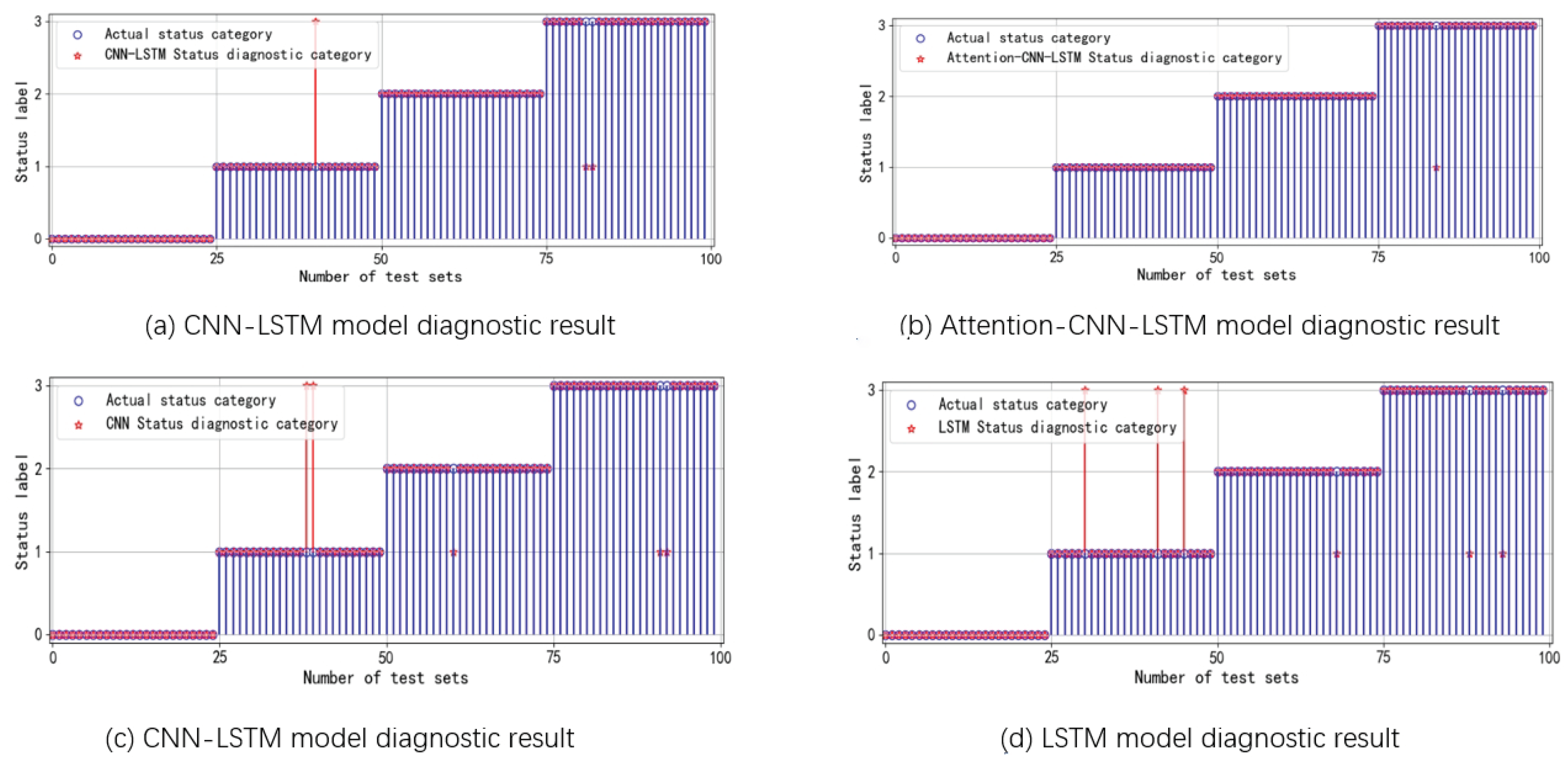
5.2. Detection Performance Analysis
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, G.; Yu, C.; Liu, Y.; Fan, H.; Wen, F.; Song, Y. Power transformer fault prediction and health management: Challenges and prospects. Power Syst. Autom. 2017, 41, 156–167. [Google Scholar]
- Hussain, M.R.; Refaat, S.S.; Abu-Rub, H. Overview and partial discharge analysis of power transformers: A literature review. IEEE Access 2021, 9, 64587–64605. [Google Scholar] [CrossRef]
- Duval, M. The duval triangle for load tap changers, non-mineral oils and low temperature faults in transformers. IEEE Electr. Insul. Mag. 2008, 24, 22–29. [Google Scholar] [CrossRef]
- Duval, M. New techniques for dissolved gas-in-oil analysis. IEEE Electr. Insul. Mag. 2003, 19, 6–15. [Google Scholar] [CrossRef]
- Ghoneim, S.S.; Taha, I.B. A new approach of DGA interpretation technique for transformer fault diagnosis. Int. J. Electr. Power Energy Syst. 2016, 81, 265–274. [Google Scholar] [CrossRef]
- Amora, M.A.B.; Almeida, O.d.M.; Braga, A.P.d.S.; Barbosa, F.R.; Lisboa, L.; Pontes, R. Improved DGA method based on rules extracted from high-dimension input space. Electron. Lett. 2012, 48, 1048–1049. [Google Scholar] [CrossRef]
- Kim, S.W.; Kim, S.J.; Seo, H.D.; Jung, J.R.; Yang, H.J.; Duval, M. New methods of DGA diagnosis using IEC TC 10 and related databases Part 1: Application of gas-ratio combinations. IEEE Trans. Dielectr. Electr. Insul. 2013, 20, 685–690. [Google Scholar]
- Mansour, D.E.A. Development of a new graphical technique for dissolved gas analysis in power transformers based on the five combustible gases. IEEE Trans. Dielectr. Electr. Insul. 2015, 22, 2507–2512. [Google Scholar] [CrossRef]
- Li, X.; Wu, H.; Wu, D. DGA interpretation scheme derived from case study. IEEE Trans. Power Deliv. 2010, 26, 1292–1293. [Google Scholar] [CrossRef]
- Soni, R.; Chaudhari, K. An approach to diagnose incipient faults of power transformer using dissolved gas analysis of mineral oil by ratio methods using fuzzy logic. In Proceedings of the 2016 International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), Odisha, India, 3–5 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1894–1899. [Google Scholar]
- Seo, J.; Ma, H.; Saha, T.K. A joint vibration and arcing measurement system for online condition monitoring of onload tap changer of the power transformer. IEEE Trans. Power Deliv. 2016, 32, 1031–1038. [Google Scholar] [CrossRef]
- Min, L.; Huamao, Z.; Annan, Q. Voiceprint Recognition of Transformer Fault Based on Blind Source Separation and Convolutional Neural Network. In Proceedings of the 2021 IEEE Electrical Insulation Conference (EIC), Virtual, 7–28 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 618–621. [Google Scholar]
- Wang, S.; Zhao, B.; Du, J. Research on transformer fault voiceprint recognition based on Mel time-frequency spectrum-convolutional neural network. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2022; Volume 2378, p. 012089. [Google Scholar]
- Dang, X.; Wang, F.; Ma, W. Fault Diagnosis of Power Transformer by Acoustic Signals with Deep Learning. In Proceedings of the 2020 IEEE International Conference on High Voltage Engineering and Application (ICHVE), Beijing, China, 6–10 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Yu, Z.; Li, D.; Chen, L.; Yan, H. The research on transformer fault diagnosis method based on vibration and noise voiceprint imaging technology. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 216–221. [Google Scholar]
- He, P.; Xu, H.; Yin, L.; Wang, L.; Zhu, L. Power Transformer Voiceprint Operation State Monitoring Considering Sample Unbalance. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 2137, p. 012007. [Google Scholar]
- Gu, C.; Qin, Y.; Wang, Y.; Zhang, H.; Pan, Z.; Wang, Y.; Shi, Y. A transformer vibration signal separation method based on BP neural network. In Proceedings of the 2018 IEEE International Power Modulator and High Voltage Conference (IPMHVC), Jackson, WY, USA, 3–7 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 312–316. [Google Scholar]
- Wang, F.; Wang, S.; Chen, S.; Yuan, G.; Zhang, J. Transformer voiceprint recognition model based on improved MFCC and VQ. Proc. Chin. Soc. Electr. Eng. 2017, 37, 1535–1543. [Google Scholar]
- Tossavainen, T. Sound Based Fault Detection System. Master’s Thesis, Aalto University, Espoo, Finland, 2015. [Google Scholar]
- Negi, R.; Singh, P.; Shah, G.K. Causes of noise generation & its mitigation in transformer. Int. J. Adv. Res. Electr. Electron. Instrum. Eng. 2013, 2, 1732–1736. [Google Scholar]
- Ye, F.; Yang, J. A deep neural network model for speaker identification. Appl. Sci. 2021, 11, 3603. [Google Scholar] [CrossRef]
- Sahidullah, M.; Saha, G. A novel windowing technique for efficient computation of MFCC for speaker recognition. IEEE Signal Process. Lett. 2012, 20, 149–152. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Moradzadeh, A.; Mohammadi-Ivatloo, B.; Abapour, M.; Anvari-Moghaddam, A.; Gholami Farkoush, S.; Rhee, S.B. A practical solution based on convolutional neural network for non-intrusive load monitoring. J. Ambient Intell. Humaniz. Comput. 2021, 12, 9775–9789. [Google Scholar] [CrossRef]
- Graves, A. Long short-term memory. In Supervised Sequence Labelling with Recurrent Neural Networks; Springer: Berlin/Heidelberg, Germany, 2012; pp. 37–45. [Google Scholar]
- Wang, S.; Wang, X.; Wang, S.; Wang, D. Bi-directional long short-term memory method based on attention mechanism and rolling update for short-term load forecasting. Int. J. Electr. Power Energy Syst. 2019, 109, 470–479. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Ju, Y.; Li, J.; Sun, G. Ultra-short-term photovoltaic power prediction based on self-attention mechanism and multi-task learning. IEEE Access 2020, 8, 44821–44829. [Google Scholar] [CrossRef]
- Tay, N.C.; Tee, C.; Ong, T.S.; Teh, P.S. Abnormal behavior recognition using CNN-LSTM with attention mechanism. In Proceedings of the 2019 1st International Conference on Electrical, Control and Instrumentation Engineering (ICECIE), Kuala Lumpur, Malaysia, 25 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Xiang, L.; Wang, P.; Yang, X.; Hu, A.; Su, H. Fault detection of wind turbine based on SCADA data analysis using CNN and LSTM with attention mechanism. Measurement 2021, 175, 109094. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, P.; Wang, X.; Zhang, X.; Qin, Z. A study on water quality prediction by a hybrid dual channel CNN-LSTM model with attention mechanism. In Proceedings of the International Conference on Smart Transportation and City Engineering 2021, Chongqing, China, 6–8 August 2021; SPIE: Bellingham, WA, USA, 2021; Volume 12050, pp. 797–804. [Google Scholar]
- Zhang, W.; Dong, X.; Li, H.; Xu, J.; Wang, D. Unsupervised detection of abnormal electricity consumption behavior based on feature engineering. IEEE Access 2020, 8, 55483–55500. [Google Scholar] [CrossRef]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Nandi, S.; Toliyat, H.A.; Li, X. Condition monitoring and fault diagnosis of electrical motors—A review. IEEE Trans. Energy Convers. 2005, 20, 719–729. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Quiet Environment/pcs | Thunderstorm Environment/pcs | Fan Environment/pcs |
|---|---|---|---|
| Normal operation | 125 | 60 | 75 |
| Overload | 75 | 35 | 50 |
| Discharge | 70 | 40 | 45 |
| Model | State | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Attention-CNN-LSTM | Normal operation | 99.6% | 99.8% | 0.997 |
| discharge | 99.8% | 99.8% | 0.998 | |
| overload | 99.2% | 99.4% | 0.993 | |
| CNN-LSTM | Normal operation | 96.4% | 97.6% | 0.97 |
| discharge | 98.2% | 98.8% | 0.985 | |
| overload | 96.2% | 97.2% | 0.967 | |
| CNN | Normal operation | 90.5% | 91.3% | 0.909 |
| discharge | 91.4% | 92.2% | 0.918 | |
| overload | 90.2% | 90.3% | 0.902 | |
| LSTM | Normal operation | 92.6% | 91.8% | 0.922 |
| discharge | 93.4% | 93.6% | 0.935 | |
| overload | 91.3% | 91.5% | 0.914 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, D.; Zhang, W.; Wang, H. Research on Transformer Voiceprint Anomaly Detection Based on Data-Driven. Energies 2023, 16, 2151. https://doi.org/10.3390/en16052151
Yu D, Zhang W, Wang H. Research on Transformer Voiceprint Anomaly Detection Based on Data-Driven. Energies. 2023; 16(5):2151. https://doi.org/10.3390/en16052151
Chicago/Turabian StyleYu, Da, Wei Zhang, and Hui Wang. 2023. "Research on Transformer Voiceprint Anomaly Detection Based on Data-Driven" Energies 16, no. 5: 2151. https://doi.org/10.3390/en16052151
APA StyleYu, D., Zhang, W., & Wang, H. (2023). Research on Transformer Voiceprint Anomaly Detection Based on Data-Driven. Energies, 16(5), 2151. https://doi.org/10.3390/en16052151