1. Introduction
Non-intrusive load monitoring (NILM) technology decomposes the total load information at a power entrance to obtain information about the amount of electricity consumption of each equipment load, providing technical support for efficient power management [
1,
2]. NILM technology is a low-cost energy consumption monitoring and management method that can effectively reduce energy waste in buildings and has important practical implications for achieving “carbon peaking” and “carbon neutrality” [
3,
4].
NILM was first proposed by Professor George W. Hart in 1992 and was developed to simplify the process of collecting energy consumption data [
5]. The development of instrumentation, computer technology, and the release of various public datasets such as REDD [
6] and UK-DALE [
7], provided a database and technical support system for non-invasive load decomposition [
2]. Kelly et al. developed a non-invasive load decomposition toolkit (NILMTK) based on traditional algorithms in 2014 [
8]. Then, they started investigating the application of deep learning algorithms in this field and used long short-term memory (LSTM) networks, denoising autoencoders (DAE), and convolutional neural networks (CNN) to solve non-intrusive load decomposition problems in 2015 [
9]. In 2019, Batra et al. updated the toolkit by including the latest algorithms capable of performing load decomposition tasks at that time [
10].
Up until now, the vast amount of NILM research that has been conducted by domestic and foreign scholars can be divided into two categories based on the frequency of data acquisition: (1) load decomposition methods based on high-frequency data and (2) load decomposition methods based on low-frequency data [
2]. The data acquired by high-frequency acquisition (>1 Hz) contain richer information in regard to certain electrical parameters, such as harmonics, electromagnetic interference, V-I trajectory information, etc. For example, reference [
1] collects harmonics, voltage-to-ampere ratio coefficients, and other features from real data, and proposes a non-intrusive load identification method based on the feature-weighted k-nearest neighbor (KNN) algorithm, solving the problem of misjudgment when identifying certain classes of loads in unbalanced datasets. In prior research [
3], there have been instances of U-I trajectory images being constructed using voltage and current data acquired at high frequencies, while devices are accurately identified using a non-intrusive load decomposition method based on color coding. However, the acquisition of high-frequency data requires high-level measurement equipment, which involves a complex process of high costs and is therefore not suitable for residential electricity loads [
11].
For these reasons, researchers have shifted their focus to the study of improving the accuracy of load decomposition based on low-frequency data (≤1 Hz) obtained from smart meters [
12]. Prior work [
13] proposed the adaptive density peak clustering-factorial hidden Markov model (ADP-FHMM) to reduce the dependence of prior information. Another study [
14] introduced the appliances ON-OFF state identification factor in the hidden Markov model (HMM) to improve the accuracy of load decomposition. In [
15], a non-linear support vector machine (SVM) approach is proposed to address the NILM problem. The method uses power differences to detect events for the switching states of electrical equipment, and [
16] used the K-nearest neighbor algorithm (KNN) to solve the NILM problem, investigating the optimal settings of KNN variants.
However, both HMM-based methods and machine learning methods, such as SVM and KNN-based methods, require manual feature extraction. In contrast, deep neural network methods can automatically extract features without human involvement [
17]. Prior work [
18] has used the convolutional neural nets (CNN) model with sequence to point (seq2point) to reduce the misclassification rate of load decomposition. In another study [
19], a preliminary exploration of the appliance transfer learning (ATL) and cross region transfer learning (CTL) capabilities of the model proposed in reference [
18] was conducted, and the experimental results demonstrated that, while the seq2point model displays some capacity for generalization performance, parameter tuning is still required when applied to different datasets. Others [
11] improved on this algorithm [
18] by introducing the channel attention and spatial attention mechanisms into the sequence-to-point model, which improved the load decomposition efficiency. Another study [
20] proposed a load disaggregation with attention (LDwA) model, which combines a regression sub-network with a classification sub-network. Here, the regression sub-network uses an encoder-decoder structure with an attention mechanism, and the classification sub-network uses a full convolutional network, relatively improving the generalization ability of the model. However, there is no evidence of any improvement with regard to the decomposition effect for multi-state appliances.
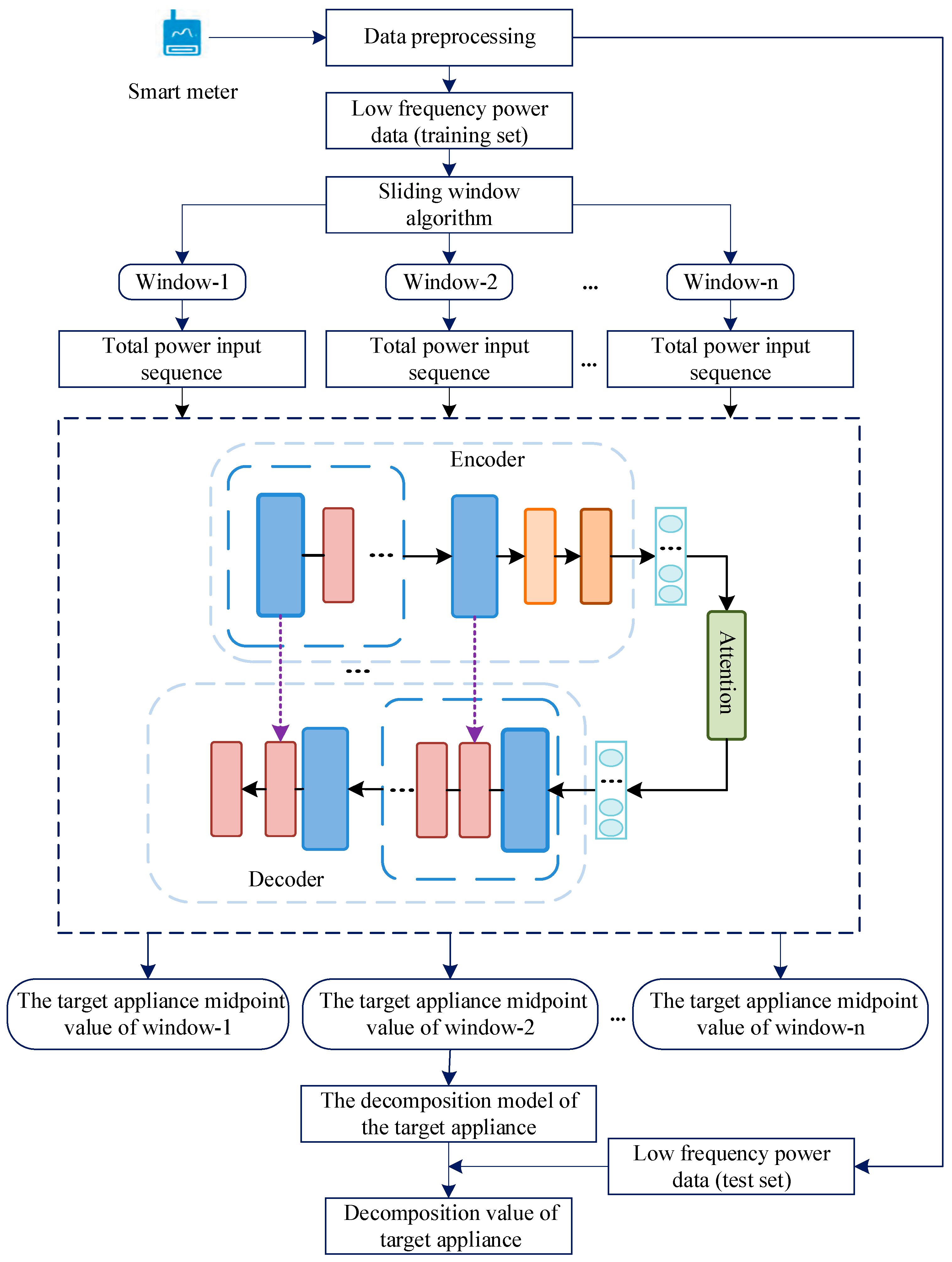
Although the performance of non-intrusive load decomposition methods for low-frequency sampling has greatly improved, generalization performance remains a comparatively difficult challenge to overcome. Therefore, in this paper, we seek to improve upon the classical seq2point model by applying instance-batch normalization networks (IBN-Net) to achieve better generalization performance capabilities in the field of non-intrusive load decomposition. The proposed model uses an encoder-decoder structure with a fused attention mechanism, in which the encoder and decoder are composed of multiple layers of IBN-Net with integrated instance normalization (IN) and batch normalization (BN) structures. This model allows the shallow output of the encoder to be fed into the corresponding layer of the decoder using a skip connection, improving the multi-scale information fusion capability of the network, and helping the encoder to construct more accurate power sequences of the target appliances. In this paper, the model is trained and tested using two publicly available datasets, REDD and UK-DALE. We also compare the proposed algorithm with current, more advanced algorithms, and the experimental results provide support for the accuracy and effectiveness of our proposed algorithm.
3. Seq2point Model Based on IBN-Net Codec Mechanism
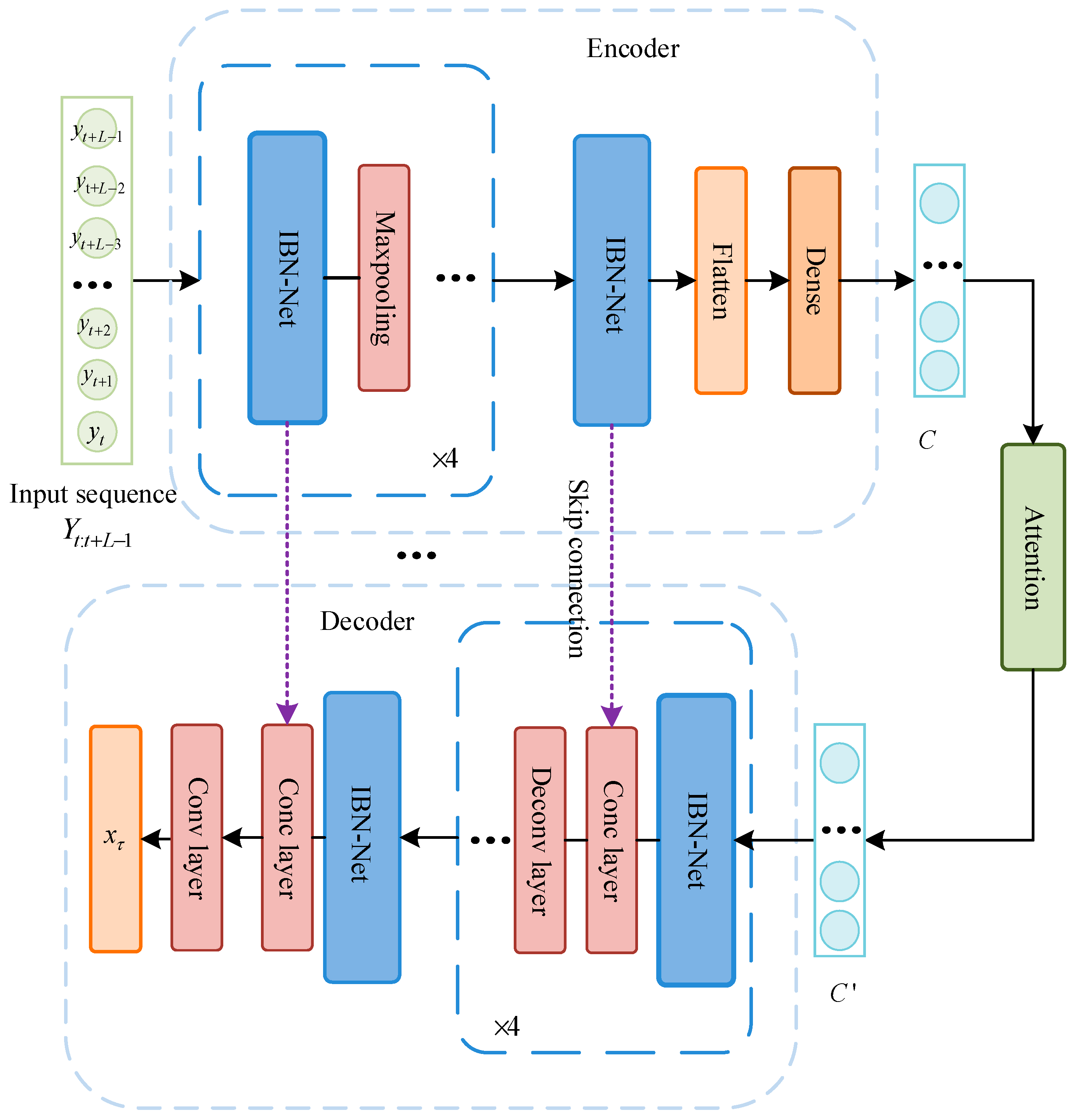
In this paper, a sequence-to-point architecture is used, with internal replacement serving as an IBN-Net-based encoding-decoding mechanism, while the whole network consists two components, as shown in
Figure 2. The encoder extracts the power information of the target appliance from the total power window sequence
and maps it to the context vector
,
,
for the hidden state at the moment of the input sequence
generated during the encoding process. This is represented by Equation (3).
The decoding process is shown by Equation (4):
where:
is the encoding function;
is the decoding function;
,
and
,
are the function weights and biases of the encoding and decoding layers, respectively; and
is the dynamically variable context vector in the decoding process, which is generated by the attention mechanism between the encoder and decoder.
The encoder primarily consists multiple IBN-Net sub-modules, each of which is followed by a maximum pooling layer to reduce the temporal resolution and facilitate the network learning the high-level features of the target device, while the output of the IBN-Net stack is converted into a context vector
C by a fully connected layer (Dense). The decoder has a similar structure to the encoder, consisting the same number of IBN-Net modules, where each IBN-Net is followed by a deconvolution layer to progressively increase the temporal resolution and reconstruct the signal from the target device. In addition, a skip connection function has been added to connect the output of the corresponding IBN-Net layer from the encoder to the decoder, as shown in
Figure 2. The skip connection can help the decoder better fuse the features extracted from the shallow network of the encoder and allow for a more accurate reconstruction of the target device power sequence. Skip connections between corresponding layers in the encoder and decoder are implemented using the concatenate (Conc) layer. After repeated experiments, the number of layers of the IBN-Net sub-module in the encoder was determined to be five layers. The maximum pooling layer divides the temporal resolution by two for each step in the encoder, while the deconvolution operation in the decoder multiplies the temporal resolution in the decoder by two.
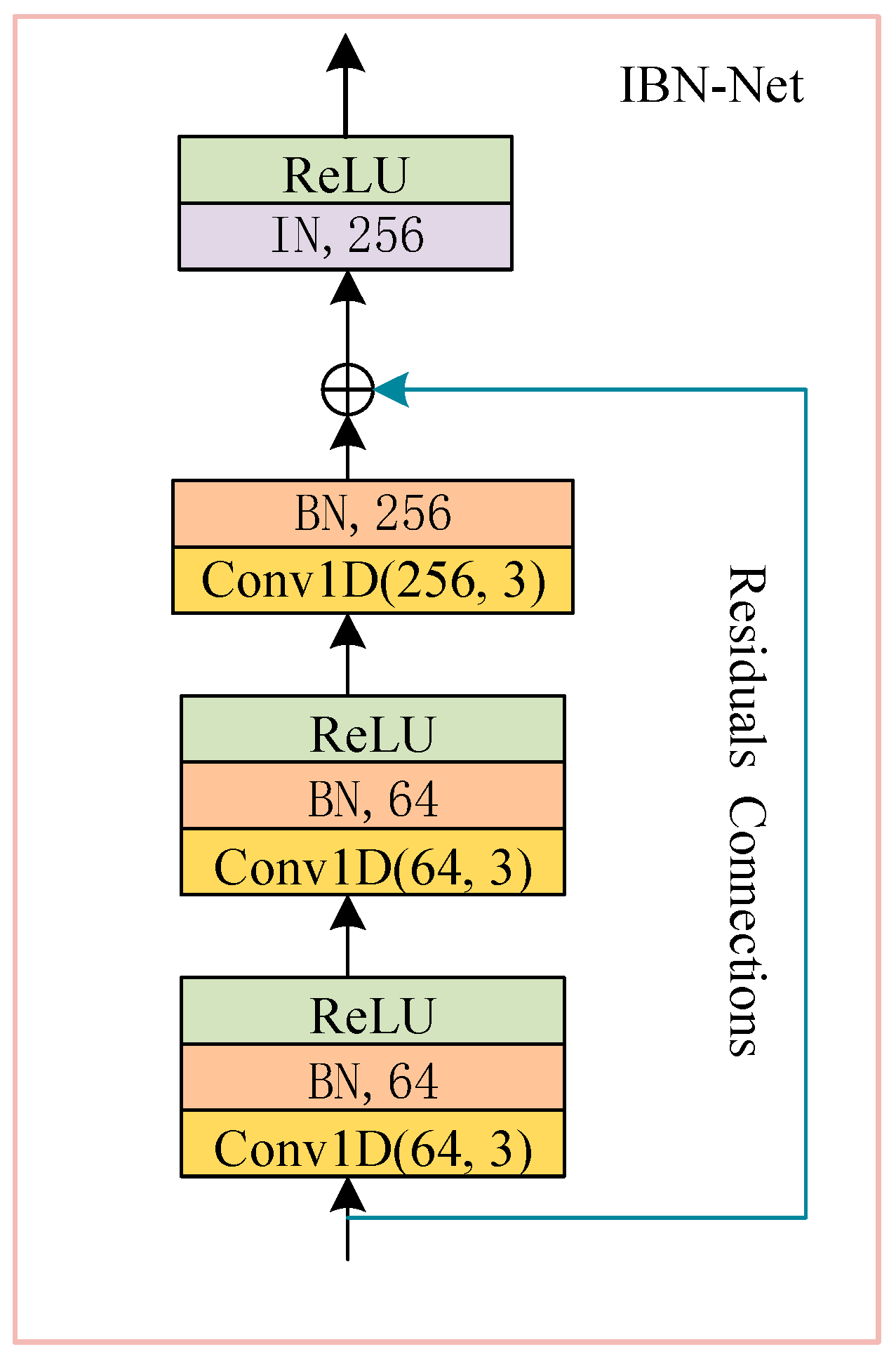
3.1. IBN-Net Sub-Module
The instance and batch normalization network is a new convolutional network structure that integrates instance normalization (IN) and batch normalization (BN) [
21,
22]. This integration enhances the CNN’s generalization ability across domains (e.g., load data of other households or other datasets) without fine-tuning [
23].
Depending on the different configurations of BN and IN, the IBN-Net can have different structures and be applied to a variety of scenarios. The structure of the IBN-Net sub-module in this paper is shown in
Figure 3. The IBN-Net consists three consecutive convolutional layers with a shallow convolutional module combining batch normalization and a corrected linear unit activation function (ReLU). The number of filters in the convolutional layers in all IBN-Net networks is either 64 or 256, respectively, and the kernel size is three. The input of the IBN-Net is connected to the instance normalization layer using residual connections so that the gradients can circulate throughout the model during training, effectively preventing the gradient disappearance problem.
3.2. Attention Mechanism
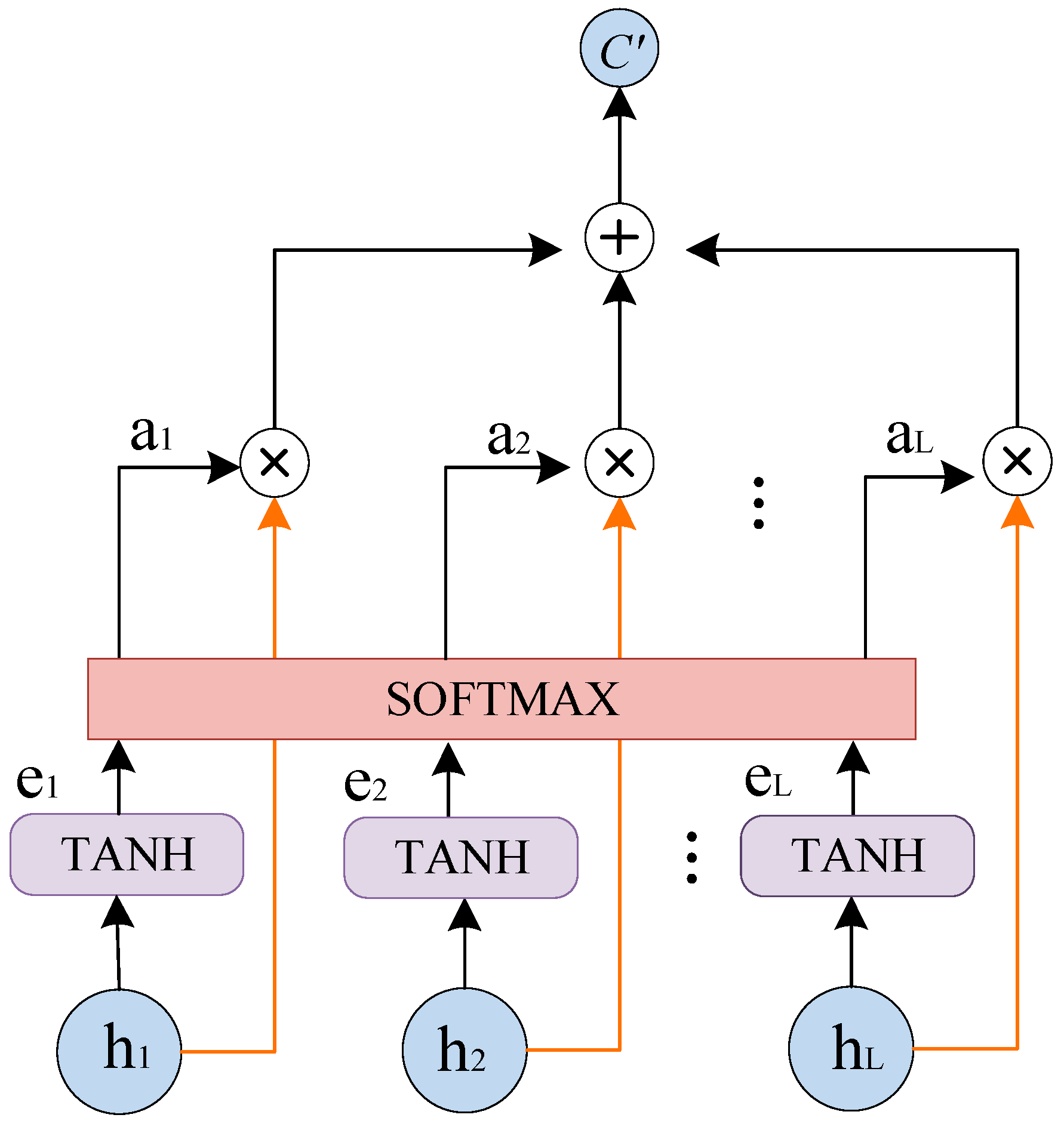
In the classical encoder-decoder architecture, only the context vector
is used between the codecs to represent the information of the whole input sequence. As a result, the fixed-length vector
is not capable of carrying all the information from the input when the length of the input sequence increases to a certain level, revealing the limitations of the model’s information processing capabilities. The introduction of the attention mechanism solves this problem by providing the model with a corresponding focus that can be enabled at different points during decoding, thus enhancing the information utilization capability of the model [
24].
Inspired by a previous study [
18], the attention mechanism between the encoder and the decoder in this study was designed as a single-layer feedforward neural network. This neural network computes the attention weights and returns a weighted average of the encoder’s output over time, i.e., the context vector
. The attention unit captures moments of significant activation by the target device in the encoder output features, extracting the feature information that is deemed to be most valuable for decomposition. This process allows the network to implicitly detect certain events (e.g., turning devices on or off) and specific signal components (e.g., high power consumption) for the purpose of assigning them higher weights. The calculation process of the attention unit is shown in
Figure 4. Its mathematical definition is shown in Equations (5)–(7).
Its mathematical definition is
where
,
, and
are parameters learned in conjunction with other components of the network and are continuously adjusted with training.
4. Data Pre-Processing and Experimental Setup
4.1. Dataset Selection
The following two publicly available datasets, which contain data from different countries, were selected for this paper.
The UK-DALE dataset [
6] was first published by Jack Kelly in 2015 and contains data on the active power (as distinguished from total power) and sub-devices of five UK homes. The five houses that were analyzed contain 54, 20, 5, 6, and 26 sub-metering devices, respectively, with a sampling period of 6 s collected over roughly 1 to 2.5 years.
The REDD dataset [
7] was released in 2011 and collected data on the total house power and sub-equipment energy consumption from six U.S. households, sampled at 1 Hz. It also contains high-frequency data on the main power supply of the two houses, though it should be noted that the model in our study is primarily concerned with energy consumption data sampled at low frequencies.
4.2. Electrical Selection
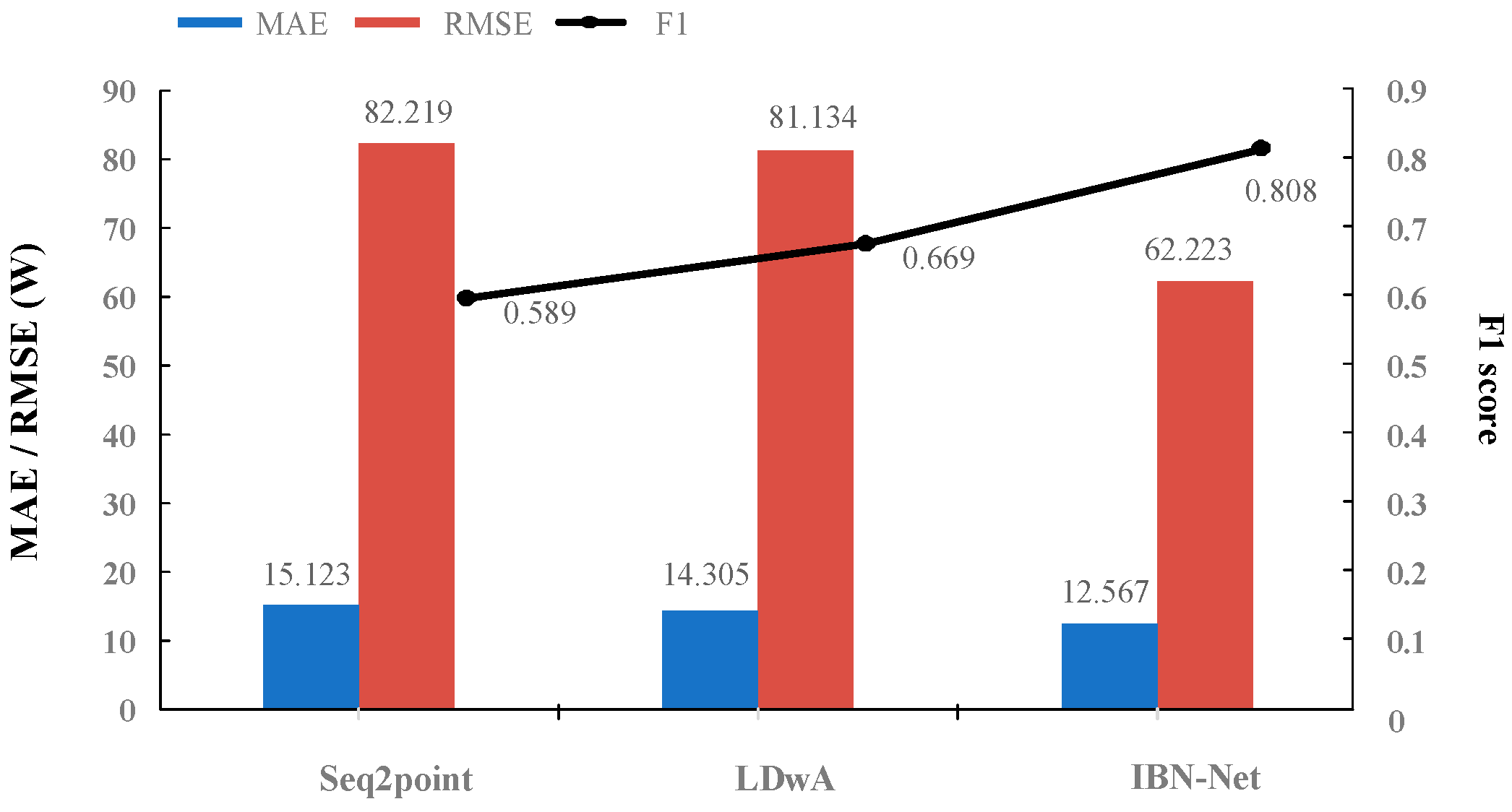
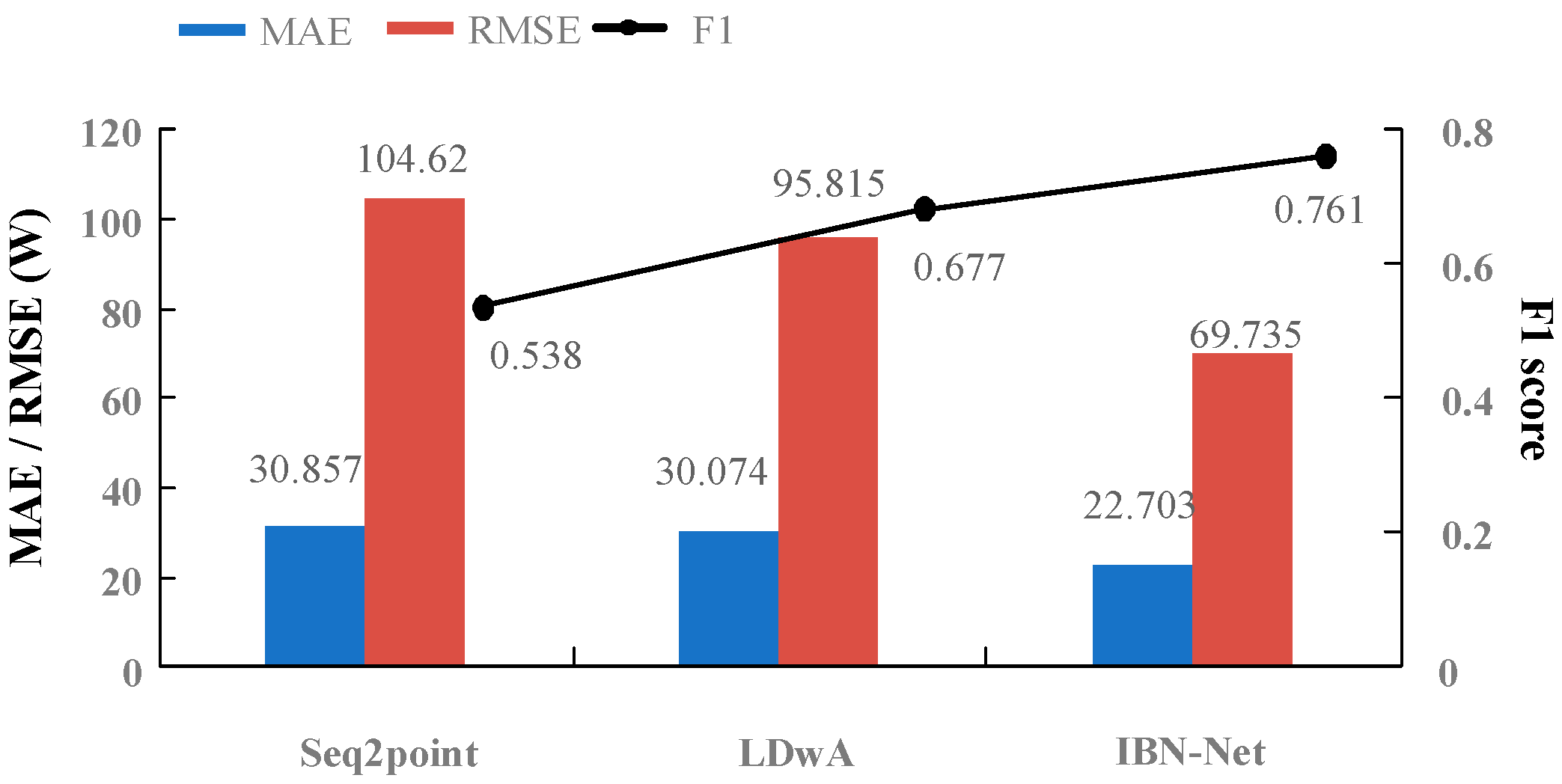
Regarding appliance selection, four appliances were selected for this paper: a refrigerator, a dishwasher, a microwave oven, and a washing machine. These four appliances were chosen in accordance with the findings of prior research, while also considering the distribution of appliances in the two aforementioned datasets. Additionally, the different operating characteristics of the four appliances allow for a full verification of the proposed model’s load decomposition performance. Refrigerators (RF) and microwaves (MW) are typical switching appliances, while washing machines (WM) and dishwashers (DW) are multi-state appliances. They exist in multiple households in both datasets, which is beneficial when testing for generalization performance.
4.3. Data Pre-Processing
Since the sampling frequencies of the two datasets are not uniform, it was necessary to downsample the REDD dataset; this downsampling was performed using a 6 s sampling interval.
After downsampling, missing data were patched and missing data longer than 3 min (i.e., those with more than 30 consecutive missing data points) were attributed to device shutdown; therefore, the corresponding elements were nullified. Gap filtering was performed for data segments that were missing data shorter than 3 min (i.e., those with less than 30 consecutive missing data points). The gap filtering was performed according to previously established methods [
25].
After obtaining the experimental data, the data were normalized using Equation (8).
where
is the normalized value;
indicates the reading of the total power supply or experimental appliance at time
t;
indicates the mean value of the total power supply or experimental appliance, and
indicates the standard deviation of the total power supply or of the experimental appliance. The mean and standard deviation were calculated from the data used in the current experiment.
4.4. Experimental Setup
The hardware environment uses a 64-bit computer with an Intel(R) CoreTM i7-11700 CPU @ 2.5 GHz and a GeForce GTX3060. The software platform is a Win10 operating system running Python 3.6.13 (64-bit) and the Tensorflow 2.4.0 framework. The development environment of the experiment was created using the NILMTK v0.4. Keras, an artificial neural network library using TensorFlow as its backend, was used to build the model in this study. The mean square error was chosen as the loss function and the Adam optimizer was used to adjust the model parameters. The validation set loss during training was monitored using the ModelCheckpoint callback function in Keras for the purpose of saving the best models that emerged during the training process. All experiments were iterated for 100 epochs, and early stopping was used during the training process to prevent overfitting. The patience of the early stopping mechanism was set to 20, i.e., we waited for 20 epochs following the last validation loss improvement before interrupting the training loop.
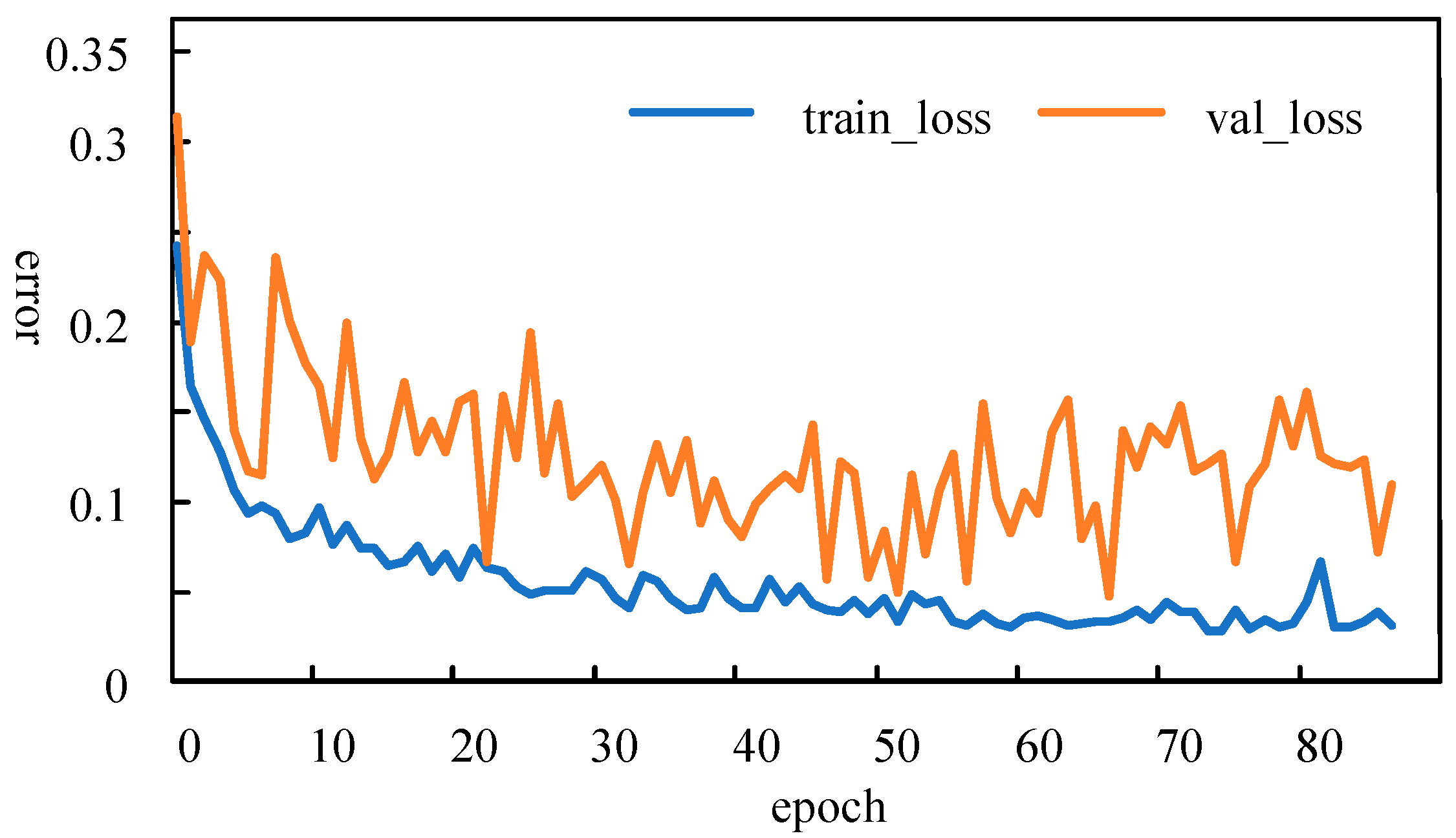
Figure 5 shows the trend of validation loss and training loss during one of the training sessions. The yellow curve represents the validation loss, and the blue curve represents the training loss. The horizontal axis indicates the number of training iterations, and the vertical axis represents the value of loss. During the training process, the validation loss reached its minimum value at the 67th iteration, at which point the weights and other training parameters were saved. The validation loss did not decrease further during the next 20 iterations, so the training loop was interrupted at the 87th iteration, according to the early stopping mechanism. It is worth noting that both the “train_loss” and “val_loss” are dimensionless values because they were normalized during the data pre-processing stage.
4.5. Performance Metrics
Mean absolute error (
MAE) and root mean square error (
RMSE) are commonly used in the field of non-invasive load decomposition as metrics to evaluate the decomposition accuracy of algorithms [
2]. Therefore, this study likewise used these two kinds of performance metrics to analyze the load decomposition accuracy. The calculation methods are shown in Equations (9) and (10), respectively.
where
m is the number of sample points;
is the true value of the
kth sample point of the target appliance; and
is the predicted value of the
k-th sample point of the target appliance. Both
MAE and
RMSE are expressed in watts.
In addition, to measure the recognition accuracy of each device being in either the on or off state, we used the classification metric
F1 score, which is the harmonic mean of precision (
P) and recall (
R).
where
TP indicates the number of samples when the target appliance is actually in operation and the predicted value is determined to be in operation;
FP indicates the number of samples when the target appliance is actually off and the predicted value is determined to be in operation; and
FN indicates the number of samples when the target appliance is actually in operation and the predicted value is determined to be off [
20]. When the active power is greater than a specific threshold, the appliance is considered to be “on”, and when the active power is less than or equal to the same threshold, it is considered to be “off.” The particular threshold, 15 W, was chosen in accordance with prior studies [
20]. Precision, recall, and the
F1 score were represented by a value between 0 and 1. A higher
F1 score indicates a better classification performance for the model [
12].














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}