
An Ultra-Short-Term PV Power Forecasting Method for Changeable Weather Based on Clustering and Signal Decomposition

Abstract
:1. Introduction
2. Weather Clustering Method Based on Photovoltaic Power Fluctuation Characteristics
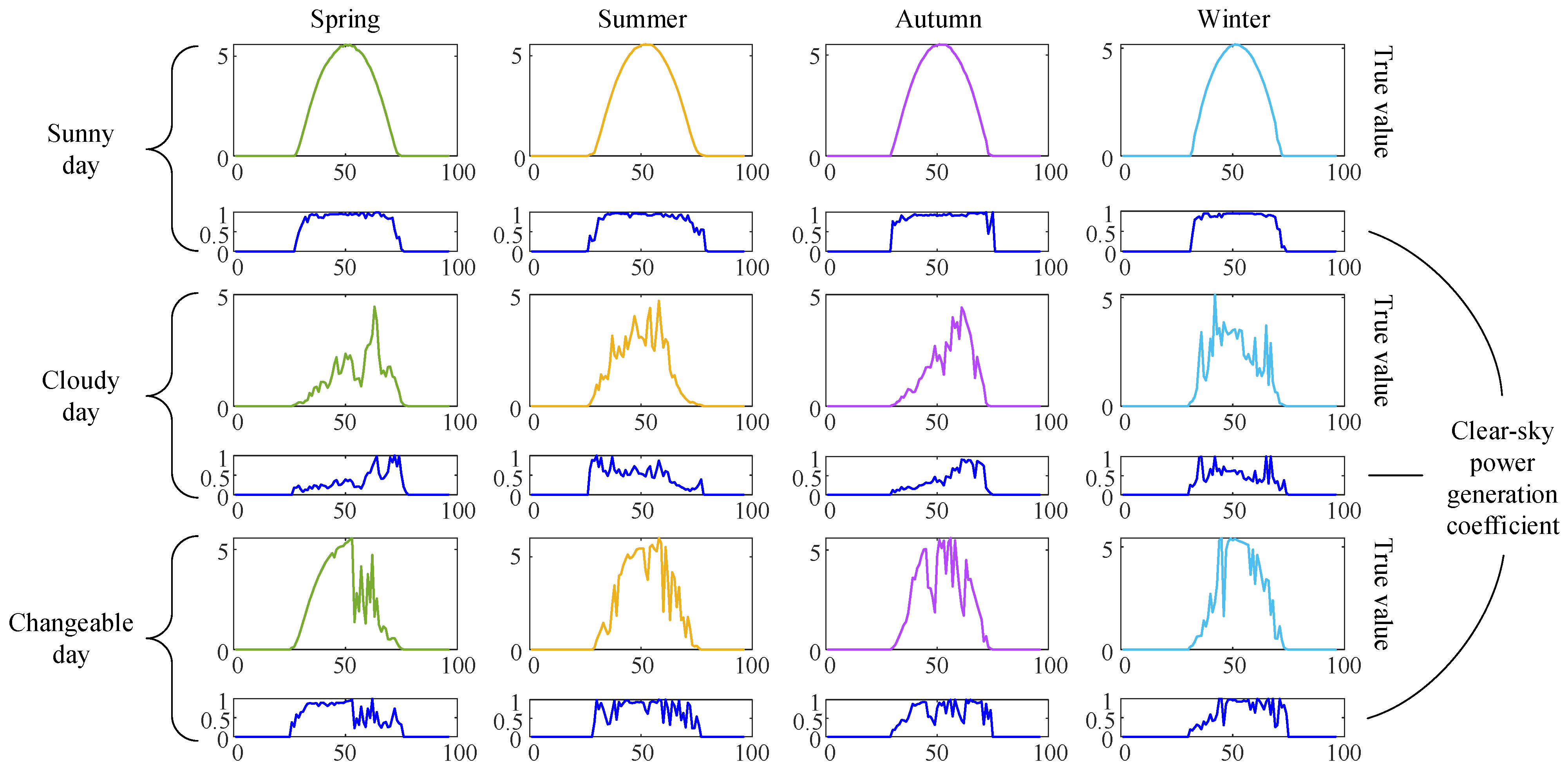
2.1. Clear-Sky Normalization
2.2. AP Clustering Algorithm
3. Photovoltaic Power Ultra-Short-Term Forecast Portfolio Model
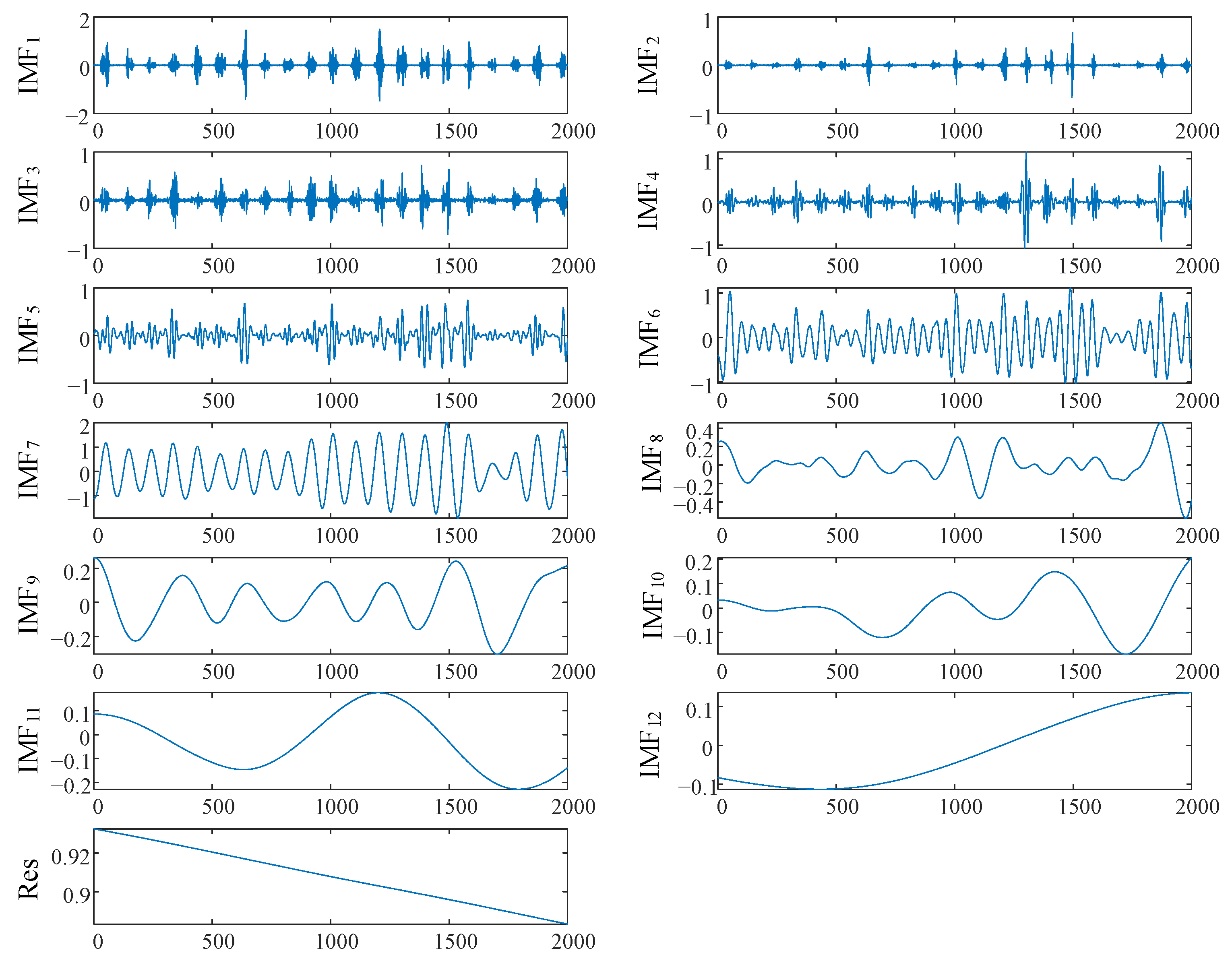
3.1. CEEMDAN Decomposition Algorithm
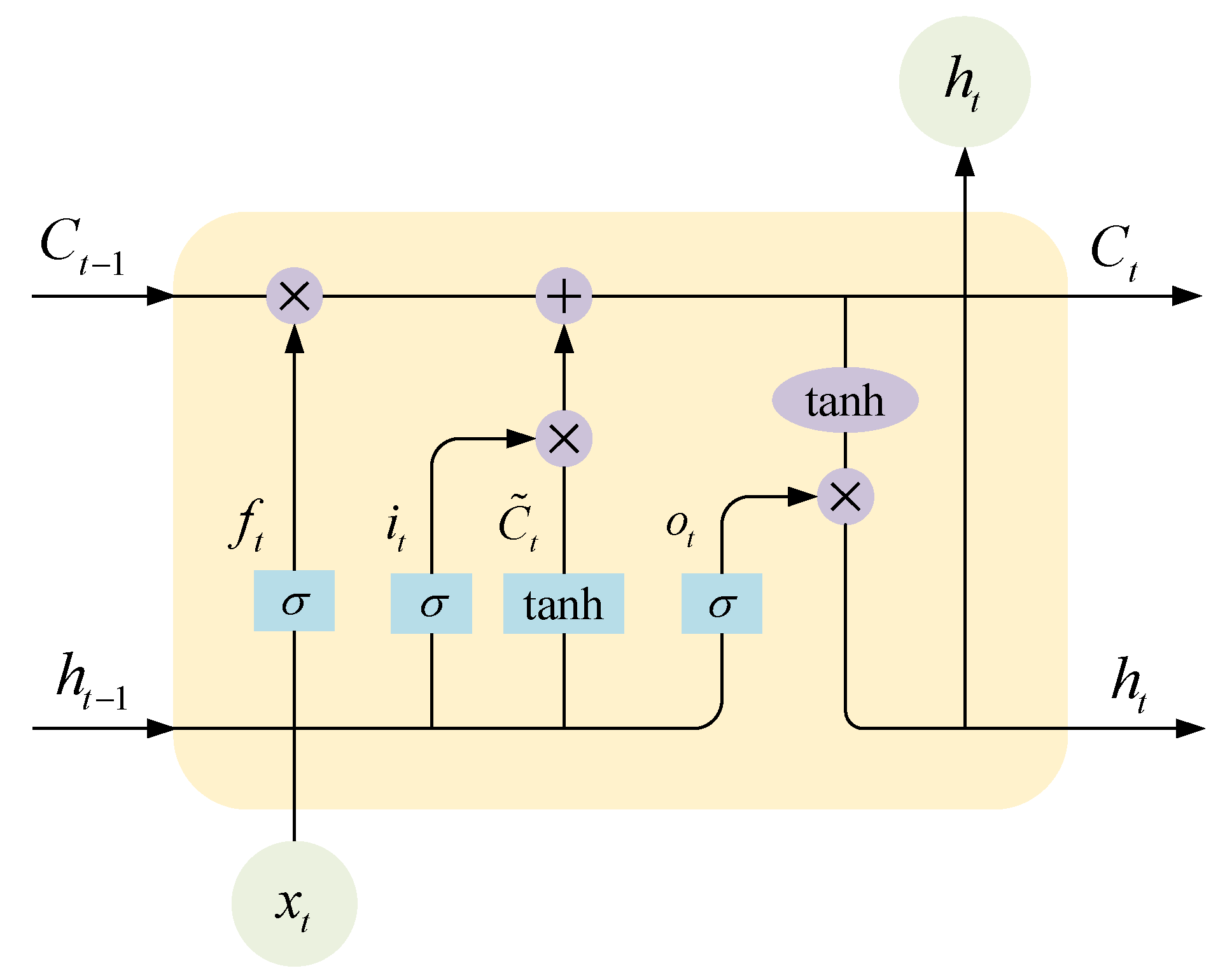
3.2. BiLSTM Neural Network
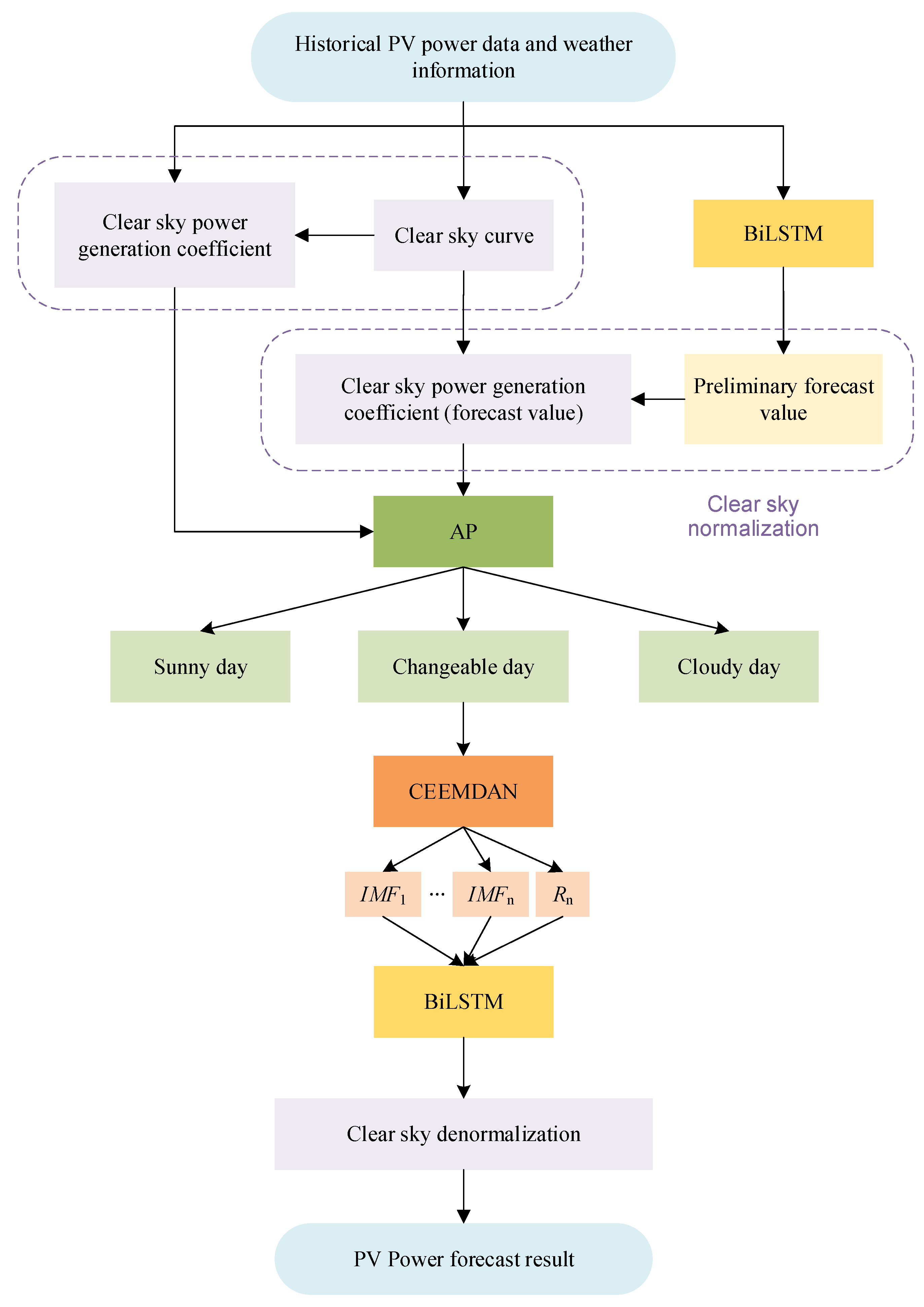
3.3. Combined Model Forecasting Process
- Clear-sky normalization: Using the PV power history data of the whole year as the dataset, the maximum value of each moment in each month in the dataset was extracted to form the monthly clear-sky curve, which represents the standard “clear-sky days” of each month. The historical power data and the preliminary forecasted value of future power were normalized with the clear-sky curve as the standard, and the CSPC (including the real value in the past and the forecasted value in the future) was obtained;
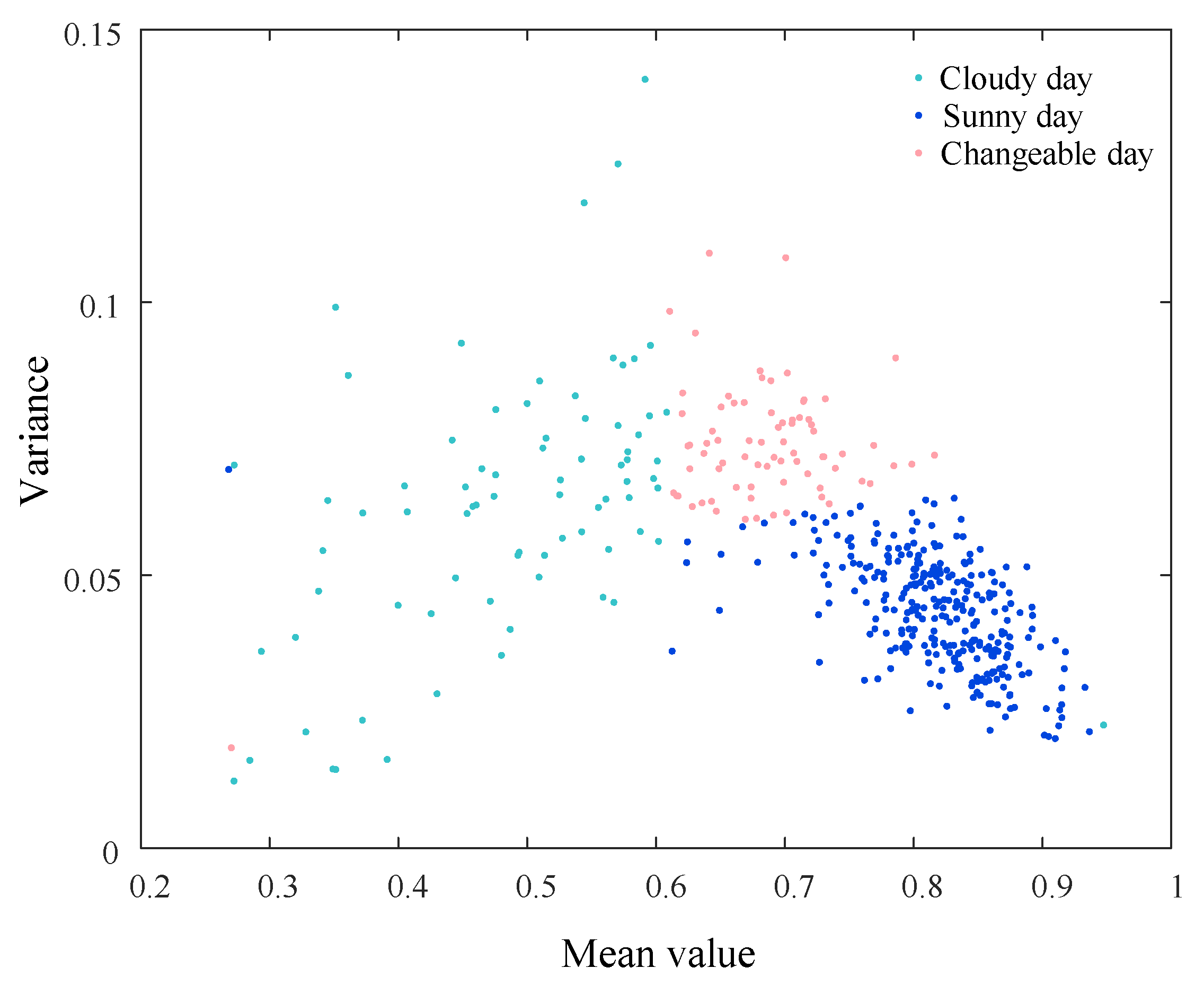
- AP weather clustering: The mean and variance of daily CSPC were calculated and subsequently used as clustering indicators for AP clustering, classifying data points into three weather types based on PV output characteristics: sunny, cloudy, and changeable weather;
- Combined CEEMDAN-BiLSTM model: The CEEMDAN decomposition algorithm was used to decompose the changeable day data into n IMF components and one residual component in order to reduce the non-stationarity of the data, and they were then input into the BiLSTM network for the forecasting;
- Clear-sky denormalization: The CSPC was denormalized according to the clear-sky curve in order to obtain the final power forecasting results.
4. Results and Analysis
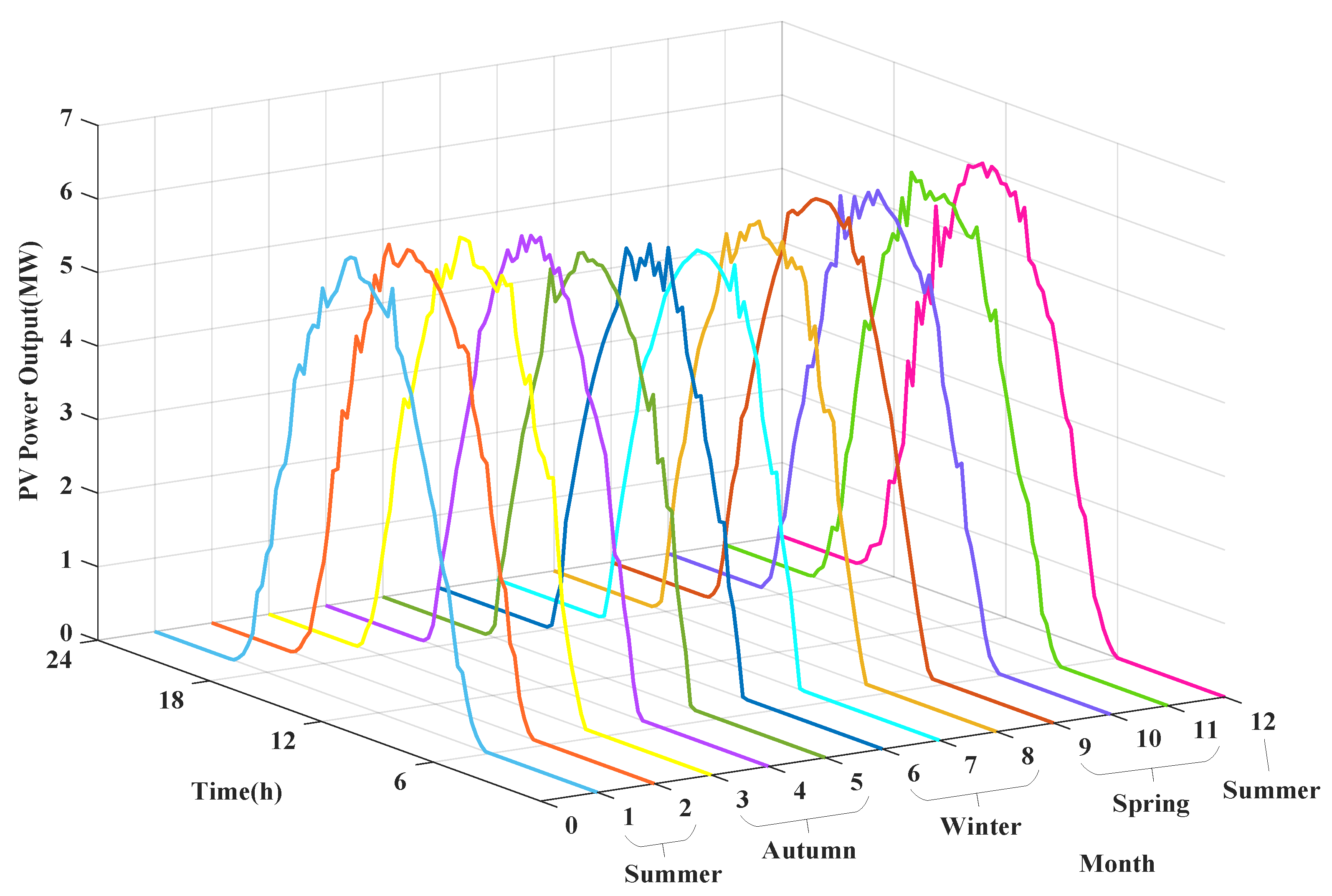
4.1. Data Description
4.2. Model Evaluation Criteria
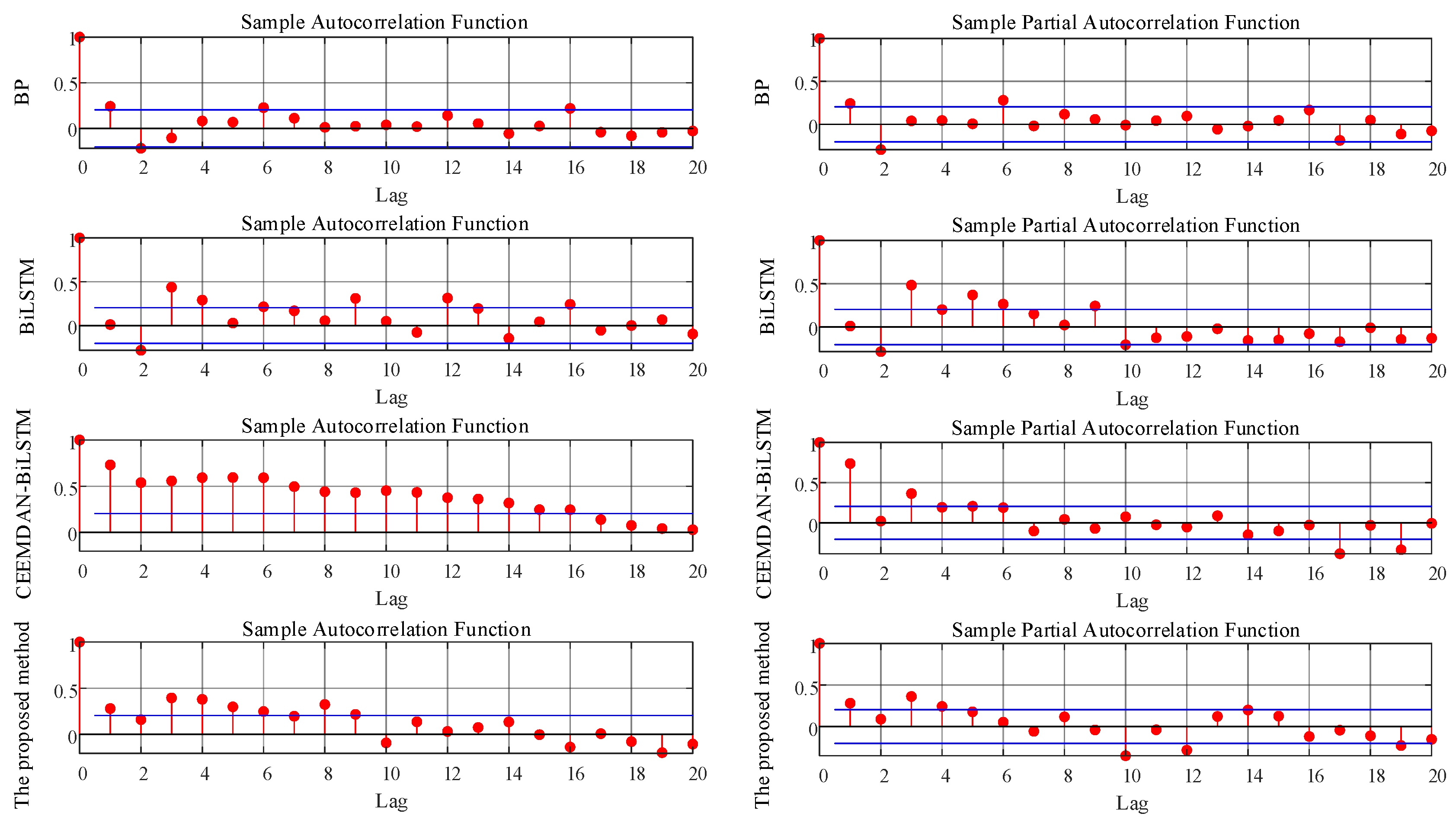
4.3. Experimental Results and Analysis
5. Conclusions
- The normalized daily CSPC could reflect the weather changes that affect photovoltaic power generation to a certain extent. In this paper, the weather types were divided into sunny days, cloudy days, and variable days, which can be further divided into more complex types based on the curve characteristics of the daily CSPC.
- Due to the complexity of changeable days, the PV power curve has a very strong non-stationary feature, which is liable to cause low forecasting accuracy. The PV output power curve in a day can be linearized by the clear-sky normalization method, the method of modal decomposition, and the strategy of forecasting each component separately are helpful to improve the accuracy.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sobri, S.; Koohi-Kamali, S.; Rahim, N.A. Solar photovoltaic generation forecasting methods: A review. Energy Convers. Manag. 2018, 156, 459–497. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, T.; Yang, H. Grid-connected photovoltaic battery systems: A comprehensive review and perspectives. Appl. Energy 2022, 328, 120182. [Google Scholar] [CrossRef]
- Hao, D.; Qi, L.; Tairab, A.M.; Ahmed, A.; Azam, A.; Luo, D.; Pan, Y.; Zhang, Z.; Yan, J. Solar energy harvesting technologies for PV self-powered applications: A comprehensive review. Renew. Energy 2022, 188, 678–697. [Google Scholar] [CrossRef]
- Wang, M.; Wang, P.; Zhang, T. Evidential Extreme Learning Machine Algorithm-Based Day-Ahead Photovoltaic Power Forecasting. Energies 2022, 15, 3882. [Google Scholar] [CrossRef]
- Alcañiz, A.; Grzebyk, D.; Ziar, H.; Isabella, O. Trends and gaps in photovoltaic power forecasting with machine learning. Energy Rep. 2023, 9, 447–471. [Google Scholar] [CrossRef]
- Feng, C.; Liu, Y.; Zhang, J. A taxonomical review on recent artificial intelligence applications to PV integration into power grids. Int. J. Electr. Power Energy Syst. 2021, 132, 107176. [Google Scholar] [CrossRef]
- Mayer, M.J.; Gróf, G. Extensive comparison of physical models for photovoltaic power forecasting. Appl. Energy 2021, 283, 116239. [Google Scholar] [CrossRef]
- Salamanis, A.I.; Xanthopoulou, G.; Bezas, N.; Timplalexis, C.; Bintoudi, A.D.; Zyglakis, L.; Tsolakis, A.C.; Ioannidis, D.; Kehagias, D.; Tzovaras, D. Benchmark Comparison of Analytical, Data-Based and Hybrid Models for Multi-Step Short-Term Photovoltaic Power Generation Forecasting. Energies 2020, 13, 5978. [Google Scholar] [CrossRef]
- Pombo, D.V.; Rincón, M.J.; Bacher, P.; Bindner, H.W.; Spataru, S.V.; Sørensen, P.E. Assessing stacked physics-informed machine learning models for co-located wind–solar power forecasting. Sustain. Energy Grids Netw. 2022, 32, 100943. [Google Scholar] [CrossRef]
- Kushwaha, V.; Pindoriya, N.M. A SARIMA-RVFL hybrid model assisted by wavelet decomposition for very short-term solar PV power generation forecast. Renew. Energy 2019, 140, 124–139. [Google Scholar] [CrossRef]
- Wolff, B.; Kühnert, J.; Lorenz, E.; Kramer, O.; Heinemann, D. Comparing support vector regression for PV power forecasting to a physical modeling approach using measurement, numerical weather prediction, and cloud motion data. Sol. Energy 2016, 135, 197–208. [Google Scholar] [CrossRef]
- Wang, Y.; Chi, P.; Nie, R.; Ma, X.; Wu, W.; Guo, B. Self-adaptive discrete grey model based on a novel fractional order reverse accumulation sequence and its application in forecasting clean energy power generation in China. Energy 2022, 253, 124093. [Google Scholar] [CrossRef]
- Korkmaz, D. SolarNet: A hybrid reliable model based on convolutional neural network and variational mode decomposition for hourly photovoltaic power forecasting. Appl. Energy 2021, 300, 117410. [Google Scholar] [CrossRef]
- Limouni, T.; Yaagoubi, R.; Bouziane, K.; Guissi, K.; Baali, E.H. Accurate one step and multistep forecasting of very short-term PV power using LSTM-TCN model. Renew. Energy 2023, 205, 1010–1024. [Google Scholar] [CrossRef]
- Bibi, N.; Shah, I.; Alsubie, A.; Ali, S.; Lone, S.A. Electricity Spot Prices Forecasting Based on Ensemble Learning. IEEE Access 2021, 9, 150984–150992. [Google Scholar] [CrossRef]
- Dong, Y.; Xiao, L.; Wang, J.; Wang, J. A time series attention mechanism based model for tourism demand forecasting. Inf. Sci. 2023, 628, 269–290. [Google Scholar] [CrossRef]
- Jan, F.; Shah, I.; Ali, S. Short-Term Electricity Prices Forecasting Using Functional Time Series Analysis. Energies 2022, 15, 3423. [Google Scholar] [CrossRef]
- Wang, Z.; Gao, R.; Wang, P.; Chen, H. A new perspective on air quality index time series forecasting: A ternary interval decomposition ensemble learning paradigm. Technol. Forecast. Soc. Chang. 2023, 191, 122504. [Google Scholar] [CrossRef]
- Gao, M.; Li, J.; Hong, F.; Long, D. Day-ahead power forecasting in a large-scale photovoltaic plant based on weather classification using LSTM. Energy 2019, 187, 115838. [Google Scholar] [CrossRef]
- Wang, X.; Sun, Y.; Luo, D.; Peng, J. Comparative study of machine learning approaches for predicting short-term photovoltaic power output based on weather type classification. Energy 2022, 240, 122733. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, X.; Ma, T.; Liu, D.; Wang, H.; Hu, W. A Multi-step ahead photovoltaic power forecasting model based on TimeGAN, Soft DTW-based K-medoids clustering, and a CNN-GRU hybrid neural network. Energy Rep. 2022, 8, 10346–10362. [Google Scholar] [CrossRef]
- Chen, C.; Duan, S.; Cai, T.; Liu, B. Online 24-h solar power forecasting based on weather type classification using artificial neural network. Sol. Energy 2011, 85, 2856–2870. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, Z.; Liu, C.; Yu, Y.; Pang, S.; Duić, N.; Shafie-khah, M.; Catalão, J.P.S. Generative adversarial networks and convolutional neural networks based weather classification model for day ahead short-term photovoltaic power forecasting. Energy Convers. Manag. 2019, 181, 443–462. [Google Scholar] [CrossRef]
- Wang, L.; Mao, M.; Xie, J.; Liao, Z.; Zhang, H.; Li, H. Accurate solar PV power prediction interval method based on frequency-domain decomposition and LSTM model. Energy 2023, 262, 125592. [Google Scholar] [CrossRef]
- Zhang, C.; Peng, T.; Nazir, M.S. A novel integrated photovoltaic power forecasting model based on variational mode decomposition and CNN-BiGRU considering meteorological variables. Electr. Power Syst. Res. 2022, 213, 108796. [Google Scholar] [CrossRef]
- Li, Z.; Xu, R.; Luo, X.; Cao, X.; Du, S.; Sun, H. Short-term photovoltaic power prediction based on modal reconstruction and hybrid deep learning model. Energy Rep. 2022, 8, 9919–9932. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, J.; Li, Z.; Lu, H. Short-term photovoltaic power forecasting based on signal decomposition and machine learning optimization. Energy Convers. Manag. 2022, 267, 115944. [Google Scholar] [CrossRef]
- Niu, D.; Wang, K.; Sun, L.; Wu, J.; Xu, X. Short-term photovoltaic power generation forecasting based on random forest feature selection and CEEMD: A case study. Appl. Soft Comput. 2020, 93, 106389. [Google Scholar] [CrossRef]
- Zhang, J.; Liu, Z.; Chen, T. Interval prediction of ultra-short-term photovoltaic power based on a hybrid model. Electr. Power Syst. Res. 2023, 216, 109035. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, B.; Huang, X.; Shi, J.; Tai, Y.; Zhang, J. Hourly forecasting of solar irradiance based on CEEMDAN and multi-strategy CNN-LSTM neural networks. Renew. Energy 2020, 162, 1665–1683. [Google Scholar] [CrossRef]
- Peng, T.; Zhang, C.; Zhou, J.; Nazir, M.S. An integrated framework of Bi-directional long-short term memory (BiLSTM) based on sine cosine algorithm for hourly solar radiation forecasting. Energy 2021, 221, 119887. [Google Scholar] [CrossRef]
- DKASC. Alice Springs. Available online: http://dkasolarcentre.com.au/download?location=alice-springs (accessed on 11 December 2022).
- Liu, L.; Liu, F.; Zheng, Y. A Novel Ultra-Short-Term PV Power Forecasting Method Based on DBN-Based Takagi-Sugeno Fuzzy Model. Energies 2021, 14, 6447. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Changeable Day | ||
|---|---|---|---|
| MAE/MW | MAPE/% | RMSE/MW | |
| BP | 0.421 | 68.755 | 0.682 |
| BiLSTM | 0.226 | 36.643 | 0.382 |
| CEEMDAN-BiLSTM | 0.096 | 15.221 | 0.133 |
| The proposed method | 0.029 | 2.771 | 0.055 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Hao, Y.; Fan, R.; Wang, Z. An Ultra-Short-Term PV Power Forecasting Method for Changeable Weather Based on Clustering and Signal Decomposition. Energies 2023, 16, 3092. https://doi.org/10.3390/en16073092
Zhang J, Hao Y, Fan R, Wang Z. An Ultra-Short-Term PV Power Forecasting Method for Changeable Weather Based on Clustering and Signal Decomposition. Energies. 2023; 16(7):3092. https://doi.org/10.3390/en16073092
Chicago/Turabian StyleZhang, Jiaan, Yan Hao, Ruiqing Fan, and Zhenzhen Wang. 2023. "An Ultra-Short-Term PV Power Forecasting Method for Changeable Weather Based on Clustering and Signal Decomposition" Energies 16, no. 7: 3092. https://doi.org/10.3390/en16073092
APA StyleZhang, J., Hao, Y., Fan, R., & Wang, Z. (2023). An Ultra-Short-Term PV Power Forecasting Method for Changeable Weather Based on Clustering and Signal Decomposition. Energies, 16(7), 3092. https://doi.org/10.3390/en16073092