
Few-Shot Metering Anomaly Diagnosis with Variable Relation Mining


Abstract
:1. Introduction
- The number of labelled samples is limited and cannot meet the training requirements of the diagnostic model;
- The distribution of anomaly categories is extremely imbalanced, resulting in the metering anomaly diagnostic model being easily overfitted;
- The traditional expert experience is not fully adapted to new application scenarios.
- We present a framework FSMAD for diagnosing anomalies in power metering based on few-shot learning. For extreme situations, we establish fault data injection models to generate anomaly data. It allows us to optimize the model without any real abnormal samples and achieve a satisfying performance.
- We offer a physical dependency learning method for SM data variables. It aims to learn inherent physical relationship among variables to overcome the experience of human experts.
- We conduct comprehensive studies using real electricity metering datasets. The results of the experiment demonstrate that our metering anomaly diagnostic approach has outstanding performance.
2. Related Work
2.1. Anomaly Diagnosis Methods
2.2. Few-Shot Learning
3. Principle of Power Metering and Anomaly
3.1. Principle of Power Metering
3.2. Description of Metering Anomaly
- SM data can be interfered with by external noise when measuring the relevant electrical parameters, resulting in abnormal data.
- The data of a specific working condition are more similar to some of the abnormalities, such as current imbalance.
4. Method
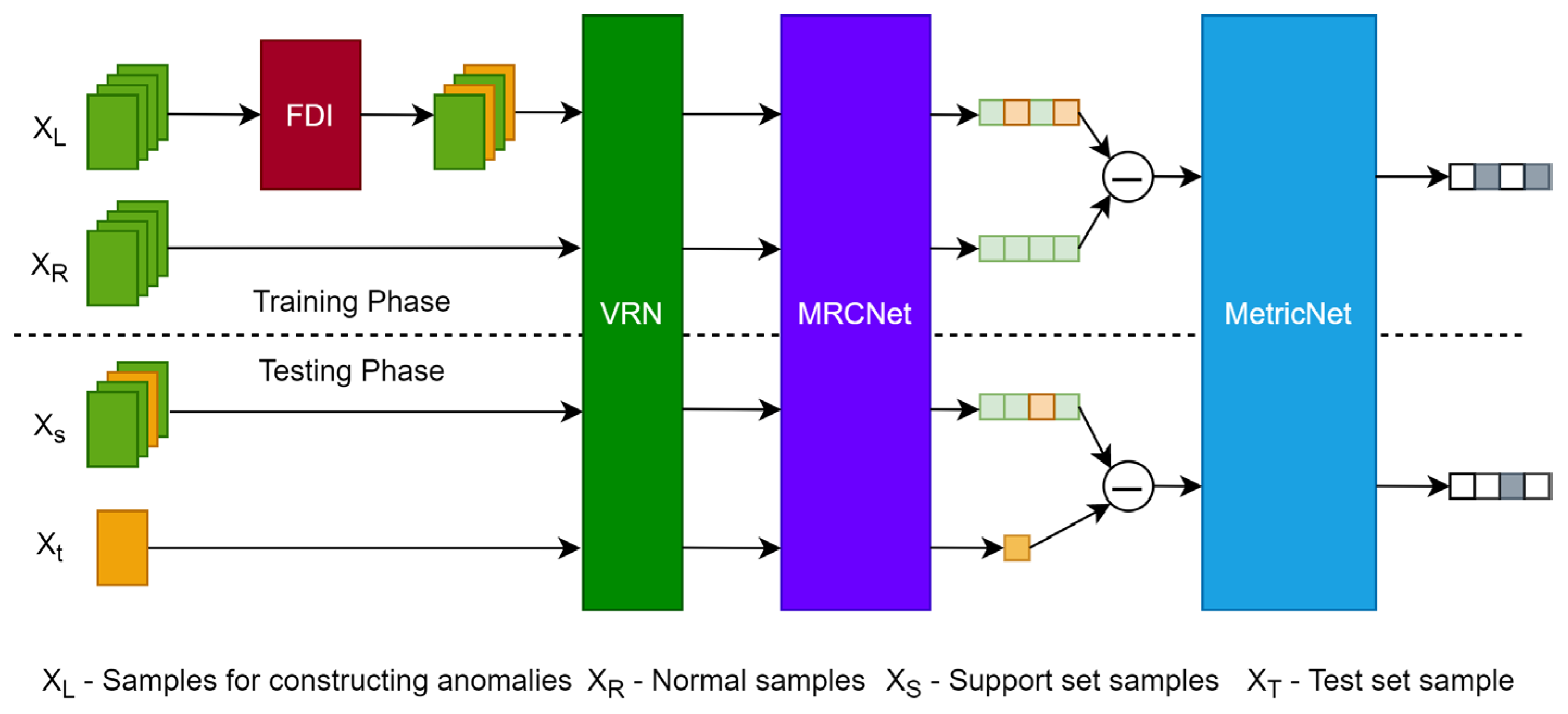
4.1. Framework
4.2. FDI Model
4.3. Variable Relation Network
4.4. Multi-Receptive Convolution Network
4.5. MetricNet
4.6. Algorithm for Training
- During training, a data batch will be split into two equal parts. In the first part, 50% of the samples will be randomly chosen to be manipulated as abnormal samples using the FDI model. The second part retains regular samples. The batch is composed of two parts that form sample pairs. Each pair is associated with a label, where 1 indicates the same class and 0 indicates a different class.
- The learning rate scheduling strategy involves reducing the rate by 50% after every 50 epochs.
- To mitigate overfitting, L2 regularization is applied to restrict the training process of the model using the specified parameter value of 5 × 10−4. It worth mentioning that we chose an empirical value of this parameter. In practice, it could be optimized by experiments.
| Algorithm 1 Mini-batch training of FSMAD |
| Require: = training inputs |
| Require: = labels for labeled inputs, fixed as 0 |
| Require: = false data injection model |
| Require: = VRN with trainable parameters |
| Require: = MRCNet with trainable parameters |
| Require: = MetricNet with trainable parameters |
|
5. Experiments and Results
5.1. Dataset
5.2. Baseline
- SVM: The kernel is set as the Radial Basis Function (RBF), and the penalty parameter is 0.01. Due to normal and abnormal imbalance, we give them proper weight according to the proportion of each category.
- XGBoost [52]: We set the number of trees to be 1000, the maximum depth of the tree to be 11, the weight of the smallest sub-node to be 10, and the learning rate to be 0.01.
- TCN [53]: is a generic architecture for time series modelling, based on dilated convolutional networks to model long-term dependencies of time series. We directly quote the official code and parameters.
- InceptionTime [54]: is a neural network model with a residual network architecture and three different sizes of receptive fields. We directly quote the official code and parameters.
- Siamese Network [27]: A shared network is used to extract the features of sample pairs, and the learnable L1 distance is used to judge whether the sample pairs are from the same class. We reproduce the method, mainly using 1D convolution instead of 2D convolution in the original paper, and the rest of the parameters are consistent with the paper.
- Relation Network [29]: Compared with the twin network, a more powerful relation network is used to evaluate whether the sample pairs are similar. We reproduce the method, mainly using one-dimensional convolution instead of the two-dimensional convolution in the original paper, and the rest of the parameters are consistent with the paper.
5.3. Evaluation Protocol and Metrics
5.3.1. Evaluation Protocol
- Training phase: Abnormal samples are simulated using the FDI model in 2000 normal samples.
- Test phase: One sample per class is randomly selected as a fixed support set, and the rest of the samples are all used as the test set.
5.3.2. Evaluation Metrics
5.4. Results and Discussion
5.4.1. Main Results
5.4.2. Component Study
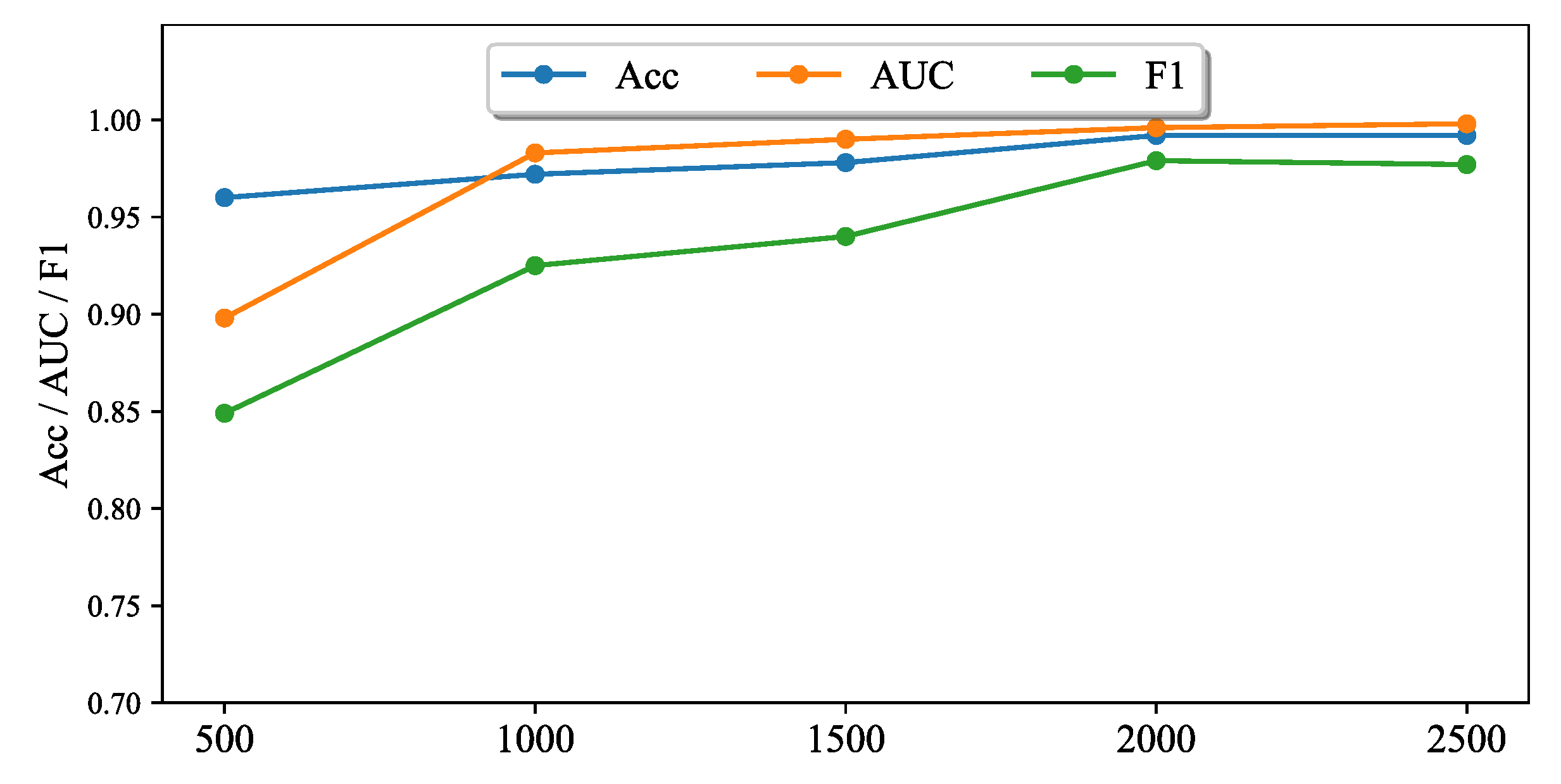
5.4.3. Parameter Study
5.4.4. Convergence Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Elbouchikhi, E.; Zia, M.F.; Benbouzid, M.; El Hani, S. Overview of Signal Processing and Machine Learning for Smart Grid Condition Monitoring. Electronics 2021, 10, 2725. [Google Scholar] [CrossRef]
- He, J.; Luo, G.; Cheng, M.; Liu, Y.; Tan, Y.; Li, M. Small Sample Smart Substation Power Equipment Component Detection Based on Deep Transfer Learning. Proc. CSEE 2020, 40, 5506–5519. [Google Scholar] [CrossRef]
- Mohassel, R.; Fung, A.; Mohammadi, F.; Raahemifar, K. A survey on Advanced Metering Infrastructure. Int. J. Electr. Power Energy Syst. 2014, 63, 473–484. [Google Scholar] [CrossRef]
- Xue, Z.; Sun, Y.; Dong, Z.C.; Fang, Y.J. Fault diagnosis method of power consumption information acquisition system based on fuzzy Petri nets. Electr. Meas. Instrum. 2019, 56, 64–69. [Google Scholar]
- Wang, Y.; Chen, Q.; Hong, T.; Kang, C. Review of smart meter data analytics: Applications, methodologies, and challenges. IEEE Trans. Smart Grid 2019, 10, 3125–3148. [Google Scholar] [CrossRef]
- Cook, A.; Mısırlı, G.; Fan, Z. Anomaly Detection for IoT Time-Series Data: A Survey. IEEE Internet Things J. 2020, 7, 6481–6494. [Google Scholar] [CrossRef]
- Luo, G.; Yao, C.; Liu, Y.; Tan, Y.; He, J. Entropy SVM–Based Recognition of Transient Surges in HVDC Transmissions. Entropy 2018, 20, 421. [Google Scholar] [CrossRef]
- Guo, M.; Yang, N.; Chen, W. Deep-learningbased fault classification using Hilbert-Huang transform and convolutional neural network in power distribution systems. IEEE Sens. J. 2019, 19, 6905–6913. [Google Scholar] [CrossRef]
- Lu, X.; Zhou, Y.; Wang, Z.; Yi, Y.; Feng, L.; Wang, F. Knowledge Embedded Semi-Supervised Deep Learning for Detecting Non-Technical Losses in the Smart Grid. Energies 2019, 12, 3452. [Google Scholar] [CrossRef]
- Li, J.; Wang, F. Non-Technical Loss Detection in Power Grids with Statistical Profile Images Based on Semi-Supervised Learning. Sensors 2020, 20, 236. [Google Scholar] [CrossRef]
- Pandit, M. Expert system-a review article. Int. J. Eng. Sci. Res. Technol. 2013, 2, 1583–1585. [Google Scholar]
- Yang, J.; Xin, M.; Ou, J.; Wang, J.; Song, Q. Automatic diagnosis and rapid location of abnormal metering point of substation based on metrological automation system. Power Syst. Big Data 2017, 20, 68–71. [Google Scholar] [CrossRef]
- Jiang, X.; Wang, D.; Ning, Y.; Zhang, C. Query Method for Optimal Diagnosis of Power System Faults. High Volt. Eng. 2017, 43, 1311–1316. [Google Scholar] [CrossRef]
- Zhou, J.; Wu, Z.; Wang, Q.; Yu, Z. Fault Diagnosis Method of Smart Meters Based on DBN-CapsNet. Electronics 2022, 11, 1603. [Google Scholar] [CrossRef]
- Wu, R.; Zhang, A.; Tian, X.; Zhang, T. Anomaly detection algorithm based on improved K-means for electric power data. J. East China Norm. Univ. (Nat. Sci.) 2020, 4, 79–87. [Google Scholar] [CrossRef]
- Zhou, F.; Cheng, Y.Y.; Du, J.; Feng, L.; Xiao, J.; Zhang, J.M. Construction of Multidimensional Electric Energy Meter Abnormal Diagnosis Model Based on Decision Tree Group. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; pp. 24–26. [Google Scholar]
- Coma-Puig, B.; Carmona, J.; Gavaldà, R.; Alcoverro, S.; Martin, V. Fraud detection in energy consumption: A supervised approach. In Proceedings of the IEEE International Conference on Data Science and Advanced Analytics (DSAA), Montreal, QC, Canada, 17–19 October 2016; pp. 120–129. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A New Convolutional Neural Network-Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Shao, H.; Jiang, H.; Lin, Y.; Li, X. A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders. Mech. Syst. Signal Process. 2018, 102, 278–297. [Google Scholar] [CrossRef]
- Wu, N.; Wang, Z. Bearing Fault Diagnosis Based on the Combination of One-Dimensional CNN and Bi-LSTM. Modul. Mach. Tool Autom. Manuf. Tech. 2021, 571, 38–41. [Google Scholar] [CrossRef]
- Ren, B.; Zheng, Y.; Wang, Y.; Sheng, S.; Li, J.; Zhang, H.; Zheng, C. Fault Location of Secondary Equipment in Smart Substation Based on Deep Learning. Power Syst. Technol. 2021, 45, 713–721. [Google Scholar] [CrossRef]
- Morais, J.; Pires, Y.; Cardoso, C.; Klautau, A. A framework for evaluating automatic classification of underlying causes of disturbances and its application to short-circuit faults. IEEE Trans. Power Deliv. 2010, 25, 2083–2094. [Google Scholar] [CrossRef]
- Kou, Y.; Cui, G.; Fan, J.; Chen, X.; Li, W. Machine learning based models for fault detection in automatic meter reading systems. In Proceedings of the 2017 International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Shenzhen, China, 15–17 December 2017; pp. 684–689. [Google Scholar] [CrossRef]
- Li, F.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 3630–3638. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Sumit, C.; Hadsell, R.; LeCun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Wang, Y.X.; Hebert, M. Learning from small sample sets by combining unsupervised meta-training with CNNs. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 244–252. [Google Scholar]
- Vilalta, R.; Drissi, Y. A perspective view and survey of meta-learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Rajendran, J.; Irpan, A.; Jang, E. Meta-learning requires meta-augmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 5705–5715. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. Int. Conf. Mach. Learn. 2017, 70, 1126–1135. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhang, S.; Ye, F.; Wang, B.; Habetler, T.G. Few-shot bearing fault diagnosis based on model-agnostic meta-learning. IEEE Trans. Ind. Appl. 2021, 57, 4754–4764. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, J.; Ye, X.; Jing, Q.; Wang, J.; Geng, Y. Few-Shot Transfer Learning With Attention Mechanism for High-Voltage Circuit Breaker Fault Diagnosis. IEEE Trans. Ind. Appl. 2022, 58, 3353–3360. [Google Scholar] [CrossRef]
- Yu, X.; Ju, X.; Wang, Y.; Qi, H. A metric learning network based on attention mechanism for Power grid defect identification. J. Phys. Conf. Ser. 2020, 1693, 012146. [Google Scholar] [CrossRef]
- Xue, L.; Jiang, A.; Zheng, X.; Qi, Y.; He, L.; Wang, Y. Few-Shot Fault Diagnosis Based on an Attention-Weighted Relation Network. Entropy 2024, 26, 22. [Google Scholar] [CrossRef]
- Akbar, S.; Vaimann, T.; Asad, B.; Kallaste, A.; Sardar, M.U.; Kudelina, K. State-of-the-Art Techniques for Fault Diagnosis in Electrical Machines: Advancements and Future Directions. Energies 2023, 16, 6345. [Google Scholar] [CrossRef]
- Fan, J.; Chen, X.; Zhou, Y. An Intelligent Analytical Method of Abnormal Metering Device Based on Power Consumption Information Collection System. Electr. Meas. Instrum. 2013, 50, 4–9. [Google Scholar]
- Wang, X.; Wu, Y.; Zhang, Y. Method of smart meter online monitoring based on data mining. Electr. Meas. Instrum. 2016, 53, 65–69. [Google Scholar]
- Jokar, P.; Arianpoo, N.; Leung, V.C.M. Electricity Theft Detection in AMI Using Customers’ Consumption Patterns. IEEE Trans. Smart Grid 2016, 7, 216–226. [Google Scholar] [CrossRef]
- Zanetti, M.; Jamhour, E.; Pellenz, M.; Penna, M.; Zambenedetti, V.; Chueiri, I. A Tunable Fraud Detection System for Advanced Metering Infrastructure Using Short-Lived Patterns. IEEE Trans. Smart Grid 2019, 10, 830–840. [Google Scholar] [CrossRef]
- Benaim, S.; Wolf, L. One-shot unsupervised cross domain translation. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2018; pp. 2104–2114. [Google Scholar]
- Zhang, Y.; Tang, H.; Jia, K. Fine-grained visual categorization using meta-learning optimization with sample selection of auxiliary data. In Proceeding of the 15th European Conference on European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 233–248. [Google Scholar]
- Wen, Q.; Sun, L.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time Series Data Augmentation for Deep Learning: A Survey. In Proceeding of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI-21), Montreal, QC, Canada, 19–27 August 2021; pp. 4653–4660. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceeding of the 22nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Ismail Fawaz, H.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.; Petitjean, F. InceptionTime: Finding AlexNet for time series classification. Data Min. Knowl. Discov. 2019, 34, 1936–1962. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| UA, UB, UC | voltage of each wire |
| IA, IB, IC | current of each wire |
| Ptotal, PA, PB, PC | active power of total and each wire |
| ftotal, fA, fB, fC | power factor of total and each wire |
| Type | Definition |
|---|---|
| LV | is defined as: where 0.5 < f < 0.8 is randomly generated, (, ) is a randomly defined time period between 1 and 4 h. f does not change with time. and are set to the constant 1. |
| LC | is defined as: where 0.01 < < 0.1 is randomly generated, (, ) is a randomly defined time period between 1 and 8 h. and are set to the constant 1. |
| CU | is defined as: where 0.7 < < 0.9 is randomly generated, (, ) is a randomly defined time period between 12 and 24 h. and are set to the constant 1. |
| VU | is defined as: where 0.85 < < 0.95 is randomly generated, (, ) is a randomly defined time period between 12 and 24 h. and are set to the constant 1. |
| FC | and are set to the constant −1, and is set to the constant 1. |
| FF | is defined as: where 0.4 < < 0.85 is randomly generated, () is a randomly defined time period between 12 and 24 h. and are set to the constant 1. |
| Class | Description | Number of Samples |
|---|---|---|
| 0 | Normal | 6212 |
| 1 | Loss of Voltage (LV) | 196 |
| 2 | Loss of Current (LC) | 85 |
| 3 | Current Unbalance (CU) | 88 |
| 4 | Voltage Unbalance (VU) | 525 |
| 5 | False Connection (FC) | 81 |
| 6 | Factor Fault (FF) | 234 |
| Methods | Acc | AUC | F1 |
|---|---|---|---|
| SVM | 0.873 | 0.889 | 0.716 |
| XGBoost | 0.932 | 0.968 | 0.830 |
| TCN | 0.910 | 0.959 | 0.703 |
| InceptionTime | 0.953 | 0.977 | 0.924 |
| Siamese Network | 0.958 | 0.974 | 0.885 |
| Relation Network | 0.961 | 0.979 | 0.941 |
| FSMAD (Ours) | 0.992 | 0.996 | 0.979 |
| Methods | Acc | AUC | F1 |
|---|---|---|---|
| TCN | 0.910 | 0.959 | 0.703 |
| TCN + VRN | 0.975 | 0.985 | 0.931 |
| InceptionTime | 0.953 | 0.977 | 0.924 |
| InceptionTime + VRN | 0.976 | 0.987 | 0.955 |
| Siamese Network | 0.958 | 0.974 | 0.885 |
| Siamese Network + VRN | 0.978 | 0.985 | 0.927 |
| Relation Network | 0.961 | 0.979 | 0.941 |
| Relation Network + VRN | 0.982 | 0.992 | 0.956 |
| Methods | Acc | AUC | F1 |
|---|---|---|---|
| Siamese Network | 0.958 | 0.974 | 0.885 |
| Siamese Network + [11] | 0.969 | 0.978 | 0.905 |
| Siamese Network + VRN | 0.978 | 0.985 | 0.927 |
| Methods | Acc | AUC | F1 |
|---|---|---|---|
| Cosine | 0.981 | 0.991 | 0.963 |
| 1 MLP | 0.988 | 0.992 | 0.968 |
| 2 MLPs | 0.990 | 0.994 | 0.971 |
| 3 MLPs (FSMAD) | 0.992 | 0.996 | 0.979 |
| 4 MLPs | 0.991 | 0.995 | 0.977 |
| Methods | Acc | AUC | F1 |
|---|---|---|---|
| 1 | 0.992 | 0.996 | 0.979 |
| 5 | 0.991 | 0.998 | 0.979 |
| 10 | 0.993 | 0.998 | 0.982 |
| 20 | 0.994 | 0.997 | 0.983 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Zhang, W.; Guo, P.; Ding, X.; Wang, C.; Wang, F. Few-Shot Metering Anomaly Diagnosis with Variable Relation Mining. Energies 2024, 17, 993. https://doi.org/10.3390/en17050993
Sun J, Zhang W, Guo P, Ding X, Wang C, Wang F. Few-Shot Metering Anomaly Diagnosis with Variable Relation Mining. Energies. 2024; 17(5):993. https://doi.org/10.3390/en17050993
Chicago/Turabian StyleSun, Jianqiao, Wei Zhang, Peng Guo, Xunan Ding, Chaohui Wang, and Fei Wang. 2024. "Few-Shot Metering Anomaly Diagnosis with Variable Relation Mining" Energies 17, no. 5: 993. https://doi.org/10.3390/en17050993
APA StyleSun, J., Zhang, W., Guo, P., Ding, X., Wang, C., & Wang, F. (2024). Few-Shot Metering Anomaly Diagnosis with Variable Relation Mining. Energies, 17(5), 993. https://doi.org/10.3390/en17050993