This section introduces the proposed Energy Peaks and Timestamping Prediction (EPTP) framework as a novel approach for peak demand detection using commercial building electricity consumption data and weather information.
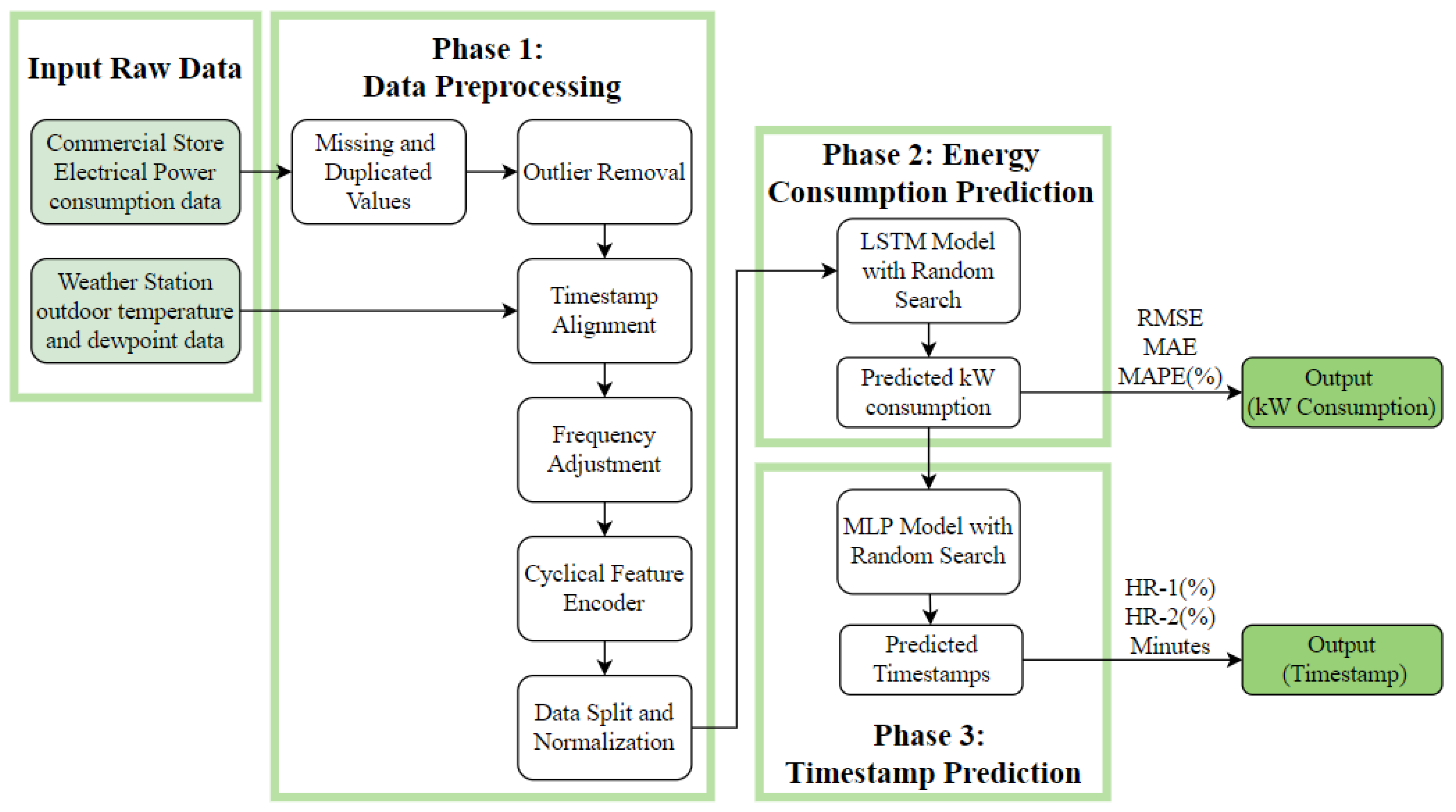
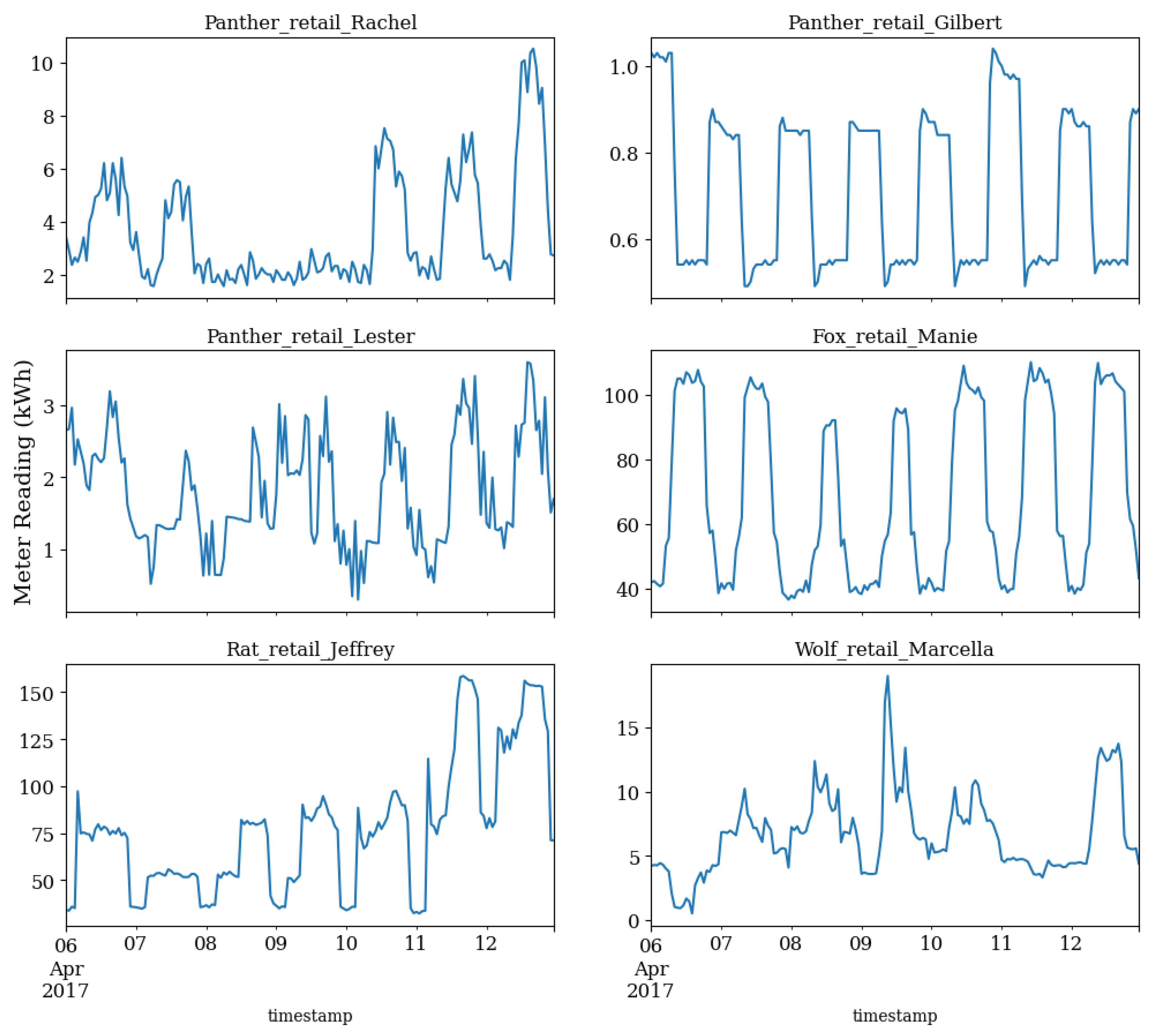
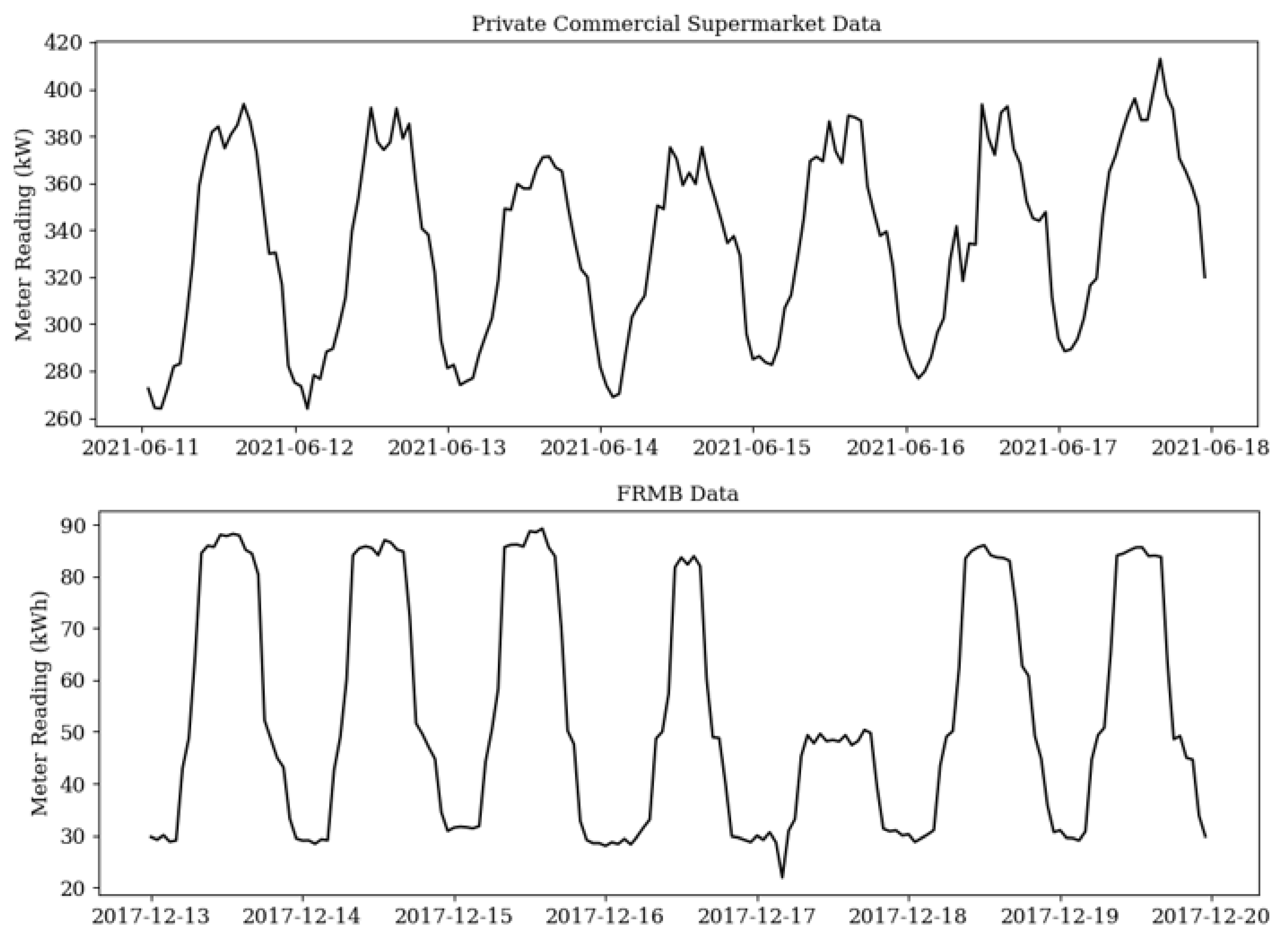
Figure 4 shows an overview of the proposed EPTP framework with three phases, namely data preprocessing, energy consumption prediction with the LSTM network, and timestamp prediction with the MLP model. The energy consumption raw data were obtained from the sensor reading in the commercial supermarket. Braun et al. [
60] studied the energy consumption pattern in commercial supermarkets and concluded that half of the electricity usage in commercial supermarkets was directly related to the weather. Therefore, the outdoor temperature and dewpoint temperatures were extracted from the closest weather station as additional features. The raw data then underwent the data preprocessing steps to sanitize the input required for the deep learning model. Time-related variables were feature engineered as part of the input. In the second stage, the sanitized dataset passed through an LSTM model to predict the energy consumption of the commercial supermarket for the next 24 h. Finally, an MLP model was trained with the predicted 24-h energy consumption as the input to obtain the indices, which were compared to the real starting, peaking, and ending labels from the original dataset. As the end goal of the proposed EPTP framework, the prediction should not only contain the peak consumption value but also the indices for which it occurs 24 h in advance. The details regarding each step are described as follows.
4.1. Phase 1: Data Preprocessing
Impurities are naturally included in data collection when obtained from real-world applications. Data preprocessing serves as a necessary step to remove impurities in the dataset and improve accuracy and reliability in model training. Starting off, missing and duplicated values may occur during the data collection stage, caused by unexpected situations such as unstable sensor connections, data corruption, or hardware failures. In this EPTP framework, short-term missing datapoints were linearly interpolated with the average of the previous and next datapoints. The daily energy consumption data were removed for any day containing long-term missing data. A two-hour threshold was used to distinguish between short- and long-term missing values. Duplicated entries were simply removed to ensure that each timestamp contained only one datapoint.
In the data collection stage, observations are recorded based on the sensor reading. However, the sensor readings may contain noise, errors, or unwanted data due to potential sensor faults or connection issues [
61]. These observations are considered outliers that should be removed to improve the data quality for better prediction accuracy. In the EPTP framework, the outliers in the commercial building energy consumption data are detected and replaced with the Hampel filter [
62]. The Hampel filter is a type of decision-based filter that implements the moving window of the Hampel identifier [
63] so that the sliding window length is
, where
represents a positive integer called the window half-width. Equation (4) shows the detection and replacement of the outliers using the Hampel filter, where
and
represent the median and the median absolute deviations of the sliding window, respectively, and
represents the threshold value. In the utilization of the Hampel filter,
and
are user-defined parameters that can be adjusted based on the specific outlier detection and replacement requirements. Specifically,
controls the size of the sliding window that is used to calculate
and
, and
determines the boundary, hence the number of outliers detected in the dataset. In this framework,
was chosen to be the number of datapoints per day;
was chosen to have the default value of 3 based on Pearson’s rule [
64].
Since the energy consumption data of the commercial building and the weather information originate from distinct sources, both the timestamp and frequency need to be aligned. In the timestamp alignment, modifications included converting from Coordinated Universal Time to local time, and accommodating any daylight-saving time changes. In the conversion from Coordinated Universal Time to local time, the time zone was determined using the geological location of the commercial building. For the observations collected during the daylight-saving time changes, the data were treated as missing and duplicated values and sanitized using the interpolation and removal methods. In frequency adjustment, the data samples were either averaged to a lower frequency or interpolated to a higher frequency based on the prediction requirements.
In the final steps of data preprocessing, cyclical feature encoder and normalization were implemented to enhance the model performance. Electricity consumption in commercial building is affected by the hour of the day [
20]. This is especially true in the retail industry, as the customer footprint increases during the store’s operating hours. Therefore, in this proposed EPTP framework, the hour of the day (i.e., ranges between 0 and 23) was included as an independent variable to predict energy consumption. A common method for encoding the cyclical feature is to transform the data into two dimensions with a trigonometric encoder. To ensure that each interval was uniquely represented, both sine and cosine transformations were included, as shown in Equation (5). The complete dataset was then split into training, validation, and test sets based on roughly a 70:15:15 ratio to normalize the data using the min–max scaling technique to transform the features into the same unit of measure as the raw attributes typically lack sufficient quality for obtaining accurate predictive models. Normalization aims to transform the original attributes to enhance the model’s predictive capability [
65].
4.2. Phase 2: Predictor Model for Energy Consumption
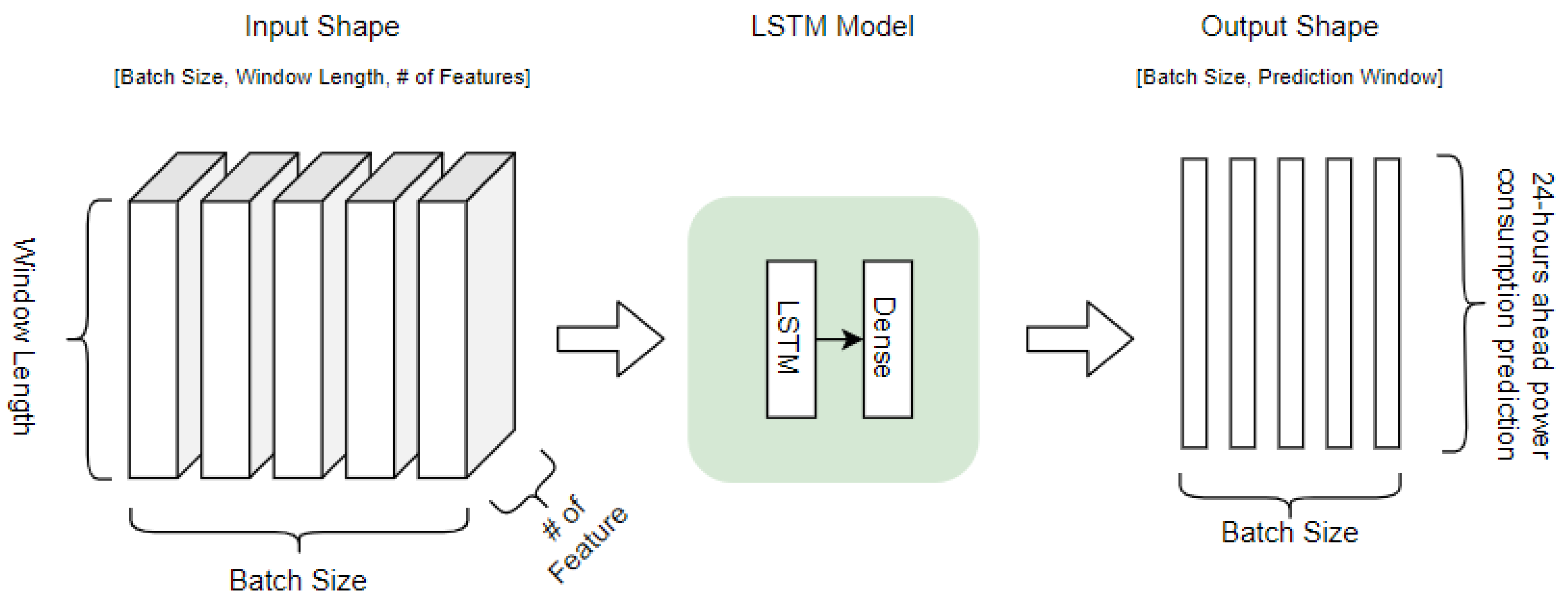
The second phase of the proposed EPTP framework was to predict energy consumption using the given features with LSTM modeling, as depicted in
Figure 5. Input features included energy consumption (unit: kW), outdoor temperature (unit: °C), dewpoint temperature (unit: °C), and the transformed cyclical feature. The input layer of the LSTM modeling accepts 3-dimensional input in the shape of
. Shuffling was rejected on the input features to maintain the relationship for time series sequential data.
However, the output of the LSTM model depends on the frequency at which the data are processed. The objective of this EPTP framework was not only to predict the amount of energy usage for the peak consumption, but also the corresponding timestamp. Hence, it was necessary to simultaneously generate the consumption for the next day. Therefore, the output shape for Phase 2 was , , for the 1-h, 30-min, and 15-min frequencies, respectively. The hyperparameters for the LSTM modeling included the sliding window length, activation function, number of LSTM layers, batch size, and learning rate. The random search algorithm was utilized for hyperparameter optimization as the search space included a combination of continuous and categorical variables. Random search optimization also aims to reduce computational power and resources as tuning is processed with five hyperparameters.
In this framework, the energy consumption predictions were evaluated against the MAE, RMSE, and MAPE. Equations (6)–(8) provide the formula for the calculations where
and
represent the grounded truth and predicted values, respectively. Among all three metrics, MAPE provides a better understanding of the error scale, whereas RMSE and MAE are not normalized regarding the prediction scale. For MAPE, the higher the value, the better the result, while for the RMSE and MAE, the lower the value, the better the result.
4.3. Phase 3: Peak Index Model for Timestamp Prediction
In the final phase of the EPTP framework, an MLP model was proposed to predict the timestamps of the daily starting, peaking, and ending indices. To train for the MLP network, three timestamps per day were designated as true labels, allowing for a comparison with the model prediction. In such labeling, the peak consumption was defined using the BM approach in the extreme value theory. BM consists of dividing the observation period into non-overlapping blocks of equal size and retrieving the maximum value within each block [
66]. Consider the total number of observations as
, which can be divided into
blocks of size
so that
. Equation (9) shows the retrieval of the peak value where
represents all the datapoints in block
and
represents the corresponding peak value in the same block.
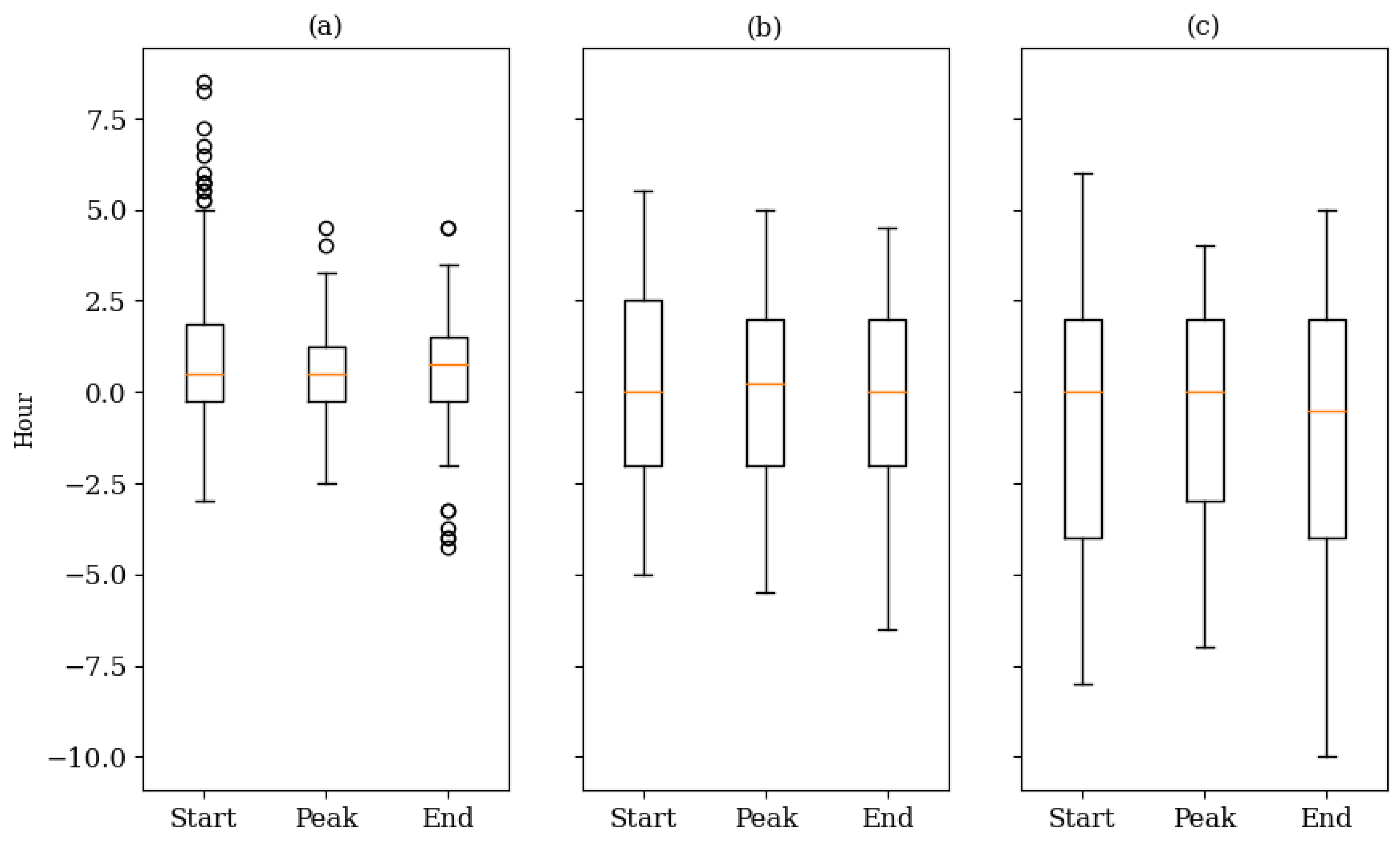
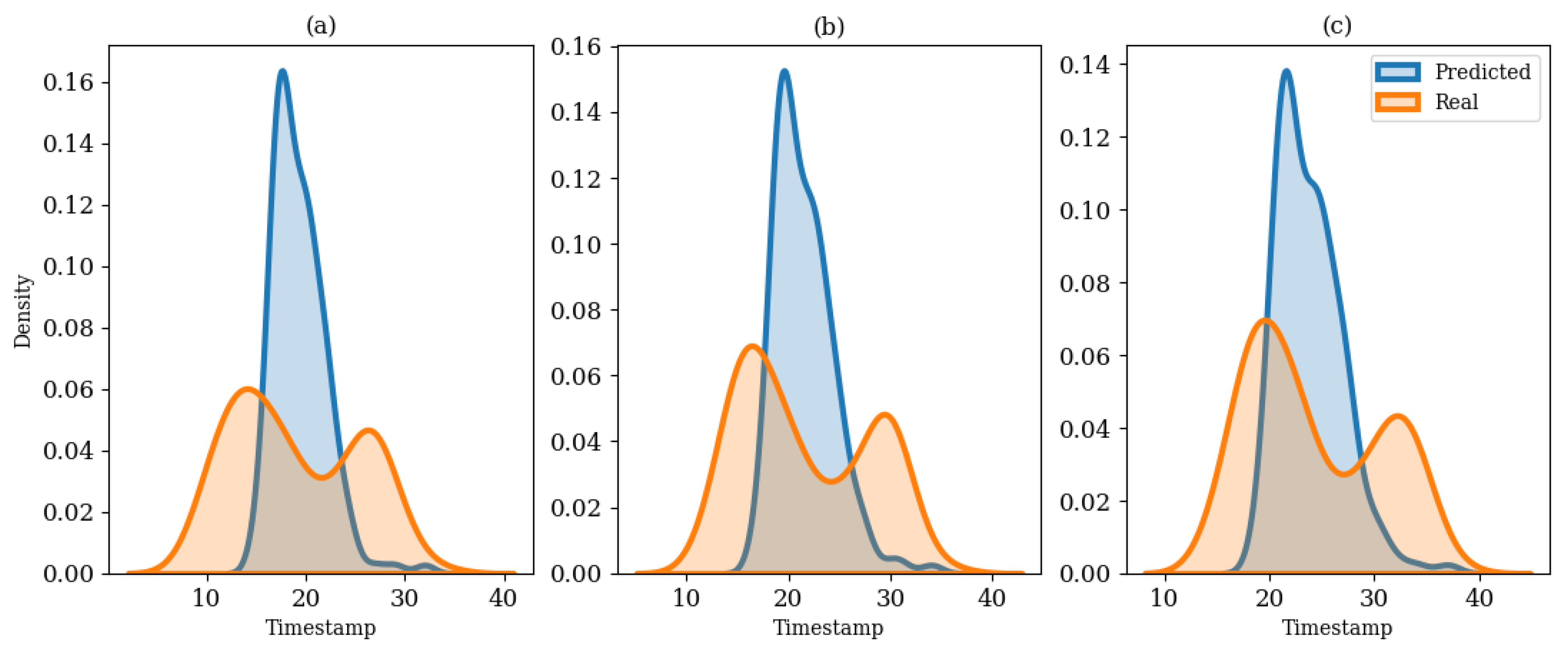
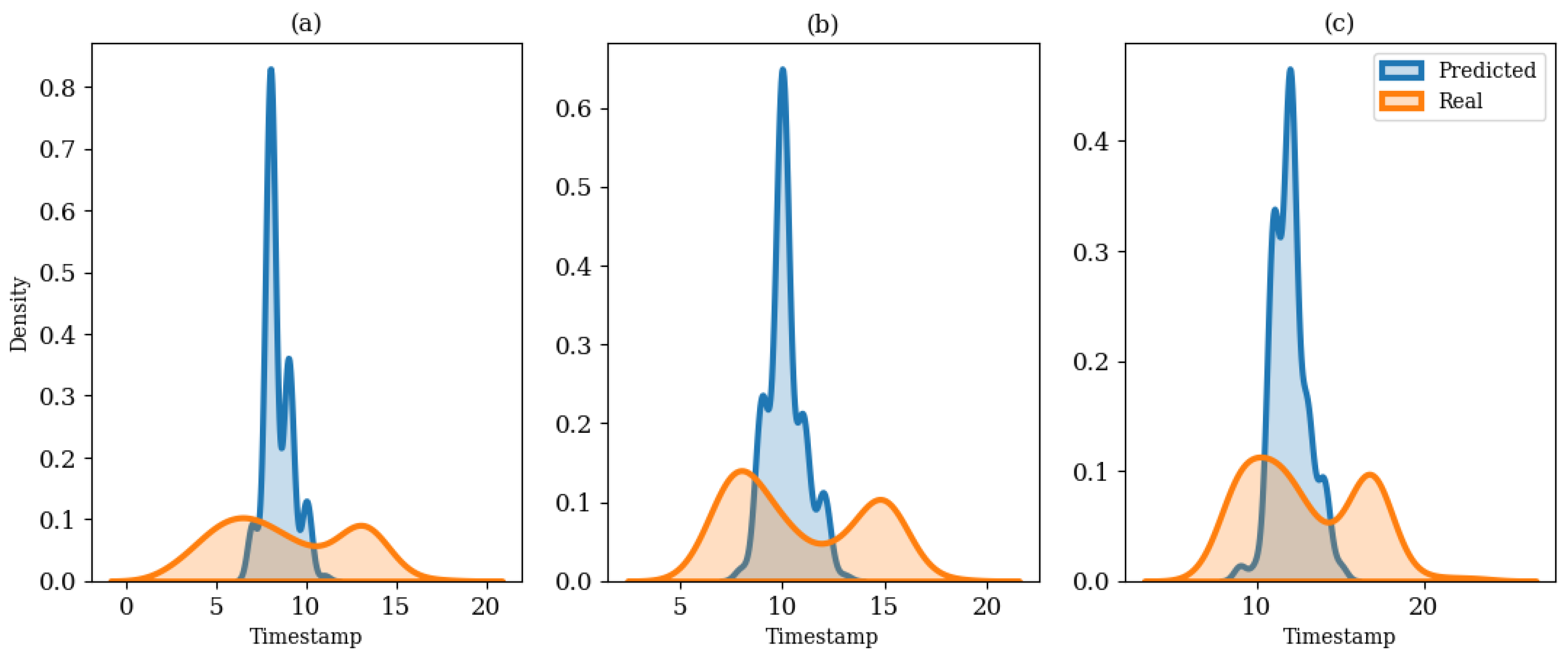
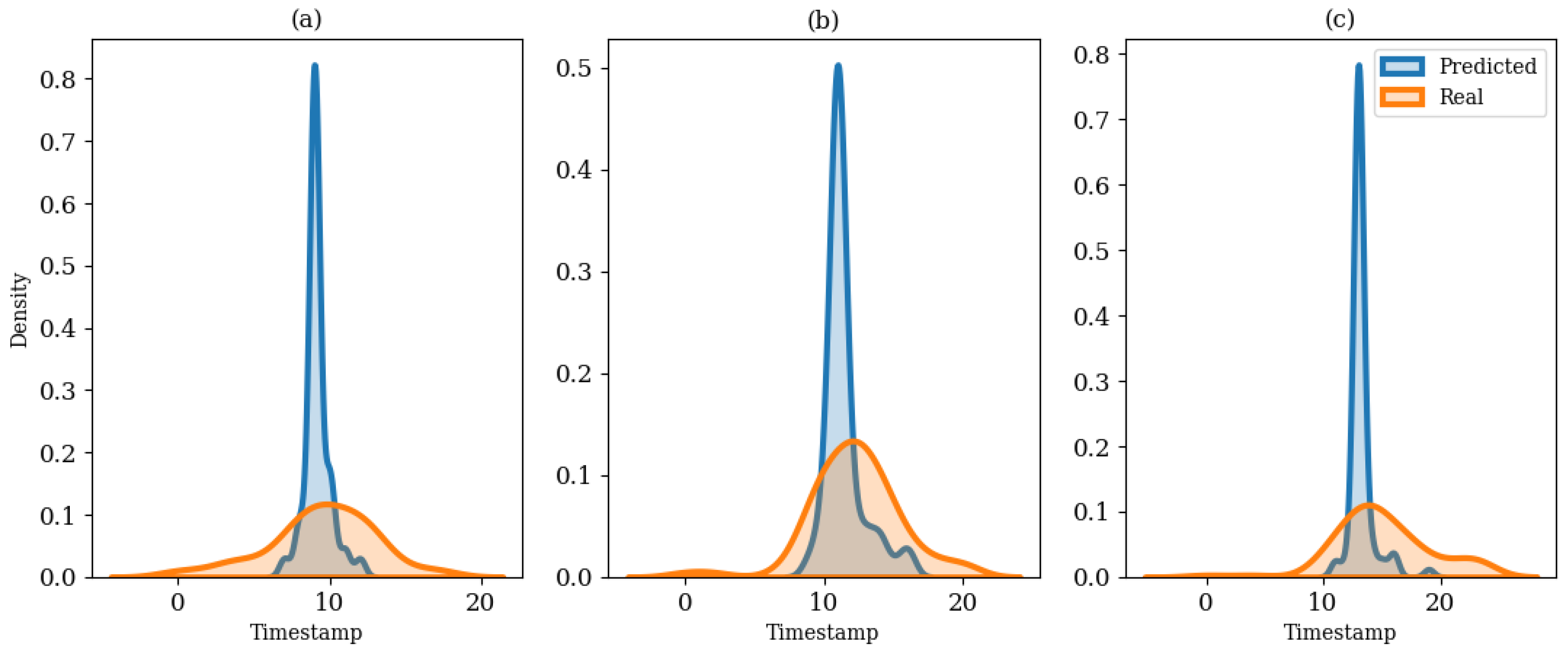
After defining the peak consumption, the main contribution of this study was to label the starting, peaking, and ending indices in each block . The peaking index is defined as the timestamp so that the maximum energy consumption has occurred in the predefined window. In the EPTP framework, the window was defined to be 24 h so that for the 1-h, 30-min, and 15-min resolutions, respectively. The starting index was extracted using the base value on the left-hand side of the peak. The peak occurrence was led by an increasing trend where the start timestamp of the increment was defined as the starting index of the peak. Similarly, the ending index was defined using the base value on the right-hand side. In addition, the duration of the peak was also validated so that a long period of peak occurrence was avoided, especially for the low-frequency data. This proposed EPTP framework used a four-hour threshold to validate the peak duration. If the peak duration lasts more than four hours based on the previous steps, the ending index will be updated if the consumption at the ending index is lower than that of the starting index. Likewise, the starting index will be adjusted if the consumption at the starting index is lower than that of the ending index. The justification ensures the duration between the starting and peaking indices was equal to the duration between the peaking and ending indices. This modification preserves the shape of the peak consumption while preventing excessively long peak durations, especially for low-frequency data. Once the true labels are extracted, these indices will be compared to the MLP model’s output for performance evaluation.
As mentioned, MLP models have successfully detected delays and time deviations for flight and traffic control applications. In this proposed EPTP framework, the MLP input layer accepts a 2-dimensional input in the shape of . Since the model was designed to predict the daily peak indices, the input needs to encompass the consumption data for the entire day. Consequently, depending on the prediction frequency, the input shape for the final phase of the EPTP framework was presented as , , and with respect to the 1-h, 30-min, and 15-min frequencies, respectively. Shuffling was introduced at this stage as each day was treated as a standalone sample.
The output of the MLP model was , as each neuron represents a single index. In the proposed EPTP framework, the starting, peaking, and ending indices need to be predicted for upcoming peak-shaving strategies in commercial building applications. As a consequence, the output layer contained three neurons. As previously mentioned, the predicted index was then compared with the day ahead labels to identify the model performance. The hyperparameters in this phase included the number of hidden layers and neurons on each layer, activation function, and learning rate. As the MLP model predicts the timestamps on a daily frequency (i.e., contains only 365 samples per year) and MLP is less computationally heavy compared to LSTM modeling, batching was not required in this phase.
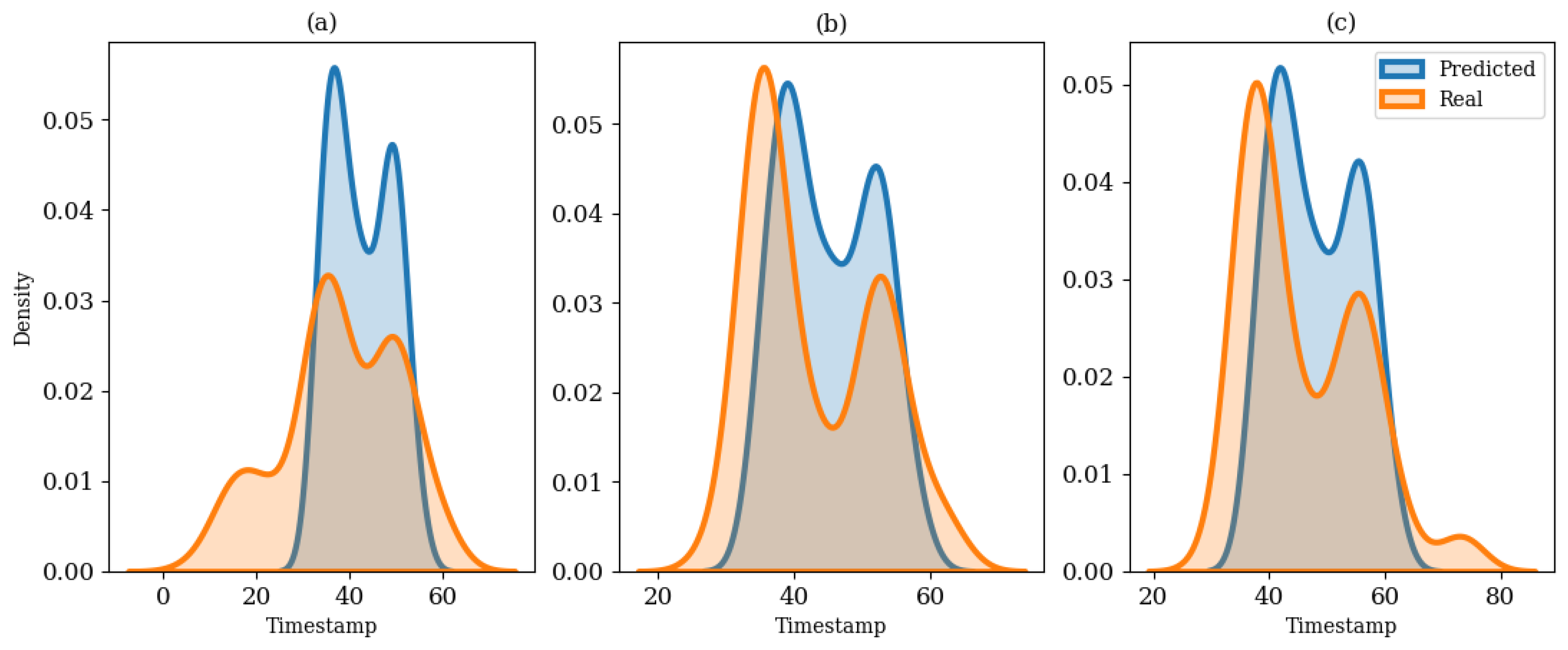
The timestamp prediction was evaluated using the hit rate (HR) metric [
67] and mean absolute minute deviation. Equation (10) shows the calculation of the HR metric, where
represents the tolerance residual for the expected timestamp and
is a flag representing whether the predicted timestamp is within the tolerance interval. In this study, the tolerance interval was chosen to be one hour (HR-1) and two hours (HR-2) for a better comparison. This means that
was {1, 2}, {2, 4}, and {4, 8} for the 1-h, 30-min, and 15-min resolutions, respectively. The higher the HR value, the better the results. Equation (11) shows the calculation for translating the timestamp MAE error into minute deviations for consistency as the model works with different resolutions.



 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}