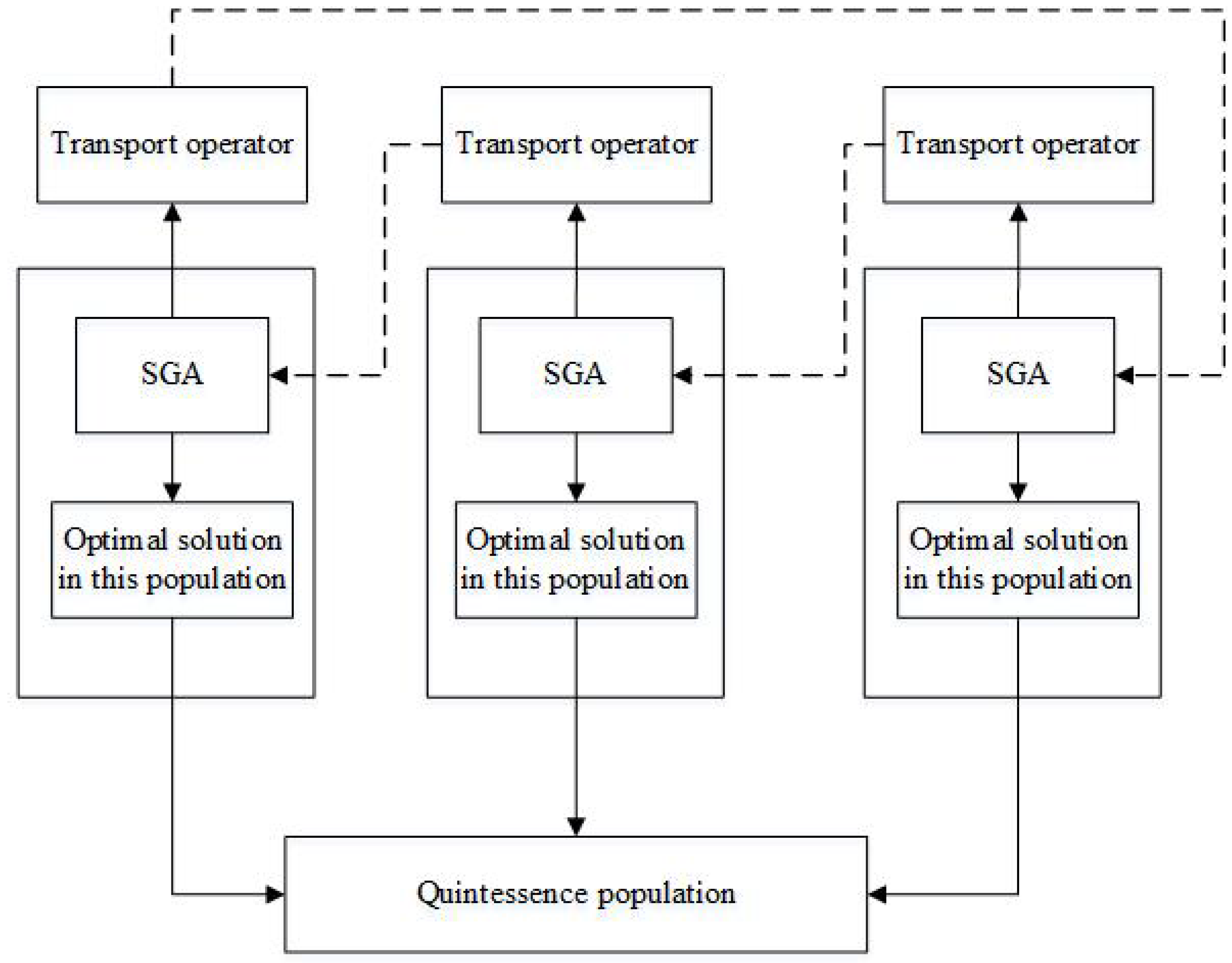
Figure 2.
Multi-population genetic algorithm structure diagram. Standard genetic algorithm: SGA.
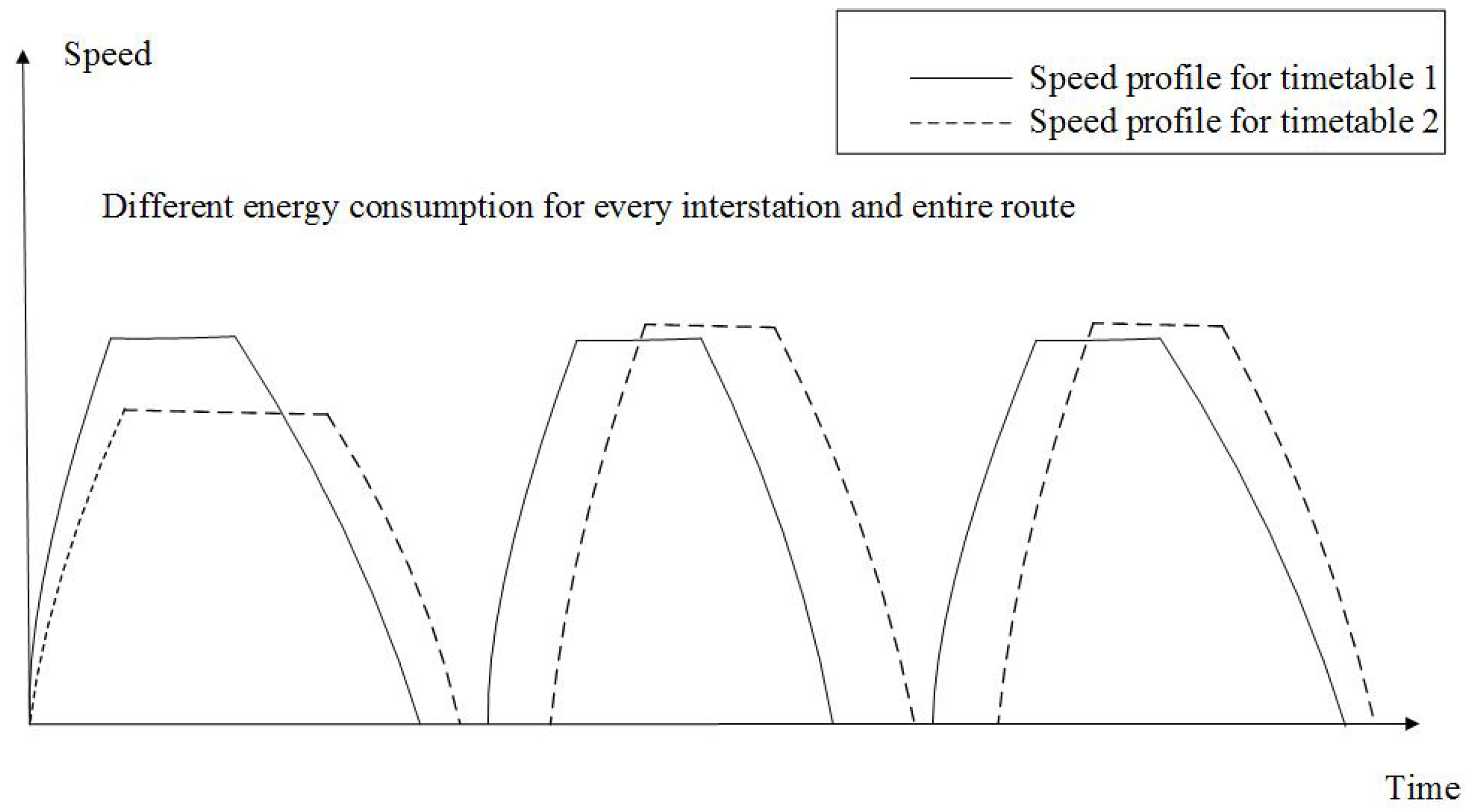
3.1. Energy-Efficient Operation Strategy
The trip time and energy consumption of multiple interstations is determined by the order and switching positions of the driving regime, which include maximum acceleration, coasting and maximum braking. There are many feasible speed profiles that satisfy the constraints on trip time and trip distance; each of them determines a driving strategy and the corresponding energy consumption. The energy-efficient optimization is to find a driving strategy that costs the minimum energy consumption on the condition that the total trip time is relatively constant.
Previous research [
39] shows that the energy-efficient driving strategy in the interstation includes acceleration, coasting and braking. Thomas [
40] explained the optimal phases as follows.
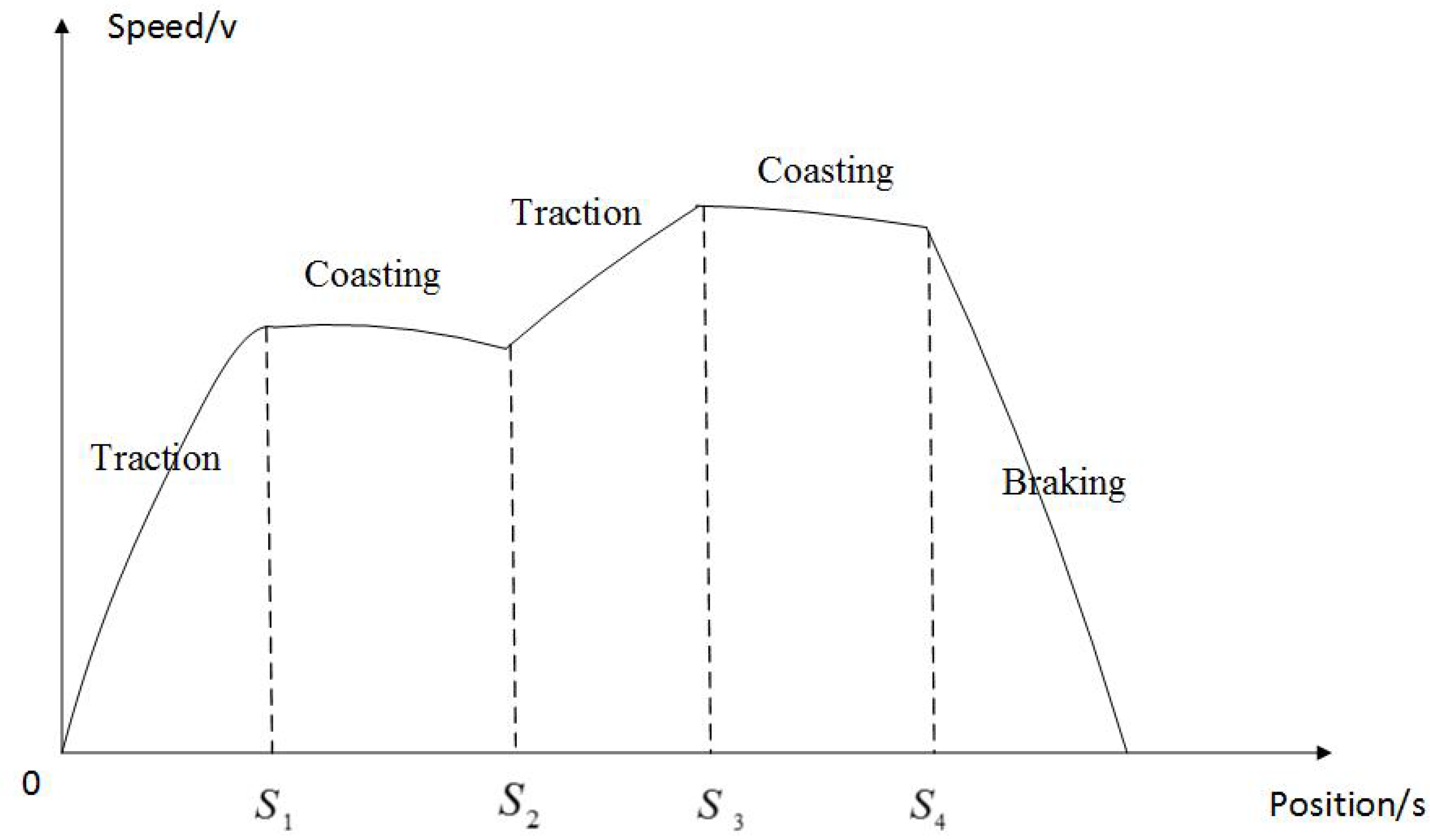
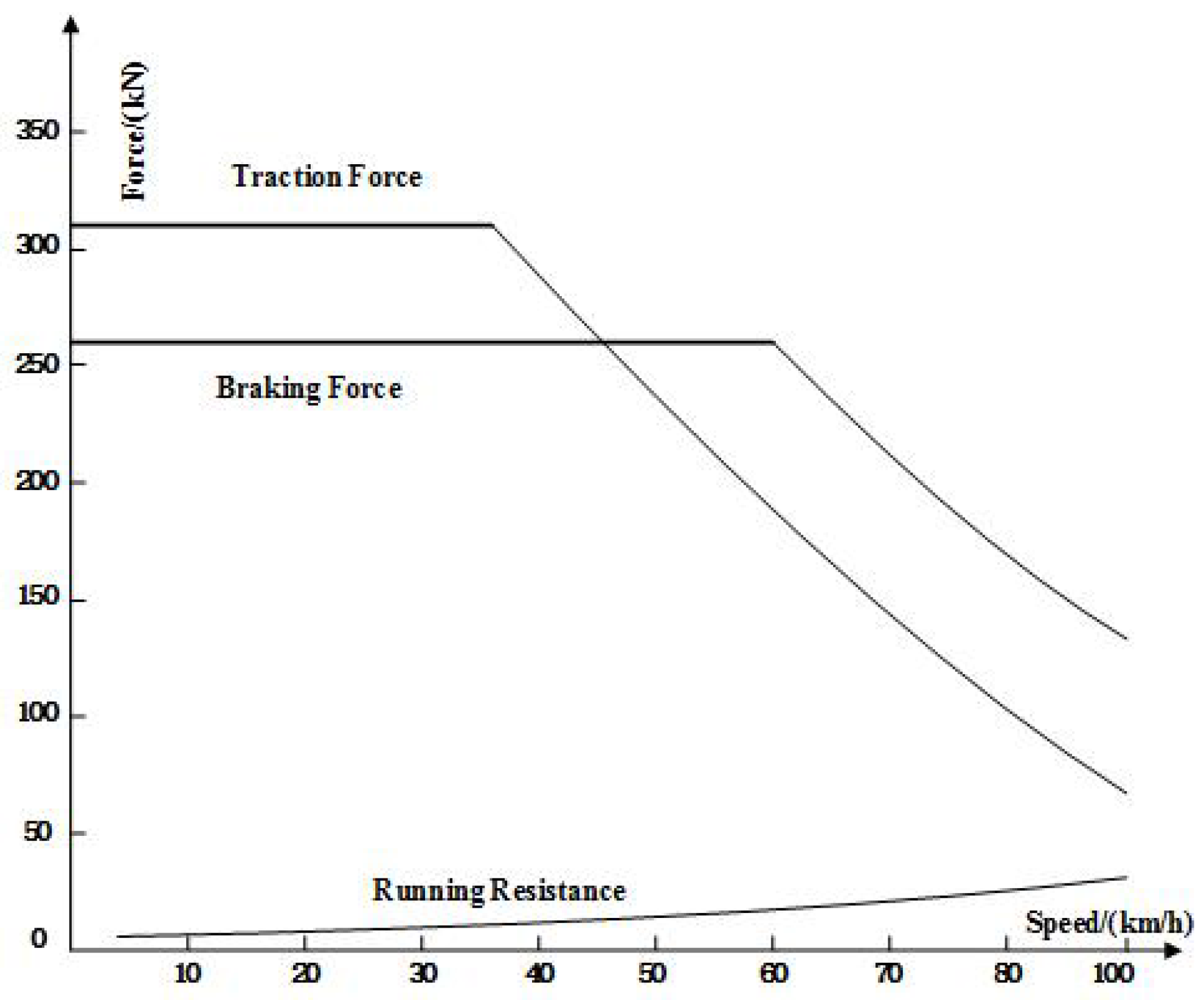
Maximum acceleration and braking: The slower a train accelerates or brakes, the more time it needs to come to a standstill. To obtain the same trip time with a lower acceleration or braking rate, the train should accelerate to a higher speed, which consumes more energy. Therefore, the maximum acceleration and braking must be the most energy efficient.
Coasting: During coasting, when no traction force and braking force are applied, the train only rolls forward and consumes no energy. Thus, the earlier coasting can start, the more energy can be saved.
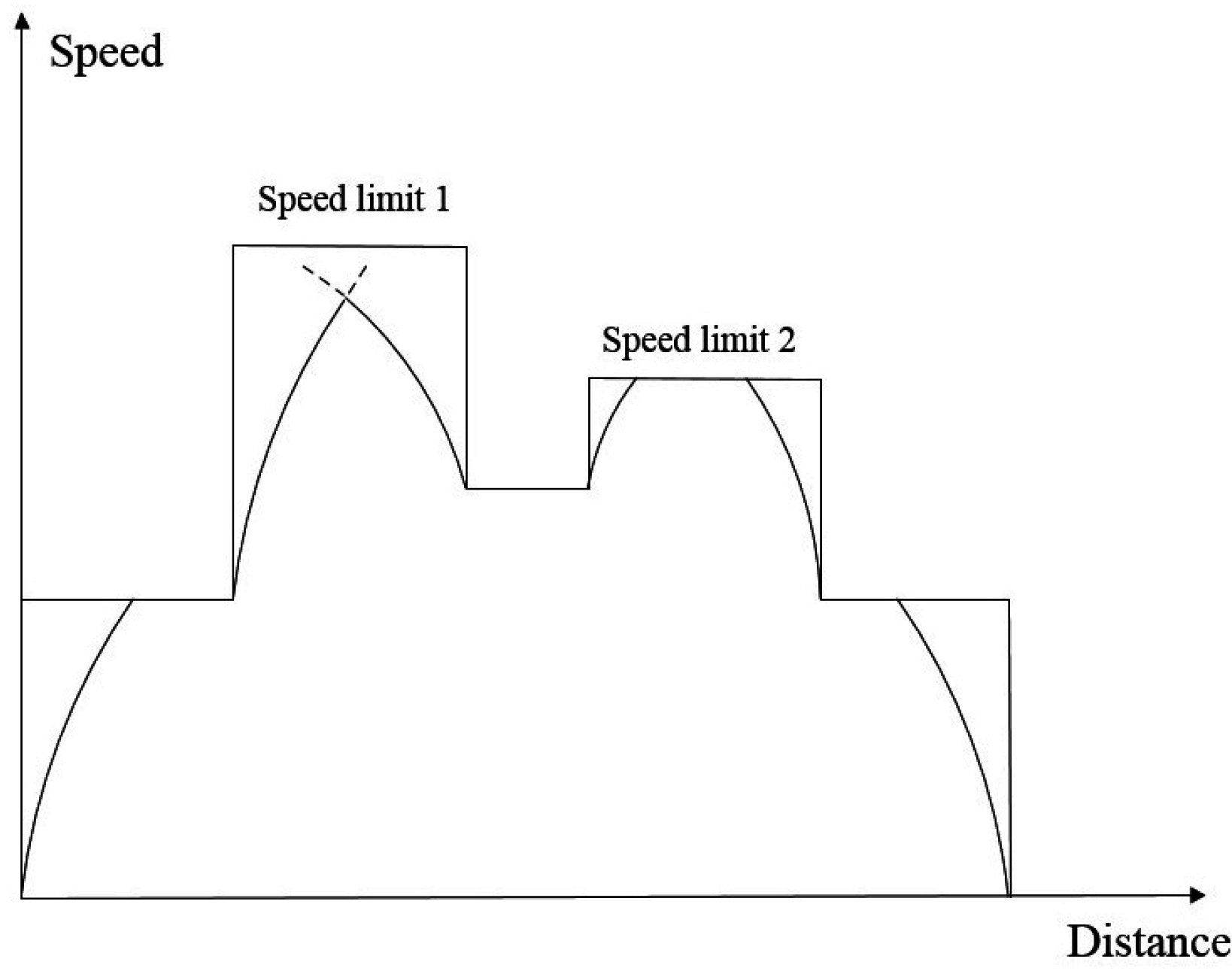
As shown in
Figure 3,
S,
S denotes the switching position from acceleration to coasting,
S denotes the switching position from coasting to acceleration and
S denotes the switching position from coasting to braking.
Figure 3.
Optimal driving strategy for interstations.
Figure 3.
Optimal driving strategy for interstations.
It is assumed that the total trip distance of multiple interstations is
L; then,
L is divided into n sections, and the trip distance of each section can be expressed as
. Each section is short enough to allow only one driving regime, so there are n driving regimes, which could be regarded as a driving regime sequence
for the entire route. Here, the corresponding relations between the driving regimes are listed in
Table 2.
Table 2.
Definition for driving regimes.
Table 2.
Definition for driving regimes.
| Number | Driving Regimes | Value |
|---|
| 1 | Traction | 1 |
| 2 | Coasting | 2 |
| 3 | Braking | 3 |
The driving regime sequence
C must follow the constraint as follows:
Table 3.
Rules for the change of the driving regimes.
Table 3.
Rules for the change of the driving regimes.
| Driving Regime | Traction | Coasting | Braking |
|---|
| Traction | √ | √ | × |
| Coasting | √ | √ | √ |
| Braking | × | √ | √ |
Table 4.
Constraints for the driving regimes’ change times.
Table 4.
Constraints for the driving regimes’ change times.
| Number | Distance (m) | Maximum Change Times |
|---|
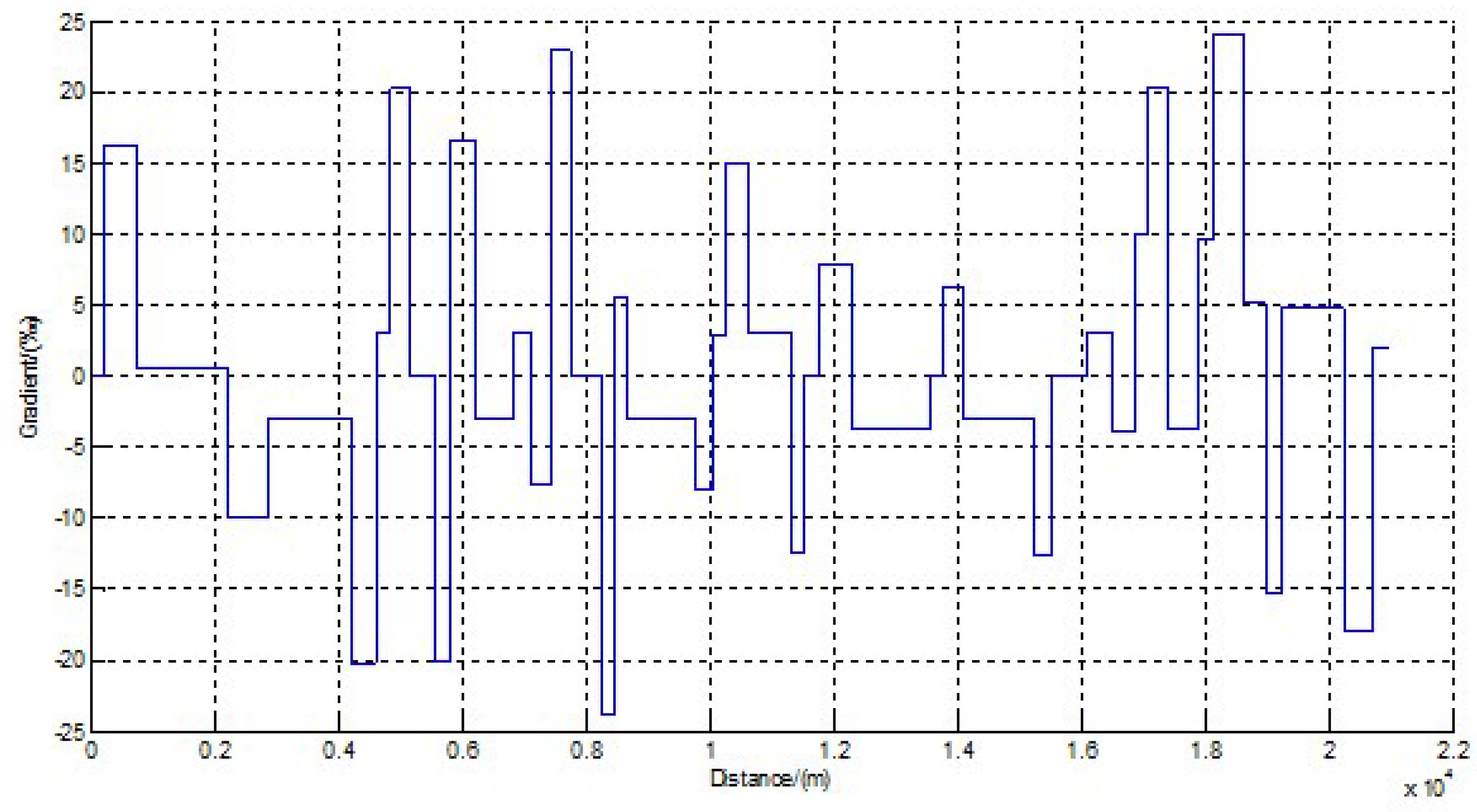
| 1 | 0–1000 | 3 |
| 2 | 1000–3000 | 5 |
| 3 | 3000–5000 | 7 |
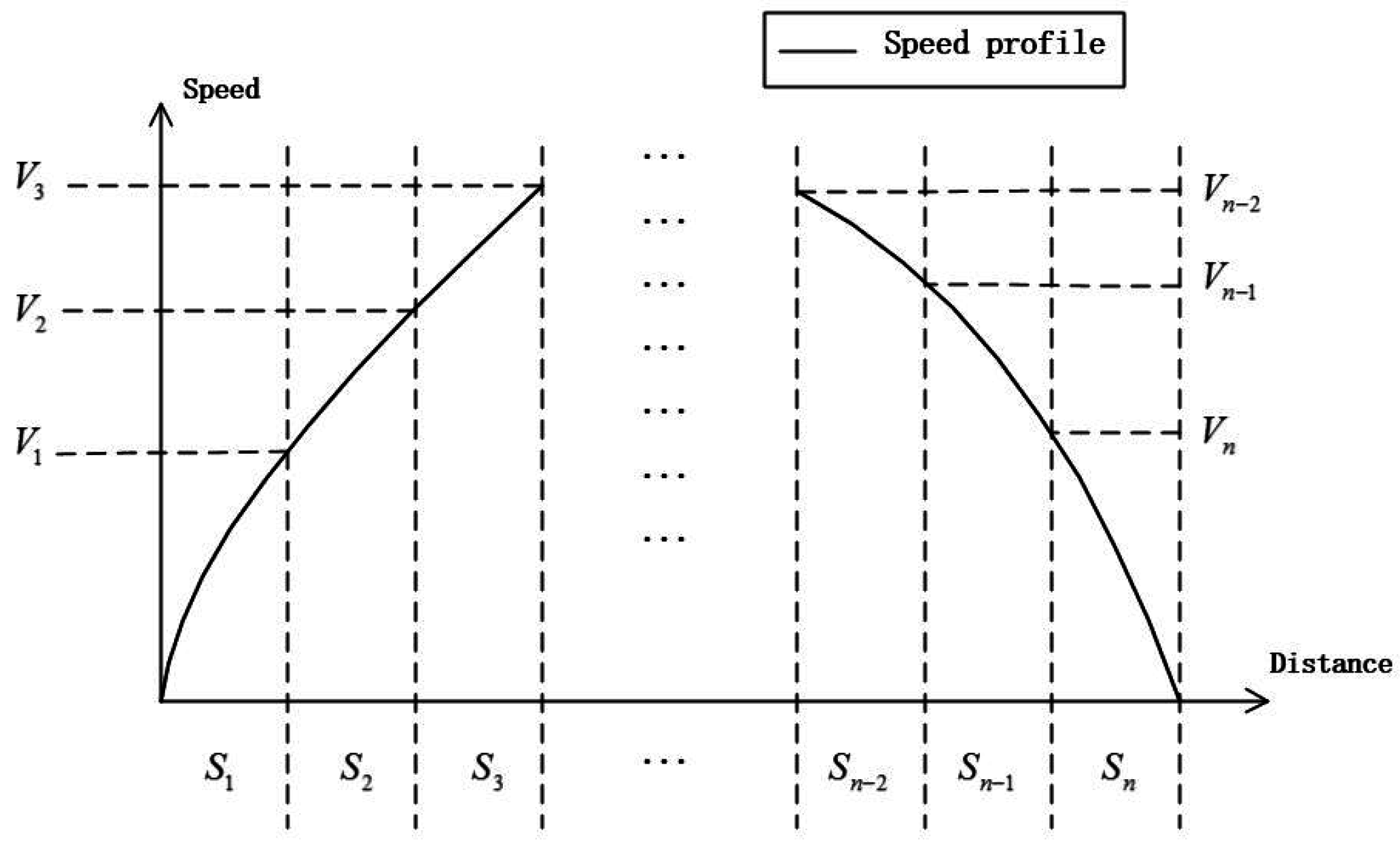
As shown in
Figure 4, the final speed of each section
V, trip time
T and energy consumption
E can be calculated according to the driving regime
C, the trip distance
S and the initial speed
V. The final speed of the section “
i” will be iterated as the initial speed of the section “
i + 1”. Then, the total trip time and energy consumption of the interstation can be obtained when the driving strategy is determined for all sections. Both the energy consumption reduction and the computing time of the algorithm will be influenced by the value of
S. On the one hand, a smaller value of
S may leads to a larger energy consumption reduction, because the driving regime could be more changeable; on the other hand, a smaller value of
S means more variables in the algorithm, which will lead to longer computing. In this paper,
S is 50 m in order to keep the balance of the two sides.
Figure 4.
Calculation model.
Figure 4.
Calculation model.
In order to ensure the accuracy of the results, a section should be divided into small subsections for calculation. It is assumed that there are m subsections in the
i-th section; the trip distance of each subsection is
d. The final speed
v, trip time
t and energy consumption
e of each subsection can be calculated according to the initial speed
v, trip distance
d and driving regime
C. In addition, with the consideration of the number of commuters, the mass of the train for each interstation
M varies with different interstations. In this paper, the authors define
M as a random variable obeying a normal distribution. Thus, the probability distribution of
M can be expressed as Equation (4), in which μ can be defined as Equation (5). In Equation 5,
M denotes the full load mass of the train, and
M denotes the empty mass of the train.
Here, t, e of each subsection are firstly calculated. Here, in this paper, the acceleration for the traction process is considered to be varied with the traction force. The acceleration for the braking process is considered to be a constant.
When the driving regime in the
i-th section is acceleration, traction force is used to speed up the train and overcome resistance (Equation (6)):
Then, the final speed
, trip time
and energy consumption
of the
i-th section can be calculated. The final speed
of the section is the final speed
of the last subsection. The trip time of the section is the sum of subsections (Equation (7)).
Similarly, when the driving regime in the i-th section is coasting or braking, the final speed , trip time and energy consumption of the i-th section can be calculated according to the above method.
When the driving regime in the
i-th section is coasting, the acceleration varies with the basic resistance and gradient resistance. The train is without traction, so the
is zero (Equations (8) and (9)).
When the driving regime in the
i-th section is braking (Equations (10) and (11)):
The basic resistance, gradient resistance and curve resistance are calculated as follows.
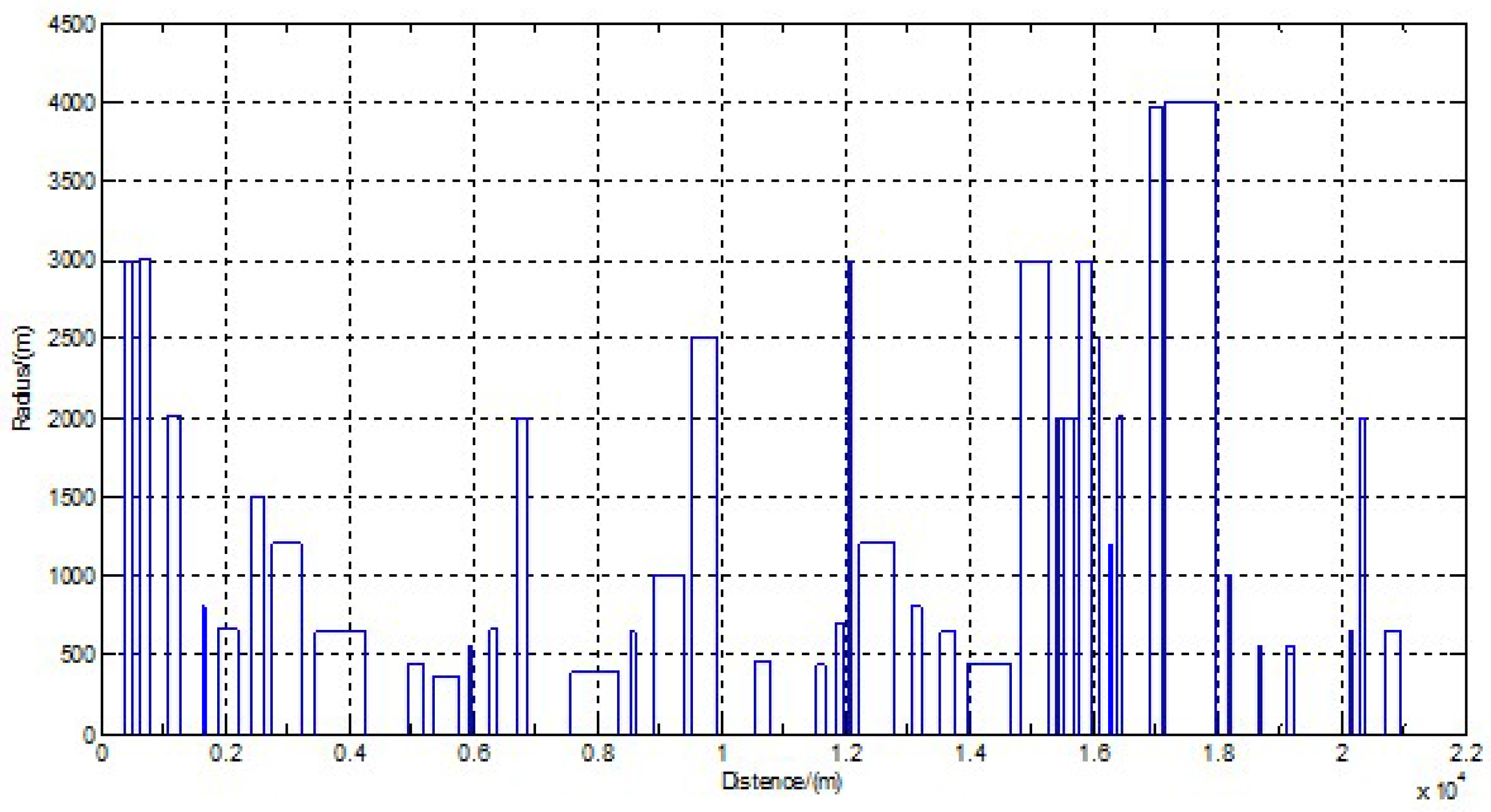
In Equation (12), a, b and c are empirical constants that vary with the vehicle type. In Equation (13), i denotes the value of the gradient. In Equation (14), R denotes the curve radius.
Therefore, there is a driving regime sequence , which corresponds a trip time sequence and an energy consumption sequence . Additionally, the corresponding total trip time is . The total energy consumption is . Therefore, the optimization problem can be formulated to obtain one driving regime sequence with minimum energy consumption on the condition that the total trip time is relatively constant.
There are constraints on trip time and constraints on speed in the optimization model mentioned above, so the optimization model for the MPGA is as follow:
In the model above, the first equation denotes the optimality criterion, in which num denotes the times that the speed does not satisfy the speed constraints in the speed profile, α denotes the penalty coefficient of time in the objective function and β denotes the penalty coefficient of speed in the objective function. α should be a very large number in order to ensure that the trip time is relatively constant. β is also very large because the speed profile must satisfy the speed constraints. In this way, individuals that do not satisfy the constraints will get large fitness values, and finally, they are eliminated. The following six equations denote the constraints on energy consumption, trip time, train speed and the constraints about the comfort of passengers.
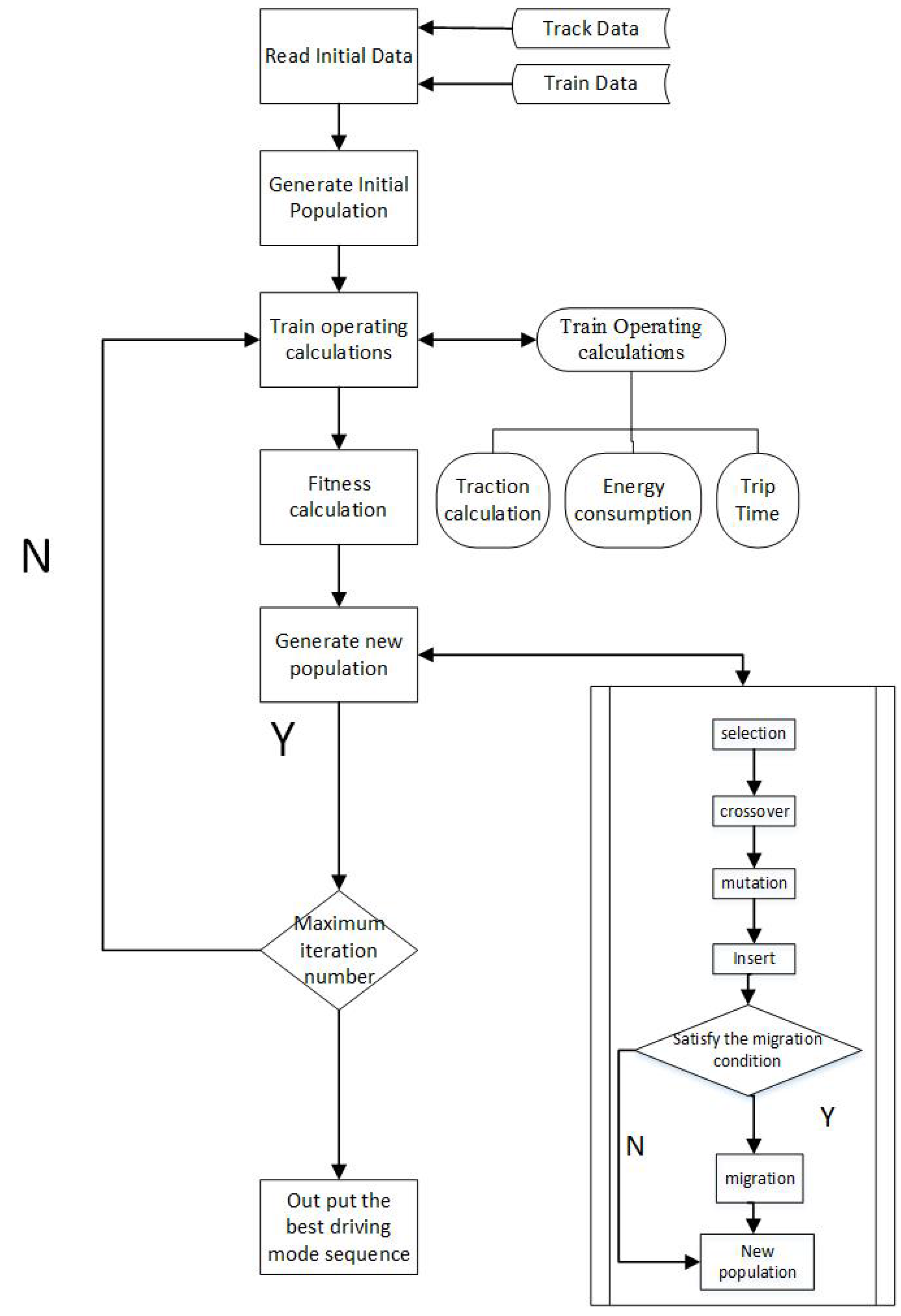
3.3. Algorithm
This problem is solved based on MPGA, and the process is as follows: Step 1: Initialize the initial data, including track limited speed, track slope value and train parameter value.
Step 2: Generate the initial population. Here, the authors use real code, describing the driving regime sequence by an individual ; the gene denotes a driving regime.
Step 3: Train operating calculations for calculating the total trip time and total energy consumption with the given driving regime sequence according to Equations (6)–(11).
Step 4: Fitness calculation. The fitness function is the objective function of the optimization Model 3a,3b. and are inserted into the fitness function, and the fitness value of each individual is calculated.
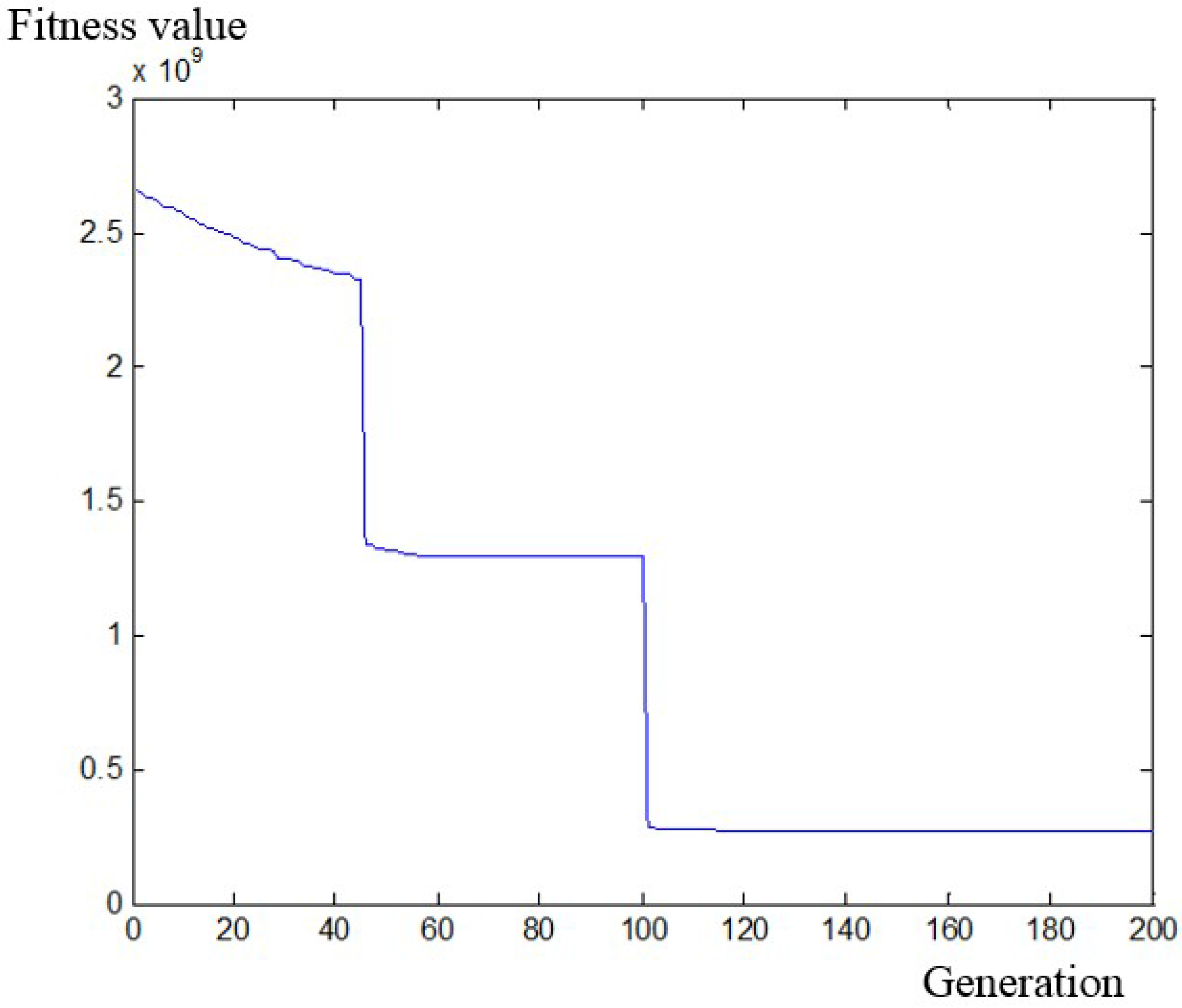
Step 5: Generate new population. First, the selected operator is stochastic universal sampling; the crossover operator is discrete recombination; the mutation operator is real mutation. The insert strategy is to replace the worst individual in the father generation, so it is ensured that the best individual is always copiedinto the next generation. When satisfying the migration condition, a part of the best individuals migrate into adjacent subpopulations. Thus, a new generation consisting of new driving regime sequences is generated.
Step 6: Iteration number plus one. Make a judgment about whether the maximum iteration number is reached. If it is, skip to Step 7; if not, returnto Step 3.
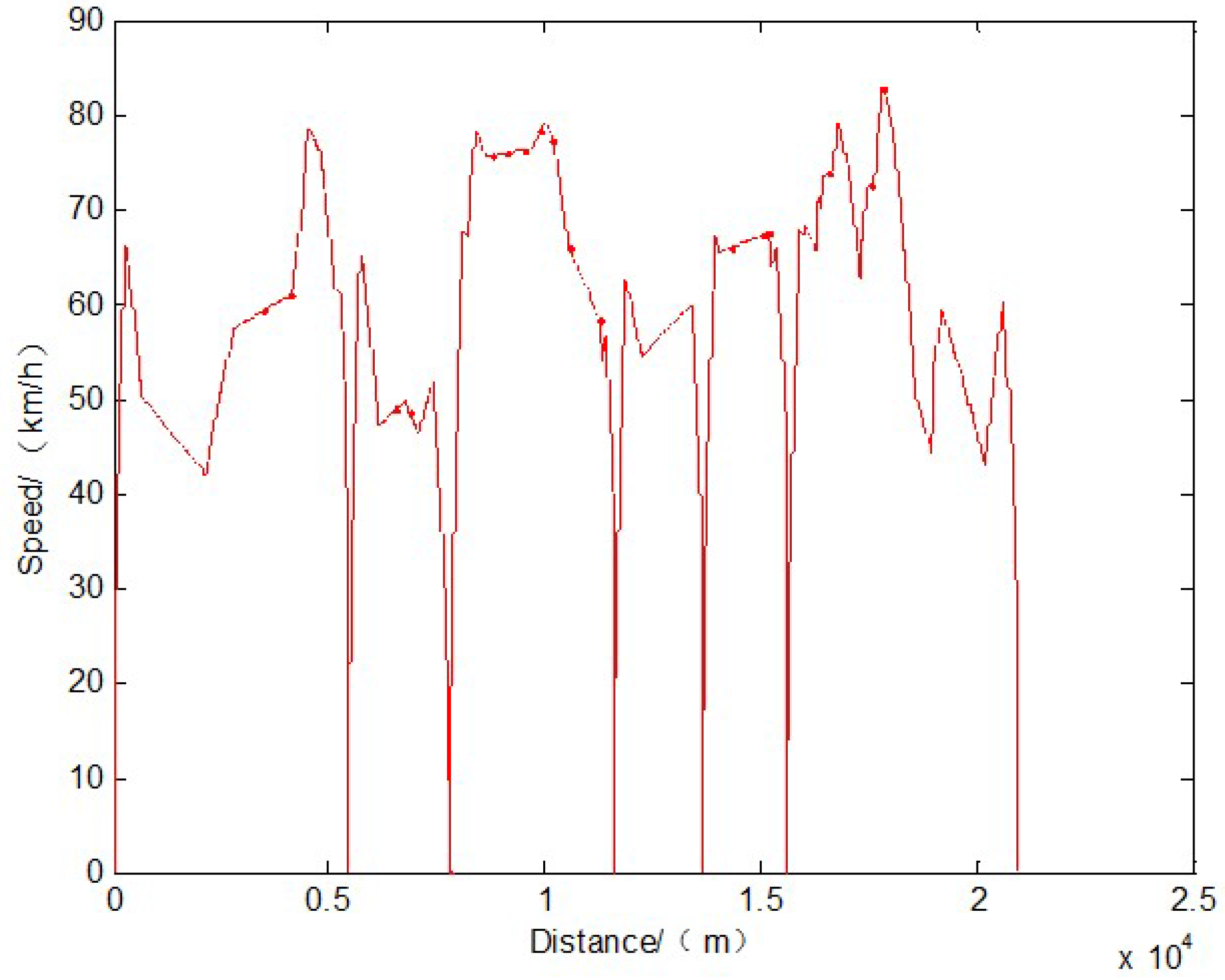
Step 7: Output the best driving regime sequence. , and the speed profile with the given driving regime sequence are calculated.
The algorithm flowchart is shown in
Figure 6.
Figure 6.
Algorithm flowchart for the multi-population genetic algorithm (MPGA).
Figure 6.
Algorithm flowchart for the multi-population genetic algorithm (MPGA).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











