
A Long-Term Wind Speed Ensemble Forecasting System with Weather Adapted Correction



Abstract
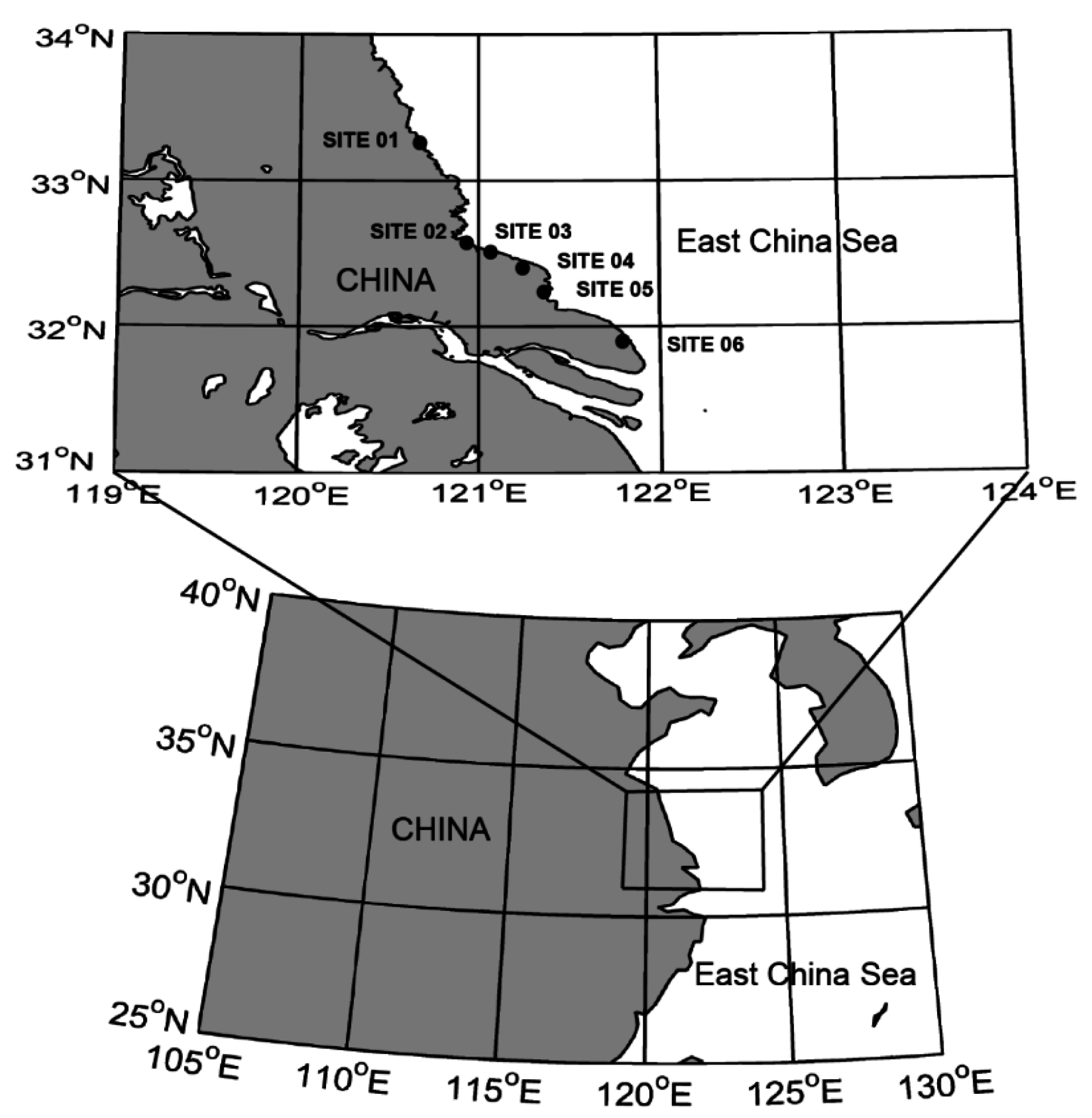
:1. Introduction
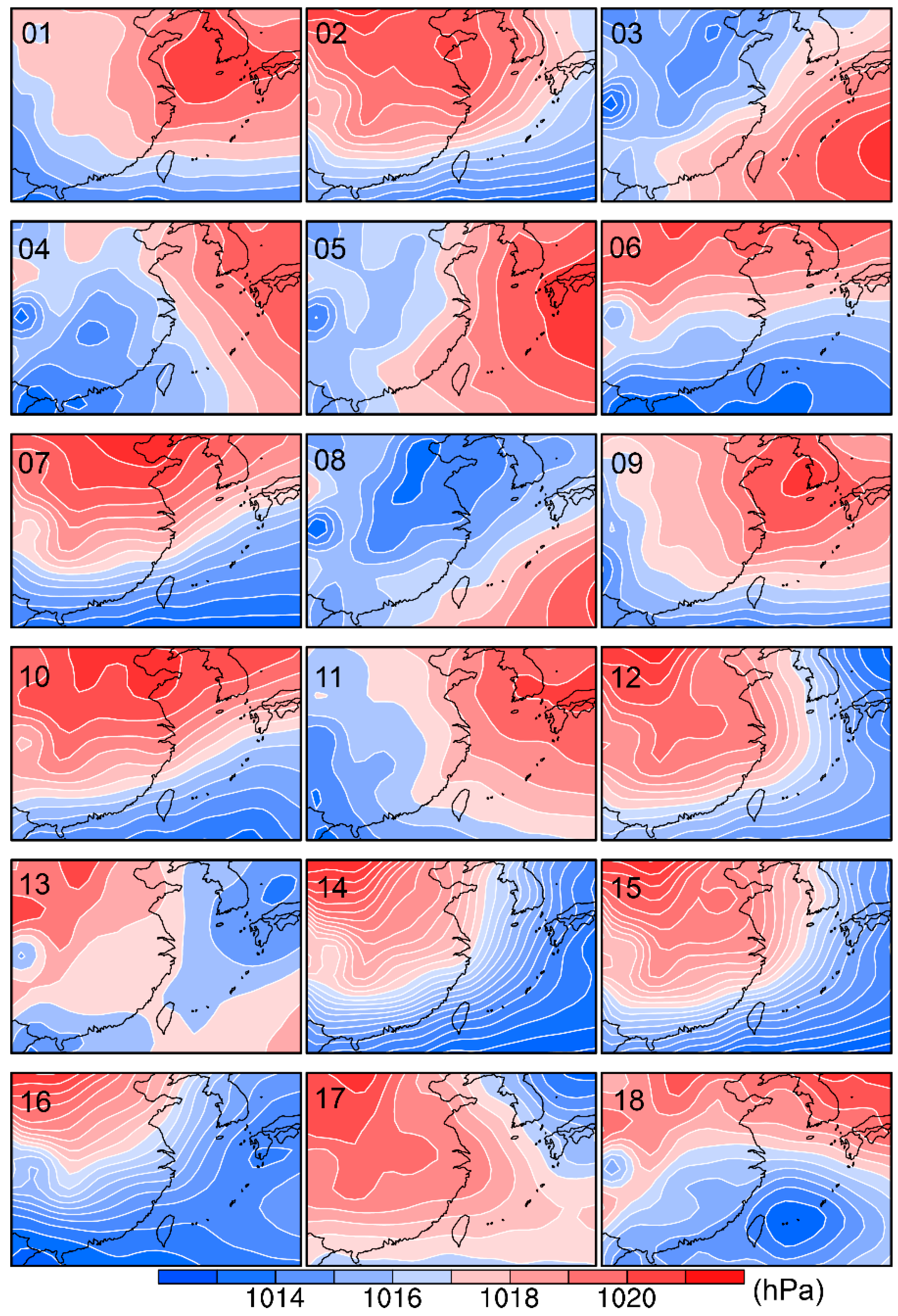
2. Weather Classification System
2.1. Weather Classification
2.2. Cost733 System
2.3. The Operational Process
3. The Ensemble Forecasting System
3.1. Ensemble Forecasting
3.2. Ensemble Member Production
3.3. Forecasting System Design
4. Statistical Correction
4.1. Average Bias Correction
4.2. Combined Correction Method
5. Results
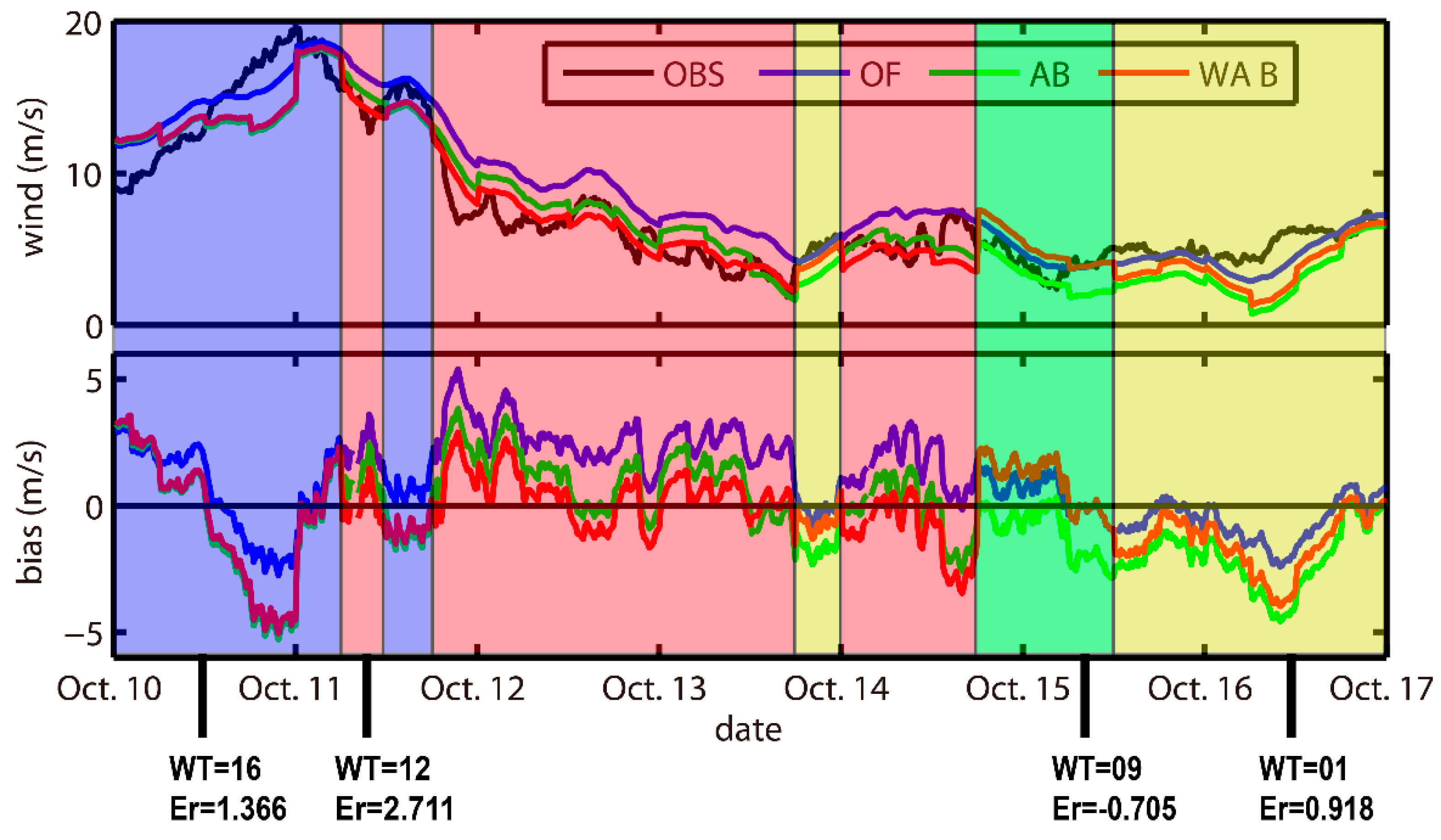
5.1. Weather Classification
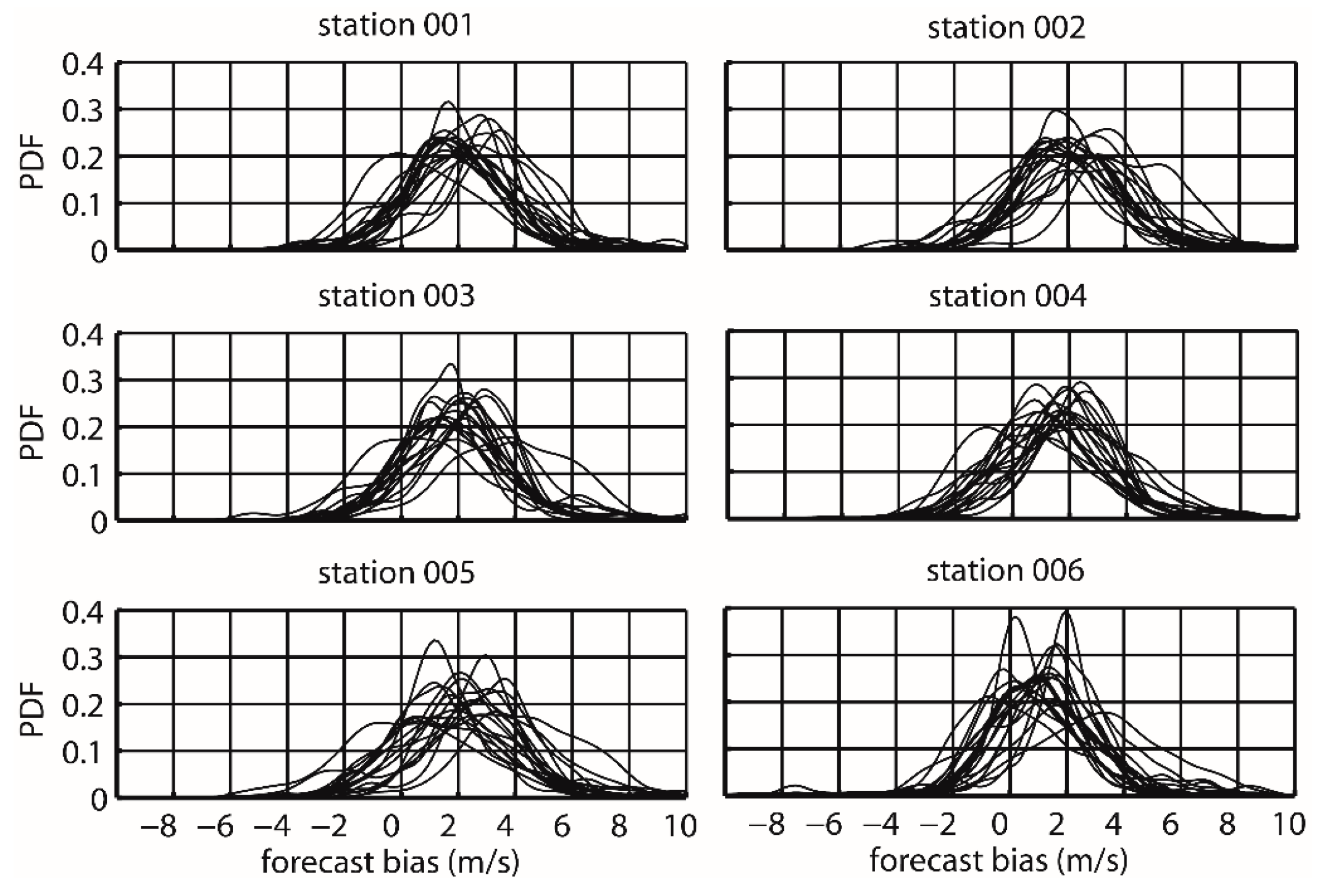
5.2. Ensemble Forecast Evaluation
5.2.1. Deterministic Forecasting
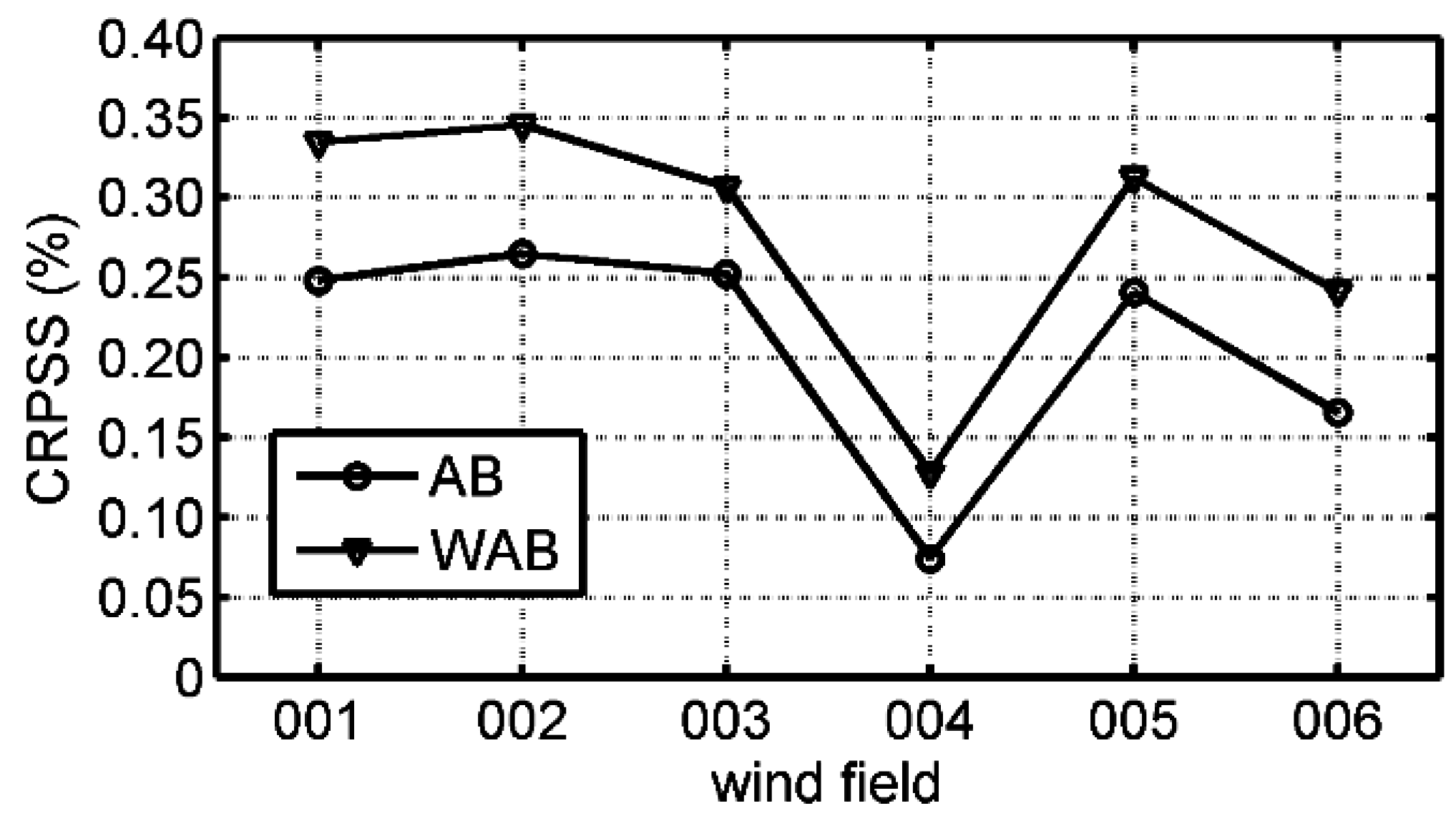
5.2.2. Continuous Ranked Probability Skill (CRPS)
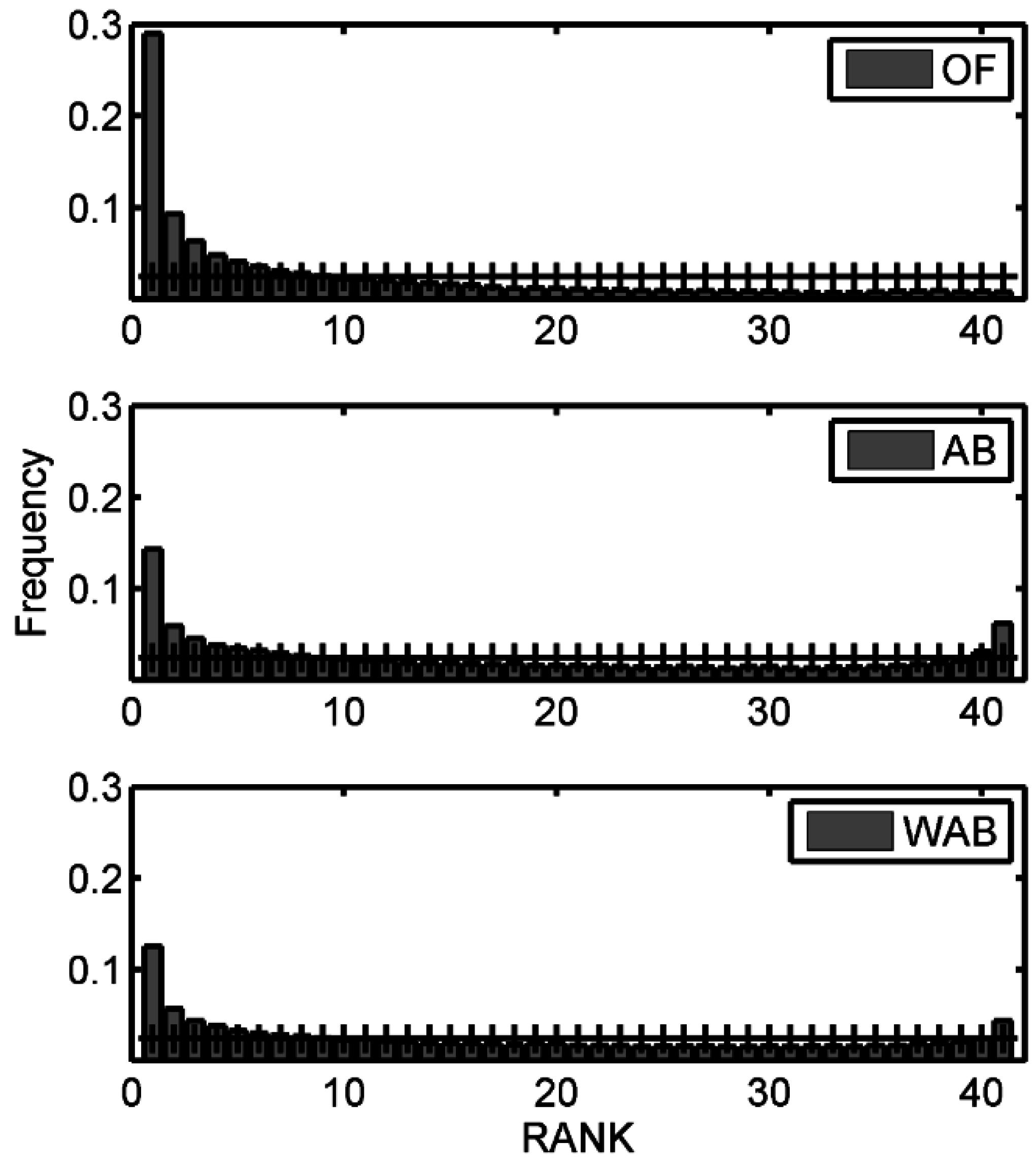
5.2.3. Rank Histogram
6. Conclusions and Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| AB | average bias correction |
| BE | background error |
| CDF | cumulative distribution function |
| COST733 | the European Cooperation in Science and Technology Action 733 |
| CRPS | Continuous Ranked Probability Skill |
| disp | dispersion error |
| ENS | ensemble prediction |
| FNL | final |
| GFS | the Global Forecasting System |
| GMT | Greenwich Mean Time |
| LST | Local Standard Time |
| MAE | mean absolute error |
| mnbias | mean bias of prediction |
| MYJ | the Mellor–Yamada–Janjić |
| NCEP | the National Centers for Environmental Prediction |
| NWP | numerical weather prediction |
| OF | original forecast |
| probability density function | |
| RMSE | root mean square error |
| RUC | the Rapid Update Cycle |
| sdbias | bias of standard deviation |
| sde | standard deviation of prediction bias |
| SINGLE | single member prediction |
| SLP | sea level pressure |
| WAB | weather adapted bias correction |
| WRF | the Weather Research and Forecasting Model |
| WSM | WRF single moment |
| YSU | the Yonsei University |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Microphysics | Surface | Cumulus | Boundary Layer |
|---|---|---|---|
| 14 Lin | 4 thermal diffusion scheme | 2 Kain–Fritsch | 1 YSU; 1 MYJ |
| 1 Betts–Miller | 1 YSU | ||
| 1 Grell–Devenyi | 1 YSU | ||
| 4 unified Noah | 2 Kain–Fritsch | 1 YSU; 1 MYJ | |
| 1 Betts–Miller | 1 YSU | ||
| 1 Grell–Devenyi | 1 YSU | ||
| 3 RUC | 1 Kain–Fritsch | 1 YSU | |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi | |||
| 3 Pleim-Xu | 1 Kain–Fritsch | 1 YSU | |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi | |||
| 13 WSM 3-class simple ice scheme | 3 thermal diffusion scheme | 1 Kain–Fritsch | 1 YSU |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi | |||
| 4 unified Noah | 2 Kain–Fritsch | 1 YSU; 1 MYJ 1 YSU 1 YSU | |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi | |||
| 3 RUC | 1 Kain–Fritsch | YSU | |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi | |||
| 3 Pleim-Xu | 1 Kain–Fritsch | YSU | |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi | |||
| 13 WSM 6-class scheme | 3 thermal diffusion scheme | 1 Kain–Fritsch | YSU |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi | |||
| 4 unified Noah | 2 Kain–Fritsch | 1 YSU; 1 MYJ 1 YSU 1 YSU | |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi | |||
| 3 RUC | 1 Kain–Fritsch | YSU | |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi | |||
| 3 Pleim-Xu | 1 Kain–Fritsch | YSU | |
| 1 Betts–Miller | |||
| 1 Grell–Devenyi |
| Weather Types | Site 01 | Site 02 | Site 03 | Site 04 | Site 05 | Site 06 |
|---|---|---|---|---|---|---|
| 01 | 1.23977 | 1.18559 | 1.14319 | 0.987266 | 0.649091 | 0.918064 |
| 02 | 2.18727 | 1.82632 | 2.59693 | 2.38776 | 3.16838 | 1.43187 |
| 03 | 1.67154 | 1.58716 | 1.70714 | 0.77744 | 1.15744 | 0.209118 |
| 04 | 1.42473 | 1.58379 | 1.04783 | 0.764425 | 1.11299 | −0.1966 |
| 05 | 1.62067 | 1.67296 | 1.34391 | 1.39182 | 1.96115 | 0.449447 |
| 06 | 1.4323 | 1.84642 | 2.2545 | 1.82924 | 1.70808 | 1.35626 |
| 07 | 2.80638 | 1.70231 | 1.14023 | 1.94397 | 2.04169 | 1.53158 |
| 08 | 1.21735 | 1.46985 | 1.4147 | 0.389931 | 1.72153 | 0.136346 |
| 09 | −0.06956 | 1.236 | 0.492679 | −0.88616 | −0.78387 | −0.70555 |
| 10 | 3.08536 | 3.34946 | 2.92031 | 2.60398 | 3.64069 | 1.66283 |
| 11 | 1.6559 | 1.16625 | 1.52237 | 0.873545 | 1.3636 | 1.17054 |
| 12 | 2.64311 | 3.39535 | 1.93689 | 2.34948 | 2.78504 | 2.71129 |
| 13 | 1.56285 | 1.14944 | 1.88875 | 1.58339 | 2.20748 | 0.991559 |
| 14 | 3.43315 | 3.25248 | 3.64207 | 1.95077 | 3.26691 | 3.34844 |
| 15 | 3.05847 | 2.9717 | 2.99038 | 2.37237 | 2.96116 | 1.97132 |
| 16 | 2.7078 | 3.01587 | 2.2667 | 1.89914 | 3.37813 | 1.36602 |
| 17 | 1.92407 | 2.71989 | 2.25191 | 1.94155 | 2.61543 | 1.68193 |
| 18 | 1.63197 | 1.97719 | 2.01428 | 1.59431 | 2.71998 | 1.38041 |
References
- Jung, J.; Broadwater, R.P. Current status and future advances for wind speed and power forecasting. Renew. Sustain. Energy Rev. 2014, 31, 762–777. [Google Scholar] [CrossRef]
- Zhou, W.; Lou, C.; Li, Z.; Lu, L.; Yang, H. Current status of research on optimum sizing of stand-alone hybrid solar-wind power generation systems. Appl. Energy 2010, 87, 380–389. [Google Scholar] [CrossRef]
- Christensen, J.F. New control strategies for utilizing power system networks more effectively: The state of the art and the future trends based on a synthesis of the work in the cigre study committee 38. Control Eng. Pract. 1998, 6, 1495–1510. [Google Scholar] [CrossRef]
- Al-Yahyai, S.; Charabi, Y.; Gastli, A. Review of the use of Numerical Weather Prediction (NWP) Models for wind energy assessment. Renew. Sustain. Energy Rev. 2010, 14, 3192–3198. [Google Scholar] [CrossRef]
- Milligan, M.R.; Miller, A.H.; Chapman, F. Estimating the Economic Value of Wind Forecasting to Utilities. In Proceedings of the Windpower, Washington, DC, USA, 27–30 March 1995.
- Kalney, E. Atmospheric Modeling, Data Assimilation, and Predictability; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Negnevitsky, M.; Johnson, P.; Santoso, S. Short term wind power forecasting using hybrid intelligent systems. In Proceedings of the 2007 IEEE Power Engineering Society General Meeting, Tampa, FL, USA, 24–28 June 2007; p. 4.
- Giebel, G.; Kariniotakis, G.; Brownsword, R. The state-of-the-art in short term prediction of wind power from a Danish perspective. J. Virol. 2003, 82, 9513–9524. [Google Scholar]
- Ma, L.; Luan, S.; Jiang, C.; Liu, H.; Zhang, Y. A review on the forecasting of wind speed and generated power. Renew. Sustain. Energy Rev. 2009, 13, 915–920. [Google Scholar]
- Soman, S.S.; Zareipour, H.; Malik, O.; Mandal, P. A review of wind power and wind speed forecasting methods with different time horizons. In Proceedings of the North American Power Symposium, Arlington, TX, USA, 26–28 September 2010; pp. 1–8.
- Pinson, P.; Nielsen, H.A.; Madsen, H.; Kariniotakis, G. Skill forecasting from ensemble predictions of wind power. Appl. Energy 2009, 86, 1326–1334. [Google Scholar] [CrossRef] [Green Version]
- Zhao, E.; Zhao, J.; Liu, L.; Su, Z.; An, N. Hybrid Wind Speed Prediction Based on a Self-Adaptive ARIMAX Model with an Exogenous WRF Simulation. Energies 2016, 9, 7. [Google Scholar] [CrossRef]
- Bouzgou, H.; Benoudjit, N. Multiple architecture system for wind speed prediction. Appl. Energy 2011, 88, 2463–2471. [Google Scholar] [CrossRef]
- Sun, W.; Liu, M.; Liang, Y. Wind Speed Forecasting Based on FEEMD and LSSVM Optimized by the Bat Algorithm. Energies 2015, 8, 6585–6607. [Google Scholar] [CrossRef]
- Alessandrini, S.; Sperati, S.; Pinson, P. A comparison between the ECMWF and COSMO Ensemble Prediction Systems applied to short-term wind power forecasting on real data. Appl. Energy 2013, 107, 271–280. [Google Scholar] [CrossRef]
- Traiteur, J.J.; Callicutt, D.J.; Smith, M.; Roy, S.B. A Short-Term Ensemble Wind Speed Forecasting System for Wind Power Applications. J. Appl. Meteorol. Clim. 2012, 51, 1763–1774. [Google Scholar] [CrossRef]
- Cui, B.; Toth, Z.; Zhu, Y.; Hou, D. Bias Correction for Global Ensemble Forecast. Weather Forecast 2012, 27, 396–410. [Google Scholar] [CrossRef]
- Erdem, E.; Shi, J. ARMA based approaches for forecasting the tuple of wind speed and direction. Appl. Energy 2011, 88, 1405–1414. [Google Scholar] [CrossRef]
- Gallego, C.; Pinson, P.; Madsen, H.; Costa, A.; Cuerva, A. Influence of local wind speed and direction on wind power dynamics—Application to offshore very short-term forecasting. Appl. Energy 2011, 88, 4087–4096. [Google Scholar] [CrossRef] [Green Version]
- De Giorgi, M.G.; Ficarella, A.; Tarantino, M. Assessment of the benefits of numerical weather predictions in wind power forecasting based on statistical methods. Energy 2011, 36, 3968–3978. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W.; Campos-Amezcua, R.; Heard, C. Wind Speed Prediction Using a Univariate ARIMA Model and a Multivariate NARX Model. Energies 2016, 9, 109. [Google Scholar] [CrossRef]
- Ambach, D.; Croonenbroeck, C. Space-time short- to medium-term wind speed forecasting. Stat. Methods Appl. 2016, 25, 5–20. [Google Scholar] [CrossRef]
- Barry, R.G.; Perry, A.H. Synoptic Climatology: Methods and Applications; Routledge Kegan & Paul: Methuen, MA, USA, 1973. [Google Scholar]
- Spinoni, J.; Szalai, S.; Szentimrey, T.; Lakatos, M.; Bihari, Z.; Nagy, A.; Németh, Á.; Kovács, T.; Mihic, D.; Dacic, M.; et al. Climate of the Carpathian Region in the period 1961–2010: Climatologies and trends of 10 variables. Int. J. Climatol. 2015, 35, 1322–1341. [Google Scholar] [CrossRef]
- Casado, M.J.; Pastor, M.A. Circulation types and winter precipitation in Spain. Int. J. Climatol. 2016, 36, 2727–2742. [Google Scholar] [CrossRef]
- Burlando, M. The synoptic-scale surface wind climate regimes of the Mediterranean Sea according to the cluster analysis of ERA-40 wind fields. Theor. Appl. Climatol. 2009, 96, 69–83. [Google Scholar] [CrossRef]
- Saavedra-Moreno, B.; de la Iglesia, A.; Magdalena-Saiz, J.; Carro-Calvo, L.; Durán, L.; Salcedo-Sanz, S. Surface wind speed reconstruction from synoptic pressure fields: Machine learning versus weather regimes classification techniques. Wind Energy 2014, 18, 1531–1544. [Google Scholar] [CrossRef]
- Ramos, A.M.; Pires, A.C.; Sousa, P.M.; Trigo, R.M. The use of circulation weather types to predict upwelling activity along the western Iberian Peninsula coast. Cont. Shelf Res. 2013, 69, 38–51. [Google Scholar] [CrossRef]
- Addor, N.; Rohrer, M.; Furrer, R.; Seibert, J. Propagation of biases in climate models from the synoptic to the regional scale: Implications for bias adjustment. J. Geophys. Res. Atmos. 2016, 121, 2075–2089. [Google Scholar] [CrossRef] [Green Version]
- Huth, R.; Beck, C.; Philipp, A.; Demuzere, M.; Ustrnul, Z.; Cahynova, M.; Kyselý, J.; Tveito, O.E. Classifications of Atmospheric Circulation Patterns Recent Advances and Applications. Ann. N. Y. Acad. Sci. 2008, 1146, 105–152. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.P.; Zhu, T.; Zhang, Q.H.; Li, C.C.; Shu, H.L.; Ying, Y.; Dai, Z.P.; Wang, X.; Liu, X.Y.; Liang, A.M.; et al. The impact of circulation patterns on regional transport pathways and air quality over Beijing and its surroundings. Atmos. Chem. Phys. 2012, 12, 5031–5053. [Google Scholar] [CrossRef]
- Philipp, A.; Bartholy, J.; Beck, C.; Erpicum, M.; Esteban, P.; Fettweis, X.; Huth, R.; James, P.; Jourdain, S.; Kreienkamp, F.; et al. Cost733cat—A database of weather and circulation type classifications. Phys. Chem. Earth 2010, 35, 360–373. [Google Scholar] [CrossRef]
- Hoy, A.; Sepp, M.; Matschullat, J. Large-scale atmospheric circulation forms and their impact on air temperature in Europe and northern Asia. Theor. Appl. Climatol. 2013, 113, 643–658. [Google Scholar] [CrossRef]
- Cahynova, M.; Huth, R. Circulation vs. climatic changes over the Czech Republic: A comprehensive study based on the COST733 database of atmospheric circulation classifications. Phys. Chem. Earth 2010, 35, 422–428. [Google Scholar] [CrossRef]
- Demuzere, M.; Kassomenos, P.; Philipp, A. The COST733 circulation type classification software: An example for surface ozone concentrations in Central Europe. Theor. Appl. Climatol. 2011, 105, 143–166. [Google Scholar] [CrossRef]
- Huth, R. A circulation classification scheme applicable in GCM studies. Theor. Appl. Climatol. 2000, 67, 1–18. [Google Scholar] [CrossRef]
- Huth, R. An intercomparison of computer-assisted circulation classification methods. Int. J. Climatol. 1996, 16, 893–922. [Google Scholar] [CrossRef]
- Toreti, A.; Fioravanti, G.; Perconti, W.; Desiato, F. Annual and seasonal precipitation over Italy from 1961 to 2006. Int. J. Climatol. 2009, 29, 1976–1987. [Google Scholar] [CrossRef]
- Skamarock, W.C.; Klemp, J.B. A time-split nonhydrostatic atmospheric model for weather research and forecasting applications. J. Comput. Phys. 2008, 227, 3465–3485. [Google Scholar] [CrossRef]
- Lin, Y.-L.; Farley, R.D.; Orville, H.D. Bulk Parameterization of the Snow Field in a Cloud Model. J. Clim. Appl. Meteorol. 1983, 22, 1065–1092. [Google Scholar] [CrossRef]
- Hong, S.-Y.; Dudhia, J.; Chen, S.-H. A Revised Approach to Ice Microphysical Processes for the Bulk Parameterization of Clouds and Precipitation. Mon. Weather Rev. 2004, 132, 103–120. [Google Scholar] [CrossRef]
- Hong, S.-Y.; Lim, J.-O.J. The WRF single-moment 6-class microphysics scheme (WSM6). J. Korean Meteor. Soc. 2006, 42, 129–151. [Google Scholar]
- Ek, M.B.; Mitchell, K.E.; Lin, Y.; Rogers, E.; Grunmann, P.; Koren, V.; Gayno, G.; Tarpley, J.D. Implementation of Noah land surface model advances in the National Centers for Environmental Prediction operational mesoscale Eta model. J. Geophys. Res. 2003, 108. [Google Scholar] [CrossRef]
- Benjamin, S.G.; Dévényi, D.; Weygandt, S.S.; Brundage, K.J.; Brown, J.M.; Grell, G.A.; Kim, D.; Schwartz, B.E.; Smirnova, T.G.; Smith, T.L.; et al. An Hourly Assimilation–Forecast Cycle: The RUC. Mon. Weather Rev. 2004, 132, 495–518. [Google Scholar] [CrossRef]
- Xiu, A.; Pleim, J.E. Development of a Land Surface Model. Part I: Application in a Mesoscale Meteorological Model. J. Appl. Meteorol. 2001, 40, 192–209. [Google Scholar] [CrossRef]
- Kain, J.S.; Fritsch, J.M. Convective Parameterization for Mesoscale Models: The Kain-Fritsch Scheme. In The Representation of Cumulus Convection in Numerical Models; Emanuel, K.A., Raymond, D.J., Eds.; American Meteorological Society: Boston, MA, USA, 1993. [Google Scholar]
- Betts, A.K.; Miller, M.J. The Betts-Miller Scheme. In The Representation of Cumulus Convection in Numerical Models; Emanuel, K.A., Raymond, D.J., Eds.; American Meteorological Society: Boston, MA, USA, 1993. [Google Scholar]
- Grell, G.A.; Dévényi, D. A generalized approach to parameterizing convection combining ensemble and data assimilation techniques. Geophys. Res. Lett. 2002, 29, 38. [Google Scholar] [CrossRef]
- Hong, S.-Y.; Noh, Y.; Dudhia, J. A New Vertical Diffusion Package with an Explicit Treatment of Entrainment Processes. Mon. Weather Rev. 2006, 134, 2318–2341. [Google Scholar] [CrossRef]
- Mellor, G.L.; Yamada, T. Development of a turbulence closure model for geophysical fluid problems. Rev. Geophys. 1982, 20, 851–875. [Google Scholar] [CrossRef]
- Schemm, C.E.; Unger, D.A.; Faller, A.J. Statistical Corrections to Numerical Predictions III. Mon. Weather Rev. 1981, 109, 96–109. [Google Scholar] [CrossRef]
- Madsen, H.; Pinson, P.; Kariniotakis, G.; Nielsen, H.A.; Nielsen, T.S. Standardizing the Performance Evaluation of ShortTerm Wind Power Prediction Models. Wind Eng. 2005, 29, 475–489. [Google Scholar] [CrossRef] [Green Version]
- Calinski, T. A Dendrite Method for Cluster Analysis. Biometrics 1968, 24, 207. [Google Scholar]
- Hou, D.; Kalnay, E.; Droegemeier, K.K. Objective verification of the SAMEX’98 ensemble forecasts. Mon. Weather Rev. 2001, 129, 73–91. [Google Scholar] [CrossRef]
- Takacs, L.L. A 2-step scheme for the advection equation with minimized dissipation and dispersion errors. Mon. Weather Rev. 1985, 113, 1050–1065. [Google Scholar] [CrossRef]
- Hersbach, H. Decomposition of the continuous ranked probability score for ensemble prediction systems. Weather Forecast 2000, 15, 559–570. [Google Scholar] [CrossRef]
- Alessandrini, S.; Delle Monache, L.; Sperati, S.; Nissen, J.N. A novel application of an analog ensemble for short-term wind power forecasting. Renew. Energy 2015, 76, 768–781. [Google Scholar] [CrossRef]
- Anderson, J.L. A method for producing and evaluating probabilistic forecasts from ensemble model integrations. J. Clim. 1996, 9, 1518–1530. [Google Scholar] [CrossRef]
- Hamill, T.M. Interpretation of rank histograms for verifying ensemble forecasts. Mon. Weather Rev. 2001, 129, 550–560. [Google Scholar] [CrossRef]
- Guidelines on Ensemble Prediction Systems and Forecasting; WMO-No. 1091; World Meteorological Organization (WMO): Geneva, Switzerland, 2012.







| Wind Field | K con | K ens |
|---|---|---|
| 001 | 0.28 | 0.45 |
| 002 | 0.20 | 0.43 |
| 003 | 0.17 | 0.43 |
| 004 | 0.30 | 0.45 |
| 005 | 0.29 | 0.56 |
| 006 | 0.24 | 0.55 |
| average | 0.25 | 0.48 |
| Wind Field | SINGLE | ENS | ||||
|---|---|---|---|---|---|---|
| OF | AB | WAB | OF | AB | WAB | |
| 001 | 2.68 | 2.29 | 2.21 | 2.71 | 2.09 | 1.86 |
| 002 | 3.41 | 2.87 | 2.75 | 2.83 | 2.14 | 1.90 |
| 003 | 3.22 | 2.80 | 2.74 | 2.70 | 2.09 | 1.96 |
| 004 | 1.53 | 1.53 | 1.63 | 2.42 | 1.95 | 1.84 |
| 005 | 2.94 | 2.56 | 2.45 | 3.01 | 2.35 | 2.17 |
| 006 | 2.47 | 2.29 | 2.28 | 2.23 | 1.95 | 1.78 |
| average | 2.71 | 2.39 | 2.34 | 2.65 | 2.10 | 1.92 |
| Wind Field | OF | AB | WAB | ||
|---|---|---|---|---|---|
| 001 | 2.40 | 0.68 | 0.72 | 0.64 | 0.73 |
| 002 | 2.47 | 0.81 | 0.67 | 0.78 | 0.68 |
| 003 | 2.33 | 0.77 | 0.67 | 0.75 | 0.68 |
| 004 | 1.95 | 0.68 | 0.65 | 0.62 | 0.68 |
| 005 | 2.57 | 0.85 | 0.67 | 0.80 | 0.69 |
| 006 | 1.67 | 0.51 | 0.70 | 0.46 | 0.72 |
| average | 2.23 | 0.72 | 0.68 | 0.68 | 0.70 |
| Wind Field | OF | AB | WAB | ||
|---|---|---|---|---|---|
| 001 | 0.77 | 0.89 | −0.16 | 0.65 | 0.16 |
| 002 | 0.64 | 0.75 | −0.17 | 0.48 | 0.25 |
| 003 | 0.46 | 0.55 | −0.18 | 0.38 | 0.18 |
| 004 | 0.44 | 0.52 | −0.17 | 0.42 | 0.05 |
| 005 | 0.75 | 0.85 | −0.14 | 0.61 | 0.18 |
| 006 | 0.50 | 0.57 | −0.14 | 0.31 | 0.38 |
| average | 0.59 | 0.69 | −0.16 | 0.47 | 0.20 |
| Wind Field | OF | AB | WAB | ||
|---|---|---|---|---|---|
| 001 | 2.13 | 2.34 | −0.09 | 2.15 | −0.01 |
| 002 | 2.26 | 2.43 | −0.08 | 2.24 | 0.01 |
| 003 | 2.26 | 2.43 | −0.07 | 2.31 | −0.02 |
| 004 | 2.18 | 2.28 | −0.05 | 2.19 | −0.01 |
| 005 | 2.47 | 2.65 | −0.07 | 2.51 | −0.01 |
| 006 | 2.22 | 2.32 | −0.04 | 2.17 | 0.02 |
| average | 2.25 | 2.41 | −0.07 | 2.26 | −0.00 |
| Wind Field | OF | AB | WAB |
|---|---|---|---|
| 001 | 2.10 | 1.58 | 1.39 |
| 002 | 2.20 | 1.62 | 1.44 |
| 003 | 2.09 | 1.56 | 1.45 |
| 004 | 1.52 | 1.41 | 1.33 |
| 005 | 2.37 | 1.80 | 1.63 |
| 006 | 1.71 | 1.43 | 1.30 |
| average | 2.00 | 1.57 | 1.42 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, Y.; Li, C.; Wang, Y.; Li, J.; Li, J. A Long-Term Wind Speed Ensemble Forecasting System with Weather Adapted Correction. Energies 2016, 9, 894. https://doi.org/10.3390/en9110894
Chu Y, Li C, Wang Y, Li J, Li J. A Long-Term Wind Speed Ensemble Forecasting System with Weather Adapted Correction. Energies. 2016; 9(11):894. https://doi.org/10.3390/en9110894
Chicago/Turabian StyleChu, Yiqi, Chengcai Li, Yefang Wang, Jing Li, and Jian Li. 2016. "A Long-Term Wind Speed Ensemble Forecasting System with Weather Adapted Correction" Energies 9, no. 11: 894. https://doi.org/10.3390/en9110894
APA StyleChu, Y., Li, C., Wang, Y., Li, J., & Li, J. (2016). A Long-Term Wind Speed Ensemble Forecasting System with Weather Adapted Correction. Energies, 9(11), 894. https://doi.org/10.3390/en9110894