1. Introduction
In recent years, swarm intelligence algorithms have received a wide spread attention. The artificial bee colony (ABC) algorithm is a relatively new approach that was proposed by Karaboga [
1,
2], motivated by the collective foraging behavior of honey bees. In the process of foraging, the bees need to find the place of food source with the highest nectar amount. In ABC system, artificial bees search in the given search space and the food sources represent possible solutions for the optimisation problems. The bees update the candidate solutions by means of solution search equation (SSE) and if the new solution is better than the previous one in their memory, they memorize the new position and forget the previous one. Due to its simplicity and ease of implementation, the ABC algorithm has captured much attention and has been applied successfully to a variety of fields, such as classification and function approximation [
3], feature selection [
4], inverse modelling of a solar collector [
5], electric power system optimization [
6], multi-objective optimisation [
7], complex network optimization [
8], transportation energy demand [
9], large-scale service composition for cloud manufacturing [
10], job-shop scheduling problem with no-wait constraint [
11], respiratory disease detection from medical images [
12].
Although the ABC algorithm has been widely used in different fields, some researchers have also pointed out that the ABC algorithm suffers from low solution accuracy and poor convergence performance. To solve the optimization problem, the intelligent optimization algorithm should combine global search methods, used to locate the potential optimal regions, with local search methods, used to fine-tune the candidate solutions, to balance exploration and exploitation process. However, exploration strategies and exploitation strategies contradict each other and to achieve good performance, they should be well balanced. While the SSE of ABC, which is used to generate new candidate solutions based on the information of the present solutions, does well in exploration but poorly in exploitation, which results in the poor convergence rate. Thus, many related and improved ABC algorithms have been proposed [
13,
14,
15,
16].
Inspired by a operator of global best (gbest) solution in particle swarm optimization (PSO) algorithm [
17], Zhu and Kwong proposed a modified ABC algorithm called gbest-guided ABC (GABC) algorithm to improve the exploitation [
18]; the gbest term in the modified SSE can drive the new candidate solution towards the global best solution. Although the GABC algorithm accelerated the convergence rate, the exploration performance decreased. Therefore, how to balance exploration and exploitation has become the main goal in the ABC research. Inspired by differential evolution [
19], Gao and Liu introduced a new initialization approach and proposed an improved SSE which is based on that the bee searches only around the best solution of the previous iteration to improve the exploitation; by hybridizing the original SSE and the improved SSE with the fixed selective probability, the new search mechanism obtains better performance [
20]. After that, based on the two SSEs, Gao and Liu proposed the modified ABC (MABC) algorithm which excludes the onlooker and scout bee stage. In MABC, a selective probability was introduced to balance exploration of the original SSE and exploitation of the improved SSE [
21]; if the new candidate solution obtained using the improved SSE is worse than the original one, the bee uses the original SSE to generate a new candidate solution with a certain probability. To well balance exploration and exploitation, Akay and Karaboga constructed an adaptive scaling factor (SF) which regulates the range of parameter in SSE by using Rechenberg’s 1/5 mutation rule; a smaller SF makes the candidate solution fine-tuned with a small steps while causing slow convergence rate and the bigger SF speeds up the search, but it reduces the exploitation performance [
22]. In the original SSE in ABC algorithm, since the guidance of the last two term may be in opposite directions, it may cause an oscillation phenomenon. To overcome the oscillation phenomenon, Gao et al. presented a new SSE with two different candidate solutions selected from the solution space; moreover, an orthogonal learning strategy was developed to discover more effective information from the search experiences and to get more promising and efficient candidate solutions [
23]. When the candidate solutions converge to the similar points, the SSE can cause a stagnation behavior during the search process, that means the value of the new candidate solution is the same with the value of the current solution. To overcome stagnation behavior of the algorithm, Babaoglu proposed a novel algorithm called distABC algorithm based on the distributed solution update rule, which uses the mean and standard deviation of the selected two solution to obtain a new candidate solution [
24].
The above methods have achieved some progress, but there still exist some problems. The GABC algorithm improved the exploitation, but the exploration decreased. Even though MABC algorithm used two SSEs to balance exploration and exploitation, the selection mechanism and the fixed selective probability cannot adapt to the changing environment. Moreover, when the global best solution trapped in local optimum, GABC and MABC algorithm cannot escape from the local optimum effectively. The distABC algorithm overcame stagnation behavior, but distABC does poorly in exploitation. For population-based optimization methods, it is desirable to encourage the individuals to wander through the entire search space at the initial phase of the optimization; on the other hand, it is very important to fine-tune the candidate solutions in the succeeding phases of the optimization [
25]. However, one SSE of original ABC algorithm cannot balance two aspects. Therefore, this paper proposes an achievable ABC algorithm which uses five SSEs as the candidate operator pool. The same with the SSE in ABC algorithm, the first SSE uses a solution selected randomly from the population to maintain population diversity and it emphasizes the exploration. Inspired by the PSO algorithm, the second SSE takes advantage of the information of the global best solution to guide the new candidate solution towards the global best solution. Therefore, the second SSE can improve the exploitation. To achieve good performance, the third SSE combines the above two SSEs which means that a randomly selected solution and the global best solution are all used in the SSE to balance exploration and exploitation. It seems that the global optimal solution is most likely around the best solution of the previous iteration. Therefore, the fourth SSE is the same with the one proposed in MABC algorithm which is based on that the bee searches only around the best solution of the previous iteration to improve the exploitation. When the candidate solutions trapped in local optimum, the above SSEs cannot escape from the local optimum effectively. To solve such problem, this paper proposes a novel SSE with Lévy flight step-size which can generate smaller step-size with high frequency and bigger step-size occasionally. The fifth SSE cannot only balance exploration and exploitation but also escape from the local optimum effectively. The five SSEs have both advantages and disadvantages and in order to make full use of the advantages of each SSE, this paper proposes a simple self-learning mechanism, wherein the SSE is selected according to the previous success ratio in generating promising solutions at each iteration. The SSE with a high success ratio means that the SSE can generate a better candidate solution with a large probability. Therefore, the self-learning mechanism cannot only select the appropriate SSE to generate new candidate solution but also adapt to the changing environment.
The following sections are organized as follows.
Section 2 outlines the reviews of the classical ABC algorithm.
Section 3 introduces the proposed self-learning mechanism (SLABC) algorithm. In
Section 4, experiments are carried out to verify the effectiveness of SLABC algorithm based on nine benchmark functions in terms of
t-test.
Section 5 presents and discusses the experimental results. Finally, the conclusion is drawn in
Section 6.
3. SLABC Algorithm
To improve the performance, the SLABC algorithm uses five SSEs as the candidate operator pool. One of the SSEs with Lévy flight step-size cannot only balance exploration and exploitation but also avoid trapping in the local optimum. This section first introduces the Lévy flight in detail.
3.1. Lévy Flight Step-Size
A Lévy flight is a random walk and the step-size satisfies a probability distribution which can be expressed as follows [
26]:
where
s is the step-size with
. Lévy flight can generate smaller step-size with high frequency and generate larger step-size occasionally. In the search process, the bee with a large step-size can reach anywhere of the entire search space to locate the potential optimal solution; when the bees are trapped in the local optimum, the large step-size can make the bees escape from the local optimum. The bees with a small step-size tend to fine-tune the current solution to obtain the optimal solution. The foraging behaviors of many creatures in nature satisfy Lévy flight, such as albatrosses’ foraging flight trajectory [
27,
28] and drosophilas’ intermittent foraging flight trajectory [
29]. Viswanathan et al. suggest that Lévy flight is an optimal search strategy when the target sites are sparse and distributed randomly [
26].
This paper uses the method proposed by [
30] to calculate Lévy flight step-size:
where
,
u and
v are two normal stochastic variables with standard deviation
and
.
where the notation
is gamma function. If the real part of the complex number
z is positive
, then the integral
converges absolutely.
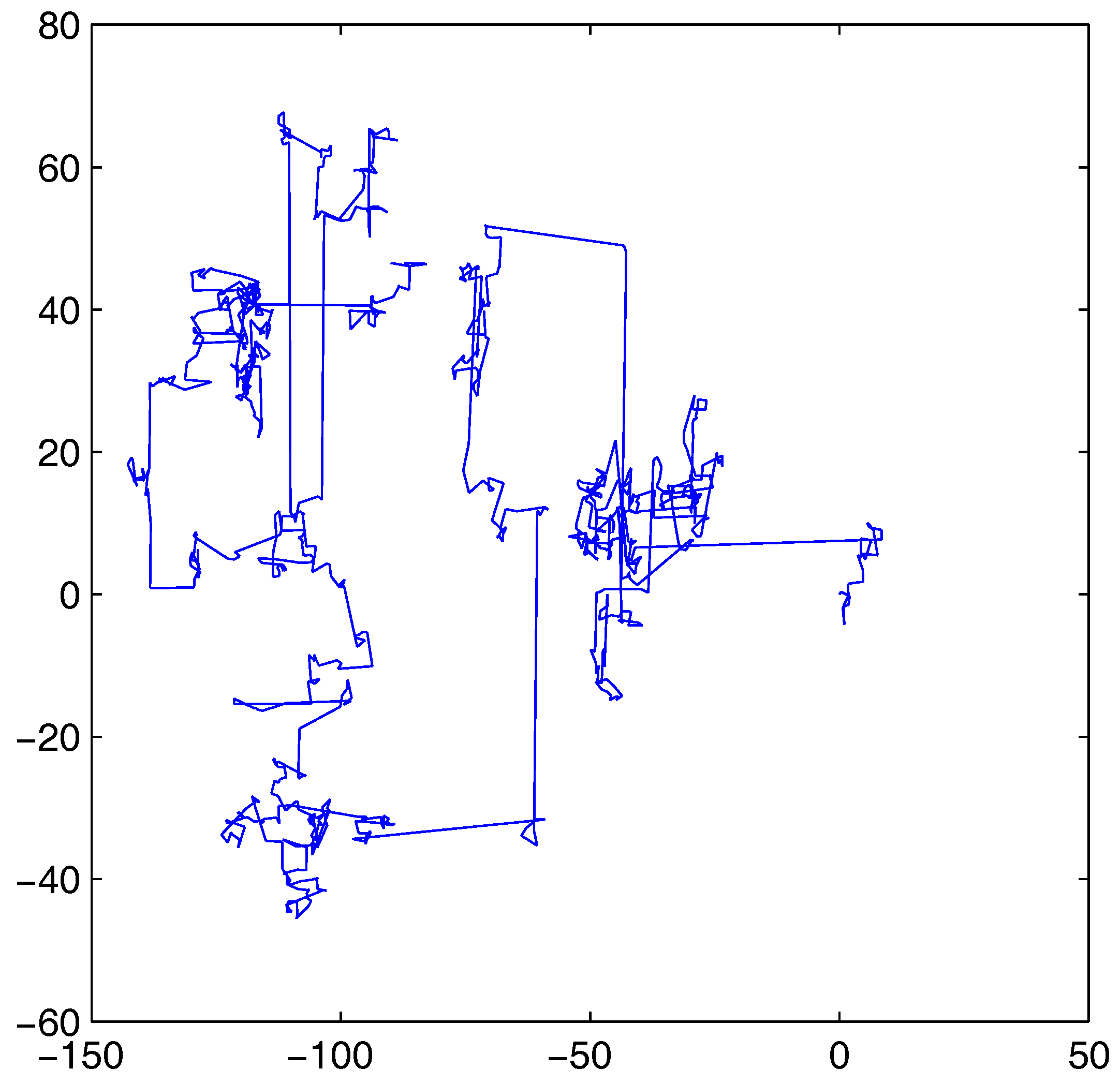
As shown in
Figure 1, Lévy flight with a mix of large step-size and small step-size can balance exploration and exploitation. Therefore, SLABC introduces Lévy flight step-size to the modified SSEs to improve the performance.
3.2. The Modified Solution Search Equations
To solve the optimization problem, the intelligent optimization algorithm should combine global search methods with local search methods to balance exploration and exploitation. However, exploration strategies and exploitation strategies contradict each other and one SSE in ABC algorithm cannot balance two aspects. Therefore, this paper proposes an achievable ABC algorithm which uses five SSEs as the candidate operator pool.
Following the classical ABC algorithm, SLABC employs the original SSE as the first search equations to improve exploration of SLABC algorithm.
where
and
are randomly chosen indexes;
is different with
i;
is a random number in the range
.
To improve exploitation, the second SSE introduces the global best solution to guide the new candidate solutions towards the global best solution.
where
is the global best solution. Generally speaking, there may be a better solution around the global best solution; therefore, we set random number
in the range
.
The Equation (
9) is good at exploration and Equation (
10) is good at exploitation, therefore to well balance exploration and exploitation, the third SSE combine the two equations as follows.
where
are randomly chosen indexes and
is different with
i;
and
are random numbers.
It seems that the global optimal solution is most likely around the best solution of the previous iteration. Therefore, the fourth SSE is the same with the one proposed in MABC algorithm which is based on that the bee searches only around the best solution of the previous iteration to improve the exploitation.
where
and
are mutually different random integer indices selected from
;
is a random number in the range
.
Because the above four SSEs are based on the current solutions, when the present solutions converge to the similar point or are trapped in local optimum, the above SSEs cannot escape from the local minimum effectively. Therefore, this paper introduces Lévy flight step-size to the last SSE to solve this problem.
where
s is the Lévy flight step-size which can be calculated in Equation (
5).
Different from the GABC, MABC algorithm, the range of the weight
,
,
in Equations (
11) and (
12) with the
term are all reduced and the interval length are set to 1. Therefore, the new generated candidate solution can be in a smaller range and the accuracy of the solution will be improved. Moreover, to make the candidate solution nearer to the global best solution, the range of the weight
in Equation (
10) is further reduced and interval length are set to 0.5.
After all the employed (onlooker) bees produce the new candidate solutions using the improved SSEs, then, a greedy selection mechanism is used to select a better solution between and .
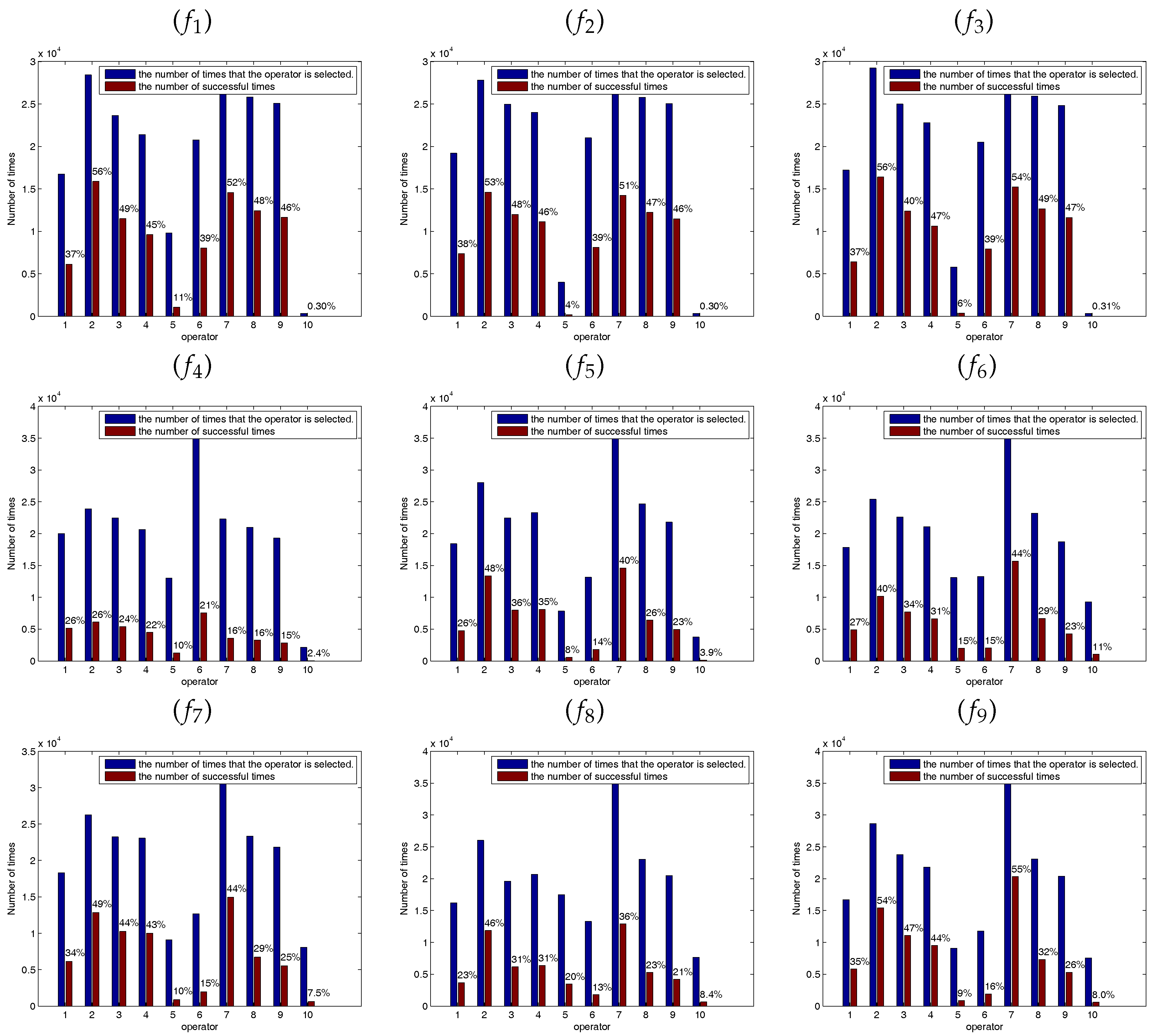
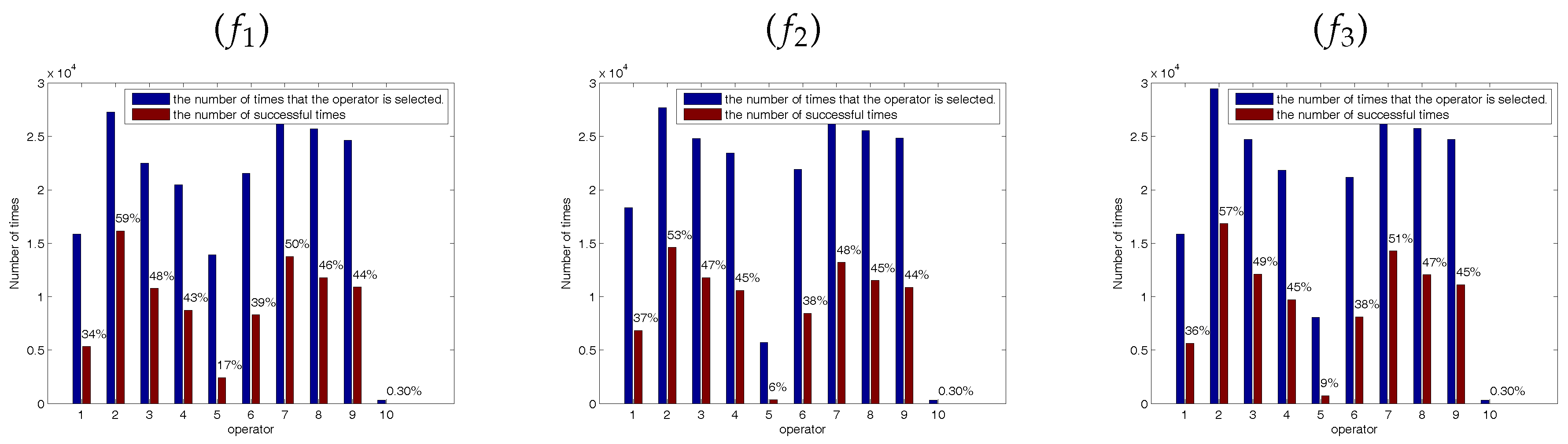
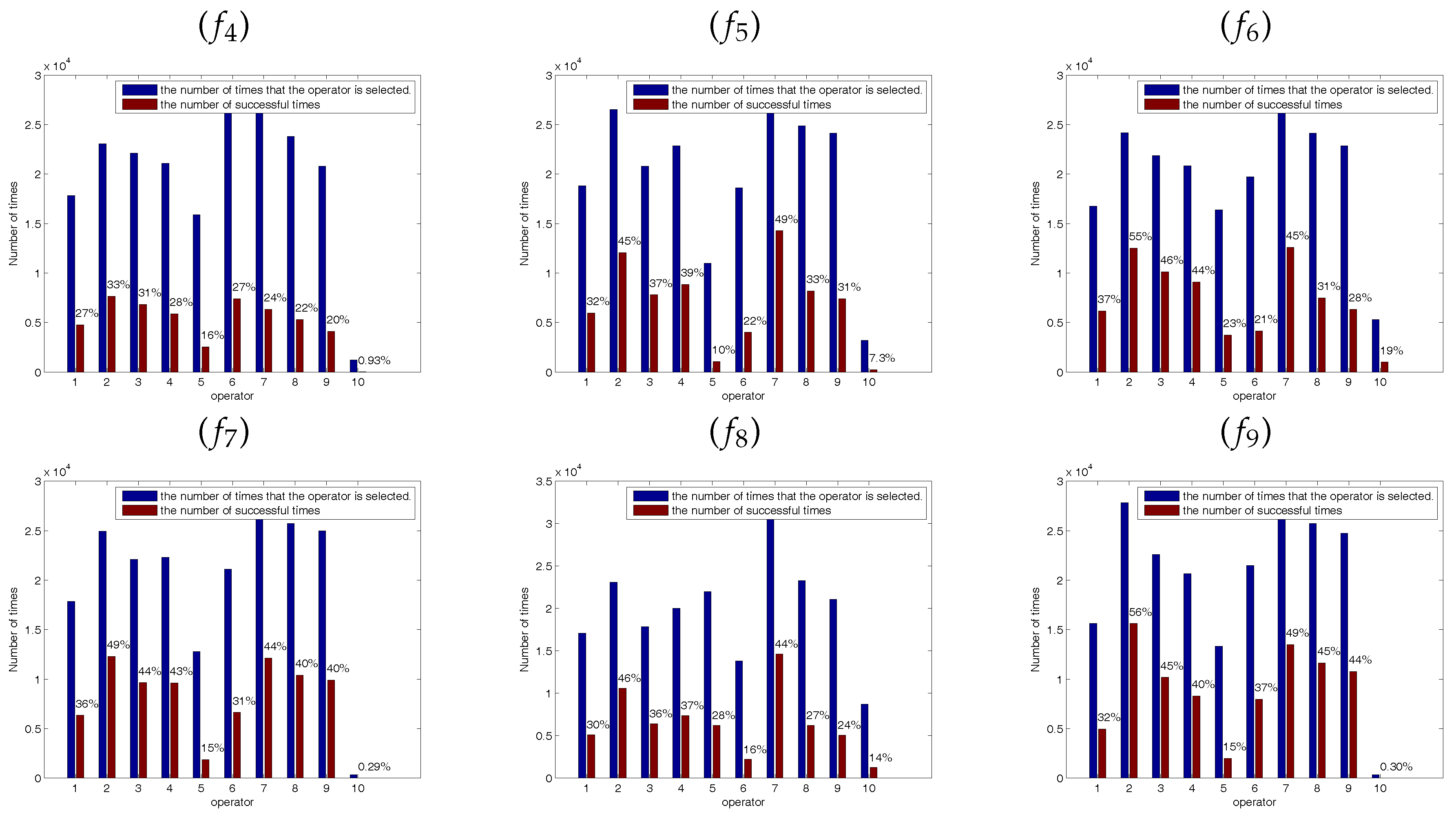
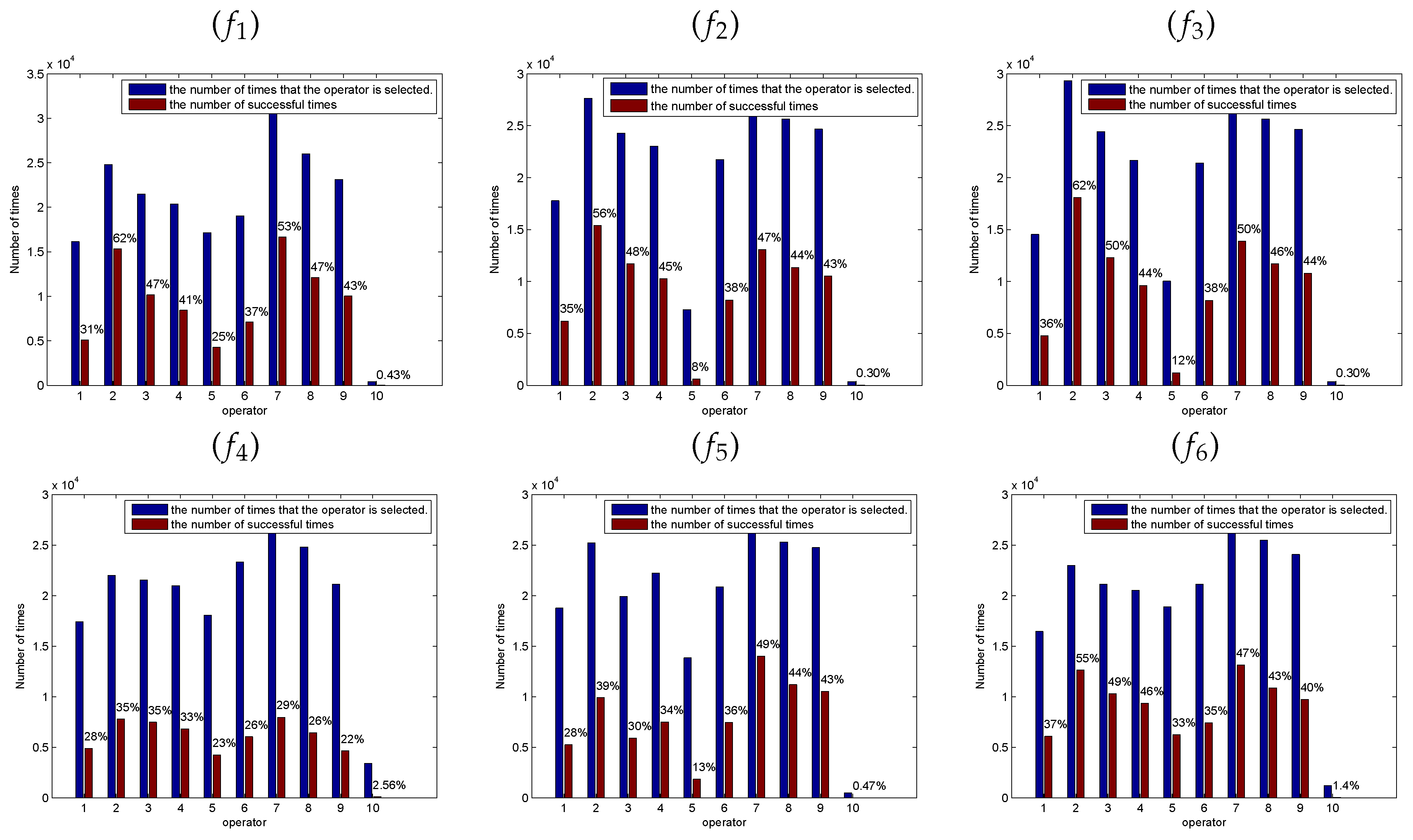
3.3. Self-Learning Mechanism
The five SSEs are regarded as the candidate operator pool and different operator is more effective at different stage. At each iteration, each employed (onlooker) bee will select a SSE from the candidate operator pool to update the corresponding solution. This paper proposes a simple self-learning mechanism to realize such optimal choice, wherein the SSE is selected according to the previous success ratio in generating promising solutions at each iteration.
In the self-learning mechanism, each SSE is assigned to a probability: success ratio. It is defined as
where
denotes the counter that records the number of successful updating times of the
k-th SSE, where the new candidate solution is better than the old one;
is the total number of updating times of the
k-th SSE is selected;
is the success ratio of the
k-th SSE. At each iteration, each SSE
k is selected according to the success ratio
through roulette wheel selection. The new candidate solutions are then produced by the selected SSE. In the initialization stage, each success ratio
is given an equal selection probability.
It is well known that at the early stage of the optimization, the bees are inclined to locate the potential optimal regions by wandering through the entire search space. Conversely, most of the bees are apt to fine-tune the present solutions to obtain the global optimal solution at the latter stage of the optimization. Therefore, in order to avoid the interference between the early stage and the latter stage, this paper divides the whole optimization process into two stages. At each stage, , and the success ratio all will be initialized.
3.4. Description of the SLABC Algorithm
The pseudo code of the SLABC algorithm can be described as follows (Algorithm 1):
| Algorithm 1 |
| Initialize the population of the bees as N and ; set the number of trials as . |
| Randomly generate points in the search space to form an initial solution. |
| Find the global best solution and the its position from the points. |
| Set the maximum number of function evaluations, ; , and . |
| While |
| If |
| Initialize , and . |
| End If |
| Employed bee stage: |
| for to |
| Set the candidate solution and randomly choose j from . |
| Randomly choose a SSE k from the candidate strategy pool through roulette wheel selection |
| and count . |
| Update the candidate solution using the selected SSE. |
| If |
| , , . |
| Else |
| . |
| End If |
| End For |
| Update the and and calculate the probability value using Equation (2). |
| Onlooker bee stage: |
| for to |
| Select one solution to update based on and roulette wheel selection. |
| The update process is same as that in the employed bee stage. |
| End For |
| Update the and and calculate the probability value using Equation (2). |
| Scout stage: |
| If |
| Initialize with a new randomly generated point in the search space. |
| End If |
|
| End While |
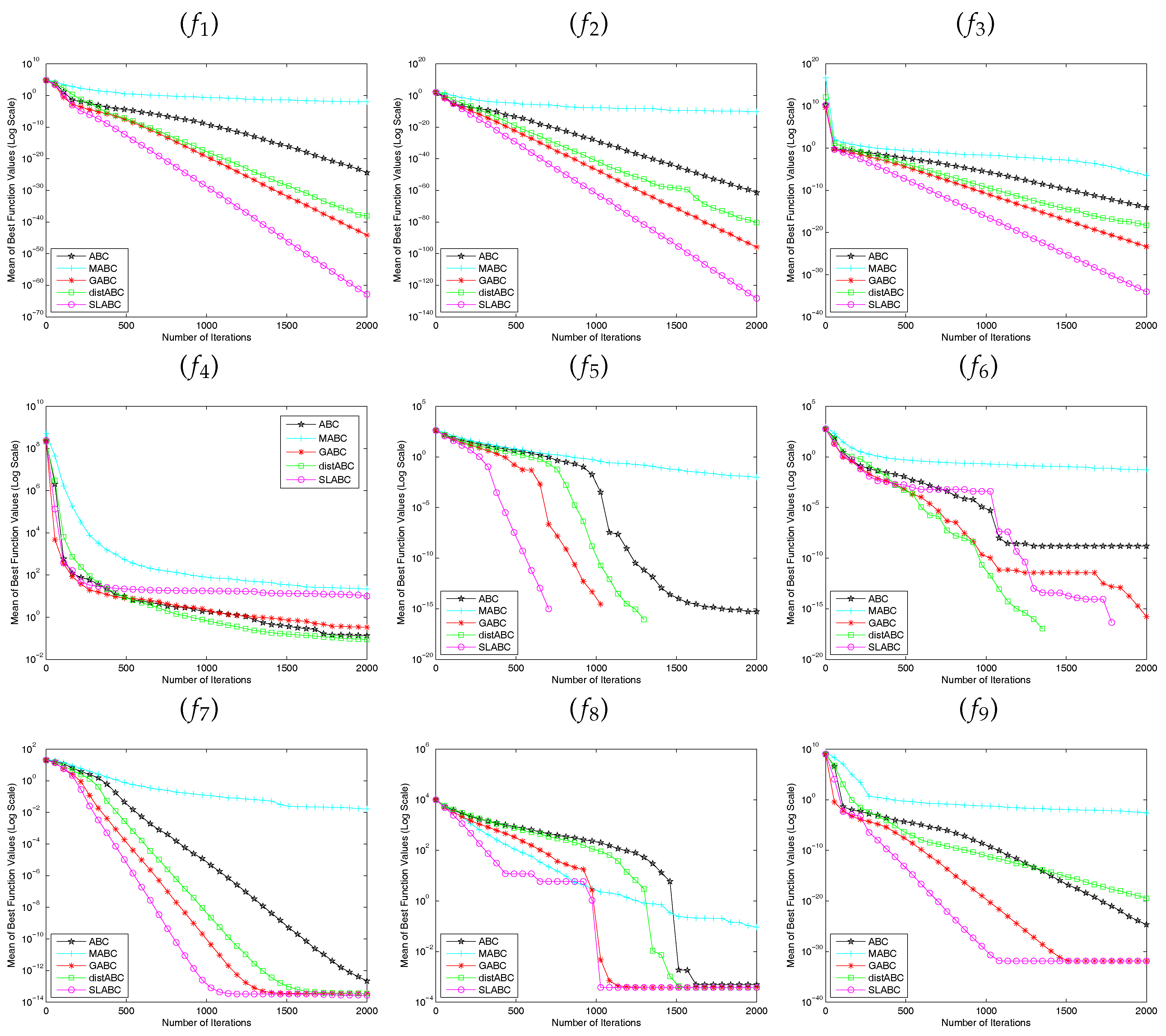
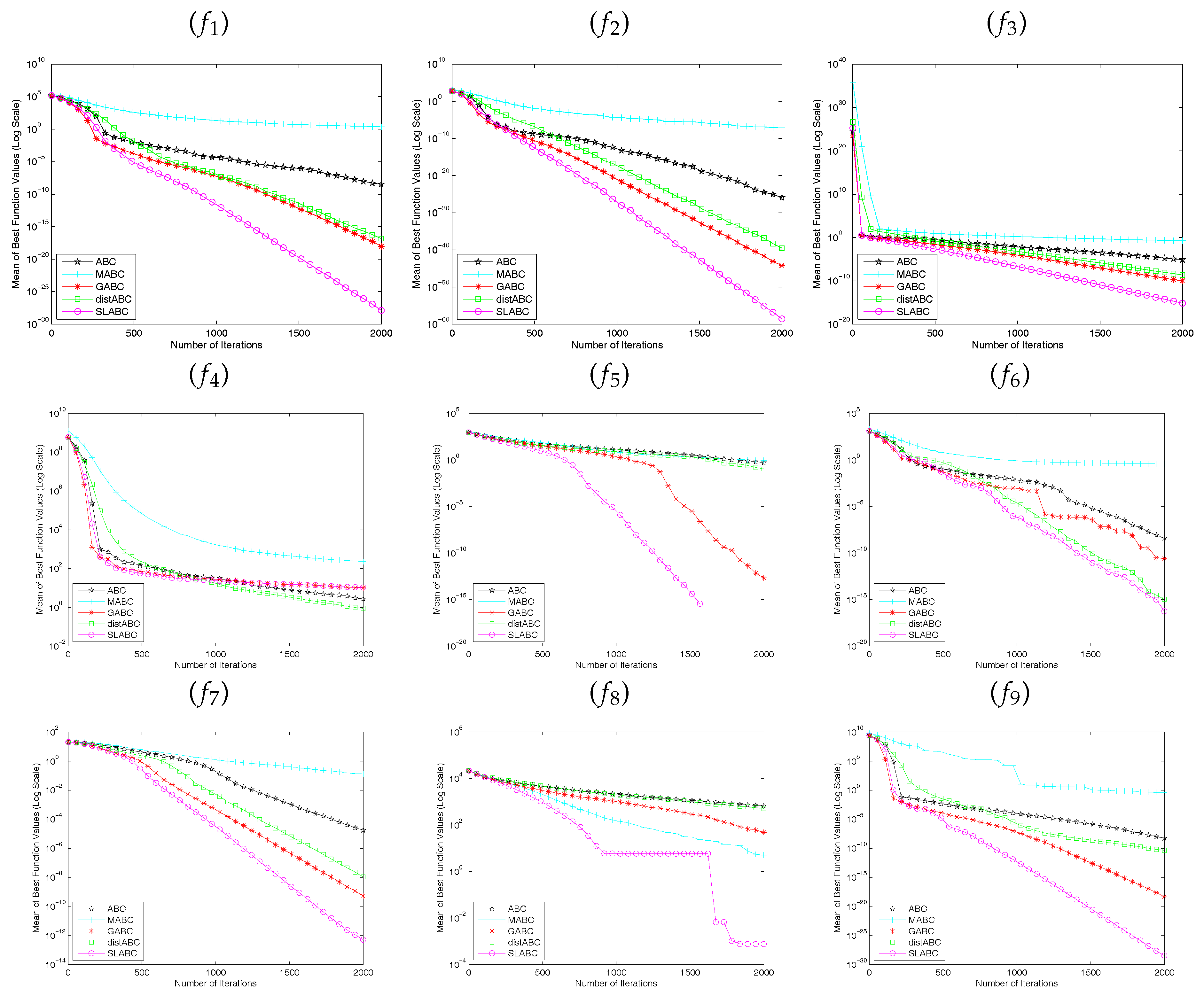
5. Discussion
In the previous sections, comparative results of ABC, GABC, MABC and distABC were presented. In this section, we offer a thorough analysis on the proposed SLABC algorithm and all the algorithms were tested using the same parameters with
Section 4.
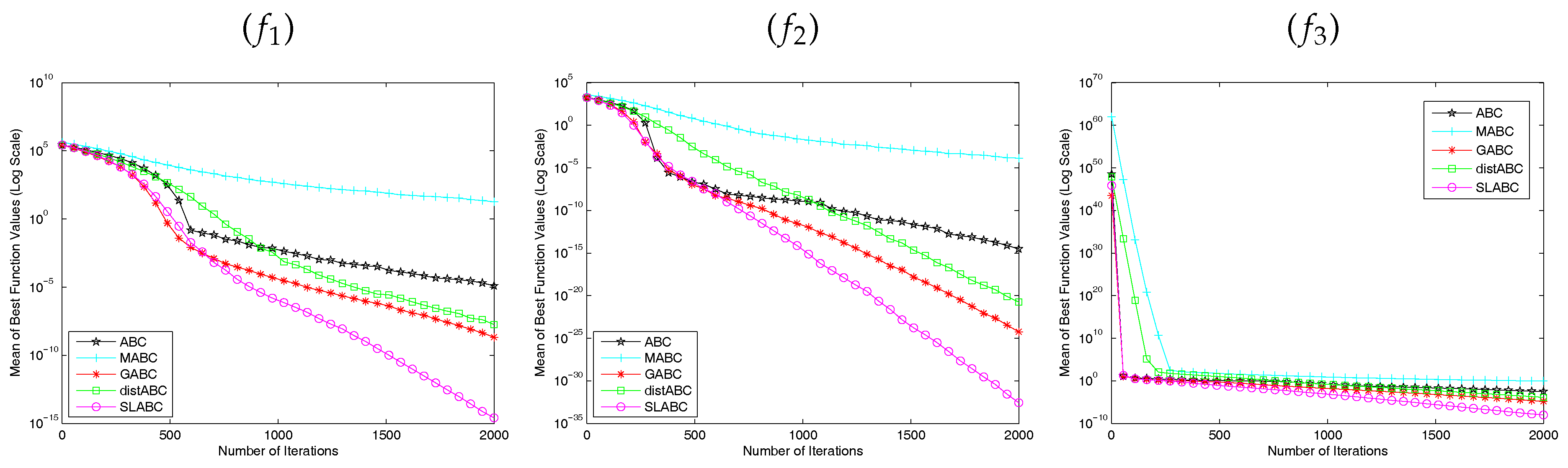
When constructing the SSE, the value range of the coefficients were adjusted to improve the performance of the SLABC algorithm. This section constructed two SLABC algorithm variants (SLABC1, SLABC2) and experiments on a set of 6 benchmark functions were carried out to clearly show how these coefficients influence the performance in various optimization problems. In SLABC1, the value range of the coefficient
are reduced to half of the corresponding value range in SLABC. In SLABC2, the value range of the coefficient
are increased to double of the corresponding value range in SLABC. The new generated candidate solutions can appear in a large range using the SLABC2 algorithm and can appear in a small range using the SLABC1 algorithm. From
Table 6, the SLABC2 is worse than SLABC and SLABC1, which shows that the increased value range reduced the performance of the SLABC algorithm. Moreover, SLABC is better than SLABC1 except function
, which means that too small value range can reduce solution accuracy. Through the analysis of experimental data, the changes of the value range can influence the performance of SLABC algorithm and only the appropriate value range can generate the better solutions.
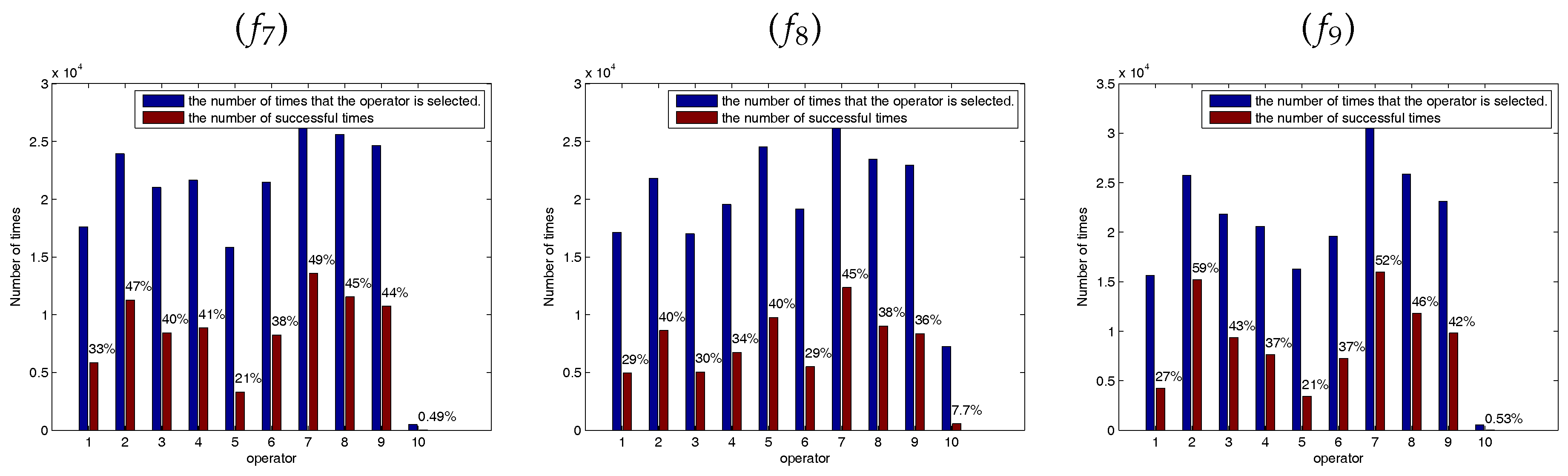
Five SSEs are used to solve the optimization problem and each SSE has different effect. For example, the fifth SSE with Lévy flight step-size can help the artificial bees escape from the local optimum effectively. However, when solving the optimization problem of unimodal function, the fifth SSE is ineffective. This section constructed another SLABC algorithm variants (SLABC3 without the fifth SSEs) to illustrate the effect of such combination. As can be seen from
Table 6, SLABC3 obtained the better solution than SLABC on the unimodal functions
. Therefore, we can choose combination of different SSEs to solve different optimization problems in the future applications.
In order to avoid the interference between the early stage and the latter stage, SLABC algorithm divides the whole optimization process into two stages. We can divide the optimization process into much more stages to further reduce interference between each stage. To show the effect of such division, this section constructed another SLABC algorithm variants (SLABC4) which divides the whole optimization process into ten stages. As can be seen from
Table 6, SLABC4 obtained the better solution than SLABC on most of the functions. Dividing the optimization process into several stages can improve the performance of SLABC algorithm and how to divide the optimization process remains to be a problem should be further studied.
This paper proposes a self-learning mechanism to select the appropriate SSE according to the previous success ratio. Such mechanism is a reinforcement mechanism and other optimization algorithms can construct novel algorithms variants to improve the performance by using the self-learning mechanism.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}