Efficient Deep Learning-Based Automated Pathology Identification in Retinal Optical Coherence Tomography Images

Abstract
:1. Introduction
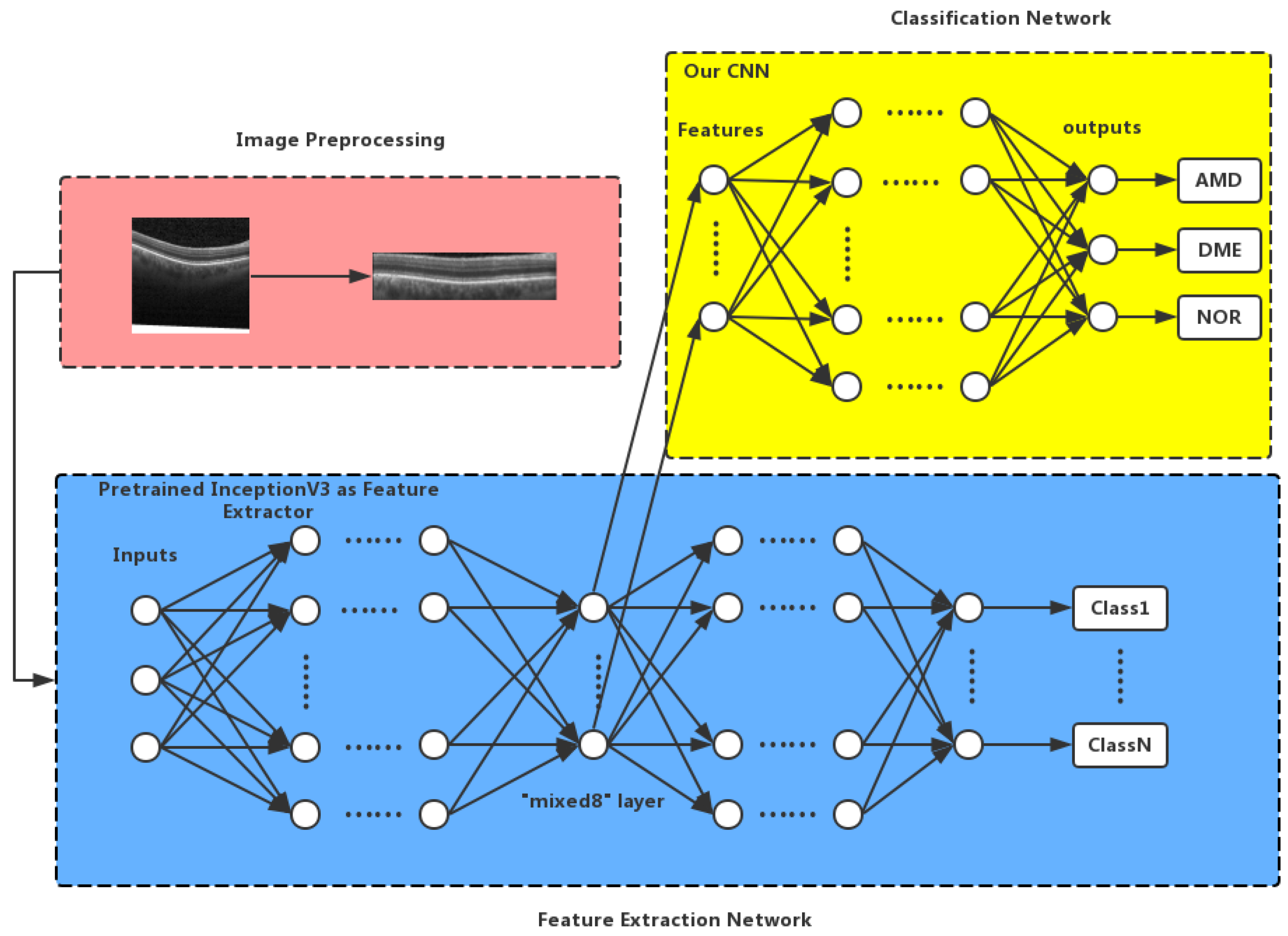
2. Proposed Method
2.1. Image Preprocessing
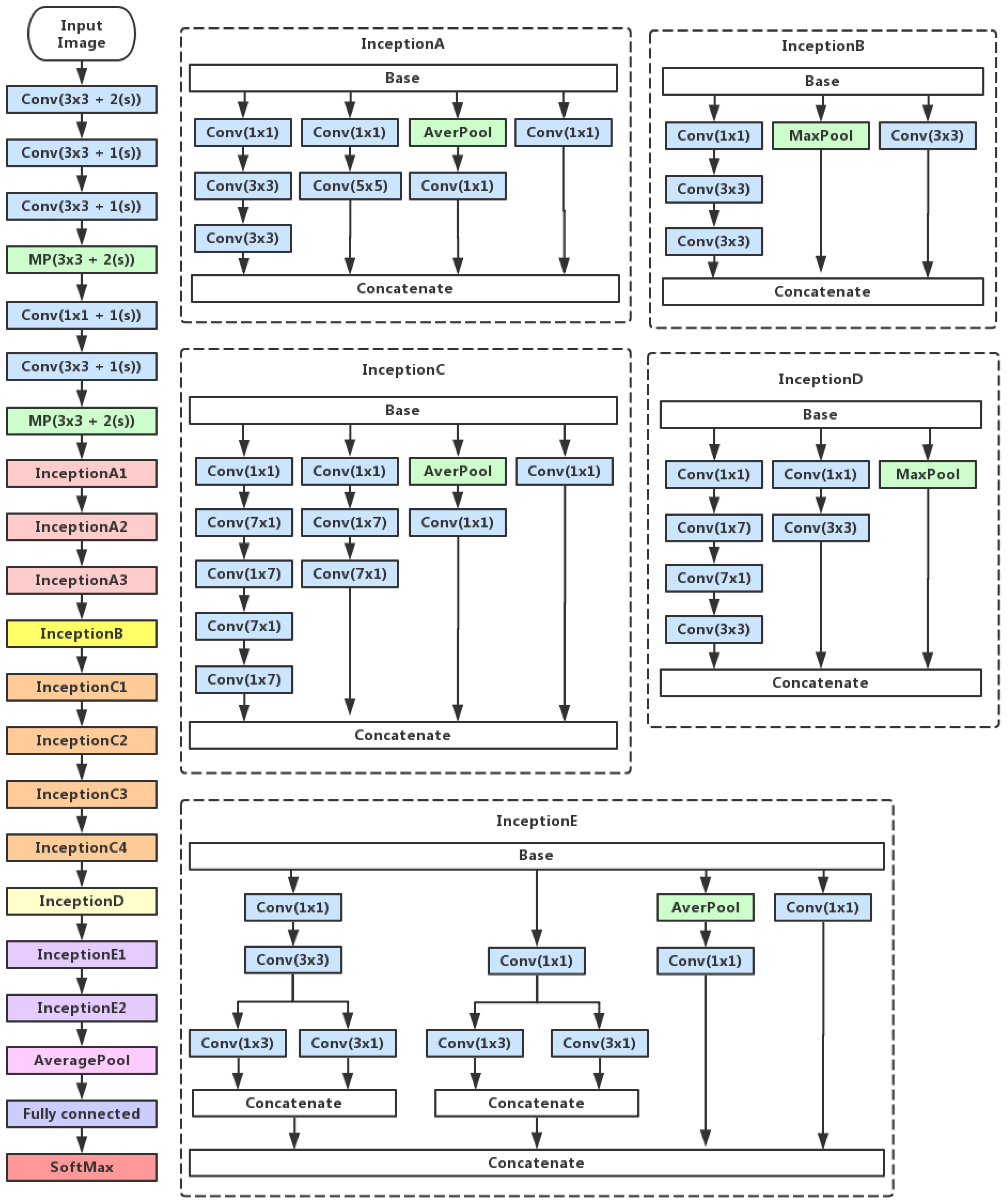
2.2. Inception V3 Feature Extraction
2.3. Convolutional Neural Network
3. Experiments and Results
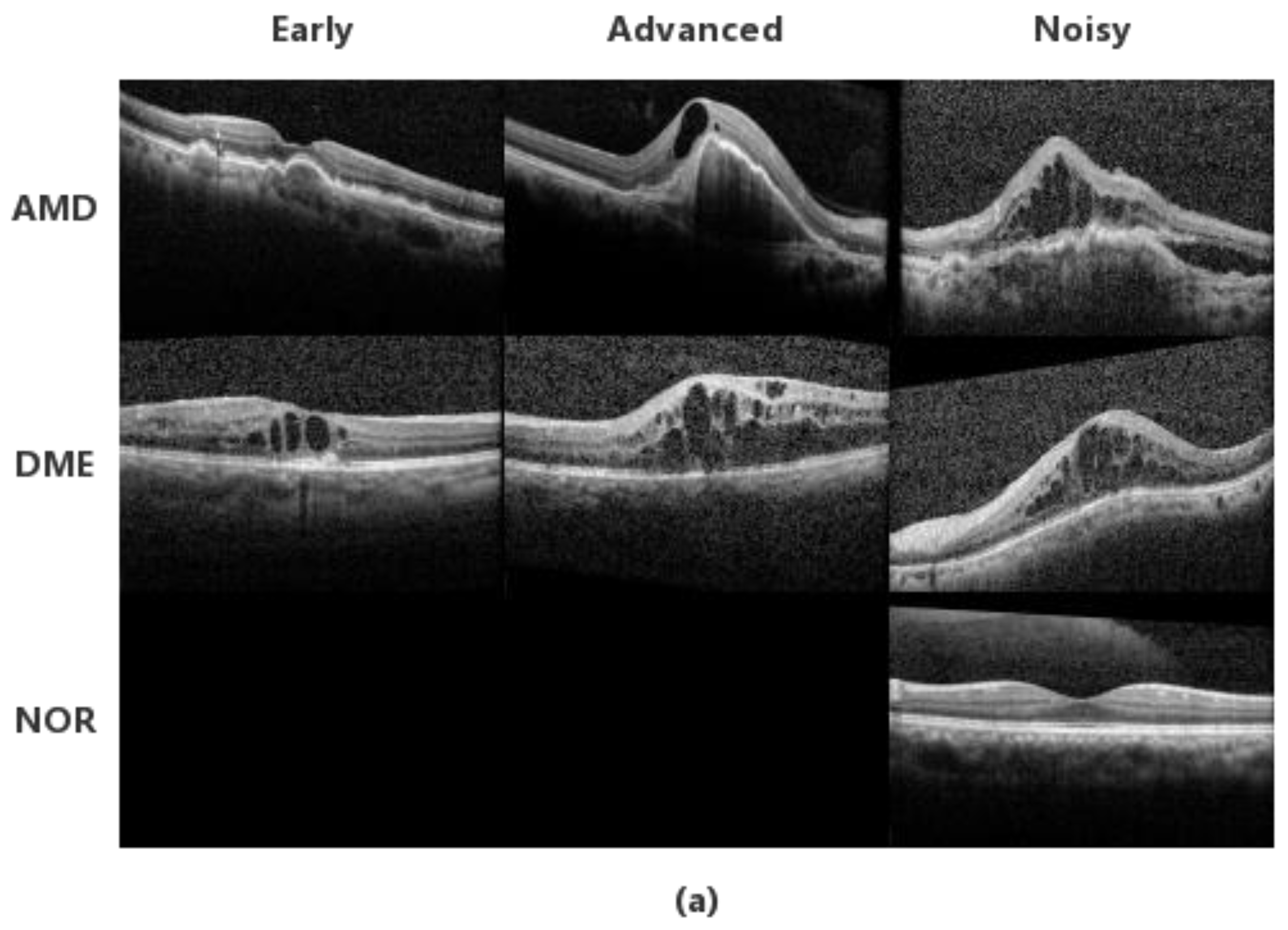
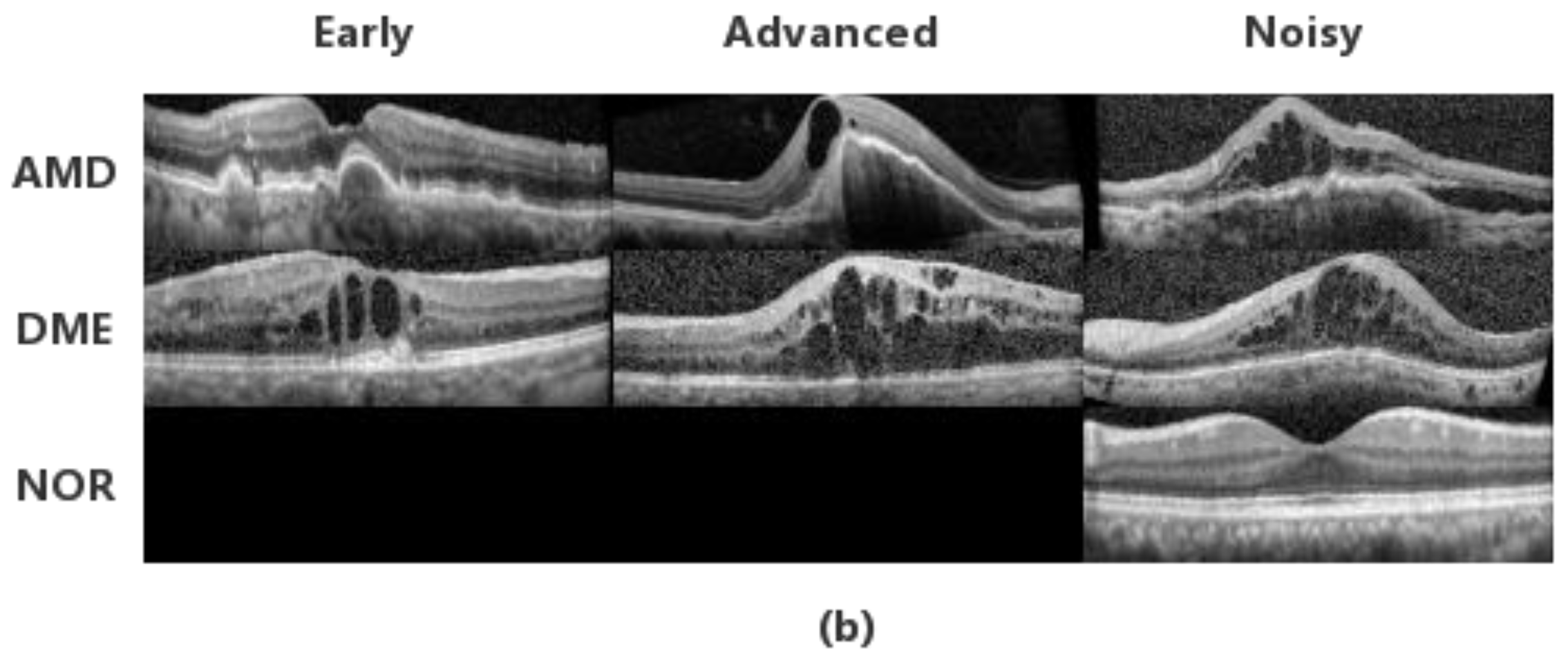
3.1. Datasets
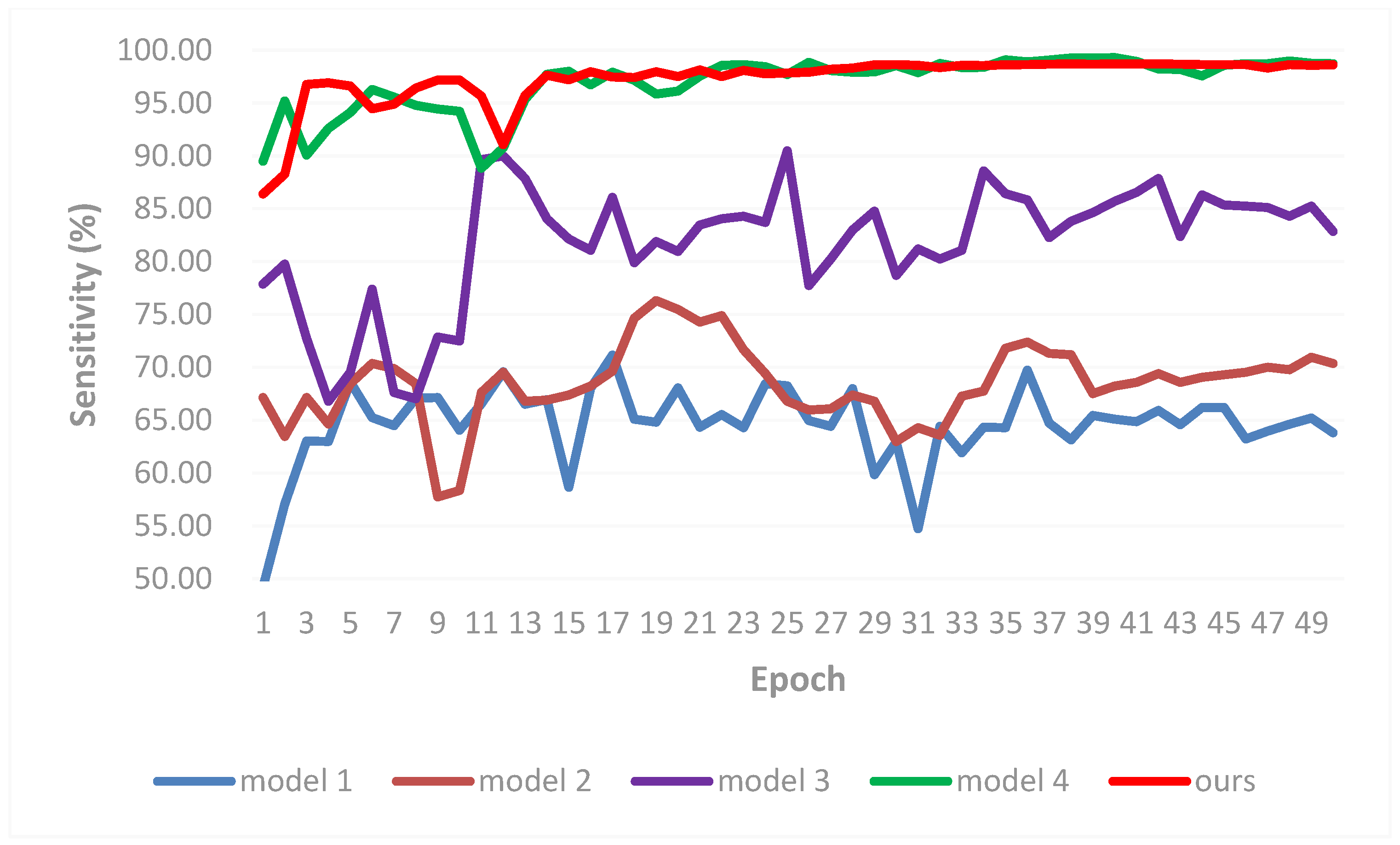
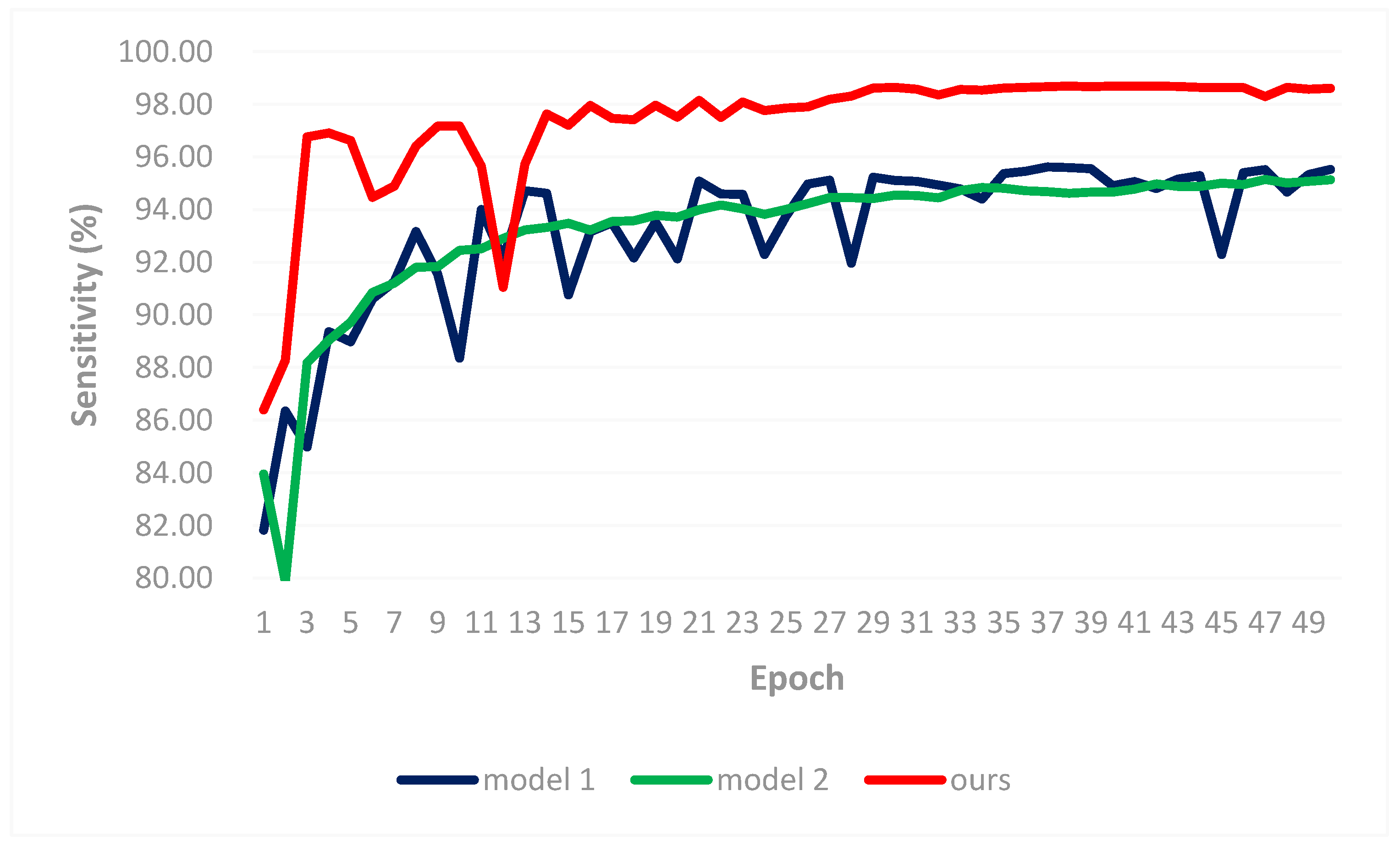
3.2. Result Comparisons
- Experiment 2: Comparison to transfer learning-based method [31]
- Experiment 3: Comparisons on classification performance of retinal OCT B-scans
- Experiment 4: Comparison with the efficiency of the fine-tuning
- Experiment 5: Effectiveness of different architectures
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Grogory, K.; Puliafito, C.A.; et al. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Podoleanu, A.G.; Rosen, R.B. Combinations of techniques in imaging the retina with high resolution. Prog. Retinal Eye Res. 2008, 27, 464–499. [Google Scholar] [CrossRef] [PubMed]
- Cogliati, A.; Canavesi, C.; Hayes, A.; Tankam, P.; Duma, V.-F.; Santhanam, A.; Thompson, K.P.; Rolland, J.P. MEMS-based handheld scanning probe with pre-shaped input signals for distortion-free images in Gabor-Domain Optical Coherence Microscopy. Opt. Express 2016, 24, 13365–13374. [Google Scholar] [CrossRef] [PubMed]
- Choma, M.A.; Sarunic, M.V.; Yang, C.; Izatt, J.A. Sensitivity advantage of swept-source and Fourier-domain optical coherence tomography. Opt. Express 2003, 11, 2183–2189. [Google Scholar] [CrossRef] [PubMed]
- Virgili, G.; Menchini, F.; Casazza, G.; Hogg, R.; Das, R.R.; Wang, X.; Michelessi, M. Optical coherence tomography (OCT) for detection of macular oedema in patients with diabetic retinopathy. Cochrane Database Syst. 2015, 1, CD008081. [Google Scholar] [CrossRef] [PubMed]
- Keane, P.A.; Patel, P.J.; Liakopoulos, S.; Heussen, F.M.; Sadda, S.R.; Tufail, A. Evaluation of age-related macular degeneration with optical coherence tomography. Surv. Ophthalmol. 2012, 57, 389–414. [Google Scholar] [CrossRef] [PubMed]
- Antony, B.J.; Abràmoff, M.D.; Harper, M.M.; Jeong, W.; Sohn, E.H.; Kwon, Y.H.; Kardon, R.; Garvin, M.K. A combined machine-learning and graph-based framework for the segmentation of retinal surfaces in SD-OCT volumes. Biomed. Opt. Express 2013, 4, 2712–2728. [Google Scholar] [CrossRef] [PubMed]
- Carass, A.; Lang, A.; Hauser, M.; Calabresi, P.A.; Ying, H.S.; Prince, J.L. Multiple-object geometric deformable model for segmentation of macular OCT. Biomed. Opt. Express 2014, 5, 1062–1074. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chiu, S.J.; Izatt, J.A.; O’Connell, R.V.; Winter, K.P.; Toth, C.A.; Farsiu, S. Validated automatic segmentation of AMD pathology including drusen and geographic atrophy in SD-OCT images. Investig. Ophthalmol. Vis. Sci. 2012, 53, 53–61. [Google Scholar] [CrossRef] [PubMed]
- Chiu, S.J.; Li, X.T.; Nicholas, P.; Toth, C.A.; Izatt, J.A.; Farsiu, S. Automatic segmentation of seven retinal layers in SDOCT images congruent with expert manual segmentation. Opt. Express 2010, 18, 19413–19428. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- DeBuc, D.C.; Somfai, G.M.; Ranganathan, S.; Tátrai, E.; Ferencz, M.; Puliafito, C.A. Reliability and reproducibility of macular segmentation using a custom-built optical coherence tomography retinal image analysis software. J. Biomed. Opt. 2009, 14, 064023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fernández, D.C.; Salinas, H.M.; Puliafito, C.A. Automated detection of retinal layer structures on optical coherence tomography images. Opt. Express 2005, 13, 10200–10216. [Google Scholar] [CrossRef]
- Ishikawa, H.; Stein, D.M.; Wollstein, G.; Beaton, S.; Fujimoto, J.G.; Schuman, J.S. Macular segmentation with optical coherence tomography. Investig. Ophthalmol. Vis. Sci. 2005, 46, 2012–2017. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.; Carass, A.; Hauser, M.; Sotirchos, E.S.; Calabresi, P.A.; Ying, H.S.; Prince, J.L. Retinal layer segmentation of macular OCT images using boundary classification. Biomed. Opt. Express 2013, 4, 1133–1152. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mayer, M.A.; Hornegger, J.; Mardin, C.Y.; Tornow, R.P. Retinal nerve fiber layer segmentation on FD-OCT scans of normal subjects and glaucoma patients. Biomed. Opt. Express 2010, 1, 1358–1383. [Google Scholar] [CrossRef] [PubMed]
- Mishra, A.; Wong, A.; Bizheva, K.; Clausi, D.A. Intra-retinal layer segmentation in optical coherence tomography images. Opt. Express 2009, 17, 23719–23728. [Google Scholar] [CrossRef] [PubMed]
- Mujat, M.; Chan, R.; Cense, B.; Park, B.; Joo, C.; Akkin, T.; Chen, T.; de Boer, J. Retinal nerve fiber layer thickness map determined from optical coherence tomography images. Opt. Express 2005, 13, 9480–9491. [Google Scholar] [CrossRef] [PubMed]
- Paunescu, L.A.; Schuman, J.S.; Price, L.L.; Stark, P.C.; Beaton, S.; Ishikawa, H.; Wollstein, G.; Fujimoto, J.G. Reproducibility of nerve fiber thickness, macular thickness, and optic nerve head measurements using StratusOCT. Investig. Ophthalmol. Vis. Sci. 2004, 45, 1716–1724. [Google Scholar] [CrossRef]
- Shahidi, M.; Wang, Z.; Zelkha, R. Quantitative thickness measurement of retinal layers imaged by optical coherence tomography. Am. J. Ophthalmol. 2005, 139, 1056–1061. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Zhang, T.; Zhao, Y.; He, Y. 3D automatic segmentation method for retinal optical coherence tomography volume data using boundary surface enhancement. J. Innov. Opt. Health Sci. 2016, 9, 1650008. [Google Scholar] [CrossRef]
- Vermeer, K.A.; van der Schoot, J.; Lemij, H.G.; de Boer, J.F. Automated segmentation by pixel classification of retinal layers in ophthalmic OCT images. Biomed. Opt. Express 2011, 2, 1743–1756. [Google Scholar] [CrossRef] [PubMed]
- Reisman, C.A.; Chan, K.; Ramachandran, R.; Raza, A.; Hood, D.C. Automated segmentation of outer retinal layers in macular OCT images of patients with retinitis pigmentosa. Biomed. Opt. Express 2011, 2, 2493–2503. [Google Scholar] [CrossRef]
- Liu, Y.Y.; Chen, M.; Ishikawa, H.; Wollstein, G.; Schuman, J.S.; Rehg, J.M. Automated macular pathology diagnosis in retinal OCT images using multi-scale spatial pyramid and local binary patterns in texture and shape encoding. Med. Image Anal. 2011, 15, 748–759. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sugruk, J.; Kiattisin, S.; Leelasantitham, A. Automated classification between age-related macular degeneration and diabetic macular edema in OCT image using image segmentation. In Proceedings of the 7th Biomedical Engineering International Conference, Fukuoka, Japan, 26–28 November 2014; pp. 1–4. [Google Scholar]
- Srinivasan, P.P.; Kim, L.A.; Mettu, P.S.; Cousins, S.W.; Comer, G.M.; Izatt, J.A.; Farsiu, S. Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images. Biomed. Opt. Express 2014, 5, 3568–3577. [Google Scholar] [CrossRef] [PubMed]
- Hassan, B.; Raja, G.; Hassan, T.; Usman Akram, M. Structure tensor based automated detection of macular edema and central serous retinopathy using optical coherence tomography images. J. Opt. Soc. Am. A 2016, 33, 455–463. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.K.; Li, S.; Sun, Z.Y. Fully automated macular pathology detection in retina optical coherence tomography images using sparse coding and dictionary learning. J. Biomed. Opt. 2017, 22, 16012. [Google Scholar] [CrossRef] [PubMed]
- Venhuizen, F.G.; van Ginneken, B.; Bloemen, B.; van Grinsven, M.J.J.P.; Philipsen, R.; Hoyng, C.; Theelen, T.; Sánchez, C.I. Automated age-related macular degeneration classification in OCT using unsupervised feature learning. Med. Imaging Comput.-Aided Diagn. 2015, 9414. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Yao, Z.; Zhao, R.; Zhou, F. Machine learning based detection of age-related macular degeneration (AMD) and diabetic macular edema (DME) from optical coherence tomography (OCT) images. Biomed. Opt. Express 2016, 7, 4928–4940. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 1097–1105. [Google Scholar] [CrossRef]
- Karri, S.; Chakraborty, D.; Chatterjee, J. Transfer learning based classification of optical coherence tomography images with diabetic macular edema and dry age-related macular degeneration. Biomed. Opt. Express 2017, 8, 579–592. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1–9. [Google Scholar]
- Rasti, R.; Mehridehnavi, A. Macular OCT Classification using a Multi-Sacle Convolutional Neural Network Ensemble. IEEE Trans. Med. Imaging 2018. [Google Scholar] [CrossRef] [PubMed]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.S.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef] [PubMed]
- Albarrak, A.; Coenen, F.; Zheng, Y.; Yu, W. Volumetric image mining based on decomposition and graph analysis: An application to retinal optical coherence tomography. Comput. Intell. Inform. 2012, 263–268. [Google Scholar] [CrossRef]
- Fang, L.; Wang, C.; Li, S.; Yan, J.; Chen, X.; Rabbani, H. Automatic classification of retinal three-dimensional optical coherence tomography images using principal component analysis network with composite kernels. J. Biomed. Opt. 2017, 22, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 22–25 June 2009; pp. 248–255. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhou, Z.; Shin, J.; Zhang, L.; Gurudu, S.; Gotway, M.; Liang, J. Fine-tuning convolutional neural networks for biomedical image analysis: Actively and incrementally. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 7340–7349. [Google Scholar]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Matthew, D.Z. ADADELTA: An adaptive learning rate method. Tech. Rep. 2012, arXiv:1212.5701. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Patch Size/Stride | Padding | Output Size |
|---|---|---|---|
| Convolution1 | 3 × 3/1 | same | 128 × 8 × 8 |
| Max Pooling1 | 2 × 2/2 | valid | 128 × 4 × 4 |
| BatchNormalization1 | 128 × 4 × 4 | ||
| Convolution2 | 3 × 3/1 | same | 128 × 4 × 4 |
| Max Pooling2 | 2 × 2/2 | valid | 128 × 2 × 2 |
| BatchNormalization2 | 128 × 2 × 2 | ||
| Convolution3 | 3 × 3/1 | same | 128 × 2 × 2 |
| BatchNormalization3 | 128 × 2 × 2 | ||
| Flatten | 512 | ||
| Dense | 3 |
| HOG-SVM [25] | ScSPM [27] | Ours | |
|---|---|---|---|
| AMD | 15/15 = 100.00% | 15/15 = 100.00% | 15/15 = 100.00% |
| DME | 15/15 = 100.00% | 15/15 = 100.00% | 15/15 = 100.00% |
| NOR | 13/15 = 86.67% | 14/15 = 93.33% | 15/15 = 100.00% |
| Overall | 43/45 = 95.56% | 44/45 = 97.78% | 45/45 = 100.00% |
| HOG-SVM [25] | Deep CNN [31] | Ours | |
|---|---|---|---|
| AMD | 89 | 89 | 89 |
| DME | 83 | 86 | 92 |
| NOR | 90 | 99 | 100 |
| Methods | Classes | Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|
| ScSPM | AMD | 97.35 ± 0.58 | 96.19 ± 0.85 | 97.94 ± 0.45 |
| DME | 97.17 ± 0.44 | 93.81 ± 0.51 | 98.87 ± 0.46 | |
| NOR | 97.87 ± 0.15 | 98.73 ± 0.49 | 97.44 ± 0.08 | |
| IBDL | AMD | 91.23 ± 0.38 | 85.40 ± 0.81 | 94.25 ± 0.58 |
| DME | 94.77 ± 0.29 | 96.83 ± 0.22 | 93.65 ± 0.57 | |
| NOR | 91.63 ± 0.40 | 85.32 ± 0.40 | 94.92 ± 0.66 | |
| Ours | AMD | 98.51 ± 0.19 | 98.14 ± 0.49 | 98.69 ± 0.44 |
| DME | 97.80 ± 0.35 | 94.57 ± 0.76 | 99.43 ± 0.31 | |
| NOR | 98.35 ± 0.20 | 99.33 ± 0.41 | 97.85 ± 0.38 |
| Methods | Classes | Accuracy | Sensitivity | Specificity |
|---|---|---|---|---|
| ScSPM | AMD | 97.75 ± 0.21 | 96.43 ± 0.58 | 98.43 ± 0.08 |
| DME | 97.60 ± 0.29 | 95.48 ± 0.89 | 98.67 ± 0.09 | |
| NOR | 97.91 ± 0.31 | 98.10 ± 0.84 | 97.81 ± 0.40 | |
| IBDL | AMD | 93.36 ± 0.32 | 88.84 ± 2.78 | 95.66 ± 1.02 |
| DME | 96.96 ± 0.14 | 98.13 ± 0.46 | 96.33 ± 0.24 | |
| NOR | 93.39 ± 0.25 | 89.11 ± 2.21 | 95.57 ± 0.99 | |
| Ours | AMD | 99.01 ± 0.30 | 99.02 ± 0.39 | 99.01 ± 0.37 |
| DME | 98.51 ± 0.27 | 96.34 ± 1.08 | 99.60 ± 0.20 | |
| NOR | 99.07 ± 0.21 | 99.55 ± 0.46 | 98.83 ± 0.32 |
| Partition | Methods | Overall-Acc | Overall-Se | Overall-Sp |
|---|---|---|---|---|
| 1/4 dataset | ScSPM | 97.46 | 96.24 | 98.08 |
| IBDL | 92.54 | 89.18 | 94.27 | |
| Ours | 98.22 | 97.35 | 98.66 | |
| 1/2 dataset | ScSPM | 97.75 | 96.67 | 98.30 |
| IBDL | 94.57 | 92.03 | 95.85 | |
| Ours | 98.86 | 98.30 | 99.15 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, Q.; He, W.; Huang, J.; Sun, Y. Efficient Deep Learning-Based Automated Pathology Identification in Retinal Optical Coherence Tomography Images. Algorithms 2018, 11, 88. https://doi.org/10.3390/a11060088
Ji Q, He W, Huang J, Sun Y. Efficient Deep Learning-Based Automated Pathology Identification in Retinal Optical Coherence Tomography Images. Algorithms. 2018; 11(6):88. https://doi.org/10.3390/a11060088
Chicago/Turabian StyleJi, Qingge, Wenjie He, Jie Huang, and Yankui Sun. 2018. "Efficient Deep Learning-Based Automated Pathology Identification in Retinal Optical Coherence Tomography Images" Algorithms 11, no. 6: 88. https://doi.org/10.3390/a11060088
APA StyleJi, Q., He, W., Huang, J., & Sun, Y. (2018). Efficient Deep Learning-Based Automated Pathology Identification in Retinal Optical Coherence Tomography Images. Algorithms, 11(6), 88. https://doi.org/10.3390/a11060088