Long Length Document Classification by Local Convolutional Feature Aggregation

Abstract
:1. Introduction
2. Related Works
2.1. Convolution Neural Network in NLP
2.2. Recurrent Neural Network in NLP
3. Model
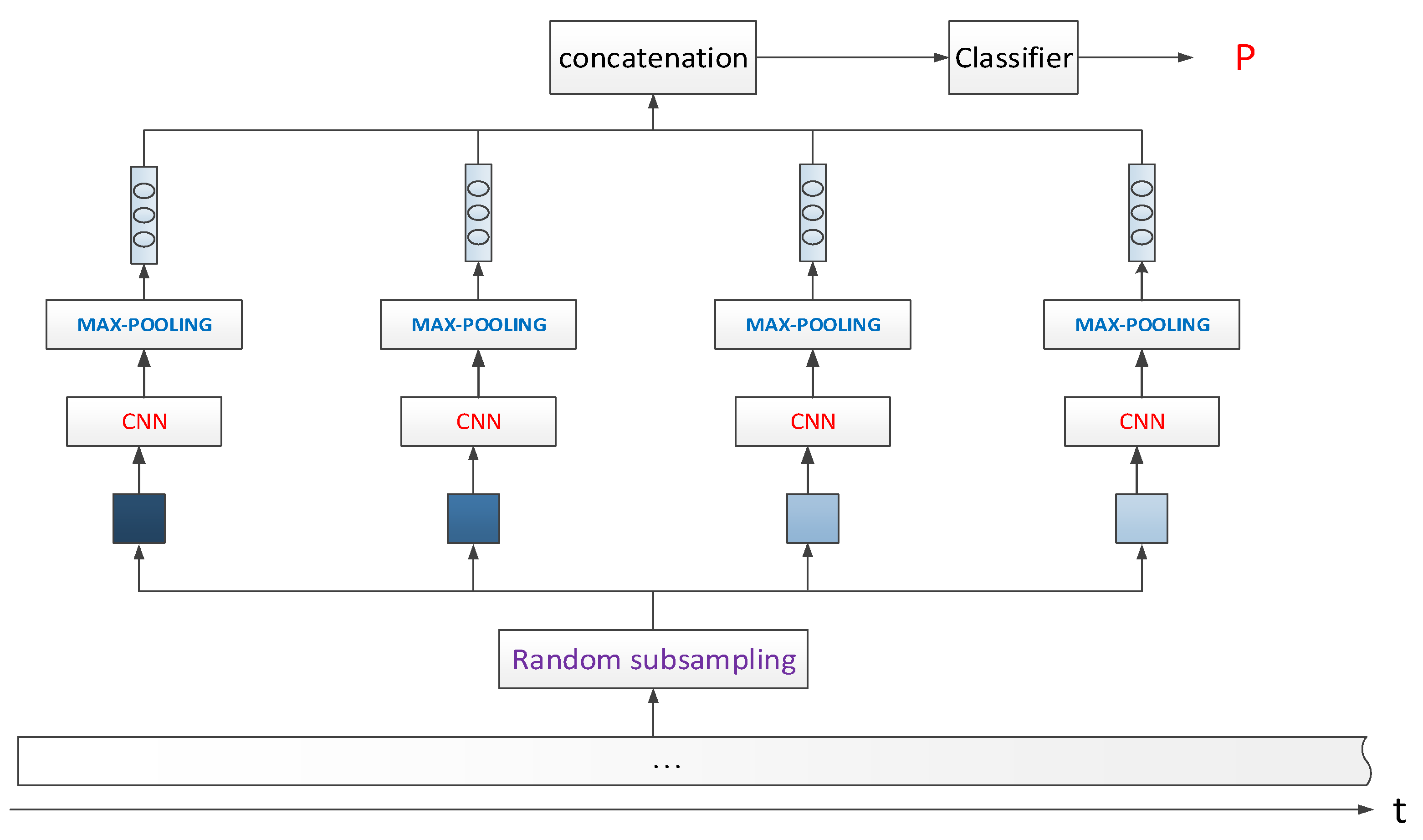
3.1. Model_1: Random Sampling and CNN Feature Aggregation
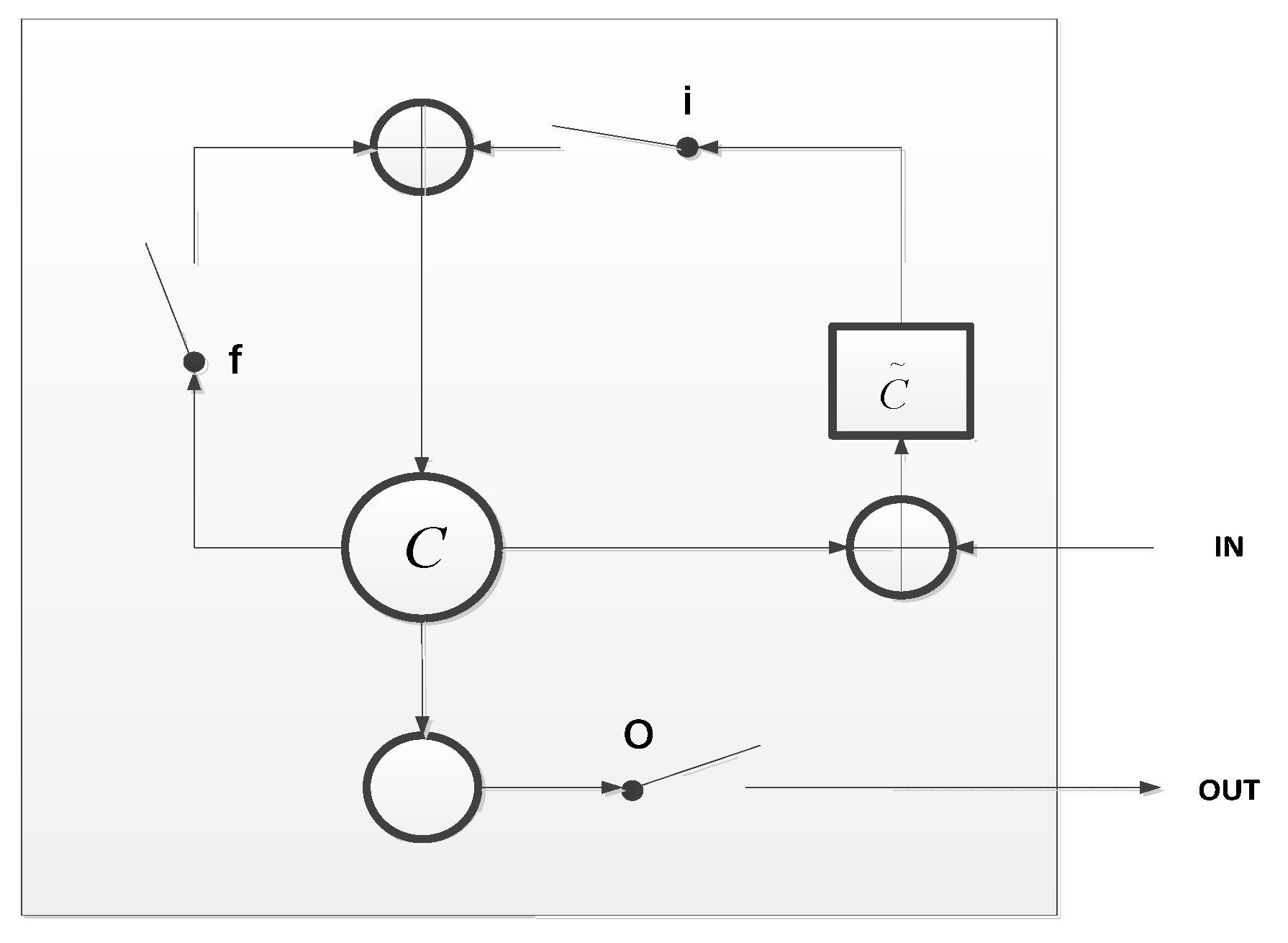
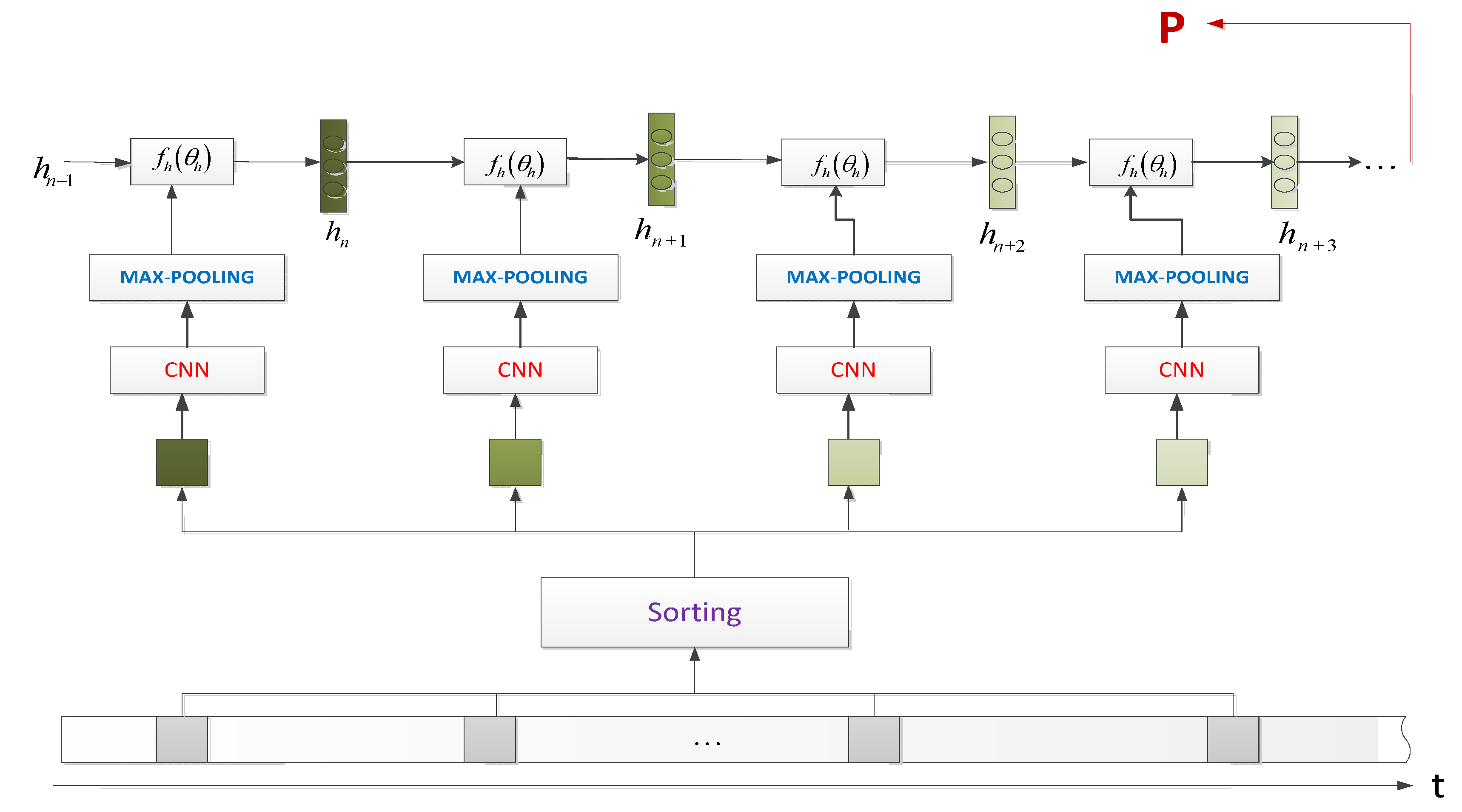
3.2. Model_2: CNN Feature with LSTM Aggregation
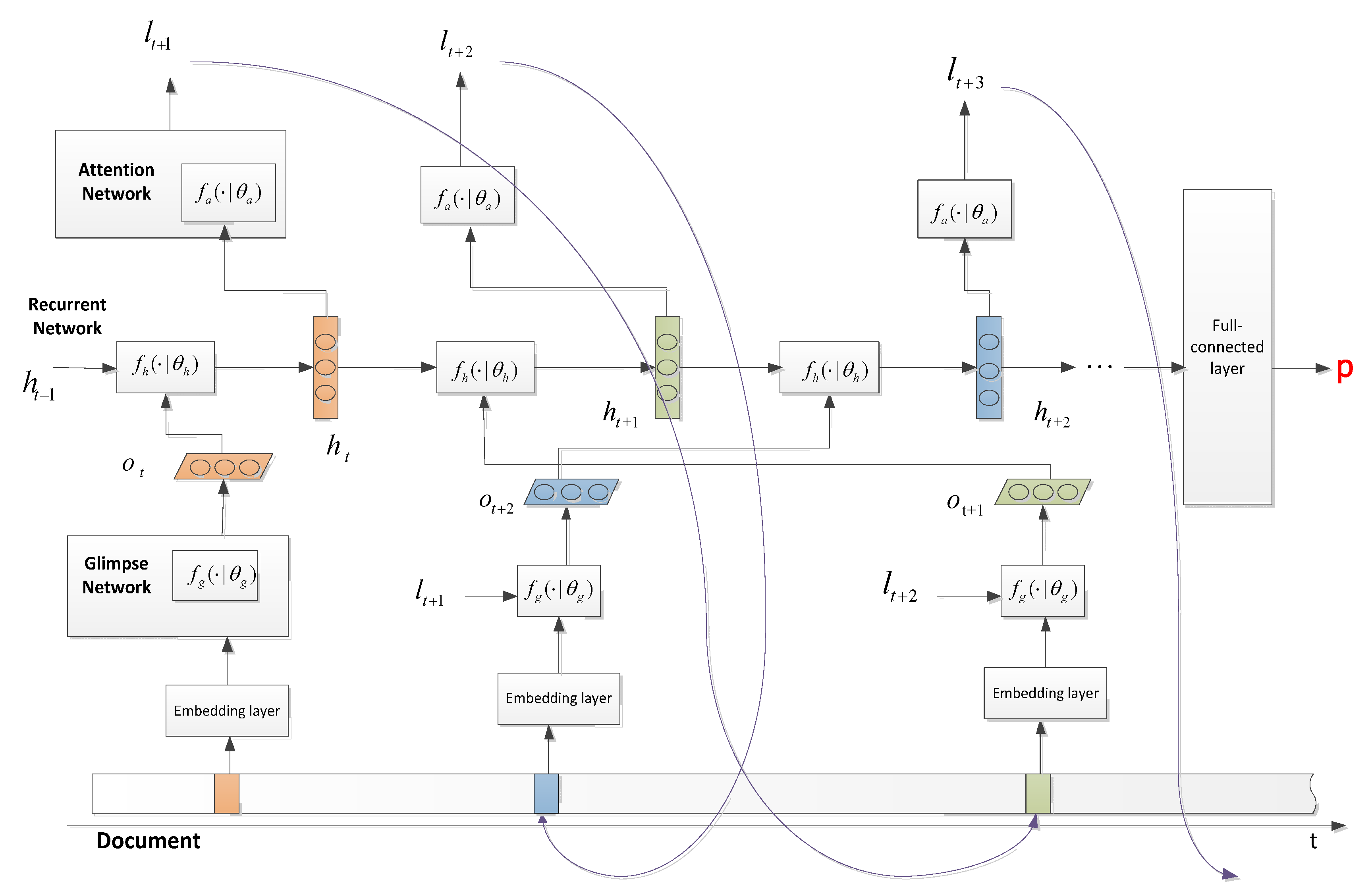
3.3. Model_3: CNN Feature with Recurrent Attention Model
| Algorithm 1: CNN_RAM_Agg |
| 1: Input: Document D, GloVe dictionary, initial network parameter ( for attention network, for recurrent network, for glimpse network), number of glimpse T, maximum iteration maxIter. 2: for i = 0, 1, 2, …, maxIter do 3: for t = 0, 1, 2, … T do ( is initialized by a random location) Extract words near the position and use GloVe to obtain the word vectors Use the glimpse network to extract feature vectors Input to the LSTM network to obtain a new hidden state Predict the next location by the attention network with 4: end for 5: Using the aggregated feature emitted from the last step of LSTM to obtain the predicted label. 6: If predicted label is correct then get reward 1 otherwise get none reward. 7: Update parameters with reinforcement learning; update parameters and parameter with back propagation 8: end for |
4. Experiment Analysis
4.1. Data Set
4.2. Experiment Setup
- Experiment platform: The experimental platform is a deep learning workstation with 32 Gb RAM and NVIDIA Titan X GPU with 12 Gb memory. The computer is installed with Ubuntu16.04 system and the program mentioned in the experiment is implemented with TensorFlow 1.8 [24].
- Word vector: The word vector used in this article is GloVe. GloVe originally stored 400,000 word vectors, but there are around 730,000 missing words in our arXiv dataset. Then, the number of the final embedding lookup word vector table is around 1.13 million. Therefore, if we use a 300-dimension word vector, we cannot store the lookup table in GPU memory. For this reason, we chose to use a 100-dimension word vector.
- Training parameters: In the experiment, we set 5000 steps, and we used Adam’s optimization method to train our model. The learning rate was set to 0.001, and it gradually became 0.0001. Dropout’s coefficient is set to 0.5. The input batch size is 64. For the convolution layer, convolution kernels with convolution kernel sizes 3, 4, and 5 are used, with 128 convolution kernels of each size.
4.3. Experiment Results
4.3.1. Baseline Model
4.3.2. Model 1: CNN_Random_Agg
4.3.3. Model 2: CNN_LSTM_Agg
4.3.4. Model 3: CNN_RAM_Agg
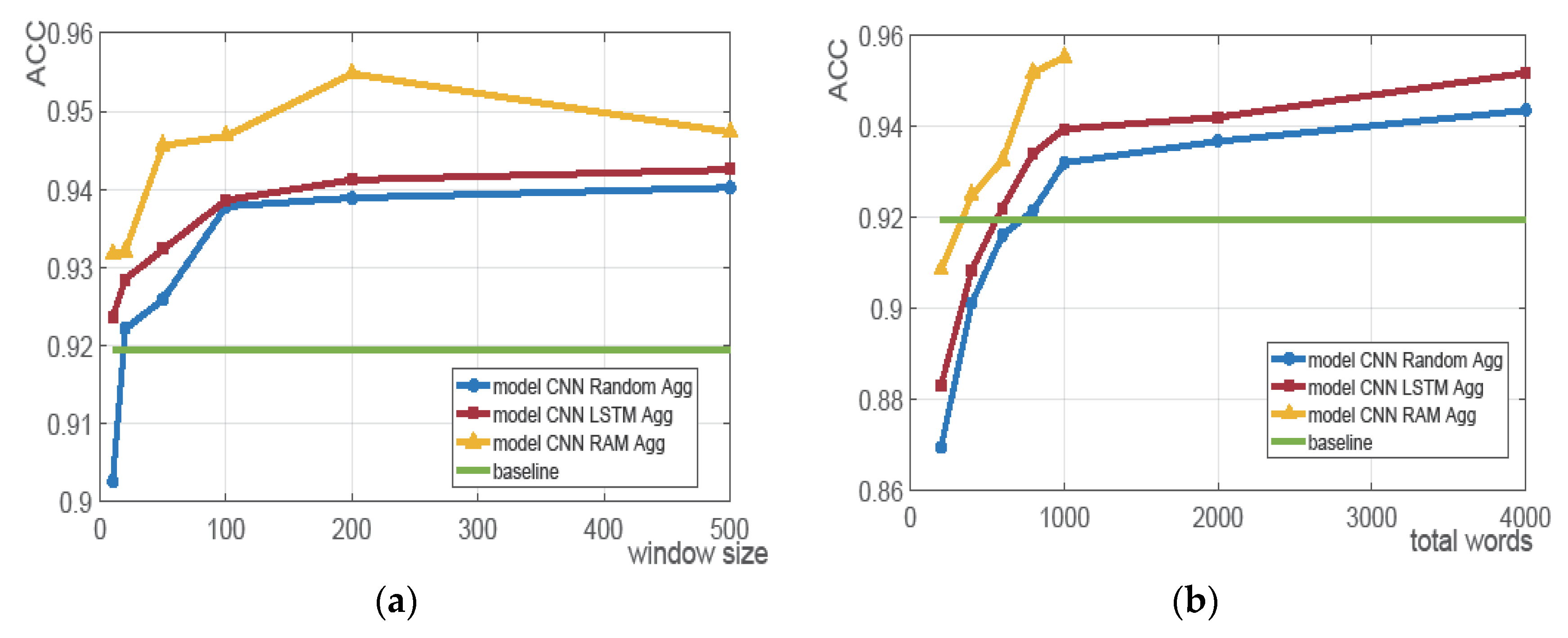
4.3.5. Experimental Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, S.; Manning, C.D. Baselines and bigrams: Simple, good sentiment and topic classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics: Short Papers-Volume 2, Jeju Island, Korea, 8–14 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 90–94. [Google Scholar]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 115–124. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. Eprint Arxiv 2014, arXiv:1408.5882. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 333, pp. 2267–2273. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention net-works for document classification. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Zhang, X.; Zhao, J.; Lecun, Y. Character-level Convolutional Networks for Text Classification. In Proceedings of the NIPS’15 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisboa, Portugal, 17 September 2015; pp. 1422–1432. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1406.6247. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Maas, A.L.; Daly, R.E.; Pham, P.T.; Huang, D.; Na, A.Y.; Potts, D. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Stroudsburg, PA, USA, 2011; pp. 142–150. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation Extraction: Perspective from Convolutional Neural Networks. In Workshop on Vector Modeling for NLP; Blunsom, P., Cohen, S., Dhillon, P., Liang, P., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 39–48. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 4, pp. 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Nallapati, R.; Zhou, B.; dos Santos, C.; Gulcehre, C.; Xiang, B. Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond. arXiv 2016, arXiv:1602.06023. [Google Scholar]
- Wang, Z.; He, W.; Wu, H.; Wu, H.; Li, W.; Wang, H.; Chen, E. Chinese Poetry Generation with Planning based Neural Network. arXiv 2016, arXiv:1610.09889. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. arXiv 2016, arXiv:1605.05101. [Google Scholar]
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. A novel connectionist system for unconstrained handwriting recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 855–868. [Google Scholar] [CrossRef] [PubMed]
- Miao, Y.; Gowayyed, M.; Metze, F. EESEN: End-to-end speech recognition using deep RNN models and WFST-based decoding. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 167–174. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 27th Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Tensorflow. Available online: https://github.com/tensorflow/tensorflow (accessed on 23 July 2018).
- Stra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Snoek, J.; Larochell, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. In Proceedings of the Advances in neural information processing systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2951–2959. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Number of Documents | Average Words |
|---|---|---|
| cs.IT | 3233 | 5938 |
| cs.NE | 3012 | 5856 |
| math.AC | 2885 | 5984 |
| math.GR | 3065 | 6642 |
| Window Size | 10 | 20 | 50 | 100 | 200 | 400 | 500 | |
|---|---|---|---|---|---|---|---|---|
| Total Words | ||||||||
| 200 | 86.37% | 86.53% | 86.98% | 87.03% | 87.21% | |||
| 400 | 87.48% | 90.11% | 90.33% | 90.60% | 92.08% | 92.12% | ||
| 600 | 88.36% | 91.21% | 91.88% | 92.16% | 93.35% | |||
| 800 | 89.14% | 92.13% | 92.32% | 92.63% | 93.38% | 93.41% | ||
| 1000 | 90.26% | 92.21% | 92.59% | 93.78% | 93.89% | 94.02% | ||
| Window Size | 10 | 20 | 50 | 100 | 200 | 400 | 500 | |
|---|---|---|---|---|---|---|---|---|
| Total Words | ||||||||
| 200 | 88.16% | 88.21%% | 90.67% | 90.96% | 91.32% | |||
| 83.42% | 86.05% | 86.71% | 87.23% | 88.06% | ||||
| 400 | 89.05% | 91.03% | 91.35% | 91.62% | 92.21% | 92.33% | ||
| 86.28% | 88.41% | 89.08% | 89.27% | 90.08% | 90.12% | |||
| 600 | 89.52% | 91.96% | 92.03% | 92.85% | 93.87% | |||
| 86.66% | 89.59% | 89.92% | 90.23% | 90.51% | ||||
| 800 | 90.28% | 92.41% | 93.12% | 93.32% | 94.01% | 94.35% | ||
| 89.44% | 90.28% | 90.37% | 90.56% | 90.82% | 90.94% | |||
| 1000 | 92.36% | 92.85% | 93.23% | 93.86% | 94.12% | 94.25% | ||
| 89.48% | 90.36% | 90.61% | 91.77% | 91.96% | 92.34% | |||
| Window Size | 10 | 20 | 50 | 100 | 200 | 400 | 500 | |
|---|---|---|---|---|---|---|---|---|
| Total Words | ||||||||
| 200 | 89.84% | 90.15% | 91.67% | 91.89% | 92.23% | |||
| 400 | 90.05% | 92.22% | 93.08% | 93.56% | 93.67% | 93.53% | ||
| 600 | 90.11% | 92.38% | 93.68% | 94.24% | 94.11% | |||
| 800 | 92.36% | 92.53% | 93.86% | 94.36% | 94.41% | 93.87% | ||
| 1000 | 93.17% | 93.21% | 94.56% | 94.68% | 95.48% | 94.73% | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Liu, K.; Cong, Z.; Zhao, J.; Ji, Y.; He, J. Long Length Document Classification by Local Convolutional Feature Aggregation. Algorithms 2018, 11, 109. https://doi.org/10.3390/a11080109
Liu L, Liu K, Cong Z, Zhao J, Ji Y, He J. Long Length Document Classification by Local Convolutional Feature Aggregation. Algorithms. 2018; 11(8):109. https://doi.org/10.3390/a11080109
Chicago/Turabian StyleLiu, Liu, Kaile Liu, Zhenghai Cong, Jiali Zhao, Yefei Ji, and Jun He. 2018. "Long Length Document Classification by Local Convolutional Feature Aggregation" Algorithms 11, no. 8: 109. https://doi.org/10.3390/a11080109
APA StyleLiu, L., Liu, K., Cong, Z., Zhao, J., Ji, Y., & He, J. (2018). Long Length Document Classification by Local Convolutional Feature Aggregation. Algorithms, 11(8), 109. https://doi.org/10.3390/a11080109