1. Introduction
Proposed by Taylor and Lee in 1993, phase-sensitive optical time-domain reflectometry (Φ-OTDR) is a typical monitoring technique for distributed vibrations [
1]. Capable of positioning distributed signals, this technique has been widely applied to health monitoring of large buildings [
2], perimeter security of important places [
3], etc. Compared to traditional 1D monitoring of vibration signals [
4,
5,
6,
7,
8], Φ-OTDR can realize long-term and high-accuracy monitoring. However, these advantages are achieved at the cost of a huge amount of distributed vibration data, which may lead to insufficient storage and inefficient data processing.
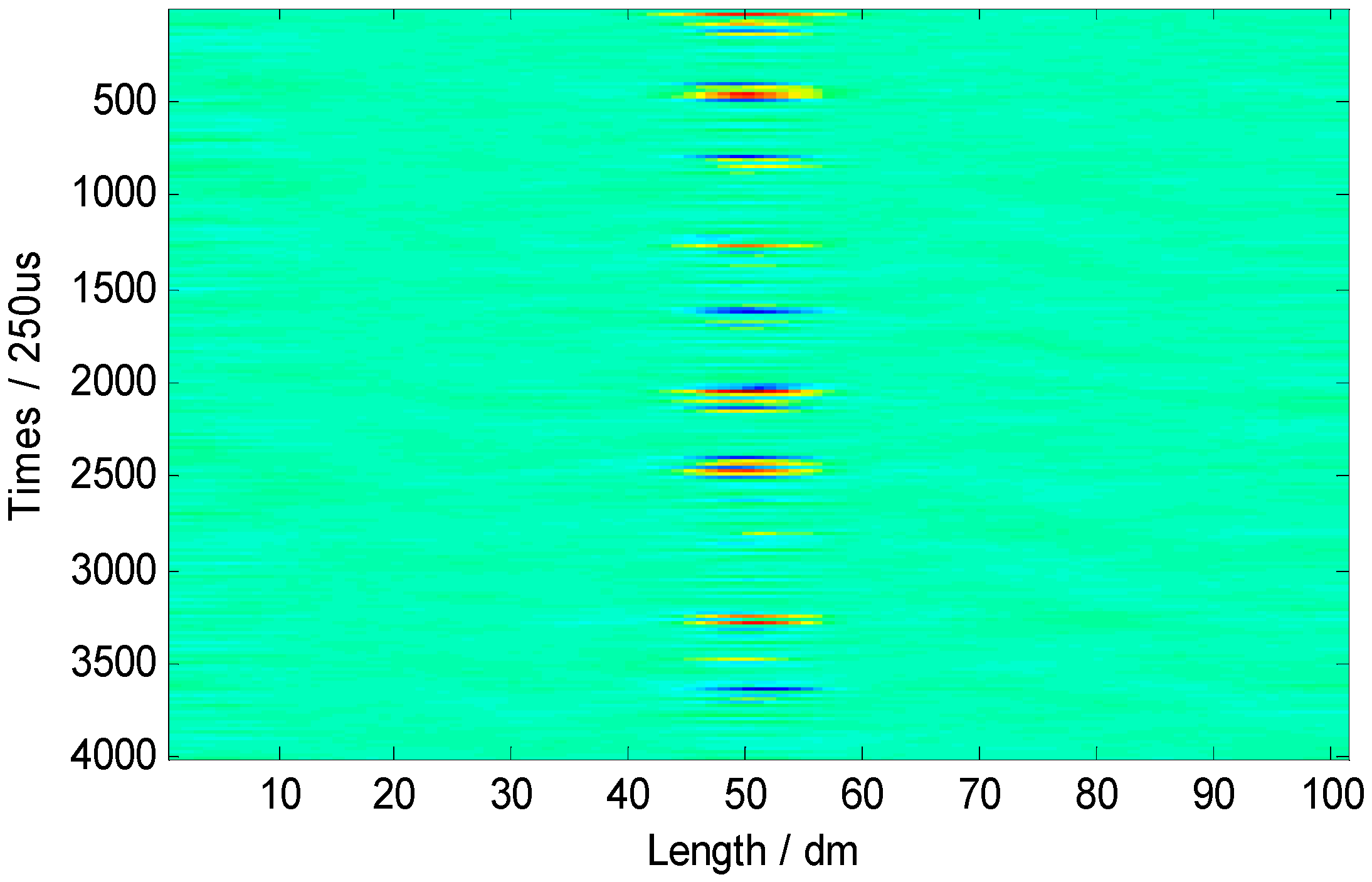
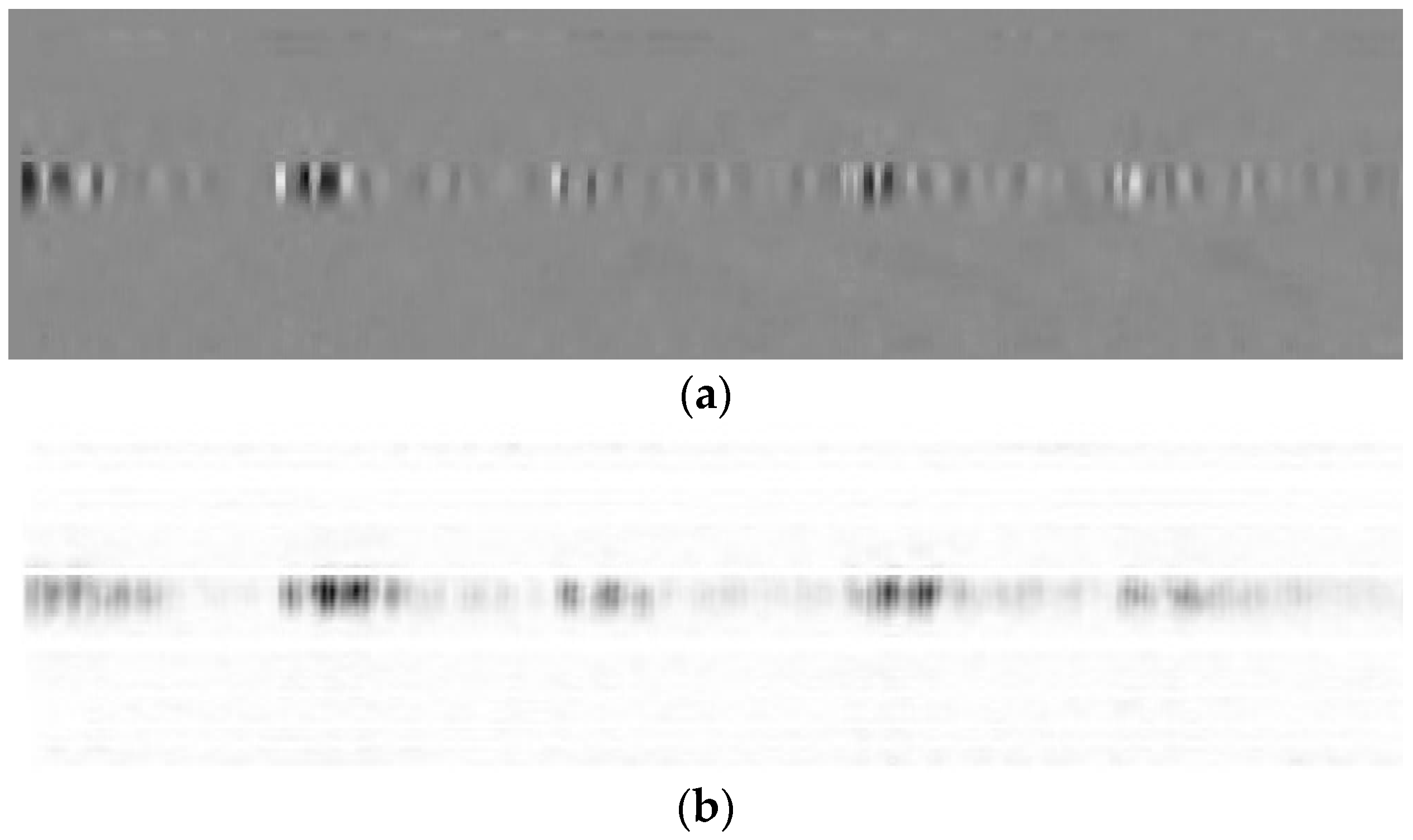
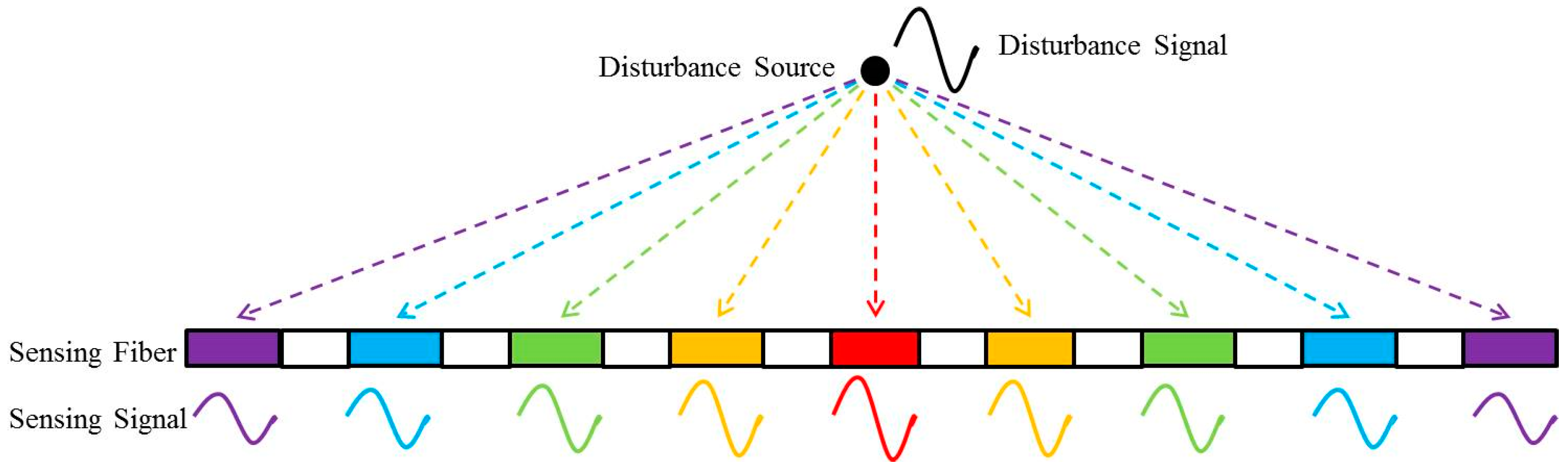
To solve this defect, this paper attempts to store and process the vibration signals as images according to existing image-based approaches for vibration signal processing [
9,
10,
11,
12,
13,
14]. Specifically, the vibration signals were converted into storable images, and then an integrated strategy was proposed to extract features of these images. Next, the proposed strategy was applied to analyze Φ-OTDR signals and track the vibration source. Overall, our research mainly tackles two issues, namely, signal storage (i.e., the conversion of signals into images for storage) and signal analysis (i.e., the processing of the stored images by the proposed method).
Concerning signal storage, Han et al. [
15] combined autoregressive-moving-average (ARMA) with swing door trending (SDT) to compress the vibration signals without sacrificing the key features. Malovic et al. [
16] applied time delay estimation (TDE) in conjunction with differential pulse code modulation (DPCM) as the entropy coding of preprocessor, revealing that the integrated method can encode different types of aperiodic signals and compress vibration signals. Inspired by block compression, Huang et al. [
17] put forward a lossless compression plan that draws on the merits of both lossy and lossless compressions. Guo et al. [
18] developed a vibration signal compression technique called intrinsic mode function (IMF) based on ensemble empirical mode decomposition (EEMD), aiming to decompose the components of vibration signals in different frequency bands. To sum up, the above signal storage methods can be easily derived through analyzing and calculating the vibration signals. However, most of these methods require complex computation and do not apply to exceptional cases. By contrast, the Φ-OTDR technique can overcome these problems by collecting distributed vibrations signals with two dimensions: Time and length. Therefore, this paper aims to convert vibration signals directly into storable images after a few simple steps of preprocessing.
Concerning signal analysis, image target recognition has long been regarded as the key problem. The existing methods of image target recognition fall into five categories: Color feature extraction, texture feature extraction, shape feature extraction, intrinsic feature extraction, and spatial feature extraction. The color and spatial features are neglected here due to the lack of color and spatial information in the grayscale images generated from vibration signals. Because signal types of features cannot meet engineering requirements, many scholars have explored integrated feature extraction for image processing. For instance, Yang et al. [
19] achieved high-speed tracking of image targets via hybrid rotation invariant description and skip search. Xia et al. [
20] use color and edge feature distribution to build a mixture model to search for matching targets in the next frame image. Xiao et al. [
21] combined the effective region index and multi-scale edge index for image processing. Considering the shape feature and other details of moving objects, Ren et al. [
22] presented a robust visual tracking method called the SURF Mean Shift Deep Learning Tracker (SMS-DLT). Nevertheless, the above integrated methods are not comprehensive enough to process the images generated from distributed vibration signals. In these images, there is no complex background, light conversion or other factors common in traditional image processing. Hence, the texture, shape and intrinsic features should be taken into account.
In light of all three types of features, this paper adjusts the weight of each pixel in the original image by the speeded-up robust features (SURF) method and embeds the extraction methods of the three features in the particle filter. Based on the extraction of hybrid image features, a method was proposed to track the vibration source of Φ-OTDR signals. The steps of the proposed method are presented in
Figure 1 below. First, the vibration signals of optical fiber in different sources were acquired by the Φ-OTDR technique, subjected to pre-processing, and stored as images to reduce storage space; then, three types of features (i.e., texture features, shape features and intrinsic features) were extracted from the images; finally, the effect of the proposed method was verified through experiments. The research findings shed new light on the tracking of vibration sources.
3. Vibration Source Tracking Based on Various Types of Image Features
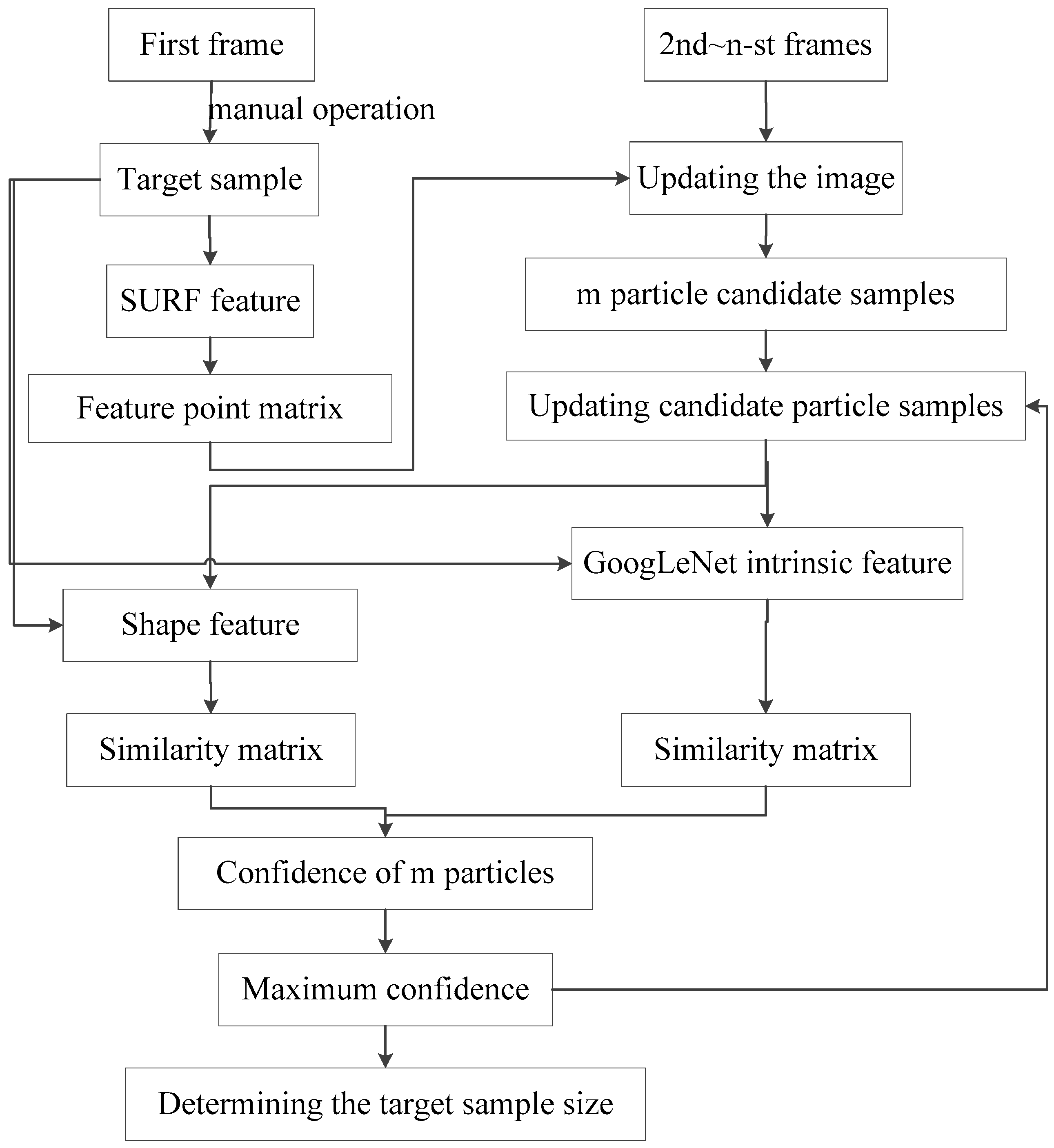
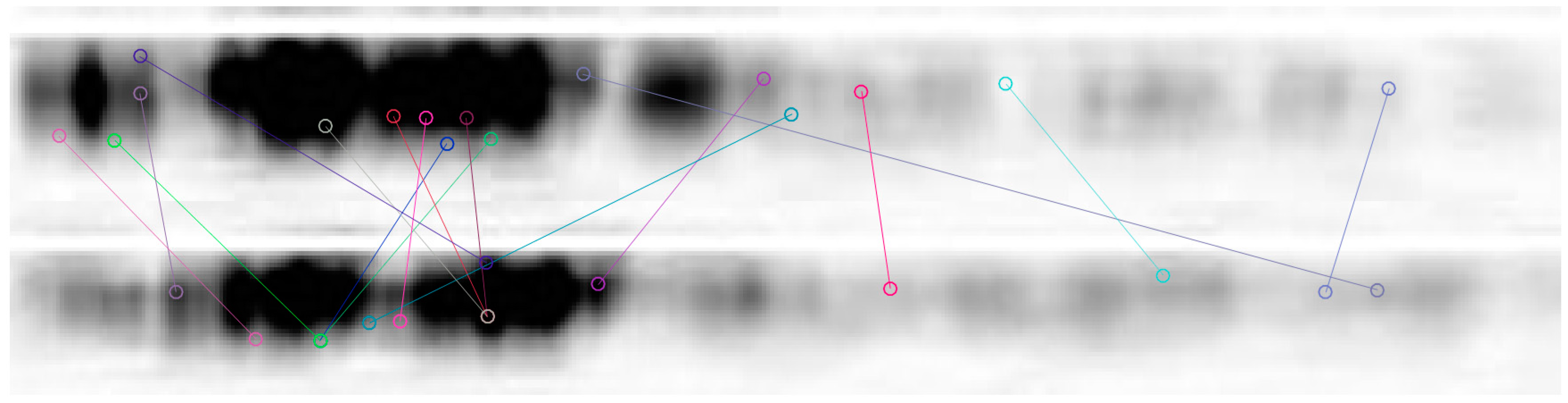
In this research, the tracking target is the change in the image of vibration signals. To track the target, three types of features were extracted from the image: Texture features, intrinsic features and shape features. The shape features were obtained by the histogram of gradient directions, while the intrinsic features were acquired by GoogLeNet (Google, San Francisco, CA, USA). Then, the particle filter was adopted to track the target on the image based on the shape and intrinsic features. Subsequently, the greyscales of the original image pixels were adjusted by the SURF matching algorithm. The salient pixels were given relatively high greyscales. The adjustment helps improve the feature extraction results. The flow of the vibration source tracking is shown in
Figure 3.
As shown in
Figure 3, the vibration sources were tracked in the following steps:
Step 1: The first frame (f1) of the image was sampled and the target and background templates were obtained manually; the target template was obtained by shape feature extraction, intrinsic feature extraction, and SURF feature extraction.
Step 2: Let fi be the i-th frame of the image (i = 2, 3, …, n).
- (1)
The candidate sample sets were obtained through random generation of sampled particles.
- (2)
A set of SURF features (Si) was established to reflect the target positions from fi to fi−1. After matching, the SURF feature point mapping matrix (Wis) was obtained. The grayscale of the original image was multiplied by 0.7 and then increased by 0.3 at the feature point position, forming the updated samples.
- (3)
The shape and intrinsic similarities (ρi) between each candidate sample and the target template were calculated, respectively.
- (4)
The confidence was obtained for each particle, and the particle with the highest confidence was determined as the target position of fi.
Step 3: If the update condition was satisfied, the target and background templates were resampled. If not, let i = i + 1 and return to Step 2.
3.1. Target Contour Feature Extraction
As mentioned previously, the shape features of the sample image were extracted by the histogram of gradient directions [
26,
27], and the similarity between the sample and the target template was calculated, laying the basis for subsequent motion estimation. The first step is to determine the gradient direction (i.e., the angle between the
x- and
y-axis gradients of a pixel). Let
a ×
b be the number of pixels of the greyscale image and
be the gradient angles of these pixels. Then, we have:
where
grayij is gray value of the point (
i,
j), and
and
are the
x-axis and
y-axis gradients of point (
i,
j), respectively.
Then, the histogram of gradient directions can be determined by dividing the gradient angle into different intervals:
where {
Hk}
k∈[1,n] is the interval and Δφ is size of interval. The histogram of gradient directions is the probability of the encoded pixels in the image in each direction (
Hk).
Next, the histogram of gradient directions was weighted to ensure the robustness of density estimation. Through the weighting process, the pixels were assigned their respective weights according to their proximity to the target center. In the weighted histogram, the probability of the
k-th interval,
pk, can be expressed as:
where
y is the center of the sample; {
xi}
i∈[1,nh] is the position of each pixel in the sample;
k(
x) is the kernel function;
H is the window width of the kernel function;
b(
xi) is direction encoding index of pixel
xi; and,
δ is the Dirichlet function. The importance of each particle in each frame image was determined according to the particle’s confidence. To obtain the confidence, the histogram of gradient directions was established for each candidate sample, and the similarity between each sample and the target template was computed at the same time. The similarity,
ρ(
y), between the histogram of gradient directions,
p(
y), of each candidate sample and
p(
y0) of the target template was measured by the Bhattacharyya distance:
3.2. GoogLeNet-Based Feature Extraction
At the frontier of machine learning, deep learning mimics the mechanism of the human brain to interpret such data as images, audio and text, and supports the automatic extraction of the intrinsic features of an image. A typical example of deep learning is GoogLeNet, a deep convolutional neural network designed by Google [
28,
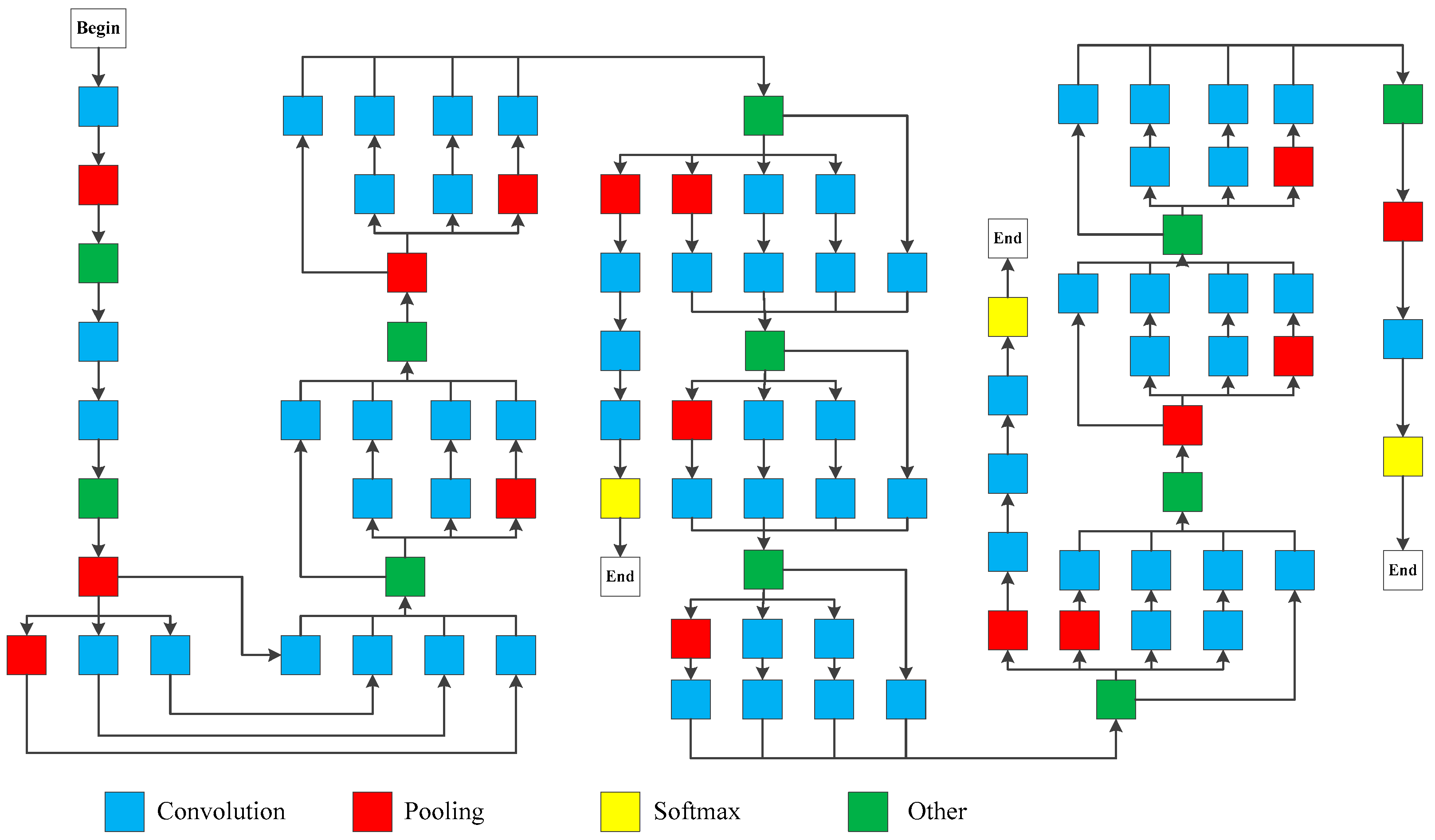
29] for the Large Scale Visual Recognition Challenge 2014. As shown in
Figure 4, the GoogLeNet consists of 22 layers and reflects the idea of sparse learning. The size of GoogLeNet can be expanded by adjusting the parameters of the sparse network.
The GoogLeNet adopts a modular structure that is easily addable or modifiable. The fully-connected layer is replaced by the average pooling, which improves the accuracy by 0.6%. Despite the removal of the fully-connected layer, the dropout concept is still used in the network. To prevent the vanishing gradient problem, two additional modules are added for the forward propagation of gradient. Here, the GoogLeNet is employed to extract feature samples from images, and the confidence of the target sample is discussed according to both intrinsic and shape features.
3.3. Feature Extraction Based on SURF Method
The SURF is a simple and fast algorithm to extract interest points and describe eigenvectors [
30,
31]. The classical SURF uses the difference of Gaussians (DoG) operator, which is inspired by the Laplacian of Gaussian (LoG) operator in scale invariant feature transform (SIFT). In general, the SURF contains five steps: Constructing the Hessian matrix; calculating eigenvalue; constructing Gaussian pyramid; determining the principal direction of feature point and locating feature points; and, constructing feature descriptors.
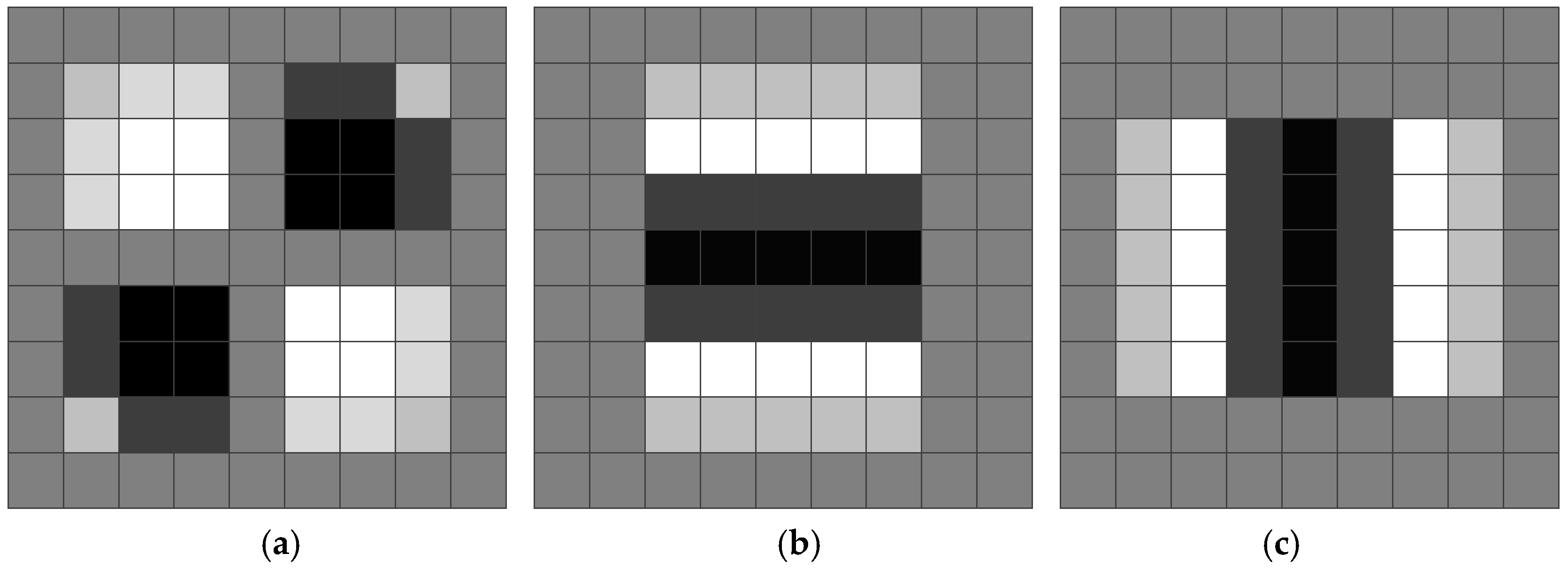
The box filter plays an important role in these steps: It can simplify and approximate the Hessian matrix, making it possible to segment the second-order Gaussian template. With three values (i.e., 1-white, 0-gray and −1-black), the traditional box filter approximates white and light white regions as white regions, and black and light black regions as black regions. In this way, the speed is increased but the accuracy is not preserved. This gives rise to the improved box filter that has five values: 1, 0.5, 0, −0.5 and −1. The improved box filter (
Figure 5) ensures that the regional size increases consistently in the SURF.
In this paper, the SURF was adopted to extract the set of feature points from each frame image to form a new grayscale matrix of the same size as that of the original image. In the new matrix, the feature points were in black, and the other points were in white. Then, the original image was generated from the new matrix. The grayscale matrix weights of the original image and the new matrix were 0.7 and 0.3, respectively. The two values were added together to derive the grayscale matrix of the updated image:
where
is the gray scale matrix of updated image;
is the gray scale matrix of the original image; and,
is the black-white matrix of SURF feature points.
3.4. Particle Filter Tracking Algorithm
In particle filtering, the particle states are described by affine transformation parameters, each of which is a six-dimensional vector. For each particle, the variables are distributed randomly and obey a probability distribution in the state space. The next most probable state is estimated by probability calculation according to the previous state:
where
x and
y are the abscissa and ordinate of the center of the particle sample;
sc is the length-width ratio of the sample;
ro is the rotation angle of the particle sample;
ra is the height-width ratio of the particle sample; and,
sa is the gradient of the tracking window.
Particle filtering is an important resampling process that places a number of particles, by certain rules, in the current frame. According to the placement rules, the particles are either placed evenly or denser near the target. The similarity between the particles and the target template is measured by particle weights. For simplicity, the weights should be normalized so that the sum of weights of all particles equals 1.
In this paper, the particle filter tracking algorithm is implemented as follows. First,
n particle samples were obtained by random sampling in the initial frame. The weights of the particles were set to 1/
n. Let
be the state of the
n particles at time
t − 1 and
be the weights of these particles. Then,
n particle samples were selected from the particle set based on the weights. The normalized weight probability set
can be expressed as:
The n sets of variables evenly distributed between 0 and 1 were randomly generated and denoted as . Then, , the set of n minimum indices , was established (). Then, was instated to the , marking the end of the resampling process.
The updated particle set was transmitted via the system state-change equation. When a new frame arrives, the state of the particle state can be obtained as:
where
A is the state transition matrix and
vt−1 are the multivariate Gaussian variables randomly generated by affine transformation parameters. The confidence of each particle can be obtained as:
where
ρ(
y) is the similarity between the histogram of gradient directions of the candidate sample and that of the target template and
w(
y) is the particle weight obtained by GoogLeNet. The maximum confidence particle was considered as the final estimation of the output frame. In this way, the texture features were combined with the shape features, and the sample with maximum similarity was identified to enhance the tracking accuracy.
5. Conclusions
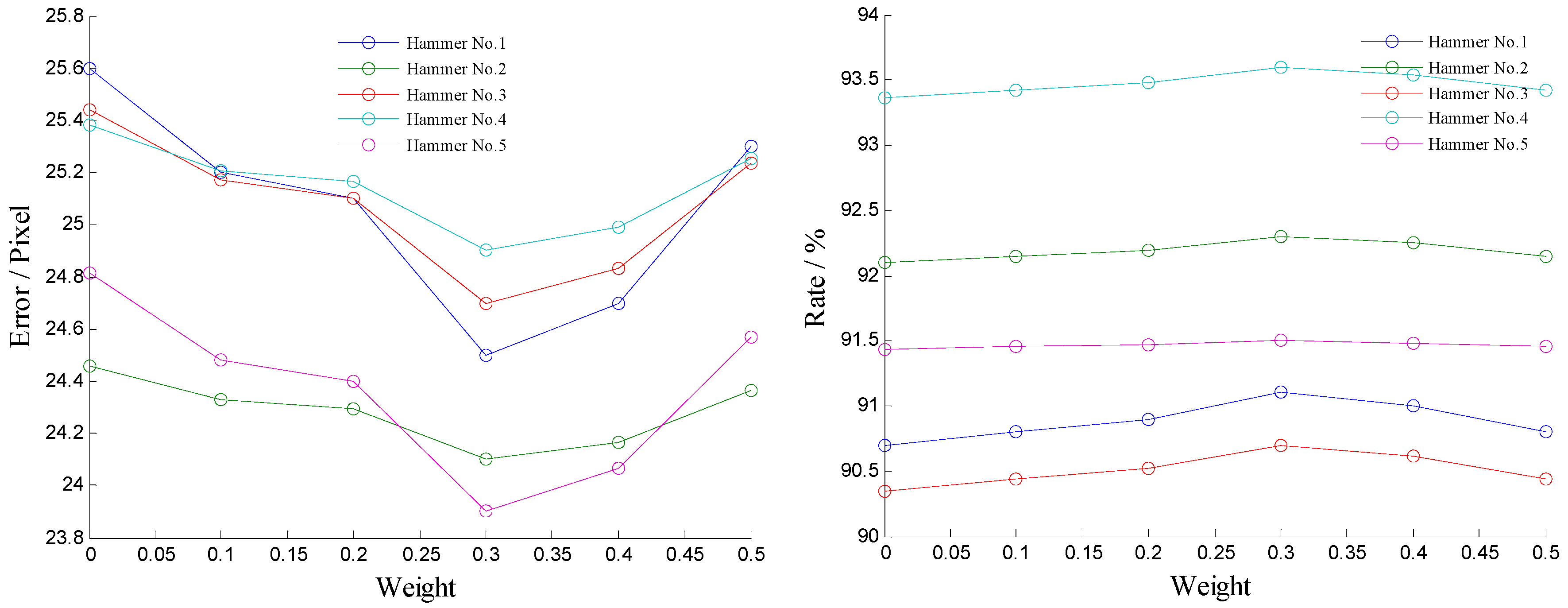
This paper proposes an integrated image feature extraction method for vibration source tracking of Φ-OTDR signals and compares the method with other popular approaches via experiments. According to the experimental results, it can be concluded that: Hard drive space is greatly conserved by saving the distributed vibration signals as images; the proposed particle filter is a desirable way to screen the vibration signals for monitoring; the integrated feature extraction outperforms the individual extraction methods for texture features, shape features and intrinsic features; the proposed method has a better effect than other popular integrated feature extraction methods; and, the signal source tracking method has little impact on the positioning accuracy of the vibration source.
Through our research, a simple, fast and lightweight source tracking method has been developed for Φ-OTDR signals. Considering the complexity of actual conditions and the fast development of deep learning networks and image processing methods, future research will improve the proposed method to suit other types of Φ-OTDR signals, such as non-damped leakage signals, and to reflect the latest techniques in image processing, such as the parallel use of multiple methods.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}