Parallelism Strategies for Big Data Delayed Transfer Entropy Evaluation



Abstract
:1. Introduction
2. Initial Concepts
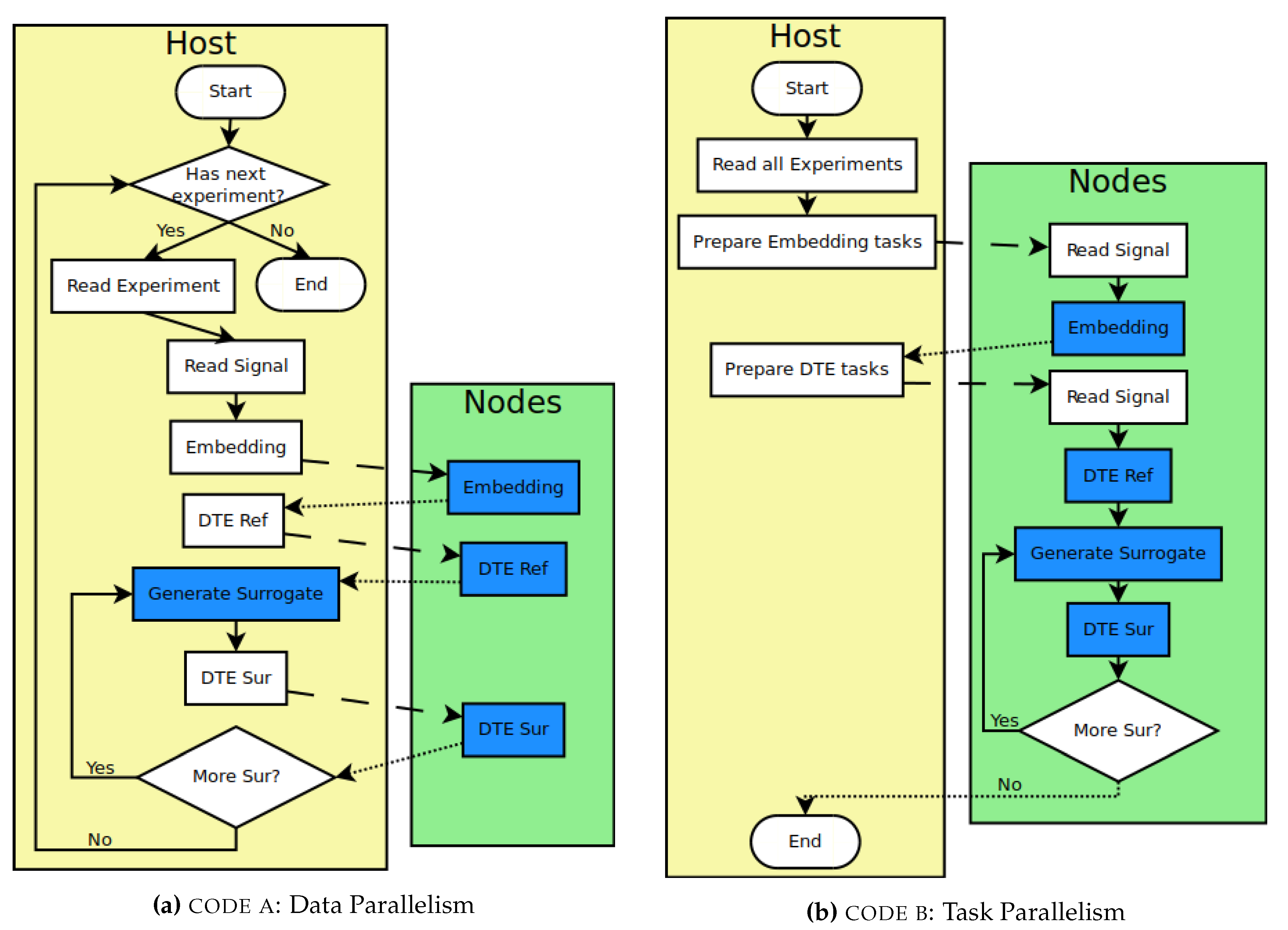
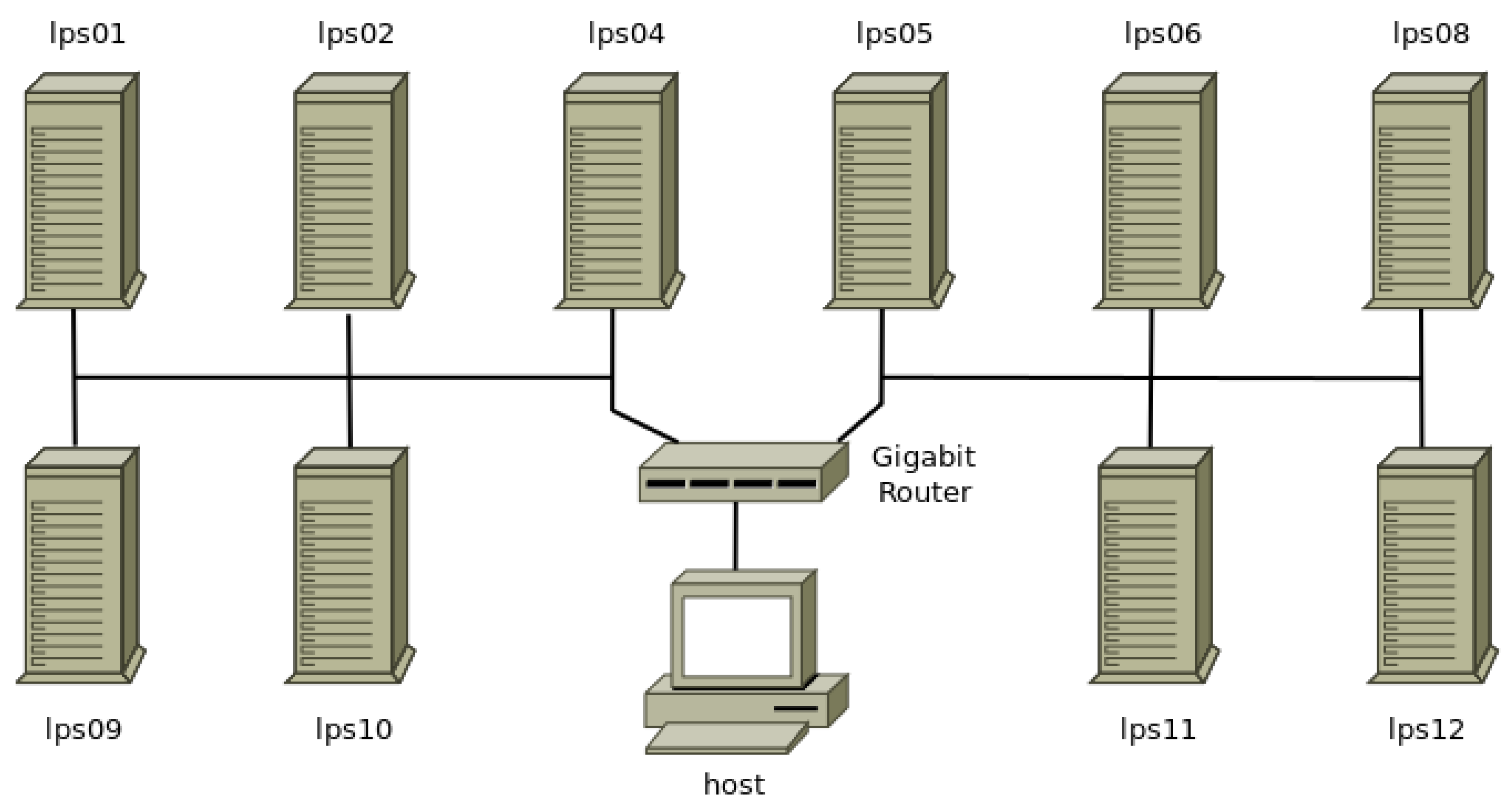
2.1. Computer Cluster
2.2. IPython Parallel Environment
2.3. Algorithms
Surrogate
| Algorithm 1 IAAFT |
|
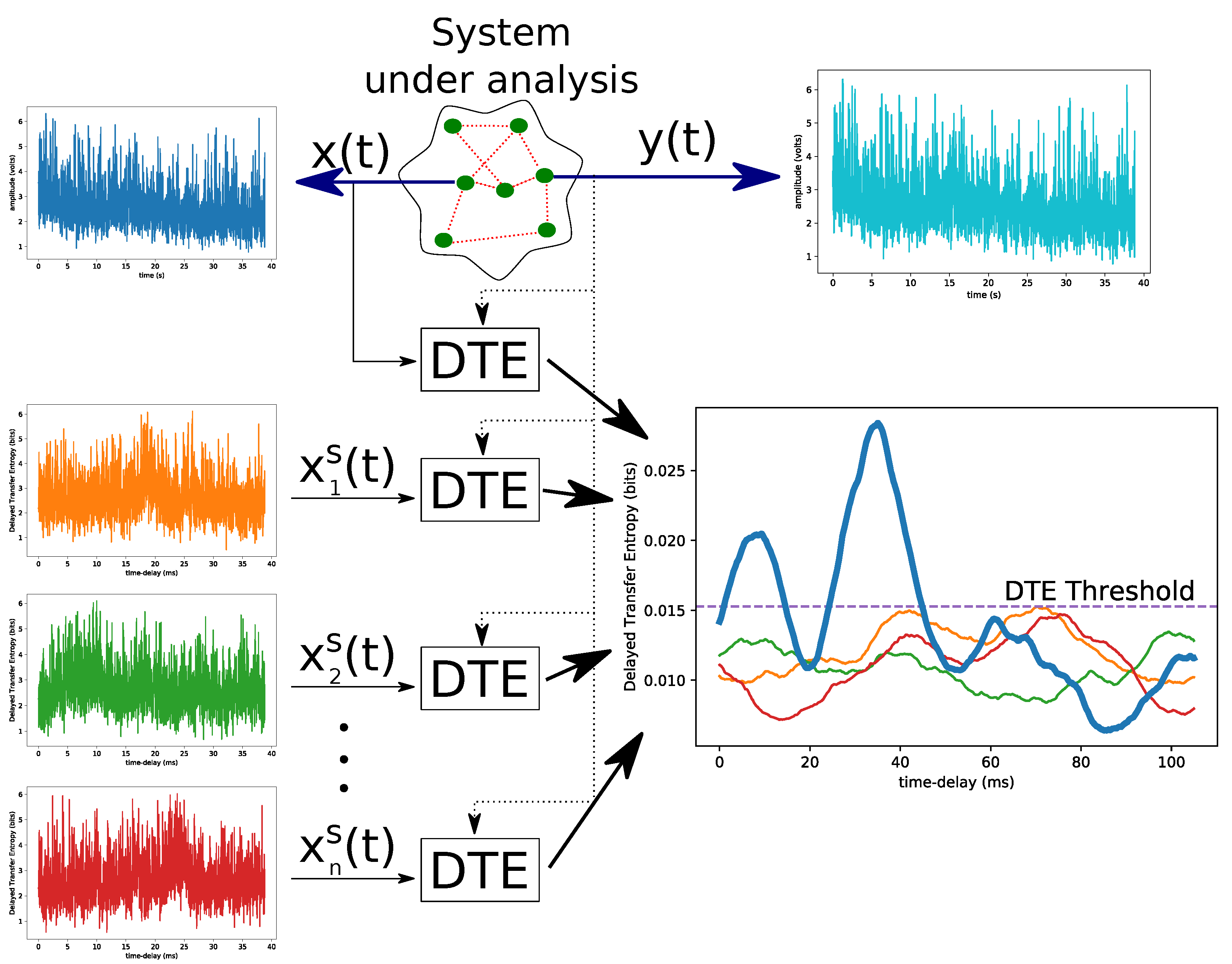
3. Material and Methods
Transfer Entropy
| Algorithm 2 Execute DTE with surrogate |
|
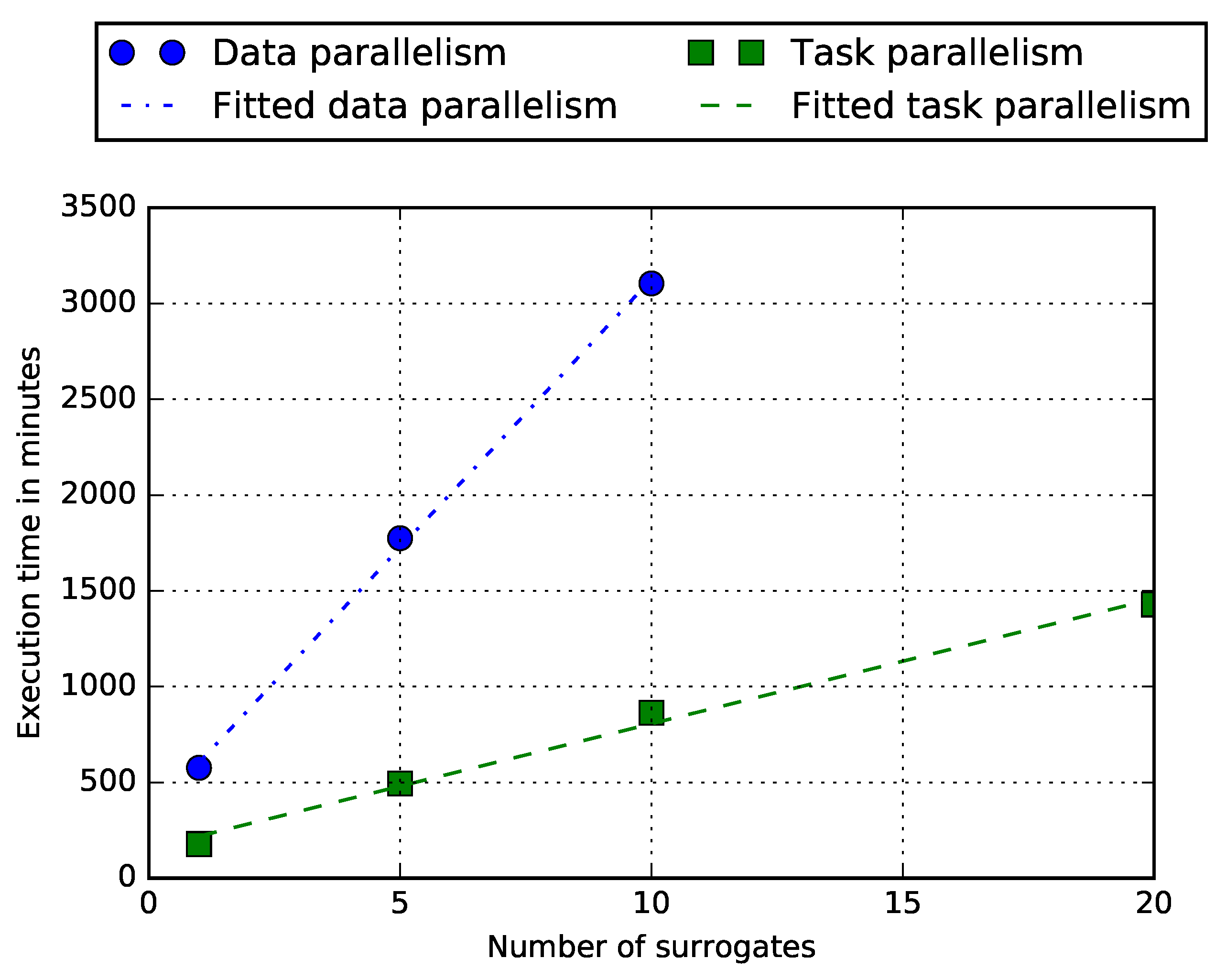
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Source Code

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parallel Strategy | Revision Hash |
|---|---|
| Data Parallelism | f85aac7e8ff46c74b8e758211197dfc8b069571d |
| Task Parallelism | e97a687c51cfad61ac097fb5fc26b029967615da |
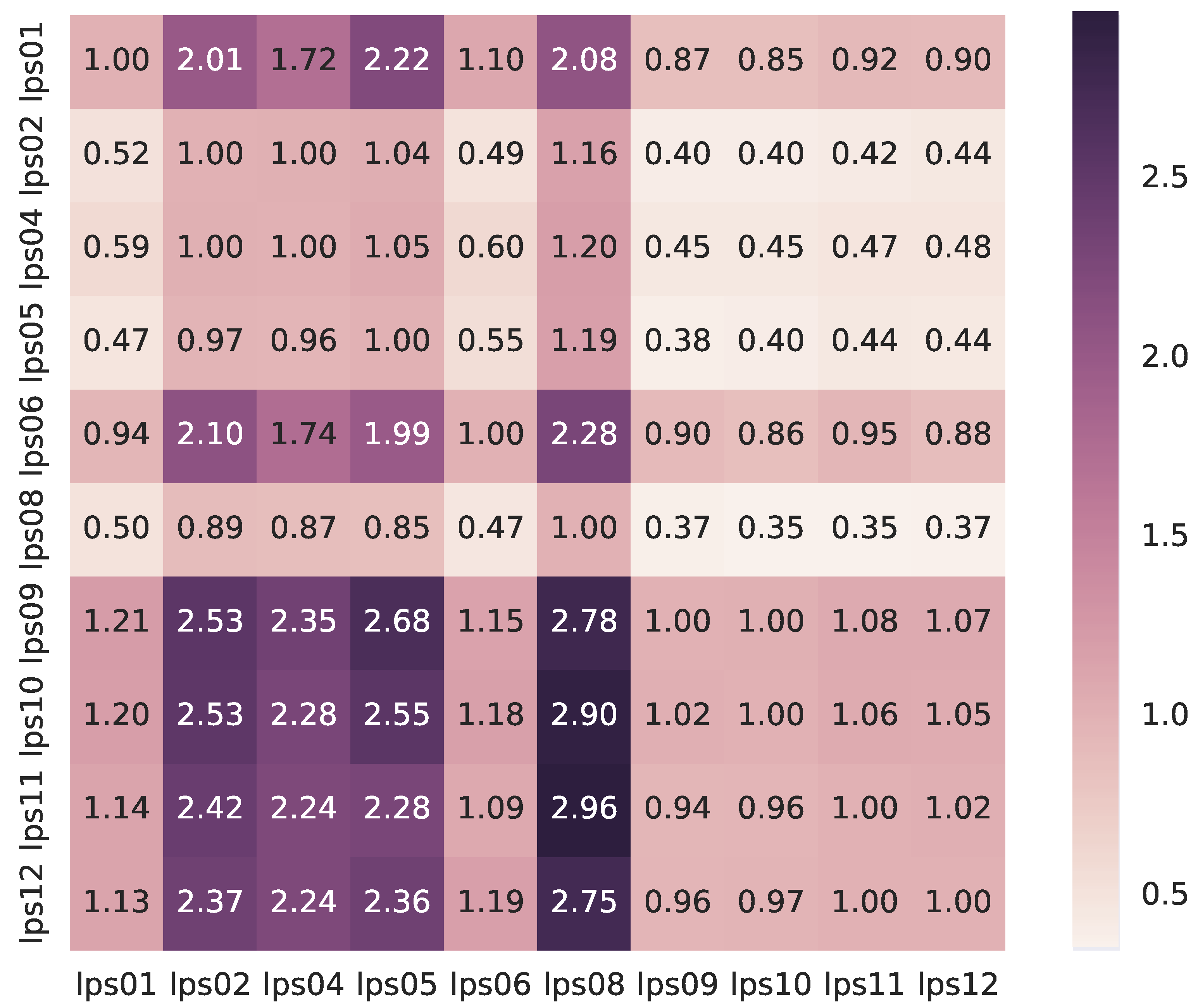
Appendix A.2. Cluster Configuration
| Node | Processor (cores) | RAM (speed) | Main Storage Size (model) | Ethernet |
|---|---|---|---|---|
| host | i5-2500 CPU @ 3.30GHz | 4 + 4 GiB (1333MHz) | 2TB WDC WD20EARX-00P | Gigabit |
| lps01 | i7-4770 CPU @ 3.40GHz (8) | 8 + 8 GiB (1333MHz) | 1TB ST1000DM003-1CH1 | Gigabit |
| lps02 | i7-3770 CPU @ 3.40GHz (8) | 8 GiB (1333MHz) | 60GB KINGSTON SV300S3 | Gigabit |
| lps04 | i7-4820K CPU @ 3.70GHz (8) | 8 GiB (1333MHz) | 2TB ST2000DM001-1CH1 | Gigabit |
| lps05 | i7-4820K CPU @ 3.70GHz (8) | 8 GiB (1333MHz) | 1863GiB ST2000DM001-1CH1 | Gigabit |
| lps06 | i7-4820K CPU @ 3.70GHz (8) | 8 + 8 GiB (1333MHz) | 60GB KINGSTON SV300S3 | Gigabit |
| lps08 | i7 950 CPU @ 3.07GHz (8) | 4 + 4 + 4 GiB (1066MHz) | 2TB ST32000542AS | Gigabit |
| lps09 | i7-4790 CPU @ 3.60GHz (8) | 8 + 8 GiB (1600MHz) | 256GB SMART SSD SZ9STE | Gigabit |
| lps10 | i7-4790 CPU @ 3.60GHz (8) | 8 + 8 GiB (1600MHz) | 256GB SMART SSD SZ9STE | Gigabit |
| lps11 | i7-4790 CPU @ 3.60GHz (8) | 8 + 8 GiB (1600MHz) | 256GB SMART SSD SZ9STE | Gigabit |
| lps12 | i7-4790 CPU @ 3.60GHz (8) | 8 + 8 GiB (1600MHz) | 256GB SMART SSD SZ9STE | Gigabit |
| Node | Operating System (updated at) | Numpy | IPython | pyfftw | Linux Kernel |
|---|---|---|---|---|---|
| host | Fedora 24 Workstation (17-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps01 | Fedora 24 Server (16-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps02 | Fedora 24 Server (16-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps04 | Fedora 24 Server (16-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps05 | Fedora 24 Server (16-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps06 | Fedora 24 Server (16-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps08 | Fedora 24 Server (16-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps09 | Fedora 24 Workstation (2016-08-16) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps10 | Fedora 24 Server (16-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps11 | Fedora 24 Server (16-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
| lps12 | Fedora 24 Server (16-08-2016) | 1.11.0 | 3.2.1 | 0.10.3.dev0+e827cb5 | 4.6.6-300.fc24.x86_64 |
Appendix A.3. Dataset
References
- Firouzi, F.; Rahmani, A.M.; Mankodiya, K.; Badaroglu, M.; Merrett, G.V.; Wong, P.; Farahani, B. Internet-of-Things and big data for smarter healthcare: From device to architecture, applications and analytics. Future Gener. Comput. Syst. 2018, 78, 583–586. [Google Scholar] [CrossRef] [Green Version]
- Hashem, I.A.T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of “big data” on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Cheng, M.; Hackett, R.; Li, C. In Search of a Language of Causality in the Age of Big Data for Management Practices. Acad. Manag. Glob. Proc. 2018, Surrey, 170. [Google Scholar]
- Song, M.L.; Fisher, R.; Wang, J.L.; Cui, L.B. Environmental performance evaluation with big data: Theories and methods. Ann. Oper. Res. 2018, 270, 459–472. [Google Scholar] [CrossRef]
- Manogaran, G.; Lopez, D. Spatial cumulative sum algorithm with big data analytics for climate change detection. Comput. Electr. Eng. 2018, 65, 207–221. [Google Scholar] [CrossRef]
- Duncan, D.; Vespa, P.; Pitkänen, A.; Braimah, A.; Lapinlampi, N.; Toga, A.W. Big data sharing and analysis to advance research in post-traumatic epilepsy. Neurobiol. Dis. 2019, 123, 127–136. [Google Scholar] [CrossRef] [PubMed]
- Vidaurre, D.; Abeysuriya, R.; Becker, R.; Quinn, A.J.; Alfaro-Almagro, F.; Smith, S.M.; Woolrich, M.W. Discovering dynamic brain networks from big data in rest and task. Neuroimage 2018, 180, 646–656. [Google Scholar] [CrossRef] [PubMed]
- Mooney, S.J.; Garber, M.D. Sampling and Sampling Frames in Big Data Epidemiology. Curr. Epidemiol. Rep. 2019, 6, 14–22. [Google Scholar] [CrossRef]
- Saracci, R. Epidemiology in wonderland: Big data and precision medicine. Eur. J. Epidemiol. 2018, 33, 245–257. [Google Scholar] [CrossRef]
- Bragazzi, N.L.; Guglielmi, O.; Garbarino, S. SleepOMICS: How big data can revolutionize sleep science. Int. J. Environ. Res. Public Health 2019, 16, 291. [Google Scholar] [CrossRef]
- Yetton, B.D.; McDevitt, E.A.; Cellini, N.; Shelton, C.; Mednick, S.C. Quantifying sleep architecture dynamics and individual differences using big data and Bayesian networks. PLoS ONE 2018, 13, e0194604. [Google Scholar] [CrossRef] [PubMed]
- Papana, A.; Kugiumtzis, D.; Larsson, P. Reducing the bias of causality measures. Phys. Rev. E 2011, 83, 036207. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Endo, W.; Santos, F.P.; Simpson, D.; Maciel, C.D.; Newland, P.L. Delayed mutual information infers patterns of synaptic connectivity in a proprioceptive neural network. J. Comput. Neurosci. 2015, 38, 427–438. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arellano-Valle, R.B.; Contreras-Reyes, J.E.; Genton, M.G. Shannon Entropy and Mutual Information for Multivariate Skew-Elliptical Distributions. Scand. J. Stat. 2013, 40, 42–62. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring Information Transfer. Phys. Rev. Lett. 2000, 85, 19. [Google Scholar] [CrossRef] [PubMed]
- Lindner, B.; Auret, L.; Bauer, M. A systematic workflow for oscillation diagnosis using transfer entropy. IEEE Trans. Control Syst. Technol. 2019. [Google Scholar] [CrossRef]
- Wang, X.; Hui, X. Cross-Sectoral Information Transfer in the Chinese Stock Market around Its Crash in 2015. Entropy 2018, 20, 663. [Google Scholar] [CrossRef]
- Cao, G.; Zhang, Q.; Li, Q. Causal relationship between the global foreign exchange market based on complex networks and entropy theory. Chaos Solitons Fractals 2017, 99, 36–44. [Google Scholar] [CrossRef]
- Van Milligen, B.P.; Hoefel, U.; Nicolau, J.; Hirsch, M.; García, L.; Carreras, B.; Hidalgo, C. Study of radial heat transport in W7-X using the transfer entropy. Nuclear Fusion 2018, 58, 076002. [Google Scholar] [CrossRef] [Green Version]
- Berger, E.; Grehl, S.; Vogt, D.; Jung, B.; Amor, H.B. Experience-based torque estimation for an industrial robot. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 144–149. [Google Scholar]
- Hartich, D.; Barato, A.C.; Seifert, U. Sensory capacity: An information theoretical measure of the performance of a sensor. Phys. Rev. E 2016, 93, 022116. [Google Scholar] [CrossRef] [Green Version]
- Zhai, L.S.; Bian, P.; Han, Y.F.; Gao, Z.K.; Jin, N.D. The measurement of gas–liquid two-phase flows in a small diameter pipe using a dual-sensor multi-electrode conductance probe. Meas. Sci. Technol. 2016, 27, 045101. [Google Scholar] [CrossRef]
- Ashikaga, H.; Asgari-Targhi, A. Locating order-disorder phase transition in a cardiac system. Sci. Rep. 2018, 8, 1967. [Google Scholar] [CrossRef] [PubMed]
- Marzbanrad, F.; Kimura, Y.; Palaniswami, M.; Khandoker, A.H. Quantifying the Interactions between Maternal and Fetal Heart Rates by Transfer Entropy. PLoS ONE 2015, 10, e0145672. [Google Scholar] [CrossRef] [PubMed]
- Murari, A.; Lungaroni, M.; Peluso, E.; Gaudio, P.; Lerche, E.; Garzotti, L.; Gelfusa, M.; Contributors, J. On the Use of Transfer Entropy to Investigate the Time Horizon of Causal Influences between Signals. Entropy 2018, 20, 627. [Google Scholar] [CrossRef]
- Haruna, T.; Fujiki, Y. Hodge Decomposition of Information Flow on Small-World Networks. Front. Neural Circuits 2016, 10, 77. [Google Scholar] [CrossRef] [PubMed]
- Oh, M.; Kim, S.; Lim, K.; Kim, S.Y. Time series analysis of the Antarctic Circumpolar Wave via symbolic transfer entropy. Phys. A Stat. Mech. Its Appl. 2018, 499, 233–240. [Google Scholar] [CrossRef]
- Sendrowski, A.; Sadid, K.; Meselhe, E.; Wagner, W.; Mohrig, D.; Passalacqua, P. Transfer Entropy as a Tool for Hydrodynamic Model Validation. Entropy 2018, 20, 58. [Google Scholar] [CrossRef]
- Yao, C.Z.; Kuang, P.C.; Lin, Q.W.; Sun, B.Y. A Study of the Transfer Entropy Networks on Industrial Electricity Consumption. Entropy 2017, 19, 159. [Google Scholar] [CrossRef]
- Hilbert, M.; Ahmed, S.; Cho, J.; Liu, B.; Luu, J. Communicating with algorithms: A transfer entropy analysis of emotions-based escapes from online echo chambers. Commun. Methods Meas. 2018, 12, 260–275. [Google Scholar] [CrossRef]
- Jafari-Mamaghani, M.; Tyrcha, J. Transfer entropy expressions for a class of non-Gaussian distributions. Entropy 2014, 16, 1743–1755. [Google Scholar] [CrossRef]
- Kirst, C.; Timme, M.; Battaglia, D. Dynamic information routing in complex networks. Nat. Commun. 2016, 7, 11061. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, G.; Ye, C.; Liang, X.; Xie, Z.; Yu, Z. Nonlinear Dynamic Identification of Beams Resting on Nonlinear Viscoelastic Foundations Based on the Time-Delayed Transfer Entropy and Improved Surrogate Data Algorithm. Math. Probl. Eng. 2018, 2018, 6531051. [Google Scholar] [CrossRef]
- Berger, E.; Müller, D.; Vogt, D.; Jung, B.; Amor, H.B. Transfer entropy for feature extraction in physical human-robot interaction: Detecting perturbations from low-cost sensors. In Proceedings of the 2014 14th IEEE-RAS International Conference on Humanoid Robots (Humanoids), Madrid, Spain, 18–20 November 2014; pp. 829–834. [Google Scholar]
- Li, G.; Qin, S.J.; Yuan, T. Data-driven root cause diagnosis of faults in process industries. Chemom. Intell. Lab. Syst. 2016, 159, 1–11. [Google Scholar] [CrossRef]
- Shao, S.; Guo, C.; Luk, W.; Weston, S. Accelerating transfer entropy computation. In Proceedings of the 2014 International Conference on Field-Programmable Technology (FPT), Shanghai, China, 10–12 December 2014; pp. 60–67. [Google Scholar]
- Wollstadt, P.; Martínez-Zarzuela, M.; Vicente, R.; Díaz-Pernas, F.J.; Wibral, M. Efficient Transfer Entropy Analysis of Non-Stationary Neural Time Series. PLoS ONE 2014, 9, e102833. [Google Scholar] [CrossRef] [PubMed]
- Shen, C.; Tong, W.; Choo, K.K.R.; Kausar, S. Performance prediction of parallel computing models to analyze cloud-based big data applications. Cluster Comput. 2018, 21, 1439–1454. [Google Scholar] [CrossRef]
- Booth, J.D.; Kim, K.; Rajamanickam, S. A Comparison of High-Level Programming Choices for Incomplete Sparse Factorization Across Different Architectures. In Proceedings of the 2016 IEEE International Parallel and Distributed Processing Symposium Workshops, Chicago, IL, USA, 23–27 May 2016; pp. 397–406. [Google Scholar]
- Gordon, M.I.; Thies, W.; Amarasinghe, S. Exploiting Coarse-grained Task, Data, and Pipeline Parallelism in Stream Programs. SIGARCH Comput. Archit. News 2006, 34, 151–162. [Google Scholar] [CrossRef]
- Choudhury, O.; Rajan, D.; Hazekamp, N.; Gesing, S.; Thain, D.; Emrich, S. Balancing Thread-level and Task-level Parallelism for Data-Intensive Workloads on Clusters and Clouds. In Proceedings of the 2015 IEEE International Conference on Cluster Computing, Chicago, IL, USA, 8–11 September 2015; pp. 390–393. [Google Scholar]
- Yao, L.; Ge, Z. Big data quality prediction in the process industry: A distributed parallel modeling framework. J. Process Control 2018, 68, 1–13. [Google Scholar] [CrossRef]
- Alaei, A.R.; Becken, S.; Stantic, B. Sentiment analysis in tourism: Capitalizing on big data. J. Travel Res. 2019, 58, 175–191. [Google Scholar] [CrossRef]
- Hassan, M.K.; El Desouky, A.I.; Elghamrawy, S.M.; Sarhan, A.M. Big Data Challenges and Opportunities in Healthcare Informatics and Smart Hospitals. In Security in Smart Cities: Models, Applications, and Challenges; Springer: Cham, Switzerland, 2019; pp. 3–26. [Google Scholar]
- Hu, H.; Wen, Y.; Chua, T.S.; Li, X. Toward scalable systems for big data analytics: A technology tutorial. IEEE Access 2014, 2, 652–687. [Google Scholar]
- Kitchin, R. Big Data, new epistemologies and paradigm shifts. Big Data Soc. 2014, 1, 2053951714528481. [Google Scholar] [CrossRef]
- Song, H.; Basanta-Val, P.; Steed, A.; Jo, M.; Lv, Z. Next,-generation big data analytics: State of the art, challenges, and future research topics. IEEE Trans. Ind. Inform. 2017, 13, 1891–1899. [Google Scholar]
- Reyes-Ortiz, J.L.; Oneto, L.; Anguita, D. Big Data Analytics in the Cloud: Spark on Hadoop vs. MPI/OpenMP on Beowulf. Procedia Comput. Sci. 2015, 53, 121–130. [Google Scholar] [CrossRef]
- Ameur, M.S.B.; Sakly, A. FPGA based hardware implementation of Bat Algorithm. Appl. Soft Comput. 2017, 58, 378–387. [Google Scholar] [CrossRef]
- Maldonado, Y.; Castillo, O.; Melin, P. Particle swarm optimization of interval type-2 fuzzy systems for FPGA applications. Appl. Soft Comput. 2013, 13, 496–508. [Google Scholar] [CrossRef]
- Ting, T.O.; Ma, J.; Kim, K.S.; Huang, K. Multicores and GPU utilization in parallel swarm algorithm for parameter estimation of photovoltaic cell model. Appl. Soft Comput. 2016, 40, 58–63. [Google Scholar] [CrossRef]
- Nasrollahzadeh, A.; Karimian, G.; Mehrafsa, A. Implementation of neuro-fuzzy system with modified high performance genetic algorithm on embedded systems. Appl. Soft Comput. 2017, 60, 602–612. [Google Scholar] [CrossRef]
- Bazow, D.; Heinz, U.; Strickland, M. Massively parallel simulations of relativistic fluid dynamics on graphics processing units with CUDA. Comput. Phys. Commun. 2018, 225, 92–113. [Google Scholar] [CrossRef] [Green Version]
- Kapp, M.N.; Sabourin, R.; Maupin, P. A dynamic model selection strategy for support vector machine classifiers. Appl. Soft Comput. 2012, 12, 2550–2565. [Google Scholar] [CrossRef]
- Gou, J.; Lei, Y.X.; Guo, W.P.; Wang, C.; Cai, Y.Q.; Luo, W. A novel improved particle swarm optimization algorithm based on individual difference evolution. Appl. Soft Comput. 2017, 57, 468–481. [Google Scholar] [CrossRef]
- Naderi, E.; Narimani, H.; Fathi, M.; Narimani, M.R. A novel fuzzy adaptive configuration of particle swarm optimization to solve large-scale optimal reactive power dispatch. Appl. Soft Comput. 2017, 53, 441–456. [Google Scholar] [CrossRef]
- Sánchez-Oro, J.; Sevaux, M.; Rossi, A.; Martí, R.; Duarte, A. Improving the performance of embedded systems with variable neighborhood search. Appl. Soft Comput. 2017, 53, 217–226. [Google Scholar] [CrossRef]
- Yao, Y.; Chang, J.; Xia, K. A case of parallel eeg data processing upon a beowulf cluster. In Proceedings of the 2009 15th International Conference on Parallel and Distributed Systems (ICPADS), Shenzhen, China, 8–11 December 2009; pp. 799–803. [Google Scholar]
- Sterling, T.; Becker, D.J.; Savarese, D.; Dorband, J.E.; Ranawake, U.A.; Packer, C.V. Beowulf: A Parallel Workstation For Scientific Computation. In Proceedings of the International Conference on Parallel Processing, Champain, IL, USA, 14–18 August 1995; CRC Press: Boca Raton, FL, USA, 1995; pp. 11–14. [Google Scholar]
- Yamakov, V.I. Parallel Grand Canonical Monte Carlo (ParaGrandMC) Simulation Code; Technical Report; published by NASA; 2016. Available online: https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20160007416.pdf (accessed on 7 September 2019).
- Moretti, L.; Sartori, L. A Simple and Resource-efficient Setup for the Computer-aided Drug Design Laboratory. Mol. Inform. 2016, 35, 489–494. [Google Scholar] [CrossRef] [PubMed]
- Schuman, C.D.; Disney, A.; Singh, S.P.; Bruer, G.; Mitchell, J.P.; Klibisz, A.; Plank, J.S. Parallel evolutionary optimization for neuromorphic network training. In Proceedings of the 2016 2nd Workshop on Machine Learning in HPC Environments (MLHPC), Salt Lake City, UT, USA, 14 November 2016; pp. 36–46. [Google Scholar]
- Hulsey, S.; Novikov, I. Comparison of two methods of parallelizing GEANT4 on beowulf computer cluster. Bull. Am. Phys. Soc. 2016, 61, 19. [Google Scholar]
- Pérez, F.; Granger, B.E. IPython: A System for Interactive Scientific Computing. Comput. Sci. Eng. 2007, 9, 21–29. [Google Scholar] [CrossRef]
- IPython developers (open source). IPython 3.2.1 Documentation—0.11 Series. 2011. Available online: https://ipython.org/ipython-doc/3/index.html (accessed on 7 September 2019).
- IPython developers (open source). Ipyparallel 5.2.0 Documentation–Changes in IPython Parallel. 2016. Available online: https://ipyparallel.readthedocs.io/en/5.2.0/ (accessed on 7 September 2019).
- IPython developers. Ipyparallel 5.2.0 Documentation–IPython Parallel Overview and Getting Started. 2016. Available online: https://ipyparallel.readthedocs.io/en/5.2.0/ (accessed on 7 September 2019).
- Kershaw, P.; Lawrence, B.; Gomez-Dans, J.; Holt, J. Cloud hosting of the IPython Notebook to Provide Collaborative Research Environments for Big Data Analysis. In Proceedings of the EGU General Assembly Conference Abstracts, Vienna, Austria, 12–17 April 2015; Volume 17, p. 13090. [Google Scholar]
- Stevens, J.L.R.; Elver, M.; Bednar, J.A. An automated and reproducible workflow for running and analyzing neural simulations using Lancet and IPython Notebook. Front. Neuroinform. 2013, 7, 44. [Google Scholar] [CrossRef] [PubMed]
- Päeske, L.; Bachmann, M.; Põld, T.; Oliveira, S.P.M.d.; Lass, J.; Raik, J.; Hinrikus, H. Surrogate data method requires end-matched segmentation of electroencephalographic signals to estimate nonlinearity. Front. Physiol. 2018, 9, 1350. [Google Scholar] [CrossRef] [PubMed]
- Lindner, M.; Vicente, R.; Priesemann, V.; Wibral, M. TRENTOOL: A Matlab open source toolbox to analyse information flow in time series data with transfer entropy. BMC Neurosci. 2011, 12, 1. [Google Scholar] [CrossRef] [PubMed]
- Magri, C.; Whittingstall, K.; Singh, V.; Logothetis, N.K.; Panzeri, S. A toolbox for the fast information analysis of multiple-site LFP, EEG and spike train recordings. BMC Neurosci. 2009, 10, 1. [Google Scholar] [CrossRef] [PubMed]
- Lucio, J.; Valdés, R.; Rodríguez, L. Improvements to surrogate data methods for nonstationary time series. Phys. Rev. E 2012, 85, 056202. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Jeannès, R.L.B.; Faucon, G.; Shu, H. Detecting information flow direction in multivariate linear and nonlinear models. Signal Process. 2013, 93, 304–312. [Google Scholar] [CrossRef] [Green Version]
- Schreiber, T.; Schmitz, A. Improved Surrogate Data for Nonlinearity Tests. Phys. Rev. Lett. 1996, 77, 635–638. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Venema, V.; Ament, F.; Simmer, C. A stochastic iterative amplitude adjusted Fourier transform algorithm with improved accuracy. Nonlinear Process. Geophys. 2006, 13, 321–328. [Google Scholar] [CrossRef]
- Schreiber, T.; Schmitz, A. Surrogate time series. Phys. D Nonlinear Phenom. 2000, 142, 346–382. [Google Scholar] [CrossRef] [Green Version]
- Bessani, M.; Fanucchi, R.Z.; Delbem, A.C.C.; Maciel, C.D. Impact of operators’ performance in the reliability of cyber-physical power distribution systems. IET Gener. Transm. Distrib. 2016, 10, 2640–2646. [Google Scholar] [CrossRef]
- Camillo, M.H.; Fanucchi, R.Z.; Romero, M.E.; de Lima, T.W.; da Silva Soares, A.; Delbem, A.C.B.; Marques, L.T.; Maciel, C.D.; London, J.B.A. Combining exhaustive search and multi-objective evolutionary algorithm for service restoration in large-scale distribution systems. Electr. Power Syst. Res. 2016, 134, 1–8. [Google Scholar] [CrossRef]
- De Lima, D.R.; Santos, F.P.; Maciel, C.D. Network Structural Reconstruction Base on Delayed Transfer Entropy and Synthetic data. In Proceedings of the CBA 2016, Manitou/Colorado Springs, CO, USA, 28 April–1 May 2016; pp. 1–6. [Google Scholar]
- Mao, X.; Shang, P. Transfer entropy between multivariate time series. Commun. Nonlinear Sci. Numer. Simul. 2017, 47, 338–347. [Google Scholar] [CrossRef]
- Ito, S.; Hansen, M.E.; Heiland, R.; Lumsdaine, A.; Litke, A.M.; Beggs, J.M. Extending transfer entropy improves identification of effective connectivity in a spiking cortical network model. PLoS ONE 2011, 6, e27431. [Google Scholar] [CrossRef]
- Vicente, R.; Wibral, M.; Lindner, M.; Pipa, G. Transfer entropy—A model-free measure of effective connectivity for the neurosciences. J. Comput. Neurosci. 2011, 30, 45–67. [Google Scholar] [CrossRef]
- Frigo, M.; Johnson, S.G. The Design and Implementation of FFTW3. Proc. IEEE 2005, 93, 216–231. [Google Scholar] [CrossRef]
- Kantz, H.; Schreiber, T. Nonlinear Time Series Analysis; Cambridge University Press: Cambridge, UK, 2004; Volume 7. [Google Scholar]
- Van Rossum, G.; Drake, F.L. The Python Language Reference Manual; Network Theory Ltd.: Bristol, UK, 2011. [Google Scholar]
- Van Der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy Array: A Structure for Efficient Numerical Computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef] [Green Version]
- Muhammad, H. Htop-an Interactive Process Viewer for Linux; 2015. Available online: http://hisham.hm/htop/ (accessed on 7 September 2019).
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach; Elsevier Morgan Kaufmann: Burlington, MA, USA, 2011. [Google Scholar]
- Baker, M. Is there a reproducibility crisis? Nature 2016, 533, 452–454. [Google Scholar] [CrossRef] [PubMed]
- Reality check on reproducibility. Nature 2016, 533, 437. [CrossRef] [PubMed]





© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dourado, J.R.; Oliveira Júnior, J.N.d.; Maciel, C.D. Parallelism Strategies for Big Data Delayed Transfer Entropy Evaluation. Algorithms 2019, 12, 190. https://doi.org/10.3390/a12090190
Dourado JR, Oliveira Júnior JNd, Maciel CD. Parallelism Strategies for Big Data Delayed Transfer Entropy Evaluation. Algorithms. 2019; 12(9):190. https://doi.org/10.3390/a12090190
Chicago/Turabian StyleDourado, Jonas R., Jordão Natal de Oliveira Júnior, and Carlos D. Maciel. 2019. "Parallelism Strategies for Big Data Delayed Transfer Entropy Evaluation" Algorithms 12, no. 9: 190. https://doi.org/10.3390/a12090190
APA StyleDourado, J. R., Oliveira Júnior, J. N. d., & Maciel, C. D. (2019). Parallelism Strategies for Big Data Delayed Transfer Entropy Evaluation. Algorithms, 12(9), 190. https://doi.org/10.3390/a12090190