Optimal Learning and Self-Awareness Versus PDI



Abstract
:1. Introduction
1.1. The Contributions
1.2. The Literature Review
2. Materials and Methods
2.1. Rigid Body Mechanics
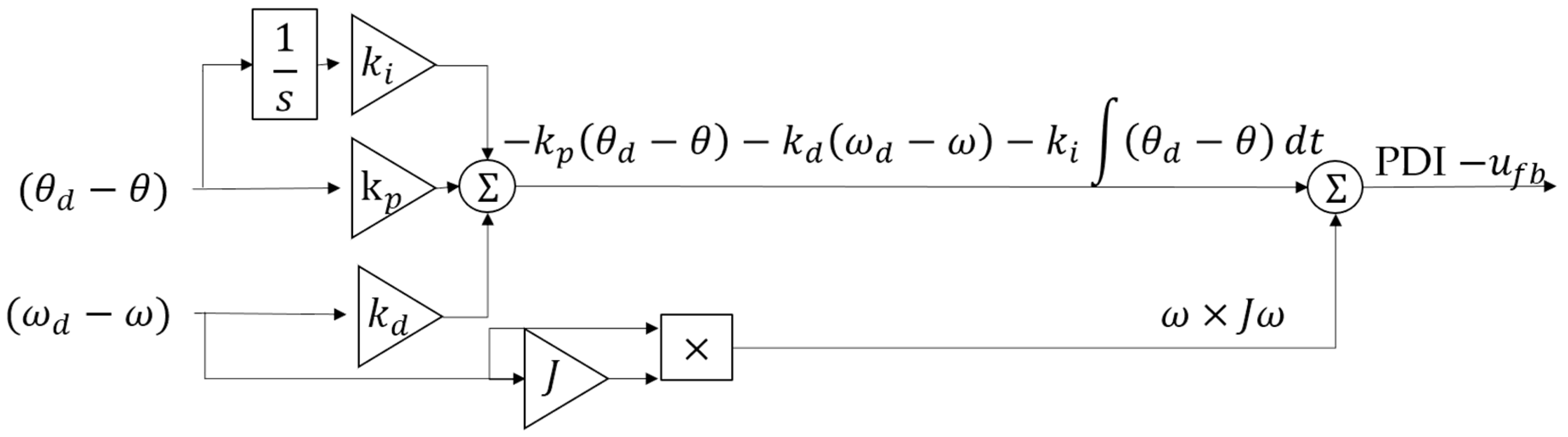
2.2. Luenberger-Like Controllers (i.e., Nonliner-Enhanced Proportional-Derivative-Integral, PDI)
2.3. Deterministic Artificial Intelligence
Error-Analysis Yields Deterministic Self-Awareness Statement
3. Results
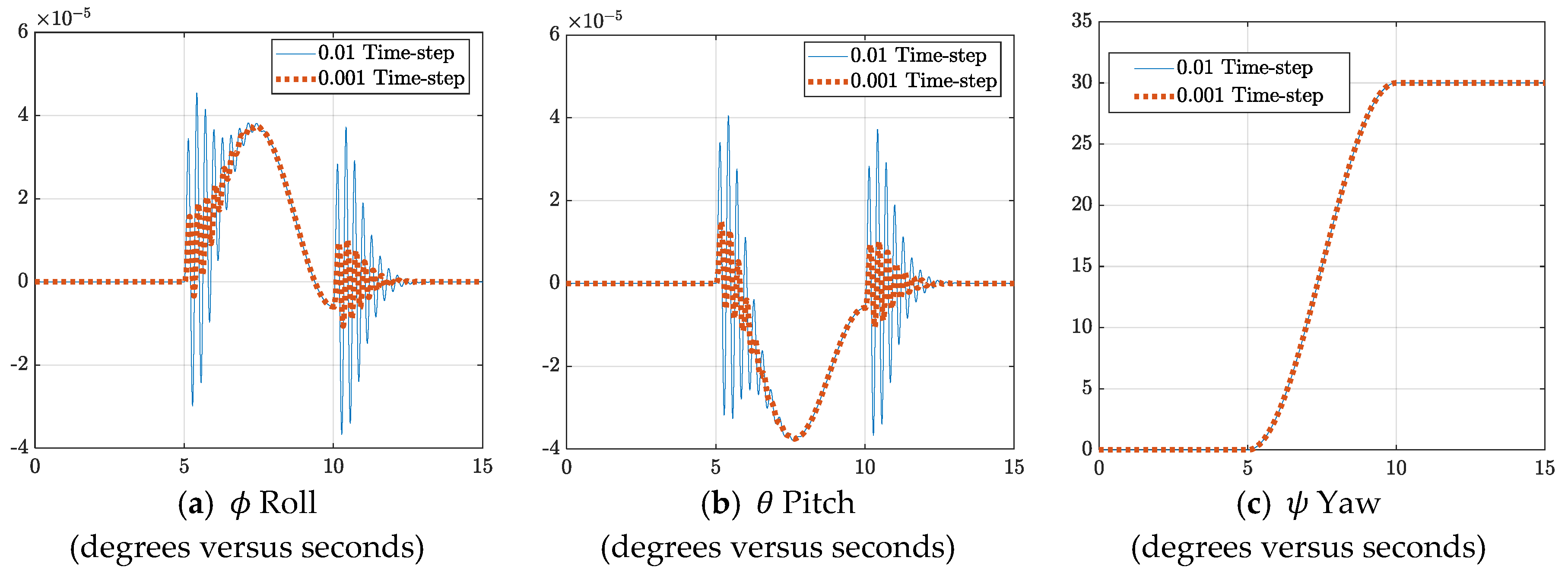
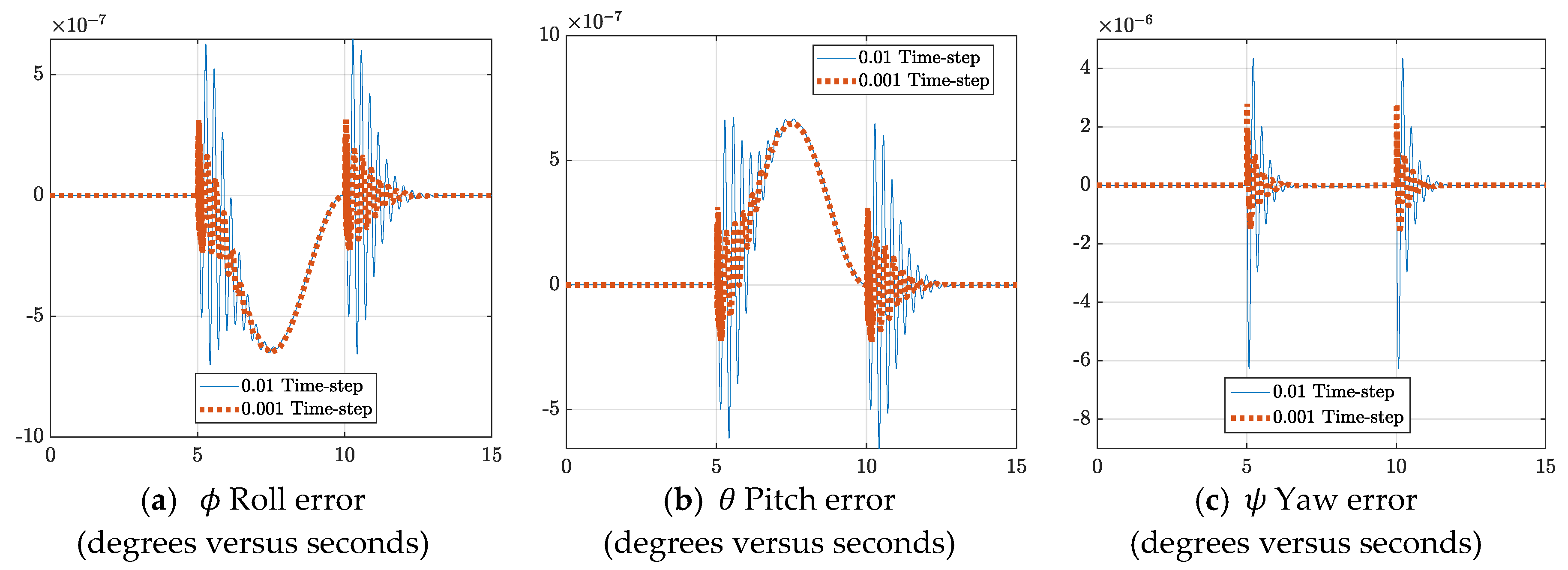
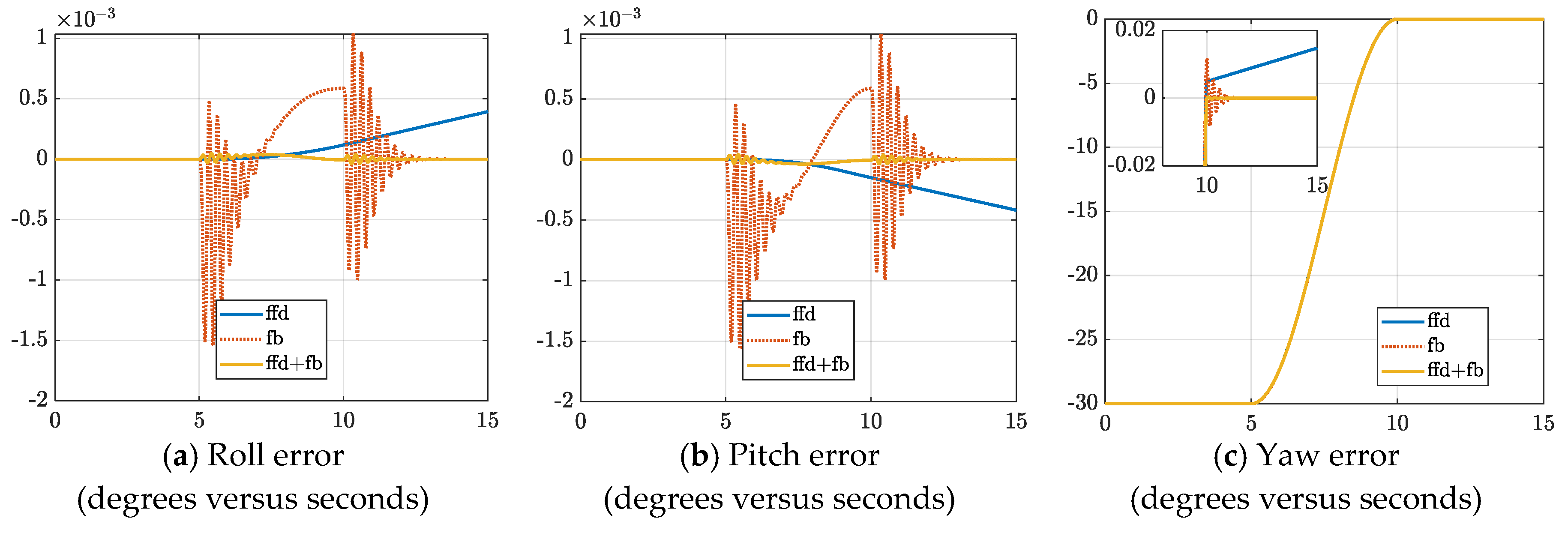
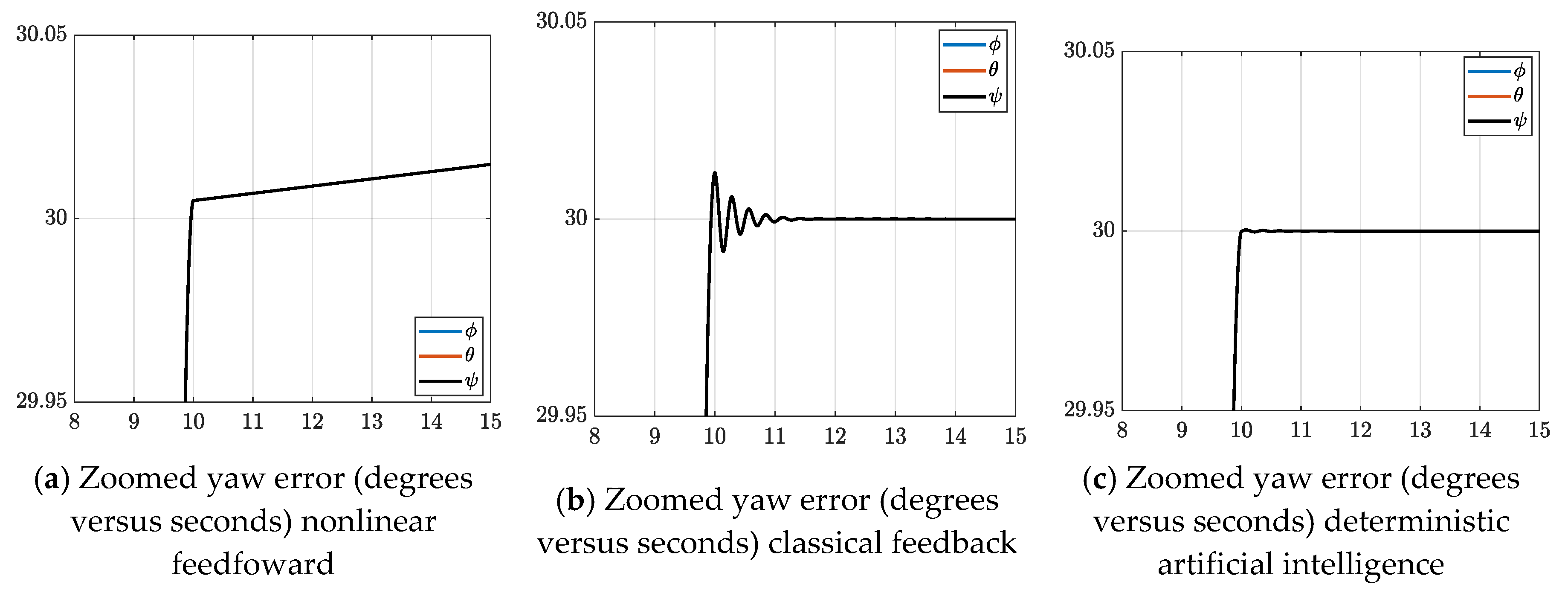
3.1. Time-Step Analysis
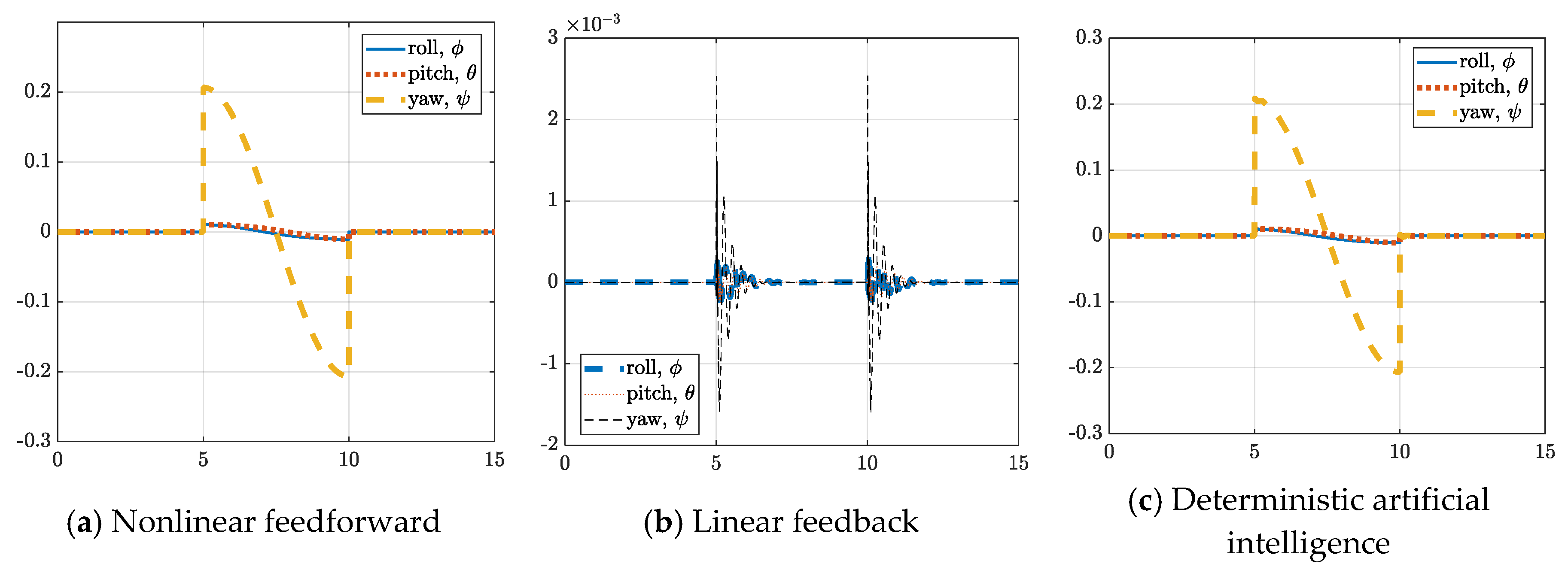
3.2. Control Implementation
4. Discussion
Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Smeresky, B.; Rizzo, A.; Sands, T. Kinematics in the Information Age. Mathematics 2018, 6, 148. [Google Scholar] [CrossRef] [Green Version]
- Cooper, M.; Heidlauf, P.; Sands, T. Controlling Chaos—Forced van der pol equation. Mathematics 2017, 5, 70. [Google Scholar] [CrossRef] [Green Version]
- Sands, T. Nonlinear-Adaptive Mathematical System Identification. Computation 2017, 5, 47. [Google Scholar] [CrossRef] [Green Version]
- Nakatani, S.; Sands, T. Battle-damage tolerant automatic controls. Electr. Electron. Eng. 2018, 8, 10–23. [Google Scholar]
- Nakatani, S.; Sands, T. Simulation of rigid body damage tolerance and adaptive controls. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 1–8 March 2014; pp. 1–16. [Google Scholar]
- Nakatani, S.; Sands, T. Autonomous Damage Recovery in Space. Int. J. Autom. Control Intell. Syst. 2016, 2, 23–36. [Google Scholar]
- EPICA Lastest News Blog. Deterministic Approach to Machine Learning and AI. 2018. Available online: https://www.epica.ai/thinking/blog/deterministic-approach-to-machine-learning-and-ai.html (accessed on 19 November 2019).
- Deterministic Data-based AI Key for Security. Available online: https://www.computerweekly.com/news/252464484/Deterministic-data-based-AI-key-for-security (accessed on 25 November 2019).
- DeGrazia, D. Self-awareness in animals. In The Philosophy of Animal Minds; Lurz, R.W., Ed.; Cambridge University Press: Cambridge, UK, 2009; pp. 201–217. [Google Scholar]
- Bekoff, M. Awareness: Animal reflections. Nature 2002, 419, 255. [Google Scholar] [CrossRef]
- Gallup, G.G., Jr.; Anderson, J.R.; Shillito, D.J. The mirror test. In The Cognitive Animal: Empirical and Theoretical Perspectives on Animal Cognition; Bekoff, M., Allen, C., Burghardt, G.M., Eds.; MIT Press: Cambridge, MA, USA, 2002; pp. 325–333. [Google Scholar]
- Plotnik, J.M.; De Waal, F.B.; Reiss, D. Self-recognition in an Asian elephant. Proc. Natl. Acad. Sci. USA 2006, 103, 17053–17057. [Google Scholar] [CrossRef] [Green Version]
- Prior, H.; Schwarz, A.; Güntürkün, O. Mirror-Induced Behavior in the Magpie (Pica pica): Evidence of Self-Recognition. PLoS Biol. 2008, 6, e202. [Google Scholar] [CrossRef]
- Alison, M. Mirror Test Shows Magpies Aren’t So Bird-Brained. Available online: https://www.newscientist.com/article/dn14552-mirror-test-shows-magpies-arentso-birdbrained.html#.VHVdHf4tDIV (accessed on 26 November 2014).
- Tennesen, M. Do Dolphins Have a Sense of Self? Natl. Wildl. 2003, 41, 66. [Google Scholar]
- Bard, K. Self-Awareness in Human and Chimpanzee Infants: What is Measured and What is Meant by the Mark and Mirror Test? Infancy 2006, 9, 191–219. [Google Scholar] [CrossRef] [Green Version]
- Cammaerts Tricot, M.C.; Cammaerts, R. Are Ants (Hymenoptera Formicide) Capable of Self Recognition? J. Sci. 2015, 5, 521–532. [Google Scholar]
- Pfeifer, R.; Bongard, J. How the Body Shapes the Way We Think: A New View of Intelligence; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Lieberman, P. The Unpredictable Species: What Makes Humans Unique; Princeton University Press: Princeton, NJ, USA, 2013. [Google Scholar]
- Rochat, P. Five levels of self-awareness as they unfold early in life. Conscious. Cognit. 2003, 12, 717–731. [Google Scholar] [CrossRef]
- Geangu, E. Notes on Self-Awareness Development in Early Infancy. Cognit. Brain Behav. 2008, 12, 103–113. [Google Scholar]
- Yawkey, T.D.; Johnson, J.E. (Eds.) Integrative Processes and Socialization Early to Middle Childhood; Psychology Press: East Sussex, UK, 2013; ISBN 9780203767696. [Google Scholar]
- Rochat, P. Self-Perception and Action in Infancy. Exp. Brain Res. 1998, 123, 102–109. [Google Scholar] [CrossRef] [Green Version]
- Broesch, T.; Callaghan, T.; Henrich, J.; Murphy, C.; Rochat, P. Cultural Variations in Children’s Mirror Self-Recognition. J. Cross Cult. Psychol. 2011, 42, 1018–1029. [Google Scholar] [CrossRef] [Green Version]
- Locke, J. An Essay Concerning Human Understanding; Wentworth Press: Sidney, Australia, 1775; ISBN 0526315180. [Google Scholar]
- Kendra, C. What Is Self-Awareness? Available online: http://psychology.about.com/od/cognitivepsychology/fl/What-Is-Self-Awareness.htm (accessed on 25 November 2014).
- Abraham, S. Goldstein the Insanity Defense; Yale University Press: New Haven, CT, USA, 1967; p. 9. ISBN 978-0-300-00099-3. [Google Scholar]
- Uddin, L.Q.; Davies, M.S.; Scott, A.A.; Zaidel, E.; Bookheimer, S.Y.; Iacoboni, M.; Dapretto, M. Neural Basis of Self and Other Representation in Autism: An fMRI Study of Self-Face Recognition. PLoS ONE 2008, 3, e3526. [Google Scholar] [CrossRef]
- Razzaq, M.A.; Villalonga, C.; Lee, S.; Akhtar, U.; Ali, M.; Kim, E.-S.; Khattak, A.M.; Seung, H.; Hur, T.; Bang, J.; et al. mlCAF: Multi-Level Cross-Domain Semantic Context Fusioning for Behavior Identification. Sensors 2017, 17, 2433. [Google Scholar] [CrossRef]
- Sysoev, M.; Kos, A.; Guna, J.; Pogačnik, M. Estimation of the Driving Style Based on the Users’ Activity and Environment Influence. Sensors 2017, 17, 2404. [Google Scholar] [CrossRef] [Green Version]
- Roldán, J.J.; Peña-Tapia, E.; Martín-Barrio, A.; Olivares-Méndez, M.A.; Del Cerro, J.; Barrientos, A. Multi-Robot Interfaces and Operator Situational Awareness: Study of the Impact of Immersion and Prediction. Sensors 2017, 17, 1720. [Google Scholar] [CrossRef] [Green Version]
- Mcheick, H.; Saleh, L.; Ajami, H.; Mili, H. Context Relevant Prediction Model for COPD Domain Using Bayesian Belief Network. Sensors 2017, 17, 1486. [Google Scholar] [CrossRef] [Green Version]
- García, Ó.; Alonso, R.S.; Prieto, J.; Corchado, J.M. Energy Efficiency in Public Buildings through Context-Aware Social Computing. Sensors 2017, 17, 826. [Google Scholar] [CrossRef] [PubMed]
- Chang, J.; Yao, W.; Li, X. A Context-Aware S-Health Service System for Drivers. Sensors 2017, 17, 609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scholze, S.; Barata, J.; Stokic, D. Holistic Context-Sensitivity for Run-Time Optimization of Flexible Manufacturing Systems. Sensors 2017, 17, 455. [Google Scholar] [CrossRef] [Green Version]
- Moore, P. Do We Understand the Relationship between Affective Computing, Emotion and Context-Awareness? Machines 2017, 5, 16. [Google Scholar] [CrossRef] [Green Version]
- Lewis, P.R.; Platzner, M.; Rinner, B.; Tørresen, J.; Yao, X. (Eds.) Self-Aware Computing Systems: An Engineering Approach; Springer International Publishing AG: Cham, Switzerland, 2016. [Google Scholar]
- Abba, S.; Lee, J.-A. An Autonomous Self-Aware and Adaptive Fault Tolerant Routing Technique for Wireless Sensor Networks. Sensors 2015, 15, 20316–20354. [Google Scholar] [CrossRef]
- Kao, H.-A.; Jin, W.; Siegel, D.; Lee, J. A Cyber Physical Interface for Automation Systems—Methodology and Examples. Machines 2015, 3, 93–106. [Google Scholar] [CrossRef]
- Jauk, E.; Kanske, P. Perspective Change and Personality State Variability: An Argument for the Role of Self-Awareness and an Outlook on Bidirectionality (Commentary on Wundrack et al., 2018). J. Intell. 2019, 7, 10. [Google Scholar] [CrossRef] [Green Version]
- Wundrack, R.; Prager, J.; Asselmann, E.; O’Connell, G.; Specht, J. Does Intraindividual Variability of Personality States Improve Perspective Taking? An Ecological Approach Integrating Personality and Social Cognition. J. Intell. 2018, 6, 50. [Google Scholar] [CrossRef] [Green Version]
- Kosak, O.; Wanninger, C.; Hoffmann, A.; Ponsar, H.; Reif, W. Multipotent Systems: Combining Planning, Self-Organization, and Reconfiguration in Modular Robot Ensembles. Sensors 2019, 19, 17. [Google Scholar] [CrossRef] [Green Version]
- Van Pham, H.; Moore, P. Robot Coverage Path Planning under Uncertainty Using Knowledge Inference and Hedge Algebras. Machines 2018, 6, 46. [Google Scholar] [CrossRef] [Green Version]
- Sands, T.; Kim, J.J.; Agrawal, B.N. Spacecraft fine tracking pointing using adaptive control. In Proceedings of the 58th International Astronautical Congress, Hyderabad, India, 24–28 September 2007. [Google Scholar]
- Sands, T.; Kim, J.J.; Agrawal, B. Spacecraft Adaptive Control Evaluation. In Proceedings of the Infotech@Aerospace, Garden Grove, CA, USA, 19–21 June 2012. [Google Scholar]
- Sands, T.; Kim, J.J.; Agrawal, B. Improved Hamiltonian adaptive control of spacecraft. In Proceedings of the Aerospace Conference, Big Sky, MT, USA, 7–14 March 2009; pp. 1–10. [Google Scholar]
- Sands, T.; Lorenz, R. Physics-Based Automated Control of Spacecraft. In Proceedings of the AIAA Space Conference & Exposition, Pasadena, CA, USA, 14–17 September 2009. [Google Scholar]
- Sands, T. Physics-Based Control Methods. In Advances in Spacecraft Systems and Orbit Determination; InTech Publishers: London, UK, 2012; pp. 29–54. [Google Scholar]
- Sands, T. Improved Magnetic Levitation via Online Disturbance Decoupling. Phys. J. 2015, 1, 272–280. [Google Scholar]
- Baker, K.; Cooper, M.; Heidlauf, P.; Sands, T. Autonomous trajectory generation for deterministic artificial intelligence. Electr. Electron. Eng. 2018, 8, 59–68. [Google Scholar]
- Kalman, R.E. A New Approach to Linear Filtering and Prediction Problems. J. Basic Eng. 1960, 82, 35. [Google Scholar] [CrossRef] [Green Version]
- Sands, T. Control Moment Gyroscope Singularity Reduction via Decoupled Control. In Proceedings of the IEEE SEC Proceedings, Atlanta, GA, USA, 5–8 March 2009. [Google Scholar]
- Sands, T. Phase Lag Elimination at All Frequencies for Full State Estimation of Rigid body Attitude. Phys. J. 2017, 3, 1–12. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| kp Gain | kd Gain | ki Gain | |
|---|---|---|---|
| Enhanced-PDI Controller | 1000 | 10 | 0.1 |
| Luenberger Observer for | 1000 | 10 | 0.1 |
(degrees) | (degrees) | (degrees) | Computational Burden (s) | |
|---|---|---|---|---|
| 24.7 | ||||
| 36.3 | ||||
| 24.1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Smeresky, B.; Rizzo, A.; Sands, T. Optimal Learning and Self-Awareness Versus PDI. Algorithms 2020, 13, 23. https://doi.org/10.3390/a13010023
Smeresky B, Rizzo A, Sands T. Optimal Learning and Self-Awareness Versus PDI. Algorithms. 2020; 13(1):23. https://doi.org/10.3390/a13010023
Chicago/Turabian StyleSmeresky, Brendon, Alex Rizzo, and Timothy Sands. 2020. "Optimal Learning and Self-Awareness Versus PDI" Algorithms 13, no. 1: 23. https://doi.org/10.3390/a13010023
APA StyleSmeresky, B., Rizzo, A., & Sands, T. (2020). Optimal Learning and Self-Awareness Versus PDI. Algorithms, 13(1), 23. https://doi.org/10.3390/a13010023