Blind Quality Evaluation for Screen Content Images Based on Regionalized Structural Features


Abstract
:1. Introduction
- (1)
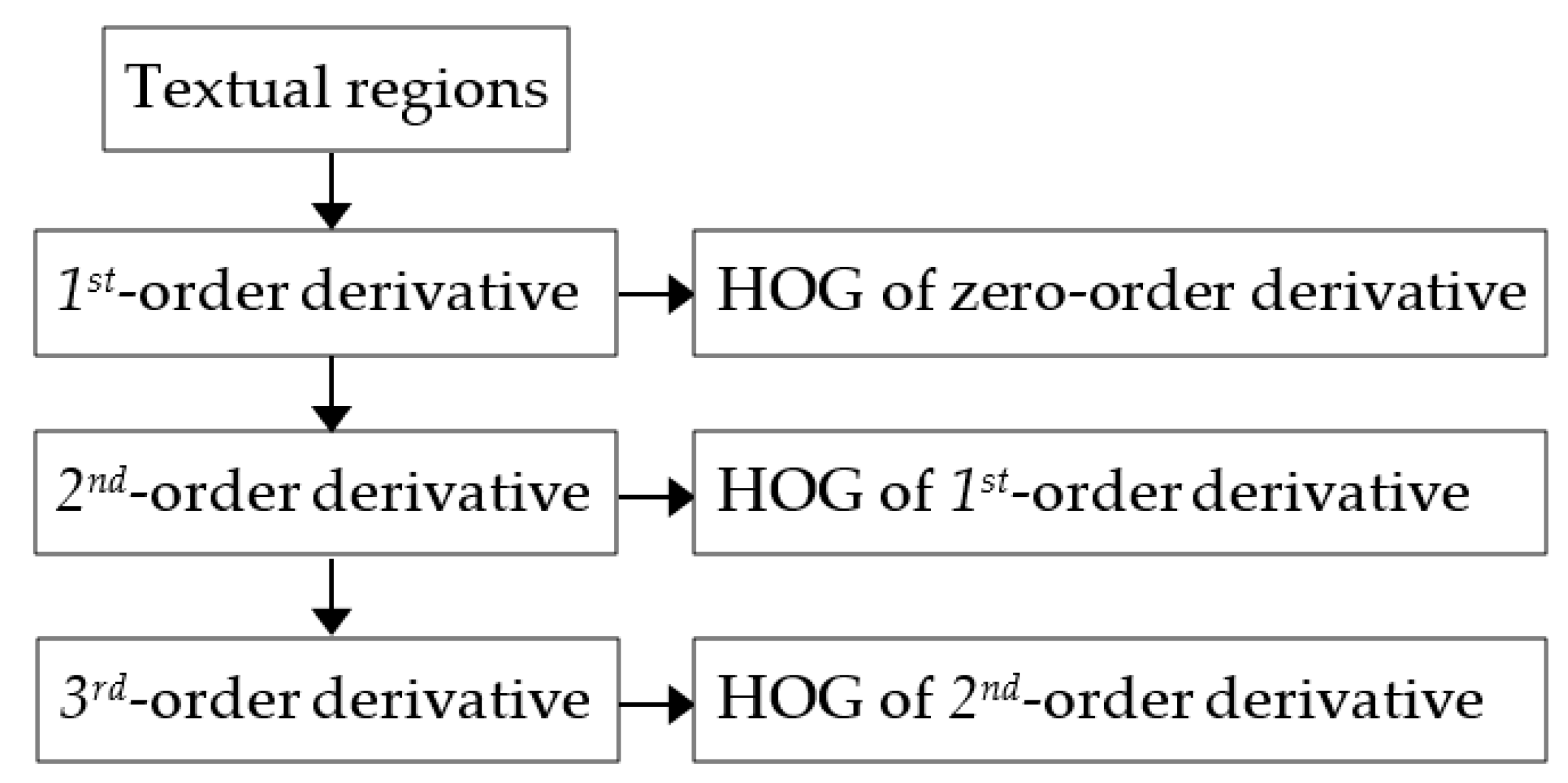
- We propose improved histograms of the oriented gradients, which are extracted from the multi-order derivatives. In the proposed method, these histograms are adopted as structural features to predict the quality of textual regions of SCIs.
- (2)
- We extract texture features from both the spatial and shearlet domains as structural features of pictorial regions. The statistical histograms of the local derivative pattern are used as texture features in the spatial domain. We propose a new local pattern descriptor called the shearlet local binary pattern to represent texture features in the shearlet domain. To the best of our knowledge, this is the first attempt to extract texture features from the shearlet domain.
- (3)
- We propose an activity weighting strategy to combine the visual quality of textual and pictorial regions. This strategy is based on the activity degree of different regions in the SCI, in which the weights are extracted from gradient values of this SCI.
2. Proposed Method
2.1. SCI Partition
2.2. Feature Extraction of Textual Regions
2.3. Feature Extraction of Pictorial Regions
2.3.1. Texture Features of Pictorial Regions in the Spatial Domain
2.3.2. Texture Features of Pictorial Regions in the Shearlet Domain
2.3.3. Luminance Features of Pictorial Regions
2.4. Regression Models
2.5. Weighting Combination
3. Experimental Results
3.1. Experimental Protocol
3.2. Performance Comparison Experiments
3.3. Performance Comparison for Different Distortion Categories
3.4. Statistical Significance Comparison
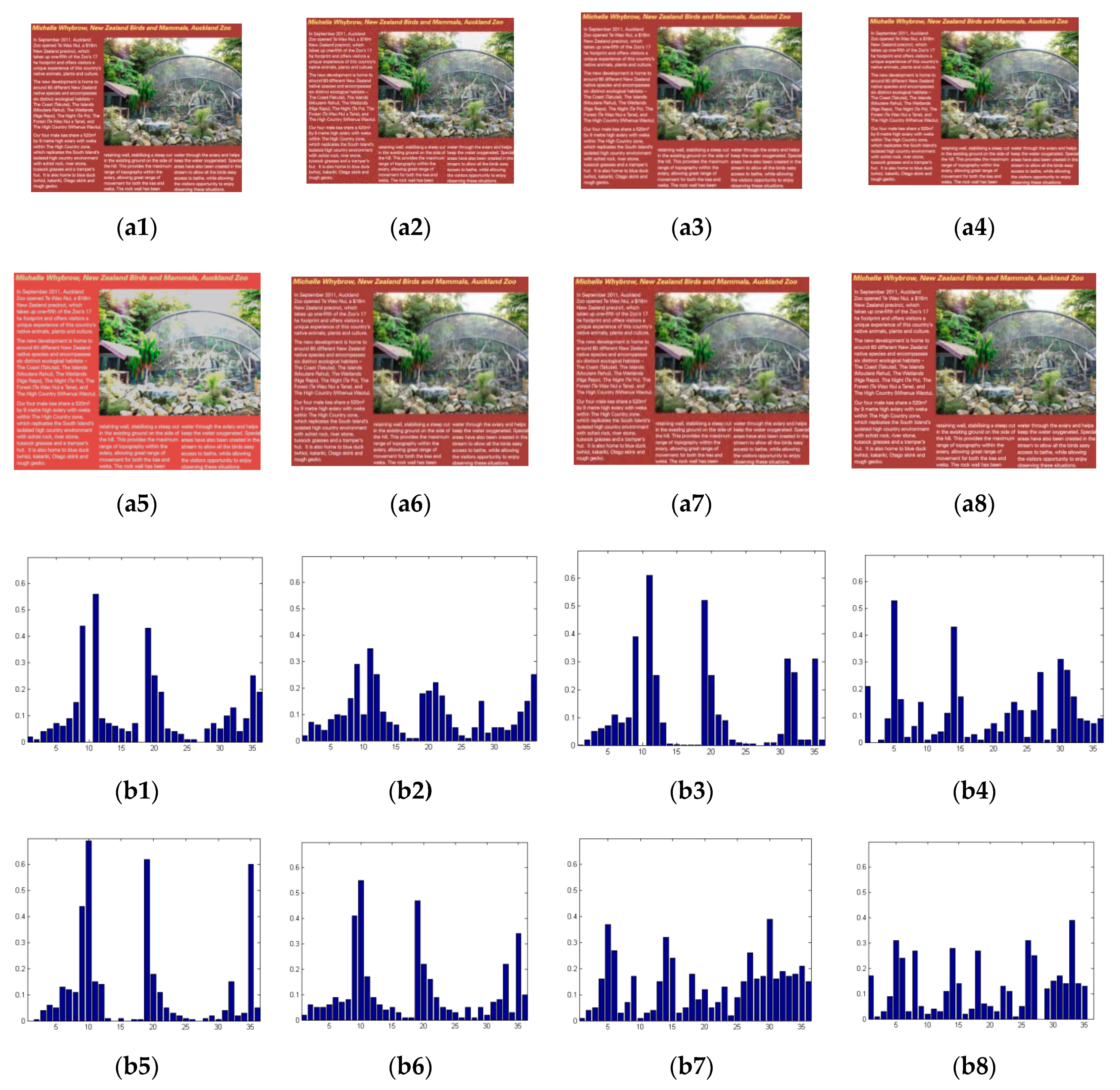
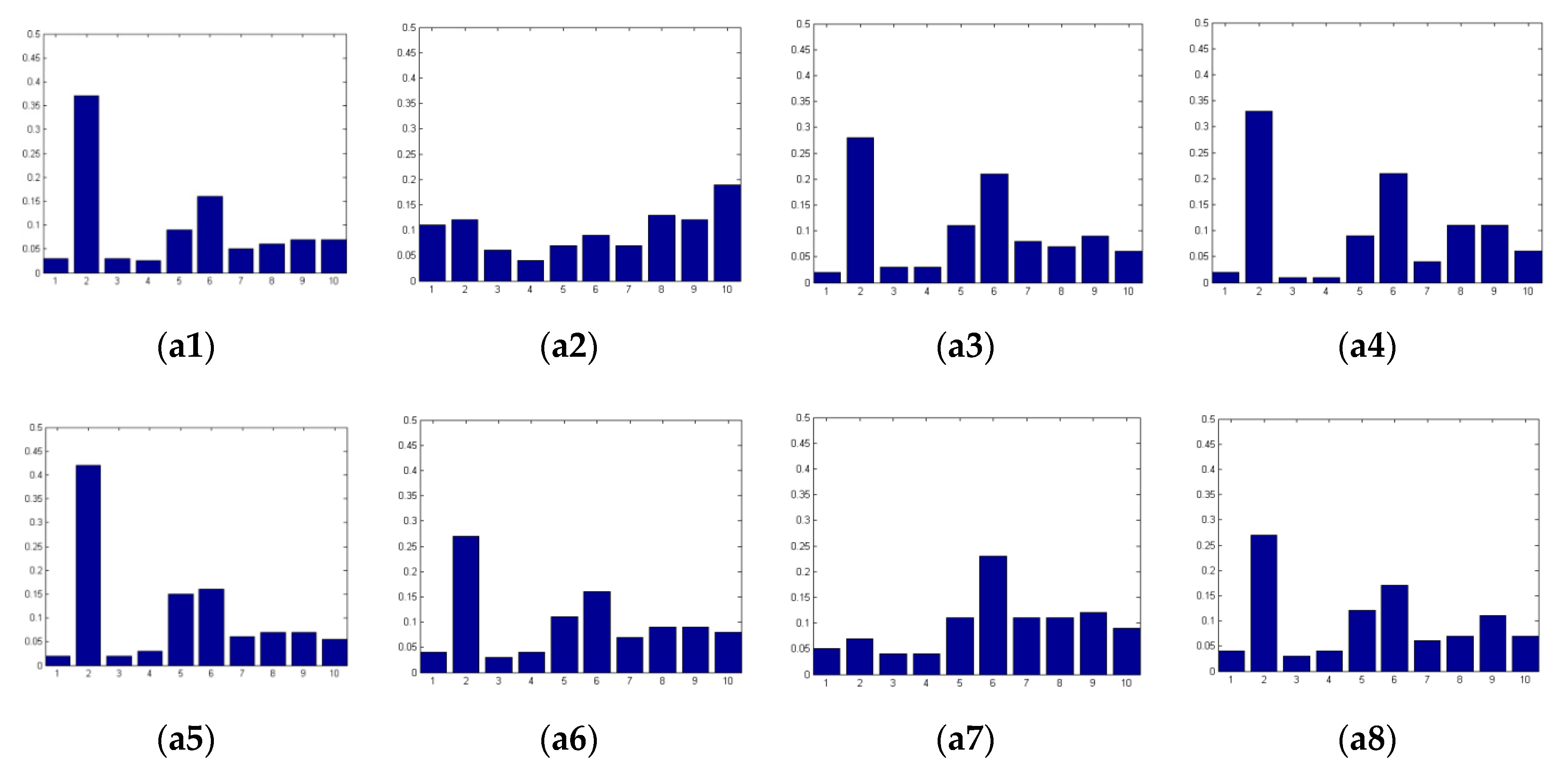
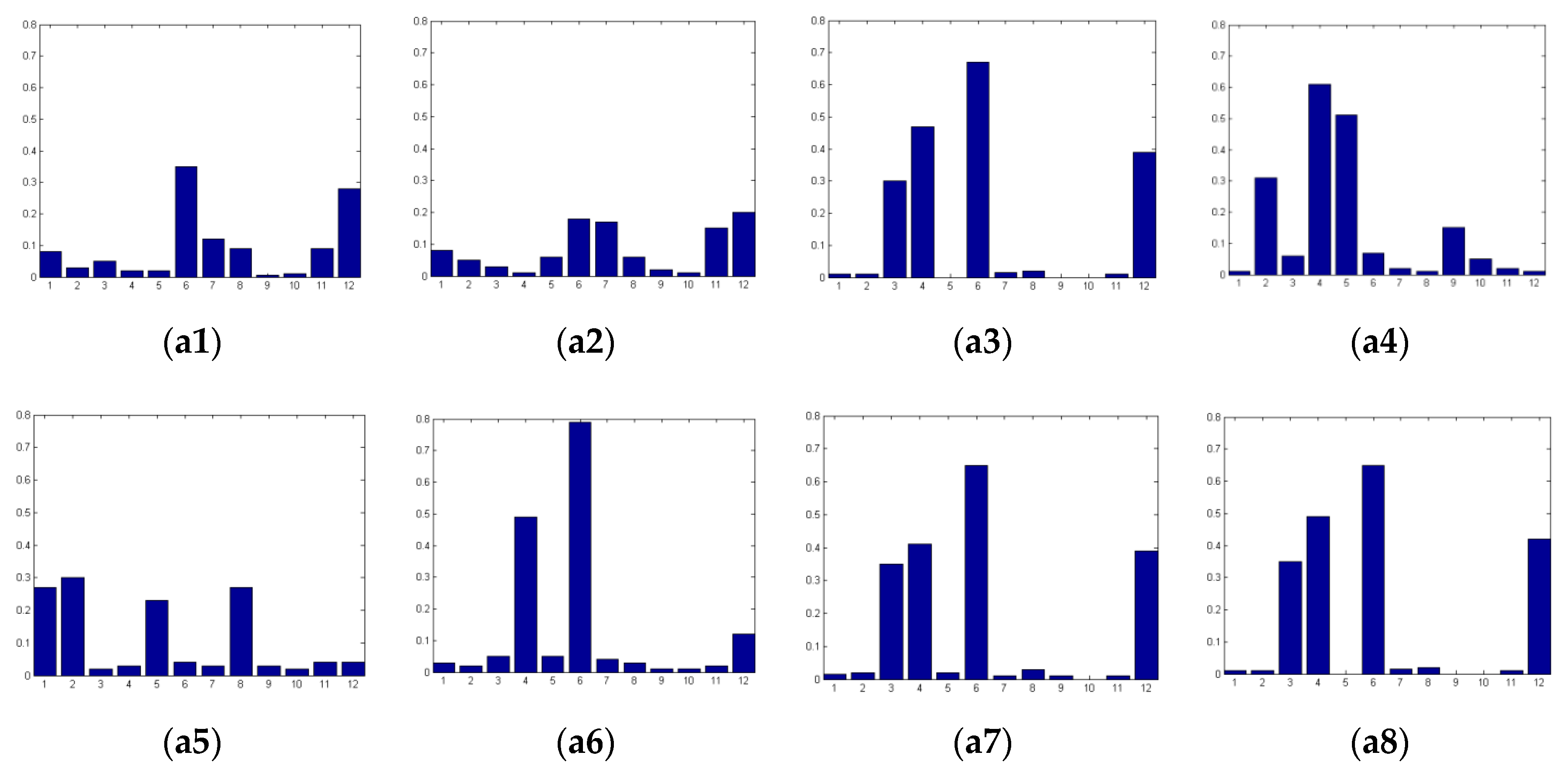
3.5. Order Selection of Derivatives of IHOG Features Used in Textual Regions
3.6. Effect of Features from Textual and Pictorial Regions
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, S.; Ma, L.; Fang, Y.; Lin, W.; Ma, S.; Gao, W. Just noticeable difference estimation for screen content images. IEEE Trans. Image Process. 2016, 25, 3838–3851. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Yu, M.; Jiang, Q.; Jiang, G.; Zhu, Z. Learning content-specific codebooks for blind quality assessment of screen content images. Signal Process. 2019, 161, 248–258. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A feature similarity index for image quality assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sheikh, H.R.; Bovik, A.C. Image information and visual quality. IEEE Trans. Image Process. 2006, 15, 430–444. [Google Scholar] [CrossRef]
- Xue, W.; Zhang, L.; Mou, X.; Bovik, A.C. Gradient magnitude similarity deviation: A highly efficient perceptual image quality index. IEEE Trans. Image Process. 2014, 23, 684–695. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, J.; Lin, W.; Shi, G.; Liu, A. Perceptual quality metric with internal generative mechanism. IEEE Trans. Image Process. 2013, 22, 43–54. [Google Scholar] [PubMed]
- Gao, F.; Wang, Y.; Li, P.; Tan, M.; Yu, J.; Zhu, Y. Deepsim: Deep similarity for image quality assessment. Neurocomputing 2017, 257, 104–114. [Google Scholar] [CrossRef]
- Golestaneh, S.; Karam, L.J. Reduced-reference quality assessment based on the entropy of DWT coefficients of locally weighted gradient magnitudes. IEEE Trans. Image Process. 2016, 25, 5293–5303. [Google Scholar] [CrossRef]
- Fu, Y.; Wang, S. A no reference image quality assessment metric based on visual perception. Algorithms 2016, 9, 87. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Lin, W.; Xu, J.; Fang, Y. Blind image quality assessment using statistical structural and luminance features. IEEE Trans. Multimedia 2016, 18, 2457–2469. [Google Scholar] [CrossRef]
- Li, Q.; Lin, W.; Fang, Y. No-reference quality assessment for multiply-distorted images in gradient domain. IEEE Signal Process. Lett. 2016, 23, 541–545. [Google Scholar] [CrossRef]
- Zhang, M.; Muramatsu, C.; Zhou, X.; Hara, T.; Fujita, H. Blind image quality assessment using the joint statistics of generalized local binary pattern. IEEE Signal Process. Lett. 2015, 22, 207–210. [Google Scholar] [CrossRef]
- Rezaie, F.; Helfroush, M.S.; Danyali, H. No-reference image quality assessment using local binary pattern in the wavelet domain. Multimedia Tools Appl. 2018, 77, 2529–2541. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Bovik, A.C. A feature-enriched completely blind image quality evaluator. IEEE Trans. Image Process. 2015, 24, 2579–2591. [Google Scholar] [CrossRef] [Green Version]
- Gu, K.; Zhou, J.; Qiao, J.F.; Zhai, G.; Lin, W.; Bovik, A.C. No-reference quality assessment of screen content pictures. IEEE Trans. Image Process. 2017, 26, 4005–4018. [Google Scholar] [CrossRef]
- Yang, H.; Fang, Y.; Lin, W. Perceptual quality assessment of screen content images. IEEE Trans. Image Process. 2015, 24, 4408–4421. [Google Scholar] [CrossRef]
- Yang, H.; Wu, S.; Deng, C.; Lin, W. Scale and orientation invariant text segmentation for born-digital compound images. IEEE Trans. Cybern. 2015, 45, 533–547. [Google Scholar]
- Fang, Y.; Yan, J.; Liu, J.; Wang, S.; Li, Q.; Guo, Z. Objective quality assessment of screen content image by uncertainty weighting. IEEE Trans. Image Process. 2017, 26, 2016–2027. [Google Scholar] [CrossRef]
- Ni, Z.; Ma, L.; Zeng, H.; Chen, J.; Cai, C.; Ma, K.K. ESIM: Edge similarity for screen content image quality assessment. IEEE Trans. Image Process. 2017, 26, 4818–4831. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Zeng, H.; Ma, L.; Ni, Z.; Zhu, J.; Ma, K.K. Screen content image quality assessment using multi-scale difference of Gaussian. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 2428–2432. [Google Scholar] [CrossRef]
- Wang, R.; Yang, H.; Pan, Z.; Huang, B.; Hou, G. Screen content image quality assessment with edge features in gradient domain. IEEE Access 2019, 7, 5285–5295. [Google Scholar] [CrossRef]
- Ni, Z.; Zeng, H.; Ma, L.; Hou, J.; Chen, J.; Ma, K.K. A Gabor feature-based quality assessment model for the screen content images. IEEE Trans. Image Process. 2018, 27, 4516–4528. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Gu, K.; Zhang, X.; Lin, W.; Ma, S.; Gao, W. Reduced-reference quality assessment of screen content images. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1–14. [Google Scholar] [CrossRef]
- Wang, S.; Gu, K.; Zhang, X.; Lin, W.; Zhang, L.; Ma, S.; Gao, W. Subjective and objective quality assessment of compressed screen content images. IEEE J. Emerg. Sel. Top. Circuits Syst. 2016, 6, 532–543. [Google Scholar] [CrossRef]
- Rahul, K.; Tiwari, A.K. FQI: Feature-based reduced-reference image quality assessment method for screen content images. IET Image Process. 2019, 13, 1170–1180. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Lin, W.; Yang, X.; Zhang, W. Learning a blind quality evaluation engine of screen content images. Neurocomputing 2016, 196, 140–149. [Google Scholar] [CrossRef] [Green Version]
- Yue, G.; Hou, C.; Yan, W.; Choi, L.K.; Zhou, T.; Hou, Y. Blind quality assessment for screen content images via convolutional neural network. Digit. Signal Process. 2019, 91, 21–30. [Google Scholar] [CrossRef]
- Shao, F.; Gao, Y.; Li, F.; Jiang, G. Toward a blind quality predictor for screen content images. IEEE Trans. Syst. Man Cybern. Syst. 2018, 48, 1521–1530. [Google Scholar] [CrossRef]
- Lu, N.; Li, G. Blind quality assessment for screen content images by orientation selectivity mechanism. Signal Process. 2018, 145, 225–232. [Google Scholar] [CrossRef]
- Min, X.; Ma, K.; Gu, K.; Zhai, G.; Wang, Z.; Lin, W. Unified blind quality assessment of compressed natural, graphic, and screen content images. IEEE Trans. Image Process. 2017, 26, 5462–5474. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Yan, J.; Li, L.; Wu, J.; Lin, W. No reference quality assessment for screen content images with both local and global feature representation. IEEE Trans. Image Process. 2018, 27, 1600–1610. [Google Scholar] [CrossRef] [PubMed]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. Turbopixels: Fast superpixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [Green Version]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An evaluation of the state-of-the-art. Comput. Vision Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Gaetano, R.; Masi, G.; Poggi, G.; Verdoliva, L.; Scarpa, G. Marker-controlled watershed-based segmentation of multiresolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2987–3004. [Google Scholar] [CrossRef]
- Cousty, J.; Bertrand, G.; Najman, L.; Couprie, M. Watershed cuts: Thinnings, shortest path forests, and topological watersheds. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 925–939. [Google Scholar] [CrossRef] [Green Version]
- Ciecholewski, M. An edge-based active contour model using an inflation/deflation force with a damping coefficient. Expert Syst. Appl. 2016, 44, 22–36. [Google Scholar] [CrossRef]
- Zhang, X.; Xiong, B.; Dong, G.; Kuang, G. Ship Segmentation in SAR Images by Improved Nonlocal Active Contour Model. Sensors 2018, 18, 4220. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.; Zhu, C.; Wang, Y.; Chen, L. HSOG: A novel local image descriptor based on histograms of the second-order gradients. IEEE Trans. Image Process. 2014, 23, 4680–4695. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Gao, Y.; Zhao, S.; Liu, J. Local derivative pattern versus local binary pattern: Face recognition with high-order local pattern descriptor. IEEE Trans. Image Process. 2010, 19, 533–544. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Wu, J.; Xia, Z.; Zhang, H.; Li, H. Blind quality assessment for screen content images by combining local and global features. Digit. Signal Process. 2019, 91, 31–40. [Google Scholar] [CrossRef]
- Ding, Y.; Zhao, X.; Zhang, Z.; Dai, H. Image quality assessment based on multi-order local features description, modeling and quantification. IEICE Trans. Inf. Syst. 2017, E100D, 1303–1315. [Google Scholar] [CrossRef] [Green Version]
- Ding, Y.; Zhao, Y.; Zhao, X. Image quality assessment based on multi-feature extraction and synthesis with support vector regression. Signal Process. Image Commun. 2017, 54, 81–92. [Google Scholar] [CrossRef]
- Lim, W.Q. Nonseparable shearlet transform. IEEE Trans. Image Process. 2013, 22, 2056–2065. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Gu, K.; Zeng, K.; Wang, Z.; Lin, W. objective quality assessment and perceptual compression of screen content images. IEEE Comput. Graph. Appl. 2018, 38, 47–58. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Databases | Criteria | PSNR | SSIM | GMSD | SPQA | ESIM | SQI | SFUW | BSRSF |
|---|---|---|---|---|---|---|---|---|---|
| SIQAD | PLCC | 0.5869 | 0.7561 | 0.7259 | 0.8584 | 0.8788 | 0.8644 | 0.8910 | 0.8905 |
| SROCC | 0.5605 | 0.7566 | 0.7305 | 0.8416 | 0.8632 | 0.8548 | 0.8800 | 0.8714 | |
| RMSE | 11.5876 | 9.3676 | 9.4684 | 7.3421 | 6.8310 | 7.1782 | 6.4990 | 7.2569 | |
| SCID | PLCC | 0.7622 | 0.7343 | 0.8337 | - | 0.8630 | - | 0.8590 | 0.7024 |
| SROCC | 0.7512 | 0.7146 | 0.8138 | - | 0.8478 | - | 0.8950 | 0.7204 | |
| RMSE | 9.1682 | 9.6133 | 7.8210 | - | 7.1552 | - | 7.3100 | 9.8849 |
| Databases | Criteria | RRSCI | BRISQUE | GWH-GLBP | IL- NIQE | BQMS | SIQE | NRLT | BLIQUP- SCI | BSRSF |
|---|---|---|---|---|---|---|---|---|---|---|
| SIQAD | PLCC | 0.8014 | 0.7684 | 0.7903 | 0.3996 | 0.8108 | 0.7905 | 0.8387 | 0.7705 | 0.8905 |
| SROCC | 0.7655 | 0.7094 | 0.7233 | 0.3496 | 0.7619 | 0.7609 | 0.8197 | 0.7990 | 0.8714 | |
| RMSE | 8.5620 | 8.2565 | 8.7480 | 13.2082 | 9.3110 | 8.7775 | 7.5847 | 10.0200 | 7.2569 | |
| SCID | PLCC | 0.6602 | 0.6137 | 0.6468 | 0.2569 | 0.6338 | 0.6457 | 0.6324 | - | 0.7024 |
| SROCC | 0.7526 | 0.5795 | 0.6348 | 0.2432 | 0.6132 | 0.6022 | 0.6387 | - | 0.7204 | |
| RMSE | 11.5401 | 12.2565 | 12.2831 | 13.6863 | 10.9519 | 10.9343 | 10.6327 | - | 9.8849 |
| Metrics | GN | GB | MB | CC | JPEG | JP2K | LSC | |
|---|---|---|---|---|---|---|---|---|
| FR Metrics | PSNR | 0.9053 | 0.8603 | 0.7044 | 0.7401 | 0.7545 | 0.7893 | 0.7805 |
| SSIM | 0.8806 | 0.9014 | 0.8060 | 0.7435 | 0.7487 | 0.7749 | 0.7307 | |
| GMSD | 0.8956 | 0.9094 | 0.8436 | 0.7827 | 0.7746 | 0.8509 | 0.8559 | |
| SPQA | 0.8921 | 0.9058 | 0.8315 | 0.7992 | 0.7696 | 0.8252 | 0.7958 | |
| ESIM | 0.8891 | 0.9234 | 0.8886 | 0.7641 | 0.7999 | 0.7888 | 0.7915 | |
| SQI | 0.8829 | 0.9202 | 0.8789 | 0.7724 | 0.8218 | 0.8271 | 0.8310 | |
| SFUW | 0.8870 | 0.9230 | 0.8780 | 0.8290 | 0.7570 | 0.8150 | 0.7590 | |
| RR Metrics | RRSCI | 0.8798 | 0.8810 | 0.8465 | 0.6812 | 0.7638 | 0.6807 | 0.7110 |
| Blind Metrics | BRISQUE | 0.8423 | 0.8247 | 0.7783 | 0.5548 | 0.7018 | 0.6823 | 0.5615 |
| GWH-GLBP | 0.8537 | 0.8917 | 0.8297 | 0.4973 | 0.5687 | 0.7043 | 0.5678 | |
| IL-NIQE | 0.7667 | 0.5304 | 0.4136 | 0.1171 | 0.2945 | 0.4172 | 0.1754 | |
| BQMS | 0.8353 | 0.8048 | 0.6969 | 0.5125 | 0.6686 | 0.7059 | 0.6562 | |
| SIQE | 0.8590 | 0.8531 | 0.7817 | 0.5905 | 0.7639 | 0.7637 | 0.7752 | |
| NRLT | 0.9101 | 0.8903 | 0.8865 | 0.7994 | 0.7851 | 0.7035 | 0.7219 | |
| BLIQUP-SCI | 0.9015 | 0.9453 | 0.6341 | 0.7278 | 0.6691 | 0.6001 | 0.4253 | |
| BSRSF | 0.9307 | 0.9405 | 0.9364 | 0.7807 | 0.8547 | 0.8554 | 0.8701 | |
| Metrics | BRISQUE | GWH-GLBP | IL-NIQE | BQMS | SIQE | NRLT | BLIQUP-SCI | BSRSF |
|---|---|---|---|---|---|---|---|---|
| BRISQUE | 0 | 1 | 1 | −1 | −1 | −1 | −1 | −1 |
| GWH-GLBP | −1 | 0 | 1 | −1 | −1 | −1 | −1 | −1 |
| IL-NIQE | −1 | −1 | 0 | −1 | −1 | −1 | −1 | −1 |
| BQMS | 1 | 1 | 1 | 0 | 0 | −1 | −1 | −1 |
| SIQE | 1 | 1 | 1 | 0 | 0 | −1 | 1 | −1 |
| NRLT | 1 | 1 | 1 | 1 | 1 | 0 | 0 | −1 |
| BLIQUP-SCI | 1 | 1 | 1 | 1 | −1 | 0 | 0 | −1 |
| BSRSF | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 |
| Criteria | Com-0 | Com-1 | Com-2 | Com-3 | Com-4 | Com-5 |
|---|---|---|---|---|---|---|
| PLCC | 0.8654 | 0.8801 | 0.8905 | 0.8865 | 0.8805 | 0.8795 |
| Criteria | Metric-T | Metric-P | BSRSF |
|---|---|---|---|
| PLCC | 0.8727 | 0.7829 | 0.8905 |
| SROCC | 0.8524 | 0.7684 | 0.8714 |
| RMSE | 7.7843 | 8.3547 | 7.2569 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, W.; Bie, H.; Lu, L.; Li, Y. Blind Quality Evaluation for Screen Content Images Based on Regionalized Structural Features. Algorithms 2020, 13, 257. https://doi.org/10.3390/a13100257
Dong W, Bie H, Lu L, Li Y. Blind Quality Evaluation for Screen Content Images Based on Regionalized Structural Features. Algorithms. 2020; 13(10):257. https://doi.org/10.3390/a13100257
Chicago/Turabian StyleDong, Wu, Hongxia Bie, Likun Lu, and Yeli Li. 2020. "Blind Quality Evaluation for Screen Content Images Based on Regionalized Structural Features" Algorithms 13, no. 10: 257. https://doi.org/10.3390/a13100257
APA StyleDong, W., Bie, H., Lu, L., & Li, Y. (2020). Blind Quality Evaluation for Screen Content Images Based on Regionalized Structural Features. Algorithms, 13(10), 257. https://doi.org/10.3390/a13100257