Efficient Approaches to the Mixture Distance Problem



Abstract
:1. Introduction
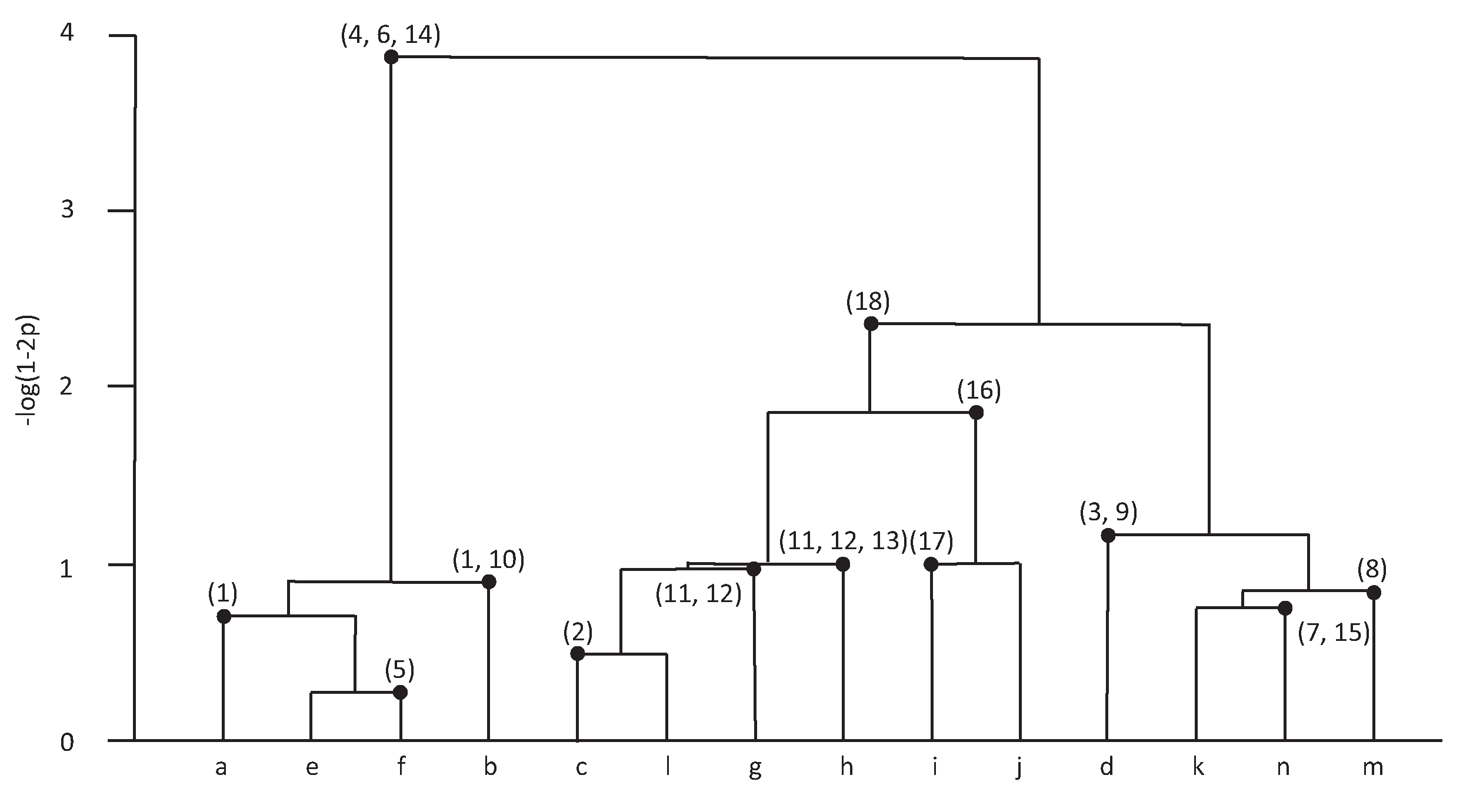
2. Mixture Distance Metric
- 1.
- Reflexivity: for any two comparable mixture trees and , if and only if and are identical.
- 2.
- Symmetry: for any two comparable mixture trees and , .
- 3.
- Triangle inequality: for any three comparable mixture trees , and , .
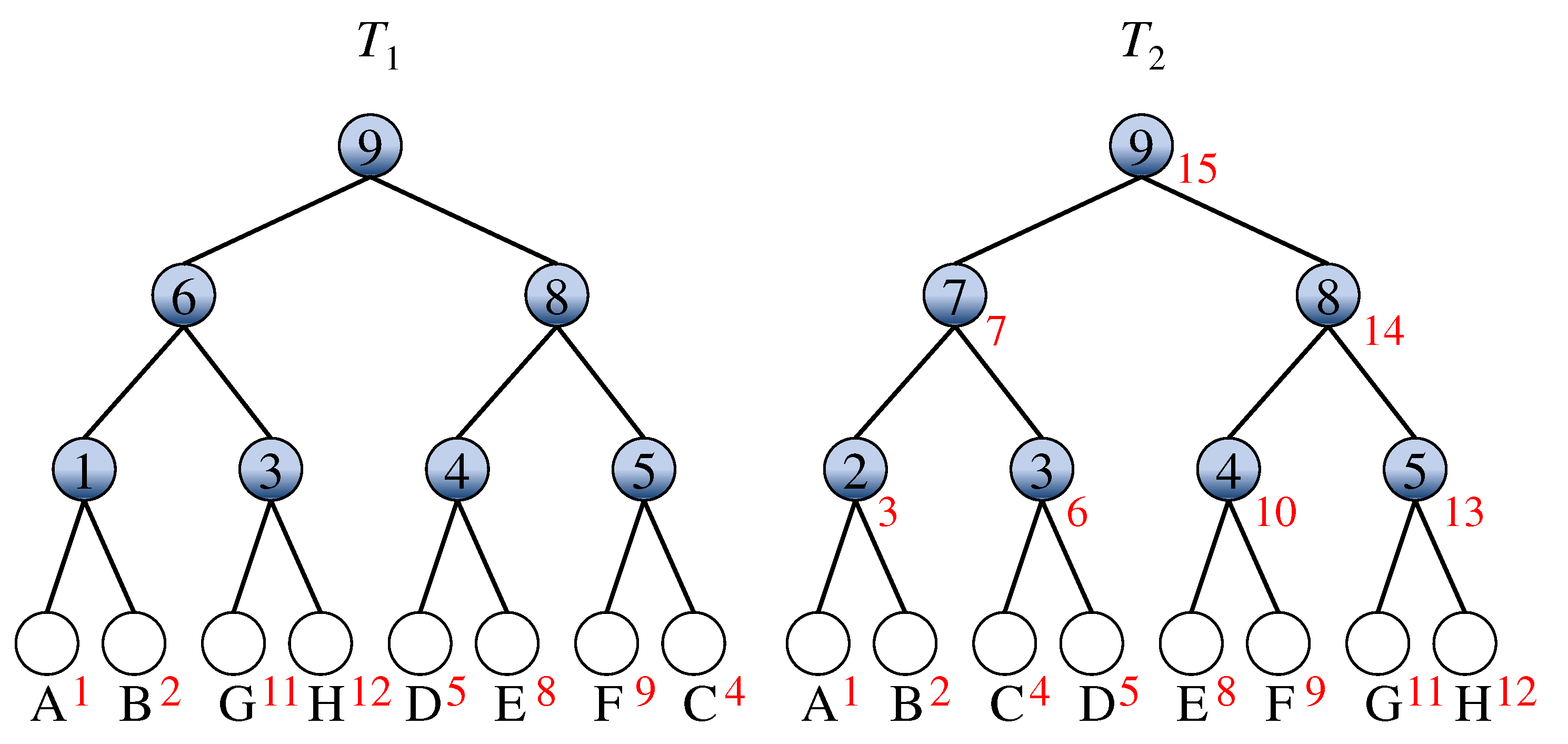
3. An -Time Algorithm
3.1. Algorithm MixtureDistance
| Algorithm 1: MixtureDistance. |
| Input: Two comparable mixture trees and , with mutation times (, respectively) for every internal node v of (u of , respectively). |
| Output: The mixture distance between and . |
| . |
| Traverse by the breadth-first search from its root and keep a list of the internal nodes in order. |
| Traverse by the breadth-first search from its root and keep a list of the internal nodes in reverse order. |
| for each node do |
| 5 In , color red the leaves of the left subtree rooted by v and green the leaves of the right subtree rooted by v. |
| 6 for each node do // Initialize the coloring information of u’s children |
| 7 for each child w of u in do |
| 8 if w is a leaf then |
| 9 if w is colored by red in then |
| 10 . |
| 11 else if w is colored by green in then |
| 12 . |
| 13 else |
| 14 . |
| 15 Let and be the left and right children of u in , respectively. // Calculate the difference of the mutation times of u and v and sum them up for computing mixture distance |
| 16 . |
| 17 . // Calculate the coloring information of u |
| 18 . |
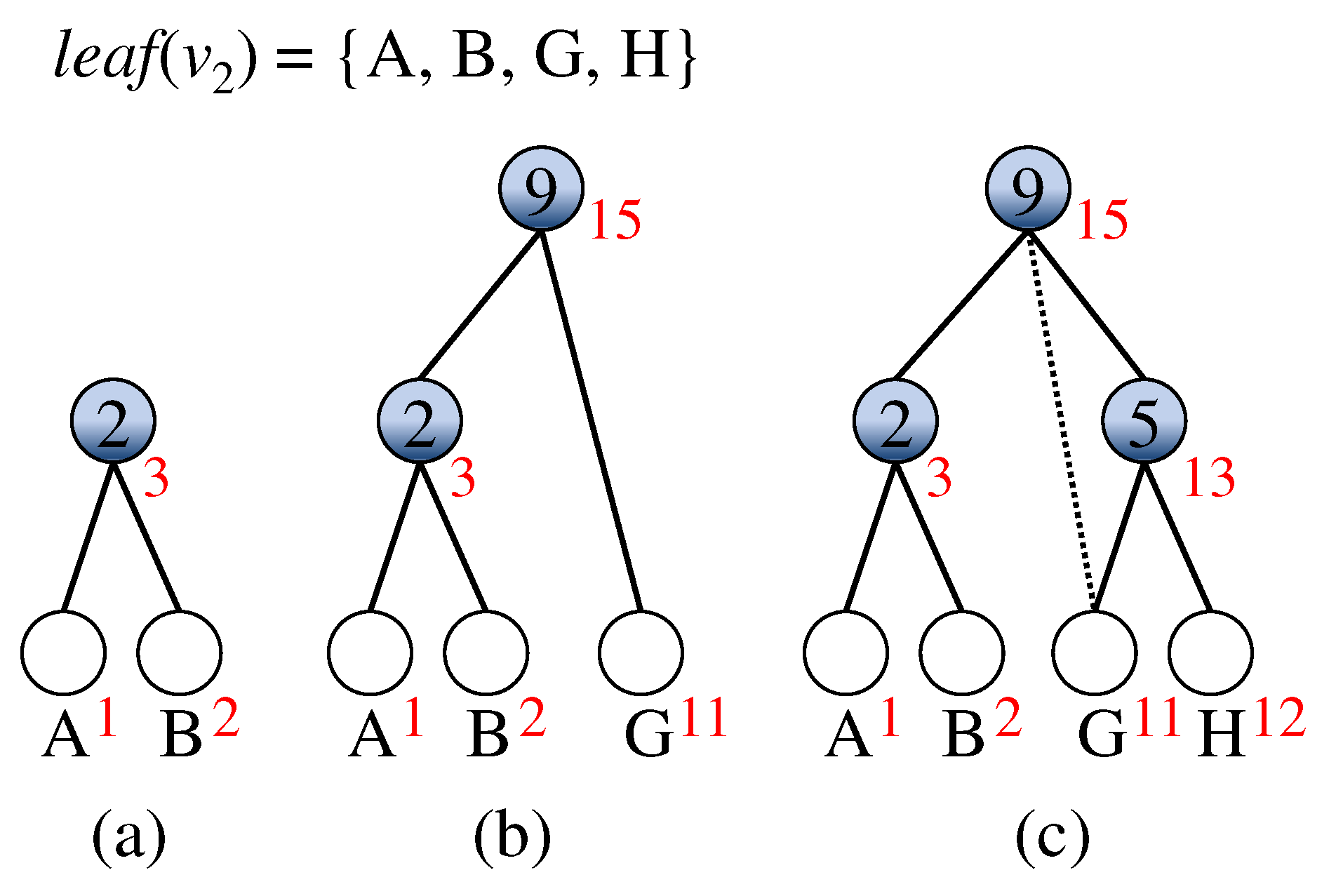
3.2. Modified Algorithm
- Rank the leaves in and .
- Construct a minimal subtree of involved in colored leaves with respect to node v, for each internal node v in .
- Compute the mixture distance between v and each internal node in .
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Saitou, N.; Nei, M. The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 1987, 4, 406–425. [Google Scholar] [PubMed]
- Lesperance, M.L.; Kalbfleisch, J.D. An algorithm for computing the nonparametric MLE of a mixing distribution. J. Am. Stat. Assoc. 1992, 87, 120–126. [Google Scholar] [CrossRef]
- Chen, S.C.; Lindsay, B.G. Building mixture trees from binary sequence data. Biometrika 2006, 93, 843–860. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.C.; Rosenberg, M.; Lindsay, B.G. MixtureTree: A program for constructing phylogeny. BMC Bioinform. 2011, 12, 111–114. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Griffiths, R.C.; Tavare, S. Ancestral inference in population genetics. Statist. Sci. 1994, 9, 307–319. [Google Scholar] [CrossRef]
- Ward, R.H.; Frazier, B.L.; Dew-Jager, K.; Paabo, S. Extensive mitochondrial diversity within a single amerindian tribe. Proc. Nat. Acad. Sci. USA 1991, 88, 6720–6724. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Steel, M.A. The maximum likelihood point for a phylogenetic tree is not unique. Syst. Biol. 1994, 43, 560–564. [Google Scholar] [CrossRef]
- Robinson, D.F.; Foulds, L.R. Comparison of phylogenetic trees. Biosciences 1981, 53, 131–147. [Google Scholar] [CrossRef]
- Estabrook, G.F.; McMorris, F.R.; Meacham, C.A. Comparison of undirected phylogenetic trees based on subtrees of four evolutionary units. Syst. Zool. 1985, 34, 193–200. [Google Scholar] [CrossRef]
- Dasgupta, B.; He, X.; Jiang, T.; Li, M.; Tromp, J.; Zhang, L. On computing the nearest neighbor interchange distance. In Proceedings of the Discrete Mathematical Problems with Medical Applications: DIMACS Workshop on Discrete Problems with Medical Applications, Piscataway, NJ, USA, 8–10 December 1999; American Mathematical Society: Washington, DC, USA, 2000; Volume 55, pp. 125–143. [Google Scholar]
- Bluis, J.; Shin, D. Nodal distance algorithm: Calculating a phylogenetic tree comparison metric. In Proceedings of the Third IEEE Symposium on BioInformatics and BioEngineering, Bethesda, MD, USA, 12 March 2003; pp. 87–94. [Google Scholar]
- Robinson, D.F.; Foulds, L.R. Comparison of weighted labelled trees. In Combinatorial Mathematics VI; Springer: Berlin/Heidelberg, Germany, 1979; pp. 119–126. [Google Scholar]
- Billera, L.J.; Holmes, S.P.; Vogtmann, K. Geometry of the space of phylogenetic trees. Adv. Appl. Math. 2001, 27, 733–767. [Google Scholar] [CrossRef] [Green Version]
- Steel, M.A.; Penny, D. Distributions of tree comparison metrics—Some new results. Syst. Biol. 1993, 42, 126–141. [Google Scholar]
- Day, W.H. Optimal algorithms for comparing trees with labeled leaves. J. Classif. 1985, 2, 7–28. [Google Scholar] [CrossRef]
- Pattengale, N.D.; Gottlieb, E.J.; Moret, B.M. Efficiently computing the Robinson-Foulds metric. J. Comput. Biol. 2007, 14, 724–735. [Google Scholar] [CrossRef] [PubMed]
- Battagliero, S.; Puglia, G.; Vicario, S.; Rubino, F.; Scioscia, G.; Leo, P. An efficient algorithm for approximating geodesic distances in tree space. IEEE/ACM Trans. Comput. Biol. Bioinform. 2010, 8, 1196–1207. [Google Scholar] [CrossRef] [PubMed]
- Amenta, N.; Godwin, M.; Postarnakevich, N.; John, K.S. Approximating geodesic tree distance. Inf. Process. Lett. 2007, 103, 61–65. [Google Scholar] [CrossRef]
- Owen, M.; Provan, J.S. A fast algorithm for computing geodesic distances in tree space. IEEE/ACM Trans. Comput. Biol. Bioinform. 2010, 8, 2–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Felsenstein, J. Inferring Phylogenies; Sinauer Associates: Sunderland, MA, USA, 2004. [Google Scholar]
- Bender, M.A.; Farach-Colton, M. The LCA problem revisited. Lat. Am. Theor. Inform. 2000, 1776, 88–94. [Google Scholar]
- Brodal, G.S.; Fagerberg, R.; Pedersen, C.N.S. Computing the quartet distance between evolutionary trees in time O(nlogn). Algorithmica 2003, 38, 377–395. [Google Scholar] [CrossRef]
- Lee, R.C.T.; Chang, R.C.; Tseng, S.S.; Tsai, Y.T. Introduction to the Design and Analysis of Algorithms; McGraw-Hill Education: Berkshire, UK, 2005. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| wRF | ||||
|---|---|---|---|---|
| 3 | 8 | 7 | ||
| 7 | 4 | |||
| 3 |
| 1 | 4 | 3 | ||
| 3 | 2 | |||
| 1 |
| Metric | Consideration | Time Complexity | |
|---|---|---|---|
| Full Binary Trees | Complete Binary Trees | ||
| Mixture distance | Structure and mutation time | ||
| Nodal distance | Structure | ||
| Geodesic tree distance | Structure and mutation number | ||
| Weighted path difference distance | Structure and mutation number | ||
| Weighted RF distance | Structure and mutation number | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juan, J.S.-T.; Chen, Y.-C.; Lin, C.-H.; Chen, S.-C. Efficient Approaches to the Mixture Distance Problem. Algorithms 2020, 13, 314. https://doi.org/10.3390/a13120314
Juan JS-T, Chen Y-C, Lin C-H, Chen S-C. Efficient Approaches to the Mixture Distance Problem. Algorithms. 2020; 13(12):314. https://doi.org/10.3390/a13120314
Chicago/Turabian StyleJuan, Justie Su-Tzu, Yi-Ching Chen, Chen-Hui Lin, and Shu-Chuan Chen. 2020. "Efficient Approaches to the Mixture Distance Problem" Algorithms 13, no. 12: 314. https://doi.org/10.3390/a13120314
APA StyleJuan, J. S.-T., Chen, Y.-C., Lin, C.-H., & Chen, S.-C. (2020). Efficient Approaches to the Mixture Distance Problem. Algorithms, 13(12), 314. https://doi.org/10.3390/a13120314