A New Click-Through Rates Prediction Model Based on Deep&Cross Network

Abstract
:1. Introduction
- The modeling of feature interactions is still limited. When a neural network learns high-order features, it is unable to effectively identify the importance and association of combined features, which further restricts the prediction accuracy of the model.
- Noise interference can be introduced in the embedding phase, and then it can skew the final prediction results.
- The data for CTR prediction is unbalanced, which leads to the issue that the classic deep model can not predict accurately, since it needs a lot of data of the same category to learn the discriminative features.
- The optimization algorithm to train the DNN may not work well because of the underlying distribution of data may be more complex than the assumption.
- Some preprocessing techniques, such as Synthetic Minority Oversampling Technique (SMOTE) [23], have been applied to optimize FO-FTRL-DCN, which aim to denoise and balance the data, leading to better performance.
- The proposed FO-FTRL-DCN model has been evaluated on multiple datasets of the prestigious benchmark of iPinYou, showing that the model has better performance compared with state-of-the-art baselines, and better generalization across different datasets.
2. Preliminaries
2.1. Embedding
2.2. Oversampling
| Algorithm 1 SMOTE. |
| Input: unbalanced data of positive and negative samples; Output: synthesized new minority samples; 1: Initializing minority samples ; 2: For to N: The Euclidean distance between and other samples is calculated, and the corresponding K-Nearest neighbor is obtained; 3: Determine the sampling rate R according to the proportion of positive and negative samples; 4: For to N: According to the sampling ratio R, several samples are randomly selected from the K-Nearest neighbors of , which are determined as ; Construct a new sample according to the determined ; 5: return ; |
2.3. Optimization for DNN
2.3.1. Batch Normalization
| Algorithm 2 Batch Normalization (based on Mini-Batch). |
| Input:x value based on Mini-Batch: ; parameters to learn: ; Output: ; 1: ; // mini-batch mean 2: ; // mini-batch variance 3: ; // normalize 4: ; // scale and shift 5: return ; |
2.3.2. Dropout
2.3.3. Activation Functions
2.3.4. Training Techniques
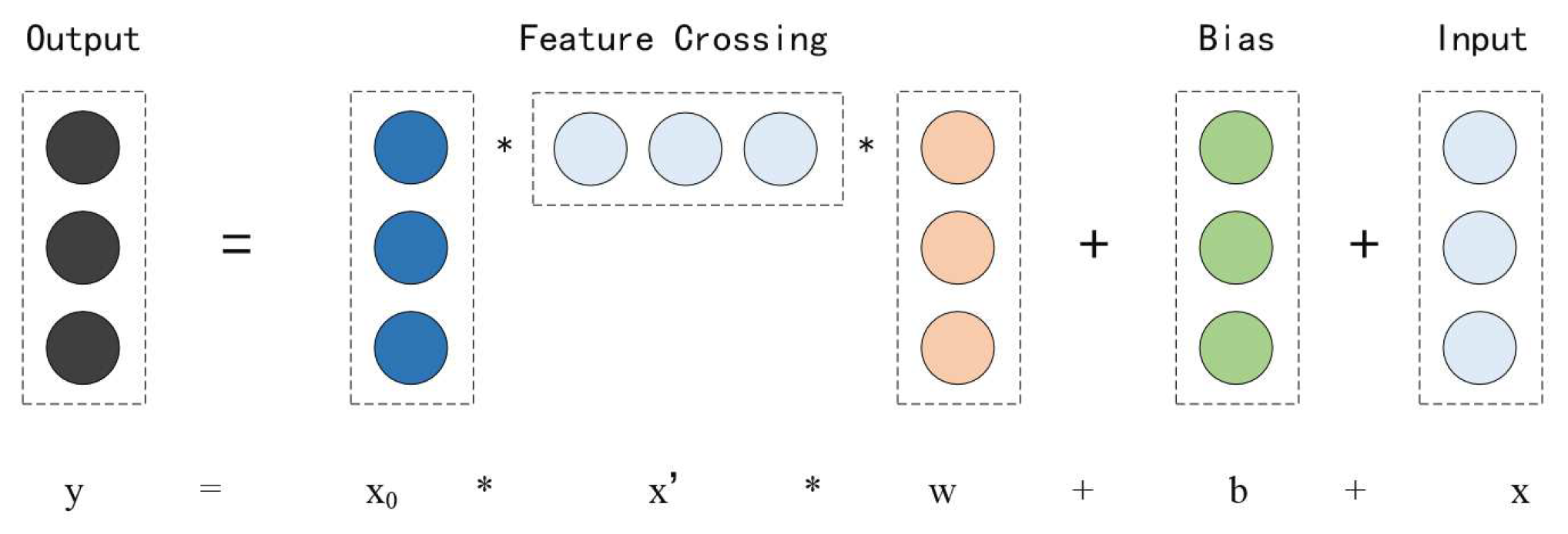
3. The Proposed Model
- First, in the embedding phase, the truncated normal distribution is introduced, which is a special normal distribution that limits the value range of variables. In the embedding stage, the truncated normal distribution can be used to replace the normal distribution to reduce some noise interference.
- Secondly, SMOTE is applied to tackle the imbalance of data, which can analyze the data of minority classes, synthesize new minority samples and add them to the original data, and balance the ratio of positive and negative samples.
- Thirdly, the advanced FTRL optimization algorithm is applied, which can greatly improve the optimization effect of CTR model in complex situations. FTRL is an efficient optimization algorithm and online learning algorithm in information retrievel and recommendation, combining the power of forward backward splitting (FOBOS) [12] and regularized dual averaging (RDA) [13]. It uses both and regularization terms in the iterative process, which greatly improves the prediction of the model. The latest version of FTRL-Proximal [8] is adopted in the proposed model and has gained substantial improvements in performance.
3.1. The Pipeline
3.2. The Feature Optimization
4. Experimental Results
4.1. The Datasets
4.2. Experimental Settings
4.3. Results and Analysis
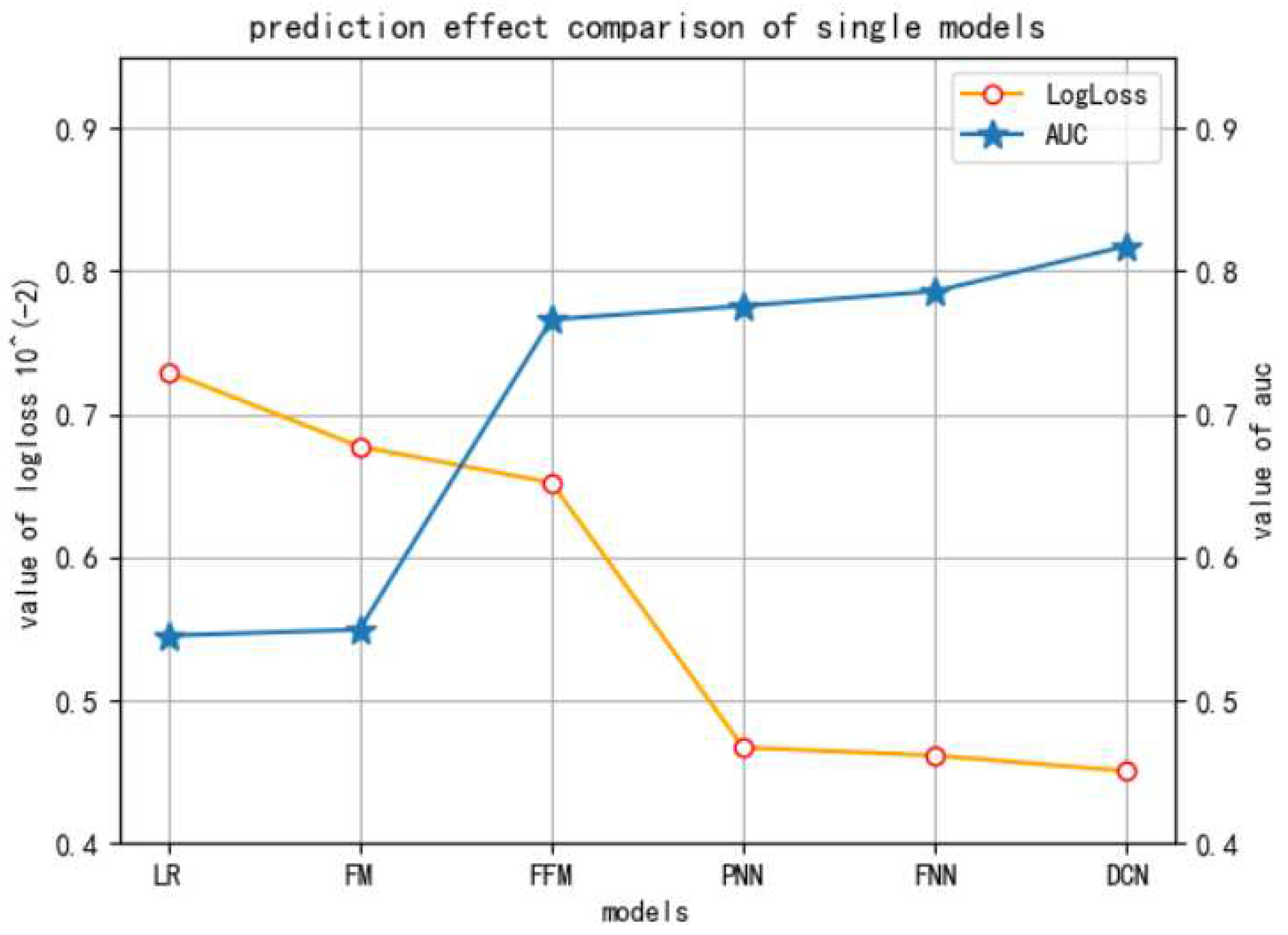
4.3.1. The First Experiment
4.3.2. The Second Experiment
4.3.3. The Third Experiment
4.3.4. The Fourth Experiment
4.3.5. The Fifth Experiment
4.3.6. The Sixth Experiment
4.3.7. Summarization
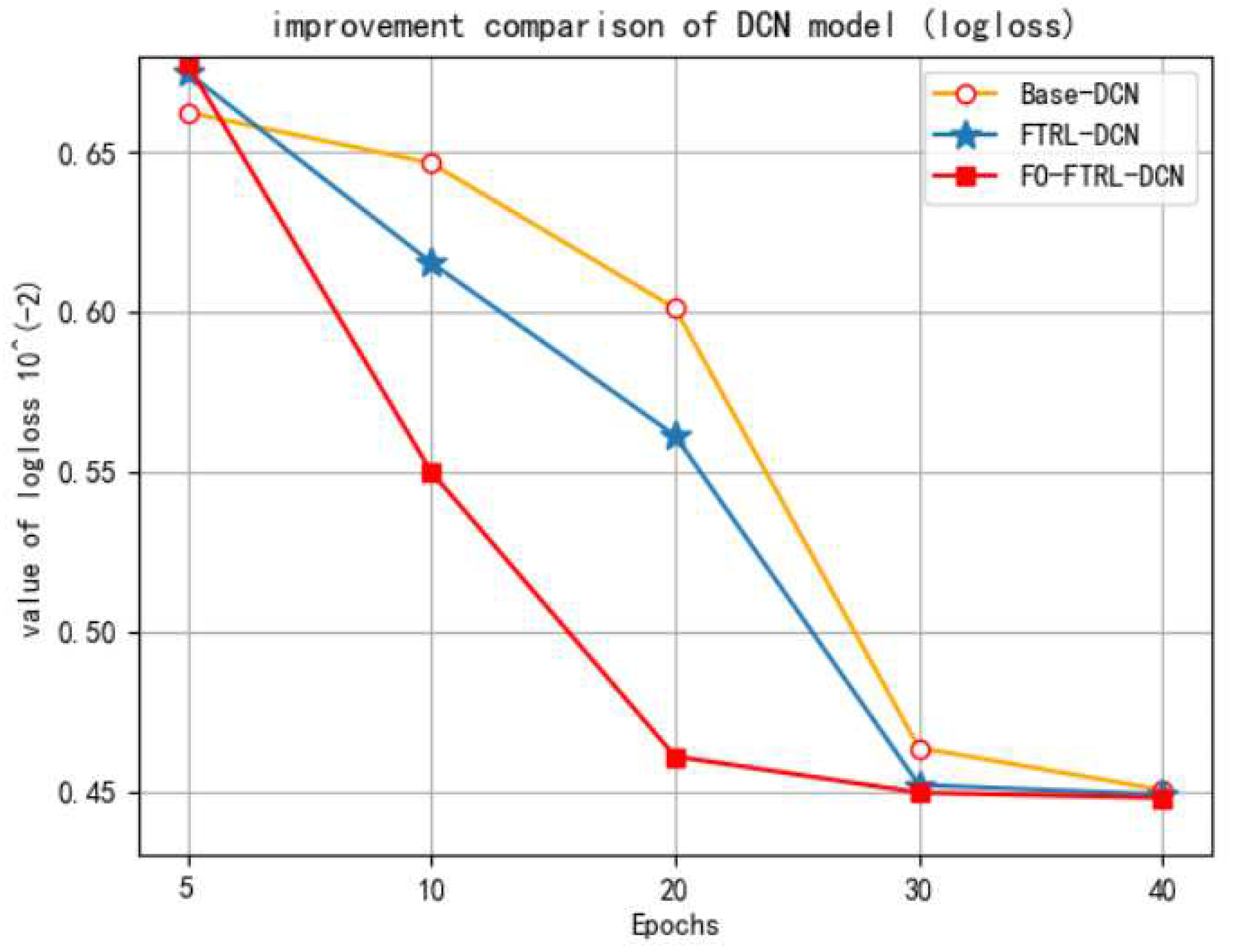
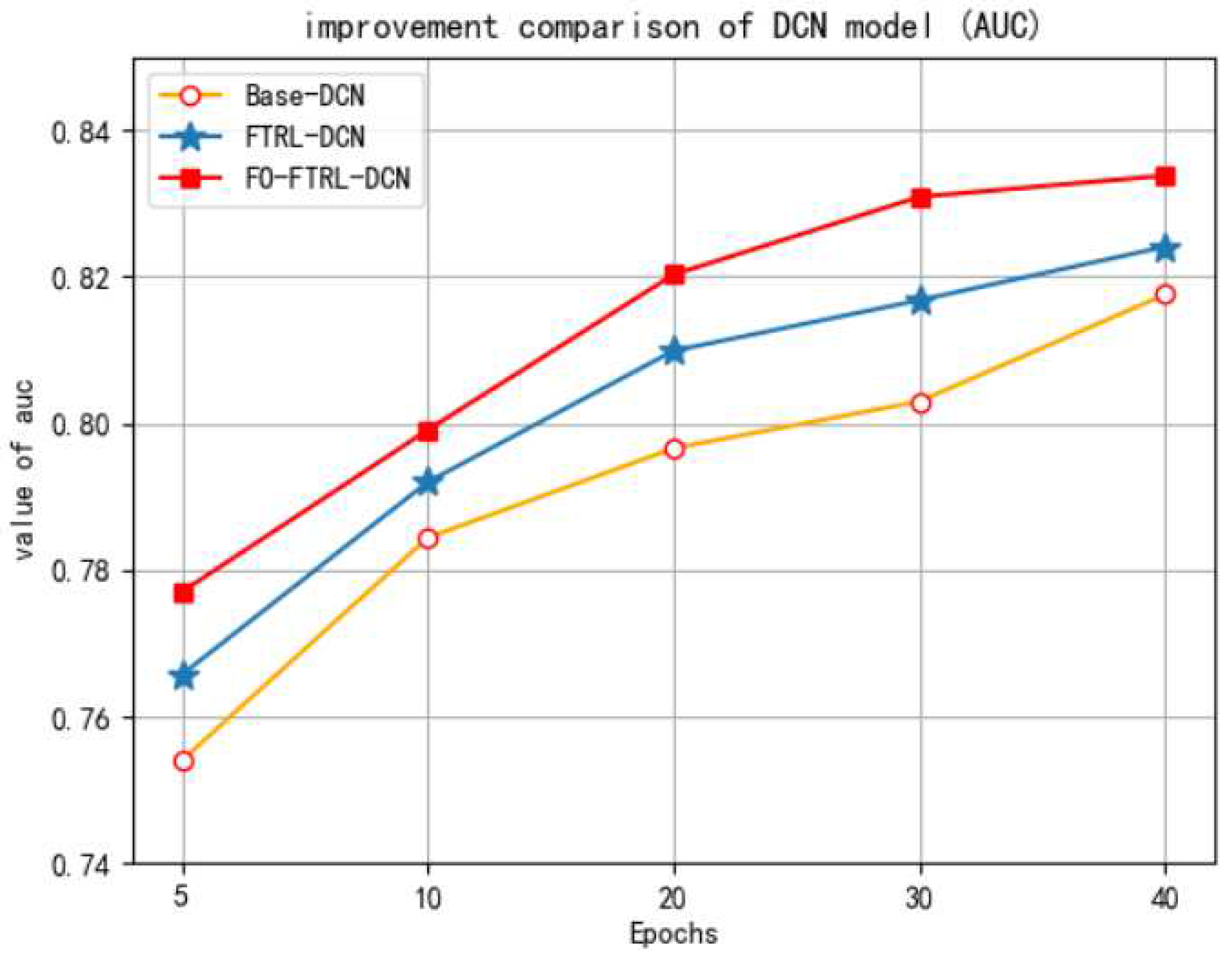
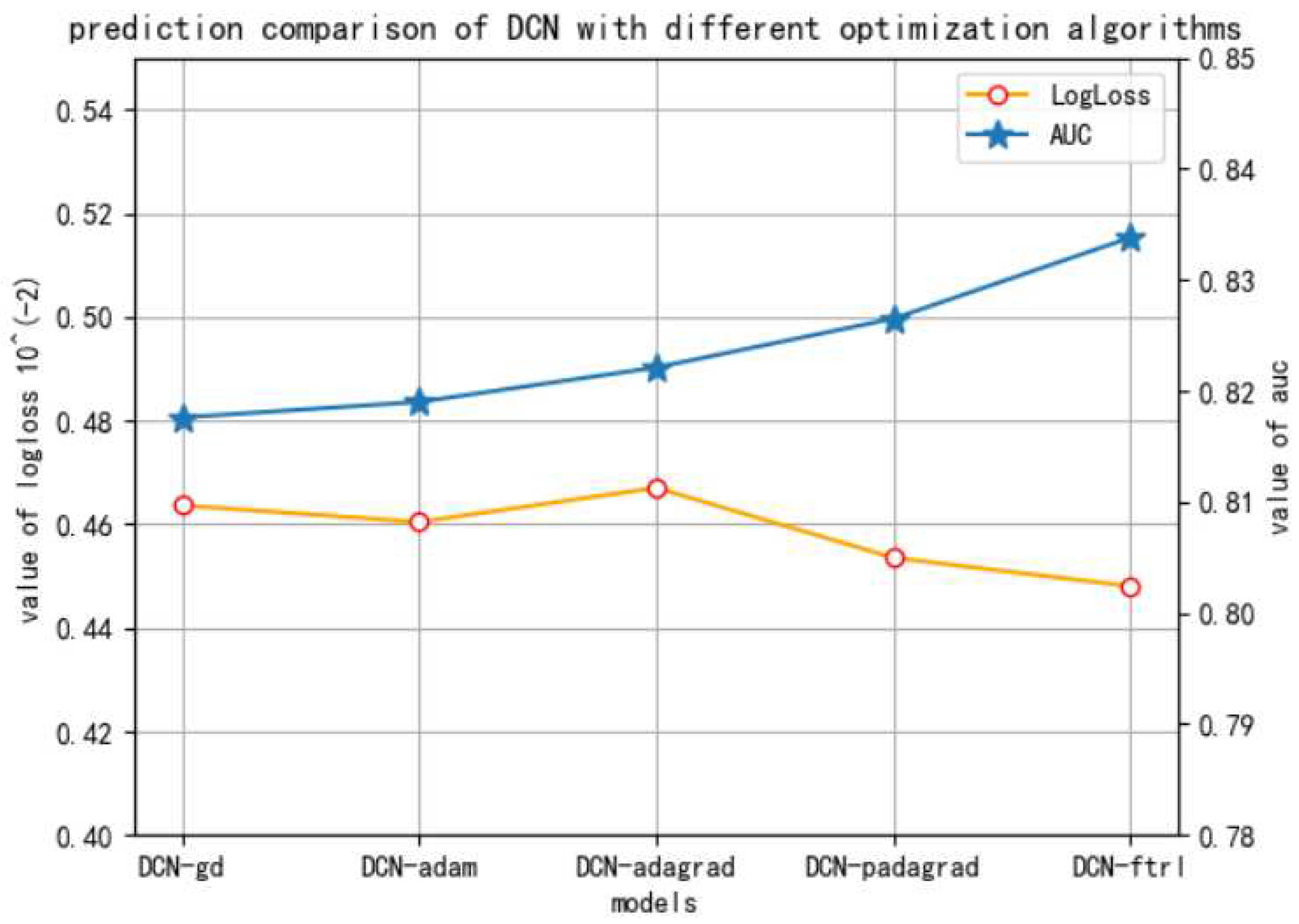
- The base model of DCN can be empowered with the integration of FO and FTRL.
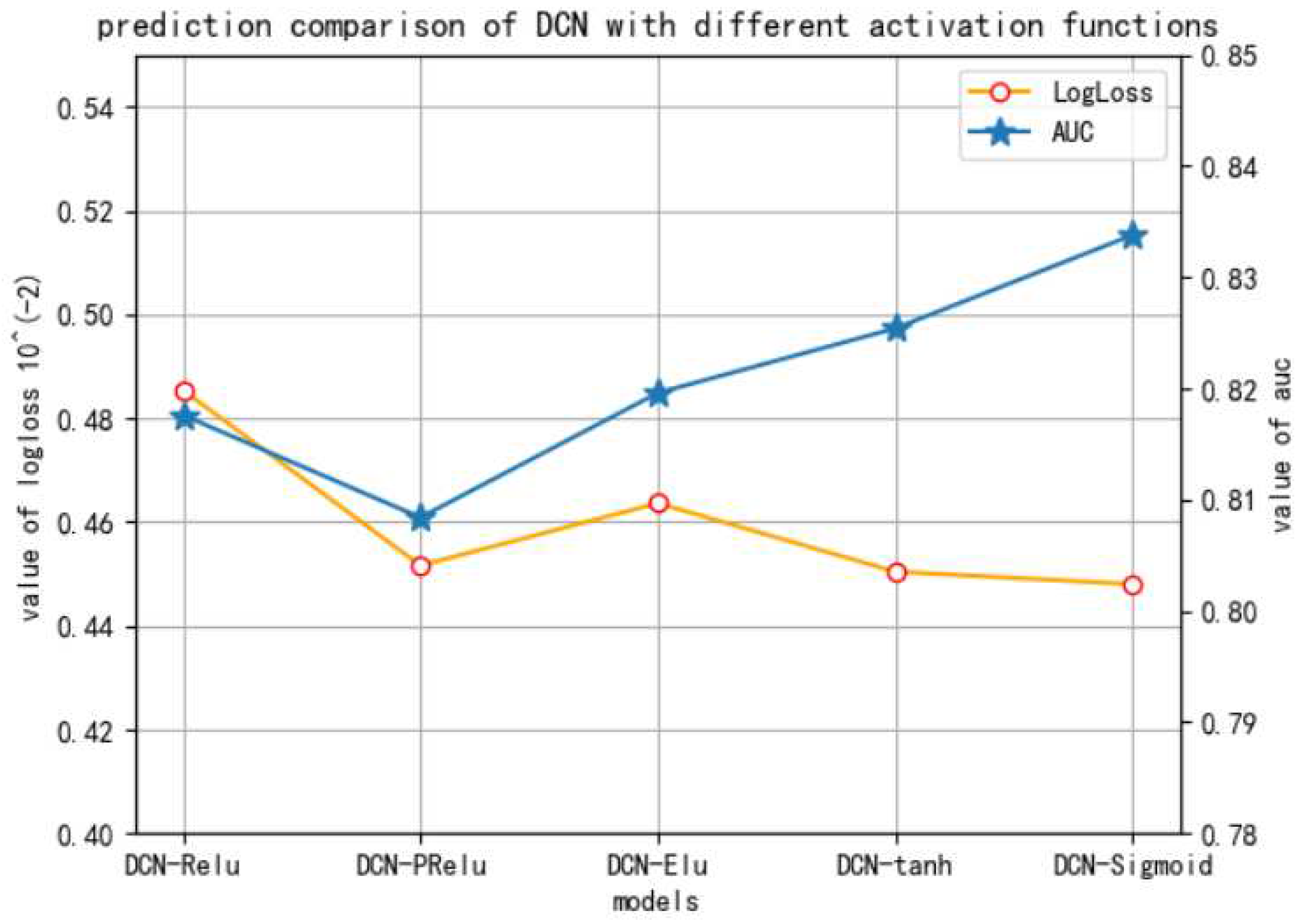
- The sigmoid activation function works the best for the proposed FO-FTRL-DCN model.
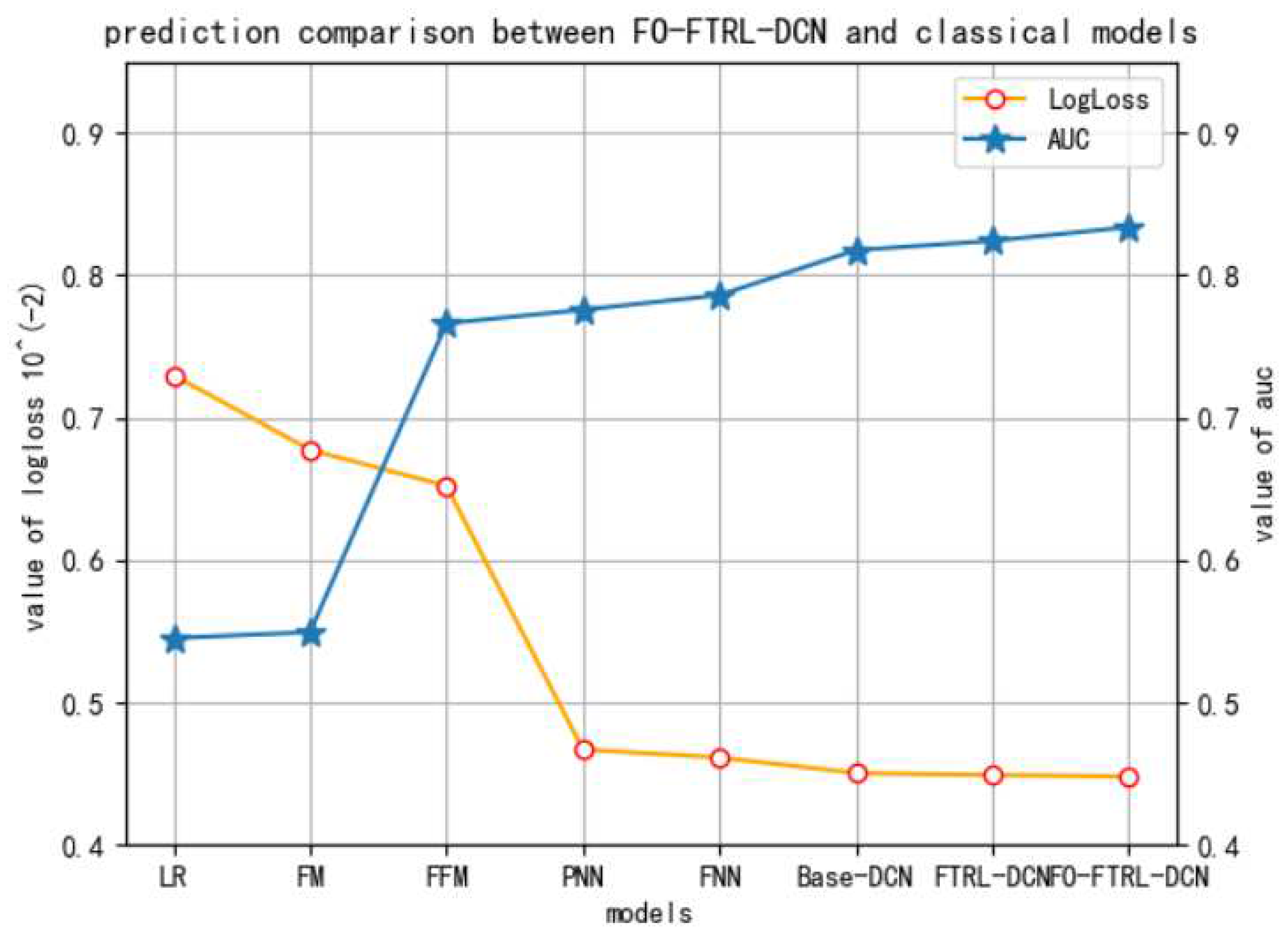
- The overall performance of the proposed FO-FTRL-DCN model is better than prestigious state-of-the-art counterparts across different datasets of iPinYou, implying good generalization.
5. Conclusions and Future Research
Author Contributions
Funding
Conflicts of Interest
References
- Bayer, E.; Srinivasan, S.; Riedl, E.; Skiera, B. The impact of online display advertising and paid search advertising relative to offline advertising on firm performance and firm value. Int. J. Res. Market. 2020. [Google Scholar] [CrossRef]
- Gligorijevic, J.; Gligorijevic, D.; Stojkovic, I.; Bai, X.; Goyal, A.; Obradovic, Z. Deeply supervised model for click-through rate prediction in sponsored search. Data Min. Knowl. Disc. 2019, 33, 1446–1467. [Google Scholar] [CrossRef]
- Kim, K.H.; Han, S. The effect of youtube Pre-Roll advertising on VTR (View through rate) and CTR (Click through rate). Indian J. Public Health Res. Dev. 2018, 9, 428. [Google Scholar] [CrossRef]
- Zhu, L.; Lin, J. A Pricing Strategy of E-Commerce Advertising Cooperation in the Stackelberg Game Model with Different Market Power Structure. Algorithms 2019, 12, 24. [Google Scholar] [CrossRef] [Green Version]
- McMahan, H.B.; Holt, G.; Sculley, D.; Young, M.; Ebner, D.; Grady, J.; Nie, L.; Phillips, T.; Davydov, E.; Golovin, D.; et al. Ad click prediction: A view from the trenches. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD 2013, Chicago, IL, USA, 11–14 August 2013; Dhillon, I.S., Koren, Y., Ghani, R., Senator, T.E., Bradley, P., Parekh, R., He, J., Grossman, R.L., Uthurusamy, R., Eds.; ACM: New York, NY, USA, 2013; pp. 1222–1230. [Google Scholar]
- Chapelle, O.; Manavoglu, E.; Rosales, R. Simple and Scalable Response Prediction for Display Advertising. ACM Trans. Intell. Syst. Tech. 2014, 5, 61:1–61:34. [Google Scholar] [CrossRef]
- Rendle, S. Factorization Machines. In Proceedings of the ICDM 2010, The 10th IEEE International Conference on Data Mining, Sydney, Australia, 14–17 December 2010; Webb, G.I., Liu, B., Zhang, C., Gunopulos, D., Wu, X., Eds.; IEEE Computer Society: New York, NY, USA, 2010; pp. 995–1000. [Google Scholar]
- Ta, A. Factorization machines with follow-the-regularized-leader for CTR prediction in display advertising. In Proceedings of the 2015 IEEE International Conference on Big Data, Big Data 2015, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2889–2891. [Google Scholar]
- Juan, Y.; Zhuang, Y.; Chin, W.; Lin, C. Field-aware Factorization Machines for CTR Prediction. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 43–50. [Google Scholar]
- He, X.; Pan, J.; Jin, O.; Xu, T.; Liu, B.; Xu, T.; Shi, Y.; Atallah, A.; Herbrich, R.; Bowers, S.; et al. Practical Lessons from Predicting Clicks on Ads at Facebook. In Proceedings of the Eighth International Workshop on Data Mining for Online Advertising, ADKDD 2014, New York, NY, USA, 24 August 2014; pp. 5:1–5:9. [Google Scholar]
- McMahan, H.B. Follow-the-Regularized-Leader and Mirror Descent: Equivalence Theorems and L1 Regularization. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, AISTATS 2011, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 525–533. [Google Scholar]
- Duchi, J.C.; Singer, Y. Efficient Online and Batch Learning Using Forward Backward Splitting. J. Mach. Learn. Res. 2009, 10, 2899–2934. [Google Scholar]
- Xiao, L. Dual Averaging Methods for Regularized Stochastic Learning and Online Optimization. J. Mach. Learn. Res. 2010, 11, 2543–2596. [Google Scholar]
- Zhang, W.; Du, T.; Wang, J. Deep Learning over Multi-field Categorical Data—A Case Study on User Response Prediction. In Proceedings of the Advances in Information Retrieval—38th European Conference on IR Research, ECIR 2016, Padua, Italy, 20–23 March 2016; pp. 45–57. [Google Scholar]
- Cheng, H.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & Deep Learning for Recommender Systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, DLRS@RecSys 2016, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Qu, Y.; Cai, H.; Ren, K.; Zhang, W.; Yu, Y.; Wen, Y.; Wang, J. Product-Based Neural Networks for User Response Prediction. In Proceedings of the IEEE 16th International Conference on Data Mining, ICDM 2016, Barcelona, Spain, 12–15 December 2016; pp. 1149–1154. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017; pp. 1725–1731. [Google Scholar]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & Cross Network for Ad Click Predictions. In Proceedings of the ADKDD’17, Halifax, NS, Canada, 13–17 August 2017; pp. 12:1–12:7. [Google Scholar]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep Interest Network for Click-Through Rate Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, 19–23 August 2018; pp. 1059–1068. [Google Scholar]
- Huang, T.; Zhang, Z.; Zhang, J. FiBiNET: Combining feature importance and bilinear feature interaction for click-through rate prediction. In Proceedings of the 13th ACM Conference on Recommender Systems, RecSys 2019, Copenhagen, Denmark, 16–20 September 2019; pp. 169–177. [Google Scholar]
- Feng, Y.; Lv, F.; Shen, W.; Wang, M.; Sun, F.; Zhu, Y.; Yang, K. Deep Session Interest Network for Click-Through Rate Prediction. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, 10–16 August 2019; pp. 2301–2307. [Google Scholar]
- Liang, M.; Du, J.; Yang, C.; Xue, Z.; Li, H.; Kou, F.; Geng, Y. Cross-Media Semantic Correlation Learning Based on Deep Hash Network and Semantic Expansion for Social Network Cross-Media Search. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3634–3648. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Barkan, O.; Koenigstein, N. Item2vec: Neural Item Embedding for Collaborative Filtering. In Proceedings of the Poster Track of the 10th ACM Conference on Recommender Systems (RecSys 2016), Boston, MA, USA, 17 September 2016; Guy, I., Sharma, A., Eds.; ACM: New York, NY, USA, 2016; Volume 1688. [Google Scholar]
- Zhu, Q.; Carriere, K. Detecting and correcting for publication bias in meta-analysis C A truncated normal distribution approach. Stat. Methods Med. Res. 2018, 27, 2722–2741. [Google Scholar] [CrossRef]
- Wang, Q.; Zhou, Y.; Zhang, W.; Tang, Z.; Chen, X. Adaptive sampling using self-paced learning for imbalanced cancer data pre-diagnosis. Exp. Syst. Appl. 2020, 152, 113334. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Savvopoulos, A.; Kanavos, A.; Mylonas, P.; Sioutas, S. LSTM Accelerator for Convolutional Object Identification. Algorithms 2018, 11, 157. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015; Bach, F.R., Blei, D.M., Eds.; MIT Press: Cambridge, MA, USA, 2015; Volume 37, pp. 448–456. [Google Scholar]
- Ba, L.J.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V.S. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Wu, Y.; He, K. Group Normalization. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part XIII, Lecture Notes in Computer Science; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin, Germany, 2018; Volume 11217, pp. 3–19. [Google Scholar]
- Luo, P.; Ren, J.; Peng, Z.; Zhang, R.; Li, J. Differentiable Learning-to-Normalize via Switchable Normalization. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Andrade, B.; Gois, J.; Xavier, V.; Luna, A. Comparison of the performance of the multiclass classifiers: A new approach to overfitting test. Chemometr. Intell. Lab. Syst. 2020, 201, 104013. [Google Scholar] [CrossRef]
- Leshno, M.; Lin, V.Y.; Pinkus, A.; Schocken, S. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw. 1993, 6, 861–867. [Google Scholar] [CrossRef] [Green Version]
- Jang, J.; Cho, H.; Kim, J.; Lee, J.; Yang, S. Deep neural networks with a set of node-wise varying activation functions. Neural Netw. 2020, 126, 118–131. [Google Scholar] [CrossRef]
- Yin, X.; Goudriaan, J.; Lantinga, E.A.; Vos, J.; Spiertz, H.J. A Flexible Sigmoid Function of Determinate Growth. Ann. Bot. 2003, 91, 361–371. [Google Scholar] [CrossRef]
- Elwakil, S.A.; El-labany, S.K.; Zahran, M.A.; Sabry, R. Modified extended tanh-function method for solving nonlinear partial differential equations. Phys. Lett. A 2003, 299, 179–188. [Google Scholar] [CrossRef]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Vydana, H.K.; Vuppala, A.K. Investigative study of various activation functions for speech recognition. In Proceedings of the Twenty-third National Conference on Communications, NCC 2017, Chennai, India, 2–4 March 2017; IEEE: New York, NY, USA, 2017; pp. 1–5. [Google Scholar]
- Wang, T.; Qin, Z.; Zhu, M. An ELU Network with Total Variation for Image Denoising. In Neural Information Processing—Proceedings of the 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; Part III Lecture Notes in Computer Science; Liu, D., Xie, S., Li, Y., Zhao, D., El-Alfy, E.M., Eds.; Springer: Berlin, Germany, 2017; Volume 10636, pp. 227–237. [Google Scholar]
- van den Bergh, F.; Engelbrecht, A.P. Cooperative learning in neural networks using particle swarm optimizers. S. Afr. Comp. J. 2000, 26, 84–90. [Google Scholar]
- Faris, H.; Aljarah, I.; Mirjalili, S. Training feedforward neural networks using multi-verse optimizer for binary classification problems. Appl. Intell. 2016, 45, 322–332. [Google Scholar] [CrossRef]
- Bottou, L. Large-Scale Machine Learning with Stochastic Gradient Descent. In Proceedings of the 19th International Conference on Computational Statistics, COMPSTAT 2010, Paris, France, 22–27 August 2010; Lechevallier, Y., Saporta, G., Eds.; Physica-Verlag: Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Wilson, A.C.; Recht, B.; Jordan, M.I. A Lyapunov Analysis of Momentum Methods in Optimization. arXiv 2016, arXiv:1611.02635. [Google Scholar]
- Mukkamala, M.C.; Hein, M. Variants of RMSProp and Adagrad with Logarithmic Regret Bounds. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; PMLR: Cambridge, MA, USA, 2017; Volume 70, pp. 2545–2553. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Andrei, N. Scaled conjugate gradient algorithms for unconstrained optimization. Comp. Opt. Appl. 2007, 38, 401–416. [Google Scholar] [CrossRef]
- Schraudolph, N.N.; Yu, J.; Günter, S. A Stochastic Quasi-Newton Method for Online Convex Optimization. In Proceedings of the Eleventh International Conference on Artificial Intelligence and Statistics, AISTATS 2007, San Juan, Puerto Rico, 21–24 March 2007; Meila, M., Shen, X., Eds.; PMLR: Cambridge, MA, USA, 2007; Volume 2, pp. 436–443. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sample Number | Click Number | Click Rate () | Feature Domain | Feature Number | |
|---|---|---|---|---|---|---|
| ID = 1458 | Training set | 3083056 | 2454 | 0.79596 | 16 | 560802 |
| Test set | 614638 | 515 | 0.83789 | 16 | 560802 | |
| ID = 3358 | Training set | 1742104 | 1358 | 0.77952 | 16 | 491700 |
| Test set | 300928 | 260 | 0.86399 | 16 | 491700 | |
| ID = 3386 | Training set | 2847802 | 2076 | 0.72898 | 16 | 556884 |
| Test set | 545421 | 445 | 0.81588 | 16 | 556884 | |
| ID = 3427 | Training set | 2593765 | 1926 | 0.74255 | 16 | 551158 |
| Test set | 536795 | 366 | 0.68182 | 16 | 551158 |
| Models | 1458 | 3358 | 3386 | 3427 | ||||
|---|---|---|---|---|---|---|---|---|
| AUC | LogLoss () | AUC | LogLoss () | AUC | LogLoss () | AUC | LogLoss () | |
| LR | 0.5452 | 0.7298 | 0.6463 | 0.6461 | 0.5217 | 0.6523 | 0.6741 | 1.720 |
| FM | 0.5493 | 0.6774 | 0.7007 | 0.9144 | 0.5415 | 0.6378 | 0.7327 | 1.270 |
| FFM | 0.7662 | 0.6521 | 0.8698 | 0.7680 | 0.7348 | 0.6978 | 0.8264 | 0.7152 |
| PNN | 0.7757 | 0.4669 | 0.8860 | 0.4756 | 0.7640 | 0.6245 | 0.8440 | 0.4607 |
| FNN | 0.7860 | 0.4613 | 0.8793 | 0.4804 | 0.7642 | 0.6013 | 0.8381 | 0.4680 |
| Base-DCN | 0.8176 | 0.4504 | 0.8860 | 0.4707 | 0.7941 | 0.5928 | 0.8337 | 0.4704 |
| FTRL-DCN | 0.8241 | 0.449 | 0.8914 | 0.4759 | 0.8017 | 0.5927 | 0.8543 | 0.4576 |
| FO-FTRL-DCN | 0.8338 | 0.448 | 0.8969 | 0.4697 | 0.8040 | 0.5891 | 0.8574 | 0.4564 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, G.; Chen, Q.; Deng, C. A New Click-Through Rates Prediction Model Based on Deep&Cross Network. Algorithms 2020, 13, 342. https://doi.org/10.3390/a13120342
Huang G, Chen Q, Deng C. A New Click-Through Rates Prediction Model Based on Deep&Cross Network. Algorithms. 2020; 13(12):342. https://doi.org/10.3390/a13120342
Chicago/Turabian StyleHuang, Guojing, Qingliang Chen, and Congjian Deng. 2020. "A New Click-Through Rates Prediction Model Based on Deep&Cross Network" Algorithms 13, no. 12: 342. https://doi.org/10.3390/a13120342
APA StyleHuang, G., Chen, Q., & Deng, C. (2020). A New Click-Through Rates Prediction Model Based on Deep&Cross Network. Algorithms, 13(12), 342. https://doi.org/10.3390/a13120342