Latency-Bounded Target Set Selection in Signed Networks


{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Results and Discussion
3. Model and Problems Definitions
4. Complexity of Approximation of USTSS and 2-USTSS
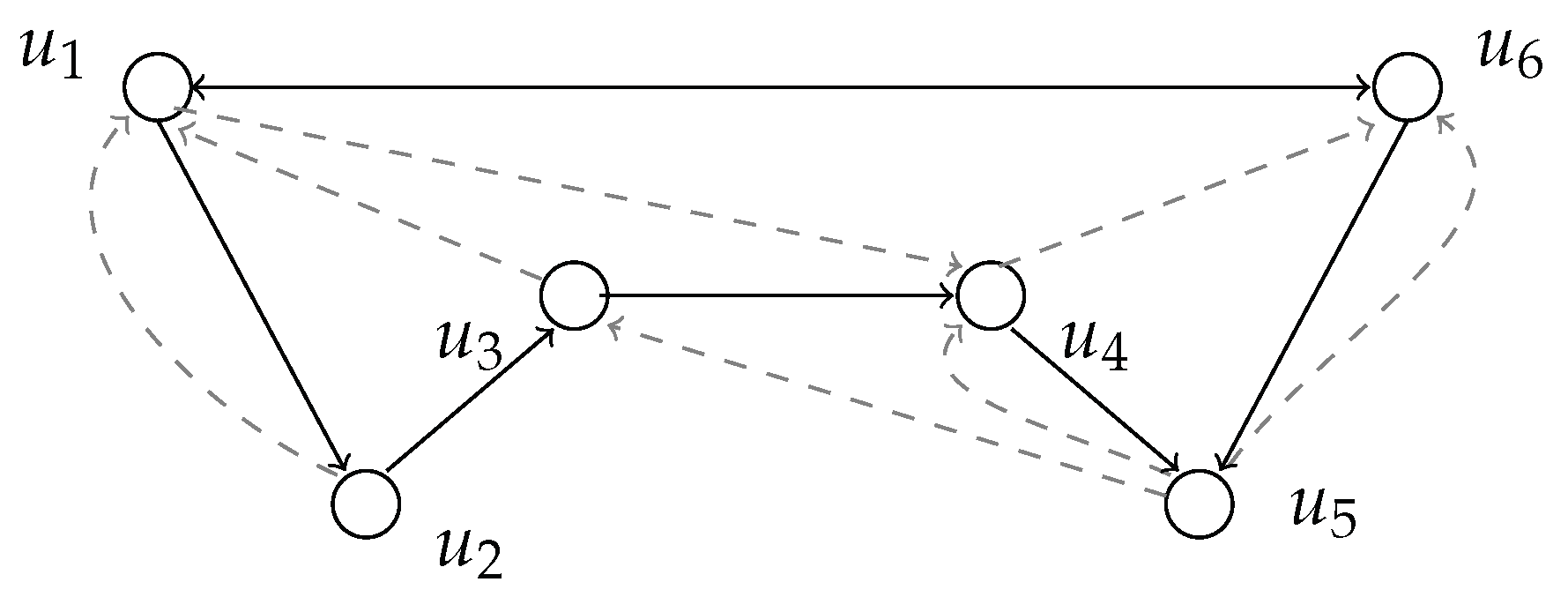
4.1. weakly positive-minimum ones 2-USTSS
- we set , where , and ;
- for each , is an arc in and is an arc in ;
- for each , is an arc in and is an arc in (that is, nodes in form a clique of positive arcs);
- for each clause and for each positively contained in , is an arc in and is an arc in ;
- if is a negative clause and is its negative variable, then is an arc in ;
- if is a positive clause then, for any , is an arc in .
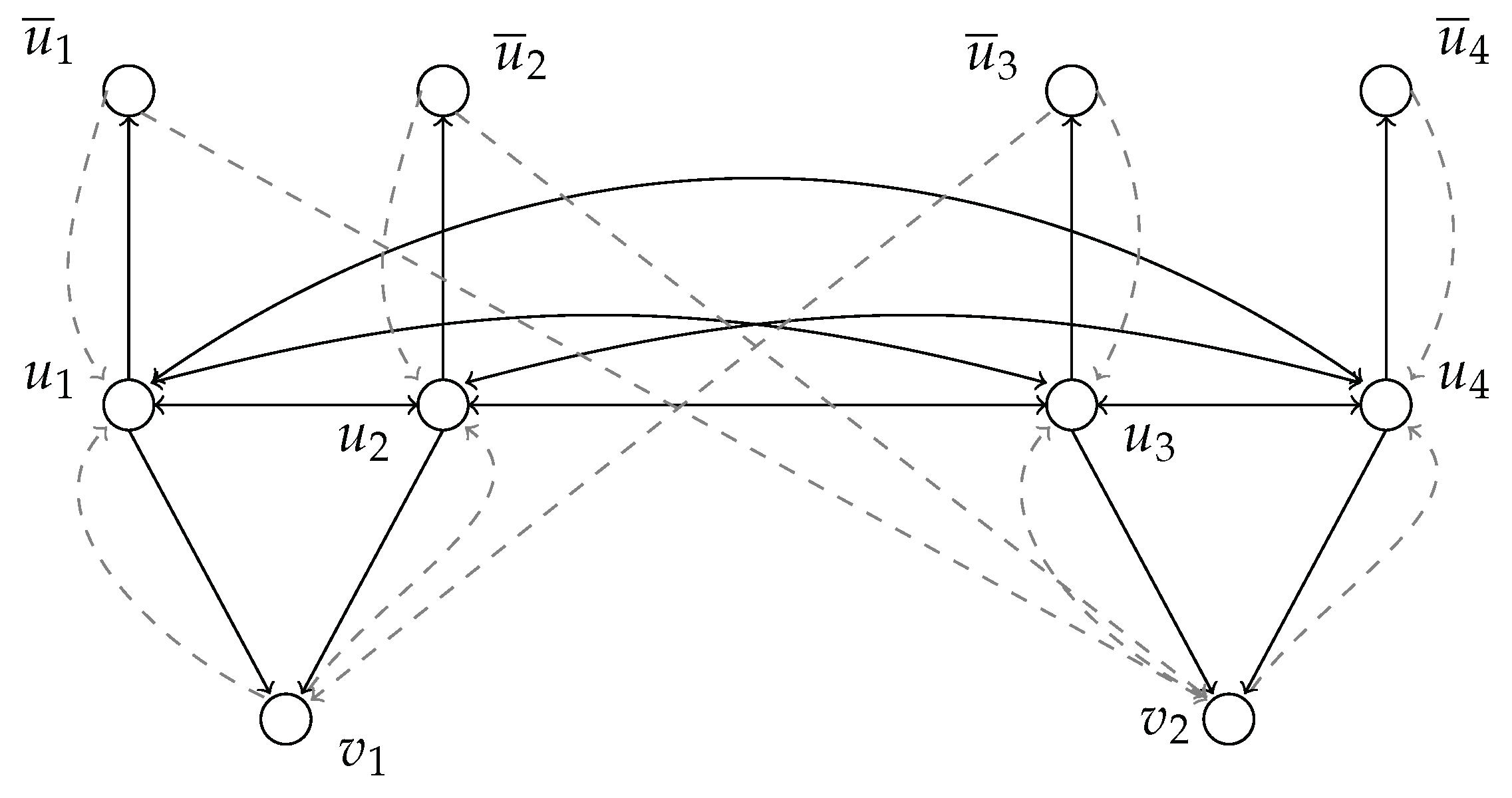
4.2. USTSSweakly positive-minimum ones
- , and
- for any , it holds that .
5. The 1-USTSS Problem
- , and
- for any , it holds that .
5.1. 1-USTSS and
- since , there exists such that (that is, y may inform x at time step 1) and, furthermore,
- since for any , , then, for any such that , since and , (that is, any node that could forbid x to become informed is not in I). □
6. Conclusions and Open Problems
Author Contributions
Funding
Conflicts of Interest
References
- Domingos, P.; Richardson, M. Mining the Network Value of Customers. In Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26 August 2001; pp. 57–66. [Google Scholar]
- Richardson, M.; Domingos, P. Mining Knowledge-sharing Sites for Viral Marketing. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23 July 2002; pp. 61–70. [Google Scholar]
- Ben-Zwi, O.; Hermelin, D.; Lokshtanov, D.; Newman, I. Treewidth governs the complexity of target set selection. Discret. Optim. 2011, 8, 87–96. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Wang, C.; Wang, Y. Scalable Influence Maximization for Prevalent Viral Marketing in Large-scale Social Networks. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25 July 2010; pp. 1029–1038. [Google Scholar]
- Granovetter, M. Threshold Models of Collective Behavior. Am. J. Sociol. 1978, 6, 1420–1443. [Google Scholar] [CrossRef] [Green Version]
- Kempe, D.; Kleinberg, J.; Tardos, É. Maximizing the Spread of Influence Through a Social Network. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24 August 2003; pp. 137–146. [Google Scholar]
- Kempe, D.; Kleinberg, J.; Tardos, É. Influential Nodes in a Diffusion Model for Social Networks. In Automata, Languages and Programming; Caires, L., Italiano, G.F., Monteiro, L., Palamidessi, C., Yung, M., Eds.; Springer: Berlin, Germany, 2005; Volume 3580, pp. 1127–1138. [Google Scholar]
- Leskovec, J.; Adamic, L.A.; Huberman, B.A. The Dynamics of Viral Marketing. ACM Trans. Web 2007, 1, 5-es. [Google Scholar] [CrossRef] [Green Version]
- Contagion, M.S. The Review of Economic Studies; Oxford University Press: New York, NY, USA, 2000; pp. 57–78. [Google Scholar]
- Ackerman, E.; Ben-Zwi, O.; Wolfovitzv, G. Combinatorial Model and Bounds for Target Set Selection. Theor. Comput. Sci. 2010, 411, 4017–4022. [Google Scholar] [CrossRef] [Green Version]
- Bazgan, C.; Chopin, M.; Nichterlein, A.; Sikora, F. Parameterized approximability of maximizing the spread of influence in networks. J. Discret. Algorithms 2014, 27, 54–65. [Google Scholar] [CrossRef]
- Centeno, C.C.; Dourado, M.C.; Penso, L.D.; Rautenbach, D.; Szwarcfiter, J.L. Irreversible conversion of graphs. Theor. Comput. Sci. 2011, 412, 3693–3700. [Google Scholar] [CrossRef] [Green Version]
- Chen, N. On the approximability of influence in social networks. SIAM J. Discret. Math. 2009, 23, 1400–1415. [Google Scholar] [CrossRef]
- Chiang, C.Y.; Huang, L.H.; Li, B.J.; Wu, J.; Yeh, H.G. Some results on the target set selection problem. J. Comb. Optim. 2013, 25, 702–715. [Google Scholar] [CrossRef] [Green Version]
- Chiang, C.Y.; Huang, L.H.; Yeh, H.G. Target Set Selection Problem for Honeycomb Networks. SIAM J. Discret. Math. 2013, 27, 310–328. [Google Scholar] [CrossRef] [Green Version]
- Chopin, M.; Nichterlein, A.; Niedermeier, R.; Weller, M. Constant Thresholds Can Make Target Set Selection Tractable. Theor. Comput. Syst. 2014, 55, 61–83. [Google Scholar] [CrossRef] [Green Version]
- Zaker, M. On dynamic monopolies of graphs with general thresholds. Discret. Math. 2012, 312, 1136–1143. [Google Scholar] [CrossRef] [Green Version]
- Bettencourt, L.M.A.; Cintron-Arias, A.; Kaiser, D.I.; Castillo-Chavez, C. The power of a good idea: Quantitative modeling of the spread of ideas from epidemiological models. Phys. Stat. Mech. Appl. 2006, 364, 513–536. [Google Scholar] [CrossRef] [Green Version]
- Nekovee, M.; Moreno, Y.; Bianconi, G.; Marsili, M. Theory of rumour spreading in complex social networks. Phys. Stat. Mech. Appl. 2007, 374, 467–470. [Google Scholar] [CrossRef] [Green Version]
- Goldenberg, J.; Libai, B.; Muller, E. Talk of the network: A complex systems look at the underlying process of word-of-mouth. Market. Lett. 2001, 12(3), 211–223. [Google Scholar] [CrossRef]
- Flocchini, P.; Lodi, E.; Luccio, F.; Pagli, L.; Santoro, N. Irreversible dynamos in tori. In Euro-Par’98 Parallel Processing; Pritchard, D., Reeve, J., Eds.; Springer: Berlin, Germany, 1998; Volume 1470, pp. 554–562. [Google Scholar]
- Luccio, F.; Pagli, L.; Sanossian, H. Irreversible dynamos in butterflies. In Proceedings of the 6th Colloquium on Structural Information and Communication Complexity, Lacanau-Ocean, France, 1–3 July 1999; pp. 204–218. [Google Scholar]
- Peleg, D. Size bounds for dynamic monopolies. Discret. Appl. Math. 1998, 86, 263–273. [Google Scholar] [CrossRef] [Green Version]
- Cicalese, F.; Cordasco, G.; Gargano, L.; Milanic̎, M.; Vaccaro, U. Latency-Bounded Target Set Selection in Social Networks. Theor. Comput. Sci. 2014, 535, 1–15. [Google Scholar] [CrossRef]
- Dreyer Jr, P.A.; Roberts, F.S. Irreversible k-threshold processes: Graph-theoretical threshold models of the spread of disease and of opinion. Discret. Appl. Math. 2009, 157, 1615–1627. [Google Scholar] [CrossRef]
- Gargano, L.; Hell, P.; Peters, J.G.; Vaccaro, U. Influence Diffusion in Social Networks under Time Window Constraints. Theor. Comput. Sci. 2015, 584, 53–66. [Google Scholar] [CrossRef]
- Dreyer, P.A. Applications and Variations of Domination in Graphs. Ph.D. Thesis, Rutgers University, Camden, NJ, USA, 2000. [Google Scholar]
- Alba, J.W.; Hutchinson, J.W.; Lynch, J.G. Memory and decision making. In Handbook of Consumer Behavior; Robertson, T.S., Kassarjian, H., Eds.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1991; pp. 1–49. [Google Scholar]
- Chen, Y.; Iver, G.; Pazgal, A. Limited Memory, Categorization and Competition. Market. Sci. 2010, 29, 650–670. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Collins, A.; Cummings, R.; Ke, T.; Liu, Z.; Rincon, D.; Sun, X.; Wang, Y.; Wei, W.; Yuan, Y. Influence maximization in social networks when negative opinions may emerge and propagate. In Proceedings of the 2011 SIAM International Conference on Data Mining, Mesa, AZ, USA, 28–30 April 2011; pp. 379–390. [Google Scholar]
- Nazemian, A.; Taghiyareh, F. Influence maximization in independent cascade model with positive and negative word of mouth. In Proceedings of the 6th International Symposium on Telecommunications (IST), Tehran, Iran, 6–8 November 2012; pp. 854–860. [Google Scholar]
- Stich, L.; Golla, G.; Nanopoulos, A. Modelling the spread of negative word-of-mouth in online social networks. J. Decis. Syst. 2014, 23, 203–221. [Google Scholar] [CrossRef]
- Yang, S.; Wang, S.; Truong, V.A. Online Learning and Optimization Under a New Linear-Threshold Model with Negative Influence. arXiv 2019, arXiv:1911.03276. [Google Scholar]
- Ahmed, S.; Ezeife, C.I. Discovering influential nodes from trust network. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, New York, NY, USA, 18 March 2013; pp. 121–128. [Google Scholar]
- Li, Y.; Chen, W.; Wang, Y.; Zhang, Z.L. Influence diffusion dynamics and influence maximization in social networks with friend and foe relationships. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4 February 2013; pp. 657–666. [Google Scholar]
- Easley, D.; Kleinberg, J. Networks, Crowds, and Markets: Reasoning about a Highly Connected World. Significance 2012, 9, 43–44. [Google Scholar]
- Galhotra, S.; Arora, A.; Roy, S. Holistic influence maximization: Combining scalability and efficiency with opinion-aware models. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 14 June 2016; pp. 743–758. [Google Scholar]
- Hosseini-Pozveh, M.; Zamanifar, K.; Naghsh-Nilchi, A.R.; Dolog, P. Maximizing the spread of positive influence in signed social networks. Intell. Data Anal. 2016, 20, 199–218. [Google Scholar] [CrossRef]
- Baumeister, R.F.; Bratslavsky, E.; Finkenauer, C. Bad is stronger than good. Rev. Gen. Psychol. 2001, 5, 323–370. [Google Scholar] [CrossRef]
- Peeters, G.; Czapinski, J. Positive-negative asymmetry in evaluations: The distinction between affective and informational negativity effects. Eur. Rev. Soc. Psychol. 1990, 1, 33–60. [Google Scholar] [CrossRef]
- Rozin, P.; Royzman, E.B. Negativity bias, negativity dom- inance, and contagion. Personal. Soc. Psychol. Rev. 2001, 5, 296–320. [Google Scholar] [CrossRef]
- Taylor, S.E. Asymmetrical effects of positive and negative events: The mobilization-minimization hypothesis. Psychol. Bull. 1991, 110, 67–85. [Google Scholar] [CrossRef]
- Foerster, K.T. Approximating Fault-Tolerant Domination in General Graphs. In Proceedings of the Tenth Workshop on Analytic Algorithmics and Combinatorics (ANALCO), New Orleans, LA, USA, 6 January 2013. [Google Scholar]
- Khanna, S.; Sudan, M.; Trevisan, L.; Williamson, D.P. The approximability of constraint satisfaction problems. SIAM J. Comput. 2000, 30(6), 1863–1920. [Google Scholar] [CrossRef] [Green Version]
- Chvátal, V. A greedy heuristic for the set covering problem. Math. Oper. Res. 1979, 4, 233–235. [Google Scholar] [CrossRef]


© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Ianni, M.; Varricchio, G. Latency-Bounded Target Set Selection in Signed Networks. Algorithms 2020, 13, 32. https://doi.org/10.3390/a13020032
Di Ianni M, Varricchio G. Latency-Bounded Target Set Selection in Signed Networks. Algorithms. 2020; 13(2):32. https://doi.org/10.3390/a13020032
Chicago/Turabian StyleDi Ianni, Miriam, and Giovanna Varricchio. 2020. "Latency-Bounded Target Set Selection in Signed Networks" Algorithms 13, no. 2: 32. https://doi.org/10.3390/a13020032
APA StyleDi Ianni, M., & Varricchio, G. (2020). Latency-Bounded Target Set Selection in Signed Networks. Algorithms, 13(2), 32. https://doi.org/10.3390/a13020032