On a Hybridization of Deep Learning and Rough Set Based Granular Computing



Abstract
:1. Introduction
2. Reducing the Size of Decision-Making Systems Based on Their Granular Reflections
- First step: granulation. We begin with computation of granules around each training object using selected method. In the method used in this article, by surrounding the objects of the training system class with objects indiscernible to the degree determined by the granulation radius.
- Second step: the process of covering. The training decision system is covered by selected granules. After the calculation of granules in point 1, a group of granules that cover the entire training system with their objects is searched for.
- Third step: building the granular reflections. The granular reflection of original training decision system is derived from the granules selected in step 2. We form new objects by converting granules using majority voting.
2.1. Standard Granulation
2.2. Concept Dependent Granulation
2.2.1. Toy Example of Concept Dependent Granulation
3. Design of the Experimental Part
4. Procedure for Performed Experiments
- 1.
- Data input (original decision system),
- 2.
- Data random split in the ratio 70-30 per cent TRN-TST,
- 3.
- Granulation step, covering step, new objects generation—see Section 2.2.1,
- 4.
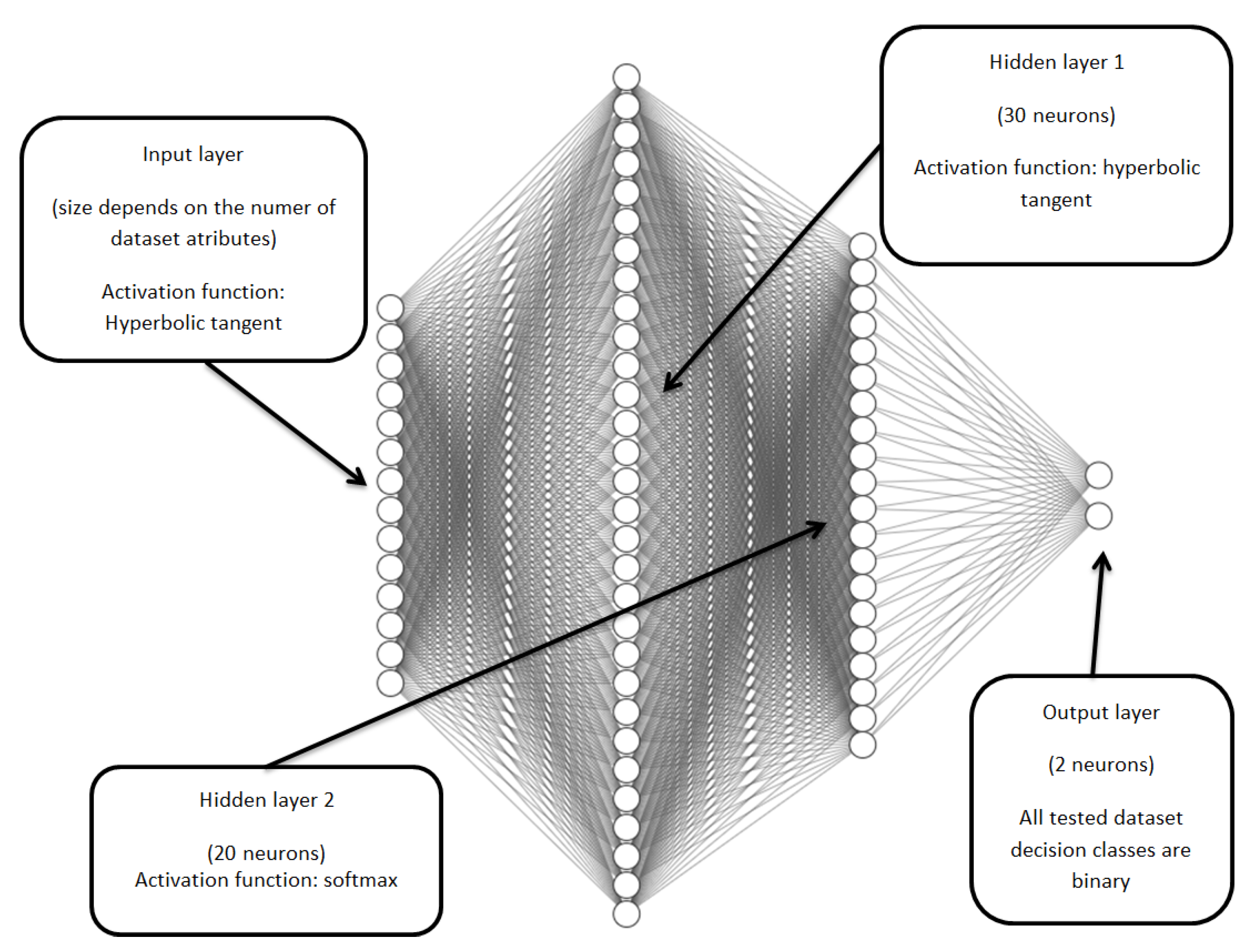
- Neural network learning step for each set of objects (for each granulation radius) see Figure 1,
- 5.
- Classification step for each test set, based on approximated data see Figure 2,
- 6.
- Compute accuracy, time, number of objects and compare vs first set. The whole procedure is repeated 10 times.
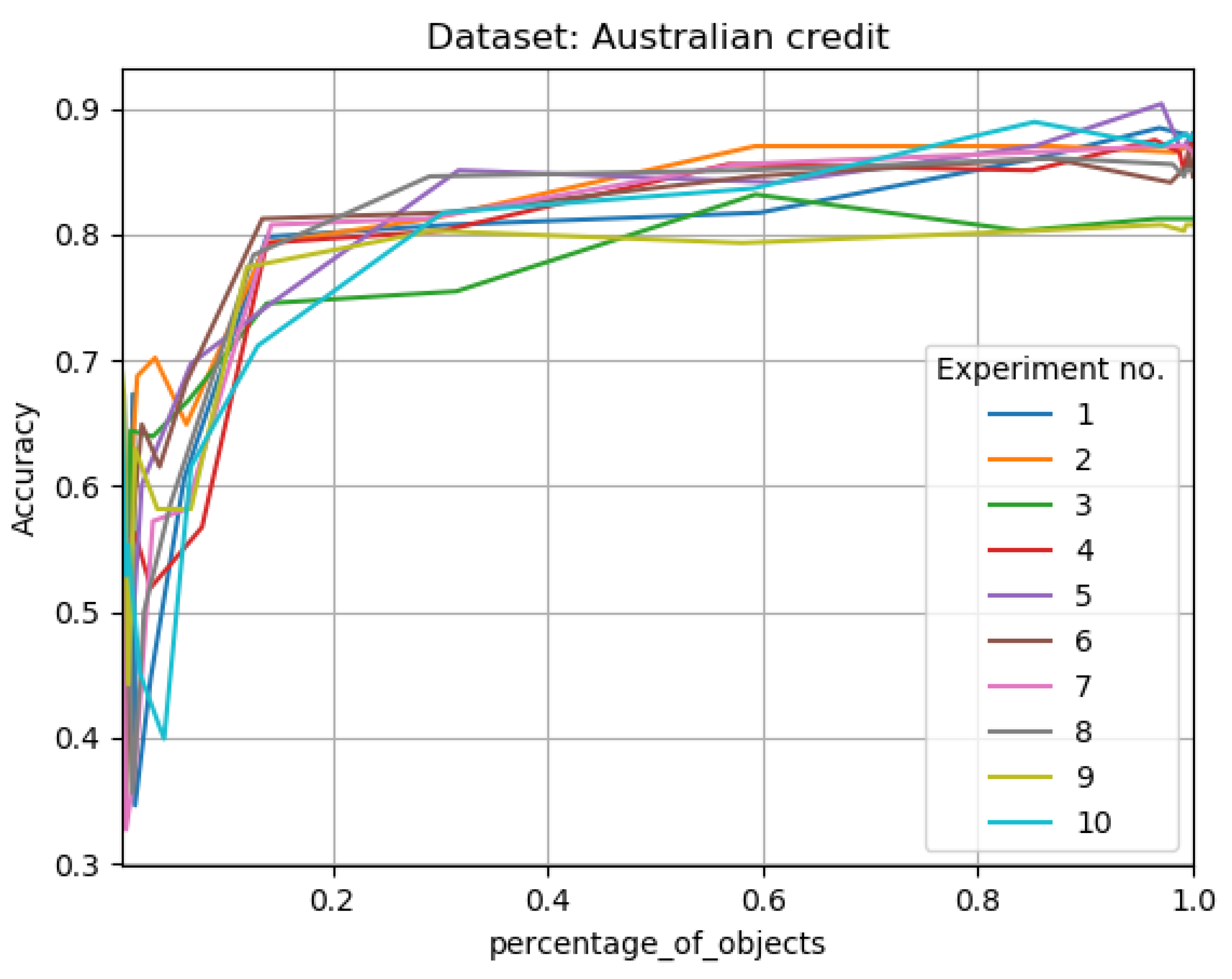
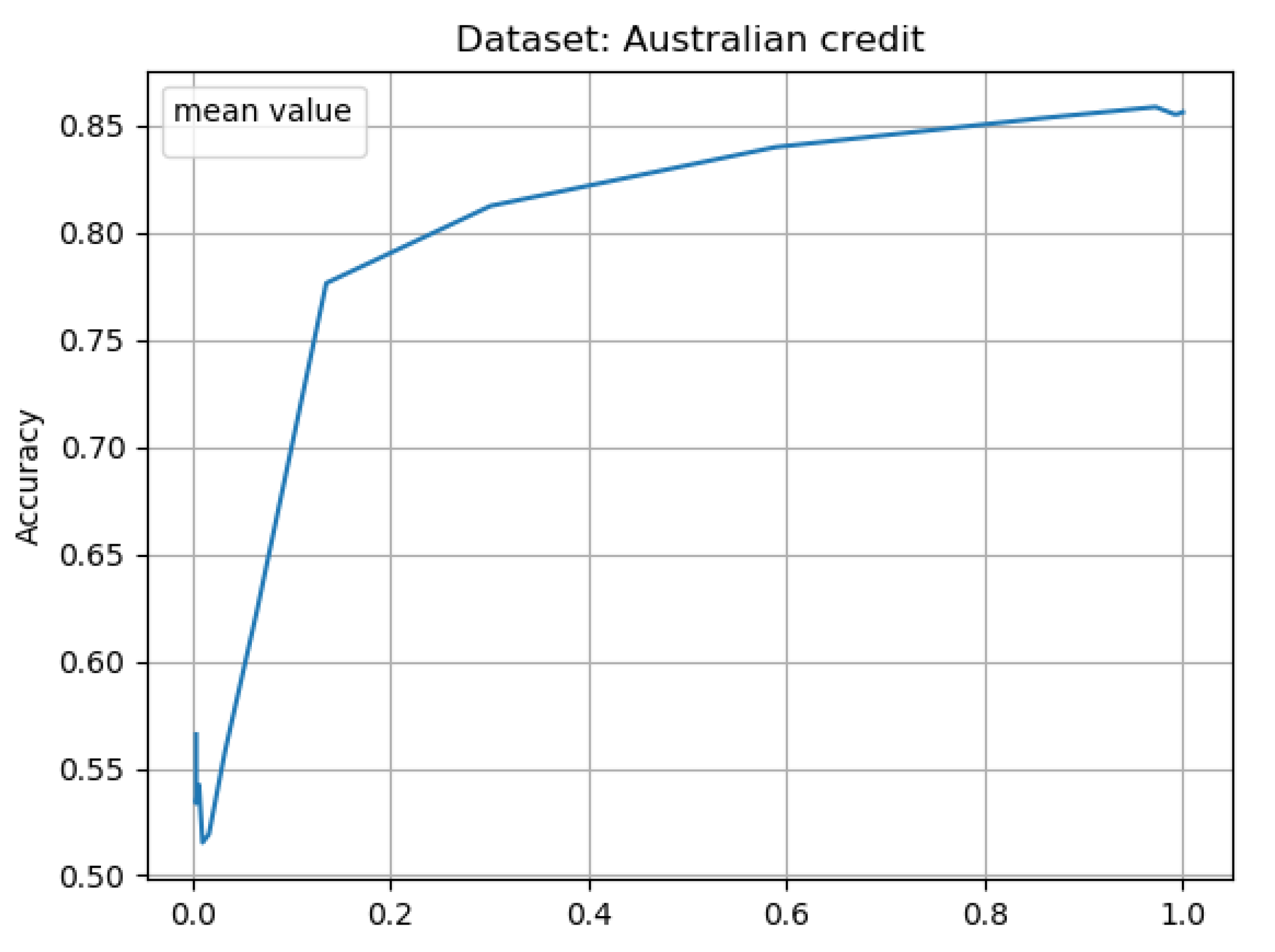
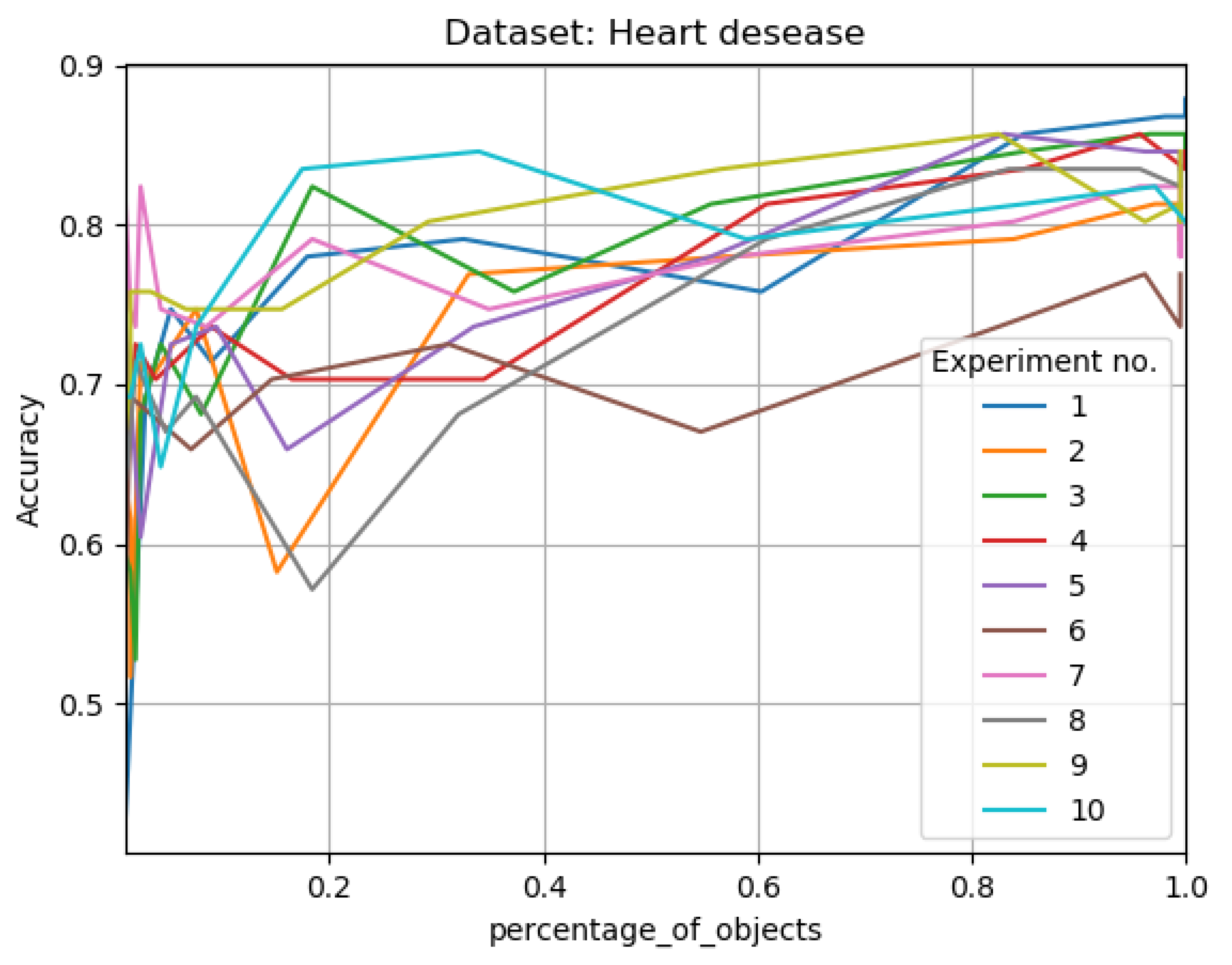
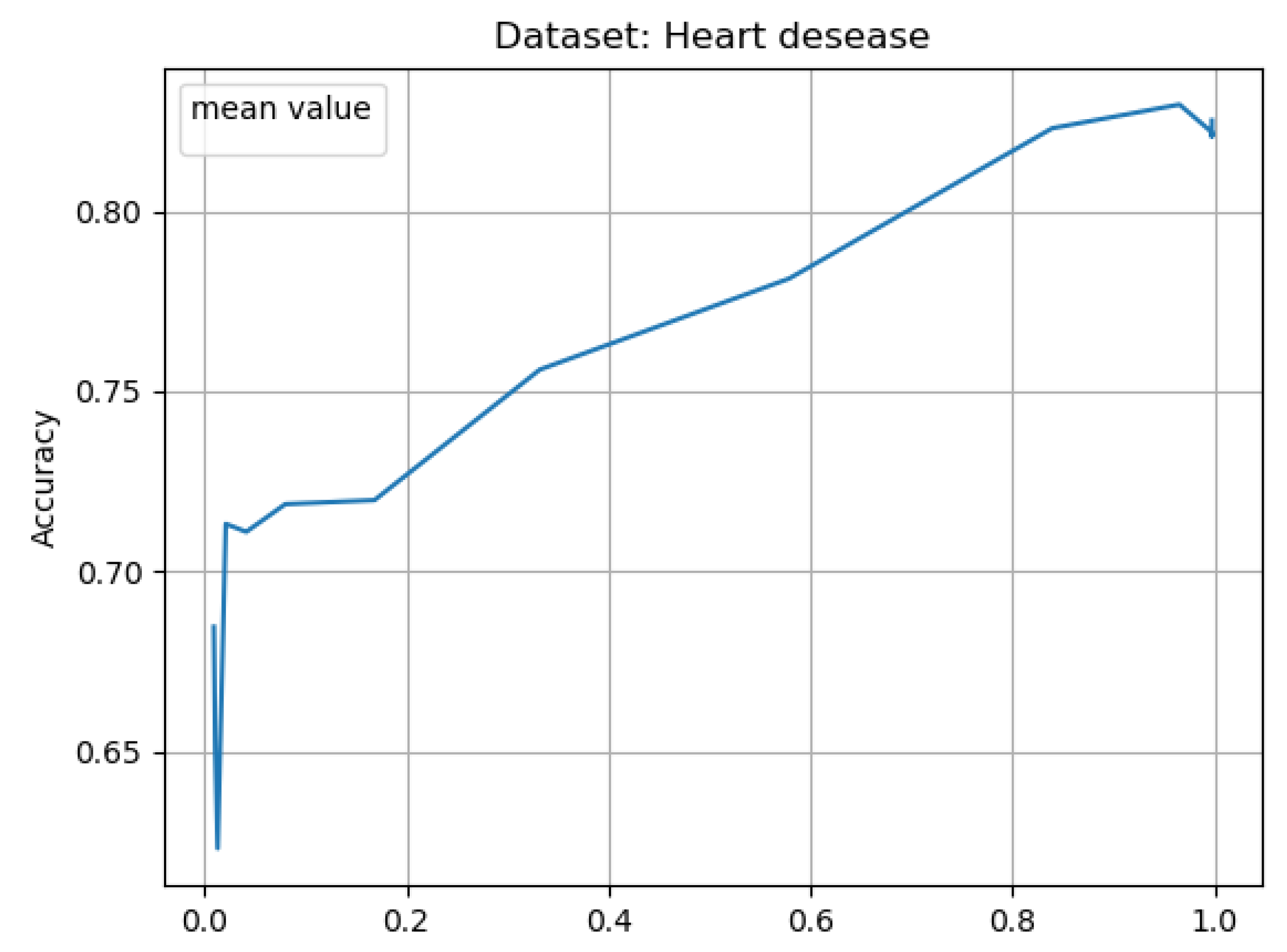
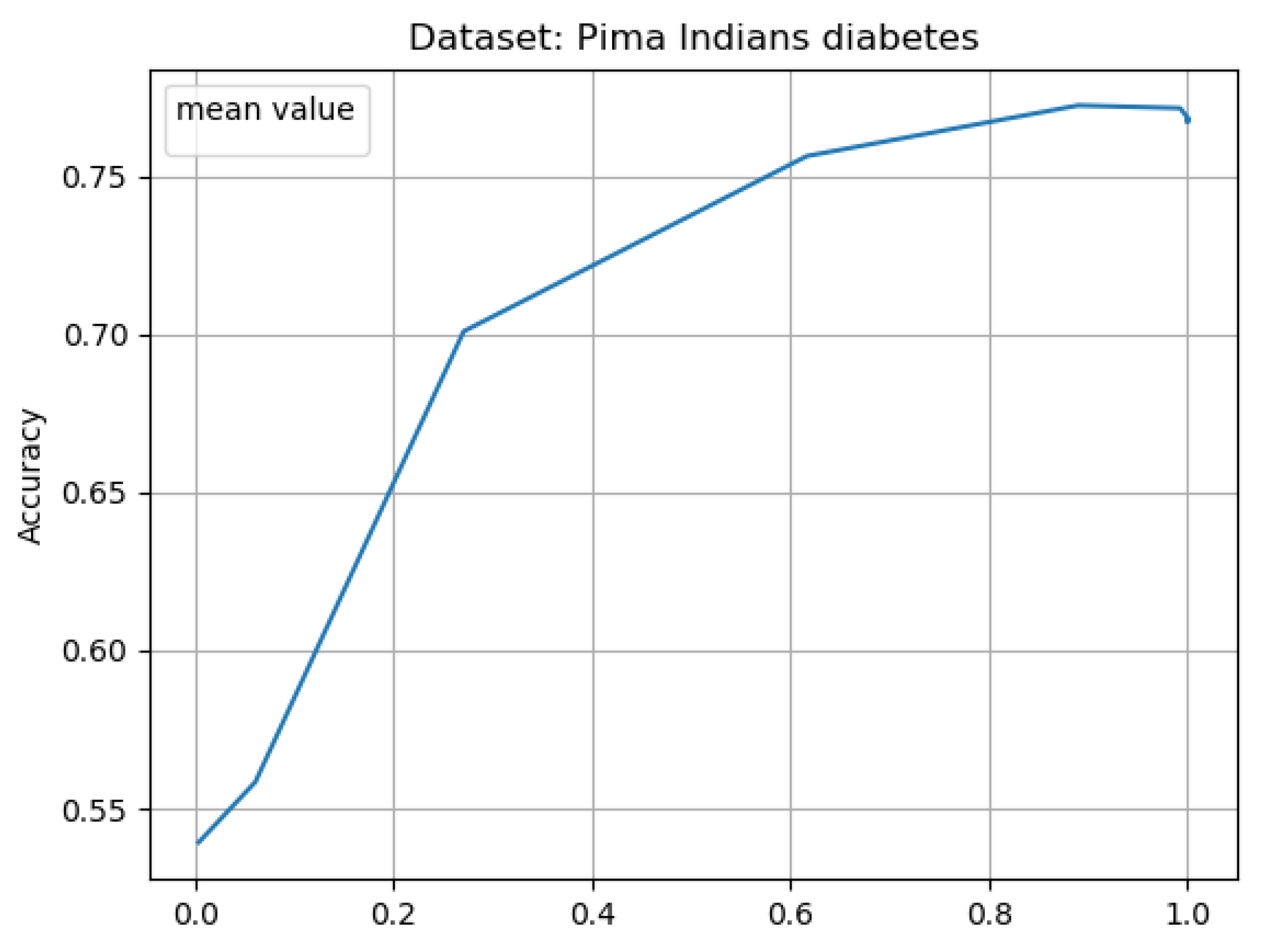
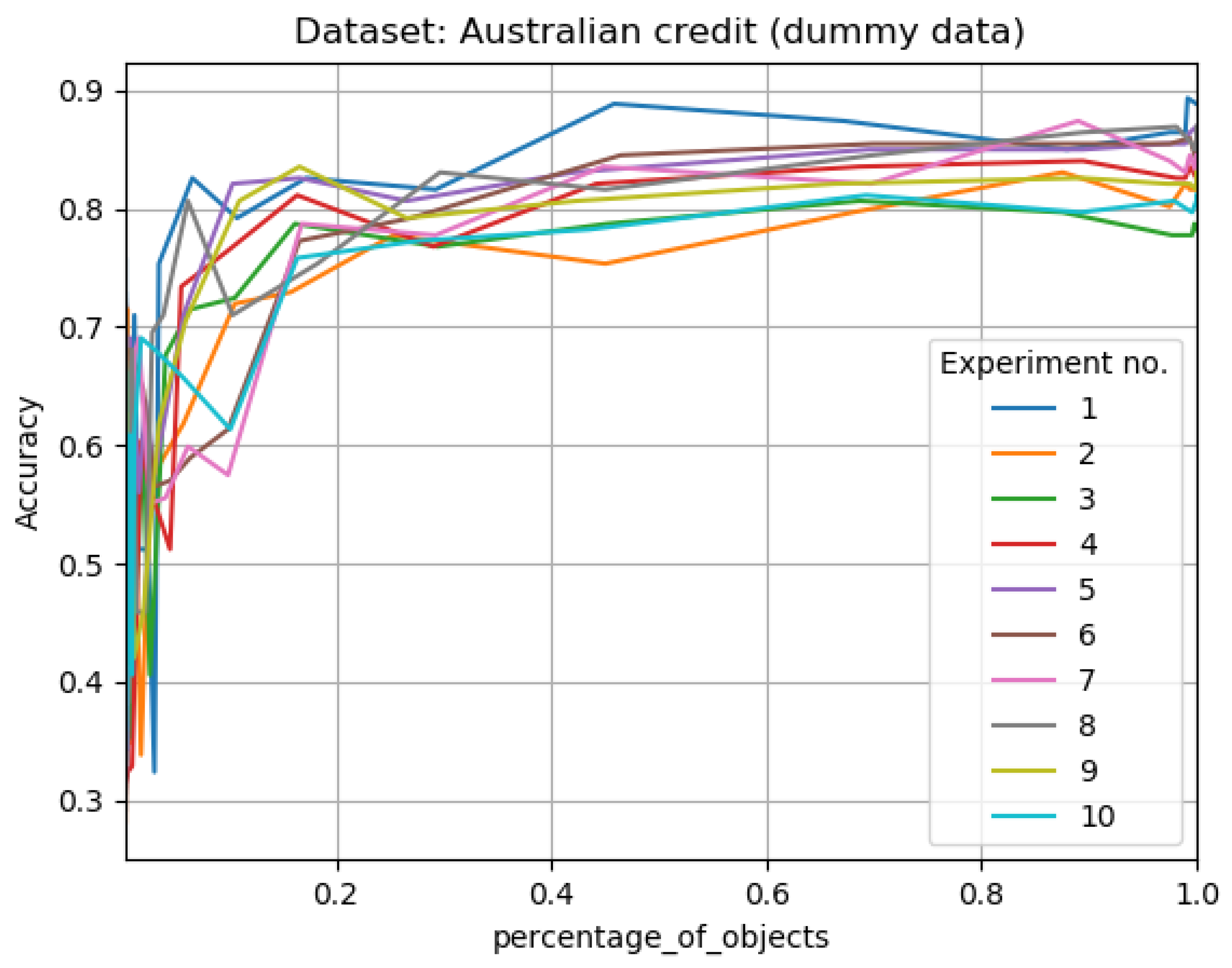
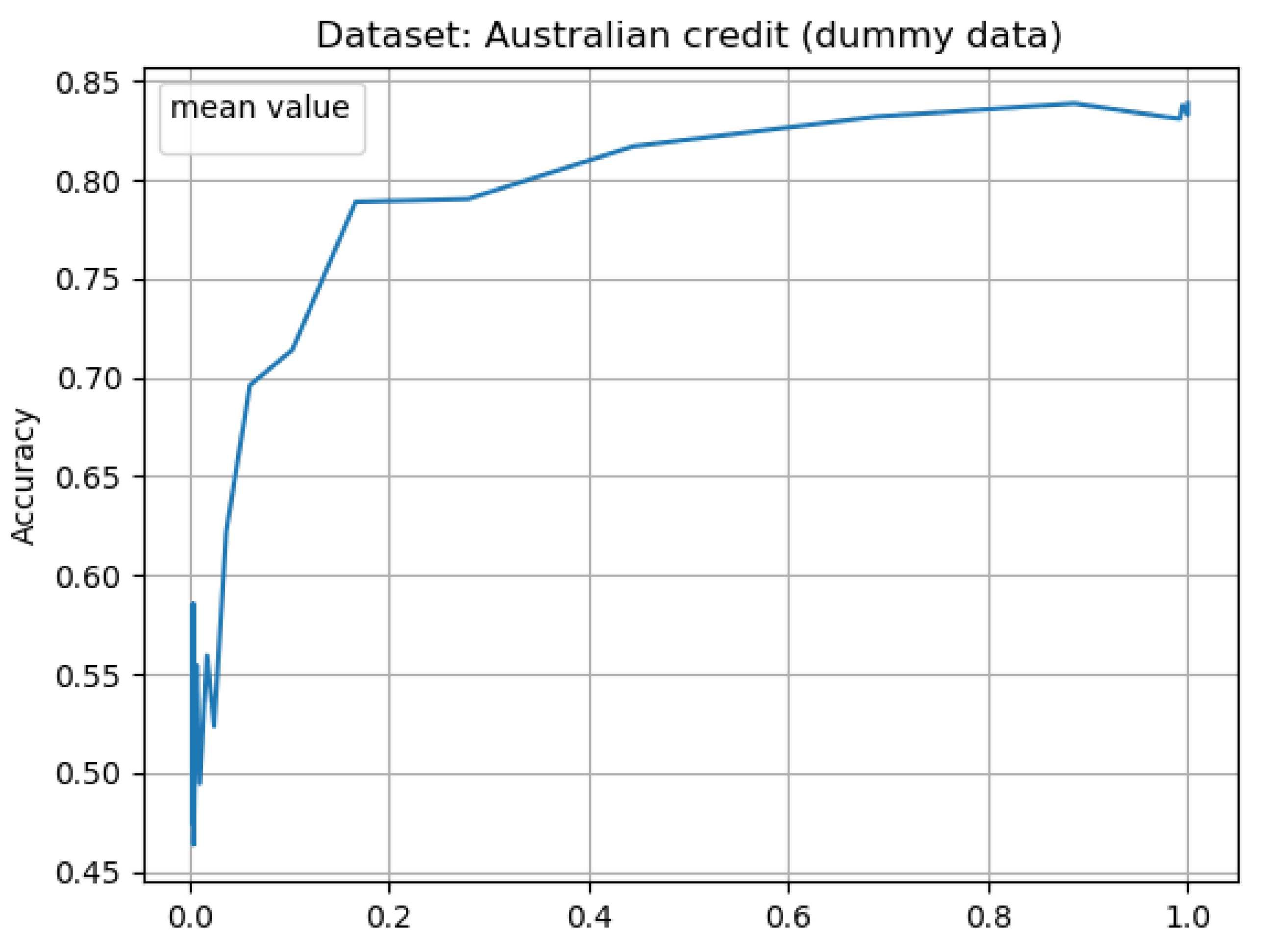
The Results of Experiments
- gran_rad—granulation radius as a percentage value,
- no_of_gran_objects—number of new objects in tested decision system after the granulation process,
- percentage_of_objects—percentage of objects in tested decision system comparing to the primary decision system size,
- time_to_learn—time that was needed to complete the learning process using given data,
- accuracy—classification accuracy for given neural network.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Haykin, S.S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Upper Saddle River, NJ, USA, 1999; ISBN 978-0-13-273350-2. [Google Scholar]
- Połap, D.; Woźniak, M.; Wei, W.; Damaševičius, R. Multi-threaded learning control mechanism for neural networks. Future Gener. Comput. Syst. 2018, 87, 16–34. [Google Scholar] [CrossRef]
- Woźniak, M.; Połap, D. Intelligent Home Systems for Ubiquitous User Support by Using Neural Networks and Rule-Based Approach. IEEE Trans. Ind. Inform. 2020, 16, 2651–2658. [Google Scholar] [CrossRef]
- Novikoff, A.B. On convergence proofs on perceptrons. In Proceedings of the Symposium on the Mathematical Theory of Automata, New York, NY, USA, 24–26 April 1962; Polytechnic Institute of Brooklyn: Brooklyn, NY, USA, 1962; Volume 12, pp. 615–622. [Google Scholar]
- Bryson, A.E.; Ho, Y.-C. Applied Optimal Control: Optimization, Estimation, and Control; Blaisdell Publishing Company: Waltham, MA, USA; Xerox College Publishing: Lexington, MA, USA, 1969; p. 481. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, M. Neural Networks and Deep Learning; Determination Press: San Francisco, CA, USA, 2015. [Google Scholar]
- Dick, S.; Kandel, A. Granular Computing in Neural Networks. In Granular Computing. Studies in Fuzziness and Soft Computing; Pedrycz, W., Ed.; Physica: Heidelberg, Germany, 2001; Volume 70. [Google Scholar]
- Leng, J.; Chen, Q.; Mao, N.; Jiang, P. Combining granular computing technique with deep learning for service planning under social manufacturing contexts. Knowl.-Based Syst. 2018, 143, 295–306, ISSN 0950-7051. [Google Scholar] [CrossRef]
- Ghiasi, B.; Sheikhian, H.; Zeynolabedin, A.; Niksokhan, M.H. Granular computing-neural network model for prediction of longitudinal dispersion coefficients in rivers. Water Sci. Technol. 2020. [Google Scholar] [CrossRef] [PubMed]
- Pawlak, Z. Rough Sets: Theoretical Aspects of Reasoning about Data; Kluwer: Alphen aan den Rijn, The Netherlands, 1991. [Google Scholar]
- Skowron, A.; Rauszer, C. The discernibility matrices and functions in information systems. In Intelligent Decision Support. Handbook of Applications and Advances of Rough Set Theory; Słowiński, R., Ed.; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1992; pp. 331–362. [Google Scholar]
- Pawlak, Z.; Skowron, A. A rough set approach for decision rules generation. In Proceedings of the IJCAI’93 Workshop W12: The Management of Uncertainty in AI, Chambery Savoie, France, 30 August 1993; ICSResearch Report 23/93. Warsaw University of Technology: Warsaw, Poland, 1993. [Google Scholar]
- Polkowski, L.; Skowron, A. Rough mereology. In Proceedings of the ISMIS’94, Charlotte, NC, USA, 16–19 October 1994. LNCS 867. [Google Scholar]
- Polkowski, L. Approximate Reasoning by Parts. An Introduction to Rough Mereology; Springer: Berlin, Germany, 2011. [Google Scholar]
- Polkowski, L. A model of granular computing with applications. In Proceedings of the 2006 IEEE International Conference on Granular Computing, Atlanta, GA, USA, 10–12 May 2006. [Google Scholar]
- Polkowski, L. A unified approach to granulation of knowledge and granular computing based on rough mereology: A survey. In Handbook of Granular Computing; John Wiley and Sons: New York, NY, USA, 2008; pp. 375–401. [Google Scholar]
- Polkowski, L. Formal granular calculi based on rough inclusions. In Proceedings of the IEEE 2005 Conference on Granular Computing GrC05, Beijing, China, 25–27 July 2005; IEEE Press: New York, NY, USA; pp. 57–62. [Google Scholar]
- Polkowski, L.; Artiemjew, P. Granular Computing in Decision Approximation—An Application of Rough Mereology. In Intelligent Systems Reference Library 77; Springer: Berlin/Heidelberg, Germany, 2015; pp. 1–422. ISBN 978-3-319-12879-5. [Google Scholar]
- University of California. Irvine Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 5 March 2020).
- Szypulski, J.; Artiemjew, P. The Rough Granular Approach to Classifier Synthesis by Means of SVM. In Proceedings of the International Joint Conference on Rough Sets, IJCRS’15, Tianjin, China, 20–23 November 2015; Lecture Notes in Computer Science (LNCS). Springer: Heidelberg, Germany, 2015; pp. 256–263. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| d | |||||
|---|---|---|---|---|---|
| 2 | 1 | 2 | 1 | 1 | |
| 3 | 2 | 3 | 3 | 1 | |
| 1 | 5 | 1 | 2 | 1 | |
| 6 | 2 | 3 | 8 | 2 | |
| 4 | 5 | 8 | 6 | 2 | |
| 5 | 1 | 8 | 1 | 2 |
| 1 | 0 | 0 | x | x | x | |
| 0 | 1 | 0 | x | x | x | |
| 0 | 0 | 1 | x | x | x | |
| x | x | x | 1 | 0 | 0 | |
| x | x | x | 0 | 1 | 1 | |
| x | x | x | 0 | 1 | 1 |
| 2 | 1 | 2 | 1 | 1 | |
| 3 | 2 | 3 | 3 | 1 | |
| 1 | 5 | 1 | 2 | 1 | |
| 6 | 2 | 3 | 8 | 2 | |
| 5 | 5 | 8 | 6 | 2 |
| 15 | 690 | |
| 9 | 768 | |
| 14 | 270 |
| no_of_gran_objects | percentage_of_objects | time_to_learn | accuracy | |
|---|---|---|---|---|
| Mean | Mean | Mean | Mean | |
| gran_rad | ||||
| 0.0667 | 2.0 | 0.4149 | 0.3666 | 0.5646 |
| 0.1333 | 2.0 | 0.4149 | 0.3607 | 0.5337 |
| 0.2000 | 3.4 | 0.7054 | 0.3691 | 0.5423 |
| 0.2667 | 5.1 | 1.0581 | 0.3685 | 0.5154 |
| 0.3333 | 8.2 | 1.7012 | 0.3696 | 0.5192 |
| 0.4000 | 16.0 | 3.3195 | 0.3778 | 0.5577 |
| 0.4667 | 31.6 | 6.5560 | 0.3777 | 0.6236 |
| 0.5333 | 65.3 | 13.5477 | 0.3916 | 0.7764 |
| 0.6000 | 145.3 | 30.1452 | 0.4287 | 0.8125 |
| 0.6667 | 283.8 | 58.8797 | 0.7464 | 0.8399 |
| 0.7333 | 412.9 | 85.6639 | 0.8210 | 0.8534 |
| 0.8000 | 468.8 | 97.2614 | 0.8585 | 0.8587 |
| 0.8667 | 477.9 | 99.1494 | 0.8532 | 0.8553 |
| 0.9333 | 479.3 | 99.4398 | 0.8817 | 0.8553 |
| 1.0000 | 482.0 | 100.0000 | 0.8995 | 0.8562 |
| no_of_gran_objects | percentage_of_objects | time_to_learn | accuracy | |
|---|---|---|---|---|
| Mean | Mean | Mean | Mean | |
| gran_rad | ||||
| 0.0714 | 2.0 | 0.9434 | 0.3702 | 0.6801 |
| 0.1429 | 2.3 | 1.0849 | 0.3786 | 0.6505 |
| 0.2143 | 2.8 | 1.3208 | 0.3708 | 0.6231 |
| 0.2857 | 4.5 | 2.1226 | 0.3758 | 0.7132 |
| 0.3571 | 8.8 | 4.1509 | 0.3928 | 0.7110 |
| 0.4286 | 17.0 | 8.0189 | 0.4064 | 0.7187 |
| 0.5000 | 35.7 | 16.8396 | 0.4209 | 0.7198 |
| 0.5714 | 70.4 | 33.2075 | 0.4299 | 0.7560 |
| 0.6429 | 122.7 | 57.8774 | 0.4571 | 0.7813 |
| 0.7143 | 177.9 | 83.9151 | 0.4872 | 0.8231 |
| 0.7857 | 204.6 | 96.5094 | 0.4942 | 0.8297 |
| 0.8571 | 211.4 | 99.7170 | 0.4995 | 0.8220 |
| 0.9286 | 211.4 | 99.7170 | 0.5023 | 0.8209 |
| 1.0000 | 211.4 | 99.7170 | 0.5010 | 0.8253 |
| no_of_gran_objects | percentage_of_objects | time_to_learn | accuracy | |
|---|---|---|---|---|
| Mean | Mean | Mean | Mean | |
| gran_rad | ||||
| 0.1111 | 2.0 | 0.3724 | 0.3679 | 0.5392 |
| 0.2222 | 32.6 | 6.0708 | 0.4544 | 0.5584 |
| 0.3333 | 145.3 | 27.0577 | 0.4899 | 0.7009 |
| 0.4444 | 331.0 | 61.6387 | 0.7895 | 0.7563 |
| 0.5556 | 477.8 | 88.9758 | 0.8457 | 0.7723 |
| 0.6667 | 533.0 | 99.2551 | 0.8643 | 0.7714 |
| 0.7778 | 537.0 | 100.0000 | 0.8882 | 0.7684 |
| 0.8889 | 537.0 | 100.0000 | 0.9313 | 0.7671 |
| 1.0000 | 537.0 | 100.0000 | 0.9417 | 0.7680 |
| no_of_gran_objects | percentage_of_objects | time_to_learn | accuracy | |
|---|---|---|---|---|
| Mean | Mean | Mean | Mean | |
| gran_rad | ||||
| 0.025 | 2.0 | 0.4149 | 0.3598 | 0.5534 |
| 0.050 | 2.0 | 0.4149 | 0.4274 | 0.5647 |
| 0.075 | 2.0 | 0.4149 | 0.4314 | 0.4836 |
| 0.100 | 2.0 | 0.4149 | 0.4373 | 0.4744 |
| 0.125 | 2.0 | 0.4149 | 0.4391 | 0.5536 |
| 0.150 | 2.0 | 0.4149 | 0.4327 | 0.5841 |
| 0.175 | 2.0 | 0.4149 | 0.4305 | 0.5778 |
| 0.200 | 2.0 | 0.4149 | 0.4349 | 0.4928 |
| 0.225 | 2.0 | 0.4149 | 0.4404 | 0.4826 |
| 0.250 | 2.0 | 0.4149 | 0.4348 | 0.5048 |
| 0.275 | 2.0 | 0.4149 | 0.4342 | 0.5082 |
| 0.300 | 2.0 | 0.4149 | 0.4586 | 0.5261 |
| 0.325 | 2.0 | 0.4149 | 0.4494 | 0.5652 |
| 0.350 | 2.0 | 0.4149 | 0.4476 | 0.5130 |
| 0.375 | 2.0 | 0.4149 | 0.4369 | 0.4797 |
| 0.400 | 2.0 | 0.4149 | 0.4608 | 0.5329 |
| 0.425 | 2.0 | 0.4149 | 0.4444 | 0.5256 |
| 0.450 | 2.0 | 0.4149 | 0.4443 | 0.5179 |
| 0.475 | 2.0 | 0.4149 | 0.4516 | 0.5135 |
| 0.500 | 2.0 | 0.4149 | 0.4436 | 0.5855 |
| 0.525 | 2.0 | 0.4149 | 0.4417 | 0.5034 |
| 0.550 | 2.2 | 0.4564 | 0.4517 | 0.4638 |
| 0.575 | 2.9 | 0.6017 | 0.4431 | 0.5063 |
| 0.600 | 3.7 | 0.7676 | 0.4476 | 0.5546 |
| 0.625 | 5.2 | 1.0788 | 0.4571 | 0.4947 |
| 0.650 | 8.7 | 1.8050 | 0.4506 | 0.5594 |
| 0.675 | 12.1 | 2.5104 | 0.4754 | 0.5237 |
| 0.700 | 18.0 | 3.7344 | 0.4782 | 0.6222 |
| 0.725 | 29.4 | 6.0996 | 0.5029 | 0.6961 |
| 0.750 | 49.9 | 10.3527 | 0.5087 | 0.7140 |
| 0.775 | 80.4 | 16.6805 | 0.5228 | 0.7889 |
| 0.800 | 134.8 | 27.9668 | 0.7577 | 0.7903 |
| 0.825 | 214.3 | 44.4606 | 0.8252 | 0.8169 |
| 0.850 | 331.3 | 68.7344 | 0.8719 | 0.8319 |
| 0.875 | 427.3 | 88.6515 | 0.9257 | 0.8386 |
| 0.900 | 470.7 | 97.6556 | 0.9505 | 0.8319 |
| 0.925 | 478.2 | 99.2116 | 0.9665 | 0.8309 |
| 0.950 | 479.5 | 99.4813 | 0.9729 | 0.8377 |
| 0.975 | 482.0 | 100.0000 | 0.9688 | 0.8329 |
| 1.000 | 482.0 | 100.0000 | 0.9697 | 0.8386 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ropiak, K.; Artiemjew, P. On a Hybridization of Deep Learning and Rough Set Based Granular Computing. Algorithms 2020, 13, 63. https://doi.org/10.3390/a13030063
Ropiak K, Artiemjew P. On a Hybridization of Deep Learning and Rough Set Based Granular Computing. Algorithms. 2020; 13(3):63. https://doi.org/10.3390/a13030063
Chicago/Turabian StyleRopiak, Krzysztof, and Piotr Artiemjew. 2020. "On a Hybridization of Deep Learning and Rough Set Based Granular Computing" Algorithms 13, no. 3: 63. https://doi.org/10.3390/a13030063
APA StyleRopiak, K., & Artiemjew, P. (2020). On a Hybridization of Deep Learning and Rough Set Based Granular Computing. Algorithms, 13(3), 63. https://doi.org/10.3390/a13030063