A Survey of Low-Rank Updates of Preconditioners for Sequences of Symmetric Linear Systems


Abstract
:1. Introduction
2. Low-Rank Updates
2.1. Deflation
| Algorithm 1 Deflated CG. |
| Choose an full column rank matrix W. Compute . |
| Choose ; Set and . |
| Compute ; |
| Set , |
| repeat until convergence |
| end repeat. |
2.2. Tuning
Digression
2.3. Spectral Preconditioners
3. Implementation and Computational Complexity
- All low-rank updates: Computation of operations).
- Broyden and SR1 only: Computation of (p applications of the initial preconditioner).
- All low-rank updates: Computation of operations).
- Multiplication of an matrix times a vector ( operations)
- Solution of a small linear system with matrix . ( operations).
- Multiplication of a matrix times a vector ( operations)
4. Choice of the Vectors
Using Previous Solution Vectors
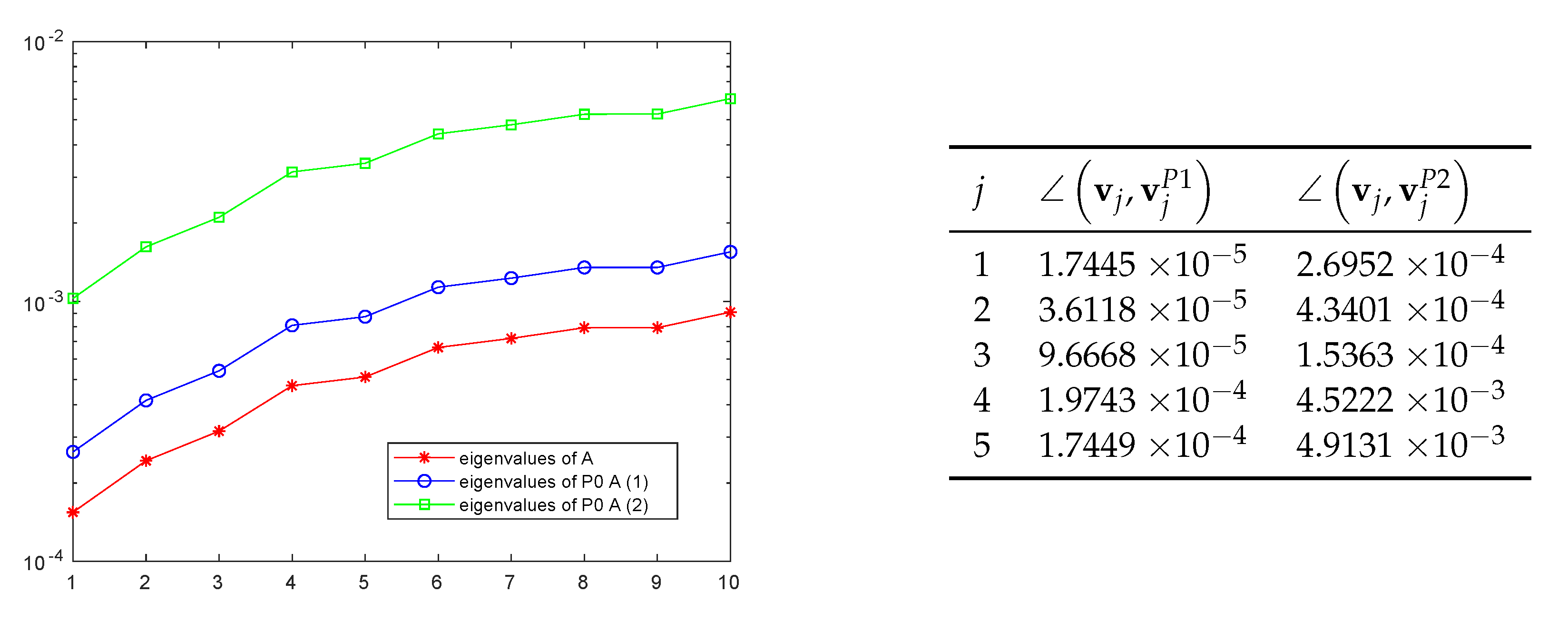
- A solution of the k-th linear system has with high probability non-negligible components in the directions of the leftmost eigenvectors of since, if , then , with the largest weights provided by the smallest eigenvalues.
- The leftmost eigenvector of are good approximation of the leftmost eigenvectors of .
- BFGS, with update directions as in (11).
- Spectral preconditioner, with update directions as in (11).
- BFGS, with the accurate leftmost eigenvectors of as the update directions.
5. Cost-Free Approximation of the Leftmost Eigenpairs
The Lanczos-PCG Connection
6. Sequences of Nonsymmetric Linear Systems
7. Numerical Results
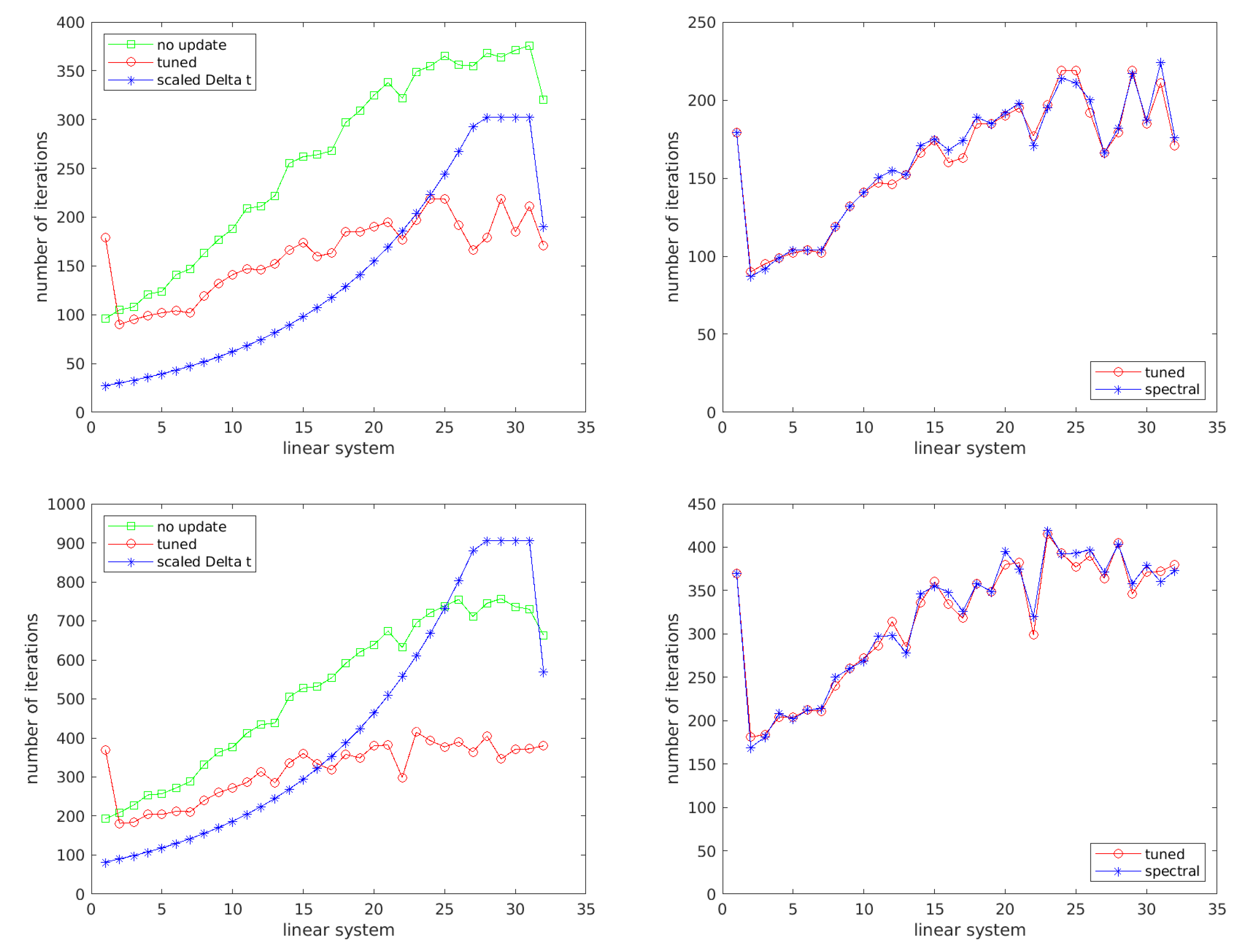
7.1. Fe Discretization of a Parabolic Equation
- (1)
- droptol applied to to enhance diagonal dominance; this resulted in a triangular Cholesky factor with density and
- (2)
- droptol applied to (density ).
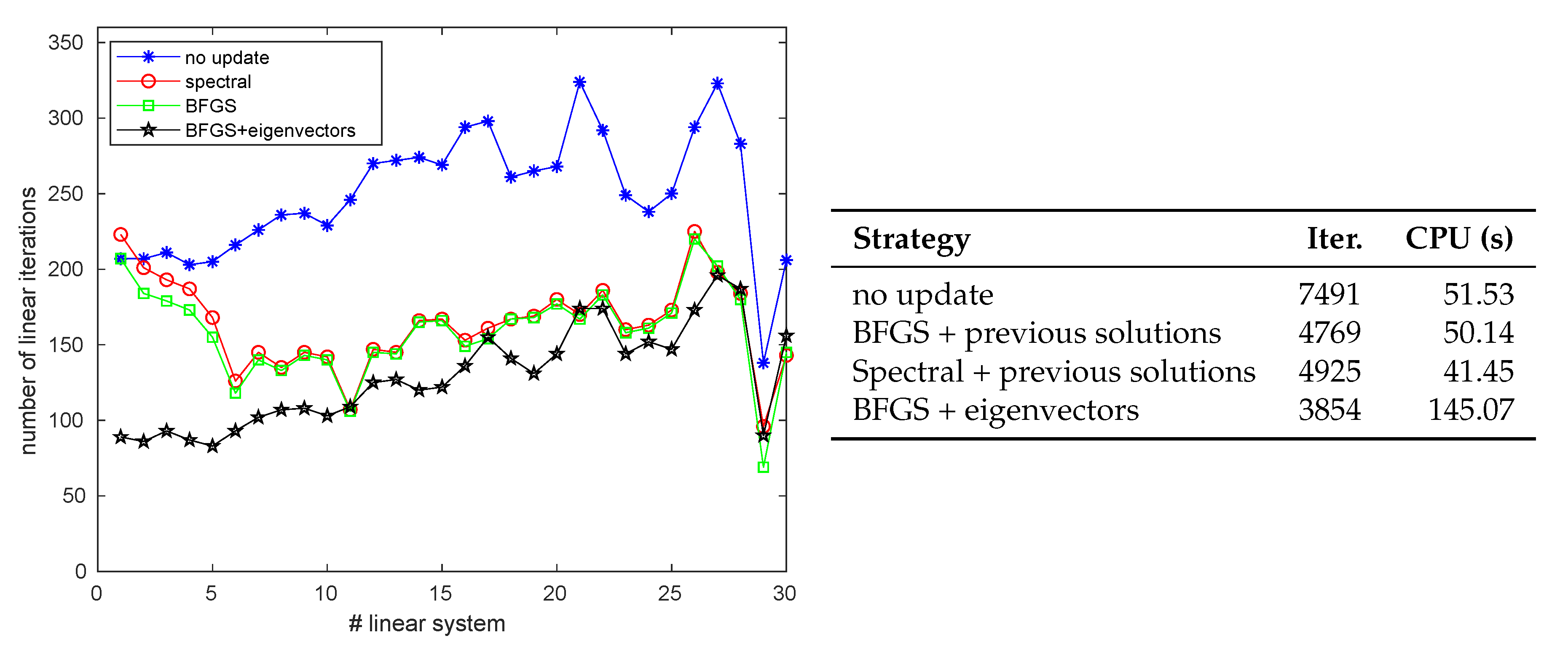
- Case (1). 179 PCG iterations for the first linear system; .
- Case (2). 370 PCG iterations for the first linear system; .
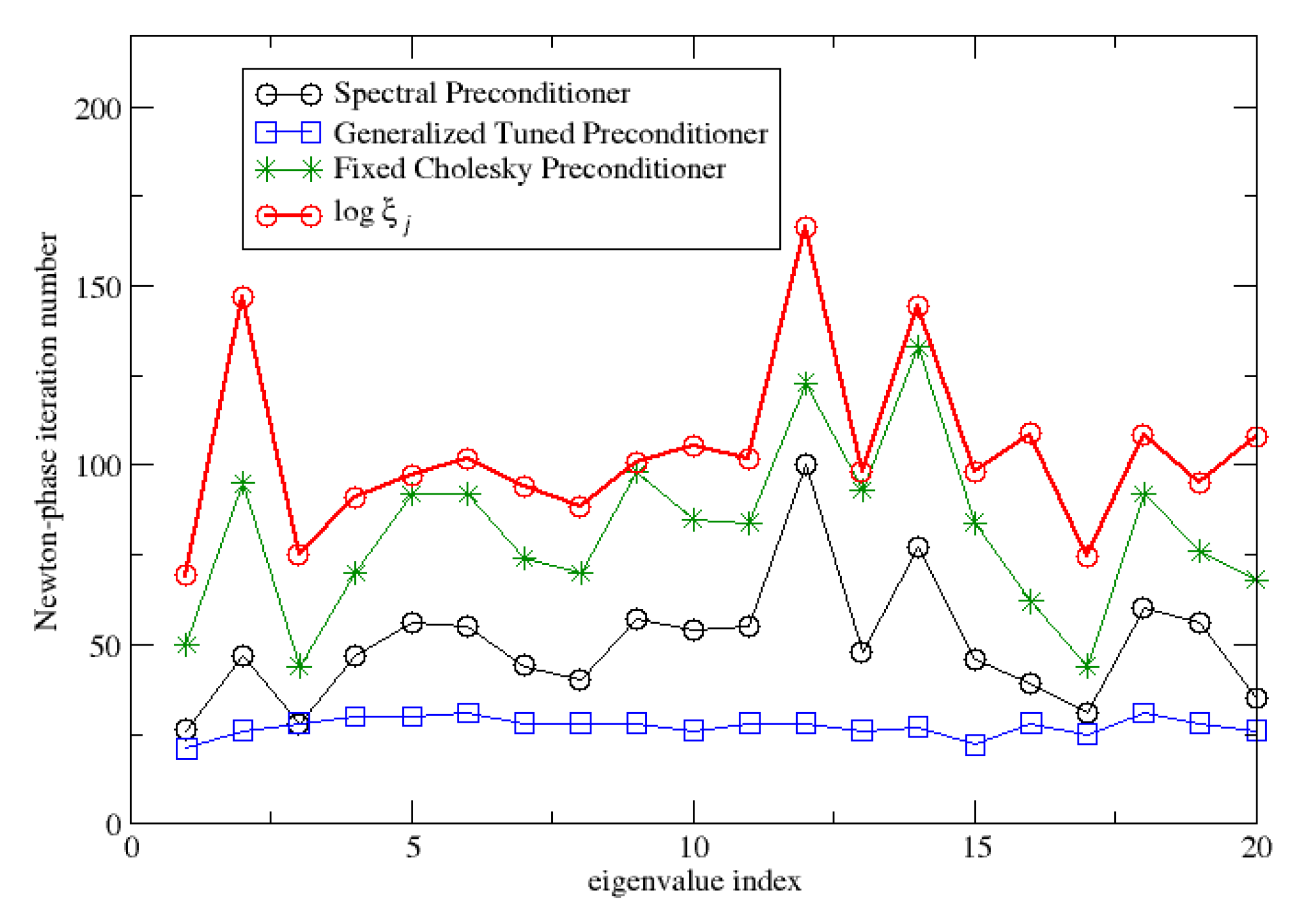
7.2. Iterative Eigensolvers
| Phase | When | What | Relevant Cost |
| C | once and for all | MVPs and applications of dot products. | |
| C | for every eigenpair | daxpys | |
| A | at each iteration | dot products 1 system solve of size 1 application of , daxpys |
8. Conclusions
- Deflation, aimed at shifting to zero a number of approximate eigenvalues of .
- Tuning, aimed at shifting to one a number of approximate eigenvalues of .
- Spectral preconditioners, aimed at adding one to a number of approximate eigenvalues of .
- A sequence of linear systems with constant or slightly varying matrices has to be solved.
- Either the smallest or the largest eigenvalues do not form a cluster.
Funding
Acknowledgments
Conflicts of Interest
References
- Kolotilina, L.Y.; Yeremin, A.Y. Factorized Sparse Approximate Inverse Preconditionings I. Theory. SIAM J. Matrix Anal. Appl. 1993, 14, 45–58. [Google Scholar] [CrossRef]
- Benzi, M.; Meyer, C.D.; Tůma, M. A Sparse Approximate Inverse Preconditioner for the Conjugate Gradient Method. SIAM J. Sci. Comput. 1996, 17, 1135–1149. [Google Scholar] [CrossRef] [Green Version]
- Elman, H.C.; Silvester, D.J.; Wathen, A.J. Finite Elements and Fast Iterative Solvers: With Applications in Incompressible Fluid Dynamics, 2nd ed.; Numerical Mathematics and Scientific Computation; Oxford University Press: New York, NY, USA, 2014; p. xiv+400. [Google Scholar]
- Nicolaides, R.A. Deflation of Conjugate Gradients with Applications to Boundary Value Problems. SIAM J. Numer. Anal. 1987, 24, 355–365. [Google Scholar] [CrossRef]
- Saad, Y.; Yeung, M.; Erhel, J.; Guyomarc’h, F. A deflated version of the conjugate gradient algorithm. SIAM J. Sci. Comput. 2000, 21, 1909–1926. [Google Scholar] [CrossRef] [Green Version]
- Morgan, R.B. A Restarted GMRES method augmented with eigenvectors. SIAM J. Matrix Anal. Appl. 1995, 16, 1154–1171. [Google Scholar] [CrossRef] [Green Version]
- Gu, X.M.; Huang, T.Z.; Yin, G.; Carpentieri, B.; Wen, C.; Du, L. Restarted Hessenberg method for solving shifted nonsymmetric linear systems. J. Comput. Appl. Math. 2018, 331, 166–177. [Google Scholar] [CrossRef] [Green Version]
- Carpentieri, B.; Duff, I.S.; Giraud, L. A class of spectral two-level preconditioners. SIAM J. Sci. Comput. 2003, 25, 749–765. [Google Scholar] [CrossRef] [Green Version]
- Giraud, L.; Gratton, S.; Martin, E. Incremental spectral preconditioners for sequences of linear systems. Appl. Numer. Math. 2007, 57, 1164–1180. [Google Scholar] [CrossRef]
- Tebbens, J.D.; Tůma, M. Efficient Preconditioning of Sequences of Nonsymmetric Linear Systems. SIAM J. Sci. Comput. 2007, 29, 1918–1941. [Google Scholar] [CrossRef] [Green Version]
- Duintjer Tebbens, J.; Tůma, M. Preconditioner updates for solving sequences of linear systems in matrix-free environment. Numer. Linear Algebra Appl. 2010, 17, 997–1019. [Google Scholar] [CrossRef] [Green Version]
- Benzi, M.; Bertaccini, D. Approximate inverse preconditioning for shifted linear systems. BIT 2003, 43, 231–244. [Google Scholar] [CrossRef]
- Bertaccini, D. Efficient preconditioning for sequences of parametric complex symmetric linear systems. Electron. Trans. Numer. Anal. 2004, 18, 49–64. [Google Scholar]
- Dostál, Z. Conjugate gradient method with preconditioning by projector. Int. J. Comput. Math. 1988, 23, 315–323. [Google Scholar] [CrossRef]
- Mansfield, L. On the use of deflation to improve the convergence of conjugate gradient iteration. Commun. Appl. Numer. Methods 1988, 4, 151–156. [Google Scholar] [CrossRef]
- Frank, J.; Vuik, C. On the Construction of Deflation-Based Preconditioners. SIAM J. Sci. Comput. 2001, 23, 442–462. [Google Scholar] [CrossRef] [Green Version]
- Gutknecht, M.H. Spectral deflation in Krylov solvers: A theory of coordinate space based methods. Electron. Trans. Numer. Anal. 2012, 39, 156–185. [Google Scholar]
- Freitag, M.A.; Spence, A. Convergence of inexact inverse iteration with application to preconditioned iterative solves. BIT Numer. Math. 2007, 47, 27–44. [Google Scholar] [CrossRef] [Green Version]
- Freitag, M.A.; Spence, A. A tuned preconditioner for inexact inverse iteration applied to Hermitian eigenvalue problems. IMA J. Numer. Anal. 2008, 28, 522–551. [Google Scholar] [CrossRef]
- Bergamaschi, L.; Bru, R.; Martínez, A.; Putti, M. Quasi-Newton preconditioners for the inexact Newton method. Electron. Trans. Numer. Anal. 2006, 23, 76–87. [Google Scholar]
- Bergamaschi, L.; Bru, R.; Martínez, A. Low-Rank Update of Preconditioners for the Inexact Newton Method with SPD Jacobian. Math. Comput. Model. 2011, 54, 1863–1873. [Google Scholar] [CrossRef]
- Bergamaschi, L.; Martínez, A. Efficiently preconditioned Inexact Newton methods for large symmetric eigenvalue problems. Optim. Methods Softw. 2015, 30, 301–322. [Google Scholar] [CrossRef] [Green Version]
- Bergamaschi, L.; Bru, R.; Martínez, A.; Mas, J.; Putti, M. Low-rank Update of Preconditioners for the nonlinear Richard’s Equation. Math. Comput. Model. 2013, 57, 1933–1941. [Google Scholar] [CrossRef]
- Bergamaschi, L.; Bru, R.; Martínez, A.; Putti, M. Quasi-Newton Acceleration of ILU Preconditioners for Nonlinear Two-Phase Flow Equations in Porous Media. Adv. Eng. Softw. 2012, 46, 63–68. [Google Scholar] [CrossRef]
- Martínez, A. Tuned preconditioners for the eigensolution of large SPD matrices arising in engineering problems. Numer. Linear Algebra Appl. 2016, 23, 427–443. [Google Scholar] [CrossRef]
- Freitag, M.A.; Spence, A. Shift-invert Arnoldi’s method with preconditioned iterative solves. SIAM J. Matrix Anal. Appl. 2009, 31, 942–969. [Google Scholar] [CrossRef]
- Bergamaschi, L.; Martínez, A. Two-stage spectral preconditioners for iterative eigensolvers. Numer. Linear Algebra Appl. 2017, 24, e2084. [Google Scholar] [CrossRef]
- Bergamaschi, L.; Marín, J.; Martínez, A. Compact Quasi-Newton preconditioners for SPD linear systems. arXiv 2020, arXiv:2001.01062. [Google Scholar]
- Nabben, R.; Vuik, C. A comparison of deflation and the balancing preconditioner. SIAM J. Sci. Comput. 2006, 27, 1742–1759. [Google Scholar] [CrossRef]
- Xue, F.; Elman, H.C. Convergence analysis of iterative solvers in inexact Rayleigh quotient iteration. SIAM J. Matrix Anal. Appl. 2009, 31, 877–899. [Google Scholar] [CrossRef] [Green Version]
- Bergamaschi, L.; De Simone, V.; di Serafino, D.; Martínez, A. BFGS-like updates of constraint preconditioners for sequences of KKT linear systems. Numer. Linear Algebra Appl. 2018, 25, 1–19. [Google Scholar] [CrossRef]
- Gratton, S.; Mercier, S.; Tardieu, N.; Vasseur, X. Limited memory preconditioners for symmetric indefinite problems with application to structural mechanics. Numer. Linear Algebra Appl. 2016, 23, 865–887. [Google Scholar] [CrossRef] [Green Version]
- Bergamaschi, L.; Gondzio, J.; Martínez, A.; Pearson, J.; Pougkakiotis, S. A New Preconditioning Approach for an Interior Point-Proximal Method of Multipliers for Linear and Convex Quadratic Programming. arXiv 2019, arXiv:1912.10064. [Google Scholar]
- Duff, I.S.; Giraud, L.; Langou, J.; Martin, E. Using spectral low rank preconditioners for large electromagnetic calculations. Int. J. Numer. Methods Eng. 2005, 62, 416–434. [Google Scholar] [CrossRef] [Green Version]
- Bergamaschi, L.; Facca, E.; Martínez, A.; Putti, M. Spectral preconditioners for the efficient numerical solution of a continuous branched transport model. J. Comput. Appl. Math. 2019, 254, 259–270. [Google Scholar] [CrossRef]
- Golub, G.H.; van Loan, C.F. Matrix Computation; Johns Hopkins University Press: Baltimore, MD, USA, 1991. [Google Scholar]
- Saad, Y. Iterative Methods for Sparse Linear Systems, 2nd ed.; SIAM: Philadelphia, PA, USA, 2003. [Google Scholar]
- Stathopoulos, A.; Orginos, K. Computing and deflating eigenvalues while solving multiple right-hand side linear systems with an application to quantum chromodynamics. SIAM J. Sci. Comput. 2010, 32, 439–462. [Google Scholar] [CrossRef]
- Greenbaum, A. Iterative Methods for Solving Linear Systems; SIAM: Philadelphia, PA, USA, 1997. [Google Scholar]
- Embree, M. How Descriptive Are GMRES Convergence Bounds? Technical Report; Technical Report; Oxford University Computing Laboratory: Oxford, UK, 1999. [Google Scholar]
- Morgan, R.B. GMRES with Deflated Restarting. SIAM J. Sci. Comput. 2002, 24, 20–37. [Google Scholar] [CrossRef] [Green Version]
- Simoncini, V. Restarted Full Orthogonalization Method for Shifted Linear Systems. BIT Numer. Math. 2003, 43, 459–466. [Google Scholar] [CrossRef]
- Bellavia, S.; De Simone, V.; Di Serafino, D.; Morini, B. Efficient preconditioner updates for shifted linear systems. SIAM J. Sci. Comput. 2011, 33, 1785–1809. [Google Scholar] [CrossRef]
- Luo, W.H.; Huang, T.Z.; Li, L.; Zhang, Y.; Gu, X.M. Efficient preconditioner updates for unsymmetric shifted linear systems. Comput. Math. Appl. 2014, 67, 1643–1655. [Google Scholar] [CrossRef]
- Zhu, L.; Gong, H.; Li, X.; Wang, R.; Chen, B.; Dai, Z.; Teatini, P. Land subsidence due to groundwater withdrawal in the northern Beijing plain, China. Eng. Geol. 2015, 193, 243–255. [Google Scholar] [CrossRef]
- Knyazev, A. Toward the optimal preconditioned eigensolver: Locally optimal block preconditioned conjugate gradient method. SIAM J. Sci. Comput. 2001, 23, 517–541. [Google Scholar] [CrossRef]
- Bergamaschi, L.; Gambolati, G.; Pini, G. Asymptotic Convergence of Conjugate Gradient Methods for the Partial Symmetric Eigenproblem. Numer. Linear Algebra Appl. 1997, 4, 69–84. [Google Scholar] [CrossRef]
- Sleijpen, G.L.G.; van der Vorst, H.A. A Jacobi-Davidson method for Linear Eigenvalue Problems. SIAM J. Matrix Anal. Appl. 1996, 17, 401–425. [Google Scholar] [CrossRef]
- Notay, Y. Combination of Jacobi-Davidson and conjugate gradients for the partial symmetric eigenproblem. Numer. Linear Algebra Appl. 2002, 9, 21–44. [Google Scholar] [CrossRef]
- Bergamaschi, L.; Martínez, A. Generalized Block Tuned preconditioners for SPD eigensolvers. Springer INdAM Ser. 2019, 30, 237–252. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| direct | ||
| inverse | ||
| block |
| direct | , | |
| inverse | , | |
| block | , |
| direct | |
| inverse | |
| block | (1) |
| No Update | Tuned | Deflated | Spectral | |
|---|---|---|---|---|
| exact | 466 | 254 | 254 | 254 |
| 466 | 261 | 259 | 290 | |
| 466 | 378 | 260 | 286 |
| No Update | Tuned | Deflated | Spectral | |
|---|---|---|---|---|
| exact | 466 | 254 | 254 | 254 |
| 466 | 296 | 296 | 297 | |
| 466 | 362 | 361 | 369 |
| IC () | IC () | |||||
|---|---|---|---|---|---|---|
| update | # its | CPU | CPU per it. | # its | CPU | CPU per it. |
| no update | 8231 | 805.8 | 0.098 | 16582 | 1177.2 | 0.071 |
| spectral | 5213 | 557.3 | 0.107 | 10225 | 817.5 | 0.080 |
| SR1 tuned | 5161 | 551.7 | 0.107 | 10152 | 811.4 | 0.080 |
| BFGS tuned | 5178 | 612.3 | 0.118 | 10198 | 924.6 | 0.091 |
| deflated | † | † | † | † | † | † |
| DACG | Newton | Total | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Iterations | CPU | |||||||||
| Prec. | win | Its. | CPU | OUT | Inner | MVP | CPU | |||
| Fixed | 0 | 0 | 1510 | 15.86 | 153 | 2628 | 34.12 | 4291 | 52.97 | |
| SR1 Tuned | 10 | 10 | 1335 | 14.89 | 137 | 2187 | 32.19 | 3659 | 51.48 | |
| GBT | 5 | 10 | 777 | 11.16 | 44 | 607 | 9.42 | 1428 | 20.74 | |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bergamaschi, L. A Survey of Low-Rank Updates of Preconditioners for Sequences of Symmetric Linear Systems. Algorithms 2020, 13, 100. https://doi.org/10.3390/a13040100
Bergamaschi L. A Survey of Low-Rank Updates of Preconditioners for Sequences of Symmetric Linear Systems. Algorithms. 2020; 13(4):100. https://doi.org/10.3390/a13040100
Chicago/Turabian StyleBergamaschi, Luca. 2020. "A Survey of Low-Rank Updates of Preconditioners for Sequences of Symmetric Linear Systems" Algorithms 13, no. 4: 100. https://doi.org/10.3390/a13040100
APA StyleBergamaschi, L. (2020). A Survey of Low-Rank Updates of Preconditioners for Sequences of Symmetric Linear Systems. Algorithms, 13(4), 100. https://doi.org/10.3390/a13040100