p-Refined Multilevel Quasi-Monte Carlo for Galerkin Finite Element Methods with Applications in Civil Engineering

 , , and
, , and
Abstract
:1. Introduction
2. p-Refined Multilevel Quasi-Monte Carlo
2.1. The Multilevel and Multilevel Quasi Monte Carlo Methods
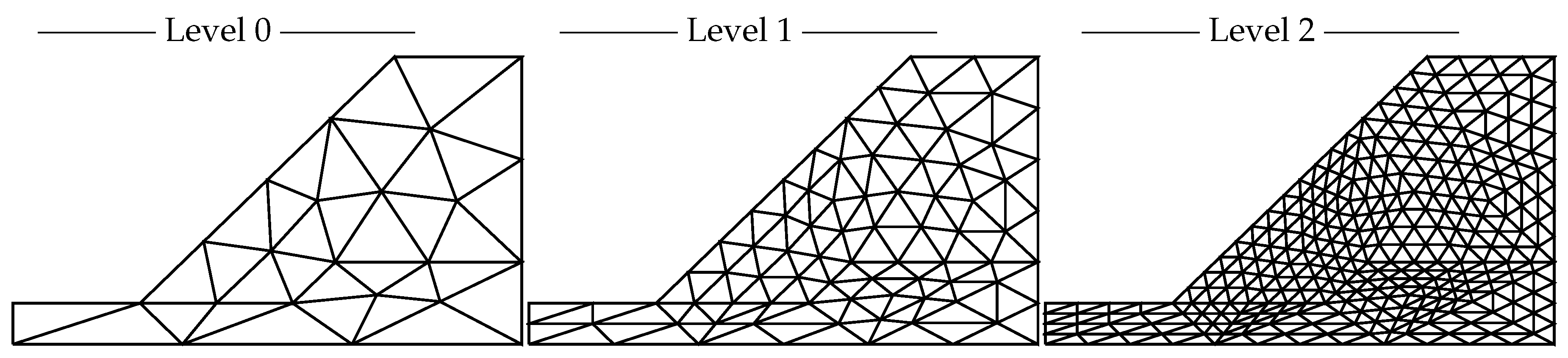
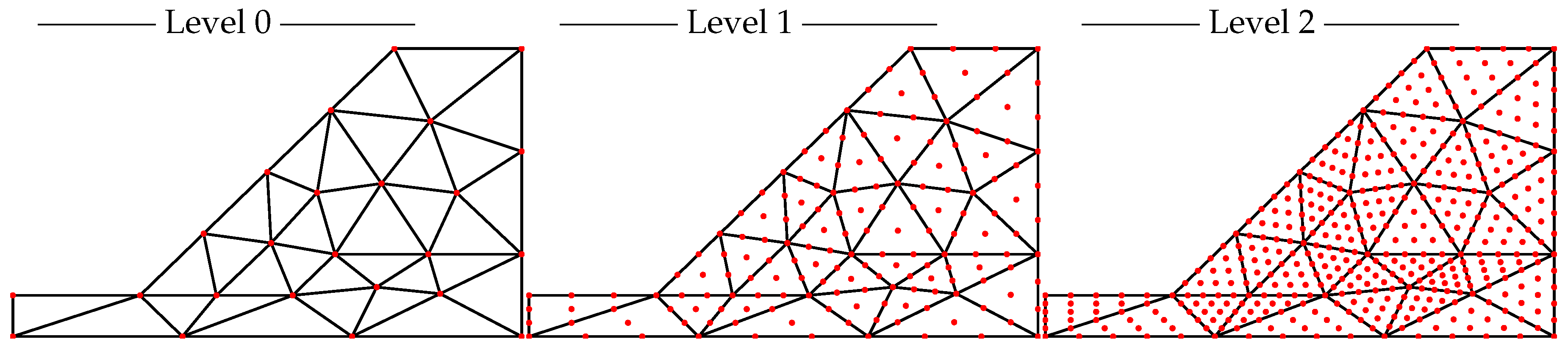
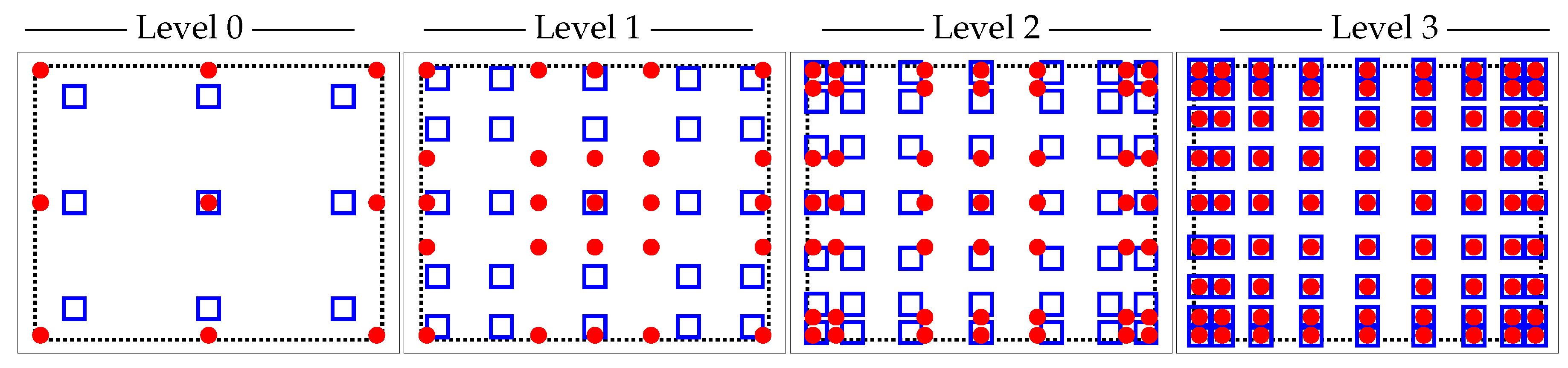
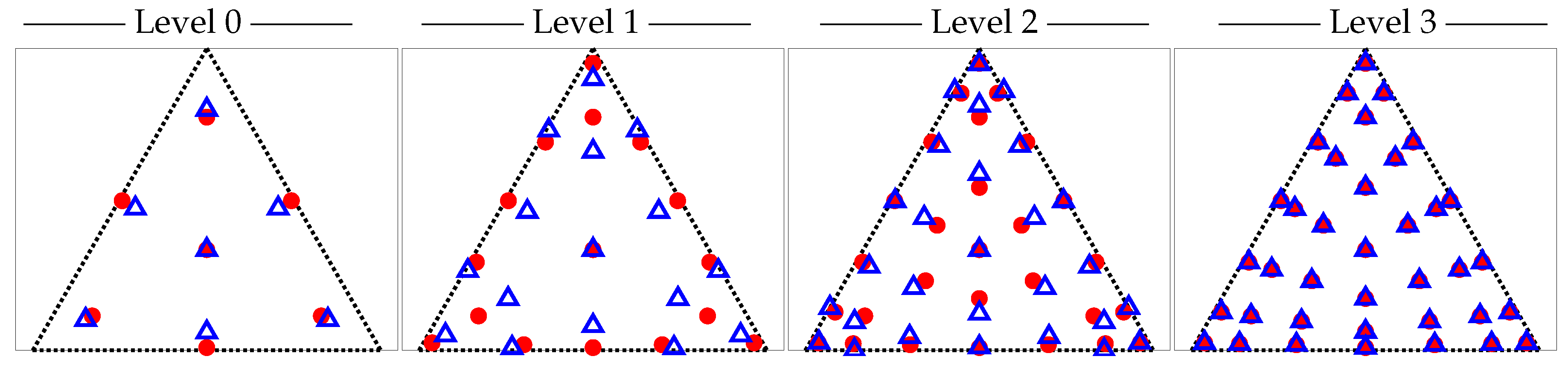
2.2. Mesh Hierarchies
- 1.
- a closed subset with nonempty interior and piecewise smooth boundary, i.e., the element domain,
- 2.
- a finite-dimensional space of functions on T, i.e., the space of shape functions, and
- 3.
- a basis for, i.e., the set of nodal variables.
2.3. Algorithm
| Algorithm 1: p-MLQMC. |
 |
| Algorithm 2: Point Set Generation |
 |
2.4. Cost Complexity Theorem
- 1.
- ,
- 2.
- and
- 3.
- .
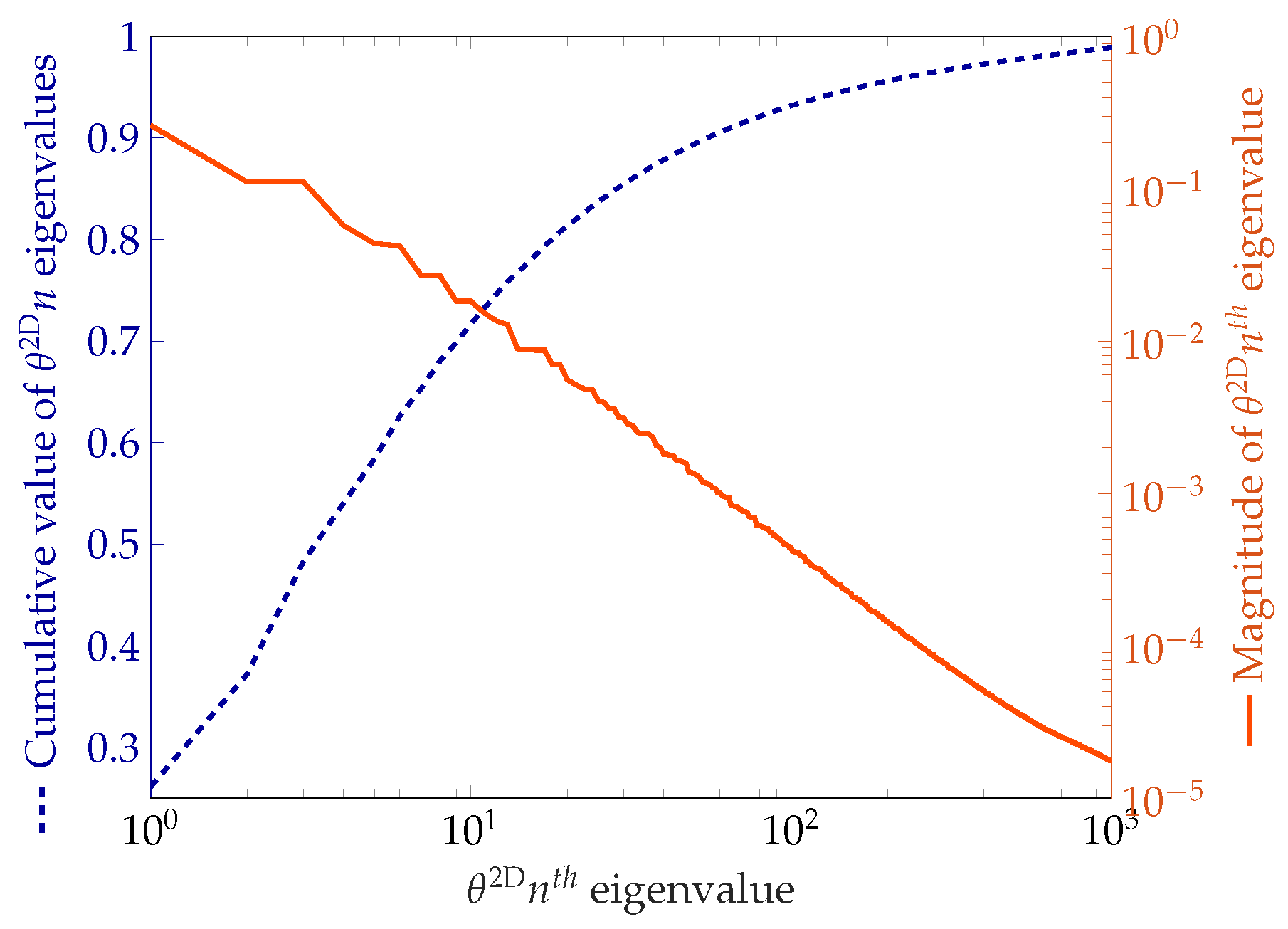
2.5. Modeling the Spatial Variability
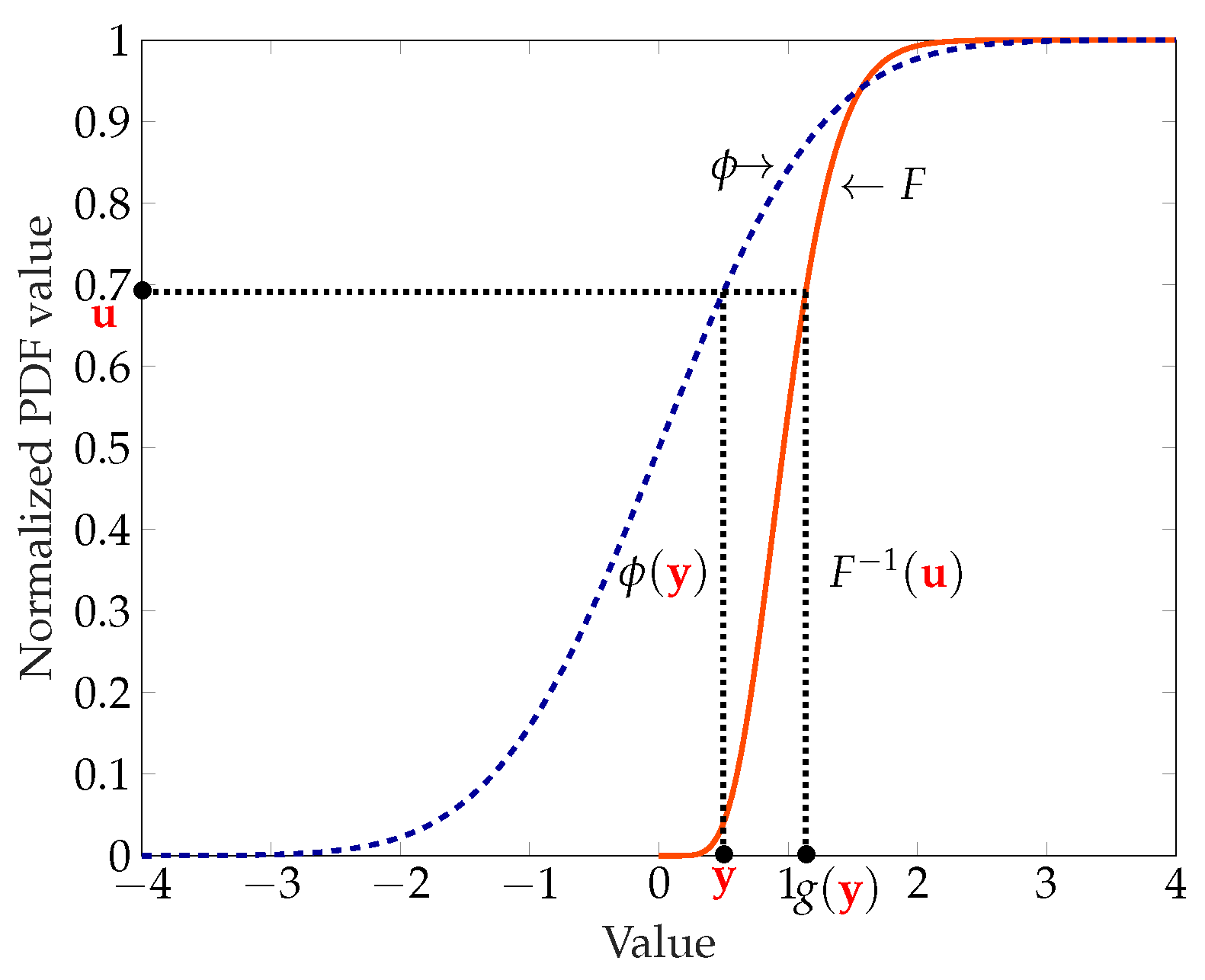
2.6. Incorporating the Uncertainty in the Model
3. Model Problems and Numerical Results
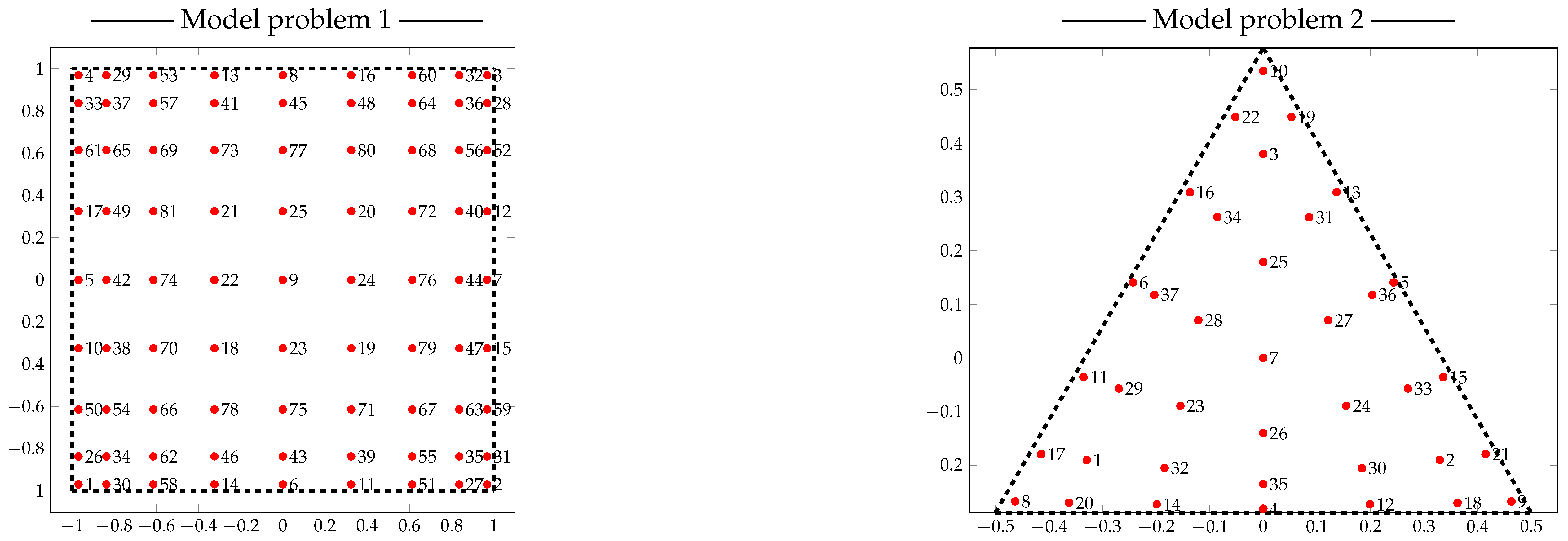
3.1. Model Problem 1
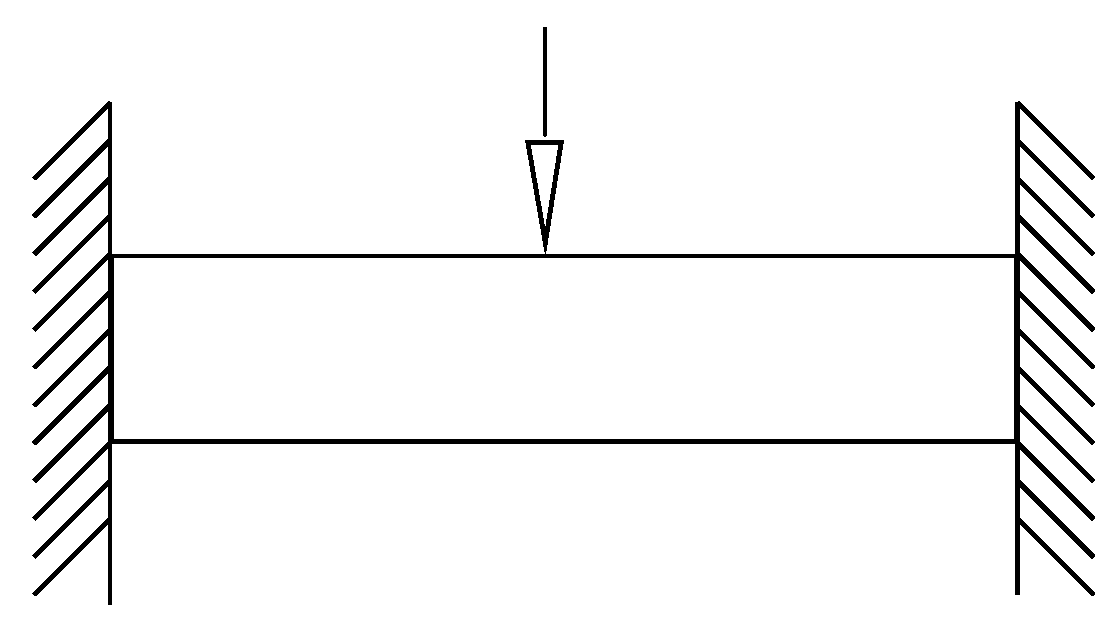
3.1.1. Description
3.1.2. Finite Element Method
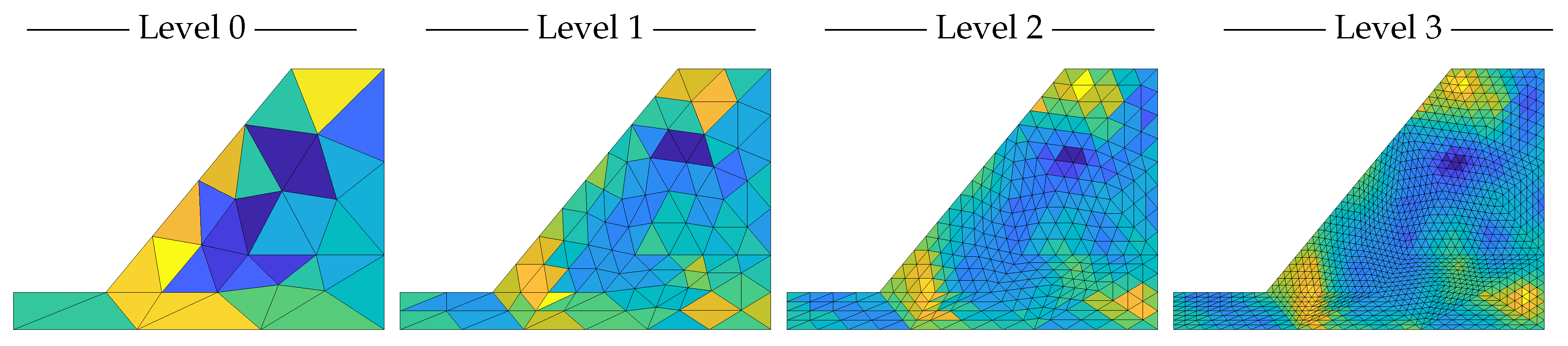
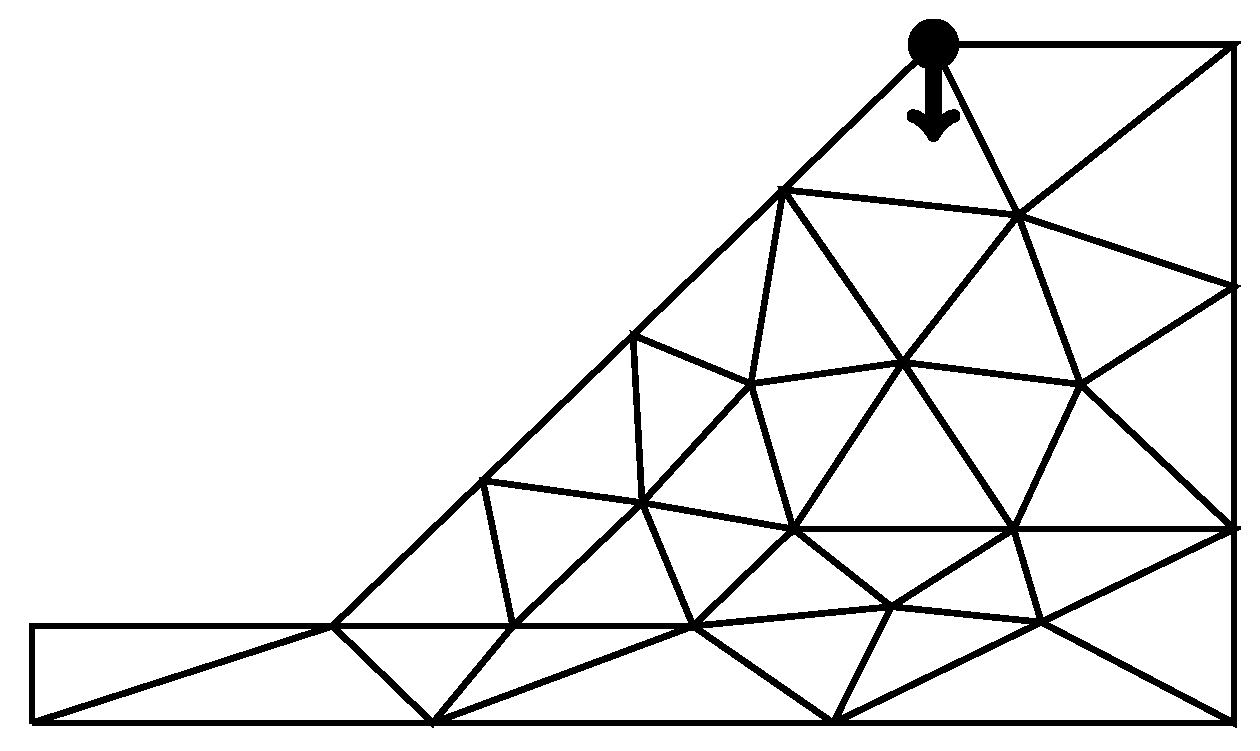
3.1.3. Mesh Discretization
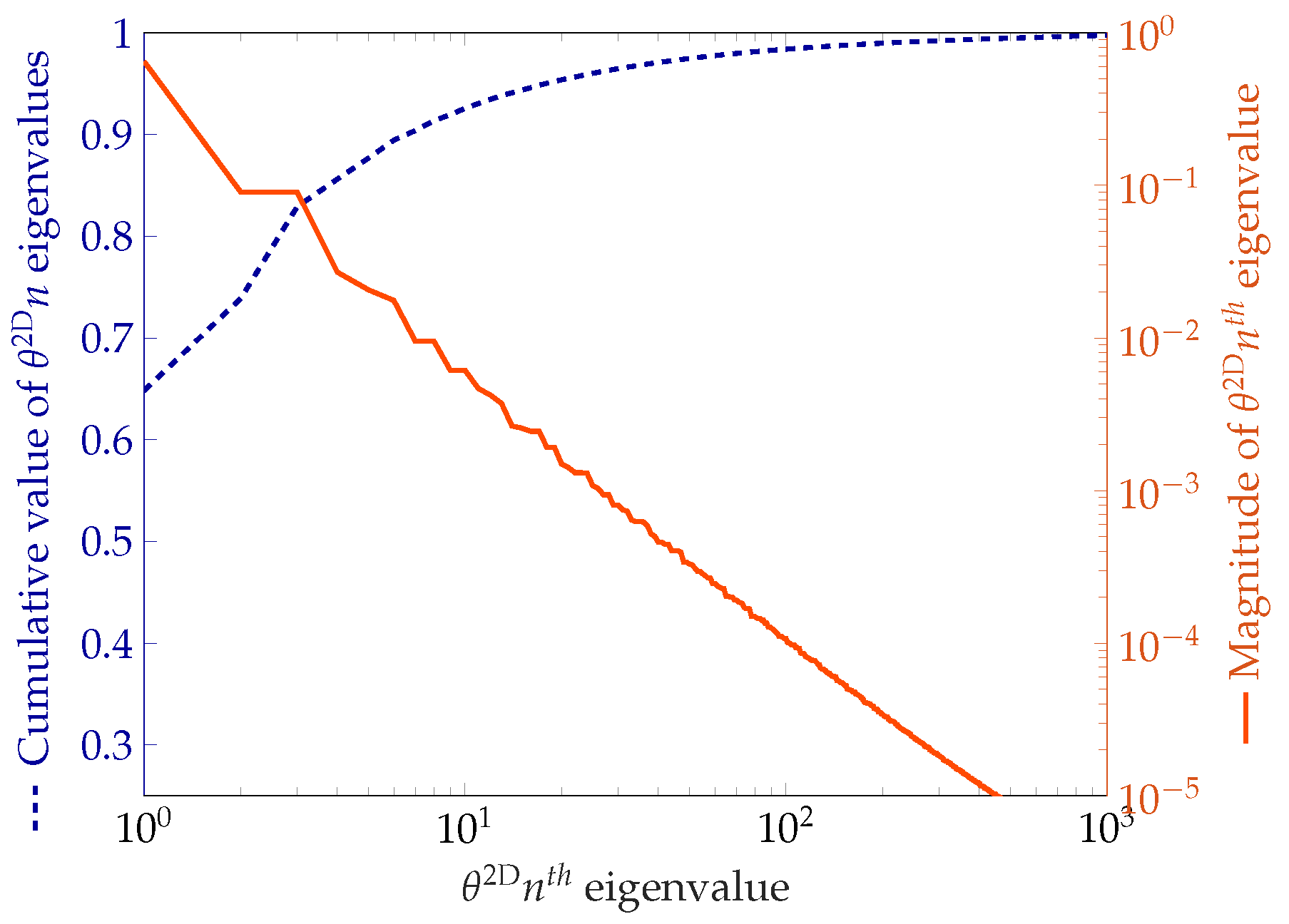
3.1.4. Modeling the Spatial Variability
3.1.5. Quantity of Interest
3.2. Numerical Results for Model Problem 1
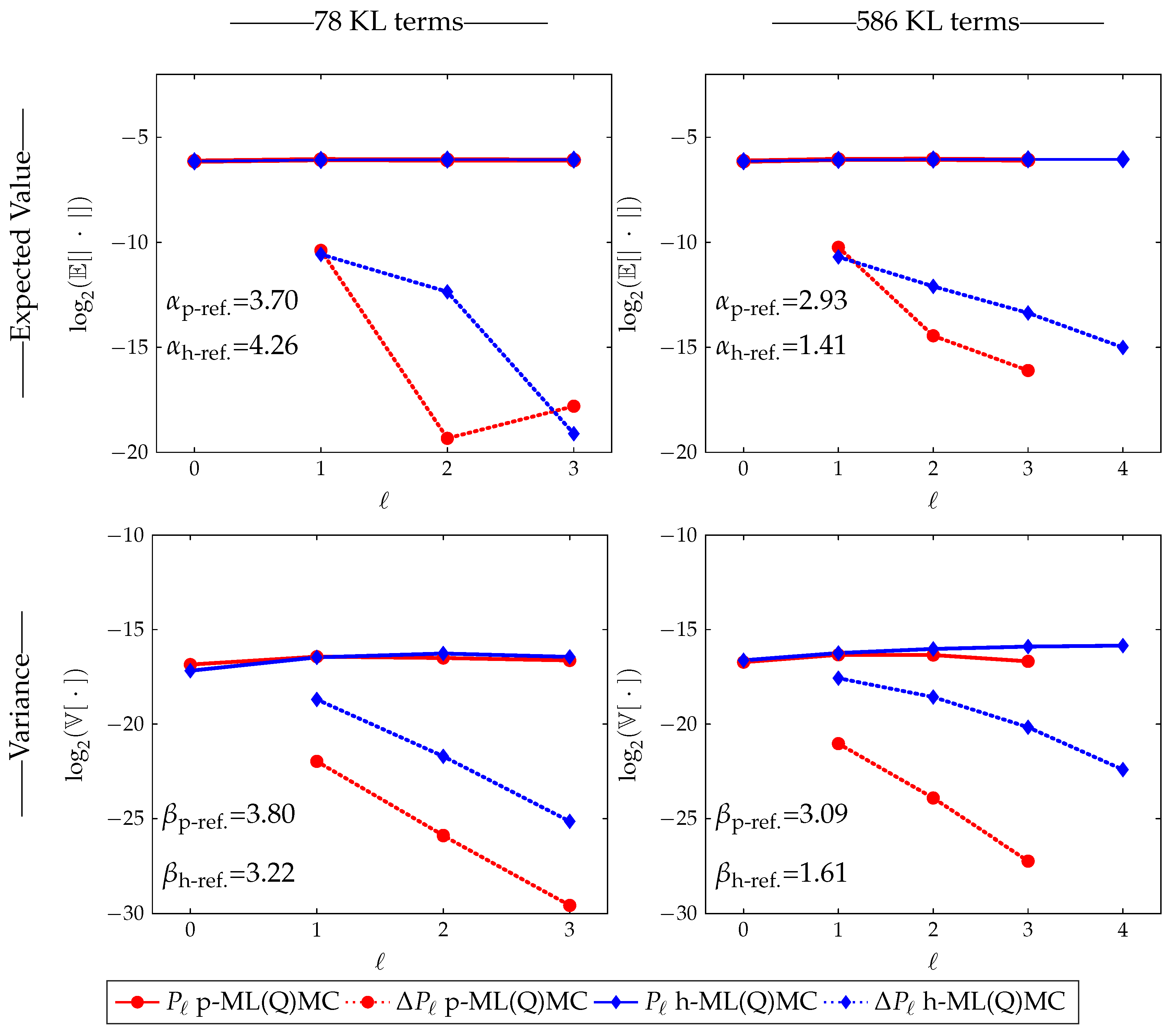
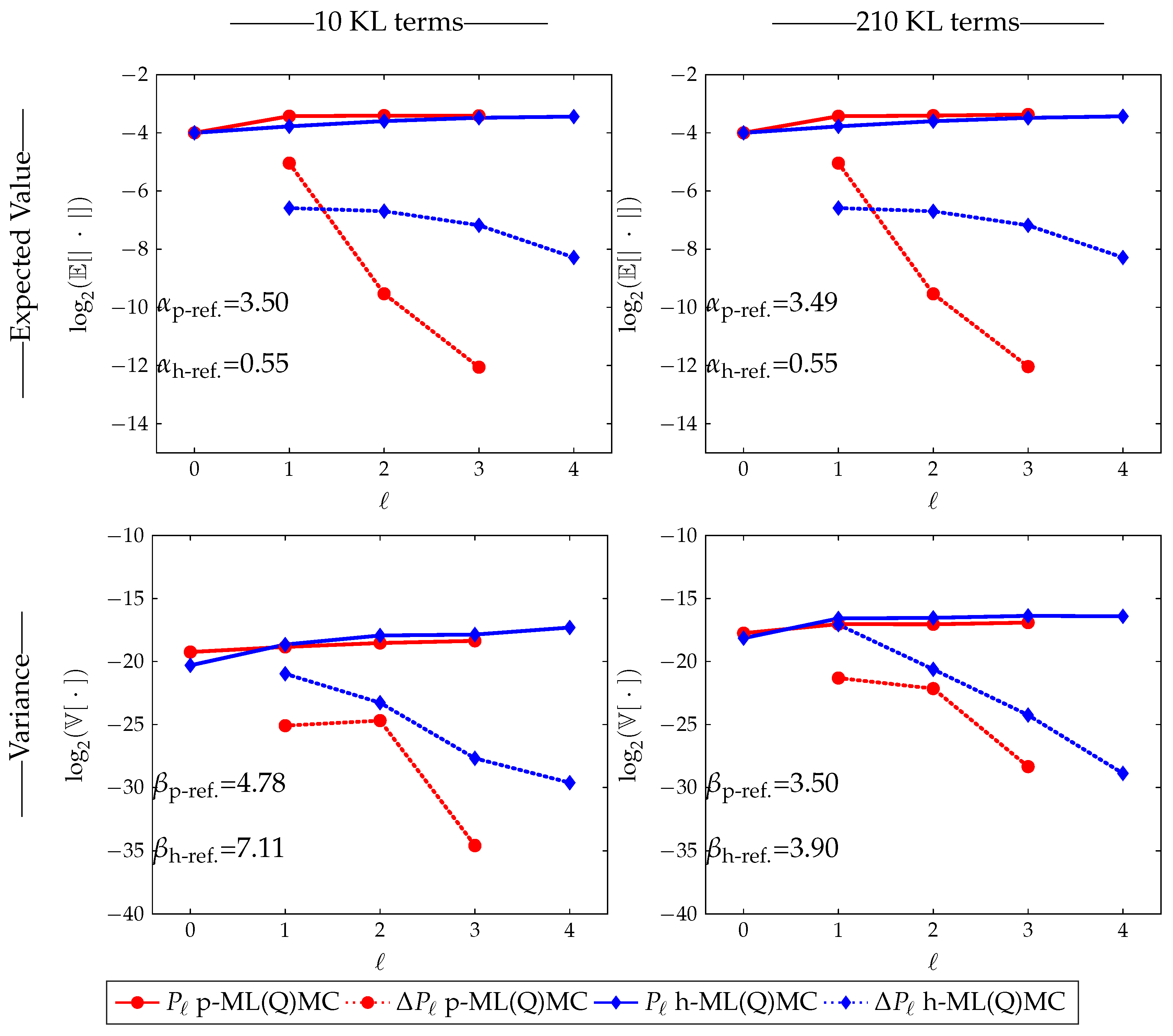
3.2.1. Rates
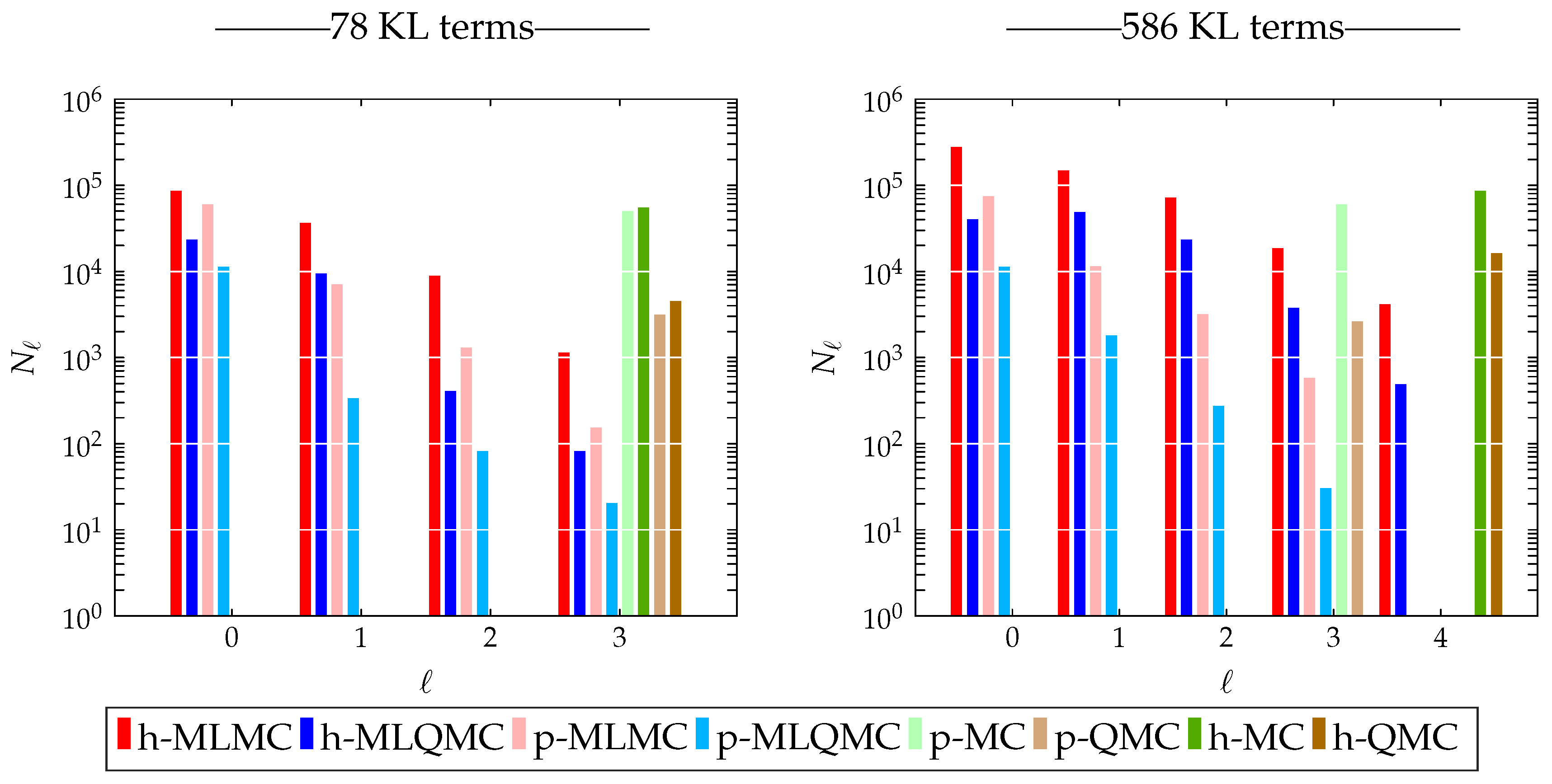
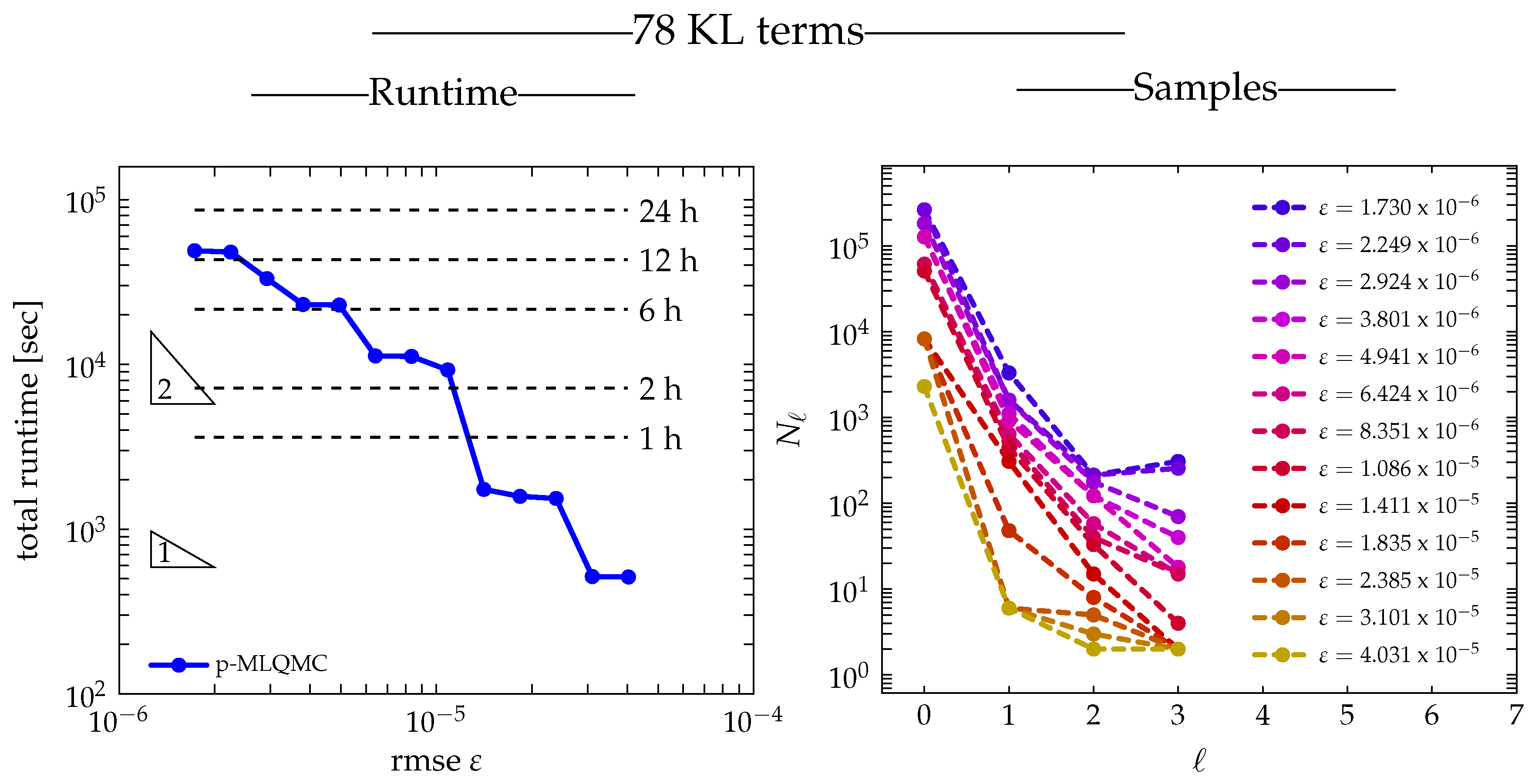
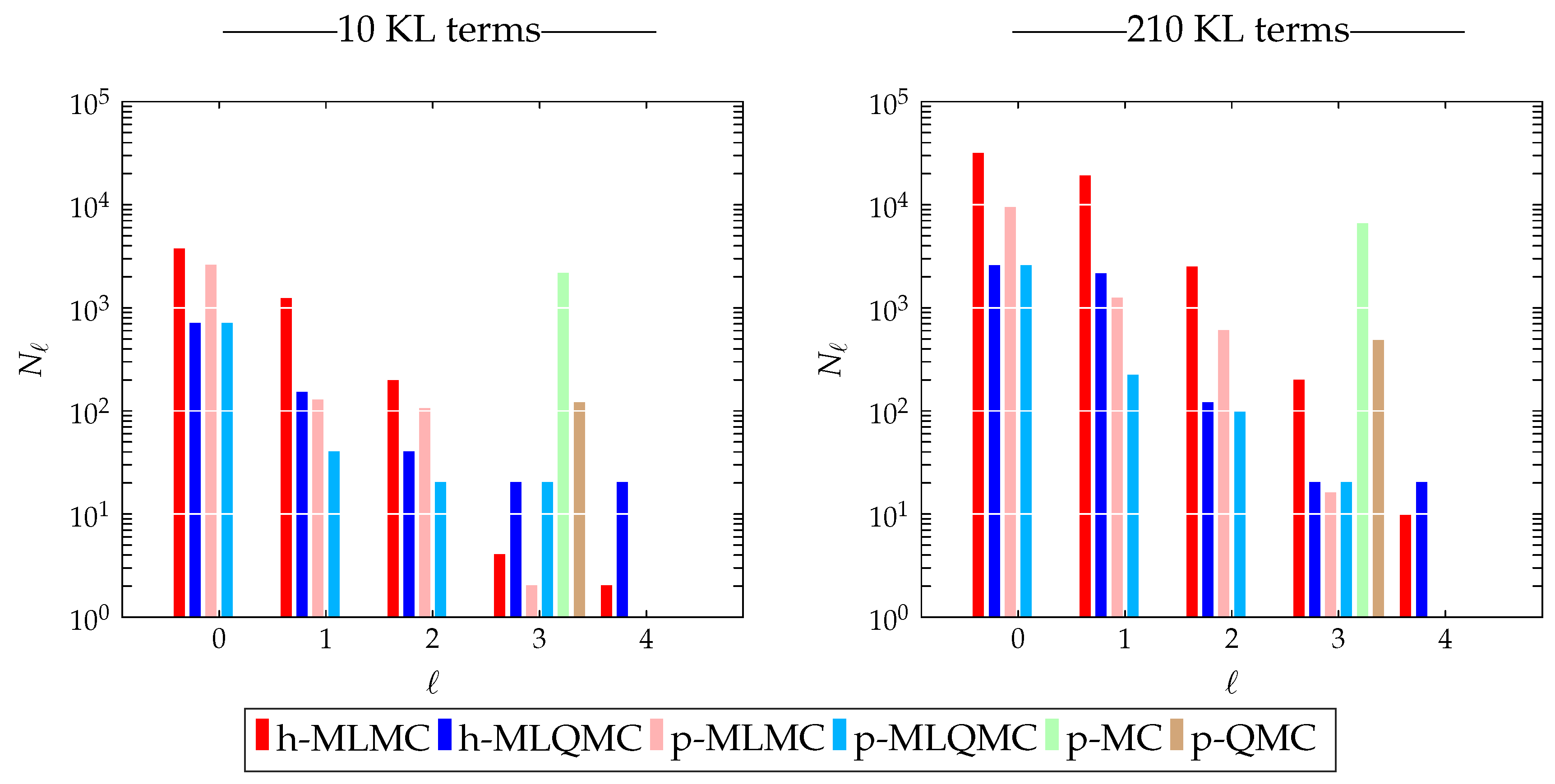
3.2.2. Number of Samples
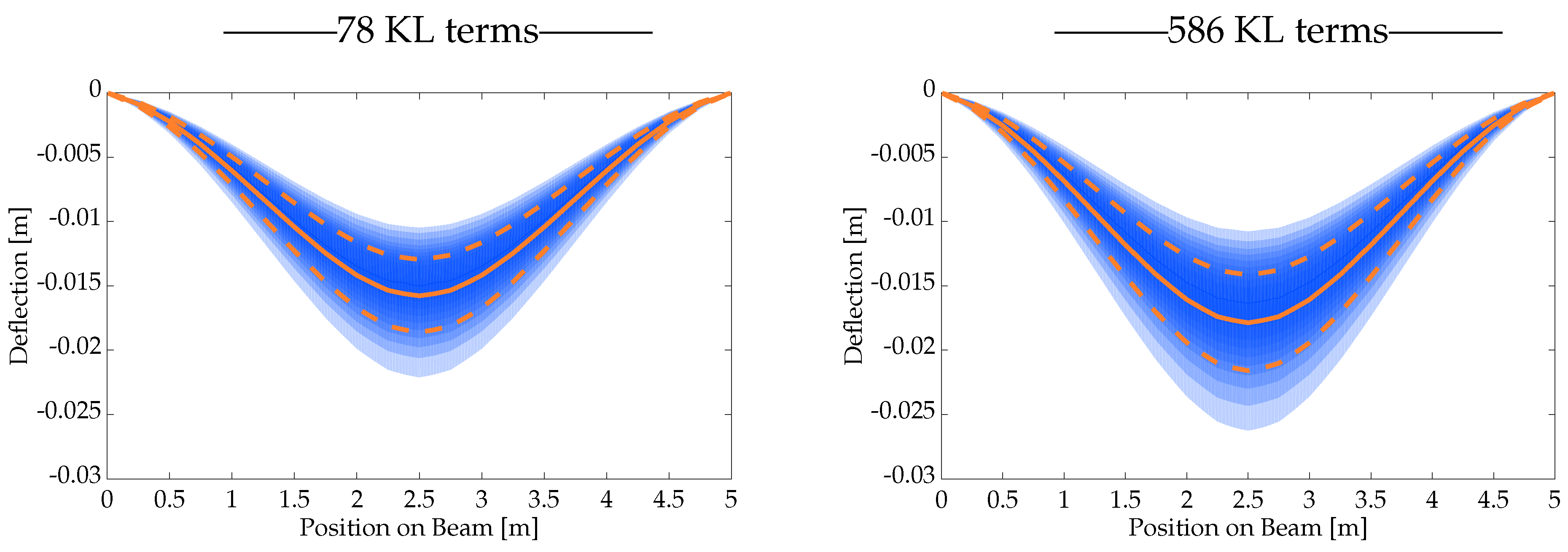
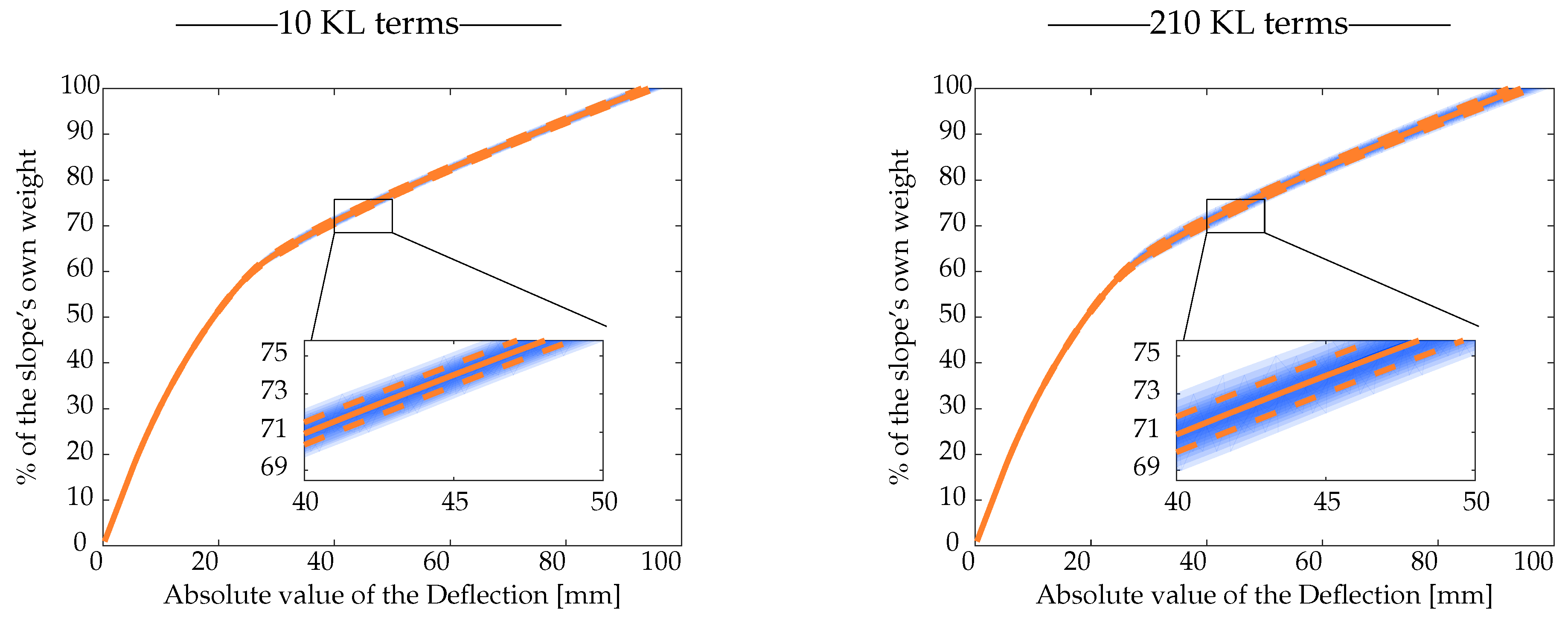
3.2.3. Uncertainty Propagation in the Solution
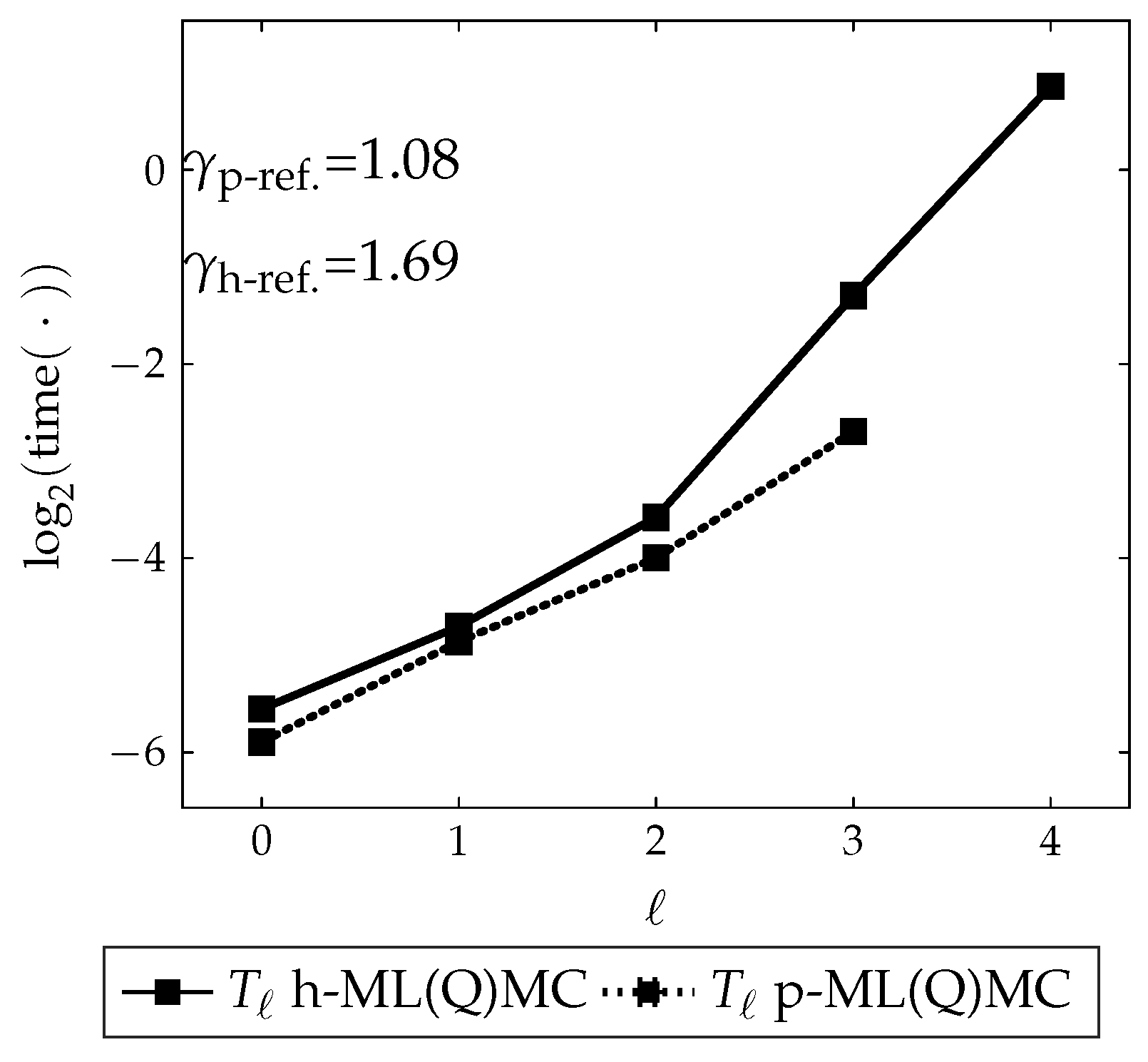
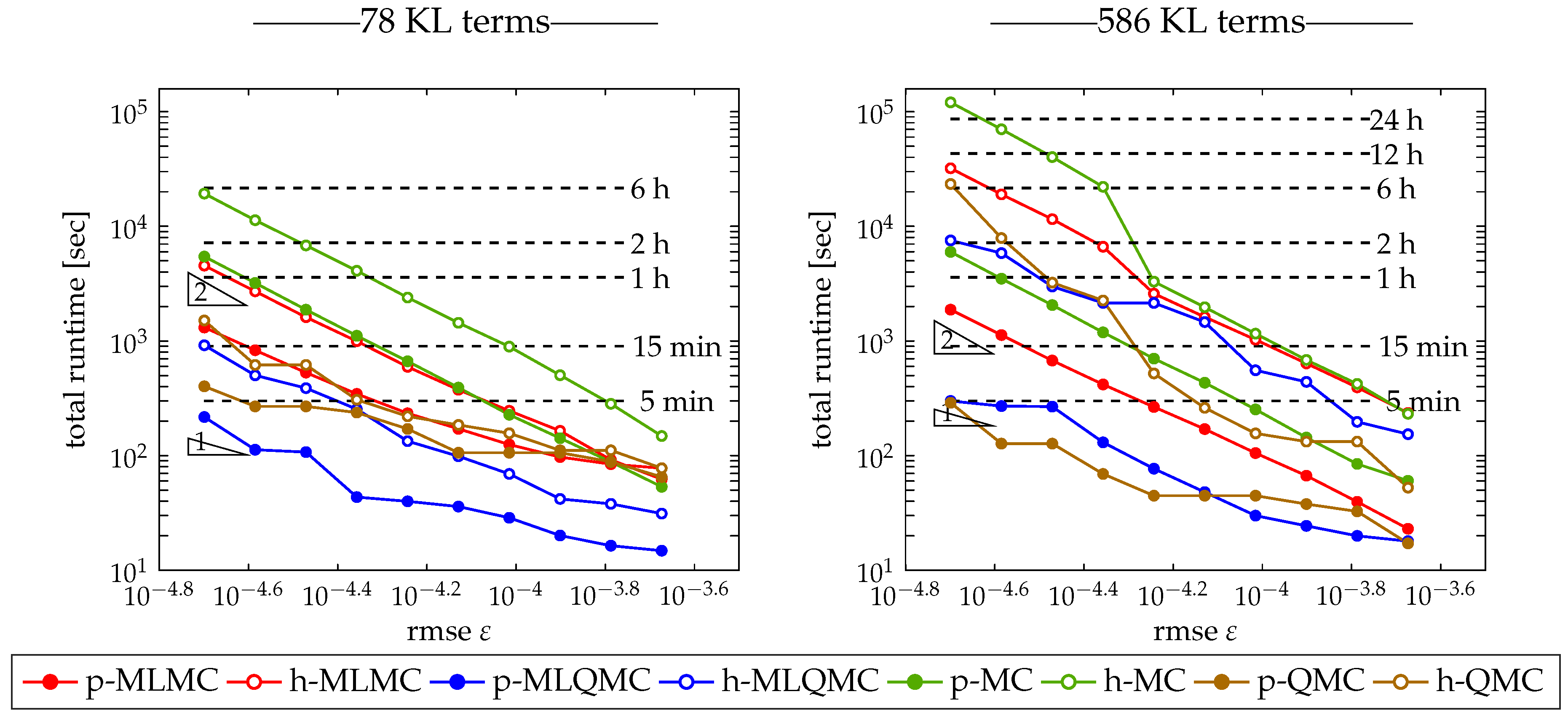
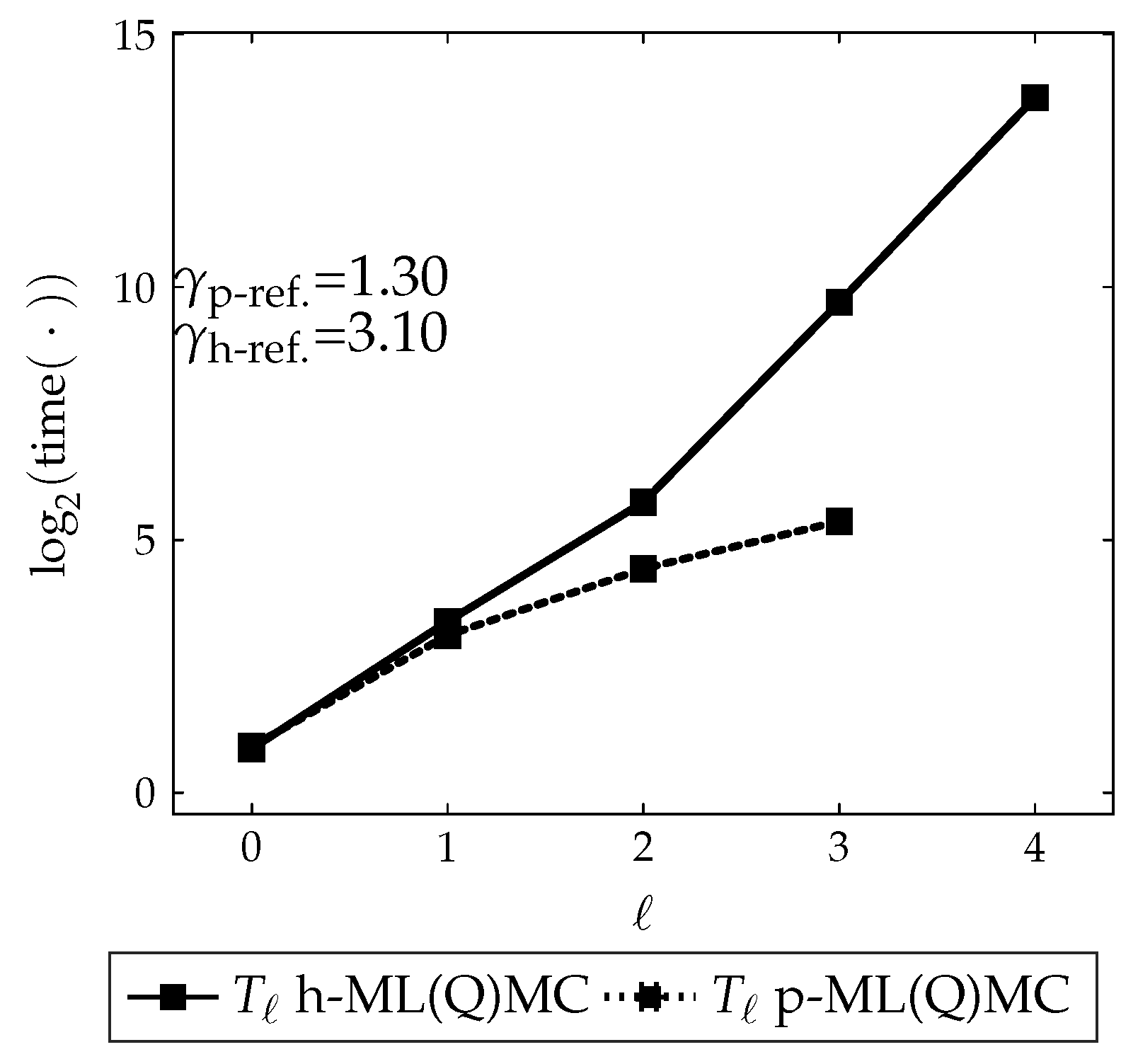
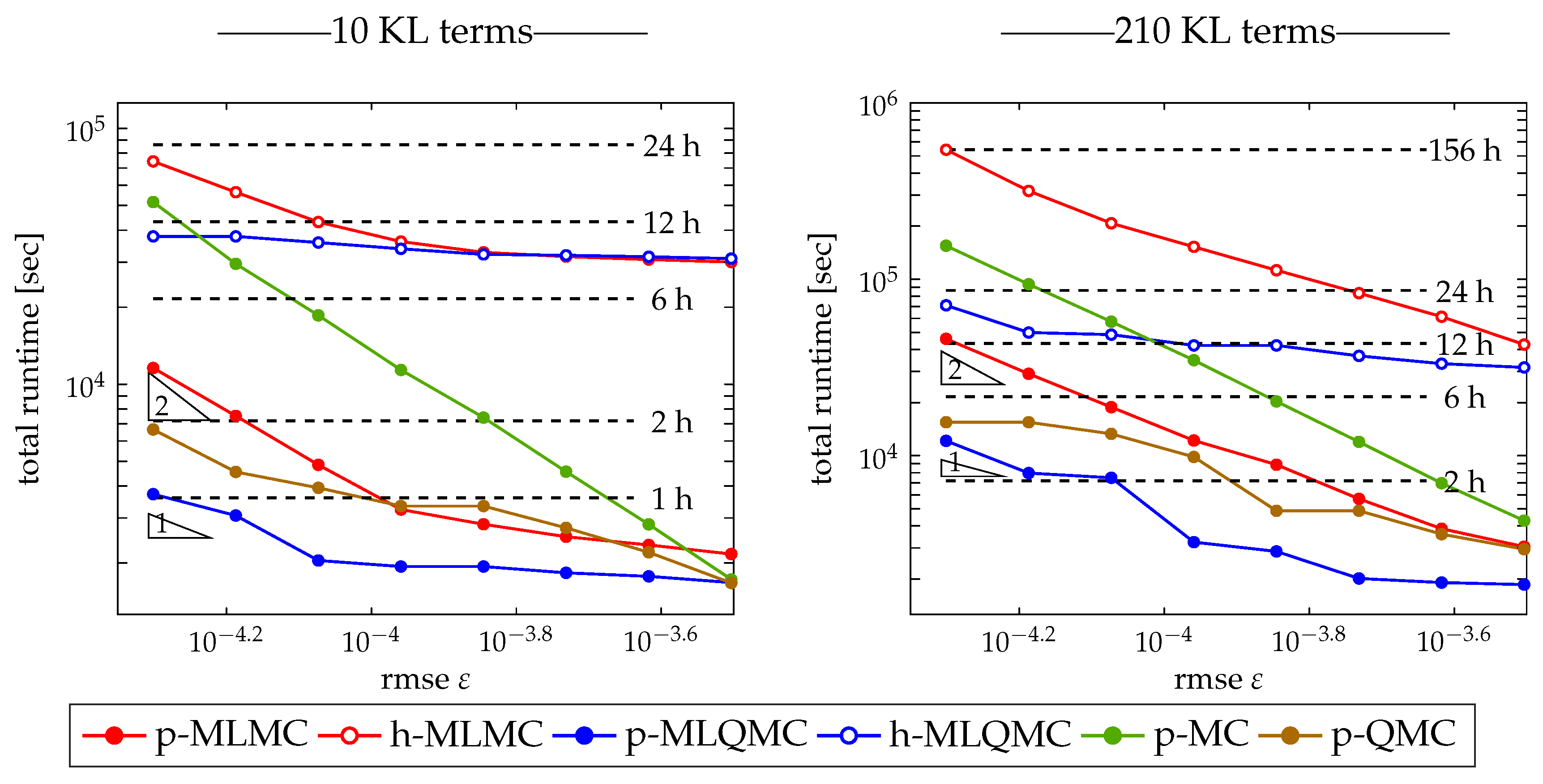
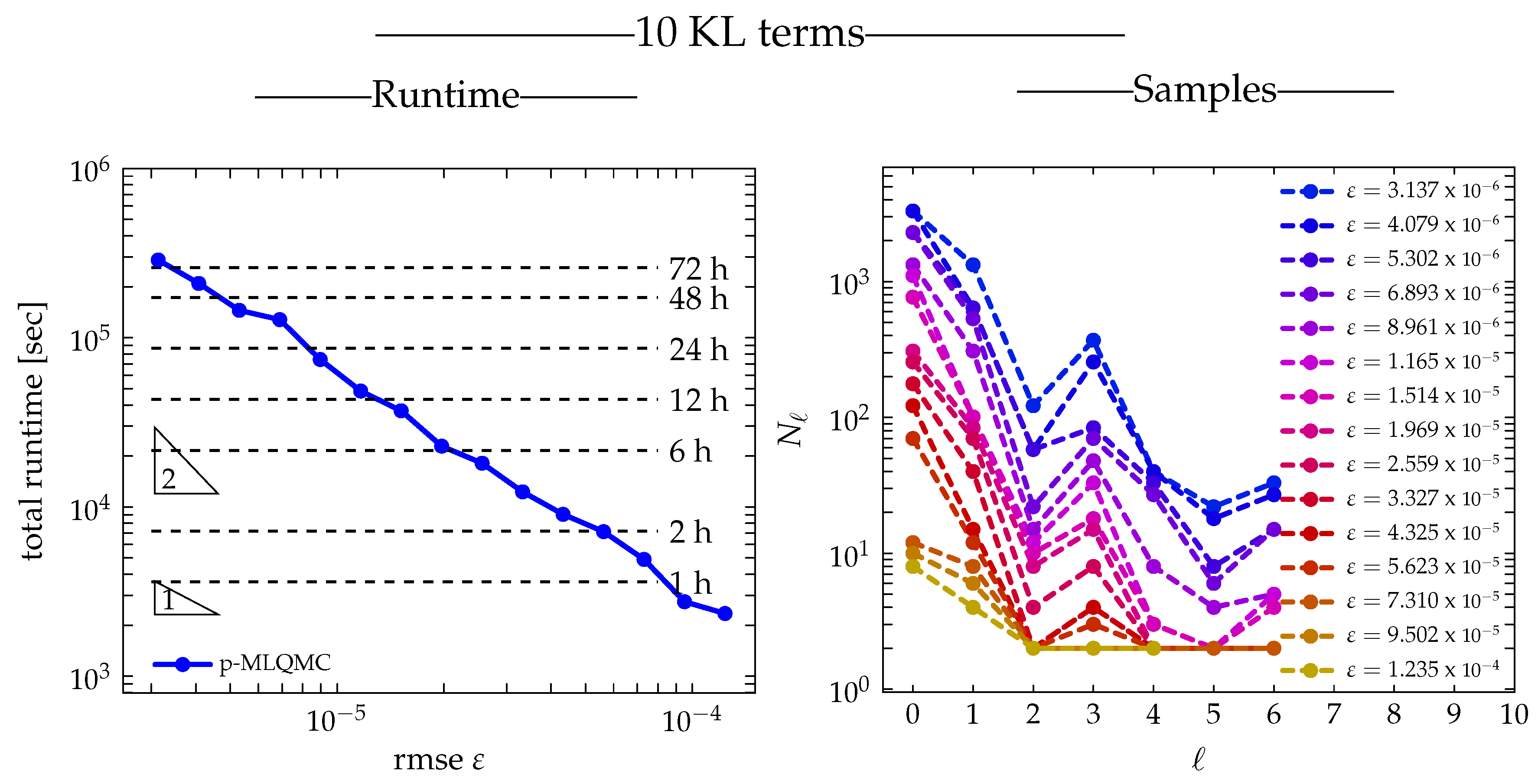
3.2.4. Runtime
3.2.5. Level Adaptivity
3.3. Model Problem 2
3.3.1. Description
3.3.2. Finite Element Method
3.3.3. Mesh Discretization
3.3.4. Modeling the Spatial Variability
3.3.5. Quantity of Interest
3.4. Numerical Results for Model Problem 2
3.4.1. Rates
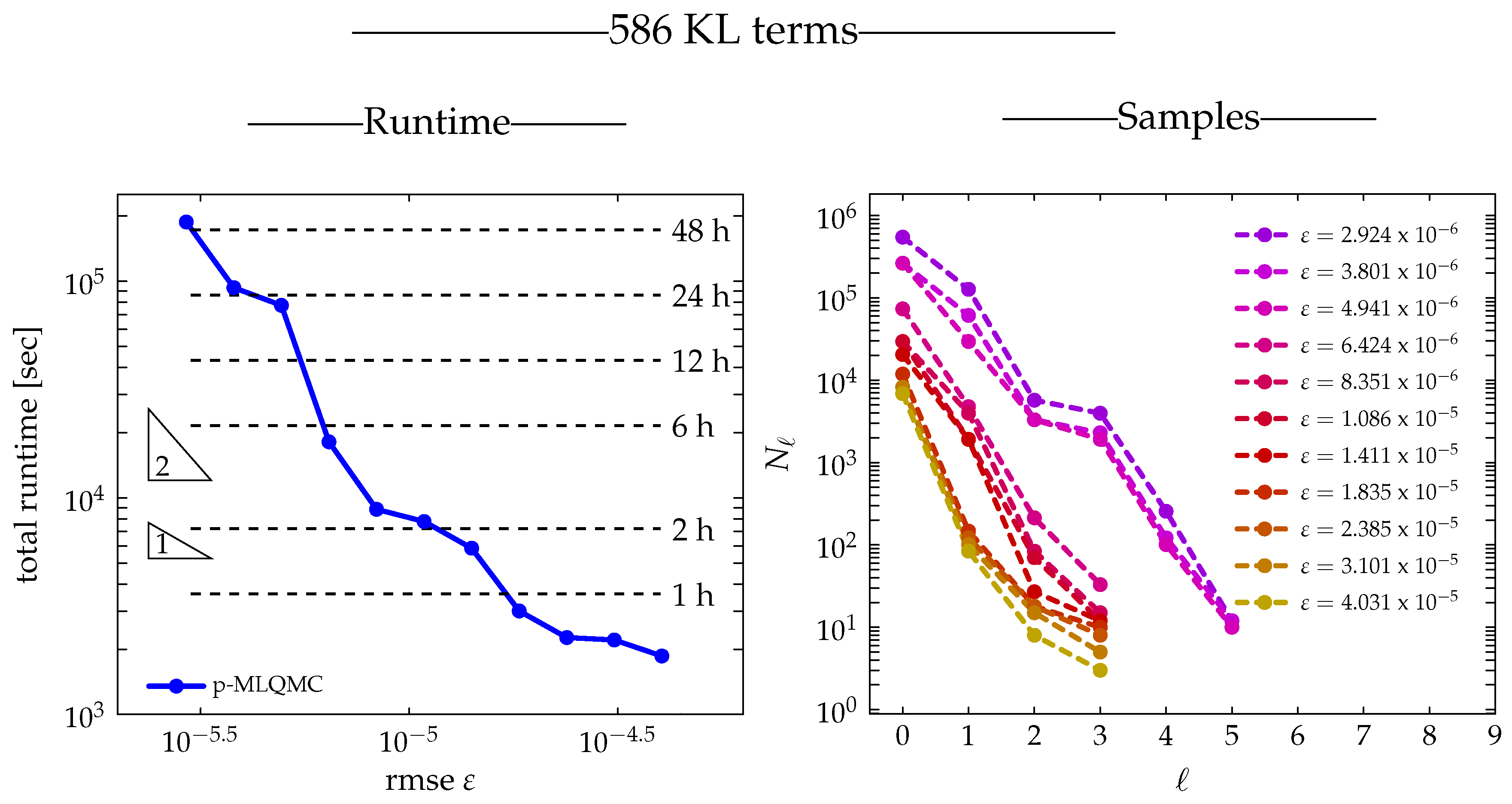
3.4.2. Number of Samples
3.4.3. Uncertainty Propagation in the Solution
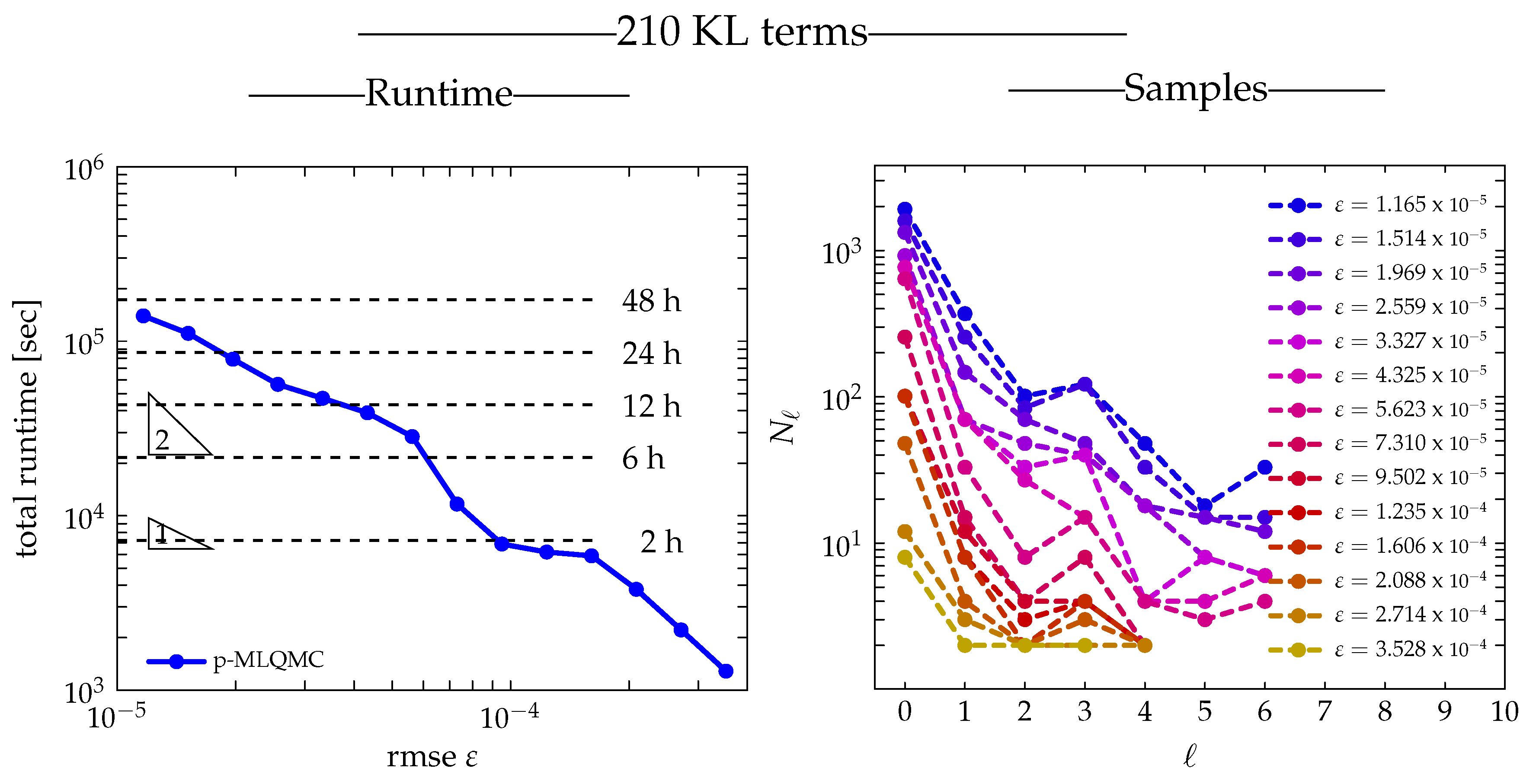
3.4.4. Runtime
3.4.5. Level Adaptivity
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kleiber, M.; Hien, T.D. The Stochastic Finite Element Method Basic Perturbation Technique and Computer Implementation; Wiley: Chichester, UK, 1992. [Google Scholar]
- Ghanem, R.G.; Spanos, P.D. Stochastic Finite Elements: A Spectral Approach; Dover Publications: New York, NY, USA, 2003. [Google Scholar]
- Babuška, I.; Nobile, F.; Tempone, R. A Stochastic Collocation Method for Elliptic Partial Differential Equations with Random Input Data. SIAM J. Numer. Anal. 2007, 45, 1005–1034. [Google Scholar] [CrossRef]
- Fishman, G.S. Monte Carlo: Concepts, Algorithms and Applications; Springer: New York, NY, USA, 1996. [Google Scholar]
- Caflisch, R.E. Monte Carlo and Quasi-Monte Carlo methods. Acta Numer. 1998, 7, 1–49. [Google Scholar] [CrossRef] [Green Version]
- Niederreiter, H. Monte Carlo and Quasi-Monte Carlo Methods; Springer: Berlin, Germany, 2004. [Google Scholar]
- Loh, W.L. On Latin hypercube sampling. Ann. Stat. 1996, 24, 2058–2080. [Google Scholar] [CrossRef]
- Giles, M.B. Multilevel Monte Carlo Path Simulation. Oper. Res. 2008, 56, 607–617. [Google Scholar] [CrossRef]
- Giles, M.B.; Waterhouse, B.J. Multilevel Quasi-Monte Carlo path simulation. Radon Ser. Comput. Appl. Math. 2009, 8, 1–18. [Google Scholar]
- Robbe, P.; Nuyens, D.; Vandewalle, S. A Multi-Index Quasi-Monte Carlo Algorithm for Lognormal Diffusion Problems. SIAM J. Sci. Comput. 2017, 39, S851–S872. [Google Scholar] [CrossRef] [Green Version]
- Robbe, P.; Nuyens, D.; Vandewalle, S. A Dimension-Adaptive Multi-Index Monte Carlo Method Applied to a Model of a Heat Exchanger. In Monte Carlo and Quasi-Monte Carlo Methods; Owen, A.B., Glynn, P.W., Eds.; Springer: Cham, Switzerland, 2018; pp. 429–445. [Google Scholar]
- Ghanem, R. Hybrid stochastic finite elements and generalized Monte Carlo simulation. J. Appl. Mech. 1998, 65, 1004–1009. [Google Scholar] [CrossRef] [Green Version]
- Acharjee, S.; Zabaras, N. A non-intrusive stochastic Galerkin approach for modeling uncertainty propagation in deformation processes. Comput. Struct. 2007, 85, 244–254. [Google Scholar] [CrossRef]
- Blondeel, P.; Robbe, P.; Van hoorickx, C.; Lombaert, G.; Vandewalle, S. The Multilevel Monte Carlo method applied to structural engineering problems with uncertainty in the Young’s modulus. In Proceedings of the 28th edition of the Biennial ISMA conference on Noise and Vibration Engineering (ISMA 2018), Leuven, Belgium, 17–19 September 2018; pp. 4899–4913. [Google Scholar]
- Blondeel, P.; Robbe, P.; Van hoorickx, C.; Lombaert, G.; Vandewalle, S. Multilevel sampling with Monte Carlo and Quasi-Monte Carlo methods for uncertainty quantification in structural engineering. In Proceedings of the 13th International Conference on Applications of Statistics and Probability in Civil Engineering (ICASP13), Seoul, Korea, 26–30 May 2019. [Google Scholar] [CrossRef]
- Motamed, M.; Appelö, D. A MultiOrder Discontinuous Galerkin Monte Carlo Method for Hyperbolic Problems with Stochastic Parameters. SIAM J. Numer. Anal. 2018, 56, 448–468. [Google Scholar] [CrossRef]
- Giles, M.B. Multilevel Monte Carlo methods. Acta Numer. 2015, 24, 259–328. [Google Scholar] [CrossRef] [Green Version]
- Dick, J.; Kuo, F.Y.; Sloan, I.H. High-dimensional integration: The Quasi-Monte Carlo way. Acta Numer. 2013, 22, 133–288. [Google Scholar] [CrossRef]
- Hickernell, F.J.; Hong, H.S.; L’Ecuyer, P.; Lemieux, C. Extensible Lattice Sequences for Quasi-Monte Carlo Quadrature. SIAM J. Sci. Comput. 2000, 22, 1117–1138. [Google Scholar] [CrossRef] [Green Version]
- Graham, I.G.; Kuo, F.Y.; Nichols, J.A.; Scheichl, R.; Schwab, C.; Sloan, I.H. Quasi-Monte Carlo finite element methods for elliptic PDEs with lognormal random coefficients. Numer. Math. 2015, 131, 329–368. [Google Scholar] [CrossRef]
- Robbe, P. Multilevel Uncertainty Quantification Methods for Robust Design of Industrial Applications. Ph.D. Thesis, KU Leuven, Leuven, Belgium, 2019. [Google Scholar]
- Kuo, F.Y.; Scheichl, R.; Schwab, C.; Sloan, I.H.; Ullmann, E. Multilevel Quasi-Monte Carlo methods for lognormal diffusion problems. Math. Comput. 2017, 86, 2827–2860. [Google Scholar] [CrossRef]
- Sobol’, I. On the distribution of points in a cube and the approximate evaluation of integrals. USSR Comput. Math. Math. Phys. 1967, 7, 86–112. [Google Scholar] [CrossRef]
- Kuo, F. Lattice Rule Generating Vectors. 2007. Available online: https://web.maths.unsw.edu.au/~fkuo/lattice/index.html (accessed on 12 April 2019).
- Ciarlet, P.G. The Finite Element Method for Elliptic Problems; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2002. [Google Scholar] [CrossRef]
- Geuzaine, C.; Remacle, J.F. Gmsh: A 3-D finite element mesh generator with built-in pre- and post-processing facilities. Int. J. Numer. Meth. Eng. 2009, 79, 1309–1331. [Google Scholar] [CrossRef]
- MATLAB, version 9.2.0 (R2017a); The MathWorks Inc.: Natick, MA, USA, 2017.
- Graham, I.; Kuo, F.; Nuyens, D.; Scheichl, R.; Sloan, I. Quasi-Monte Carlo methods for elliptic PDEs with random coefficients and applications. J. Comput. Phys. 2011, 230, 3668–3694. [Google Scholar] [CrossRef] [Green Version]
- Teckentrup, A.L. Multilevel Monte Carlo Methods and Uncertainty Quantification. Ph.D. Thesis, University of Bath, Bath, UK, 2013. [Google Scholar]
- Sloan, I.H.; Woźniakowski, H. When Are Quasi-Monte Carlo Algorithms Efficient for High Dimensional Integrals? J. Complex. 1998, 14, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Kuo, F.Y.; Nuyens, D. Application of Quasi-Monte Carlo Methods to Elliptic PDEs with Random Diffusion Coefficients: A Survey of Analysis and Implementation. Found. Comput. Math. 2016, 16, 1631–1696. [Google Scholar] [CrossRef] [Green Version]
- Loève, M. Probability Theory; Springer: New York, NY, USA, 1977. [Google Scholar]
- Atkinson, K.; Han, W. Numerical Solution of Fredholm Integral Equations of the Second Kind. In Theoretical Numerical Analysis: A Functional Analysis Framework; Springer: New York, NY, USA, 2009; pp. 473–549. [Google Scholar] [CrossRef]
- Li, J.; Chen, J. Stochastic Dynamics of Structures; John Wiley & Sons: New York, NY, USA, 2010. [Google Scholar]
- Brenner, C.E.; Bucher, C. A contribution to the SFE-based reliability assessment of nonlinear structures under dynamic loading. Probab. Eng. Mech. 1995, 10, 265–273. [Google Scholar] [CrossRef]
- Teckentrup, A.L.; Scheichl, R.; Giles, M.B.; Ullmann, E. Further analysis of multilevel Monte Carlo methods for elliptic PDEs with random coefficients. Numer. Math. 2013, 125, 569–600. [Google Scholar] [CrossRef] [Green Version]
- Gittelson, C.J.; Könnö, J.; Schwab, C.; Stenberg, R. The multi-level Monte Carlo finite element method for a stochastic Brinkman Problem. Numer. Math. 2013, 125, 347–386. [Google Scholar] [CrossRef] [Green Version]
- Grigoriu, M. Simulation of Stationary Non-Gaussian Translation Processes. J. Eng. Mech. (ASCE) 1998, 124, 121–126. [Google Scholar] [CrossRef]
- Simoen, E.; Moaveni, B.; Conte, J.P.; Lombaert, G. Uncertainty Quantification in the Assessment of Progressive Damage in a 7-Story Full-Scale Building Slice. J. Eng. Mech. 2013, 139, 1818–1830. [Google Scholar] [CrossRef]
- Sakamoto, S.; Ghanem, R. Simulation of multi-dimensional non-gaussian non-stationary random fields. Probab. Eng. Mech. 2002, 17, 167–176. [Google Scholar] [CrossRef]
- Phoon, K.; Huang, H.; Quek, S. Simulation of strongly non-Gaussian processes using Karhunen–Loeve expansion. Probab. Eng. Mech. 2005, 20, 188–198. [Google Scholar] [CrossRef]
- Phoon, K.; Huang, S.; Quek, S. Simulation of second-order processes using Karhunen–Loeve expansion. Comput. Struct. 2002, 80, 1049–1060. [Google Scholar] [CrossRef]
- Kim, H.; Shields, M.D. Modeling strongly non-Gaussian non-stationary stochastic processes using the Iterative Translation Approximation Method and Karhunen–Loève expansion. Comput. Struct. 2015, 161, 31–42. [Google Scholar] [CrossRef]
- Shields, M.; Deodatis, G.; Bocchini, P. A simple and efficient methodology to approximate a general non-Gaussian stationary stochastic process by a translation process. Probab. Eng. Mech. 2011, 26, 511–519. [Google Scholar] [CrossRef]
- Whenham, V.; De Vos, M.; Legrand, C.; Charlier, R.; Maertens, J.; Verbrugge, J.C. Influence of Soil Suction on Trench Stability. In Experimental Unsaturated Soil Mechanics; Schanz, T., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 495–501. [Google Scholar]
- de Borst, R.; Crisfield, M.A.; Remmers, J.J.C. Non Linear Finite Element Analysis of Solids and Structures; Wiley: London, UK, 2012. [Google Scholar]
- Pérez-Foguet, A.; Rodríguez-Ferran, A.; Huerta, A. Consistent tangent matrices for substepping schemes. Comput. Methods Appl. Mech. Eng. 2001, 190, 4627–4647. [Google Scholar] [CrossRef] [Green Version]































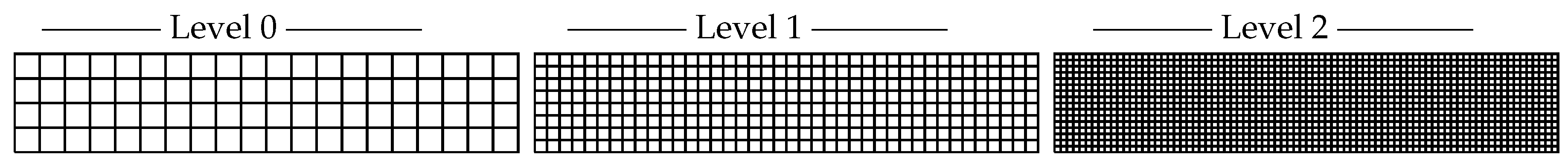{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| h-ML(Q)MC | p-ML(Q)MC | |||||||
|---|---|---|---|---|---|---|---|---|
| Level | Nel | DOF | Order | Nquad | Nel | DOF | Order | Nquad |
| 0 | 80 | 210 | 1 | 9 | 80 | 210 | 1 | 9 |
| 1 | 320 | 738 | 1 | 9 | 80 | 738 | 2 | 25 |
| 2 | 1280 | 2754 | 1 | 9 | 80 | 1586 | 3 | 49 |
| 3 | 5120 | 10,626 | 1 | 9 | 80 | 2754 | 4 | 81 |
| 4 | 20,480 | 41,730 | 1 | 9 | / | / | / | / |
| h-ML(Q)MC | p-ML(Q)MC | |||||||
|---|---|---|---|---|---|---|---|---|
| Level | Nel | DOF | Order | Nquad | Nel | DOF | Order | Nquad |
| 0 | 33 | 48 | 1 | 7 | 33 | 48 | 1 | 7 |
| 1 | 132 | 160 | 1 | 7 | 33 | 338 | 3 | 16 |
| 2 | 528 | 582 | 1 | 7 | 33 | 892 | 5 | 28 |
| 3 | 2112 | 2218 | 1 | 7 | 33 | 1720 | 7 | 37 |
| 4 | 8448 | 8658 | 1 | 7 | / | / | / | / |
| p-ML(Q)MC | ||||
|---|---|---|---|---|
| Level | Nel | DOF | Order | Nquad |
| 0 | 80 | 210 | 1 | 25 |
| 1 | 80 | 738 | 2 | 81 |
| 2 | 80 | 1586 | 3 | 121 |
| 3 | 80 | 2754 | 4 | 225 |
| 4 | 80 | 4242 | 5 | 289 |
| 5 | 80 | 6050 | 6 | 441 |
| 6 | 80 | 8178 | 7 | 625 |
| 7 | 80 | 10,626 | 8 | 729 |
| p-ML(Q)MC | ||||
|---|---|---|---|---|
| Level | Nel | DOF | Order | Nquad |
| 0 | 33 | 48 | 1 | 7 |
| 1 | 33 | 160 | 2 | 13 |
| 2 | 33 | 338 | 3 | 19 |
| 3 | 33 | 582 | 4 | 25 |
| 4 | 33 | 892 | 5 | 28 |
| 5 | 33 | 1268 | 6 | 33 |
| 6 | 33 | 1720 | 7 | 37 |
| 7 | 33 | 2218 | 8 | 61 |
| 8 | 33 | 2792 | 9 | 73 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Blondeel, P.; Robbe, P.; Van hoorickx, C.; François, S.; Lombaert, G.; Vandewalle, S. p-Refined Multilevel Quasi-Monte Carlo for Galerkin Finite Element Methods with Applications in Civil Engineering. Algorithms 2020, 13, 110. https://doi.org/10.3390/a13050110
Blondeel P, Robbe P, Van hoorickx C, François S, Lombaert G, Vandewalle S. p-Refined Multilevel Quasi-Monte Carlo for Galerkin Finite Element Methods with Applications in Civil Engineering. Algorithms. 2020; 13(5):110. https://doi.org/10.3390/a13050110
Chicago/Turabian StyleBlondeel, Philippe, Pieterjan Robbe, Cédric Van hoorickx, Stijn François, Geert Lombaert, and Stefan Vandewalle. 2020. "p-Refined Multilevel Quasi-Monte Carlo for Galerkin Finite Element Methods with Applications in Civil Engineering" Algorithms 13, no. 5: 110. https://doi.org/10.3390/a13050110
APA StyleBlondeel, P., Robbe, P., Van hoorickx, C., François, S., Lombaert, G., & Vandewalle, S. (2020). p-Refined Multilevel Quasi-Monte Carlo for Galerkin Finite Element Methods with Applications in Civil Engineering. Algorithms, 13(5), 110. https://doi.org/10.3390/a13050110