Automobile Fine-Grained Detection Algorithm Based on Multi-Improved YOLOv3 in Smart Streetlights


Abstract
:1. Introduction
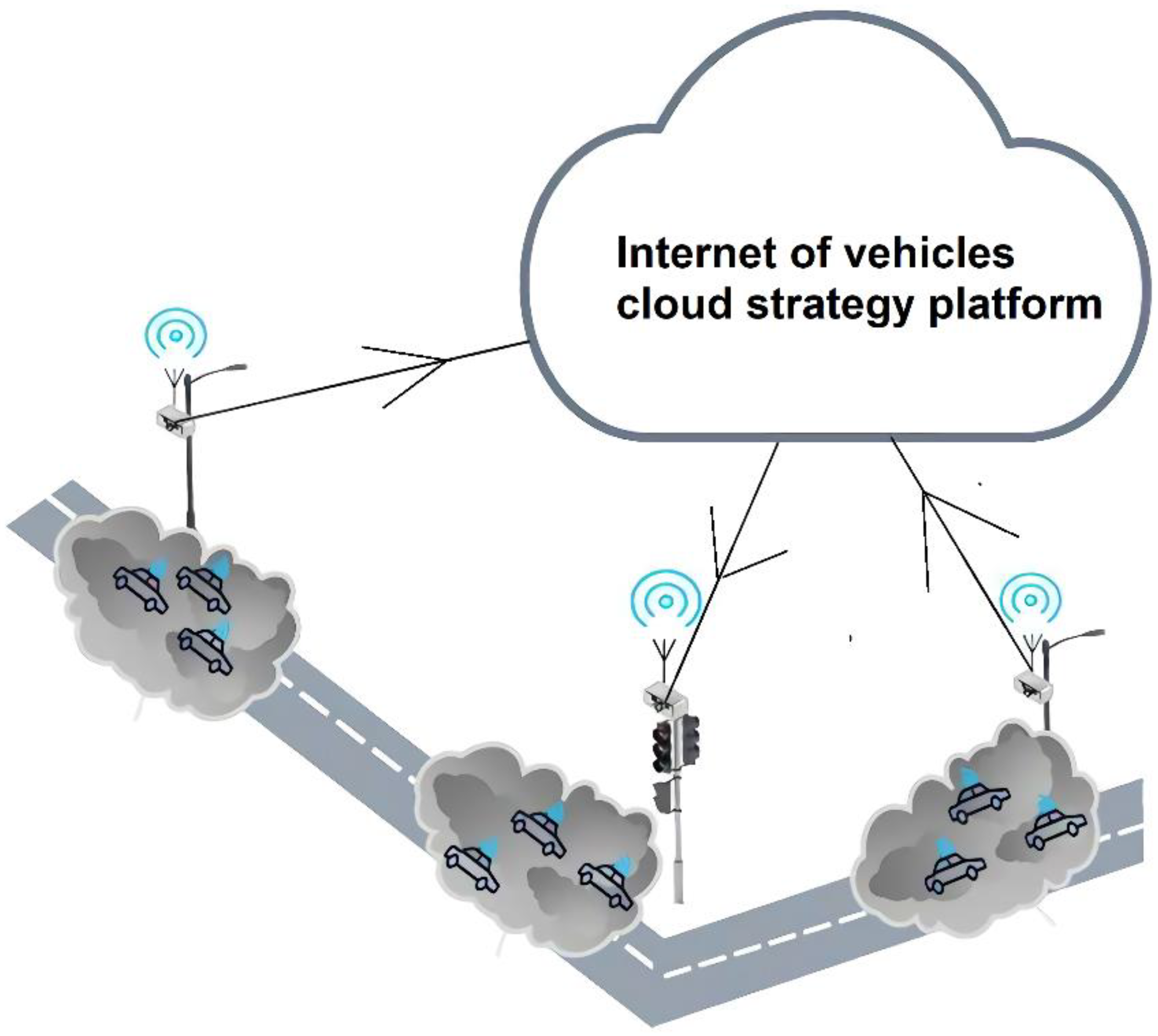
- In order to realize high-precision and large-scale traffic situation detection, we propose a distributed system based on smart streetlights.
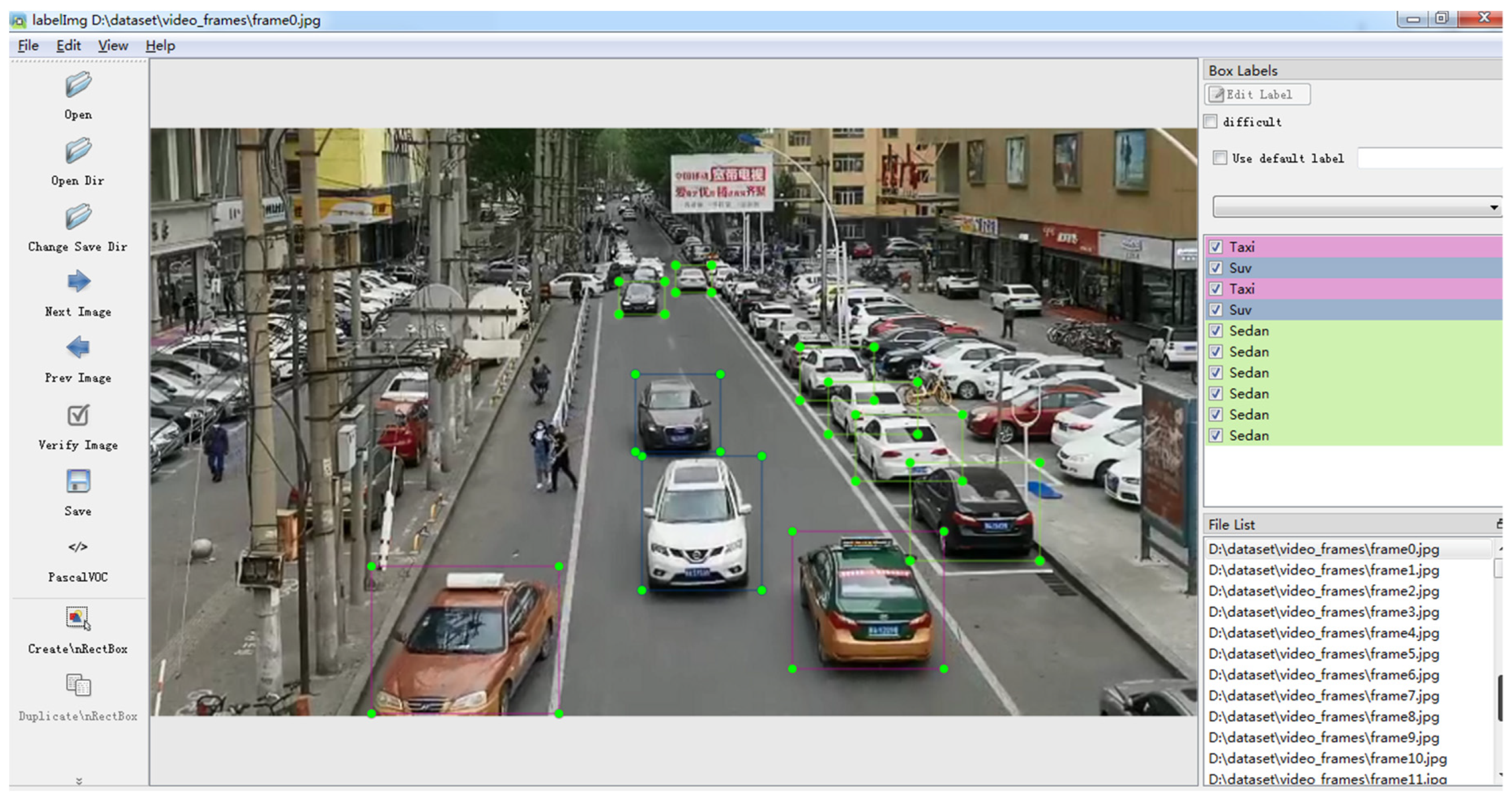
- Based on the dataset UA-DETRAC, we add the local manually labeled data images in the sight of smart streetlights, establish the classification dataset for SUVs, sedans, taxis, commercial vehicles, small commercial vehicles, vans, buses, trucks, and pickup trucks, and build the dataset UA-DETRAC-LITE-NEW.
- We optimize the YOLOv3 algorithm in various respects to improve the detection accuracy for distant cars in the sight of smart lights and then combine it with multi-scale training and anchor clustering methods to improve the accuracy of automobile target detection. In addition, we apply label smoothing and mixup approaches to increase the generalization ability of the model and adopt optimized position regression loss functions of IOU (Intersection Over Union) and GIOU to increase the system accuracy. Each step of the improvement is experimentally verified.
2. Smart Streetlights and Experimental Datasets
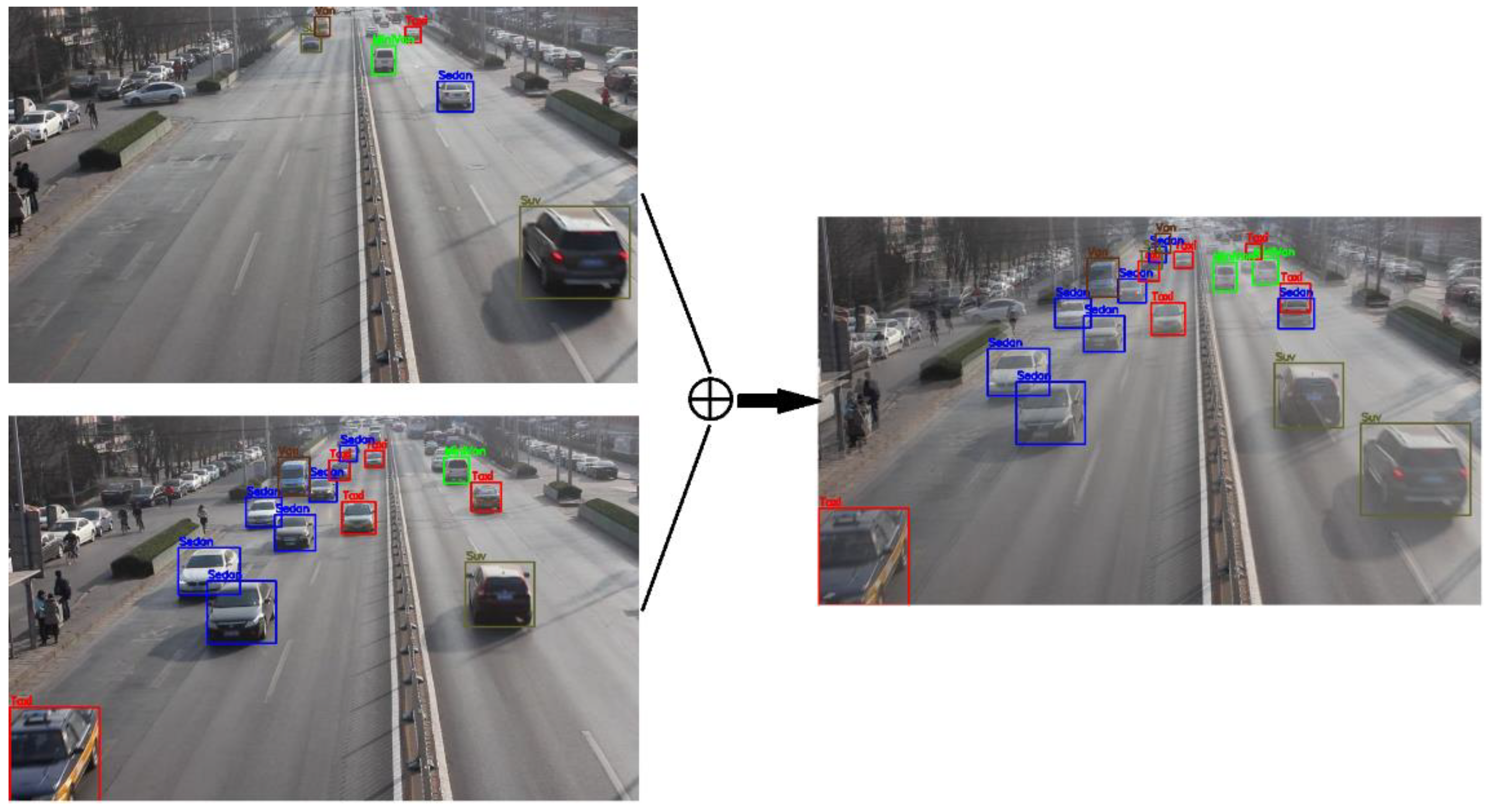
2.1. Smart Streetlights
2.2. Experimental Dataset
3. Methodology
3.1. Introduction of YOLOv3
- (1)
- During calculation of position loss, the L2 distance does not have scale invariability relative to the bounding box, so the loss of a small bounding box should be distinguished from that of a big bounding box, which is more reasonable. The author multiplies factor α () with the L2 distance loss of position to weaken the negative influence of scale on position loss. and are the width and height of normalized true-value bounding boxes. Factor α is smaller when encountering large-scale targets and bigger when encountering small-scale targets, and in this way, the loss of small bounding boxes can be improved.
- (2)
- During calculation of loss, no matter whether it is position loss or other loss, the true value should correspond to the predicted values one by one to realize calculation. However, in reality, the number of targets in each image is not fixed. When the output image has a scale of 416, assuming m image targets participate in the training, while the YOLOv3 model will predict 10,647 targets, they cannot correspond to each other one by one in this case. Therefore, YOLOv3 employs a matching mechanism to reconstruct m targets in true-value tag into the data in the format of 10,647 targets. m targets are placed in their proper positions in the 10,647 constructed data, and, at this moment, the calculation and training process is completed.
- (3)
- In the YOLOv3 algorithm, only the lattice with the scale which best matches the anchor is used to predict the target. However, under normal circumstances, it is also highly possible to use the lattices near this lattice to predict this target. This situation is normal, which does not require punishing this lattice. However, when the lattice far away from this lattice is also used to predict this target, this situation is abnormal, which requires punishment. Therefore, in YOLOv3, the predicted value and corresponding position of constructed real-value tag are used to calculate IoU, then the IoU is used to decide when punishment is required and when it is not. In general, a hyper-parameter will be defined in the algorithm: ignore thresh. When the IoU of a lattice is bigger than the ignore thresh, this lattice is regarded as being close to the real lattice, and it is normal that it has high confidence, which does not require punishment; when the IoU of a lattice is smaller than the ignore thresh, this lattice is regarded as being far from this lattice, and it is abnormal when it has high confidence, which requires punishment.
- (4)
- In (2), the m targets are reconstructed into the data in the format of 10,647 targets, and all the parts without targets are 0. In (3), it is mentioned that the IoU of the corresponding position of predicted value and real-value tag need to be calculated, while in the real-value tags without targets, all data are 0, and in this case, the confidence in the predicted value and corresponding real-value tags cannot be calculated. Therefore, in YOLOv3, the lattices of all real-value tags and current predicted value are used to calculate the IoU, and the highest one is used as the final IoU of this lattice to participate in the subsequent operation.
3.2. Scale Optimization for Vehicle Target Detection Scenario
3.2.1. Multi-Scale Training
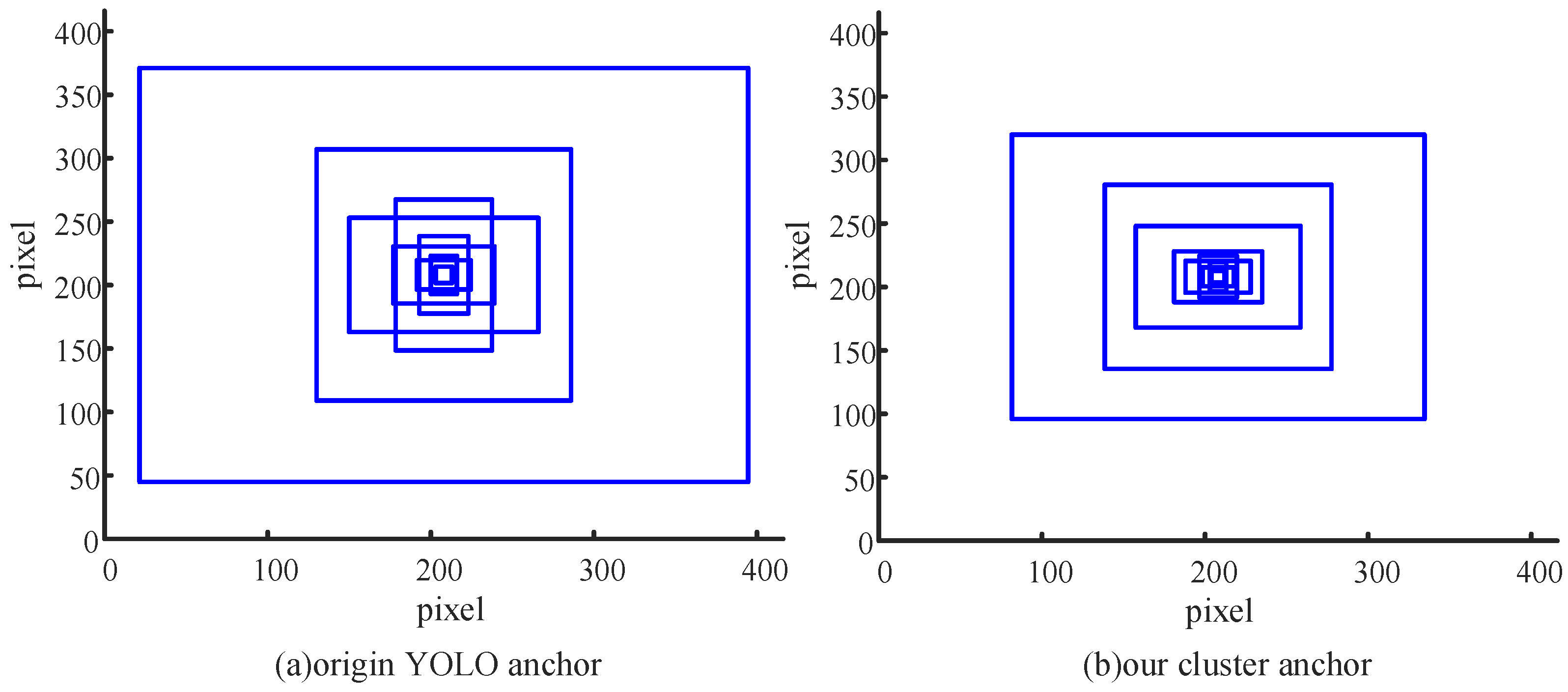
3.2.2. Anchor Clustering
- (1)
- Select k initial centroids (as the k initial clusters);
- (2)
- For each sample point, obtain the nearest centroid based on calculation, and label its class as the corresponding cluster of this centroid;
- (3)
- Recalculate the centroids corresponding to k clusters;
- (4)
- The algorithm will end when the centroids of k clusters do not change anymore; otherwise, jump to Step 2.
3.3. Improvement of the Model’s Generalization Ability
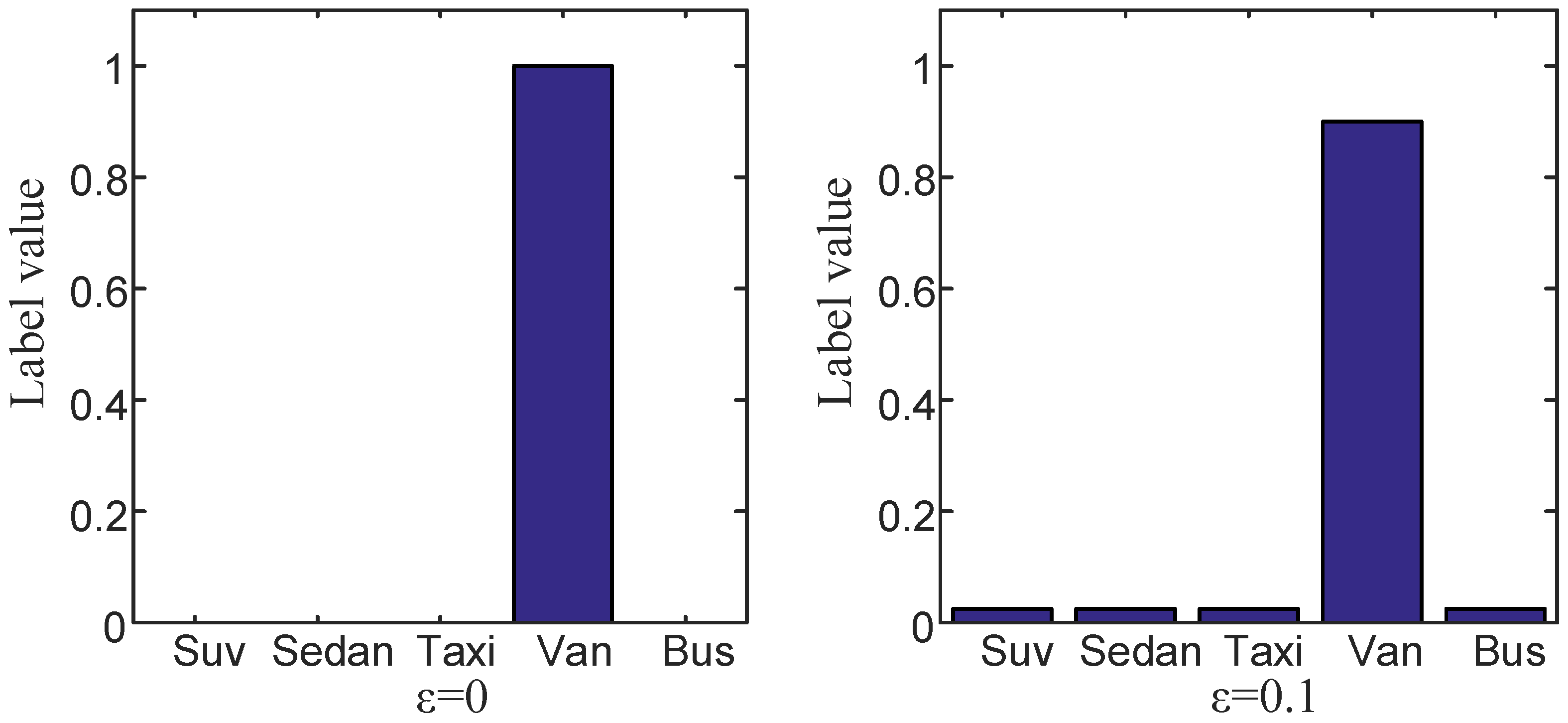
3.3.1. Improvement Based on Label Smoothing
3.3.2. Improvement Based on Mixup
3.4. Improvement Based on the Position Regression Loss Function
3.4.1. Improvement of Loss Function Based on IoU
3.4.2. Improvement of Loss Function Based on GIOU
- (1)
- In order to ensure the coordinates of the predicted box satisfy and , conduct data manipulation as in Formulas (12)–(15):
- (2)
- Calculate the area of :
- (3)
- Calculate the area of :
- (4)
- Calculate the intersection between and :
- (5)
- Find the smallest rectangular box enclosing and :
- (6)
- Calculate the area of :
- (7)
- Calculate IoU and GIOU:
- (8)
- Obtain the loss function based on GIOU:
4. Experiment and Results
4.1. Evaluation Metrics
4.2. Experimental Results
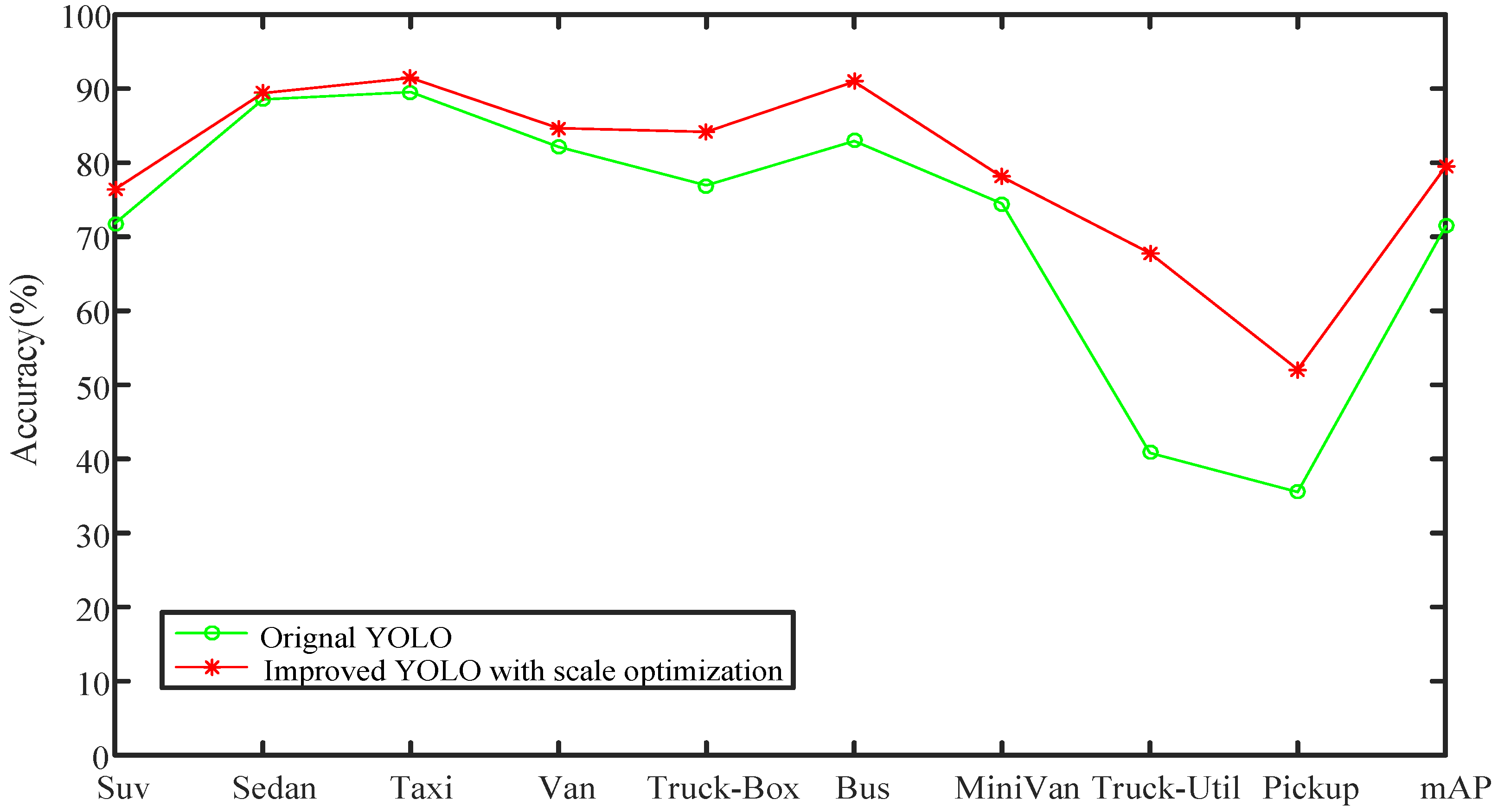
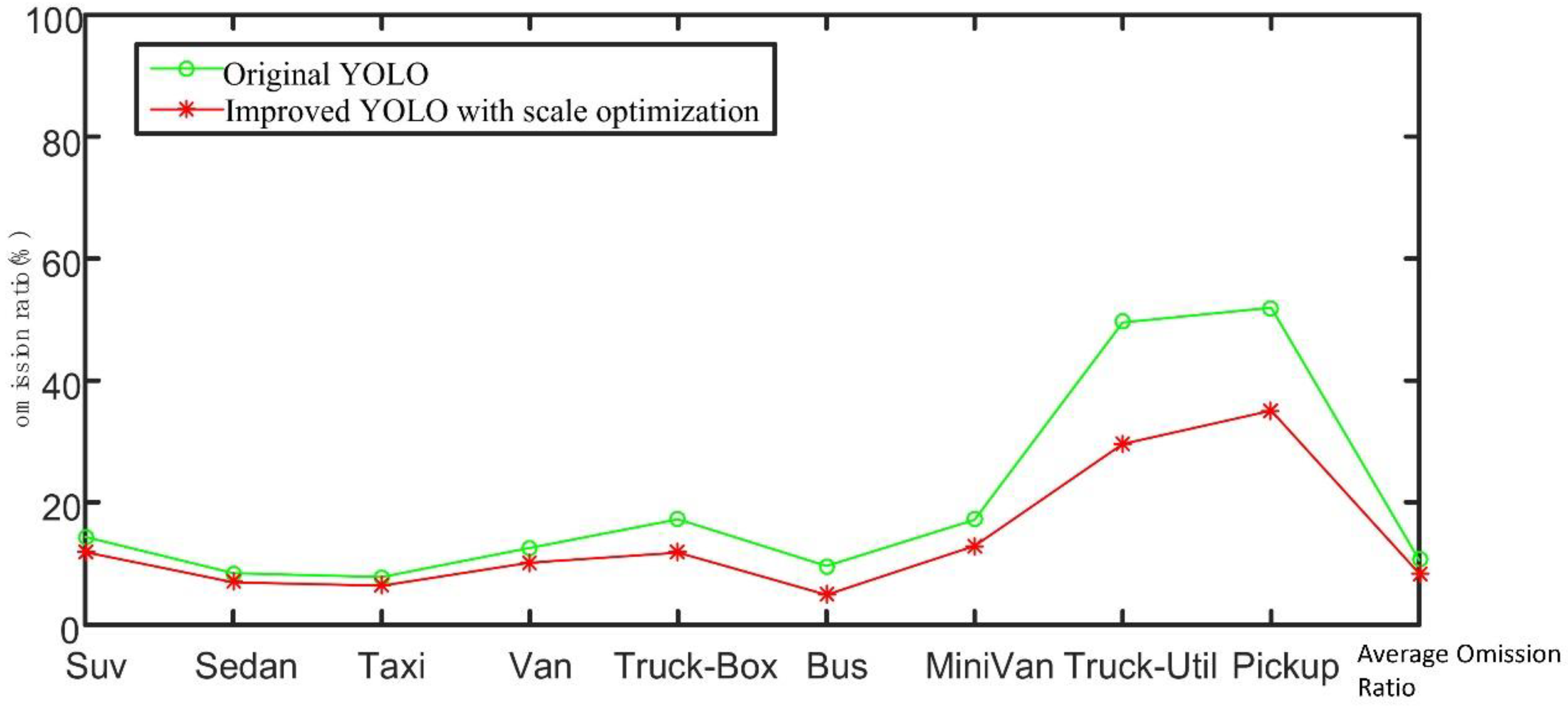
4.2.1. Improved Experimental Results Based on Results of Scale Optimization
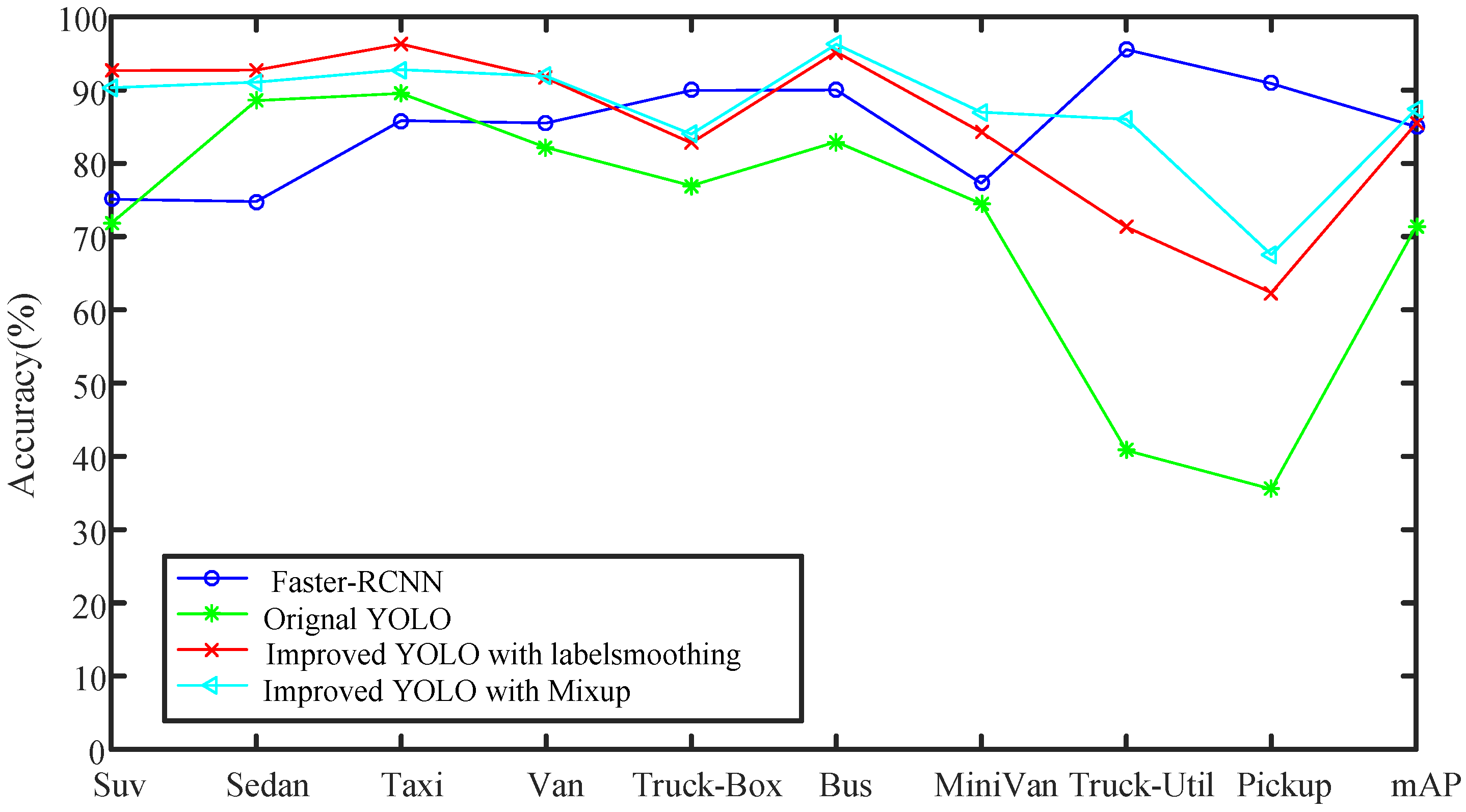
4.2.2. Improved Experimental Results Based on Improving Model’s Generalization Ability
4.2.3. Improved Experimental Results Based on IoU Loss
4.2.4. Improved Experimental Results Based on GIOU Loss
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhu, L.; Yu, F.R.; Wang, Y.; Ning, B.; Tang, T. Big Data Analytics in Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2019, 20, 383–398. [Google Scholar] [CrossRef]
- Maddio, S. A Compact Circularly Polarized Antenna for 5.8-GHz Intelligent Transportation System. Antennas Wirel. Propag. Lett. 2017, 16, 533–536. [Google Scholar] [CrossRef]
- Herrera-Quintero, L.F.; Vega-Alfonso, J.C.; Banse, K.B.A.; Carrillo Zambrano, E. Smart ITS Sensor for the Transportation Planning Based on IoT Approaches Using Serverless and Microservices Architecture. IEEE Intell. Transp. Syst. Mag. 2018, 10, 17–27. [Google Scholar] [CrossRef]
- Ferreira, D.L.; Nunes, B.A.A.; Obraczka, K. Scale-Free Properties of Human Mobility and Applications to Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3736–3748. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. arXiv 2016, arXiv:1512.02325. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Chu, W.; Liu, Y.; Shen, C.; Cai, D.; Hua, X.-S. Multi-Task Vehicle Detection With Region-of-Interest Voting. IEEE Trans. Image Process. 2018, 27, 432–441. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Cao, C.-Y.; Zheng, J.-C.; Huang, Y.-Q.; Liu, J.; Yang, C.-F. Investigation of a Promoted You Only Look Once Algorithm and Its Application in Traffic Flow Monitoring. Appl. Sci. 2019, 9, 3619. [Google Scholar] [CrossRef] [Green Version]
- Lyu, S.; Chang, M.-C.; Du, D.; Li, W.; Wei, Y.; Del Coco, M.; Carcagnì, P.; Schumann, A.; Munjal, B.; Choi, D.-H.; et al. UA-DETRAC 2018: Report of AVSS2018 & IWT4S challenge on advanced traffic monitoring. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.-C.; Qi, H.; Lim, J.; Yang, M.-H.; Lyu, S. UA-DETRAC: A New Benchmark and Protocol for Multi-Object Detection and Tracking. Comput. Vis. Image Underst. 2020, 193, 102907. [Google Scholar] [CrossRef] [Green Version]
- Lyu, S.; Chang, M.-C.; Du, D.; Wen, L.; Qi, H.; Li, Y.; Wei, Y.; Ke, L.; Hu, T.; Del Coco, M.; et al. UA-DETRAC 2017: Report of AVSS2017 & IWT4S Challenge on Advanced Traffic Monitoring. In Proceedings of the Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–7. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Ju, M.; Luo, H.; Wang, Z.; Hui, B.; Chang, Z. The Application of Improved YOLO V3 in Multi-Scale Target Detection. Appl. Sci. 2019, 9, 3775. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Original YOLO (%) | YOLO with Scale Optimization (%) |
|---|---|---|
| Suv | 71.80 | 76.42 |
| Sedan | 88.55 | 89.41 |
| Taxi | 89.55 | 91.45 |
| Van | 82.15 | 84.67 |
| Truck-Box | 76.94 | 84.16 |
| Bus | 82.94 | 90.94 |
| MiniVan | 74.48 | 78.08 |
| Truck-Util | 40.82 | 67.80 |
| Pickup | 35.54 | 52.08 |
| mAP | 71.42 | 79.45 |
| Type | Suv | Sedan | Taxi | Van | Truck-Box | Bus | MiniVan | Truck-Util | Pickup |
|---|---|---|---|---|---|---|---|---|---|
| Suv | 88.35 | 9.36 | 0.25 | 0.17 | 0 | 0 | 1.87 | 0 | 0 |
| Sedan | 0.21 | 99.48 | 0.22 | 0.05 | 0 | 0 | 0.05 | 0 | 0 |
| Taxi | 0 | 0.42 | 99.52 | 0 | 0 | 0 | 0.05 | 0 | 0 |
| Van | 0.45 | 0.57 | 0.11 | 95.69 | 0 | 0 | 3.17 | 0 | 0 |
| Truck-Box | 0 | 1.55 | 0 | 1.55 | 96.37 | 0 | 0 | 0.52 | 0 |
| Bus | 0 | 0.17 | 0 | 0 | 0 | 99.83 | 0 | 0 | 0 |
| MiniVan | 1.94 | 2.53 | 0.17 | 1.6 | 0 | 0 | 93.76 | 0 | 0 |
| Truck-Util | 0 | 0 | 0 | 1.27 | 0 | 0 | 0 | 98.73 | 0 |
| Pickup | 0 | 8.33 | 0 | 2.08 | 0 | 0 | 0 | 2.08 | 87.5 |
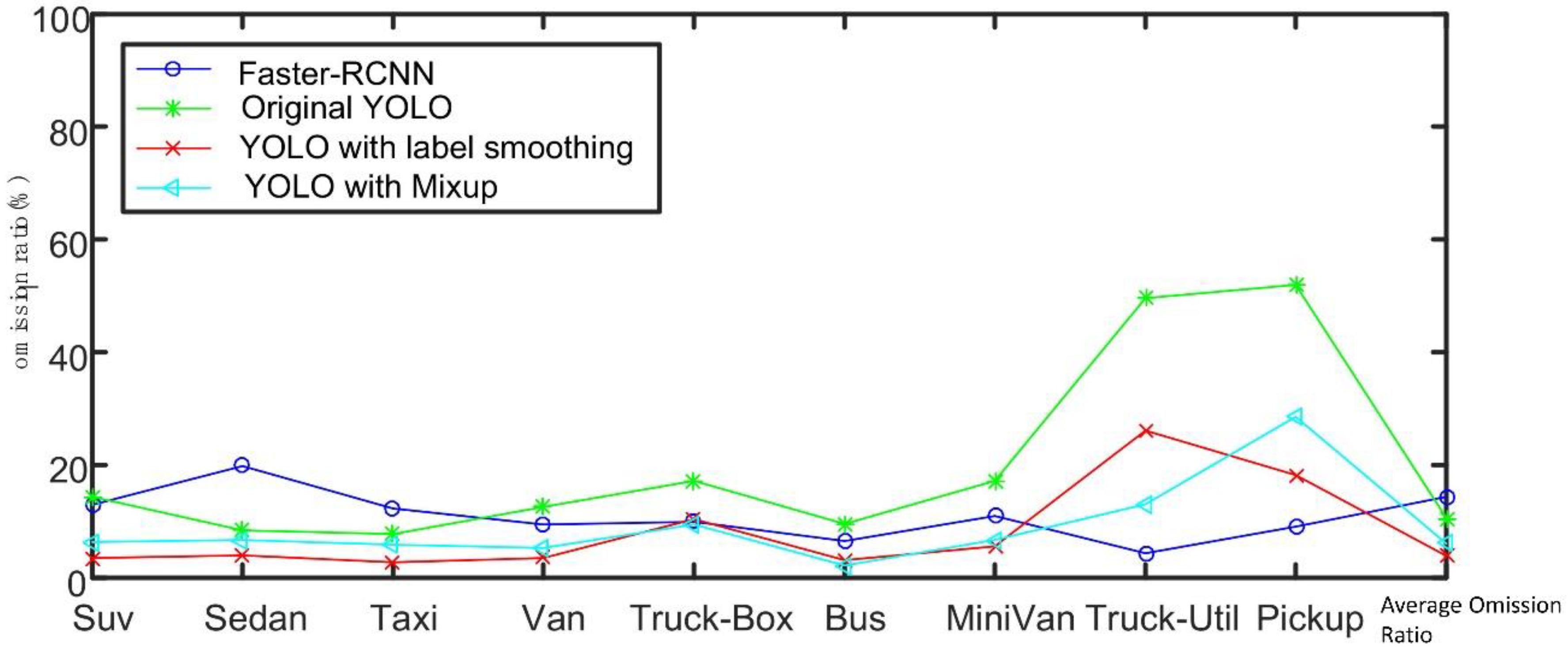
| Type | Faster-RCNN (%) | Original YOLO (%) | Label Smoothing (%) | Mixup (%) |
|---|---|---|---|---|
| Suv | 75.10 | 71.80 | 92.66 | 90.33 |
| Sedan | 74.78 | 88.55 | 92.72 | 91.08 |
| Taxi | 85.83 | 89.55 | 96.27 | 92.79 |
| Van | 85.50 | 82.15 | 91.63 | 91.88 |
| Truck-Box | 89.95 | 76.94 | 82.78 | 83.98 |
| Bus | 90.01 | 82.94 | 95.19 | 96.25 |
| MiniVan | 77.27 | 74.48 | 84.25 | 86.98 |
| Truck-Util | 95.53 | 40.82 | 71.30 | 86.02 |
| Pickup | 90.89 | 35.54 | 62.34 | 67.53 |
| mAP | 84.99 | 71.42 | 85.46 | 87.43 |
| Type | Suv | Sedan | Taxi | Van | Truck-Box | Bus | MiniVan | Truck-Util | Pickup |
|---|---|---|---|---|---|---|---|---|---|
| Suv | 98.35 | 1.57 | 0 | 0 | 0 | 0 | 0.8 | 0 | 0 |
| Sedan | 0.23 | 99.7 | 0.2 | 0.2 | 0.3 | 0 | 0 | 0 | |
| Taxi | 0.5 | 0.21 | 99.68 | 0 | 0 | 00 | 0.5 | 0 | 00 |
| Van | 0.43 | 1.18 | 0 | 97.33 | 0 | 0 | 1.7 | 0 | 0 |
| Truck-Box | 0 | 0.53 | 0 | 0 | 98.41 | 0 | 0 | 1.6 | 0 |
| Bus | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| MiniVan | 3.58 | 0.7 | 0 | 0.62 | 0 | 0 | 95.9 | 0 | 0 |
| Truck-Util | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| Pickup | 0 | 0 | 0 | 1.85 | 0 | 0 | 0 | 1.85 | 96.3 |
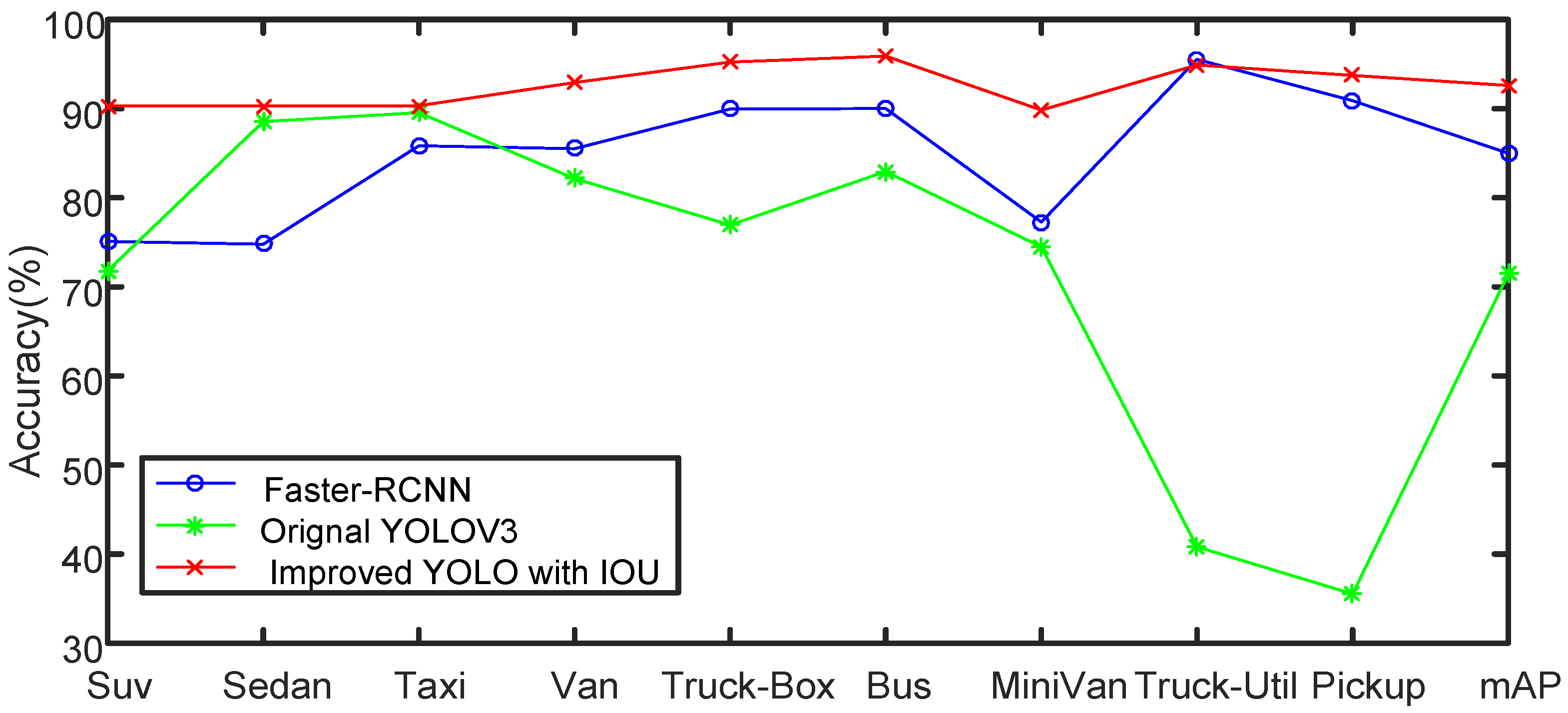
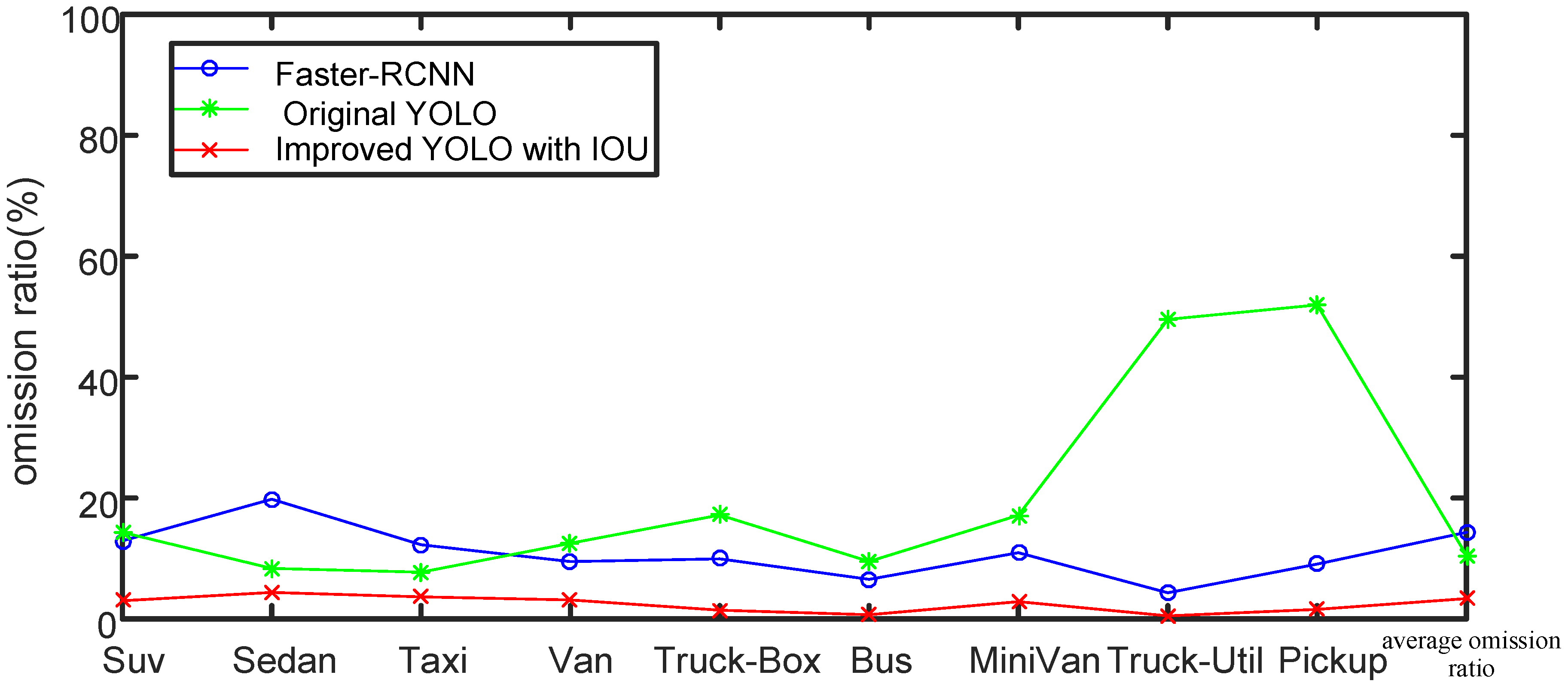
| Type | Faster-RCNN (%) | Original YOLO (%) | Improved YOLO with IoU (%) |
|---|---|---|---|
| Suv | 75.10 | 71.80 | 90.29 |
| Sedan | 74.78 | 88.55 | 90.32 |
| Taxi | 85.83 | 89.55 | 90.32 |
| Van | 85.50 | 82.15 | 92.92 |
| Truck-Box | 89.95 | 76.94 | 95.23 |
| Bus | 90.01 | 82.94 | 95.90 |
| MiniVan | 77.27 | 74.48 | 89.84 |
| Truck-Util | 95.53 | 40.82 | 94.89 |
| Pickup | 90.89 | 35.54 | 93.73 |
| mAP | 84.99 | 71.42 | 92.60 |
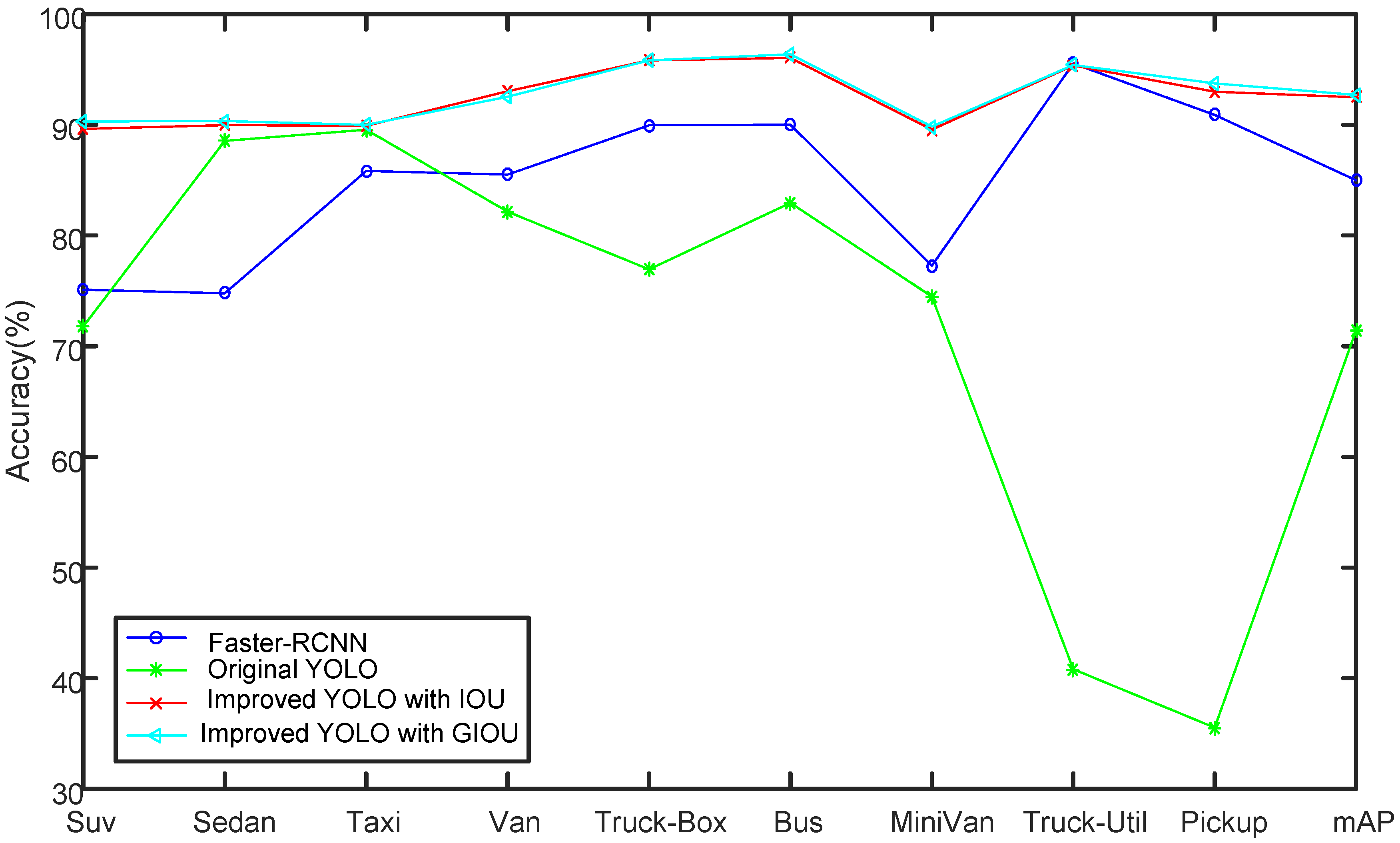
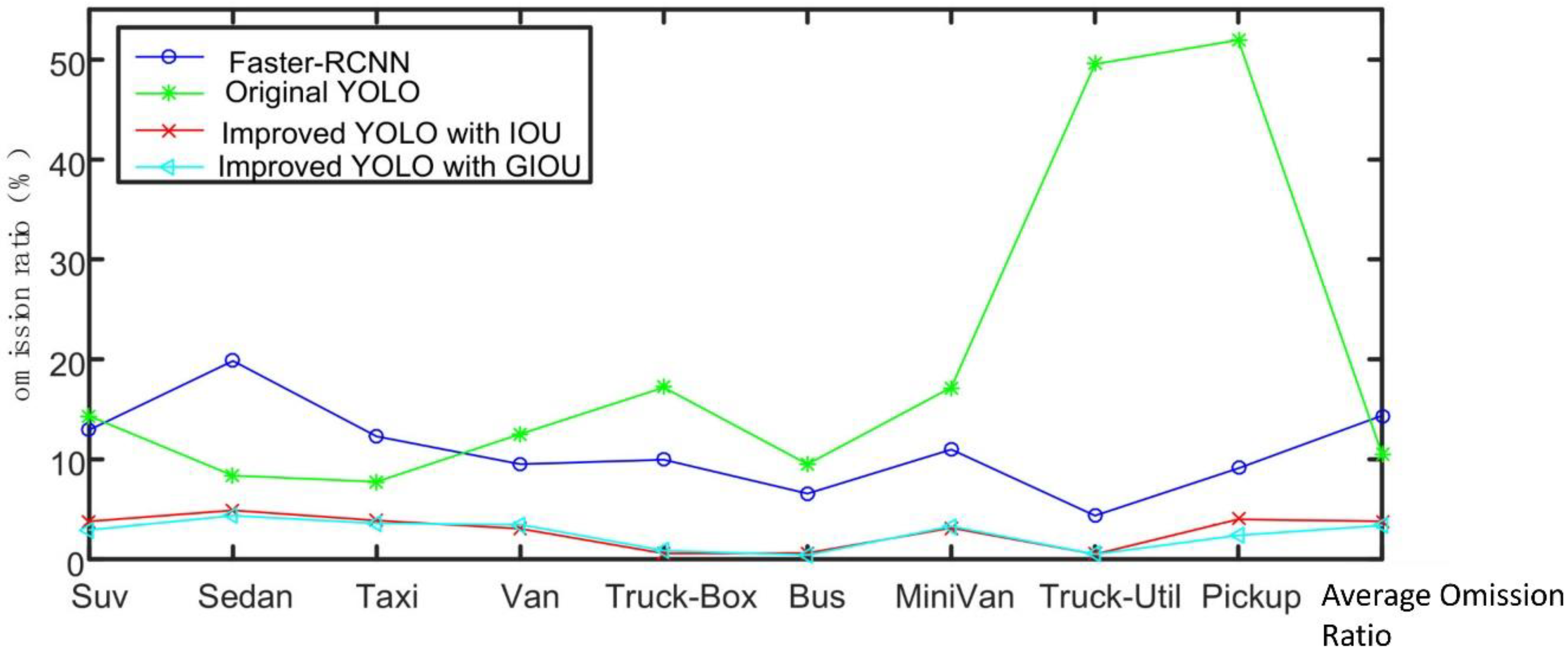
| Type | Faster-RCNN (%) | Original YOLO (%) | Improved YOLO with IoU (%) | Improved YOLO with GIOU (%) |
|---|---|---|---|---|
| Suv | 75.10 | 71.80 | 89.63 | 90.30 |
| Sedan | 74.78 | 88.55 | 89.97 | 90.34 |
| Taxi | 85.83 | 89.55 | 89.91 | 89.99 |
| Van | 85.50 | 82.15 | 93.03 | 92.53 |
| Truck-Box | 89.95 | 76.94 | 95.82 | 95.82 |
| Bus | 90.01 | 82.94 | 96.04 | 96.36 |
| MiniVan | 77.27 | 74.48 | 89.56 | 89.83 |
| Truck-Util | 95.53 | 40.82 | 95.36 | 95.4 |
| Pickup | 90.89 | 35.54 | 92.99 | 93.74 |
| mAP | 84.99 | 71.42 | 92.48 | 92.70 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, F.; Yang, D.; He, Z.; Fu, Y.; Jiang, K. Automobile Fine-Grained Detection Algorithm Based on Multi-Improved YOLOv3 in Smart Streetlights. Algorithms 2020, 13, 114. https://doi.org/10.3390/a13050114
Yang F, Yang D, He Z, Fu Y, Jiang K. Automobile Fine-Grained Detection Algorithm Based on Multi-Improved YOLOv3 in Smart Streetlights. Algorithms. 2020; 13(5):114. https://doi.org/10.3390/a13050114
Chicago/Turabian StyleYang, Fan, Deming Yang, Zhiming He, Yuanhua Fu, and Kui Jiang. 2020. "Automobile Fine-Grained Detection Algorithm Based on Multi-Improved YOLOv3 in Smart Streetlights" Algorithms 13, no. 5: 114. https://doi.org/10.3390/a13050114
APA StyleYang, F., Yang, D., He, Z., Fu, Y., & Jiang, K. (2020). Automobile Fine-Grained Detection Algorithm Based on Multi-Improved YOLOv3 in Smart Streetlights. Algorithms, 13(5), 114. https://doi.org/10.3390/a13050114