1. Introduction
The global financial crisis of 2007–2009 was the most severe crisis over the last few decades with, according to the National Bureau of Economic Research, a peak to trough contraction of 18 months. The consequences were severe in most aspects of life including economy (investment, productivity, jobs, and real income), social (inequality, poverty, and social tensions), leading in the long run to political instability and the need for further economic reforms. In an attempt to “think outside the box” and bypass the governments and financial institutions manipulation and control, Satoshi Nakamoto [
1] proposed Bitcoin which is an electronic cash allowing online payments, where the double-spending problem was elegantly solved using a novel purely peer-to-peer decentralized blockchain along with a cryptographic hash function as a proof-of-work.
Nowadays, there are over 5000 cryptocurrencies available; however, when it comes to scientific research there are several issues to deal with. The large majority of these are relatively new, indicating that there is an insufficient amount of data for quantitative modeling or price forecasting. In the same manner, they are not highly ranked when it comes to market capitalization to be considered as market drivers. A third aspect which has not attracted attention in the literature is the separation of cryptocurrencies between mineable and non-mineable. Minable cryptocurrencies have several advantages i.e., the performance of different mineable coins can be monitored within the same blockchain which cannot be easily said for non-mineable coins, and they are community driven open source where different developers can contribute, ensuring the fact that a consensus has to be reached before any major update is done, in order to avoid splitting. Finally, when it comes to the top cryptocurrencies, it appears that mineable cryptocurrencies like Bitcoin (BTC) and Ethereum (ETH), recovered better the 2018 crash rather than Ripple (XRP) which is the highest ranked pre-mined coin. In addition, the non-mineable coins transactions are powered via a centralized blockchain, endangering price manipulation through inside trading, since the creators keep a given percentage to themselves, or through the use of pump and pull market mechanisms. Looking at the number one cryptocurrency exchange in the world, Coinmarketcap, by January 2020 at the time of writing there are only 31 mineable cryptocurrencies out of the first 100, ranked by market capitalization. The classical investing strategy in cryptocurrency market is the “buy, hold and sell” strategy, in which cryptocurrencies are bought with real money and held until reaching a higher price worth selling in order for an investor to make a profit. Obviously, a potential fractional change in the price of a cryptocurrency may gain opportunities for huge benefits or significant investment losses. Thus, the accurate prediction of cryptocurrency prices can potentially assist financial investors for making their proper investment policies by decreasing their risks. However, the accurate prediction of cryptocurrency prices is generally considered a significantly complex and challenging task, mainly due to its chaotic nature. This problem is traditionally addressed by the investor’s personal experience and consistent watching of exchanges prices. Recently, the utilization of intelligent decision systems based on complicated mathematical formulas and methods have been adopted for potentially assisting investors and portfolio optimization.
Let
be the observations of a time series. Generally, a nonlinear regression model of order
m is defined by
where
m values of
,
is the parameter vector. After the model structure has been defined, function
can be determined by traditional time-series methods such as ARIMA (Auto-Regressive Integrated Moving Average) and GARCH-type models and their variations [
2,
3,
4] or by machine learning methods such as Artificial Neural Networks (ANNs) [
5,
6]. However, both mentioned approaches fail to depict the stochastic and chaotic nature of cryptocurrency time-series and be successfully effective for accurate forecasting [
7]. To this end, more sophisticated algorithmic approaches have to be applied such as deep learning and ensemble learning methods. From the perspective of developing strong forecasting models, deep learning and ensemble learning constitute two fundamental learning strategies. The former is based on neural networks architectures and it is able to achieve state-of-the-art accuracy by creating and exploiting new more valuable features by filtering out the noise of the input data; while the latter attempts to generate strong prediction models by exploiting multiple learners in order to reduce the bias or variance of error.
During the last few years, researchers paid special attention to the development of time-series forecasting models which exploit the advantages and benefits of deep learning techniques such as convolutional and long short-term memory (LSTM) layers. More specifically, Wen and Yuan [
8] and Liu et al. [
9] proposed Convolutional Neural Network (CNN) and LSTM prediction models for stock market forecasting. Along this line, Livieris et al. [
10] and Pintelas et al. [
11] proposed CNN-LSTM models with various architectures for efficiently forecasting gold and cryptocurrency time-series price and movement, reporting some interesting results. Nevertheless, although deep learning models are tailored to cope with temporal correlations and efficiently extract more valuable information from the training set, they failed to generate reliable forecasting models [
7,
11]; while in contrast ensemble learning models although they are an elegant solution to develop stable models and address the high variance of individual forecasting models, their performance heavily depends on the diversity and accuracy of the component learners. Therefore, a time-series prediction model, which exploits the benefits of both mentioned methodologies may significantly improve the prediction performance.
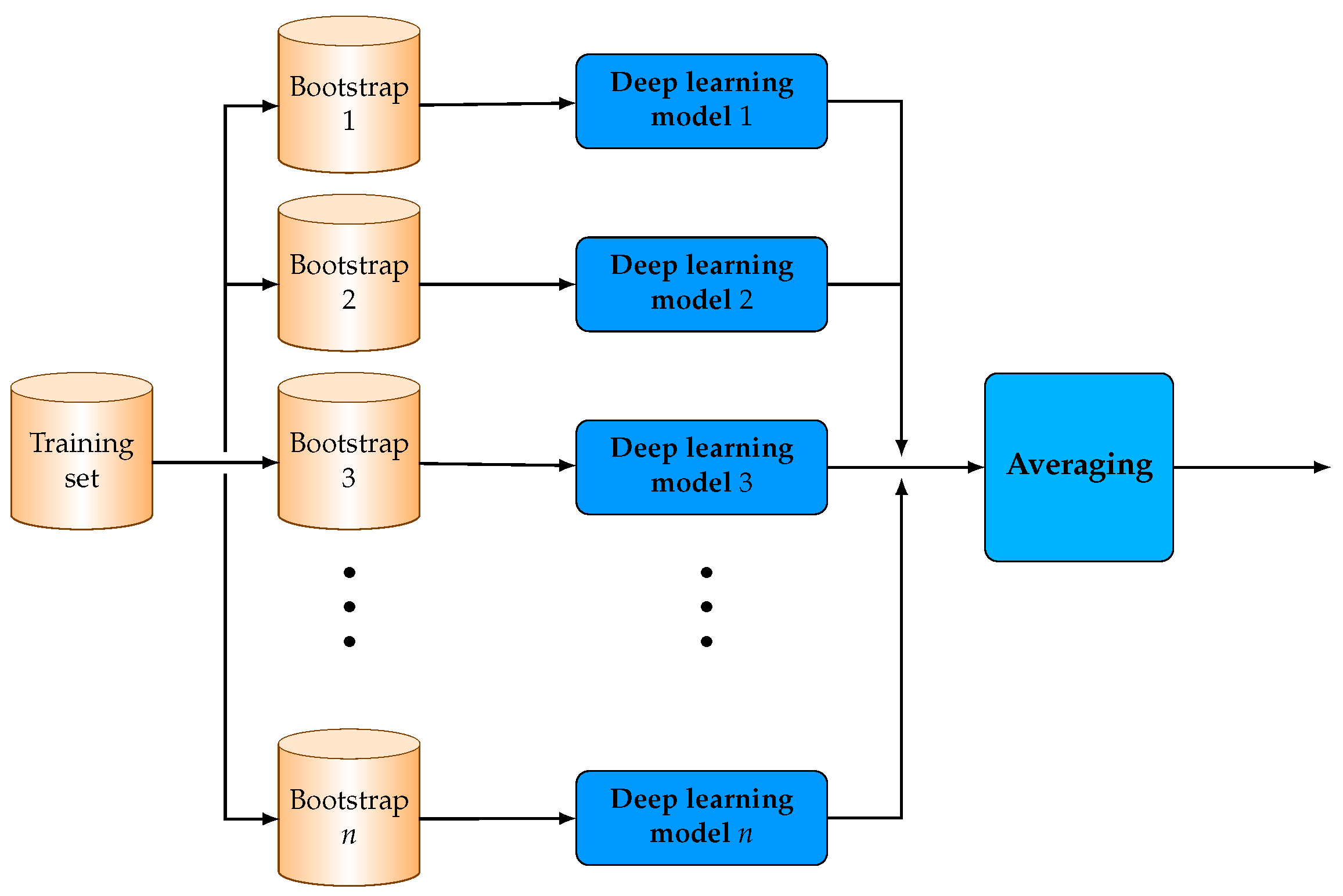
The main contribution of this research is the combination of ensemble learning strategies with advanced deep learning models for forecasting cryptocurrency hourly prices and movement. The proposed ensemble models utilize state-of-the-art deep learning models as component learners which are based on combinations of Long Short-Term Memory (LSTM), Bi-directional LSTM (BiLSTM) and convolutional layers. An extensive experimental analysis is performed considering both classification and regression problems, to evaluate the performance of averaging, bagging and stacking ensemble strategies. More analytically, all ensemble models are evaluated on prediction of the cryptocurrency price on the next hour (regression) and also on the prediction if the price on the following hour will increase or decrease with respect to the current price (classification). It is worth mentioning that the information of predicting the movement of a cryptocurrency is probably more significant that the prediction of the price for investors and financial institutions. Additionally, the efficiency of the predictions of each forecasting model is evaluated by examining for autocorrelation of the errors, which constitutes a significant reliability test of each model.
The remainder of the paper is organized as follows:
Section 2 presents a brief review of state of the art deep learning methodologies for cryptocurrency forecasting.
Section 3 presents the advanced deep learning models, while
Section 4 presents the ensemble strategies utilized in our research.
Section 5 presents our experimental methodology including the data preparation and preprocessing as well as the detailed experimental analysis, regarding the evaluation of ensemble of deep learning models.
Section 6 discusses the obtained results and summarizes our findings. Finally,
Section 7 presents our conclusions and presents some future directions.
2. Deep Learning in Cryptocurrency Forecasting: State-of-the-Art
Yiying and Yeze [
12] focused on the price non-stationary dynamics of three cryptocurrencies Bitcoin, Etherium, and Ripple. Their approach aimed at identifying and understand the factors which influence the value formation of these digital currencies. Their collected data contained 1030 trading days regarding opening, high, low, and closing prices. They conducted an experimental analysis which revealed the efficiency of LSTM models over classical ANNs, indicating that LSTM models are more capable of exploiting information hidden in historical data. Additionally, the authors stated that probably the reason for the efficiency of LSTM networks is that they tend to depend more on short-term dynamics while ANNs tends to depend more on long-term history. Nevertheless, in case enough historical information is given, ANNs can achieve similar accuracy to LSTM networks.
Nakano et al. [
13] examined the performance of ANNs for the prediction of Bitcoin intraday technical trading. The authors focused on identifying the key factors which affect the prediction performance for extracting useful trading signals of Bitcoin from its technical indicators. For this purposed, they conducted a series of experiments utilizing various ANN models with shallow and deep architectures and datasets structures The data utilized in their research regarded Bitcoin time-series return data at 15-min time intervals. Their experiments illustrated that the utilization of multiple technical indicators could possibly prevent the prediction model from overfitting of non-stationary financial data, which enhances trading performance. Moreover, they stated that their proposed methodology attained considerably better performance than the primitive technical trading and buy-and-hold strategies, under realistic assumptions of execution costs.
Mcnally et al. [
14] utilized two deep learning models, namely a Bayesian-optimised Recurrent Neural Network and a LSTM network, for Bitcoin price prediction. The utilized data ranged from the August 2013 until July 2016, regarding open, high, low and close of Bitcoin prices as well as the block difficulty and hash rate. Their performance evaluation showed that the LSTM network demonstrated the best prediction accuracy, outperforming the other recurrent model as well as the classical statistical method ARIMA.
Shintate and Pichl [
15] proposed a new trend prediction classification framework which is based on deep learning techniques. Their proposed framework utilized a metric learning-based method, called Random Sampling method, which measures the similarity between the training samples and the input patterns. They used high frequency data (1-min) ranged from June 2013 to March 2017 containing historical data from OkCoin Bitcoin market (Chinese Yuan Renminbi and US Dollars). The authors concluded that the profit rates based on utilized sampling method considerably outperformed those based on LSTM networks, confirming the superiority of the proposed framework. In contrast, these profit rates were lower than those obtained of the classical buy-and-hold strategy; thus they stated that it does not provide a basis for trading.
Miura et al. [
16] attempted to analyze the high-frequency Bitcoin (1-min) time series utilizing machine learning and statistical forecasting models. Due to the large size of the data, they decided to aggregate the realized volatility values utilizing 3-h long intervals. Additionally, they pointed out that these values presented a weak correlation based on high-low price extent with the relative values of the 3-h interval. In their experimental analysis, they focused on evaluating various ANNs-type models, SVMs and Ridge Regression and the Heterogeneous Auto-Regressive Realized Volatility model. Their results demonstrated that Ridge Regression considerably presented the best performance while SVM exhibited poor performance.
Ji et al. [
17] evaluated the prediction performance on Bitcoin price of various deep learning models such as LSTM networks, convolutional neural networks, deep neural networks, deep residual networks and their combinations. The data used in their research, contained 29 features of the Bitcoin blockchain from 2590 days (from 29 November 2011 to 31 December 2018). They conducted a detailed experimental procedure considering both classification and regression problems, where the former predicts whether or not the next day price will increase or decrease and the latter predicts the next day’s Bitcoin price. The numerical experiments illustrated that the deep neural DNN-based models performed the best for price ups-and-downs while the LSTM models slightly outperformed the rest of the models for forecasting Bitcoin’s price.
Kumar and Rath [
18] focused on forecasting the trends of Etherium prices utilizing machine learning and deep learning methodologies. They conducted an experimental analysis and compared the prediction ability of LSTM neural networks and Multi-Layer perceptron (MLP). They utilized daily, hourly, and minute based data which were collected from the CoinMarket and CoinDesk repositories. Their evaluation results illustrated that LSTM marginally outperformed MLP but not considerably, although their training time was significantly high.
Pintelas et al. [
7,
11] conducted a detailed research, evaluating advanced deep learning models for predicting major cryptocurrency prices and movements. Additionally, they conducted a detailed discussion regarding the fundamental research questions: Can deep learning algorithms efficiently predict cryptocurrency prices? Are cryptocurrency prices a random walk process? Which is a proper validation method of cryptocurrency price prediction models? Their comprehensive experimental results revealed that even the LSTM-based and CNN-based models, which are generally preferable for time-series forecasting [
8,
9,
10], were unable to generate efficient and reliable forecasting models. Moreover, the authors stated that cryptocurrency prices probably follow an almost random walk process while few hidden patterns may probably exist. Therefore, new sophisticated algorithmic approaches should be considered and explored for the development of a prediction model to make accurate and reliable forecasts.
In this work, we advocate combining the advantages of ensemble learning and deep learning for forecasting cryptocurrency prices and movement. Our research contribution aims on exploiting the ability of deep learning models to learn the internal representation of the cryptocurrency data and the effectiveness of ensemble learning for generating powerful forecasting models by exploiting multiple learners for reducing the bias or variance of error. Furthermore, similar to our previous research [
7,
11], we provide detailed performance evaluation for both regression and classification problems. To the best of our knowledge, this is the first research devoted to the adoption and combination of ensemble learning and deep learning for forecasting cryptocurrencies prices and movement.
5. Numerical Experiments
In this section, we evaluate the performance of the three presented ensemble strategies which utilize advanced deep learning models as component learners. The implementation code was written in Python 3.4 while for all deep learning models Keras library [
40] was utilized and Theano as back-end.
For the purpose of this research, we utilized data from 1 January 2018 to 31 August 2019 from the hourly price of the cryptocurrencies BTC, ETH and XRP. For evaluation purposes, the data were divided in training set and in testing set as in [
7,
11]. More specifically, the training set comprised data from 1 January 2018 to 28 February 2019 (10,177 datapoints), covering a wide range of long and short term trends while the testing set consisted of data from 1 March 2019 to 31 August 2019 (4415 datapoints) which ensured a substantial amount of unseen out-of-sample prices for testing.
Next, we concentrated on the experimental analysis to evaluate the presented ensemble strategies using the advanced deep learning models CNN-LSTM and CNN-BiLSTM as base learners. A detailed description of both component models is presented in
Table 1. These models and their hyper-parameters were selected in previous research [
7] after extensive experimentation, in which they exhibited the best performance on the utilized datasets. Both component models were trained for 50 epochs with Adaptive Moment Estimation (ADAM) algorithm [
41] with a batch size equal to 512, using a mean-squared loss function. ADAM algorithm ensures that the learning steps, during the training process, are scale invariant relative to the parameter gradients.
The performance of all ensemble models was evaluated utilizing the performance metric: Root Mean Square Error (RMSE). Additionally, the classification accuracy of all ensemble deep models was measured, relative to the problem of predicting whether the cryptocurrency price would increase or decrease on the next day. More analytically, by analyzing a number of previous hourly prices, the model predicts the price on the following hour and also predicts if the price will increase or decrease, with respect to current cryptocurrency price. For this binary classification problem, three performance metrics were used: Accuracy (Acc), Area Under Curve (AUC) and -score ().
All ensemble models were evaluated using 7 and 11 component learners which reported the best overall performance. Notice that any attempt to increase the number of classifiers resulted to no improvement to the performance of each model. Moreover, stacking was evaluated using the most widely used state-of-the-art algorithms [
42] as meta-learners: Support Vector Regression (SVR) [
43], Linear Regression (LR) [
44],
k-Nearest Neighbor (
kNN) [
45] and Decision Tree Regression (DTR) [
46]. For fairness and for performing an objective comparison, the hyper-parameters of all meta-learners were selected in order to maximize their experimental performance and are briefly presented in
Table 2.
Summarizing, we evaluate the performance of the following ensemble models:
“Averaging” and “Averaging” stand for ensemble-averaging model utilizing 7 and 11 component learners, respectively.
“Bagging” and “Bagging” stand for bagging ensemble model utilizing 7 and 11 component learners, respectively.
“Stacking” and “Stacking” stand for stacking ensemble model utilizing 7 and 11 component learners, respectively and DTR model as meta-learner.
“Stacking” and “Stacking” stand for stacking ensemble model utilizing 7 and 11 component learners, respectively and LR model as meta-learner.
“Stacking” and “Stacking” stand for stacking ensemble model utilizing 7 and 11 component learners, respectively and SVR as meta-learner.
“Stacking” and “Stacking” stand for stacking ensemble model utilizing 7 and 11 component learners, respectively and kNN as meta-learner.
Table 3 and
Table 4 summarize the performance of all ensemble models using CNN-LSTM as base learner for
and
, respectively. Stacking using LR as meta-learner exhibited the best regression performance, reporting the lowest RMSE score, for all cryptocurrencies. Notice that stacking
and Stacking
reported the same performance, which implies that the increment of component learners from 7 to 11 did not affect the regression performance of this ensemble algorithm. In contrast, stacking
exhibited better classification performance than Stacking
, reporting higher accuracy, AUC and
-score. Additionally, the stacking ensemble reported the worst performance utilizing DTR and SVR as meta-learners among all ensemble models, also reporting worst performance than CNN-LSTM model; while the best classification performance was reported using
kNN as meta-learner in almost all cases.
The average and bagging ensemble reported slightly better regression performance, compared to the single model CNN-LSTM. In contrast, both ensembles presented the best classification performance, considerably outperforming all other forecasting models, regarding all datasets. Moreover, the bagging ensemble reported the highest accuracy, AUC and in most cases, slightly outperforming the average-ensemble model. Finally, it is worth noticing that both the bagging and average-ensemble did not improve their performance when the number of component classifiers increased. for while for a slightly improvement in their performance was noticed.
Table 5 and
Table 6 present the performance of all ensemble models utilizing CNN-BiLSTM as base learner for
and
, respectively. Firstly, it is worth noticing that stacking model using LR as meta-learner exhibited the best regression performance, regarding to all cryptocurrencies. Stacking
and Stacking
presented almost identical RMSE score Moreover, stacking
presented slightly higher accuracy, AUC and
-score than stacking
, for ETH and XRP datasets, while for BTC dataset Stacking
reported slightly better classification performance. This implies that the increment of component learners from 7 to 11 did not considerably improved and affected the regression and classification performance of the stacking ensemble algorithm. Stacking ensemble reported the worst (highest) RMSE score utilizing DTR, SVR and
kNN as meta-learners. It is also worth mentioning that it exhibited the worst performance among all ensemble models and also worst than that of the single model CNN-BiLSTM. However, stacking ensemble reported the highest classification performance using
kNN as meta-learner. Additionally, it presented slightly better classification performance using DTR or SVR than LR as meta-learners for ETH and XRP datasets, while for BTC dataset it presented better performance using LR as meta-learner as meta-learner.
Regarding the other two ensemble strategies, averaging and bagging, they exhibited slightly better regression performance compared to the single CNN-BiLSTM model. Nevertheless, both averaging and bagging reported the highest accuracy, AUC and -score, which implies that they presented the best classification performance among all other models with bagging exhibiting slightly better classification performance. Furthermore, it is also worth mentioning that both ensembles slightly improved their performance in term of RMSE score and Accuracy, when the number of component classifiers increased from 7 to 11.
In the follow-up, we provided a deeper insight classification performance of the forecasting models by presenting the confusion matrices of averaging, bagging, stacking and stacking for , which exhibited the best overall performance. The use of the confusion matrix provides a compact and to the classification performance of each model, presenting complete information about mislabeled classes. Notice that each row of a confusion matrix represents the instances in an actual class while each column represents the instances in a predicted class. Additionally, both stacking ensembles utilizing DTR and SVM as meta-learners were excluded from the rest of our experimental analysis, since they presented the worst regression and classification performance, relative to all cryptocurrencies.
Table 7,
Table 8 and
Table 9 present the confusion matrices of the best identified ensemble models using CNN-LSTM as base learner, regarding BTC, ETH and XRP datasets, respectively. The confusion matrices for BTC and ETH revealed that stacking
is biased, since most of the instances were misclassified as “Down”, meaning that this model was unable to identify possible hidden patterns despite the fact that it exhibited the best regression performance. On the other hand, bagging
exhibited a balanced prediction distribution between “Down” or “Up” predictions, presenting its superiority over the rest forecasting models, followed by averaging
and stacking
. Regarding XRP dataset, bagging
and stacking
presented the highest prediction accuracy and the best trade-off between true positive and true negative rate, meaning that these models may have identified some hidden patters.
Table 10,
Table 11 and
Table 12 present the confusion matrices of averaging
, bagging
, stacking
and Stacking
using CNN-BiLSTM as base learner, regarding BTC, ETH and XRP datasets, respectively. The confusion matrices for BTC dataset demonstrated that both average
and bagging
presented the best performance while stacking
was biased, since most of the instances were misclassified as “Down”. Regarding ETH dataset, both average
and bagging
were considered biased since most “Up” instances were misclassified as “Down”. In contrast, both stacking ensembles presented the best performance, with stacking
reporting slightly considerably better trade-off between sensitivity and specificity. Regarding XRP dataset, bagging
presented the highest prediction accuracy and the best trade-off between true positive and true negative rate, closely followed by stacking
.
In the rest of this section, we evaluate the reliability of the best reported ensemble models by examining if they have properly fitted the time series. In other words, we examine if the models’ residuals defined by
are identically distributed and asymptotically independent. It is worth noticing the residuals are dedicated to evaluate whether the model has properly fitted the time series.
For this purpose, we utilize the AutoCorrelation Function (ACF) plot [
47] which is obtained from the linear correlation of each residual
to the others in different lags,
and illustrates the intensity of the temporal autocorrelation. Notice that in case the forecasting model violates the assumption of no autocorrelation in the errors implies that its predictions may be inefficient since there is some additional information left over which should be accounted by the model.
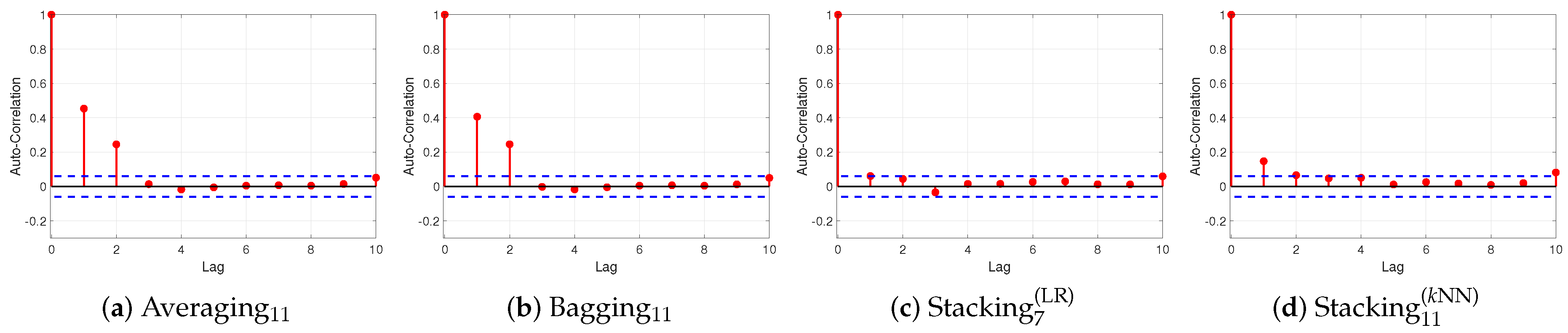
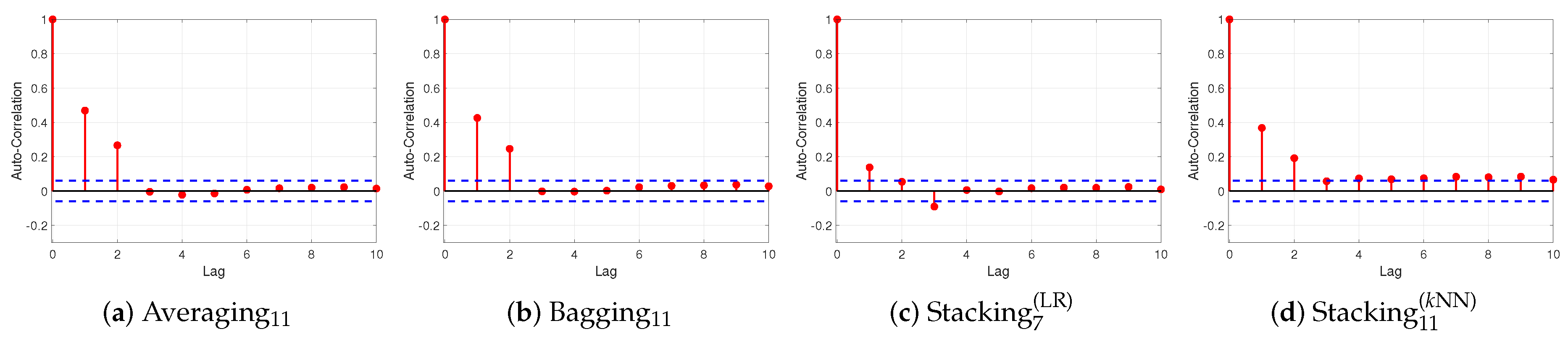
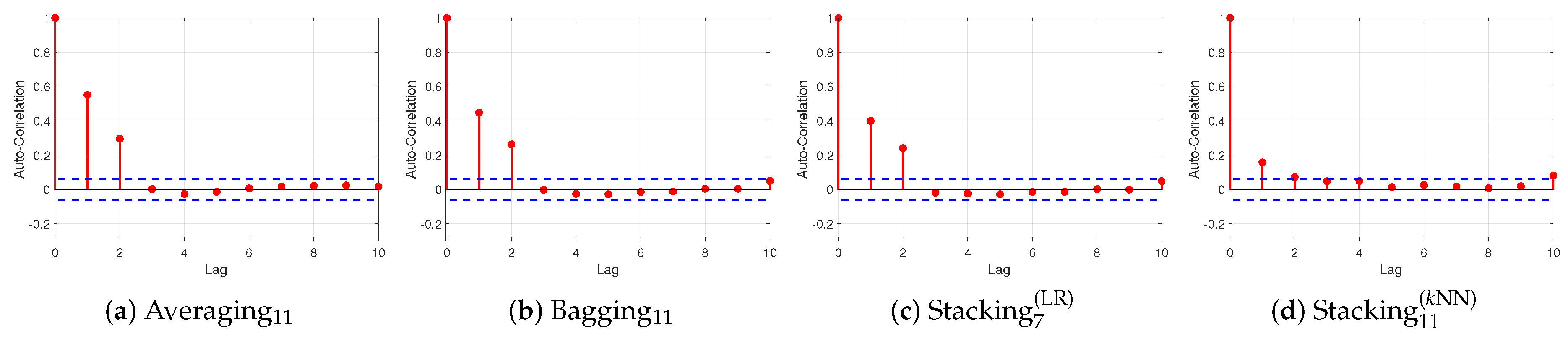
Figure 4,
Figure 5 and
Figure 6 present the ACF plots for BTC, ETH and XRP datasets, respectively. Notice that the confident limits (blue dashed line) are constructed assuming that the residuals follow a Gaussian probability distribution. It is worth noticing that averaging
and bagging
ensemble models violate the assumption of no autocorrelation in the errors which suggests that their forecasts may be inefficient, regarding BTC and ETH datasets. More specifically, the significant spikes at lags 1 and 2 imply that there exists some additional information left over which should be accounted by the models. Regarding XRP dataset, the ACF plot of average
presents that the residuals have no autocorrelation; while the ACF plot of bagging
presents that there is a spike at lag 1, which violates the assumption of no autocorrelation in the residuals. Both ACF plots of stacking ensemble are within 95% percent confidence interval for all lags, regarding BTC and XRP datasets, which verifies that the residuals have no autocorrelation. Regarding the ETH dataset, the ACF plot of stacking
reported a small spike at lag 1, which reveals that there is some autocorrelation of the residuals but not particularly large; while the ACF plot of stacking
reveals that there exist small spikes at lags 1 and 2, implying that there is some autocorrelation.
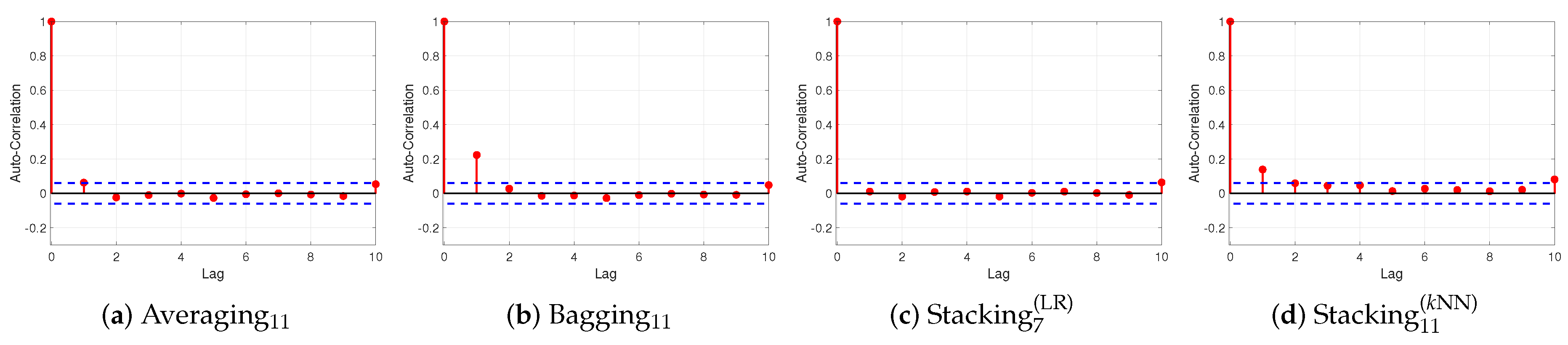
Figure 7,
Figure 8 and
Figure 9 present the ACF plots of averaging
, bagging
, stacking
and stacking
ensembles utilizing CNN-BiLSTM as base learner for BTC, ETH and XRP datasets, respectively. Both averaging
and bagging
ensemble models violate the assumption of no autocorrelation in the errors, relative to all cryptocurrencies, implying that these models are not properly fitted the time-series. In more detail, the significant spikes at lags 1 and 2 suggest that the residuals are not identically distributed and asymptotically independent, for all datasets. The ACF plot of stacking
ensemble for BTC dataset verify that the residuals have no autocorrelation since are within 95% percent confidence interval for all lags. In contrast, for ETH and XRP datasets the spikes at lags 1 and 2 illustrate that there is some autocorrelation of the residuals. Regarding the ACF plots of stacking
present that there exists some autocorrelation in the residuals but not particularly large for BTC and XRP datasets; while for ETH dataset, the significant spikes at lags 1 and 2 suggest that the model’s prediction may be inefficient.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}