Sensitivity Analysis for Microscopic Crowd Simulation


Abstract
:1. Introduction
1.1. Parameter Studies in Crowd Simulations
1.2. Overview of Sensitivity Analysis Methods
1.3. State-of-the-Art of Sensitivity Analysis for Crowd Simulations
1.4. Outline of Our Work
2. Materials and Methods
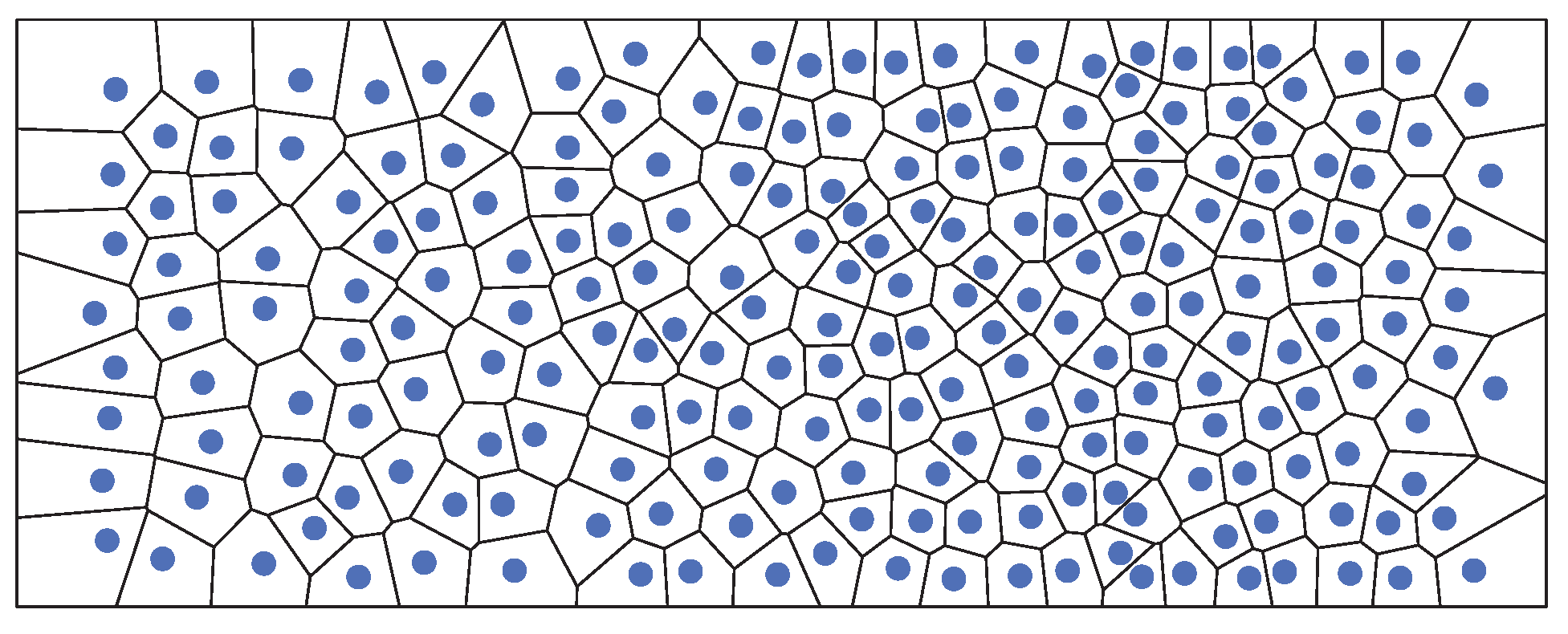
2.1. Crowd Simulation with the Optimal Steps Model
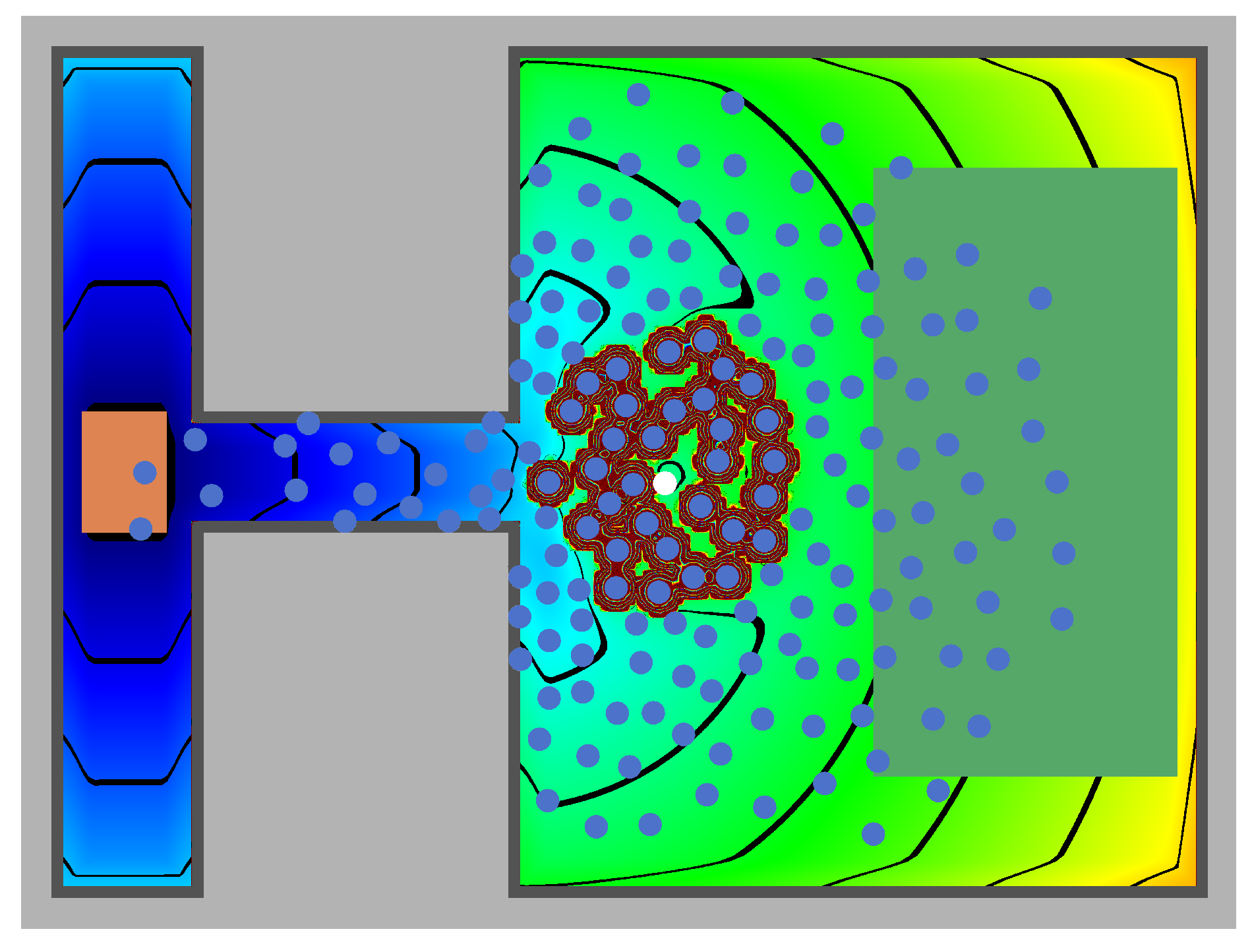
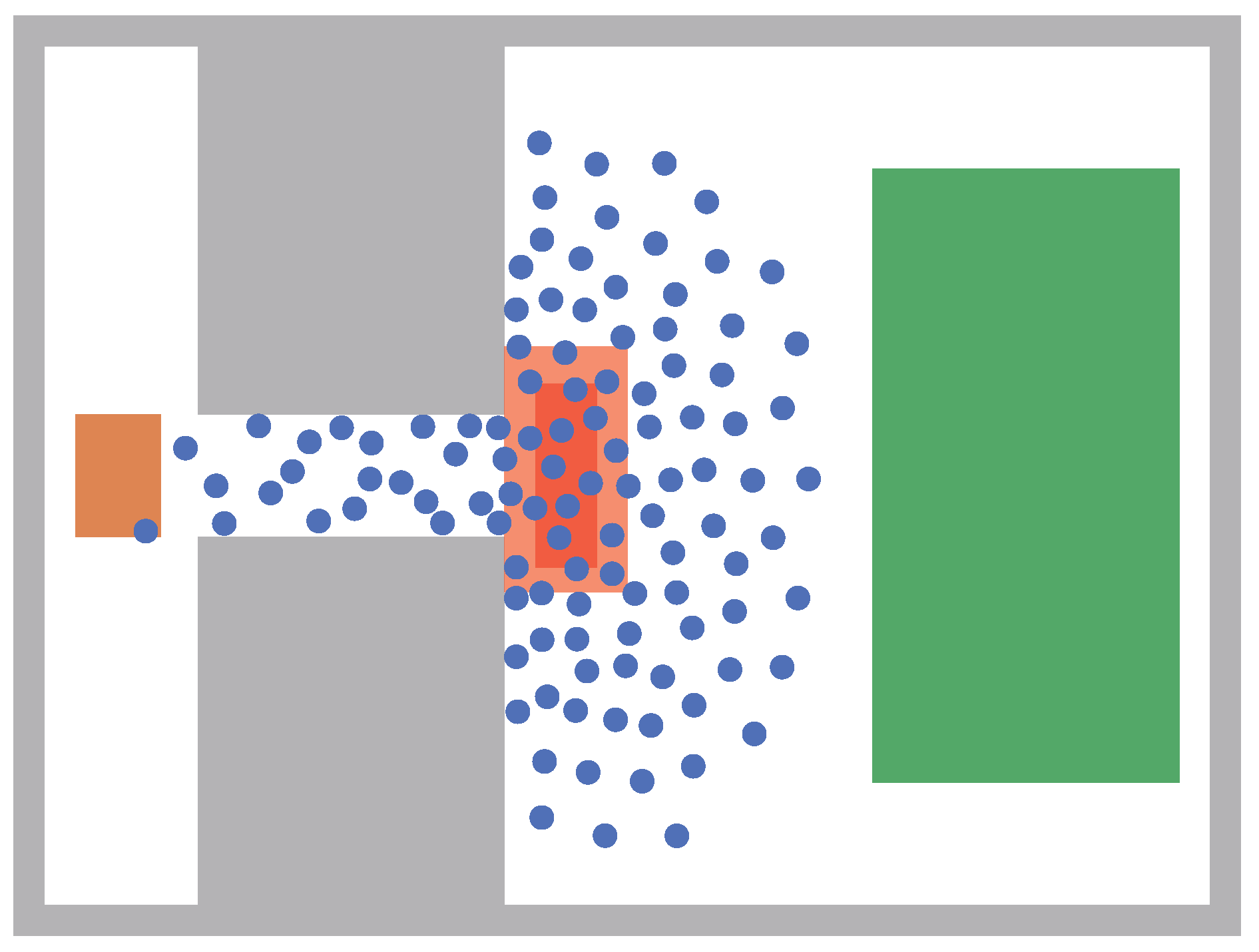
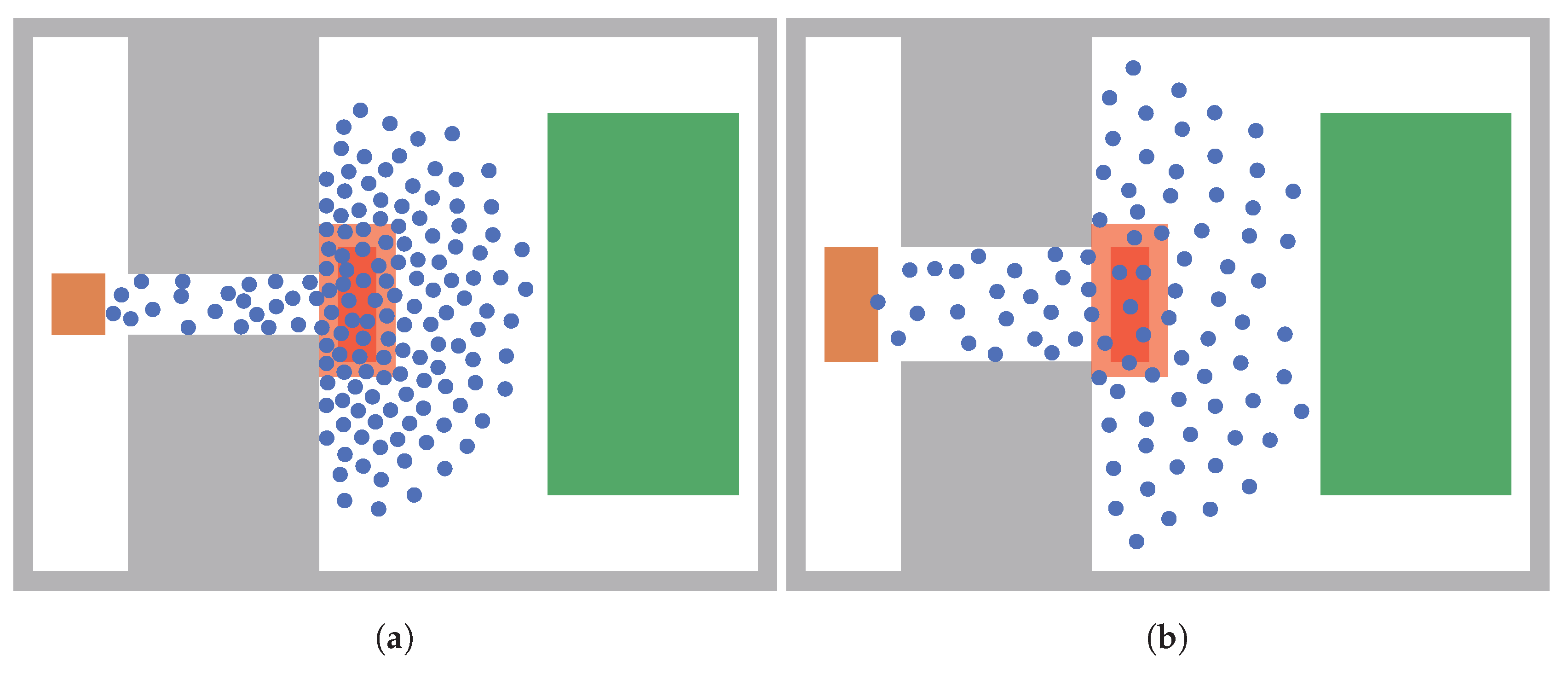
2.2. Bottleneck Scenario: Crucial for Improving Safety
2.3. Choice of Sensitivity Analysis Methods
2.3.1. Sobol’ Indices (Variance-Based Method)
2.3.2. Activity Scores (Derivative-Based Method)
2.4. Implementation of the Methods
3. Results and Discussion
3.1. Configuration of the Simulation
3.2. Uncertain Input Parameters in the Bottleneck Scenario
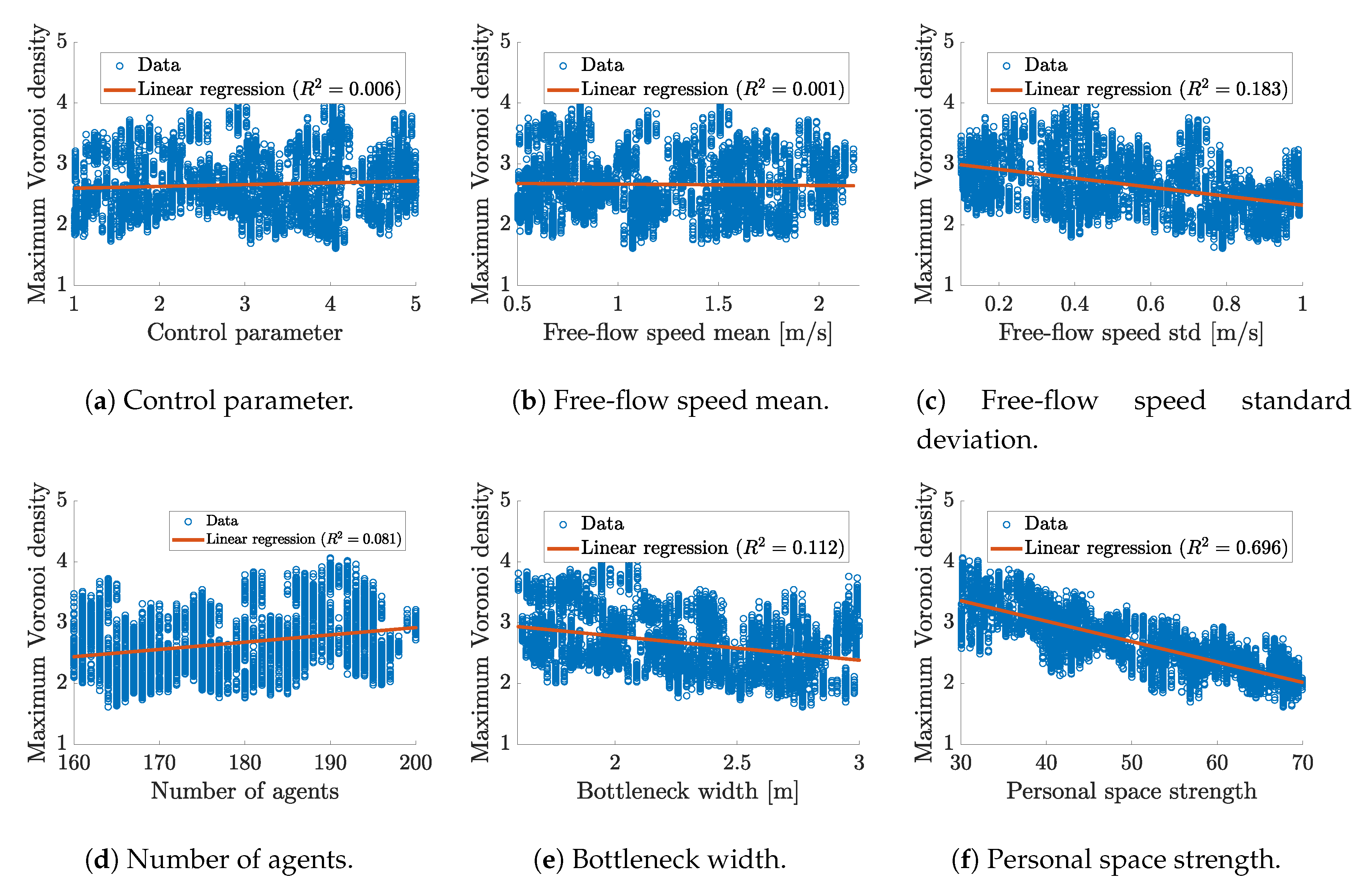
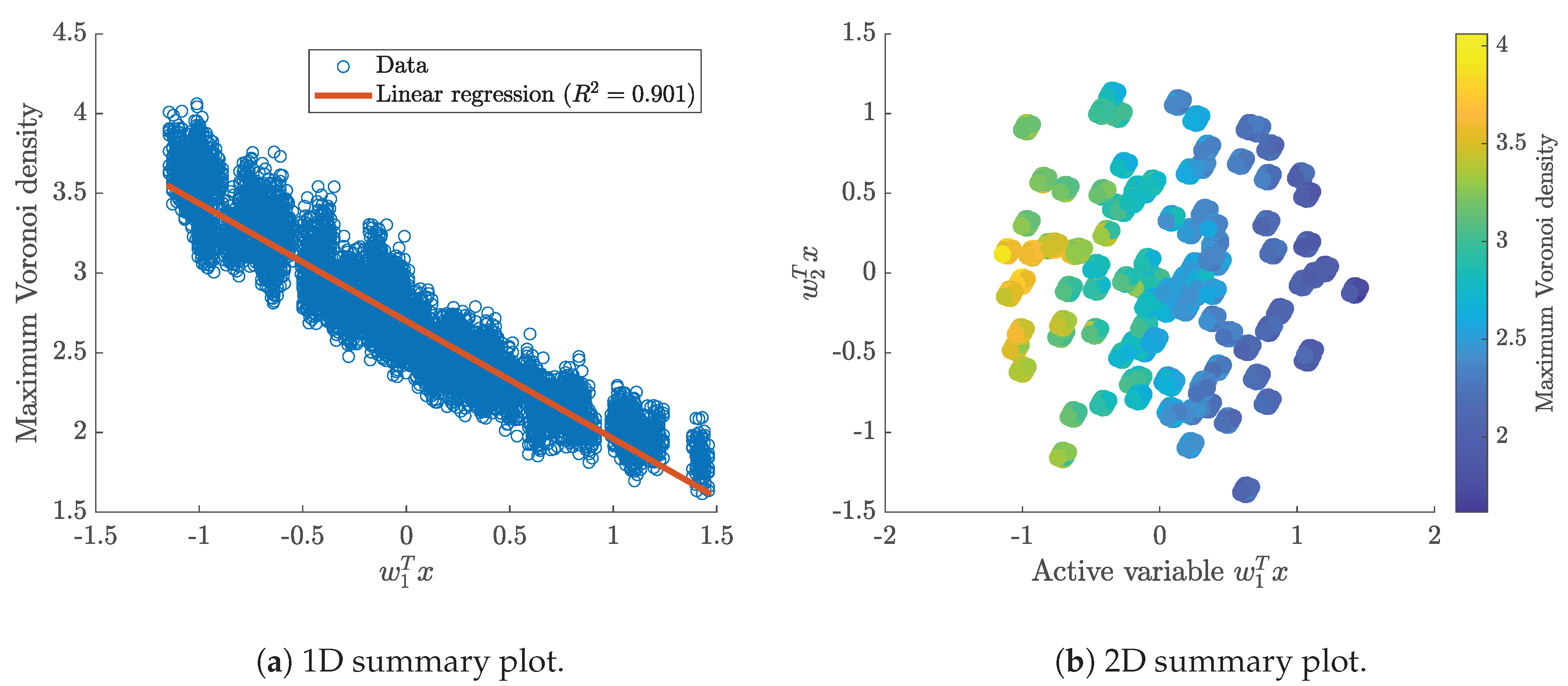
3.3. Relation between Parameter and Quantity of Interest
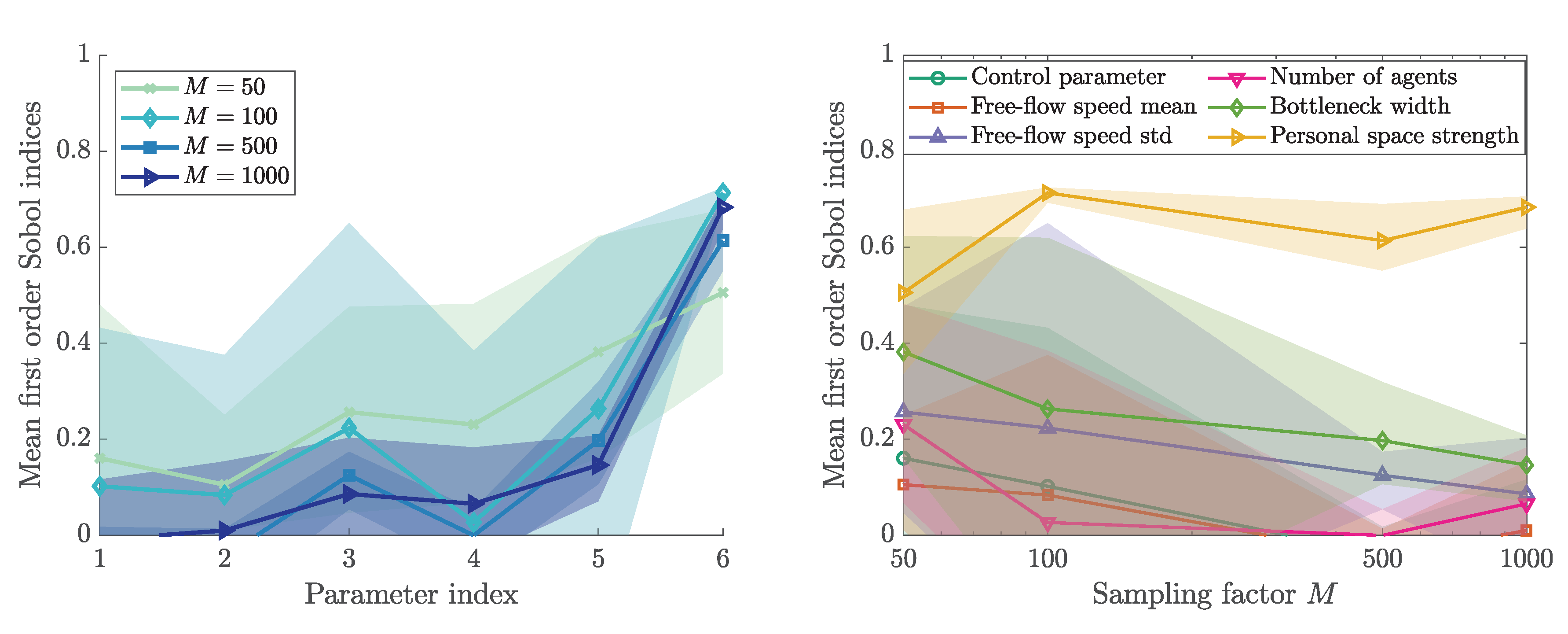
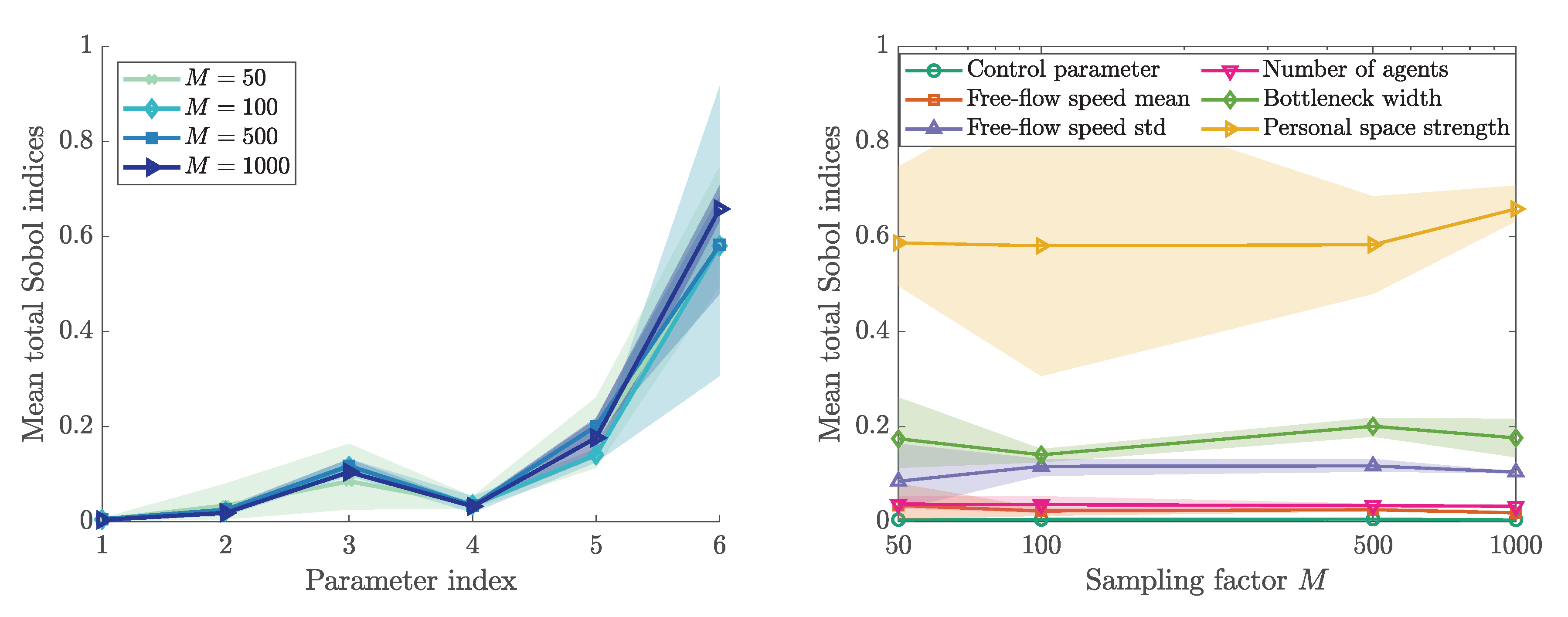
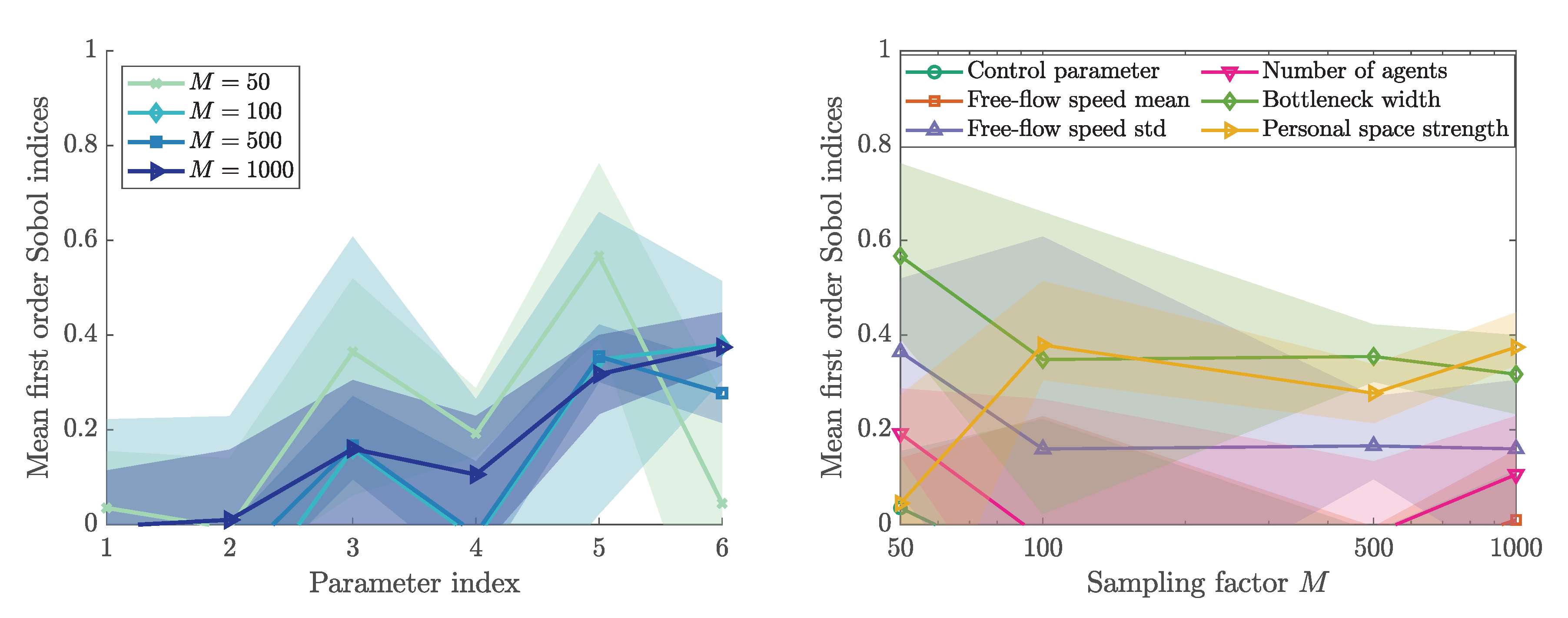
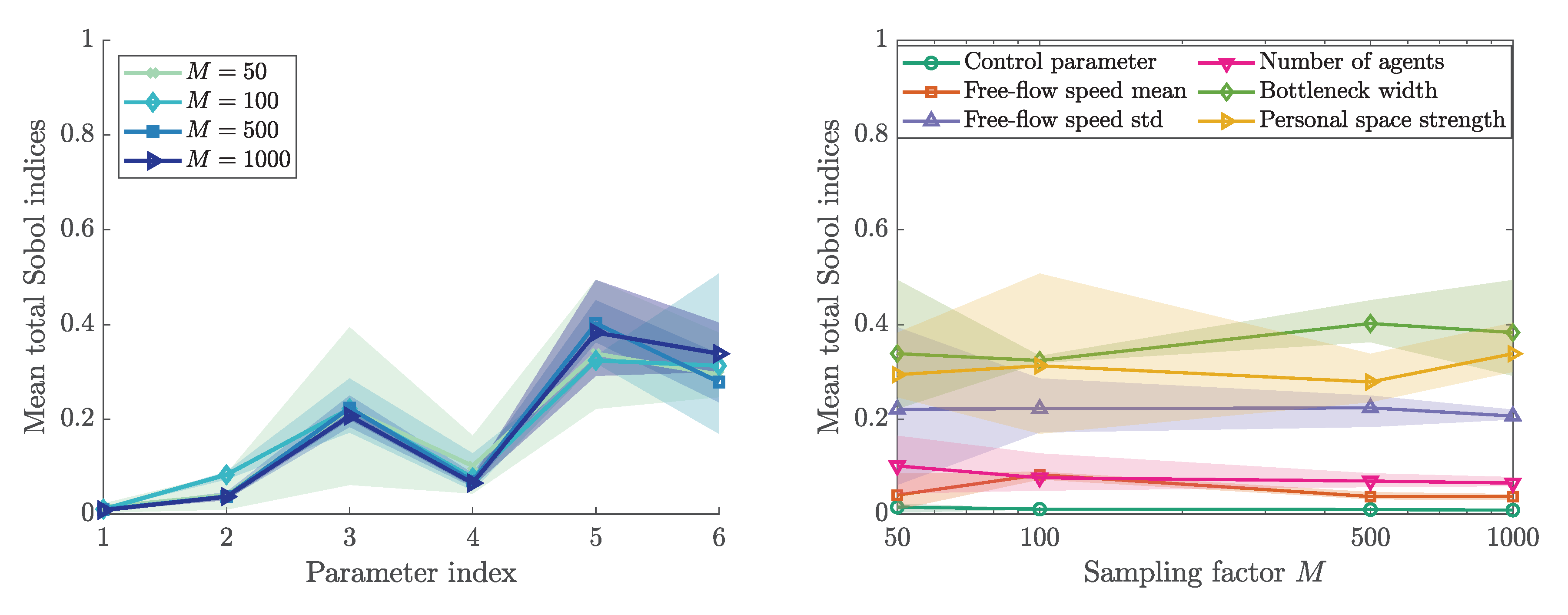
3.4. Sobol’ First and Total Order Indices
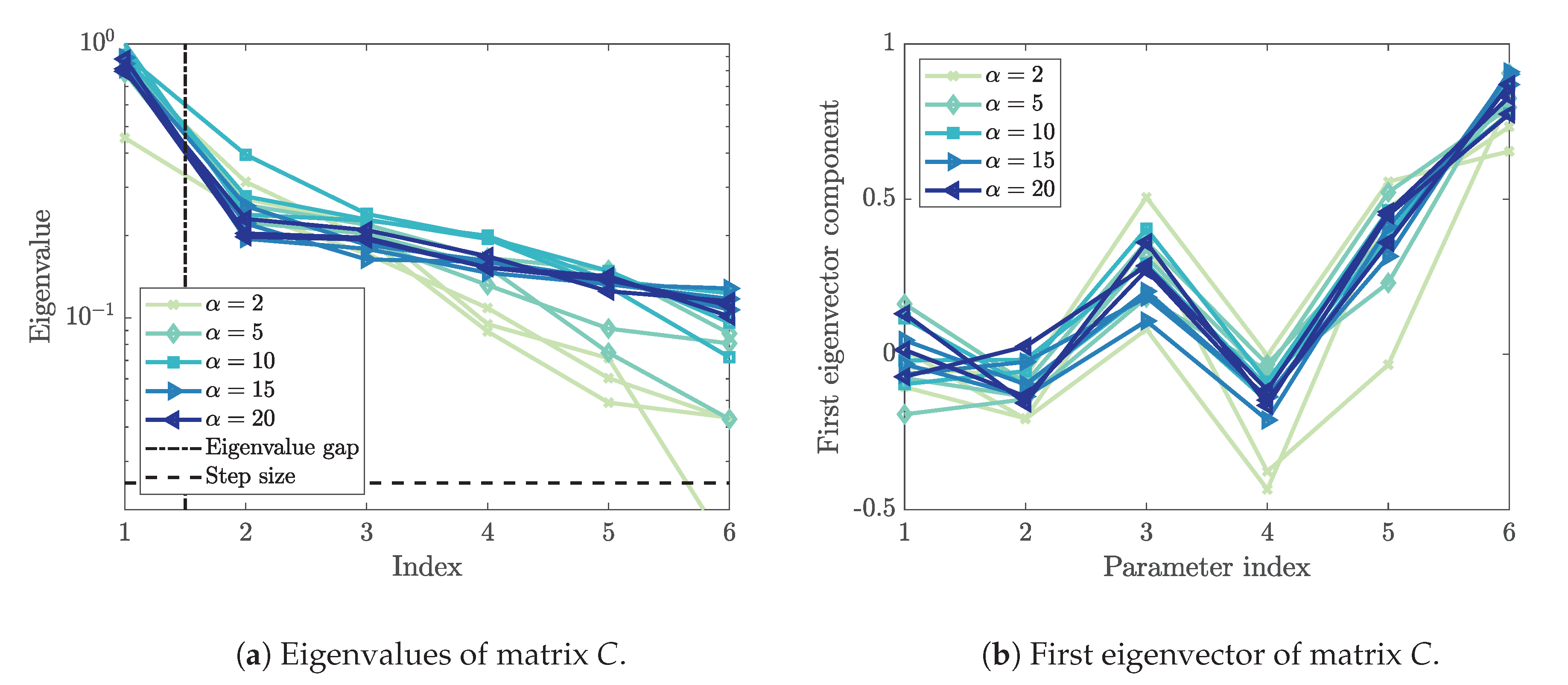
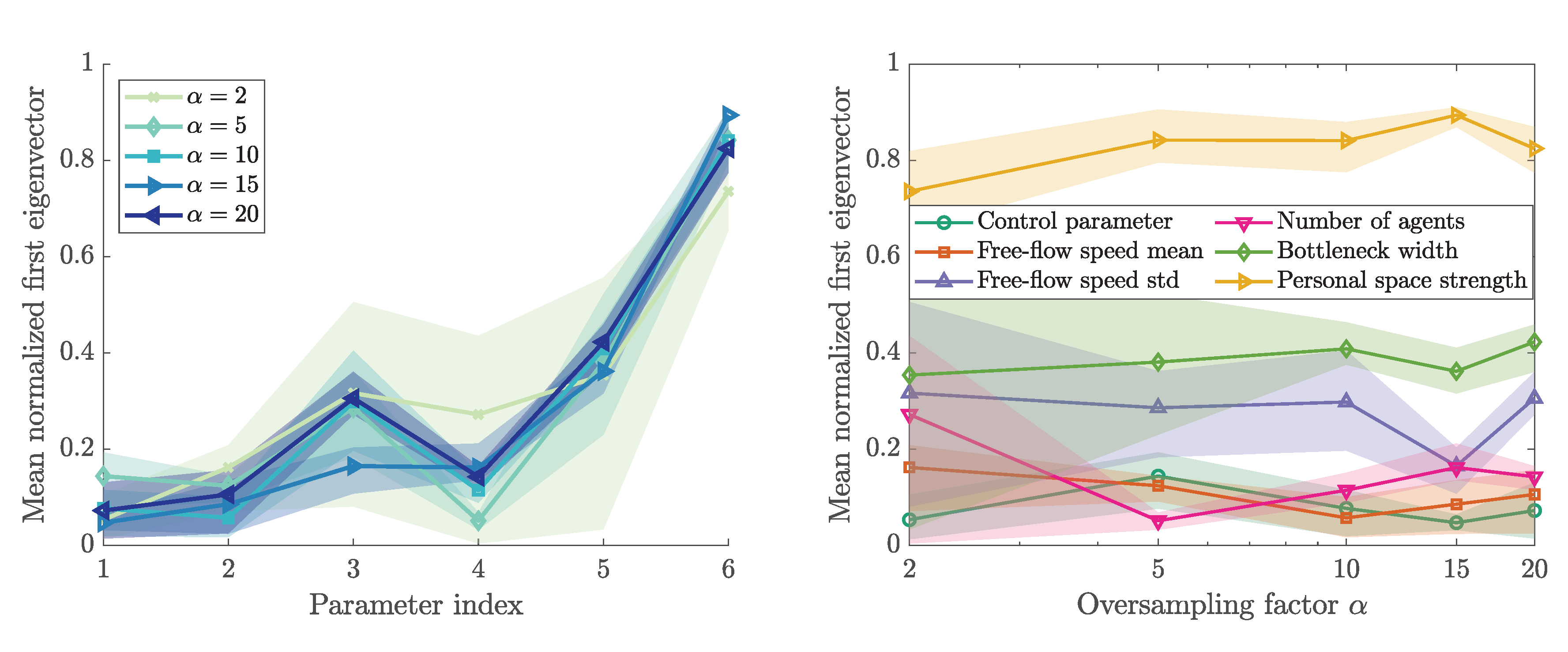
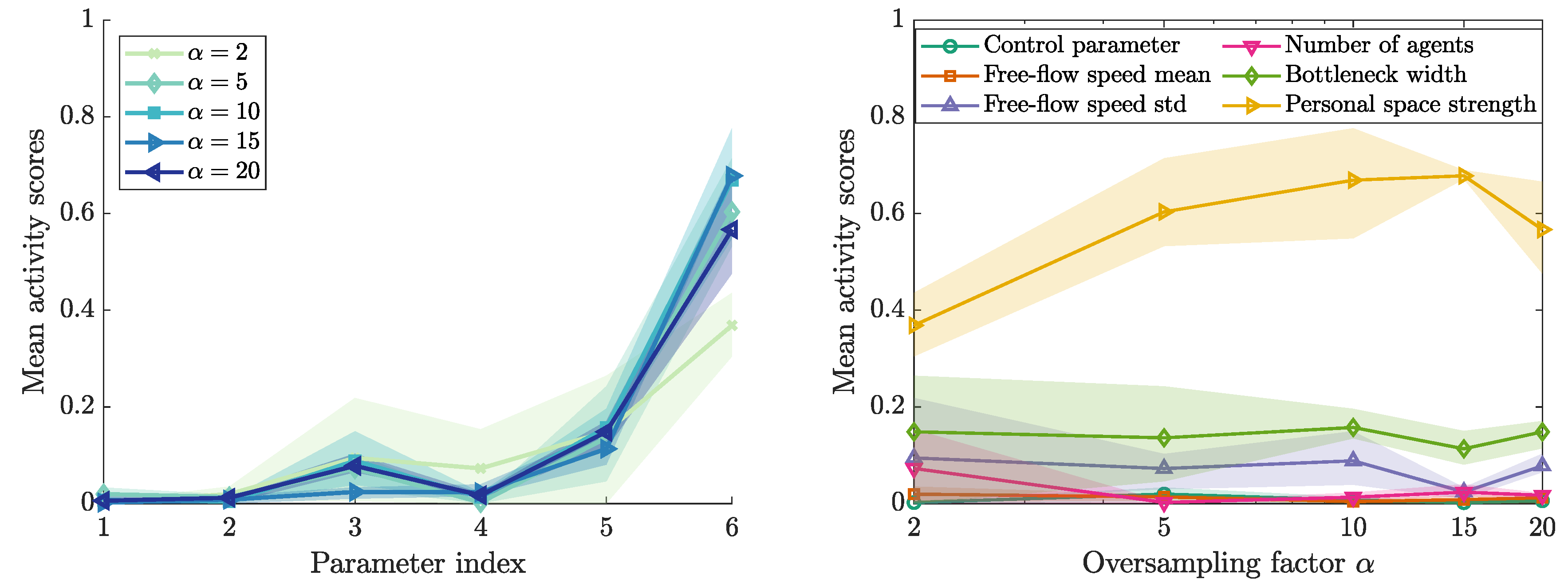
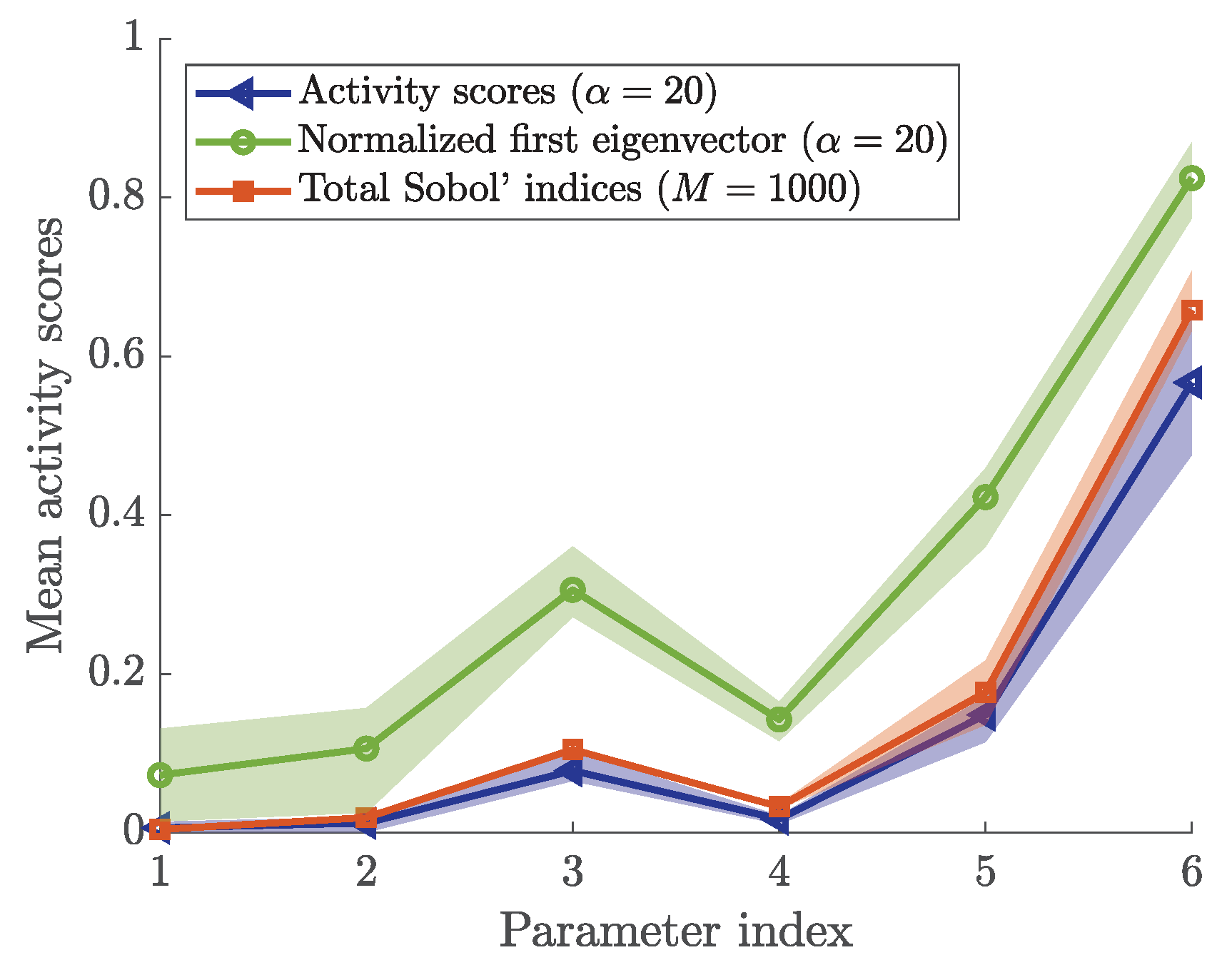
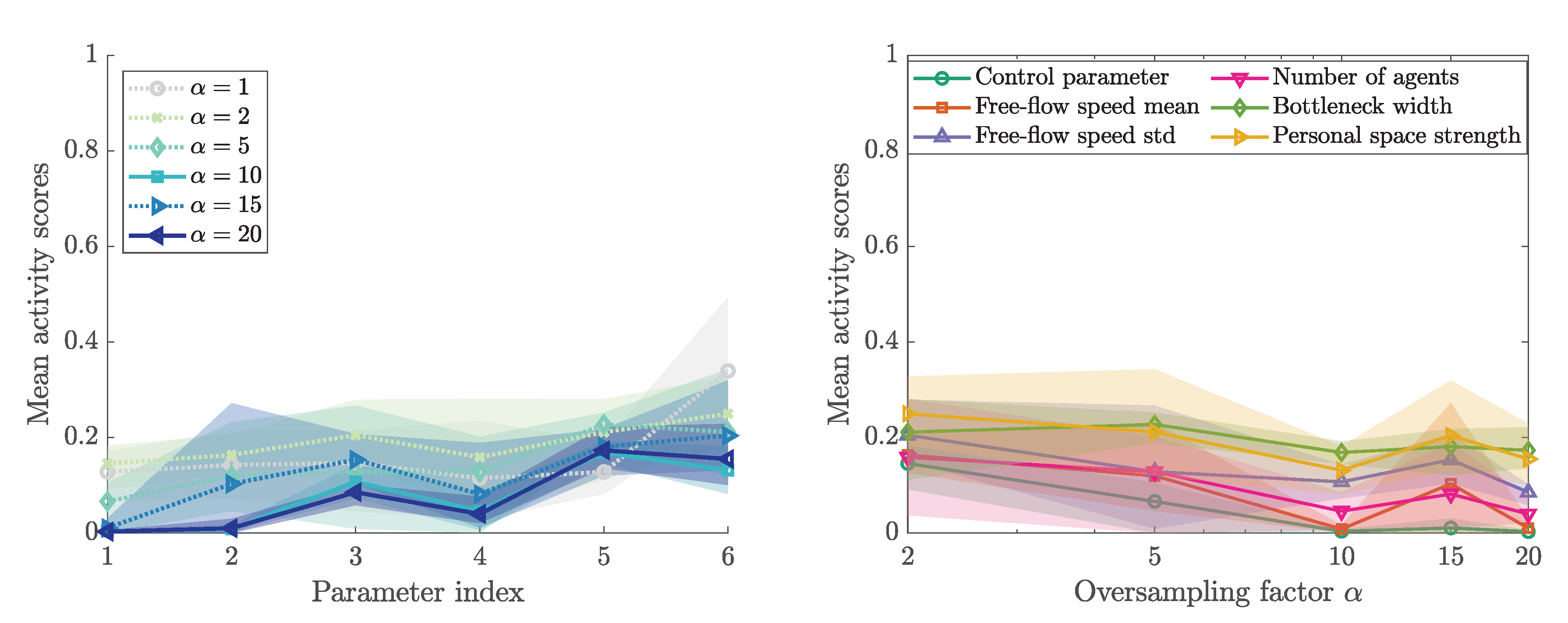
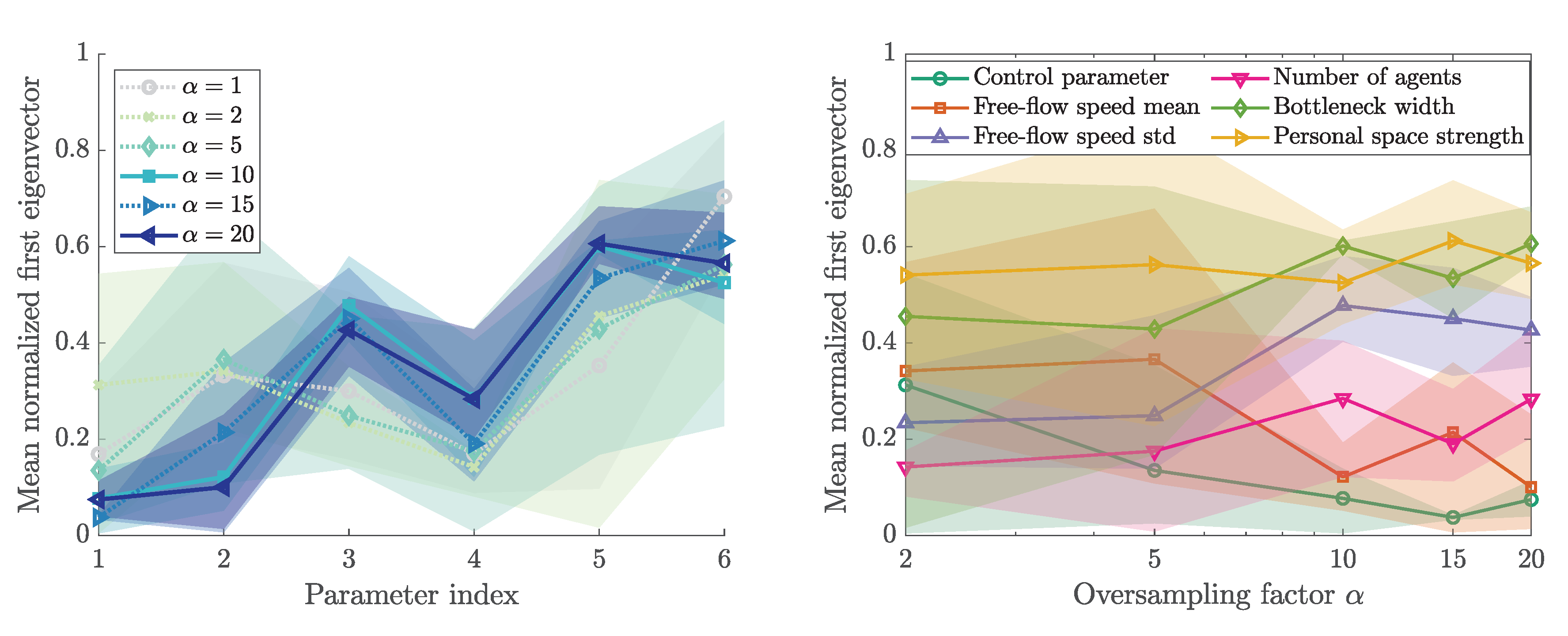
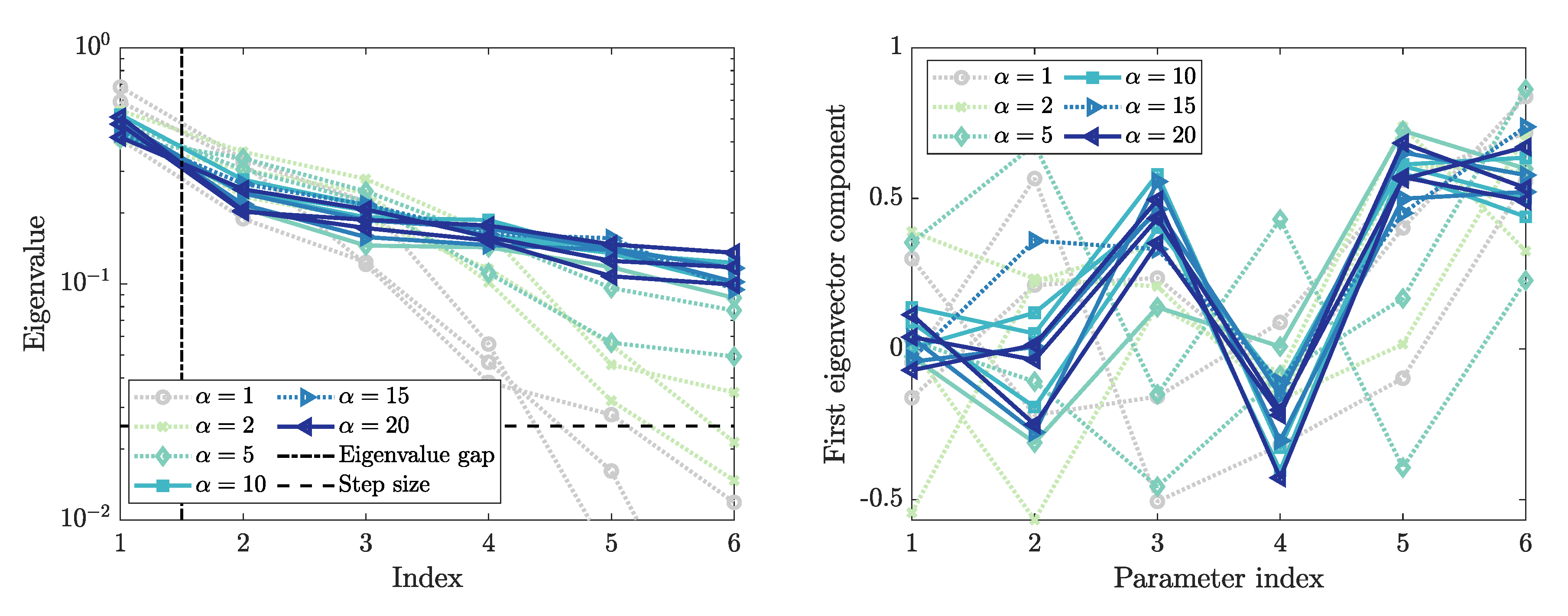
3.5. First Eigenvector and Activity Scores
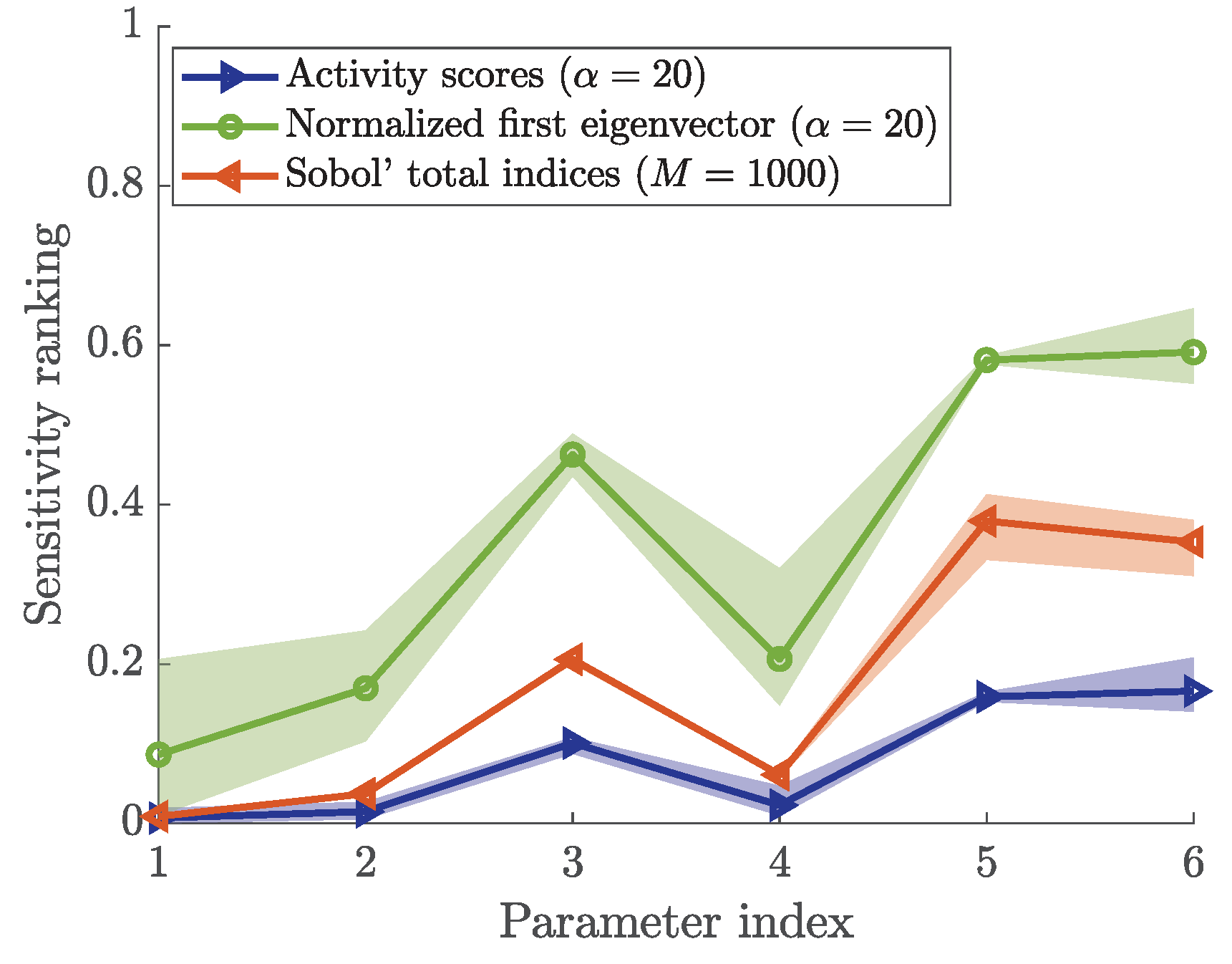
3.6. Sensitivity Ranking
3.7. Impact of the Parameter Range
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Optimal Steps Model Utilities

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable (Equation) | Variable (Code) | Default Value | Unit |
|---|---|---|---|
| intimateSpaceFactor | 1.2 | ||
| intimateSpacePower | 1 | ||
| personalSpacePower | 1 | ||
| pedPotentialPersonalSpaceWidth | 1.2 | m | |
| pedPotentialIntimateSpaceWidth | 0.45 | m | |
| pedPotentialHeight | 50.0 | ||
| obstPotentialHeight | 6.0 | ||
| obstPotentialWidth | 0.8 |
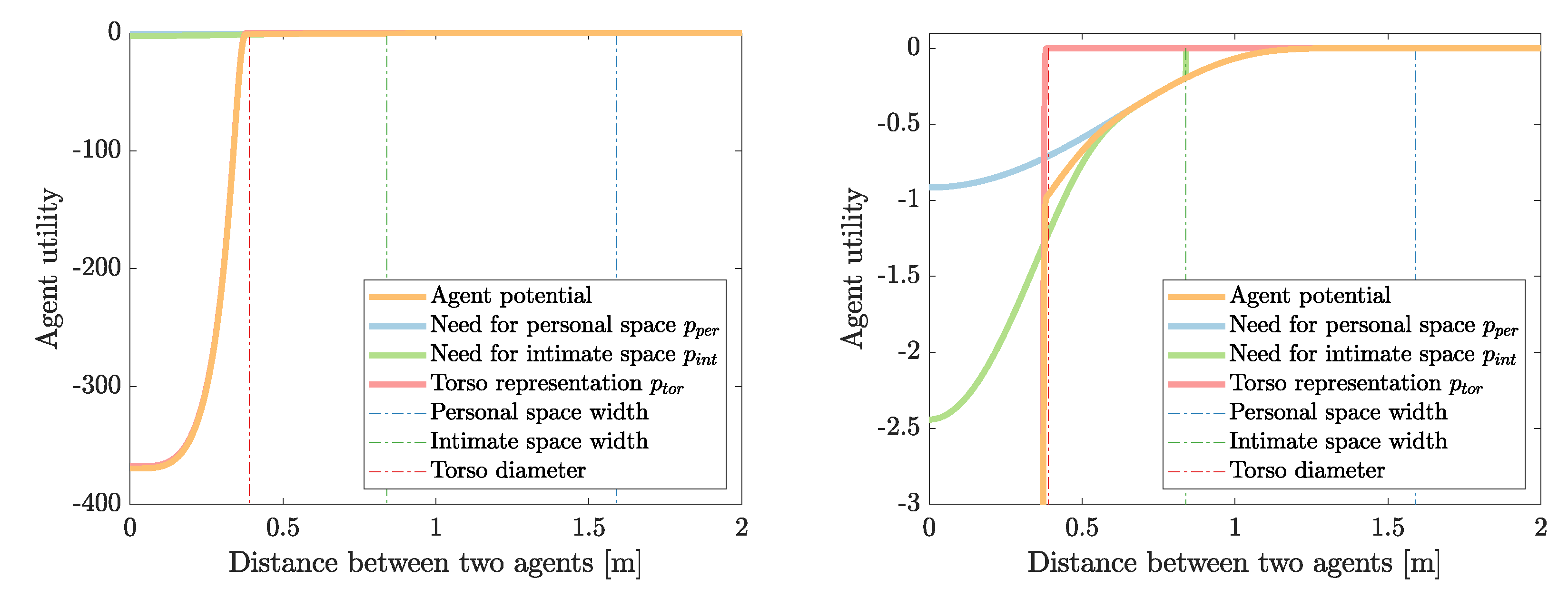
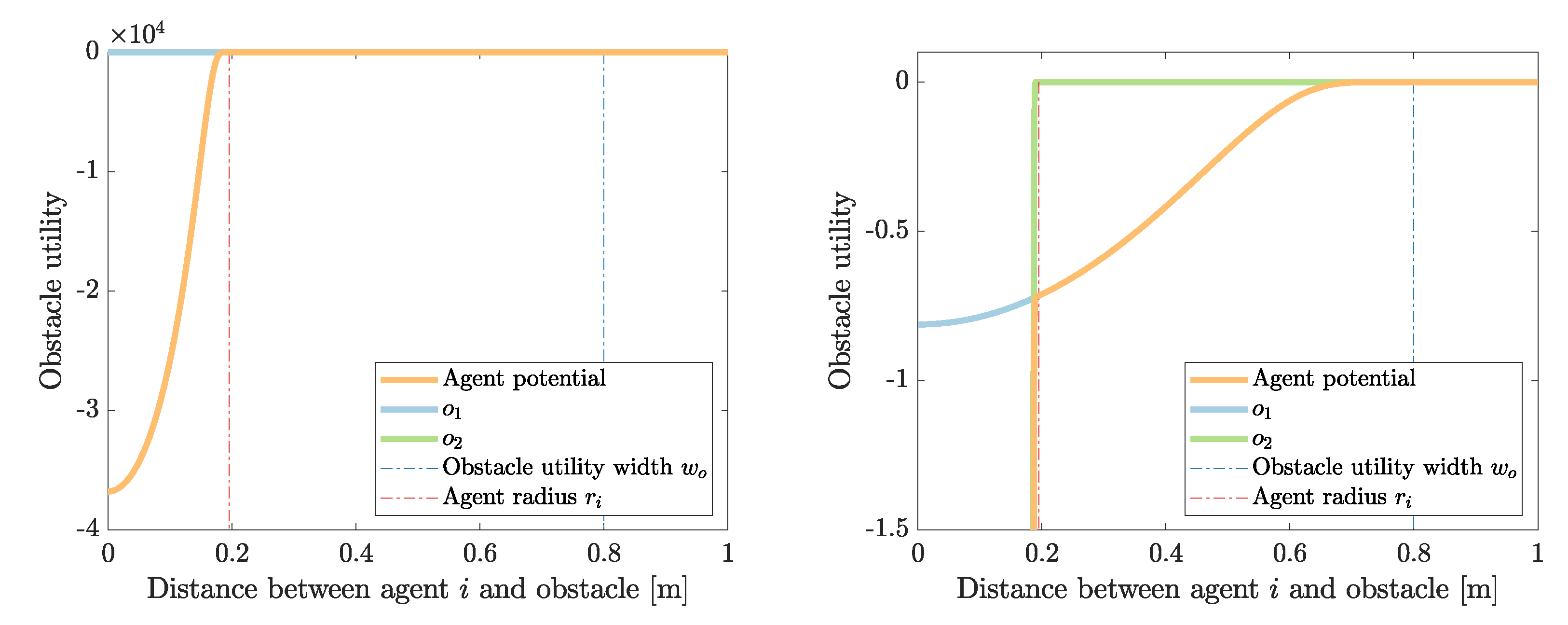
Appendix A.1. Agent Utility

Appendix A.2. Obstacle Utility

Appendix B. Impact of Parameter Ranges
| Index | Parameter | Range | Type |
|---|---|---|---|
| 1 | Control parameter | float | |
| 2 | Free-flow speed mean [m/s] | float | |
| 3 | Free-flow speed std [m/s] | float | |
| 4 | Number of agents [1] | int | |
| 5 | Bottleneck width [m] | float | |
| 6 | Personal space strength [1] | float |
Appendix B.1. Sobol’ First and Total Order Indices


Appendix B.2. First Eigenvector and Activity Scores



Appendix B.3. Sensitivity Study for a Use Case Study with Non-Physical Parameters
References
- Sieben, A.; Schumann, J.; Seyfried, A. Collective phenomena in crowds-Where pedestrian dynamics need social psychology. PLoS ONE 2017, 12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- von Sivers, I.; Templeton, A.; Künzner, F.; Köster, G.; Drury, J.; Philippides, A.; Neckel, T.; Bungartz, H.J. Modelling social identification and helping in evacuation simulation. Saf. Sci. 2016, 89, 288–300. [Google Scholar] [CrossRef] [Green Version]
- Haghani, M.; Sarvi, M. Crowd behaviour and motion: Empirical methods. Transp. Res. Part B Methodol. 2018, 107, 253–294. [Google Scholar] [CrossRef]
- Hoogendoorn, S.P.; Bovy, P.H.L. Pedestrian route-choice and activity scheduling theory and models. Transp. Res. Part B Methodol. 2004, 38, 169–190. [Google Scholar] [CrossRef]
- Gipps, P.G.; Marksjö, B.S. A micro-simulation model for pedestrian flows. Math. Comput. Simul. 1985, 27, 95–105. [Google Scholar] [CrossRef]
- Hirai, K.; Tarui, K. A simulation of the behavior of a crowd in panic. In Proceedings of the 1975 International Conference on Cybernetics and Society, San Francisco, CA, USA, 23–25 September 1975; p. 409. [Google Scholar]
- Helbing, D.; Farkas, I.; Vicsek, T. Simulating dynamical features of escape panic. Nature 2000, 407, 487–490. [Google Scholar] [CrossRef] [Green Version]
- Tordeux, A.; Seyfried, A. Collision-free nonuniform dynamics within continuous optimal velocity models. Phys. Rev. E 2014, 90, 042812. [Google Scholar] [CrossRef] [Green Version]
- Dietrich, F.; Köster, G. Gradient navigation model for pedestrian dynamics. Phys. Rev. E 2014, 89, 062801. [Google Scholar] [CrossRef] [Green Version]
- Martinez-Gil, F.; Lozano, M.; Fernández, F. Emergent behaviors and scalability for multi-agent reinforcement learning-based pedestrian models. Simul. Model. Pract. Theory 2017, 74, 117–133. [Google Scholar] [CrossRef] [Green Version]
- Seitz, M.J.; Köster, G. Natural discretization of pedestrian movement in continuous space. Phys. Rev. E 2012, 86, 046108. [Google Scholar] [CrossRef]
- von Sivers, I.; Köster, G. Dynamic Stride Length Adaptation According to Utility And Personal Space. Transp. Res. Part B Methodol. 2015, 74, 104–117. [Google Scholar] [CrossRef] [Green Version]
- Kleinmeier, B.; Zönnchen, B.; Gödel, M.; Köster, G. Vadere: An Open-Source Simulation Framework to Promote Interdisciplinary Understanding. Collect. Dyn. 2019, 4. [Google Scholar] [CrossRef] [Green Version]
- Seitz, M.J.; Dietrich, F.; Köster, G. The effect of stepping on pedestrian trajectories. Phys. A Stat. Mech. Its Appl. 2015, 421, 594–604. [Google Scholar] [CrossRef]
- Seer, S. A Unified Framework for Evaluating Microscopic Pedestrian Simulation Models. Ph.D. Thesis, Technische Universität Wien, Fakultät für Mathematik und Geoinformation, Institut für Analysis und Scientific Computing, Vienna, Austria, 2015. [Google Scholar]
- RiMEA. Guideline for Microscopic Evacuation Analysis; RiMEA e.V., 3.0.0, Ed.; RiMEA: East Providence, RI, USA, 2016. [Google Scholar]
- Saltelli, A.; Tarantola, S. On the Relative Importance of Input Factors in Mathematical Models. J. Am. Stat. Assoc. 2002, 97, 702–709. [Google Scholar] [CrossRef]
- Saltelli, A.; Ratto, M.; Andres, T.; Campolongo, F.; Cariboni, J.; Gatelli, D.; Saisana, M.; Tarantola, S. Global Sensitivity Analysis. The Primer; John Wiley & Sons, Ltd.: West Sussex, UK, 2008. [Google Scholar] [CrossRef] [Green Version]
- Constantine, P.G.; Dow, E.; Wang, Q. Active Subspace Methods in Theory and Practice: Applications to Kriging Surfaces. SIAM J. Sci. Comput. 2013, 36, A1500–A1524. [Google Scholar] [CrossRef]
- Sobol, I.M. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math. Comput. Simul. 2001, 55, 271–280. [Google Scholar] [CrossRef]
- Borgonovo, E. A new uncertainty importance measure. Reliab. Eng. Syst. Saf. 2007, 92, 771–784. [Google Scholar] [CrossRef]
- Morris, M.D. Factorial Sampling Plans for Preliminary Computational Experiments. Technometrics 1991, 33, 161–174. [Google Scholar] [CrossRef]
- Iooss, B.; Lemaître, P. A Review on Global Sensitivity Analysis Methods. In Uncertainty Management in Simulation-Optimization of Complex Systems: Algorithms and Applications; Dellino, G., Meloni, C., Eds.; Springer: Boston, MA, USA, 2015; pp. 101–122. [Google Scholar] [CrossRef] [Green Version]
- Saltelli, A.; Aleksankina, K.; Becker, W.; Fennell, P.; Ferretti, F.; Holst, N.; Li, S.; Wu, Q. Why so many published sensitivity analyses are false: A systematic review of sensitivity analysis practices. Environ. Model. Softw. 2019, 114, 29–39. [Google Scholar] [CrossRef]
- Kucherenko, S.; Rodriguez-Fernandez, M.; Pantelides, C.; Shah, N. Monte Carlo evaluation of derivative-based global sensitivity measures. Reliab. Eng. Syst. Saf. 2009, 94, 1135–1148. [Google Scholar] [CrossRef]
- Constantine, P.G.; Diaz, P. Global sensitivity metrics from active subspaces. Reliab. Eng. Syst. Saf. 2017, 162, 1–13. [Google Scholar] [CrossRef] [Green Version]
- de Rocquigny, E.; Devictor, N.; Tarantola, S. (Eds.) Uncertainty in Industrial Practice; John Wiley & Sons, Ltd.: West Sussex, UK, 2008. [Google Scholar] [CrossRef]
- Lamboni, M.; Iooss, B.; Popelin, A.L.; Gamboa, F. Derivative-based global sensitivity measures: General links with Sobol’ indices and numerical tests. Math. Comput. Simul. 2013, 87, 45–54. [Google Scholar] [CrossRef] [Green Version]
- Sobol, I.; Kucherenko, S. Derivative based global sensitivity measures. Procedia Soc. Behav. Sci. 2010, 2, 7745–7746. [Google Scholar] [CrossRef] [Green Version]
- Sobol’, I.; Kucherenko, S. Derivative based global sensitivity measures and their link with global sensitivity indices. Math. Comput. Simul. 2009, 79, 3009–3017. [Google Scholar] [CrossRef]
- Borgonovo, E.; Plischke, E. Sensitivity analysis: A review of recent advances. Eur. J. Oper. Res. 2016, 248, 869–887. [Google Scholar] [CrossRef]
- Haghani, M.; Sarvi, M.; Rajabifard, A. Simulating Indoor Evacuation of Pedestrians: The Sensitivity of Predictions to Directional-Choice Calibration Parameters. Transp. Res. Rec. 2018. [Google Scholar] [CrossRef] [Green Version]
- Duives, D.C.; Daamen, W.; Hoogendoorn, S.P. Continuum modelling of pedestrian flows - Part 2: Sensitivity analysis featuring crowd movement phenomena. Phys. A Stat. Mech. Its Appl. 2016, 447, 36–48. [Google Scholar] [CrossRef]
- Chen, J.; Yu, J.; Wen, J.; Zhang, C.; Yin, Z.; Wu, J.; Yao, S. Pre-evacuation Time Estimation Based Emergency Evacuation Simulation in Urban Residential Communities. Int. J. Environ. Res. Public Health 2019, 16, 4599. [Google Scholar] [CrossRef] [Green Version]
- Punzo, V.; Montanino, M.; Ciuffo, B. Do We Really Need to Calibrate All the Parameters? Variance-Based Sensitivity Analysis to Simplify Microscopic Traffic Flow Models. IEEE Trans. Intell. Transp. Syst. 2015, 16, 184–193. [Google Scholar] [CrossRef]
- Sfeir, G.; Antoniou, C.; Abbas, N. Simulation-based evacuation planning using state-of-the-art sensitivity analysis techniques. Simul. Model. Pract. Theory 2018, 89, 160–174. [Google Scholar] [CrossRef]
- Ingram, J.K. A History of Political Economy. Adam and Charles Black: Edinburgh, UK, 1888. [Google Scholar]
- Sethian, J.A. A fast marching level set method for monotonically advancing fronts. Proc. Natl. Acad. Sci. USA 1996, 93, 1591–1595. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hall, E.T. The Hidden Dimension; Doubleday: New York, NY, USA, 1966. [Google Scholar]
- Kretz, T.; Grünebohm, A.; Schreckenberg, M. Experimental study of pedestrian flow through a bottleneck. J. Stat. Mech. Theory Exp. 2006, 2006, P10014. [Google Scholar] [CrossRef] [Green Version]
- Liddle, J.; Seyfried, A.; Klingsch, W.; Rupprecht, T.; Schadschneider, A.; Winkens, A. An Experimental Study of Pedestrian Congestions: Influence of Bottleneck Width and Length. arXiv 2009, arXiv:0911.4350. [Google Scholar]
- Seyfried, A.; Passon, O.; Steffen, B.; Boltes, M.; Rupprecht, T.; Klingsch, W. New Insights into Pedestrian Flow Through Bottlenecks. Transp. Sci. 2009, 43, 395–406. [Google Scholar] [CrossRef]
- Rupprecht, T.; Klingsch, W.; Seyfried, A. Influence of Geometry Parameters on Pedestrian Flow through Bottleneck. In Pedestrian and Evacuation Dynamics; Peacock, R.D., Kuligowski, E.D., Averill, J.D., Eds.; Springer: Boston, MA, USA, 2011; pp. 71–80. [Google Scholar] [CrossRef]
- Liao, W.; Seyfried, A.; Zhang, J.; Boltes, M.; Zheng, X.; Zhao, Y. Experimental Study on Pedestrian Flow through Wide Bottleneck. Transp. Res. Procedia 2014, 2, 26–33. [Google Scholar] [CrossRef] [Green Version]
- Nishinari, K.; Kirchner, A.; Namazi, A.; Schadschneider, A. Extended Floor Field CA Model for Evacuation Dynamics. IEICE Trans. Inf. Syst. 2004, E87-D, 726–732. [Google Scholar]
- Martinez-Gil, F.; Lozano, M.; Fernández, F. Strategies for simulating pedestrian navigation with multiple reinforcement learning agents. Auton. Agents -Multi-Agent Syst. 2015. [Google Scholar] [CrossRef]
- Gao, Z.; Qu, Y.; Li, X.; Long, J.; Huang, H.J. Simulating the Dynamic Escape Process in Large Public Places. Oper. Res. 2014, 62, 1344–1357. [Google Scholar] [CrossRef]
- Steffen, B.; Seyfried, A. Methods for measuring pedestrian density, flow, speed and direction with minimal scatter. Phys. A Stat. Mech. Its Appl. 2010, 389, 1902–1910. [Google Scholar] [CrossRef] [Green Version]
- Schadschneider, A.; Seyfried, A. Empirical results for pedestrian dynamics and their implications for modeling. Networks Heterog. Media 2011, 6, 545–560. [Google Scholar] [CrossRef]
- Sudret, B. Global sensitivity analysis using polynomial chaos expansions. Reliab. Eng. Syst. Saf. 2008, 93, 964–979. [Google Scholar] [CrossRef]
- Constantine, P.G. Active Subspaces: Emerging Ideas for Dimension Reduction in Parameter Studies; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2015. [Google Scholar] [CrossRef]
- Saltelli, A.; Annoni, P.; Azzini, I.; Campolongo, F.; Ratto, M.; Tarantola, S. Variance based sensitivity analysis of model output. Design and estimator for the total sensitivity index. Comput. Phys. Commun. 2010, 181, 259–270. [Google Scholar] [CrossRef]
- Jansen, M.J. Analysis of variance designs for model output. Comput. Phys. Commun. 1999, 117, 35–43. [Google Scholar] [CrossRef]
- Ishigami, T.; Homma, T. An importance quantification technique in uncertainty analysis for computer models. In Proceedings of the First International Symposium on Uncertainty Modeling and Analysis, College Park, MD, USA, 3–5 December 1990; pp. 398–403. [Google Scholar] [CrossRef]
- Ronchi, E.; Reneke, P.A.; Peacock, R.D. A Method for the Analysis of Behavioural Uncertainty in Evacuation Modelling. Fire Technol. 2013, 50, 1545–1571. [Google Scholar] [CrossRef]
- Beaulieu, C. Intercultural Study of Personal Space: A Case Study. J. Appl. Soc. Psychol. 2004, 34, 794–805. [Google Scholar] [CrossRef]
- Novelli, D.; Drury, J.; Reicher, S. Come together: Two studies concerning the impact of group relations on personal space. Br. J. Soc. Psychol. 2010, 49, 223–236. [Google Scholar] [CrossRef]













| Index | Parameter | Unit | Range | Type |
|---|---|---|---|---|
| 1 | Control parameter | float | ||
| 2 | Free-flow speed mean | m/s | float | |
| 3 | Free-flow speed std | m/s | float | |
| 4 | Number of agents | int | ||
| 5 | Bottleneck width | m | float | |
| 6 | Personal space strength | float |
| Index | Parameter | Range | Type |
|---|---|---|---|
| 6 | Personal space strength | float |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gödel, M.; Fischer, R.; Köster, G. Sensitivity Analysis for Microscopic Crowd Simulation. Algorithms 2020, 13, 162. https://doi.org/10.3390/a13070162
Gödel M, Fischer R, Köster G. Sensitivity Analysis for Microscopic Crowd Simulation. Algorithms. 2020; 13(7):162. https://doi.org/10.3390/a13070162
Chicago/Turabian StyleGödel, Marion, Rainer Fischer, and Gerta Köster. 2020. "Sensitivity Analysis for Microscopic Crowd Simulation" Algorithms 13, no. 7: 162. https://doi.org/10.3390/a13070162
APA StyleGödel, M., Fischer, R., & Köster, G. (2020). Sensitivity Analysis for Microscopic Crowd Simulation. Algorithms, 13(7), 162. https://doi.org/10.3390/a13070162