1. Introduction
While there are many technological gaps that inhibit the development of the autonomous systems field, there is no doubt that a significant factor in this delay is that it has been much harder than expected to give robotic agents the capabilities to analyze their ever-changing environment, detect and classify the objects surrounding them, and interpret the interaction between them. Visual object recognition is an extremely difficult computational task. The core problem is that each object in the world can cast an infinite number of different 2D images onto the retina as the object’s position (translation and rotation), pose, lighting, and background vary relative to the viewer.
The state-of-the-art computer vision algorithms, convolutional neural networks (CNNs), although achieving remarkable results in object detection and classification challenges, still are not robust enough for many applications. They are sensitive to ambient light conditions [
1] and to additive noise [
2] as a result of pockets in their manifold. These algorithms are based on bottom-up object detection and recognition process. As such, they do not include the means to use top-down contextual information for a more holistic process.
In the human brain, for comparison, there are quick projections of Low Spatial Frequency (LSF) information, in parallel to the bottom-up systematic progression of the image details along the visual pathways. These coarse but rapid blurred representations are used for an initial rough classification hypothesis with low discrimination. These hypotheses are followed by higher discriminability tests for an overall improved efficiency of object recognition in cases of ambiguity. This model was proven by a series of functional Magnetic Resonance Imaging (fMRI) and Magnetoencephalography (MEG) studies, which showed early Orbitofrontal Cortex (OFC) activation by LSF information, preceding the corresponding object recognition activation in Inferior Temporal Cortex (ITC) by about 50 ms [
3].
The idea that context-based predictions make object recognition more efficient is prominent in
Figure 1. The hairdryer in the right image and the drill in the left image are identical objects. Nevertheless, contextual information uniquely resolves ambiguity in each case. In this case, recognition cannot be accomplished quickly based only on the physical attributes of the target; contextual information provides more relevant input for the recognition of that object than can its intrinsic properties.
The working assumption underlying this research is that setting the human visual system as a source of inspiration and getting better in imitating its architecture and mechanisms, will enable us to develop a more robust and accurate object recognition algorithm with better results than exists today. Specifically, integrating the state-of-the-art bottom-up feed-forward algorithms (CNNs), together with the top-down mechanisms of the human visual system. The main contributions in this paper can be highlighted in the following aspects:
Design of a biologically inspired architecture for integration of top-down and bottom-up processes into one holistic solution (
Section 4).
Demonstration of the importance of contextual-based predictions and their potential to improve the performance of bottom-up computer vision algorithms, such as deep CNNs (
Section 5.1).
Evaluation of the performance of a methodology for continuously updating models based on encounters with visual stimuli different than the ones they have been trained on (
Section 5.2).
The rest of the paper is organized as follows: Review and analysis of the different pathways and mechanism of the human brain, focusing on the “associative generation of predictions” mechanism, is given in
Section 2. Review of CNNs and their vulnerability to perturbations from the dataset they were trained on is in
Section 3. Finally, discussion and future work are summarized in
Section 6, followed by concluding remarks in
Section 7.
2. The Human Visual System
It is well known that the feature hierarchies in neural networks are often compared with the structure of the primate visual system, which has been shown to use a hierarchy of features of increasing complexity, from simple local features in the primary visual cortex to complex shapes and object views in higher cortical areas. Until recently, the leading analysis of the object recognition process in the human cortex was focused on the ventral visual pathway that runs from the primary visual cortex, V1, over extra-striate visual areas, V2 and V4, to the inferotemporal cortex [
4]. While most neurons show specificity for a certain object view or lighting condition [
5], the ITC cells show robustness in their firing to stimulus transformations, such as scale, position changes, and light conditions. In addition, the ITC has been seen as a major source of input to the Prefrontal Cortex (PFC), which is seen as “the center of cognitive control” involved in linking perception to memory. This traditional bottom-up view of the human visual system strongly resembles the nature of neural networks, showing strong specificity in the first layers and more robust and complex activations in the higher layers. Nevertheless, this bottom-up view arises from the fact that most of the early research activities were focused on the low-level parts of the human visual system, due to the complexity involved in analyzing the higher-level parts of the human visual system. Extensive research in recent years that used advanced techniques, such as accurate fMRI, shows the main role of the high-level parts of the visual system, which integrate top-down signals with the bottom-up signals of the ventral pathway.
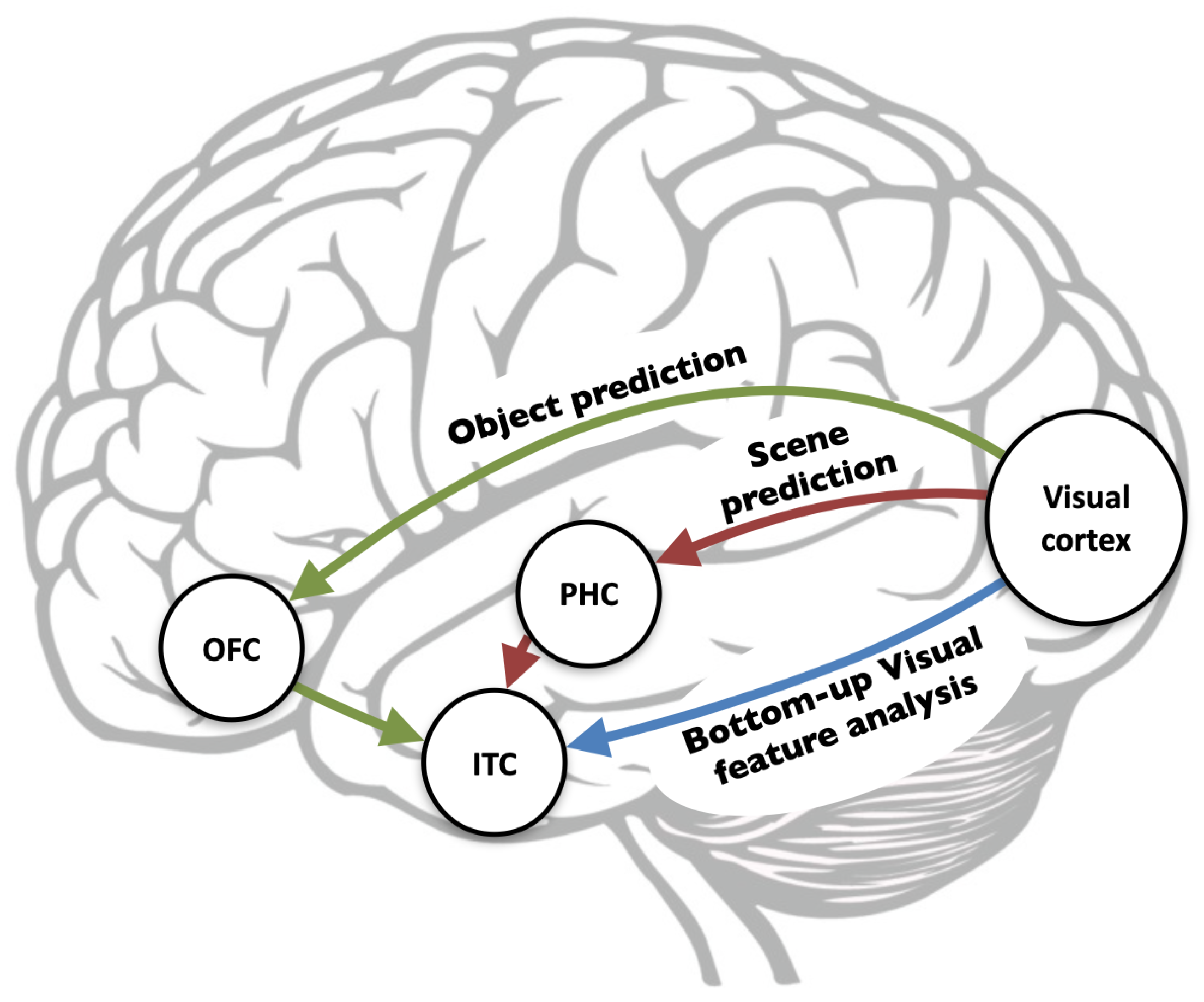
In general, the human visual system has two main pathways that participate in the continuous processing of the visual input. The ventral stream, which is a bottom-up feedforward visual features analysis that plays a major role in the perceptual identification of objects, and the dorsal stream, which governs the analysis of objects’ spatial location and mediates the required sensorimotor transformations [
6]. In addition to these pathways, there are two additional top-down projections: (1) The object prediction projection, which brings the low spatial information of the object to the orbitofrontal cortex that in turn uses this information to create fast gross object recognition; and (2) the scene prediction projection, which brings the low spatial information of the entire field of view to the parahippocampal cortex that in turn uses this information for scene recognition and contextual hypothesis [
7,
8]. These two top-down projections merge with the bottom-up ventral pathway in the inferotemporal cortex, as illustrated in
Figure 2. The inferotemporal cortex integrates the three inputs and uses the top-down hypotheses to bias the recognition process.
Furthermore, recent studies on the motor control in humans and animals suggests that predictions play a key role in the visual learning process. Differences between the predictions and the visual feedback are used to evoke learning process. For example, when reaching the hand to grasp an object, the brain processes the visual feedback in order to compare the object location and the actual position of our limb in order to modify our motion. Studies that applied Electroencephalography (EEG) to analyze the temporal nature of visual cue utilization during movement planning have found that visual observation of a movement error evokes an Event-Related brain Potential (ERP) waveform with a timing and topography consistent with the Feedback Related Negativity (FRN) [
9]. In cases where there is no predetermined target, but rather an intrinsic motivation to learn the environment, information gain serves as the intrinsic goal, and novelty is reached by detecting errors in predictions [
10]. These findings suggest that humans and animals perceive the world by continuous attempts to predict the outcomes of their actions. Errors in prediction result in novelty that triggers learning and activates action for further exploration.
This paper suggests that an artificial agent operating in the world should use both its own predictions of the world and the perceived visual feedback for a reinforcement-learning mechanism, in order to improve with time the detection and recognition model of the platform. Though CNNs achieve state-of-the-art results in various fields, these results are largely dependent on large annotated data. In cases where such data does not exist and or requires substantial resources to achieve, the proposed visual reinforcement learning mechanism can enable exploiting the unsupervised stream of visual data that reaches the agent during its operation. The deployed agent will start its operation with a poorly trained model, due to the lack of labeled data, and will improve its recognition capabilities with time. The proposed algorithm can even be used in cases where large labeled dataset exists, as it could potentially improve the performance of the pre-trained model, by utilizing a gradually increasing data stream tailored for the agents specific environment, in contrast to the global nature of training datasets.
In addition, in 2015, researchers used multi-electrode arrays to measure hundreds of neurons in the visual ventral stream of nonhuman primates and compared their firing to the object recognition performance of more than 100 human observers. The results show that simple learned weighted sums of firing rates of neurons in monkey ITC accurately predicted human performance [
11]. As we are aiming to design a biologically inspired architecture, this means that simulating the operation of the IT is a key factor in successfully creating an architecture that has a human-like accuracy and robustness.
Attempts to combine bottom-up and top-down processes in a computational model have been made in the past, by researchers from the computer vision field and the brain research field. Nevertheless, due to different research goals and technical barriers, these attempts were mainly single field centric. While the goal of brain researchers was mainly to build a model that will predict eyes’ behavior and neural activity [
12,
13,
14,
15], computer vision researchers’ main goal was to improve overall performance on specific tasks (segmentation [
16]/detection [
17]/tracking [
18]/scene understanding [
19]) with little or no bio-inspired architecture. In addition, there was a technological gap to design, train, and use a CNN-based system with the complexity of multi-level lateral and recurrent connections that exist in the human visual system.
3. Convolutional Neural Networks (CNNs)
In recent decades, the human brain inspired researchers to develop CNNs. One of the main benefits of CNNs are their inherent ability to use labeled datasets to automatically train layers of convolution filters to create task-specific feature space. Until recently, CNNs did not manage to keep up with the state-of-the-art traditional computer vision algorithms. However, in the last few years, the publication of large image databases, such as ImageNet, the advancement of high performance computing systems, and the improvements in training deep models, boosted CNNs’ performance and enabled them to gain popularity and achieve dramatic progress on object classification tasks [
20,
21,
22]. In addition, empirical evidence [
23], as well as mathematical proofs [
11,
24,
25], show that deep CNNs, with tens and hundreds of layers, have a high expressive power and can create complex feature space, which outperforms traditional computer vision algorithms, as well as shallower CNNs.
Generally speaking, the output layer unit of a neural network is a highly nonlinear function of its input. It represents a conditional distribution of the label given the input and the training set. It is therefore possible for the output unit to assign non-significant probabilities to regions of the input space that contain no training examples in their vicinity. Such regions can represent, for instance, examples of the same objects the CNN was trained on, but from different viewpoints. These examples, though belonging to the same objects and sharing both the label and the statistical structure of the original inputs, can be relatively far in pixel space and be misclassified.
Even more, we expect imperceptibly tiny perturbations of a given image not to change the class at the output and that an input image that is in the vicinity of a given training input x (in pixel space) to be assigned a high probability of the correct class by the model. Nevertheless, it has been shown that for deep neural networks, this smoothness assumption does not hold. Specifically, one can find adversarial examples, which are obtained by imperceptibly small perturbations to a correctly classified input image, so that it is no longer classified correctly [
26]. Adversarial examples represent low-probability (high-dimensional) “pockets” in the manifold [
27]. These perturbed examples are called “adversarial examples” and have been shown to exist in neural networks with varied numbers of layers and varied training data. Although the common practice in training CNNs includes employing input deformations to the training dataset in order to increase the robustness of the models, it does not solve the “blind spots” in the manifold of the trained neural network. This phenomenon enables easily fooling the neural network as demonstrated recently in Reference [
2,
28].
In addition, recent successes of deep reinforcement learning (RL) techniques have raised widespread interest in their potential for solving practical problems, with most famous cases being in the field of autonomous driving [
29] and game playing [
30,
31]. However, most state-of-the-art algorithms for RL require vast amounts of data and training time. Decomposing the problem into state inference, value updating, and action selection components, as is done in the brain, may allow for more efficient learning and the ability to track changes in the environment on fast timescales, similar to biological systems [
32].
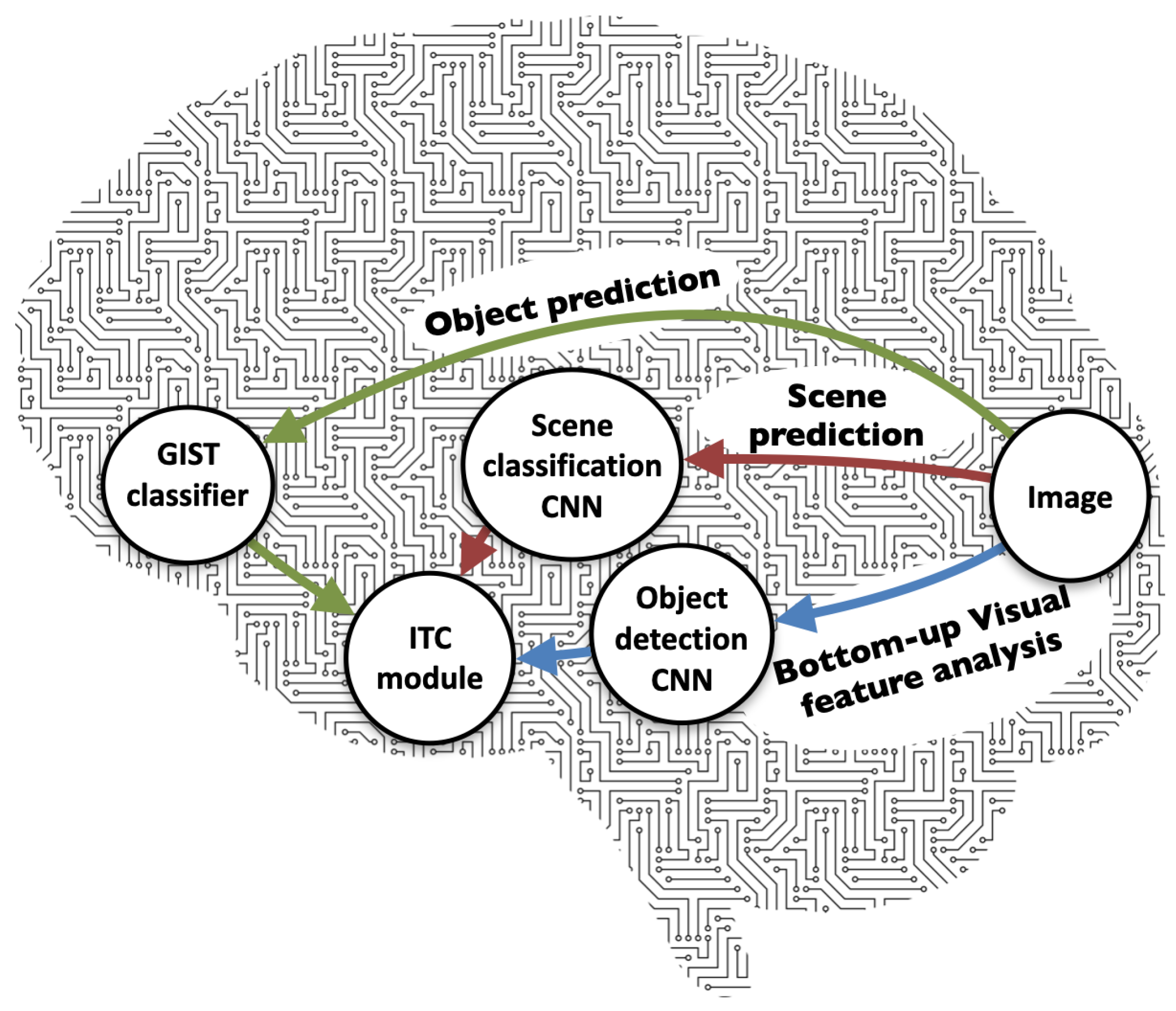
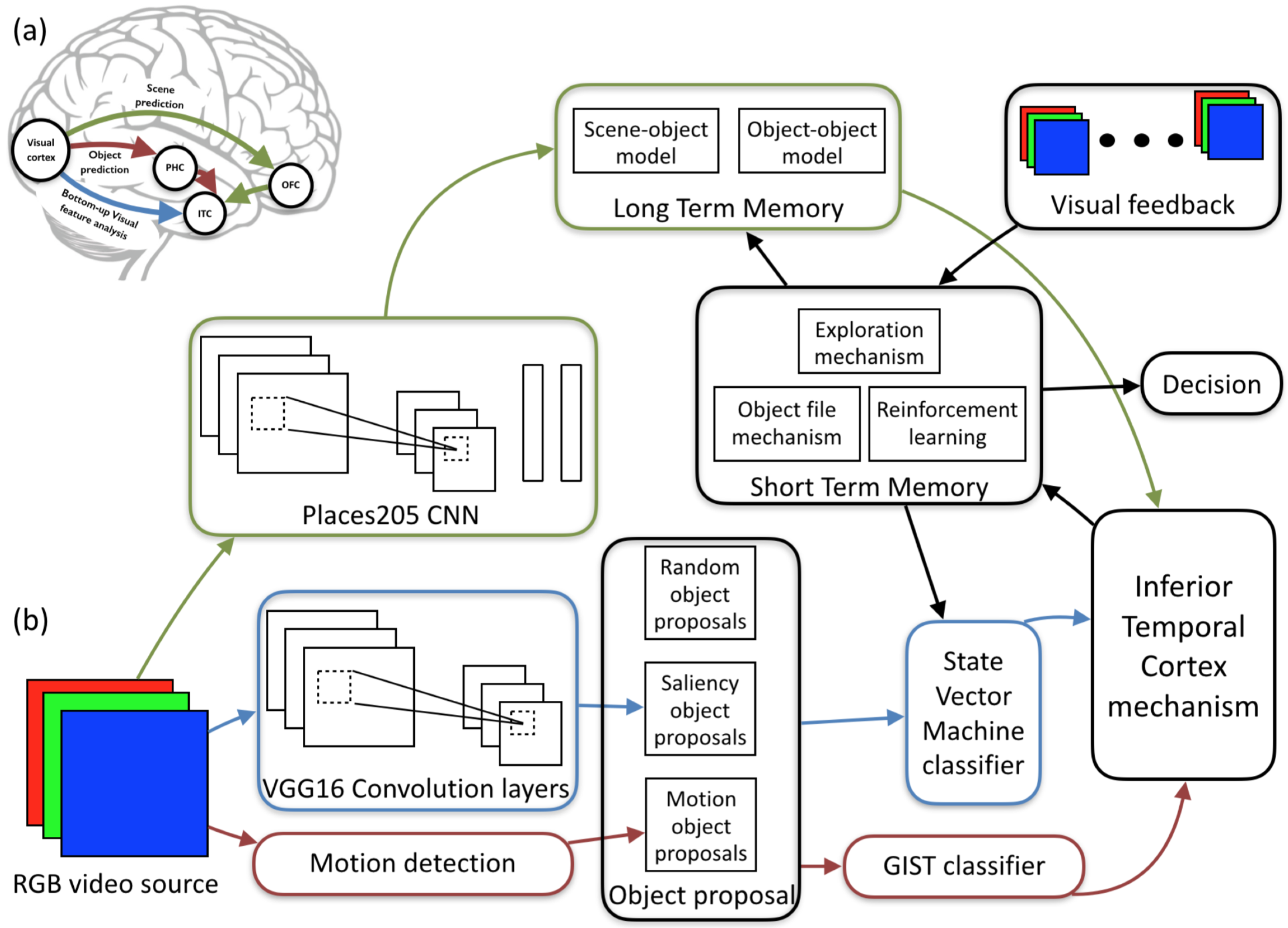
4. The Proposed Architecture
Our hypothesis is that the sensitivity of the neural networks comes from their bottom-up feed-forward nature and from their limited ability to include the time space in their analysis of the incoming video stream. The proposed Visual Associative Predictive (VAP) architecture is based on the concepts behind the integration of the top-down and bottom-up processes of the human visual system, combined with state-of-the-art object recognition models, e.g., deep CNNs. As a first step, the proposed model was designed to have a similar structure to that of the human visual system. The pathways of the VAP model, which imitate those illustrated in
Figure 2, can be seen in
Figure 3. We show that imitating these top-down mechanisms, within a framework, which integrates them with a bottom-up deep CNN, results in a target recognition model that is more accurate and robust than the conventional use of CNN models alone.
The proposed model also includes implementation of the human brain visual feedback driven learning mechanism. This learning mechanism is based on imitating two mechanism of the human visual system: the Object-file mechanism and the reinforcement learning mechanism. The Object-file mechanism is considered a midlevel visual representation that “sticks” to a moving object over time, stores and updates information about the object’s properties [
33]. This mechanism is simulated in the VAP model by an objects tracker that accumulates the predictions being made on the object in each frame. The reinforcement learning mechanism then uses the information gathered by the Object-file mechanism for an ongoing autonomous refinement of the recognition model.
To generate the information required for its operation, the VAP model uses three types of classifiers. For the bottom-up object classification process we used the FRCNN [
34] with the VGG 16 model [
22]. For the top-down scene prediction, we used the Places205 deep CNN [
35]. Finally, for the top-down object prediction, we used a “gist” classifier (described in
Section 4.2) that gives gross classification of the objects into two categories: man-made or natural. The outputs of the three classifiers are sent to a module that aims to imitate the operation of the ITC and integrate the three signals into one decision.
4.1. Attention Mechanism
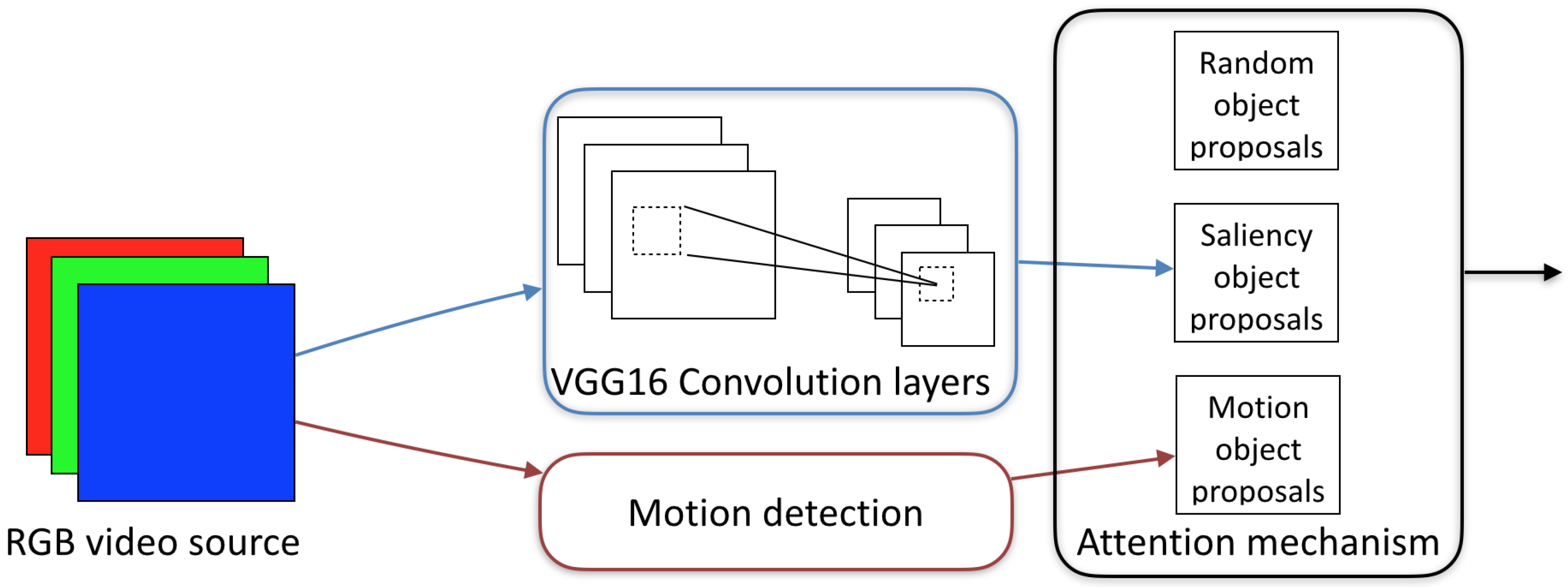
In order to improve its efficiency, the algorithm does not process the entire image at once, but rather processes a bounded number of small areas, using the attention mechanism illustrated in
Figure 4. The attention of the algorithm is determined according to three biologically inspired attention generators. The first mechanism is the saliency detection mechanism. Saliency stands for the quality by which an object stands out relative to its neighborhood. Our eyes do not move smoothly across the scene, instead they make short and rapid movements between areas containing more meaningful features. Saliency detection is considered to be a key attentional mechanism that facilitates learning and survival by enabling organisms to focus their limited perceptual and cognitive resources on the most pertinent subset of the available sensory data [
36]. In our model, we used the FRCNN natural structure and its Region Proposal Network (RPN) module, which is based on the activity feature map created by the convolutional layers, as a source for saliency objects proposal.
A motion detection algorithm was used to draw attention to moving objects. Visual motion is known to be processed by neurons in the primary visual cortex that are sensitive to spatial orientation and speed and are considered a pre-attentive mechanism, which help focus attention on moving objects. A simple motion detection algorithm is used, which conducts two main operations: foreground-background separation and adjacent frames subtraction. The foreground-background separation is based on pixel value statistics [
37]. The frames subtraction was performed on five adjacent frames in order to detect local changes caused by moving objects. The results of the two algorithms were merged into single object proposal mechanism.
Finally, a random attention generator was employed to focus attention on random locations in the scene, in order to complement the other two search mechanisms. This random generator imitates the saccades movement of the human eyes that make rapid random jittering movements while scanning a visual scene, even when we are fixated on one point. The random attention generator proposes bounding boxes for exploration that are between the saliency and the motion detector bounding boxes. The output of the attention mechanism is a list of bounding boxes object proposals that is passed forward for further processing, as can be seen in Figure 7.
4.2. Object Prediction
The gross classification of the objects in the VAP model are based on the observation made by Antonio and Aude [
38] about the nature of the power spectrum difference between man-made and natural objects. They suggest that the differentiation among man-made objects resides mainly in the relationship between horizontal and vertical contours at different scales, while the spectral signatures of natural objects have a broader variation in spectral shapes. The object prediction module takes each image of an object and calculates its spatial envelope model, also known as the “gist” descriptor [
39], which is a low-dimensional representation that encapsulates the spatial structure of the object. The descriptor is based on Friedman work [
40], who suggested that an abstract representation of a scene, which he named “gist”, spontaneously activates memory representations of scene categories (a city, a mountain, etc.)
The “gist” descriptor divides each object into 4 × 4 blocks. In each block, the “gist” features are calculated using three frequency scales 0.02, 0.08, and 0.32 cycles/pixel. For the first two scales, eight orientations are used, and, for the third scale, four orientations are used. In total, the “gist” descriptor generates 960 (=3 colors * 16 blocks * (2*8 orientations + 1*4 orientations)) features. A State Vector machine was pre-trained on the 19,319 segmented objects from the SUN2012 dataset. The VAP model uses this pre-trained SVM to classify each object into man-made or natural object. For example, cars and bicycles will be classified as man-made objects, while people and cats will be classified as natural objects. This gross classification and its score are sent to the IT module to be integrated with the other VAP pathways.
4.3. Scene Contextual Prediction
The scene contextual prediction module contains the Scene-Object (SO) matrix and the Object-Object (OO) matrix that represent the cumulative contextual information the robotic agent gathered during its operation. The size of the SO matrix SxO is determined by the number of scenes S the scene classifier can recognize and the number of objects O the bottom-up CNN can recognize. The SO matrix easily encapsulates contextual probabilities about the dataset, such as that cows are seen mainly in “open country” and scenes, while seagulls are seen mainly in “coastal” scenes. The OO matrix in turn encapsulates the model’s information on objects that tend to co-appear.
During the entire operation of the robotic platform, the VAP model uses the Places205 deep CNN for scene classification. Once the current scene classification is determined, it is accompanied by information on the typical sets of objects that tend to co-appear within that context. This joined information sets the model’s expectation in the current context. The VAP model then uses the global scene classification, as well as the contextual cues that are provided by the objects in the scene that have been detected so far, to generate a vector of probabilities containing the probability for each object class to be seen in the current scene. This vector of probabilities is sent to the ITC module to be integrated with the other VAP pathways. In parallel, the continuous stream of information is used to update the scene contextual prediction module. In this way, the SO matrix is kept dynamic and the agent’s knowledge about the world gets richer and better the more it operates in the world.
4.4. Inferotemporal Cortex Module
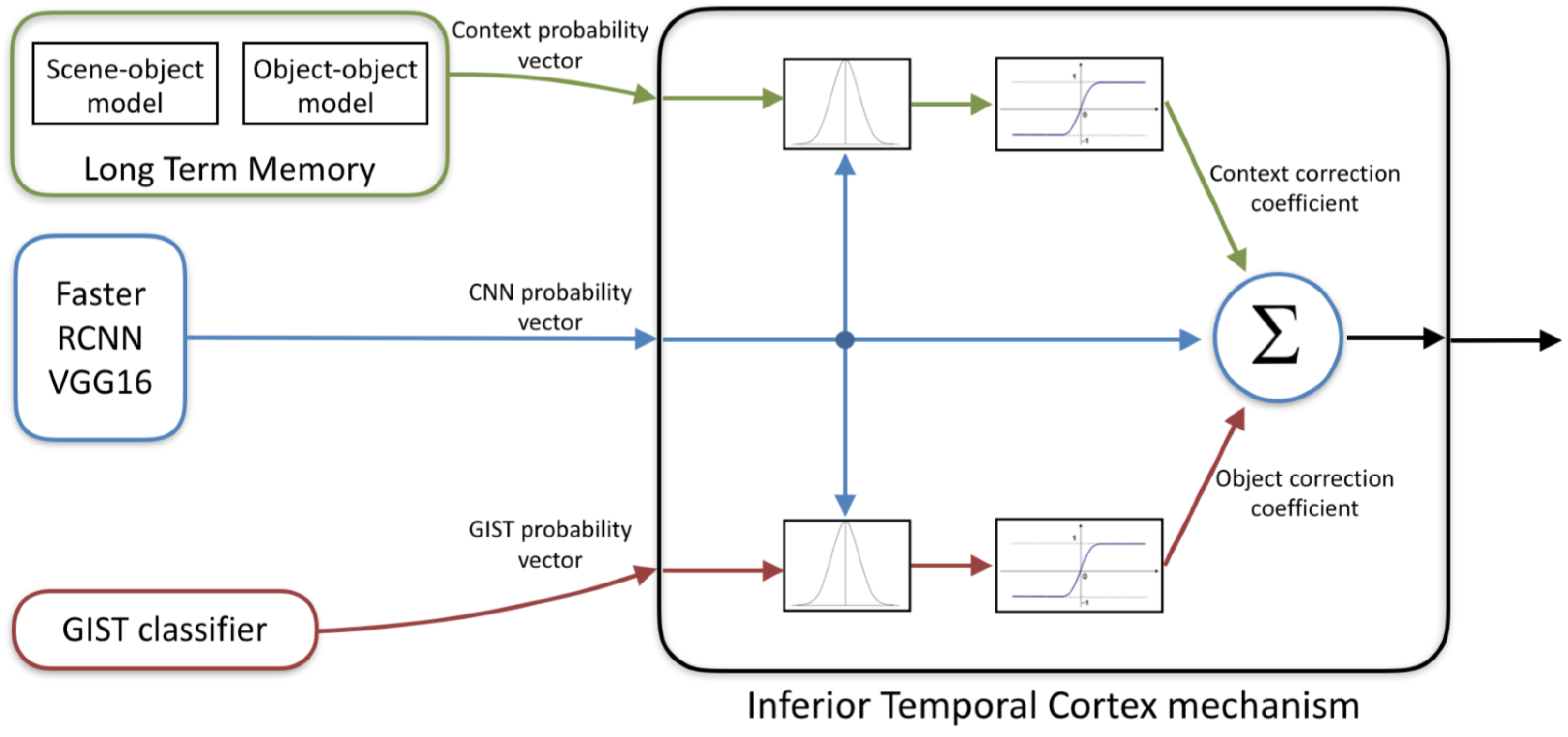
Although it is widely accepted that the brain fuse pre-attentive bottom-up processing and attentive top-down task-specific cues, current computer vision models are still based on a bottom-up process only. The proposed model suggests a framework where the recognition process includes integrating the traditional bottom-up process in deep CNN with rapid top-down contextual information, in order to improve the performance in cases of ambiguity. In the human visual system the bottom-up High Spatial Frequencies (HSF) ventral stream meets the top-down LSF scene and object hypothesis in the ITC. Similarly, in the VAP model the bottom-up stream and the top-down prediction meet in a module named the ITC mechanism. It is important to note that there is evidence to suggest that the integration of top-down and bottom-up processes in the human brain is not exclusive to ITC and may also take place in other areas of the brain. Nevertheless, we limited our scope of work to the major role of the ITC in this process.
The VAP model decision is based on adding a correction factor to each element in the probabilities vector given by the bottom-up classification process. The ITC mechanism in the VAP model uses two functions to regulate the integration of the two top-down pathways into the bottom-up pathway. Therefore, the output of the ITC module can be written as:
where
PBottom-up is the probability vector from the CNN, marked in blue in
Figure 5.
CContext and
CGist are the two top-down correction pathways, marked in green and red, respectively.
CContext is the correction vector that takes into account the top-down LSF scene hypothesis, while
CGist is the correction vector that takes into account the top-down LSF object hypothesis. As the formulas governing both pathways are similar, we will focus our explanation on one of them, the
CContext correction vector.
First, a Gaussian function is used to regulate the correction factors magnitude and give a higher correction factor in cases of ambiguity. The Gaussian function, which has high values in the center and low values at its edges, expresses the notion that if the bottom-up classifier is “pretty sure” that the analyzed object is very similar (probability above a specific threshold) or very different (probability below a specific threshold) from the object model stored in the long term memory module, the correction should be minimal. This correction factor magnitude regulator,
RMagnitude, is given by:
where
and
are the parameters governing the shape of the
RMagnitude regulation function and where set to
and
, respectively. Second, a hyperbolic tangent function (tanh) is used to regulate the sign of the correction factors. The hyperbolic tangent function, which has positive values on one side and negative values on the other side, expresses the notion that for objects with high probability to appear in the current context the correction will be positive and that for objects with low probability to appear in the current context the correction will be negative. This correction factor sign regulator,
RSign, is given by:
where
PObject|Context is the probability of each object to be in the scene given the current context.
b and
c are the parameters governing the shape of the
RSign regulation function and where set to 10 and
, respectively. Following this logic, the correction coefficients for each top-down pathway is calculated as follows:
where
PContext is the confidence level in the context classification.
Figure 5 illustrates this structure of the ITC mechanism.
For a specific scene, the scene-dependent prior probability is extracted from the SO matrix. For the set of objects currently in the scene, the OO matrix is used to extract the co-occurrence probability. The SO and OO matrices (defined in
Section 4.3) are being continuously updated according to the information gathered by the VAP model during its operation. Therefore, more accurate and continuously improving context-dependent prior probabilities are being generated with time. As a result, the VAP model is more accurate and more robust as the prior probabilities become more accurate.
4.5. Object Files
As mentioned, it is widely accepted that the brain attaches an Object-file to each moving object in its field of view. The Object-file stores and updates information about the changes in the object’s appearance and properties with time and plays a critical role in the retrieval of the object’s previous characteristics, some of which may no longer be visible [
41]. We implemented the Object-file mechanism in the following way. The Object-file mechanism includes a Kalman filter-based tracker that tracks each moving object in the scene from the moment it enters until it is out of the field of view. During the motion of the object in the field of view, the Object-file attached to it stores the output of the classification process in each frame. It then filters out observations with high Mahalanobis distance for all classes, which may result in false classification.
The Object-file is integrated in the classification process of moving objects in three ways. First, in cases where the initial observations of an object are all with low probabilities for all classes, the Object-file mechanism will pick those with the highest probabilities. When samples with higher probabilities will begin to arrive, it will filter out the samples it used so far and will base its decision only on the top observations. In this way, the VAP model imitates the Object-file mechanism in the human visual system, gradually increasing its confidence in the classification of an object, the longer the object stays in the field of view. In addition, the Object-file mechanism uses only samples in which Mahalanobis distance to at least one class is low enough. When some aspects of the object are no longer visible and the classification probability drops, it uses information from previous frames that resulted in high probability score. As such, the Object-file mechanism enables the VAP model to retain perceptual continuity, even in periods when the object’s classification is ambiguous due to challenging views, such as partial occlusion and shade. A final contribution of the Object-file mechanism is that it gathers information on the object that is later used by the reinforcement module in order to improve the classification process.
4.6. Reinforcement Learning Module
Recent successes of reinforcement learning techniques matured into algorithms that yields state-of-the-art performance that in some cases match and even exceed human capabilities in a wide variety of practical problems [
42,
43,
44]. However, much of this increase in performance is due to breakthroughs in deep neural networks that are in the core of deep reinforcement learning models. In addition, deep reinforcement learning networks require enormous amounts of trials [
44,
45] that are independent and identically distributed, to avoid catastrophic forgetting [
46]. As a result, the training and inference phases are separated, which prevents from deployed agents to learn from ongoing experience and adapting to changes in their environment.
Adding reinforcement learning abilities to the robotic agent reduces the burden of the information gathering for the training phase, while enabling it to improve its classifier using the visual data encountered during its operation. For example, in the experiments done using the VAP model, the training was done on an open source dataset. This dataset, like others, contains mainly images taken by a photographer that was located on the same surface as the object. However, the experiments of the VAP model were conducted using an elevated camera with a top view of the objects. Therefore, the initial classification performance of the VAP model was lower than expected. Nevertheless, as the reinforcement module accumulated information on the objects in the scene, the VAP model became more accurate.
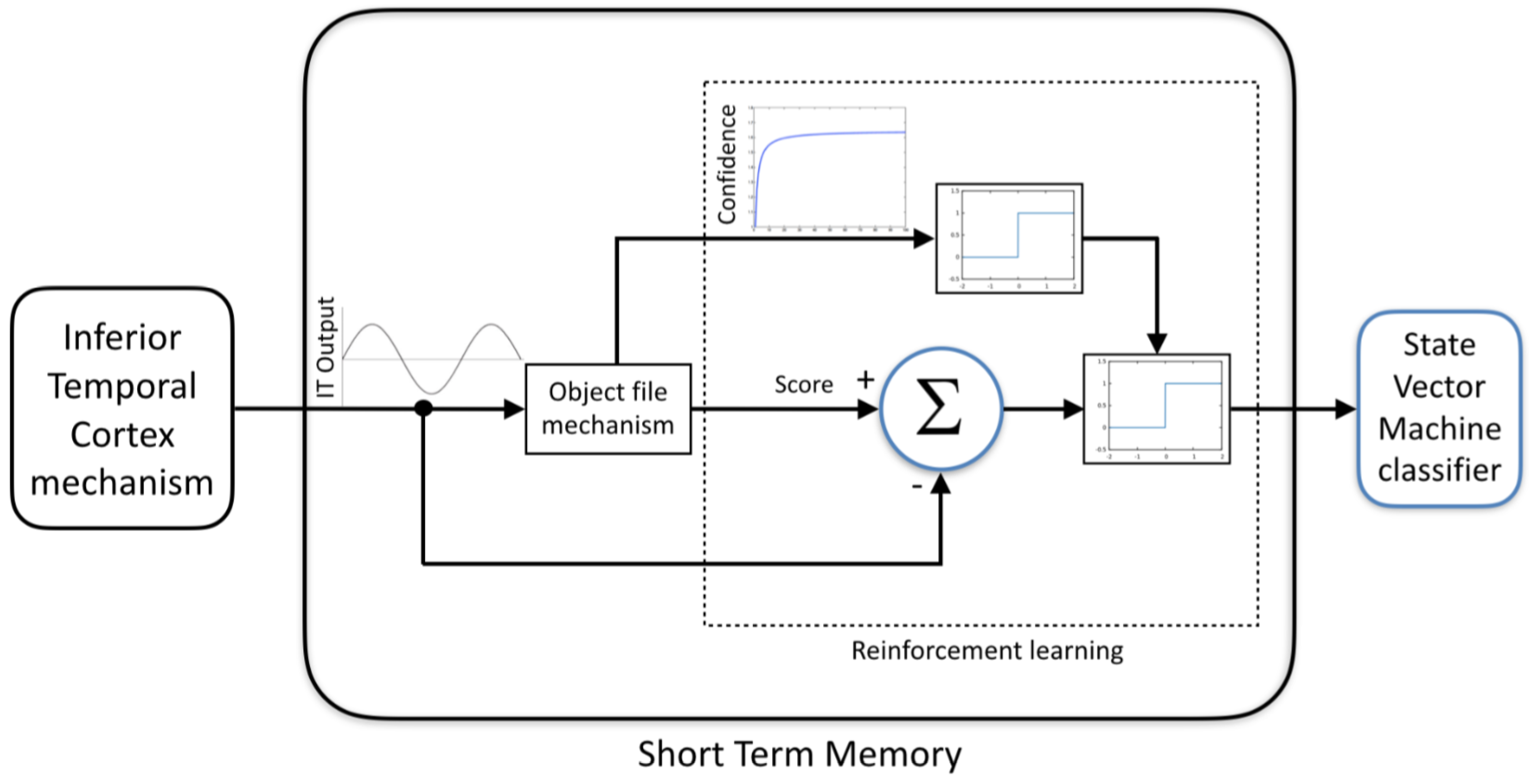
An object moving around the scene may be varied visually in a number of ways, due to the new viewing conditions in each frame. For the sake of terminology, each specific realization variation of an object, which may result in a different feature vector, is called an instance. For each object tracked by the Object-file mechanism, the reinforcement learning mechanism is looking for instances where there is a gap between the instantaneous visual feedback received from the CNN in the current frame and the stable Object-file semantic description of the objects. Meaning, after the Object-file has accumulated enough instances to reach high confidence level recognition of the object, the reinforcement learning mechanism compares all new incoming instances from the ITC mechanism to this representation of the object, as can be seen in
Figure 6. When a new instance creates a false prediction, it evokes a learning process, which uses the features of this instance to refine the model.
The proposed model uses an SVM coupled with a CNN as part of a multistage process. A CNN, which is an efficient mechanism for learning an invariant features space from images, is used as a first stage. The deep CNN is first trained to learn good invariant representations and then used on incoming frames as a feature extraction mechanism. As a second stage, the feature vectors are fed into a kernel SVM, which produces good decision surfaces by maximizing margins. It has been shown that this multistage process and its variations usually result in similar performance [
47,
48,
49] to the fully connected layers of a CNN.
Working in a high-dimensional feature space increases the generalization error of support vector machines, as there are not enough data points in the training set to accurately define the boundaries between the classes. Our reinforcement learning model detects and stores samples in video sources that: (a) belong to a specific class but were on the wrong side of the hyper plane and were wrongly classified; or (b) close to the hyper plane where there are naturally fewer samples as it is far away from the mean of the distribution of the class. It then uses these samples to refine the SVM decision function when there is no more movement in the scene.
5. Results
In this work, a novel architecture for object recognition in video sources is proposed. The Visual Associative Predictive (VAP) architecture integrated several biological mechanisms into one system that imitates the concepts behind the efficiency of the human visual system.
Figure 7 demonstrates the similarity between the VAP model and the human visual system. Using the same color code (green for scene prediction pathway, red for object prediction pathway, and blue for the bottom-up pathway), this figure shows the pathways in the VAP model that correspond to those in the human visual system.
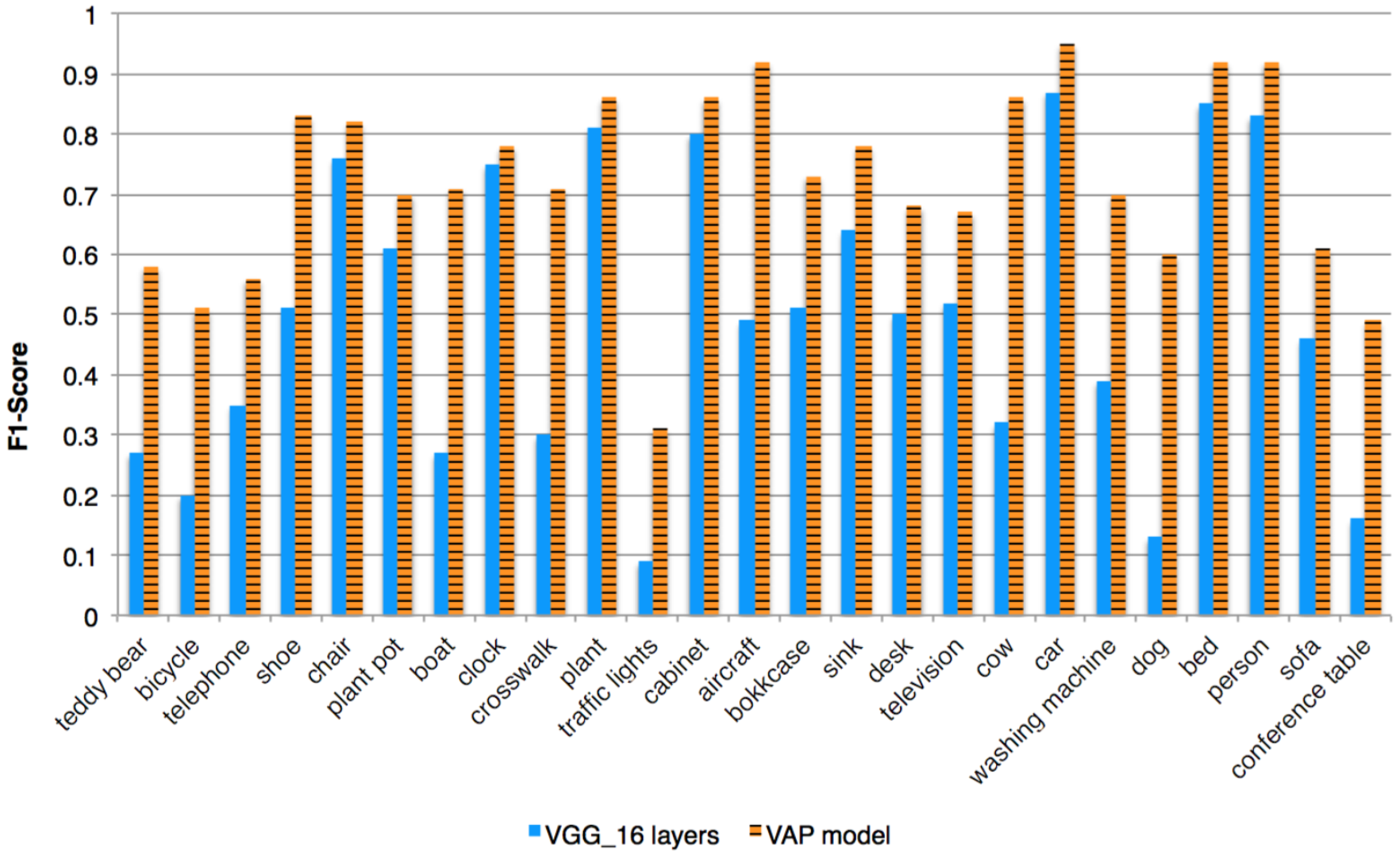
The SUN2012 dataset was used for the purpose of pre-training the VAP model. This dataset was chosen because the scene of each image in the dataset was labeled and all the main objects in each image were segmented and labeled, as well. Overall, the SUN2012 covers 313,884 segmented objects from 908 scene categories. Nevertheless, a subset of the object categories was chosen, which had dozens of samples in the dataset and in which appearance was shown on numerous scenes. The chosen object categories are: cabinet, chair, person, bed, car, plant, plant pot, desk, sink, clock, sofa, bookcase, television, telephone, boat, shoe, washing machine, traffic lights, bicycle, teddy bear, cow, dog, crosswalk, conference table, and aircraft. In total, we got 19,319 segmented objects divided to 25 object categories that appear in 727 scene categories. In order to simulate the use case where large labeled dataset does not exist, only 2063 segmented objects were randomly chosen for training the model. This in turn also serves our goal to demonstrate how the model improves with time, the same way humans usually get a small set of examples from parents/teachers and enrich their capabilities with time, based on self exploration of their environment.
5.1. Results on Images
First, the contribution of the contextual scene information on the recognition of objects in still images was examined. The 17,256 images from the SUN2013 dataset that were not used for training, were classified using both the FRCNN with the VGG16 model and the VAP model. As explained, the fully connected layers of the FRCNN were replaced with SVM. Standardization was applied to the data fed to the SVM. The main advantage of standardizing is to avoid attributes in greater numeric ranges dominating those in smaller numeric ranges. Of course, the same standardization was used to scale both training and testing data.
The results, seen in
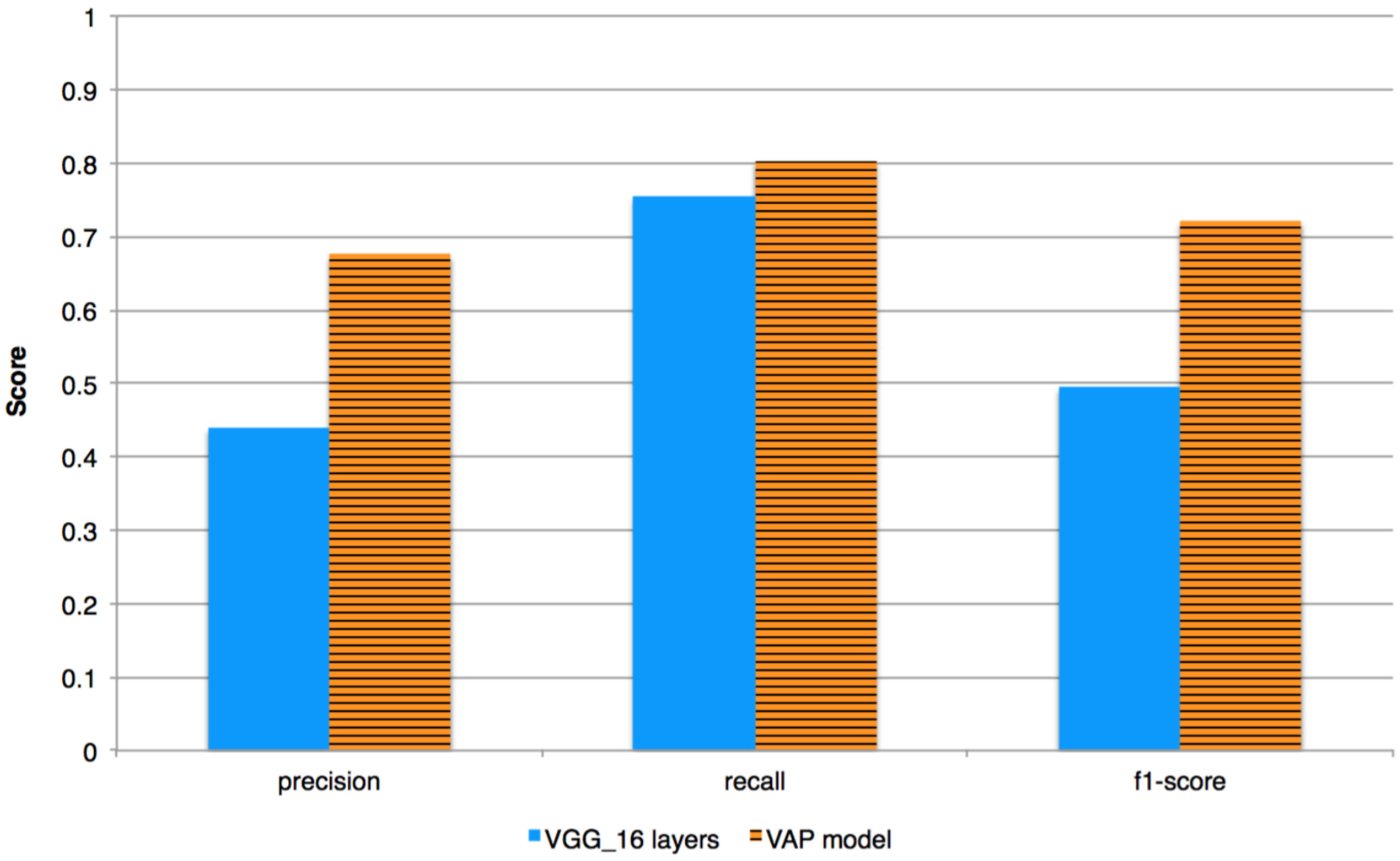
Figure 8, show that the contribution of the contextual information resulted in better performance of the VAP model for all class categories. The F1-score, which is the harmonic mean of precision and recall, was used for the comparison, as it considered both the precision and the recall of the experiment results. The improvement is in all three measures (precision, recall, and F1-score), as seen in
Figure 9.
5.2. Results on Videos
The evaluation of the VAP model capability to improve with time was done on a set of 39 short video clips, filmed during a period of few weeks from a fixed camera located on the third floor. The position was chosen in order to generate a view angle that is different then the common view angle in the training set that was used to pre-train the FRCNN model. As the view angle in the training set is usually in the vicinity of a zero angle (camera in the same height of the objects), placing the camera on the third floor made the objects look different (top view vs. front view). Hence, we can observe and analyze the learning process of the VAP model, which needs to start with somewhat low recognition scores and gradually improve with time, based on its reinforcement learning mechanism.
The video clips were taken over a period of few weeks in order to capture the scene in different lighting, weather conditions and object arrangements. Each video clip was 45–150 s long, which resulted in a 30-min-long test set with 45,613 instances of 181 moving objects, mainly belonging to the categories: Car, Person, Bicycle, and Cat. The overall performance evaluation was done three stages, which we named: “Bottom-up VGG1024”, “Contextual pathways included”, and “Full VAP model”, where the “Bottom-up VGG1024” represent the results with the FRCNN model only, the “Contextual pathways included” represents the VAP model that integrates the top-down contextual priming with the bottom-up FRCNN process, and the “Full VAP model” represents the addition of the Object-file mechanism and the reinforcement-learning scheme. For further research, the video clips are available at:
VAP’s video dataset.
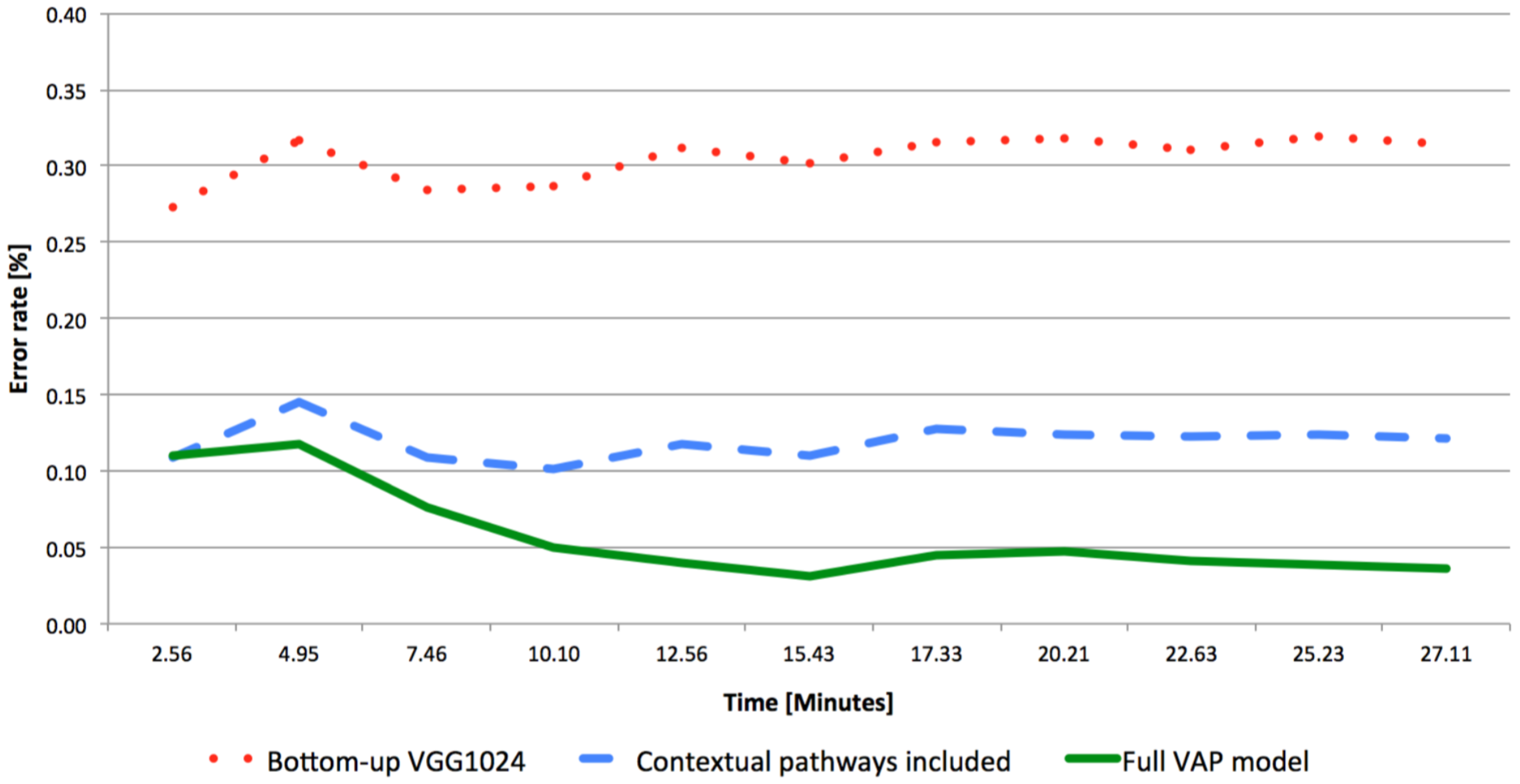
For the evaluation of the classifier’s performance, the error rate was calculated by dividing the number of instances with false classification by the total number of instances. In
Figure 10, we can see that the proposed model outperformed the buttom-up model performance. This figure shows the cumulative error rate, where the error rate is measured as the sum of false classified instances divided by the total number of instances. It is clear that the VAP model is learning from past examples, improves its accuracy, and outperforms the bottom-up FRCNN classifier (with VGG1024 model). Furthermore, even without applying the reinforcement learning, the model uses the contextual information it learned from the SUN2012 dataset and uses this prior information to perform better than the bottom-up process alone.
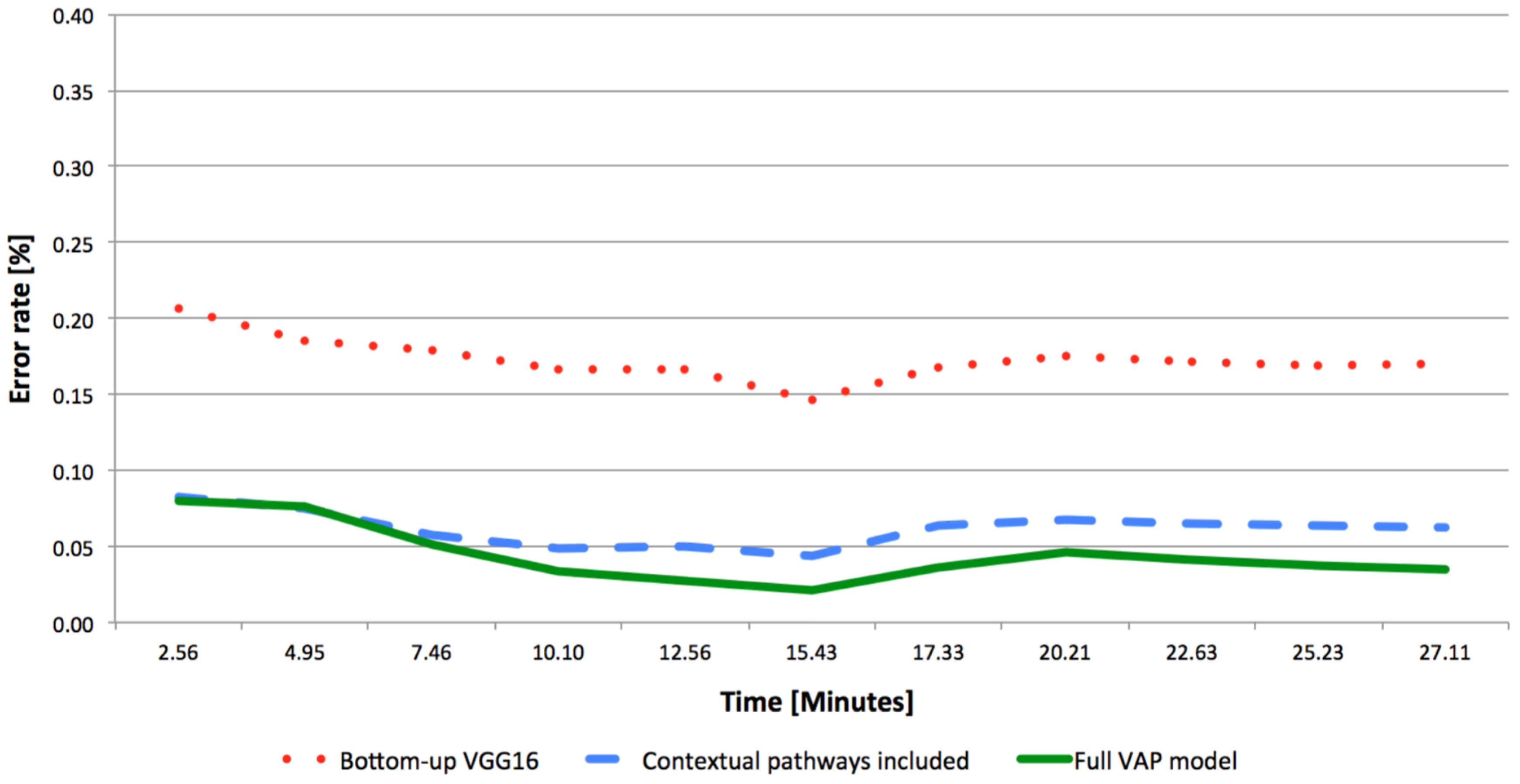
These results emphasize the importance of the Object-file module for video sources as a tool to retain perceptual continuity, as well as to enable the reinforcement learning. Comparing the results between
Figure 10, with the shallower VGG1024, and
Figure 11, with the deeper VGG16, suggests that the superior performance of the proposed model is especially prominent for shallow CNNs with reduced performance. When using shallow CNNs, there are more cases of ambiguity where the ability of the Scene-Object-Matrix to contribute differentiating information is higher. In addition, the rate of false prediction is higher in these cases, and the reinforcement learning gains new information more rapidly. As a result, the proposed model converges faster and becomes extremely beneficial in cases of platforms with strict low computational resources that dictate shallow CNNs, such as small autonomous systems.
As explained, the training dataset of SUN2012 includes mainly objects with low altitude angle view. As a result, when the system started to work it generated low scores for the objects picked up by the video motion detector. Nevertheless, after few minutes of watching the scene, it managed to learn from frames, which resulted in visual feedback that is different than the system prediction. These samples were used to update the SVM, by adding the upper view samples of the different classes to the existing low altitude angle training samples and refining the hyperplanes defining each class. An example of the learning process can be seen in
Figure 12 that shows the classification and confidence level of the VAP model to the several appearances of bicyclists in the scene. It is evident that at the beginning the confidence level is low, but, with time, the system’s confidence increases as the reinforcement mechanism learns from past examples.
The same frames when running the bottom-up pathway only can be seen in
Figure 13. It is clear that the confidence levels for the bicyclists are approximately constant and are lower than those achieved by the VAP model. Furthermore, the classification of the people in the scene gets a lower confidence level, and, in
Figure 13d, one person is also misclassified as a plant due to the background of vegetation behind him.
The strength of the reinforcement learning mechanism is evident when examining
Figure 14. The bicycle rider naturally competes with the person class as it shares many similar features originating from the person riding the bicycle. As a result, the person in the scene is being correctly classified in both cases but yields much higher confidence level with the full VAP model. The ability of the full VAP model to resolve this ambiguity is even more prominent for the bicycle rider, as the full VAP model correctly classifies him, while the non-learning model yields a very low confidence level that results in no recognition decision.
Finally,
Table 1 quantifies the performance comparison between the VAP model and the FRCNN algorithm. The values in the table are the accumulated mean average precision (mAP) and error rate of the system, after running the VAP model on all video clips in the dataset. These results validate the hypothesis underlying this work and show that including biologically-inspired mechanisms in computer vision systems would yield more robust and better-performing object recognition architectures.
6. Discussion
The VAP model described in this work is proposed as a starting point for interaction between the computer vision and brain science communities and the development of synergistic models of artificial and biological vision. As the dynamics of neural processing is much more complex than the proposed computational model, lateral and recurrent interactions between the different levels of the model should be added to the VAP model. Such additions can improve the resemblance to the human visual system and can lead to a computational model that takes into account important aspects of human perception, such as detail preservation and active vision. A first step of adding lateral and recurrent interactions between the different levels of the model can be made by adding to the bottom-up CNN lateral interactions, such as in the U-Net CNN [
50] and recurrent interactions, such as in the Recurrent CNN [
51].
The results using the VAP model show that the proposed method solves ambiguous classification cases better than bottom-up based algorithms, as well as achieving better classification performance throughout its operation. Nevertheless, one can argue that using a biologically-inspired predictive mechanism may result in false recognition, the same way the human visual perception is limited, as can be seen by numerous optical illusions. In addition, continual learning poses particular challenges for artificial neural networks due to the tendency for previously learned knowledge to be abruptly lost as new information is incorporated [
46]. This phenomenon, termed catastrophic forgetting, is specifically relevant for the VAP model as the model is trained on a specific dataset and then continuously trained on a different scene. Analyzing and clarifying these effects and modifying the model in order to cope with them is left for future work.
Furthermore, keeping the original line of thinking of imitating the human visual system, it can be interesting to adapt the VAP model in order to examine the hypothesis that predictions play not only a modulatory but also a driving role in awareness. A human observer can get a task to look for a specific type of a car in an entrance to a facility or counting the number of people entering the gate. For a human observer, these two different tasks will result in different priming and search strategies. The human eye-movement patterns, cognitive state, and thought processes are systematically modulated by top-down task demands [
52,
53]. In order to add such mechanism to the VAP model, a new task/mission input should be introduced to the model, as well as new modules that will enable top-down high-level cognitive factors, such as task input, to modulate the the different parts of the model. Such a “mission control” management building block should lead to performance enhancement in the specific task, with a reduction in performance for competing visual inputs.
7. Conclusions
Recent progress in understanding the way the human brain processes visual information should lead to the development of computer vision systems that are inspired by the human visual system. Such an approach is important not only for the computer vision community, for tasks where a human-like performance is required, but also for the brain research community, due to its potential to provide a tool for testing and evaluating the success in understanding the human visual system and its mechanisms. The proposed model investigates the argument arising from recent brain research experiments which suggested that, when visual input is ambiguous, predictions may help in the decision process and in maintaining a coherent interpretation of the environment. The VAP model imitates this expectation-driven perception mechanism, which is behind the recognition process in the human brain. The results using the model show that the proposed method solves ambiguous classification cases better than bottom-up based algorithms, while sustaining high classification performance throughout its operation.
In addition, the results support the notion that an ongoing visual reinforcement learning can enable the exploitation of the unsupervised stream of data that the autonomous agent receives during its operation, in order to improve its recognition abilities with time. In the proposed model, predictions play a driving role in a learning process that feeds a reinforcement learning mechanism. The results achieved with the model show that this mechanism can enable a robotic agent to improve its performance with time by means of novel exploration and reinforcement learning. Overall, the results strongly support the integration of top-down contextual cues and continuous reinforcement learning in visual perception algorithms. Furthermore, it implies that, in the same way animals and humans actively explore their environment for new information by means of novelty exploration, a robotic platform should employ the same tactic and use the continuous input of unlabeled images of its video stream for unsupervised learning, in order to discover and gain knowledge that was not available in the labeled data it was trained with.
Creating a computer vision algorithm that is massively inspired by the human visual system can be a useful tool in the brain research field, as well as in the computer vision field. However, the human visual system has not been fully mapped yet, and this gap in knowledge also translates to our inability to accurately model this system. Even for mechanisms that were well-researched, such as the mechanisms that are the basis of this work, there is a wide gap between our understandings of their general principles and the actual biological mechanisms that are dynamic in nature and based on multi-level excitatory and inhibitory interactions. Nevertheless, although the task of building a computational model of the human visual system is extremely complex and far from being accomplished, the potential benefits of developing such a model exceed the field of computer vision. It is important to note that there are inherent limitations for applying general principles of a biological mechanism, while not imitating all of the actual complex interactions in the human visual system. Nonetheless, a mutual multidisciplinary work on developing such a model can be used as a common ground for researchers from both fields to cooperate and develop a computational model of the human visual system for the benefit of both fields of research.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}