1. Introduction
We focus on the comparison of structured objects, i.e., objects defined by both a feature and a structure information. Abstractly, the feature information cover all the attributes of an object; for example, it can model the value of a signal when objects are time series, or the node labels over a graph. In shape analysis, the spatial positions of the nodes can be regarded as features, or, when objects are images, local color histograms can describe the image’s feature information. As for the structure information, it encodes the specific relationships that exist among the components of the object. In a graph context, nodes and edges are representative of this notion, so that each label of the graph may be linked to some others through the edges between the nodes. In a time series context, the values of the signal are related to each other through a temporal structure. This representation can be related with the concept of relational reasoning (see [
1]), where some entities (or elements with attributes, such as the intensity of a signal) coexist with some relations or properties between them (or some structure, as described above). Including structural knowledge about objects in a machine learning context has often been valuable in order to build more generalizable models. As shown in many contexts, such as graphical models [
2,
3], relational reinforcement learning [
4], or Bayesian nonparametrics [
5], considering objects as a complex composition of entities together with their interactions is crucial in order to learn from small amounts of data.
Unlike recent deep learning end-to-end approaches [
6,
7] that attempt to avoid integration of prior knowledge or assumptions about the structure wherever possible,
ad hoc methods, depending on the kind of structured objects involved, aim to build meaningful tools that include structure information in the machine learning process. In graph classification, the structure can be taken into account through dedicated graph kernels, in which the structure drives the combination of the feature information [
8,
9,
10]. In a time series context, Dynamic Time Warping and related approaches are based on the similarity between the features while allowing limited temporal (i.e., structural) distortion in the time instants that are matched [
11,
12]. Closely related, an entire field has focused on predicting the structure as an output and it has been deployed on tasks, such as segmenting an image into meaningful components or predicting a natural language sentence [
10,
13,
14].
All of these approaches rely on meaningful representations of the structured objects that are involved. In this context, distributions or probability measures can provide an interesting representation for machine learning data. This allows their comparison within the Optimal Transport (OT) framework that provides a meaningful way of comparing distributions by capturing the underlying geometric properties of the space through a cost function. When the distributions dwell in a common metric space
, the Wasserstein distance defines a metric between these distributions under mild assumptions [
15]. In contrast, the Gromov–Wasserstein distance [
16,
17] aims at comparing distributions that support live in different metric spaces through the intrinsic pair-to-pair distances in each space. Unifying both distances, the Fused Gromov–Wasserstein distance was proposed in a previous work in [
18] and used in the discrete setting to encode, in a single OT formulation, both feature and structure information of structured objects. This approach considers structured objects as joint distributions over a common feature space associated with a structure space specific to each object. An OT formulation is derived by considering a tradeoff between the feature and the structure costs, respectively, defined with respect to the Wasserstein and the Gromov–Wasserstein standpoints.
This paper presents the theoretical foundations of this distance and states the mathematical properties of the metric in the general setting. We first introduce a representation of structured objects using distributions. We show that classical Wasserstein and Gromov–Wasserstein distance can be used in order to compare either the feature information or the structure information of the structured object but that they both fail at comparing the entire object. We then present the Fused Gromov–Wasserstein distance in its general formulation and derive some of its mathematical properties. Particularly, we show that it is a metric in a given case, we give a concentration result, and we study its interpolation and geodesic properties. We then provide a conditional-gradient algorithm to solve the quadratic problem resulting from in the discrete case and we conclude by illustrating and interpreting the distance in several applicative contexts.
Notations. Let be the set of all probability measures on a space and the set of all Borel sets of a -algebra A. We note # the push-forward operator, such, that for a measurable function T, , .
We note supp the support of is the minimal closed subset such that . Informally, this is the set where the measure “is not zero”.
For two probability measures and we note the set of all couplings or matching measures of and , i.e., the set .
For two metric spaces and , we define the distance on such that, for .
We note the simplex of N bins as . For two histograms and we note with some abuses the set of all couplings of a and b, i.e., the set . Finally, for , denotes the dirac measure in x.
Assumption. In this paper, we assume that all metric spaces are non-trivial Polish metric spaces (i.e., separable and completely metrizable topological spaces) and that all measures are Borel.
2. Structured Objects as Distributions and Fused Gromov–Wasserstein Distance
The notion of structured objects used in this paper is inspired from the discrete point of view where one aims at comparing labeled graphs. More formally, we consider undirected labeled graphs as tuples of the form
, where
are the set of vertices and edges of the graph.
is a labelling function that associates each vertex
with a feature
in some feature metric space
. Similarly,
maps a vertex
from the graph to its structure representation
in some structure space
specific to each graph.
is a symmetric application which aims at measuring the similarity between the nodes in the graph. In the graph context,
can either encode the neighborhood information of the nodes, the edge information of the graph or more generally it can model a distance between the nodes such as the shortest path distance or the harmonic distance [
19]. When
is a metric, such as the shortest-path distance, we naturally endow the structure with the metric space
.
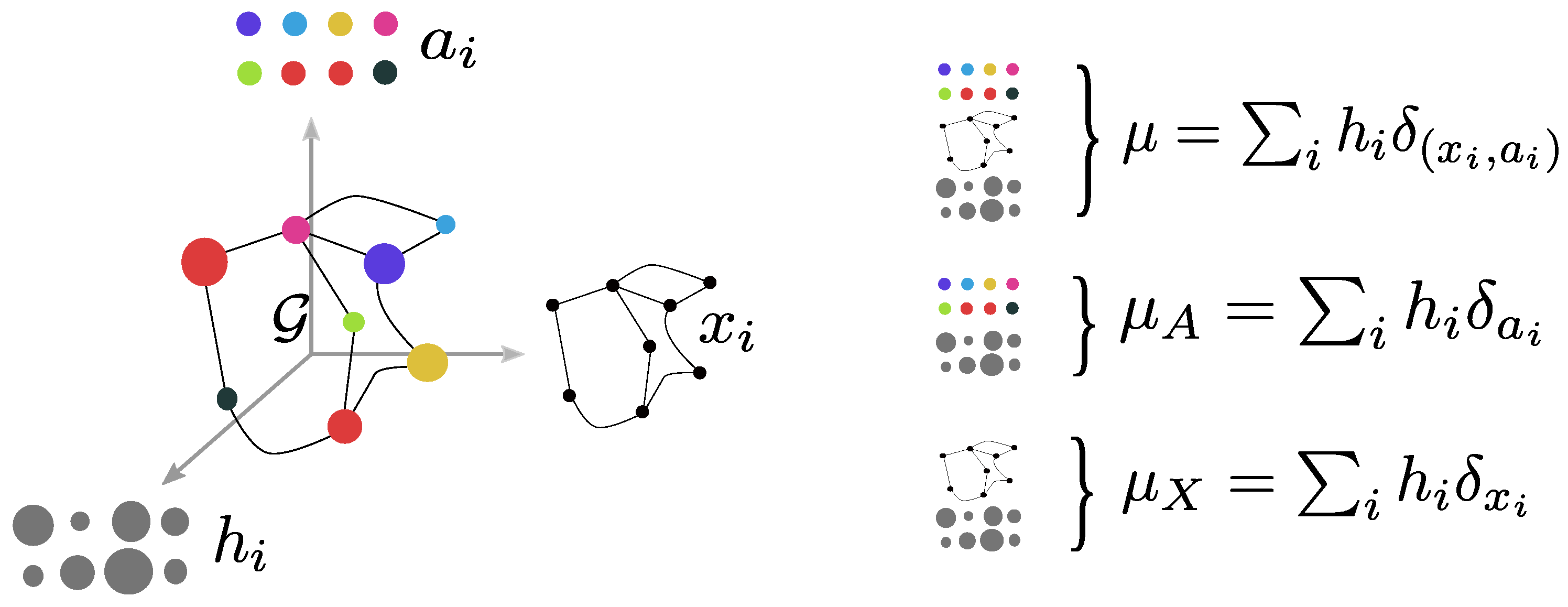
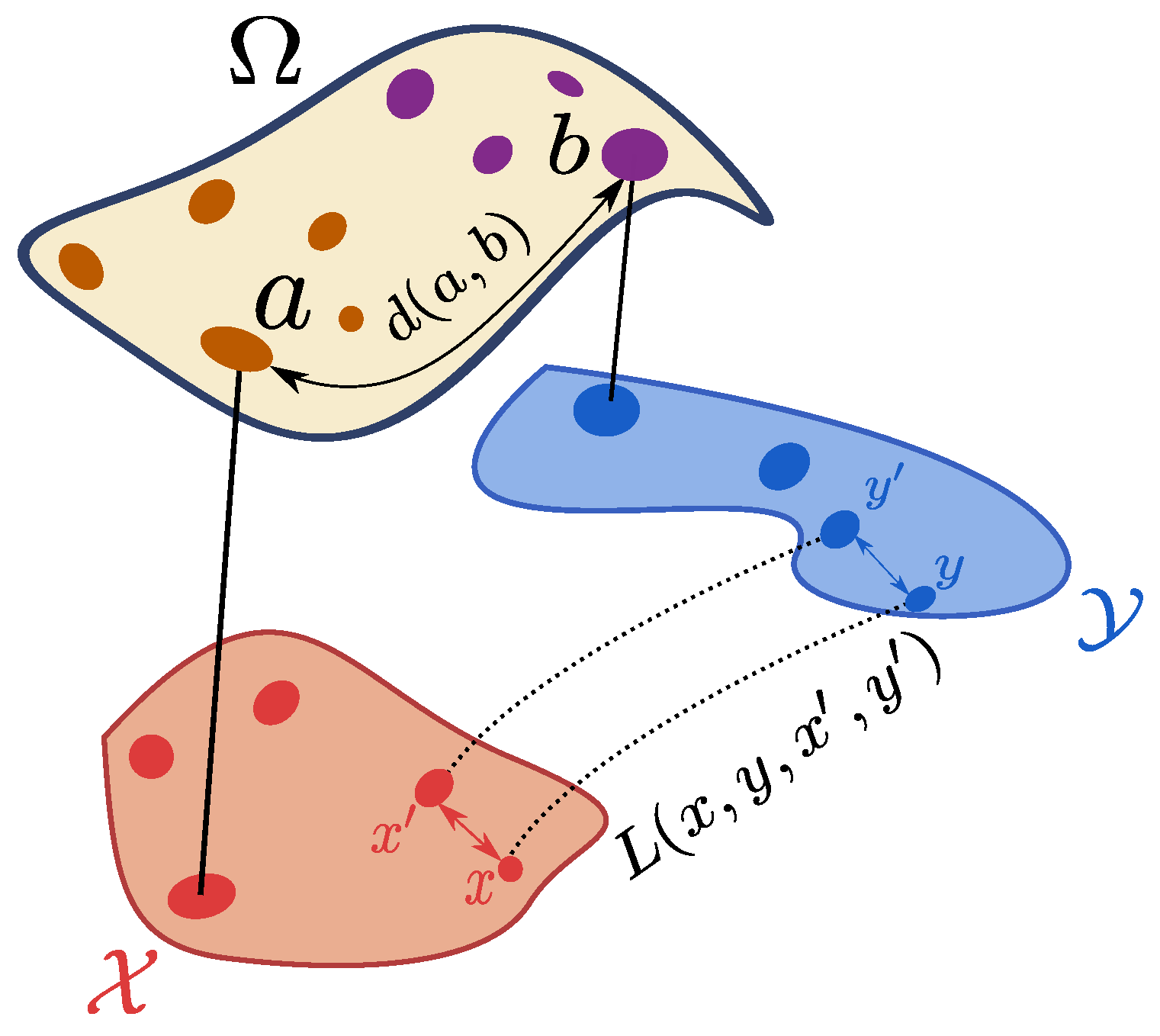
In this paper, we propose enriching the previous definition of a structured object with a probability measure which serves the purpose of signaling the relative importance of the object’s elements. For example, we can add a probability (also denoted as weight)
to each node in the graph. This way, we define a fully supported probability measure
, which includes all the structured object information (see
Figure 1 for a graphical depiction).
This graph representation for objects with a finite number of points/vertices can be generalized to the continuous case and leads to a more general definition of structured objects:
Definition 1. (Structured objects). A structured object over a metric space is a triplet , where is a metric space and μ is a probability measure over . is denoted as the feature space, such that is the distance in the feature space and the structure space, such that is the distance in the structure space. We will note and the structure and feature marginals of μ.
Definition 2. (Space of structured objects).
We note the set of all metric spaces. The space of all structured objects over will be written as and is defined by all the triplets where and . To avoid finiteness issues in the rest of the paper we define for the space such that if we have:(the finiteness of this integral does not depend on the choice of ) For the sake of simplicity, and when it is clear from the context, we will sometimes denote only by
the whole structured object. The marginals
encode very partial information since they focus only on independent feature distributions or only on the structure. This definition encompasses the discrete setting discussed in above. More precisely, let us consider a labeled graph of
n nodes with features
with
and
the structure representation of the nodes. Let
be an histogram, then the probability measure
defines structured object in the sense of Definition 1, since it lies in
. In this case, an example of
,
, and
is provided in
Figure 1.
Note that the set of structured objects is quite general and also allows considering discrete probability measures of the form with possibly different than n. We propose focusing on a particular type of structured objects, namely the generalized labeled graphs, as described in the following definition:
Definition 3. (Generalized labeled graph). We call generalized labeled graph a structured object such that μ can be expressed as where is surjective and pushes forward to , i.e., .
This definition implies that there exists a function , which associates a feature to a structure point and, as such, one structure point can not have two different features. The labeled graph described by is a particular instance of a generalized labeled graph in which is defined by .
2.1. Comparing Structured Objects
We now aim to define a notion of equivalence between two structured objects and . We note in the following the marginals of . Intuitively, two structured objects are the same if they share the same feature information, if their structure information are lookalike, and if the probability measures are corresponding in some sense. In this section, we present mathematical tools for individual comparison of the elements of structured objects. First, our formalism implies comparing metric spaces, which can be done via the notion of isometry.
Definition 4. (Isometry).
Let and be two metric spaces. An isometry is a surjective map that preserves the distances: An isometry is bijective, since for we have and hence (in the same way is also a isometry). When it exists, X and Y share the same “size” and any statement about X, which can be expressed through its distance is transported to Y by the isometry f.
Example 1. Let us consider the two following graphs whose discrete metric spaces are obtained as shortest path between the vertices (see corresponding graphs in Figure 2). These spaces are isometric since the map f, such that , , , verifies Equation (3). The previous definition can be used in order to compare the structure information of two structured objects. Regarding the feature information, because they all lie in the same ambient space , a natural way for comparing them is by the standard set equality . Finally, in order to compare measures on different spaces, the notion of preserving map can be used.
Definition 5. (Measure preserving map).
Let and be two measurable spaces. A function (usually called a map) is said to be measure preserving if it transports the measure on such thatIf there exists such a measure preserving map, the properties about measures of are transported via f to .
Combining these two ideas together leads to the notion of measurable metric spaces (often called
mm-spaces [
17]), i.e., a metric space
enriched with a probability measure and described by a triplet
. An interesting notion for comparing mm-spaces is the notion of isomorphism.
Definition 6. (Isomorphism). Two mm-spaces are isomorphic if there exists a surjective measure preserving isometry between the support of the measures .
Example 2. Let us consider two mm-spaces and , as depicted in Figure 3. These spaces are isometric, but not isomorphic, as there exists no measure preserving map between them. All of this considered, we can now define a notion of equivalence between structured objects.
Definition 7. (Strong isomorphism of structured objects).
Two structured objects are said to be strongly isomorphic if there exists an isomorphism I between the structures such that is bijective between and and measure preserving. More precisely, f satisfies the following properties:
- P.1
.
- P.2
The function f statisfies: - P.3
The function is surjective, satisfies and:
It is easy to check that the strong isomorphism defines an equivalence relation over .
Remark 1. The function f described in this definition can be seen as a feature, structure, and measure preserving function. Indeed, fromP.1f is measure preserving. Moreover, and are isomorphic through I. Finally usingP.1andP.2we have that , so that the feature information is also preserved.
Example 3. To illustrate this definition, we consider a simple example of two discrete structured objects:with for i, and for , (see Figure 4). The two structured objects have isometric structures and same features individually, but they are not strongly isomorphic. One possible map , such that leads to an isometry is , , , . Yet, this map does not satisfy for any x, since and . The other possible functions, such that leads to an isometry are simply permutations of this example, yet it is easy to check that none of them verifiesP.2(for example, with ). 2.2. Background on OT Distances
The Optimal Transport (OT) framework defines distances between probability measures that describe either the feature or the structure information of structured objects.
Wasserstein distance. The classical OT theory aims at comparing probability measures
. In this context the quantity:
is usually called the
p-Wasserstein distance (also known, for
, as Earth Mover’s distance [
20] in the computer vision community) between distributions
and
. It defines a distance on probability measures, especially
iff . This distance also has a nice geometrical interpretation as it represents an optimal cost (
w.r.t. d) to move the measure
onto
with
the amount of probability mass shifted from
a to
b (see
Figure 5). To this extent, the Wasserstein distance quantifies how “far”
is from
by measuring how “difficult” it is to move all the mass from
onto
. Optimal transport can deal with smooth and discrete measures and it has proved to be very useful for comparing distributions in a shared space, but with different (and even non-overlapping) supports.
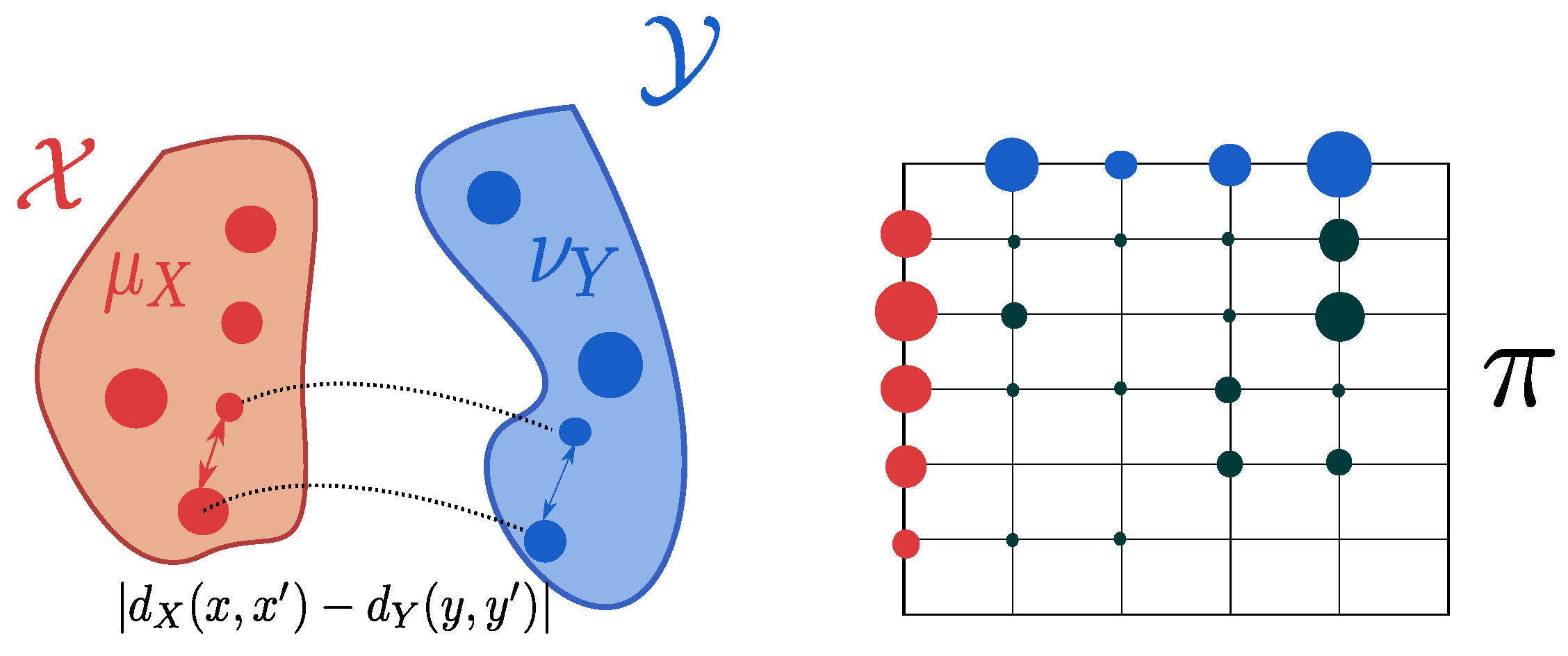
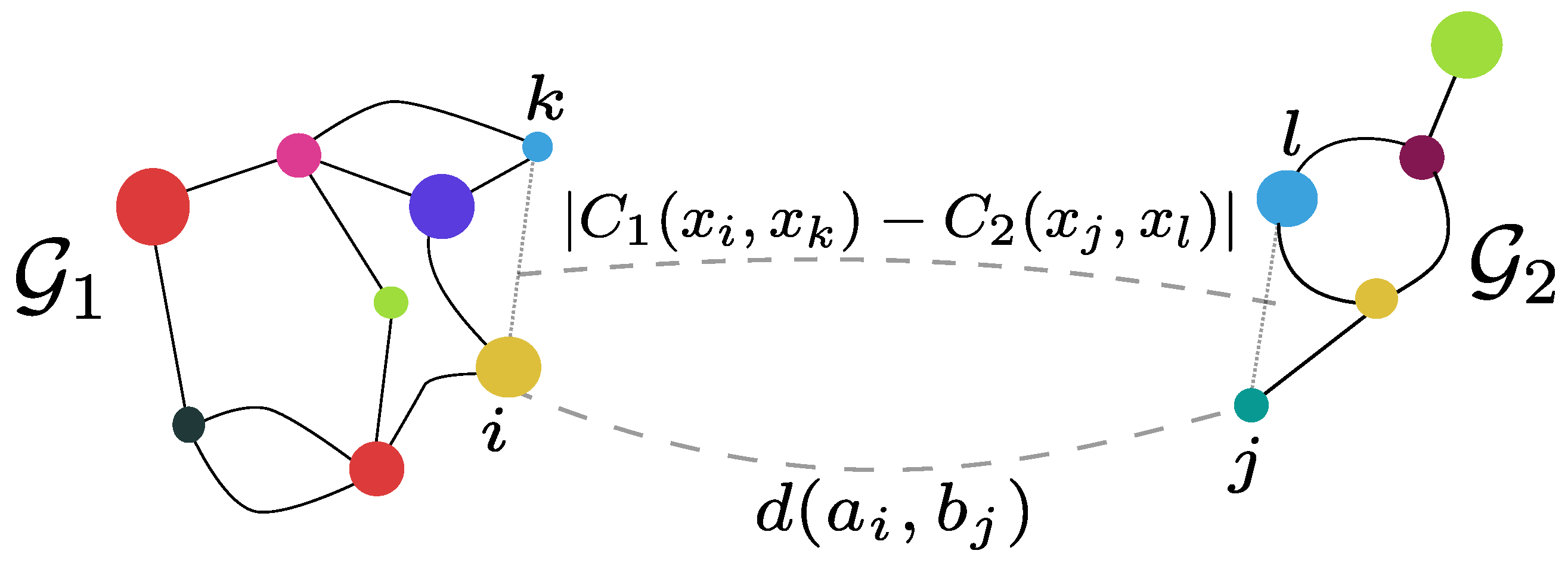
Gromov–Wasserstein distance. In order to compare measures whose support are not necessarily in the same ambient space [
16,
17] define a new OT distance. By relaxing the classical Hausdorff distance [
15,
17], authors build a distance over the space of all mm-spaces. For two compact mm-spaces
and
, the Gromov–Wasserstein distance is defined as:
where:
The Gromov–Wasserstein distance depends on the choice of the metrics
and
and with some abuse of notation we denote the entire mm-space by its probability measure. When it is not clear from the context, we will specify using
. The resulting coupling tends to associate pairs of points with similar distances within each pair (see
Figure 6). The Gromov–Wasserstein distance allows for the comparison of measures over different ground spaces and defines a metric over the space of all mm-spaces quotiented by the isomoprhisms (see Definitions 4 and 5). More precisely, it vanishes if the two mm-spaces are isomorphic. This distance has been used in the context of relational data e.g., in shape comparison [
17,
22], deep metric alignment [
23], generative modelling [
24] or to align single-cell multi-omics datasets [
25].
2.3. Fused Gromov–Wasserstein Distance
Building on both Gromov–Wasserstein and Wasserstein distances, we define the Fused Gromov–Wasserstein () distance on the space of structured objects:
Definition 8. (Fused Gromov-Wasserstein distance).
Let and . We consider and . The Fused-Gromov–Wasserstein distance is defined as:where Figure 7 illustrates this definition. When it is clear from the context we will simply note
instead for
for brevity.
acts as a trade-off parameter between the cost of the structures represented by
and the feature cost
. In this way, the convex combination of both terms leads to the use of both information in one formalism resulting on a single map
that “moves” the mass from one joint probability measure to the other.
Many desirable properties arise from this definition. Among them, one can define a topology over the space of structured objects using the distance to compare structured objects, in the same philosophy as for Wasserstein and Gromov–Wasserstein distances. The definition also implies that acts as a generalization of both Wasserstein and Gromov-Wasserstein distances, with achieving an interpolation between these two distances. More remarkably, distance also realizes geodesic properties over the space of structured objects, allowing the definition of gradient flows. All of these properties are detailed in the next section. Before reviewing them, we first compare with and W (by assuming for now that exists, which will be shown later in Theorem 1).
Proposition 1. (Comparaison between , and W). We have the following results for two structured objects μ and ν:
The following inequalities hold: Let us suppose that the structure spaces , are part of a single ground space (i.e., and ). We consider the Wasserstein distance between μ and ν for the distance on : . Then:
Proof of this proposition can be found in
Section 7.1. In particular, following this proposition, when the
distance vanishes then both
and
W distances vanish so that the structure and the feature of the structure object are individually “the same” (with respect to their corresponding equivalence relation). However, the converse is not necessarily true, as shown in the following example.
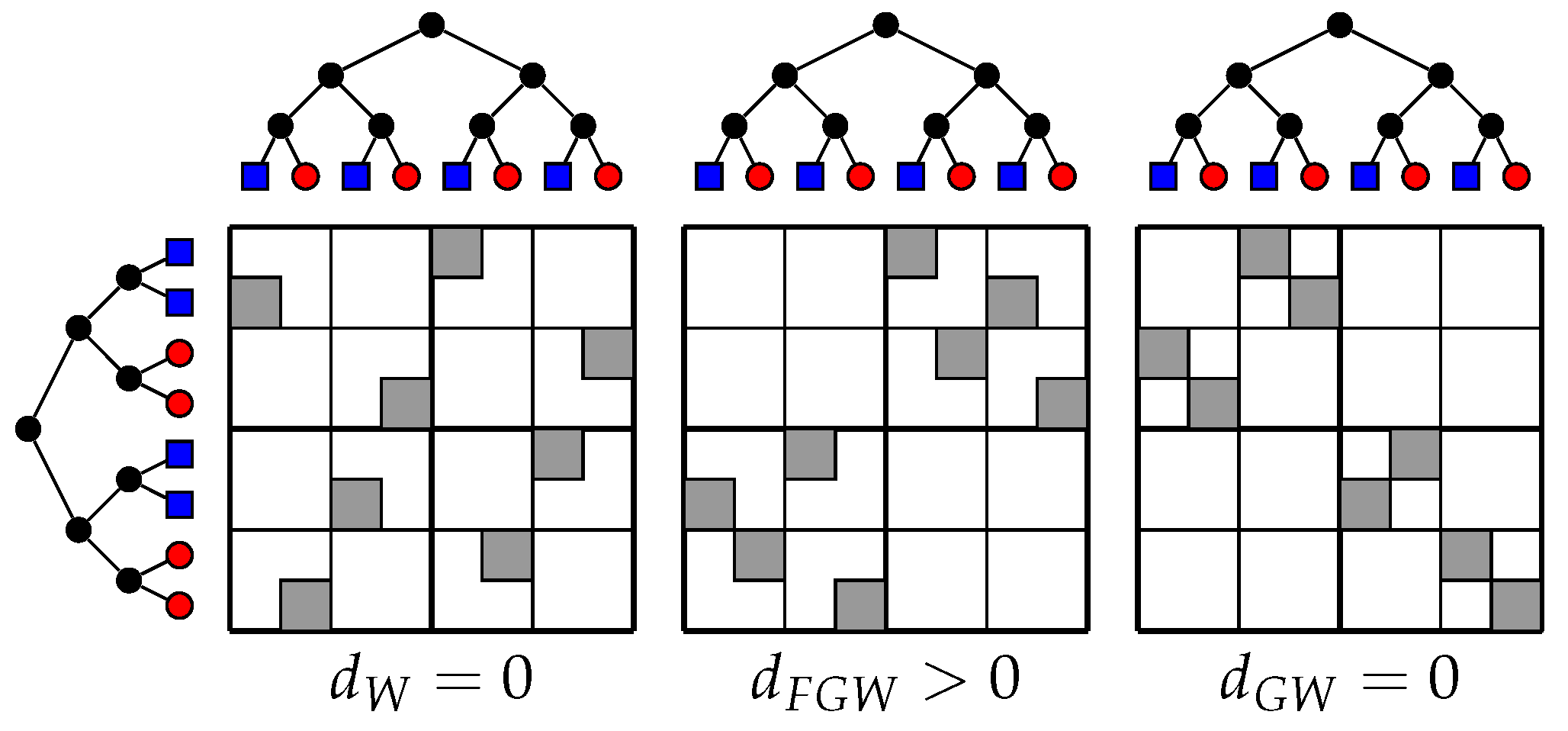
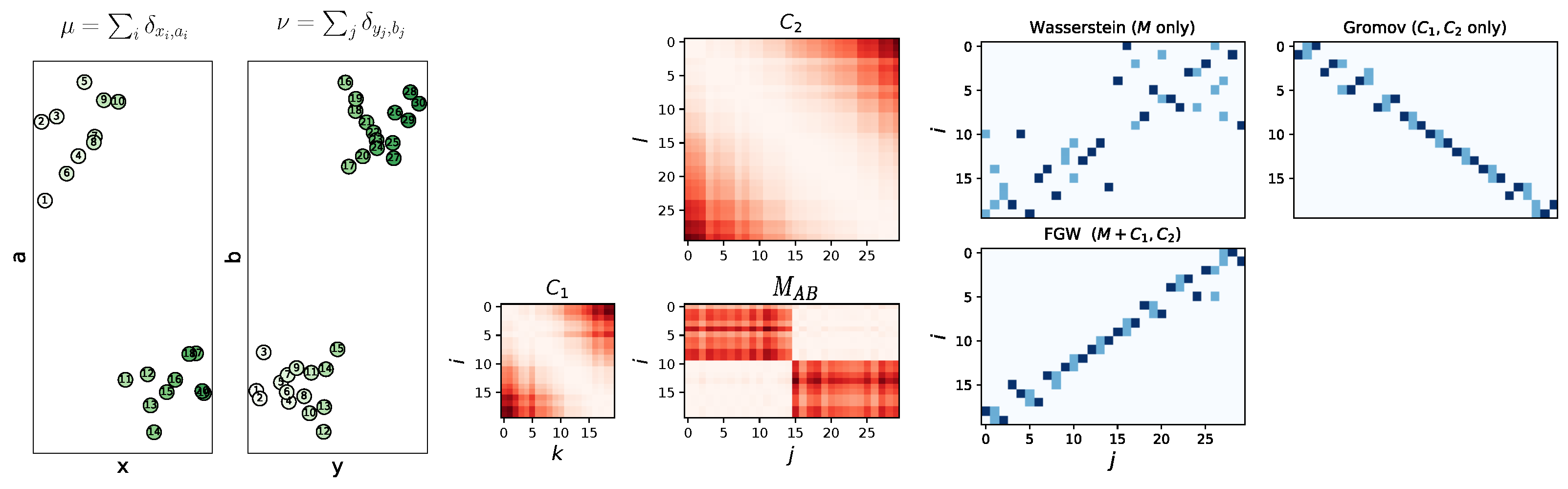
Example 4. (Toy trees).
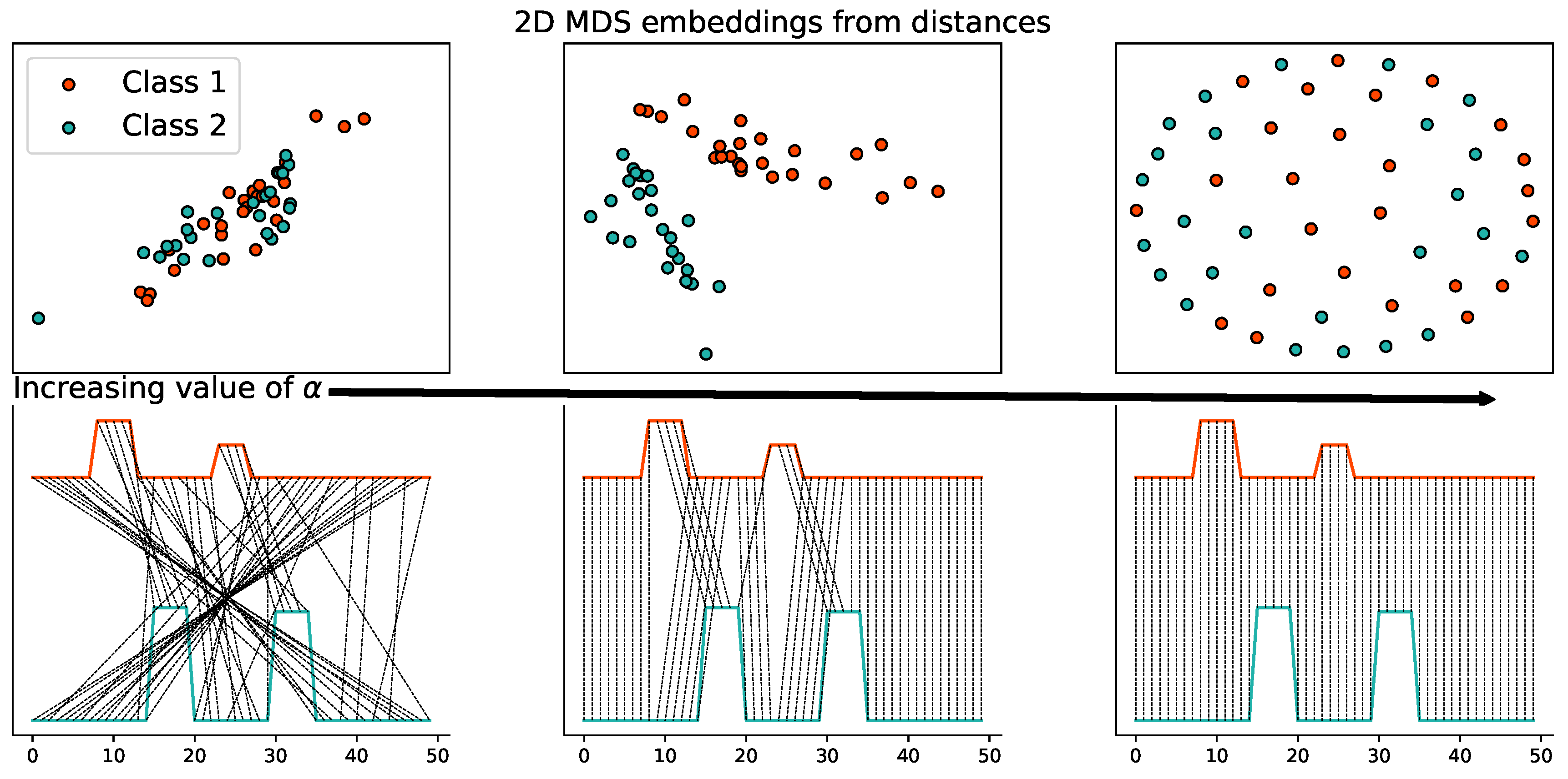
We construct two trees as illustrated in Figure 8 where the 1D node features are shown with colors. The shortest path between the nodes is used to capture the structures of the two structured objects and the Euclidean distance is used for the features. We consider uniform weights on all nodes. Figure 8 illustrates the differences between , , and W distances. The left part is the Wasserstein coupling between the features: red nodes are transported on red ones and the blue nodes on the blue ones but tree structures are completely discarded. In this case, the Wasserstein distance vanishes. In the right part, we compute the Gromov–Wasserstein distance between the structures: all couples of points are transported to another couple of points, which enforces the matching of tree structures without taking into account the features. Because structures are isometric, the Gromov–Wasserstein distance is null. Finally, we compute the using intermediate α (center), the bottom and first level structure is preserved as well as the feature matching (red on red and blue on blue) and discriminates the two structured objects. 3. Mathematical Properties of
In this section, we establish some mathematical properties of the distance. The first result relates to the existence of the distance and the topology of the space of structured objects. We then prove that the distance is indeed a distance regarding the equivalence relation between structured objects, as defined in Defintion 7, allowing us to derive a topology on .
3.1. Topology of the Structured Object Space
The distance has the following properties:
Theorem 1. (Metric properties). Let , and . The functional always achieves an infimum in s.t. . Moreover:
- •
is symmetric and, for , satisfies the triangle inequality. For , the triangular inequality is relaxed by a factor .
- •
For , if an only if there exists a bijective function such that: - •
If are generalized labeled graphs then if and only if and are strongly isomorphic.
Proof of this theorem can be found in
Section 7.2. The identity of indiscernibles is the most delicate part to prove and it is based on using the Gromov–Wasserstein distance between the spaces
and
. The previous theorem states that
is a distance over the space of generalized labeled graphs endowed with the strong isomorphism as equivalence relation defined in Definition 7. More generally, for any structured objects the equivalence relation is given by (
12)–(
14). Informally, invariants of the
are structured objects that have both the same structure and the same features in the same place. Despite the fact that
leads to a proper metric, we will further see in
Section 4.1 that the case
can be computed more efficiently using a separability trick from [
26].
Theorem 1 allows a wide set of applications for
, such as
k-nearest-neighbors, distance-substitution kernels, pseudo-Euclidean embeddings, or representative-set methods [
27,
28,
29]. Arguably, such a distance allows for a better interpretation than to end-to-end learning machines, such as neural networks, because the
matrix exhibits the relationships between the elements of the objects in a pairwise comparison.
3.2. Can We Adapt W and GW for Structured Objects?
Despite the appealing properties of both Wasserstein and Gromov–Wasserstein distances, they fail at comparing structured objects by focusing only on the feature and structure marginals, respectively. However, with some hypotheses, one could adapt these distances for structured objects.
Adapting Wasserstein. If the structure spaces
and
are part of a same ground space
, i.e., (
and
), one can build a distance
between couples
and
and apply the Wasserstein distance, so as to compare the two structured objects. In this case, when the Wasserstein distance vanishes it implies that the structured objects are equal in the sense
. This approach is very related with the one discussed in [
30], where the authors define the Transportation
distance for signal analysis purposes. Their approach can be viewed as a transport between two joint measures
,
for function
representative of the signal values and
the Lebesgue measure. The distance for the transport is defined as
for
and
the
norm. In this case,
and
can be interpreted as encoding the feature information of the signal, while
encode its structure information. This approach is very interesting, but cannot be used on structured objects, such as graphs that will not share a common structure embedding space.
Adapting Gromov-Wasserstein. The Gromov–Wasserstein distance can also be adapted to structured objects by considering the distances and within each space and , respectively, and . When the resulting distance vanishes, structured objects are isomorphic with respect to and . However, the strong isomorphism is stronger than this notion, since the isomorphism allows for “permuting the labels”, but not the strong isomorphism. More precisely, we have the following lemma:
Lemma 1. Let be two structured objects and .
If and are strongly isomorphic then and are isomorphic. However the converse is not true in general.
Proof. To see this, if we consider
f as defined in Theorem 1, then, for
, we have
. In this way:
which can be rewritten as:
and so
f is an isometry with respect to
and
. Because
f is also measure preserving and surjective
and
are isomorphic. □
However, the converse is not necessarily true, as it is easy to cook up an example with the same structure but with permuted labels, so that objects are isomorphic but not strongly isomorphic. For example, in the tree example
Figure 4, the structures are isomorphic and the distances between the features within each space are the same between each structured objects, so that
and
are isomorphic, yet not strongly isomorphic, as shown in the example since
.
3.3. Convergence of Structured Objects
The metric property naturally endows the structured object space with a notion of convergence, as described in the next definition:
Definition 9. Convergence of structured objects.
Let be a sequence of structured objects. It converges to in the Fused Gromov–Wasserstein sense if: Using Proposition 1, it is straightforward to see that if the sequence converges in the
sense, both the features and the structure converge respectively in the Wasserstein and Gromov–Wasserstein sense (see [
17] for the definition of convergence in the Gromov–Wasserstein sense).
An interesting question arises from this definition. Let us consider a structured object and let us sample the joint distribution so as to consider with where are sampled from . Does this sequence converges to in the sense and how fast is the convergence?
This question can be answered thanks to a notion of “size” of a probability measure. For the sake of conciseness, we will not exhaustively present the theory, but the reader can refer to [
31] for more details. Given a measure
on
, we denote as
its upper Wasserstein dimension. It coincides with the intuitive notion of “dimension” when the measure is sufficiently well behaved. For example, for any absolutely continuous measure
with respect to the Lebesgue measure on
, we have
for any
. Using this definition and the results presented in [
31], we answer the question of convergence of finite sample in the following theorem (proof can be found in
Section 7.3):
Theorem 2. Convergence of finite samples and a concentration inequality
Moreover, suppose that . Then there exists a constant C that does not depend on n such that: The expectation is taken over the i.i.d samples . A particular case of this inequality is when so that we can use the result above to derive a concentration result for the Gromov-Wasserstein distance. More precisely, if denotes the empirical measure of and if , we have: This result is a simple application of the convergence of finite sample properties of the Wasserstein distance, since in this case
and
are part of the same ground space so that (
18) derive naturally from (
11) and the properties of Wasserstein. In contrast to the Wasserstein distance case, this inequality is not necessarily sharp and future work will be dedicated to the study of its tightness.
3.4. Interpolation Properties between Wasserstein and Gromov-Wasserstein Distances
distance is a generalization of both Wasserstein and Gromov–Wasserstein distances in the sense that it achieves an interpolation between them. More precisely, we have the following theorem:
Theorem 3. Interpolation properties.
As α tends to zero, one recovers the Wasserstein distance between the features information and as α goes to one, one recovers the Gromov–Wasserstein distance between the structure information: This result shows that can revert to one of the other distances. In machine learning, this allows for a validation of the parameter to better fit the data properties (i.e., by tuning the relative importance of the feature vs. structure information). One can also see the choice of as a representation learning problem and its value can be found by optimizing a given criterion.
3.5. Geodesic Properties
One desirable property in OT is the underlying geodesics defined by the mass transfer between two probability distributions. These properties are useful in order to define the dynamic formulation of OT problems. This dynamic point of view is inspired by fluid dynamics and found its origin in the Wasserstein context with [
32]. Various applications in machine learning can be derived from this formulation: interpolation along geodesic paths were used in computer graphics for color or illumination interpolations [
33]. More recently, Ref. [
34] used Wasserstein gradient flows in an optimization context, deriving global minima results for non-convex particles gradient descent. In [
35], the authors used Wasserstein gradient flows in the context of reinforcement learning for policy optimization.
The main idea of this dynamic formulation is to describe the optimal transport problem between two measures as a curve in the space of measures minimizing its total length. We first describe some generality about geodesic spaces and recall classical results for dynamic formulation in both Wasserstein and Gromov–Wasserstein contexts. In a second part, we derive new geodesic properties in the context.
Geodesic spaces. Let be a metric space and two points in X. We say that a curve joining the endpointsx and y (i.e., with and ) is a constant speed geodesic if it satisfies for . Moreover, if is a length space (i.e., if the distance between two points of X is equal to the infimum of the lengths of the curves connecting these two points) then the converse is also true and a constant speed geodesic satisfies . It is easy to compute distances along such curves, as they are directly embedded into .
In the Wasserstein context, if the ground space is a complete separable, locally compact length space, and if the endpoints of the geodesic are given, then there exists a geodesic curve. Moreover, if the transport between the endpoints is unique, then there is a unique displacement interpolation between the endpoints (see Corollary 7.22 and 7.23 in [
15]). For example, if the ground space is
and the distance between the points is measured via the
norm, then geodesics exist and are uniquely determined (this can be generalized to strictly convex costs). In the Gromov–Wasserstein context, there always exists constant speed geodesics as long as the endpoints are given. These geodesics are unique modulo the isomorphism equivalence relation (see [
16]).
The case. In this paragraph, we suppose that . We are interested in finding a geodesic curve in the space of structured objects i.e., a constant speed curve of structured objects joining two structured objects. As for Wasserstein and Gromov–Wasserstein, the structured object space endowed with the Fused Gromov–Wasserstein distance maintains some geodesic properties. The following result proves the existence of such a geodesic and characterizes it:
Theorem 4. Constant speed geodesic.
Let and and in . Let be an optimal coupling for the Fused Gromov–Wasserstein distance between , and . We equip with the norm for .
We define such that: Then:is a constant speed geodesic connecting and in the metric space . Proof of the previous theorem can be found in
Section 7.5. In a sense, this result combines the geodesics in the Wasserstein space and in the space of all mm-spaces, since it suffices to interpolate the distances in the structure space and the features to construct a geodesic. The main interest is that it defines the minimum path between two structured objects. For example, when considering two discrete structured objects represented by the measures
and
, the interpolation path is given for
by the measure
where
is an optimal coupling for the
distance. However this geodesic is difficult to handle in practice, since it requires the computation of the cartesian product
. To overcome this obstacle, an extension using theFréchet mean is defined in
Section 4.2. The proper definition and properties of velocity fields associated to this geodesic is postponed to further works.
6. Conclusions
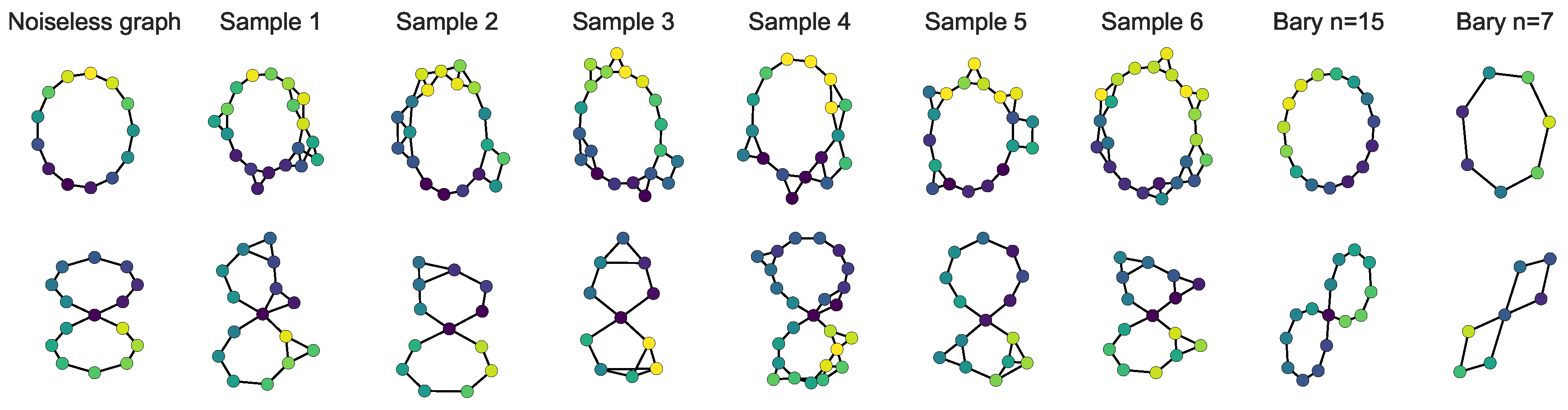
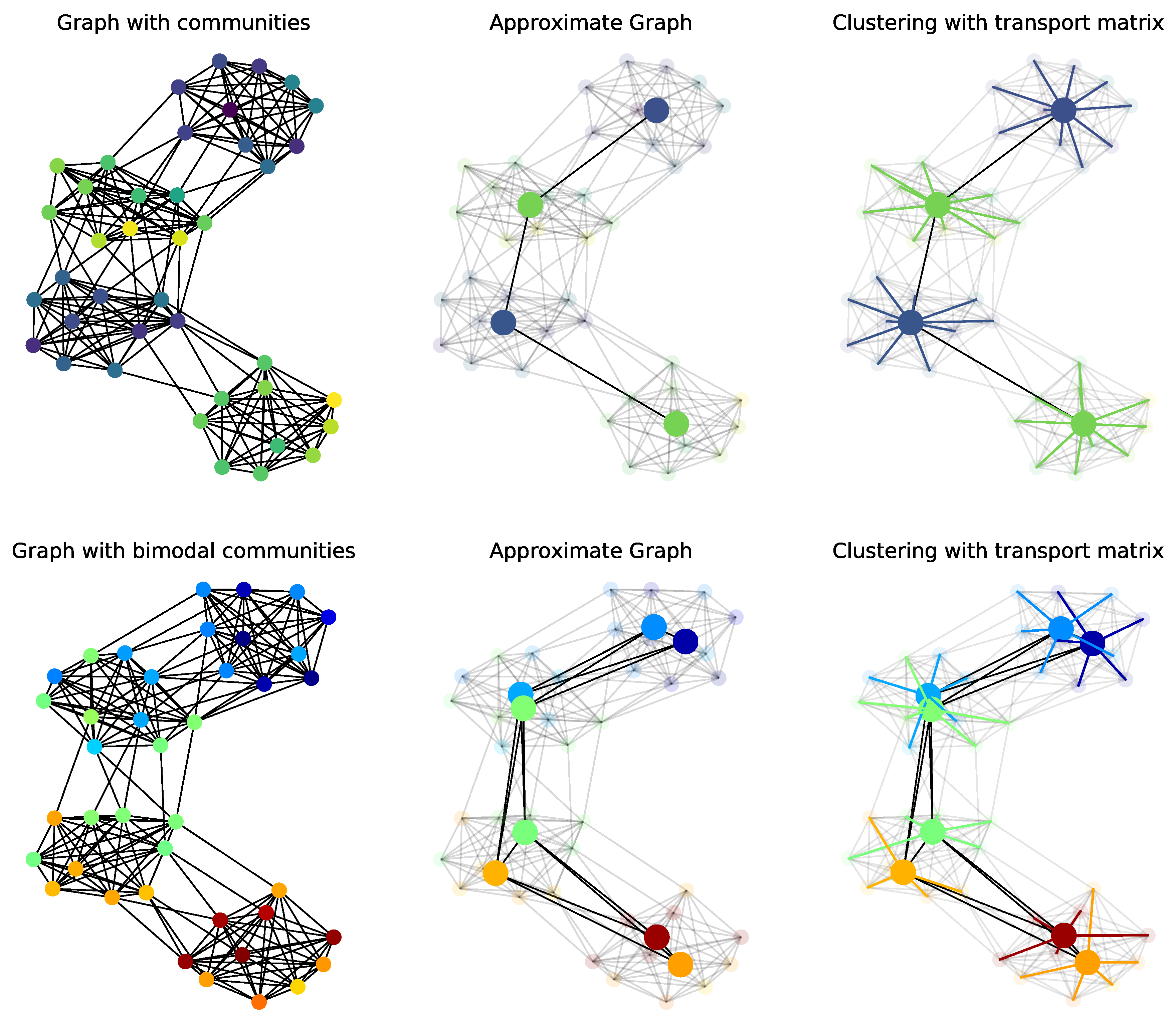
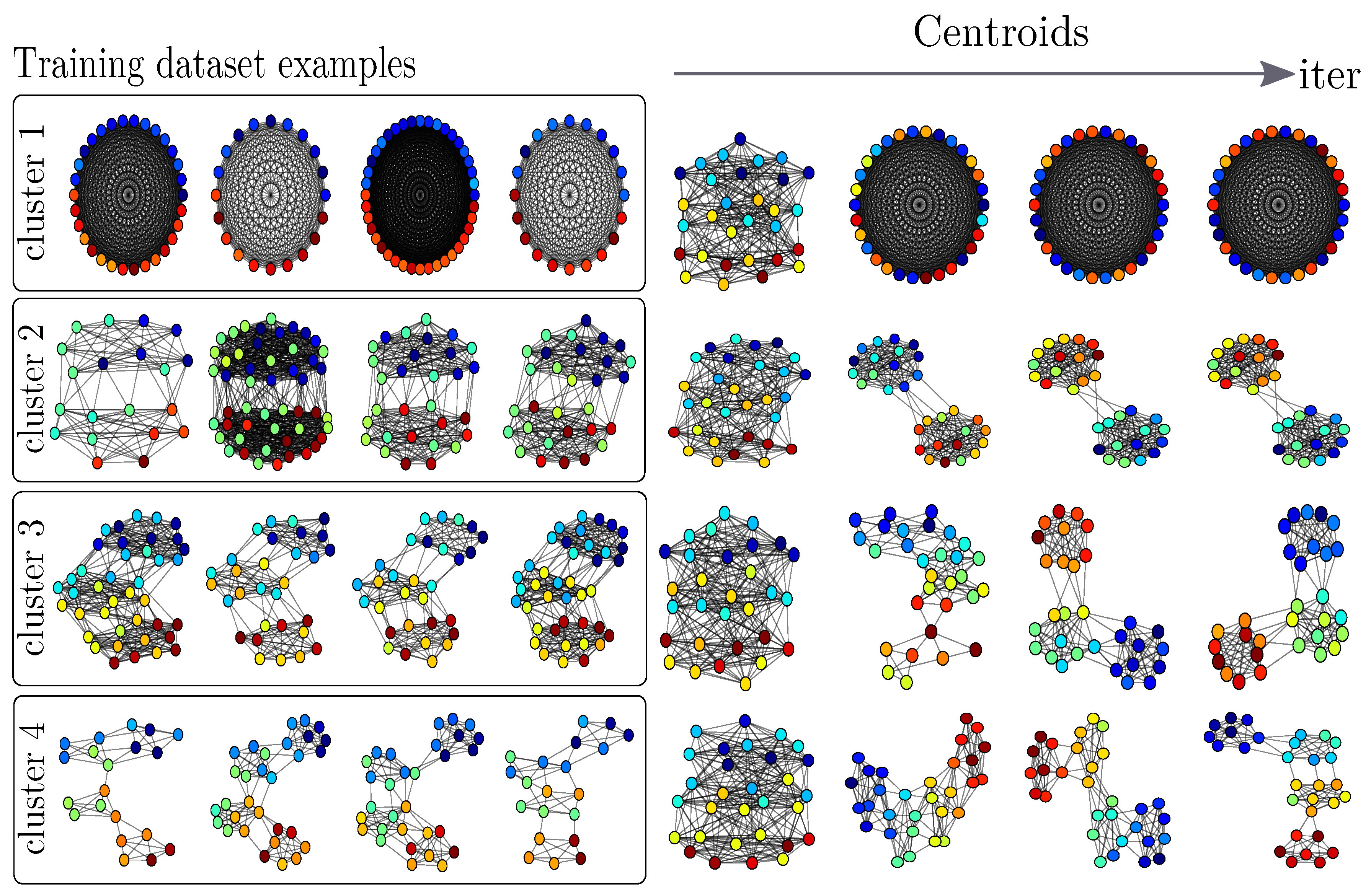
This paper presents the Fused Gromov–Wasserstein () distance. Inspired by both Wasserstein and Gromov–Wasserstein distances, can compare structured objects by including the inherent relations that exist between the elements of the objects, constituting their structure information, and their feature information, part of a common ground space between each structured objects. We have stated mathematical results about this new distance, such as metric, interpolation, and geodesic properties. We have also provided a concentration result for the convergence of finite samples. In the discrete case, algorithms to compute itself and related Fréchet means are provided. The use of this new distance is illustrated on problems involving structured objects, such as time series embedding, graph classification, graph barycenter computation, and graph clustering. Several questions are raised by this work. From a practical side, the FGW method is quite expensive to compute and further works will try to lower the computational complexity of the underlying optimization problem to ensure better scalability to very large graphs. Moreover, while we mostly consider in this work structure of graphs described by the shortest path, other choices could be made, such as the distances based on the Laplacian of the graph. Finally, from a theoretical point of view, it is often valuable that the geodesic path be unique, so as to defined properly objects, such as gradient flows. One interesting result would be, for example, to see if the geodesic is unique with respect to the strong isomorphism relation.

















{kind=link}
{kind=link}
{kind=link}
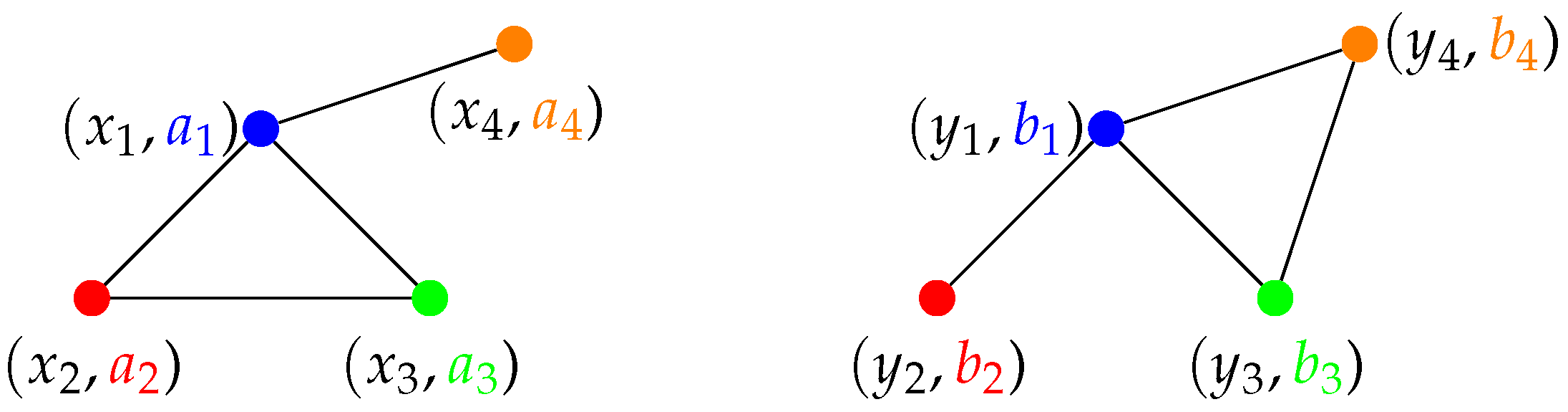{kind=link}
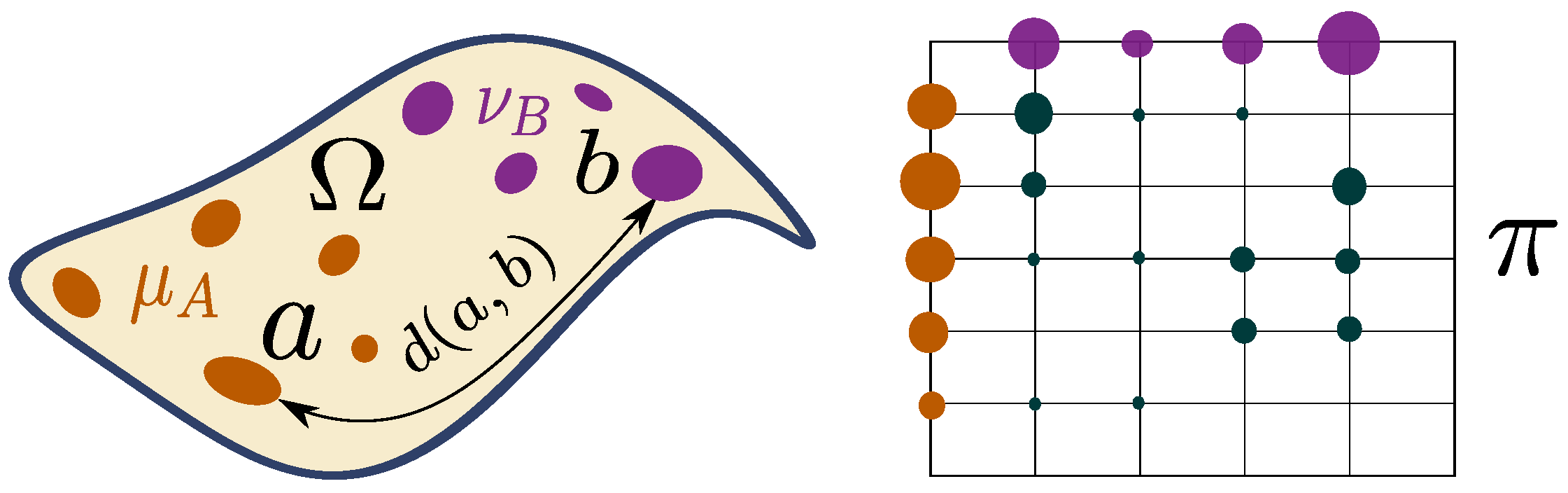{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}