A Dynamic Clause Specific Initial Weight Assignment for Solving Satisfiability Problems Using Local Search



Abstract
:1. Introduction
2. Preliminaries
3. Clause Weight in SLS
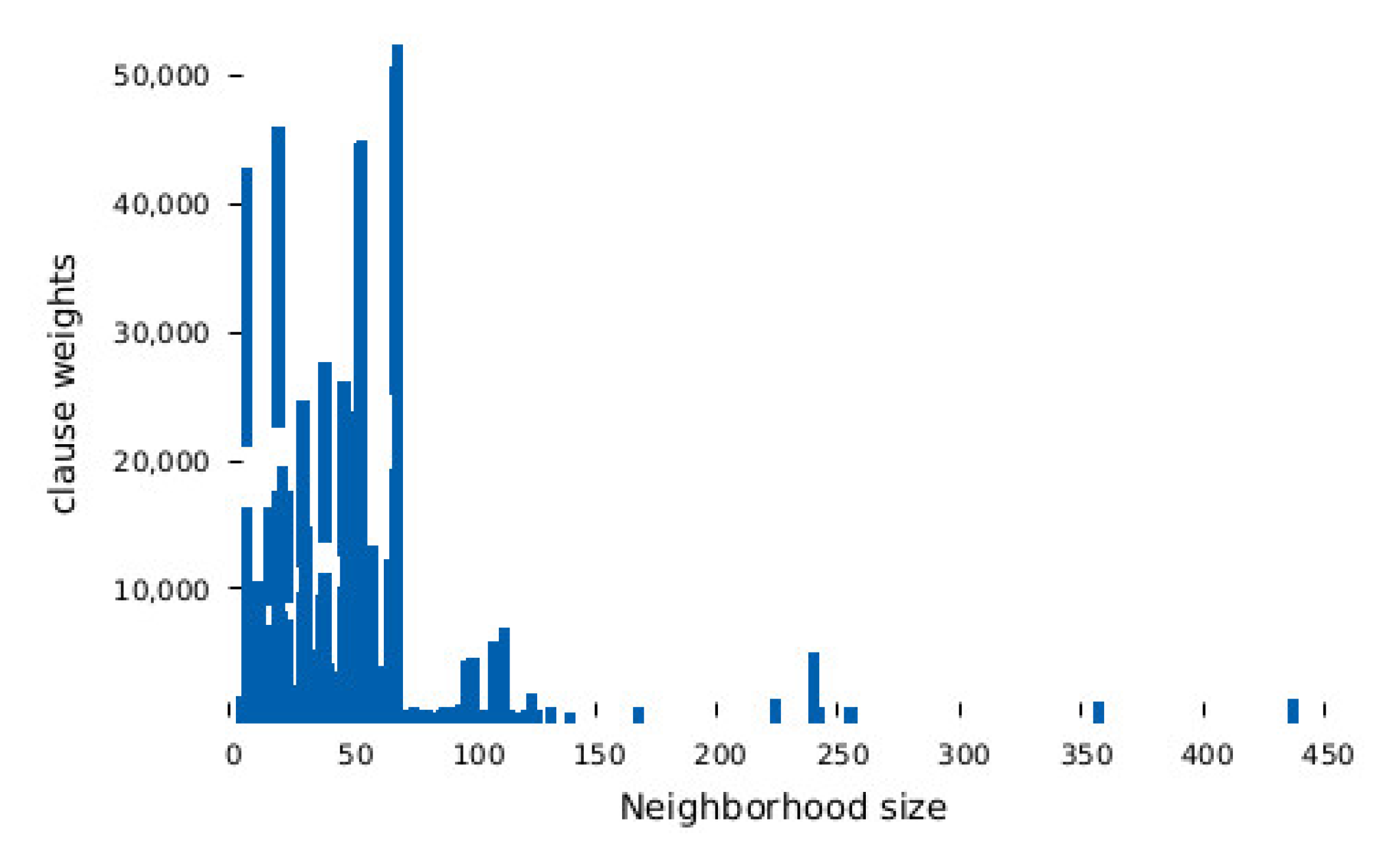
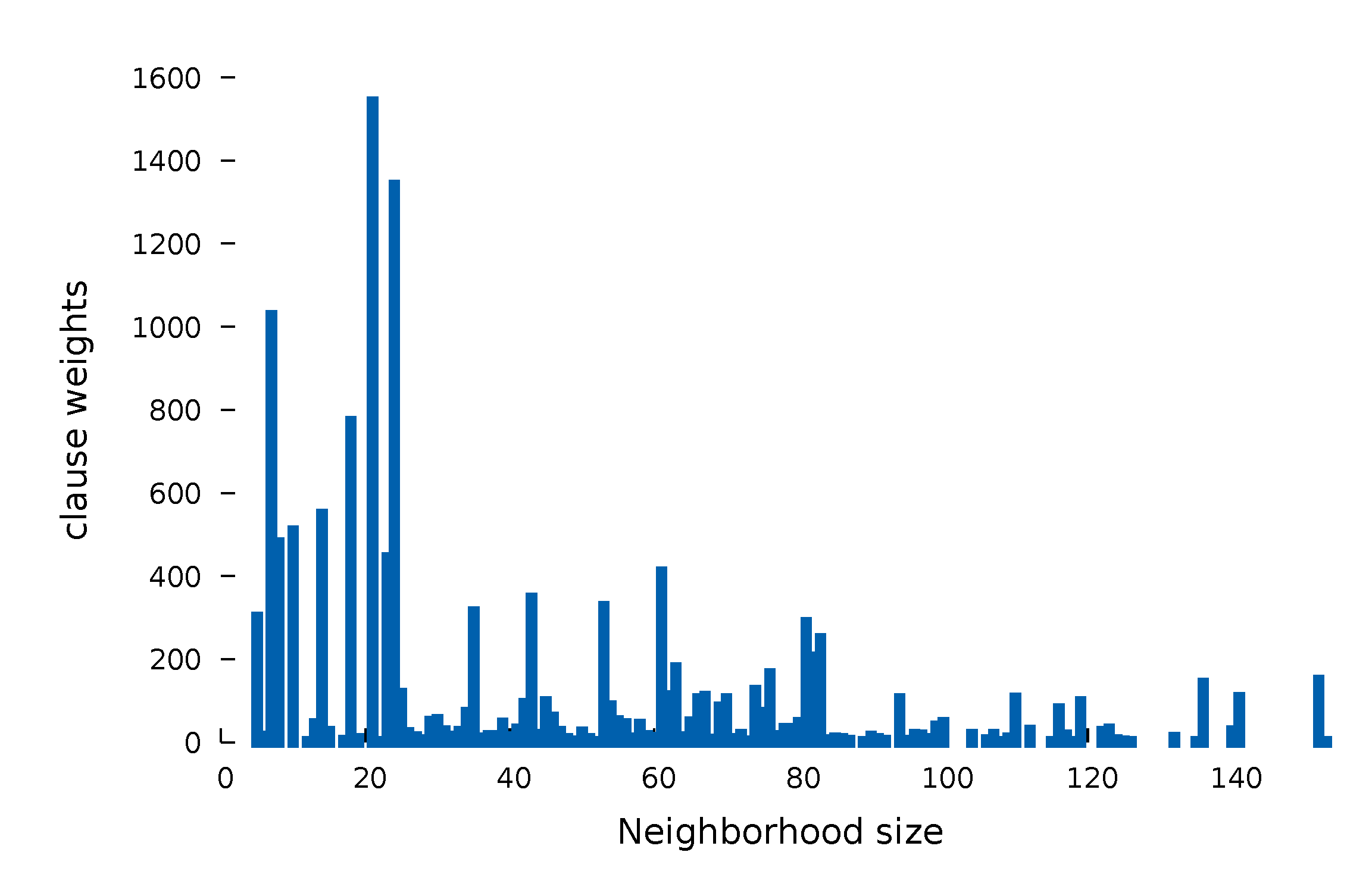
3.1. Assessment of the Initial Weight Distribution and Its Impact
- a small clause in a small neighborhood
- a small clause in a large neighborhood
- a large clause in a small neighborhood
- a large clause in a large neighborhood
4. The Dynamic Initial Weights Assignment in SLS
| Algorithm 1 DDFW() + DynamicInitWeight. |
|
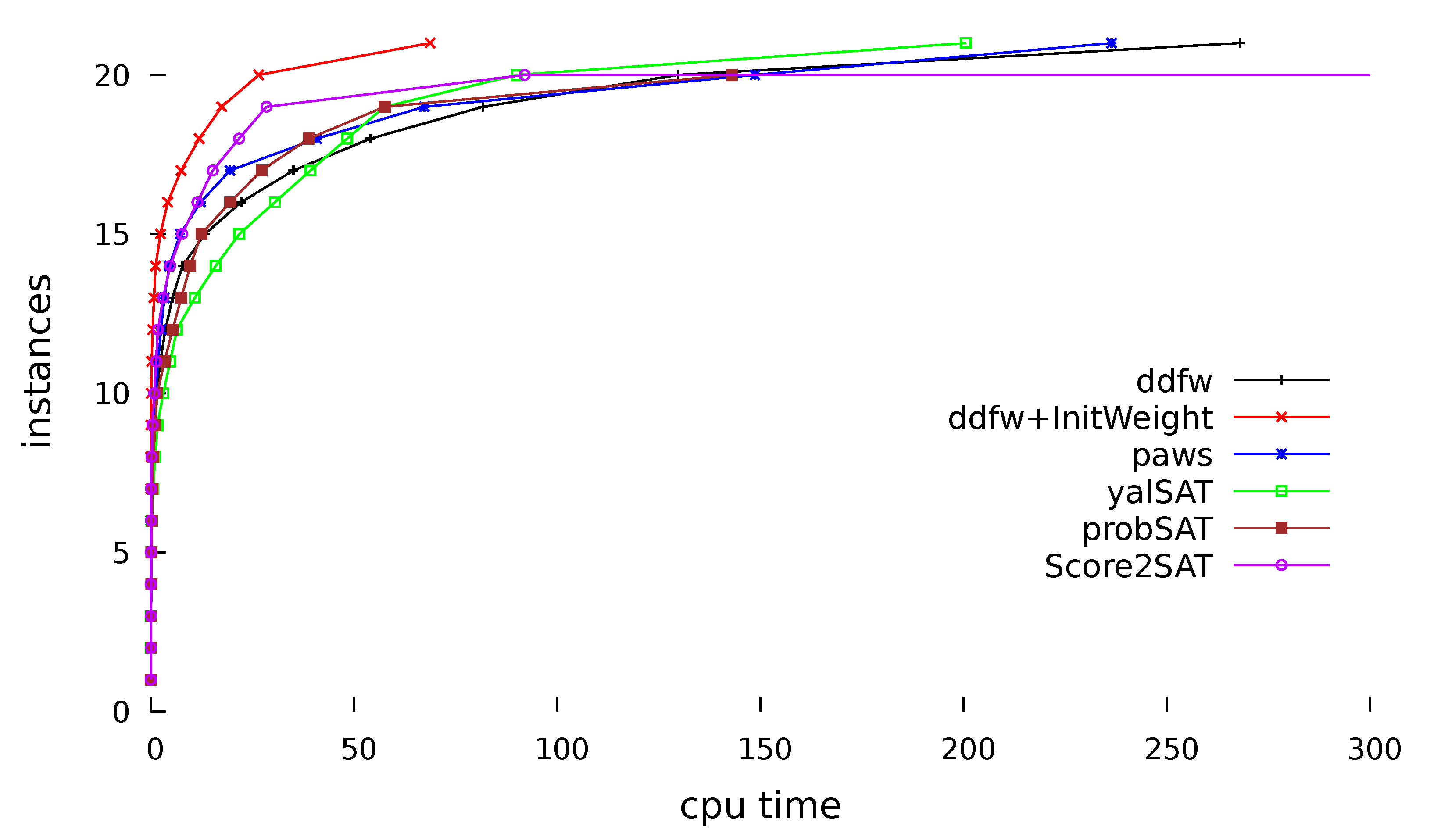
5. Experimental Results and Analyses
- small problems that are hard to solve, i.e., flat200-hard
- small problems that are easy to solve, i.e., BMS-499
- large problems that are hard to solve, i.e., bw_large.d
- large problems that are easy to solve, i.e., g125.18
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Bianchi, L.; Dorigo, M.; Gambardella, L.M.; Gutjahr, W.J. A Survey on Metaheuristics for Stochastic Combinatorial Optimization. Nat. Comput. Int. J. 2009, 8, 239–287. [Google Scholar] [CrossRef] [Green Version]
- Slowik, A.; Kwasnicka, H. Nature Inspired Methods and Their Industry Applications-Swarm Intelligence Algorithms. IEEE Trans. Ind. Inform. 2018, 14, 1004–1015. [Google Scholar] [CrossRef]
- Umamaheswari, H.A.K. A bio-inspired swarm intelligence technique for social aware cognitive radio handovers. Comput. Electr. Eng. 2018, 925–937. [Google Scholar] [CrossRef]
- Dorigo, M.; Stützle, T. Ant Colony Optimization; Bradford Company: Holland, MI, USA, 2004. [Google Scholar]
- Eiben, A.E.; Raué, P.E.; Ruttkay, Z. Genetic Algorithms with Multi-Parent Recombination. In Proceedings of the International Conference on Evolutionary Computation, The Third Conference on Parallel Problem Solving from Nature: Parallel Problem Solving from Nature, Erusalem, Israel, 9–14 October 1994; Springer: Berlin/Heidelberg, Germany, 1994; pp. 78–87. [Google Scholar]
- Patanella, D. Darwin’s Theory of Natural Selection. In Encyclopedia of Child Behavior and Development; Goldstein, S., Naglieri, J.A., Eds.; Springer: Boston, MA, USA, 2011; pp. 461–463. [Google Scholar] [CrossRef]
- Effatparvar, M.; Aghayi, S.; Asadzadeh, V.; Dashti, Y. Swarm Intelligence Algorithm for Job Scheduling in Computational Grid. In Proceedings of the 2016 7th International Conference on Intelligent Systems, Modelling and Simulation (ISMS), Bangkok, Thailand, 25–27 January 2016; pp. 315–317. [Google Scholar] [CrossRef]
- Dulebenets, M.A. Application of Evolutionary Computation for Berth Scheduling at Marine Container Terminals: Parameter Tuning Versus Parameter Control. IEEE Trans. Intell. Transp. Syst. 2018, 19, 25–37. [Google Scholar] [CrossRef]
- Pasha, J.; Dulebenets, M.A.; Kavoosi, M.; Abioye, O.F.; Wang, H.; Guo, W. An Optimization Model and Solution Algorithms for the Vehicle Routing Problem With a “Factory-in-a-Box”. IEEE Access 2020, 8, 134743–134763. [Google Scholar] [CrossRef]
- Cook, S.A. The Complexity of Theorem-proving Procedures. In Proceedings of the Third Annual ACM Symposium on Theory of Computing, Shaker Heights, OH, USA, 3–5 May 1971; ACM: New York, NY, USA, 1971; pp. 151–158. [Google Scholar] [CrossRef] [Green Version]
- Hoos, H.H.; Stützle, T. Local Search Algorithms for SAT: An Empirical Evaluation. J. Autom. Reason. 2000, 24, 421–481. [Google Scholar] [CrossRef]
- Kautz, H.A.; Sabharwal, A.; Selman, B. Incomplete Algorithms. In Handbook of Satisfiability; Biere, A., Heule, M., van Maaren, H., Walsh, T., Eds.; Frontiers in Artificial Intelligence and Applications; IOS Press: Amsterdam, The Netherland, 2009; Volume 185, pp. 185–203. [Google Scholar] [CrossRef]
- Lin, S.; Kernighan, B.W. An Effective Heuristic Algorithm for the Traveling-Salesman Problem. Oper. Res. 1973, 21, 498–516. [Google Scholar] [CrossRef]
- Minton, S.; Johnston, M.D.; Philips, A.B.; Laird, P. Solving Large-scale Constraint Satisfaction and Scheduling Problems Using a Heuristic Repair Method. In Proceedings of the Eighth National Conference on Artificial Intelligence, Boston, MA, USA, 29 July–3 August 1990; Volume 1, pp. 17–24. [Google Scholar]
- Selman, B.; Kautz, H.A.; Cohen, B. Noise Strategies for Improving Local Search. In Proceedings of the Twelfth National Conference on Artificial Intelligence, American Association for Artificial Intelligence, Seattle, WA, USA, 31 July–4 August 1994; Volume 1, pp. 337–343. [Google Scholar]
- Dechter, R. Enhancement schemes for constraint processing: Backjumping, learning, and cutset decomposition. Artif. Intell. 1990, 273–312. [Google Scholar] [CrossRef]
- Selman, B.; Levesque, H.; Mitchell, D. A New Method for Solving Hard Satisfiability Problems. In Proceedings of the 10th AAAI, San Jose, CA, USA, 12–16 July 1992; pp. 440–446. [Google Scholar]
- Johnson, D.S.; Aragon, C.R.; McGeoch, L.A.; Schevon, C. Optimization by Simulated Annealing: An Experimental Evaluation; Part II, Graph Coloring and Number Partitioning. Oper. Res. 1991, 39, 37–406. [Google Scholar] [CrossRef]
- Černý, V. Thermodynamical approach to the traveling salesman problem: An efficient simulation algorithm. J. Optim. Theory Appl. 1985, 45, 41–51. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.; Vecchi, M. Optimization by Simulated Annealing. In Readings in Computer Vision; Fischler, M.A., Firschein, O., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 1987; pp. 606–615. [Google Scholar] [CrossRef]
- Selman, B.; Kautz, H. Domain-Independent Extensions to GSAT: Solving Large Structured Satisfiability Problems. In Proceedings of the 13th International Joint Conference on Artificial Intelligence, San Mateo, CA, USA, 1–3 June 1993; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1993; Volume 1, pp. 290–295. [Google Scholar]
- Morris, P. The Breakout Method for Escaping from Local Minima. In Proceedings of the Eleventh National Conference on Artificial Intelligence, Washington, DC, USA, 11–15 July 1993; pp. 40–45. [Google Scholar]
- Thornton, J.; Pham, D.N.; Bain, S.; Ferreira, V. Additive versus Multiplicative Clause Weighting for SAT. In Proceedings of the 19th National Conference on Artificial Intelligence, San Jose, CA, USA, 25–29 July 2004; pp. 191–196. [Google Scholar]
- Hutter, F.; Tompkins, D.A.D.; Hoos, H.H. Scaling and Probabilistic Smoothing: Efficient Dynamic Local Search for SAT. In Principles and Practice of Constraint Programming—CP 2002; Van Hentenryck, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 233–248. [Google Scholar]
- Glover, F. Tabu Search—Part I. ORSA J. Comput. 1989, 1, 190–206. [Google Scholar] [CrossRef]
- Glover, F. Future paths for integer programming and links to artificial intelligence. Comput. Oper. Res. 1986, 13, 533–549. [Google Scholar] [CrossRef]
- Glover, F. Heuristics for Integer Programming Using Surrogate Constraints. Decis. Sci. 1977, 8, 156–166. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989. [Google Scholar]
- Amin, S.; Fernandez-Villacanas, J.L. Dynamic local search. In Proceedings of the Second International Conference On Genetic Algorithms in Engineering Systems, Innovations and Applications, Glasgow, UK, 2–4 September 1997; pp. 129–132. [Google Scholar]
- Wu, Z.; Wah, B.W. An Efficient Global-Search Strategy in Discrete Lagrangian Methods for Solving Hard Satisfiability Problems. In Proceedings of the Seventeenth National Conference on Artificial Intelligence and Twelfth Conference on Innovative Applications of Artificial Intelligence, Austin, TX, USA, 30 July–3 August 2000; pp. 310–315. [Google Scholar]
- Feo, T.A.; Resende, M.G.C. A Probabilistic Heuristic for a Computationally Difficult Set Covering Problem. Oper. Res. Lett. 1989, 8, 67–71. [Google Scholar] [CrossRef]
- Lourenço, H.R.; Martin, O.C.; Stützle, T. Iterated Local Search: Framework and Applications. In Handbook of Metaheuristics; Springer: Boston, MA, USA, 2010; pp. 363–397. [Google Scholar] [CrossRef]
- KhudaBukhsh, A.R.; Xu, L.; Hoos, H.H.; Leyton-Brown, K. SATenstein: Automatically Building Local Search SAT Solvers from Components. In Proceedings of the 21st International Jont Conference on Artifical Intelligence, San Francisco, CA, USA, 11–17 July 2009; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2009; pp. 517–524. [Google Scholar]
- Ishtaiwi, A.; Thornton, J.; Sattar, A.; Pham, D.N. Neighbourhood Clause Weight Redistribution in Local Search for SAT. In Principles and Practice of Constraint Programming—CP 2005; van Beek, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 772–776. [Google Scholar]
- Hoos, H.H.; Stützle, T. Stochastic Local Search Algorithms: An Overview. In Springer Handbook of Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2015; pp. 1085–1105. [Google Scholar] [CrossRef]
- Ishtaiwi, A.; Issa, G.; Hadi, W.; Nawaf, A. Weight Resets in Local Search for SAT. Int. J. Mach. Learn. Comput. 2019, 9, 874–879. [Google Scholar] [CrossRef]
- Luo, C.; Cai, S.; Wu, W.; Su, K. Double Configuration Checking in Stochastic Local Search for Satisfiability. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; pp. 2703–2709. [Google Scholar]
- Luo, C.; Cai, S.; Su, K.; Wu, W. Clause States Based Configuration Checking in Local Search for Satisfiability. IEEE Trans. Cybern. 2015, 45, 1014–1027. [Google Scholar] [CrossRef] [PubMed]
- Sinz, C.; Egly, U. (Eds.) Theory and Applications of Satisfiability Testing—SAT 2014—17th International Conference, Held as Part of the Vienna Summer of Logic, VSL 2014, Vienna, Austria, 14–17 July 2014, Proceedings; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8561. [Google Scholar] [CrossRef] [Green Version]
- Gaspers, S.; Walsh, T. (Eds.) Theory and Applications of Satisfiability Testing—SAT 2017—20th International Conference, Melbourne, VIC, Australia, 28 August–1 September 2017, Proceedings; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10491. [Google Scholar] [CrossRef]
- Janota, M.; Lynce, I. (Eds.) Theory and Applications of Satisfiability Testing—SAT 2019. In Proceedings of the 22nd International Conference, SAT, Lisbon, Portugal, 9–12 July 2019; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2019; Volume 11628. [Google Scholar] [CrossRef]
- Pulina, L.; Seidl, M. (Eds.) Theory and Applications of Satisfiability Testing—SAT 2020. In Proceedings of the 23rd International Conference, Alghero, Italy, 3–10 July 2020; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2020; Volume 12178. [Google Scholar] [CrossRef]
- Balint, A.; Fröhlich, A. Improving Stochastic Local Search for SAT with a New Probability Distribution. In Proceedings of the 13th International Conference on Theory and Applications of Satisfiability Testing, Edinburgh, UK, 11–14 July 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 10–15. [Google Scholar] [CrossRef]
- Balint, A.; Schöning, U. Choosing Probability Distributions for Stochastic Local Search and the Role of Make versus Break. In Proceedings of the 15th International Conference on Theory and Applications of Satisfiability Testing, Trento, Italy, 17–20 June 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–29. [Google Scholar] [CrossRef]
- Hoos, H.H.; Stützle, T. SATLIB: An Online Resource for Research on SAT; IOS Press: Amsterdam, The Netherlands, 2000; pp. 283–292. [Google Scholar]
- Beyersdorff, O.; Wintersteiger, C.M. (Eds.) Theory and Applications of Satisfiability Testing—SAT 2018. In Proceedings of the 21st International Conference, SAT 2018, Held as Part of the Federated Logic Conference, FloC 2018, Oxford, UK, 9–12 July 2018; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2018; Volume 10929. [Google Scholar] [CrossRef]
- Schuurmans, D.; Southey, F.; Holte, R.C. The Exponentiated Subgradient Algorithm for Heuristic Boolean Programming. In Proceedings of the 17th International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; Volume 1, pp. 334–341. [Google Scholar]
- Schuurmans, D.; Southey, F. Local Search Characteristics of Incomplete SAT Procedures. Artif. Intell. 2001, 132, 121–150. [Google Scholar] [CrossRef] [Green Version]
- Gent, I.P.; Walsh, T. The SAT Phase Transition. In Proceedings of the ECAI-94, Amsterdam, The Netherlands, 8–12 August 1994; pp. 105–109. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Problems | nCl | MinN | MaxN | AvgN | sCl&sN | sCl&lN | lCl&sN | lCl&lN |
|---|---|---|---|---|---|---|---|---|
| 4blocks | 47,820 | 3 | 740 | 433 | 26,670 | 21,137 | 0 | 13 |
| ais12 | 5666 | 12 | 143 | 95 | 197 | 3672 | 11 | 12 |
| BMS-499 | 278 | 7 | 23 | 14 | 88 | 190 | 0 | 0 |
| bw_large.c | 50,457 | 5 | 465 | 69 | 38,780 | 11,636 | 23 | 18 |
| bw_large.d | 131,973 | 5 | 741 | 86 | 111,741 | 20,178 | 32 | 22 |
| CBS | 403 | 8 | 33 | 21 | 171 | 23 | 0 | 0 |
| f800-hard | 3440 | 9 | 37 | 22 | 1511 | 1929 | 0 | 0 |
| f1600-hard | 6880 | 8 | 41 | 22 | 3067 | 3813 | 0 | 0 |
| f2000 | 8500 | 7 | 41 | 22 | 3797 | 4703 | 0 | 0 |
| fla-barthel | 1720 | 10 | 39 | 22 | 724 | 996 | 0 | 0 |
| flat200-har | 2237 | 3 | 20 | 13 | 641 | 1596 | 0 | 0 |
| g125.17 | 66,272 | 17 | 149 | 125 | 31,042 | 35,105 | 0 | 125 |
| g125.18 | 70,163 | 18 | 149 | 125 | 32,868 | 37,170 | 0 | 125 |
| huge | 7054 | 5 | 171 | 63 | 3000 | 4037 | 7 | 10 |
| logistics.d | 21,991 | 5 | 235 | 26 | 11,317 | 8824 | 1325 | 525 |
| uf400-hard | 1700 | 9 | 38 | 22 | 768 | 932 | 0 | 0 |
| unif-k5-v200 | 4223 | 214 | 321 | 269 | 2081 | 2142 | 0 | 0 |
| unif-k7-v98 | 8603 | 1957 | 2327 | 2158 | 4179 | 4424 | 0 | 0 |
| unif-k7-v102 | 8955 | 2000 | 2328 | 2158 | 4466 | 4489 | 0 | 0 |
| Problems | nCls | MinClS | #MinClsS | MaxClS | #MaxClsS | AvgS | #AvgS |
|---|---|---|---|---|---|---|---|
| 4blocks | 47,820 | 2 | 9898 | 33 | 12 | 2 | 9896 |
| ais12 | 5666 | 2 | 4191 | 12 | 12 | 2 | 4189 |
| BMS-499 | 278 | 3 | 278 | 3 | 0 | 3 | 278 |
| bw-large.c | 50,457 | 2 | 37,493 | 16 | 17 | 2 | 37,491 |
| bw-large.d | 131,973 | 2 | 102,580 | 20 | 25 | 2 | 102,578 |
| CBS | 403 | 3 | 403 | 3 | 0 | 3 | 403 |
| f800-hard | 3440 | 3 | 3440 | 3 | 0 | 3 | 3440 |
| f1600-hard | 6880 | 3 | 6880 | 3 | 6880 | 3 | 6880 |
| f2000 | 8500 | 3 | 8500 | 3 | 8500 | 3 | 8500 |
| fla-barthel | 1720 | 3 | 1720 | 3 | 1720 | 3 | 1720 |
| flat200-har | 2237 | 2 | 2037 | 3 | 200 | 2 | 2037 |
| g125.17 | 66,272 | 2 | 66,147 | 17 | 125 | 2 | 66,145 |
| g125.18 | 70,163 | 2 | 70,038 | 18 | 125 | 2 | 70,036 |
| huge | 7054 | 2 | 5682 | 10 | 5 | 2 | 5681 |
| logistics.d | 21,991 | 2 | 19,647 | 16 | 7 | 2 | 19,645 |
| uf400-hard | 1700 | 3 | 1700 | 3 | 1700 | 3 | 1700 |
| unif-k5-v200 | 4223 | 5 | 4223 | 5 | 4223 | 5 | 4223 |
| unif-k7-v98 | 8603 | 7 | 8603 | 7 | 8603 | 7 | 8603 |
| unif-k7-v102 | 8955 | 7 | 8955 | 7 | 8955 | 7 | 8955 |
| Problems | ddfw | Paws | Yalsat | probSAT | ddfw+dynIniWeight | Score2SAT | Ratio |
|---|---|---|---|---|---|---|---|
| 4blocks.cn | 8.71 | 2.67 | 1.67 | 0.28 | 0.45 | 0.51 | 19 |
| ais12.cnf | 0.65 | 0.10 | 1.66 | 7.10 | 0.09 | 0.02 | 7.2 |
| BMS-499 | 0.17 | 0.04 | 0.00 | 0.06 | 0.00 | 0.00 | ≈20 |
| bw_large.c | 0.00 | 0.63 | 5.81 | 1.99 | 0.00 | 0.25 | n/a |
| bw_large.d | 0.19 | 1.22 | 9.22 | 7.71 | 0.09 | 1.7 | 2.1 |
| CBS | 0.04 | 0.10 | 0.04 | 0.03 | 0.00 | 0.00 | ≈4 |
| f800-hard | 0.56 | 0.46 | 1.47 | 0.47 | 0.13 | 2.94 | 4.3 |
| f1600-hard | 6.15 | 5.02 | 5.18 | 2.74 | 0.52 | 3.79 | 11.8 |
| f2000 | 3.92 | 87.80 | 0.56 | 0.42 | 0.95 | 6.45 | 4.1 |
| fla-barthe | 0.23 | 0.12 | 0.41 | 0.10 | 0.07 | 0.09 | 3.3 |
| flat200-har | 0.30 | 0.83 | 8.72 | 1.82 | 0.03 | timed out | 10 |
| g125.17.cn | 0.55 | 0.02 | 8.75 | timed out | 0.09 | 3.57 | 6.1 |
| g125.18.cn | 0.02 | 0.02 | 0.02 | 11.67 | 0.01 | 0.45 | 2 |
| huge.cnf | 0.17 | 0.02 | 0.01 | 0.00 | 0.00 | 0.00 | ≈17 |
| logistics. | 0.00 | 7.25 | 0.52 | 0.07 | 0.00 | 0.03 | n/a |
| uf400-hard | 3.13 | 0.72 | 9.01 | 2.12 | 0.73 | 0.41 | 4.3 |
| unif-k5-v200 | 3.34 | 21.30 | 4.37 | 2.20 | 0.65 | 1.28 | 5.1 |
| unif-k7-v98 | 20.30 | 26.50 | 32.55 | 18.66 | 4.56 | 6.76 | 4.5 |
| unif-k7-v102 | 90.25 | 81.30 | 110.51 | 85.46 | 42.15 | 63.51 | 2.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ishtaiwi, A.; Alshahwan, F.; Jamal, N.; Hadi, W.; AbuArqoub, M. A Dynamic Clause Specific Initial Weight Assignment for Solving Satisfiability Problems Using Local Search. Algorithms 2021, 14, 12. https://doi.org/10.3390/a14010012
Ishtaiwi A, Alshahwan F, Jamal N, Hadi W, AbuArqoub M. A Dynamic Clause Specific Initial Weight Assignment for Solving Satisfiability Problems Using Local Search. Algorithms. 2021; 14(1):12. https://doi.org/10.3390/a14010012
Chicago/Turabian StyleIshtaiwi, Abdelraouf, Feda Alshahwan, Naser Jamal, Wael Hadi, and Muhammad AbuArqoub. 2021. "A Dynamic Clause Specific Initial Weight Assignment for Solving Satisfiability Problems Using Local Search" Algorithms 14, no. 1: 12. https://doi.org/10.3390/a14010012
APA StyleIshtaiwi, A., Alshahwan, F., Jamal, N., Hadi, W., & AbuArqoub, M. (2021). A Dynamic Clause Specific Initial Weight Assignment for Solving Satisfiability Problems Using Local Search. Algorithms, 14(1), 12. https://doi.org/10.3390/a14010012