
SENSE: A Flow-Down Semantics-Based Requirements Engineering Framework




Abstract
:1. Introduction
- (a)
- the establishment of integrated sets of boilerplates, namely standardized expressions of natural language with well-defined semantics;
- (b)
- the proposal of the most appropriate standard expressions (boilerplates) for the systematization of a given requirement in natural language, based on the type of requirement (e.g., functional, performance, interfaces, design constraints, etc.), the type of system, the framework in which it is included, as well as an interactive process that takes into account the semantic distance between the requirements in the natural language and the standard expressions and proposes appropriate conversions;
- (c)
- the proposal of systematic checks to verify the validity and completeness of the requirements, based on the boilerplate used, the type of requirement, the type of system, and the framework in which it is included.
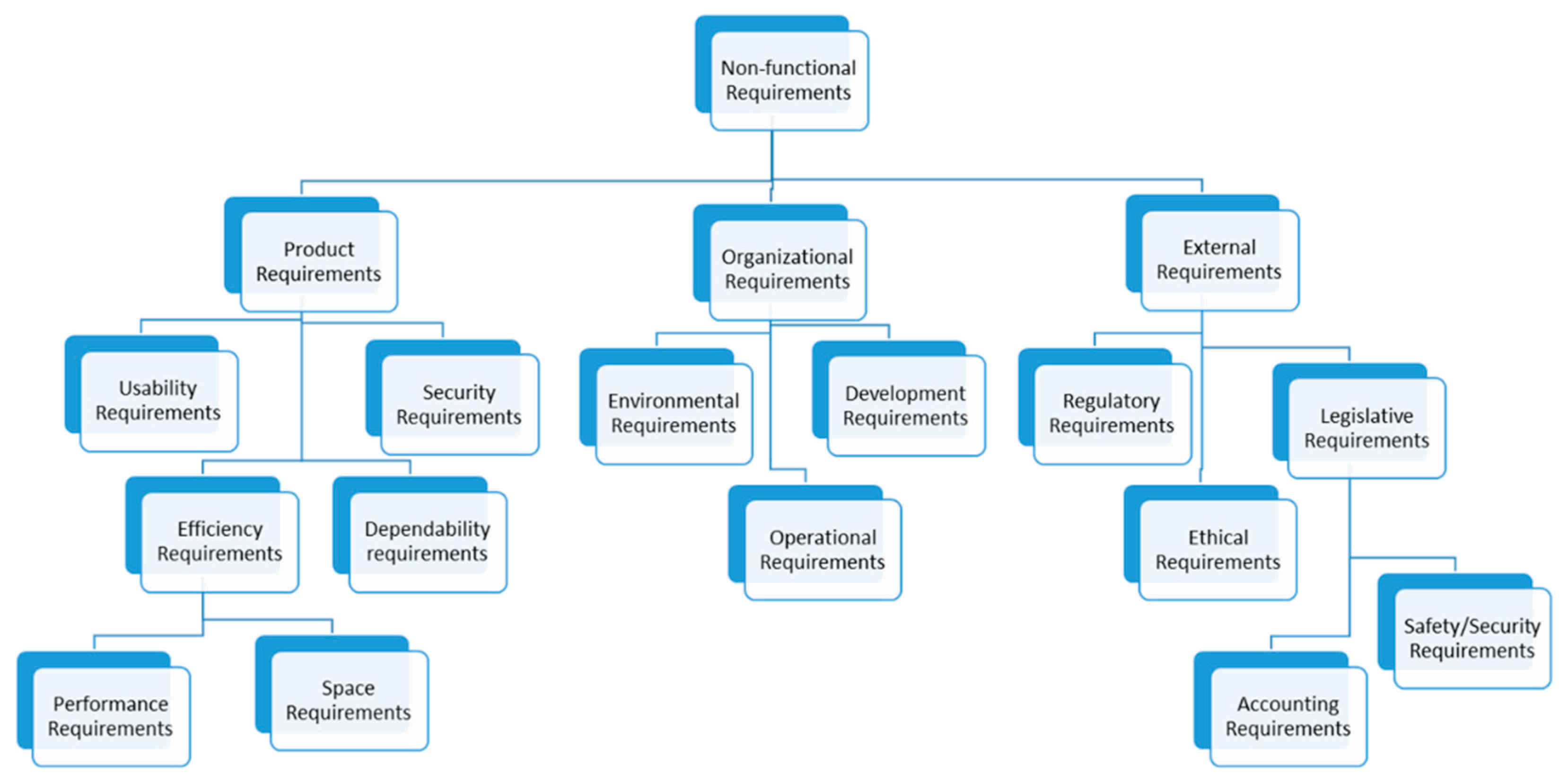
2. Requirements, Properties, and Taxonomies
3. SENSE Methodology
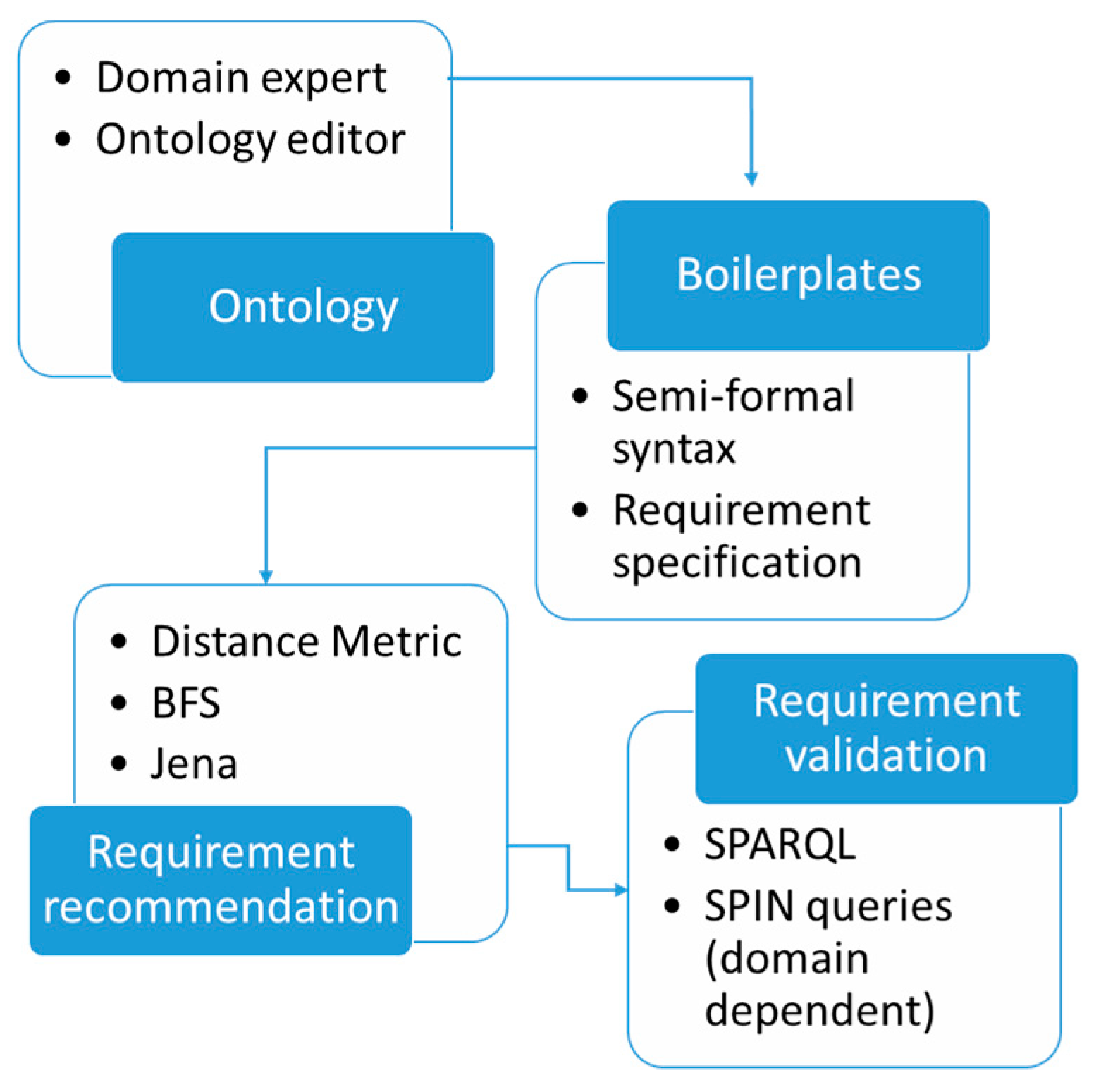
3.1. SENSE Abstract Architecture
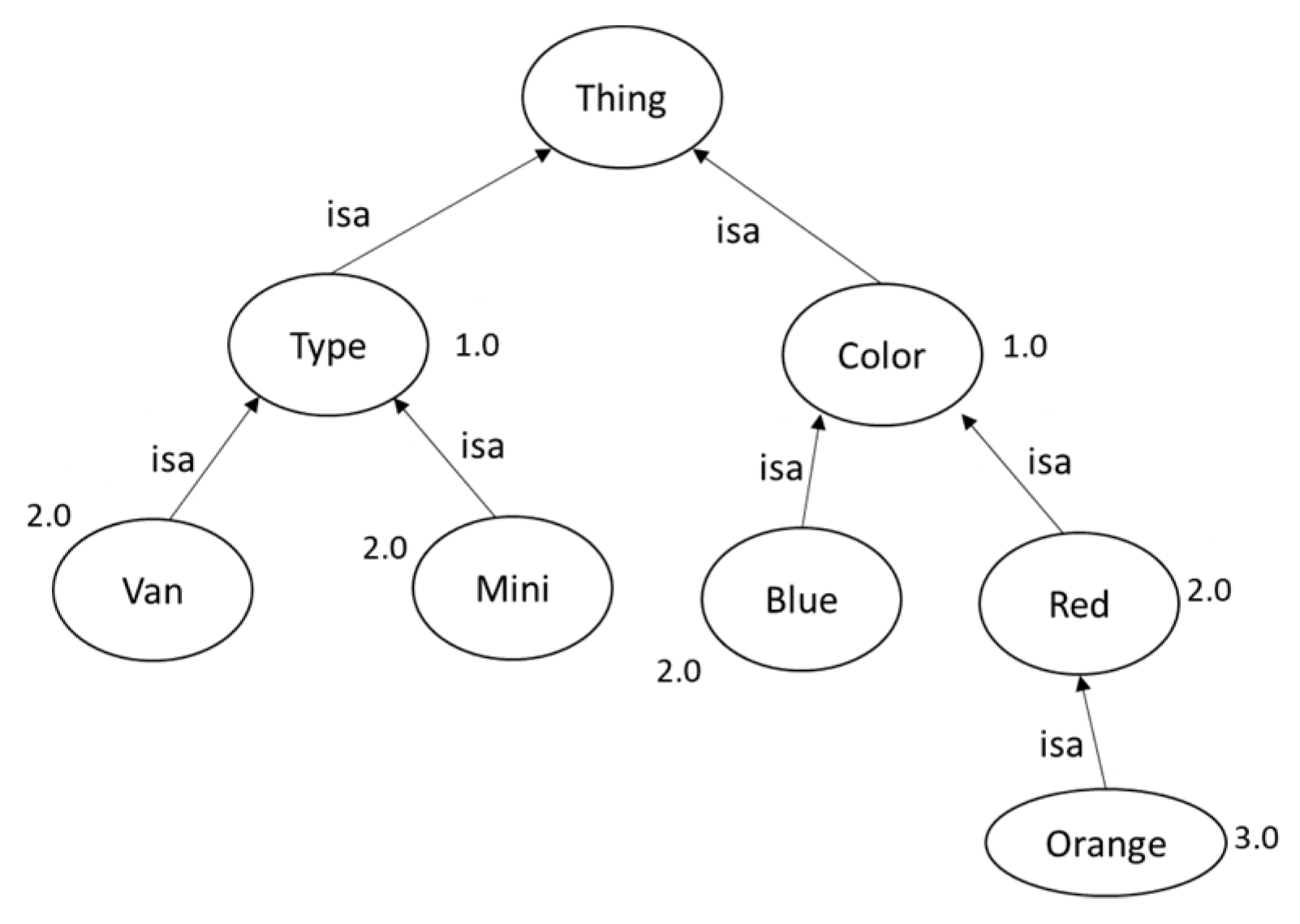
3.2. Ontologies
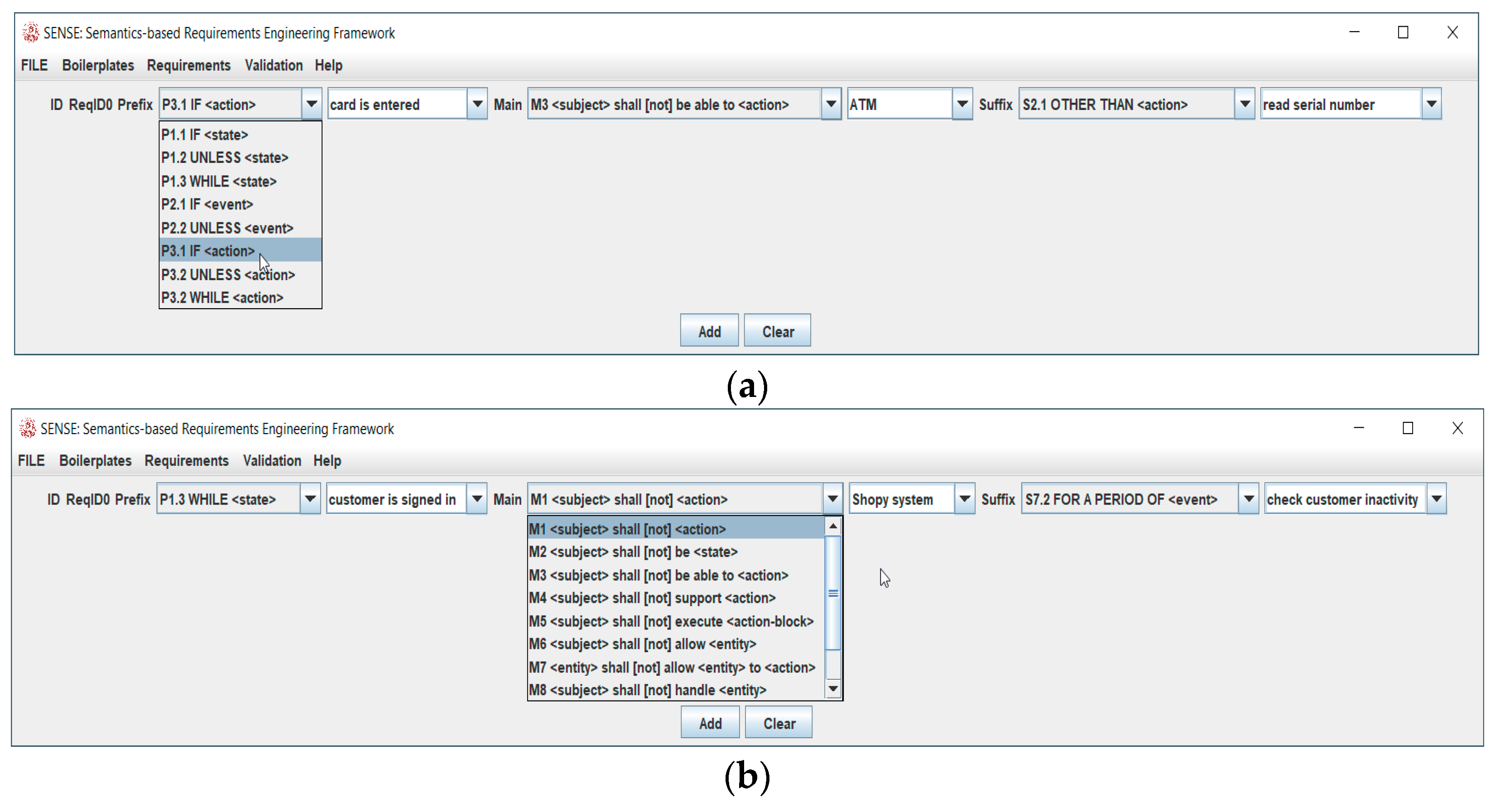
3.3. Form and Language Standardization
3.4. Boilerplates and Recommendations
| Algorithm 1. BFS_RDF_JENA. |
| BFS_RDF_Jena List <List<Resource>> BFS(model, <List<Resource>> queue, depth ) Initialize List <List<Resource>> results while queue is not empty{ set queue to List<Resource> path add results to path if (path size < depth) { Resource last = get path size minus 1 Model list Statements ( RDFS.subClassOf, last ) while (stmt has Next) { set List<Resource> extPath <> path get Subject as Resource (stmt next) and add to extPath queue offer extPath} return results |
3.5. Validity/Completeness Checks
- Check incompleteness requirements.
- Check for inconsistency requirements.
- Check the system model for deficiencies based on the requirements.
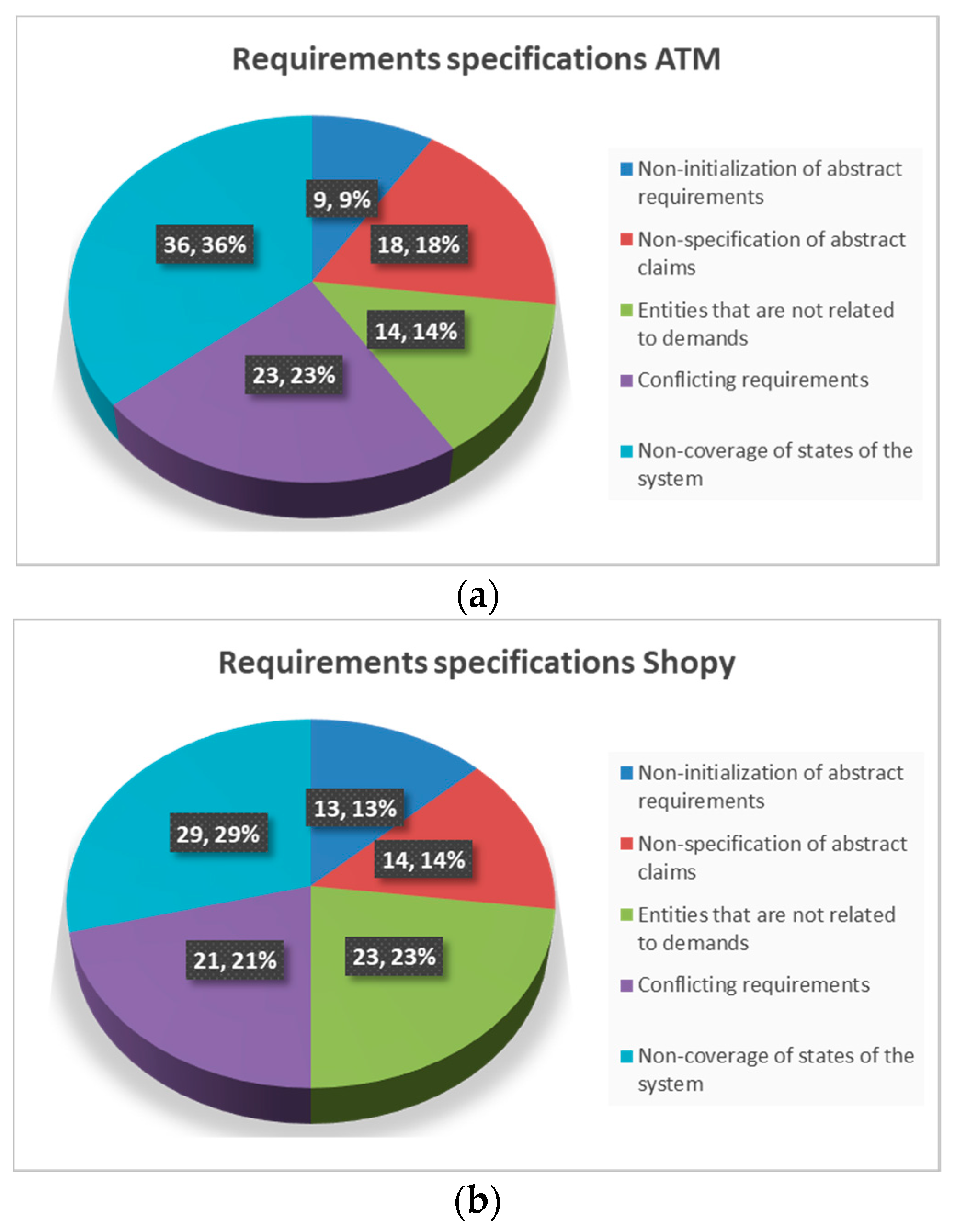
- Non-initialization of abstract requirements: This validation check discovers abstract requirements that are not initialized for each instance of its main entity.
- Non-specification of abstract claims: This check detects abstract requirements that are not specified, in other words that there are no instances of the abstract entity. This validation check is, in essence, an indication of an incomplete requirement.
- Entities that are not related to demands: This check will return all entities that do not have a requirement. Thus, it can be used as a deficit check, identifying entities that are not yet associated with a requirement or entities that have ceased to be used as not required by a requirement, possibly due to new requirements or revisions.
- Conflicting requirements: This check will return pairs of requirements that may conflict with each other.
- Non-coverage of states of the system: This check will return the states that are not covered by a requirement.
4. Testing System
5. Discussion
6. Related Work
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
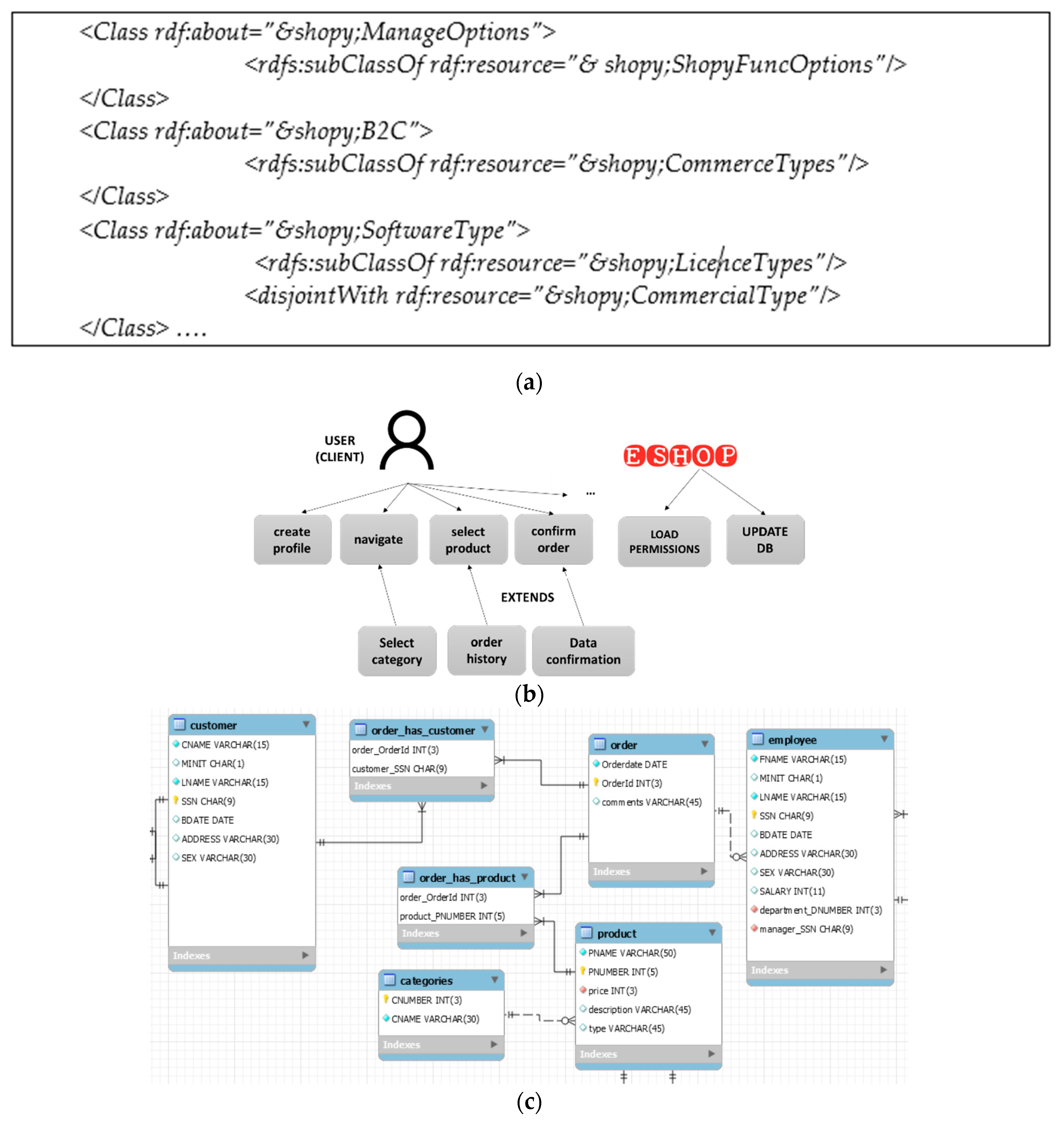
| Part of Shopy Requirements Specification |
| Functionality |
| Ordered and Sell Products |
| R1.1 The system shall allow user to select a product |
| R1.2 The system shall display all the available product properties |
| R1.3 The system shall allow user (staff) to update the configuration of a product. R1.4 The system shall allow user (staff) to confirm the configuration |
| Product Categorizations |
| R1.5 The system shall display product categorization to the user (staff and client) Customer Profile |
| R1.6 The system shall allow user (customer) to create profile |
| R1.7 The system shall authenticate user (customer) credentials |
| R1.8 The system shall allow user (customer) to update the profile |
| Shopping Cart Facilities |
| R1.9 The system shall optionally allow user to print invoice |
| R1.10 The system shall provide shopping cart etc. |
| Security |
| Data Transfer |
| R2.1 The system shall automatically log out customer after a period of inactivity |
| Data Storage |
| R2.2 The system’s databases shall be encrypted |
| R2.3 The system’s servers shall only be accessible to authenticated administrators, etc. |
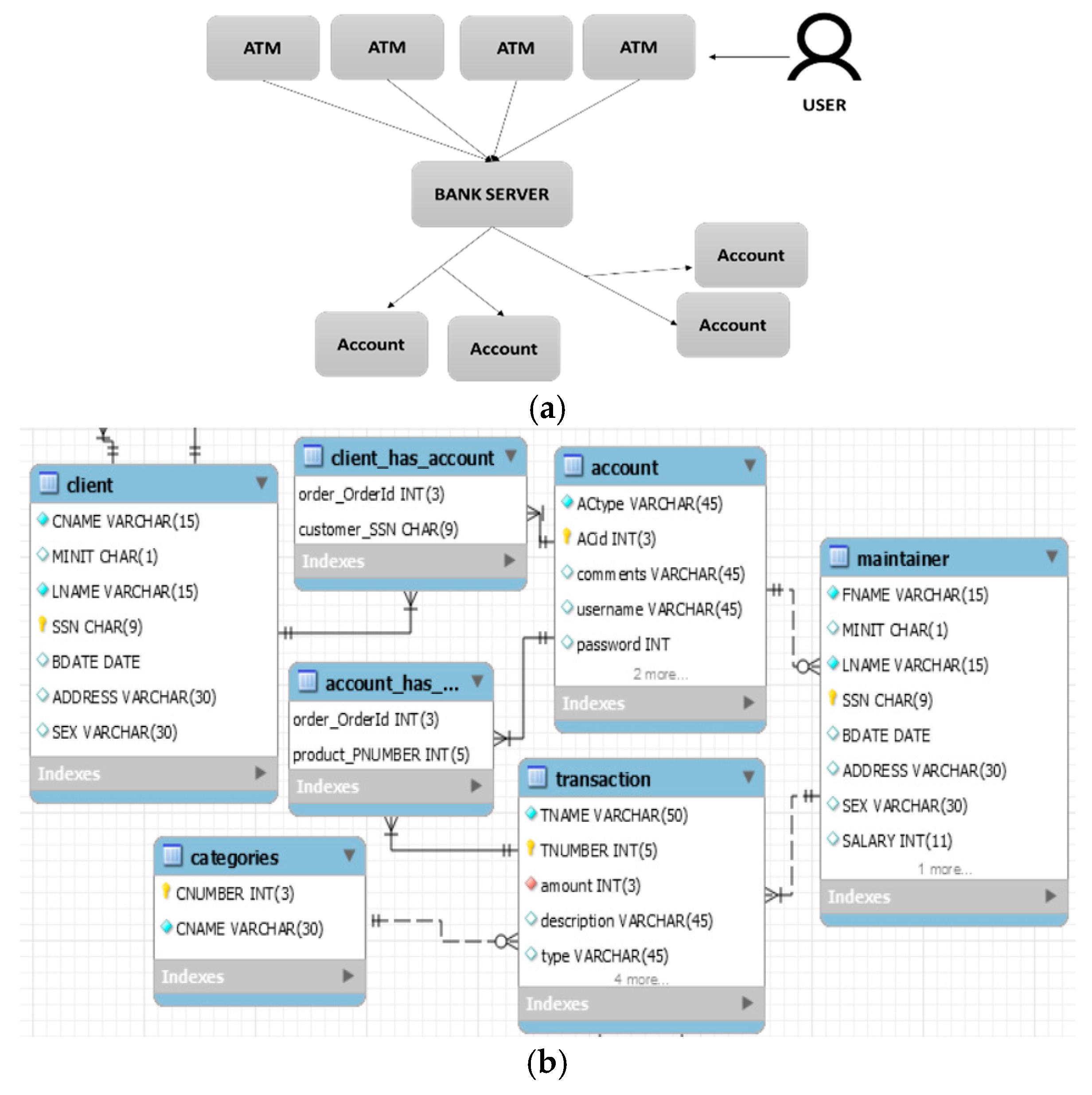
| Part of ATM Requirements Specification |
| Functionality |
| ATM Functionality |
| R1.1 The ATM has to check if the entered card is valid |
| R1.2 The ATM has to read the serial number of the card |
| R1.3 The ATM has to verify the bank code and password with the bank server |
| Client Options |
| R1.4 The client can abort a transaction |
| R1.5 The ATM also allows the client to clear off his/her bills |
| R1.6 A maintainer has the permission to suspend an account |
| Constraints |
| R2.1 The ATM must service at most one client at a time |
| R2.2 The maximum invalid pin entries is three, then the account is blocked |
| R2.3 The maximum amount of money a client can withdraw is 600€ per day |
| User Interface |
| R3.1 A screen will be provided for client to perform login |
| R3.2 A screen will be provided to display the other ATMs’ location |
References
- Suhaib, M. Conflicts Identification among Stakeholders in Goal Oriented Requirements Engineering Process. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 4926–4930. [Google Scholar] [CrossRef]
- Khan, H.U.; Niazi, M.; El-Attar, M.; Ikram, N.; Khan, S.U.; Gill, A.Q. Empirical Investigation of Critical Requirements Engineering Practices for Global Software Development. IEEE Access 2021, 9, 93593–93613. [Google Scholar] [CrossRef]
- Rajan, A.; Wahl, T. Requirements Engineering. In CESAR—Cost-Efficient Methods and Processes for Safety-Relevant Embedded Systems; Springer: Wien, Austria, 2013; pp. 69–143. [Google Scholar]
- Hull, E.; Jackson, K.; Dick, J. Writing and Reviewing Requirements. In Requirements Engineering; Springer Science & Business Media: London, UK, 2010; pp. 77–91. [Google Scholar]
- Liu, S.; Nakajima, S. Automatic Test Case and Test Oracle Generation based on Functional Scenarios in Formal Specifications for Conformance Testing. IEEE Trans. Softw. Eng. 2020, 1, 1. [Google Scholar] [CrossRef]
- Mazo, R.; Jaramillo, C.A.; Vallejo, P.; Medina, J. Towards a new template for the specification of requirements in semi-structured natural language. J. Softw. Eng. Res. Dev. Braz. Comput. Soc. 2020, 8, 3. [Google Scholar] [CrossRef] [Green Version]
- Barbosa, P.A.M.; Pinheiro, P.R.; De Vasconcelos Silveira, F.R. Towards the Verbal Decision Analysis Paradigm for Implementable Prioritization of Software Requirements. Algorithms 2018, 11, 176. [Google Scholar] [CrossRef] [Green Version]
- Darlan, A.; Ibtehal, N. A Validation Study of a Requirements Engineering Artefact Model for Big Data Software Development Projects. In Proceedings of the 14th International Conference on Software Technologies (ICSOFT 2019), Prague, Czech Republic, 26–28 July 2019. [Google Scholar] [CrossRef]
- Akbar, M.A.; Sang, J.; Khan, A.A.; Hussain, S. Investigation of the requirements change management challenges in the domain of global software development. J. Softw. Evol. Proc. 2019, 31, e2207. [Google Scholar] [CrossRef]
- Sommerville, I. Software Engineering, 10th ed.; Pearson: London, UK, 2015; ISBN 13-9780133943030. [Google Scholar]
- Pill, I.H. Requirements Engineering and Efficient Verification of PSL Properties. Ph.D. Thesis, Technische Universität Graz, Graz, Austria, 2008. [Google Scholar]
- IEEE/ISO/IEC 21839-2019—ISO/IEC/IEEE International Standard—Systems and Software Engineering—System of Systems (SoS) Considerations in Life Cycle Stages of a System. 2019. Available online: https://standards.ieee.org/ (accessed on 16 June 2021).
- IEEE 12207-2-2020—ISO/IEC/IEEE International Standard—Systems and Software Engineering—Software life Cycle Processes—Part 2: Relation and Mapping between ISO/IEC/IEEE 12207:2017 and ISO/IEC 12207:2008. 2020. Available online: https://standards.ieee.org/ (accessed on 16 June 2021).
- IEEE/ISO/IEC 12207-2017—ISO/IEC/IEEE International Standard—Systems and Software Engineering—Software Life Cycle Processes. 2017. Available online: https://standards.ieee.org/ (accessed on 16 June 2021).
- SWEBOK Version 3. Software Engineering Body of Knowledge. IEEE Computer Society. 2014. Available online: www.swebok.org (accessed on 14 August 2021).
- Thayer, R.H.; Dorfman, M. Software Requirements Engineering, 2nd ed.; IEEE Computer Society Press: Piscataway Township, NJ, USA, 1997. [Google Scholar]
- 29148-2018—ISO/IEC/IEEE International Standard—Systems and Software Engineering—Life Cycle Processes—Requirements Engineering. Available online: https://standards.ieee.org/ (accessed on 16 June 2021).
- Kravari, K.; Antoniou, C.; Bassiliades, N. Towards a Requirements Engineering Framework based on Semantics. In Proceedings of the 24th Pan-Hellenic Conference on Informatics (PCI 2020); Athens, Greece, 20–22 November 2020, Association for Computing Machinery: New York, NY, USA, 2020; pp. 72–76. [Google Scholar] [CrossRef]
- Requirements Document for an Automated Teller Machine Network, Department of CSE, SDBCT, Indore, Software Engineering & Project Management Lab Manual. Available online: https://www.cs.toronto.edu/~sme/CSC340F/2005/assignments/inspections/atm.pdf (accessed on 16 June 2021).
- Arora, C.; Sabetzadeh, M.; Briand, L.C.; Zimmer, F. Requirement boilerplates: Transition from manually-enforced to automatically-verifiable natural language patterns. In Proceedings of the 2014 IEEE 4th International Workshop on Requirements Patterns (RePa), Karlskrona, Sweden, 26 August 2014; pp. 1–8. [Google Scholar] [CrossRef]
- Farfeleder, S.; Moser, T.; Krall, A.; Stålhane, T.; Zojer, H.; Panis, C. DODT: Increasing requirements formalism using domain ontologies for improved embedded systems development. In Proceedings of the 14th IEEE International Symposium on Design and Diagnostics of Electronic Circuits and Systems, Cottbus, Germany, 13–15 April 2011; pp. 271–274. [Google Scholar] [CrossRef] [Green Version]
- Mokos, K.; Katsaros, P. A survey on the formalisation of system requirements and their validation. Array 2020, 7, 100030. [Google Scholar] [CrossRef]
- Stachtiari, E.; Mavridou, A.; Katsaros, P.; Bliudze, S.; Sifakis, J. Early validation of system requirements and design through correctness-by-construction. J. Syst. Softw. 2018, 145, 25–78. [Google Scholar] [CrossRef] [Green Version]
- Anu, V.; Hu, W.; Carver, J.C.; Walia, G.S.; Bradshaw, G. Development of a human error taxonomy for software requirements: A systematic literature review. Inf. Softw. Technol. 2018, 103, 112–124. [Google Scholar] [CrossRef]
- Perini, A.; Susi, A.; Avesani, P. A Machine Learning Approach to Software Requirements Prioritization. IEEE Trans. Softw. Eng. 2013, 39, 445–461. [Google Scholar] [CrossRef]
- Clarke, E.M.; Emerson, E.A.; Sifakis, J. Model checking: Algorithmic verification and debugging. Commun. ACM 2009, 52, 74–84. [Google Scholar] [CrossRef]
- Li, F.-L.; Horko, J.; Borgida, A.; Guizzardi, G.; Liu, L.; Mylopoulos, J. From stakeholder requirements to formal specifications through refinement. In Requirements Engineering: Foundation for Software Quality; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9013, pp. 164–180. [Google Scholar]
- Zareen, S.; Akram, A.; Ahmad Khan, S. Security Requirements Engineering Framework with BPMN 2.0.2 Extension Model for Development of Information Systems. Appl. Sci. 2020, 10, 4981. [Google Scholar] [CrossRef]
- Deeptimahanti, D.K.; Babar, M.A. An Automated Tool for Generating UML Models from Natural Language Requirements. In Proceedings of the 2009 IEEE/ACM International Conference on Automated Software Engineering, Washington, DC, USA, 16–20 November 2009; pp. 680–682. [Google Scholar] [CrossRef] [Green Version]
- Vidya Sagar, V.B.R.; Abirami, S. Conceptual modeling of natural language functional requirements. J. Syst. Softw. 2014, 88, 25–41. [Google Scholar] [CrossRef]
- Kiyavitskaya, N.; Zannone, N. Requirements model generation to support requirements elicitation: The Secure Tropos experience. Autom. Softw. Eng. 2008, 15, 2–149. [Google Scholar] [CrossRef]
- van Erp, M.; Reynolds, C.; Maynard, D.; Starke, A.; Martín, R.I.; Andres, F.; Leite, M.C.A.; de Toledo, D.A.; Rivera, X.S.; Trattner, C.; et al. Using Natural Language Processing and Artificial Intelligence to explore the nutrition and sustainability of recipes and food. Front. Artif. Intell. 2021, 3, 115. [Google Scholar] [CrossRef]
- Jena. The Apache Software Foundation. 2021. Available online: https://www.apache.org/ (accessed on 16 June 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning |
|---|---|
| […] | Optional |
| … | … | Or |
| * | >= 0 occurrences |
| + | >= 1 occurrences |
| <…> | boilerplate attribute |
| <boilerplate> ::= <prefix><main><suffix> |
| <prefix> ::= <simple prefix> <logic connective> <prefix> | <simple prefix> |
| <suffix> ::= <simple suffix> <logic connective> <suffix> | <simple suffix> |
| <logic connective> ::= or | and | xor |
| <simple prefix> ::= <Pi> |
| <simple suffix> ::= <Sj> |
| <main> ::= <Mk> |
| M1: <subject> shall [not] <action> |
| M2: <subject> shall [not] be <state> |
| M3: <subject> shall [not] be able to <action> |
| M4: <subject> shall [not] support <action> |
| M5: <subject> shall [not] execute <action-block> |
| M6: <subject> shall [not] allow <entity> |
| M7: <entity> shall [not] allow <entity> to <action> |
| M8: <subject> shall [not] handle <entity> |
| M9: <subject> shall [not] make available <entity> |
| M10: <entity> shall [not] be defined in <entity> |
| P1: if | unless | while <state> |
| P2: if | unless <event> |
| P3: if | unless | while <action> |
| S1: after | before <event> |
| S2: other than (<action>|<entity>) |
| S3: using <entity> |
| S4: without (<action>|<entity>) |
| S5: in the order (<entity>) |
| S6: at even intervals |
| S7: every | for a period of | within | for at least (time) <event> |
| <subject> ::= system-function |
| <entity> ::= <simple entity> | <simple entity> <preposition> <entity> |
| <preposition> ::= to | in | on | from | with | without | between | among |
| <action> ::= <simple action> |<simple action><preposition><action> |
| <state> ::= <entity> mode |
| <event> ::= <entity> <action> |
| select ?c1 ?c2 ?c3 where { |
| values ?c1 { :a } ?c1 ^rdfs:subClassOf ?c2. |
| OPTIONAL { |
| ?c2 ^rdfs:subClassOf ?c3}} |
| order by ?c3 ?c2 ?c1 |
| ASK WHERE { ?this client:age ?age. FILTER (?age < 18). } |
| [ a sp:Ask ; rdfs:comment "must be at least 18 years old"^^xsd:string ; sp:where ([ sp:object sp:_age ; sp:predicate my:age ; sp:subject spin:_this] [ a sp:Filter ; sp:expression [ sp:arg1 sp:_age ; sp:arg2 18 ; a sp:lt ] ]) ] |
| Select * WHERE { |
| ?r a sense:User . |
| ?r sense:hasRole ?x . |
| ?x a sense:Maintainer. |
| ?x sense:isRelatedToPermission ?Permission. |
| NOT EXISTS { ?pr a sense:suspendAccount. |
| ?pr sense: isRelatedToPermission ?Permission.} . |
| Select * WHERE { |
| ?r a sense:User . |
| ?r sense:hasRole ?x . |
| ?x a sense:Customer. |
| ?x sense:isAllowedToAction ?AlAction. |
| NOT EXISTS { ?pr a sense: selectProduct. |
| ?pr sense: isAllowedToAction ?AlAction.} . |
| ASK WHERE { |
| ? this sense:isRelatedToPermission ?Permission. |
| NOT EXISTS { |
| ?pr a sense: suspendAccount. |
| ?pr sense: isRelatedToPermission ?Permission .} .} |
| ASK WHERE { |
| ? this sense: isAllowedToAction ?AlAction. |
| NOT EXISTS { |
| ?pr a sense: selectProduct. |
| ?pr sense: isAllowedToAction ?AlAction.} .} |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kravari, K.; Antoniou, C.; Bassiliades, N. SENSE: A Flow-Down Semantics-Based Requirements Engineering Framework. Algorithms 2021, 14, 298. https://doi.org/10.3390/a14100298
Kravari K, Antoniou C, Bassiliades N. SENSE: A Flow-Down Semantics-Based Requirements Engineering Framework. Algorithms. 2021; 14(10):298. https://doi.org/10.3390/a14100298
Chicago/Turabian StyleKravari, Kalliopi, Christina Antoniou, and Nick Bassiliades. 2021. "SENSE: A Flow-Down Semantics-Based Requirements Engineering Framework" Algorithms 14, no. 10: 298. https://doi.org/10.3390/a14100298
APA StyleKravari, K., Antoniou, C., & Bassiliades, N. (2021). SENSE: A Flow-Down Semantics-Based Requirements Engineering Framework. Algorithms, 14(10), 298. https://doi.org/10.3390/a14100298