
Compensating Data Shortages in Manufacturing with Monotonicity Knowledge

 , , ,
, , ,
Abstract
:1. Introduction
2. Semi-Infinite Optimization Approach to Monotonic Regression
2.1. Semi-Infinite Optimization Formulation of Monotonic Regression
- and indicate that is expected to be, respectively, monotonically increasing or decreasing in the jth coordinate direction;
- indicates that one has no monotonicity knowledge in the jth coordinate direction.
2.2. Adaptive Solution Strategy
2.3. Algorithm and Implementation Details
| Algorithm 1. Adaptive discretization algorithm for monotonic regression. |
Choose a coarse (but non-empty) rectangular grid in X. Set and iterate over k.
|
3. Applications in Manufacturing
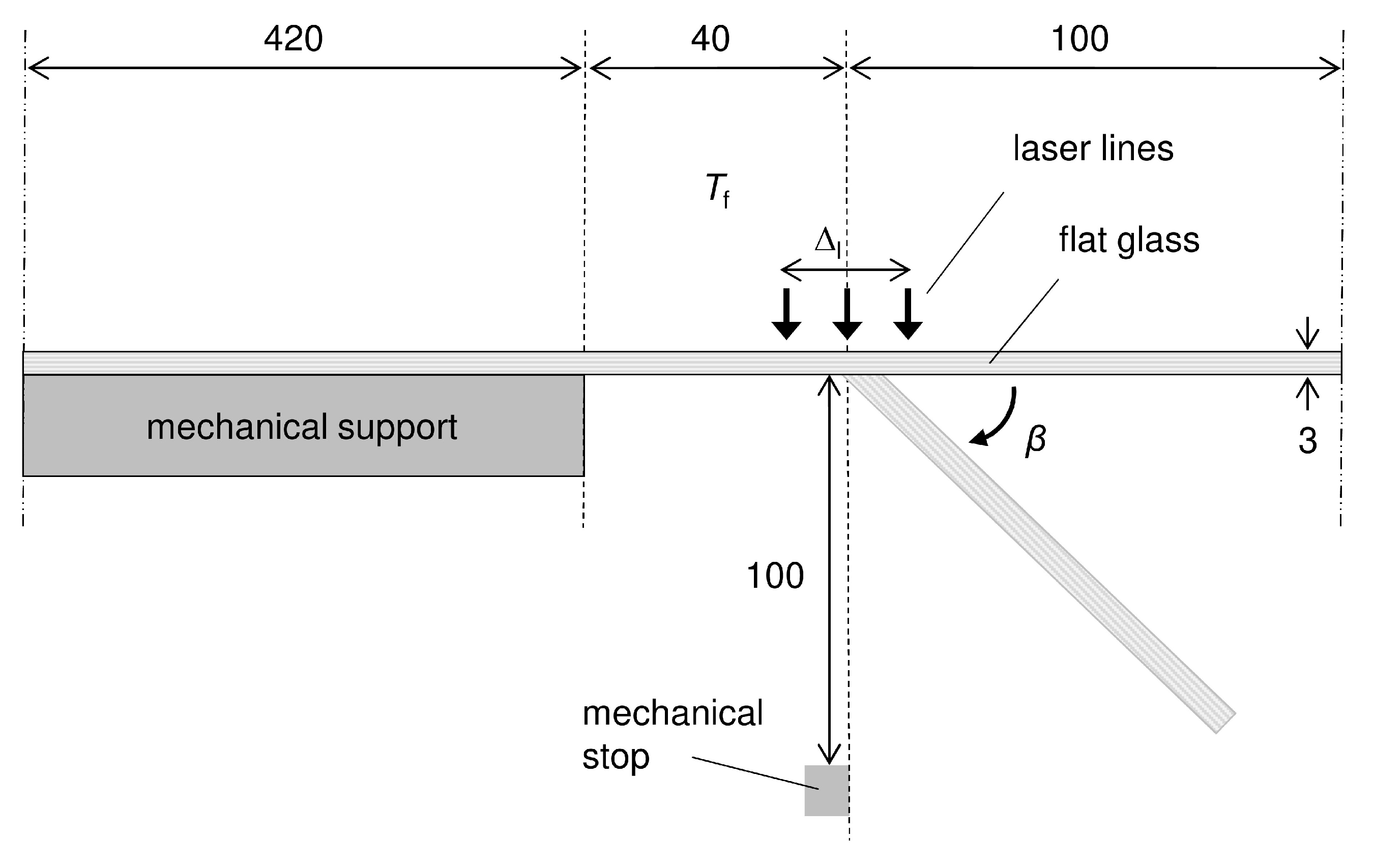
3.1. Laser Glass Bending
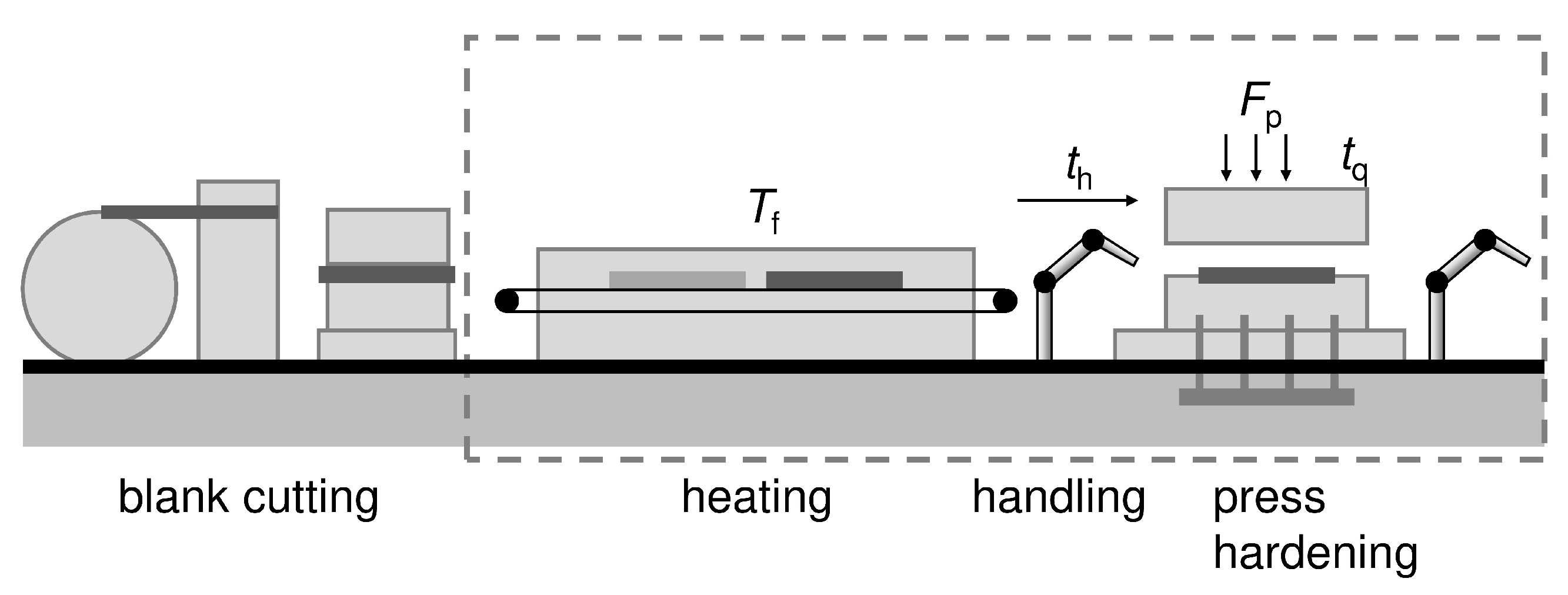
3.2. Forming and Press Hardening of Sheet Metal
4. Results and Discussion
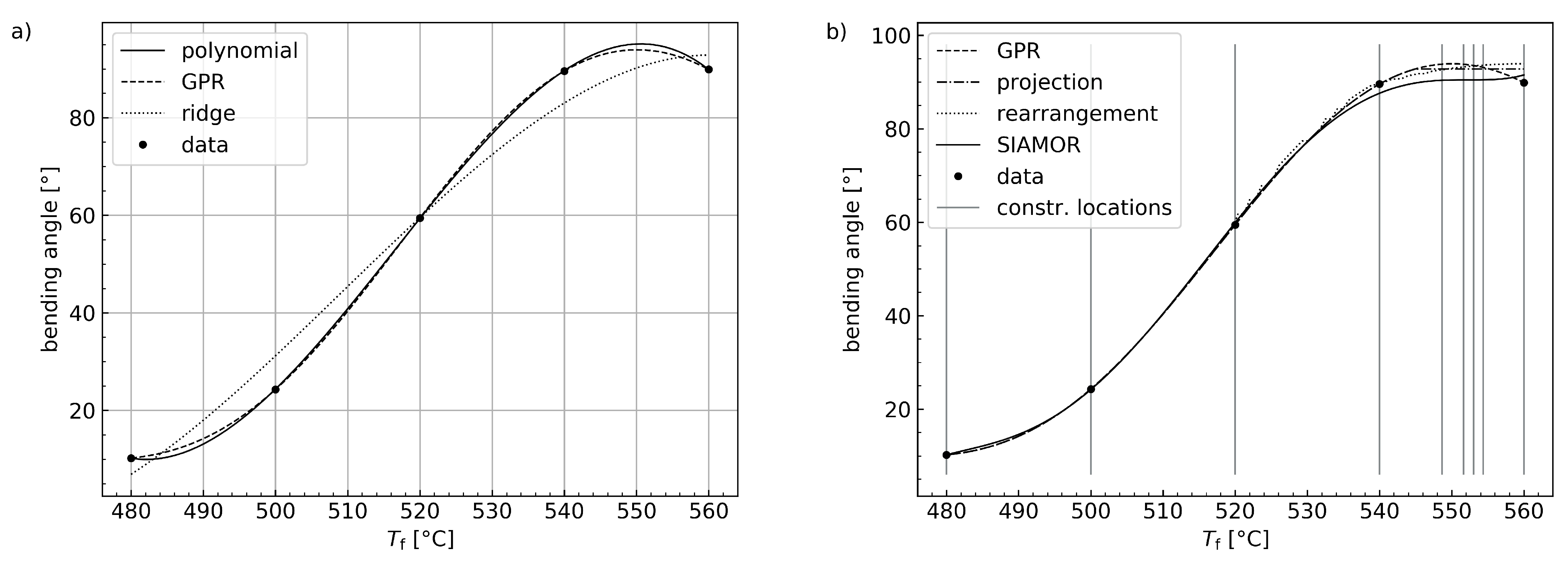
4.1. Informed Machine Learning Models for Laser Glass Bending
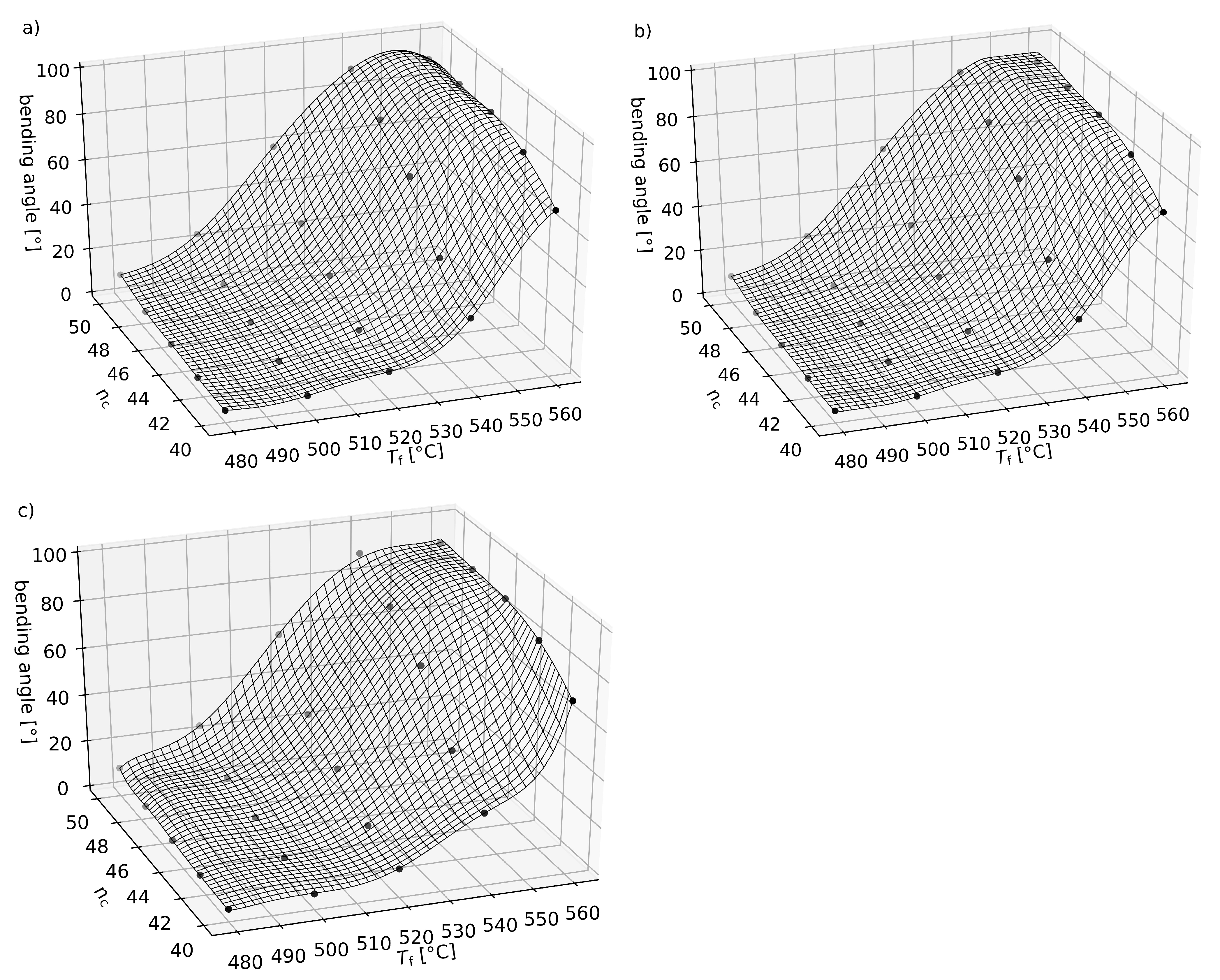
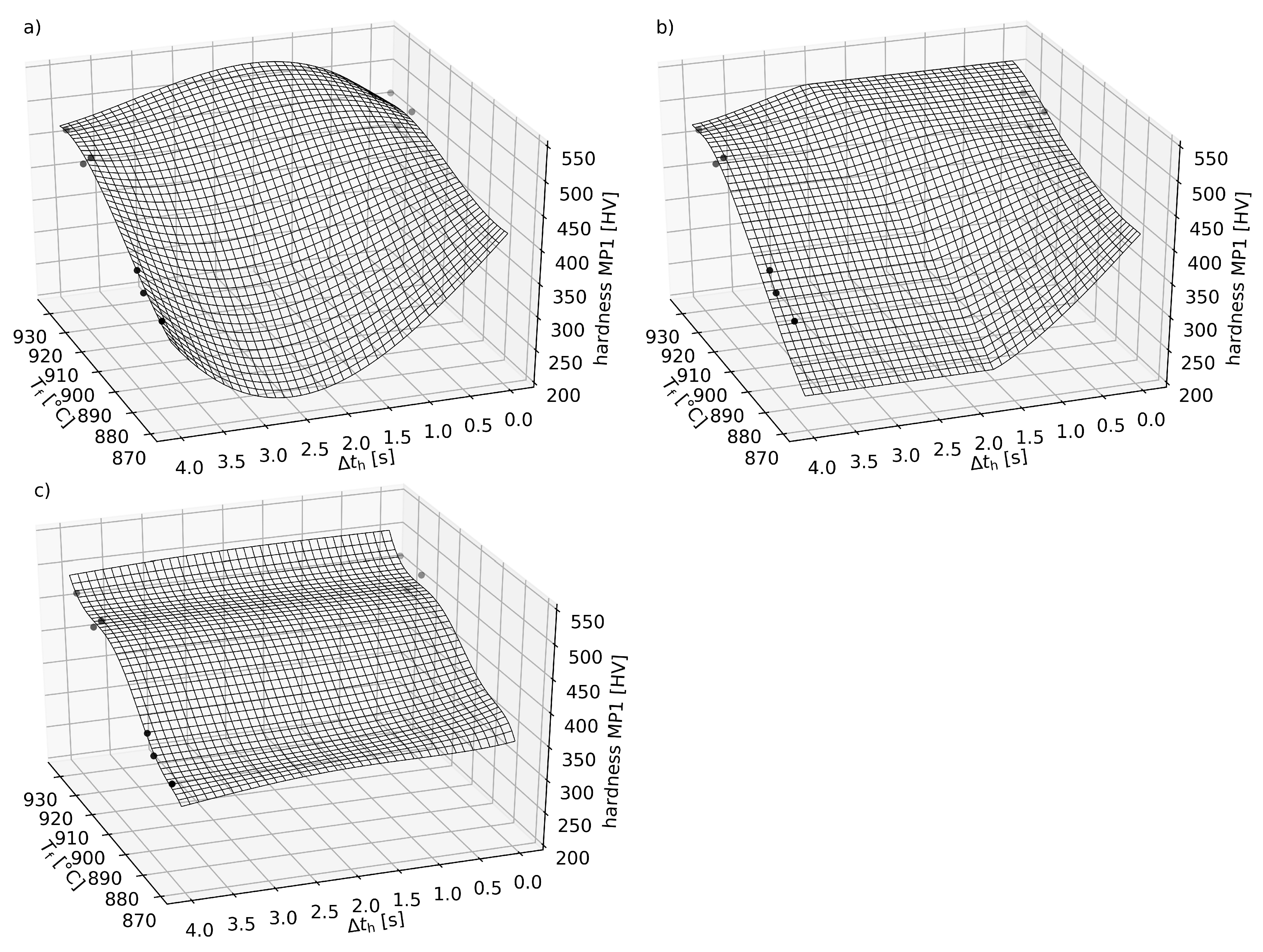
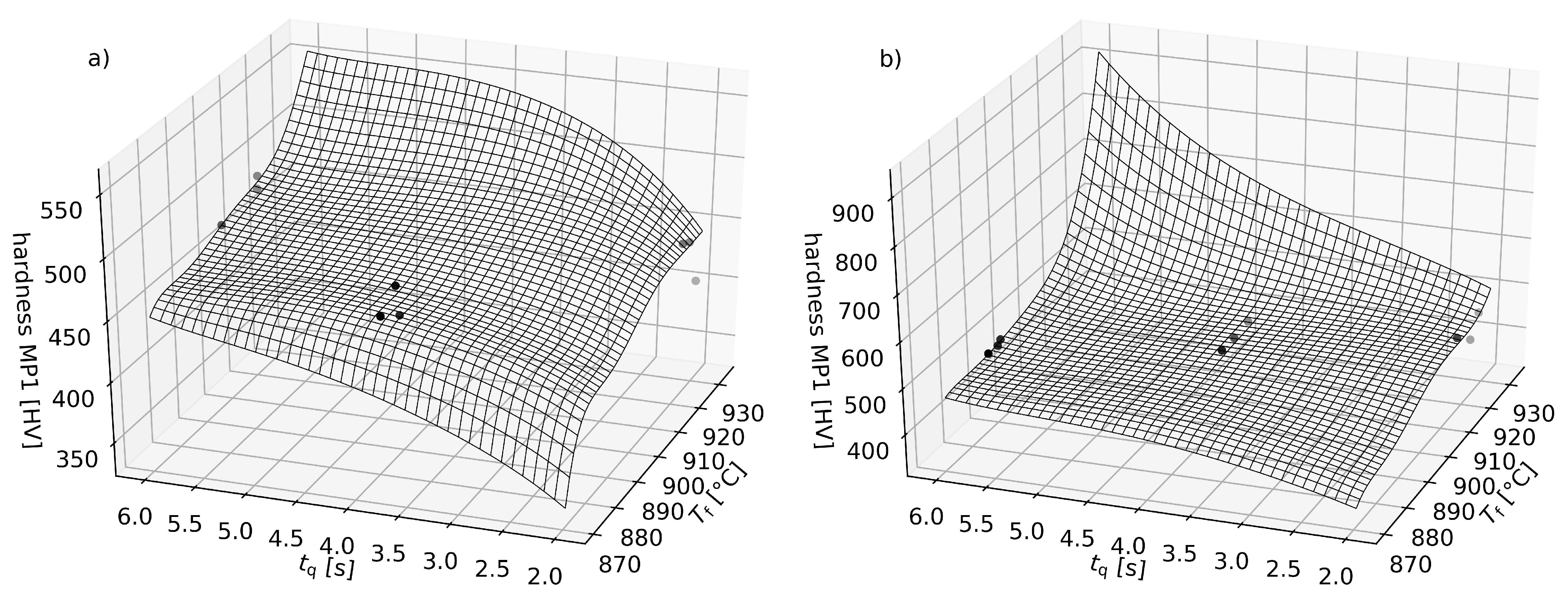
4.2. Informed Machine Learning Models for Forming and Press Hardening
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SIAMOR | Semi-infinite optimization approach to monotonic regression |
| GPR | Gaussian process regression |
| RBF | Radial basis function |
| RMSE | Root mean squared error |
Appendix A. Computing Monotonic Projections
References
- Weichert, D.; Link, P.; Stoll, A.; Rüping, S.; Ihlenfeldt, S.; Wrobel, S. A review of machine learning for the optimization of production processes. Int. J. Adv. Manuf. Technol. 2019, 104, 1889–1902. [Google Scholar] [CrossRef]
- MacInnes, J.; Santosa, S.; Wright, W. Visual classification: Expert knowledge guides machine learning. IEEE Comput. Graph. Appl. 2010, 30, 8–14. [Google Scholar] [CrossRef]
- Heese, R.; Walczak, M.; Morand, L.; Helm, D.; Bortz, M. The Good, the Bad and the Ugly: Augmenting a Black-Box Model with Expert Knowledge. In Artificial Neural Networks and Machine Learning—ICANN 2019: Workshop and Special Sessions; Lecture Notes in Computer, Science; Tetko, I.V., Kůrková, V., Karpov, P., Theis, F., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11731, pp. 391–395. [Google Scholar] [CrossRef] [Green Version]
- Rueden, L.V.; Mayer, S.; Beckh, K.; Georgiev, B.; Giesselbach, S.; Heese, R.; Kirsch, B.; Pfrommer, J.; Pick, A.; Ramamurthy, R.; et al. Informed Machine Learning—A Taxonomy and Survey of Integrating Knowledge into Learning Systems. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Johansen, T.A. Identification of non-linear systems using empirical data and prior knowledge—An optimization approach. Automatica 1996, 32, 337–356. [Google Scholar] [CrossRef]
- Mangasarian, O.L.; Wild, E.W. Nonlinear knowledge in kernel approximation. IEEE Trans. Neural Netw. 2007, 18, 300–306. [Google Scholar] [CrossRef] [Green Version]
- Mangasarian, O.L.; Wild, E.W. Nonlinear knowledge-based classification. IEEE Trans. Neural Netw. 2008, 19, 1826–1832. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cozad, A.; Sahinidis, N.V.; Miller, D.C. A combined first-principles and data-driven approach to model building. Comput. Chem. Eng. 2015, 73, 116–127. [Google Scholar] [CrossRef]
- Wilson, Z.T.; Sahinidis, N.V. The ALAMO approach to machine learning. Comput. Chem. Eng. 2017, 106, 785–795. [Google Scholar] [CrossRef] [Green Version]
- Wilson, Z.T.; Sahinidis, N.V. Automated learning of chemical reaction networks. Comput. Chem. Eng. 2019, 127, 88–98. [Google Scholar] [CrossRef]
- Asprion, N.; Böttcher, R.; Pack, R.; Stavrou, M.E.; Höller, J.; Schwientek, J.; Bortz, M. Gray-Box Modeling for the Optimization of Chemical Processes. Chem. Ing. Tech. 2019, 91, 305–313. [Google Scholar] [CrossRef]
- Heese, R.; Nies, J.; Bortz, M. Some Aspects of Combining Data and Models in Process Engineering. Chem. Ing. Tech. 2020, 92, 856–866. [Google Scholar] [CrossRef] [Green Version]
- Altendorf, E.E.; Restificar, A.C.; Dietterich, T.G. Learning from Sparse Data by Exploiting Monotonicity Constraints. In Proceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence, UAI’05, Edinburgh, UK,, 26–29 July 2005; AUAI Press: Arlington, VA, USA, 2005; pp. 18–26. [Google Scholar]
- Kotłowski, W.; Słowiński, R. Rule learning with monotonicity constraints. In Proceedings of the 26th Annual International Conference on Machine Learning—ICML’09, Montreal, QC, Canada, 14–18 June 2009; Danyluk, A., Bottou, L., Littman, M., Eds.; ACM Press: New York, NY, USA, 2009; pp. 1–8. [Google Scholar]
- Lauer, F.; Bloch, G. Incorporating prior knowledge in support vector machines for classification: A review. Neurocomputing 2008, 71, 1578–1594. [Google Scholar] [CrossRef] [Green Version]
- Groeneboom, P.; Jongbloed, G. Nonparametric Estimation under Shape Constraints; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar] [CrossRef]
- Gupta, M.; Cotter, A.; Pfeifer, J.; Voevodski, K.; Canini, K.; Mangylov, A.; Moczydlowski, W.; van Esbroeck, A. Monotonic Calibrated Interpolated Look-Up Tables. J. Mach. Learn. Res. (JMLR) 2016, 17, 1–47. [Google Scholar]
- Mukerjee, H. Monotone Nonparametric Regression. Ann. Stat. 1988, 16, 741–750. [Google Scholar] [CrossRef]
- Mammen, E. Estimating a smooth monotone regression function. Ann. Stat. 1991, 19, 724–740. [Google Scholar] [CrossRef]
- Mammen, E.; Marron, J.S.; Turlach, B.A.; Wand, M.P. A General Projection Framework for Constrained Smoothing. Stat. Sci. 2001, 16, 232–248. [Google Scholar] [CrossRef]
- Hall, P.; Huang, L.S. Nonparametric kernel regression subject to monotonicity constraints. Ann. Stat. 2001, 29, 624–647. [Google Scholar] [CrossRef]
- Dette, H.; Neumeyer, N.; Pilz, K.F. A simple nonparametric estimator of a strictly monotone regression function. Bernoulli 2006, 12, 469–490. [Google Scholar] [CrossRef]
- Dette, H.; Scheder, R. Strictly monotone and smooth nonparametric regression for two or more variables. Can. J. Stat. 2006, 34, 535–561. [Google Scholar] [CrossRef] [Green Version]
- Lin, L.; Dunson, D.B. Bayesian monotone regression using Gaussian process projection. Biometrika 2014, 101, 303–317. [Google Scholar] [CrossRef] [Green Version]
- Chernozhukov, V.; Fernandez-Val, I.; Galichon, A. Improving point and interval estimators of monotone functions by rearrangement. Biometrika 2009, 96, 559–575. [Google Scholar] [CrossRef] [Green Version]
- Lauer, F.; Bloch, G. Incorporating prior knowledge in support vector regression. Mach. Learn. 2007, 70, 89–118. [Google Scholar] [CrossRef] [Green Version]
- Chuang, H.C.; Chen, C.C.; Li, S.T. Incorporating monotonic domain knowledge in support vector learning for data mining regression problems. Neural Comput. Appl. 2020, 32, 11791–11805. [Google Scholar] [CrossRef]
- Riihimäki, J.; Vehtari, A. Gaussian processes with monotonicity information. Proc. Mach. Learn. Res. 2010, 9, 645–652. [Google Scholar]
- Neumann, K.; Rolf, M.; Steil, J.J. Reliable integration of continuous constraints into extreme learning machines. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2013, 21, 35–50. [Google Scholar] [CrossRef] [Green Version]
- Friedlander, F.G.; Joshi, M.S. Introduction to the Theory of Distributions, 2nd ed.; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; Adaptive Computation and Machine Learning; MIT: Cambridge, MA, USA; London, UK, 2006. [Google Scholar]
- Hettich, R.; Zencke, P. Numerische Methoden der Approximation und Semi-Infiniten Optimierung; Teubner Studienbücher: Mathematik; Teubner: Stuttgart, Germany, 1982. [Google Scholar]
- Polak, E. Optimization: Algorithms and Consistent Approximations; Applied Mathematical Sciences; Springer: New York, NY, USA; London, UK, 1997; Volume 124. [Google Scholar]
- Reemtsen, R.; Rückmann, J.J. Semi-Infinite Programming; Nonconvex Optimization and Its Applications; Kluwer Academic: Boston, MA, USA; London, UK, 1998; Volume 25. [Google Scholar]
- Stein, O. Bi-Level Strategies in Semi-Infinite Programming; Nonconvex Optimization and Its Applications; Kluwer Academic: Boston, MA, USA; London, UK, 2003; Volume 71. [Google Scholar]
- Stein, O. How to solve a semi-infinite optimization problem. Eur. J. Oper. Res. 2012, 223, 312–320. [Google Scholar] [CrossRef]
- Shimizu, K.; Ishizuka, Y.; Bard, J.F. Nondifferentiable and Two-Level Mathematical Programming; Kluwer Academic Publishers: Boston, MA, USA; London, UK, 1997. [Google Scholar]
- Dempe, S.; Kalashnikov, V.; Pérez-Valdés, G.A.; Kalashnykova, N. Bilevel Programming Problems; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Blankenship, J.W.; Falk, J.E. Infinitely constrained optimization problems. J. Optim. Theory Appl. 1976, 19, 261–281. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer Series in Operations Research; Springer: New York, NY, USA, 2006. [Google Scholar]
- Goldfarb, D.; Idnani, A. A numerically stable dual method for solving strictly convex quadratic programs. Math. Program. 1983, 27, 1–33. [Google Scholar] [CrossRef]
- Endres, S.C.; Sandrock, C.; Focke, W.W. A simplicial homology algorithm for Lipschitz optimisation. J. Glob. Optim. 2018, 72, 181–217. [Google Scholar] [CrossRef] [Green Version]
- Neugebauer, J. Applications for curved glass in buildings. J. Facade Des. Eng. 2014, 2, 67–83. [Google Scholar] [CrossRef] [Green Version]
- Rist, T.; Gremmelspacher, M.; Baab, A. Feasibility of bent glasses with small bending radii. CE/Papers 2018, 2, 183–189. [Google Scholar] [CrossRef]
- Rist, T.; Gremmelspacher, M.; Baab, A. Innovative Glass Bending Technology for Manufacturing Expressive Shaped Glasses with Sharp Curves. Glass Performance Days. 2019, pp. 34–35. Available online: https://www.glassonweb.com/article/innovative-glass-bending-technology-manufacturing-expressive-shaped-glasses-with-sharp (accessed on 26 November 2021).
- Williams, M.L.; Landel, R.F.; Ferry, J.D. The Temperature Dependence of Relaxation Mechanisms in Amorphous Polymers and Other Glass-forming Liquids. J. Am. Chem. Soc. 1955, 77, 3701–3707. [Google Scholar] [CrossRef]
- Neugebauer, R.; Schieck, F.; Polster, S.; Mosel, A.; Rautenstrauch, A.; Schönherr, J.; Pierschel, N. Press hardening—An innovative and challenging technology. Arch. Civ. Mech. Eng. 2012, 12, 113–118. [Google Scholar] [CrossRef]
- Schmid, J. Approximation, characterization, and continuity of multivariate monotonic regression functions. Anal. Appl. 2021. [Google Scholar] [CrossRef]
- Andersen, M.; Dahl, J.; Liu, Z.; Vandenberghe, L. Interior-point methods for large-scale cone programming. In Optimization for Machine Learning; Sra, S., Nowozin, S., Wright, S.J., Eds.; MIT Press: Cambridge, MA, USA, 2011; pp. 55–83. [Google Scholar]
- Barlow, R.E. Statistical Inference under Order Restrictions: The Theory and Application of Isotonic Regression; Wiley Series in Probability and Mathematical Statistics; Wiley: London, UK; New York, NY, USA, 1972; Volume 8. [Google Scholar]
- Robertson, T.; Wright, F.T.; Dykstra, R. Statistical Inference under Inequality Constraints; Wiley Series in Probability and Mathematical Statistics. Probability and Mathematical Statistics Section; Wiley: Chichester, UK; New York, NY, USA, 1988. [Google Scholar]
- Qian, S.; Eddy, W.F. An Algorithm for Isotonic Regression on Ordered Rectangular Grids. J. Comput. Graph. Stat. 1996, 5, 225–235. [Google Scholar] [CrossRef]
- Spouge, J.; Wan, H.; Wilbur, W.J. Least Squares Isotonic Regression in Two Dimensions. J. Optim. Theory Appl. 2003, 117, 585–605. [Google Scholar] [CrossRef]
- Stout, Q.F. Isotonic Regression via Partitioning. Algorithmica 2013, 66, 93–112. [Google Scholar] [CrossRef] [Green Version]
- Stout, Q.F. Isotonic Regression for Multiple Independent Variables. Algorithmica 2015, 71, 450–470. [Google Scholar] [CrossRef] [Green Version]
- Kyng, R.; Rao, A.; Sachdeva, S. Fast, Provable Algorithms for Isotonic Regression in all lp-norms. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2015; pp. 2719–2727. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Min | Max | Phys. Unit |
|---|---|---|---|
| 480 | 560 | C | |
| 40 | 50 | — |
| Variable | Min | Max | Phys. Unit |
|---|---|---|---|
| 871 | 933 | C | |
| 0 | 4 | s | |
| 1750 | 2250 | kN | |
| 2 | 6 | s |
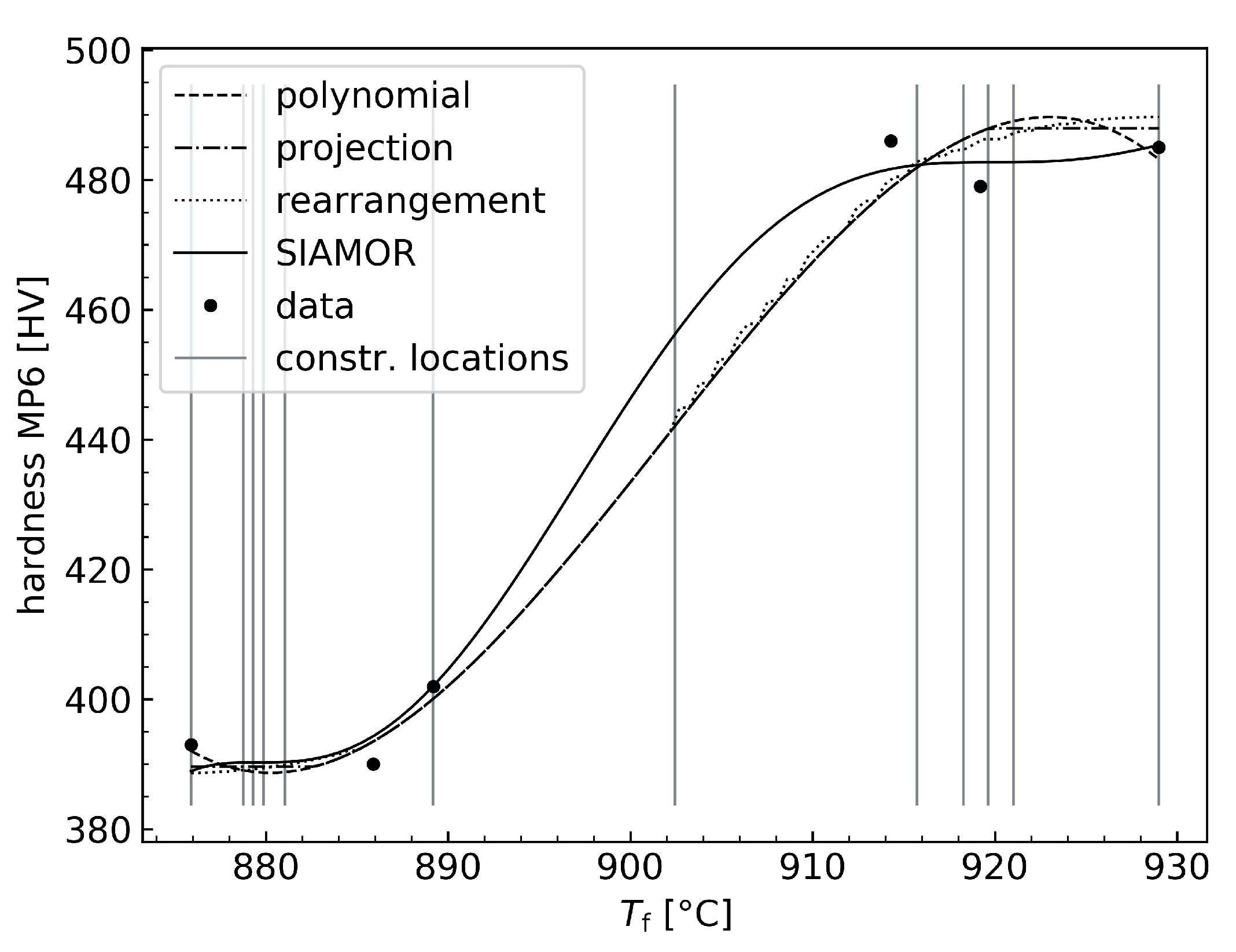
| Monotonic Regression Type | RMSE [] |
|---|---|
| projection [24] | 1.3822 |
| rearrangement [22] | 1.8432 |
| SIAMOR | 1.1598 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kurnatowski, M.v.; Schmid, J.; Link, P.; Zache, R.; Morand, L.; Kraft, T.; Schmidt, I.; Schwientek, J.; Stoll, A. Compensating Data Shortages in Manufacturing with Monotonicity Knowledge. Algorithms 2021, 14, 345. https://doi.org/10.3390/a14120345
Kurnatowski Mv, Schmid J, Link P, Zache R, Morand L, Kraft T, Schmidt I, Schwientek J, Stoll A. Compensating Data Shortages in Manufacturing with Monotonicity Knowledge. Algorithms. 2021; 14(12):345. https://doi.org/10.3390/a14120345
Chicago/Turabian StyleKurnatowski, Martin von, Jochen Schmid, Patrick Link, Rebekka Zache, Lukas Morand, Torsten Kraft, Ingo Schmidt, Jan Schwientek, and Anke Stoll. 2021. "Compensating Data Shortages in Manufacturing with Monotonicity Knowledge" Algorithms 14, no. 12: 345. https://doi.org/10.3390/a14120345
APA StyleKurnatowski, M. v., Schmid, J., Link, P., Zache, R., Morand, L., Kraft, T., Schmidt, I., Schwientek, J., & Stoll, A. (2021). Compensating Data Shortages in Manufacturing with Monotonicity Knowledge. Algorithms, 14(12), 345. https://doi.org/10.3390/a14120345