
Smart Black Box 2.0: Efficient High-Bandwidth Driving Data Collection Based on Video Anomalies


Abstract
:1. Introduction
2. Related Work
2.1. Event Data Recorders
2.2. Traffic Video Anomaly Detection and Classification
2.3. Real-World Driving Datasets
3. Preliminaries
3.1. Smart Black Box Design
3.2. SBB Value Estimation
4. Materials and Methods
4.1. Data Classification and Representation
4.1.1. Frame Classification
4.1.2. Data Frame Representation
- Image: The video frame captured by the camera. In this paper, we use RGB images at resolution.
- Value: The value of the frame . The value is calculated according to the value function defined in Section 4.3 and is used in the DMM, as well as in buffer value computation.
- Cost: The normalized storage cost of the frame .
- Anomaly score: The anomaly score of the frame generated using video anomaly detection. More details can be found in Section 4.3.1.
- Classification scores: The output scores for each event class in Table 3 from online action detection. More details can be found in Section 4.3.2.
- Object data: The tracking ID, object type, bounding box, and detector confidence of each object detected in the frame. Object data are used to support buffer tagging; details can be found in Section 4.1.3.
4.1.3. Frame Buffer Representation
- Anomaly score: The mean, max, and variance of the anomaly scores of the frames in the buffer.
- Frame classifications: A list of event classes for which there is a frame in the buffer where and is a user-defined threshold score for class .
- Objects: The tracking ID, object type, and bounding boxes and detector confidences over time of each object in the buffer.
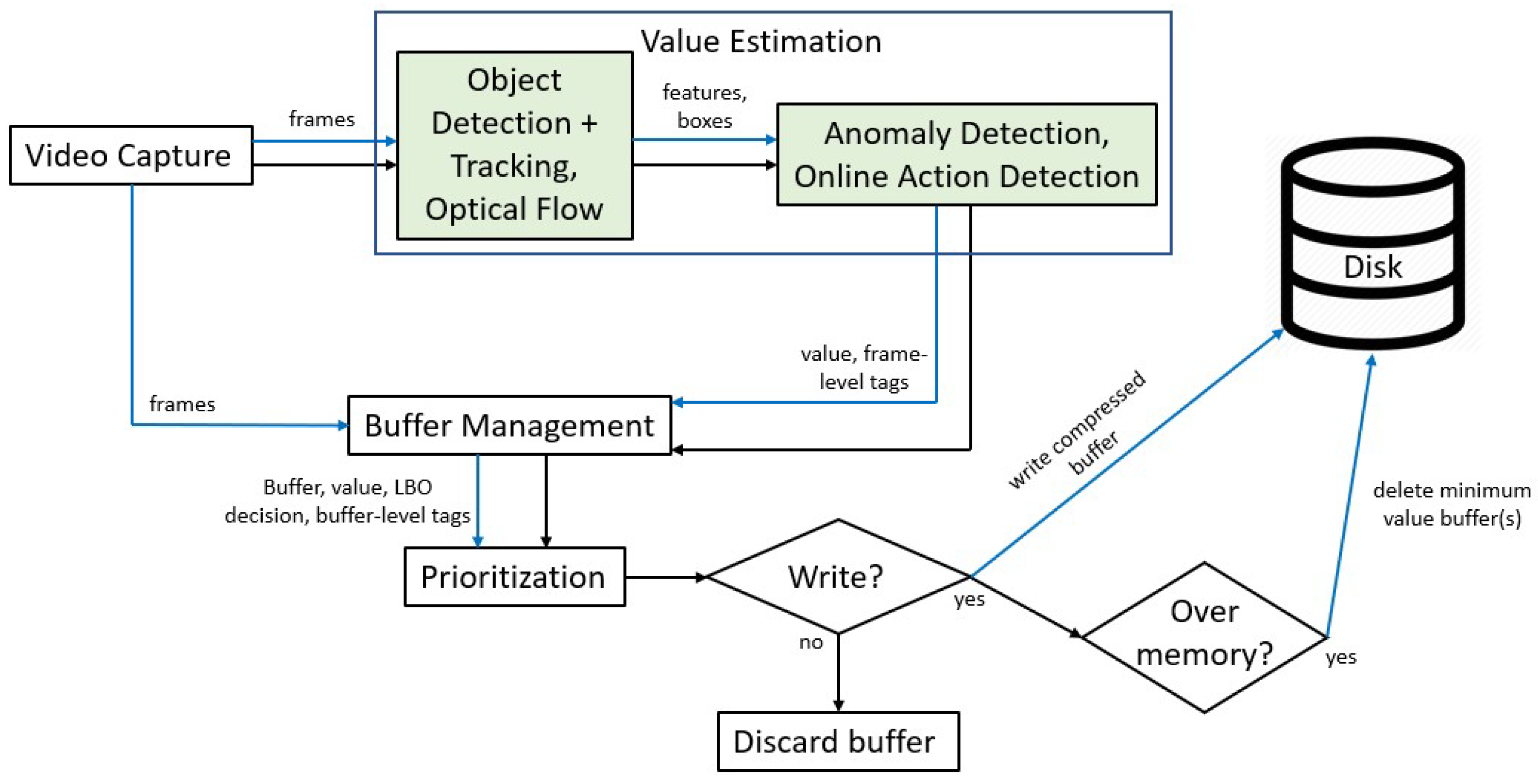
4.2. Updated SBB Design
- Video Capture reads video input and publishes each video frame to value estimation and buffer management. This module remains unchanged from the original SBB.
- Value Estimation assigns a value for each frame to be used in buffer management and storage prioritization. The value estimation module first executes object detection, object tracking [5], and optical flow estimation [35]. The outputs are then used in video anomaly detection and online action detection, which are used to compute the value. Details on this calculation can be found in Section 4.3. The value estimation method used differs significantly from [13]. In [13], perfect EOI detection using pre-defined rules was assumed, and the data value was computed based on detected EOIs. In this paper, we instead use video anomaly detection and action detection methods for generalized EOI detection and calculate the data value based on their output scores. More details on the value estimation of the original SBB can be found in Section 3.2. More details on our updated value estimation can be found in Section 4.3.
- Buffer Management groups frames into buffers using the DMM from [13] after receiving each frame from Video Capture and its corresponding value from Value Estimation. The similarity of a data frame to the current buffer is computed as the percentage of object tracking IDs in the frame that have already appeared in the buffer. With A being the set of tracking IDs in the frame and B being the set of tracking IDs that have appeared in the buffer, we compute the similarity . Once the DMM terminates, LBO solves an optimization problem over the output buffer to determine the compression quality of each frame.
4.3. Value Estimation Method
4.3.1. Video Anomaly Detection
4.3.2. Online Action Detection
4.3.3. Hybrid Value
5. Experiments
5.1. Dataset
5.2. Results
- SBB data compression: SBB data compression statistics with no memory limit are presented in Table 5. It can be seen that the storage cost of normal frames is significantly reduced (427.20 GB to 65.53 GB, 85%) by the SBB. This leads to a 24.4% increase in the ratio of anomalous data storage-to-normal data storage. Both the average (avg.) and median (med.) compression factor decisions of the SBB are higher for the anomalous frames, indicating that the SBB is able to identify and preserve anomalous frames over normal ones. Figure 2 displays normal frames that were highly compressed by the SBB along with preserved anomalous frames; Figure 3 shows two failure cases where anomalous frames were mistakenly compressed. Both of these failures showcase a lack of robustness against cases where anomalous objects are occluded.
- Priority queue vs. FIFO:Table 6 compares the recorded frames of a prioritized recording system against that of an FIFO queue at memory limits of GB, GB, GB, and 25 GB. These values represent a non-trivial amount of data to upload (depending on Internet connection quality) assuming continuous Internet access is not available. In all scenarios, the prioritized recording saved fewer normal frames and more anomalous frames than with the FIFO strategy. We also note that while the anomaly ratio stays roughly the same in each memory limit for the FIFO queue, the ratio increases at each level for the priority queue. The prioritization strategy of the SBB removes ∼95% of the normal frames while still recording ∼10% anomalous frames at GB. Compared to the FIFO queue, the anomalous-to-normal count ratio of SBB-recorded data is ∼25% to ∼100% higher.
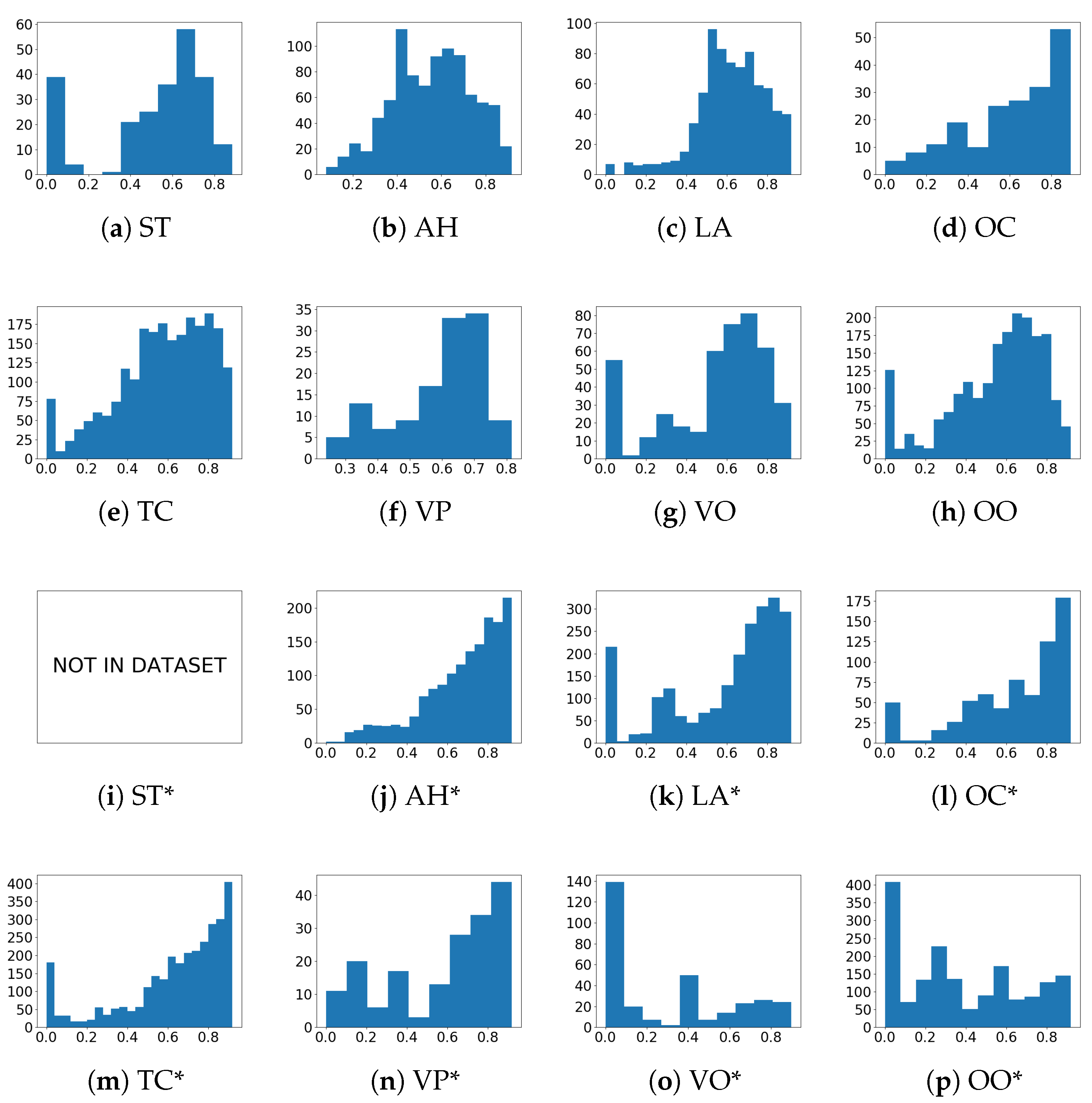
- Performance per anomaly class:Figure 4 displays the decision histograms for each anomaly class. The performance of the SBB varies heavily depending on the anomaly category. For example, the decision distribution of class OCindicates very good detection of this anomaly. In OC, an ego-vehicle collision with an oncoming vehicle, the anomalous object (the oncoming vehicle), is almost always both near the camera and largely unoccluded. However, ST, VO, LA*, VO*, and OO*have notably poor performance. ST is an extremely difficult case for OAD due to its visual similarity to AHand LA anomalies, resulting in lower OAD confidence that an anomaly has occurred. VO and VO* involve vehicles hitting obstacles in the roadway. In some scenarios, such as hitting a traffic cone or a fire hydrant, the obstacle may be blocked from view by the anomalous vehicle in a non-ego incident or outside the camera’s field of view in an ego-incident. LA* often involves vehicles slowly moving closer together, making the collision relatively subtle. OO*, a non-ego vehicle leaving the roadway, can be challenging to detect simply due to the distance at which the anomaly occurs.
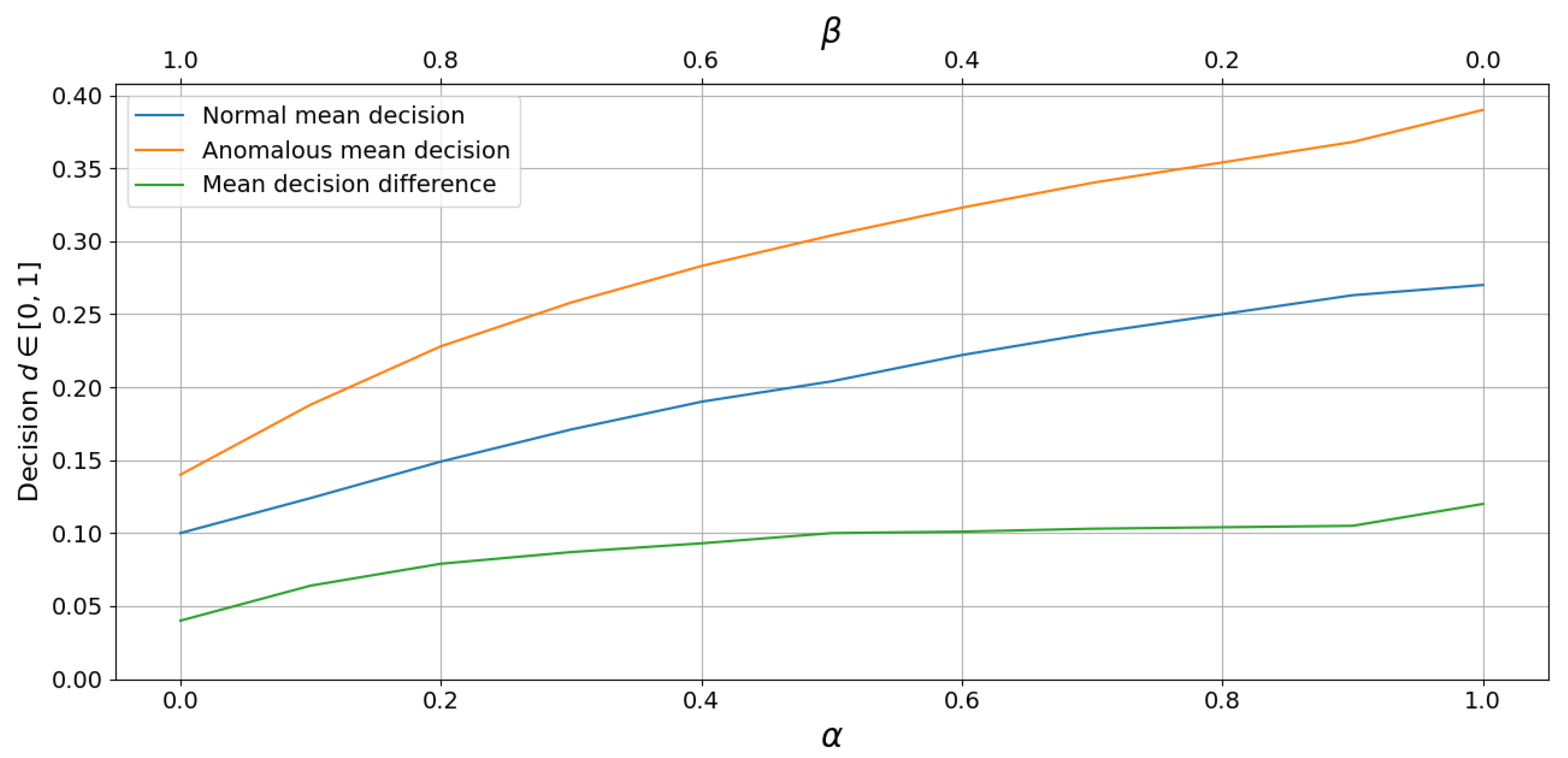
- Value estimation method comparison:Table 7 compares the decision statistics for hybrid value estimation with several parameter combinations. We note that the VAD-only method generates the largest decision difference in normal and anomalous frames; we suspect this to be a result of OAD’s inability to consistently differentiate between anomalous and normal frames. Readers are directed to [15] for an in-depth discussion on the poor performance of OAD algorithms.
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Enoch, M.; Cross, R.; Potter, N.; Davidson, C.; Taylor, S.; Brown, R.; Huang, H.; Parsons, J.; Tucker, S.; Wynne, E.; et al. Future local passenger transport system scenarios and implications for policy and practice. Transp. Policy 2020, 90, 52–67. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. arXiv 2017, arXiv:1703.07402. [Google Scholar]
- Choi, W. Near-Online Multi-target Tracking with Aggregated Local Flow Descriptor. arXiv 2015, arXiv:1504.02340. [Google Scholar]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to Track: Online Multi-object Tracking by Decision Making. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 4705–4713. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Li, F.-F.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yao, Y.; Xu, M.; Choi, C.; Crandall, D.J.; Atkins, E.M.; Dariush, B. Egocentric Vision-based Future Vehicle Localization for Intelligent Driving Assistance Systems. arXiv 2019, arXiv:1809.07408. [Google Scholar]
- Yao, Y.; Atkins, E.; Johnson-Roberson, M.; Vasudevan, R.; Du, X. BiTraP: Bi-directional Pedestrian Trajectory Prediction with Multi-modal Goal Estimation. arXiv 2020, arXiv:2007.14558. [Google Scholar]
- Salzmann, T.; Ivanovic, B.; Chakravarty, P.; Pavone, M. Trajectron++: Multi-Agent Generative Trajectory Forecasting With Heterogeneous Data for Control. arXiv 2020, arXiv:2001.03093. [Google Scholar]
- Yao, Y.; Atkins, E. The smart black box: A value-driven automotive event data recorder. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Yao, Y.; Atkins, E. The Smart Black Box: A Value-Driven High-Bandwidth Automotive Event Data Recorder. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef] [Green Version]
- Yao, Y.; Xu, M.; Wang, Y.; Crandall, D.J.; Atkins, E.M. Unsupervised Traffic Accident Detection in First-Person Videos. arXiv 2019, arXiv:1903.00618. [Google Scholar]
- Yao, Y.; Wang, X.; Xu, M.; Pu, Z.; Atkins, E.; Crandall, D. When, Where, and What? A New Dataset for Anomaly Detection in Driving Videos. arXiv 2020, arXiv:2004.03044. [Google Scholar]
- Xu, M.; Gao, M.; Chen, Y.T.; Davis, L.S.; Crandall, D.J. Temporal Recurrent Networks for Online Action Detection. arXiv 2019, arXiv:1811.07391. [Google Scholar]
- DaSilva, M. Analysis of Event Data Recorder Data for Vehicle Safety Improvement; National Highway Traffic Safety Administration: Washington, DC, USA, 2014; pp. 21–143.
- Gabler, H.C.; Hampton, C.E.; Hinch, J. Crash Severity: A Comparison of Event Data Recorder Measurements with Accident Reconstruction Estimates. In Proceedings of the SAE 2004 World Congress & Exhibition, Detroit, MI, USA, 8–11 March 2004. [Google Scholar] [CrossRef] [Green Version]
- Takeda, K.; Miyajima, C.; Suzuki, T.; Angkititrakul, P.; Kurumida, K.; Kuroyanagi, Y.; Ishikawa, H.; Terashima, R.; Wakita, T.; Oikawa, M.; et al. Self-Coaching System Based on Recorded Driving Data: Learning From One’s Experiences. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1821–1831. [Google Scholar] [CrossRef]
- Zhao, D.; Lam, H.; Peng, H.; Bao, S.; LeBlanc, D.J.; Nobukawa, K.; Pan, C.S. Accelerated Evaluation of Automated Vehicles Safety in Lane-Change Scenarios Based on Importance Sampling Techniques. IEEE Trans. Intell. Transp. Syst. 2017, 18, 595–607. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dingus, T.A.; Neale, V.L.; Klauer, S.G.; Petersen, A.D.; Carroll, R.J. The development of a naturalistic data collection system to perform critical incident analysis: An investigation of safety and fatigue issues in long-haul trucking. Accid. Anal. Prev. 2006, 38, 1127–1136. [Google Scholar] [CrossRef] [PubMed]
- Li, N.; Misu, T.; Miranda, A. Driver behavior event detection for manual annotation by clustering of the driver physiological signals. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2583–2588. [Google Scholar] [CrossRef]
- Chan, F.H.; Chen, Y.; Xiang, Y.; Sun, M. Anticipating Accidents in Dashcam Videos. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Herzig, R.; Levi, E.; Xu, H.; Gao, H.; Brosh, E.; Wang, X.; Globerson, A.; Darrell, T. Spatio-Temporal Action Graph Networks. arXiv 2019, arXiv:1812.01233. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. arXiv 2016, arXiv:1608.00859. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. arXiv 2018, arXiv:1711.11248. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. arXiv 2019, arXiv:1812.03982. [Google Scholar]
- Lewis, V.; Dingus, T.; Klauer, S.; Sudweeks, J. An Overview of the 100-Car Naturalistic Study and Findings; National Highway Traffic Safety Administration: Washington, DC, USA, 2005.
- Bezzina, D.; Sayer, J. Safety Pilot Model Deployment: Test Conductor Team Report 2015; Tech. Rep. DOT HS 812 171, 2014; NHTSA: Washington, DC, USA, 2015.
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. arXiv 2016, arXiv:1604.01685. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Video Database with Scalable Annotation Tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Fang, J.; Yan, D.; Qiao, J.; Xue, J. DADA: A Large-scale Benchmark and Model for Driver Attention Prediction in Accidental Scenarios. arXiv 2019, arXiv:1912.12148. [Google Scholar]
- Espié, E.; Guionneau, C.; Wymann, B.; Dimitrakakis, C.; Coulom, R.; Sumner, A. TORCS, The Open Racing Car Simulator. 2005. Available online: http://torcs.sourceforge.net/ (accessed on 13 December 2020).
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. arXiv 2016, arXiv:1612.01925. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chong, Y.S.; Tay, Y.H. Abnormal event detection in videos using spatiotemporal autoencoder. In International Symposium on Neural Networks; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection—A new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ionescu, R.T.; Khan, F.S.; Georgescu, M.I.; Shao, L. Object-centric auto-encoders and dummy anomalies for abnormal event detection in video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Morais, R.; Le, V.; Tran, T.; Saha, B.; Mansour, M.; Venkatesh, S. Learning regularity in skeleton trajectories for anomaly detection in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Pasha, J.; Dulebenets, M.A.; Kavoosi, M.; Abioye, O.F.; Theophilus, O.; Wang, H.; Kampmann, R.; Guo, W. Holistic tactical-level planning in liner shipping: An exact optimization approach. J. Shipp. Trade 2020, 5, 1–35. [Google Scholar] [CrossRef]
- Dulebenets, M.A. An Adaptive Island Evolutionary Algorithm for the berth scheduling problem. Memetic Comput. 2020, 12, 51–72. [Google Scholar] [CrossRef]
- Kağan Albayrak, M.B.; Özcan, İ.Ç.; Can, R.; Dobruszkes, F. The determinants of air passenger traffic at Turkish airports. J. Air Transp. Manag. 2020, 86, 101818. [Google Scholar] [CrossRef]
- Trösterer, S.; Meneweger, T.; Meschtscherjakov, A.; Tscheligi, M. Transport companies, truck drivers, and the notion of semi-autonomous trucks: A contextual examination. In Proceedings of the 9th International Conference on Automotive User Interfaces and Interactive Vehicular Applications Adjunct, Oldenburg, Germany, 24–27 September 2017; pp. 201–205. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Aim | Description |
|---|---|---|
| TAD [14] | Anomaly detection (unsupervised) | Predicts future bounding boxes using RNN encoder-decoders, then takes the standard deviation of the predictions as the anomaly score. |
| DSA-RNN [23] | Anomaly detection (supervised) | Uses a dynamic-spatial-attention (DSA)-RNN, which learns to distribute soft attention to objects and model the temporal dependencies of detected cues. |
| STAG [24] | Anomaly detection (supervised) | Uses a spatio-temporal action graph (STAG) network to model the spatial and temporal relations among objects. |
| TSN [25] | Action recognition (offline) | Sparsely samples video snippets and predicts action using RGB and optical flow data. |
| R(2+1)D [26] | Action recognition (offline) | Uses a 3D convolutional neural network with separate 2D and 1D convolutional blocks. |
| SlowFast [27] | Action recognition (offline) | Extracts frames from a low frame rate stream to capture spatial information and a high frame rate stream to capture motion. |
| TRN [16] | Action recognition (online) | Simultaneously detects the current action and predicts the action of the following frame. |
| Dataset | # of Frames | Data Size (GB) | Anomaly-Focused | # of Anomalous Videos | |
|---|---|---|---|---|---|
| KITTI | 7481 | (15 fps) | 12 | No | N/A |
| Cityscapes | 24,999 | (17 fps) | 55 | No | N/A |
| BDD100K | 120,000,000 | (30 fps) | ∼1800 | No | N/A |
| A3D | 128,174 | (10 fps) | 15 | Yes | 1500 |
| DADA | 648,476 | (30 fps) | 53 | Yes | 2000 |
| DoTA | 732,932 | (10 fps) | 57 | Yes | 4677 |
| Name | ID | Description |
|---|---|---|
| N | 0 | No anomaly |
| ST | 1 | Collision with another vehicle which starts, stops, or is stationary |
| AH | 2 | Collision with another vehicle moving ahead or waiting |
| LA | 3 | Collision with another vehicle moving laterally in the same direction |
| OC | 4 | Collision with another oncoming vehicle |
| TC | 5 | Collision with another vehicle that turns into or crosses a road |
| VP | 6 | Collision between vehicle and pedestrian |
| VO | 7 | Collision with an obstacle in the roadway |
| OO | 8 | Out-of-control and leaving the roadway to the left or right |
| ST | AH | LA | OC | TC | VP | VO | OO | ST * | AH * | LA * | OC * | TC * | VP * | VO * | OO * | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Likelihood | 0.011 | 0.057 | 0.054 | 0.023 | 0.163 | 0.012 | 0.010 | 0.089 | 0.010 | 0.091 | 0.104 | 0.081 | 0.207 | 0.010 | 0.011 | 0.070 |
| Normalized info.measure | 0.977 | 0.635 | 0.633 | 0.816 | 0.395 | 0.957 | 0.995 | 0.525 | 1.0 | 0.521 | 0.491 | 0.546 | 0.342 | 1.0 | 0.990 | 0.576 |
| Normal | Anomaly | Anomaly Ratio | ||
|---|---|---|---|---|
| Raw Data | # of Frames | 3,967,977 | 16,768 | |
| size (GB) | 427.20 | 1.76 | 0.41% | |
| SBB w/VAD+OAD | size (GB) | 65.53 | 0.33 | 0.51% |
| avg. | 0.51 | 0.58 | ||
| med. | 0.55 | 0.63 | ||
| std. | 0.24 | 0.26 | ||
| SBB w/GT VAD+OAD | size (GB) | 11.05 | 0.73 | 6.60% |
| avg. | 0.00 | 0.92 | ||
| med. | 0.00 | 0.92 | ||
| std. | 0.03 | 0.00 |
| M | Normal↓ | Anomaly↑ | Anomaly Ratio↑ | |
|---|---|---|---|---|
| 25 GB | FIFO | 1,739,855 | 7851 | 0.45% |
| Priority | 1,487,570 | 8545 | 0.57% | |
| 12.5 GB | FIFO | 889,679 | 4335 | 0.49% |
| Priority | 734,625 | 5154 | 0.70% | |
| 6.25 GB | FIFO | 437,673 | 2029 | 0.46% |
| Priority | 364,666 | 2898 | 0.79% | |
| 3.125 GB | FIFO | 207,951 | 962 | 0.46% |
| Priority | 183,951 | 1706 | 0.93% |
| Value Estimation | Normal | Anomaly | |||
|---|---|---|---|---|---|
| VAD Only | 1.0 | 0.0 | avg. | 0.27 | 0.38 |
| med. | 0.15 | 0.38 | |||
| std. | 0.30 | 0.34 | |||
| OAD Only | 0.0 | 1.0 | avg. | 0.10 | 0.14 |
| med. | 0.0 | 0.07 | |||
| std. | 0.15 | 0.17 | |||
| Hybrid | 1.0 | 1.0 | avg. | 0.51 | 0.58 |
| med. | 0.55 | 0.63 | |||
| std. | 0.24 | 0.26 | |||
| 0.9 | 0.1 | avg. | 0.26 | 0.37 | |
| med. | 0.14 | 0.36 | |||
| std. | 0.29 | 0.33 | |||
| 0.5 | 0.5 | avg. | 0.20 | 0.30 | |
| med. | 0.10 | 0.27 | |||
| std. | 0.24 | 0.28 | |||
| 0.1 | 0.9 | avg. | 0.12 | 0.19 | |
| med. | 0.02 | 0.16 | |||
| std. | 0.16 | 0.19 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, R.; Yao, Y.; Atkins, E. Smart Black Box 2.0: Efficient High-Bandwidth Driving Data Collection Based on Video Anomalies. Algorithms 2021, 14, 57. https://doi.org/10.3390/a14020057
Feng R, Yao Y, Atkins E. Smart Black Box 2.0: Efficient High-Bandwidth Driving Data Collection Based on Video Anomalies. Algorithms. 2021; 14(2):57. https://doi.org/10.3390/a14020057
Chicago/Turabian StyleFeng, Ryan, Yu Yao, and Ella Atkins. 2021. "Smart Black Box 2.0: Efficient High-Bandwidth Driving Data Collection Based on Video Anomalies" Algorithms 14, no. 2: 57. https://doi.org/10.3390/a14020057
APA StyleFeng, R., Yao, Y., & Atkins, E. (2021). Smart Black Box 2.0: Efficient High-Bandwidth Driving Data Collection Based on Video Anomalies. Algorithms, 14(2), 57. https://doi.org/10.3390/a14020057