1. Introduction
The algorithmic complexity of solving combinatorial games is an important part of algorithmic game theory. Some famous games can be solved efficiently. For example, the ancient game of nim was solved by Bouton in [
1].
A position
x of nim is determined by
n heaps of pebbles. It can be considered to be a
n-dimensional integer vector. By one move it is allowed to reduce (strictly) exactly one heap. Two players move alternately. One who is out of moves loses. In fact, in his paper Bouton obtained an explicit formula for the Sprague-Grundy (SG) function of the disjunctive compound (or, for brevity, the sum) of impartial games. Informally, the SG function is a homomorphism of an impartial game to nim with one heap. In particular,
and
indicate that the player who moves at the position
x and, respectively, the opponent has a winning strategy; such positions are called N- and P-positions. See
Section 2.1 and [
2,
3,
4] for more details.
It is important for our purposes that the formula for the SG function of nim can be computed efficiently even if the sizes of the heaps are given in binary notation.
Similar efficient solutions were found for several versions and/or generalizations of nim: Wythoff’s nim [
5,
6], Fraenkel’s nim [
6,
7], nim
game [
8], Moore’s
-nim with
[
9,
10,
11], and the exact
-nim with
[
11,
12]. In all these versions it is allowed to reduce by one move several heaps, not necessarily only one. Specifying the rules of choosing heaps and the numbers of pebbles that can be taken, one gets different versions of nim. For example, in the exact (resp., Moore)
-nim a player by one move reduces exactly (resp., at most)
k from
n heaps, strictly but otherwise arbitrarily, where
n and
k are fixed integer parameters such that
.
Another way to change the rules is to restrict moves to
slow ones. A move is called
slow if at most one pebble is taken from each heap. The Moore and exact
slow -nim were introduced in [
13,
14]. In the study of the exact slow
-nim explicit and efficiently computable formulas for the SG function were obtained for
[
13] and for
[
14]. However, for larger values of
k, no explicit formula for the SG function of the exact or Moore slow
-nim is known. Moreover, numerical experiments show that even P-positions look rather chaotic.
Is it possible that there is no efficient algorithm solving these variants of nim? Right now, we have no answer to this question and even no clue.
As for hardness results, we could mention numerous examples of
-complete combinatorial games (see, e.g., [
15,
16]) and also
-hardness of hypergraph nim for some classes of hypergraphs [
17,
18].
The game
hypergraph nim,
, is specified by a hypergraph
on the ground set
. It is played as follows. By one move a player chooses an edge
and strictly reduces all heaps of
H. The games of standard (not slow) exact and Moore’s nim considered above provide examples of the hypergraph nim. The
height of a position
of
is the maximum number of successive moves that players can make beginning in
x. (Clearly, they can restrict themselves by their slow moves.) A hypergraph
is called
intersecting if
for any two edges
. It was proved in [
17,
18] that for any intersecting hypergraph
, its height and SG function are equal. In [
17] it was proved that computing
is
-hard already for the intersecting hypergraphs with edges of size at most 4. Thus,
-hardness of computing the SG function for such family of hypergraphs follows from these two statements.
This example is a typical hardness result in this area. Hardness is established for growing ‘dimension’ of games (in this case, ‘dimension’ is the number of heaps). For the case of a fixed number of heaps Larsson and Wästlund [
19] obtained an important result. They studied a wider class of games, so-called
vector subtraction games (subtraction games for brevity). These games were introduced by Golomb [
20], they also were studied under the name of
invariant games [
21]. The subtraction games include all versions of nim mentioned above. In these games, the positions are
d-dimensional vectors with nonnegative integer coordinates. A move in a position is a subtraction of a ‘permitted’ vector from the vector determining this position. The set of ‘permitted’ vectors is called the
difference set. Thus the game is completely specified by the difference set. Larsson and Wästlund considered subtraction games of finite dimension with a finite difference set (FDG for brevity: fixed dimension and fixed difference set).
It is easy to see that the P-positions of a 1-dimensional FDG form an eventually periodic set [
22] (actually, the values of the SG function are also eventually periodic in this case). It gives an efficient algorithm of solving such games. Yet, the FDG of higher dimensions may behave in a highly complicated way. More exactly, Larsson and Wästlund proved in [
19] that in some fixed dimension the equivalence problem for FDG is undecidable.
However, this remarkable result does not answer the main question: whether efficient algorithms solving FDG exist. For example, there are polynomial algorithms solving the membership problem for context-free languages but the equivalence problem for them is undecidable [
23].
In this paper, we extend arguments of Larsson and Wästlund and prove the existence of a FDG such that solving the game is -complete and requires time , where n is the input size. Furthermore, this bound is optimal up to a polynomial speed-up.
The rest of the paper is organized as follows. In
Section 2 we introduce the concepts that we will need and outline our contribution. The proof of the main theorem is outlined in
Section 3. The following sections contain some more detailed exposition of main steps of the proof. In
Section 4 we describe a relation between binary cellular automata and subtraction games. In
Section 5 we describe a simulation of a Turing machine by a binary cellular automaton. In
Section 6 we present a way to launch a Turing machine on all inputs simultaneously.
Section 7 contains the main proof itself. Finally, in
Section 8 we discuss possible lines of future research in this direction.
2. Concepts and Results
2.1. Impartial Games
Positions and moves of an impartial game form a directed acyclic graph (DAG). It implies that positions in a play cannot be repeated. Such DAG may be infinite, but the set of positions reachable (by one or several moves) from any given position is finite. A choice of an initial position specifies an instance of a game. Two players move alternately. One who must move but is out of moves loses.
Positions of an impartial game are divided in N-
positions and P-
positions (from words Next and Previous). A player who moves at an N-position has a winning strategy. A player who moves at a P-position has not a winning strategy (therefore the opponent has a winning strategy). In graph theory, the set of P-positions of a DAG is called its
kernel; it can be found in time linear in the size of the DAG [
24]. It gives an efficient algorithm solving an impartial game represented by the list of positions and moves. However, many games admit succinct description. The size of DAG may be exponential in size of the succinct description. It makes the kernel construction algorithm exponential.
The Sprague-Grundy (SG) function refines the concept of N- and P-positions. For a set
S of nonnegative integers the
minimum excluded value of
S is defined as the smallest nonnegative integer that is not in
S and denoted by
. In particular,
. The SG value of a position
x is defined recursively as
where
G is the corresponding DAG. A position of SG value
t is called a
t-position. Then, P-positions are exactly 0-positions, while N-positions have positive SG values.
Taking in mind the relation with the Sprague-Grundy function, we assign to P- and N-positions the (Boolean) values 0 and 1, respectively. The basic relation between values of positions is
where all the possible moves from the position
v are to the positions
, ⋯,
. If
v is a sink then
. We will use notation
introduced in [
19] for Boolean functions in Equation (
2).
2.2. Subtraction Games and Modular Games
Now we introduce the class FDG of subtraction games. Subtraction games generalize naturally all versions of nim mentioned above. Please note that a position in a version of nim with d heaps is specified by a d-dimensional vector with nonnegative integer coordinates which are just the numbers of pebbles in a heap. A move in the game decreases some coordinates of this vector. Thus, possible moves are specified by a set of d-dimensional vectors with nonnegative integer coordinates (the difference set). A move from x to y is possible if .
Example 1. Suppose that is a position in the exact slow -nim introduced in Section 1. Any legal move in this position should decrease exactly k values of the coordinates by 1. Therefore is the set of d-dimensional -vectors with exactly k ones, for any x. A subtraction game is defined by similar rules. There are two important differences. In a subtraction game the difference set
is the same for all positions. In a general subtraction game
may contain integer vectors with negative coordinates. It terms of heaps and pebbles it means that a player is allowed to add pebbles to heaps. To avoid infinite plays, we require that the total number of pebbles should be strictly reduced by each move. It is equivalent to the following condition on coordinates of difference vectors:
for any difference vector
.
Finally, a game from the class FDG is defined by a
finite difference set
of
d-dimensional vectors satisfying (
3). In particular, the exact slow
-nim belongs to FDG.
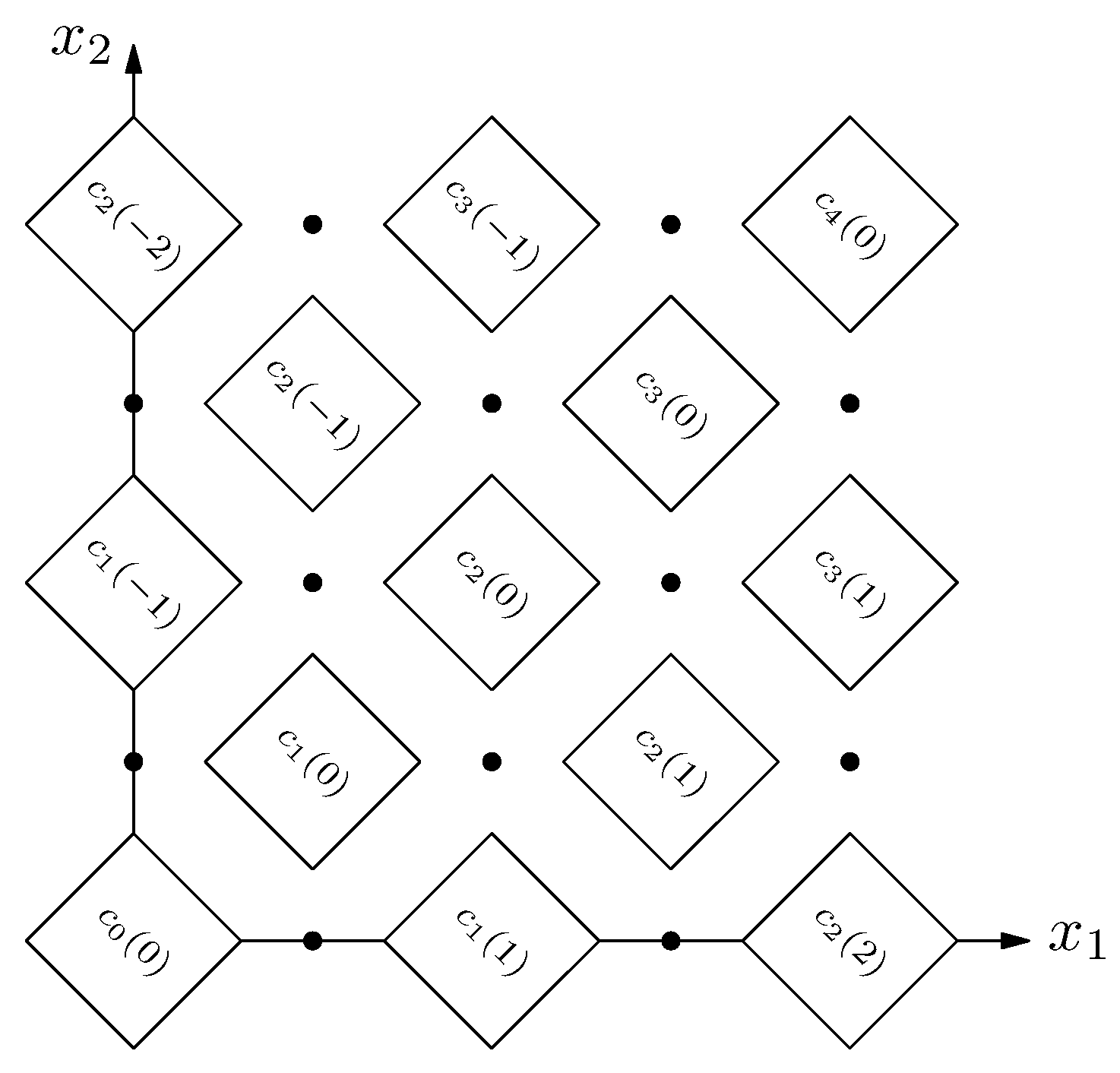
Example 2. Let . Then possible moves from position are to positions and . It is an easy exercise to compute the value of the position: , i.e., it is a P-position.
Due to (
3), any play of a FDG starting at a position
includes only positions with smaller sums of the coordinates. Therefore, computing the value of
by the basic recurrence relation (
2) requires the values at most
positions, where
. Therefore, due to the kernel construction algorithm mentioned above, solving FDG belongs to the class
if the
are presented in binary notation.
This exponential bound on the complexity of solving FDG holds in the case when the difference set is a part of the input. It is easy to show that in this case solving FDG is -hard. For this purpose, we reduce solving the game called NODE KAYLES to solving a FDG. Recall the rules of NODE KAYLES. It is played on a graph G. At each move a player puts a pebble on an unoccupied vertex of G that is non-adjacent to any occupied vertex. As usual, the player unable to make a move loses.
Proposition 1. Solving NODE KAYLES is polynomially reducible to solving FDG.
Proof. Let
be a graph of NODE KAYLES. Construct a
-dimensional subtraction game with the difference set
indexed by the vertices of
G:
, where
We assume in the definition that the coordinates are indexed by the edges of the graph G.
Take the position with all coordinates equal 1. We are going to prove that this position is a P-position of the FDG iff the graph G is a P-position of NODE KAYLES.
Indeed, after subtracting a vector , coordinates indexed by the edges incident to v are zero. It means that after this move it is impossible to subtract the vector and any vector such that .
On the other hand, if the current position is
and there are no edges between a vertex
u and the vertices of the set
X, then the subtraction of the vector
is a legal move at this position.
Thus, the subtraction game starting from the position is isomorphic to the game NODE KAYLES on the graph G. □
Since solving NODE KAYLES is
-complete [
15], we get
-hardness of solving FDG as an immediate corollary of Proposition 1.
In the rest of the paper, we consider a more restricted case. Specifically, we assume that the difference set is fixed and an instance of a computational problem is a vector specifying a position, and the coordinates of the vector are presented in binary notation. The problem is to decide whether is a P-position. In other words, we are going to determine algorithmic complexity of the language consisting of the binary representations of all P-positions of the FDG with the difference set .
Our main result is unconditional hardness of this problem.
Theorem 1. There exist a constant d and a finite set such that the language is -complete and , where n is the input size.
As an immediate corollary of Theorem 1 we see that for some languages the kernel construction algorithm is optimal up to polynomial speed-up.
In the proofs we need a more general class of games introduced in [
19]. They are called
k-modular FDG. A
k-modular
d-dimensional FDG is determined by
k finite sets
of vectors from
. Each vector from each
should satisfy the condition (
3). The rules are similar to those of FDG, but the set of possible moves at a position
x is
, where
r is the residue of
modulo
k.
Example 3. Let , . Then the possible moves from position in 2-modular game are to positions and (since is even). Possible moves from are to and (since is odd).
2.3. Turing Machines and Cellular Automata
Turing machines are a well-known universal model of computation. For the formal definition we refer to Sipser’s book [
25].
Although the cellular automata are also well-known, for the reader’s convenience we provide the definition. Informally, a cellular automaton operates on a tape consisting of cells. The tape is infinite in both directions. Each cell carries a symbol from some fixed set which is called the alphabet. At each step all the symbols in cells are changed simultaneously. The change is governed by the same rule for all cells. This rule specifies a new symbol in a cell depending on a content of a fixed neighborhood of the cell. Formally, a cellular automaton (CA) C is a pair , where A is an alphabet, and is the transition function. The number r is called the size of a neighborhood. A configuration of C is a function .
An operation of a CA starting at a configuration
generates the infinite sequence of configurations. The sequence is defined by the recurrence
Please note that the changes are local: the content of a cell depends only on the content of neighbor cells. It is easy to see that these formal definitions fit the informal description of an operation of a CA.
We assume that there exists a blank symbol in the alphabet and the transition function satisfies the condition (“nothing will come of nothing”). If a CA with the blank symbol starts from a configuration containing only a finite number of non-blank symbols, then its operation generates the sequence of configurations with the same property.
A 2CA (a binary CA) is a CA with the binary alphabet . We assume that 1 is the blank symbol in 2CAs. This non-standard assignment is convenient due to connections with games.
Example 4. Let . It is a 2CA with and the blank symbol 1. Indeed, . If C starts from the configuration , where the dots substitute 1s, then the next configuration is .
It is well-known that Turing machines can be simulated by CA with and any CA can be simulated by a 2CA (with a neighborhood of a larger size).
We will need some specific requirements on these simulations; see
Section 5 for more details.
5. From Turing Machines to Cellular Automata
In this section, we describe how to simulate a Turing machine by a binary cellular automaton. It is standard, except for some specific requirements.
Let be a Turing machine, where the input alphabet is binary, , is the set of states, is the tape alphabet, is the blank symbol, is the transition function, and are the start, accept, and reject states, respectively. The tape of the machine assumed to be infinite in both directions.
A configuration of M specifies the content of the tape, the position of the head and the state of the machine. We encode the configuration by a doubly infinite string , where the set used to combine the content of a cell and the information about the head. Please note that . So, we assume that the head position is indicated by a pair , , ; the content of any other cell is encoded as , .
An operation of M starting from the configuration generates a sequence of encoded configurations . It is easy to see that is determined by , , . In other words, there is a function such that for all u and . Thus, the CA over the alphabet A simulates the operation of M in encoded configurations. The symbol is the blank symbol: (indeed, ℓ is the blank symbol of M, and 0 in the first coordinate indicates that the head is not over the cell).
The next step is to simulate
by a 2CA
. The idea of simulation is simple: just a binary encoding of symbols from
A. But in the chain of reductions outlined in
Section 3 we rely on specific features of the simulation. Therefore, we provide a detailed formal definition.
Let
be an automaton isomorphic to
, where
and
. The transition function
of the automaton is defined as follows
where
is a bijection. To keep the relation between the start configurations, we require that
,
. Recall that 1 is the start state of
M and
ℓ is the blank symbol of
M.
The symbols of
are encoded by binary words as follows
Thus, each symbol is encoded by a word of length . In particular, and . The encoding is naturally extended to words in the alphabet (finite or infinite). The extended encoding is also denoted by .
Thus, the start configuration of M with the empty tape corresponds to the configuration of . Recall that 1 is the blank symbol of .
To construct the transition function of , we use the following alignment of configurations: if , then is the th bit of .
The size of a neighborhood of is . To define the transition function , we use a local inversion property of the encoding : looking at the r-neighborhood of an ith bit of , where , , one can restore symbols , , , and position k of the bit provided the neighborhood contains zeroes (0 is the non-blank symbol of ).
Example 6. Let , . Assume that the neighborhood of the i-th bit, for some unknown i, is The series of three zeroes containing the i-th bit (underlined) is surrounded by ones. Therefore, it is a part of the symbol code . It gives us a decomposition of the neighborhood into symbol codes: Thus, , , , (the fourth bit of the symbol code). Of course, we cannot restore the value q and the absolute position i of the bit.
Please note that if the r-neighborhood of a bit does not contain zeroes then the bit is a part of encoding of the blank symbol 0 of and, moreover, .
We generalize the arguments from the above example to prove the following fact.
Lemma 1. There exists a function such that a 2CA simulates : starting from , it produces the sequence of configurations such that for any t, where is the sequence of configurations produced by starting from the configuration
Proof. The function
should satisfy the following property. If
then
for all integers
,
. This property means that applying the function
to
b produces the configuration
, where
is the configuration produced by the transition function
from the configuration
c. Therefore, the sequence of configurations produced by
starting at
is the sequence of the encodings of configurations
produced by
starting at
.
Please note that , and are in the r-neighborhood of a bit i.
Thus, from the condition on blank symbols in the alphabets and , we conclude that the required property holds if the r-neighborhood of a bit i does not contain zeroes (non-blank symbols of ). In this case, the ith bit of b is a part of the encoding of the blank symbol 0 in the alphabet and, moreover, .
Now suppose that the r-neighborhood of the ith bit contains zeroes. Take the nearest zero to this bit (either from the left or from the right) and the maximal series containing it. The series is a part of the encoding of a symbol in c. Therefore, there are at least ones to the left of it. They all are contained in the r-neighborhood of the bit. Thus, we locate an encoding of a symbol , , and we are able to determine . It depends on relative position of the ith bit with respect to the first bit j of the symbol located. If then ; if then ; otherwise, and . Therefore, the symbols , , can be restored from the r-neighborhood of the ith bit. Moreover, a relative position k of the ith bit in can also be restored.
Because the symbols
,
,
and the position
k are the functions of the
r-neighborhood of the bit
i, it is correct to define the function
as
if the restore process is successful on
; for other arguments, the function can be defined arbitrarily. It is clear that this function satisfies the property (
6). □
6. Parallel Execution of a Turing Machine
In our plan of the proof (see
Section 3), we simulate an operation of a specific Turing machine
M on a specific input
w by an operation of a 2CA on the fixed starting configuration (as it described in the previous section). Thus we need yet another construction: a Turing machine
U simulating an operation of a Turing machine
M on all inputs. The idea of simulation is well-known, but again, we need to specify some details of the construction.
We use notation from the previous section and assume that on each input of length n the machine M makes at most steps, where . It is convenient to include in the alphabet of U the set . Note in advance that there are some additional symbols in the alphabet.
An operation of U is divided into stages while its tape is divided into zones. Each zone is used to simulate an operation of M on a specific input w. All the zones are placed between delimiters, say, ◃ and ▹. In calculations below we assume that ◃ is placed in the cell 0. Also, the zones are separated by a delimiter, say, ⋄.
At the start of a stage there are zones corresponding to the inputs , , ⋯, of M. We order inputs (i.e., binary words) by their lengths and words of equal length are ordered lexicographically.
Each zone consists of three blocks. The blocks in a zone are separated by a delimiter, say #. They are pictured in
Figure 2.
Machine
U maintains the following content in the blocks at the start of a stage
. The content of the second block of a zone
i specifies the input
of the machine
M. The size of the first block is 1. The cell in this block carries the symbol
iff
M accepts the input
. Otherwise, it carries the symbol
. In this way we do not distinguish an unfinished computation and the negative result. However, it does not affect the correctness of reductions built on this construction. The last block of the zone contains a configuration of
M after running
steps on input
. In particular, the last zone contains the initial configuration on input
. The configurations are represented by words over the alphabet
A, as described in
Section 5.
During the first stage, machine U writes on the tape the first zone containing the initial configuration on the input . The zone is surrounded by ◃ and ▹.
During the stage
, machine
U traverses the tape from the left delimiter ◃ to the right delimiter ▹. Entering a zone, it simulates the next step of operation of
M on the corresponding input. At the end of the stage machine
U creates a new zone corresponding to the input
and the initial configuration of
M on this input. The initial configuration is extended in both directions by white space of size
, see
Figure 3.
If the simulation procedure detects that the operation of M on an input is finished, machine U updates the resulting block if necessary and it does not change the zone on the subsequent stages.
In the arguments below we need U to satisfy specific properties.
Proposition 4. If for some integer constant then there exists U operating as is described above such that
- (1)
For all sufficiently large n machine U produces the result of operation of M on the input w of length n in time .
- (2)
The head of U visits the first blocks of zones only on steps t that are divisible by 3.
Proof. At first, we show how to construct a machine satisfying the property 1. More exactly, we explain how to construct a machine satisfying the following claims.
Claim 1. Updating a configuration of the simulated machine M into a zonetakes a time , where S is the size of the zone.
A straightforward way to implement the update is the following. The head of scans the zone until it detects a symbol with . It means that the head of the simulated machine M is over the current cell. Then updates the neighborhood of the cell detected with respect to the transition function of M. If q is a final state then no changes are made. After that continues a motion until it detects the next zone.
If machine M finishes its operation on a configuration written in the current zone and the final state is accept then additional actions should be done. Machine should update the resulting block. For this purpose it returns to the left end of the zone, updates the result block and continues a motion to the right until it detects the next zone.
In this way, each cell in the zone is scanned times. The total time for update is .
Claim 2. A fresh zone on the stage k is created in time , where .
Creation of the resulting block takes a time .
To compute the next input word machine copies the previous input into the second block of the fresh zone. The distance between positions of the second blocks is . Here the term counts delimiters between the blocks. Machine should copy at most n symbols. Therefore, the copying takes a time .
After that, machine computes the next word in the lexicographical order. It can be done by adding 1 modulo to , where is the integer represented in binary by w (the empty word represents 0). It requires a time . If an overflow occurs, then the machine should write an additional zero. It also requires a time .
To mark the third block in the fresh zone machine computes a binary representation of by a polynomial time algorithm using the second block as an input to the algorithm (thus, n is given in unary). Then it makes steps to the right using the computed value as a counter and decreasing the counter each step. The counter should be moved along a tape to save time. The length of binary representation of is . Therefore, each step requires time and totally marking of free space requires time.
Then copies the input word to the right of marked free space. It requires time. The first cell of the copied word should be modified to indicate the initial state of the simulated machine M. In addition, finally, it repeat the marking procedure to the right of the input.
The overall time is .
Let us prove that the property 1 is satisfied by the machine . Counting time in stages, the zone corresponding to an input word w of length n appears after stages. After that, the result of operation of M appears after stages.
Let
. At stage
k there are at most
zones. Updating the existing zones requires time
due to Claim 1. Creation of a fresh zone requires time
due to Claim 2. Thus, the overall time for a stage is
Therefore, the result of operation of
M appears in time
for sufficiently large
n.
Now we explain how to modify the machine to satisfy the property 2. Please note that the resulting block of a zone is surrounded by delimiters: # to the right of it and either ◃ or ⋄ to the left.
We enlarge the state set of adding a counter modulo 3. It is increased by at each step of operation. If the head of the modified machine U is over the ◃ or ⋄ and should go to the right, then machine U makes dummy moves in the opposite direction and back to ensure that it visits the cell to the right on a step t divisible by 3. In a similar way machine U simulates the move to the left from the cell carrying the delimiter #.
The running time after this modification is multiplied by a factor
. Thus, after the modification the last inequality in Equation (
7) holds for sufficiently large
n. □
7. Proof of the Main Theorem
As a hard language, we use the language of the bounded halting problem
which is obviously
-complete. The following proposition is an easy corollary of the time hierarchy theorem [
25].
Proposition 5. , where n is the input size.
Proof. Take an arbitrary language
, where
n is the input size. Let
be a Turing machine recognizing
in time
, where
c is a suitable constant. The function
provides a polynomial reduction of
to
L.
Let us suppose for the sake of contradiction that L is recognized by a Turing machine M in time , where n is the input size. Consider an algorithm to decide :
- (1)
Compute (requires time).
- (2)
Run M on the input (requires time).
The total running time of this algorithm is .
Thus, . It contradicts the time hierarchy theorem. □
Using universal Turing machine and counters it is easy to get an upper bound of the algorithmic complexity of L.
Proposition 6. , where n is the input size.
Proof. To verify one needs to implement a universal Turing machine and a counter of size k. To speed up computation, the description and the counter are shifting along the tape. Shifting by 1 requires time as well as updating the counter. To apply the transition function of M, it suffices to align the corresponding entry of the transition function with the current position of the head.
Thus, to simulate a step of computation made by M on the input x, one needs time, where n is the input size.
The total number of simulation steps is at most . □
Based on Proposition 6, we fix a Turing machine M recognizing L such that for some constant C the machine M makes at most steps on inputs of size n.
For machine
M apply the construction from
Section 6 and Proposition 4 to construct the machine
U. Then convert
U into 2CA
as described in
Section 5. We put an additional requirement on bijection
, namely
. It locates the result of computation of
M in the third bit of the encoding of the result block. More specifically, this bit is 0 iff
M accepts the corresponding input. Finally, construct
-dimensional FDG
as it described in
Section 4. The dimension
of the game is determined by machine
M. By Corollary 1, the symbol
on the tape of
equals the value of position
of the game.
Define the function as follows. Set , where n is the size of w. Set u be the position of the bit carrying the result of computation of M on input w in the image of the resulting block of the zone k corresponding to the input w.
Proposition 7. (i) There exists a polynomial reduction of the language L to the languagebased on the function; (ii).
Proof. The reduction is defined by the function
for sufficiently large inputs (taking into account Proposition 4). For the rest of inputs (there are
of them), the reduction is defined in an arbitrary way preserving correctness.
To compute the function one needs to compute two values.
- (1)
The number k of the zone corresponding to the input w of length n.
- (2)
The position u of the bit carrying the result of computation of M on input w in the image of the resulting block of the zone k.
We are going to prove that computations on step 1 and 2 require time polynomial in n (part (i) of the proposition) and (part (ii)).
For the first claim, note that (recall that is the integer represented in binary by w). Indeed, there are shorter words, all of them precede w in the ordering of binary words that we use. Also, there are exactly words of length n preceding the word w. The formula for k follows from these observations (note that we count words starting from 1).
It is quite obvious now that k is computed in polynomial time.
For the second claim, we should count the sizes of zones preceding the zone for
w and add a constant to take into account delimiters. Let count the size of a zone including the delimiter to the left of it. Then the size of a zone for an input word of length
ℓ is
There are
words of length
ℓ. Thus, the total size of the zones preceding the zone of
w is
For this expression can be computed in polynomial time in n by a straightforward procedure (the expression above has arithmetic operations and the results of these operations are integers represented in binary by bits).
Thus, the resulting block of the zone of w is (the delimiter to the left of the zone adds 1).
To compute u we should multiply by (the size of encoding) and add 3 (because the third bit indicates the result of computation of the simulated machine M).
All these calculations can be done in polynomial time.
Now the required upper bound on
u can be easily verified:
□
Now the first claim of Theorem 1 follows from part (i) of Proposition 7. For the second claim, we use the part (ii) of Proposition 7. It implies that the reduction maps a word of size n to a vector of size at most . So, if an algorithm solves the game in time , then the composition of the reduction and recognizes L in time . By Proposition 5 this value is . We conclude that .
8. Discussion
Our hardness result drastically contrasts with the results on slow nim in [
13,
14]. For these games, a rather simple formula was obtained for the SG function. So, these games are solved efficiently.
Slow versions of nim can be considered to be FDG, see Example 1. The difference sets for these games consist of -vectors.
A more general subclass of FDG is formed by games whose difference vectors are nonnegative. In other words, players are not allowed to add pebbles to heaps.
In our proof we use the construction by Larsson and Wästlund. The negative coordinates of difference vectors are essential in it. We see no way to maintain a counter modulo N without such vectors in the difference set.
Moreover, we believe that the existence of difference vectors with negative coordinates is essential for both hardness results: ours and the undecidability result from [
19].
Conjecture 1. For any FDG game such that for each , there exists a polynomial algorithm solving the game, i.e., .
To the best of our knowledge, P-positions of all efficiently solved FDG form semilinear sets. Recall that a
semilinear set is a set of vectors from
that can be expressed in Presburger arithmetic; see, e.g., [
26]. Presburger arithmetic admits quantifier elimination. Therefore, a semilinear set can be expressed as a finite union of solutions of systems of linear inequalities and equations modulo some integer (fixed for the set).
Conjecture 2. For any FDG game such that for each , the set of P-positions is semilinear.
It is well-known that evaluating a formula in Presburger arithmetic is a very hard problem. The first doubly exponential time bound for this problem was established by Fischer and Rabin [
27]. Berman proved that the problem requires doubly exponential space [
28].
However, these hardness results are irrelevant for our needs. In solving FDG games we deal with sets of dimension and we may hardwire the description of the set of P-positions in an algorithm solving the game. Verifying a linear inequality takes a polynomial time as well as verifying an equation modulo some integer. Thus, any semilinear set of dimension can be recognized by a polynomial time algorithm. Therefore Conjecture 2 implies Conjecture 1.
Conjecture 2 also implies that the equivalence problem for FDG with nonnegative difference vectors is decidable, since Presburger arithmetic is decidable. Indeed, by Post’s theorem a set is decidable if it is enumerable and co-enumerable. The set is trivially co-enumerable, since it is decidable to check whether applying the kernel construction algorithm. On the other hand, the set , where is a description of a semilinear set S, is decidable: the statement can be expressed in Presburger arithmetic. Therefore set E is enumerable.
Why do we believe in Conjecture 2 despite results from [
19] and ours? It seems that some inductive arguments can be applied in the case of nonnegative difference vectors. Please note that Conjecture 2 holds for a 1-dimensional FDG [
22]. If a coordinate becomes zero it remains zero during the rest of the game (if all difference vectors are nonnegative). Thus, it might be possible to prove the implication: if “boundary conditions” are semilinear then the solution of a game is also semilinear. (After the paper was submitted, Michael Raskin pointed out that this claim is false for
arbitrary semilinear boundary conditions. However, his arguments cannot be applied to boundary conditions produced by games). The above observations show a way to Conjecture 2.



{kind=link}
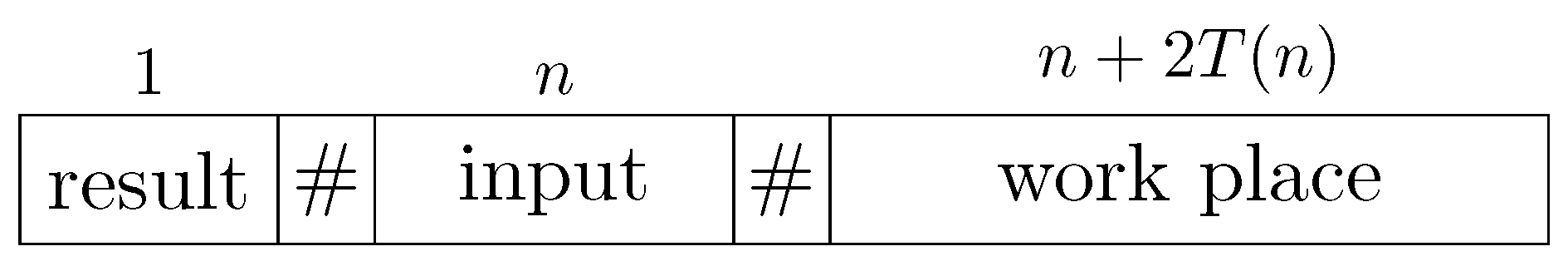{kind=link}
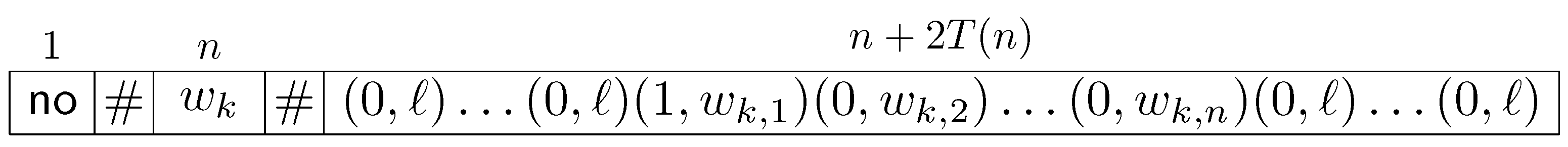{kind=link}


