DynASP2.5: Dynamic Programming on Tree Decompositions in Action †


Abstract
:1. Introduction
1.1. Contributions
- We present a new dynamic programming algorithm on a graph representation that is somewhat in-between the incidence and primal graph and show its correctness.
- We establish a novel fixed-parameter linear algorithm (), which works in multiple traversals and computes existential and universal parts separately.
- We present an implementation (DynASP2.5) and an experimental evaluation.
1.2. Related Work
1.3. Journal Version
2. Preliminaries
2.1. Tree Decompositions
- 1.
- for every vertex there is a node with ;
- 2.
- for every edge there is a node with ; and
- 3.
- for any three nodes whenever lies on the unique path from to , then we have .
2.2. Answer Set Programming (ASP)
2.2.1. Syntax
 . A rule is either a disjunctive, a choice, or an optimization rule. For a choice or disjunctive rule r, let , , and . Usually, if we write for a rule r simply instead of . For an optimization rule r, if , let and ; and if , let and . For a rule r, let denote its atoms and its body. Let a program P be a set of rules, and denote its atoms. Furthermore, let , , and denote the set of all choice, disjunctive, and optimization rules in P, respectively.
. A rule is either a disjunctive, a choice, or an optimization rule. For a choice or disjunctive rule r, let , , and . Usually, if we write for a rule r simply instead of . For an optimization rule r, if , let and ; and if , let and . For a rule r, let denote its atoms and its body. Let a program P be a set of rules, and denote its atoms. Furthermore, let , , and denote the set of all choice, disjunctive, and optimization rules in P, respectively.2.2.2. Semantics
2.3. Graph Representations of Programs
2.4. Sub-Programs
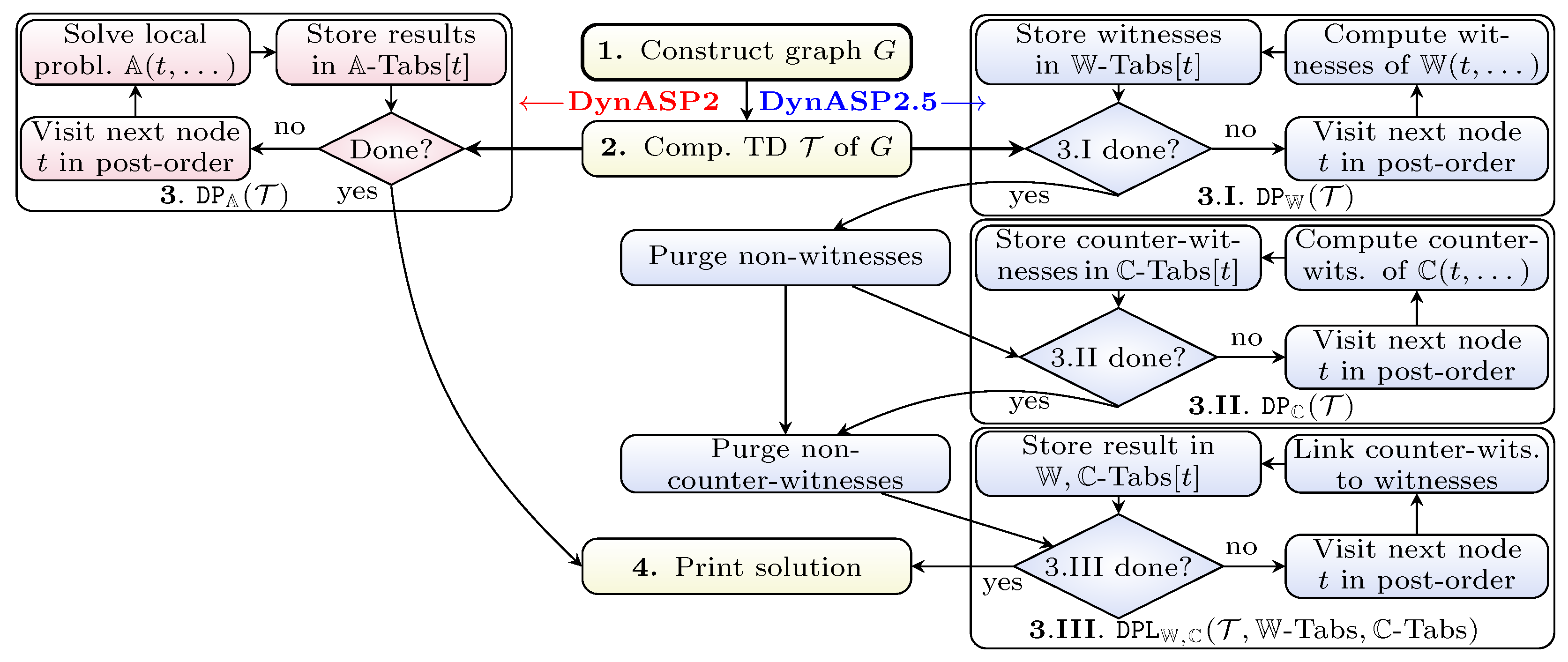
3. A Single Traversal DP Algorithm
- 1.
- Construct a graph representation of the given input program P.
- 2.
- Compute a TD of the graph by means of some heuristic, thereby decomposing into several smaller parts and fixing an ordering in which P will be evaluated.
- 3.
- For every node in the tree decomposition (in a bottom-up traversal), run an algorithm , which we call table algorithm, and compute a “table” , which is a set of tuples (or rows for short). Intuitively, algorithm transforms tables of child nodes of t to the current node, and solves a “local problem” using bag-program . The algorithm thereby computes (i) sets of atoms called (local) witness sets and (ii) for each local witness set M subsets of M called counter-witness sets [11], and directly follows the definition of answer sets being (i) models of P and (ii) subset minimal with respect to .
- 4.
- For root n interpret the table (and tables of children, if necessary) and print the solution to the considered ASP problem.
| Algorithm 1: Algorithm for Dynamic Programming on TD for ASP [11]. |
 |
An Algorithm on the Semi-Incidence Graph
| Algorithm 2: Table algorithm . |
 |
3.1. Correctness and Runtime of Algorithm 2 ()
- 1.
- ,
- 2.
- for we require:
- 3.
- (a)
- for disjunctive rule , we have or or if and only if ;
- (b)
- for choice rule , we have or or both and if and only if .
- 1.
- ,
- 2.
- , and
- 3.
- .
 where is defined in accordance with Algorithm 2 as follows:
where is defined in accordance with Algorithm 2 as follows:

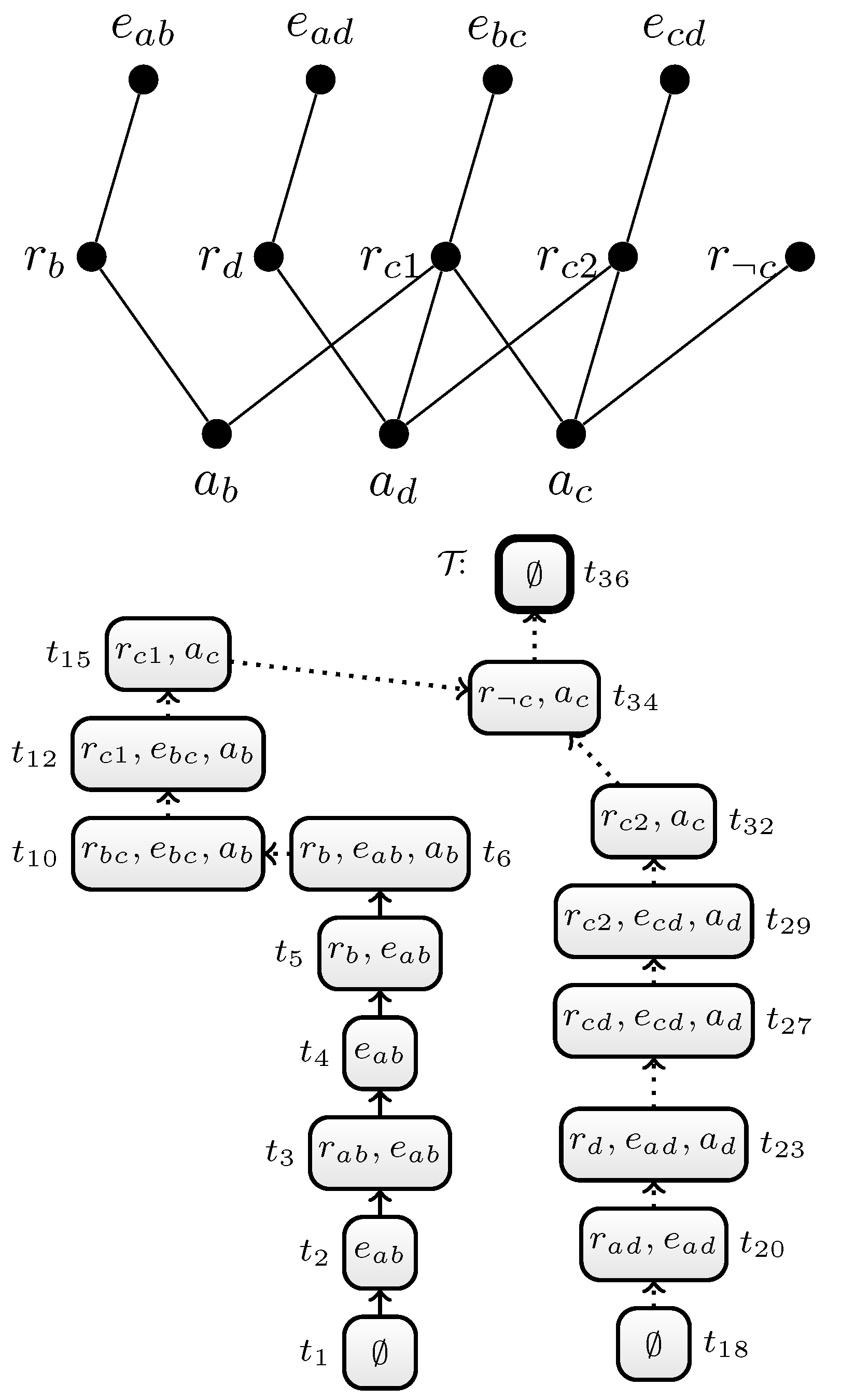
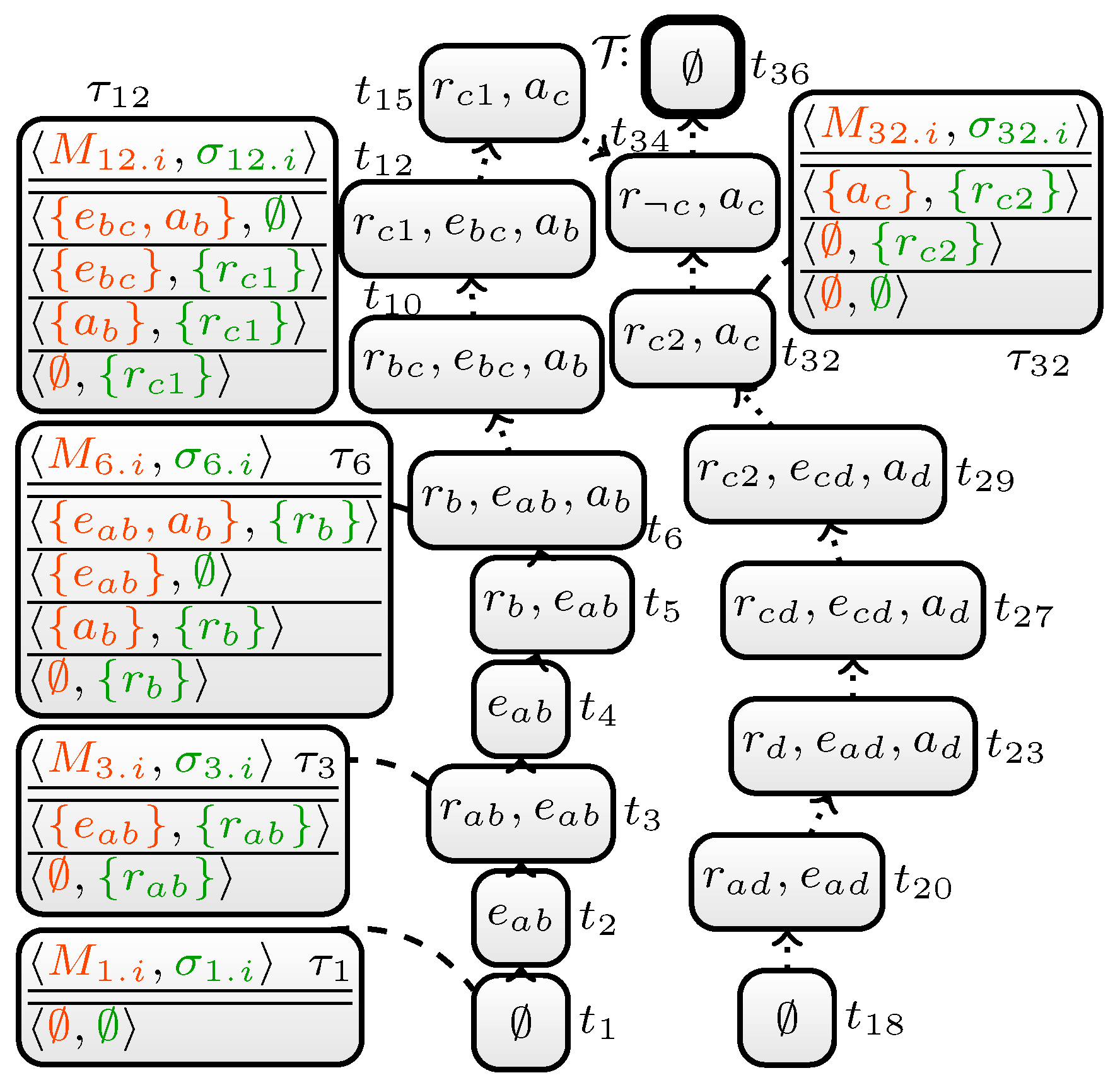
3.2. An Extended Example
4. DynASP2.5: Towards a III Traversal DP Algorithm
4.1. The Algorithm
- 3.I.
- First, we run the algorithm , which computes in a bottom-up traversal for every node t in the tree decomposition a table of witnesses for t. Then, in a top-down traversal for every node t in the TD remove from tables witnesses, which do not extend to a witness in the table for the parent node (“Purge non-witnesses”); these witnesses can never be used to construct a model (nor answer set) of the program.
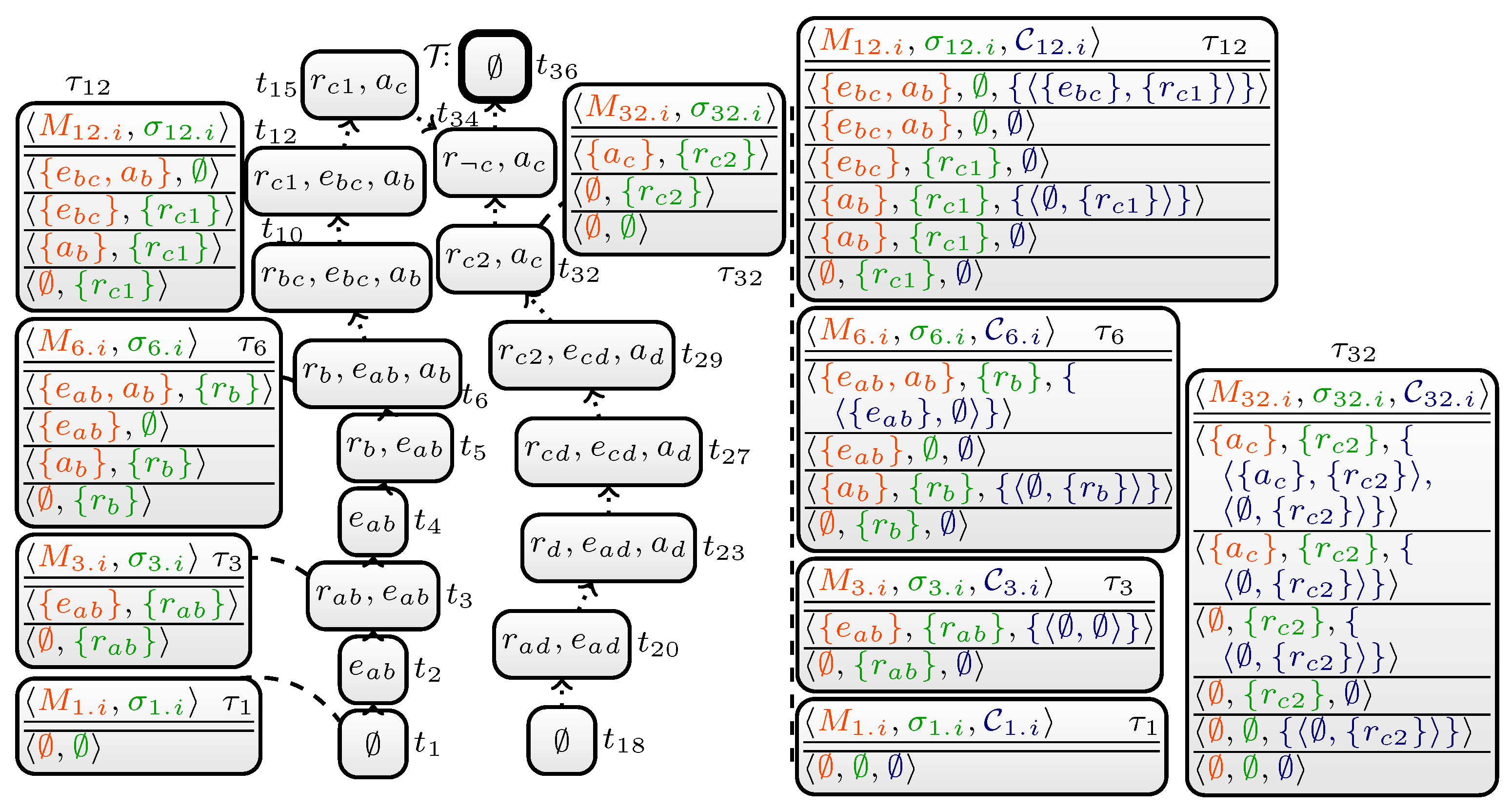
- 3.II.
- For this step, let be a table algorithm computing only counter-witnesses of (blue parts of Algorithm 2). We execute , for all witnesses, compute counter-witnesses at once and store the resulting tables in . For every node t, table contains counter-witnesses to witness being ⊂-minimal. Again, irrelevant rows are removed (“Purge non-counter-witnesses”).
- 3.III.
- Finally, in a bottom-up traversal for every node t in the TD, witnesses and counter-witnesses are linked using algorithm (see Algorithm 3). takes previous results and maps rows in to a table (set) of rows in .
| Algorithm 3: Algorithm for linking counter-witnesses to witnesses. |
 |
4.2. An Elaborated Example
4.3. Correctness and Runtime of DynASP2.5
- 1.
- For all rows of the form , we have .
- 2.
- For all with it holds that .
- 3.
- For all , , , and it holds that and .
- 4.
- No element of has been α-illegally introduced and no element of has been β-illegally introduced.
- 5.
- No element of has been α-illegally removed and no element of has been β-illegally removed.
- 1.
- : By construction of F we have for any , which implies that . However, this contradicts our assumption that M is an answer set of P.
- 2.
- : By construction of F there is at least one atom with , but . Consequently, . This contradicts again that M is an answer set of P.
- 1.
- N is not a model of P: We construct and show that X is indeed a model of F. For this, for every where we have , since by definition of X. For formulas constructed by using remaining rules r, we also have , since . In conclusion, and , and therefore X contradicts Y is a subset-minimal model of F.
- 2.
- N is also a model of P: Observe that then is also a model of F, which contradicts optimality of Y since .
- 1.
- For any , and , there is a row with and .
- 2.
- For any with such that , and the following holds: Let with , with , and with or . Then, there is a row with if and only if and .
5. Experimental Evaluation
5.1. Implementation Details
5.2. Benchmark Set
5.2.1. Steiner Tree Problem
- 1.
- all terminal vertices are covered : , and
- 2.
- the number of edges in forms a minimum : there is no tree, where all terminal vertices are covered that consists of no more than many edges.
. It is easy to see that the answer sets of the program and the uniform Steiner trees are in a one-to-one correspondence.5.2.2. Considered Encodings
vertex(X) ← edge(X,_).
vertex(Y) ← edge(_,Y).
edge(X,Y) ← edge(Y,X).
0 { selectedEdge(X,Y) } 1 ← edge(X,Y), X < Y.
s1(X) ∨ s2(X) ← vertex(X).
saturate ← selectedEdge(X,Y), s1(X), s2(Y), X < Y.
saturate ← selectedEdge(X,Y), s2(X), s1(Y), X < Y.
saturate ← N #count{ X : s1(X), terminalVertex(X) }, numVertices(N).
saturate ← N #count{ X : s2(X), terminalVertex(X) }, numVertices(N).
s1(X) ← saturate, vertex(X).
s2(X) ← saturate, vertex(X).
← not saturate.
#minimize{ 1,X,Y : selectedEdge(X,Y) }.
edge(X,Y) ← edge(Y,X).
{ selectedEdge(X,Y) : edge(X,Y), X < Y }.
reached(Y) ← Y = #min{ X : terminalVertex(X) }.
reached(Y) ← reached(X), selectedEdge(X,Y).
reached(Y) ← reached(X), selectedEdge(Y,X).
← terminalVertex(X), not reached(X).
#minimize{ 1,X,Y : selectedEdge(X,Y) }.
5.3. Experimental Evaluation
5.3.1. Benchmark Environment
5.3.2. Runtime Limits
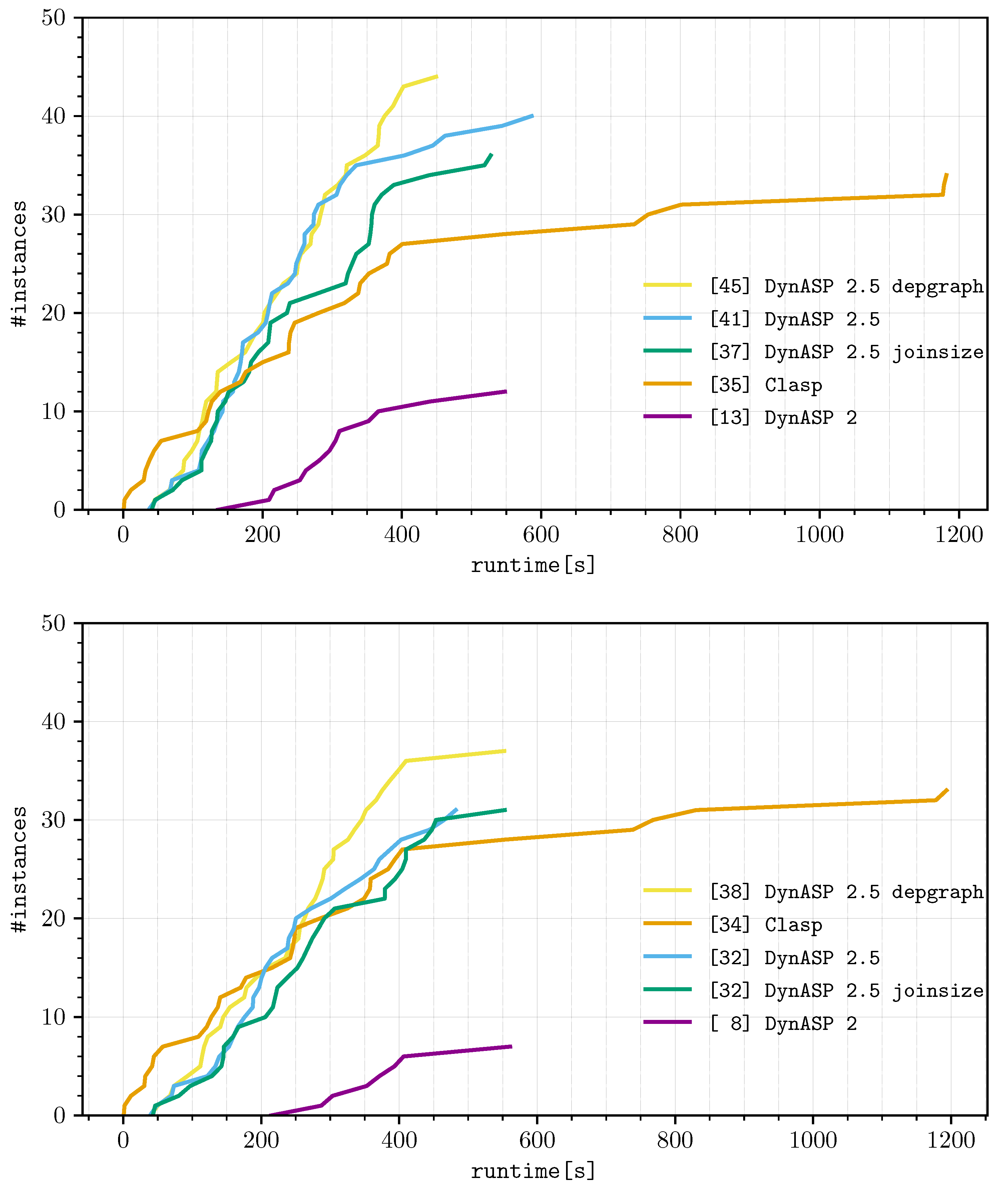
5.3.3. Summary of the Results
5.4. A Brief Remark on Instances without Optimization
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Janhunen, T.; Niemelä, I. The Answer Set Programming Paradigm. AI Mag. 2016, 37, 13–24. [Google Scholar] [CrossRef] [Green Version]
- Simons, P.; Niemelä, I.; Soininen, T. Extending and implementing the stable model semantics. Artif. Intell. 2002, 138, 181–234. [Google Scholar] [CrossRef] [Green Version]
- Eiter, T.; Gottlob, G. On the computational cost of disjunctive logic programming: Propositional case. Ann. Math. Artif. Intell. 1995, 15, 289–323. [Google Scholar] [CrossRef]
- Egly, U.; Eiter, T.; Tompits, H.; Woltran, S. Solving Advanced Reasoning Tasks Using Quantified Boolean Formulas. In Proceedings of the 17th National Conference on Artificial Intelligence (AAAI’00), Austin, TX, USA, 30 July–3 August 2000; pp. 417–422. [Google Scholar]
- Egly, U.; Eiter, T.; Klotz, V.; Tompits, H.; Woltran, S. Computing Stable Models with Quantified Boolean Formulas: Some Experimental Results. In Proceedings of the 1st International Workshop on Answer Set Programming (ASP’01), Stanford, CA, USA, 26–28 March 2001. [Google Scholar]
- Jakl, M.; Pichler, R.; Woltran, S. Answer-Set Programming with Bounded Treewidth. In Proceedings of the 21st International Joint Conference on Artificial Research (IJCAI’09), Pasadena, CA, USA, 14–17 July 2009; pp. 816–822. [Google Scholar]
- Lampis, M.; Mitsou, V. Treewidth with a Quantifier Alternation Revisited. In Proceedings of the 12th International Symposium on Parameterized and Exact Computation (IPEC’17), Vienna, Austria, 6–8 September 2017; Volume 89, pp. 26:1–26:12. [Google Scholar]
- Fichte, J.K.; Hecher, M.; Pfandler, A. Lower Bounds for QBFs of Bounded Treewidth. In Proceedings of the 35th Annual ACM/IEEE Symposium on Logic in Computer Science (LICS’20), Rome, Italy, 29 June–2 July 2021; pp. 410–424. [Google Scholar] [CrossRef]
- Gebser, M.; Kaufmann, B.; Schaub, T. The Conflict-Driven Answer Set Solver clasp: Progress Report. In Proceedings of the 10th International Conference on Logic Programming and Nonmonotonic Reasoning (LPNMR’09), Potsdam, Germany, 14–18 September 2009; Erdem, E., Lin, F., Schaub, T., Eds.; Lecture Notes in Computer Science. Springer: Potsdam, Germany, 2009; Volume 5753, pp. 509–514. [Google Scholar] [CrossRef] [Green Version]
- Alviano, M.; Dodaro, C.; Faber, W.; Leone, N.; Ricca, F. WASP: A Native ASP Solver Based on Constraint Learning. In Proceedings of the 12th International Conference on Logic Programming and Nonmonotonic Reasoning (LPNMR’13); Son, P.C.C., Ed.; Lecture Notes in Computer Science; Springer: Corunna, Spain, 2013; Volume 8148, pp. 54–66. [Google Scholar] [CrossRef]
- Fichte, J.K.; Hecher, M.; Morak, M.; Woltran, S. Answer Set Solving with Bounded Treewidth Revisited. In Proceedings of the 14th International Conference on Logic Programming and Nonmonotonic Reasoning (LPNMR’17), Espoo, Finland, 3–6 July 2017; Balduccini, M., Janhunen, T., Eds.; Lecture Notes in Computer Science. Springer: Espoo, Finland, 2017; Volume 10377, pp. 132–145. [Google Scholar] [CrossRef] [Green Version]
- Abseher, M.; Musliu, N.; Woltran, S. Improving the Efficiency of Dynamic Programming on Tree Decompositions via Machine Learning. J. Artif. Intell. Res. 2017, 58, 829–858. [Google Scholar] [CrossRef]
- Fichte, J.K.; Hecher, M. Treewidth and Counting Projected Answer Sets. In Proceedings of the 15th International Conference on Logic Programming and Nonmonotonic Reasoning (LPNMR’19), Philadelphia, PA, USA, 3–7 June 2019; Lecture Notes in Computer Science. Springer: Philadelphia, PA, USA, 2019; Volume 11481, pp. 105–119. [Google Scholar] [CrossRef] [Green Version]
- Hecher, M.; Morak, M.; Woltran, S. Structural Decompositions of Epistemic Logic Programs. In Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI’20), New York, NY, USA, 7–12 February 2020; Conitzer, V., Sha, F., Eds.; The AAAI Press: New York, NY, USA, 2020; pp. 2830–2837. [Google Scholar] [CrossRef]
- Hecher, M. Treewidth-aware Reductions of Normal ASP to SAT—Is Normal ASP Harder than SAT after All? In Proceedings of the 17th International Conference on Principles of Knowledge Representation and Reasoning (KR’20), Rhodes, Greece, 12–18 September 2020; Calvanese, D., Erdem, E., Thielscher, M., Eds.; IJCAI Organization: Rhodes, Greece, 2020; pp. 485–495. [Google Scholar] [CrossRef]
- Kneis, J.; Langer, A.; Rossmanith, P. Courcelle’s theorem—A game-theoretic approach. Discret. Optim. 2011, 8, 568–594. [Google Scholar] [CrossRef] [Green Version]
- Bliem, B.; Charwat, G.; Hecher, M.; Woltran, S. D-FLAT^2: Subset Minimization in Dynamic Programming on Tree Decompositions Made Easy. Fundam. Inf. 2016, 147, 27–34. [Google Scholar] [CrossRef] [Green Version]
- Abseher, M.; Musliu, N.; Woltran, S. htd—A Free, Open-Source Framework for (Customized) Tree Decompositions and Beyond. In Proceedings of the CPAIOR’17, Padova, Italy, 5–8 June 2017; Volume 10335, pp. 376–386. [Google Scholar]
- Dell, H.; Komusiewicz, C.; Talmon, N.; Weller, M. The PACE 2017 Parameterized Algorithms and Computational Experiments Challenge: The Second Iteration. In Proceedings of the 12th International Symposium on Parameterized and Exact Computation (IPEC’17), Vienna, Austria, 6–8 September 2017; Lokshtanov, D., Nishimura, N., Eds.; Leibniz International Proceedings in Informatics (LIPIcs). Dagstuhl Publishing: Wadern, Germany, 2018; Volume 89, pp. 30:1–30:12. [Google Scholar] [CrossRef]
- Fichte, J.K.; Szeider, S. Backdoors to Tractable Answer-Set Programming. Artif. Intell. 2015, 220, 64–103. [Google Scholar] [CrossRef]
- Fichte, J.K.; Truszczyński, M.; Woltran, S. Dual-normal logic programs—The forgotten class. Theory Pract. Log. Program. 2015, 15, 495–510. [Google Scholar] [CrossRef] [Green Version]
- Fichte, J.K.; Szeider, S. Backdoors to Normality for Disjunctive Logic Programs. ACM Trans. Comput. Log. 2015, 17. [Google Scholar] [CrossRef] [Green Version]
- Fichte, J.K.; Kronegger, M.; Woltran, S. A multiparametric view on answer set programming. Ann. Math. Artif. Intell. 2019, 86, 121–147. [Google Scholar] [CrossRef]
- Diestel, R. Graph Theory, 4th ed.; Graduate Texts in Mathematics; Springer: Berlin/Heidelberg, Germany, 2012; Volume 173, p. 410. [Google Scholar]
- Bondy, J.A.; Murty, U.S.R. Graph Theory; Graduate Texts in Mathematics; Springer: New York, NY, USA, 2008; Volume 244, p. 655. [Google Scholar]
- Bodlaender, H.; Koster, A.M.C.A. Combinatorial Optimization on Graphs of Bounded Treewidth. Comput. J. 2008, 51, 255–269. [Google Scholar] [CrossRef] [Green Version]
- Brewka, G.; Eiter, T.; Truszczyński, M. Answer set programming at a glance. Commun. ACM 2011, 54, 92–103. [Google Scholar] [CrossRef]
- Lifschitz, V. What is Answer Set Programming? In Proceedings of the 23rd AAAI Conference on Artificial Intelligence (AAAI’08), Chicago, IL, USA, 13–17 July 2008; Holte, R.C., Howe, A.E., Eds.; The AAAI Press: Chicago, IL, USA, 2008; pp. 1594–1597. [Google Scholar]
- Schaub, T.; Woltran, S. Special Issue on Answer Set Programming. KI 2018, 32, 101–103. [Google Scholar] [CrossRef] [Green Version]
- Bodlaender, H.L. A linear-time algorithm for finding tree-decompositions of small treewidth. SIAM J. Comput. 1996, 25, 1305–1317. [Google Scholar] [CrossRef]
- Kloks, T. Treewidth, Computations and Approximations; LNCS; Springer: Berlin/Heidelberg, Germany, 1994; Volume 842. [Google Scholar]
- Samer, M.; Szeider, S. Algorithms for propositional model counting. J. Discrete Algorithms 2010, 8. [Google Scholar] [CrossRef] [Green Version]
- Morak, M.; Musliu, N.; Pichler, R.; Rümmele, S.; Woltran, S. Evaluating Tree-Decomposition Based Algorithms for Answer Set Programming. In Proceedings of the 6th International Conference on Learning and Intelligent Optimization (LION’12), Paris, France, 16–20 January 2012; Hamadi, Y., Schoenauer, M., Eds.; Lecture Notes in Computer Science. Springer: Paris, France, 2012; pp. 130–144. [Google Scholar] [CrossRef] [Green Version]
- Gottlob, G.; Scarcello, F.; Sideri, M. Fixed-parameter complexity in AI and nonmonotonic reasoning. Artif. Intell. 2002, 138, 55–86. [Google Scholar] [CrossRef] [Green Version]
- Karp, R.M. Reducibility Among Combinatorial Problems. In Proceedings of the Complexity of Computer Computations, New York, NY, USA, 20–22 March 1972; The IBM Research Symposia Series; Plenum Press: New York, NY, USA, 1972; pp. 85–103. [Google Scholar]
- Fichte, J.K. daajoe/gtfs2graphs—A GTFS Transit Feed to Graph Format Converter. Available online: https://github.com/daajoe/gtfs2graphs (accessed on 17 September 2017).
- Bliem, B.; Morak, M.; Moldovan, M.; Woltran, S. The Impact of Treewidth on Grounding and Solving of Answer Set Programs. J. Artif. Intell. Res. 2020, 67, 35–80. [Google Scholar] [CrossRef]
- Gebser, M.; Harrison, A.; Kaminski, R.; Lifschitz, V.; Schaub, T. Abstract gringo. Theory Pract. Log. Program. 2015, 15, 449–463. [Google Scholar] [CrossRef] [Green Version]
- Syrjänen, T. Lparse 1.0 User’s Manual. 2002. Available online: tcs.hut.fi/Software/smodels/lparse.ps (accessed on 17 May 2017).
- Alviano, M.; Dodaro, C. Anytime answer set optimization via unsatisfiable core shrinking. Theory Pract. Log. Program. 2016, 16, 533–551. [Google Scholar] [CrossRef] [Green Version]
- Fichte, J.K.; Hecher, M.; Morak, M.; Woltran, S. Answer Set Solving Using Tree Decompositions and Dynamic Programming—The DynASP2 System; Technical Report DBAI-TR-2016-101; TU Wien: Vienna, Austria, 2016. [Google Scholar]
- Dzulfikar, M.A.; Fichte, J.K.; Hecher, M. The PACE 2019 Parameterized Algorithms and Computational Experiments Challenge: The Fourth Iteration (Invited Paper). In Proceedings of the 14th International Symposium on Parameterized and Exact Computation (IPEC’19), Munich, Germany, 11–13 September 2019; Jansen, B.M.P., Telle, J.A., Eds.; Leibniz International Proceedings in Informatics (LIPIcs). Dagstuhl Publishing: Munich, Germany, 2019; Volume 148, pp. 25:1–25:23. [Google Scholar] [CrossRef]
- Fichte, J.K.; Hecher, M.; Thier, P.; Woltran, S. Exploiting Database Management Systems and Treewidth for Counting. In Proceedings of the 22nd International Symposium on Practical Aspects of Declarative Languages (PADL’20), New Orleans, LA, USA, 20–21 January 2020; Komendantskaya, E., Liu, Y.A., Eds.; Springer: New Orleans, LA, USA, 2020; pp. 151–167. [Google Scholar] [CrossRef] [Green Version]
- Hecher, M.; Thier, P.; Woltran, S. Taming High Treewidth with Abstraction, Nested Dynamic Programming, and Database Technology. In Proceedings of the Theory and Applications of Satisfiability Testing—SAT 2020, Alghero, Italy, 5–9 July 2020; Pulina, L., Seidl, M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 343–360. [Google Scholar]
- Fichte, J.K.; Hecher, M.; Schindler, I. Default Logic and Bounded Treewidth. In Proceedings of the 12th International Conference on Language and Automata Theory and Applications (LATA’18), Ramat Gan, Israel, 9–11 April 2018; Klein, S.T., Martín-Vide, C., Eds.; Lecture Notes in Computer Science. Springer: Ramat Gan, Israel, 2018. [Google Scholar]
- Fichte, J.K.; Hecher, M.; Meier, A. Counting Complexity for Reasoning in Abstract Argumentation. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence (AAAI’19), Honolulu, HI, USA, 27 January–1 February 2019; Hentenryck, P.V., Zhou, Z.H., Eds.; The AAAI Press: Honolulu, HI, USA, 2019; pp. 2827–2834. [Google Scholar]
- Fichte, J.K.; Hecher, M.; Meier, A. Knowledge-Base Degrees of Inconsistency: Complexity and Counting. In Proceedings of the 35rd AAAI Conference on Artificial Intelligence (AAAI’21), Vancouver, BC, Canada, 2–9 February 2021; Leyton-Brown, K., Mausam, Eds.; The AAAI Press: Vancouver, BC, Canada, 2021. In Press. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solver | Solved | Runtimes (Best) among Solved Instances | PAR2 Score | ||||
|---|---|---|---|---|---|---|---|
| TD | 3.I | 3.II | 3.III | ||||
| Clasp 3.3.0 | 35 | - | - | - | - | 11,493.98 | 93,093.98 |
| DynASP2 | 13 | 7.96 (0.2%) | - | - | - | 3978.29 | 138,378.29 |
| DynASP2.5 | 41 | 21.68 (0.2%) | 130.10 (1.4%) | 585.47 (6.2%) | 8656.48 (92.2%) | 9393.73 | 76,496.74 |
| “depgraph” | 45 | 408.72 (4.0%) | 138.21 (1.4%) | 595.58 (5.8%) | 9033.70 (88.8%) | 10,176.21 | 67,667.71 |
| “joinsize” | 37 | 22.82 (0.3%) | 120.19 (1.3%) | 544.18 (6.1%) | 8250.16 (92.3%) | 8937.35 | 85,654.00 |
| Solver | Solved | Runtimes (median) among solved instances | PAR2 Score | ||||
| TD | 3.I | 3.II | 3.III | ||||
| Clasp 3.3.0 | 34 | - | - | - | - | 11,688.58 | 94,523.53 |
| DynASP2 | 8 | 8.74 (0.2%) | - | - | - | 4370.83 | 149,289.20 |
| DynASP2.5 | 32 | 21.91 (0.2%) | 140.08 (1.3%) | 685.15 (6.4%) | 9878.67 (92.1%) | 10,725.81 | 96,405.37 |
| “depgraph” | 38 | 473.12 (4.1%) | 146.33 (1.3%) | 661.00 (5.8%) | 10,118.22 (88.8%) | 11,398.67 | 81,425.39 |
| “joinsize” | 32 | 25.47 (0.2%) | 129.41 (1.3%) | 596.62 (5.8%) | 9538.77 (92.7%) | 10,290.27 | 97,260.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fichte, J.K.; Hecher, M.; Morak, M.; Woltran, S. DynASP2.5: Dynamic Programming on Tree Decompositions in Action. Algorithms 2021, 14, 81. https://doi.org/10.3390/a14030081
Fichte JK, Hecher M, Morak M, Woltran S. DynASP2.5: Dynamic Programming on Tree Decompositions in Action. Algorithms. 2021; 14(3):81. https://doi.org/10.3390/a14030081
Chicago/Turabian StyleFichte, Johannes K., Markus Hecher, Michael Morak, and Stefan Woltran. 2021. "DynASP2.5: Dynamic Programming on Tree Decompositions in Action" Algorithms 14, no. 3: 81. https://doi.org/10.3390/a14030081
APA StyleFichte, J. K., Hecher, M., Morak, M., & Woltran, S. (2021). DynASP2.5: Dynamic Programming on Tree Decompositions in Action. Algorithms, 14(3), 81. https://doi.org/10.3390/a14030081