1. Introduction
The endeavor of developing a suitable neighborhood scheme is a key factor in the success of any local search algorithm. The reason is that the critical role the size of the neighborhood plays in striking a balance between the effectiveness and computational time [
1,
2]. For striking such a balance in solving the permutation flow-shop scheduling problem, this paper presents a two-level decomposition-based, variable neighborhood search stochastic algorithm that embeds a large neighborhood scheme into a small one.
The algorithm, called Refining Decomposition-based Integrated Search (RDIS), refines a solution obtained by its small neighborhood search through its large neighborhood search, and uses the notion of decomposition in the two levels of (i) producing an initial solution, and (ii) performing large neighborhood search on the initial solution. Both neighborhood schemes employed are k-exchange [
3].
The
k-exchange schemes, as the most common types of neighborhood schemes, consider two candidate solutions as neighbors if they differ in at most
k solution elements [
3]. It is clear that larger neighborhood schemes contain more and potentially better candidate solutions but this increases the neighborhood size of these schemes exponentially with
k [
2]. In effect, when
k is as large as the size of the problem, the corresponding neighborhood scheme makes local optimal solutions global optimal; however, because of their impracticality, these kinds of neighborhood schemes are not used in practice. On the other hand, smaller values of
k require lower computational time at the cost of generating fewer candidate solutions [
1,
3].
In combing small and large neighborhood schemes, the RDIS has three synergetic characteristics of (i) generating an initial solution with a construction method that has been built upon the concept of decomposition of jobs and the extended two-machine solution strategy, (ii) improving the initial solution with a small neighborhood search, and (iii) enhancing the result produced by the small-neighborhood search with a large neighborhood search which has been built based on a decomposition technique.
The construction method for generating initial solutions is based on the recursive application of the extended 2-machine problem [
4], described in
Section 2. Aimed at generating high-quality solutions, and inspired by the famous two-machine problem [
4], this recursive algorithm repeatedly decomposes the jobs and finds the best permutation for the decomposed jobs, with the goal of improving the quality of initial solutions.
Although the employed large neighborhood search, the same as the engaged construction method, is based on decomposition, it performs decomposition in an iterative manner, and not recursively. This iterative decomposition technique starts with the top k jobs in the permutation and ends with the k bottom jobs, ignoring any unfruitful contiguous parts in the middle. In each round, it also keeps the result of calculations in memory to prevent any repeat of calculations in further rounds. In optimizing small chunks, this effective use of memory makes the optimization process as fast as simple decoding of a permutation to a solution. The main contributions of this paper are outlined in the following:
The effective embedding of a large neighborhood decomposition technique into a variable neighborhood search for the permutation flow-shop scheduling problem;
Efficient decomposition of the main problem into subproblems, and finding optimal permutations for those smaller subproblems; and
Employing the concept of the critical path, as described in
Section 4, in the employed large neighborhood search.
The paper is structured as follows. In
Section 2, the related work is discussed, and
Section 3 presents the formulation of the permutation flow-shop scheduling problem.
Section 4 presents the RDIS and provides a stepwise description of the corresponding algorithm. In
Section 5, the results of computational experiments are discussed. The concluding remarks, as well as the suggestions for the further enhancement of the stochastic algorithm, are discussed in
Section 6.
2. Related Work
In manufacturing systems, scheduling is about the allocation of resources to operations over time to somehow optimize the efficiency of the corresponding system. Quite interestingly, because of their complexity, scheduling problems have been among the first categories of problems that have promoted the development of the notion of NP-completeness [
5].
The Flow-shop Scheduling Problem (FSP), in which jobs should pass all machines in the same order, is one of the easy-to-state but hard-to-solve problems in scheduling. Because of these contrasting features, the FSP is one of the first problems in scheduling which captured the attention of pioneers in scheduling [
4,
6], and later became an attractive topic for a significant number of researchers.
Interestingly, one of the most elegant procedures in the area of algorithmic design is an efficient exact algorithm [
4] that has been presented for the two special cases of this problem, which are a two-machine problem and a restricted case of the three-machine problem. Although this algorithm has been extended [
6,
7] to tackle some less restricted cases of the three-machine problem, it has never been extended to solve problems with a larger number of machines to optimality.
Several variations and extensions of the FSP, with multiple objective function criteria, have been studied in the literature [
8,
9,
10]. Among the variants of the FSP, the Permutation Flow-shop Scheduling Problem (PFSP), in which jobs have the same sequence on all machines, plays a key role. The PFSP best suits multi-stage production systems in which conveyor belts are used to perform material handling between machines. Both the FSP and the PFSP have shown to be NP-Hard [
11,
12]. An interesting variant of the PFSP is the distributed permutation flow shop scheduling problem (DPFSP) which has been studied in [
13], and, in [
14], energy consumption is considered as one of its multi-objective criteria. The rest of this section briefly surveys the related literature with a focus on the PFSP.
Extensive literature surveys on the early efficient algorithms presented for the FSP can be found in [
15,
16]. A more recent review and classification of heuristics for the PFSP has been presented in [
17]. In the proposed framework of [
17], heuristics are analyzed in the three phases of (i) index development, (ii) solution construction and (iii) solution improvement. In the following, some related work is briefly reviewed.
The most related method is Jonson’s method that because of the complete dependence of the RDIS on it, this method will be described as part of the RDIS in
Section 4. The Palmer method developed in [
18] can be considered as another related work. The author has not provided any reference to Johnson’s paper but has mentioned that the rationale behind the development of the procedure is to minimize the makespan based on the notion of the lower bound of the single machine problem, which is obtained by the head time plus its total processing times plus its tail time. It is these heads and tails that the Palmer algorithm tries to minimize.
Based on advancing Palmer’s index method, an algorithm has been presented in [
19] which works based on a slope matching mechanism. First, assuming that only one job exists, the starting time and ending time of each job on each machine is calculated and, by running the regression, a starting slope and an ending slope are calculated for each job.
The first method, with which they have compared their two techniques, is the method presented in [
20], that finds the actual slope of jobs. For calculating this actual slope, simply the regression is run for each job.
The other method that they have compared with their two methods is the method based on the priority presented by [
21], and obtained based on Johnson’s rule.
In comparing these four methods with one another, they found the following ranking (i) TSP-approximation, (ii) slope-matching mechanism, (iii) Gupta’s method, and (iv) Palmer’s method. These ranking criteria can be used as the basis of any construction method.
As another example, in [
22] a heuristic algorithm for
n-job
m-machine sequencing problem has been presented that, based on the two-machine problem, builds a sequence by decomposing total processing times into three parts.
Among other effective heuristics developed for the permutation flow-shop problem, TB [
23], SPIRIT [
24], FSHOPH [
25], NEH [
26], and NEHLJP1 [
27] can be mentioned. It is worth noting that NEH is one of the earliest effective heuristics and it is incorporated in many other metaheuristics. For instance, an iterated greedy algorithm is presented in [
28], in which a solution is improved through repeated removal and re-insertion of the jobs, from a given solution, using the NEH heuristic.
Some effective metaheuristics developed are Ogbu and Smith’s simulated annealing [
29], Taillard’s tabu search [
30], Nowicki and Smutnicki’s fast tabu search [
31], Reeves’s genetic algorithm [
32], Nowicki and Smutnicki’s scatter search [
33], Iyer and Saxena’s genetic algorithm [
34], Yagmahan and Yenisey’s ant colony algorithm [
35], Lian et al.’s particle swarm algorithm [
36], artificial bee colony algorithm of [
37], Discrete differential evolution algorithm of [
38], algebraic decomposition-based evolutionary algorithm of [
8], and re-blocking adjustable memetic Procedure (RAMP) of [
39]. A comprehensive review and comparison of heuristics and metaheuristics for the PFSP can found in [
40].
3. Problem Formulation
Assuming that there are n jobs and m machines, and that all jobs require to be processed on machines 1, 2, 3,..., and m, one after another, the PFSP is aimed at finding a permutation of jobs, identical for all machines, that minimizes the completion time of the last job on the last machine, referred to as makespan.
Given a permutation
, in which
shows the number of job in the sequence of jobs, and denoting the processing time of job
j on machine
i, as
tji, the makespan of the problem can be calculated by rearranging the jobs based on
. In effect, by denoting the earliest completion time of job
on the machine
i as
, the value of
shows the exact amount of makespan. Hence, the objective can be stated as finding a permutation
over the set of all permutations,
, so that
is minimized. A simple formulation of the PFSP, based on the formulation presented in [
41] is as follows.
where,
It is worth noting that Formulas (2)–(5) also shows how, for a given permutation, the makespan can be calculated in .
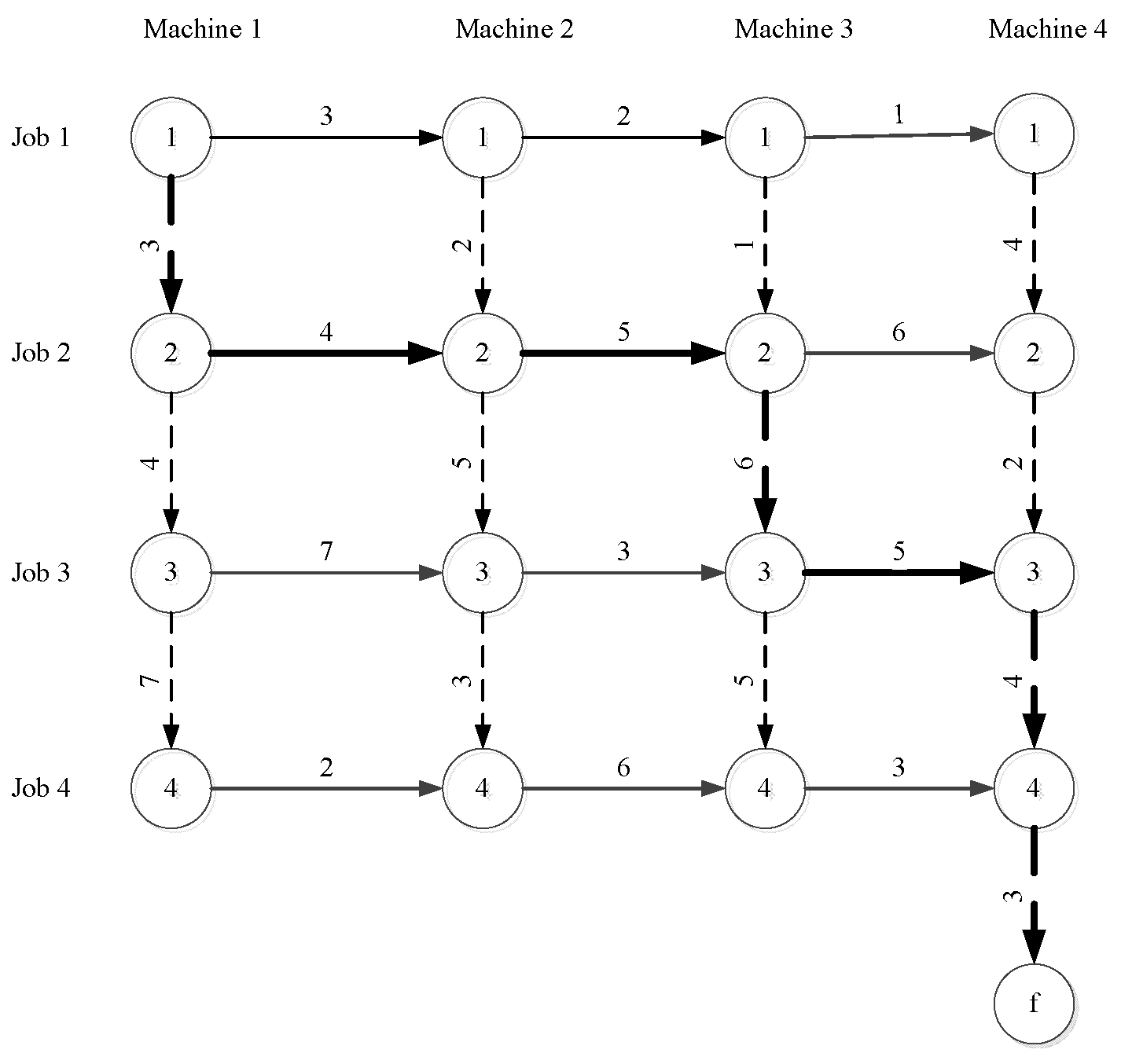
Figure 1 shows a sample 4-Job 4-Machine PFSP problem, with the permutation
of jobs leading to the solution value of 30. The arrows originating from each circle in
Figure 1, show the corresponding processing time of the corresponding job on the corresponding machine and the sum of processing times on the bold arrows indicates the makespan.
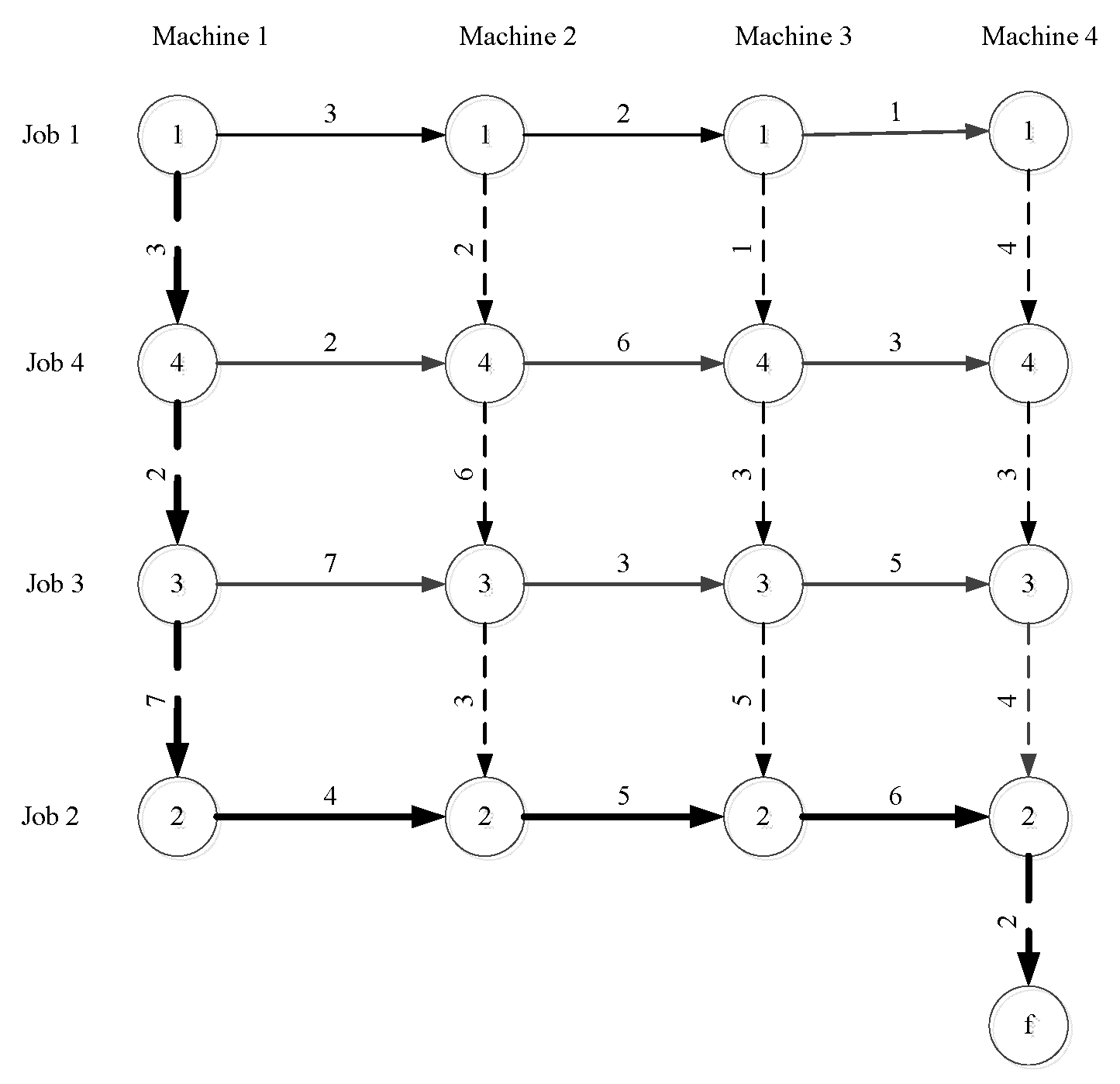
Figure 2 shows how by changing the order of
to
, the makespan has changed to 29, which is the optimal solution.
4. RDIS
A key justification for the design of the RDIS is an effective integration of decomposition, converting a non-tractable problem into tractable subproblems, with variable neighborhood search techniques, synergetically striking a balance between diversification and intensification elements of the algorithm.
Starting with the notion of decomposition, the RDIS works in the two levels of constructing an initial solution, and improving this solution through local searches. For this purpose, it first employs the recursive application of the extended two-machine problem as a seed-construction technique and constructs an initial permutation as a seed. This construction technique recursively decomposes the jobs into two groups and calculates the optimal solutions of each group based on the extended two-machine problem.
After such an initial seed is constructed, a variable neighborhood search is activated. This variable neighborhood search consists of two local searches, one with the small neighborhood and the other with the large neighborhood. The large neighborhood local search uses a decomposition technique for finding an optimal arrangement for different subsets of jobs. In effect, both the seed construction technique and the employed large neighborhood search work are based on the notion of decomposition.
The small neighborhood search component uses both the insertion and swapping operations as the basis of its moves. In both the small and large neighborhood searches, the concept of the critical path plays a crucial role in avoiding unfruitful changes. Whereas in the small neighborhood, the critical path is used to avoid unfruitful swaps or interchanges, in the large neighborhood search, it is used to re-arrange only promising contiguous parts of the permutation, leaving those parts whose re-arrangement is not beneficial.
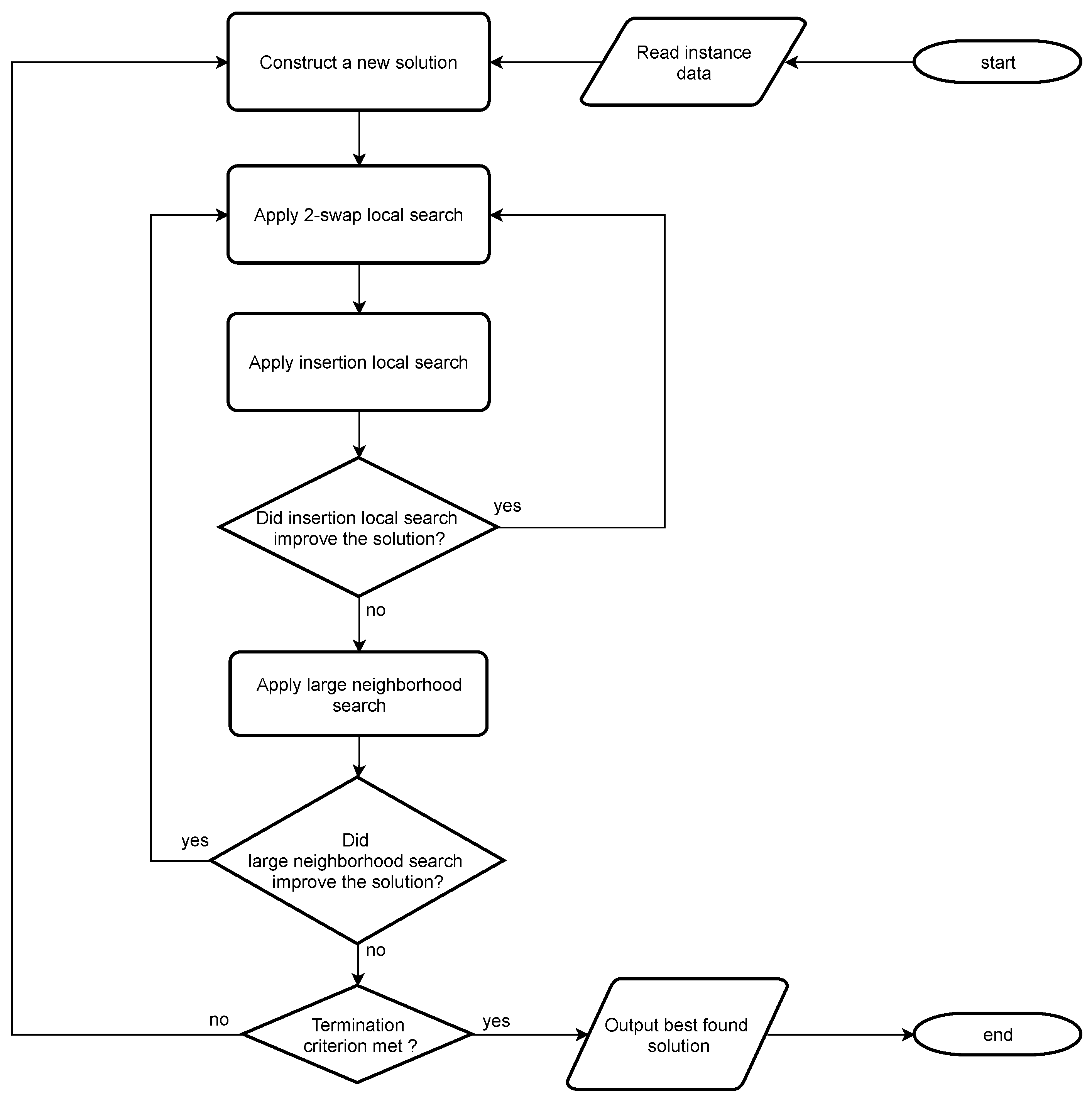
Figure 3 shows the c-type pseudocode of the RDIS, and
Figure 4 shows the flowchart of the key steps of the RDIS.
In describing different components of this pseudocode, first, we describe the way in which the seed-construction technique uses decomposition to create the initial solutions. For creating this technique, we have modified the Johnson algorithm [
4] and called the result the Recursive-Johnson Procedure (RJP). For tackling any PFSP problem, the RJP decomposes it into smaller problems and continues this in different rounds until the decomposed problem includes only one job or one machine.
The decomposition process in the RJP proceeds in several consecutive rounds. In the first round, the number of columns (machines) of the decomposed problems is divided into two equal parts, with the first machines comprising the first part and the last machines comprising the second part. All machines located in the first part comprise auxiliary machine 1, and those in the second part comprise auxiliary machine 2.
Then the corresponding two-machine problem is solved with Johnson’s algorithm and a permutation for the given jobs is determined. This permutation is only a preliminary one and the goal of further rounds is to further improve this permutation. Because of the recursive nature of the algorithm, further rounds are similar to the first round and their only difference is that they operate on a portion of jobs.
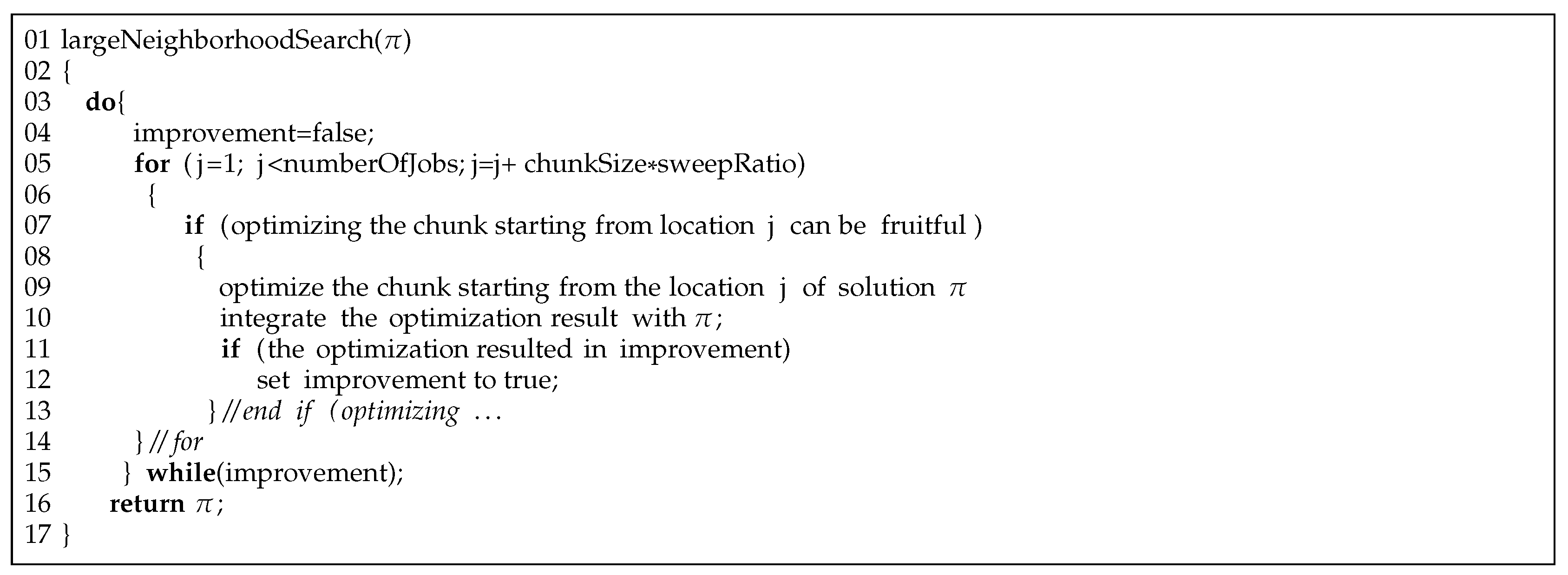
The employed large neighborhood search decomposes the problem into several distinct parts and optimizes each part separately. Based on a technique initially proposed in [
30], two forward and backward matrixes simultaneously help the optimization cost to decrease.
Whereas in the forward matrix the distance of each operation from the first performed operation is presented, in the backward matrix, the distance of each operation from the final performed operation is provided. Moreover, the preliminary evaluation renders many of these combinations unnecessary. Because of using two forward and backward matrixes, when the positions of two jobs are not far from one another in the permutation, the evaluation of their swap can be performed very fast.
The solutions provided by the RJP undergo both small and large neighborhood searches. As is seen in the pseudocode presented in
Figure 3, the large neighborhood search is called at line 11. The pseudocode presented in
Figure 5 describes how this large neighborhood search operates. As is seen in this pseudocode, the main loop starts at line 3 and is aimed at improving the given solution, shown with permutation
, through modifying different parts of this permutation.
The substrings selected for modification are called chunk and all have the same size of chunkSize. For the purpose of modification, a subproblem of the given problem is solved to optimality through evaluating all possible ordering of jobs in a given chunk, keeping other jobs fixed in their current positions. In particular, it is line 9 of the pseudocode that calculates the makespan values of all chunkSize! permutations. For instance, if the value of chunkSize is 6, line 9 has to evaluate 6! = 720, different permutations to find the optimal one.
As is shown in line 5, the number of chunks to be optimized for a given solution is controlled through a parameter named sweepRatio, which is in the range between 0 and 1. For instance, setting sweepRatio to 0.5 and chunkSize to 6 the first chunk, which starts from position 1 and ends in position 6, to be optimized and then the starting position for the next chunk to be set to .
In other words, around 50% of jobs for the optimized chunk are fixed and the remaining jobs appear in the first half of the next chunk to be optimized. After re-arranging the chunk starting at position 4, through the employed optimization process, and ending at position 9, positions 4, 5, and 6 are fixed and the next chunk starting from position 7 and ending in position 12 is selected for being re-arranged.
Fixing half of the re-arranged jobs in a chunk and carrying the other half with the next chunk continues until a chunk is selected whose ending point is the last position in the permutation, signaling the end of a cycle. As indicated in lines 3 and 15 of the pseudocode, a new cycle can again resume from position 1 if the current cycle has been able to improve the solution.
The quality of the obtained solutions depends on the values of chunkSize and sweepRatio. Whereas increasing the value of sweepRatio leads to increasing the exploration power and reduces computation time, its decreasing can produce better solutions at the expense of higher computation time. Since optimizing a chunk is involved with evaluating chunkSize! permutations, the execution time is highly dependent on the chunk size.
This implies that a combination of selecting a proper value for this parameter and a mechanism for the recognition of unfruitful chunks can greatly improve the efficiency of the stochastic algorithm. Values between 6 and 9 for chunkSize can lead to improving solution quality, without increasing execution time significantly.
With respect to having a necessary mechanism for the recognition of unfruitful chunks, line 7 detects such chunks based on the critical path properties of the current solution. This is done based on the fact that if all of the critical operations in a chunk belong to the same machine, optimizing such a chunk cannot reduce the makespan, and therefore the chunk can be skipped. In other words, regardless of the order of jobs in such an unfruitful chunk, the previous critical path persists in the new solution and this makes any decrease in the makespan impossible.
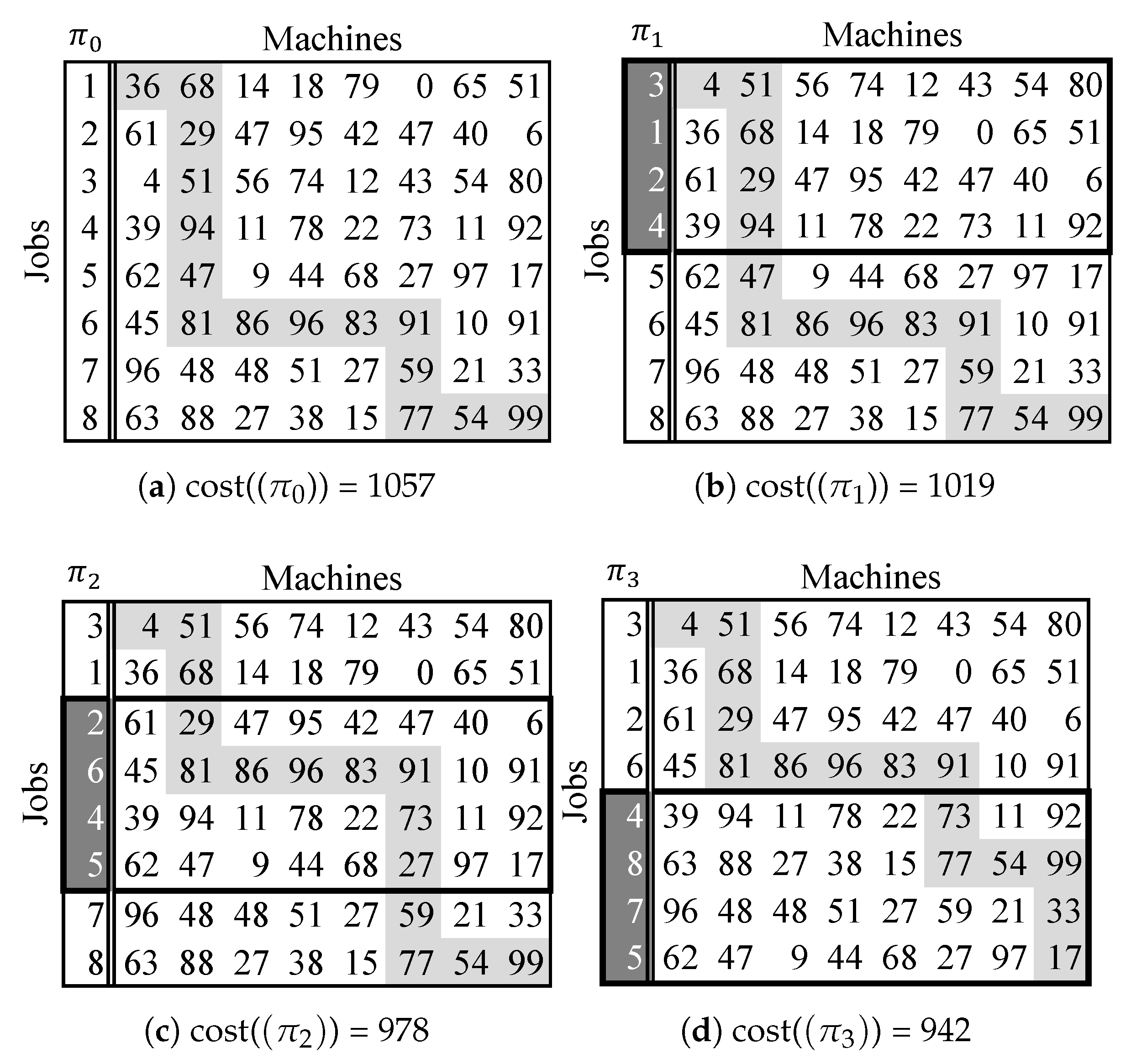
Setting the values of
chunkSize and
sweepRatio to 4 and 0.5, respectively,
Figure 6 illustrates how the application of just one cycle of the steps presented in the pseudocode leads to improving an initial solution for a sample 8-jobs 8-machines instance from 1057 to 942. In this instance, the processing times of operations have been selected as integers between 0 and 100 with a uniform distribution.
As is seen in the figure, each solution has been shown with a matrix, in which the permutation of jobs has been represented in its first column. In each matrix, the critical operations corresponding to the solution are highlighted and its makespan, which is equal to the sum of the highlighted processing times, has also been shown.
Figure 6a shows the initial solution,
with the cost of 1057.
In
Figure 6b, the first chunk
is optimized and is changed to
. This alone reduces the makespan by 38 units and changes it to 1019. Since the
sweepRatio is 0.5, the next chunk to be optimized starts from the 3rd row and is
which is optimized to
, shown in
Figure 6c.
This procedure continues accordingly and optimizes all corresponding chunks. As mentioned,
Figure 6 shows the result of applying the main loop of the psedudocode just for one cycle and as lines 3, 4 and 15 of the pseudocode show, in general, the optimization of chunks continues for consecutive cycles until no improvement occurs in a cycle.
5. Computational Experiments
The RDIS has been implemented in C++ and compiled via the Visual C++ compiler on a PC with 2.2 GHz speed. Before testing the algorithm on the benchmark instances, the parameters of the construction and large neighborhood components have been set. With respect to the construction component, tthe algorithm has two parameters, namely NRepeats and SwapProb, indicating the frequency and the probability of performing swap moves in the RJP method. Based on the preliminary experiments, we observed that setting NRepeats and SwapProb to 1 and 0.4, respectively, yields the best results by providing a balance between the quality and diversity of the initial solutions generated by the construction component.
With respect to the large neighborhood component, the RDIS has also two parameters, namely ChunkSize, and SweepRatio. Setting ChunkSize to a small value (≤5) will increase the speed of the procedure at the expense of lower solution quality. On the other hand, setting ChunkSize to any value larger than 10 will dramatically increase the running time. Moreover, the computational experiments show that setting the value of SweepRatio close to 1 or 0 degrades the performance. Due to these observations, and based on further preliminary experiments, ChunkSize and SweepRatio have been set to 7 and 0.3, respectively.
We have employed Taillard’s repository of benchmark instances [
42], available on the website supported by the University of Applied Sciences of Western Switzerland, to test the performance of the RDIS. In this repository, as many as 120 instances exist, and all of these instances have been extracted for the RDIS to be tested on. These instances are in 12 classes, with 10 instances existing in each class. The number of jobs and machines of these instances are in the range 20–500 and 5–20, respectively.
Before presenting the performance of the stochastic algorithm on the benchmark instances and comparing the results with the best available solutions in the literature, we present the internal operations and convergence of the algorithm in solving the instances
ta001, and
ta012.
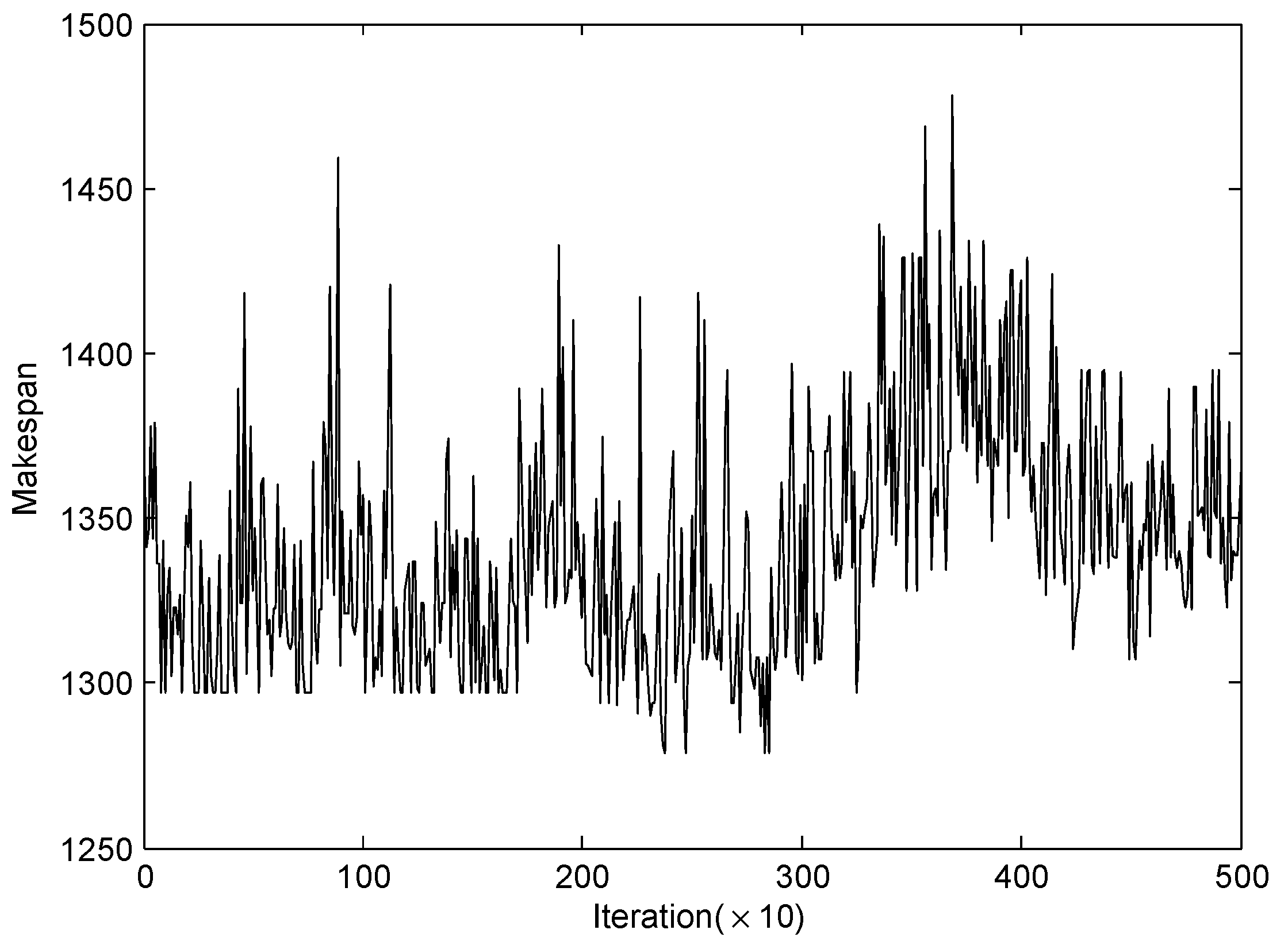
Figure 7 shows solution value versus iteration for 5000 iterations, for the instance
ta001. As is seen, a high-quality solution can follow a low-quality one, and vice versa.
In general, the quality of the best solution obtained improves as the number of iterations increases.
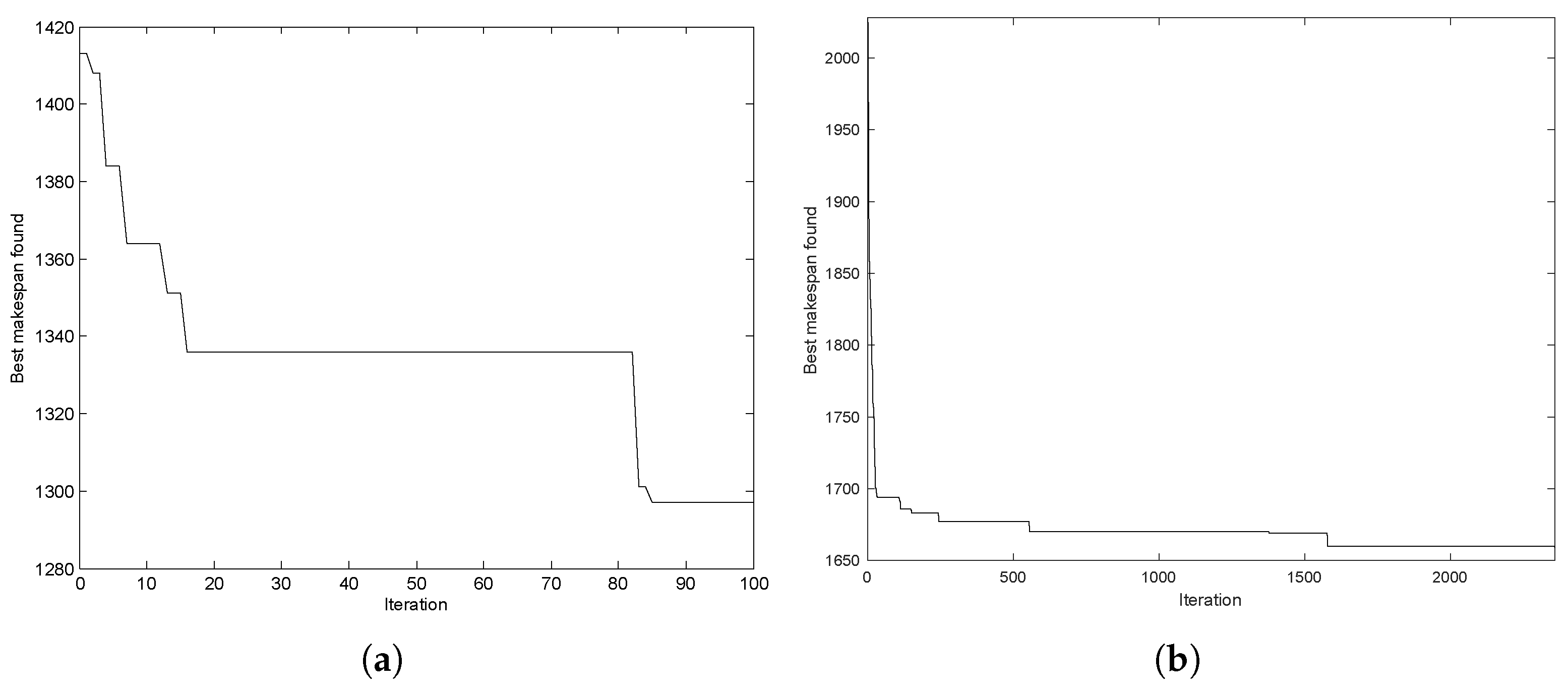
Figure 8a shows how this has happened in the first 100 iterations of the
ta001 problem instance. As is seen, before iteration 20, the quality of the best-obtained solution has improved from 1413 to 1336 and for the next 60 iterations, no improvement has occurred. Between iterations 80 and 100, two other improvements have occurred and 1336 has improved to 1297. A similar trend can be seen in other instances as well;
Figure 8b shows the convergence pattern, in just over 2000 iterations for a larger problem instance,
ta012.
Comparison with Other Metaheuristics
RDIS is compared with a variety of metaheuristic in terms of solution quality and computation time. In particular, as presented in
Table 1, RDIS is compared with the Re-blocking Adjustable Memetic Procedure (RAMP) of [
39] NEGA
VNS of [
43], Particle swarm optimization algorithm, PSO
VNS, of [
44], Simulated Annealing algorithm, SAOP, of [
45], two Ant Colony Optimization algorithms, PACO and M-MMAS, due to [
46], the iterated local search (ILS) of [
47], and Hybrid genetic algorithm, HGA_RMA, of [
48].
SAOP, PACO, M-MMAS, ILS and HGA_RMA are all run on a CPU with 2.6 GHz clock speed and the results are reported in [
48]. However, RAMP and NEGA
VNS are run on a 2.2 GHz and a 2.4 GHz CPU respectively, and PSO
VNS is run on a 2.8 GHz CPU. Furthermore, CPU clock speeds are presented in
Table 2 and a scaling factor has been calculated. However, since CPU times depend on many factors such as developer skills, compiler efficiency, implementation details, and CPU architecture, any running time comparison should be made with caution.
Table 3 shows the comparison of the real and scaled maximum allowed running time for RDIS, NEGA
VNS, PSO
VNS, and HGA_RMA. The maximum allowed running time of the other approaches in
Table 3 is equal to that of HGA_RMA, since they are re-implemented and compared in [
48]. Furthermore, since only NEGA
VNS and PSO
VNS have reported the average time needed to reach their best solution, a comparison is presented in
Table 4.
In addition, based on the fact that NEGA
VNS, RAMP, and RDIS, allow similar maximum allowed running time (ref.
Table 3), statistical testing has been performed to further analyze their difference. For this purpose, these methods are initially ranked based on their average deviation from the best-known solution %DEV
avg, for each instance group, as shown in
Table 5. In the case of tied %DEV
avg values, the average of the ranks with the assumption of no tied values, are calculated. The mean rank for NEGA
VNS, RAMP, and RDIS are 1.5, 1.667 and 2.833 respectively. Friedman test has been performed on the ranked data set, showing a statistically significant difference in the ranks, with
,
.
Further, for each pair of algorithms, post-hoc analysis using Wilcoxon signed-rank tests has been conducted with a significance level set at
(Bonferroni correction). It has been found that there were no significant differences between the ranks of NEGA
VNS and RAMP (
p = 0.482) but a significant difference between the ranks of NEGA
VNS, and RDIS (
p < 0.001 ) as well as between RAMP and RDIS (
p < 0.001). This could indicate that out of the three compared methods, NEGA
VNS and RAMP are the best performing ones and RDIS falls in second place. It is worth noting, these results should be interpreted with caution, as they are solely based on average deviation, and other factors such as best deviation, average and best running times, and implementation details have not been considered. An interested reader can see [
49] for a tutorial on nonparametric statistical tests, used for comparing metaheuristics.
For a more fine-grained analysis, an instance-by-instance performance comparison is presented in
Table 6 and
Table 7. In these tables, the performance of the RDIS on these instances is shown and compared with that of the NEGA
VNS presented in [
43]. The NEGA
VNS, which is a genetic algorithm (GA) and uses the variable neighborhood search (VNS) employs the NEH heuristic presented in [
26] for constructing its initial solutions, and that is why it has been named as NEGA
VNS. The NEH has also been named as the initial of its authors and is a famous algorithm. As further information, the performance of the NEH has also been provided in the table.
In line with [
43] (Zobolas, Tarantilis et al. 2009), we have set the running time of the RDIS to
seconds for each run. Moreover, for removing the effect of the random seed and in line with other algorithms, the RDIS has been run 10 times for each instance, with different random seeds.
In
Table 6 and
Table 7, columns 2 and 3 represent the number of jobs and machines, respectively, and columns 4 and 5 show the lower and upper bound of each instance. The value of the upper bound is the best available makespan for the corresponding instance in the literature, and in the cases where upper and lower bounds are equal, the best available makespan in the literature is equal to the optimal solution.
Columns 6, 7, and 10 provide the values of the makespan produced by NEH, RDIS, and NEGA
VNS, respectively. The value of T
best shows the shortest time taken for the best solution to be obtained in seconds, and the value of %DEV
avg shows the average of the percentage deviation from the best available makespan. The percentage deviation from the best available makespan has been calculated based on the formula of
, in which
s and
show the corresponding makespan calculated and the best available makespan, which is also an upper bound for the corresponding instance. The wide spectrum information provided in
Table 6 and
Table 7, based on 120 benchmark instances, indicates that the RDIS is highly competitive and produces comparatively high-quality solutions.
In all 120 instances, the RDIS has obtained a better solution value than the NEH heuristic. In terms of best solution value, the RDIS has obtained equal or better value in 61 out of 120 problems. Moreover, in 46 out of 120 instances the average percentage deviation has been smaller than or equal to that of the NEGAVNS, and in 100 out of 120 instances, the average shortest time to find the best solution is less than or equal to that of the NEGAVNS. Moreover, the total average running times to reach the best solution of RDIS is more than 44 times faster than that of NEGAVNS.
6. Concluding Remarks
In the area of algorithm design, the notion of decomposition is an umbrella term for obtaining a solution to a problem through its break-down into subproblems, with all these subproblems being handled with the same procedure. The RDIS is a stochastic algorithm based on such notion, in the sense that it translates non-tractable problems to tractable subproblems and obtains optimal solutions of these tractable subproblems.
The integration of the optimal sub-solutions provided for these subproblems, expectedly does not lead to the overall optimal solution, except for small-sized problems. However, computational experiments have shown that the RDIS is able to produce solutions with the accuracy of one percent from the best-known solutions in the literature. This success is not the result of one factor but that of three major factors.
First, the combination of small and large neighborhood schemes is able to create a delicate balance between speed and quality. With this respect, it should be noticed that although in local searches multi-exchanges usually lead to better results than that of pair-exchanges, nevertheless, multi-exchanges require outsized execution times.
In other words, in the RDIS, the size of k-exchange neighborhood is not , as it is the case with other k-exchange neighborhoods, but only a tiny fraction of it. The reason is that in the RDIS, the computational burden has been placed on the small neighborhood scheme and the large neighborhood scheme is used only for promising partitions, taking an immense bulk of possible k-exchanges out of considerations and contributing to the efficiency of the stochastic algorithm.
Second, the RJP, as a construction method, is able to successively rearrange jobs through informed revisions, and this makes the quality of initial solutions for the local searches high. To further emphasize the role of such informed decisions in increasing solution quality, we can mention similar algorithms like the ant colony optimization, which have simply built upon construction methods but can even compete with local searches.
Third, varying the initial permutation through randomly swapping the neighboring jobs, with the chance of SwapProb, not only has diversified the search but it has led to the feature of not losing the accumulated knowledge regarding the best permutation of jobs initially obtained by the RJP. With respect to this feature, the issue is not simply that the random swapping of jobs diversifies the permutation initially obtained by the RJP and allows different starting points to be generated. The deeper issue is that since the RJP does not care about the position of two neighboring jobs and mainly concentrates on grouping the jobs in two partitions, these random swaps, despite their contribution to diversification, cannot significantly degrade the quality of the original permutation proposed by the RJP.
The RDIS can be improved in several directions as outlined in the following:
Trivial as well as sophisticated implementation of parallelization techniques;
Efficient estimation, instead of exact evaluation, of the makespan; and
Integration with population-based techniques.
For enhancing the algorithm through the concept of parallelization, it is possible to employ this concept in a range from its trivial implementation to its most sophisticated structure. In its trivial implementation, several threads of the same procedure can start on a number of processors with different initial solutions.
In its sophisticated structure, however, parallelization can be employed for the entire algorithm as an integrated entity. In this case, two groups of threads need to be developed. In the first group, each thread can calculate the makespan of one neighbor on a separate processor, regardless of whether a small or large neighborhood is in place.
On the other hand, in the second group, each thread can be assigned to solving a two-machine problem. Since nearly the entire time of local searches is spent on calculating the values of makespan and the entire time of the RJP is spent on solving the two-machine problems, this form of parallelization speeds up the algorithm and enables the enhanced procedure to tackle larger instances more efficiently.
The other promising direction for further enhancing the RDIS is the development of novel evaluation functions. Considering the fact that a large percentage of computation time in a typical local search is spent on calculating the exact values of the makespan, the development of novel evaluation functions, which with significant precision can efficiently estimate such values, can decrease the search effort and work towards search efficiency. Based on such ease of calculation, which is obtained at the loss of insignificant precision, the local search can probe larger parts of the search space and, if conducted properly, can obtain high-quality solutions.
The final suggestion for enhancing the RDIS is the development of a population-based mechanism that can work with the current point-based local searches employed. Such a mechanism can govern how computation time is devoted to manipulating solutions with higher quality, and in this way, it can prevent solutions with lower quality from seizing computational resources. The proposed population-based mechanism can also spread the characteristics of high-quality solutions in other individuals of the population. Since, as the population is evolved, the genetic diversity among the individuals of the population declines and the population becomes homogeneous, the design of proper mutation operators exploiting the structure of the PFSP is of key importance in implementing such a possible population-based mechanism.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}