
Analysis and Prediction of Carsharing Demand Based on Data Mining Methods

Abstract
:1. Introduction
2. Data and Data Preparation
2.1. Data Introduction
2.2. Statistic Description
2.2.1. User Travel Characteristics
- (1)
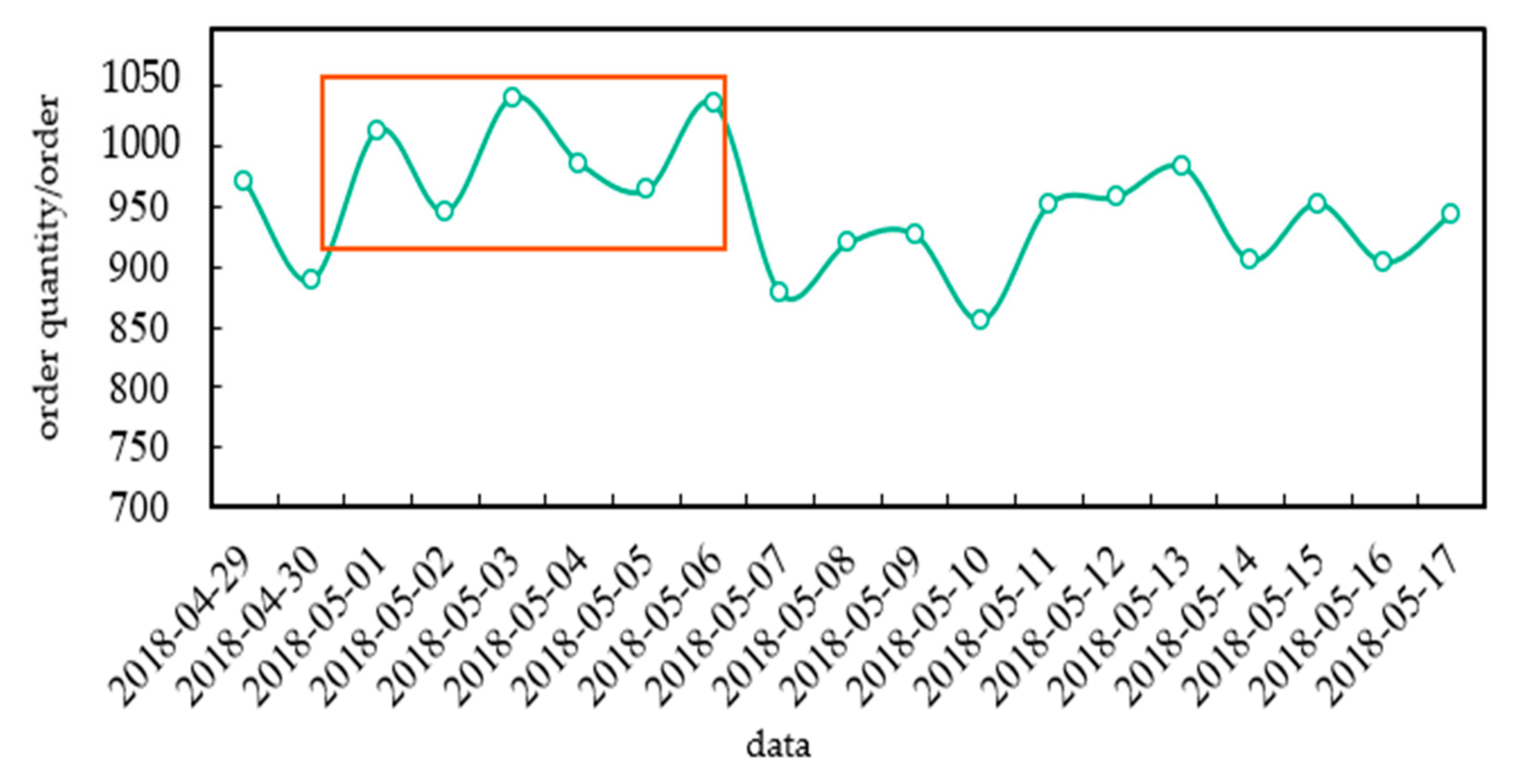
- Travel Characteristics During Holidays
- (2)
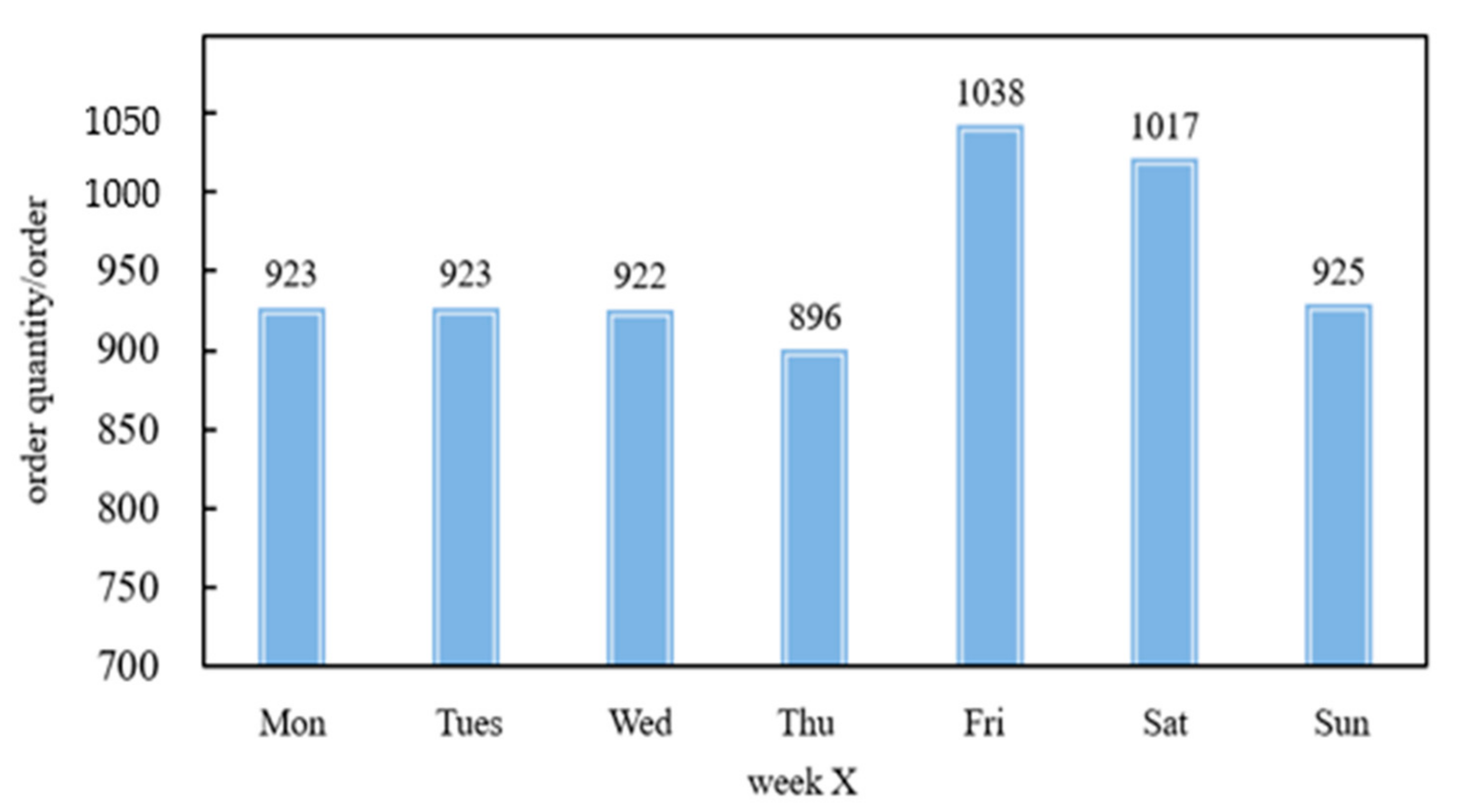
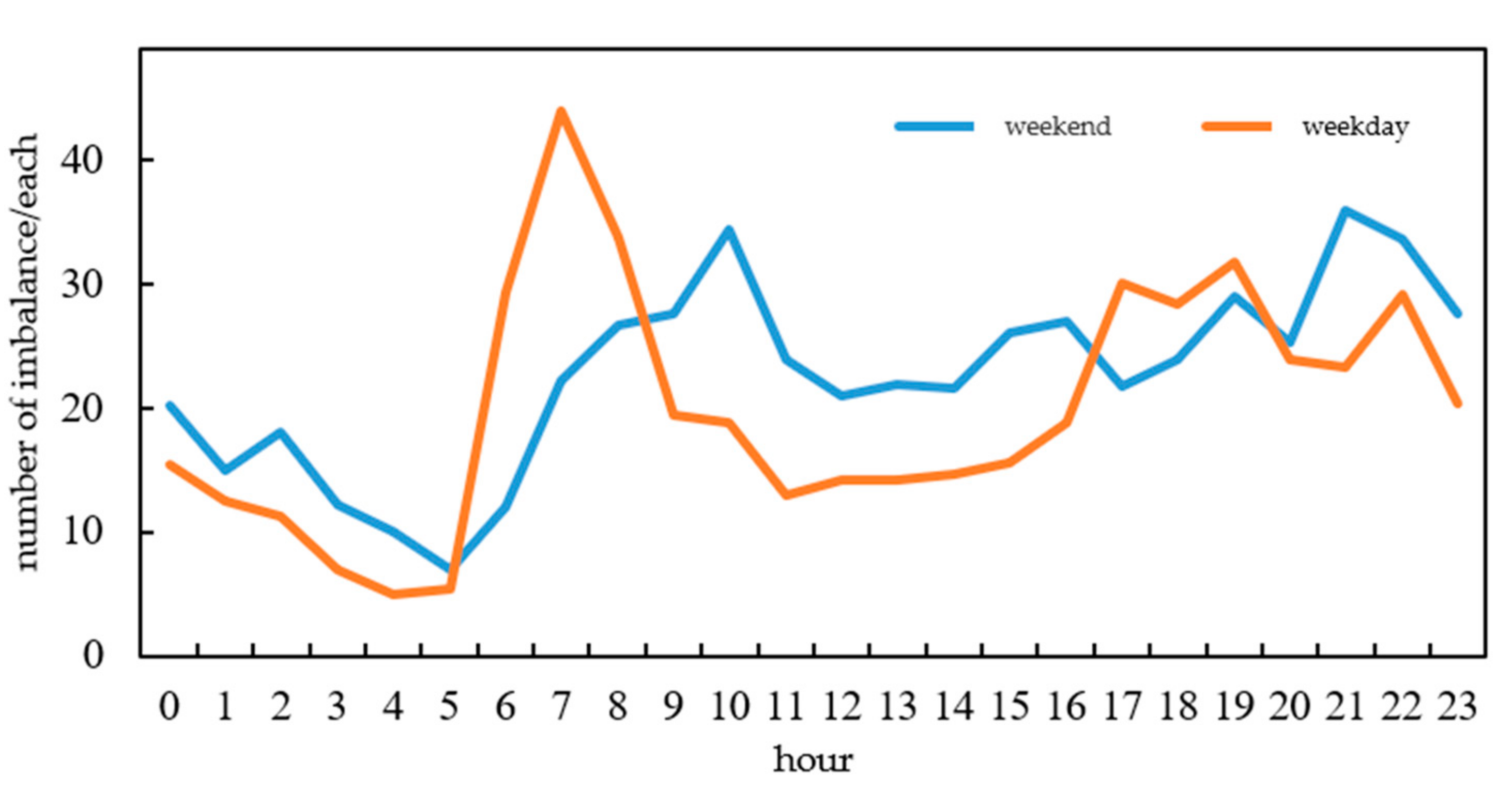
- Travel Characteristics on Weekdays and Weekends
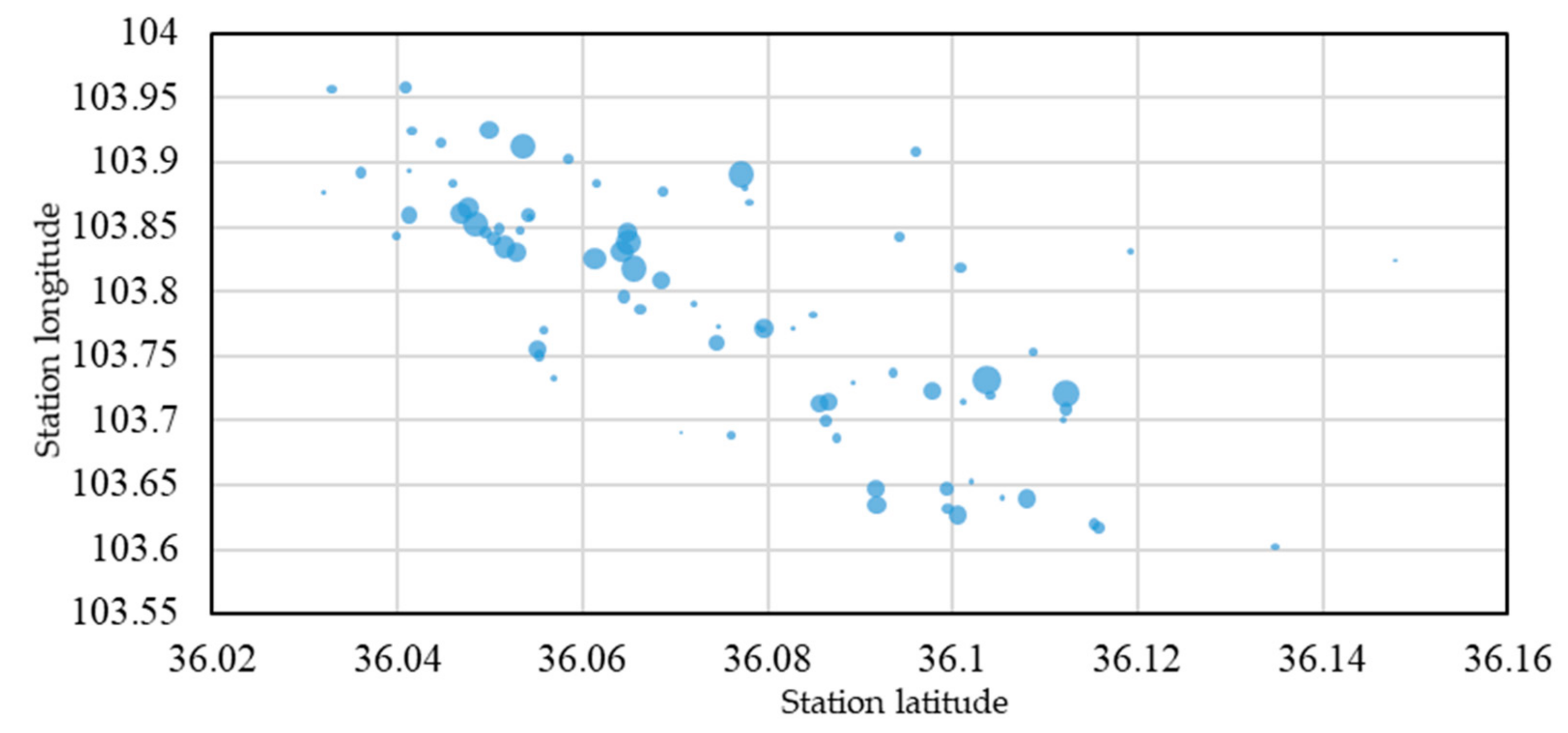
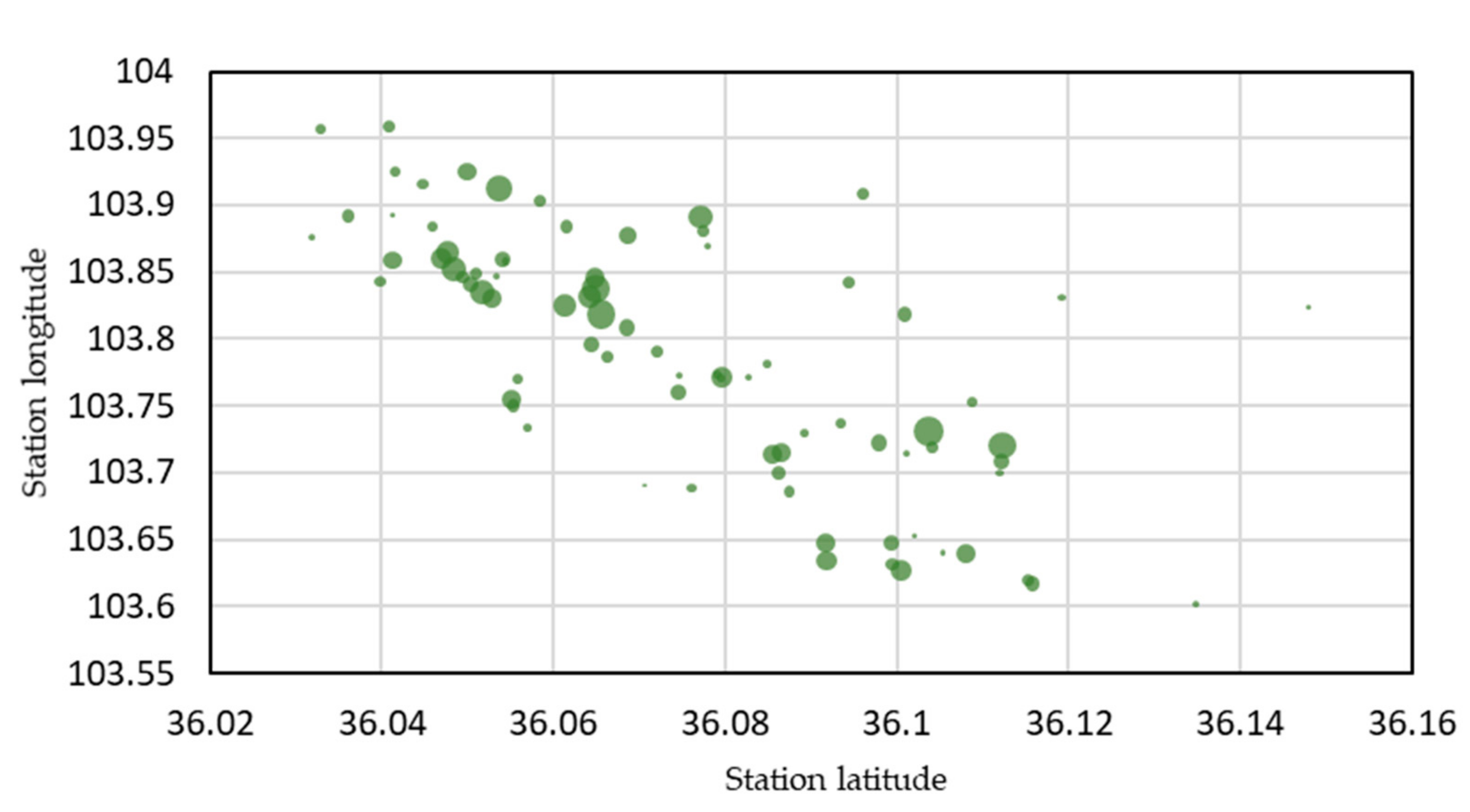
2.2.2. Analysis of the Characteristics of Space–Time Demand
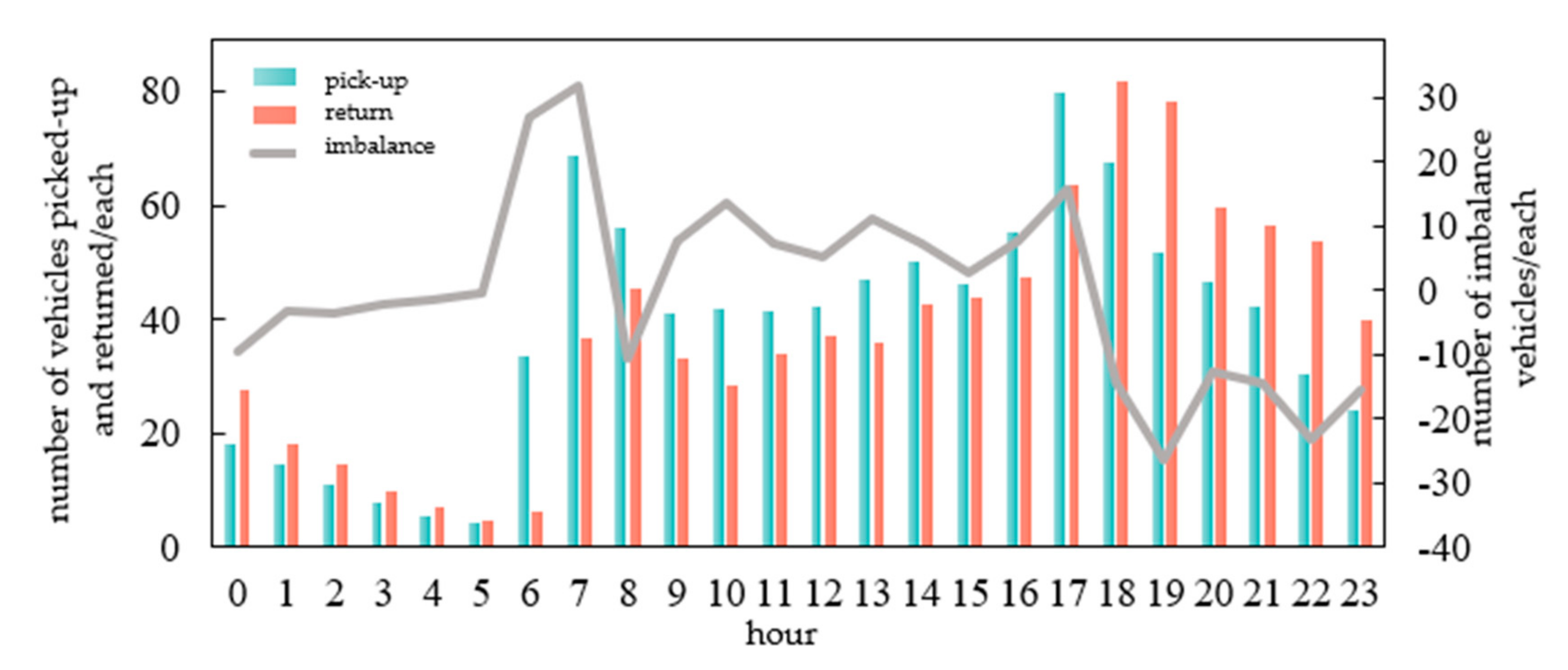
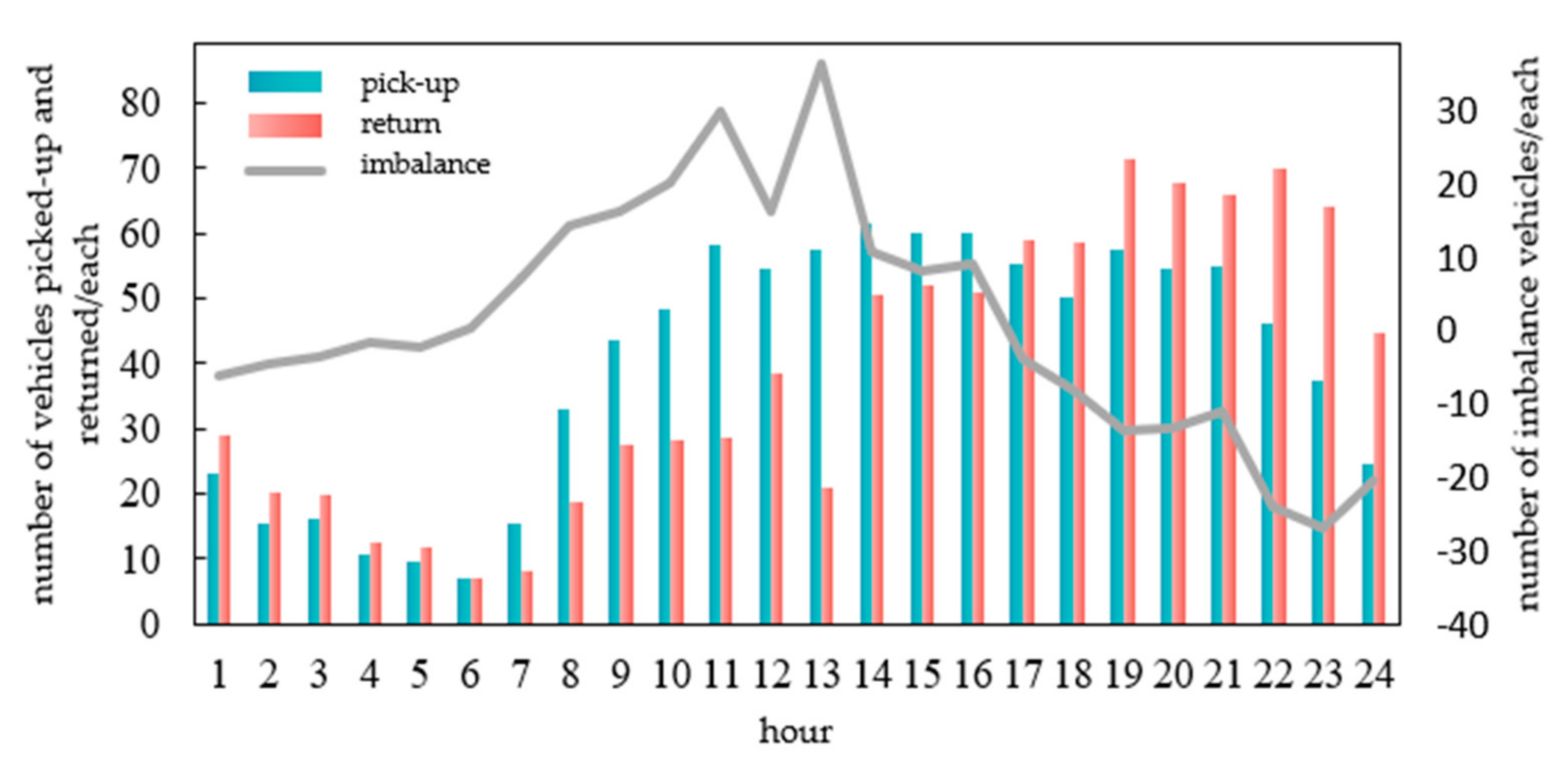
- Characteristic of Time Demand
- 2.
- Characteristic of Space Demand
2.3. Data Preparation
- (1)
- Users’ demand for picked-up vehicles is small due to the limited number of parking and vehicles in a single station. It is random and accidental; thus, accurately mining its change characteristic is impossible, and the demand cannot be predicted accurately.
- (2)
- The level of demand of adjacent stations is related to the degree of imbalance. Users located between several adjacent stations will adjust pick-up and return stations according to the real-time situation of the stations. Therefore, to make full use of the correlation between adjacent stations, adjacent stations can be classified into one class, considering the user’s selection behavior.
3. Prediction of Carsharing Demand Based on GBDT
3.1. Test Set and Training Set
3.2. Characteristic Engineering
- (1)
- Characteristic Extraction of Weather Data
- (2)
- Time Characteristics
- (3)
- The historical number of vehicles picked up and returned at the target station, time information characteristics
- (4)
- Information Characteristics of Adjacent Station Collection
3.3. GBDT Algorithm Process
- (1)
- Objective function and optimization
- (2)
- GBDT algorithm framework
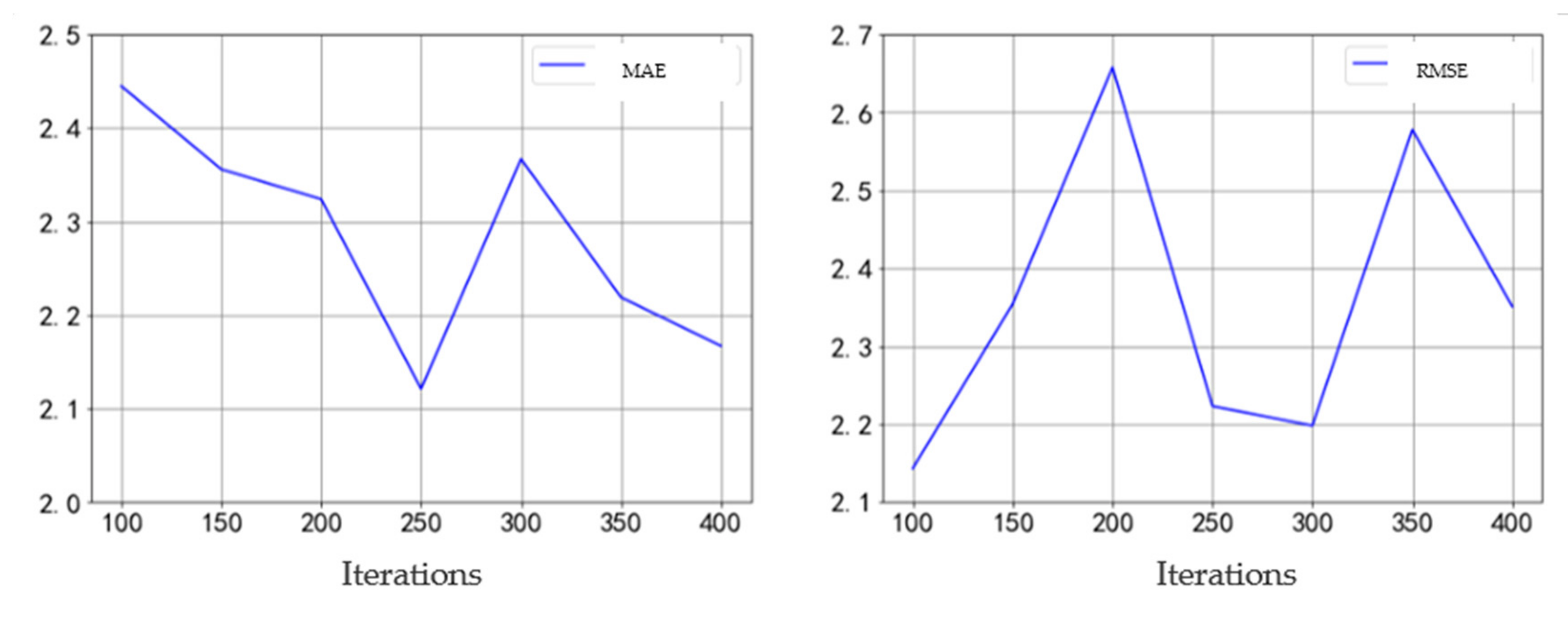
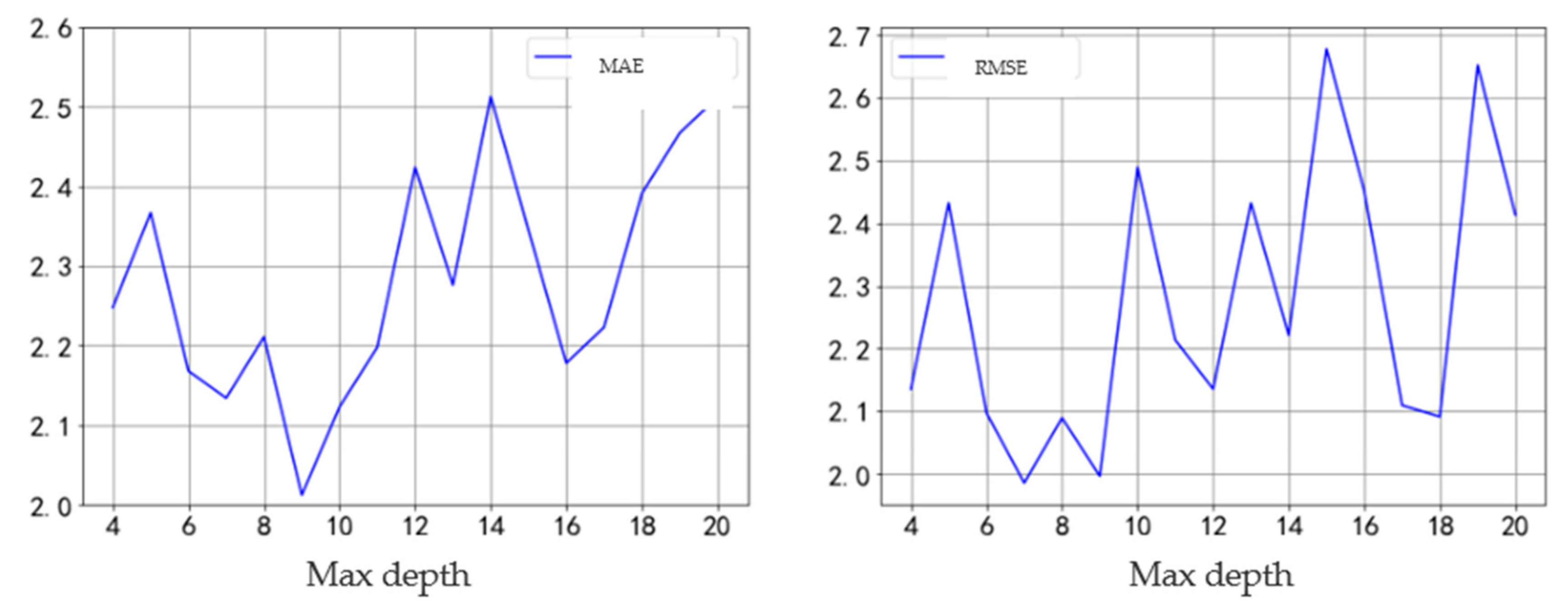
3.4. Importance of Parameters and Characteristics
- (1)
- Parameter Settings
- (2)
- Importance Calculation
3.5. MAE and RMSE
4. Results and Comparison
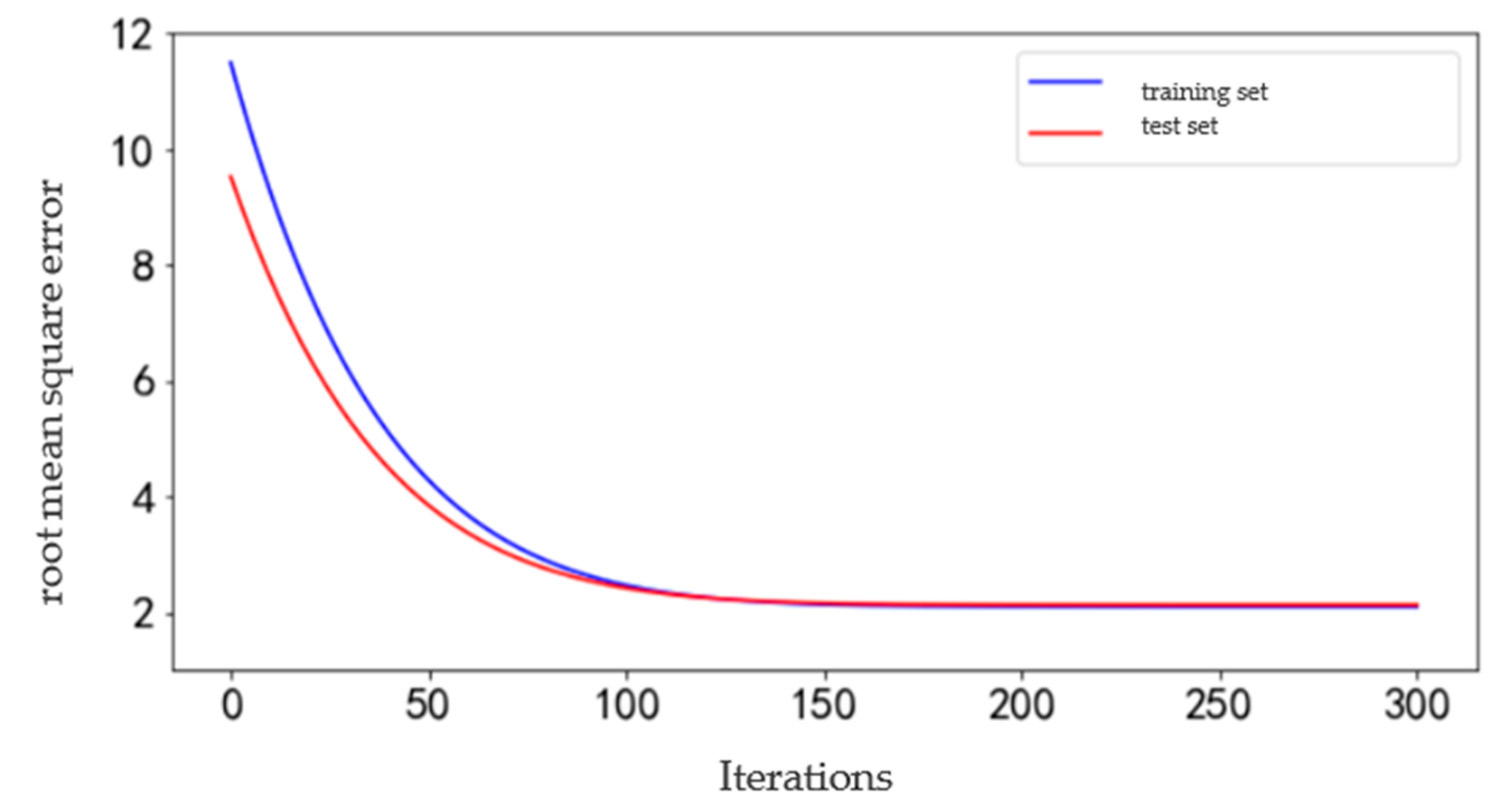
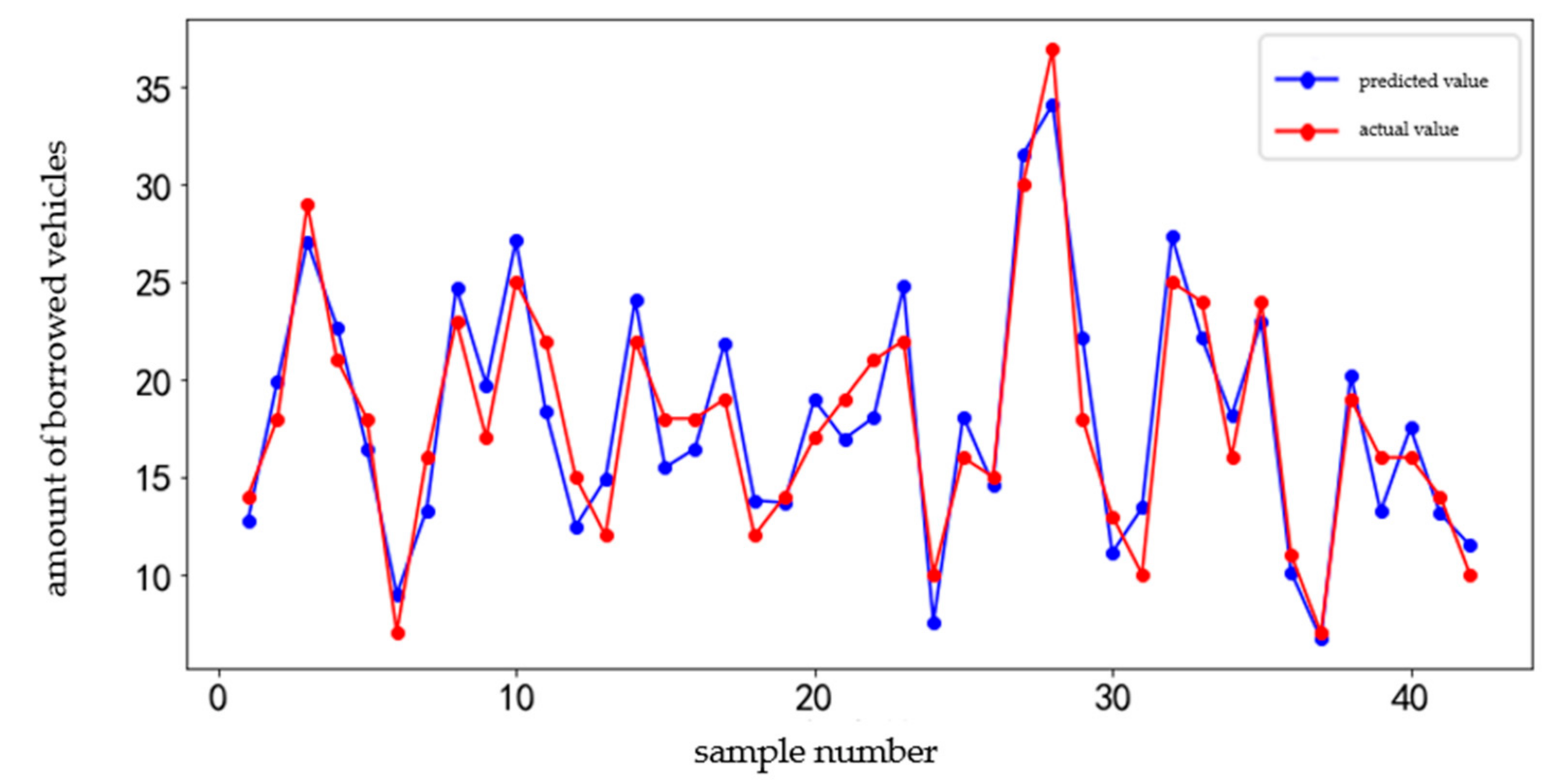
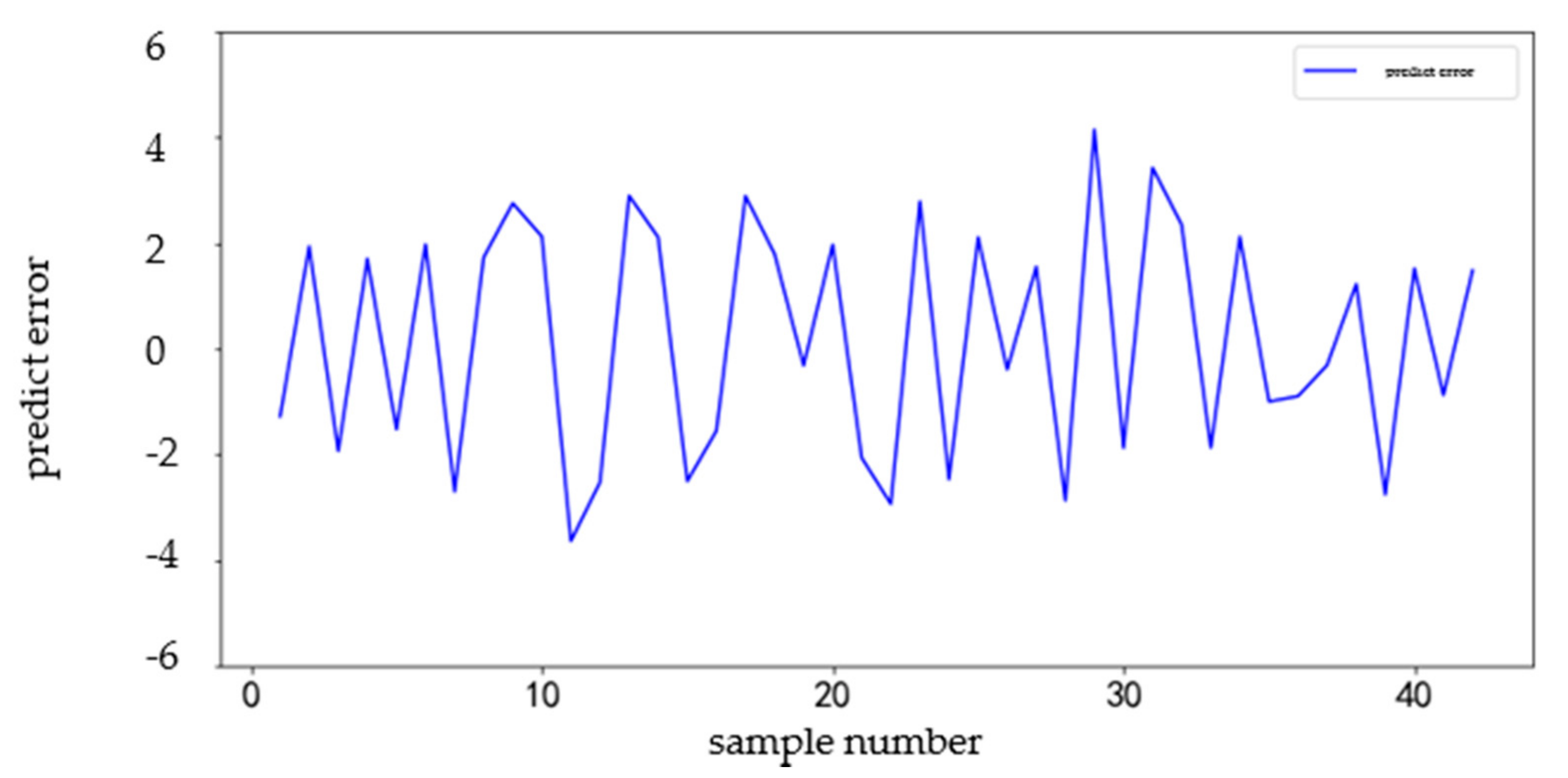
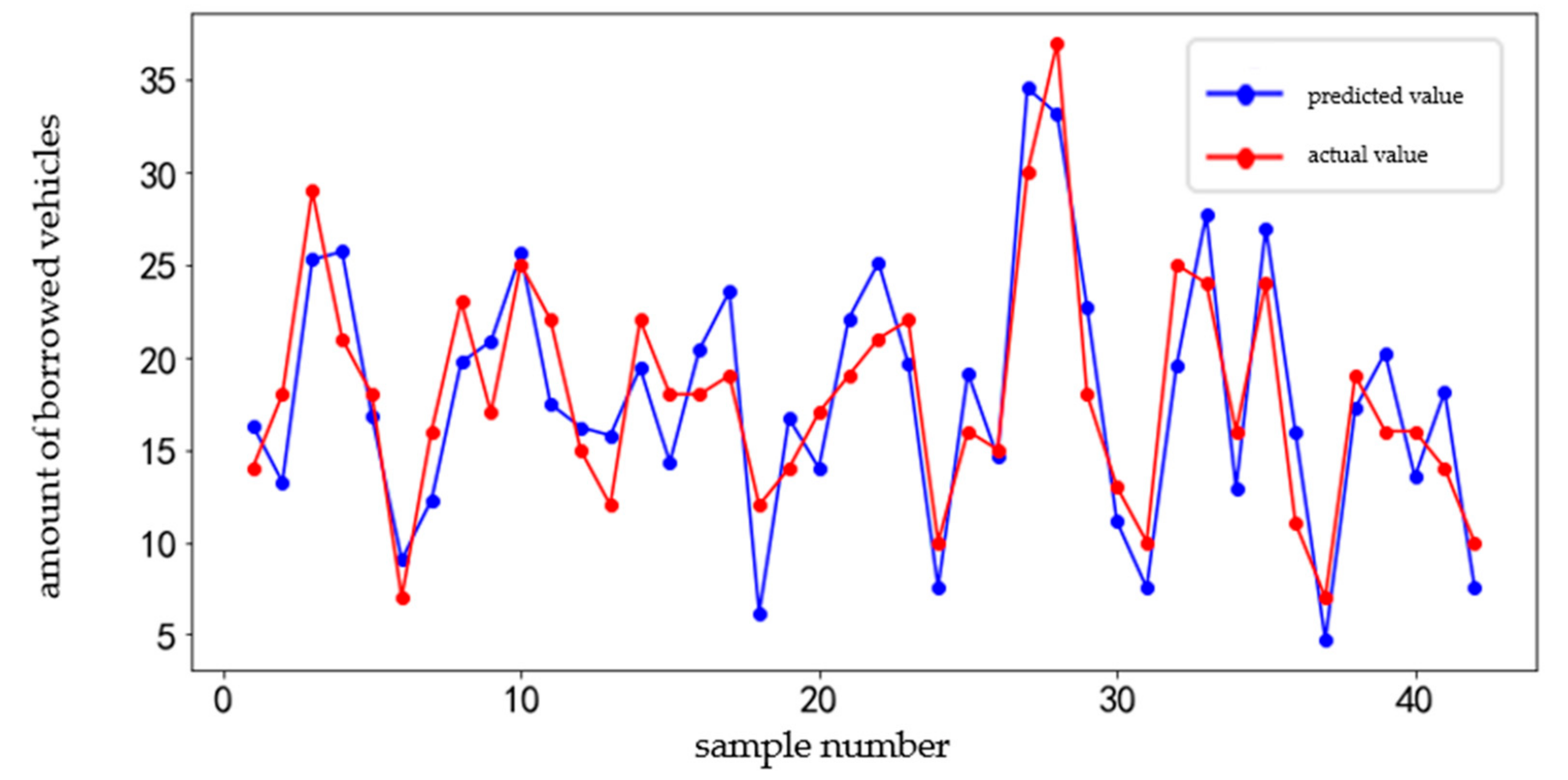
4.1. GDBT Prediction Result
4.2. Comparison
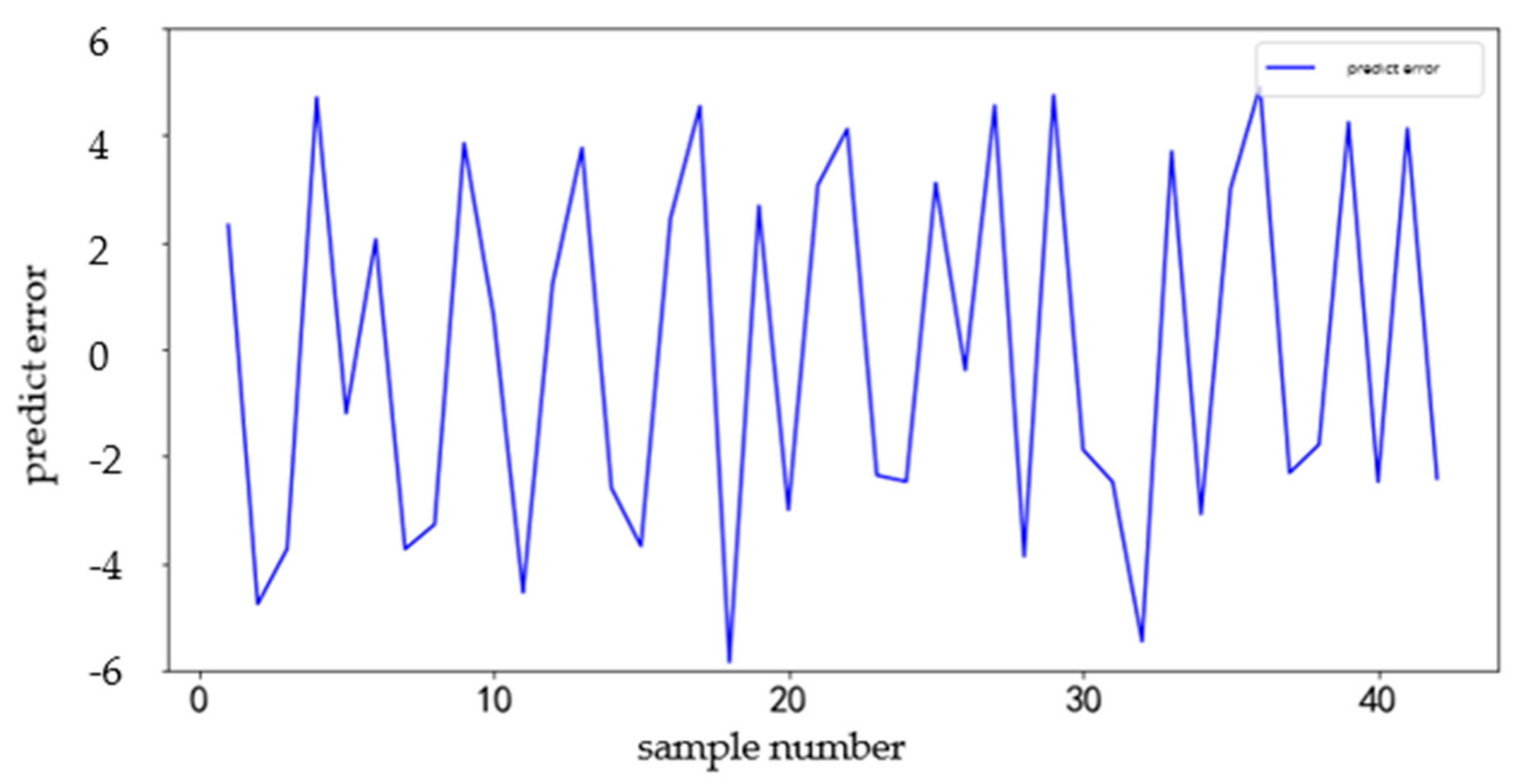
4.2.1. Analysis
4.2.2. Comparison
- (1)
- The prediction error of user demand is still large, which will lead to unreliability in actual operation.
- (2)
- The ARIMA prediction model established in this study only highlights the role of time factor in prediction and does not consider the influence of external factors. When great changes take place in the outside world, great deviations will always occur.
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ciari, F.; Bock, B.; Balmer, M. Modeling station-based and free-floating carsharing demand: Test case study for Berlin. Transp. Res. Rec. 2014, 2416, 37–47. [Google Scholar] [CrossRef]
- Shaheen, S.A.; Cohen, A.P. Growth in worldwide carsharing: An international comparison. Transp. Res. Rec. 2007, 1992, 81–89. [Google Scholar] [CrossRef] [Green Version]
- Ampudia-Renuncio, M.; Guirao, B.; Molina-Sanchez, R.; Bragança, L. Electric Free-Floating Carsharing for Sustainable Cities: Characterization of Frequent Trip Profiles Using Acquired Rental Data. Sustainability 2020, 12, 1248. [Google Scholar] [CrossRef] [Green Version]
- Kang, J.; Hwang, K.; Park, S. Finding factors that influence carsharing usage: Case study in seoul. Sustainability 2016, 8, 709. [Google Scholar] [CrossRef] [Green Version]
- Sioui, L.; Morency, C.; Trépanier, M. How carsharing affects the travel behavior of households: A case study of Montréal, Canada. Int. J. Sustain. Transp. 2013, 7, 52–69. [Google Scholar] [CrossRef]
- De Luca, S.; Di Pace, R. Modelling users’ behaviour in inter-urban carsharing program: A stated preference approach. Transp. Res. Part A Policy Pract. 2015, 71, 59–76. [Google Scholar] [CrossRef]
- Efthymiou, D.; Antoniou, C. Modeling the propensity to join carsharing using hybrid choice models and mixed survey data. Transp. Policy 2016, 51, 143–149. [Google Scholar] [CrossRef]
- Tian, L.; Jiang, X.; Liu, T.; Zhao, Y. Study on Daily Travel Behavior Considering Path Preference Based on Dogit Model. Transp. Syst. Eng. Inf. 2016, 16, 228–235. [Google Scholar]
- Schmoeller, S.; Weikl, S.; Mueller, J.; Bogenberger, K. Empirical analysis of free-floating carsharing usage: The Munich and Berlin case. Transp. Res. 2015, 56, 34–51. [Google Scholar] [CrossRef]
- Guo, R. Short-Term Predict of Online Car-Hailing Travel Demand Based on BP Neural Network; Beijing Jiaotong University: Beijing, China, 2017. [Google Scholar]
- Choi, J.; Yoon, J. Utilizing Spatial Big Data platform in evaluating correlations between rental housing car sharing and public transportation. Spat. Inf. Res. 2017, 25, 555–564. [Google Scholar] [CrossRef]
- Zohra, G.Z.; Maher, T. The antecedents of the consumer purchase intention: Sensitivity to price and involvement in organic product: Moderating role of product regional identity. Trends Food Sci. Technol. 2019, 90, 175–179. [Google Scholar]
- Hu, X.W.; An, S.; Wang, J. Taxi Driver’s Operation Behavior and Passengers’ Demand Analysis Based on GPS Data. J. Adv. Transp. 2018. [Google Scholar] [CrossRef] [Green Version]
- Hui, Y.; Ding, M.; Zheng, K.; Lou, D. Observing Trip Chain Characteristics of Round-Trip Carsharing Users in China: A Case Study Based on GPS Data in Hangzhou City. Sustainability 2017, 9, 949. [Google Scholar] [CrossRef] [Green Version]
- Wang, X. Evaluation scruples, price sensitivity and status preference-analysis of psychological factors affecting consumption behavior. J. Tianzhong 2018, 33, 86–89. [Google Scholar]
- Giordano, D.; Vassio, L.; Cagliero, L. A multi-faceted characterization of free-floating car sharing service usage. Transp. Res. Part C Emerg. Technol. 2021, 125, 102966. [Google Scholar] [CrossRef]
- Zhou, X.; Qu, D.; Jia, H. Urban traffic demand predicting under the conditions of informatization. J. Chang’an Univ. 2003, 3, 88–90. [Google Scholar]
- Müller, J.; Bogenberger, K. Time Series Analysis of Booking Data of a Free-Floating Carsharing System in Berlin. Transp. Res. Procedia 2015, 10, 345–354. [Google Scholar] [CrossRef] [Green Version]
- Li, D. Traffic Diversion Model Based on Dynamic Traffic Demand Estimation and Prediction; Beijing University of Civil Engineering and Architecture: Beijing, China, 2017. [Google Scholar]
- Müller, J.; Correia, G.; Bogenberger, K. An Explanatory Model Approach for the Spatial Distribution of Free-Floating Carsharing Bookings: A Case-Study of German Cities. Sustainability 2017, 9, 1290. [Google Scholar] [CrossRef] [Green Version]
- Alonso, M.J.; Samaranayake, S.; Wallar, A.; Frazzoliet, E.; Rus, D. On-demand high-capacity ride-sharing via dynamic trip-vehicle assignment. Proc. Natl. Acad. Sci. USA 2017, 114, 462–467. [Google Scholar] [CrossRef] [Green Version]
- Wang, C. Research on Traffic Flow Prediction Method Based on Neural Network in Hadoop Environment; Beijing Jiaotong University: Beijing, China, 2017. [Google Scholar]
- Lin, Y.; Zou, N. Short-term prediction model of taxi travel demand based on operating system. J. Northeast. Univ. 2016, 37, 1235–1240. [Google Scholar]
- Li, Q.; Liao, F.X.; Harry, J.P.T.; Huang, H.J.; Zhou, J. Incorporating free-floating car-sharing into an activity-based dynamic user equilibrium model: A demand-side model. Transp. Res. Part B Methodol. 2018, 107, 102–123. [Google Scholar] [CrossRef]
- Le Vine, S.; Adamou, O.; Polak, J. Predicting new forms of activity/mobility patterns enabled by shared-mobility services through a needs-based stated-response method: Case study of grocery shopping. Transp. Policy 2014, 32, 60–68. [Google Scholar] [CrossRef]
- Ampudia-Renuncio, M.; Guirao, B.; Molina-Sánchez, R.; Engel de Álvarez, C. Understanding the spatial distribution of free-floating carsharing in cities: Analysis of the new Madrid experience through a web-based platform. Cities 2020, 98, 102593, SSN 0264–2751. [Google Scholar] [CrossRef]
- Daraio, E. Predicting Car Availability in Free Floating Car Sharing Systems: Leveraging Machine Learning in Challenging Contexts. Electronics 2020, 9, 1322. [Google Scholar] [CrossRef]
- Cocca, M.; Teixeira, D.; Vassio, L.; Mellia, M.; Almeida, J.M.; da Silva, A.P.C. On car-sharing usage prediction with open socio-demographic data. Electronics 2020, 9, 72. [Google Scholar] [CrossRef] [Green Version]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Order Number | User Number | Pick-Up Station | Return Station | Order Time | Pick-Up Time | Return Time |
|---|---|---|---|---|---|---|
| 18093011130044347495 | 10343586900119 | Changhong Jiayuan Station | Baoshihua Road Station | 7:58:08 5 August 2018 | 8:03:00 5 August 2018 | 11:09:06 5 August 2018 |
| Feature Name | Description |
|---|---|
| Max-T | Maximum temperature |
| Min-T | Lowest temperature |
| Precipitation | Cumulative precipitation |
| Visibility | Visibility level |
| Feature Name | Description |
|---|---|
| Week | Week |
| Period | Time periods |
| Month | Months |
| Characteristics | Description |
|---|---|
| Number of vehicles picked up in the first six periods of the prediction period | |
| Number of vehicles returned in the first six periods of the prediction period | |
| Number of vehicles picked up in the same period 28 days before the prediction period | |
| Number of vehicles returned in the same period 28 days before the prediction period | |
| Statistics of the number of picked-up vehicles in the same period of 28 days before the prediction period, including the maximum, minimum and variance |
| Characteristics | Description |
|---|---|
| Number of picked-up vehicles in the first six periods of neighboring station set n | |
| Number of returned vehicles in the first six periods of neighboring station set n | |
| Number of picked-up vehicles in the same period in the first 7 days of neighboring station set n | |
| Number of returned vehicles in the same period in the first 7 days of neighboring station set n | |
| Statistics of the number of picked-up vehicles in the same period in the first 7 days of neighboring station set n, including maximum value, minimum value, and variance |
| Max Depth | N | L | |
|---|---|---|---|
| 0.05 | 9 | 250 | Square loss function |
| Model | Station Collection | Mean Absolute Error/Per | Root Mean Square Error/Per |
|---|---|---|---|
| GBDT | Station collection 1 | 2.01 | 1.99 |
| Station collection 2 | 1.89 | 1.92 | |
| Station collection 3 | 0.53 | 0.62 | |
| Station collection 4 | 0.48 | 0.54 | |
| Station collection 5 | 1.32 | 1.45 | |
| Station collection 6 | 0.38 | 0.46 | |
| Station collection 7 | 0.44 | 0.32 | |
| Station collection 8 | 1.03 | 0.92 | |
| Station collection 9 | 0.87 | 1.02 | |
| Station collection 10 | 0.52 | 0.65 | |
| Station collection 11 | 1.01 | 0.91 | |
| Station collection 12 | 0.74 | 0.68 | |
| Station collection 13 | 0.23 | 0.31 | |
| Station collection 14 | 1.34 | 1.28 | |
| Station collection 15 | 0.31 | 0.34 | |
| ARIMA | Station collection 1 | 3.22 | 3.47 |
| Station collection 2 | 3.15 | 3.32 | |
| Station collection 3 | 0.94 | 0.88 | |
| Station collection 4 | 0.85 | 0.91 | |
| Station collection 5 | 2.11 | 1.98 | |
| Station collection 6 | 1.13 | 1.34 | |
| Station collection 7 | 0.78 | 0.64 | |
| Station collection 8 | 1.87 | 2.08 | |
| Station collection 9 | 1.51 | 1.72 | |
| Station collection 10 | 1.02 | 0.99 | |
| Station collection 11 | 1.42 | 1.28 | |
| Station collection 12 | 1.33 | 1.41 | |
| Station collection 13 | 0.58 | 0.57 | |
| Station collection 14 | 2.12 | 2.01 | |
| Station collection 15 | 0.62 | 0.73 |
| Model | Error Term | Error Value/Per |
|---|---|---|
| ARIMA | Maximum error | 7.23 |
| Minimum error | −0.04 | |
| Mean absolute error | 1.51 | |
| Root mean square error | 1.56 | |
| GBDT | Maximum error | 5.84 |
| Minimum error | 0.02 | |
| Mean absolute error | 0.87 | |
| Root mean square error | 0.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Bi, J.; Sai, Q.; Yuan, Z. Analysis and Prediction of Carsharing Demand Based on Data Mining Methods. Algorithms 2021, 14, 179. https://doi.org/10.3390/a14060179
Wang C, Bi J, Sai Q, Yuan Z. Analysis and Prediction of Carsharing Demand Based on Data Mining Methods. Algorithms. 2021; 14(6):179. https://doi.org/10.3390/a14060179
Chicago/Turabian StyleWang, Chunxia, Jun Bi, Qiuyue Sai, and Zun Yuan. 2021. "Analysis and Prediction of Carsharing Demand Based on Data Mining Methods" Algorithms 14, no. 6: 179. https://doi.org/10.3390/a14060179
APA StyleWang, C., Bi, J., Sai, Q., & Yuan, Z. (2021). Analysis and Prediction of Carsharing Demand Based on Data Mining Methods. Algorithms, 14(6), 179. https://doi.org/10.3390/a14060179