
Using Machine Learning for Quantum Annealing Accuracy Prediction


Abstract
:1. Introduction
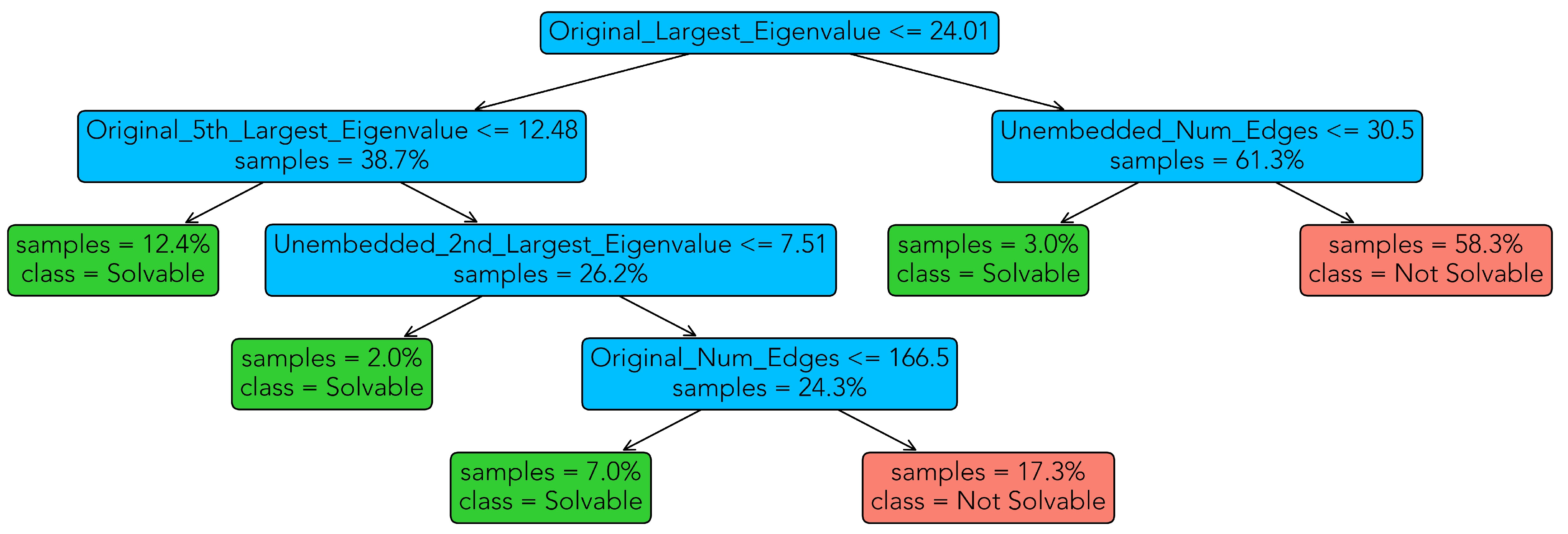
- The task of finding a maximum clique has to be mapped to a formulation of the type of Equation (1). As shown in [1,4], the QUBO functionfor all , achieves a minimum if and only if the vertices for which form a maximum clique, where the two constants can be chosen as , [4]. It is noteworthy that any function of the type of Equation (1) can be represented as a graph P itself, which is used to embed the QUBO problem into the quantum processor. In this representation, each of the n variables becomes a vertex with vertex weight , and each edge between vertices i and j is assigned an edge weight . We call P the unembedded graph.
- To minimize Equation (1) on D-Wave, its corresponding unembedded graph has to be mapped onto the physical hardware qubits on the chip of the D-Wave 2000Q. Since the connectivity of the hardware qubits, called the Chimera graph (see Figure 1), is limited (in particular, all pairwise connections are not possible), a minor embedding of P onto the Chimera graph has to be computed. In a minor embedding, each vertex of P (referred to as a logical qubit) is mapped onto a connected set of hardware qubits, called a chain. Note that in Equation (1), all pairwise connections require the specification of a weight, and, as such, a coupler weight, called the chain strength, is also required for each pair of connected chain qubits. If chosen appropriately, the chain strength ensures that hardware qubits representing the same logical qubit take the same value after annealing is complete. The minor embedding of P onto the Chimera graph is a subgraph of the Chimera graph and, thus, a new graph . We call the embedded graph. Roughly speaking, the closer the topology of P resembles the one of the Chimera graph, the easier it will be to embed it onto the D-Wave 2000Q hardware, and the larger the embeded problems P can be.
- After annealing, it is not guaranteed that chained qubits on the Chimera graph take the same value, even though they represent the same logical qubit. This phenomenon is called a broken chain. To obtain an interpretable solution of logical qubits, definite values have to be assigned to each logical qubit occurring in Equation (1). Although there is no unique way to accomplish this task, D-Wave offers several default methods to unembed chains. Those include majority vote or minimize energy. Majority vote sets the value of a chained qubit to the value (zero or one) taken most often among the hardware qubits which represent the logical qubit. In case of a draw, an unbiased coin flip is used. The minimize energy option determines the final value of all logical qubits via a post-processing step using some form of gradient descent. We employ majority vote in the remainder of the article.
2. Methods
2.1. Classification
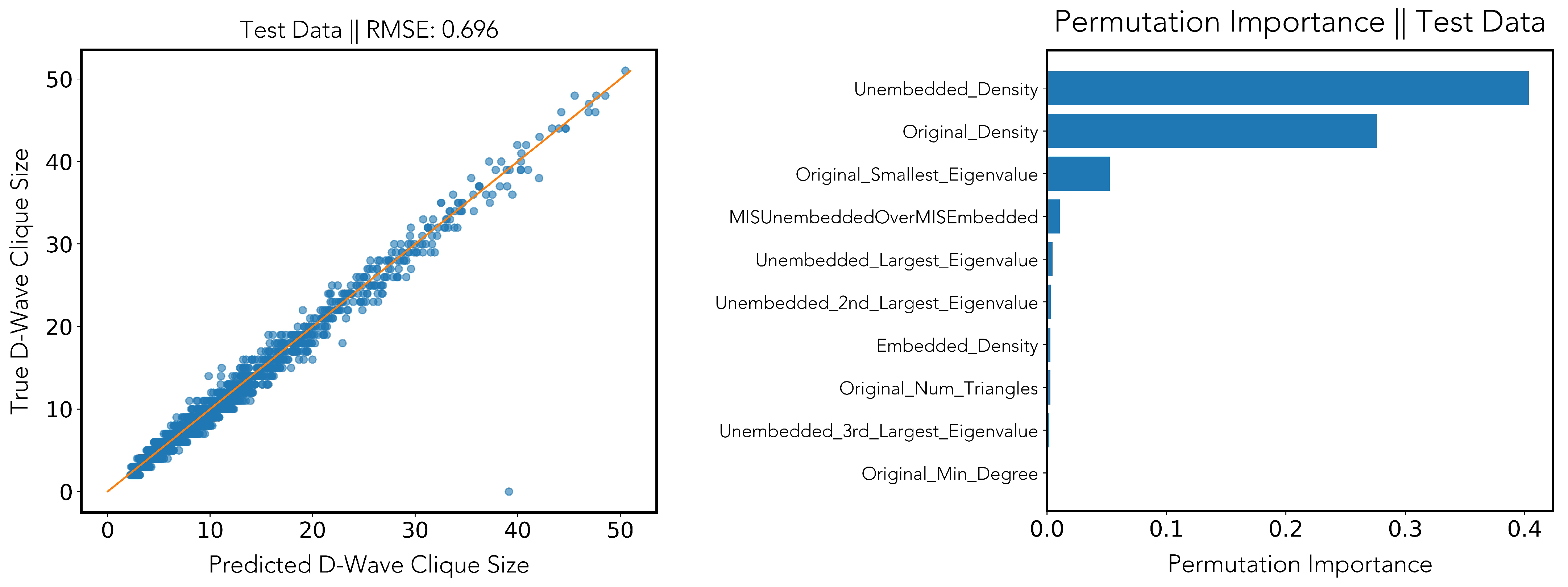
- the graph density (Graph_Density);
- the minimal, maximal, and average degree of any vertex (Graph_Min_Degree,Graph_Max_Degree, and Graph_Mean_Degree);
- the number of triangles in the input and unembedded graphs (Graph_Num_Triangles);
- the number of nodes and edges (Graph_Num_Nodes and Graph_Num_Edges);
- the five largest eigenvalues of the adjacency matrix (Graph_Largest_Eigenvalue,Graph_2nd_Largest_Eigenvalue, etc., up to Graph_5th_Largest_Eigenvalue), and the spectral gap (the difference between the moduli of the two largest eigenvalues) of the adjacency matrix (Graph_Spectral_Gap). For brevity of notation, we refer with “eigenvalue of a graph” to the eigenvalue of its adjacency matrix.
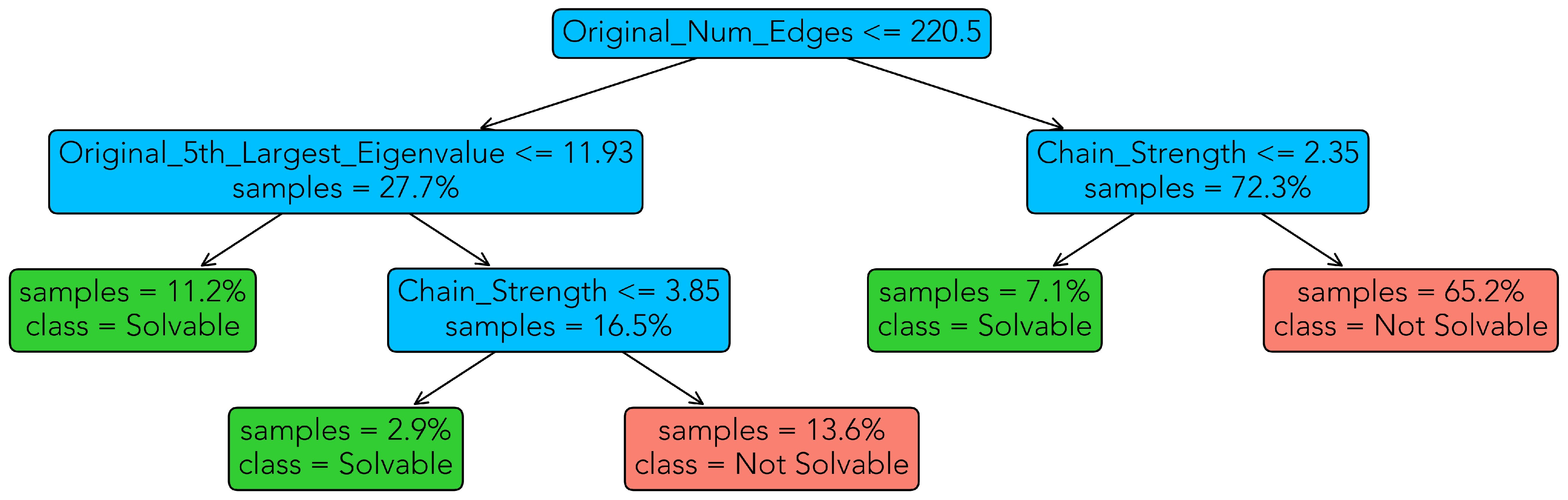
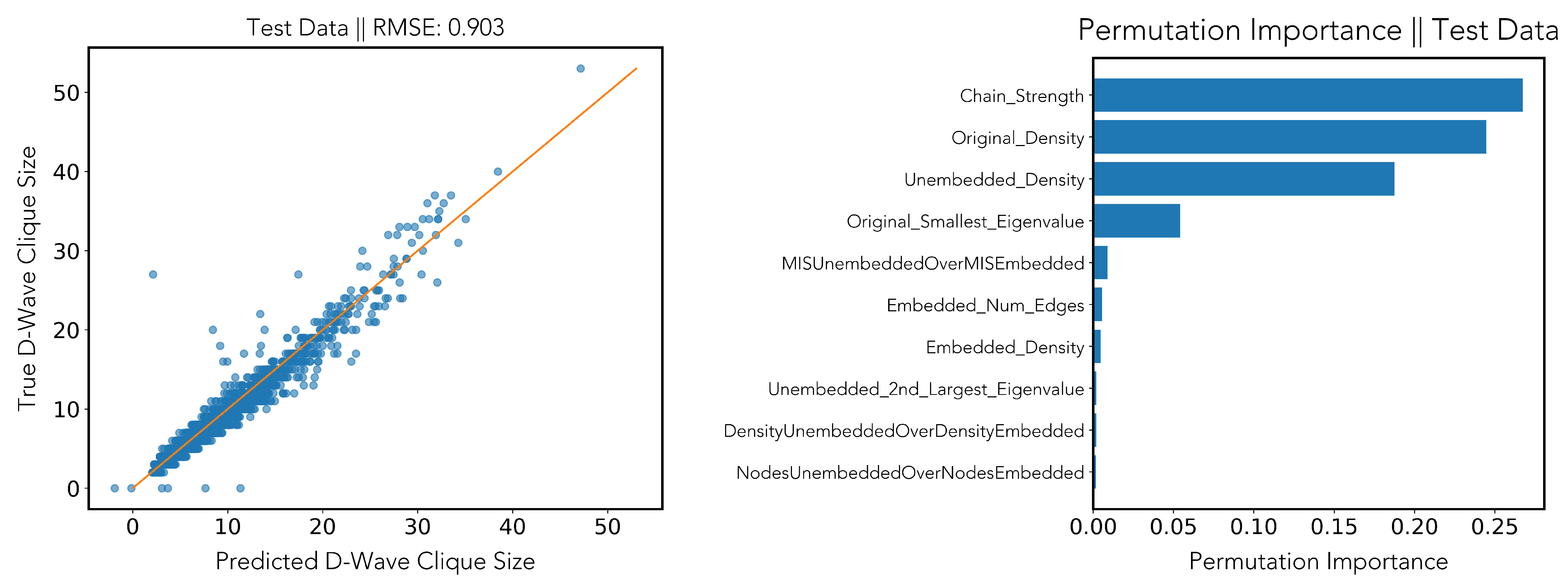
- the minimal, maximal, and average chain length occurring in the embedding(Min_Chain_Length, Max_Chain_Length, and Avg_Chain_Length);
- the chain strength computed with D-Wave’s uniform torque compensation feature (Chain_Strength), see [18], using either a fixed UTC prefactor (Section 3.1) or a randomly selected one in (Section 3.2);
- the annealing time (in microseconds), which was selected uniformly at random in (Annealing_Time).
2.2. Regression
3. Experimental Results
3.1. Fixed Annealing Time and Fixed UTC Prefactor
3.1.1. Classification
3.1.2. Regression
3.2. Random Annealing Time and Random UTC Prefactor
3.2.1. Classification
3.2.2. Regression
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chapuis, G.; Djidjev, H.; Hahn, G.; Rizk, G. Finding Maximum Cliques on the D-Wave Quantum Annealer. J. Signal Process. Syst. 2019, 91, 363–377. [Google Scholar] [CrossRef] [Green Version]
- Lucas, A. Ising formulations of many NP problems. Front. Phys. 2014, 2, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Pelofske, E.; Hahn, G.; Djidjev, H. Solving large Maximum Clique problems on a quantum annealer. In International Workshop on Quantum Technology and Optimization Problems; Springer: Munich, Germany, 2019; pp. 63–70. [Google Scholar]
- Cincio, L.; Subaşı, Y.; Sornborger, A.; Coles, P. Learning the quantum algorithm for state overlap. New J. Phys. 2018, 20, 113022. [Google Scholar] [CrossRef]
- Verdon, G.; Broughton, M.; McClean, J.R.; Sung, K.J.; Babbush, R.; Jiang, Z.; Neven, H.; Mohseni, M. Learning to learn with quantum neural networks via classical neural networks. arXiv 2019, arXiv:1907.05415. [Google Scholar]
- Fösel, T.; Niu, M.Y.; Marquardt, F.; Li, L. Quantum circuit optimization with deep reinforcement learning. arXiv 2021, arXiv:2103.07585. [Google Scholar]
- Magesan, E.; Gambetta, J.M.; Córcoles, A.; Chow, J.M. Machine Learning for Discriminating Quantum Measurement Trajectories and Improving Readout. Phys. Rev. Lett. 2015, 114, 200501. [Google Scholar] [CrossRef] [PubMed]
- Rivera-Dean, J.; Huembeli, P.; Acín, A.; Bowles, J. Avoiding local minima in Variational Quantum Algorithms with Neural Networks. arXiv 2021, arXiv:2104.02955. [Google Scholar]
- Farhi, E.; Goldstone, J.; Gutmann, S.; Neven, H. Quantum Algorithms for Fixed Qubit Architectures. arXiv 2017, arXiv:1703.06199. [Google Scholar]
- Wauters, M.M.; Panizon, E.; Mbeng, G.B.; Santoro, G.E. Reinforcement-learning-assisted quantum optimization. Phys. Rev. Res. 2020, 2, 033446. [Google Scholar] [CrossRef]
- Moussa, C.; Calandra, H.; Dunjko, V. To quantum or not to quantum: Towards algorithm selection in near-term quantum optimization. Quantum Sci. Technol. 2020, 5, 044009. [Google Scholar] [CrossRef]
- Pelofske, E.; Hahn, G.; Djidjev, H. Optimizing the Spin Reversal Transform on the D-Wave 2000Q. In Proceedings of the 2019 IEEE International Conference on Rebooting Computing (ICRC), San Mateo, CA, USA, 4–8 November 2019; pp. 1–8. [Google Scholar]
- Barbosa, A.; Pelofske, E.; Hahn, G.; Djidjev, H. Optimizing embedding-related quantum annealing parameters for reducing hardware bias. arXiv 2020, arXiv:2011.00719. [Google Scholar]
- Håstad, J. Clique is hard to approximate within n1−ε. Acta Math. 1999, 182, 105–142. [Google Scholar] [CrossRef]
- Chen, J.; Huang, X.; Kanj, I.A.; Xia, G. Strong computational lower bounds via parameterized complexity. J. Comput. Syst. Sci. 2006, 72, 1346–1367. [Google Scholar] [CrossRef] [Green Version]
- D-Wave Systems. D-Wave Ocearn: Minorminer. 2021. Available online: https://docs.ocean.dwavesys.com/projects/minorminer/en/latest/ (accessed on 15 May 2021).
- D-Wave Systems. D-Wave System Documentation: Uniform Torque Compensation. 2019. Available online: https://docs.ocean.dwavesys.com/projects/system/en/stable/reference/generated/dwave.embedding.chain_strength.uniform_torque_compensation.html (accessed on 15 May 2021).
- Hagberg, A.A.; Schult, D.A.; Swart, P.J. Exploring Network Structure, Dynamics, and Function using NetworkX. In Proceedings of the 7th Python in Science Conference, Pasadena, CA, USA, 19–24 August 2008; pp. 11–15. [Google Scholar]
- NetworkX. Return the Clique Number (Size of the Largest Clique) for a Graph. 2021. Available online: https://networkx.org/documentation/networkx-1.10/reference/generated/networkx.algorithms.clique.graph_clique_number.html (accessed on 15 May 2021).
- Scikit Learn. Gradient Boosting for Regression. 2021. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html (accessed on 15 May 2021).
- Cvetković, D.; Simić, S. The second largest eigenvalue of a graph (a survey). Filomat 1995, 9, 449–472. [Google Scholar]
- Lovász, L. Eigenvalues of Graphs. 2007. Available online: https://web.cs.elte.hu/~lovasz/eigenvals-x.pdf (accessed on 15 May 2021).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted | |||
|---|---|---|---|
| Not Solvable | Solvable | ||
| Actual | Not Solvable | 3458 | 654 |
| Solvable | 97 | 497 | |
| Predicted | |||
|---|---|---|---|
| Not Solvable | Solvable | ||
| Actual | Not Solvable | 3731 | 672 |
| Solvable | 68 | 425 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barbosa, A.; Pelofske, E.; Hahn, G.; Djidjev, H.N. Using Machine Learning for Quantum Annealing Accuracy Prediction. Algorithms 2021, 14, 187. https://doi.org/10.3390/a14060187
Barbosa A, Pelofske E, Hahn G, Djidjev HN. Using Machine Learning for Quantum Annealing Accuracy Prediction. Algorithms. 2021; 14(6):187. https://doi.org/10.3390/a14060187
Chicago/Turabian StyleBarbosa, Aaron, Elijah Pelofske, Georg Hahn, and Hristo N. Djidjev. 2021. "Using Machine Learning for Quantum Annealing Accuracy Prediction" Algorithms 14, no. 6: 187. https://doi.org/10.3390/a14060187
APA StyleBarbosa, A., Pelofske, E., Hahn, G., & Djidjev, H. N. (2021). Using Machine Learning for Quantum Annealing Accuracy Prediction. Algorithms, 14(6), 187. https://doi.org/10.3390/a14060187