1. Introduction
Social media and e-commerce platforms have become a fundamental element of today’s society [
1]; as a result, the data on the Web is hugely growing, but the quality of this data requires more investigation [
2]. Social media platforms have become where people share the urge to stay connected and express themselves by discussing the news, giving opinions about politics, watching movies or products, but, unluckily, this online data can be fast and quickly disseminated [
3], and it is not so hard to manipulate with it. The fake news and misleading information have become apparent today, especially in moments of crisis, such as what we face today, the COVID-19 pandemic [
4]. Different studies have proven that there is a need to flatten the curve of the rumors and misinformation about the virus with a view to flatten the curve of COVID-19 [
5]. Besides, e-commerce websites are also an essential instance where a large number of fake reviews and fake profiles exist due to the rising number of new products and the intense competition between companies [
6].
Nevertheless, online reviews can be fraudulent and are yet necessary for both consumers and firms. For the consumers, it is necessary to check them to decide for the quality of the products and whether to buy it or not. In contrast, firms need online reviews in order to improve their products and boost the sales [
7].
Thus, developing fact-checking tools that can detect fake reviews or fake users will help improve the clarity and quality of online data; otherwise, the Web will be a sea of abnormal distribution of rumors and false information.
Obviously, this is not an easy task: researchers in this domain invested a lot of effort, but it still needs to be improved. To understand the problem well, we should first recognize the characteristics of such data and the behavior patterns of the fake users.
In References [
8,
9], sockpuppets are individuals with pretended profiles that incorporate wrong information and do not show their real identities; they have suspicious activities, like spamming or flooding, to mislead other users and hide the facts. Those activities can be exposed by their behavioral patterns and the other accounts who cooperate with them; for instance, by checking the IP addresses, it is possible to obtain information indicating spamming behaviors, mainly when the same user with the same IP address uses multiple fake accounts. Accordingly, identifying those accounts is highly important and removing them requires well-designed systems, which can identify such strange behaviors and malicious patterns.
This work is an extensive study of this kind of user’s behavior that writes fake reviews and has malicious patterns to detect it. We define a knowledge base (KB) and a reasoning rules-based approach, using Answer Set Programming (ASP), where the following study [
10] showcases the established usage of ASP in industry fields.
Our approach works as follows: the input is the movie reviews. Then, each review is checked using natural language processing to determine the sentiment to distinguish positive and negative criticism; next, a Levenshtein-distance algorithm [
2] identifies deviations between user review data. Afterwards, the results of these algorithms and user data, such as review rating and IP addresses data, are grounded and put in all in an ASP KB with predefined rules that fact check them. This way, the framework can identify reviews that are not trustworthy and label them accordingly in the output. The evaluation showed that this technique is able to detect fake reviews and works well with high flexibility since more algorithms can later be considered as extended rules can be for better performance.
The remainder of the paper is organized as follows:
Section 2 and
Section 3 gives an overview of related work and highlight the importance of reasoning systems for fake review detection.
Section 4 discusses the basic patterns of user behavior in the context of detecting fake reviews.
Section 5.2 explains the original dataset used for this work.
Section 5 presents our approach using an ASP technique to realize a fake review detection system.
Section 6 and
Section 7 demonstrate the output results and the evaluation of it.
Section 8 covers a discussion of the presented approach, and
Section 9 concludes the paper.
2. Related Works
The fake reviews detection problem was introduced first by Jindal [
11] and Liu [
12] concerning product reviews in 2008. The problem has been tackled using several approaches, like analyzing the review content or the user behavioral characteristics, or applying sentiment analysis techniques, to classify the reviews as fake or genuine.
Many researchers tried to create state-of-the-art techniques for detecting reviews as spam or genuine reviews. Various detection levels should be taken into consideration as stated in Reference [
13], they are mainly the following: (a) review content-based detection, (b) deviations among rating-based detection, and (c) review content along with user behavior-based detection. Supervised models use the first two categories, but it may not be easy to obtain precise results as training the models may require a big dataset to get accurate results. Thus, the authors recommended considering the third category (c) to enhance the overall performance.
Lately, intensive research has been done for developing spamming detection systems using machine learning techniques. In Reference [
14], two different approaches for fake review recognition are presented, where supervised learning techniques have been used for extracting and classifying new semantic features from real Yelp review dataset. The paper proposes a set of behavioral features and proves that, by using such features, it helps to achieve better accuracy than using n-grams.
Support Vector Machine (SVM) has been used in Reference [
14] for classification and the authors reported that they achieved high accuracy when including the following behavioral features that are: the length of the review, time intervals of each review, and the ratio of each positive/negative reviews.
In Reference [
15], a feature framework for fake review detection has been introduced based on a classification approach. The work addresses the problem by scraping information from real Yelp dataset (
https://www.kaggle.com/yelp-dataset/yelp-dataset (accessed on 31 May 2021)) in order to construct a new dataset concerning the customer electronics domain. The framework did use two types of features for extracting features: review-centric features that are related to review itself as a text, and user-centric features, which concern the behavioral patterns of the reviewers, like personal, social, and review activity.
The approach presented in Reference [
16] showed that non-verbal behavioral features, such as the number of likes/dislikes, average posting rate, review updates, etc., can be effective to detect fake reviews as much as verbal features, such as the review length or review content. The paper recommended non-machine learning techniques, such as graph-based or pattern matching methods, where these different techniques examine the relationship between the reviewers, reviews, and content similarities.
Furthermore, the work in Reference [
17] demonstrates that using the reviewers behavioral features boosted the accuracy of approximately 20 percent in comparison to n-grams, but they also mentioned that more information could be used in order to improve the results, like IP addresses, user logs, or duration of sessions.
Other approaches, e.g., Reference [
18], proposed a fake review recognition system by capturing doubtful time intervals of reviews. Both refs. [
17,
18] agree that using the private information, like IP addresses and MAC addresses, can boost the fake detection system performance. Both papers agree on the problem that there are no quality standards for datasets that can be used to achieve 100 percent of accuracy to tell if a review is fake or not.
Moreover, the approach presented in Reference [
19] demonstrates diverse features that help to spot the fake reviews. Those features are mainly used to spot the review content similarities including the reviewers, their reviews, and the ability of repeating reviews. In addition, the items that have been reviewed, as well as the frequency of each review, are taken into consideration.
Studies in Reference [
20] showed the direct impact of online reviews on the box office revenue of a given movie, implying that people are using these online services to sometimes decide if they are going to watch a movie or not.
Based on the previous papers, and as mentioned in Reference [
21], one of the significant challenges when using machine learning approaches arises from the imbalance in the state of two classes, false and factual information from the previously mentioned approaches. Obtaining labels for fraudulent information is also a challenging task. In many cases, these are obtained manually by experts, trained volunteers, or Amazon Mechanical Turk workers. The process requires considerable manual effort, and the evaluators are possibly unable to classify all misinformation that they face. In contrast to those approaches, rule-based techniques are recognized as a white box, which provides traceability and transparency for significant decisions that require a higher degree of explanation than usually produced by machine learning approaches. Furthermore, the decision of whether to go for a rule-based system or machine learning system depends on the problem, and it is mainly a trade-off between effectiveness, training costs, and understanding.
Furthermore, the following papers are all describing and related to how ASP can be used. Authors in Reference [
10] gave a good explanation and introduction on ASP use cases. It is more interesting to take a look at if and how ASP can be used to create recognition systems. According to the authors, ASP can solve classification problems and detect inconsistency of information. They have given an example of using ASP for an e-tourism portal. It can be similar to the proposed approach as a recognition system because both systems are knowledge-dependent and have particular rules/algorithms to follow. Furthermore, they hinted that ASP could be used to detect fake news and inconsistency in data.
However, ref. [
22] emphasizes how straightforward the implementation of ASP can be and how easy difficult-looking problems can be solved. In this paper, the authors demonstrate a simple process of building artificial intelligence system for games, which is usually not an easy task for imperative programming. They reported that ASP is excellent in dealing with knowledge incomplete and intensive applications.
As mentioned in the literature, fake review detection systems would work more efficiently if the sentimental analysis is used, but natural language processing (NLP) is not an easy task at all for the machines. Reference [
23] describes the usage of ASP function elements together with some external NLP modules, which have textual entailment functions. Furthermore, the authors mentioned that similar approaches are essential because they provide the machines with the possibility to solve reasoning problems with background knowledge written in natural language.
In addition, Refs. [
24,
25] are both focusing on discovering inconsistencies by using ASP. Although they are different papers and have different application domains, it is possible to see similarities in using the approach and motivation behind choosing ASP. Both papers search for inconsistencies in a specific type of data by determining minimal representations of conflicts. Both papers claim that ASP provides a straightforward method to model and represent the problem.
4. On the Characteristics of Fake Reviewers and Reviews
Behind every fake review, there is a user that normally has a well-defined malicious behavior. As described in Reference [
14], certain patterns, such as posting only positive or negative reviews, or posting reviews in a specific time interval, for example, every day or every week at the same period of time, can be detected as a spamming behavior. Another interesting pattern for a fake review can be the content itself. For example, there are many redundant reviews with only minor changes or spam reviews with a bad quality texting and few counts of words [
27].
Another well-described pattern of malicious behavior, described in both References [
27,
28], is the control of different accounts by a single spammer, who uses them for spamming and domination. These accounts are also known as bot accounts or sockpuppets and can be recognized by following their actions in connection with other similar users. Most likely, the grouping that will appear is going to be bot users. Another aspect for fake review recognition could be a single individual user coupling in a group, which describes the behavior of multiple users acting similarly relatively at the same time, which is often done by bot accounts [
27]. Furthermore, accounts with some special “sequential” user naming are often associated with bot users. Another way to detect fake reviews can be achieved by checking the dislike counts. Many e-commerce websites offer some functionality that allows people to vote if a review was helpful or not. Sometimes the community is doing the job for us by disliking the suspicious reviews. This makes the dislike count be represented as a feature that needs to be taken into consideration.
The work in Reference [
9] discusses the anonymity factor that may need further consideration, as well. For example, on Amazon, users can post a review under a nickname or as an anonymous user. Anonymous users post many fake reviews because the user may want to avoid getting tracked. In our proposed system, the requirement to post a new review is that the user initially registers with the help of the registration step; the anonymous review feature is not feasible.
Another significant factor in the recognition process is the review feature similarities of a new or updated review with all other reviews in the system. It is possible to compute these similarities by using dynamic algorithmic approaches as discussed in Reference [
2]. Given the deviation values results of the analyzed reviews, the three reviews with the highest similarity scores are considered, and the number of high and low deviating reviews is used in the ASP knowledge base (see
Section 5.5).
5. Approach
ASP is a well-known technique in the domain of Knowledge Representation and Reasoning (KRR) [
29]. It belongs to the group of so-called constraint programming languages. In ASP, the specification of the problem is given, and the specification model delivers the solution. It is also a form of declarative programming, which is mainly used to solve non-deterministic search problems. As described in References [
24,
25], it got prevalent
“because of its appealing combination of a rich yet simple modeling language with high-performance solving potentials". In ASP, search problems are reduced to compute solid models and answer sets. It utilizes solvers that are reasoners, which outcome stable model generation [
24].
Figure 1 presents the ASP solving process. The aim is to deliver one or several solutions to the given problem. The primary step is to model the problem into a logic program with rules, first-order predicates, and variables. Then, the grounder will reduce the variables by substituting them with ground terms in the language. As a consequence, a propositional program will only contain propositional atoms. The program is then taken by the solver, which will calculate all the stable models and interpret the solution [
30]. Therefore, it is essential to understand the data and the problem itself to start building our KB.
This will allow for creating a formal model of the problem and the input data by means of a KB, constraints, and rules that have to be satisfied (see
Section 5.5 and
Section 5.5.2). In the upcoming illustrating example, we show the approach considering only three movies just for simplicity. This simplification does not cause any limitation of the approach.
While developing the KB, with all the constraints and facts, we have used the online tool Potassco (The Potsdam Answer Set Solving Collection,
https://potassco.org/clingo/run/ (accessed on 31 May 2021)) to test the resulting labels and analyze the running time of the solver. Solving a KB with four reviews, including their facts, such as IP address, sentiment, star rating, and cosine similarity, took a total of 0.013 s to solve, showcasing the efficiency of ASP solvers.
5.1. ASP Fundamentals
As previously mentioned, the KB consists of various facts and rules which are used to generate an answer set, which includes the possible solutions of the given problem. ASP programs are based on the AnsProlog (also called A-Prolog [
31]) programming language and use the predefined rules and facts, instead of a classical algorithmic approach, to find a solution to a given problem. The following shows examples of defining a rule and constraint.
The example rule (
1), shows a list of atoms in first order logic
, which is called the body of the rule, whereas
is called the head of the rule. It is also important to note that rules without a body are called facts [
32].
The example constraint (
2), shows a list of atoms in first order logic
, which is different from a rule in such a way that the head is empty. A constraint is used to remove some elements from the answer set, as in the given example constraint, and the answer set will not include
if
is not generated.
5.2. Dataset
To achieve accurate results that mimic real-world scenarios, we implemented a website for evaluating movie reviews. It allowed us to create a more extensive dataset that can help us explain the reviewers’ behavior. We wanted to have complete control over the dataset so that we can get all the required attributes. In order to achieve this, the website uses a local database instance for storing all related data, including user data, review data, and movie-related data. The dataset can be used later to inspect the best or worst-rated movies, movies with many fake reviews, and similar measurements.
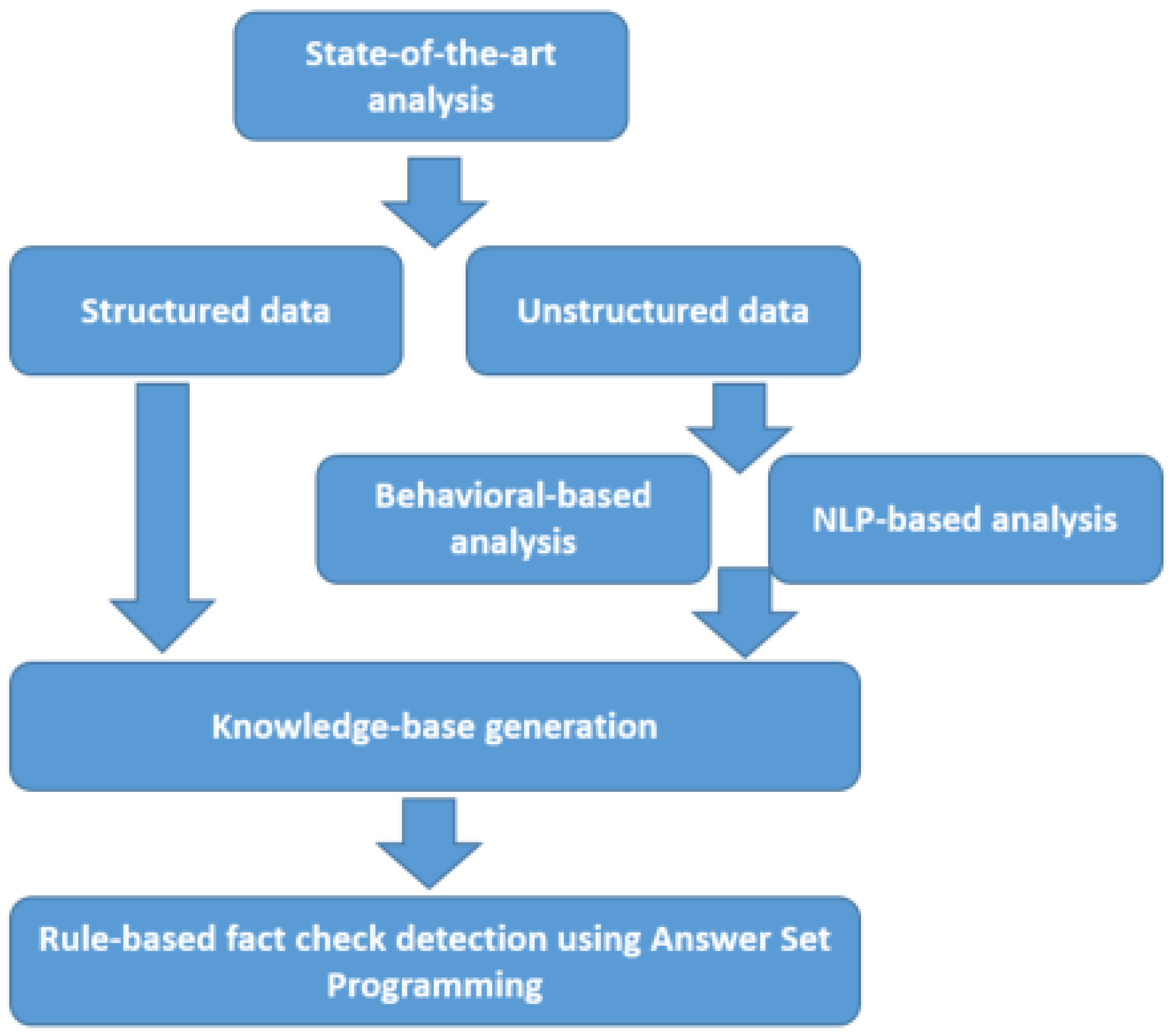
5.3. Analysis of Structured and Unstructured Data
The approaches of analyzing fake data on the web can be categorized in two segments. The first one is based on structured data, where the content can be directly analyzed as such. As structured data is well organized, depending on the type of the data, it is much easier to generate a well defined KB, which will yield clear answer sets, given the rules and constraints defined in the KB.
On the other side, with unstructured data, the approach includes different steps of organizing the unstructured raw data, to result in processed data that can be used in the KB. These steps include behavioral based analysis steps, that can be used to analyze predefined classifications of behaviors or to generate new behavioral patterns from the given data. Another way of interpreting the data is using natural language processing steps, to analyze, i.e., the sentiment of the data. The main idea behind these approaches is to transform the unstructured data into well structured data, which can be used as a basis for the KB generation. These steps are crucial to understand, implement and evaluate in the early steps of generating the KB, meaning that the rules and constraints within the KB need to comply with the processed unstructured data, to establish a well defined answer set.
The final step of the process is to evaluate the inputs to the KB, and generate the answer set that recognizes the given data as, in our case, fake or genuine. These classifications can be extended and adapted to other requirements, giving the opportunity to evaluate different data inputs for other, possibly more domain-specific, datasets, based on an existing KB that can be easily extended to meet the new requirements. This is one of the aspects that illustrate the advantage of ASP approaches for problem solving tasks.
Figure 2 shows the given steps of the analysis of structured and unstructured data, regarding the generation of a KB.
Levenshtein/Cosine Similarity
Presents a technique that helps in pinpointing contradicting and deviating pieces of information in structured data sources. It incorporates two algorithms, Levenshtein Distance (LD) and Cosine Similarity (CS). LD measures the similarity of two input strings [
33]. It is also known as “edit distance”, which helps in many applications, like text analyzing and correcting errors [
34]. In this case, the distance is the number of substitutions, deletions, and insertions required to create the target string from the source string. A high distance would indicate that the two inputs are notable and deviate from each other. Moreover, a low distance indicates higher similarity and that the strings do not deviate as much. According to Reference [
2], obtaining these results involves three succeeding steps: The first step is to edit input data to compare them. This step includes extracting unnecessary characters from strings with regular expressions and parsing dates to a standard format. The second step is to calculate pairwise deviations between the reference object and each item in a dataset, where every reference object or a single object in the compared dataset consists of a movie title, a movie date, and the movie cast names. After normalizing the computed values, the distance matrix is then calculated. The next step of the algorithm is to specify further the Levenshtein distance analysis matrix, which was created in the second part of the algorithm and comprises ordering the results in descending or ascending order, which is done using what so-called sensitivity vectors. It allows investigating which sort of deviation to examine out of all movie features. For example, a sensitivity vector of (1, 1, 1) would look for significantly deviating data and creates a list as output, which shows movies that have a high deviation across all categories. In contrast, a vector (0, 0, 0), on the other hand, does the opposite: It orders the created list by non or most minor deviating data, which results in a list that holds low deviating movies in the front. The chosen sensitivity vector contributes to a cosine similarity function with the deviation matrix created in step 2. The output is a list that orders the deviating data by the preferences earlier defined in the sensitivity vector and later used to analyze the algorithms’ calculations by initially ordering the feature list received by the function.
This algorithm is a robust tool in identifying deviating data in structured data elements. The most significant part of this algorithm is that it does not require a training phase, like machine learning approaches. Another advantage is that there is no need to use sample data to determine a specific models’ parameters [
2]. Consolidating this algorithm into a given project is very straightforward because, as discussed earlier, it does not need sample data or training phase.
5.4. Demo Application Scenario
In our demo application, we assume that there are movies, each of them having assigned some reviews written by some users. Each review has assigned a number of (dis)likes reflecting the opinion of other users, number of stars reflecting the author opinion of the movie, a sentiment score of the review (ranging from 1 as strongly negative to 5 as strongly positive), a timestamp encoding the time the review was posted, and an IP address encoding the users’ machine as the source of the review.
All information about reviews and authors, such as (dis)likes, star ratings, sentiment scores, timestamps, and IP addresses, are encoded in a KB which we briefly discuss in
Section 5.5.
In our application, it is assumed that reviews may be considered fake, possiblyFake, possiblyGenuine, genuine, or contradicted. We include many rules that will lead us to detect the correct classification of the reviews, helping the users to decide whether a review on a certain movie can be trusted or not.
All these rules determine the results by labeling a review as
fake,
possiblyFake,
possiblyGenuine,
genuine, or
contradicted, determining which reviews where posted from the same IP address, and labeling reviews as candidates for spam in case they have been written within a short time interval and stemming from the same IP address (e.g., a pattern often observed in the case of sockpuppetry [
8]), determining the polarity scores of the reviews between the review star rating and the review sentiment analysis score, finally analyzing the review similarity with all other reviews in the system. In
Section 5.5.2, we illustrate some sample rules.
5.5. Knowledge Base
The system uses two knowledge bases, one for the review classification and another for the author classification.
5.5.1. Review Knowledge Base
In the review KB (see
Listing 1), all constants should be declared first. The only constant value in the KB is 30 s refers to the time interval between the posting time of two reviews.
Next, we declare some timestamps and IP addresses , followed by the declaration of movies and reviews . Subsequently, we declare which reviews are assigned to a movie (see hasRev).
Review features are being set, such as the review stars (see stars), sentiment score (see sentScore), and review Levenshtein/Cosine similarity scores (see revLCS).
Then, the timestamps and the source IP addresses for all reviews are modeled (see timestamp_of_Review and hasIp). Finally, we declare the labels used for the classification of reviews.
Listing 1.
Abstracted samples of facts from the review KB.
Listing 1.
Abstracted samples of facts from the review KB.
5.5.2. Review Constraints and Rules
Based on the facts from the KB, constraints and rules satisfying conditions on the facts are declared such that they formally encode the problem that needs to be solved. In our scenario, the problem we want to solve can be stated like this: Given some facts about reviews on movies, we want to detect fake and genuine reviews and identify candidates for spam reviews.
In our case, a set of illustrating constraints and rules (see
Listing 2) has been declared, which state the following:
Each review can be assigned as highly, moderately, or normal regarding the review polarity. A review will be of highPolarityDiff if the difference between the sentiment score and the star rating of the review is greater or equal to 3.
Analogously to the previous rule, moderatePolarityDiff checks if the difference between the sentiment score and the star rating of the review is greater or equal to 1 and is not believed to be of highPolarityDiff.
Analogously to the previous two rules, normalPolarityDiff checks if the difference between the sentiment score and the star rating of the review is not believed to be of highPolarityDiff and moderatePolarityDiff.
A review is considered as a unique review (spamByLCS) if the Levenshtein/Cosine similarity scores are higher in the number of lower deviating reviews than high deviating reviews.
The given rule states that, if any two different reviews of a certain movie have an identical source, IP address, and both reviews were written within a short time interval (e.g., 30 s, i.e., s), it has to be derived and concluded that both reviews are spam candidates.
The given rule checks if the review can be concluded to be a genuine review if the review is not a spam candidate by the spamByCS rule, not spam by timestamp, and neither high nor moderate polar (see genuineReview).
The given rule checks if the review can be concluded to be a possibly genuine review if all previous rules match. However, the review is considered to be of moderate polarity (see possiblyGenuineReview).
The given rule checks if the review can be concluded to be a possibly fake review if the review is considered to be spam by the Levenshtein Cosine similarity measure, spam by timestamp, and a moderately polar review (see possiblyFakeReview).
The given rule checks if the review can be concluded to be a fake review if the review is considered to be spam by the Levenshtein Cosine similarity measure, spam by timestamp, and a highly polar review. (see fakeReview).
If the review is not believed to be of any of the previous classifications, it is considered to be a contradicted review (see contradictedReview).
Listing 2.
Sample review constraints and rules.
Listing 2.
Sample review constraints and rules.
5.5.3. Author Knowledge Base
In the author KB (see
Listing 3), the main focus lies on the number of reviews posted by the author for a given movie and how these reviews are rated by other users of the system.
The facts include the author’s object, movies and reviews, the number of likes and dislikes of a review, and what review is assigned to which movie.
Listing 3.
Abstracted samples of facts from the author KB.
Listing 3.
Abstracted samples of facts from the author KB.
5.5.4. Author Constraints and Rules
Based on the facts from the KB, constraints and rules satisfying conditions on the facts are declared such that they formally encode the problem that needs to be solved. In our scenario, the problem we want to solve can be declared like this: Given some facts about reviews on movies, we want to detect fake and genuine reviews and identify candidates for spam reviews.
In our case, a set of illustrating constraints and rules (see
Listing 4) has been declared, which state the following:
Using the sum aggregate, the number of likes overall reviews is being calculated.
Using the sum aggregate, the number of dislikes overall reviews are being calculated.
The highDiff rule checks how many reviews have a higher number of likes compared to the number of dislikes, and returns the positive number of likes of a review. For example, if review r1 has 15 likes and 5 dislikes, the rule will return highDiff(r1,10) as an answer set.
To get the best-rated review, the rule bestRev, uses the max aggregate and the highDiff rule, calculates which review has the highest number of likes compared to the number of dislikes, over all reviews.
Analogously to the highDiff rule lowDiff, this rule calculates the reviews that have a higher dislike count than like count. For example, if review r1 has 3 likes and 20 dislikes, the answer set of this rule will be lowDiff(r1,−17).
Analogously to the bestRev rule, worstRev uses the min aggregate and the lowDiff rule to calculate which review has the highest number of dislikes compared to the number of likes, over all reviews.
The highCount rule gets the number of liked reviews.
The lowCount rule gets the number of disliked reviews.
Using the liked rule, it returns if the author has more liked than disliked reviews.
Using the neutral rule, it returns if the author has the same number of liked and disliked reviews.
Using the disliked rule, the author is classified as disliked if the author is not believed to be liked or neutral.
5.6. Computed Results
The results computed by an ASP solver always satisfy all the constraints and rules. The computed results are considered as an optimal solution with the highest accuracy and precision compared to other work we previously mentioned in
Section 2, where most of them apply machine learning techniques and natural language processing for fake reviews detection.
The set of constraints and rules can be easily extended to cover much more complicated scenarios built upon a variety of behavior patterns, and not just a few characteristics the spammers or the spams may have, which are well understood and studied in the literature [
35].
Listing 4.
Sample author constraints and rules.
Listing 4.
Sample author constraints and rules.
7. Data Analysis and Evaluation
Regarding the sentiment analysis of the review content, a trained logistic regression model is used as an adapted version of the Stanford Treebank dataset(
https://nlp.stanford.edu/sentiment/treebank.html (accessed on 31 May 2021)). The adapted version uses the review content from the dataset. The dataset is preprocessed, and the sentiment score in the training and test datasets vary from 1 to 5, strongly negative to strongly positive, respectively. The trained sentiment analysis model, which was used as a tool in the review analysis system, has accomplished an accuracy of 41.22%, which is closely related to the accuracy of 40.7%, Ref. [
36] and the authors of the used dataset have achieved that. In the analysis of the model, many of the neutral sentiment reviews were assigned either a weakly positive or weakly negative sentiment, as the trained model was kept very simplistic for this approach. In the future, the aim is to use a more sophisticated model for sentiment analysis to enhance the accuracy of the whole system, such as in Reference [
3], where Convolutional Neural Network (CNN) and Shallow Neural Network (SNN) reached 81.0% and 87.0% accuracies, respectively, using the IMDB dataset. For this paper, a simple trained model was sufficient, as the main idea was to show how ASP can be used in combination with different tools to classify movie reviews considering the review content and its sentiment.
The following figures show examples of classified reviews on the website. They show the functionality of how a review is classified based on the review itself and the author, additionally including any reviews that have been flagged as highly similar with the current review by the Levenshtein/Cosine Similarity value.
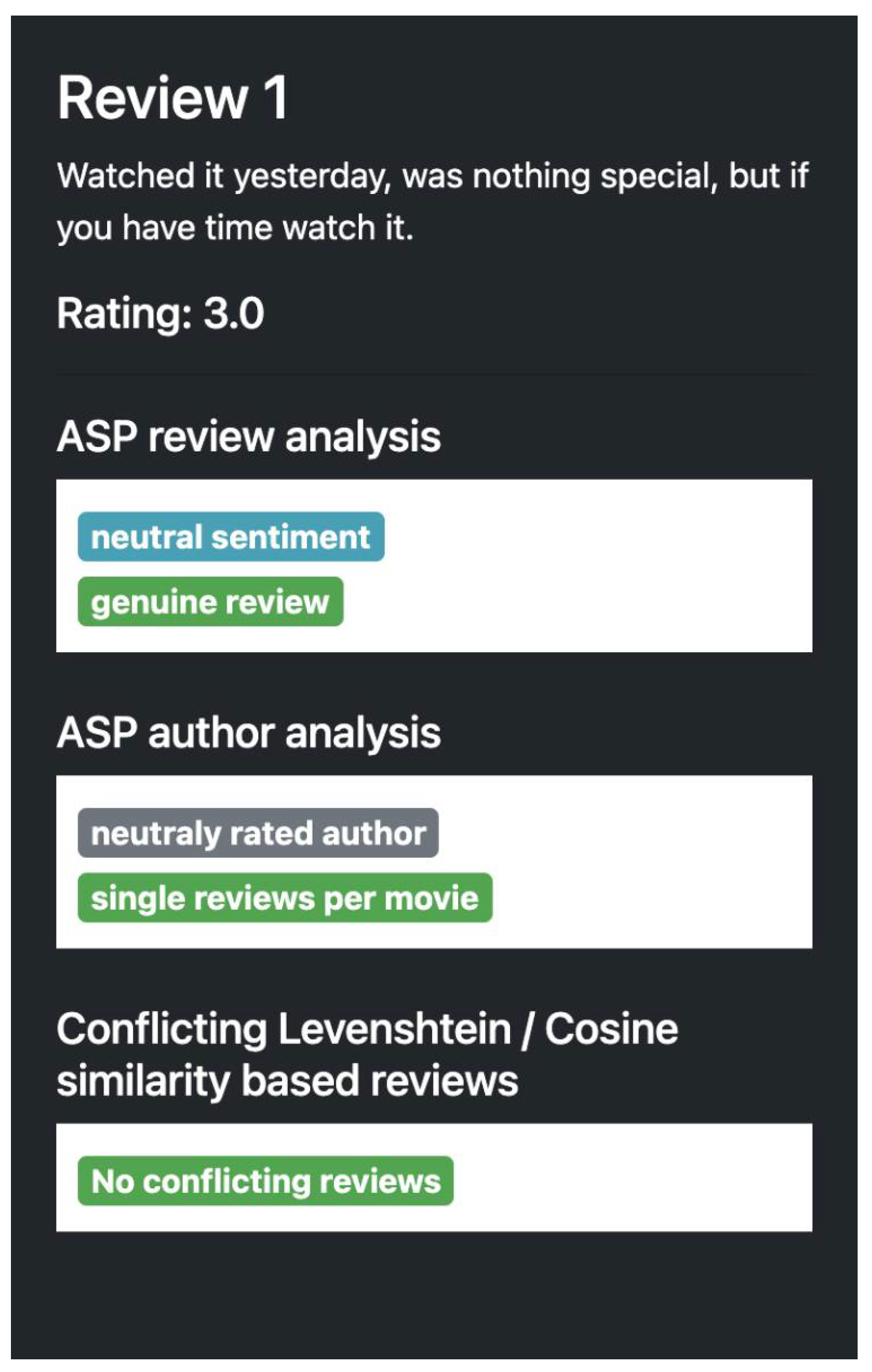
Figure 3 shows a genuine review with a neutral sentiment, where the author has no ratings yet. In contrast,
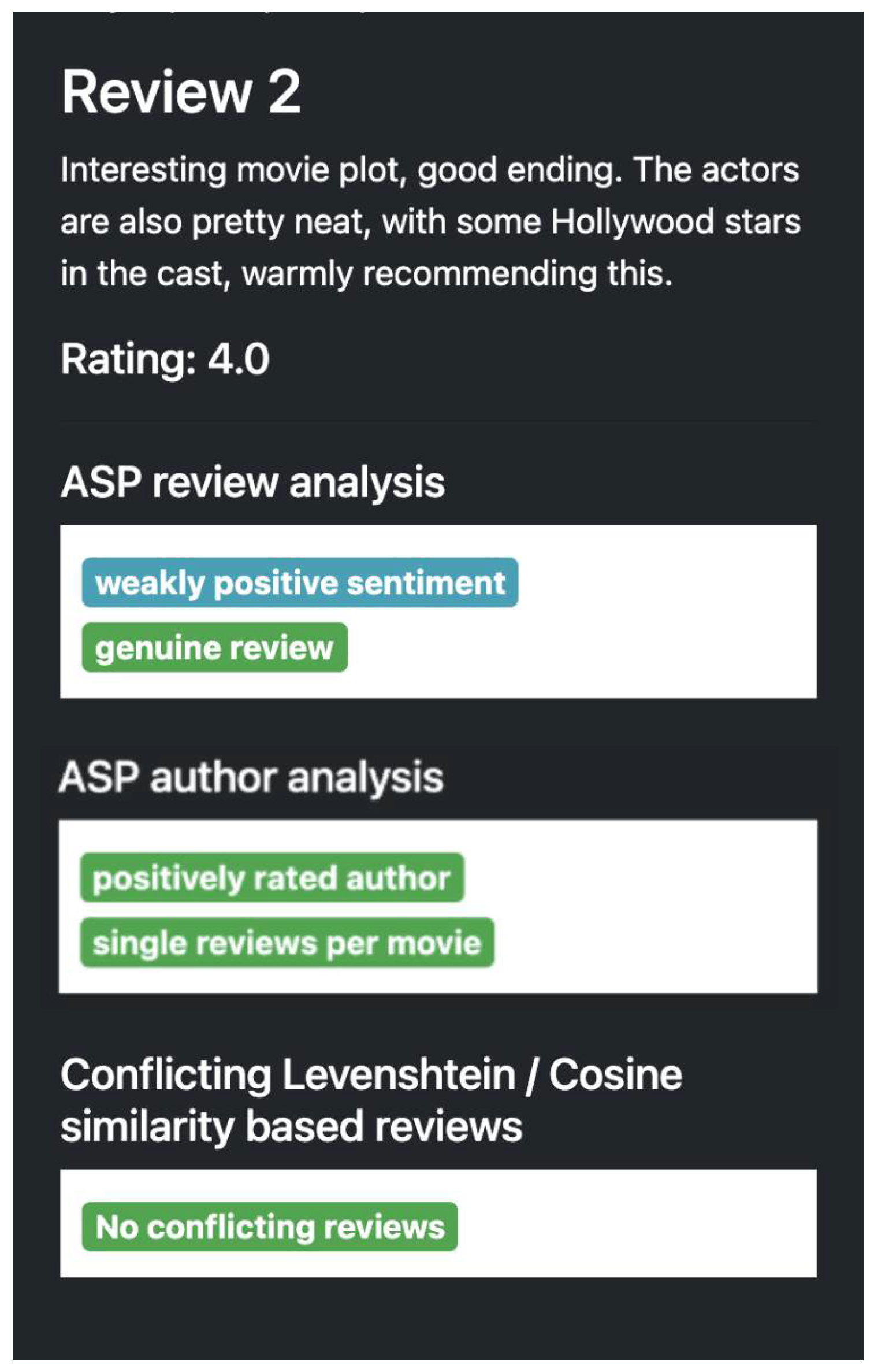
Figure 4 shows a weakly positive genuine review where the author has reviews that other users have liked.
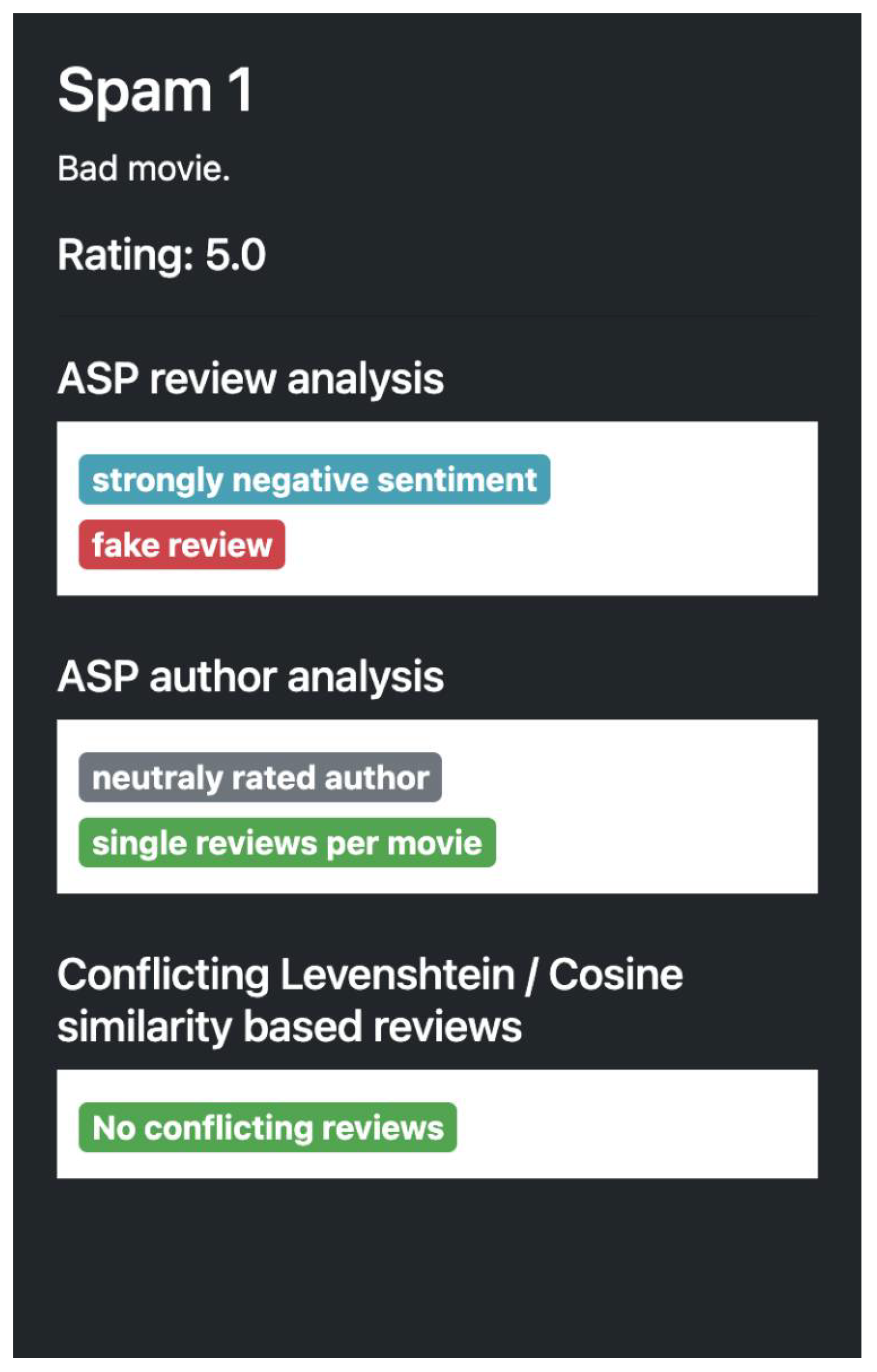
Figure 5 shows a spam review with a strongly negative sentiment, that has been posted from the same IP address.
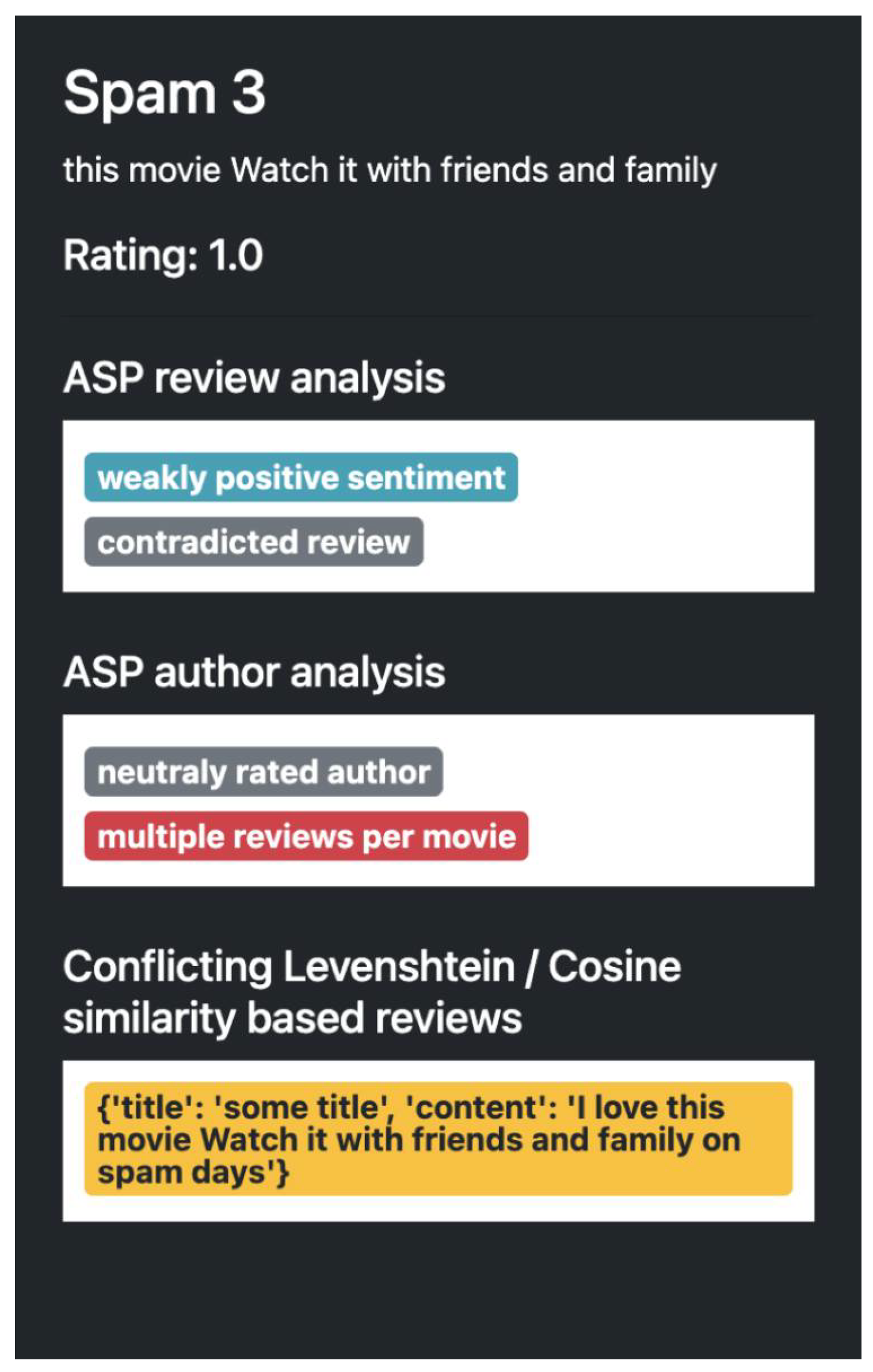
Figure 6 shows a contradicted review, as it has a positive sentiment but a low star rating; additionally, it is very similar to another review in the system, which has been flagged accordingly. It is also important to note that the review shown in
Figure 6 has a label showing that the author posts multiple reviews for a single movie, which is considered to be negative.
8. Discussion
The problem of fake review detection is complicated since fake reviews are linked to at least two sources: the review content and the reviewers’ behavior. Commonly, the content is analyzed and classified by adopting natural language processing techniques. However, determining the behavior of a fake reviewer is a complex problem. Various spatial-temporal patterns of behavior can be modeled as part of an optimization problem and because of the complexity, these problems are time-consuming and require a lot of computational resources to be solved. ASP is an exciting and powerful tool to address such problems, mainly offering a declarative way to specify the problem and properties of the desired solution(s). ASP inherits the advantage of rule-based approaches, (a) flexibility which means that adding new rules or updating the system requires only a few changes compared to other paradigms, (b) it does not require a vast amount of training data, (c) rule-based techniques are considered a white box; thus, it provides traceability and transparency for critical decisions that demand a higher degree of explanation usually provided by machine learning approaches, (d) same rules can be used for another data type, like tweets or Facebook posts, for fact-checking purposes, and (e) clear and understandable specification for users. Regarding threshold values used in ASP approaches, they can be calculated regularly and automatically based on newly inserted data. Additionally, adding new threshold values can help in restricting and limiting the spamming behavior.
Table 1 shows a list of different reviews, representing examples of labeled reviews by the ASP solver, using the proposed review-centric KB. The table consists of the review content in the first column, following the review rating, sentiment score using the trained model, the Levenshtein/Cosine review similarity score, the triggered rules, and the actual label has given review. The last two reviews show an example of two reviews posted shortly after each other, thus resulting in the second review being labeled as a contradicted review, according to the given input parameters for the ASP solver.
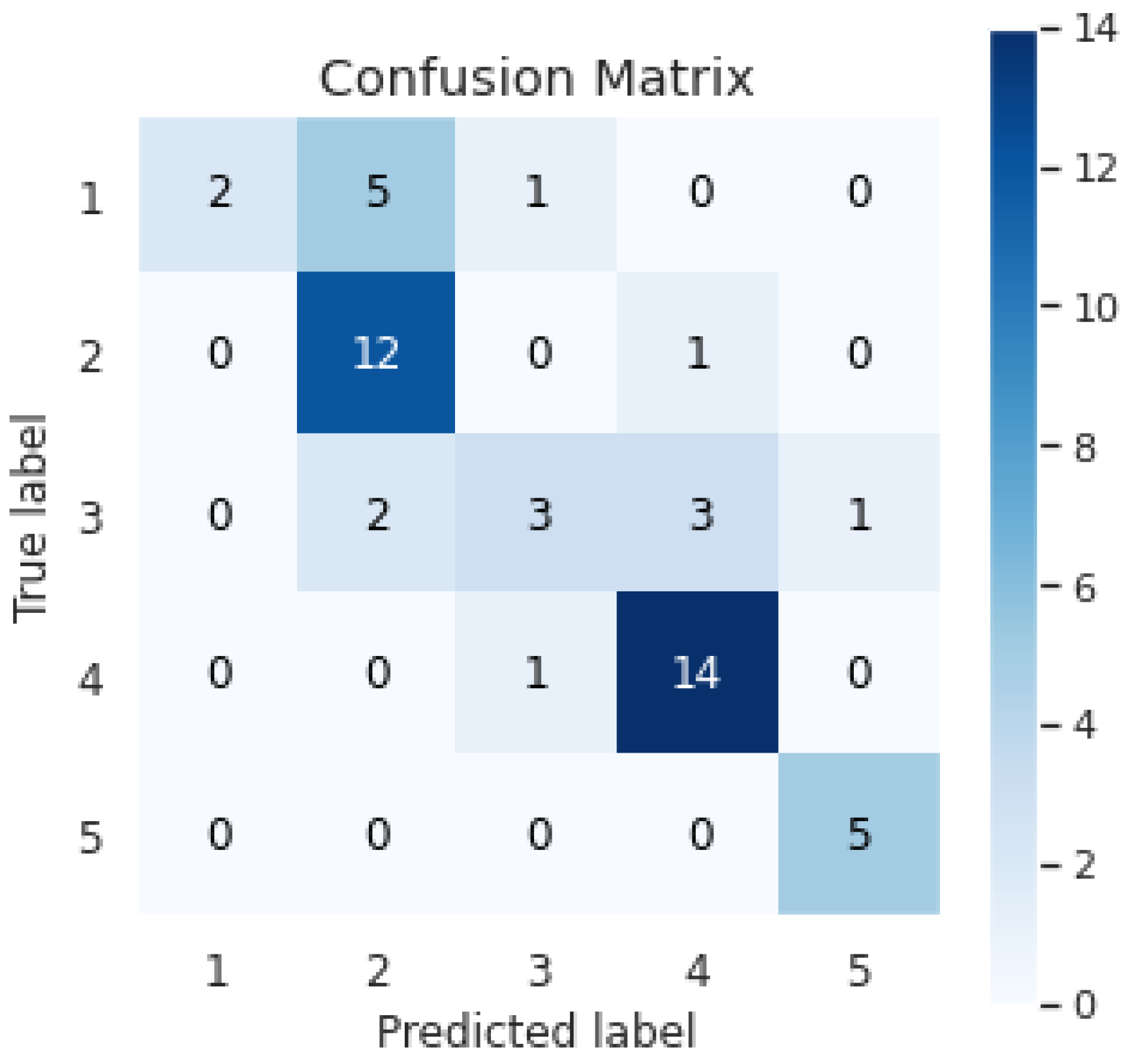
Figure 7 shows a confusion matrix of 50 movie reviews, obtained from the Rotten Tomatoes dataset, including their sentiment score from 1 to 5, that were processed by the website to analyze the accuracy of the sentiment analysis. The matrix shows that the prediction of the sentiment analysis is correct for most of the reviews, while only few reviews had a difference higher than 1, as, for example, the one review that had a true sentiment score of 1 and the system predicted a score of 3. The highest accuracy was for reviews with the sentiment score of 4.
9. Conclusions
This paper proposes a dynamic recognition system for detecting fake reviews, spam, and spammers on the Web introducing fake reviews. After looking in-depth at the behavioral patterns of users known from the state-of-the-art literature, a set of illustrating constraints and rules has been designed. The problem could be transformed into an optimization problem that can be solved using ASP. As proven in Reference [
10], ASP is already established in the industrial segment as a state-of-the-art tool for different approaches, such as search or scheduling problems and usages for engineering tasks and optimizing systems, such as caching strategies for optimizing performance in network systems.
Different components used in the reasoning system, which process movie reviews and user data, were implemented and combined under a fact-checking framework. Such a system is necessary because the problem of opinion spam has increased dramatically in the past few years. The output of the implemented system and other user and review data is fact-checked with declarative rules coded in ASP. The constraints and behavioral rules can be altered, edited, and deleted easily due to the flexibility of this system. Behavioral rules are used on user data to examine the trustworthiness of said reviews and users according to their overall behavior. Sentiments of user reviews are determined, which analyzes the raw review content.
Deviations in movie features are detected with an algorithm based on Levenshtein Distance that calculates a deviation score and then provides a list that is sorted by high or low deviation.
Such rule-based systems and the KB are in high demand to be well-designed. It allows for achieving a higher degree of accuracy and a properly working model. A proper design also leads to an extensible model, which will enable us to process much more complex scenarios at the same level of high accuracy. One of our next steps is to consider the social and personal features of the users; the reason is, based on their activities and profiles, it is likely that fake users can be identified [
15].
This project shows the high capability of ASP to solve such problems and we believe that much scientific work can be done by further developing our proposed approach for fake review detection, a simple yet powerful and highly flexible tool for detecting opinion spam in movie reviews, although we believe that the same approach can work for different domains. Moreover, many more behavioral rules can be added to point out suspicious users or spamming patterns; it might require additional input data to work correctly.
For future work, we want to implement a more sophisticated machine learning model for the sentiment analysis of the reviews, using deep learning approaches.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}