1. Introduction
Querying a route planning service is now a common daily-routine activity. The majority of such services, as well as of the underlying route planning algorithms, answer queries by offering a route plan from an origin
o to a destination
d [
1]. A typical road network instance is described as a directed graph whose vertices represent junctions and arcs represent one-way road segments. Each arc is accompanied with a positive scalar (a.k.a. weight) representing its usage cost (e.g., distance or traversal-time), with respect to the assumed cost-metric. There is also a given optimization criterion (e.g., the total distance or earliest arrival time) for the selection of routes [
1]. Possibly the most typical case for daily commuters assumes that the arc-costs metric consists of traversal-times for the arcs, and the optimization criterion is the earliest arrival time at the destination.
While a standard Dijkstra run on a continental-sized road network with several millions of nodes and static arc costs would require a few seconds, modern approaches, such as oracles and speed-up schemes, have been developed that exploiting a preprocessing phase to produce a manageable amount of cost metadata and achieve response times to arbitrary route-planning queries in a few milliseconds, or even microseconds. A comprehensive survey of the subject is provided in [
1].
1.1. The Curse of Alternatives
Single-route responses to route-planning queries may not always be desirable or satisfactory. There is quite often a need for providing, not just the optimal route, but rather a handful of meaningful (by ambiguous and different aspects or features) alternative routes, e.g., for having some plan-B mobility scenarios in case of unforeseen incidents (against the scenario of having just a single computed route, which may become obsolete) or simply because the commuter is uncertain about their actual secondary preferences (e.g., quietness, view, or safety) among “sufficiently good” routes. In particular, the commuters typically:
- (i)
prefer to have choices;
- (ii)
have some secondary optimization criteria, based on their own personal preferences, that vary and depend on specialized knowledge or constraints (e.g., like/dislike certain parts of a route), which are usually difficult to quantify, and certainly unknown to the route planner;
- (iii)
occasionally prefer to follow a route different from the optimal one, according to their primary optimization criterion, due to some unforeseen or emergent traffic condition (accident, road works, etc.).
Consequently, a route planning service offering a set of meaningful alternative routes of good quality, is more likely to satisfy the commuters’ needs; and vice versa, the commuters can use alternative routes as back-up choices in case of emergent traffic conditions or other unforeseen incidents. Since, most of the time, the commuters’ secondary optimization criteria are unknown to the route planner, modern route planning systems, like Google maps, typically recommend, apart from the optimal route, also a handful of alternative routes for each route-planning query, hoping that at least one of them might positively surprise the commuter. The present work focuses exactly on this aspect, the efficient computation of a small set of meaningful alternatives to the optimal -route. In other words, the goal is the selection of a few, hopefully meaningful but also divergent, alternative routes of good quality.
When thinking about the computation of alternative routes, a first line of attack that comes to mind is to consider several criteria. In that case, one might be tempted to try to compute the set of all pareto-optimal solutions. Yet, as stated in [
2], for a network of 18Mio nodes “it turns out this input is too big for finding all Pareto routes”. Hence they had to restrict their experimentation to a graph with 77K nodes and two metrics only, reporting running times around 200 ms; as stated in the paper explicitly, more than two metrics may only be considered for very strongly correlated travel time metrics.
Other approaches were based on responding to the so-called skyline-queries in the multicriteria setting; however, they also turned out to be feasible only for small graph sizes, e.g., in [
3] a query time of 40 s on a graph with only 6K nodes and three metrics was reported. Apart from the obvious tractability issues, another challenge is that, as previously mentioned, the route planning service may not be aware of the commuters’ secondary criteria of optimization, either because they do not want to reveal them, or because they cannot even quantify them.
Another approach that would come to mind, is the computation of the
k-shortest paths from
o to
d. Unfortunately, this problem is also quite complex and computationally demanding [
4], especially for large-scale real-world instances. Moreover, the resulting routes are typically almost identical to the optimal route, differing only in a few arcs, which constitute small “detours”, rendering them rather uninteresting alternatives to the optimal route. The works [
5,
6] study the efficient computation of
k-loopless-shortest paths, in order to both speed-up the computation and provide more meaningful alternative routes. Still, each newly constructed route is only meant to avoid the creation of cycles with the previously selected routes but otherwise can be quite similar to them. Moreover, these algorithms work efficiently only for small-to-moderate network instances.
To tackle the issue of extensive overlapping in the proposed alternative routes, some more successful, mostly heuristic attempts have been considered. Some of them were based on the
penalty approach, where one starts with the optimal route but then penalizes its arcs before recomputing the next route in the network with the penalized arc costs [
7]. This approach suffers from the need of careful tuning of the penalization parameters to obtain meaningful results.
Another approach is based on the so-called
via nodes. This idea, initiated in [
8] and further extended in [
9,
10], is based on the computation of a set of routes that are concatenations of shortest paths from the origin
o to some intermediate node
v and then to the destination
d. The careful selection of intermediate nodes, called
via-nodes, may assure meaningful alternatives of acceptable quality. Criteria to measure the quality of a set of alternative routes were proposed in [
8], with some improvements in [
9,
10]. The query-response is described as this set of alternative routes.
An interesting idea for representing a set of alternative routes via the induced subgraph from the involved arcs, which is called the
alternative graph (AG), was proposed in [
7]. The same work also proposed some quality measures for assessing alternative graphs. Two quite interesting aspects of the notion of an alternative graph, compared to the selection of a set of alternative routes, are the following:
- (i)
The AG may also contain some additional routes, apart from the chosen ones, by combining parts of the chosen routes in arbitrary ways, and these could also be very good candidates.
- (ii)
The small size of the AG allows for a more thorough (but possibly more computationally demanding) search for the best possible set of alternative routes, whose quality and meaningfulness is already guaranteed by the selection of the alternative graph itself.
Consequently, [
11], which was also based on the penalty method and the alternative graph, improved on the work of [
7].
The Alternative Graph (AG) turned out to be more suitable than the Via-Nodes (VN) for high-demanding navigation systems [
12]. This is because the VN approach is restricted on fixed optimization criteria and may create (higher than required) overlapping among the alternative routes. The VN approach may not even be successful in finding a sufficient number of alternatives, for certain scenarios. The present work adopts the rationale of an alternative graph, along with the generic quality characteristics that were proposed in [
7], quantified by the following
quality-assessment criteria:
the criterion, measures the total-overlappingness of the best subset of routes within AG;
the criterion, measures the stretch of these routes; and
the number of decision edges, i.e., the sum of alternatives per intermediate node visited other than the outgoing arc belonging to the optimal remaining path towards the destination, which measures the complexity of the entire AG subgraph.
As it is shown in [
7], each of these quality-assessment criteria is important on its own, in order to produce a high-quality AG containing meaningful alternative routes. However, optimizing a single objective function for choosing the AG that combines just any two of them, is an NP-hard problem [
7]. Hence, one has to concentrate on heuristics. Four heuristic approaches were investigated in [
7], based on the Plateau [
13] and Penalty [
14] methods. Experimental evaluations in [
7,
13] demonstrated that a combination of these two heuristics appeared to be the best choice. A new set of heuristics, including improved extensions of both the Plateau and Penalty methods, was proposed in [
11]. As a result, computing an AG subgraph of much better quality than the ones in [
7] became possible, and this was verified on several static (i.e., time-independent) road networks of Western Europe.
1.2. The Curse of Time-Dependence
Most of the shortest-path algorithms traditionally consider static arc-costs. Nevertheless, a crucial aspect, at least when having to deal with real-world instances, is the temporality of the network characteristics, which is often depicted by some kind of predetermined dependence of the arc-cost metric on the actual time that each arc is used. E.g., the traversal-time of particular road segments in a city, the packet-loss rate of a connecting line in IT infrastructure, and the validity of particular relationships among pairs of individuals in a social network, depend on exactly when one considers the corresponding arc in the underlying graph model.
Perhaps the most typical application scenario also motivating our work is that of route planning in road networks, where the time to traverse an arc
(modeling a road segment) depends on the temporal traffic conditions while doing that and, thus, on the departure time from its tail
u. This gives rise to
time-varying network models and to computing time-varying solutions (i.e., collections of shortest paths) in such networks. Several variants of this model attempt to capture the time-variation of the underlying graph structure and/or the arc-cost metric, e.g., dynamic shortest paths, parametric shortest paths, stochastic shortest paths, and temporal networks; see [
15] for a discussion on these variants and their comparison.
In this work, we consider the case in which the traversal-time variation of each arc
a is determined by a function
, which is considered to be a continuous, piecewise linear (pwl), and periodic function of the time at which the resource is actually being used [
16,
17,
18,
19]. To see why this is more suitable, consider, for example, the live traffic services of major car navigator vendors (e.g., TomTom) that provide real-time estimations of average travel-time values, collected by periodically sampling the average speed of each road segment in a city, using the cars connected to the service as sampling devices. A customary, comprehensive, and computationally-lighter way to represent this historic traffic data is to consider the continuous pwl linear interpolants of the sample points as the
traversal-time functions for the arcs in the underlying graph.
When providing route plans in these types of road networks, usually called time-dependent road networks, the arc costs are determined by evaluating these traversal-time functions for the arcs for certain departure time values, while the time-dependent shortest paths are construed as minimum-travel-time paths.
The goal is then to determine the cost (total travel-time) of an optimal path from an origin vertex o to a destination vertex d as a function of the departure-time from o. Due to the time-dependence of the arc-cost metric, the actual traversal-time of an arc is unknown until the exact time at which starts being traversed from u towards v.
For the single-route case, there have been quite interesting and efficient oracles and speedup techniques to handle instances with time-dependent arc-costs. In particular, there exist approaches that compute either an optimal or an approximately optimal
-route, using heuristic methods (see e.g., [
20]), or oracles (see e.g., [
15,
21,
22]). The latter case, of an oracle, consists of a (subquadratic in size) carefully designed data structure, created during a preprocessing phase, along with a query algorithm that exploits this data structure in order to respond to arbitrary earliest-arrival-time queries in sublinear time, with a
provably small approximation guarantee for the quality of the solution.
For the alternative-routes case, at least to our knowledge, the literature has been confined to instances with static arc-costs.
1.3. Our Contribution
In this work, we investigate the problem of efficiently determining meaningful alternative routes, succinctly represented by the AG subgraph, on the more realistic setting of a
time-dependent road network. The meaningfulness is quantified by certain criteria (minimum overlap, small stretch, small size, and low complexity), which are formally defined in
Section 2.
We propose a new heuristic algorithm, called TDAG, which computes an alternative graph containing routes of guaranteed quality, for a time-dependent road network. In particular, based on precomputed minimum-travel-time metadata between a small set of (landmark) nodes and all other nodes in the graph, TDAG selects, first, an initial alternative graph (AG), which is induced by a carefully selected candidate set of routes. Consequently, TDAG improves the constructed AG during an iterative pruning phase, which discards uninteresting or low-quality routes until the resulting AG meets all the quality criteria.
Our experimental evaluation of TDAG on real-world benchmark time-dependent road networks shows that the entire AG can be computed fast, even for continental-size networks, outperforming typical baseline approaches by one to two orders of magnitude. In particular, the entire AG can be computed in less than s for the road network of Germany, and in less than s for that of Europe. TDAG also provides “quick-and-dirty” initial results of decent quality, in about of the above mentioned query times.
To our knowledge, this is the first work achieving efficient computation of alternative routes in the more realistic setting of time-dependent road networks.
2. Preliminaries
A time-dependent road network can be modeled as a directed graph , where each node represents either an intersection point along a road, or vehicle departure/arrival event with zero waiting-time, and each edge represents uninterrupted road segments between nodes. Let , . Given a time period T and any edge , if we consider any departure-time from the tail u, then is the corresponding traversal-time for the arc , determined by the evaluation of a continuous, piecewise-linear (pwl) function .
Analogously, is the corresponding function providing the arrival-time to the head v or for different departure times from the tail u. We additionally make the (typical for road networks) strict FIFO property assumption: each arc-traversal-time function has a minimum slope greater than . Equivalently, we assert that the arc-arrival-time functions are strictly increasing. This property implies that there is no reason to wait at the tail u of before traversing it towards the head v, provided that we are interested in the earliest-arrival-times.
Given a departure time
, and a path
(as a sequence of arcs),
is the
path-arrival-time function, defined by applying function composition on the arc-arrival-time functions of
’s constituent arcs. In addition,
is the corresponding
path-travel-time function.
Let be the set of all -paths in G, i.e., originating at u and ending at v. Then, , is the earliest-arrival-time function, from u to v. Analogously, is the corresponding minimum-travel-time (or shortest-path-length) function, and is the corresponding time-dependent-shortest-path function, providing the minimum-travel-time paths w.r.t. the departure time t from u. For , a function such that is called a upper-approximation for .
Our main goal is to obtain fundamentally different (but not necessarily disjoint) alternative-paths with optimal or near-optimal travel-times, from an origin-node
o to a destination-node
d in
G and departure time
from
o. The aggregation of the computed alternative
-paths is materialized by the concept of the
Alternative Graph (AG), a notion first introduced in [
7]. We shall now proceed with the adaptation of the AG concept to the time-dependent context.
Formally, an alternative graph is the induced subgraph by the arcs of several -paths in G. Let and denote the minimum-travel-time functions, whereas and denote the earliest-arrival-time functions w.r.t. G and H, respectively.
Succinctly representing the produced alternative paths with AG is reasonable because the alternative paths may share common nodes (including o and d) and arcs. Furthermore, their subpaths may be combined to form even more alternative paths, possibly better than the ones that determined the AG. In general, there can be too many alternative -paths, and the problem is to find a way to select only a meaningful subset of them. Hence, there is a need for filtering and ranking the alternative -paths, based on certain quality-assessment criteria.
The main idea of the AG approach is to rank candidate subgraphs w.r.t. their quality scores and discard the ones that have poor scores. We adapt the quality-assessment indicators proposed in [
7] for static instances to the time-dependent case. These indicators are defined on the single-arc level and then they are extended to the arc-set level. We provide, at this point, the definition of these quality-assessment criteria, adapted to time-dependent networks. Let
be any subgraph of
G, in which we are interested for route plans for the query
. For any arc
:
The criterion decisionEdges quantifies the size-complexity of H, as the number of the alternative paths within H is directly dependent on the number of the “decision” arcs offering some branch towards a new path in H. For this reason, the higher the value of decisionEdges, the more confusion is created to a typical commuter, when having to choose a route among the alternatives provided within H. Therefore, it should be limited.
Observe now that the share of a given arc has to do with its contribution (as a proportion) to some via- shortest -route in H. The criterion totalDistance captures, then, the extent to which the paths in H are non-overlapping, by summing all the shares of arcs in H. Its maximum value is decisionEdges, and it can be as large as the number of all -paths in AG, e.g., when all of them are arc-disjoint. Its minimum value is 1, corresponding to the case where H has only one -path. Our goal is to achieve as large a value as possible for the criterion.
Finally, the criterion averageDistance measures the average path-travel-time stretch for all the alternative paths in H, compared to the shortest -path in G. Its minimum value is also 1, e.g., when every -path in H is an optimal -path in G.
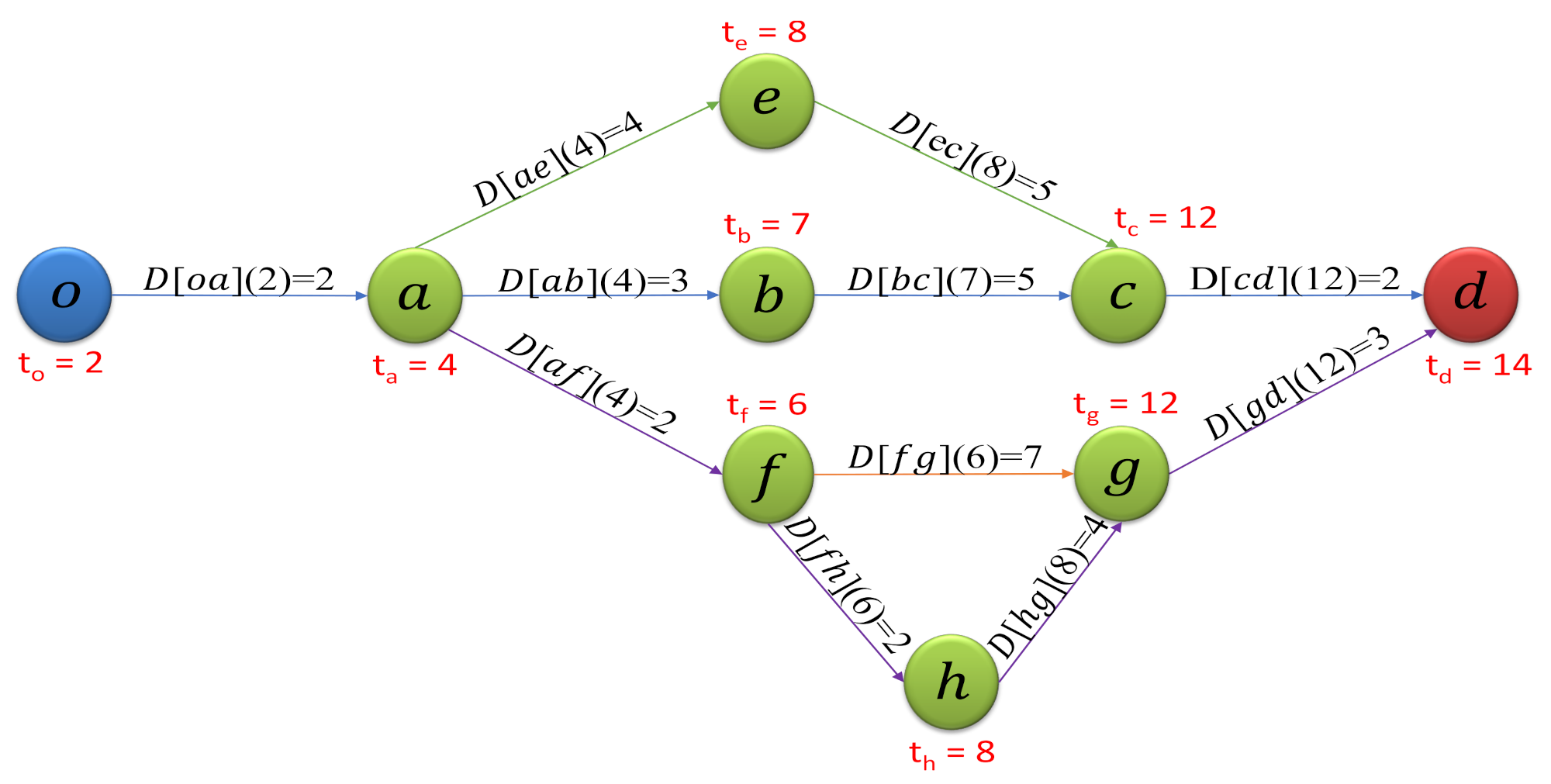
Figure 1 provides an example of a given subgraph
H, whose quality indicators as an alternative graph are computed for a given departure time
from
o. In the example, the computations of the quality quantifications of
H are based on the aforementioned functions and specifically for the
totalDistance criterion they are grouped by a common denominator with respect to the contained four distinct shortest
o-
d paths:
,
,
, and
. By considering the arcs of the first path, the travel time, the earliest arrival time, and the “share” contribution are determined as follows:
Arc :
Arc :
Arc :
2 + 2 + = 12
Arc :
The overall quality of
H in terms of the path non-overlappingness, stretch, and size-complexity are computed as follows:
In order to assess the quality of an alternative graph, one should attempt to maximize the value of some target function, which is increasing in the
and decreasing in the
, under the constraint that the
variable remains bounded. Unfortunately, achieving a lower value for
may take away the ability of collecting high-degree disjoint (non-overlapping) paths, which would lead to a high value for
, since these criteria can be contradicting with each other. In this work, we choose to maximize a target function—the linear combination of the
and
variables. In particular, following [
7,
11], we aimed to maximize the value of the function
under the constraint that the
parameter is, at most, 10.
2.1. Computing Time-Dependent Shortest Paths
In this section, we review some fundamental techniques for computing a single time-dependent shortest -path as a response to an arbitrary query , which are used as subroutines throughout the paper.
2.1.1. Time-Dependent Dijkstra
The time-dependent variant of Dijkstra’s algorithm (TDD) [
23] is a straightforward extension of the classical algorithm that computes the earliest-arrival-times “on the fly” when scanning (relaxing) the outgoing edges from a node. TDD grows a shortest-paths tree rooted at an origin
o, for a given departure time
from it. Analogously to the static case, TDD performs a breadth-first search (BFS) exploration of the graph, settling the nodes in increasing order of their tentative labels (representing the earliest-arrival-times from
o, given the departure time
from it), until the priority queue of labels becomes empty, or a given destination
d is settled.
When settling a newly popped node u from the priority queue, all the outgoing edges are relaxed, implying new evaluations of the corresponding arc-traversal-time functions, given its label (i.e., the earliest-arrival-time at u) at that time. The resulting shortest-paths tree may vary for different departure time choices .
2.1.2. Reversed Time-Dependent Dijkstra
The reversed version of TDD (RTDD) grows a full shortest path tree rooted at a node d for a given arrival time at d. The differences from the original (forward) TDD are the following:
- (a)
The arc relaxations are performed for the incoming arcs of the currently settled node.
- (b)
The algorithm computes latest departure times from the arc tails “on the fly” during an arc-relaxation, by evaluating the inverse of the arc-arrival-time function (which is strictly increasing due to the strict FIFO property).
2.1.3. The CFLAT Oracle
The time-dependent oracle CFLAT [
21] precomputes approximations
(called travel-time summaries) of minimum-travel-time functions
from each element
ℓ of a small set of carefully selected nodes (called landmarks), towards each reachable destination
v. These travel-time summaries are succinctly represented as a collection of time-stamped minimum-travel-time trees. The appropriate construction of these summaries ensures both
approximation guarantees (for any given
) for the landmark-to-destination travel-time functions
and efficient (subquadratic) space requirements.
2.2. Computing Alternative Graphs in Static Road Networks
In this section, we briefly review some typical approaches used for computing alternative graphs in time-independent (static) graphs.
2.2.1. Computing Alternative Routes within the Pareto Set
The Pareto algorithm [
2,
24,
25] computes an alternative graph
H by iteratively finding
Pareto-optimal paths on a suitably defined objective cost vector. The idea is to use, as the first edge-cost vector, one of the single-criterion problems, while the second edge-cost is defined as follows: Initially,
H only contains the shortest
-path. Then, all edges already belonging to
H set their second cost function to their initial edge cost. All edges not belonging to
H set their second cost function to zero.
A similar line of attack, for finding alternative routes via the multicriteria setting, is related to the so-called
skyline-queries [
3]. This approach was found to be feasible only for small graphs with a few thousands of nodes and three metrics for the arc costs, in which several-seconds query-response time is typically required.
The only multicriteria-based approach for alternative-routes, at least that we are aware of, that manages to efficiently compute alternative routes in million-node instances, is [
26]. Based on the idea of personalized route planning, the paper discovers extreme solutions from the convex-pareto solution set that are sufficiently dissimilar with each other. In this direction, the idea is to use different weight vectors for the arc-cost metrics that provide significantly distinguishable routes for the commuter.
The deficit of this approach, nevertheless, is that it assumes that the route planner is aware of each commuter’s personalized secondary optimization criteria (which would render some of the alternative routes more attractive than others). Of course, this is not a typical situation, mostly because it is hard for a commuter to quantify secondary criteria, such as the scenic-ness or quietness of the routes. Moreover, this approach definitely excludes dominated paths (exactly due to their domination by some other path), even if it is not much worse than other paths but is also significantly distinct from other alternative routes. It also excludes pareto-optimal solutions that do not belong to the convex-pareto solution subset, irrespectively of their significance as alternative routes.
To recap, all these multicriteria-optimization based approaches for discovering alternative routes suffer from at least one of the following severe deficiencies:
- (i)
They produce too many alternatives, causing severe computability issues even for moderate-size instances. Moreover, the produced solutions have only small deviations with each other, rendering them rather uninteresting, unless one really looks among them for actually distinguishable alternatives.
- (ii)
Relaxing the domination criteria and fine-tuning the bounds to speed-up the computational requirements is non-trivial and time consuming.
- (iii)
The secondary optimization criteria, which are rather personalized, are private information of the commuter, typically invisible to the route planner, and they are often difficult to quantify as concrete cost metrics, even for the commuters themselves.
2.2.2. Computing Alternative Routes from k-Shortest Path Solutions
The
k-shortest path routing algorithm [
4,
5,
6] finds the
k-shortest paths in order of increasing cost. The disadvantage of this approach is that the computed alternative paths typically share too many edges, making it difficult for a human to actually distinguish them and make their own selection of a route. In order for really meaningful alternatives to be revealed, one should compute the
k-shortest paths for very large values of
k, at the expense of a rather prohibitive computational cost.
A more recent approach [
27] was also based on the
k-shortest path idea, essentially enumerating the shortest paths in increasing costs and then discarding paths that are already too similar with some of the previously selected paths. In this case as well, the proposed method appeared to be viable only for small-to-moderate network sizes.
2.2.3. The Plateau Method
The Plateau method [
13] provides alternative
-paths by constructing “plateaus” that connect shortest subpaths. For a shortest-path tree
from
o and a reverse shortest-path tree
from
d, a
-plateau is a
-path that is a shortest subpath both in
and
. The candidate paths via plateaus are constructed as follows: Dijkstra’s algorithm is used from
o, and its reverse version from
d, in order to produce, respectively, the trees
and
. Consequently, for each
-plateau in
and
, the shortest
-path in
and the shortest
-path in
are connected at the endpoints of the
-plateau, in order to form an alternative
-route. All these alternative
-routes are usually of high quality; however, there are too many for the commuter to digest, requiring a size decreasing filtration.
2.2.4. The Penalty Method
The Penalty method [
14] provides alternative routes by iteratively running shortest-path queries and adjusting the weight of the arcs along the resulting path. Initially, a shortest-path query is performed. The resulting shortest path
is chosen as the firest route, and it is then penalized by increasing the weight of all its constituent arcs.
Consequently, the method enters a loop in which, in each repetition, a new shortest-path query is executed in the graph with the modified weights. The resulting shortest path is again penalized, and, if it is substantially different from the previously selected -routes and also not too long in the original graph, then it is appended to the solution set; otherwise, it is simply ignored. This repetitive process ends when a sufficient number of alternative routes, with the desired characteristics, are discovered, or the weight adjustments of -paths bring no better results anymore. For a suitable penalty scheme, the resulting set of alternative -routes can be of high quality.
3. The TDAG Algorithm
In this section, we present our new algorithm, TDAG, which, given a time-dependent road network with a small set of landmark-nodes accompanied with preprocessed landmark-to-node travel-time metadata and an arbitrary query of an origin-node , a destination-node , and a departure time from o, computes a collection of meaningful (short and significantly non-overlapping) alternative -routes. The solution set is succinctly represented by an alternative graph H, i.e., the subgraph of G induced by the arcs of the chosen -routes. Of course, within H, there may exist even better combinations of -routes for the query , which are also considered as part of the solution.
TDAG is based on the rationale of the CFLAT oracle [
21]. In a nutshell, it first grows two small-size TDD-balls, an origin-ball emanating from the origin and a destination-ball leading to the destination. It then connects the two balls by reconstructing (not necessarily the shortest, but short enough) paths ending in nodes of the destination-ball and starting from nodes within the origin-ball. This path construction is landmark-directed: the preprocessed information for the
N landmarks of the origin-ball is exploited to direct these paths. A pruning step then takes over the responsibility of “cleaning” the resulting subgraph of uninteresting arcs. Eventually, the penalty method is applied to the final alternative graph, in order to conclude with a small set of
meaningful alternative
-routes. TDAG also takes into account the following input parameters:
- (i)
the number of nearby landmarks that will be settled by TDD in the origin’s neighborhood;
- (ii)
the upper bounds
for the
criterion,
for the maximum stretch of each
-path that is accepted as an alternative route of
H, compared to the minimum-travel-time
in the alternative graph
H (Since TDAG essentially mimics the preprocessing of the CFLAT oracle [
21], one can easily deduce that
is a very good approximation of
, for all possible departure times from the origin.), and
for the
criterion.
All these input parameters directly affect the size, the quality, and the computation time for constructing H.
TDAG consists of two building blocks, the preprocessing phase and the query algorithm, which will be presented in the rest of this section.
3.1. Preprocessing Phase of TDAG
Initially, TDAG selects a small subset
of landmark-nodes. There are various methods for the selection of
L: either randomly, or according to some properties of the underlying graph, e.g., selection from boundary nodes of some balanced partition of the graph, or the selection of the most significant nodes in a node-ranking of the graph according to a centrality measure, such as betweenness-centrality [
21].
In this work, we adopt one of the most successful methods for landmark selection, called Sparse-Random (SR), according to which, the landmarks are selected randomly and sequentially, so as to avoid having landmarks that are too close to each other. In particular, each new landmark ℓ is chosen uniformly at random from the subset of currently eligible non-landmark nodes. Right after the selection of the new element , a small neighborhood of non-landmark nodes around ℓ is excluded from all the subsequent landmark selections.
TDAG proceeds with the computation and succinct storage of timestamped shortest-path trees, from each landmark
towards all reachable destinations
. The timestamp
t of a given shortest-path tree
emanating from
, denotes the assumed departure time from
ℓ, for which
is indeed a shortest-path tree. For each landmark
, the collection of SPTs
for carefully selected distinct (monotonically increasing) departure times, constitutes the travel-time summary stored for landmark
ℓ during the preprocessing phase. The computation of SPTs from each landmarks is exactly the one conducted during the preprocessing phase of CFLAT [
21]. Therefore, the preprocessing-time requirements can be fine-tuned so that they are
subquadratic in the graph size. As for the required space (also
subquadratic in the graph size [
21]), in order to be able to efficiently handle continental-size time-dependent instances, we had to significantly improve the succinct representation of CFLAT’s travel-time summaries—in particular, how they are stored in the main memory.
The main intervention of this work, w.r.t. the preprocessing space requirements of CFLAT, is a lossless sparse matrix compression methodology for the succinct and space-efficient representation of all the timestamped SPTs from the landmarks, avoiding a considerable increase in the access time of the preprocessed information. In particular, the preprocessed data structure still conceptually contains, for each
, the collection
of timestamped shortest-path trees rooted at
ℓ, which are optimal for the set of distinct, carefully selected departure times from
ℓ,
. The selection of the set
of distinct departure times from
ℓ is such that, for all possible departure times
, the collection
contains at least one tree
providing, in worst case, a
-approximation for
:
3.1.1. Data Structure for Timestamped Predecessors
The novelty of our succinct representation is the following: Rather than keeping a collection of trees per landmark, we maintain, for each pair , two sequences of the same length:
- (i)
is the sequence of sampled departure times from ℓ to v (in increasing order), and
- (ii)
is the sequence of predecessors of v in the corresponding -paths.
All the departure times for are assumed to be integers from , considering an accuracy of seconds and a period of 86,400 s. Rather than using 3 bytes per cell, we exploit the fact that most departure times are smaller than 65,536 s. In particular, we keep an index of the latest departure time in , which is smaller than . The first cells in store the absolute departure time values, but the remaining cells only store the offset of the actual departure times from the value . In this way, all the cells in require exactly 2 bytes. As for , every cell is the relative position of the predecessor of v, in its in-neighborhood list. One byte per cell is sufficient for real-world instances whose maximum in-degree is a small constant.
A first observation of an initial implementation of this data structure was that a great deal of space was consumed for storing duplicates of exactly the same pairs of sequences for different landmark–destination pairs. For example, in the the continental-size EU instance with 18,010,173 nodes, for 16,000 landmarks, one would need to store 576,325,536,000 sequences. Nevertheless, we observed that there were only 1,632,168,375 distinct sequences (1,623,701,331 departure time sequences and 8,467,044 predecessor sequences). To avoid this waste of space, we chose to store only pairs of (4-byte) pointers to sequences, among all landmark–destination pairs.
After implementing this variant as well, we also observed that, in many cases, the same destination
had many repetitions of the same pairs of (4-byte) pointers to sequences, over all the landmarks. Indeed, this is quite reasonable for landmarks located towards the same direction and roughly at the same distance from
. In order to avoid these repetitions of pairs of long pointers (8 bytes in total), we proceeded as follows (cf.
Figure 2): We maintained a landmark-indexed dictionary
per destination
, whose value for a key
is a pointer
to the cell of an array
containing a
unique pair
of pointers to the sequences
and
.
The size is exactly the number of distinct pairs of pointers (to sequences) involving , among all landmarks and, on average, is significantly smaller than . Each cell of requires 8 bytes. On the other hand, for , we used bit-level representation of the stored values, with each cell consuming only bits. Even for 16,000 landmarks, this was, at most, 14 bits per cell.
Finally, we observed from real-world instances that, more often than not, a node might always have the same predecessor, independently of landmarks and departure times. In those cases, rather than storing and , we simply stored this unique predecessor for .
3.1.2. Lookup Procedure for Timestamped Predecessors
The lookup operation of preprocessed information, in order to obtain a time-dependent predecessor per landmark-to-vertex pair, is a procedure that is repeatedly used in the path-collection phase of the TDAG query algorithm (cf. PHASE-2 in
Section 3.2). Briefly, the lookup operation takes, as input, a triple
of a landmark
, a current node
and a departure time
from
ℓ. The lookup procedure starts by locating
, and then conducts a binary search in it, to locate the closest sampled departure times
, in time
. For a constant number of sampled departure times from
ℓ towards
v, this is also the
(1) time.
Then, the corresponding predecessors of v are located at positions i and of , and, thus, are retrieved also in (1) time. Since the number of sampled departure times only partitions the period in small time intervals, it is independent of the network size (e.g., for the EU instance, the maximum length of a sampled departure times sequence is 4407). Therefore, the entire lookup procedure takes (1) time (e.g., at most 13 comparisons, even for EU).
Due to this novel methodology for the succinct representation of the preprocessed data, preprocessing a large number of landmarks is now possible, even for continental-size datasets. In terms of performance, this novel storage scheme provides a cache-friendly gain that beats the overhead of the bit-field and bit-mask extraction operations. This, in turn, leads to results of higher quality and significantly lowers the observed relative error of the travel-time approximations in the summaries of the landmarks.
3.2. Query Algorithm of TDAG
The TDAG query algorithm executes three sequential phases for serving a query .
PHASE 1: Landmark Settlement
A forward TDD tree is grown from until either the destination-node d is settled or a set of the closest landmarks are settled (whichever comes first). Subsequently, a reverse BFS tree from d is constructed that ignores, totally, the traversal-times of the arcs and exploring the neighborhood around d in a backward fashion. The growth of is interrupted when its size becomes equal to , for some constant . Our experimental analysis showed that is an appropriate choice.
We experimented also with growing a reverse TDD tree towards d; however, this approach was more time-consuming, and the resulting alternative graph, to be constructed in the next phases, was eventually similar to the one constructed using the reverse BFS tree from d.
PHASE 2: Path Collection
Using the preprocessed data, our next task was to construct a subgraph of the approximate shortest paths from the N landmarks , with their own departure times , which were already computed in PHASE 1, towards each leaf node of . This was done as follows: For each leaf-node v of and landmark with departure time , we recursively move backwards from v towards ℓ by recursively looking-up predecessors in the timestamped shortest-path trees and for which it holds that . All the arcs that participate in these -paths, for all landmarks and all leaves v of , become marked.
The initial alternative graph H consists, then, of the union of the two trees and of PHASE 1, with the set of all the marked arcs during PHASE 2.
We continue by expanding the forward TDD tree
of PHASE 1 towards
d, by working only in the subgraph
H, until all the nodes in
H are settled. This allows us to obtain a tentative arrival time
at
d:
where
is the upper-bounding
-approximate travel-time function from
ℓ to
v, stored in the preprocessed data of TDAG. As was proved in [
21],
is a constant upper-bound of the earliest-arrival-time
. The quality of this upper bound depends on the choice of the precision
of the preprocessed information, the number
N of settled landmarks within
, and the size of the reverse BFS tree
.
PHASE 3: Pruning of the Alternative Graph
The graph H produced by PHASE 2 is already smaller than G. Nevertheless, it is further pruned so as to meet the three quality criteria for an alternative graph: small path overlapping, small stretch, and small size. This is done in three steps.
- Step 3.1:
Enforcement of the small stretch. We first aim at a loose pruning over H, in order to obtain a subgraph containing candidate -paths with reasonable travel-times. Towards this direction, we consider the rationale of the via-node shortest -routes. In particular, any node v in H whose shortest travel-time from o to d via v is greater than the targeted upper-bound, i.e., , is removed.
- Step 3.2:
Decrease in the number of candidate-routes. For further reducing the number of the candidate
-paths, we initially use the Plateau method [
11,
13] within
H, by having previously run TDD from
and RTDD from
. Any arc not belonging to the resulting Plateau candidate
-paths is removed from
H. The Penalty pruning method [
11,
14] is then applied to the resulting subgraph, in order to prune it even further. At each Penalty iteration, TDD runs on
H, computing a new time-dependent shortest path
, whose constituent arcs are marked and are then appended to the solution set
. Additionally, all the arcs in
, and the all the arcs incident to nodes of
, are penalized with increasing the penalty factors
and
, respectively, both initially set to 0.
In particular, for each arc , its travel-time is increased to ; otherwise, if u or v are nodes in and e is not an arc of , its travel-time is increased to . The penalty factors of the affected arcs are increased at the end of each step to and , where and are constants.
The process is repeated until a sufficient number of alternative paths are found or the travel time adjustments of
paths bring no better results. Eventually, all the unmarked arcs are removed from
H. In order to speedup the Penalty method at path computation, the time-dependent variant of
[
28,
29] can be used in place of TDD. For each node of
H, its remaining distance towards
d, which was already computed from RTDD during the Plateau substep, can be used as a lower bound for the time-dependent
heuristic.
- Step 3.3:
Reduction in complexity of the alternative graph. The final pruning of H is performed via a ranking procedure. Initially, if a path in H has and , and (i.e., it increases by one the ), then it is considered as a decision-path and it is ranked by the function that represents the contribution of in terms of and in H.
The ranked decision paths are then sorted by increasing ranking order in a priority queue Q. Consequently, an iterative procedure starts where, in each iteration, a path is dequeued from Q. If the condition and remains in effect, then is removed from H, leading to a decrease by one of the parameter . After the removal of , if, for , it holds that , then a new decision path is revealed that has v as an internal node. is ranked and inserted in Q, in order to be considered along with the rest of decision paths. The iterative procedure stops when .
3.3. Analysis of TDAG’s Preprocessing Phase and Query Algorithm
In this section, we provide a theoretical analysis for the quality of the alternative graph produced by TDAG, by means of the stretch of the optimal -path in the alternative graph H, compared to the one in the original graph G.
Since TDAG employs a series of heuristic improvements, which make it difficult to provide a theoretical analysis, we focus here on a simplified variant of TDAG without any heuristic improvements, which we shall explain in detail later on.
Before that, we start with our working assumptions on the input instance. We consider a directed graph with vertices and arcs, which is sparse: . G is accompanied with a time-dependent cost metric, succinctly represented by periodic, continuous, pwl arc-traversal-time functions . All time-dependent distances in this metric are indeed the minimum-travel-times , for each pair of vertices and departure time from the origin o.
Apart from the travel-times metric, we also consider the Dijkstra-Ranks metric for vertex-pairs: For any pair and departure time , the (also time-dependent) Dijkstra-Rank value, is the cardinal number of d (i.e., its position in the settling order) when growing a forward TDD ball from .
For theses two metrics that we consider, we make the following assumptions that have also been considered in previous works concerning time-dependent oracles, e.g., in [
22].
Assumption 1 (Bounded Travel-Time Slopes). All the minimum-travel-time slopes are bounded in a given interval , for the given constants ( due to the FIFO property) and .
Assumption 2 (Bounded Opposite Trips). The ratio of minimum-travel-times in opposite directions between two vertices for any specific departure time, but not necessarily via the same path, is upper bounded by a given constant .
Assumption 3 (Min-Travel-Times vs. Dijkstra-Ranks). There exist constants λ and functions , s.t. the following hold:
- (i)
, and
- (ii)
.
Analogous inequalities hold for the static free-flow and the full-congestion metrics, and .
Our next consideration is the preprocessed data-structure that is created by a time-dependent oracle (e.g., the CFLAT oracle in [
22]). We start with an i.u.a.r. (i.e., independent and uniformly at random, without repetitions) selection of a small subset
of landmark-vertices: each vertex
is chosen to be included in
L with probability
, independently of the other vertices. The preprocessed data structure succinctly represents the upper-bounding functions
of the (unknown) minimum-travel-time functions
, for all landmark-to-vertex pairs
.
Our precondition is that these upper-bounding functions are also periodic, continuous, pwl, and constitute
-approximations of the optimal travel-time functions. The variant of the TDAG query algorithm that we consider, called TDAGsimple, considers that
, i.e., it attempts to exploit only the closest landmark from the origin of the route. We explain the main steps of this query algorithm for alternative routes in
Figure 3.
In order to proceed with the analysis of TDAGsimple, we first recall a theorem that concerns the analysis of the FCA query algorithm for computing an (approximation of an) earliest-arrival-time route in sparse, time-dependent networks:
Theorem 1 ([
15])
. If a TD-instance, with and compliant with Assumptions 1, 2 and 3 is preprocessed using for constructing travel-time summaries from i.u.a.r chosen landmarks, then the expected preprocessing space and time areFor the approximation guarantee,returns either an exact-path or approximate-path via the nearest landmarkℓs.t.whereis the minimum-travel-time toℓ, andis a constant that only depends on the parameters of the travel-times metric but is independent of the network size.
The following theorem provides a similar analysis for the query time and the approximation guarantee of TDAGsimple (the preprocessing requirements remain the same).
Theorem 2 TDAGsimple has the expected time-complexity), and also returns an alternative graph H in which the minimum-travel-time for is, at most, a constant approximation of the minimum-travel-time forwithin G:, for some constant.
Proof (sketch). The expected size of the landmark set is . Moreover, by a simple application of Chernoff Bounds, we know that , with high probability.
The expected size of the forward TDD-ball grown, cf. step 1, is . Again, by a simple application of Chernoff Bounds, it can be shown that , with high probability. The expected time-complexity to construct this ball is .
The size of the reverse BFS ball grown in step 4 is chosen as . In the original version of the TDAG algorithm (which we implemented in this work), we considered the case where , i.e., . For our analysis here, we consider the more general case where the BFS ball is chosen independently of the forward TDD ball (e.g., we could select , in order to reduce the number of paths to reconstruct in step 7). The time-complexity for step 4 is linear in the size of the BFS ball, i.e., .
The expected size of the reverse TDD ball, cf. step 6, is . This is because of the facts that G is a sparse graph, and moreover the Dijkstra-Rank and the minimum-travel-time metrics are correlated within polylogarithmic factors (a consequence of Assumption 3).
The expected time for constructing all the landmark-to-vertex paths in step 7 is , since there exist leaves in the BFS ball, and each path consists of, at most, edges.
The overall running time of TDAGsimple is dominated by step 7 and is, therefore, .
As for the approximation guarantee, within the constructed alternative graph
H, the earliest-arrival-time at
d when departing from
is
. To see this, consider the leaf-vertex
v in
, which also belongs to the approximating
-path
, that reaches
d at time (at most)
, when departing from
. The path
is not necessarily a subgraph of
H. Nevertheless, its subpath
exists in
H. Moreover, the optimal path
also exists in
H. By following
, we reach
v at time (at most)
. It also holds that
, because
is the latest-departure-time from
v that reaches
. Therefore, if from
we follow the path
, then we can be sure that the arrival time at
d is, at most,
, essentially due to the FIFO property in the travel-times metric:
It is already known (cf. Theorem 1) that the approximate travel-time is an -approximation of the minimum-travel-time in G, , and thus this approximation guarantee also holds for . □









{kind=link}
{kind=link}
{kind=link}
{kind=link}