In this section, we demonstrate the performance of the SCH method using four datasets (Batik, Coil100, Outext, and Corel10K). The Batik, Coil100 and Outext datasets are used to evaluate SCH in differentiating texture images. The Corel10K dataset is used to evaluate the heterogeneous image recognition capabilities of the proposed method.
Below is a concise description of datasets.
The initial experiment evaluated the accuracy of window sizes and recurrent transformations using different classifiers and different dataset features. Window sizes of 3 × 3, 5 × 5, 7 × 7, 9 × 9 and 11 × 11 and the numbers of recurrent transformations of 5, 10, 15, 20 and 25 were used for extracting features for this experiment [
34].
4.2. Image Retrieval
In this section, the proposed descriptor is evaluated in a classical CBIR task. Precision and recall metrics are used to evaluate the proposed descriptor’s performance in the CBIR task. Equations (3) and (4) present the formulae for the precision and recall metrics, respectively.
We first present the results of the machine learning approach used for the experiment.
Table 1 provides accurate results of the DCA classifier on all datasets. The window size 11 × 11 with the recurrent transformation of 5 provided the highest accuracy of 91% for Coil100. All window sizes with the recurrent transformation of 5 gave 36% accuracy as highest for Corel10K. The window sizes 7 × 7 and 9 × 9 with the recurrent transformation of 5 produced 67% accuracy for the Outext dataset. The mean accuracy of 87.64%, 32.72%, and 64.24% was recorded for Coil100, Corel10K and Outext datasets, respectively.
Table 2 displays the accuracy results of the SVM classifier on all datasets. The window size 11 × 11 with the recurrent transformations of 15, 20 and 25 yielded the highest accuracy of 97% for Coil100. The window size 11 × 11 with the recurrent transformation of 5 produced an accuracy of 43% as the highest for Corel10K. The window sizes 3 × 3, 5 × 5 and 7 × 7 with the recurrent transformations of 15, 20 and 25 produced 78% accuracy for the Outext dataset. Mean accuracies of 95.16%, 40.96%, and 77.08% were recorded for the Coil100, Corel10K and Outext datasets, respectively.
Table 3 presents accuracies obtained by applying the NB classifier on all datasets. Most 9 × 9 and 11 × 11 window sizes with the recurrent transformations of 15, 20 and 25 produced the highest accuracy of 92% for Coil100. The window sizes 5 × 5 and 11 × 11 with the recurrent transformations of 15 and 25 produced an accuracy of 36% as the highest for Corel10K. The window size 3 × 3 with the recurrent transformations of 15 and 20 produced 64%, whereas window size 5 × 5 with the recurrent transformation of 5 produced the same accuracy for the Outext dataset. The mean accuracies for Coil100, Corel10K, and Outext were 89.96%, 34.28%, and 61.08%, respectively.
Table 4 shows the accuracy outcomes by applying the DT classifier on all datasets. The window size 11 × 11 with the recurrent transformations of 15 and 25 produced the highest accuracy of 92% for Coil100. The window sizes 5 × 5 and 11 × 11 with the recurrent transformations of 15 and 25 produced an accuracy of 24% as the highest for Corel10K. The window size 5 × 5 with the recurrent transformations of 20 and 25 produced 79% accuracy for the Outext dataset. Mean accuracies of 88.96%, 22.96%, and 76.32% were recorded for the Coil100, Corel10K, and Outext datasets.
From
Table 1,
Table 2,
Table 3 and
Table 4, generally window size 11 × 11 with the recurrent transformations of 15, 20 and 25 produced good results for the four different classifiers. Khaldi et al. [
29] in their work “
Image representation using complete multi-texton histogram”, compared their results with the state-of-the art texture feature extraction techniques for indexing images or representing images. The Texton Co-occurrence Matrix (TCM), Multi-Texton Histogram (MTH), Complete Texton Matrix (CTM), Complete Multi-Texton Histogram (CMTH), and Noise Resistant Fundamental Units of Complete Texton Matrix (NRFUCTM) were compared in the paper.
Table 5 presents the results of accuracy obtained by Khaldi et al. The result compared for four different classifiers, namely Discriminant Analysis Classifier (DAC), Support Vector Machine (SVM), Naive Bayes (NB) and Decision Tree (DT) for well-established texton-based feature extraction techniques. The texton-based features presented by Khaldi et al. had worse performance in representing heterogeneous images. Our proposed SCH outperform the textons (i.e., CMTH yields 31.76% with Corel10K. However, our method SCH outperform with 32.72% for DAC).
Additionally, our method SCH remarkably represents textures and shows high performances in classifying Outext (i.e., SCH yields 64.24%, which far outperforms CMTH with 42.34% for DAC).
We conducted another evaluation using the KNN classifier on all datasets. The mean accuracies when
k = 1, 96%, 31.80%, 77.63% were recorded for Coil100, Corel10K, and Outext datasets, respectively. When
k = 3, 95%, 31.35%, 77.33% were recorded for Coil100, Corel10K, and Outext datasets, respectively. When the value of
k = 5, 94%, 34.03%, 76.04% were recorded for Coil100, Corel10K, and Outext datasets, respectively. Lastly, using
k = 9 recorded 94%, 31.93%, 77.19% for Coil100, Corel10K, and Outext datasets, respectively.
Table 6 clearly shows the obtained mean accuracies of the KNN classifier, with different values of
k, on all datasets.
The results obtained were compared with texton-based features in [
29]. The accuracy results of our SCH method denote better performance in representing heterogeneous images. Our method performs relatively well for texture images.
Table 7 clearly shows the results of SCH together with that of the textons implemented by Khaldi et al. using different values of k (KNN’s parameter).
We Present the Results of the IMAGE Retrieval Below
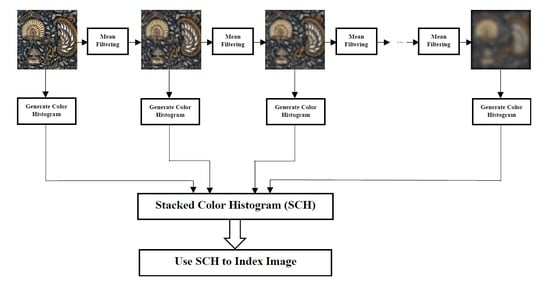
The SCH is primarily proposed for indexing images for CBIR or QBIC. We evaluated proposed descriptor in a conventional CBIR task.
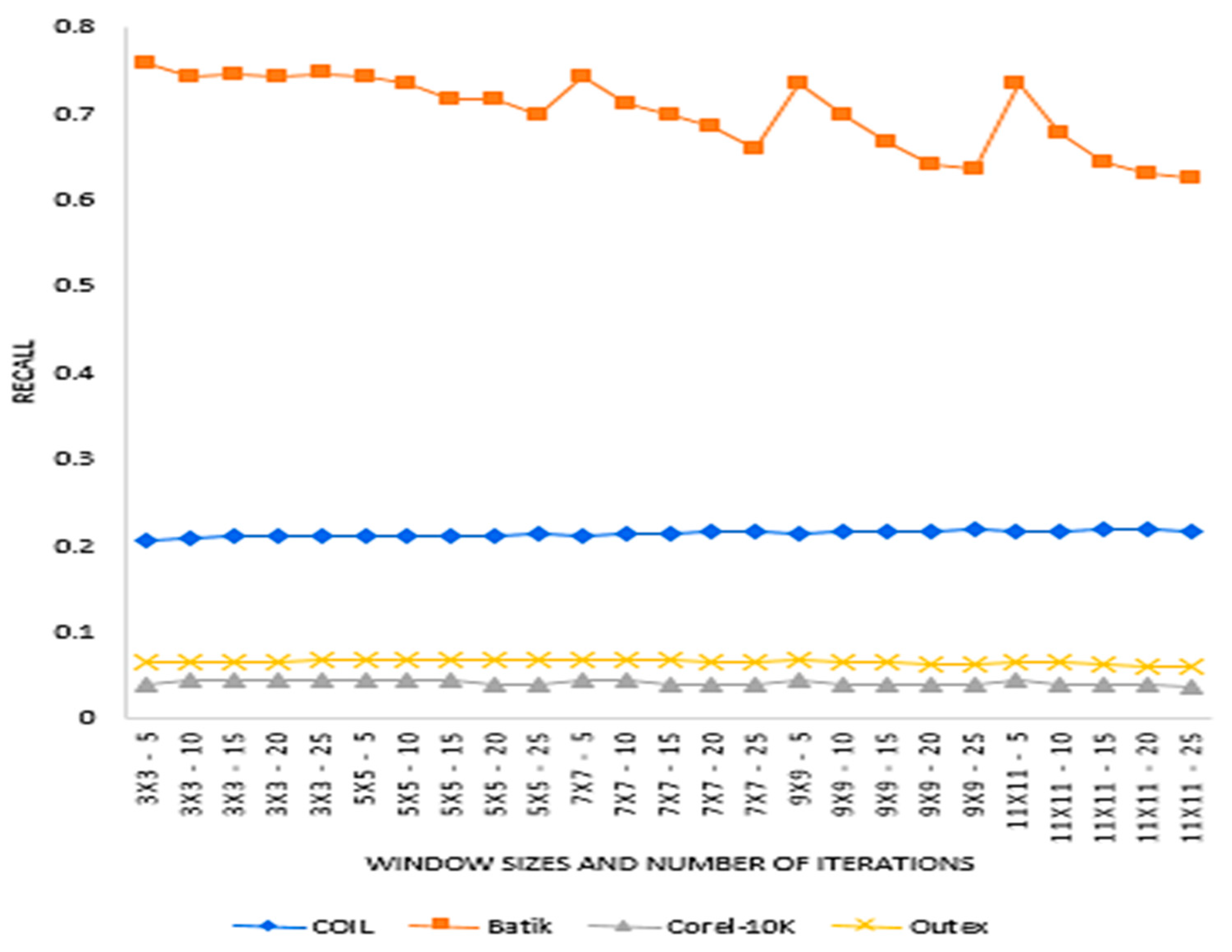
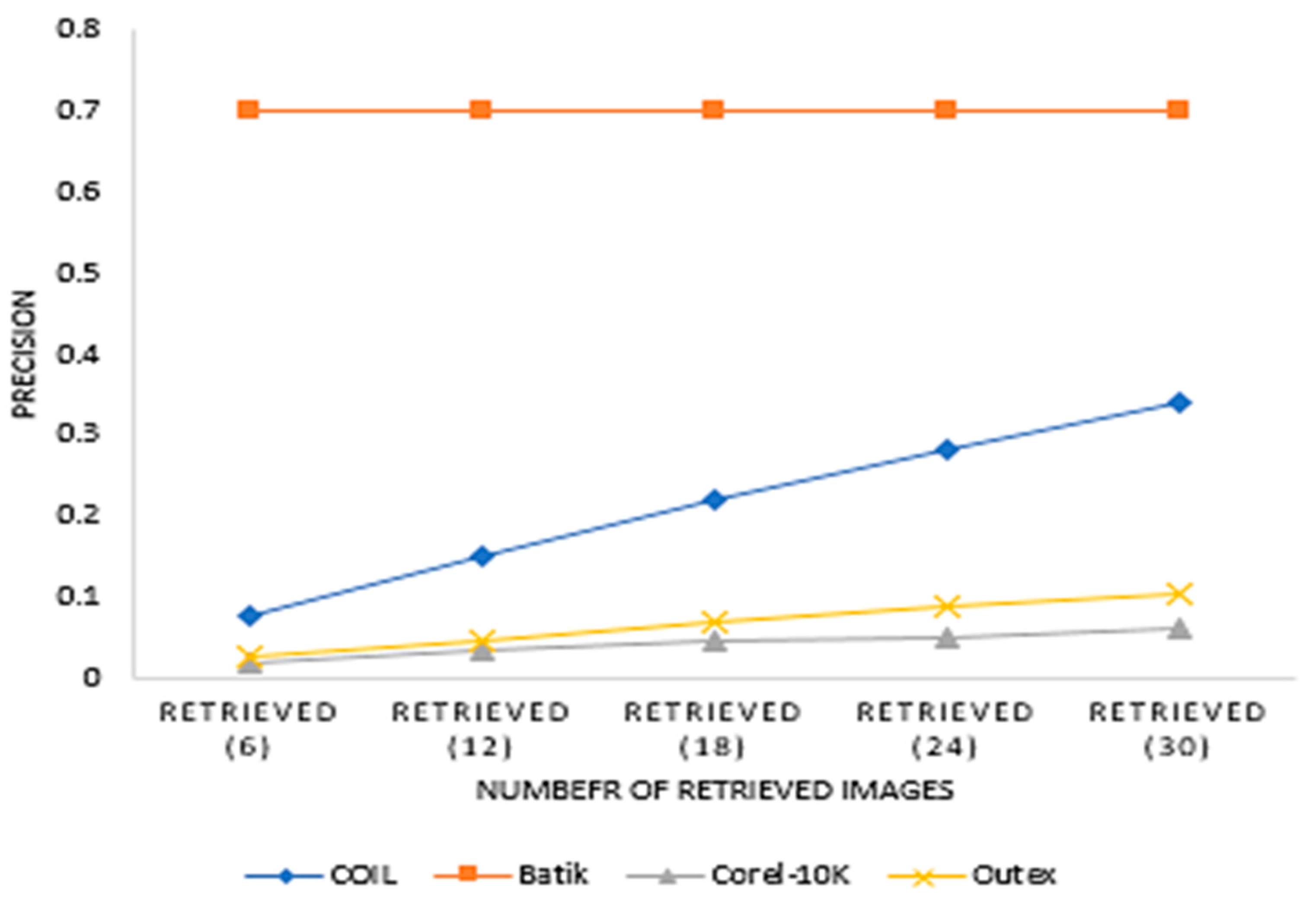
The experiment evaluated the effect of window sizes and the number of recurrent transformations on precision and recall on the identified dataset. Window sizes of 3 × 3, 5 × 5, 7 × 7, 9 × 9 and 11 × 11, and several recurrent transformations of 5, 10, 15, 20 and 25 were used for extracting features for this experiment. Again, the number of retrieved images from each dataset was 6, 12, 18, 24 and 30.
Figure 3,
Figure 4,
Figure 5 and
Figure 6 present the precision and recall performances of the proposed descriptor on Corel-10K, Outext, COIL100 and Batik datasets.
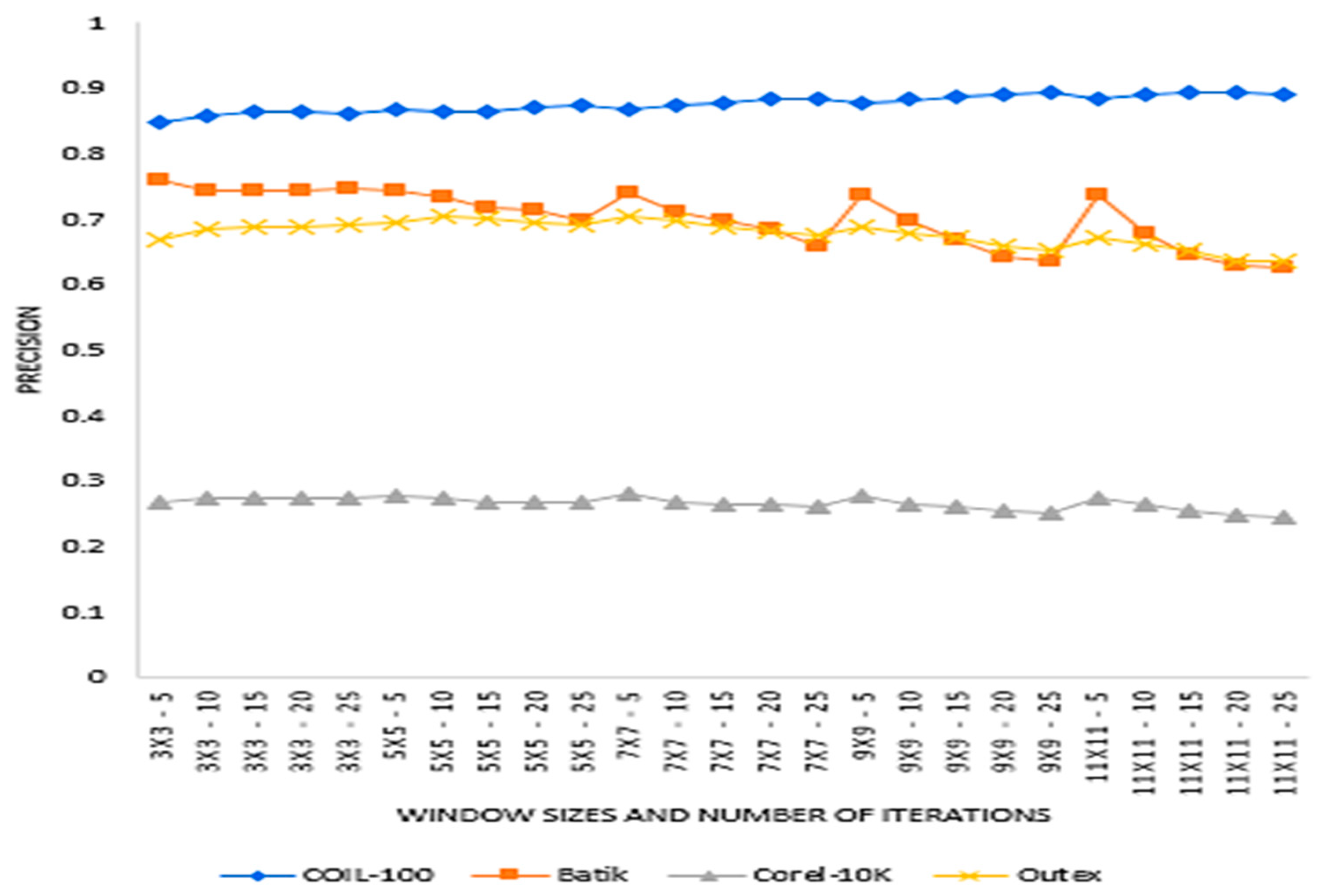
Figure 3 presents the average precision values of five window sizes and the five retrieved values (6, 12, 18, 24 and 30). The experiment determined which window size and the number of recurrent transformation will be adequate for SCH.
From
Figure 4, we can see that different datasets recorded different precision patterns. COIL-100 precision values increased with increasing window size. However, Batik, Corel-10K and Outext did not record such a pattern, especially a Batik depicting alternating precision with increasing window size.
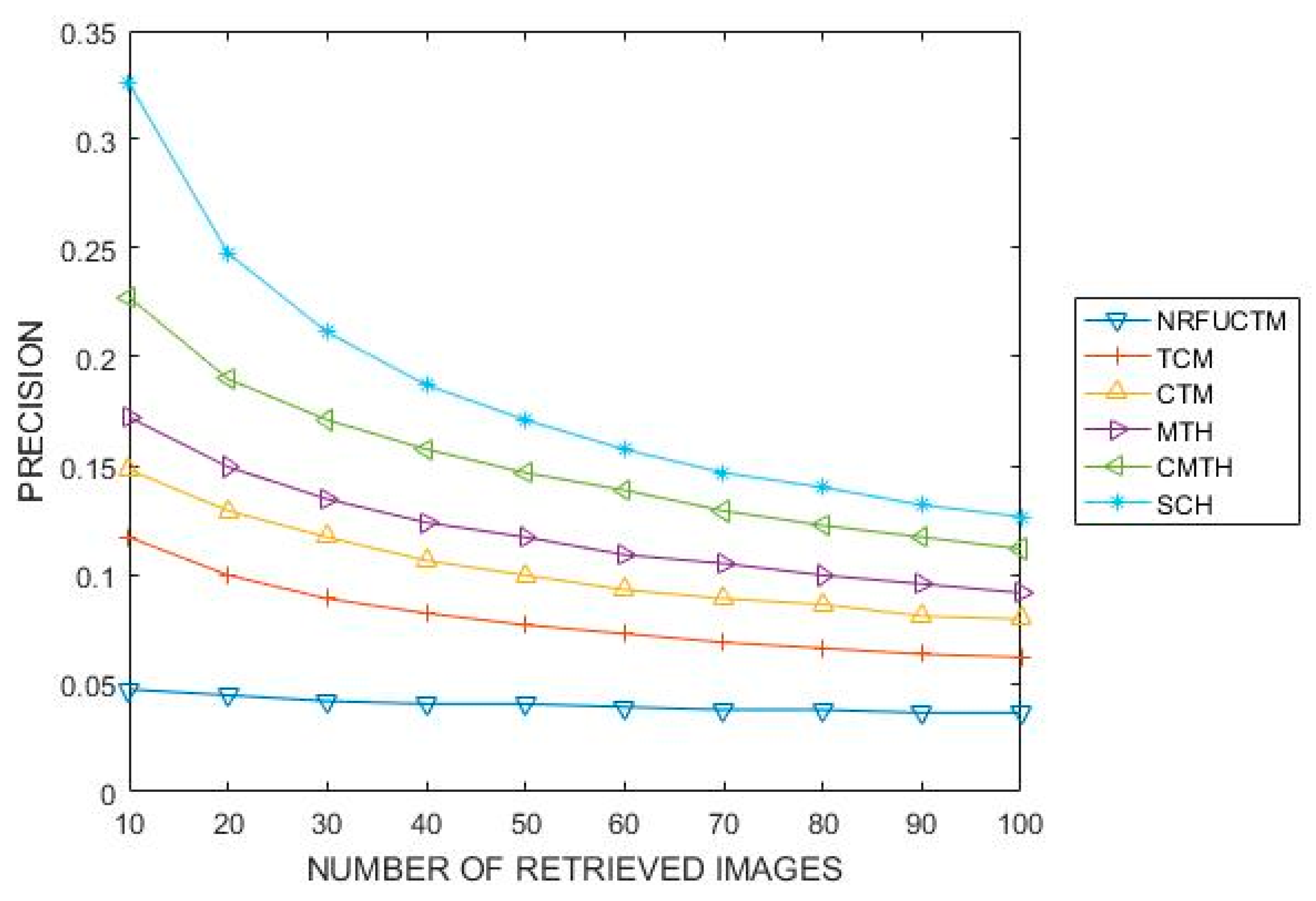
Figure 7 presents the results of SCH together with that of the Textons implemented by Khaldi et al. [
29] on Corel-10K. Both experiments used retrieval values of 10 to 100 with a step of 10. The proposed SCH outperformed TCM, MTH, CTM, NRFUCTM, and CMTH.
The results for our experiment on the retrieval efficiency of SCH is compared with that of the textons approach as proposed by Khaldi et al. [
29] for extracting textural features in an image. Textons were selected largely because the literature has demonstrated that they are very effective for extracting textural information from images [
27,
35] and hence can be used as benchmark for evaluating similar feature extraction schemes. From
Figure 7, we can see that SCH outperformed all the texton approaches that have been used to index the Corel 10K. The obtained result is a result of the transformational (rotational, scaling, translation and deformation) invariant nature SCH.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}