1. Introduction
When a pandemic is raging through a population, it is crucial for public health agencies to isolate and quarantine all infectious individuals. When an infected person is asymptomatic for several days (or indefinitely), this becomes extremely difficult. This is one of the chief motivations for public health agencies to implement a system of contact tracing [
1,
2,
3]. Unfortunately, tracing and especially testing can be extremely costly and can overwhelm available resources [
4].
In this paper, we explore the use of the geometry of the infection pattern to greatly reduce the number of tests needed in order to find a boundary that encompasses a set of infected nodes originating from the community infection from a single source of infection, which can then be extended to finding the pandemic boundary of the entire population.
The infection can either spread locally or to communities a long distance away. Typical examples of local infections are the community infection of a population by a virus (for example Ebola) or the spread of invasive plants (for example the spread of Japanese Knotweed—Fallopia Japonica—in Britain [
5]). The long-range infections of the pandemic are usually due to traveling. In general, the longer the distance between the origin and the destination, the the lower the frequency that people travel it. There are many network models for infection [
6,
7] and we study a particularly simple one: We view the world as an
grid of
cells on the real plane. We assume that individuals are mapped at random onto the
real plane. Each individual is then associated with the
cell into which it falls.
In our model, once an individual becomes infected, for a window of
x days, they are infectious and have the opportunity to infect any individual in the same cell or in any of the eight neighboring cells (cells to the N, NE, E, SE, S, SW, and W (See
Table 1 in
Section 3.2.1)). After
x days, we assume that they are either no longer infectious or are in quarantine and so will no longer pass the disease along.
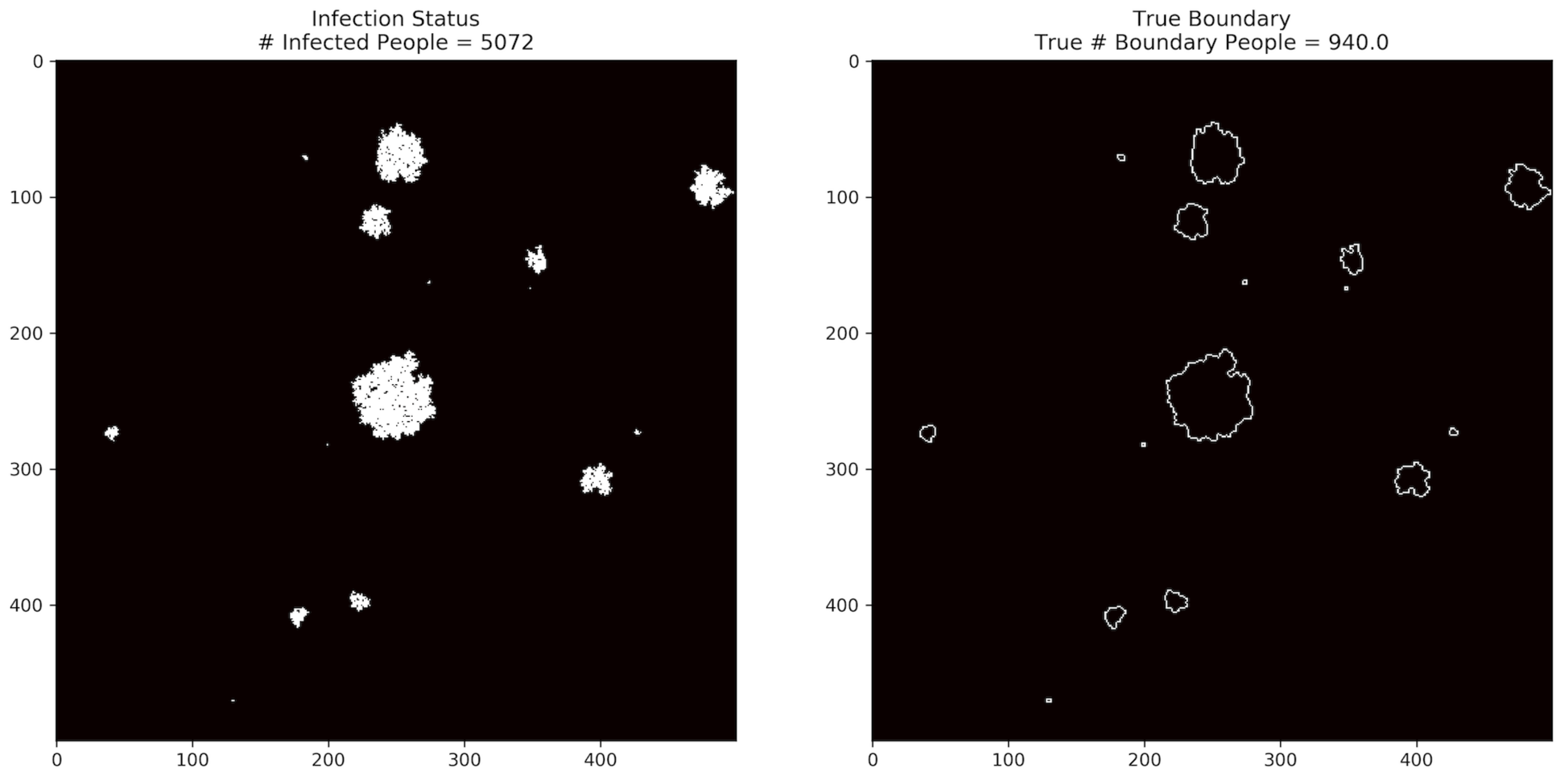
Figure 1 shows an example of the pandemic infection status of the entire population, while
Figure 2 shows an example of what the paths of infection might look like for locally infected regions, along with a boundary that encloses the infected regions. The boundary consists of uninfected cells, adjacent to at least one infected cell, so that every possible transmission path from the interior to the exterior must pass through this boundary. Our goal is to find such a boundary with the minimum possible number of tests. Efficient algorithms for this task are enabled by the local nature of the infection.
At a minimum, the number of tests and resources required to find the boundary are proportional to the length of the boundary and not the total population enclosed within the boundary. However, this assumes that we know, which individuals to test, i.e., which individuals to test in order to provably find the boundary. In this paper, we present a simple algorithm for finding this boundary efficiently and show empirically that we do indeed gain significantly over testing everybody in the infected region.
We extend our results to consider the problem of non-cooperation where individuals may refuse to be tested for infection and adjust our boundary-tracing algorithm accordingly.
3. Materials and Methods
We design a model and algorithms for the communities of each of these k patients 0, and these k communities are far from each other. Since the applications of the model and algorithms are the same across different patients 0, we can first focus on the case where there is only 1 patient 0. For simplicity, this person is assumed to reside in the center of the grid. We also assume that the grid is large enough that the entire set of outermost cells does not contain any infected individuals. We call this set of outermost cells “the end of the world”. Later, we can extend this model and our algorithms to find the boundary of all these k communities.
3.1. The Process of Infection
The set of infected individuals is determined by the following random process. Time is discrete (think of each step as a day) and the infection process proceeds for T time steps. On day 0, patient 0 becomes infected. From that point on, during the first m time steps that an individual, say in cell c, is infected, that individual can infect all individuals in cell c and in the other adjacent eight cells with the probability of p. We assume that the probability of an infected individual infecting a non-infected individual in the same or in an adjacent cell during one of the m time steps that they are infectious is p, that such events are independent, and that an individual becomes infected only once. In addition, we have multiple patients 0 in the entire grid and each one of them follows the same random process.
Definition 1. A cell is infected if it contains at least one infected individual. Otherwise, it is uninfected.
Definition 2. A cell c is called a potential uninfected boundary cell if:
- (a)
The cell c is uninfected;
- (b)
At least one of the 8 neighboring cells of c (N, NW, W, SW, S, SE, and E) is infected;
- (c)
There is a contiguous path of uninfected cells from c to the end of the world.
Definition 3. We say that a set S of uninfected cells encloses a set X of infected cells if every path from an infected node in X to the end of the world must pass through at least one cell of S.
Definition 4 (Boundary).
A set of uninfected cells is called a boundary if it is a rectilinear closed path consisting only of potential uninfected boundary cells and it encloses all infected cells. See Figure 2. We call the minimal such boundary the “true boundary”, where minimal means that it contains the lowest number of cells. Since the boundary partitions the cells into two parts, with one part containing all infected cells, the following claim is immediate:
Claim 1. A rectilinearly aligned connected and closed path of uninfected cells encloses all infected cells if and only if it encloses at least one infected cell.
Our goal is to efficiently trace and map out the boundary while performing a minimum number of tests.
3.2. Full Cooperation/No Errors
We begin by discussing the case where all individuals are cooperative, that is, they are willing to be tested and tests have no errors.
3.2.1. An Efficient Local Geometric Algorithm
One may choose (arbitrarily) either clockwise or counter-clockwise traversals of the boundary. We build up the boundary cell by cell, adding (some of the) rectilinearly adjacent cells that are potential boundary cells.
To describe the algorithm, we need to keep track of a compass direction by which we arrived at the current boundary node (North, East, South, and West) and a notion of “left“ and “right”; see
Table 1.
We now describe an Algorithm 1 for a counter-clockwise traversal to discover the boundary:
| Algorithm 1: Geometric Search Algorithm |
![Algorithms 14 00244 i001]() |
Starting from patient 0, find a boundary cell on the south—go south to the last potential boundary cell, testing each cell along the way (and marking it appropriately). This cell, , has an infected node to the North of it and no other infected neighbors; furthermore, no cell to the south of is adjacent to any infected cell.
Set the initial direction , set the current cell . This means that when one looks in from cell c facing direction D, the nearby infected nodes are on the left (could have a common edge or a common vertex). This will be the invariant throughout the algorithm.
Repeat until you return to the original boundary cell :
Let the current direction be D and let the current cell be c; the key idea is that we advance to the next boundary node by choosing a potential boundary node on the right, straight ahead, or on the left, in this order of priority:
- –
If the cell to the of cell c is a potential boundary cell, add it to boundary, set the direction and update c.
- –
Otherwise, if the cell in direction D from cell c is a potential boundary cell, add it to boundary, leave D unchanged, and update the current cell c.
- –
Otherwise, add the cell to the of cell c to the boundary, set , and update c. (Note that this new cell must also be a potential boundary cell at this stage.)
The nature of the algorithm is entirely geometric and relies on geometric arguments.
Obviously, the resulting boundary is rectilinearly connected, and as we traverse this boundary counterclockwise, all the infected cells are to the left and every one of the boundary nodes has at least one infected cell adjacent to it on the left (via edge of vertex). Ergo, all these cells are potential boundary cells.
The boundary consists of only uninfected nodes and partitions the nodes into two sets. All infected nodes are in one set and all the nodes in the other set are uninfected.
Comment 1. Claim: the boundary exists.
Take as a set all nodes that are uninfected and do not belong to the potential boundary for which there is a path from them to the end of the world that only goes through uninfected nodes. Call this set W.
The nodes that are not in W and have a neighbor in W is the true boundary; call this set B. Note that these must be uninfected since nodes in W have no infected neighbors. Claim (a): this must be a rectilinear set; (b): these must be potential boundary; and (c): the set B is rectilinearly connected.
Every node on the boundary is adjacent to exactly two nodes.
3.2.2. Non-Geometric Algorithms
We now describe a different class of algorithms for finding the boundary, where we perform a full adjacency search of the rectilinearly aligned boundary cells. Such an algorithm is useful when there are non-cooperating nodes and the definition of the boundary is adjusted accordingly.
In the context of full cooperation, both algorithms are better than brute force contact tracing, and the full adjacency search is obviously more expensive (in terms of number of tests) than the geometric local algorithm of
Section 3.2.1.
The description of the full search is as follows:
This is exactly as before. Starting from patient 0, find a boundary cell to the south. This is done by moving south until the last potential boundary cell is found, testing each cell and its east and west neighbors along the way. The cell has an infected node to the North of it and no other infected neighbors. Moreover, all cells directly south of are uninfected, and all of their east–west neighbors are uninfected. Therefore, by definition, none of the cells on the path from south to the end of the world are potential boundary nodes.
Now consider a graph G whose vertex set V consists of uninfected potential boundary cells, and where there is an edge between two cells in V if they are north–south or east–west neighbors. Note that and is a true boundary node. Our boundary tracing algorithm is now simple: we perform a search on G, starting at , stopping as soon as we find a closed path containing and enclosing ’s infected neighbor to the north.
Note that whenever a neighbor of a cell is explored during such a search, if it or any of its neighbors are not yet tested, a test is performed on individuals therein. As soon as an infected individual is discovered inside a cell, that cell is classified as infected and no further tests are conducted on individuals in that cell.
Comment 2. The potential boundary nodes form a connected graph.
Lemma 1. The algorithm just described is correct.
Proof. By definition, the set of output nodes are connected by rectilinear paths. Therefore, to verify correctness, we just need to check that the connected component of the graph G containing contains the true boundary.
By construction, is on the true boundary. To see this, observe that the set of infected cells is a connected set in the original graph, where two cells are neighbors if they share a vertex or an edge in the grid. This is because there is a path of infection back to patient 0. Now consider any potential boundary cell.
For (b), by definition, the set of cells output encloses a region that contains the infected neighbor of c to its north, northwest or northeast. This is because the cells’ output cannot contain any of the cells on the line going south from c Therefore, there are infected nodes inside the rectilinear boundary. However, this implies that all infected nodes are enclosed by this set since there is no way for the infection to pass through the rectilinear boundary and the infected set is connected. □
3.3. When Some Individuals Are Non-Cooperative
In this case, we treat each square of cells as a “supercell”, thereby creating an by size grid. The parameter t is selected so that in each supercell there will be some cooperative individuals with very high probability. On the other hand, we want to have t be as small as possible to reduce the number of tests and to get a finer-grain picture of the infection and its boundary. For our experiments, a value of appears to be a good tradeoff choice. When we test individuals in a super cell, we now compute the fraction of infected individuals out of the cooperative ones. If a supercell has at least one cooperative node and is below a threshold , then we say the supercell is not infected. Otherwise, we treat it as infected. The rest of the algorithm proceeds as before.
3.4. Asymptotic Bound
Theorem 1. In a population with size N and k known connected components. Assume the probability that the person A will spread the disease to the person B is proportional to , where d is the distance between A and B. Then, the geometric search algorithm we proposed requires to conduct tests in order to find out the transmission boundary of the pandemic.
Proof. Starting from the self-reported patient #0 in each cluster, the geometric search algorithm heads to north until it hits the outer boundary and then traces along the outer boundary until it finds a closed cycle. As a result, the number of tests conducted by the geometric algorithm is proportional to the periphery of the cluster, which is proportional to the diameter (The diameter of a graph is the shortest distance between the furthest connected vertices [
16]). of the cluster. Since the pandemic infection probability is penalized by the distance squared and the population resides on a 2-dimension grid, the diameters of those clusters are at most in the order of
[
17]. Hence, the upper bound of the cost of our geometric algorithm has been obtained. □
For the full search algorithm, its worst case scenario requires a testing of every single infected people plus the non-infected people on the boundary. The main reason is that it does not prioritize the paths that are more likely to be on the outer boundary and it searches through all individuals on boundary cells. In adversarial graphs which are filled with holes among the infected population, the full search algorithm will spend a lot of time testing the persons near these holes. However, our simulation experiments show that the adversarial graphs are very unlikely to be generated in our practical life. Most often we can find a clear geometric boundary between the non-infected population and the nearly all infected population.
5. Results and Discussion
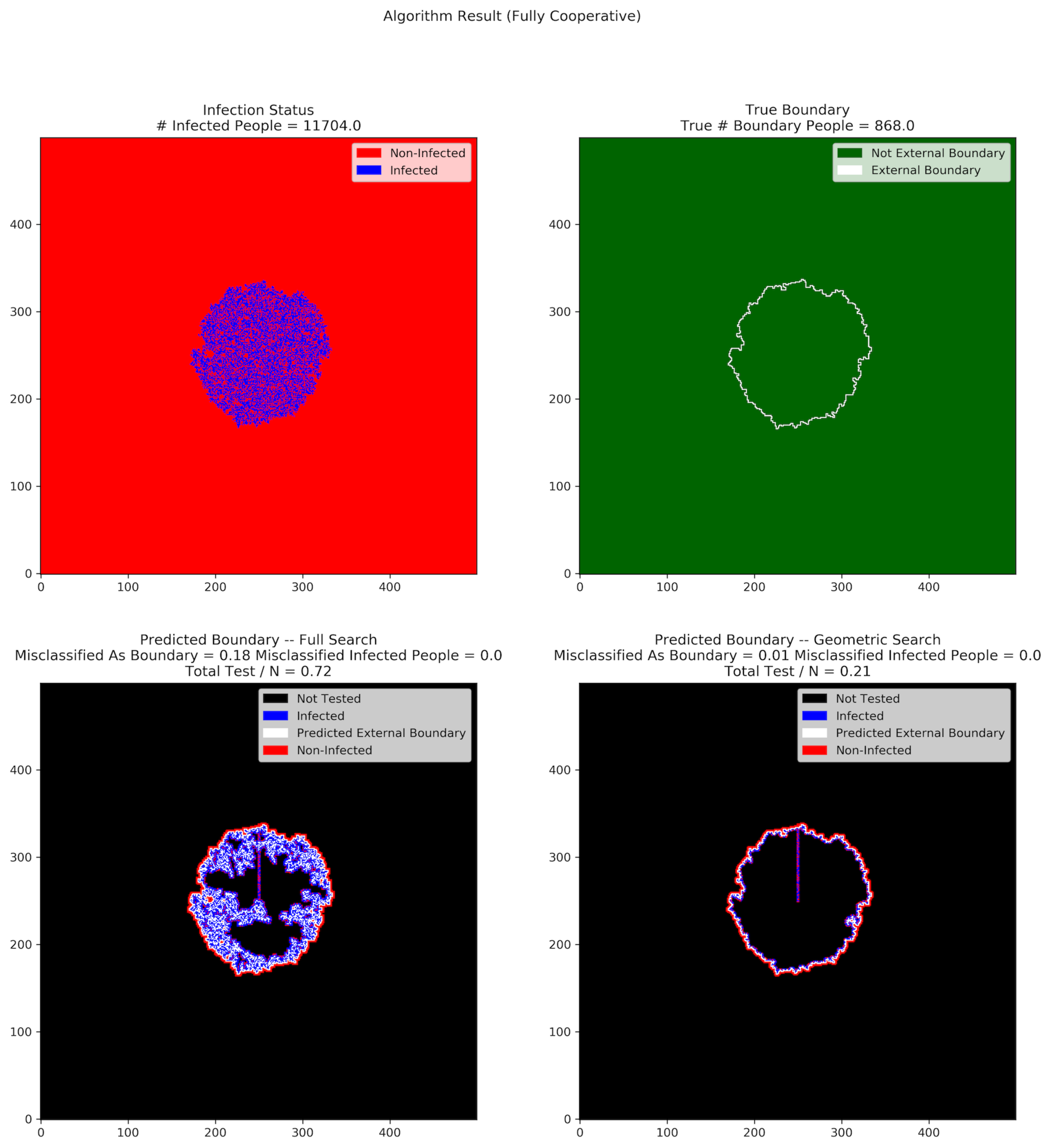
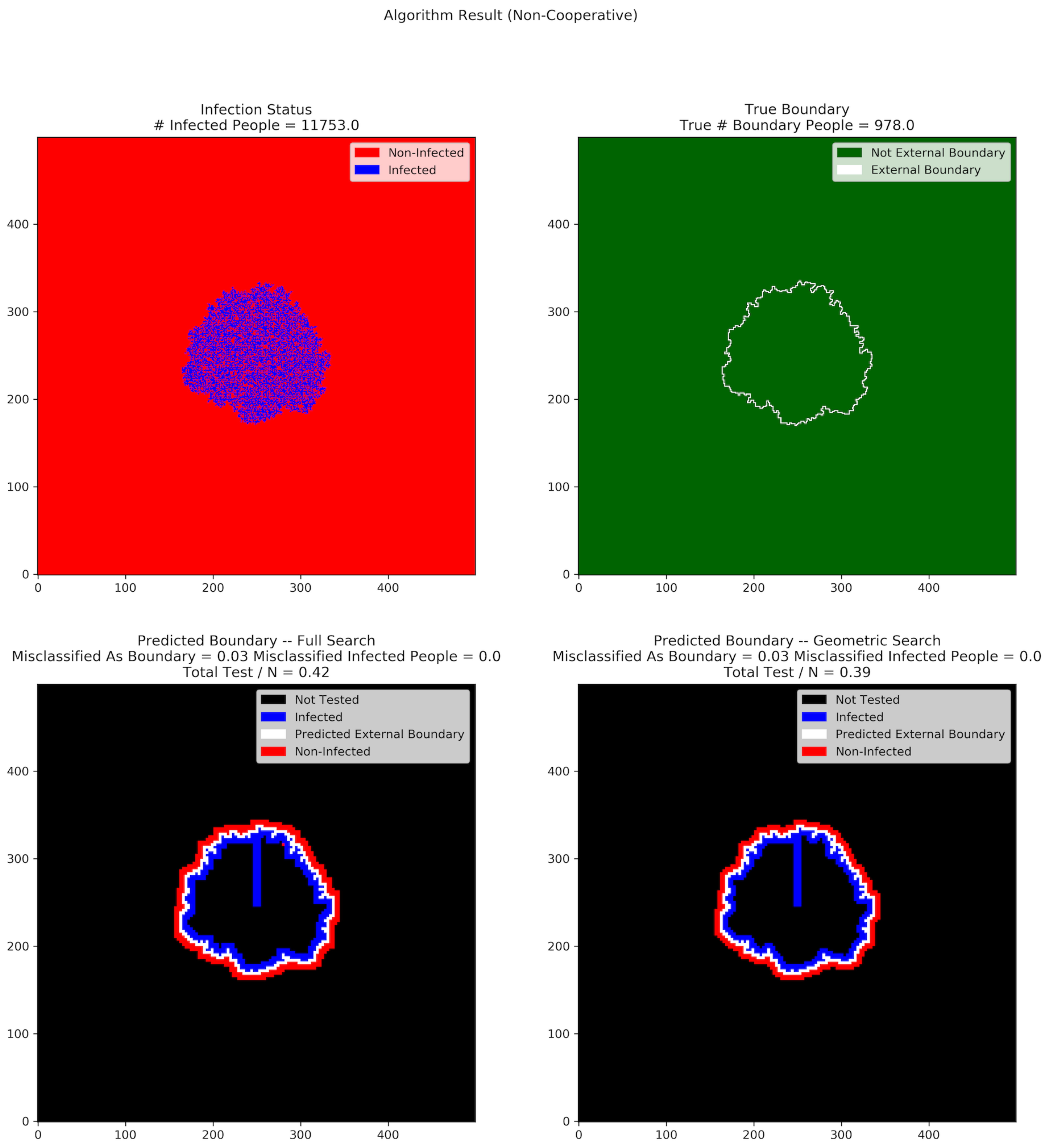
Figure 3 and
Figure 4 show the results of full search and geometric search in a single trial, where the population size is 250,000, the duration of the pandemic is 200 days, and the infection probability is 0.1.
Figure 2 shows the result when all people are cooperative, whereas
Figure 3 shows the result when approximately
of population are non-cooperative.
When all people are cooperative, the full search tests 72% of the people within the external boundary, while the geometric search only tests 21% of them. The number of people misclassified as boundary for the full search algorithm is also much higher than that of the geometric search algorithm.
When a significant fraction of the population is non-cooperative, the number of people misclassified as boundary does not differ much between the full search and the geometric search algorithms. This is because of the different resolution at which the tests are conducted (the use of supercells). The number of tests conducted is also quite close for both geometric and full search, and both are larger than in the fully cooperative case.
In all of our experiments, neither algorithm ever misclassified infected individuals, even in the presence of non-cooperation. In other words, our algorithms have the property that all infected individuals are inside the predicted boundary, regardless of the non-cooperative rate in the population.
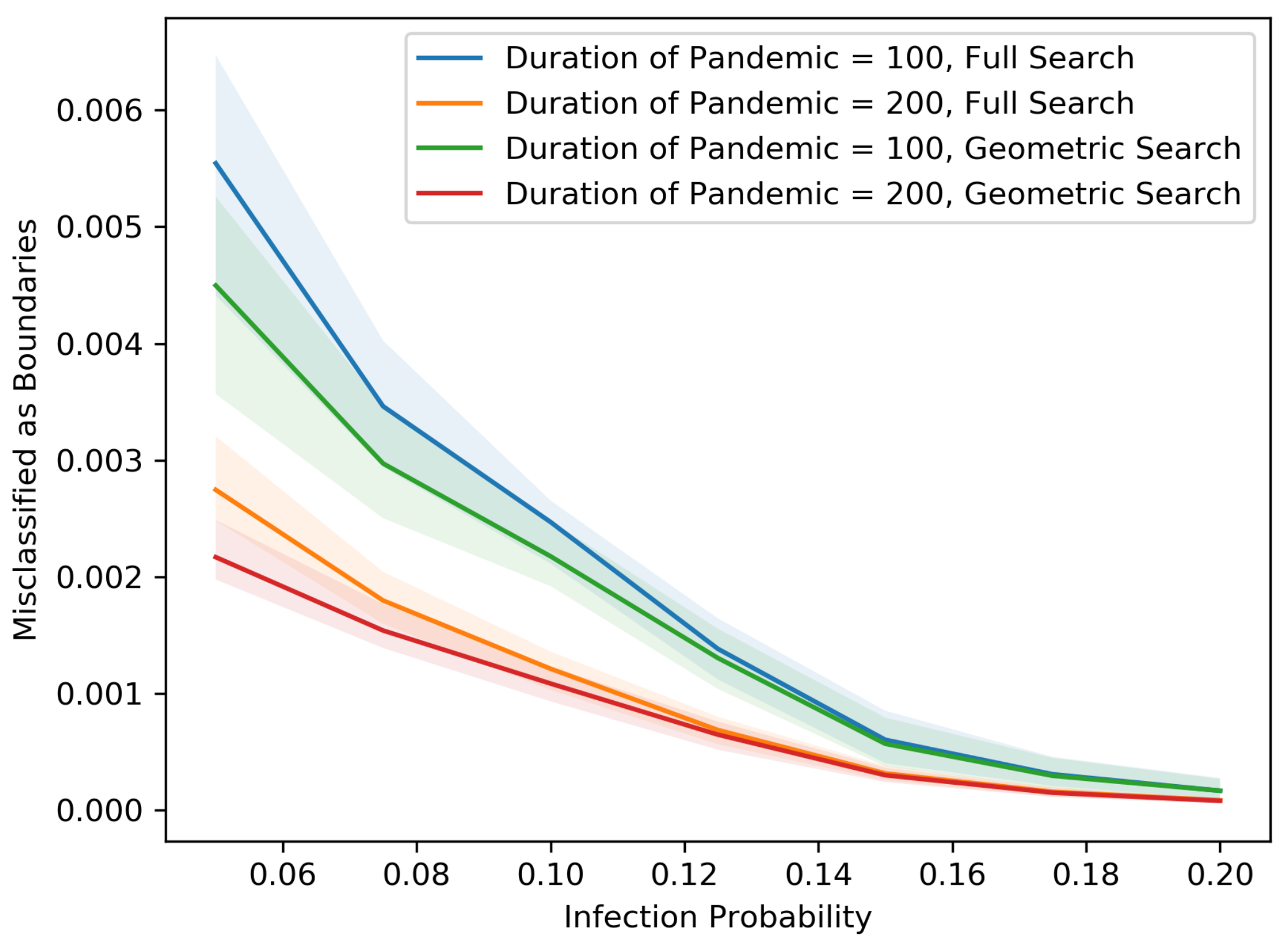
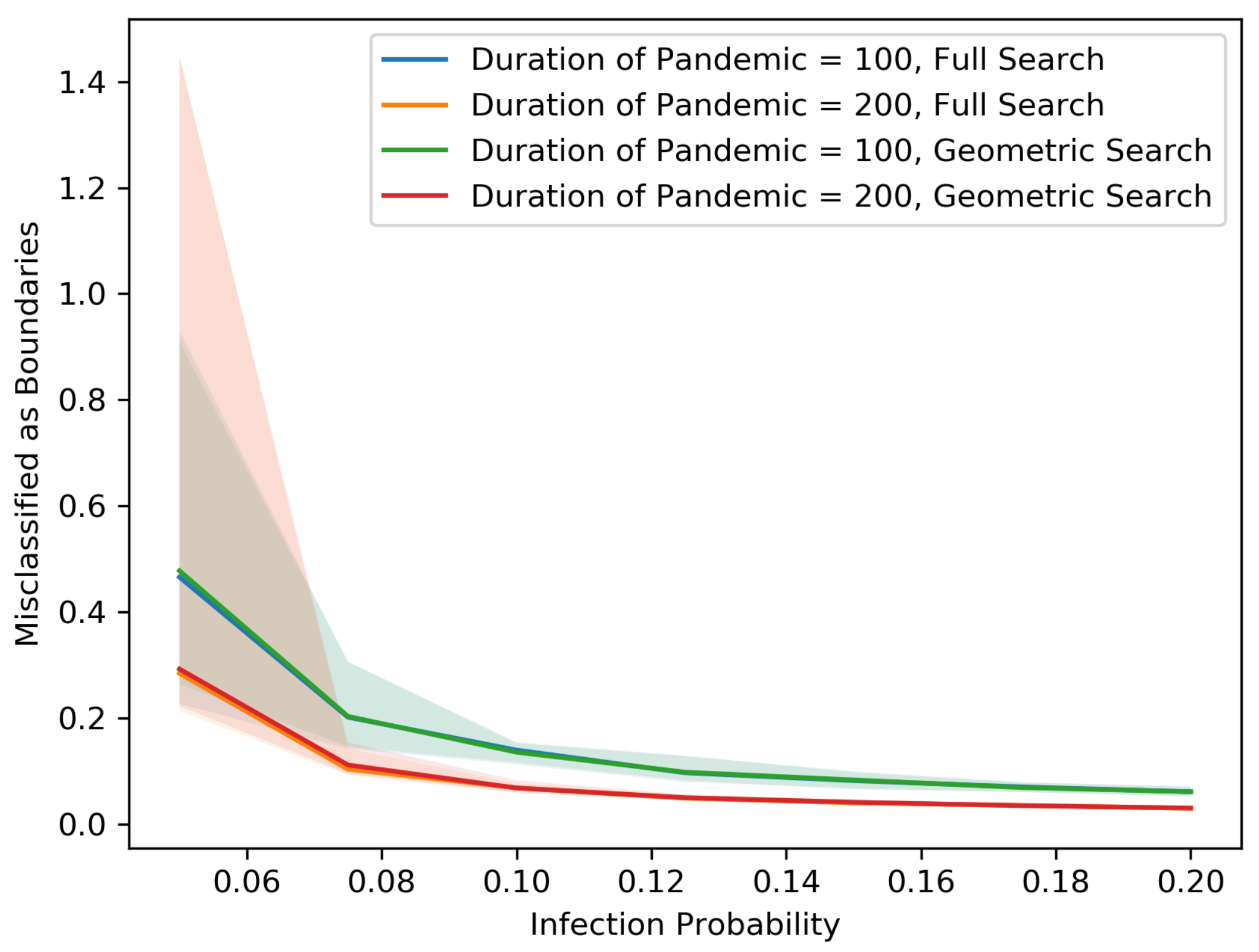
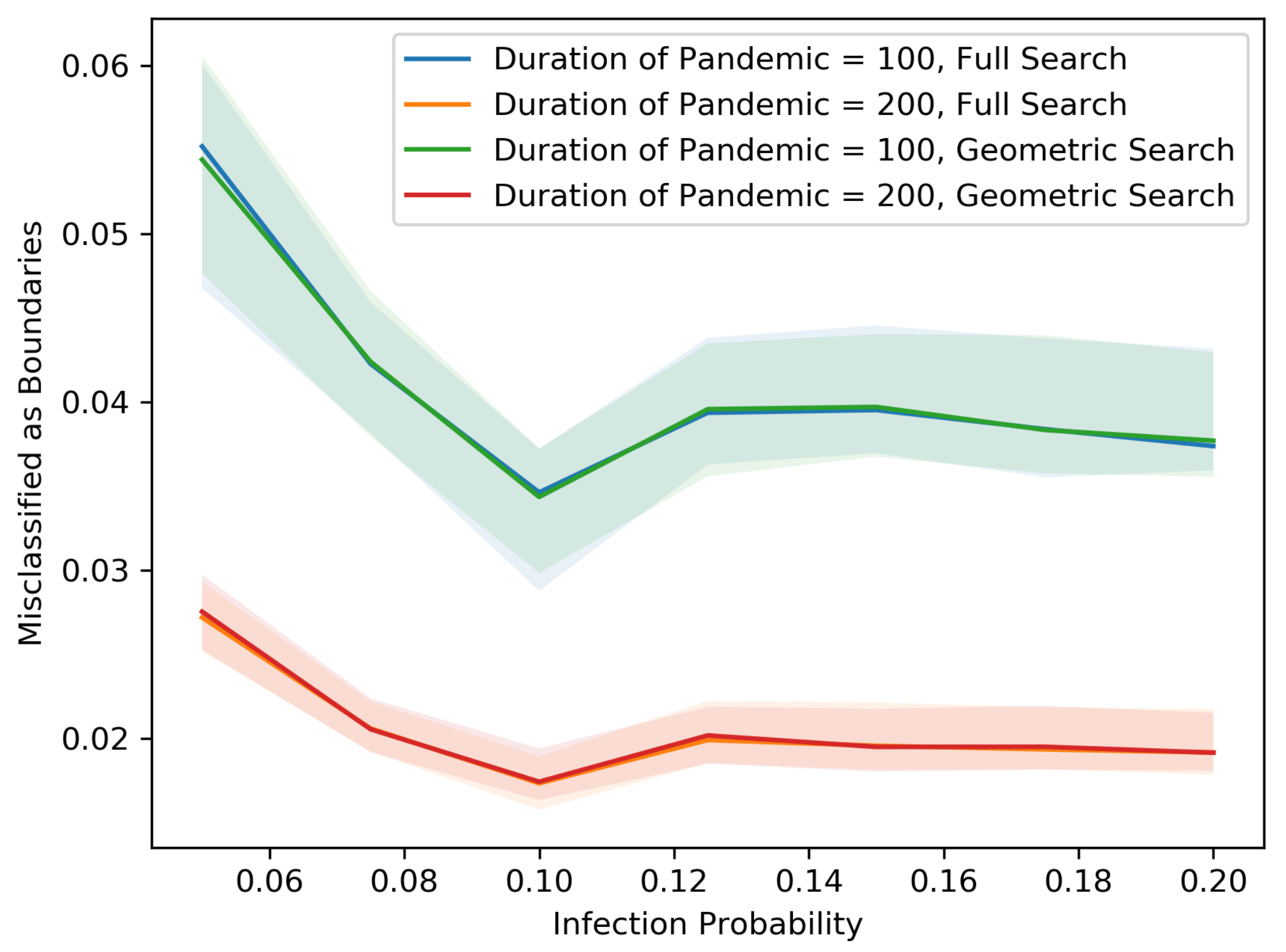
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11 and
Figure 12 show our results in a number of different settings as a function of the infection probability
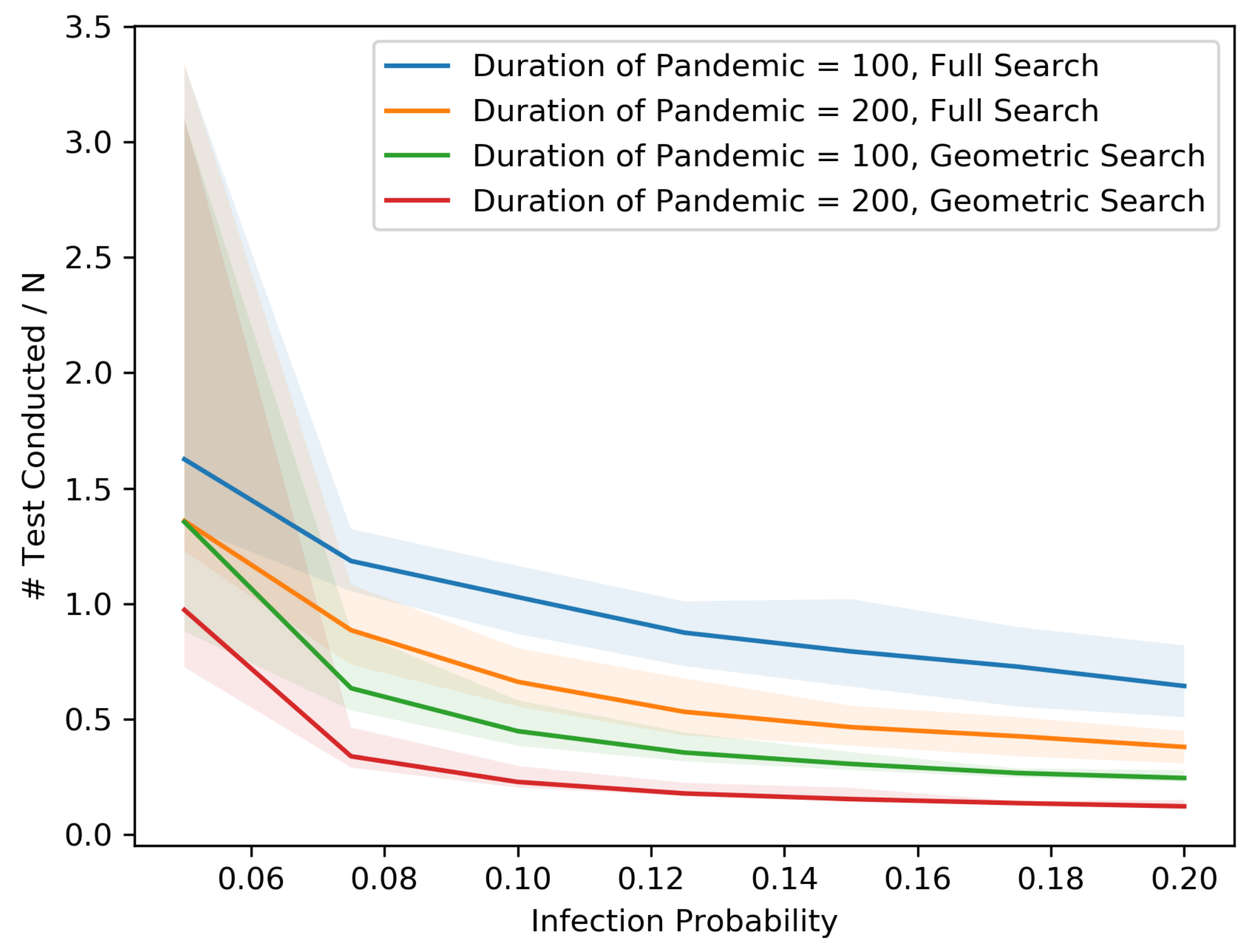
p. For these plots, each experiment is repeated 20 times. The main curve shown is the median across these experiments with the lighter region surrounding each curve representing the 5th and 95th percentiles on the low and high end, respectively. These eight plots demonstrate the differences between the two searching algorithms, for different population sizes, non-cooperative rates and pandemic duration.
As we might expect, for each population size and non-cooperative rate, both the MAB rate and the test rate for the geometric search algorithm is lower than that of the full search. In addition, an increase in population size leads to a decrease in both the MAB rate and test rate for both algorithms, holding the non-cooperative rates equal. In contrast, an increase in the non-cooperative rate leads to an increase in both the MAB rate and the test rate for both algorithms, holding the population size equal.
While our figures show that there are individuals misclassified as boundary, an additional computation that involves no additional testing can be used to correctly classify these individuals. Nonetheless, we display them in these figures to help illustrate what the searching algorithms are doing.
When there are non-cooperative people in the population, our use of supercells means that the radius of the predicted external boundary tends to be large compared to the true external boundary. As mentioned above, in this case, the MAB individuals incorrectly include non-infected people who are inside of the predicted external boundary but outside of the true boundary. Indeed, in such a situation, we would incorrectly demand that these individuals quarantine as well.
In
Figure 3, the predicted external boundary using the full search has more people than both the true external boundary and the predicted one obtained using geometric search. Taking a closer look at the plot on the lower left in
Figure 3, we see that the full search explores many cells inside the external boundary, which increases both the MAB rate and the test rate. The geometric search reduces the cost by prioritizing the testing of individuals further from the center, who are more likely to be part of the true external boundary. Zooming into the lower right of
Figure 3, we see that among all external boundary cells that have uninfected neighbors inside the true boundary, most of them take only one step inward. A consequence of this is that geometric search almost always prioritizes the correct paths.
In
Figure 4, the difference in test rate between the geometric and full search algorithms is significantly reduced. Recall that in the presence of non-cooperation, both searching algorithms tend to push the predicted external boundary outward and falsely incorporate more non-infected people inside of the predicted external boundary. However, the collapsing of cells into super-cells also reduces the complexity of the graphical structures. Therefore, the full search algorithm no longer has that many inner branches to search, and therefore its test rate is not as different from that of geometric search relative to the fully cooperative setting.
In the settings of
Figure 3 and
Figure 4, the MIP rates for both algorithms are 0. In other words, all infected individuals are contained in the predicted external boundary and there is no way for undetected infected individuals to spread the disease to the population outside of the predicted external boundary, as long as appropriate social distancing rules are implemented. This is what we had hoped for.
A comparison between
Figure 5,
Figure 7,
Figure 9,
Figure 11 and
Figure 6,
Figure 8,
Figure 10,
Figure 12 shows that as the population becomes denser, each individual is connected with more direct neighbors and therefore has a larger chance of spreading the disease. Thus, the radius of the pandemic tends to be larger. Asymptotically, the numbers of tests and MAB rates are proportional to the length of the external boundary, which is proportional to the radius, whereas the total number of people inside the external boundary is proportional to the square of radius. Therefore, as the radius becomes larger, the MAB rates and test rates tend to be smaller.
The variance in the results (as represented by the 5–95 percentile regions) also decreases as the population size grows and with cooperation. In particular, the decrease is drastic at .
All points on the median curves are below 1 when the population size is 1,000,000 or when the infection probability is larger than 0.075. Hence, if the pandemic does not die out very quickly and the population is dense, both the full search and the geometric search algorithms are better than full contact tracing and testing.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}