1. Introduction
Searching is one of the most basic, frequent and important operations performed in tasks involving computation. A common challenge involves searching to decide whether or not a given real value (termed a key) is present in a given multi-dimensional array of real values. When the search must be performed sequentially and repeatedly by comparing the key with selected entries of the array, obviously it should be carried out as efficiently as possible by minimising the number of comparisons. This classic problem can be viewed as determining the correct dimensional threshold function from a finite class of such functions within the array, based on sequential queries that take the form of point samples. The complexity of such a search is completely dependent on how the array is organised.
Clearly, when there is no information available about array organisation, every entry must be examined. An array is termed monotone nondecreasing (nonincreasing) if its entries never decrease (increase) when moving away from the origin along any path parallel to an axis. Without loss of generality, from now on in the present article, the focus is on only monotone nondecreasing arrays. When the array is already sorted so that its entries are monotone nondecreasing, the search for a key can be conducted in a far more efficient manner compared to the unsorted case.
The problem addressed here is to search for a given real-valued key in a monotone nondecreasing multi-dimensional real array, that has sizes that are not necessarily equal. The challenge is to identify among all possible suitable search algorithms, one with the lowest complexity, i.e., requiring the minimum number of comparisons in the worst case. The main question being addressed until the end of
Section 7 of the present article is to ask if the key is present in the array. Thus, if an instance of the key is found, there is no necessity to identify further possible instances of the key and the search procedure is terminated. The search for all possible occurrences of the key is briefly discussed in
Section 8.
This important search problem occurs in many computation-related fields, including computational biology, image processing, VLSI design, operations research and statistics [
1,
2,
3,
4]. The main contributions of this survey are:
an introduction to the problem of searching a (strictly) monotone real array;
a discussion of known results and the description of worst-case algorithms;
conclusions that can be drawn from the discussions and descriptions and
proposals for future work on the open problems that have been identified.
Currently, asymptotic notation to express the complexity of algorithms is commonly used. However, many of the algorithms described here were formally described and analysed at a time when this notation was not so common. The work of Linial and Saks [
5], for example, although using asymptotic notation, proposed exact lower and upper bounds on the number of comparisons necessary to determine the occurrence, or not, of a given element in an ordered array. Since then, many other authors have followed the same practice. Thus, for consistency with many of these works and due to the importance of these bounds in understanding the efficiency of the various algorithms listed here, the analyses of many of them are presented as originally developed by the respective authors. However, sometimes, asymptotic notation is used as a complementary tool for describing the complexity of algorithms.
The remainder of this paper is organised as follows. Preliminary notation, terminology and basic concepts are provided in the next section. What has been reported in the open literature on searching arrays to establish if a given key is present is reported in
Section 3,
Section 4,
Section 5 and
Section 6. The search of vectors (
) is the object of
Section 3. Seven different algorithms for this case were identified in the literature, from basic linear search algorithms of non-ordered vectors to binary search of ordered matrices. The other algorithms are Jump Search (Block Search), Interpolation Search, Exponential Search, Fibonacci Search and Ternary Search and its generalisation (
k-nary Search). The search of matrices (when
) is explored in
Section 4. Three algorithms are described: Saddleback Search for the case of balanced matrices and Shen’s and Bird’s algorithms for unbalanced matrices. Two algorithms for searching cuboids (
), one for the balanced case (the L&S algorithm) and one for the unbalanced case (an extension of Shen’s and Bird’s methods), are described in
Section 5.
Section 6 contains a description of a search algorithm for hypercubes when
(denoted as Cheng-4).
Section 7 discusses in some detail aspects of the worst case performance of some of the revised algorithms.
Many of the algorithms mentioned above call a binary search algorithm as a subroutine. This algorithm, as well its history, asymptotic complexity and some of its variants, are discussed in detail in
Section 3 and
Section 7.1. While the main focus of this survey is on the problem of verifying the occurrence or not of a key in monotone arrays, the challenge of searching for all occurrences of the key is also briefly discussed in
Section 8. The paper ends with a summary, some concluding remarks and suggestions for future work on problems that remain open, which are presented in
Section 9.
2. Preliminaries
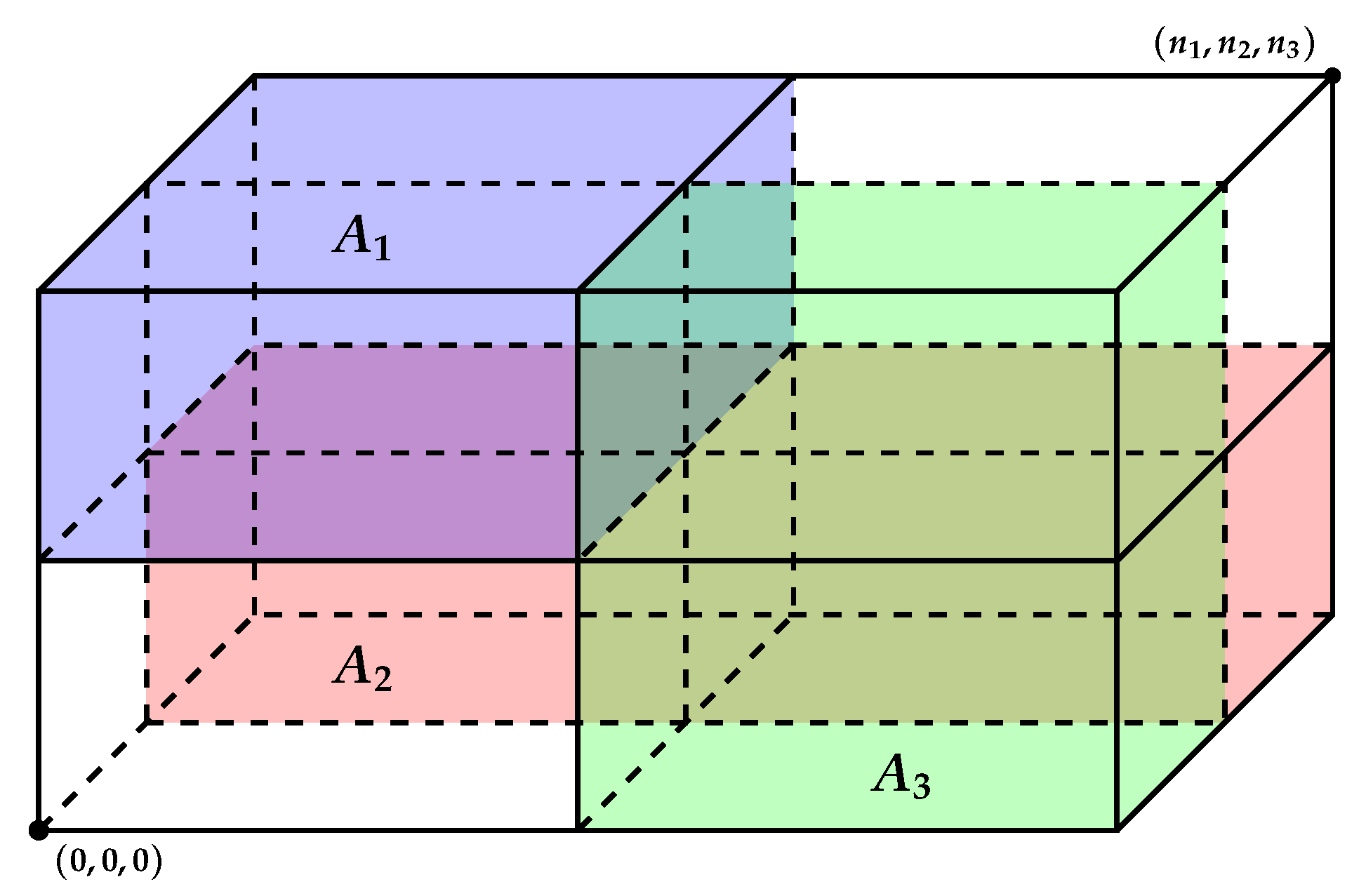
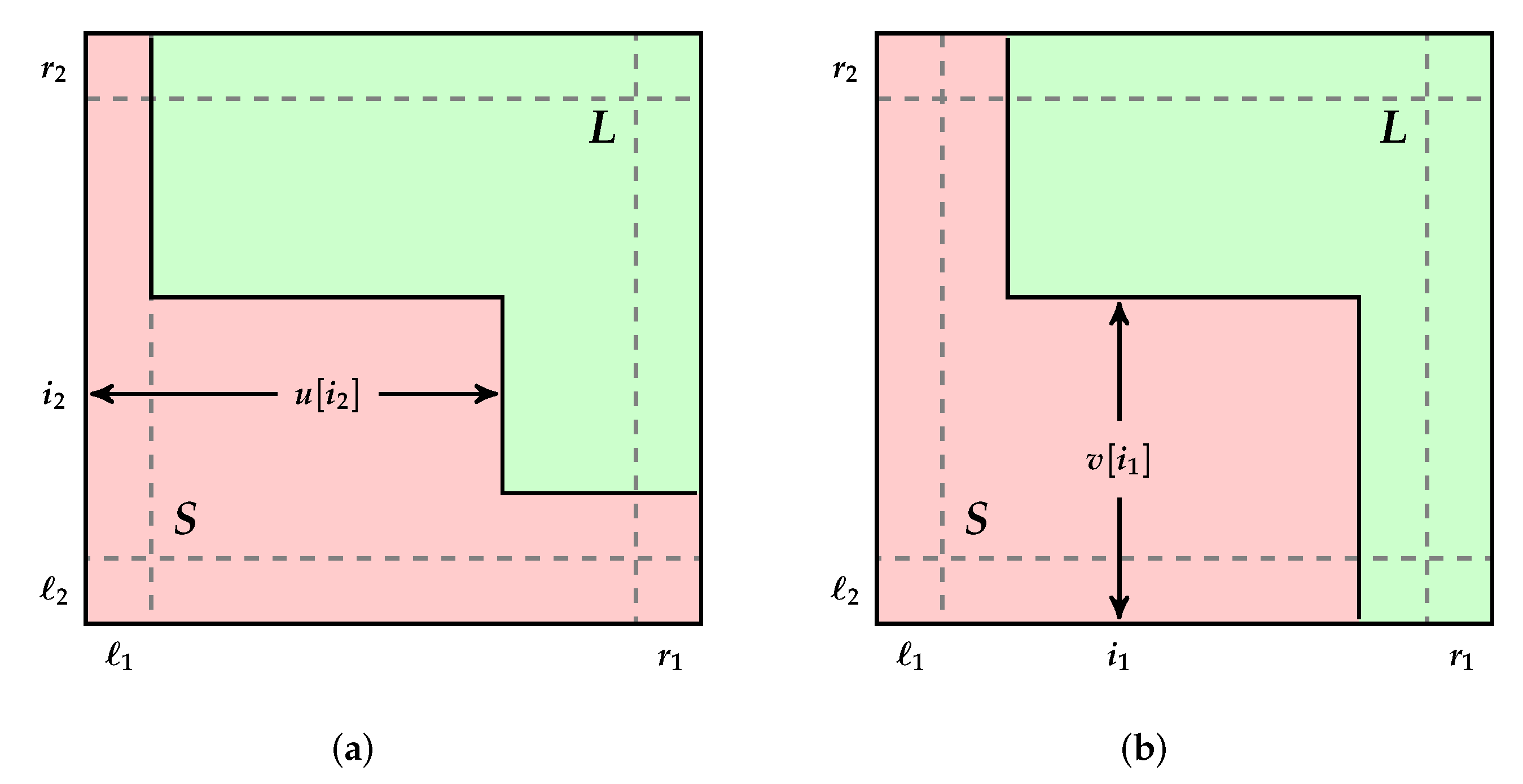
Consider a real d-dimensional array , that is monotone nondecreasing in the sense that if , for given, independent, sizes , (i.e., the entries of A are nondecreasing along its dimensions). A can be thought of as equivalent to the product of the chains of the partially ordered sets , .
A d-dimensional array A can be also defined by the indexes of its lower corner and upper corner as . Similarly, a d-dimensional subarray of A is defined as , where , for all .
The problem discussed here involves searching A in order to establish whether or not a given key is a member of A. It is assumed that the search must be carried out by sequentially comparing x with selected entries . The purpose of such comparisons is to eliminate elements of A and search the remaining subarrays in an efficient manner. It is of interest to identify search algorithms that require the minimum number of comparisons in the worst case.
When comparing
x and any entry
, one of the three following results must be obtained:
in which case the entries
for
, can be discarded; or
in which case
x has been located and the search is terminated; or
in which case the entries
for
, can be discarded. It is clear that it is necessary to make two comparisons between
x and any entry
to cover the three possibilities (
1)–(
3).
Any entry that is discarded by the comparison process as (
1) and (
3) above (as it cannot possibly be
x) is termed redundant. If, in carrying out the comparison process, an entry
of
A, causes
A to be divided into at least two nondegenerate subarrays, then this entry is termed a pivot.
An array
A is said to be
-balanced if
,
, for a given
,
. The use of the constant
is justified in the arguments given towards the end of
Section 4.2. A 1-balanced array is termed balanced, where
say, and is a hypercube. If
,
,
A is termed unbalanced. If the sizes of
A are strictly unequal,
A is a rectangular hypercuboid. From now on, all cuboids and hypercuboids to be searched will be assumed to be rectangular and the term rectangular will be dropped.
Suppose
A is a
d-dimensional array with sizes
. Let
be the the minimum number of comparisons (taken over all possible search algorithms) needed either to establish whether or not a given key
x is in
A. We denote
by.
When calculating the asymptotic time complexity of an algorithm, in general, the constant term in can be neglected. However, if an exact count of the number of comparisons is required, the constant term should be included. This has been done when establishing the time complexity of many of the algorithms described in this survey.
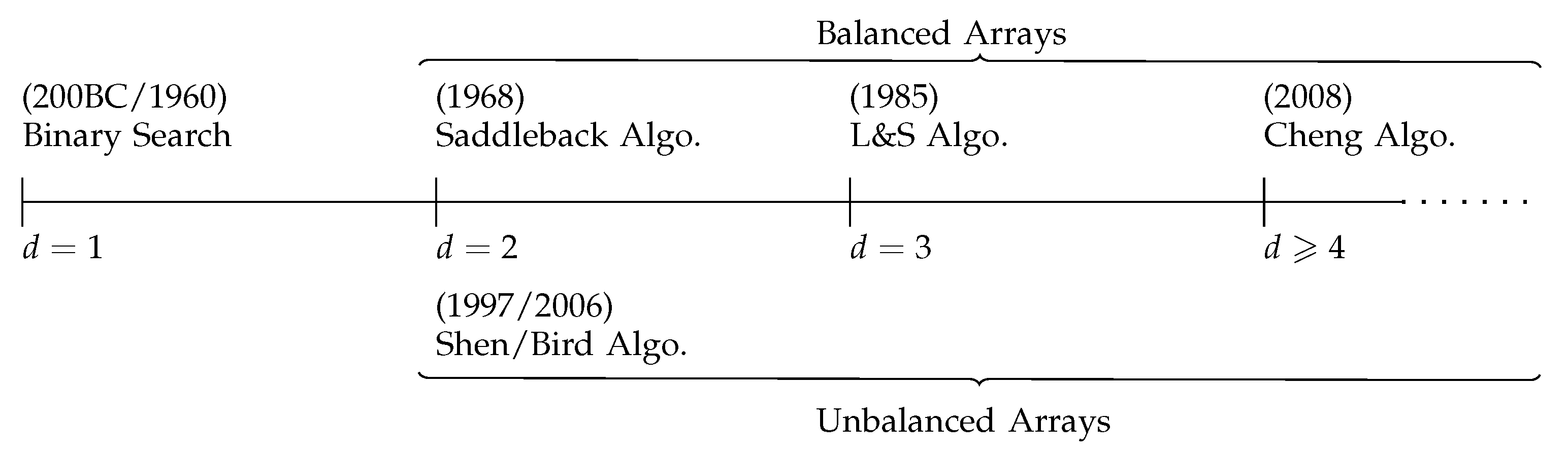
Search efficiency depends upon whether or not
A is balanced. A summary of the evolution of the best known search algorithms for the various types of arrays is given in
Figure 1.
For 1-dimensional arrays the Binary Search algorithm is worst-case optimal (see
Section 3). For balanced 2-dimensional arrays, the Saddleback Search algorithm [
1,
3,
6] is worst-case optimal, and
is
. For unbalanced 2-dimensional arrays there are asymptotically worst case optimal algorithms, and
is
[
7,
8] (see
Section 4).
For the general case of balanced
d-dimensional arrays with
, Linial and Saks [
5] demonstrated that
is
as they proved that
where
is a monotone nonincreasing function that is upper bounded by 2 and
.
Linial and Saks [
5] also demonstrated that for the general case of (possibly unbalanced) arrays, with
,
is bounded as follows:
where
and
are functions, with
monotone nonincreasing and
, and
. The proofs of the upper bounds on
in the right-hand side of (
5) and (
6) were established inductively by the authors by partitioning
A into
n isomorphic copies of its (
)-dimensional subarrays, each consisting of all entries that have identical
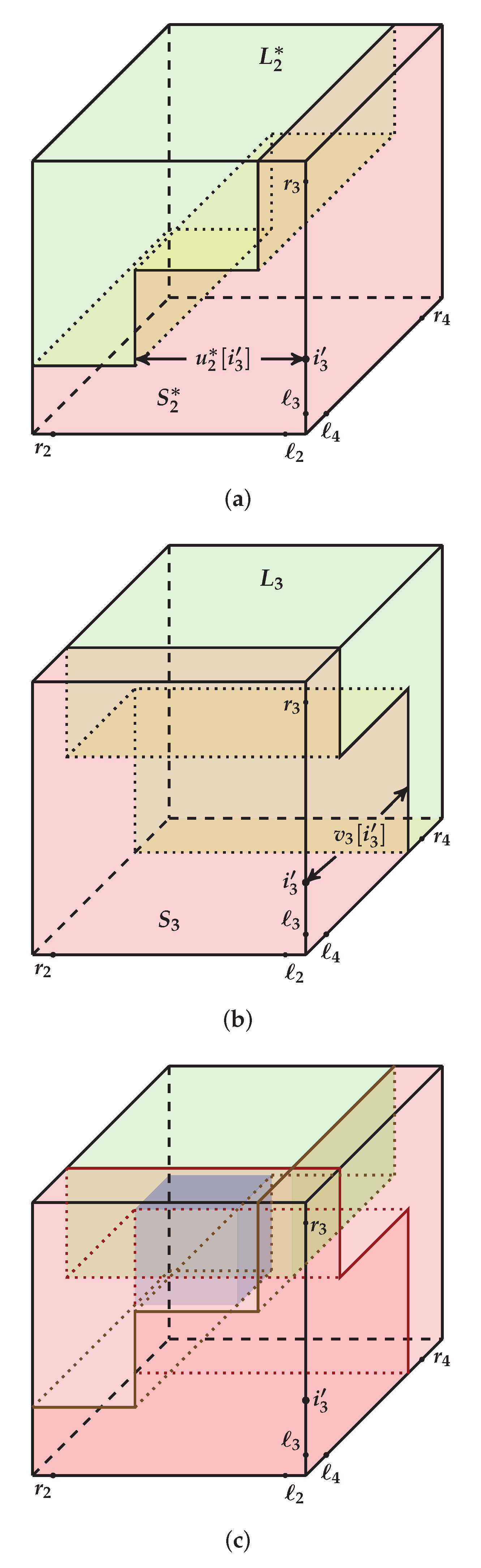
coordinates. The Linial and Saks algorithm [
5] for balanced 3-dimensional arrays will be discussed in
Section 5.
Cheng et al. [
9] proposed an algorithm for
d-dimensional hypercubes, for
(see
Section 6). Their algorithm has worst case performance upper bounded as follows:
3. The Search of Vectors
When
and
say,
A is a monotone vector (a totally ordered set). Many of the monotone vector search methods mentioned below are based on comparisons of keys and have been described in detail by Knuth [
10].
The Linear (or Sequential) Search algorithm (see the pseudocode in Algorithm 1) is a basic method for finding a key within
A, whether
A is ordered or not. The algorithm starts at the leftmost element of
A and iteratively compares the key
x with each element of
A. The search stops when either
x matches an element of
A or when all the elements have been tested. Its running time and number of comparisons are, in the worst case, linear in
n.
| Algorithm 1 LINEAR SEARCH |
| Input: Array and key .
|
| Output: True if or False otherwise.
|
| 1. ;
|
| 2. while do |
| 3. if () then |
|
4. return true.
|
|
5. else |
|
6. |
|
7. end if |
|
8. end while |
|
9. return false. |
The Jump Search algorithm [
11], also known as Block Search [
12], check fewer elements of an ordered array
than the Linear Search, by jumping ahead blocks of a fixed number
m of elements. It verifies the elements of
A in the indexes
. Once is determined that
, a linear search is done in the interval
to check if any of these elements is equal the key
x. Its pseudocode is shown in Algorithm 2.
| Algorithm 2 JUMP SEARCH |
| Input: Array and key .
|
| Output: True if or False otherwise.
|
| 1. ;
|
| 2.
;
|
| 3.
while anddo |
| 4.
|
| 5.
|
| 6.
if () then |
| 7.
|
| 8.
end if |
| 9.
end while |
| 10.
while do |
| 11.
|
| 12.
if () then |
|
13. return true. |
|
14. end if |
|
15. end while |
|
16. return false. |
Shneiderman [
11] shown that the optimal value of the jump size is
. Therefore, if the cost of a jump is
, and the cost of a sequential search is
, then the optimum jump size is
and the search cost is
. Shneiderman also describes some variations of this algorithm, as the multi-level jumping or the variable jump size.
Jump Search traverses the array back only once, that can be an advantage in situations where jumping back is costly. Note that Binary Search (the next described algorithm), in the worst case, may require up to back jumps!
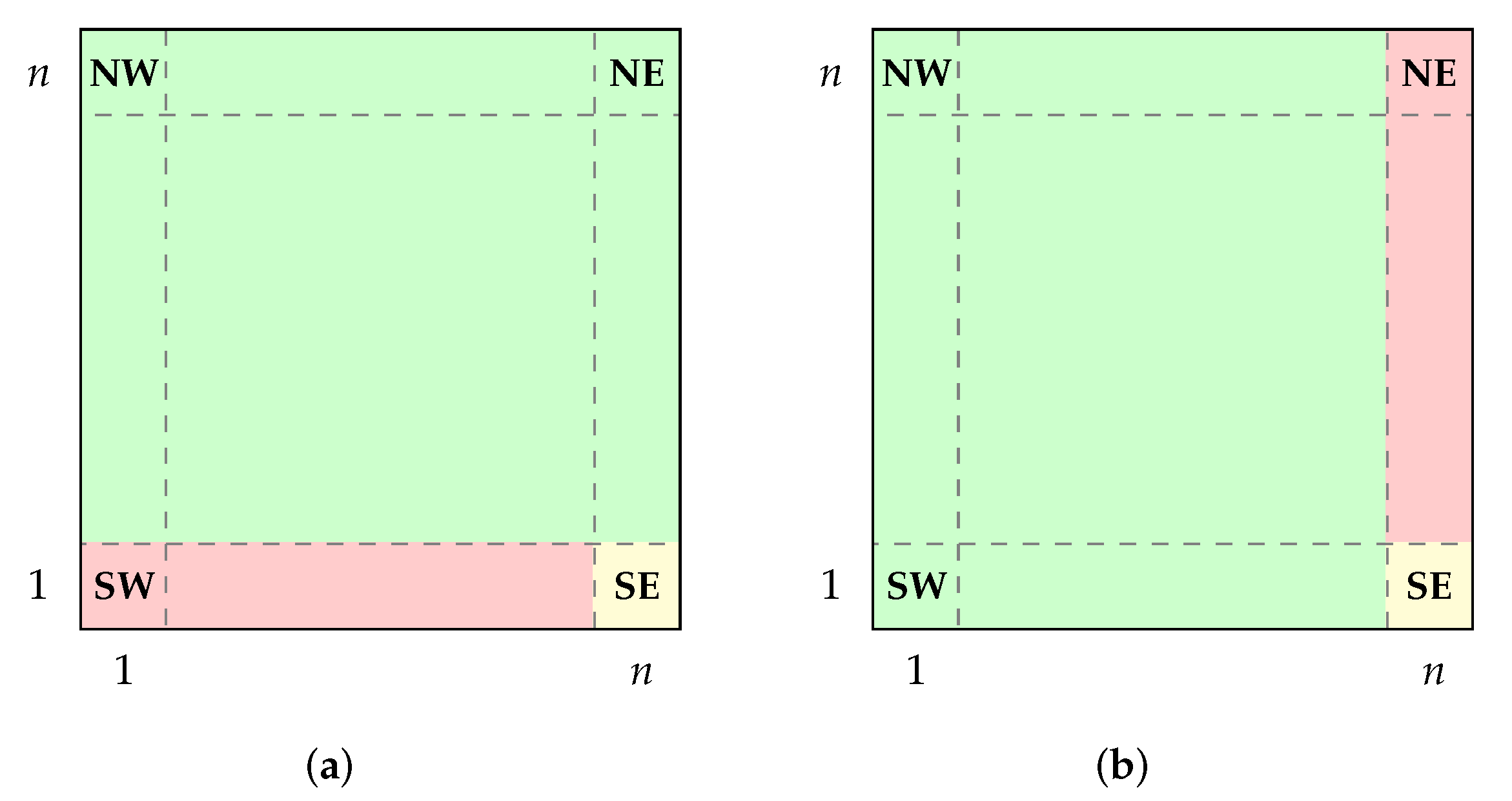
The Binary Search algorithm begins with the vector
A as the initial search interval, and repeatedly divides the current search interval into two parts that are either of the same length or differ in length by one unit. If the key
x is lower than the entry in the “middle” position of the interval (this situation is depicted in
Figure 2, where
p is the “middle” position), the search space is narrowed to its lower half (positions 1 to
). If the key
x is greater than the mentioned entry, the interval it is narrowed to the upper half (positions
to
n). The pseudocode of binary search is given in Algorithm 3. It is straightforward to show that the asymptotic complexity of this version of the algorithm is
However, it is not strictly necessary to compare the key
x with the element at position
p at each iteration of the search loop. An alternative approach, also commonly used, just checks to see if
. If this is not so,
p is returned and the procedure is terminated. Otherwise,
p is retained in the search space, which will eventually shrink to
p when
. However, after exiting the loop, i.e., after the search space is completely exhausted, it is necessary to compare the final element in the space with
x. The asymptotic implications of assuming that each iteration requires only one comparison are explored in
Section 7.1.
| Algorithm 3 BINARY SEARCH |
| Input: Array and key .
|
| Output: True if or False otherwise.
|
| 1.
;
|
| 2.
;
|
| 3.
while do |
| 4.
;
|
| 5.
if () then |
| 6.
return true; |
| 7.
else if
() then |
| 8.
|
| 9.
else |
| 10.
|
| 11. end if |
| 12. end while |
| 13. return false. |
The discovery of binary search, also known as logarithmic, divide-and-conquer or bisection search, is attributed by Knuth [
10] to Inakibit-Anu of Uruk in 200BC. Binary search was mentioned by Mauchly [
13] in what may have been the first published discussion of non-numerical programming methods, but one of the first formal descriptions of it was given by Steinhaus [
14]. Furthermore, Sandelius [
15] noted that binary search is also optimal in the average case, as cited by Reingold [
16].
This history of the evolution of the Binary Search algorithm and its related bibliography, as well as of some other search algorithms listed later here, are described in detail by Knuth [
10]. Dijkstra [
17] also produced an interesting review of the evolution of the binary search design, from an algorithmic point of view.
Some of these earlier versions of binary search considered only the case where the length of
A is a power of 2. At that time the method had become well known, but no one appeared to have reported what should be done to accommodate a general
[
15,
18,
19,
20]. It seems that Lehmer [
21] was the first to publish a Binary Search algorithm that worked for all
n. Lesuisse [
22] provides a detailed analysis of various published versions of the binary search algorithm.
In these versions of binary search the position of the central element was calculated and, in the case of fractional values, the position was set to the largest integer smaller than the calculated value. If the sequence contained duplicates of the key value, the first occurrence to the left of the calculated position was found. Bottenbruch [
23] presented a variation of the algorithm, that is nowadays most common. Setting the position to the smallest integer greater than or equal to the calculated fractional value, the Bottenbruch algorithm adjusts the left pointer, which initially references the first position of the search, to the next position of the central element whenever the key is greater than or equal to this element. Unlike earlier versions, Bottenbruch’s algorithm finds the rightmost occurrence of a given key when the sequential search identifies duplicate entries of the key. Iverson [
24] also proposed a version of binary search for every
, but without considering the possibility of an unsuccessful search. Knuth [
25] presented the same algorithm as an example of using an automated system for drawing flowcharts.
Ternary search [
26] (also known as dual-pivot binary search [
27]) is a divide and conquer algorithm similar to binary search. In this algorithm, the original array is initially divided into three parts of sizes as close as possible to each other. These segments are usually delimited by positions
and
(see the pseudocode in Algorithm 4). By testing the values at these two positions it is possible to discard
of the array and proceed with the same approach on the remaining
of the array. Since a larger portion of the array’s elements are discarded, it may appear that ternary search is faster than binary search. In fact, both algorithms have asymptotic time complexity of
. However, ternary search uses more comparisons than binary search, which adds greater constants to its asymptotic complexity. Similar arguments are also valid for any other similar higher order search algorithms that are generalised from binary search (i.e.
k-nary search,
).
Section 7.1 provides some detail on the complexity analysis of
k-nary search.
| Algorithm 4 TERNARY SEARCH |
| Input: Array and key .
|
| Output: True if or False otherwise.
|
| 1.
;
|
| 2.
;
|
| 3.
while do |
| 4.
;
|
| 5.
;
|
| 6.
if () then |
| 7.
return true. |
| 8.
else if
() then |
| 9.
return true. |
| 10.
else if
() then |
| 11.
|
| 12.
else if
() then |
| 13.
|
| 14.
else |
| 15.
|
| 16.
|
| 17.
end if |
| 18. end while |
| 19. return false. |
The Interpolation Search algorithm, due to Peterson [
28], performs similarly to binary search but unlike it, which always checks the intermediate element of the search space, the interpolation search can check different elements according to the value of the key and the statistical distribution of the elements in the array
A. For example, it is likely that the interpolation search will start at an element either near the index
n (when the key is closer to
), or near the index 1 (when the key is closer to
.) The pseudocode is shown in Algorithm 5. When the values in the array
A are uniformly distributed, the interpolation search has a performance superior of that of binary search. Perl et al. [
29] showed that this algorithm requires on the average
array accesses to check if a key is present in the array, assuming that the
n array entries are uniformly distributed.
| Algorithm 5 INTERPOLATION SEARCH |
| Input: Array and key .
|
| Output: True if or False otherwise.
|
| 1. ;
|
| 2.
;
|
| 3. while do |
| 4. ;
|
| 5. if () then |
| 6.
return true. |
| 7. else if
() then |
| 8.
|
| 9.
else |
| 10.
|
| 11.
end if |
| 12.
end while |
| 13.
if () and () then |
| 14.
return true |
| 15.
else |
| 16.
return false. |
| 17.
end if |
The Exponential Search algorithm is attributed to Bentley and Yao [
30]. This search algorithm involves a preliminary step of finding a small range of elements of the array
A (potentially containing the key
x) and a secondary step of performing a binary search in this limited range of elements. The first step starts with a subarray of size 1, compares its unique element with the key
x, then, if necessary, compares a subarray of size 2, then of 4, and so on, until the last element, index
i say, of the current subarray is not greater than the key
x. At the end of this step, the key can only be present between the indexes
and
i. Therefore, a binary search is carried out in this range. The pseudocode of this algorithm is shown in Algorithm 6. Exponential Search is particularly useful for unbounded arrays, that is, where the size of the array to be searched is infinite. This search also works better than binary search for bounded arrays when the key
x is closer to the first element of the array.
| Algorithm 6 EXPONENTIAL SEARCH |
| Input: Array and key .
|
| Output: True if or False otherwise.
|
| 1. ;
|
| 2. if () then |
| 3.
return true. |
| 4.
end if |
| 5.
while and do |
| 6.
;
|
| 7.
end while |
| 8. return BINARY SEARCH.
|
Fibonacci Search (Ferguson [
31]) splits the array
A into two subarrays with sizes that are consecutive Fibonacci numbers, which are defined as:
This search first finds the smallest Fibonacci number, the
one say, greater than or equal to
n, then uses the
Fibonacci number as the index of the array element to be compared with the key (if it is a valid index). While there are still elements to be inspected, the limits of the subarray that must be searched are calculated based on the three consecutive Fibonacci numbers currently used. The pseudocode shown in Algorithm 7, uses the
Fibonacci number just defined and a variable offset to help to discard the unnecessary positions of the array
A.
| Algorithm 7 FIBONACCI SEARCH |
| Input: Array and key .
|
| Output: True if or False otherwise.
|
| 1.
;
|
| 2.
;
|
| 3.
;
|
| 4.
;
|
| 5.
while do |
| 6.
;
|
| 7.
if () then |
| 8.
;
|
| 9.
;
|
| 10.
;
|
| 11.
;
|
| 12.
else if
() then |
| 13.
;
|
| 14.
;
|
| 15.
;
|
| 16.
else |
| 17.
return true. |
| 18.
end if |
| 19.
end while |
| 20.
if and () then |
| 21.
return true;
|
| 22.
else |
| 23.
return false. |
| 24.
end if |














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
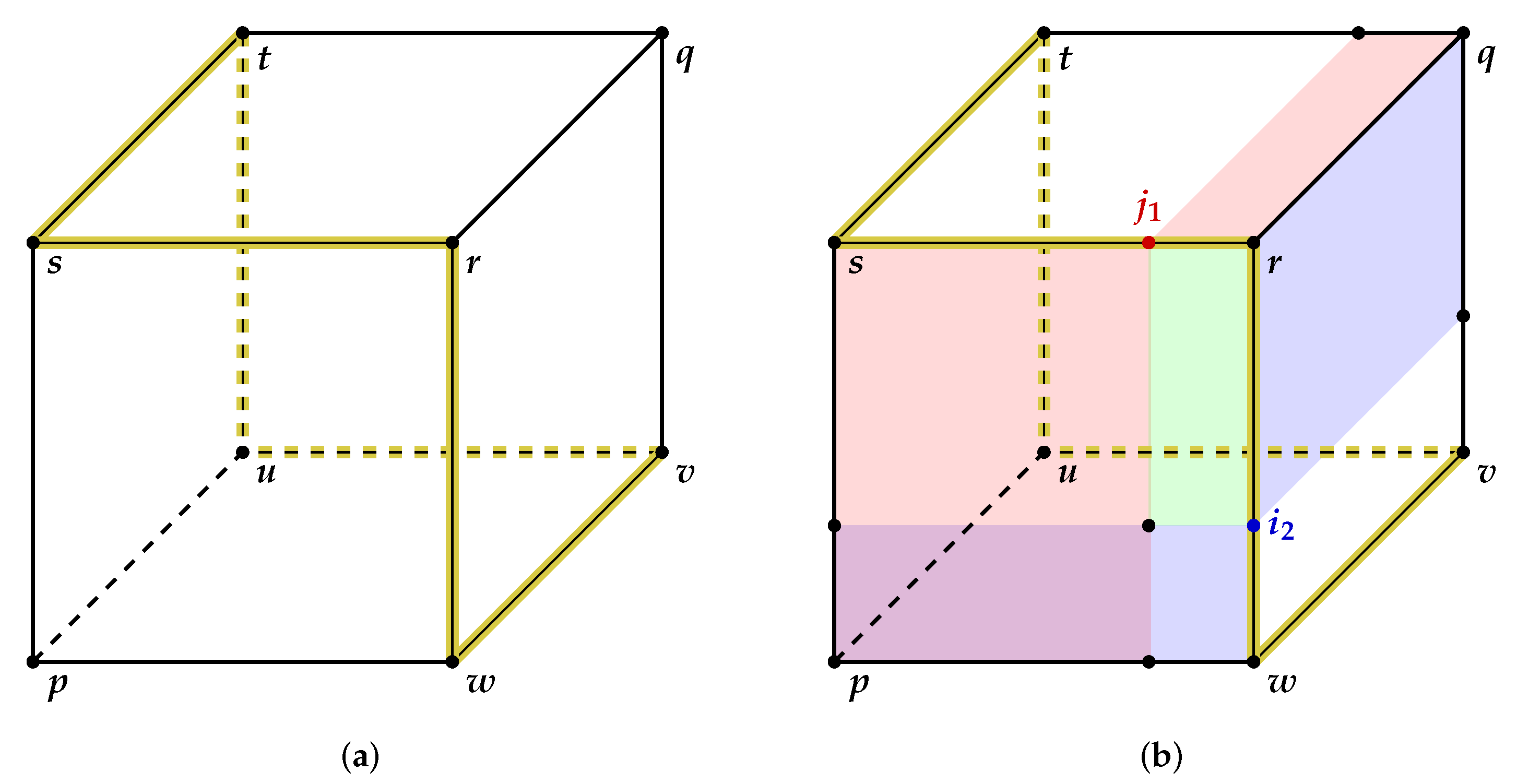{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}