



Corner Centrality of Nodes in Multilayer Networks: A Case Study in the Network Analysis of Keywords

Abstract
:1. Introduction
1.1. Main Contribution
1.2. Structure of the Paper
- Section 2 describes the mathematical model used to obtain the new centrality measure called the “corner centrality” of nodes in a multilayer network. To help readers understand the model, we have illustrated it with a toy example.
- In Section 3, we applied the model to different multilayer networks. For this, we selected three experiments to test the utility of the corner centrality measure.
- Section 4 presents the main conclusions of the paper and new research lines.
2. Mathematical Model for the Corner Centrality of Nodes in a Multilayer Network
- 1.
- The multilayer network can contain layers with the same set of nodes. In this case, the layers do not have interlinks between them.
- 2.
- The multilayer network can contain layers with different nodes. In this case, the layers can be connected using interlinks between them.
- 3.
- The multilayer network can contain interlinks and intralinks between layers.
| Algorithm 1: corner centrality. Let = {L1,L2,···, LM}, a multilayer network with M layers. Let L∗ be the target layer from . |
|
1: for every node u in L∗, do 2: for every layer L in G, do 3: if u is in L, then 4: obtain IL(u) by using Equation (1) ▷ by using intralinks within L 5: else, if u is not in L, then 6: obtain IL(u) by using Equation (2) ▷ by using interlinks between L∗ and L layers. 7: end if 8: end for 9: end for 10: for every layer L in G, do 11: Normalize IL 12: end for 13: for every node u in L∗, do 14: obtain the matrix M(u) by using Equation (9). ▷with only two layers by using Equation (10) 15: obtain the score of the node SL∗(u) ▷by using Equation (12) 16: end for 17: Obtain the rank of every node in L∗ by sorting SL∗ |
- 1.
- If the number of nodes n in every layer is bigger than the number of layers , the computational time is . Usually, and .
- 2.
- If the number of nodes n in every layer is lower than the number of layers , the computational time is .
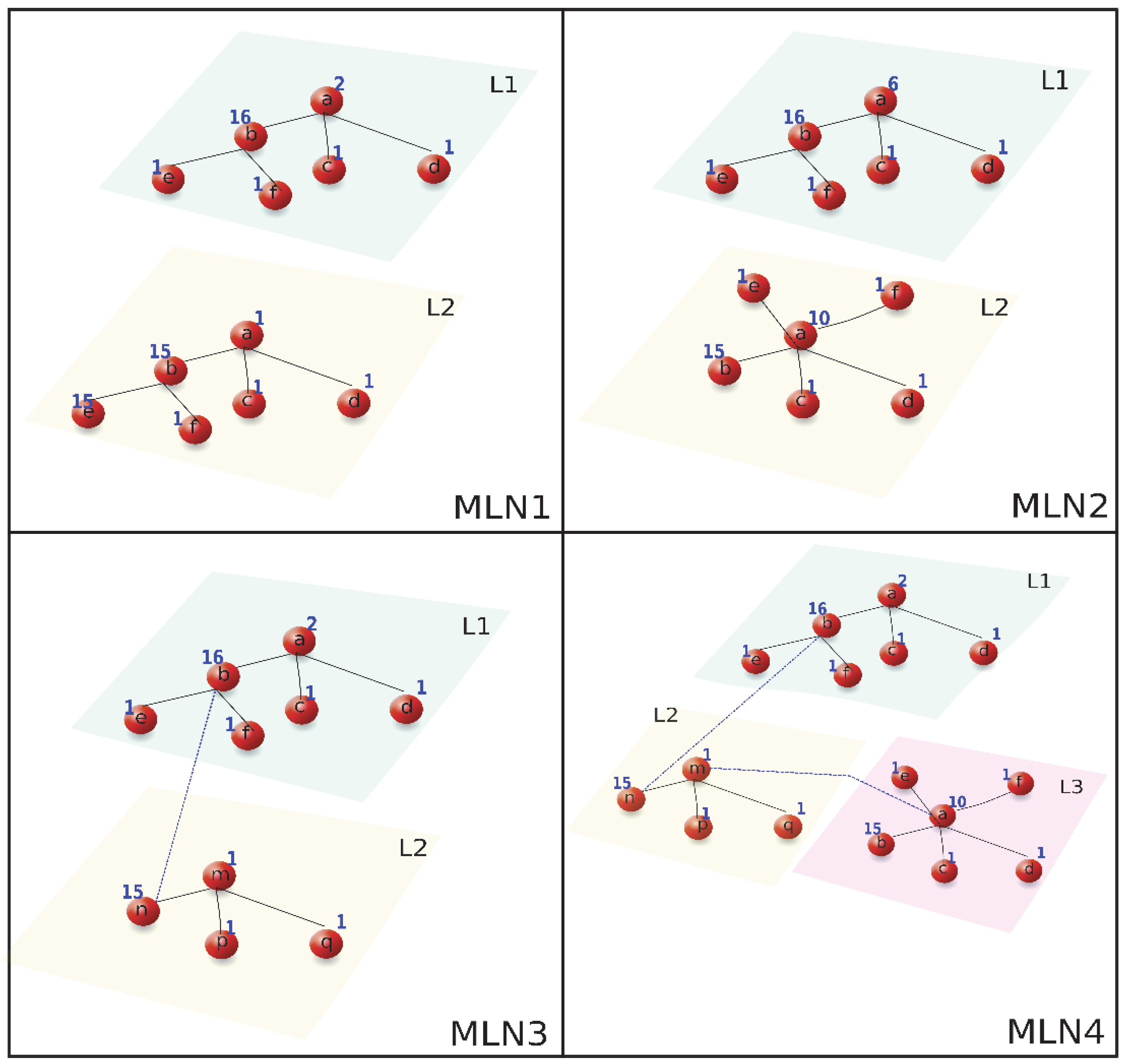
A Toy Example
3. Experimentation
3.1. Experiment 1: Biplex Networks
3.1.1. Football Team
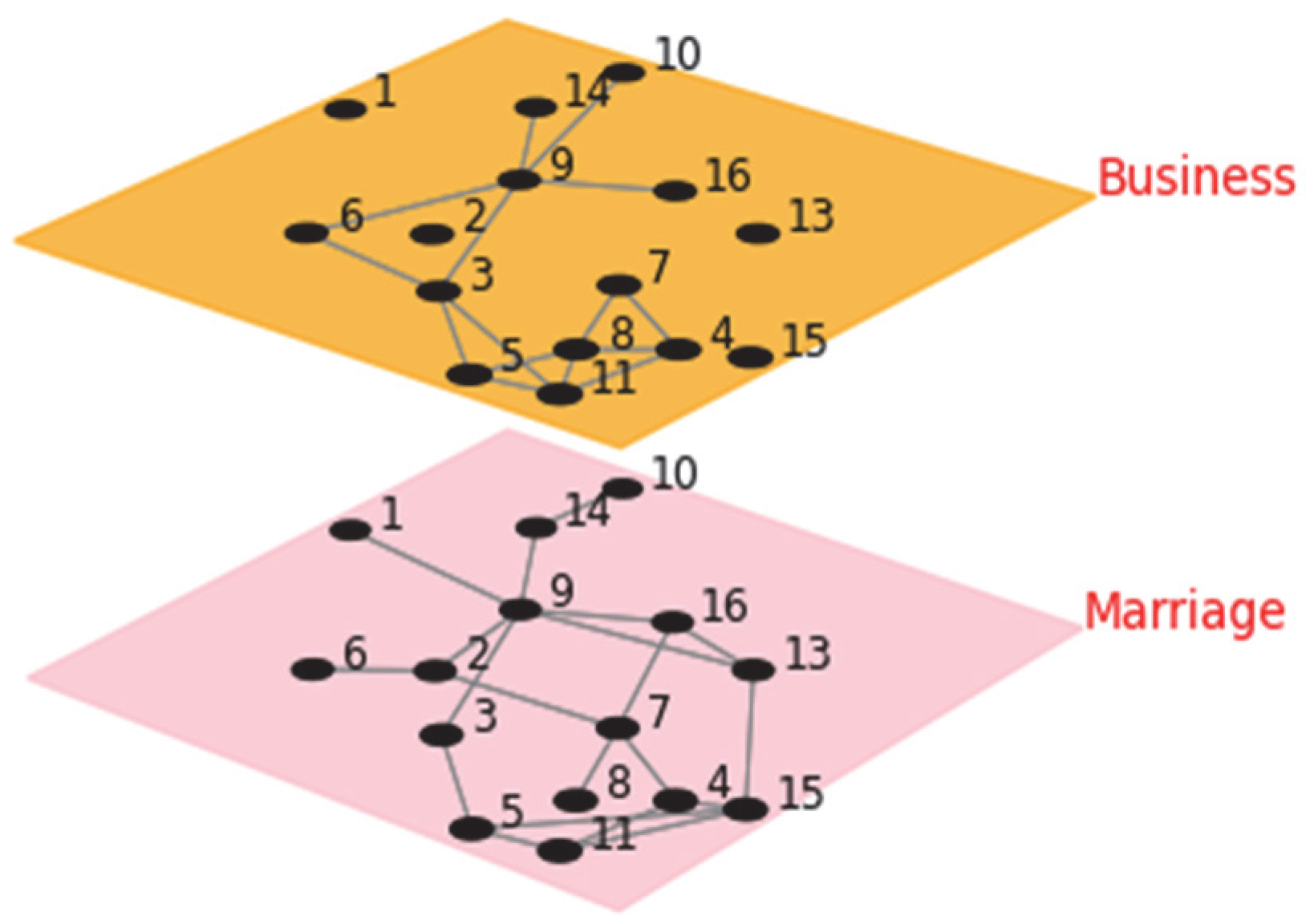
3.1.2. Florentine Families
3.2. Experiment 2: Scopus vs. Google Trend
3.3. Experiment 3: Author Keywords vs. KeyWords plus Keywords
Validation
4. Conclusions
5. Source Code
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Computational Time
| Algorithm A1: Corner centrality. Let = {L1,L2,··· ,LM} a multilayer network with M layers. Let L∗ be the target layer from . |
| 1: for every node u in L∗, do 2: for every layer L in G, do 3: if u is in L, then 4: obtain IL(u) by using Equation (1) ▷ by using intralinks within L 5: else, if u is not in L, then 6: obtain IL(u) by using Equation (2) ▷by using interlinks between L∗ and L layers. 7: end if 8: end for 9: end for 10: for every layer L in G, do 11: Normalize IL 12: end for 13: for every node u in L∗, do 14: obtain the matrix M(u) by using Equation (9). ▷with only two layers by using Equation (10) 15: obtain the score of the node SL∗(u) ▷by using Equation (12) 16: end for 17: Obtain the rank of every node in L∗ by sorting SL∗ |
- In steps 1–8, the computational time is calculated by:where is the number of nodes in the layer , and is the number of layers. We have assumed that each layer has the same number of nodes n. Within the second summation, we have , which is the time consumed by the search for the neighbors of a node in the jth layer:
- In steps 10–12, the computational time is .
- In steps 13–16, the computational time is . is the time to create the matrix in step 14. is the computational time to apply the determinant for a matrix [31]. Additionally, M is the computational time to obtain the trace for a matrix .
- Additionally, in step 17, the computational time is .
Memory Requirements
References
- Newman, M. Networks: An Introduction; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Applegate, D.L.; Bixby, R.M.; Chvátal, V.; Cook, W.J. The Traveling Salesman Problem; Princeton University Press: Princeton, NJ, USA, 2006; ISBN 978-0-691-12993-8. [Google Scholar]
- Gabow, H.N.; Galil, Z.; Spencer, T.; Tarjan, R.E. Efficient algorithms for finding minimum spanning trees in undirected and directed graphs. Combinatorica 1986, 6, 109. [Google Scholar] [CrossRef]
- Cellai, D.; Bianconi, G. Multiplex networks with heterogeneous activities of the nodes. Phys. Rev. E 2016, 93, 32302. [Google Scholar] [CrossRef] [PubMed]
- de Domenico, M.; Solé-Ribalta, A.; Cozzo, E.; Kivelä, M.; Moreno, Y.; Porter, M.; Gómez, S.; Arenas, A. Mathematical Formulation of Multilayer Networks. Phys. Rev. X 2013, 3, 041022. [Google Scholar] [CrossRef]
- Bazzi, M.; Lucas, G.; Jeub, S.; Arenas, A.; Howison, S.D.; Porter, M.A. A framework for the construction of generative models for mesoscale structure in multilayer networks. Phys. Rev. Res. 2020. [Google Scholar] [CrossRef]
- Moreno, Y.; Perc, M. Focus on multilayer networks. New J. Phys. 2019, 22, 10201. [Google Scholar] [CrossRef]
- Gosak, M.; Markovič, R.; Dolenšek, J.; Rupnik, M.S.; Marhl, M.; Stožer, A.; Perc, M. Network science of biological systems at different scales: A review. Phys. Life Rev. 2018, 24, 118–135. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Pu, C.; Li, L.; Cao, G. Traffic dynamics on multilayer networks. Digit. Commun. Netw. 2020, 6, 58–63. [Google Scholar] [CrossRef]
- Pi, B.; Zeng, Z.; Feng, M.; Kurths, J. Evolutionary multigame with conformists and profiteers based on dynamic complex networks. Chaos Interdiscip. J. Nonlinear Sci. 2022, 32, 023117. [Google Scholar] [CrossRef]
- Stella, L.; Martínez, A.P.; Bauso, D.; Colaneri, P. The role of asymptomatic infections in the COVID-19 epidemic via complex networks and stability analysis. SIAM J. Control Optim. 2022, 60, S119–S144. [Google Scholar] [CrossRef]
- Agryzkov, T.; Oliver, J.L.; Tortosa, L.; Vicent, J.F. An algorithm for ranking the nodes of an urban network based on the concept of PageRank vector. Appl. Math. Comput. 2012, 219, 2186–2193. [Google Scholar] [CrossRef]
- Agryzkov, T.; Curado, M.; Pedroche, F.; Tortosa, L.; Vicent, J.F. Extending the Adapted PageRank Algorithm Centrality to Multiplex Networks with Data Using the PageRank Two-Layer Approach. Symmetry 2019, 11, 284. [Google Scholar] [CrossRef]
- McGee, F.; Ghoniem, M.; Melançon, G.; Otjacques, B.; Pinaud, B. The State of the Art in Multilayer Network Visualization. Comput. Graph. Forum 2019, 38, 125–149. [Google Scholar] [CrossRef]
- Lv, Y.; Huang, S.; Zhang, T.; Gao, B. Application of Multilayer Network Models in Bioinformatics. Front. Genet. 2021, 12, 664860. [Google Scholar] [CrossRef] [PubMed]
- Kinsley, A.C.; Rossi, G.; Silk, M.J.; VanderWaal, K. Multilayer and Multiplex Networks: An Introduction to Their Use in Veterinary Epidemiology. Front. Vet. Sci. 2020, 7, 596. [Google Scholar] [CrossRef] [PubMed]
- Sola, L.; Romance, M.; Criado, R.; Flores, J.; Garcia del Amo, A.; Boccaletti, S. Eigenvector centrality of nodes in multiplex networks. Chaos 2013, 23, 33131. [Google Scholar] [CrossRef] [PubMed]
- Iacovacci, J.; Rahmede, C.; Arenas, A.; Bianconi, G. Functional Multiplex PageRank. Eur. Lett. 2016, 116, 28004. [Google Scholar] [CrossRef]
- Sharifi, S.S.; Barati, H. A method for routing and data aggregating in cluster-based wireless sensor networks. Int. J. Commun. Syst. 2021, 34, e4754. [Google Scholar] [CrossRef]
- Oliveira, E.M.; Ramos, H.S.; Loureiro, A.A. Centrality-based routing for wireless sensor networks. In Proceedings of the 3rd IFIP Wireless Days Conference 2010, Venice, Italy, 20–22 October 2010; pp. 1–5. [Google Scholar]
- Kenyeres, M.; Kenyeres, J. Comparative Study of Distributed Consensus Gossip Algorithms for Network Size Estimation in Multi-Agent Systems. Future Internet 2021, 13, 134. [Google Scholar] [CrossRef]
- Halu, A.; Mondragon, R.; Panzarasa, P.; Bianconi, G. Multiplex PageRank. PLoS ONE 2013, 8, e78293. [Google Scholar] [CrossRef]
- Solé-Ribalta, A.; De Domenico, M.; Gómez, S.; Arenas, A. Centrality Rankings in Multiplex Networks. In Proceedings of the 2014 ACM Conference on Web Science, Bloomington, IN, USA, 23–26 June 2014; ACM: New York, NY, USA, 2014; pp. 149–155. [Google Scholar]
- Bianconi, G. Multilayer Networks. Structure and Functions; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the 4th Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 147–151. [Google Scholar]
- de Domenico, M.; Solé-Ribalta, A.; Omodei, E.; Gómez, S.; Arenas, A. Ranking in interconnected multilayer networks reveals versatile nodes. Nat. Commun. 2015, 6, 6868. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brin, S.; Page, L. The Anatomy of a Large-Scale Hypertextual Web Search Engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Padgett, J.F.; Ansell, C.K. Robust Action and the Rise of the Medici, 1400–1434. Am. J. Sociol. 1993, 98, 1259–1319. [Google Scholar] [CrossRef]
- Lu, W.; Liu, Z.; Huang, Y.; Bu, Y.; Li, X.; Cheng, Q. How do authors select keywords? A preliminary study of author keyword selection behavior. J. Informetr. 2020, 14, 101066. [Google Scholar] [CrossRef]
- Garfield, E.; Sher, I.H. KeyWords Plus. Algorithmic Derivative Indexing. J. Am. Soc. Inf. Sci. 1993, 44, 298–299. [Google Scholar] [CrossRef]
- Aho, A.V.; Hopcroft, J.E.; Ullman, J.D. The Design and Analysis of Computer Algorithms, Theorem 6.6; Addison-Wesley: Boston, MA, USA, 1974; p. 241. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Relative Importance for Every Node | |||
|---|---|---|---|
| Node | |||
| a | −12 | 0 | 31 |
| b | 44 | 1 | 5 |
| c | −1 | 0 | −9 |
| d | −1 | 0 | −9 |
| e | −15 | 0 | −9 |
| f | −15 | 0 | −9 |
| Normalized Relative Importance for Every Node | |||
|---|---|---|---|
| Node | |||
| a | −0.584 | −0.447 | 2.098 |
| b | 2.142 | 2.236 | 0.338 |
| c | −0.049 | −0.447 | −0.609 |
| d | −0.049 | −0.447 | −0.609 |
| e | −0.730 | −0.447 | −0.609 |
| Node | Social Network Links | Messages | Game Links | Games |
|---|---|---|---|---|
| 1 | 2, 5, 7, 9, 16, 17, 19, 20 | 15 | 2, 4, 5, 6, 9, 12, 13, 14, 18, 19 | 33 |
| 2 | 1, 5, 7, 9, 20 | 9 | 1, 4, 8, 10, 13, 18, 19 | 26 |
| 3 | 7, 9, 11, 13, 14, 15, 17 | 12 | 4, 5, 6, 12, 14, 15, 17, 20 | 18 |
| 4 | 5, 9, 11, 14, 15, 16, 18, 20 | 19 | 1, 2, 3, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 16, 17, 18, 20 | 32 |
| 5 | 1, 2, 4, 6, 7, 11, 12, 14, 18, 20 | 28 | 1, 3, 4, 6, 7, 8, 11, 14, 17, 19, 20 | 20 |
| 6 | 5, 7, 10, 20 | 7 | 1, 3, 4, 5, 8, 11, 12, 19 | 12 |
| 7 | 1, 2, 3, 5, 6, 8, 9, 18, 20 | 20 | 4, 5, 10, 11, 12, 13, 15, 16, 17, 18, 19, 20 | 32 |
| 8 | 7, 10, 12, 17, 18 | 7 | 2, 4, 5, 6, 9, 12, 13, 14, 18, 19 | 6 |
| 9 | 1, 2, 3, 4, 7, 10, 15, 18, 20 | 16 | 1, 4, 8, 10, 13, 16, 18, 19 | 18 |
| 10 | 6, 8, 9, 11, 13, 14, 15, 16, 18, 20 | 21 | 2, 4, 7, 9, 13, 15, 18, 19, 20 | 25 |
| 11 | 3, 4, 5, 10, 13, 18, 19, 20 | 14 | 4, 5, 6, 7, 12, 14, 15, 17, 20 | 24 |
| 12 | 5, 8, 14, 17, 20 | 8 | 1, 3, 4, 6, 7, 8, 11, 14, 19, 20 | 18 |
| 13 | 3, 10, 11, 15, 19, 20 | 11 | 1, 2, 4, 7, 8, 9, 10, 16, 17, 19, 20 | 6 |
| 14 | 3, 4, 5, 10, 12, 16, 18, 19 | 13 | 1, 3, 4, 5, 8, 11, 12, 19 | 26 |
| 15 | 3, 4, 9, 10, 13, 17, 20 | 11 | 3, 7, 10, 11, 16, 17, 20 | 38 |
| 16 | 1, 4, 10, 14, 17, 18, 19 | 14 | 4, 7, 9, 13, 15, 18, 19, 20 | 6 |
| 17 | 1, 3, 8, 12, 15, 16, 20 | 12 | 3, 4, 5, 7, 11, 13, 15, 18, 19 | 12 |
| 18 | 4, 5, 7, 8, 9, 10, 11, 14, 16, 19, 20 | 35 | 1, 2, 4, 7, 8, 9, 10, 16, 17, 19, 20 | 30 |
| 19 | 1, 11, 13, 14, 16, 18, 20 | 15 | 1, 2, 5, 6, 7, 8, 9, 10, 12, 13, 14, 16, 17, 18, 20 | 8 |
| 20 | 1, 2, 4, 5, 6, 7, 9, 10, 11, 12, 13, 15, 17, 18, 19 | 27 | 3, 4, 5, 7, 10, 11, 12, 13, 15, 16, 18, 19 | 25 |
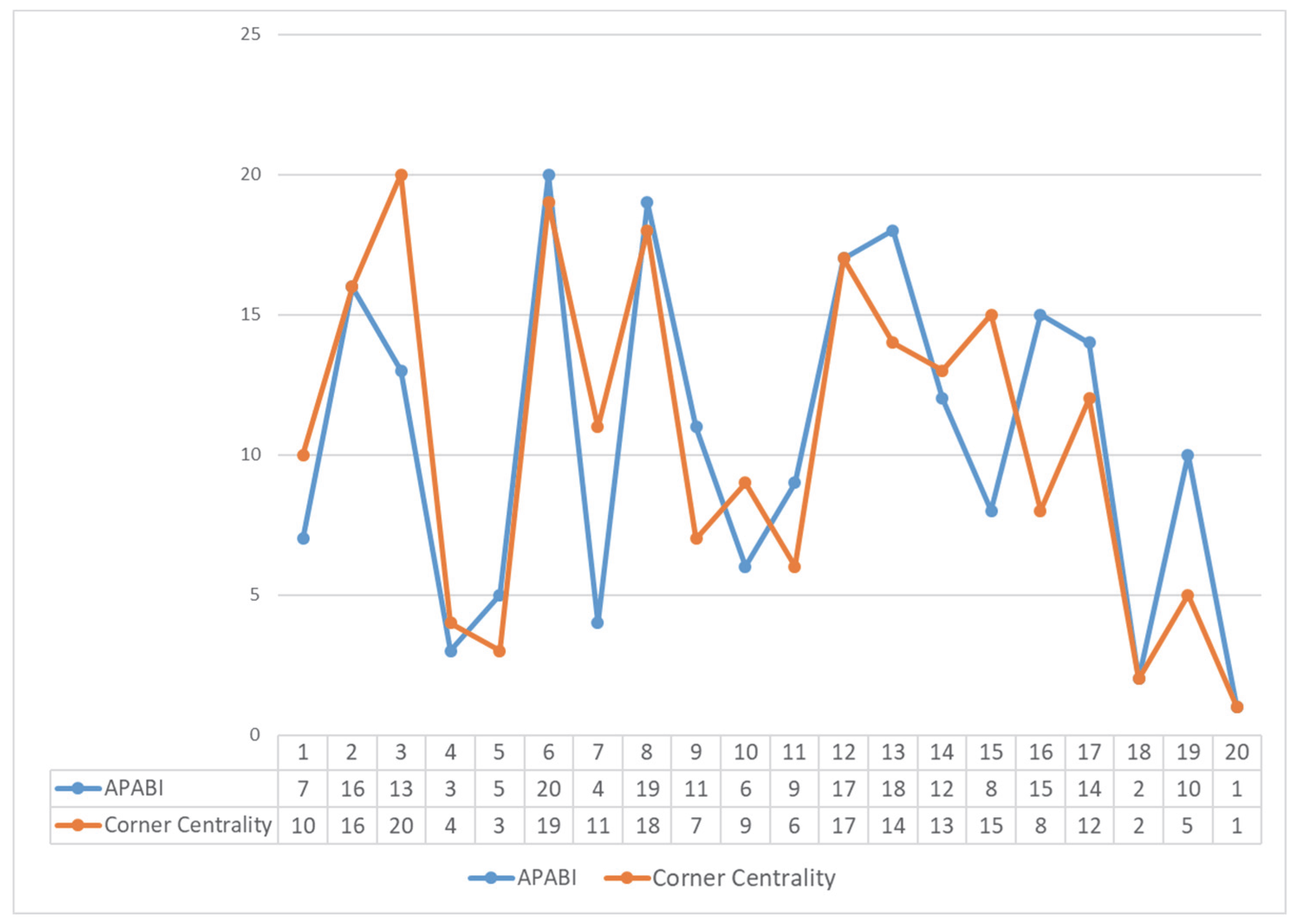
| APABI | Corner Centrality | |||
|---|---|---|---|---|
| Nodes | Value | Rank | Value | Rank |
| 1 | 0.05581 | 7 | 4.309008 | 10 |
| 2 | 0.03777 | 16 | 2.550988 | 16 |
| 3 | 0.04193 | 13 | 1.429319 | 20 |
| 4 | 0.06517 | 3 | 5.171486 | 4 |
| 5 | 0.06440 | 5 | 5.5569 | 3 |
| 6 | 0.02862 | 20 | 1.520039 | 19 |
| 7 | 0.06477 | 4 | 3.883725 | 11 |
| 8 | 0.03071 | 19 | 1.865937 | 18 |
| 9 | 0.04836 | 11 | 4.475997 | 7 |
| 10 | 0.05902 | 6 | 4.412212 | 9 |
| 11 | 0.05013 | 9 | 4.668175 | 6 |
| 12 | 0.03727 | 17 | 1.979066 | 17 |
| 13 | 0.03684 | 18 | 3.198247 | 14 |
| 14 | 0.04820 | 12 | 3.2216934 | 13 |
| 15 | 0.05085 | 8 | 3.068847 | 15 |
| 16 | 0.03781 | 15 | 4.450555 | 8 |
| 17 | 0.04033 | 14 | 3.3716 | 12 |
| 18 | 0.07590 | 2 | 6.405673 | 2 |
| 19 | 0.04838 | 10 | 4.726761 | 5 |
| 20 | 0.07775 | 1 | 8.063785 | 1 |
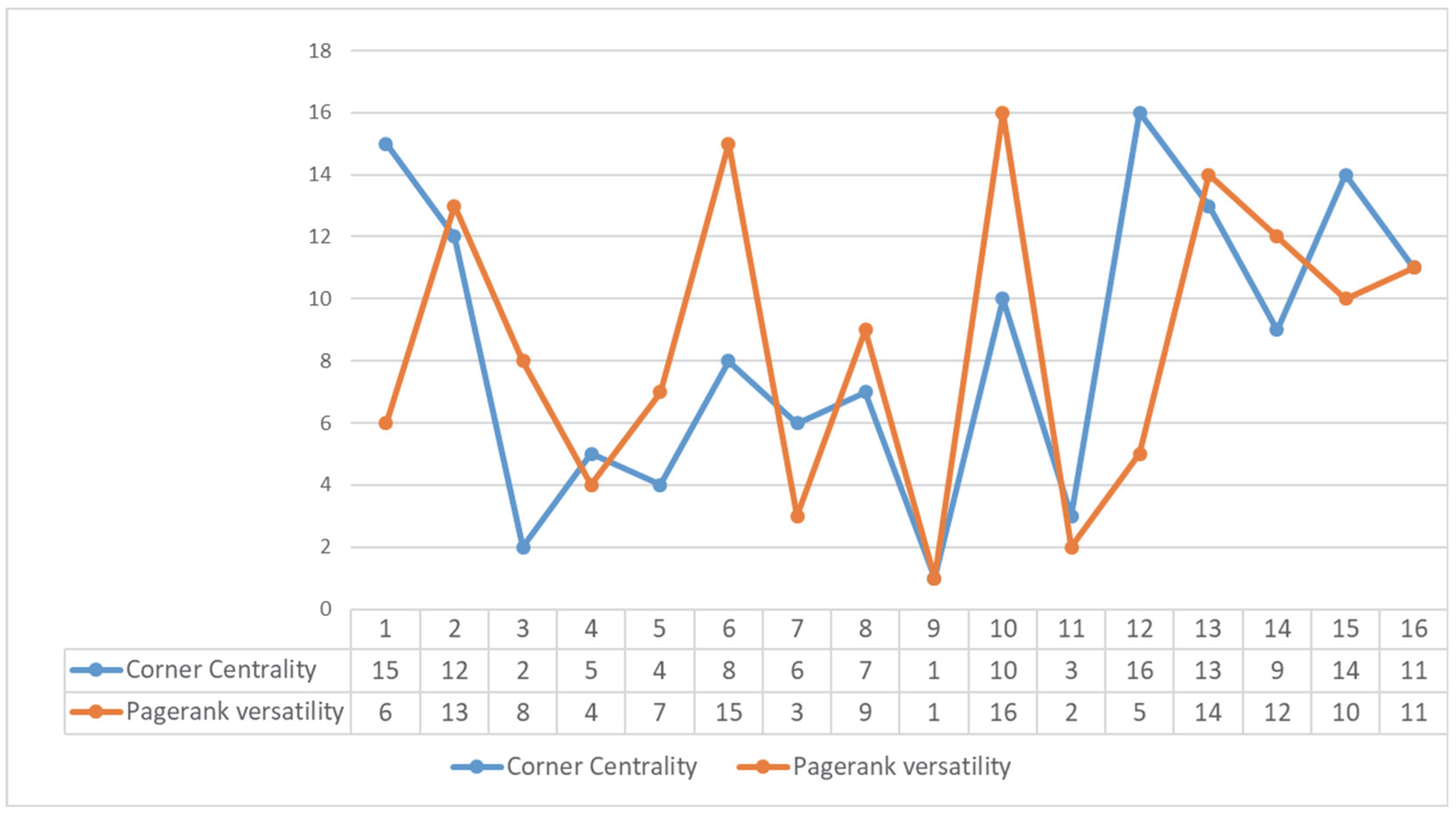
| Corner Centrality | PageRank Versatility | ||||
|---|---|---|---|---|---|
| Family Name | Node Id | Value | Rank | Value | Rank |
| Acciaiuol | 1 | 0 | 15 | 0.8638167 | 6 |
| Albizzi | 2 | 0 | 12 | 0.8389033 | 13 |
| Barbadori | 3 | 0.87675385 | 2 | 0.8567245 | 8 |
| Bischeri | 4 | 0.250263979 | 5 | 0.8732232 | 4 |
| Castellan | 5 | 0.268755428 | 4 | 0.8557555 | 7 |
| Ginori | 6 | 0.083220632 | 8 | 0.8347692 | 15 |
| Guadagni | 7 | 0.223183775 | 6 | 0.8823537 | 3 |
| Lambertes | 8 | 0.109123972 | 7 | 0.8561786 | 9 |
| Medici | 9 | 1.229130987 | 1 | 1 | 1 |
| Pazzi | 10 | 0.041761825 | 10 | 0.830739 | 16 |
| Peruzzi | 11 | 0.278145671 | 3 | 0.8975903 | 2 |
| Pucci | 12 | 0 | 16 | 0.8638167 | 5 |
| Ridolfi | 13 | 0 | 13 | 0.8370955 | 14 |
| Salviati | 14 | 0.071072416 | 9 | 0.8374698 | 12 |
| Strozzi | 15 | 0 | 14 | 0.8496274 | 10 |
| Tornabuon | 16 | 0.025402425 | 11 | 0.8430032 | 11 |
| Nodes | Spearman’s Correlation | Rank-Order | p-Value | |
|---|---|---|---|---|
| Mean | Std | Mean | Std | |
| 100 | 0.604 | 0.065 | 0.000 | 0.000 |
| 150 | 0.691 | 0.041 | 0.000 | 0.000 |
| 200 | 0.683 | 0.039 | 0.000 | 0.000 |
| 250 | 0.673 | 0.036 | 0.000 | 0.000 |
| 300 | 0.705 | 0.017 | 0.000 | 0.000 |
| 350 | 0.697 | 0.028 | 0.000 | 0.000 |
| 400 | 0.729 | 0.022 | 0.000 | 0.000 |
| 450 | 0.753 | 0.02 | 0.000 | 0.000 |
| 500 | 0.752 | 0.018 | 0.000 | 0.000 |
| 550 | 0.769 | 0.014 | 0.000 | 0.000 |
| 600 | 0.758 | 0.024 | 0.000 | 0.000 |
| 650 | 0.769 | 0.022 | 0.000 | 0.000 |
| 700 | 0.763 | 0.015 | 0.000 | 0.000 |
| 750 | 0.756 | 0.019 | 0.000 | 0.000 |
| 800 | 0.753 | 0.02 | 0.000 | 0.000 |
| 850 | 0.772 | 0.013 | 0.000 | 0.000 |
| 900 | 0.756 | 0.022 | 0.000 | 0.000 |
| 950 | 0.769 | 0.021 | 0.000 | 0.000 |
| 1000 | 0.765 | 0.025 | 0.000 | 0.000 |
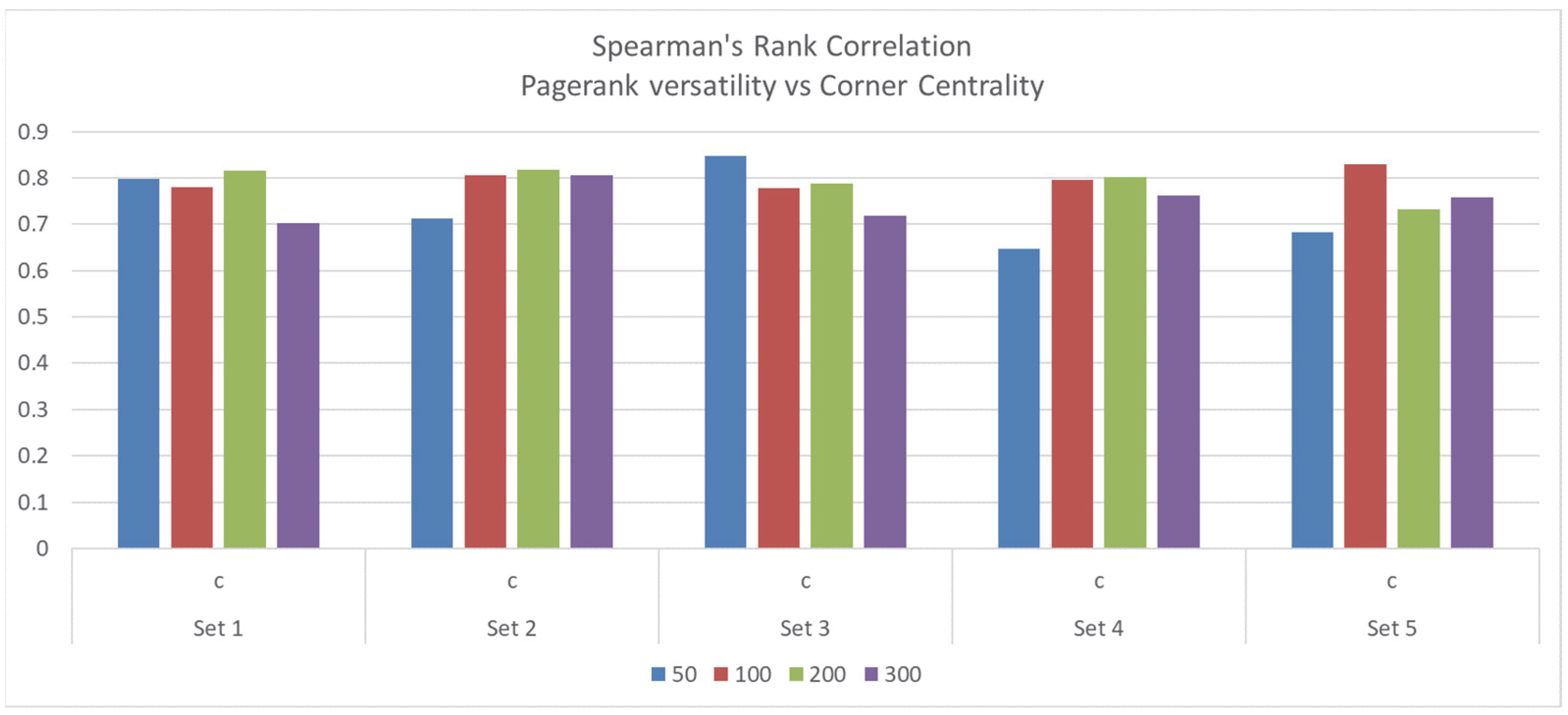
| Set 1 | Set 2 | Set 3 | Set 4 | Set 5 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| c | c | c | c | c | ||||||
| 50 | 0.7977 | 4 × 10−12 | 0.7130 | 6 × 10−9 | 0.8475 | 8 × 10−15 | 0.6463 | 3 × 10−7 | 0.6835 | 4 × 10−8 |
| 100 | 0.7798 | 1 × 10−21 | 0.8048 | 6 × 10−24 | 0.7784 | 1 × 10−21 | 0.7951 | 5 × 10−23 | 0.8295 | 1 × 10−26 |
| 200 | 0.815 | 6 × 10−49 | 0.8171 | 2 × 10−49 | 0.7878 | 1 × 10−43 | 0.8026 | 2 × 10−46 | 0.7327 | 6 × 10−26 |
| 300 | 0.7019 | 7 × 10−46 | 0.8066 | 4 × 10−70 | 0.7190 | 5 × 10−49 | 0.7627 | 2 × 10−58 | 0.7582 | 2 × 10−57 |
| 50 | 100 | 200 | 300 | |
|---|---|---|---|---|
| 0.7376 | 0.7975 | 0.7911 | 0.7497 | |
| 8 × 10−8 | 5 × 10−22 | 1 × 10−35 | 1 × 10−46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez-Sánchez, R.M.; Chamorro-Padial, J. Corner Centrality of Nodes in Multilayer Networks: A Case Study in the Network Analysis of Keywords. Algorithms 2022, 15, 336. https://doi.org/10.3390/a15100336
Rodriguez-Sánchez RM, Chamorro-Padial J. Corner Centrality of Nodes in Multilayer Networks: A Case Study in the Network Analysis of Keywords. Algorithms. 2022; 15(10):336. https://doi.org/10.3390/a15100336
Chicago/Turabian StyleRodriguez-Sánchez, Rosa María, and Jorge Chamorro-Padial. 2022. "Corner Centrality of Nodes in Multilayer Networks: A Case Study in the Network Analysis of Keywords" Algorithms 15, no. 10: 336. https://doi.org/10.3390/a15100336
APA StyleRodriguez-Sánchez, R. M., & Chamorro-Padial, J. (2022). Corner Centrality of Nodes in Multilayer Networks: A Case Study in the Network Analysis of Keywords. Algorithms, 15(10), 336. https://doi.org/10.3390/a15100336