5.4.2. Algorithm Description
INPUT:
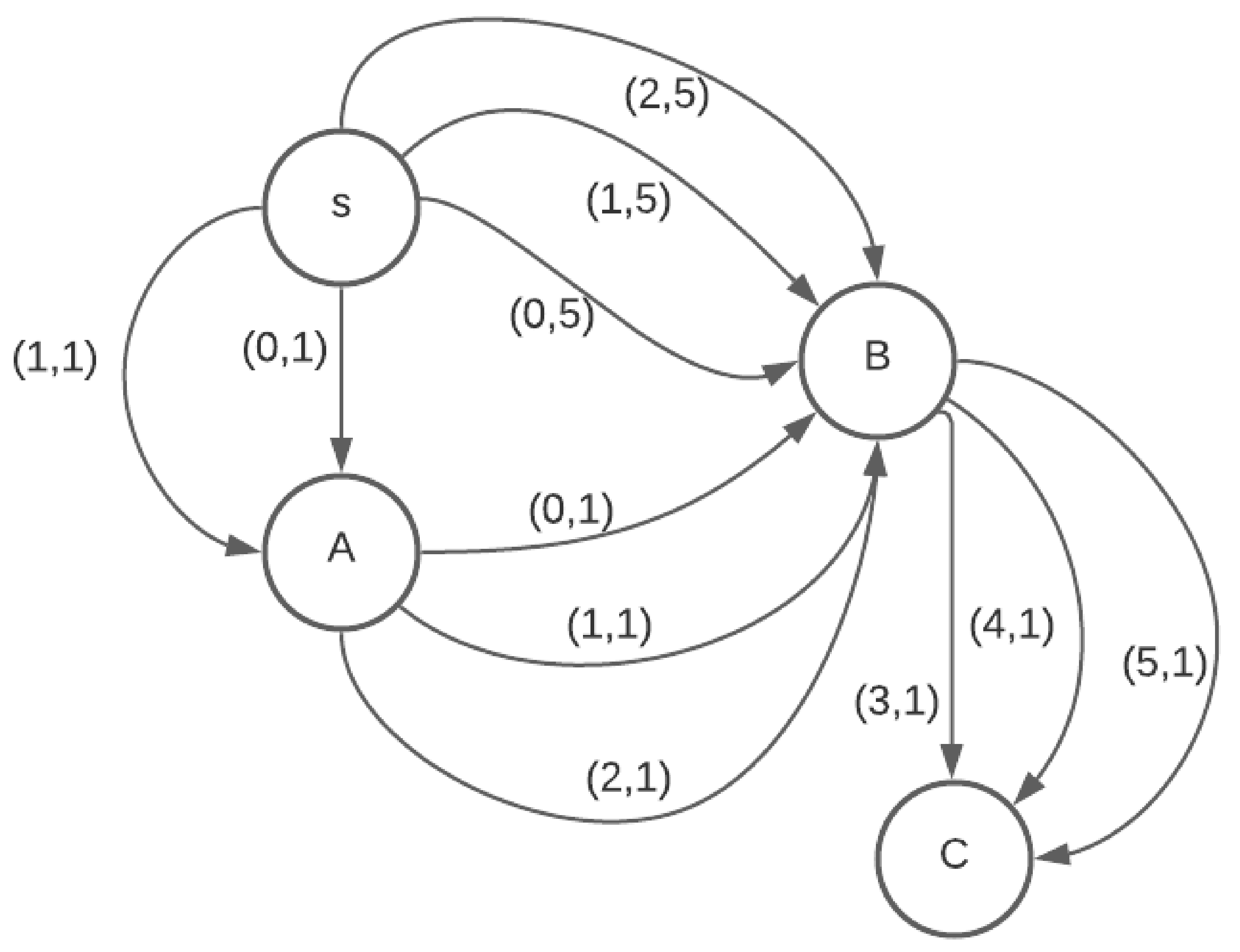
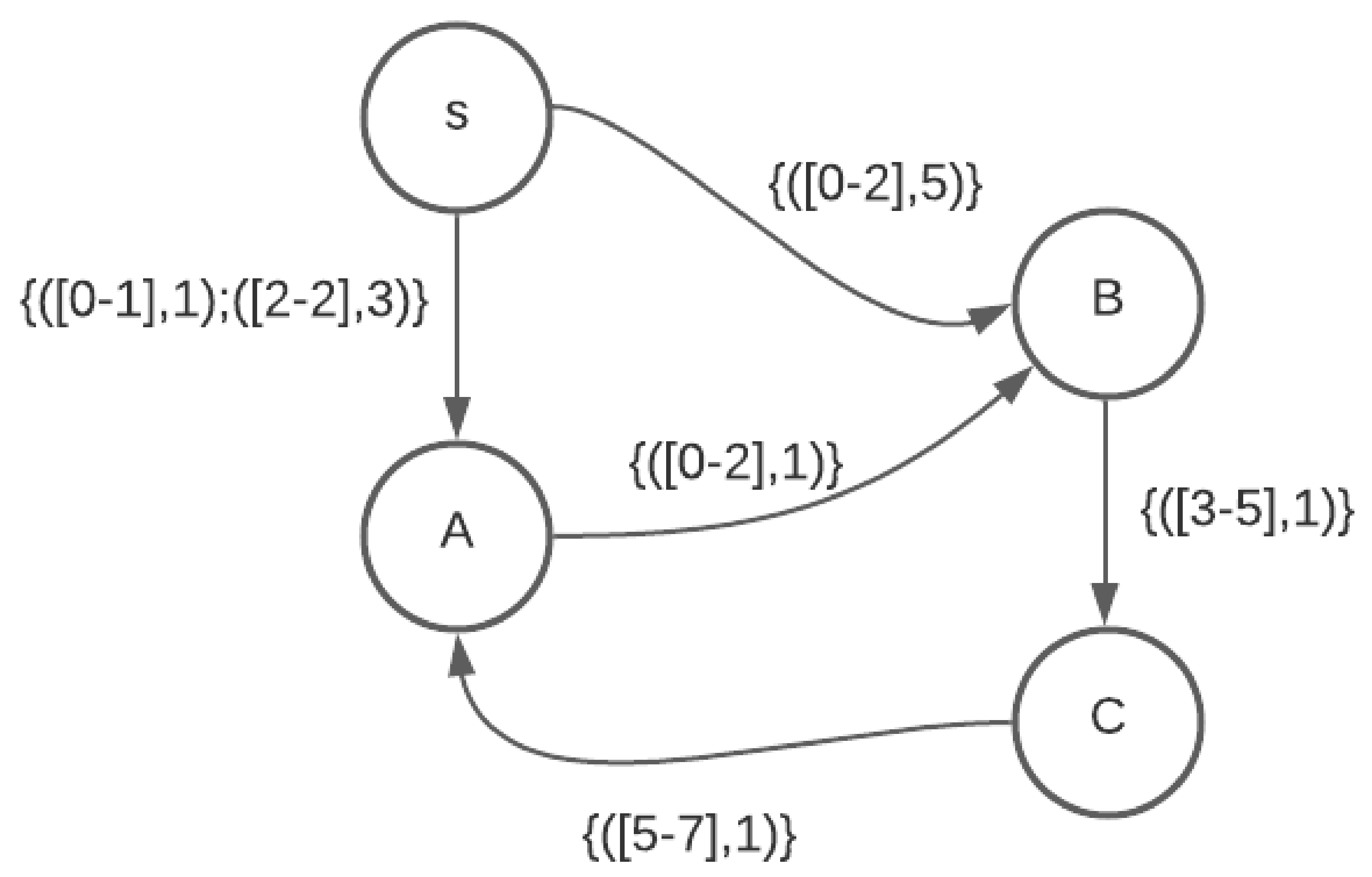
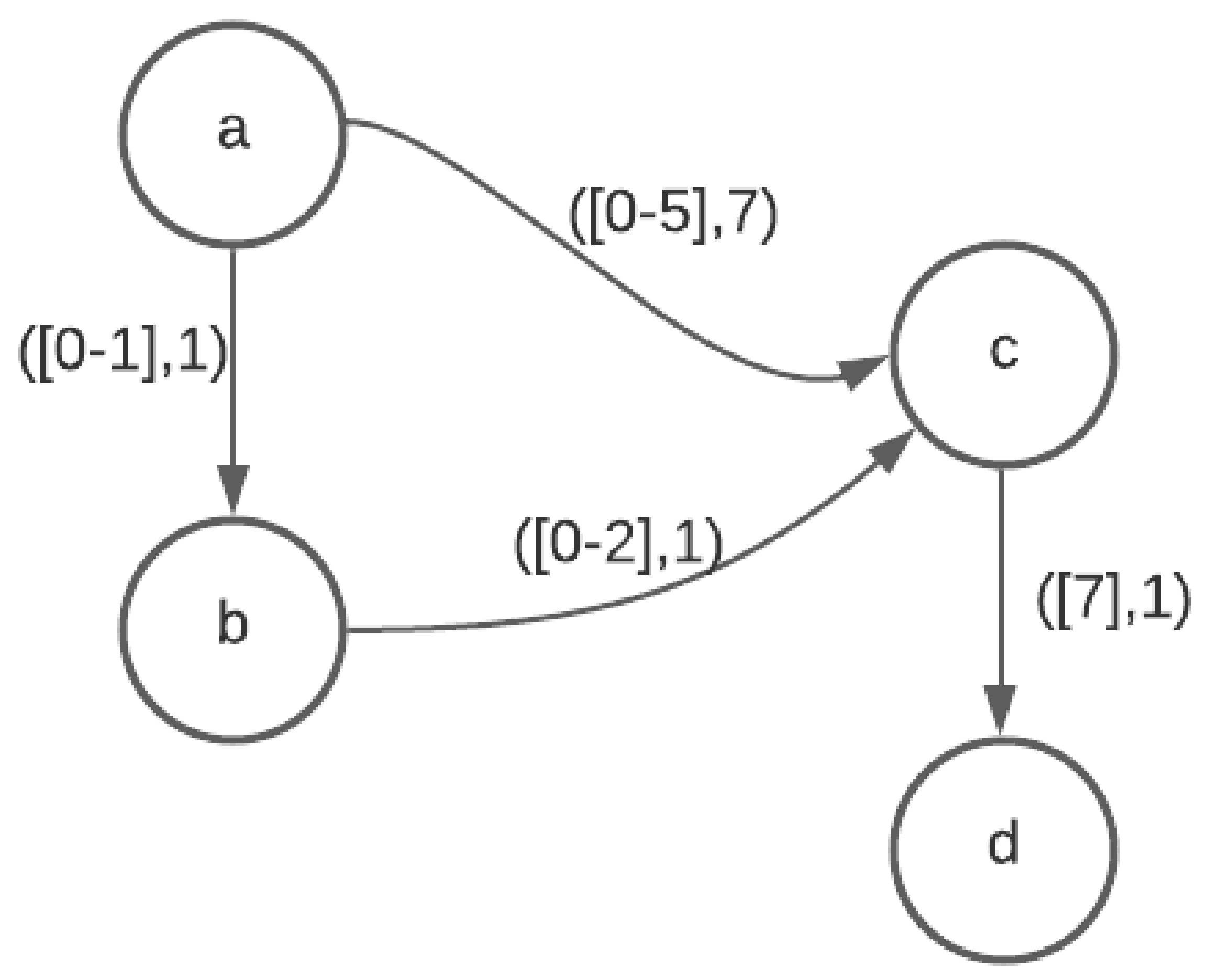
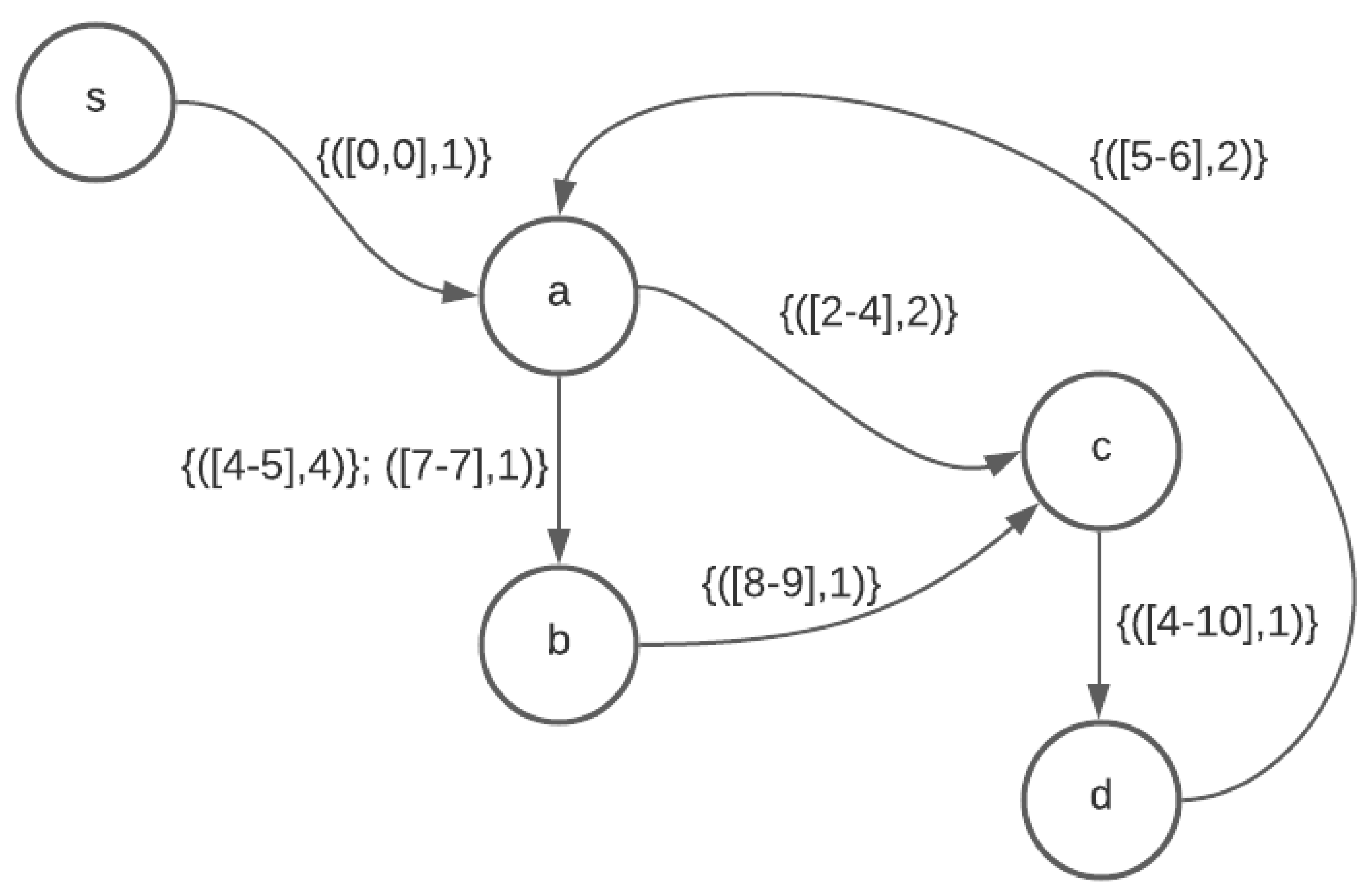
Temporal graph represented by data structure described in
Section 5.4.1, item 1
Source vertex s
OUTPUT:
- -
For simplicity, we assume that all the edge travel times are
0. Our algorithm for solving the
problem (Algorithm 2) can easily be extended to the case when some travel times are
0. Later, we show how to carry out this extension. Algorithm 2 looks at all possible departure intervals in non-decreasing order of their arrival times when departing at the start of the interval (
). In Step 8, it saves the arrival time of the latest interval being considered in the variable
. In the subsequent
loop, it keeps fetching new intervals as long as they have the same arrival time as
, when departing at the start of the interval. For each fetched interval
, at the originating vertex
u of
, it finds a walk class
with latest arrival time of the start of the walk class
such that
. No other walk arriving at
u needs to be considered for expansion on this interval due to Theorem 10. Using this previous walk at the originating vertex
u, a new walk is created from
u to
v at the start of the
using the function
. This function creates a new walk from the previous walk departing at start of
only if the second part of Theorem 12 is satisfied. The first part of Theorem 12 is already taken care of because the intervals are examined only in non-decreasing order of
.
| Algorithm 2 Min-wait foremost walks algorithm |
- 1:
Create a new as an instance of . Values are assigned to fields , respectively. Last field is an array of size out degree of vertex s. - 2:
Initialize mwfWalks[s] ← newWClass; initialize ; - 3:
; ; - 4:
- 5:
- 6:
- 7:
while ( or ) and do - 8:
- 9:
; - 10:
- 11:
while () do - 12:
if then - 13:
- 14:
if then - 15:
- 16:
if then - 17:
▹ Inserts in list of walks at v. If is best walk it is recorded in - 18:
if then - 19:
- 20:
end if - 21:
if then - 22:
- 23:
end if - 24:
end if - 25:
end if - 26:
end if - 27:
- 28:
end while - 29:
- 30:
end while
|
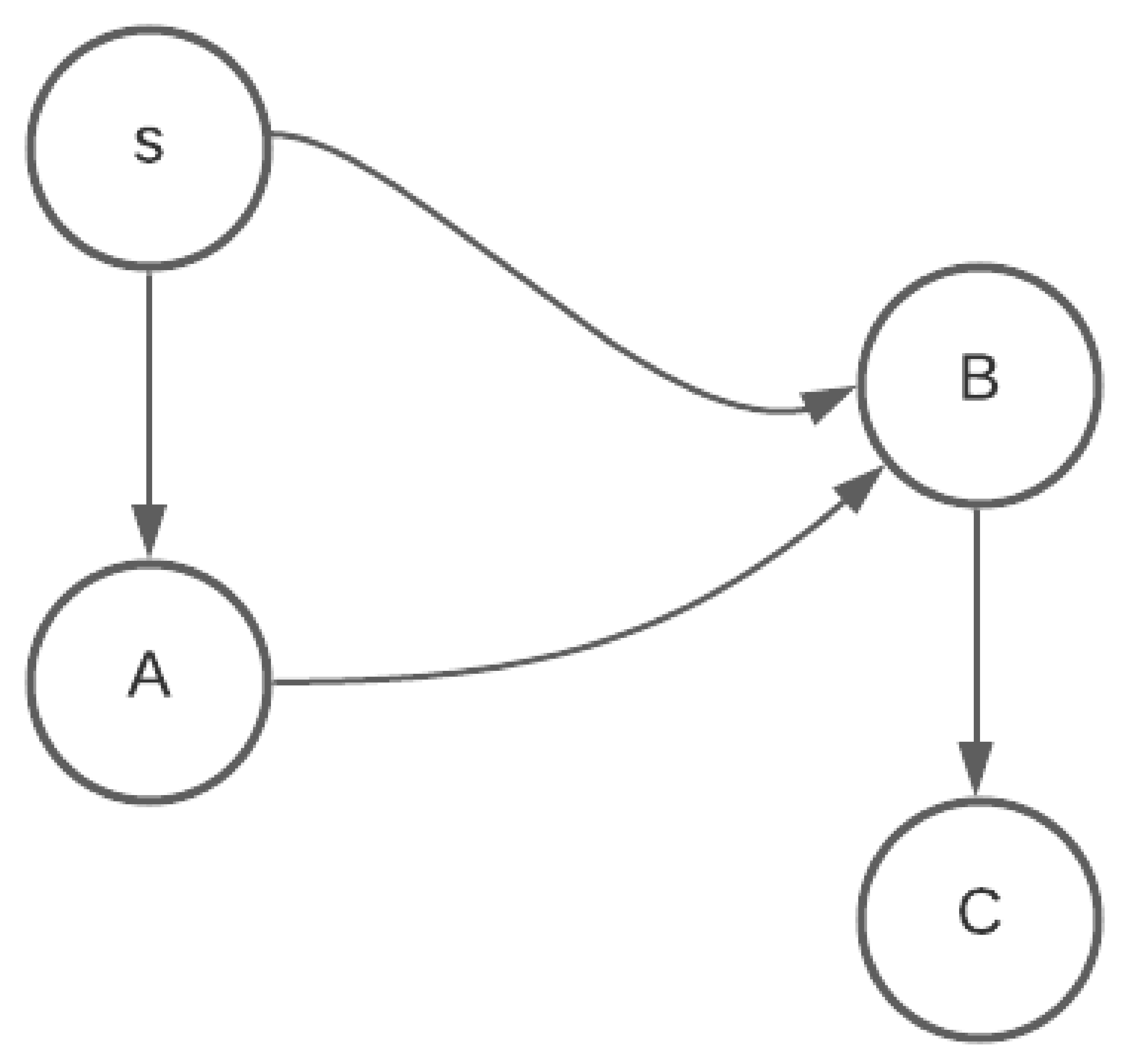
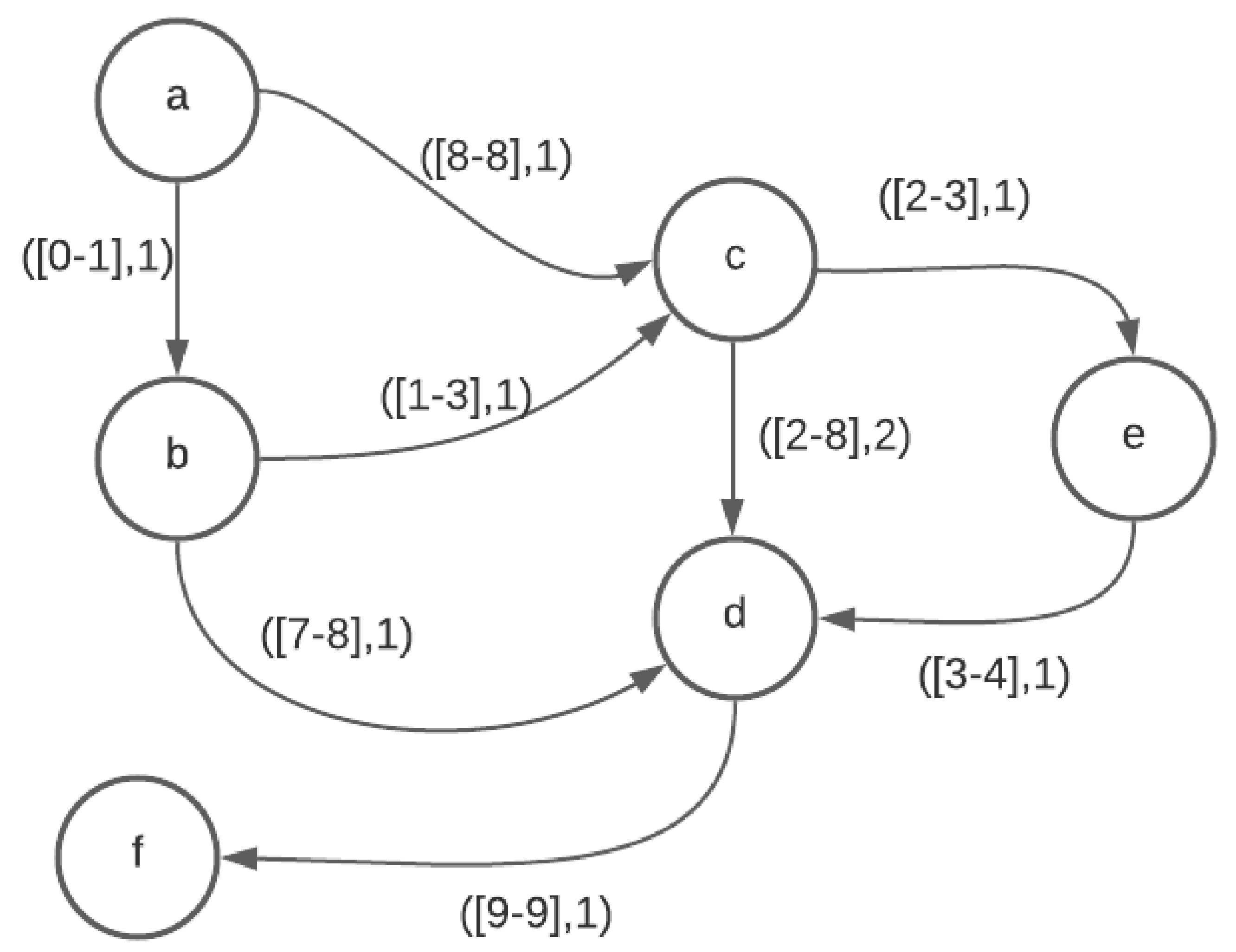
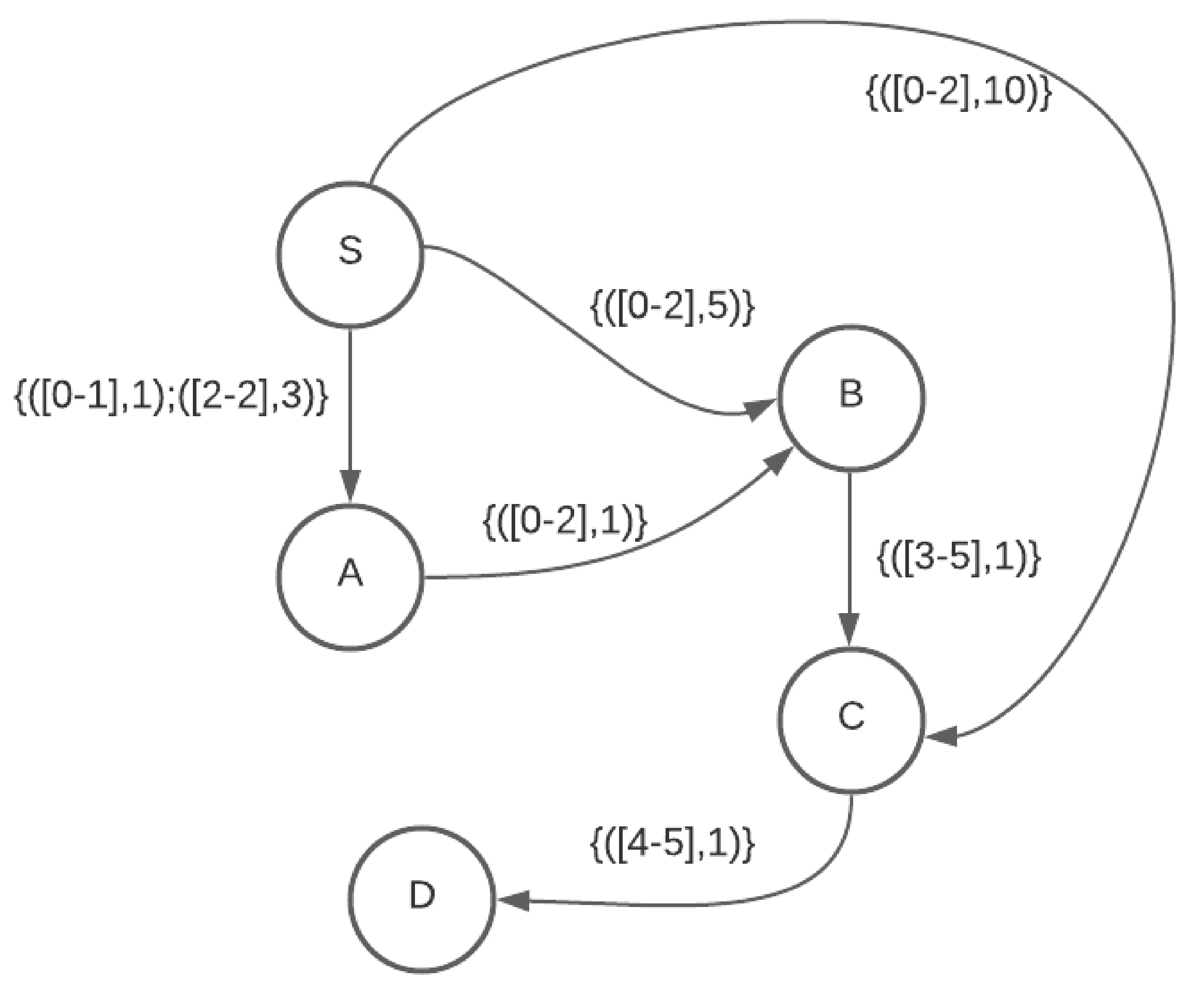
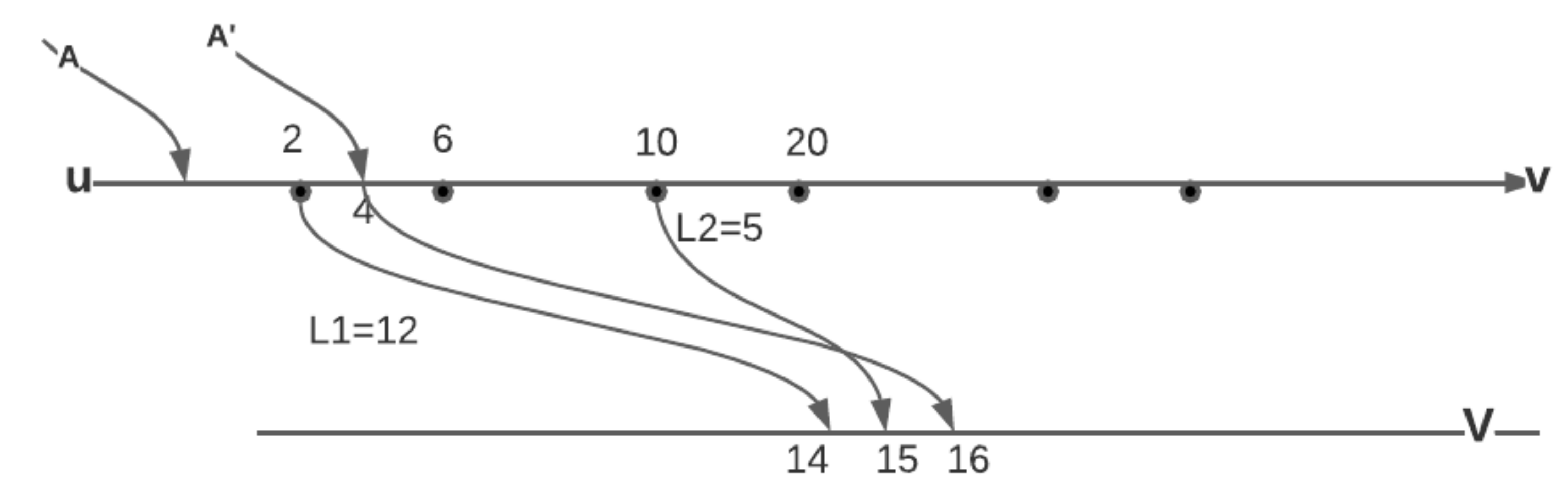
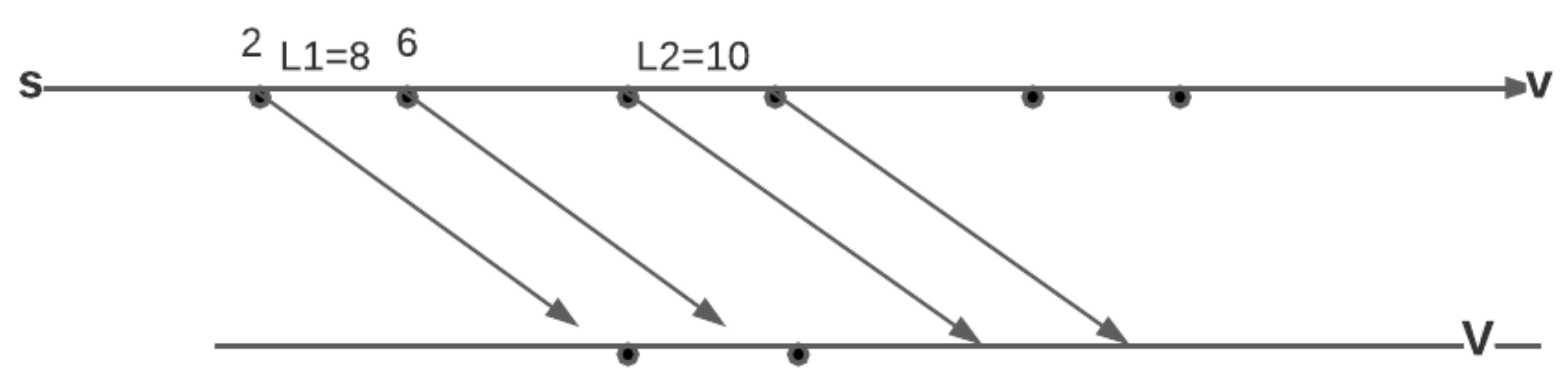
After the new walk is created on an edge , it is appended to the list of walks at v. To qualify as a valid walk to be appended to the list of walks at v, it needs to be compared for dominance with only the last walk in the list at v due to Theorem 9. This walk is appended to the list at v only if it is not dominated. The insert function also checks if this is the first walk arriving at v. If so, it updates the for vertex v and increments the count of . If this is not the first walk to arrive at v, but if it is better w.r.t arrival than the best known walk at v, is updated for vertex v. Note that the new walk cannot have an earlier arrival time than the best known walk at v as the intervals are examined in non-decreasing order of arrival times, but it may have a lesser wait time.
After a walk has been appended to the list of walks at v, the function examines all the neighbors of v. If the start time of the last arriving walk class is in the middle of an available departure interval, given, in the input graph G on an edge , a new departure sub-interval of , say , is created. The start time of is the arrival time of the walk and travel time same as that of the (). This way, every walk originates at the of an interval given in graph G or at start of a that is a sub-interval of one of the intervals given in the input graph G. This new is inserted into the priority queue . In the function, the interval with minimum arrival time (when departing at the start of the interval) from and the top of is returned.
Theorem 16. Algorithm 2 finds walks from s to all other vertices in an interval temporal graph when all edge travel times are 0.
Proof. The algorithm examines all the departure intervals in non-decreasing order of arrival time, when departing at the start of the interval. For every interval, in that order, it considers the best walk eligible for extension in this interval, as per Theorem 10, by obtaining the index for the previous walk () in the list of walks at the departure vertex u, in Step 13. It extends the with departure in only if this extension is beneficial as per Theorem 12. Once the walk is extended, it updates the for for the edge , so that subsequent departure intervals on are used for expanding only if the resultant walks may be beneficial, as per Theorem 12.
The extended walk is appended to the list of walks at v only if it is not dominated as per the dominance criterion of Equation (1). In addition, walks at v are updated if the arriving walk is better than the previous walk, w.r.t arrival at v or if it is the first walk to arrive at v.
Finally, the arriving walk at v, , is examined w.r.t all outgoing edges . If for a departure interval to any neighbor w we have , a new sub-interval, , is created that has a start time of and inserted into . When such a is the minimum interval among all the intervals from the input graph G and the s created during the course of Algorithm 2, the gets the opportunity to expand at the start time of .
Therefore, this algorithm starts at the start vertex and generates walks at all feasible departure instances w.r.t walks criteria. Feasible departure intervals are examined in non-decreasing order of arrival times; therefore, every new walk generated has an arrival time ≥ arrival time of any previously generated walk. No feasible non-dominated walk is missed due to Theorems 8–13.
Every non-dominated walk generated is preserved and expanded as per Theorems 11–13. When a walk terminating at a vertex v is discovered that is the best among the walks arriving at v w.r.t arrival, it is recorded as the walk at v. The algorithm terminates only when one of the following is true
All intervals including the created during the course of Algorithm 2 have been examined.
walks to all reachable vertices have been found and the arrival time when departing at the start of next interval being examined is bigger than the max arrival time of the walks found. Therefore, examining any more intervals cannot give a better walk.
Therefore, when the algorithm terminates, walks to all reachable vertices have been found. □
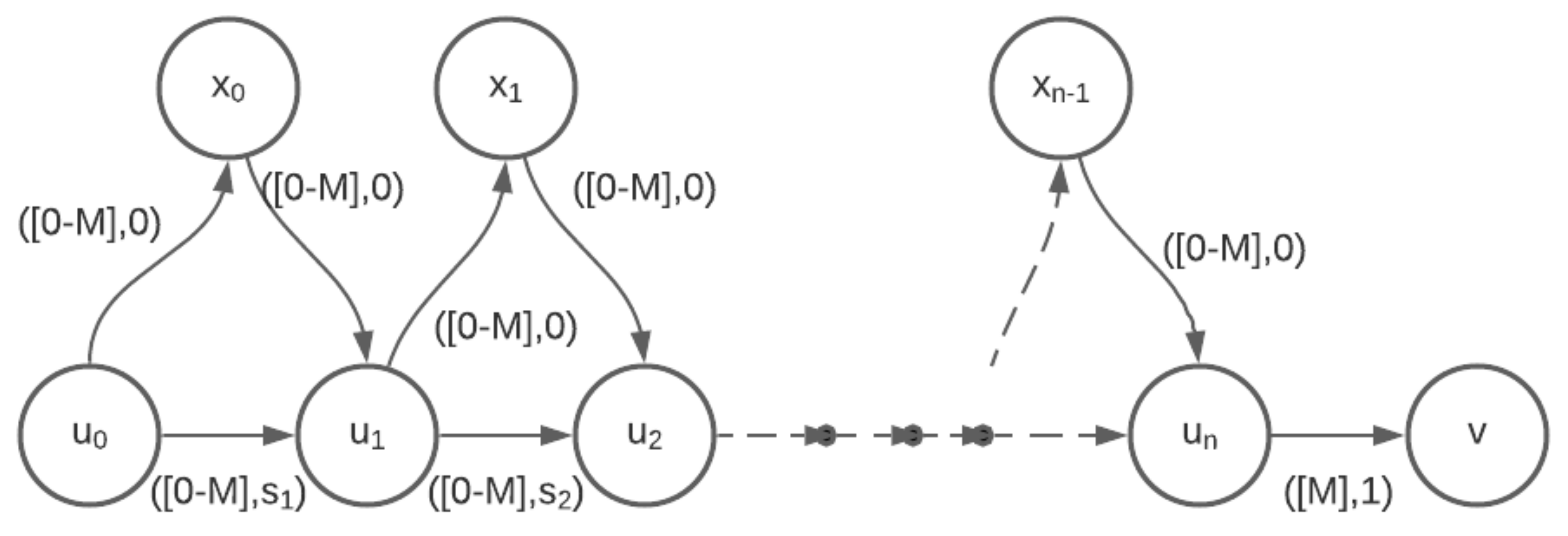
For handling the case when some travel times are 0, in the while loop of line 11, we need to first obtain all the edges with 0 travel times arriving at and form their transitive closure. Then, we can process every edge arriving at the same over this transitive closure.
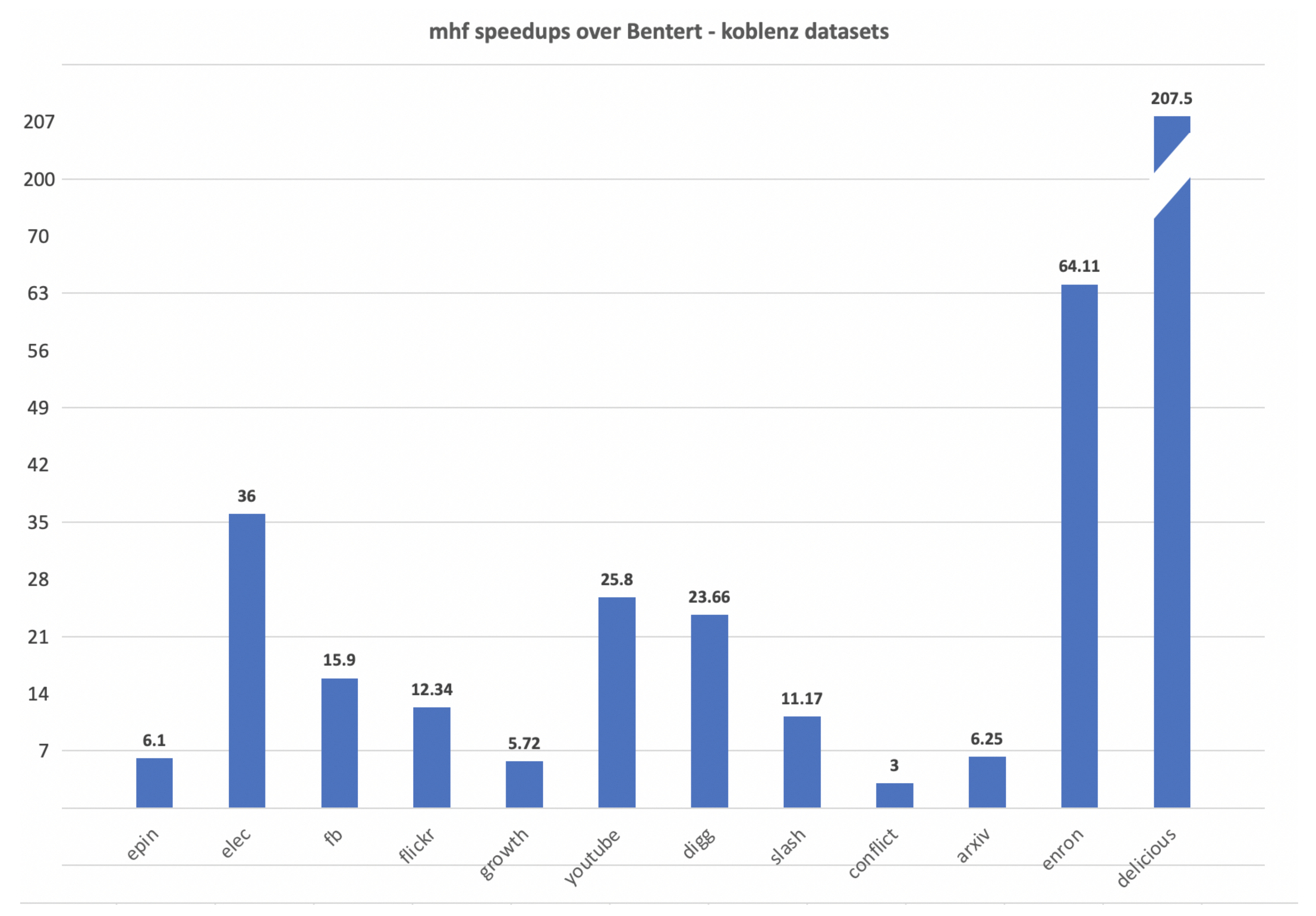
Theorem 17. When time is an integer, Algorithm 2 has pesudopolynomial complexity.
Proof. Let T be the maximum possible arrival time at any vertex. Since is an integer that increases in each iteration of the outer while loop, this outer loop is iterated times. For each value of , the while loop of line 11 is iterated times, where is number of edges in the input interval temporal graph, as the number of walks that can arrive at a vertex v at time is . The components of the time required for each iteration of the while loop of line 11 are
in step 13 to find the previous walk that can be extended at the current departure instance(). , which is the number of walks at v at time , can be at most as each preserved walk at a given vertex v has a unique arrival time. Therefore, time taken by this step is or at most .
Constant time for creating a new walk in step 15.
Constant time for inserting , in the list of walks l at v in step 17. l at every vertex v maintains a list of walks that has arrived at v in non-decreasing order of their arrival times. only needs to be compared with the last walk in l.
At most in step 22, d is the out-degree of the vertex v at which terminates and is the number of departure intervals on an outgoing edge that has maximum departure intervals among all the outgoing edges from v. Each of the departure intervals on outgoing edges from v may need to be added to .
Size of can be, at most, the maximum number of departure instances in the graph G, which is . Therefore, the maximum time taken in this step is .
Finally, in step 27, departure instance with minimum arrival time is retrieved. Maximum size of can be . Therefore, maximum time taken by this step is
Therefore, the complexity of the algorithm is , which is . Hence, the time complexity of Algorithm 2 is pseudopolynomial. □



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}