1. Introduction
In recent years, the healthcare field has experienced a massive growth in the acquisition of digital biomedical images due to a pervasive increase in ordinary and preventive medical exams. In view of this amount of medical data, new methods based on machine learning (ML) and deep learning (DL) have therefore become necessary. The application of ML and DL techniques to the biomedical imaging field can promote the development of new diagnostics and treatments, making it a challenging area of investigation. In particular, image classification represents one of the main problems in the biomedical imaging context. Its aim is to arrange medical images into different classes to help physicians in disease diagnosis. ML and DL methods are employed to predict the class membership of the unknown data instance, based on the class membership of the training set data, which is known. If the learning procedure performs a good classification, a proper automatic diagnosis of a disease can be achieved, starting only from the medical image.
From a mathematical point of view, given a training set of
n instances, a learning approach to the image classification involves the solution of a minimization problem of the form
where
F is the so-called loss function and it computes the difference between the actual ground-truth and predicted values,
n is the cardinality of the training set and
d is the number of features. Each
denotes the loss function related to the
i-th instance of the training set. Because
n can be a very large number, it is prohibitively expensive to compute all the terms of the objective function
or its gradient. Moreover, the whole dataset may be too large to be completely stored in memory. Finally, in the online learning setting, where the dataset is not available from the beginning in its completeness but is acquired during the learning process, it is impossible to work with
. In all these cases, the minimization problem is faced by exploiting stochastic approximations of the gradient that lead to the use of stochastic gradient (SG) methods [
1]. Given at each iteration
k a sample
of size
randomly and uniformly chosen from
, the SG algorithm to solve problem (
1) can be written as
where
is a positive parameter called the
learning rate (LR) and the stochastic direction
is computed as
The sample
is the
mini-batch at the
k-th iteration and its cardinality
is the mini-batch size (MBS). In order to accelerate the convergence rate of the SG method, a
momentum term [
2] can be added to the iteration (
2). In more detail, chosen
and setting
, the momentum version of the SG scheme has the following form:
where
is the positive LR.
In general, to design efficient and accurate ML or DL methodologies, it is needed to properly set the hyperparameters connected to the algorithm chosen for the training phase, particularly the LR and the MBS. We define the hyperparameters of a learning method as those parameters which are not trained during the learning process but are set a priori as the input data. In the literature, there are different philosophies to approach the problem of setting the hyperparameters. One of these is related to the Neural Architecture Search (NAS) area [
3], which explores the best configurations related to the optimization hyperparameters before the beginning of the training. However, there also exist techniques that directly address the search during the training phase, including static rules, i.e., rules that do not depend on the training phase, and dynamic rules, which only operate under certain conditions connected to the training phase itself. Regarding the LR and the MBS, the class of dynamic rules is preferable. Indeed, a variable LR strategy allows starting the iterative process with higher LR values than those employed close to the local minimum. As for the MBS, a standard approach is to dynamically increase it along the iterations, without however reaching the whole dataset in order to comply with the architectural constraints and control the possible data redundancy. There also exist techniques for decreasing the LR while the MBS is increasing.
Together with suitable choices of both the LR and the MBS, the training phase can be optimized by means of an early stopping technique. Given a validation set (VS), namely a subset of examples held back from training the model, standard early stopping procedures are based on the so-called patience parameter criterion. In more detail, if, after a number of epochs equal to the value of the patience, the loss function computed on the VS has not been reduced, the training is stopped even if the maximum number of epochs is not reached.
The aim of this paper is twofold. First, we combine the previously described strategies to reduce the training time. Indeed, we suggest a dynamic combined technique to select the LR and the MBS by modifying classical early stopping procedures. In particular, if a decrease in the loss function on the validation set is not achieved after the patience time, the patience value itself can be reduced, the learning rate is decreased and/or the mini-batch size is increased and the training is allowed to continue until the values of the learning rate and the mini-batch are acceptable from a practical point of view. Secondly, we test the SG algorithm with momentum, equipped with a such developed rule for the selection of the LR and MBS hyperparameters, in training an artificial neural network (ANN) for biomedical image classification problems. We remark that the dynamical early stopping procedure we describe in this paper can be adopted for general image classification problems. Moreover, it is worth highlighting that the suggested approach does not belong to the class of NAS hyperparameters procedures. Indeed, unlike the proposed scheme, NAS techniques aim to set good hyperparameters values at the beginning of the training phase and to keep them fixed until convergence. On the other hand, the hyperparameters selection rule developed in this work is adaptive because the hyperparameters connected to the optimizer can be conveniently changed during the training phase. This can have benefits in terms of both the performance and computational and energy savings from a GreenAI (Artificial Intelligence) perspective.
The paper is organized as follows. In
Section 2, we present a brief survey about the state-of-the-art approaches to fix both the LR and the MBS hyperparameters.
Section 3 is devoted to describing a novel technique to dynamically adjust the LR and/or the MBS, using the VS.
Section 4 reports the results of the numerical experiments on standard and biomedical image classification problems, aimed to evaluate the effectiveness of the proposed approach. In
Section 5, in addition to the conclusions, the current directions of research that we are pursuing to expand and complete the work carried out are illustrated.
3. A New Dynamic Early Stopping Technique
The previous section has shown that the LR and the MBS need to be properly selected in order to have robust and efficient learning methodologies and that many efforts have been made in the literature in this regard. In this section, we propose a novel adaptive strategy to fix both these hyperparameters by exploiting and modifying the standard early stopping procedure. The resulting approach can be seen as a new dynamic early stopping strategy able to combine the advantages of both the early stopping and the dynamic strategies to define the LR and the MBS.
In all the methodologies involving learning from examples, it is important to avoid the phenomenon of overfitting. To this end, it is effective to adopt the early stopping technique [
20] which interrupts the learning process by allowing to possibly use a number of epochs lower than the prefixed maximum, also from a GreenAI perspective [
21]. The early stopping technique is based on the idea of periodically evaluating, during the minimization process, the error that the network commits on the auxiliary VS by evaluating the performance obtained on the VS itself. In general, in the first iterations, the error on the VS decreases with the objective function, while it can increase if the error which occurs on the training set (TS) (the training set is a set of examples used to fit the parameters of the model, e.g., the weights of an ANN) becomes “sufficiently small”. In particular, the training process ends when the error on the VS starts to increase, because this might correspond to the point in which the network begins to overfit the information provided by the TS and loses its ability to generalize to data other than those of the TS. In order to practically implement the early stopping procedure, it is typical to define a patience parameter, i.e., the number of epochs to wait before early stopping the training process if no progress on the VS is achieved. Fixing the value of the patience is not obvious: it really depends on the dataset and the network. The suggested early stopping strategy aims to also overcome this difficulty.
3.1. The Proposal
In this section, we detail the new early stopping technique we are proposing. The main steps of this technique can be summarized as follows.
We borrow the basic idea of the standard early stopping in order to avoid overfitting the information related to the TS.
We introduce a patience parameter which can be adaptively modified along the training process.
We dynamically adjust both the LR and the MBS hyperparameters along the iterations, according to the progress on the VS.
The complete scheme is described in Algorithm 1. The main features are reported below.
3.1.1. Lines 4–9—Update of the Iterates for One Epoch
The iterates are updated by means of a stochastic gradient algorithm (Algorithm 1 line 8) for an entire epoch. In particular, a stochastic estimate of the gradient of the objective function is computed by means of the current mini-batch
of cardinality
chosen randomly and uniformly from
(lines 6–7). Examples of the stochastic gradient estimations are provided in (
2) and (
3).
3.1.2. Line 10—Evaluation of the Model
The model is evaluated on the VS, namely the accuracy is computed on the VS and saved in the variable .
3.1.3. Lines 11–15—Check for Accuracy Improvement
The current accuracy computed on the VS is compared to the one computed at the previous epoch and saved in the variable .
3.1.4. Lines 17–29—Dynamic Early Stopping
If the accuracy on the VS is not improved, a counter is increased (line 17). Subsequently (line 18), the value of the counter is compared to the prefixed value p of the patience. In standard early stopping strategies, if the counter is greater than the value of p, then the training phase is stopped. On the contrary, in the suggested dynamic early stopping technique, the training phase is not immediately stopped, but it is allowed to continue with different hyperparameters. In particular, the LR is decreased by a factor (line 20) and/or the MBS is increased by a proper rule (line 22) depending on and , where M is a constant related to hardware or memory limitations, for example, it can be the maximum number of samples which can be stored in the GPU. Finally (line 23), the value of the patience is divided by a factor . Thanks to a smaller LR and/or a mini-batch of a larger size, the optimizer employed in the training phase should stabilize and provide new iterates closer to the minimum point. However, if the LR becomes too small and the MBS reaches the hardware limitations, then the ending of the training process is forced. In particular, if the patience is reduced more than a prefixed value , then the training is stopped (lines 27–29).
To summarize, different from the standard early stopping, the proposed one avoids a sharp ending of the training process and the difficult tuning of a fixed value of the patience. Moreover, it allows to really exploit the nature of the dynamic selection rules for the LR and MBS, thus ensuring a more efficient learning phase. Finally, we remark that the possibility to refine the values for the LR and the MBS along the iterative process allows to make their initial setting less crucial than in the static approaches where the hyperparameters are kept fixed during the training.
| Algorithm 1: A stochastic gradient method with dynamical early stopping |
![Algorithms 15 00386 i001]() |
4. Numerical Experiments
In this section, we investigate the effectiveness of the developed early stopping procedure combined with the SG method with momentum on image classification problems. More in detail, we consider Algorithm 1 where the stochastic direction (line 7) and the update of the iterates (line 8) are performed by means of the scheme defined in (
3) with
. The loss function in (
1) is the cross entropy; hence,
where
is the probability of the Softmax function of the class
i and
is the true label. We consider both a standard database for image classification tasks as the CIFAR-100 [
22] and two different biomedical databases of 2D images obtained by computed tomography tools [
23,
24,
25,
26,
27].
4.1. Image Classification on CIFAR-100 Dataset
We present the results for three different CNNs for 100-classes classification on the CIFAR-100 dataset: ResNet18 [
28], VGG16 [
29] and MobileNet [
30]. The numerical experiments have been performed on an Intel i9-9900KF coupled with an NVIDIA RTX 2080Ti. The code has been developed starting from an established framework to train several CNNs on the CIFAR-100 dataset (
https://github.com/weiaicunzai/pytorch-cifar100, accessed on 1 October 2022) and has been made public for the sake of reproducibility (
https://github.com/mive93/pytorch-cifar100, accessed on 1 October 2022). In the considered framework, the CIFAR-100 dataset was divided into training and test sets. We used 10% of the training set to create the validation set. The optimizer employed for the reference training of the CNNs is the SG with momentum; it uses a starting LR of 0.1 and schedules its annealing at epochs [60, 120, 160], multiplying it by 0.2 in those so-called milestones.
The performance of the optimization method employed for the CNNs reference training has been compared with the performance of two different versions of Algorithm 1 (with an SG with momentum at lines 7–8). In particular, we consider the possibility of either reducing the LR while the MBS is such that or decreasing the LR and increasing the MBS. Both versions of Algorithm 1 have been implemented by setting , , , , , where is the maximum number of samples that can be stored in the GPU, and . Moreover, in order to understand how the patience values affect the performance, we consider three different values for p—8, 15 and 20—and two different values for —2 and 4. Finally, has been fixed either equal to 6 if both the LR is reduced and the MBS is increased or equal to 3 if only the LR is decreased but the MBS is not changed along the iterations. In the results, the name of the different considered algorithms for the training reports:
For example, LRBS_p20_2 points out that the selection rules for the LR and the MBS are both dynamic and the values for p and are 20 and 2, respectively.
All the tests have been performed five times, and the average accuracy on the test set and the number of epochs are reported, knowing that the standard deviation on the accuracy is at most equal to 0.0145. As usual, the best result obtained with the check on the VS is verified on the test set.
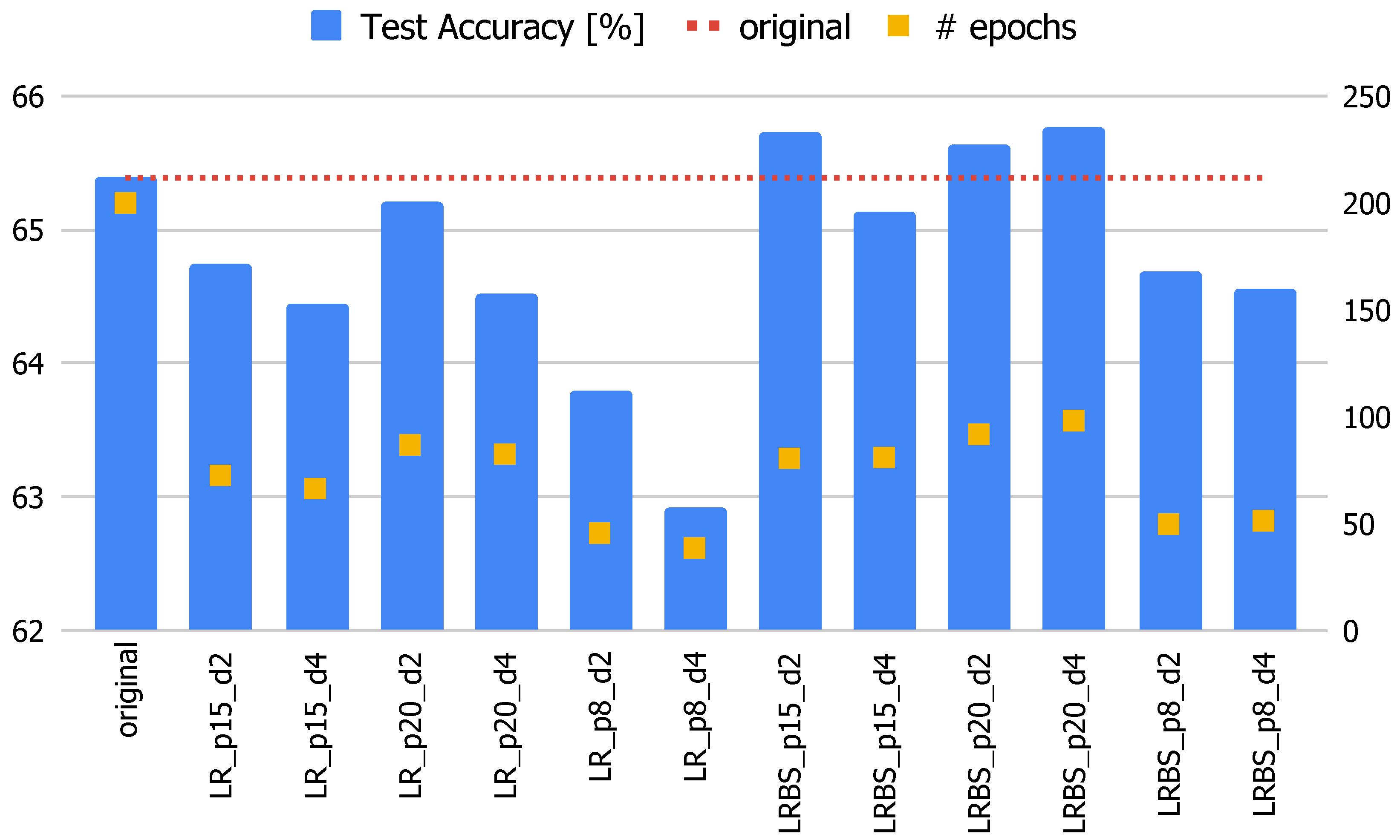
Figure 1 shows the results of all the experiments carried out on the MobileNet CNN. In this case, the reference training achieves an accuracy of 65.39% in 200 epochs. From the chart, it can be seen that all the trainings that follow the methodology proposed in this paper achieve similar results in terms of accuracy while needing less than half the epochs of the original one. Moreover, some configurations outperform the original, such as, e.g., the LRBS version with patience equal to 15 or 20.
Table 1 reports all the results for the three CNNs for the LRBS configurations. From the last two columns of
Table 1, it is possible to conclude that the accuracy results obtained by the proposed method are in line with those of the original version, sometimes slightly lower and sometimes higher. What is truly remarkable is the number of epochs required to obtain such a performance, which is at least halved compared to the original method.
4.2. Biomedical Image Classification
The second part of the numerical experiments involved two types of bidimensional biomedical image datasets for multi-class classification: MedMNIST2D OrganSMNIST (
https://medmnist.com/, accessed on 1 October 2022) and MedMNIST OCTMNIST (
https://medmnist.com/, accessed on 1 October 2022) [
26,
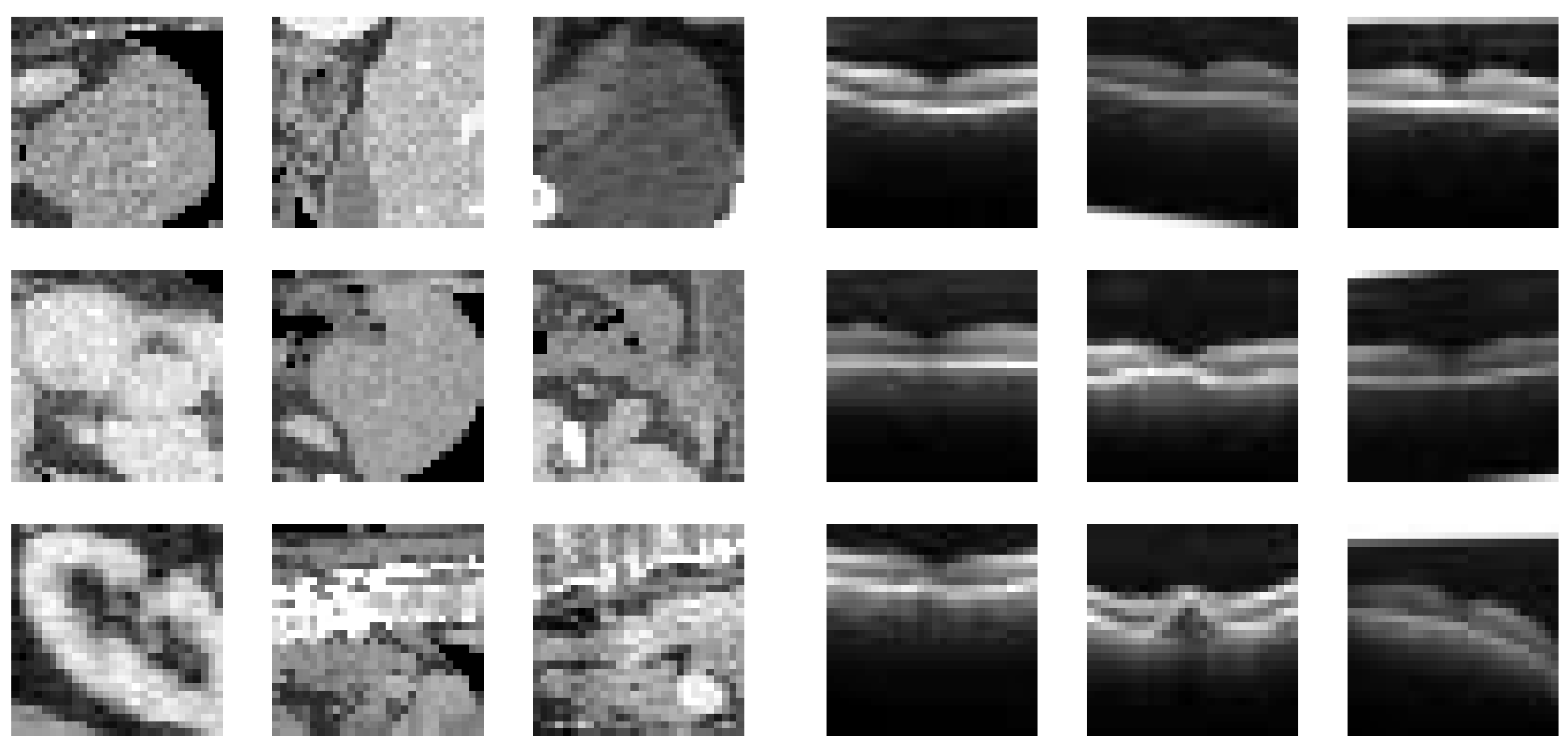
27]. The former is composed of 25,221 abdominal CT images (the first panel of
Figure 2) with labels from 0 to 10, each one corresponding to an organ or a bone of the abdomen. Each image is 28 × 28 pixels and the original dataset is split up into training, validation and test sets whose dimensions correspond to 70%, 9% and 21% of the total number of samples, respectively. The second one is made up of 109309 optical coherence tomography (OCT) images for retinal diseases (the second panel of
Figure 2) and there are four labels of which three correspond to different diseases and one is related to normal health conditions. Each image is 28 × 28 pixels and the original dataset is divided similarly to the previous case.
These two applications have been processed on MSI Sword 15 A11UC-630XIT with a GPU NVIDIA GeForce RTX 3050 Laptop, CPU i7-11800H, 8 GB of RAM, Windows 11 and Python 3.10.2. We opportunely modified the official code (
https://github.com/MedMNIST/MedMNIST, accessed on 1 October 2022) which implements various artificial neural networks, from the data splitting point of view. In particular, we divided the dataset into the following disjointed subsets: the 70% of the total examples gives the TS, the 9% is employed for the VS and the remaining 21% of the data forms the test set. Our code is publicly available (
https://github.com/AmbraCatozzi/ResNet18_Biomedical.git, accessed on 1 October 2022) for the sake of reproducibility.
For all the experiments, we compared the performance of the ResNet18 model trained by means of:
The hyperparameters setting for all the three optimization techniques are discussed in the following section.
4.2.1. Hyperparameters Setting
Because the performance of a stochastic gradient method is strictly related to the configuration of its hyperparameters, this section aims to fix the best hyperparameters setting for the algorithms employed to train the ResNet18. This preliminary study is carried out on the MedMNIST2D OrganSMNIST dataset and the best found hyperparameters configurations will be used for all the other experiments.
Setting p for the ES Method
First of all, we compare the performance of the ES method for different values of the patience
p. In particular, given
and
, we report in
Table 2 the values of the accuracy reached by ES with
p equal to 5, 20 and 30. In the same table, the results corresponding to the Original optimizer are also reported (for the same setting of
and
).
The value of p, which ensures the best accuracy on the test set, is 20. In the following, p is always set to this value for the ES method.
Setting and for the Original and the ES Methods
In order to properly tune the LR and the MBS for both the Original and the ES schemes, we performed several experiments with different settings, illustrated in
Table 3.
From the results of
Table 3, the best hyperparameters setting for both the Original and the ES approaches is
and
. We remark that to find this setting was very demanding in terms of computational costs.
Robustness of the LRBS Method against Hyperparameters
The proposed method aims to get rid of the dependence on its intrinsic hyperparameters while maintaining a high performance. In this section, we investigate the response of the LRBS method to the variation in the values of the hyperparameters used in Algorithm 1. In particular, we consider different values for:
and
. It is worth highlighting that we do not need to also properly tune the values for the patience, the LR and the MBS as performed for the Original and the ES schemes. Indeed, the LRBS algorithm automatically adjusts the values of these hyperparameters along the epochs. For this reason, we just consider
,
and
: we select a quite large value for both the patience and the initial LR and a quite small value for the initial MBS by allowing the procedure to adapt them (by increasing the former ones and decreasing the latter one). To confirm this thesis, in the next section (see Table 7), we show that the LRBS algorithm is much less sensitive to the selection of the hyperparameters than the other two methods in training the ResNet18 for the MedMNIST2D OrganSMNIST dataset. In
Table 4, we present the values of the accuracy for different configurations. We run each experiment five times with different seeds and we report the means and standard deviations in the table.
Table 4 allows to conclude that the LRBS method is very stable with respect to the reasonable choices of the hyperparameters involved; particularly, both the mean and variance over the 5 trials are very good in all cases.
A Comparison with the AdaM Optimizer
Finally, for the sake of completeness, we show that to employ the AdaM optimizer [
31], instead of the SG one with momentum, leads to analogous results.
Table 5 reports the values of the accuracy reached by the considered approaches equipped by AdaM with
and
. The value of
p is 20 for both the ES and LRBS. The LRBS method improves the accuracy obtained with the Original ResNet18 by one percentage point, with the lowest number of epochs.
4.2.2. Numerical Results
In this section, we perform three different experiments. We firstly summarize the hyperparameters setting for the three compared approaches in view of the considerations made in the previous section. For the Original, ES and LRBS, we fixed and . The value of p is 20 for both the ES and LRBS. Moreover, the other hyperparameters defining the LRBS are set as , , , , and . In the following paragraphs, we present the results obtained by fixing the maximum number of epochs, , to both 50 and 100.
Results for OrganSMNIST in a Maximum Number of 50 Epochs
In
Table 6, we show the numerical results for the abdominal CT dataset: each column reports the mean accuracy on the test set, the standard deviation and the mean number of epochs obtained in five runs for the OrganSMNIST. The proposed method outperforms both the ResNet18 model and the early stopped one in terms of accuracy with the same number of epochs needed by the classical early stopping implementation.
We also observed that if we left fixed the value for the MBS but we increase the initial learning rate by either one or two orders of magnitude, the LRBS method outperforms both the standard model and the early stopped version (see
Table 7) by confirming the less dependence on the hyperparameters setting of the LRBS approach.
Results for OCTMNIST Dataset in a Maximum Number of 50 Epochs
The results related to the MedMNIST2D OCTMNIST dataset are illustrated in the same vein, but the means are calculated on the best five values of each configuration chosen from 20 runs; the numerical outcomes are presented in
Table 8. It can be seen that the proposed method slightly improves the accuracy, but it reaches this value in half of the time with respect to the standard early stopping procedure.
Results for OCTMNIST in a Maximum Number of 100 Epochs
To highlight the effectiveness of Algorithm 1, another experiment has been conducted. We trained the same models presented in the previous section for a maximum number of 100 epochs by considering the dataset OCTMNIST (see
Table 9).
As in the previous experiments, comparable values for the accuracy can be obtained by all the considered strategies; however, the number of epochs related to the early stopped models is less than the 20% of the total number of epochs. However, we remark that the LRBS does not suffer from the computational expensive phase of the hyperparameters tuning.



 ,
, 



{kind=link}
{kind=link}