
KMC3 and CHTKC: Best Scenarios, Deficiencies, and Challenges in High-Throughput Sequencing Data Analysis


Abstract
:1. Introduction
- (1)
- KMC3 has better overall performance, less memory usage, shorter running time, and lower sensitivity to the number of k-mer species than CHTKC. However, KMC3 has poor memory utilization efficiency, and its performance degrades with excessive running memory. The scalability needs to be improved to cope with the super-scale datasets. Therefore, KMC3 is more competitive for counting tasks on ordinary hardware platforms.
- (2)
- CHTKC performs better in the case of high available memory, multi-thread, and low IO bandwidth. However, CHTKC is more sensitive to the number of distinct k-mers in the case of large datasets, and the performance degrades sharply when processing datasets with low sequencing quality or high sequencing depth data. Therefore, CHTKC is more efficient for counting tasks with high sequencing quality, short k-mer, and super-scale datasets on higher-performance computing platforms.
- (3)
- Both algorithms are seriously affected by the IO bottleneck and the number of distinct k-mers but do not correlate with the GC content. Reducing the influence of the IO bottleneck is an essential method for optimizing the k-mer counting algorithm.
2. Materials and Methods
2.1. Datasets
2.2. Test Environment
3. Influence of Hardware Configuration
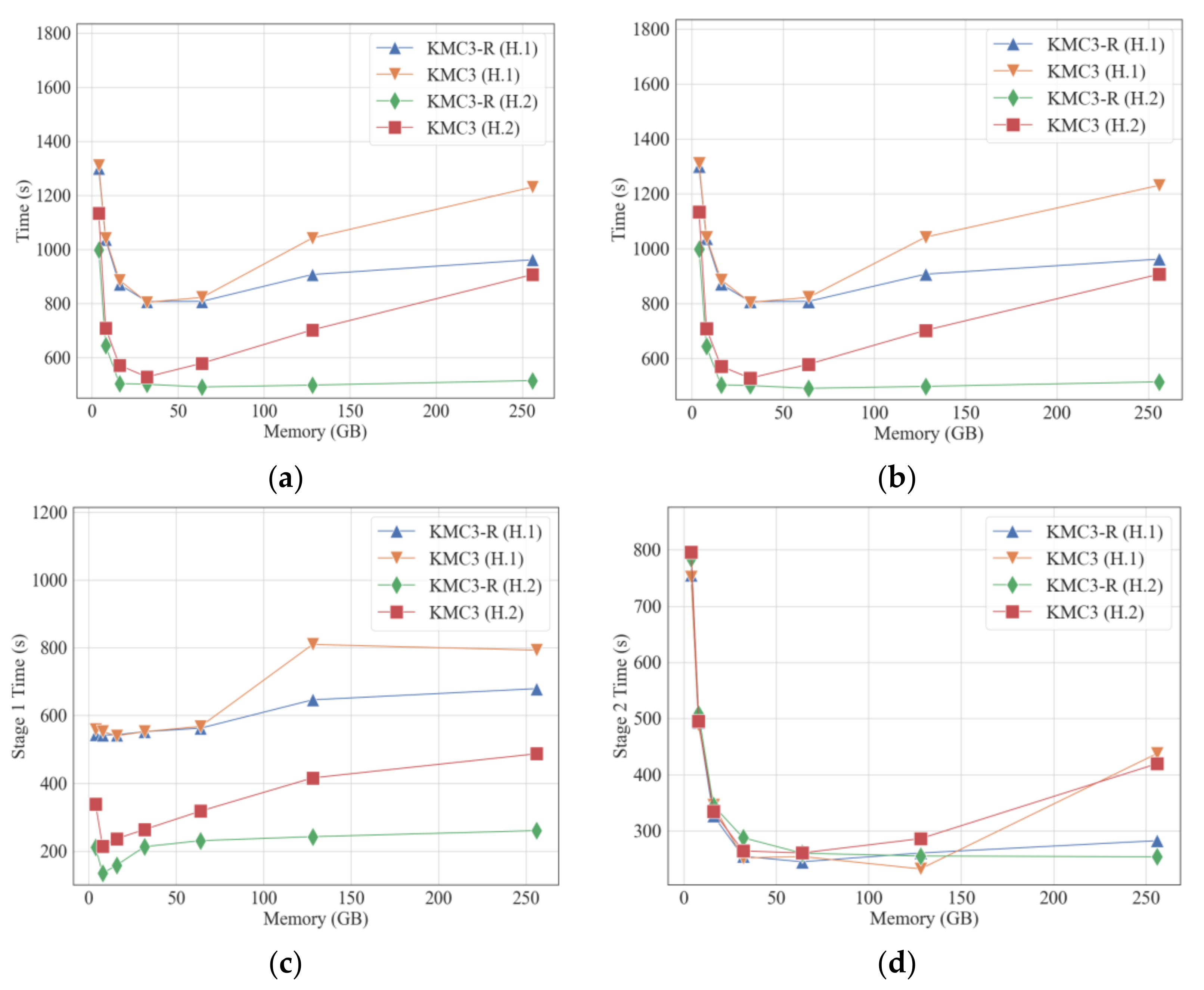
3.1. Influence of Available Memory Size
3.2. Influence of IO Bandwidth
4. Influence of Dataset Features
4.1. Correlation of GC-Ratios
4.2. Influence of Sequencing Depths and K
4.3. Influence of Sequencing Quality
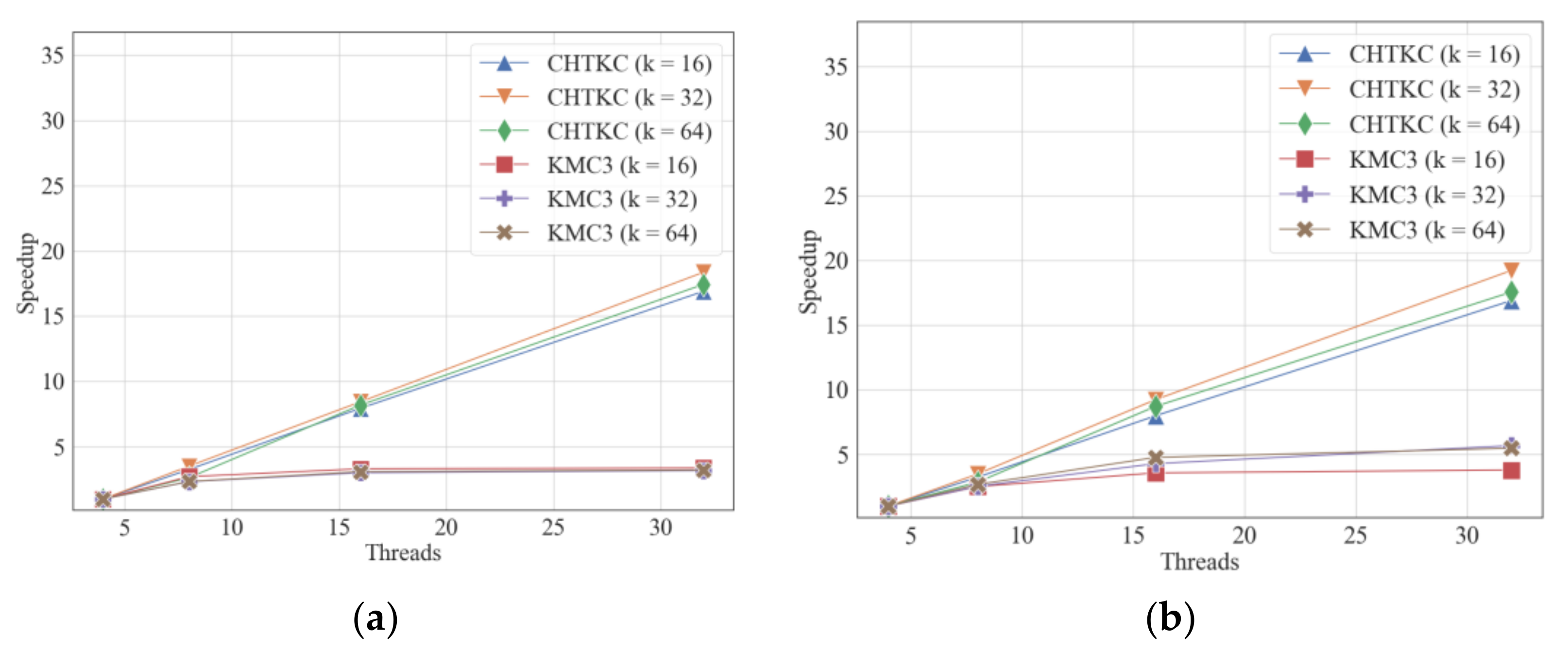
5. Scalability
5.1. Strong Scalability
5.2. Weak Scalability
6. Optimization of PBKMC Algorithm
6.1. Optimizing Disk IO with an Overlapping Sequence Set
6.2. Optimizing K-Mer Dumping with Read-Write Separation
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chor, B.; Horn, D.; Goldman, N.; Levy, Y.; Massingham, T. Genomic DNA k-mer spectra: Models and modalities. Genome Biol. 2009, 10, R108. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Audoux, J.; Philippe, N.; Chikhi, R.; Salson, M.; Gallopin, M.; Gabriel, M.; Le Coz, J.; Drouineau, E.; Commes, T.; Gautheret, D. DE-kupl: Exhaustive capture of biological variation in RNA-seq data through k-mer decomposition. Genome Biol. 2017, 18, 243. [Google Scholar] [CrossRef] [PubMed]
- Deorowicz, S. FQSqueezer: K-mer-based compression of sequencing data. Sci. Rep. 2020, 10, 578. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nasko, D.; Koren, S.; Phillippy, A.; Treangen, T.J. RefSeq database growth influences the accuracy of k-mer-based lowest common ancestor species identification. Genome Biol. 2018, 19, 165. [Google Scholar] [CrossRef] [Green Version]
- Cserhati, M.; Xiao, P.; Guda, C. K-mer-Based Motif Analysis in Insect Species across Anopheles, Drosophila, and Glossina Genera and Its Application to Species Classification. Comput. Math. Methods Med. 2019, 2019, 4259479. [Google Scholar] [CrossRef]
- Han, G.-B.; Cho, D.H.O. Genome classification improvements based on k-mer intervals in sequences. Genomics 2019, 111, 1574–1582. [Google Scholar] [CrossRef]
- Jaillard, M.; Lima, L.; Tournoud, M.; Mahé, P.; Van Belkum, A.; Lacroix, V.; Jacob, L. A fast and agnostic method for bacterial genome-wide association studies: Bridging the gap between k-mers and genetic events. PLoS Genet. 2018, 14, e1007758. [Google Scholar] [CrossRef] [Green Version]
- Kurtz, S.; Narechania, A.; Stein, J.C.; Ware, D. A new method to compute K-mer frequencies and its application to annotate large repetitive plant genomes. BMC Genom. 2008, 9, 517. [Google Scholar] [CrossRef] [Green Version]
- Marcais, G.; Kingsford, C. A fast, lock-free approach for efficient parallel counting of occurrences of k-mers. Bioinformatics 2011, 27, 764–770. [Google Scholar] [CrossRef] [Green Version]
- Melsted, P.; Pritchard, J. Efficient counting of k-mers in DNA sequences using a bloom filter. BMC Bioinform. 2011, 12, 333. [Google Scholar] [CrossRef] [Green Version]
- Deorowicz, S.; Debudaj-Grabysz, A.; Grabowski, S. Disk-based k-mer counting on a PC. BMC Bioinform. 2013, 14, 160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deorowicz, S.; Kokot, M.; Grabowski, S.; Debudaj-Grabysz, A. KMC 2: Fast and resource-frugal k-mer counting. Bioinformatics 2015, 31, 1569–1576. [Google Scholar] [CrossRef] [Green Version]
- Kokot, M.; Długosz, M.; Deorowicz, S. KMC 3: Counting and manipulating k-mer statistics. Bioinformatics 2017, 33, 2759–2761. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rizk, G.; Lavenier, D.; Chikhi, R. DSK: K-mer counting with very low memory usage. Bioinformatics 2013, 29, 652–653. [Google Scholar] [CrossRef] [PubMed]
- Roy, R.; Bhattacharya, D.; Schliep, A. Turtle: Identifying frequent k-mers with cache-efficient algorithms. Bioinformatics 2014, 30, 1950–1957. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Audano, P.; Vannberg, F. KAnalyze: A Fast Versatile Pipelined K-mer Toolkit. Bioinformatics 2014, 30, 2070–2072. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaplinski, L.; Lepamets, M.; Remm, M. GenomeTester4: A toolkit for performing basic set operations-union, intersection and complement on k-mer lists. Gigascience 2015, 4, 58. [Google Scholar] [CrossRef] [Green Version]
- Crusoe, M.R.; Alameldin, H.F.; Awad, S.; Boucher, E.; Caldwell, A.; Cartwright, R.; Charbonneau, A.; Constantinides, B.; Edvenson, G.; Fay, S.; et al. The khmer software package: Enabling efficient nucleotide sequence analysis. F1000Research 2015, 4, 900. [Google Scholar] [CrossRef] [Green Version]
- Mamun, A.-A.; Pal, S.; Rajasekaran, S. KCMBT: A k-mer Counter based on Multiple Burst Trees. Bioinformatics 2016, 32, 2783–2790. [Google Scholar] [CrossRef] [Green Version]
- Erbert, M.; Rechner, S.; Müller-Hannemann, M. Gerbil: A fast and memory-efficient k-mer counter with GPU-support. Algorithms Mol. Biol. 2017, 12, 9. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Chen, S.; Dong, L.; Wang, G. CHTKC: A robust and efficient k-mer counting algorithm based on a lock-free chaining hash table. Brief. Bioinform. 2021, 22, bbaa063. [Google Scholar] [CrossRef] [PubMed]
- Tang, D.; Li, Y.; Tan, D.; Fu, J.; Tang, Y.; Lin, J.; Zhao, R.; Du, H.; Zhao, Z. KCOSS: An ultra-fast k-mer counter for assembled genome analysis. Bioinformatics 2022, 38, 933–940. [Google Scholar] [CrossRef] [PubMed]
- Marchet, C.; Kerbiriou, M.; Limasset, A. BLight: Efficient exact associative structure for k-mers. Bioinformatics 2021, 37, 2858–2865. [Google Scholar] [CrossRef] [PubMed]
- Purcell, C.; Harris, T. Non-blocking Hashtables with Open Addressing. In Proceedings of the Distributed Computing, International Conference, DISC, Cracow, Poland, 26–29 September 2005. [Google Scholar]
- Steffen, H.; Justin, Z.; Hugh, E.W. Burst tries: A fast, efficient data structure for string keys. ACM Trans. Inf. Syst. 2002, 20, 192–223. [Google Scholar]
- Li, Y.; Yan, X. MSPKmerCounter: A Fast and Memory Efficient Approach for K-mer Counting. arXiv 2015, arXiv:1505.06550. [Google Scholar]
- Kokot, M.; Deorowicz, S.; Debudaj-Grabysz, A. Sorting Data on Ultra-Large Scale with RADULS. In International Conference: Beyond Databases, Architectures and Structures, Proceedings of the 13th International Conference, BDAS 2017, Ustroń, Poland, 30 May–2 June 2017; Springer: Cham, Switzerland, 2017; Volume 716, pp. 235–245. [Google Scholar]
- Manekar, S.C.; Sathe, S.R. A benchmark study of k-mer counting methods for high-throughput sequencing. Gigascience 2018, 7, giy125. [Google Scholar] [CrossRef] [Green Version]
- Pandey, P.; Bender, M.A.; Johnson, R.; Patro, R. Squeakr: An exact and approximate k-mer counting system. Bioinformatics 2018, 34, 568–575. [Google Scholar] [CrossRef]
- Pandey, P.; Bender, M.A.; Johnson, R.; Patro, R. A General-Purpose Counting Filter: Making Every Bit Count. In Proceedings of the 2017 ACM International Conference on Management of Data, Association for Computing Machinery, Chicago, IL, USA, 9 May 2017; pp. 775–787. [Google Scholar]
- Pérez, N.; Gutierrez, M.; Vera, N. Computational Performance Assessment of k-mer Counting Algorithms. J. Comput. Biol. 2016, 23, 248–255. [Google Scholar] [CrossRef]
- Xiao, M.; Li, J.; Hong, S.; Yang, Y.; Li, J.; Wang, J.; Yang, J.; Ding, W.; Zhang, L. K-mer Counting: Memory-efficient strategy, parallel computing and field of application for Bioinformatics. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 2561–2567. [Google Scholar]
- Liu, B.; Shi, Y.; Yuan, J.; Hu, X.; Zhang, H.; Li, N.; Li, Z.; Chen, Y.; Mu, D.; Fan, W. Estimation of genomic characteristics by analyzing k-mer frequency in de novo genome projects. arXiv 2013, arXiv:1308.2012. [Google Scholar]
- Li, R.; Fan, W.; Tian, G.; Zhu, H.; He, L.; Cai, J.; Huang, Q.; Cai, Q.; Li, B.; Bai, Y.; et al. The sequence and de novo assembly of the giant panda genome. Nature 2010, 463, 311–317. [Google Scholar] [CrossRef] [Green Version]
- Hu, X.; Yuan, J.; Shi, Y.; Lu, J.; Liu, B.; Li, Z.; Chen, Y.; Mu, D.; Zhang, H.; Li, N.; et al. pIRS: Profile-based Illumina pair-end reads simulator. Bioinformatics 2012, 28, 1533–1535. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shokrof, M.; Brown, C.T.; Mansour, T.A. MQF and buffered MQF: Quotient filters for efficient storage of k-mers with their counts and metadata. BMC Bioinform. 2021, 22, 71. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Species | Gzipped Size | GC-Ratio | Base Count | Total 32-Mers | Distinct 32-Mers |
|---|---|---|---|---|---|---|
| S-GC21 | S.ratti | 1.0 GB | 21% | 1.29 G | 893 M | 118 M |
| B-GC25 | B.marci | 8.0 GB | 25% | 10.2 G | 7038 M | 874 M |
| T-GC30 | T.fera | 18.0 GB | 30% | 22.55 G | 15,561 M | 1705 M |
| D-GC36 | D.rerio | 40.0 GB | 36% | 50.38 G | 34,759 M | 3807 M |
| H-GC41 | H.sapiens | 77.0 GB | 41% | 98.16 G | 67,733 M | 7751 M |
| T-GC45 | T.rubripes | 9.1 GB | 45% | 11.52 G | 7951 M | 975 M |
| A-GC50 | A.brassicae | 0.8 GB | 50% | 1.02 G | 707 M | 91 M |
| Dataset | Gzipped Size | Quality (Q30) | Base Count | Total 32-Mers | Distinct 32-Mers |
|---|---|---|---|---|---|
| H-69 | 95 GB | 69.29% | 98.76 G | 67.73 G | 9.57 G |
| H-75 | 93 GB | 75.30% | 98.66 G | 67.73 G | 7.67 G |
| H-80 | 91 GB | 79.95% | 98.56 G | 67.73 G | 6.28 G |
| H-86 | 87 GB | 85.56% | 98.46 G | 67.73 G | 4.72 G |
| H-91 | 80 GB | 90.86% | 98.36 G | 67.73 G | 3.54 G |
| H-96 | 74 GB | 95.81% | 98.26 G | 67.73 G | 2.93 G |
| H-100 | 35 GB | 100.00% | 98.16 G | 67.73 G | 2.55 G |
| Dataset | Gzipped Size | Depth | Base Count | 16-Mer | 32-Mer | 64-Mer | |||
|---|---|---|---|---|---|---|---|---|---|
| Total | Distinct | Total | Distinct | Total | Distinct | ||||
| H-5X | 13GB | 5X | 16.36G | 13.91G | 0.91G | 11.29G | 3.31G | 6.05G | 3.18G |
| H-10X | 26GB | 10X | 32.72G | 27.81G | 1.02G | 22.58G | 4.28G | 12.11G | 4.55G |
| H-30X | 77GB | 30X | 98.16G | 83.44G | 1.28G | 67.73G | 7.75G | 36.32G | 8.43G |
| H-60X | 154GB | 60X | 196.33G | 166.88G | 1.50G | 135.47G | 12.79G | 72.64G | 14.01G |
| Dataset | Gzipped Size | Q30 | Depth | Base Count | Total 32-Mers | Distinct 32-Mers |
|---|---|---|---|---|---|---|
| H.1 | 70.8 GB | 85.61% | 33X | 123.7 G | 91.03 G | 12.47 G |
| H.2 | 105.8 GB | 93.08% | 40X | 135.3 G | 93.53 G | 6.97 G |
| Server 1 | Server 2 | |
|---|---|---|
| OS | Ubuntu 20.04.3 | CentOS 7.9.2009 |
| CPU | 2 * Intel® Xeon® Gold 6242 | 2 * Intel® Xeon® E5-2630 |
| Cores | 32/Hyper-Threading supported | 20/Hyper-Threading supported |
| Frequency | 2.80 GHz | 2.20 GHz |
| Memory | 384 GB/DDR4/2666 MHz | 64 GB/DDR4/2666 MHz |
| Compiler | GCC 9.4.0 | GCC 9.3.1 |
| Storage | SSD, read 500 MB/s, write 350 MB/s | A: mechanical disk, read 196 MB/s, write 98 MB/s B: raid0, read 750 MB/s, write 350 MB/s |
| k | Dataset | Algorithm | Time (s) | Memory | Disk | Output File |
|---|---|---|---|---|---|---|
| 32 | T-GC45 | CHTKC-1.0.2 | 116.19 | 14.9 GB | 11.7 GB | 10.9 GB |
| KMC-3.1.1 | 97.32 | 14.9 GB | 9.3 GB | 9.3 GB | ||
| Revised KMC3 | 97.83 | 14.9 GB | 8.5 GB | 5 GB | ||
| T-GC30 | CHTKC-1.0.2 | 258.13 | 14.9 GB | 20 GB | 19.1 GB | |
| KMC-3.1.1 | 209.2 | 14.8 GB | 16.2 GB | 16.1 GB | ||
| Revised KMC3 | 191.99 | 14.9 GB | 18 GB | 9.3 GB | ||
| D-GC36 | CHTKC-1.0.2 | 985.06 | 14.9 GB | 43.2 GB | 42.5 GB | |
| KMC-3.1.1 | 381.21 | 15 GB | 37.4 GB | 35.7 GB | ||
| Revised KMC3 | 390.39 | 15 GB | 41.6 GB | 21.8 GB | ||
| H-GC41 | CHTKC-1.0.2 | 3739 | 14.9 GB | 86.9 GB | 86.6 GB | |
| KMC-3.1.1 | 809.79 | 15 GB | 75.3 GB | 72.4 GB | ||
| Revised KMC3 | 764.36 | 15 GB | 87.6 GB | 52.7 GB | ||
| 64 | T-GC45 | CHTKC-1.0.2 | 107.57 | 14.9 GB | 19.8 GB | 18.9 GB |
| KMC-3.1.1 | 113.02 | 14.9 GB | 17.2 GB | 17.2 GB | ||
| Revised KMC3 | 95.46 | 14.6 GB | 8.2 GB | 8.2 GB | ||
| T-GC30 | CHTKC-1.0.2 | 273.09 | 14.9 GB | 36.7 GB | 35.7 GB | |
| KMC-3.1.1 | 186.43 | 14.8 GB | 32.4 GB | 32.4 GB | ||
| Revised KMC3 | 180.82 | 14.9 GB | 16.2 GB | 16.2 GB | ||
| D-GC36 | CHTKC-1.0.2 | 1107.79 | 14.9 GB | 79.2 GB | 78.7 GB | |
| KMC-3.1.1 | 413.02 | 14.9 GB | 71.1 GB | 71.1 GB | ||
| Revised KMC3 | 370.38 | 15 GB | 38.7 GB | 38.7 GB | ||
| H-GC41 | CHTKC-1.0.2 | 6050.57 | 14.9 GB | 251.9 GB | 251.8 GB | |
| KMC-3.1.1 | 1739.18 | 15 GB | 226.9 GB | 226.9 GB | ||
| Revised KMC3 | 1308.88 | 15 GB | 164.1 GB | 164.1 GB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, D.; Tan, D.; Xiao, W.; Lin, J.; Fu, J. KMC3 and CHTKC: Best Scenarios, Deficiencies, and Challenges in High-Throughput Sequencing Data Analysis. Algorithms 2022, 15, 107. https://doi.org/10.3390/a15040107
Tang D, Tan D, Xiao W, Lin J, Fu J. KMC3 and CHTKC: Best Scenarios, Deficiencies, and Challenges in High-Throughput Sequencing Data Analysis. Algorithms. 2022; 15(4):107. https://doi.org/10.3390/a15040107
Chicago/Turabian StyleTang, Deyou, Daqiang Tan, Weihao Xiao, Jiabin Lin, and Juan Fu. 2022. "KMC3 and CHTKC: Best Scenarios, Deficiencies, and Challenges in High-Throughput Sequencing Data Analysis" Algorithms 15, no. 4: 107. https://doi.org/10.3390/a15040107
APA StyleTang, D., Tan, D., Xiao, W., Lin, J., & Fu, J. (2022). KMC3 and CHTKC: Best Scenarios, Deficiencies, and Challenges in High-Throughput Sequencing Data Analysis. Algorithms, 15(4), 107. https://doi.org/10.3390/a15040107