
Convolutional-Neural-Network-Based Handwritten Character Recognition: An Approach with Massive Multisource Data



Abstract
:1. Introduction
- In the proposed CNN model, four 2D convolutional layers are kept the same and unchanged to obtain the maximum comparable recognition accuracy into two different datasets, Kaggle and MNIST, for handwritten letters and digits, respectively. This proves the versatility of our proposed model.
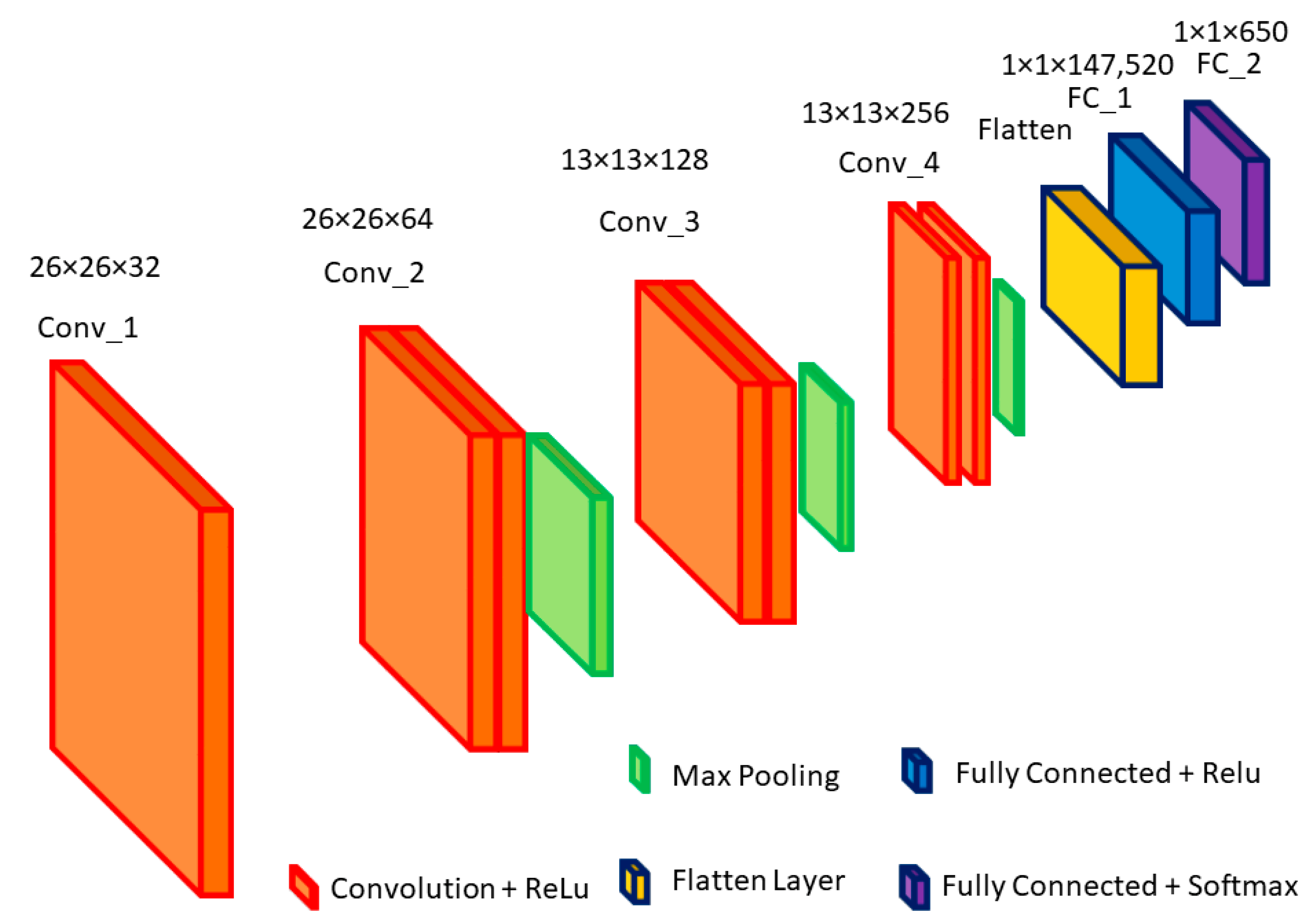
- A custom-tailored, lightweight, high-accuracy CNN model (with four convolutional layers, three max-pooling layers, and two dense layers) is proposed by keeping in mind that it should not overfit. Thus, the computational complexity of our model is reduced.
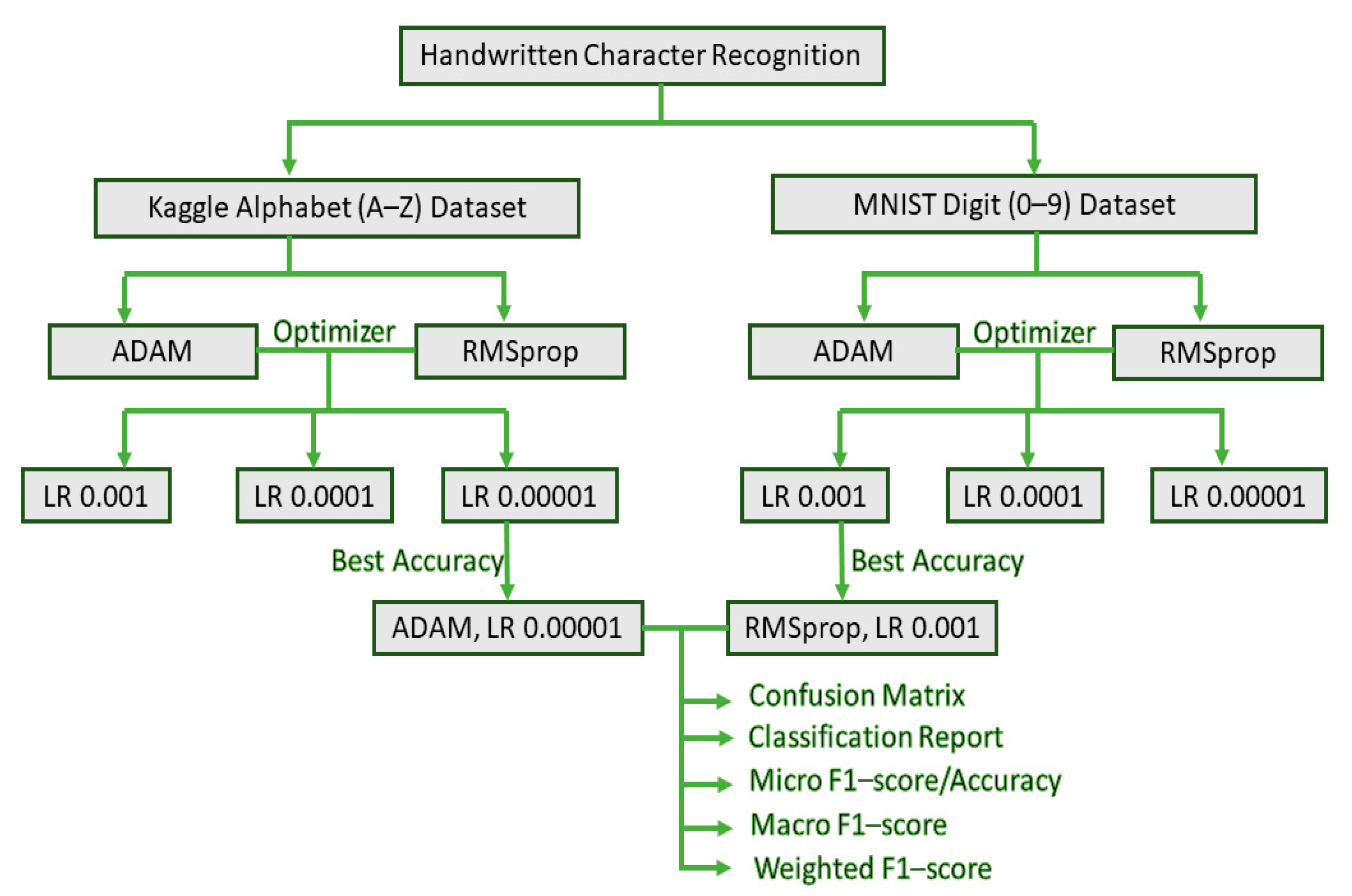
- Two different optimizers are used for each of the datasets, and three different learning rates (LRs) are used for each of the optimizers to evaluate the best models of the twelve models designed. This suitable selection will assist the research community in obtaining a deeper understanding of HCR.
- To the best of the authors’ knowledge, the novelty of this work is that no researchers to date have worked with the classification report in such detail with a tailored CNN model generalized for both handwritten English alphabet and digit recognition. Moreover, the proposed CNN model gives above 99% recognition accuracy both in compact MNIST digit datasets and in extensive Kaggle datasets for alphabets.
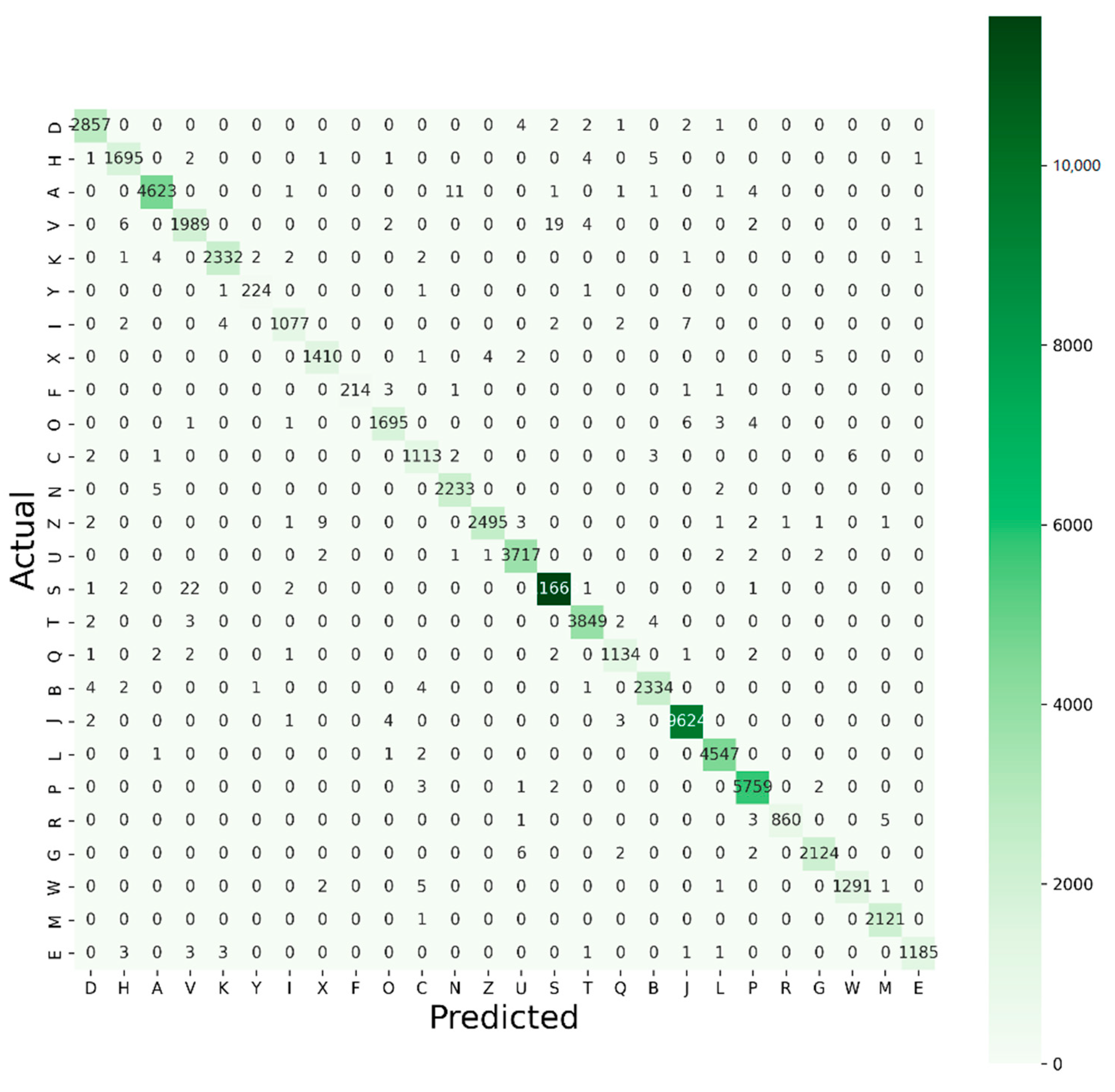
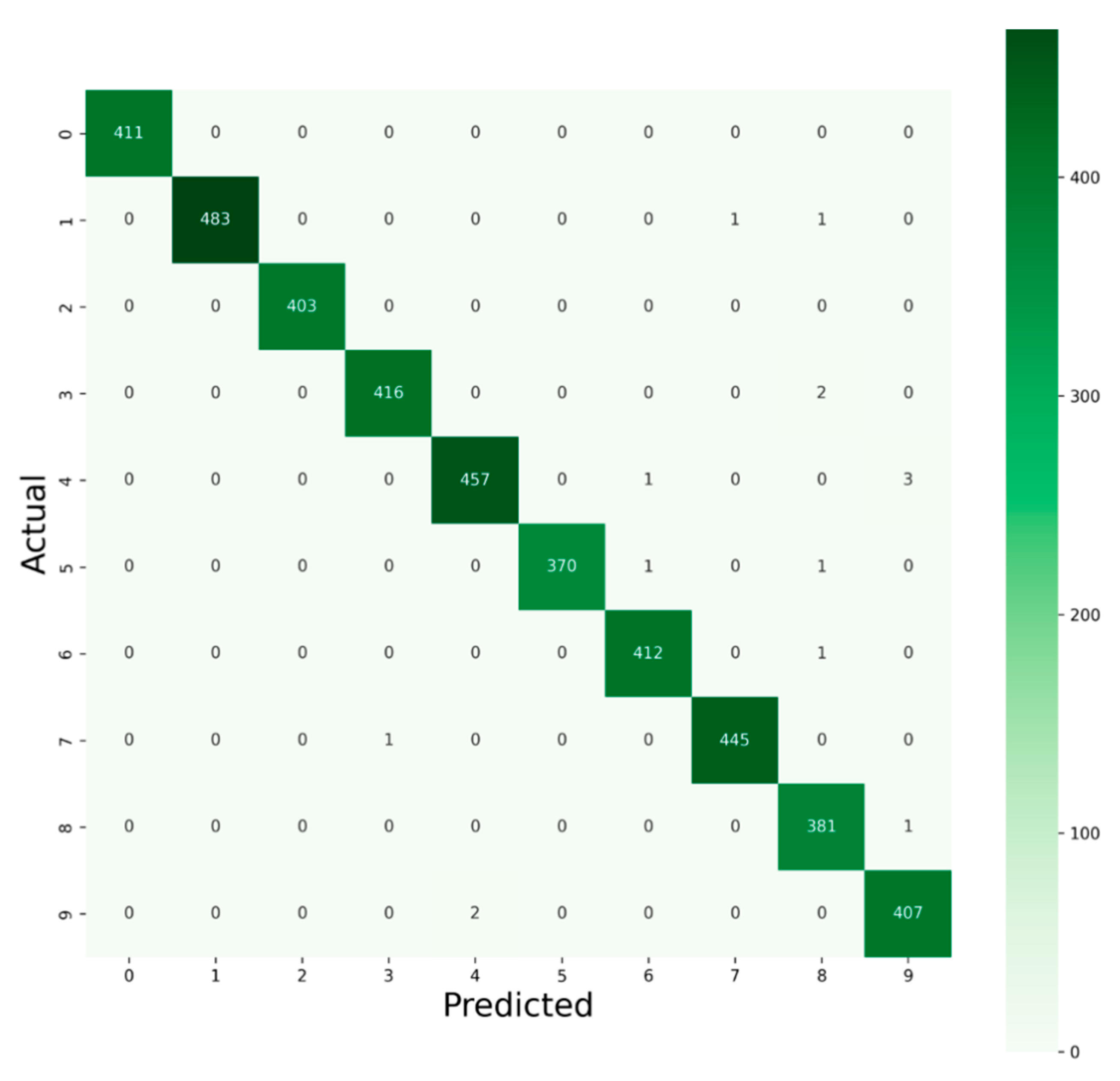
- The distribution of the dataset is imbalanced. Hence, only the accuracy would be ineffectual in evaluating model performance, so advanced performances are analyzed to a great extent with a classification report for the best two proposed models for the Kaggle and MNIST datasets, respectively. Classification reports indicate the F1 score for each of the 10 classes for digits (0–9) and each of the 26 classes for alphabet (A–Z). In our case of multiclass classification, we examined averaging methods for the F1 score, resulting in different average scores, i.e., micro, macro, and weighted average, which is another novelty of this proposed project.
2. Review of Literature and Related Works
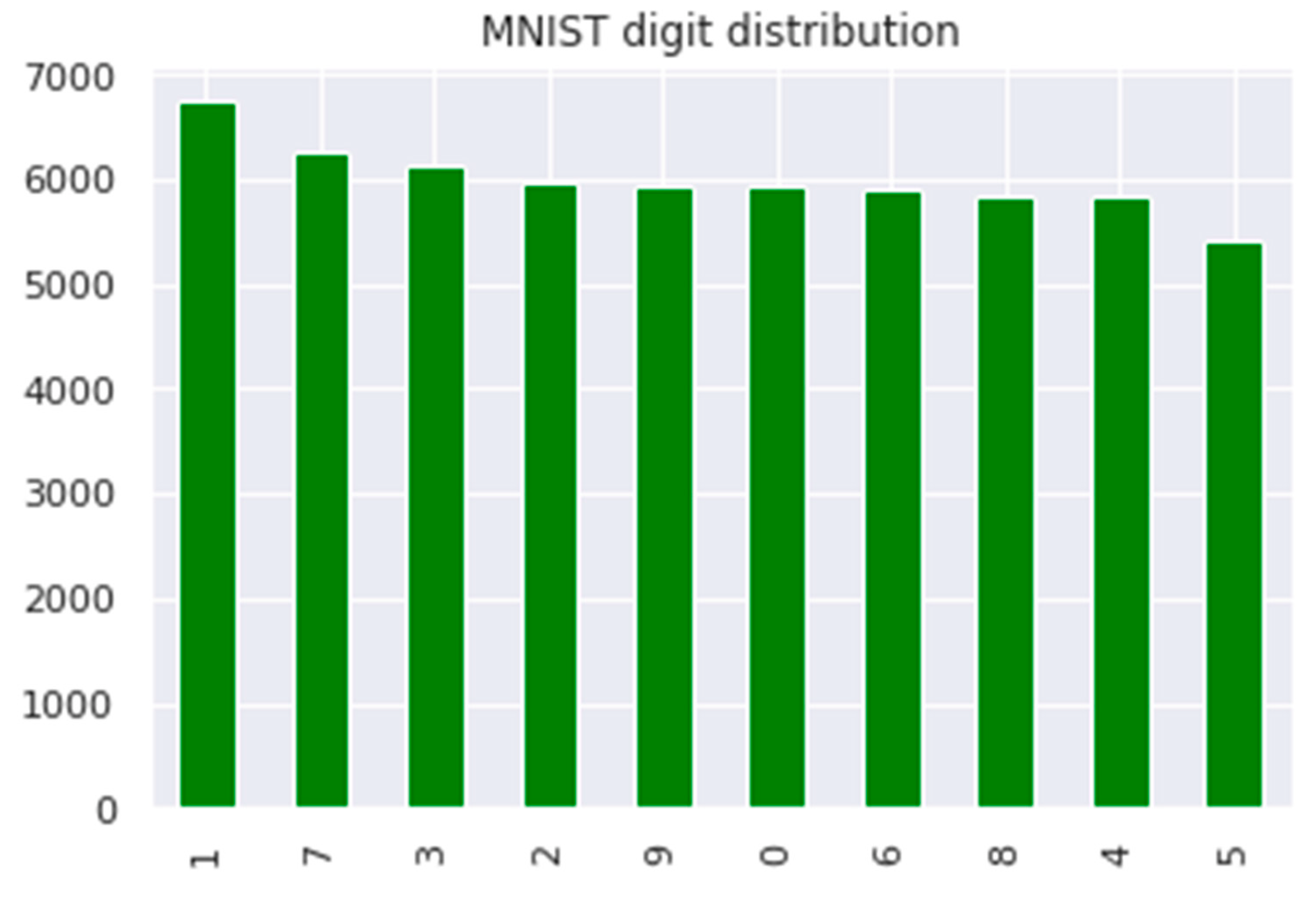
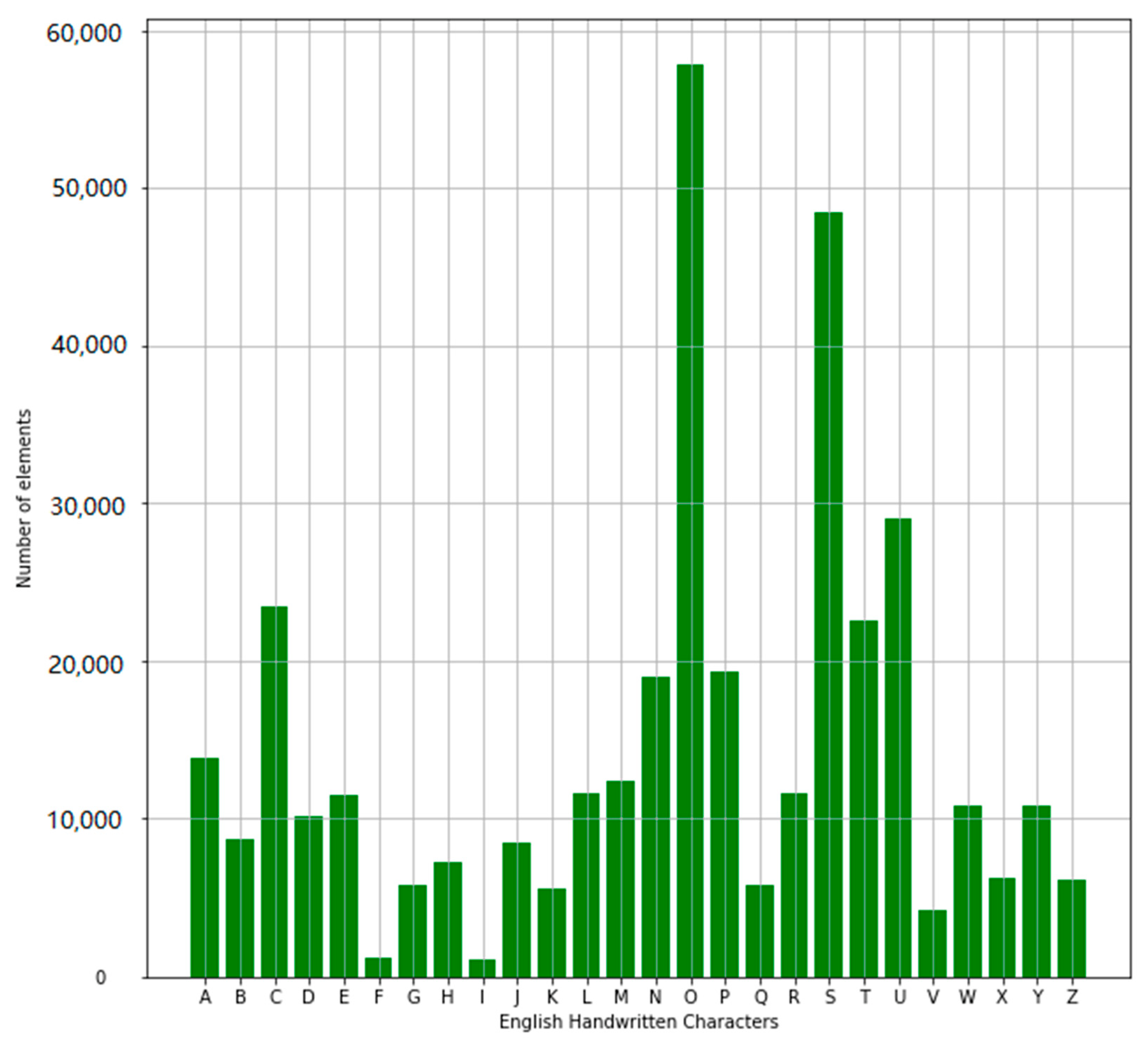
3. Datasets
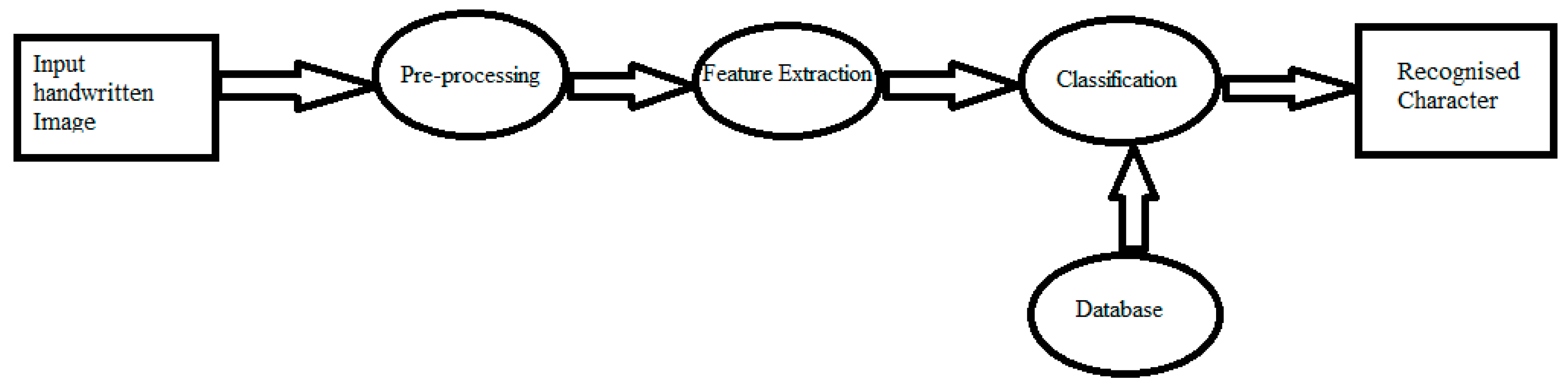
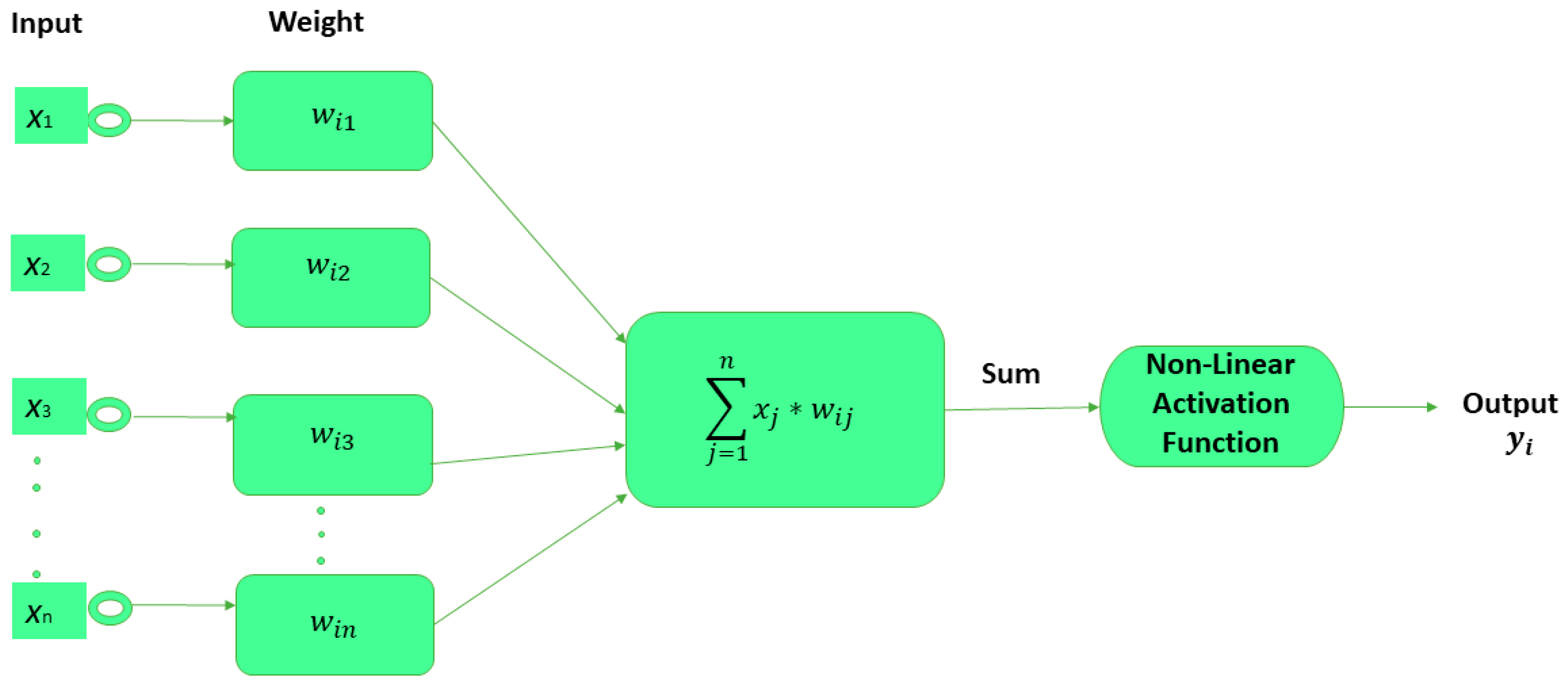
4. Proposed Convolutional Neural Network
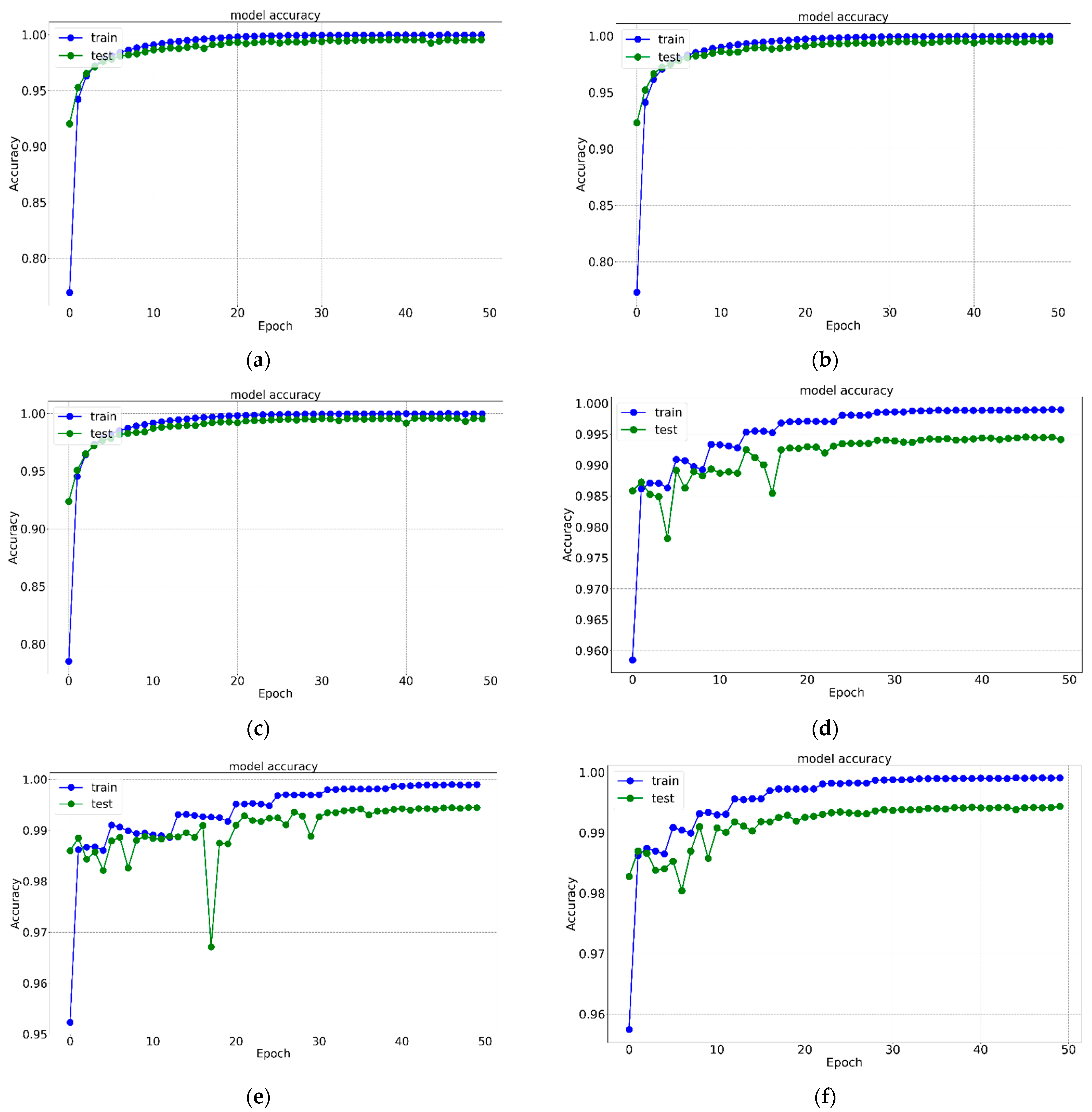
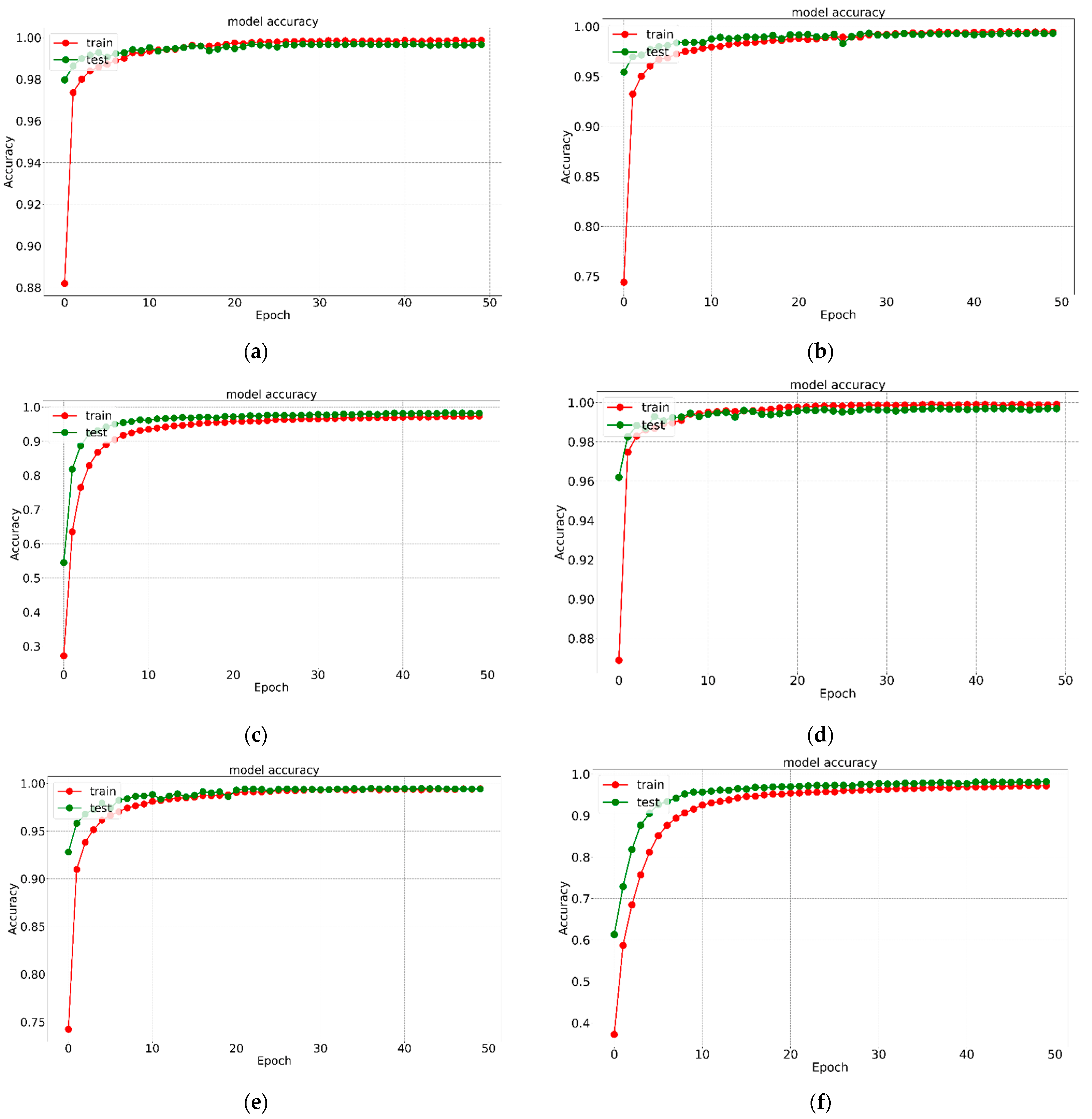
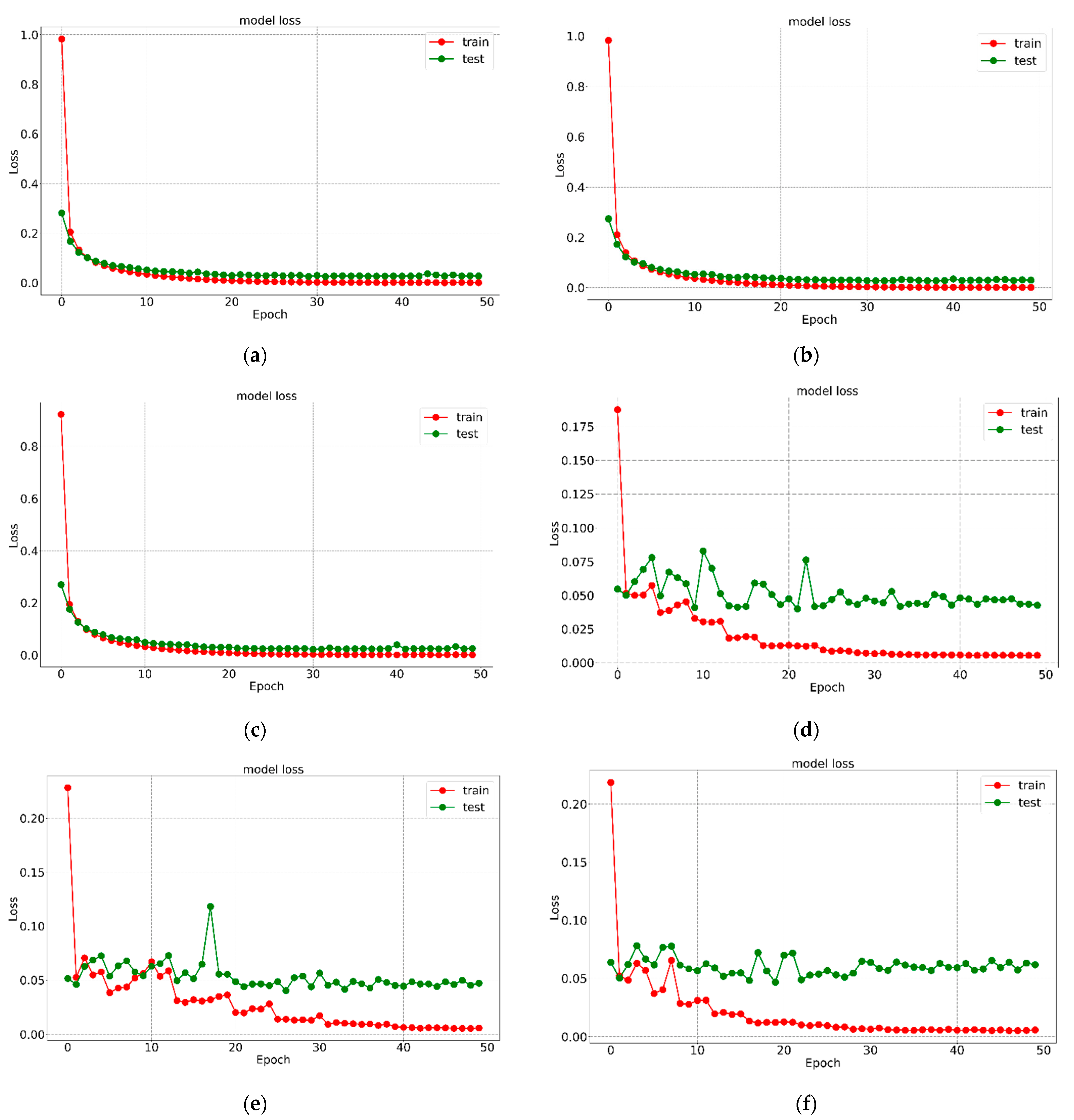
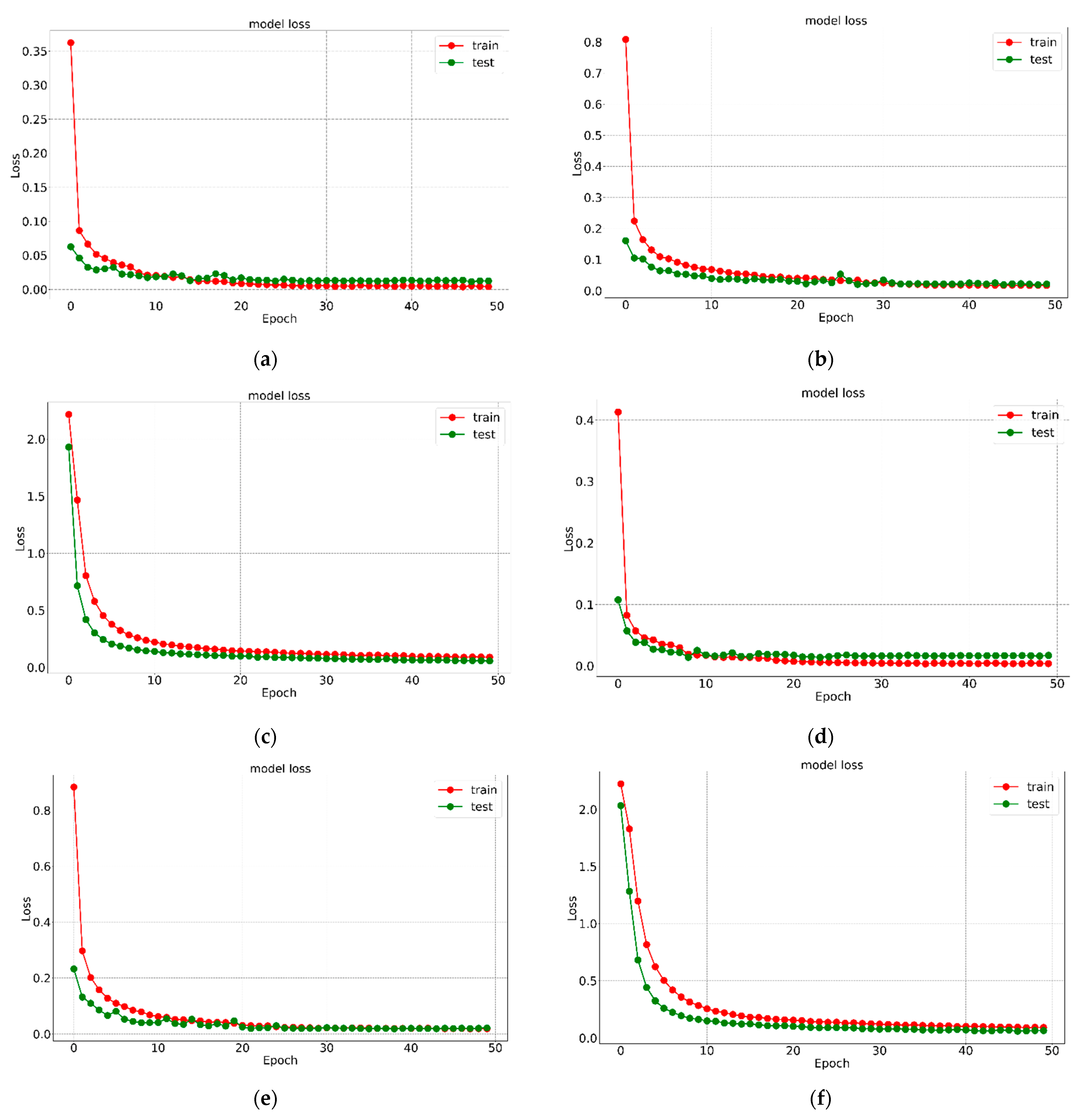
5. Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Priya, A.; Mishra, S.; Raj, S.; Mandal, S.; Datta, S. Online and offline character recognition: A survey. In Proceedings of the International Conference on Communication and Signal Processing, (ICCSP), Melmaruvathur, Tamilnadu, India, 6–8 April 2016; pp. 967–970. [Google Scholar]
- Gunawan, T.S.; Noor, A.F.R.M.; Kartiwi, M. Development of english handwritten recognition using deep neural network. Indones. J. Electr. Eng. Comput. Sci. 2018, 10, 562–568. [Google Scholar] [CrossRef]
- Vinh, T.Q.; Duy, L.H.; Nhan, N.T. Vietnamese handwritten character recognition using convolutional neural network. IAES Int. J. Artif. Intell. 2020, 9, 276–283. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Xiao, J.; Zhu, X.; Huang, C.; Yang, X.; Wen, F.; Zhong, M. A New Approach for Stock Price Analysis and Prediction Based on SSA and SVM. Int. J. Inf. Technol. Decis. Mak. 2019, 18, 35–63. [Google Scholar] [CrossRef]
- Wang, D.; Huang, L.; Tang, L. Dissipativity and synchronization of generalized BAM neural networks with multivariate discontinuous activations. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3815–3827. [Google Scholar] [CrossRef]
- Kuang, F.; Zhang, S.; Jin, Z.; Xu, W. A novel SVM by combining kernel principal component analysis and improved chaotic particle swarm optimization for intrusion detection. Soft Comput. 2015, 19, 1187–1199. [Google Scholar] [CrossRef]
- Choudhary, A.; Ahlawat, S.; Rishi, R. A binarization feature extraction approach to OCR: MLP vs. RBF. In Proceedings of the International Conference on Distributed Computing and Technology (ICDCIT), Bhubaneswar, India, 6–9 February 2014; Springer: Cham, Switzerland, 2014; pp. 341–346. [Google Scholar]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Ahlawat, S.; Choudhary, A.; Nayyar, A.; Singh, S.; Yoon, B. Improved handwritten digit recognition using convolutional neural networks (Cnn). Sensors 2020, 20, 3344. [Google Scholar] [CrossRef]
- Jarrett, K.; Kavukcuoglu, K.; Ranzato, M.; LeCun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Cireşan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. High-Performance Neural Networks for Visual Object Classification. arXiv 2011, arXiv:1102.0183v1. [Google Scholar]
- Ciresan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3642–3649. [Google Scholar]
- Niu, X.X.; Suen, C.Y. A novel hybrid CNN-SVM classifier for recognizing handwritten digits. Pattern Recognit. 2012, 45, 1318–1325. [Google Scholar] [CrossRef]
- Qu, X.; Wang, W.; Lu, K.; Zhou, J. Data augmentation and directional feature maps extraction for in-air handwritten Chinese character recognition based on convolutional neural network. Pattern Recognit. Lett. 2018, 111, 9–15. [Google Scholar] [CrossRef]
- Alvear-Sandoval, R.F.; Figueiras-Vidal, A.R. On building ensembles of stacked denoising auto-encoding classifiers and their further improvement. Inf. Fusion 2018, 39, 41–52. [Google Scholar] [CrossRef] [Green Version]
- Demir, C.; Alpaydin, E. Cost-conscious classifier ensembles. Pattern Recognit. Lett. 2005, 26, 2206–2214. [Google Scholar] [CrossRef]
- Choudhary, A.; Ahlawat, S.; Rishi, R. A Neural Approach to Cursive Handwritten Character Recognition Using Features Extracted from Binarization Technique. Stud. Fuzziness Soft Comput. 2015, 319, 745–771. [Google Scholar] [CrossRef]
- Cai, Z.W.; Huang, L.H. Finite-time synchronization by switching state-feedback control for discontinuous Cohen–Grossberg neural networks with mixed delays. Int. J. Mach. Learn. Cybern. 2018, 9, 1683–1695. [Google Scholar] [CrossRef]
- Zeng, D.; Dai, Y.; Li, F.; Sherratt, R.S.; Wang, J. Adversarial learning for distant supervised relation extraction. Comput. Mater. Contin. 2018, 55, 121–136. [Google Scholar] [CrossRef]
- Long, M.; Zeng, Y. Detecting iris liveness with batch normalized convolutional neural network. Comput. Mater. Contin. 2019, 58, 493–504. [Google Scholar] [CrossRef]
- Huang, C.; Liu, B. New studies on dynamic analysis of inertial neural networks involving non-reduced order method. Neurocomputing 2019, 325, 283–287. [Google Scholar] [CrossRef]
- Xiang, L.; Li, Y.; Hao, W.; Yang, P.; Shen, X. Reversible natural language watermarking using synonym substitution and arithmetic coding. Comput. Mater. Contin. 2018, 55, 541–559. [Google Scholar] [CrossRef]
- Huang, Y.S.; Wang, Z.Y. Decentralized adaptive fuzzy control for a class of large-scale MIMO nonlinear systems with strong interconnection and its application to automated highway systems. Inf. Sci. (Ny). 2014, 274, 210–224. [Google Scholar] [CrossRef]
- Ahlawat, S.; Rishi, R. A Genetic Algorithm Based Feature Selection for Handwritten Digit Recognition. Recent Pat. Comput. Sci. 2018, 12, 304–316. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Pham, V.; Bluche, T.; Kermorvant, C.; Louradour, J. Dropout Improves Recurrent Neural Networks for Handwriting Recognition. In Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition (ICFHR), Heraklion, Greece, 1–4 September 2014; pp. 285–290. [Google Scholar]
- Lang, G.; Li, Q.; Cai, M.; Yang, T.; Xiao, Q. Incremental approaches to knowledge reduction based on characteristic matrices. Int. J. Mach. Learn. Cybern. 2017, 8, 203–222. [Google Scholar] [CrossRef]
- Tabik, S.; Alvear-Sandoval, R.F.; Ruiz, M.M.; Sancho-Gómez, J.L.; Figueiras-Vidal, A.R.; Herrera, F. MNIST-NET10: A heterogeneous deep networks fusion based on the degree of certainty to reach 0.1% error rate. ensembles overview and proposal. Inf. Fusion 2020, 62, 73–80. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Liang, T.; Xu, X.; Xiao, P. A new image classification method based on modified condensed nearest neighbor and convolutional neural networks. Pattern Recognit. Lett. 2017, 94, 105–111. [Google Scholar] [CrossRef]
- Sueiras, J.; Ruiz, V.; Sanchez, A.; Velez, J.F. Offline continuous handwriting recognition using sequence to sequence neural networks. Neurocomputing 2018, 289, 119–128. [Google Scholar] [CrossRef]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of the International Conference on Document Analysis and Recognition(ICDAR), Edinburgh, UK, 3–6 August 2003; Volume 3, pp. 958–963. [Google Scholar]
- Wang, T.; Wu, D.J.; Coates, A.; Ng, A.Y. End-to-end text recognition with convolutional neural networks. In Proceedings of the 21st-International Conference on Pattern Recognition, Tsukuba, Japan, 11–15 November 2012; pp. 3304–3308. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2298–2304. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wu, Y.C.; Yin, F.; Liu, C.L. Improving handwritten Chinese text recognition using neural network language models and convolutional neural network shape models. Pattern Recognit. 2017, 65, 251–264. [Google Scholar] [CrossRef]
- Xie, Z.; Sun, Z.; Jin, L.; Feng, Z.; Zhang, S. Fully convolutional recurrent network for handwritten Chinese text recognition. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 4011–4016. [Google Scholar]
- Liu, C.L.; Yin, F.; Wang, D.H.; Wang, Q.F. Online and offline handwritten Chinese character recognition: Benchmarking on new datasets. Pattern Recognit. 2013, 46, 155–162. [Google Scholar] [CrossRef]
- Boufenar, C.; Kerboua, A.; Batouche, M. Investigation on deep learning for off-line handwritten Arabic character recognition. Cogn. Syst. Res. 2018, 50, 180–195. [Google Scholar] [CrossRef]
- Husnain, M.; Missen, M.M.S.; Mumtaz, S.; Jhanidr, M.Z.; Coustaty, M.; Luqman, M.M.; Ogier, J.M.; Choi, G.S. Recognition of urdu handwritten characters using convolutional neural network. Appl. Sci. 2019, 9, 2758. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, S.B.; Naz, S.; Swati, S.; Razzak, M.I. Handwritten Urdu character recognition using one-dimensional BLSTM classifier. Neural Comput. Appl. 2019, 31, 1143–1151. [Google Scholar] [CrossRef]
- Kavitha, B.R.; Srimathi, C. Benchmarking on offline Handwritten Tamil Character Recognition using convolutional neural networks. J. King Saud Univ.-Comput. Inf. Sci. 2019, 34, 1183–1190. [Google Scholar] [CrossRef]
- Dewan, S.; Chakravarthy, S. A system for offline character recognition using auto-encoder networks. In Proceedings of the the International Conference on Neural Information Processing, Doha, Qatar, 12–15 November 2012. [Google Scholar]
- Sarkhel, R.; Das, N.; Das, A.; Kundu, M.; Nasipuri, M. A multi-scale deep quad tree based feature extraction method for the recognition of isolated handwritten characters of popular indic scripts. Pattern Recognit. 2017, 71, 78–93. [Google Scholar] [CrossRef]
- Gupta, A.; Sarkhel, R.; Das, N.; Kundu, M. Multiobjective optimization for recognition of isolated handwritten Indic scripts. Pattern Recognit. Lett. 2019, 128, 318–325. [Google Scholar] [CrossRef]
- Nguyen, C.T.; Khuong, V.T.M.; Nguyen, H.T.; Nakagawa, M. CNN based spatial classification features for clustering offline handwritten mathematical expressions. Pattern Recognit. Lett. 2020, 131, 113–120. [Google Scholar] [CrossRef]
- Ziran, Z.; Pic, X.; Undri Innocenti, S.; Mugnai, D.; Marinai, S. Text alignment in early printed books combining deep learning and dynamic programming. Pattern Recognit. Lett. 2020, 133, 109–115. [Google Scholar] [CrossRef]
- Ptucha, R.; Petroski Such, F.; Pillai, S.; Brockler, F.; Singh, V.; Hutkowski, P. Intelligent character recognition using fully convolutional neural networks. Pattern Recognit. 2019, 88, 604–613. [Google Scholar] [CrossRef]
- Tso, W.W.; Burnak, B.; Pistikopoulos, E.N. HY-POP: Hyperparameter optimization of machine learning models through parametric programming. Comput. Chem. Eng. 2020, 139, 106902. [Google Scholar] [CrossRef]
- Cui, H.; Bai, J. A new hyperparameters optimization method for convolutional neural networks. Pattern Recognit. Lett. 2019, 125, 828–834. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ghosh, T.; Abedin, M.H.Z.; Al Banna, H.; Mumenin, N.; Abu Yousuf, M. Performance Analysis of State of the Art Convolutional Neural Network Architectures in Bangla Handwritten Character Recognition. Pattern Recognit. Image Anal. 2021, 31, 60–71. [Google Scholar] [CrossRef]
- LeCun, Y. The Mnist Dataset of Handwritten Digits. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 26 February 2022).
- Kaggle:A-Z Handwritten Alphabets in.csv Format. Available online: https://www.kaggle.com/sachinpatel21/az-handwritten-alphabets-in-csv-format/metadata (accessed on 26 February 2022).
- Kavitha, M.; Gayathri, R.; Polat, K.; Alhudhaif, A.; Alenezi, F. Performance evaluation of deep e-CNN with integrated spatial-spectral features in hyperspectral image classification. Measurement 2022, 191, 110760. [Google Scholar] [CrossRef]
- Foysal Haque, K.; Farhan Haque, F.; Gandy, L.; Abdelgawad, A. Automatic Detection of COVID-19 from Chest X-ray Images with Convolutional Neural Networks. In Proceedings of the 2020 International Conference on Computing, Electronics and Communications Engineering (ICCECE), Southend Campus, UK, 17–18 August 2020; pp. 125–130. [Google Scholar]
- Mor, S.S.; Solanki, S.; Gupta, S.; Dhingra, S.; Jain, M.; Saxena, R. Handwritten text recognition: With deep learning and android. Int. J. Eng. Adv. Technol. 2019, 8, 172–178. [Google Scholar]
- Alom, M.Z.; Sidike, P.; Taha, T.M.; Asari, V.K. Handwritten Bangla Digit Recognition Using Deep Learning. arXiv 2017, arXiv:1705.02680. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 2007 Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 548–556. [Google Scholar]
- Dos Santos, M.M.; da Silva Filho, A.G.; dos Santos, W.P. Deep convolutional extreme learning machines: Filters combination and error model validation. Neurocomputing 2019, 329, 359–369. [Google Scholar] [CrossRef]
- Adnan, M.; Rahman, F.; Imrul, M.; AL, N.; Shabnam, S. Handwritten Bangla Character Recognition using Inception Convolutional Neural Network. Int. J. Comput. Appl. 2018, 181, 48–59. [Google Scholar] [CrossRef]
- Xue, W.; Dai, X.; Liu, L. Remote Sensing Scene Classification Based on Multi-Structure Deep Features Fusion. IEEE Access 2020, 8, 28746–28755. [Google Scholar] [CrossRef]
- Prashanth, D.S.; Mehta, R.V.K.; Sharma, N. Classification of Handwritten Devanagari Number-An analysis of Pattern Recognition Tool using Neural Network and CNN. In Procedia Computer Science; Elsevier: Amsterdam, The Netherlands, 2020; Volume 167, pp. 2445–2457. [Google Scholar]
- Joshi, D.S.; Risodkar, Y.R. Deep Learning Based Gujarati Handwritten Character Recognition. In Proceedings of the 2018 International Conference On Advances in Communication and Computing Technology, Sangamner, India, 8–9 February 2018; pp. 563–566. [Google Scholar]
- Sen, S.; Shaoo, D.; Paul, S.; Sarkar, R.; Roy, K. Online handwritten bangla character recognition using CNN: A deep learning approach. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2018; Volume 695, pp. 413–420. ISBN 9789811075650. [Google Scholar]
- Weng, Y.; Xia, C. A New Deep Learning-Based Handwritten Character Recognition System on Mobile Computing Devices. Mob. Netw. Appl. 2020, 25, 402–411. [Google Scholar] [CrossRef] [Green Version]
- Gan, J.; Wang, W.; Lu, K. A new perspective: Recognizing online handwritten Chinese characters via 1-dimensional CNN. Inf. Sci. (Ny). 2019, 478, 375–390. [Google Scholar] [CrossRef]
- Saha, S.; Saha, N. A Lightning fast approach to classify Bangla Handwritten Characters and Numerals using newly structured Deep Neural Network. Procedia Comput. Sci. 2018, 132, 1760–1770. [Google Scholar] [CrossRef]
- Hamdan, Y.B. Sathish Construction of Statistical SVM based Recognition Model for Handwritten Character Recognition. J. Inf. Technol. Digit. World 2021, 3, 92–107. [Google Scholar] [CrossRef]
- Ukil, S.; Ghosh, S.; Obaidullah, S.M.; Santosh, K.C.; Roy, K.; Das, N. Improved word-level handwritten Indic script identification by integrating small convolutional neural networks. Neural Comput. Appl. 2020, 32, 2829–2844. [Google Scholar] [CrossRef]
- Cavalin, P.; Oliveira, L. Confusion matrix-based building of hierarchical classification. In Proceedings of the Pattern Recognition, Image Analysis, Computer Vision, and Applications, Havana, Cuba, 28–31 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11401, pp. 271–278. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | Param # |
|---|---|---|
| conv_1 (Conv 2D) | (None, 26, 26, 32) | 320 |
| conv_2 (Conv 2D) | (None, 26, 26, 64) | 18,496 |
| max_pooling2D_18 (MaxPooling2D) | (None, 13, 13, 64) | 0 |
| conv_3 (Conv 2D) | (None, 13, 13, 128) | 73,856 |
| max_pooling2D_19 (MaxPooling2D) | (None, 6, 6, 128) | 0 |
| conv_4 (Conv 2D) | (None, 6, 6, 256) | 295,168 |
| max_pooling2D_20 (MaxPooling2D) | (None, 3, 3, 256) | 0 |
| flatten (Flatten) | (None, 2304) | 0 |
| FC_1 (Dense) | (None, 64) | 147,520 |
| FC_2 (Dense) | (None, 10) | 650 |
| Total Params # | 536,010 | |
| Trainable Params # | 536,010 | |
| Non-Trainable Params # | 0 | |
| Data-Set | Learning Rate | Optimizer | Model Name | Precision (%) | Specificity (%) | Recall (%) | TFP | TFN | TTP | TTN | Overall Accuracy (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Kaggle Alphabet Recognition | 0.001 | ‘ADAM’ | K1 | 99.4 | 99.98 | 99.51 | 360 | 360 | 74,130 | 1,861,890 | 99.516 |
| RMS_prop | K2 | 99.2 | 99.97 | 99.29 | 527 | 527 | 73,963 | 1,861,723 | 99.292 | ||
| 0.0001 | ‘ADAM’ | K3 | 99.5 | 99.98 | 99.51 | 364 | 364 | 74,126 | 1,861,886 | 99.511 | |
| RMS_prop | K4 | 99.0 | 99.96 | 99.10 | 664 | 664 | 73,826 | 1,861,586 | 99.108 | ||
| 0.00001 | ‘ADAM’ | K5 | 99.5 | 99.98 | 99.56 | 325 | 325 | 74,165 | 1,861,925 | 99.563 | |
| RMS_prop | K6 | 99.1 | 99.96 | 99.19 | 602 | 602 | 73,888 | 1,861,648 | 99.191 | ||
| MNIST Digit Recognition | 0.001 | ‘ADAM’ | M1 | 99.5 | 99.95 | 99.57 | 22 | 22 | 4178 | 37,778 | 99.571 |
| RMS_prop | M2 | 99.6 | 99.96 | 99.64 | 15 | 15 | 4185 | 37,785 | 99.642 | ||
| 0.0001 | ‘ADAM’ | M3 | 99.2 | 99.92 | 99.30 | 29 | 29 | 4171 | 37,771 | 99.309 | |
| RMS_prop | M4 | 99.4 | 99.93 | 99.45 | 23 | 23 | 4177 | 37,777 | 99.452 | ||
| 0.00001 | ‘ADAM’ | M5 | 98.2 | 99.80 | 98.23 | 74 | 74 | 4126 | 37,726 | 98.238 | |
| RMS_prop | M6 | 98.1 | 99.79 | 98.14 | 78 | 78 | 4122 | 37,722 | 98.142 |
| Digit (0–9) | Precision /Class | Recall /Class | F1 Score /Class | Support /Class | Support Proportion/Class |
|---|---|---|---|---|---|
| class 0 | 1.00 | 1.00 | 1.00 | 411 | 0.098 |
| class 1 | 1.00 | 1.00 | 1.00 | 485 | 0.115 |
| class 2 | 1.00 | 1.00 | 1.00 | 403 | 0.096 |
| class 3 | 1.00 | 1.00 | 1.00 | 418 | 0.1 |
| class 4 | 1.00 | 0.99 | 0.99 | 461 | 0.11 |
| class 5 | 1.00 | 0.99 | 1.00 | 372 | 0.089 |
| class 6 | 1.00 | 1.00 | 1.00 | 413 | 0.098 |
| class 7 | 1.00 | 1.00 | 1.00 | 446 | 0.106 |
| class 8 | 0.99 | 1.00 | 0.99 | 382 | 0.091 |
| class 9 | 0.99 | 1.00 | 0.99 | 409 | 0.097 |
| Total | 4200 | 1.00 | |||
| Letters (A–Z) | Precision /Class | Recall /Class | F1 score /Class | Support /Class | Support Proportion /Class |
|---|---|---|---|---|---|
| class A | 0.99 | 0.99 | 0.99 | 1459 | 0.02 |
| class B | 1.00 | 0.99 | 1.00 | 4747 | 0.064 |
| class C | 0.99 | 1.00 | 0.99 | 2310 | 0.031 |
| class D | 1.00 | 1.00 | 1.00 | 5963 | 0.08 |
| class E | 0.99 | 0.99 | 0.99 | 1986 | 0.027 |
| class F | 0.99 | 0.99 | 0.99 | 1161 | 0.016 |
| class G | 1.00 | 0.99 | 0.99 | 1712 | 0.023 |
| class H | 0.99 | 1.00 | 0.99 | 2291 | 0.031 |
| class I | 1.00 | 1.00 | 1.00 | 3894 | 0.052 |
| class J | 0.99 | 1.00 | 0.99 | 2724 | 0.037 |
| class K | 0.99 | 0.99 | 0.99 | 2315 | 0.031 |
| class L | 0.98 | 0.99 | 0.99 | 1109 | 0.015 |
| class M | 1.00 | 0.99 | 1.00 | 3841 | 0.052 |
| class N | 1.00 | 1.00 | 1.00 | 11,524 | 0.155 |
| class O | 0.99 | 0.99 | 0.99 | 2488 | 0.033 |
| class P | 0.99 | 0.99 | 0.99 | 1235 | 0.017 |
| class Q | 1.00 | 1.00 | 1.00 | 4518 | 0.061 |
| class R | 0.99 | 0.99 | 0.99 | 1226 | 0.016 |
| class S | 1.00 | 0.98 | 0.99 | 229 | 0.003 |
| class T | 1.00 | 0.99 | 0.99 | 870 | 0.012 |
| class U | 1.00 | 0.99 | 1.00 | 2045 | 0.027 |
| class V | 1.00 | 1.00 | 1.00 | 9529 | 0.128 |
| class W | 0.99 | 0.98 | 0.99 | 1145 | 0.015 |
| class X | 0.99 | 0.99 | 0.99 | 2165 | 0.029 |
| class Y | 0.97 | 0.96 | 0.97 | 249 | 0.003 |
| class Z | 0.99 | 0.99 | 0.99 | 1755 | 0.024 |
| Total | 74,490 | 1.00 | |||
| F-Measure | Model M2 (Digit Recognition) | Model K5 (Letter Recognition) |
|---|---|---|
| Micro F1 score | 0.996 | 0.995 |
| Macro F1 score | 0.998 | 0.992 |
| Weighted F1 score | 0.997 | 0.996 |
| Sl. No. | Author(s) | Publication Year | Approach | Dataset | Preprocessing | Results |
|---|---|---|---|---|---|---|
| 1. | Mor et al. [63] | 2019 | Two convolutional layers and one dense layer. | EMNIST | X | 87.1% |
| 2. | Alom et al. [64] | 2017 | CNN with dropout and Gabor Filters. | CMATERdb 3.1.1 | Raw images passed to Normalization | 98.78% |
| 3. | Sabour et al. [65] | 2019 | A CNN with 3 convolutional layers and two capsule layers. | EMNIST | X | 95.36% (Letters) 99.79% (Digits) |
| 4. | Dos Santos et al. [66] | 2019 | Deep convolutional extreme learning machine. | EMNIST Digits | X | 99.775%. |
| 5. | Adnan et al. [67] | 2018 | Deep Belief Network (DBN), Stacked Auto encoder (AE), DenseNet | CMATERdb 3.11 | 600 images are rescaled to 32 × 32 pixels. | 99.13% (Digits) 98.31% (Alphabets) 98.18% (Special Character) |
| 6. | W. Xue et al. [68] | 2020 | Three CNN were combined into a single feature map for classification. | UC Merced, AID, and NWPU-RESISC45 | X | AID: 93.47% UC Merced: 98.85%, NWPU-RESISC45: 95% |
| 7. | D.S.Prashanth et al. [69] | 2020 | 1. CNN, 2. Modified Lenet CNN (MLCNN) and 3. Alexnet CNN (ACNN). | Own dataset of 38,750 images | X | CNN: 94% MLCNN: 99% ACNN: 98% |
| 8. | D.S.Joshi and Risodkar [70] | 2018 | K-NN classifier and Neural Network | Own dataset with 30 samples | RGB to gray conversion, skew correction, filtering, morphological operation | 78.6% |
| 9. | Ptucha et al. [51] | 2020 | Introduced an intelligent character recognition (ICR) system | IAM RIMES lexicon | X | 99% |
| 10. | Shibaprasad et al. [71] | 2018 | Convolutional Neural Network (CNN) architecture | 1000-character samples | Resized all images to 28 × 28 pixels. | 99.40% |
| 11. | Yu Weng and Cnulei Xia [72] | 2019 | Deep Neural Network (DNNs) | Own dataset of 400 types of pictures | Normalized to 52 × 52 pixels. | 93.3% |
| 12. | Gan et al. [73] | 2019 | 1-D CNN | ICDAR-2013 IAHCC-UC AS2016 | Chinese character images rescaled into 60 × 60-pixel size. | 98.11% (ICDAR-2013) 97.14% (IAHCC-UCA2016) |
| 13. | Kavitha et al. [45] | 2019 | CNN (5 convolution layers, 2 max pooling layers, and fully connected layers) | HPL-Tamil-is o-char | RGB to gray conversion | 97.7%. |
| 14. | Saha et al. [74] | 2019 | Divide and Merge Mapping (DAMM) | Own dataset with 1,66,105 images | Resize all images to 128 × 128. | 99.13% |
| 15. | Y. B. Hamdan et al. [75] | 2021 | Support vector machine (SVM) classifiers network graphical methods. | MNIST, CENPARMI | X | 94% |
| 16. | Ukil et al. [76] | 2019 | CNNs | PHD Indic_11 | RGB to grayscale conversion and resized image to 28 × 28 pixels. | 95.45% |
| 17. | Cavalin et al. al. [77] | 2019 | A hierarchical classifier by the confusion matrix of flat classifier | EMNIST | X | 99.46% (Digits) 93.63% (Letters) |
| 18. | Tapotosh Ghosh et al. [58] | 2021 | InceptionResNetV2, DenseNet121, and InceptionNetV3 | CMATERdb | The images were first converted to B&W 28 × 28 form with white as the foreground color. | 97.69% |
| 19. | Proposed Model | 2022 | CNN using ‘RMSprop’ and ‘ADAM’ optimizer with four convolutional layers, three max pooling and two dense layers are used for three different Learning rates (LR 0.001, LR 0.0001 and LR 0.00001) for multiclass classification. | MNIST: 60,000 training, 10,000 testing images. Kaggle: 297,000 training, 74,490 testing images. | Each digit/letter is of a uniform size and by computing the center of mass of the pixels, each binary image of a handwritten digit is centered into a 28 × 28 image. | 99.64% (Digits) Macro F1 score average: 0.998 99.56% (Letters) Macro F1 score average: 0.992 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saqib, N.; Haque, K.F.; Yanambaka, V.P.; Abdelgawad, A. Convolutional-Neural-Network-Based Handwritten Character Recognition: An Approach with Massive Multisource Data. Algorithms 2022, 15, 129. https://doi.org/10.3390/a15040129
Saqib N, Haque KF, Yanambaka VP, Abdelgawad A. Convolutional-Neural-Network-Based Handwritten Character Recognition: An Approach with Massive Multisource Data. Algorithms. 2022; 15(4):129. https://doi.org/10.3390/a15040129
Chicago/Turabian StyleSaqib, Nazmus, Khandaker Foysal Haque, Venkata Prasanth Yanambaka, and Ahmed Abdelgawad. 2022. "Convolutional-Neural-Network-Based Handwritten Character Recognition: An Approach with Massive Multisource Data" Algorithms 15, no. 4: 129. https://doi.org/10.3390/a15040129
APA StyleSaqib, N., Haque, K. F., Yanambaka, V. P., & Abdelgawad, A. (2022). Convolutional-Neural-Network-Based Handwritten Character Recognition: An Approach with Massive Multisource Data. Algorithms, 15(4), 129. https://doi.org/10.3390/a15040129