
MAC Address Anonymization for Crowd Counting


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. A Short Description of the Monitoring System Architecture
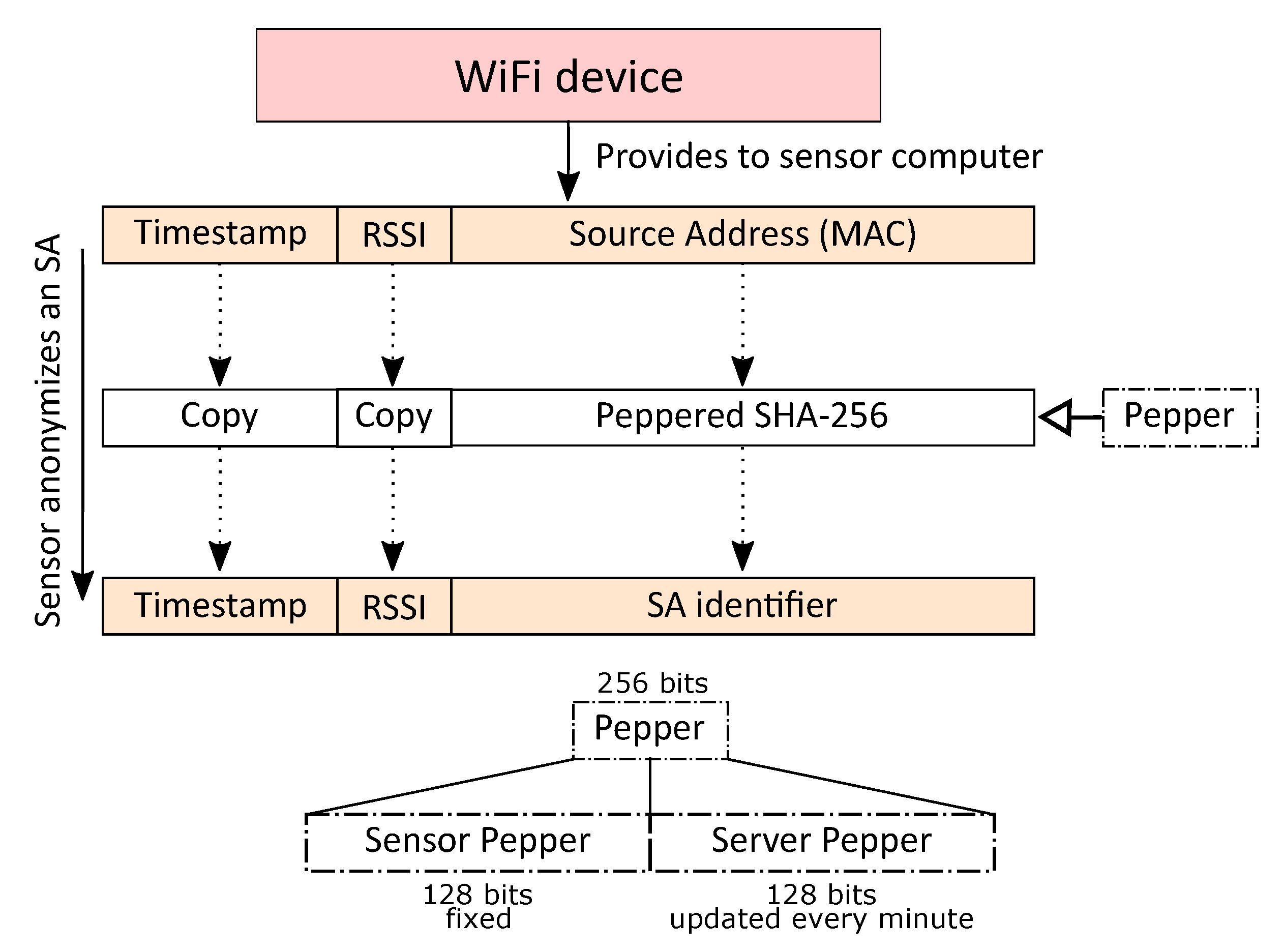
1.2. Collected Data and the Anonymization Procedure
1.3. Contributions
- It is computationally intractable to recover the original MAC addresses from the anonymous identifiers our system generates.
- Anonymous identifiers from two distinct one-minute time frames cannot be compared against one another, which entails the impossibility to track individuals over time.
- The proportion of time instants during which two sensors of our system could generate distinct anonymous identifiers for the same MAC address is negligible.
- Assuming WiFi devices in an area generate distinct MAC addresses within one minute in a monitored area, the collision rate of our anonymization procedure is lower than . The value of distinct MAC addresses corresponds roughly to an event of a few million people, which is comparable to or higher than the number of attendees of the vast majority of public events in the world.
1.4. Comparison with the State of the Art
1.5. Outline
2. Results
2.1. Requirement 1: Impossibility to Recover the Original SA from SA Identifiers
2.2. Requirement 2: Preventing Tracking for More Than One Minute
2.3. Requirement 3: Peppers Are Identical across All Sensors at a Given Time Instant
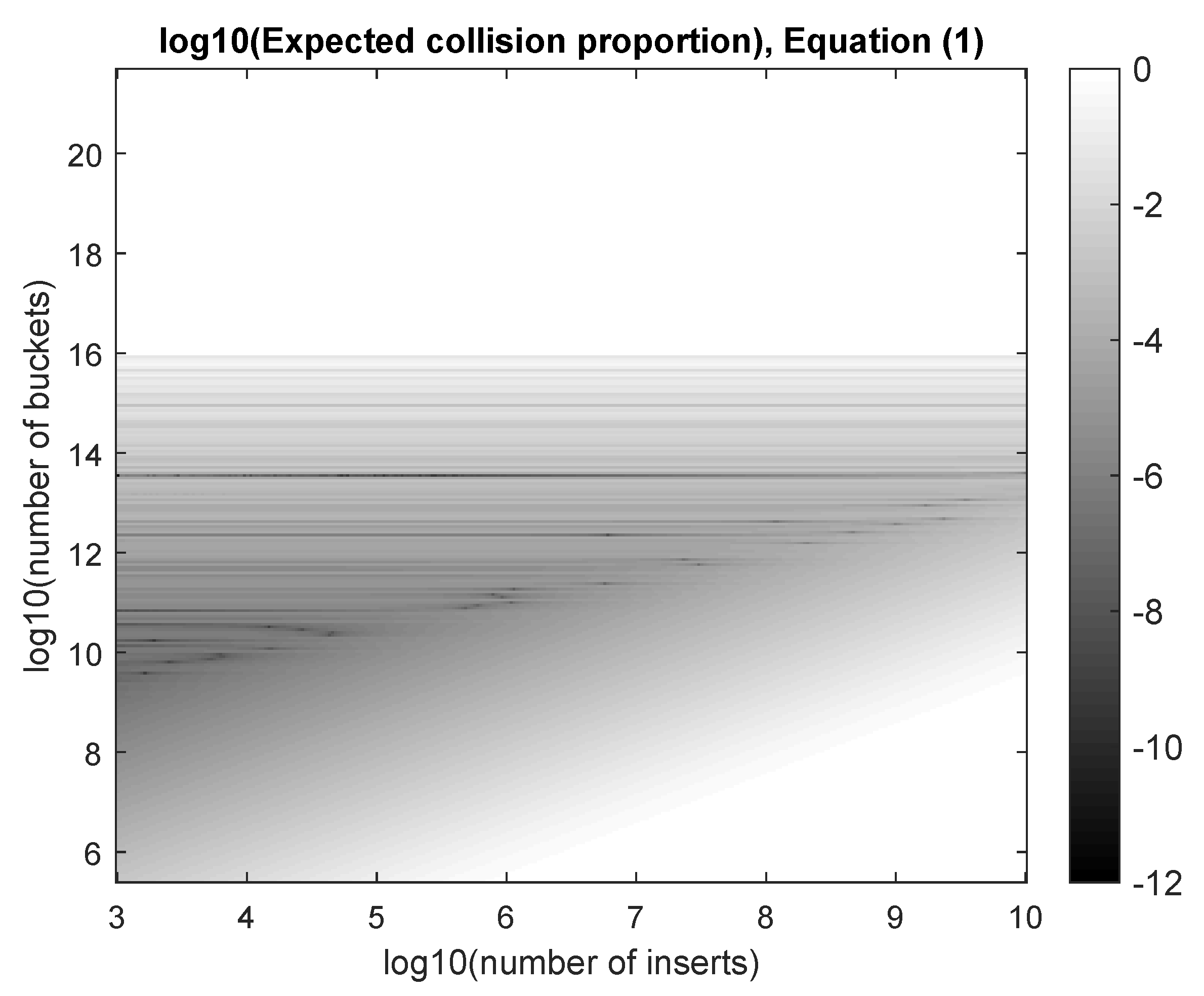
2.4. Requirement 4: A Collision Rate of Less Than for MAC Addresses
2.4.1. Mathematical Foundations
2.4.2. The Interpretation of Theorem 2
2.4.3. Proving Requirement 4 Is Satisfied
2.4.4. Concentration Inequality for the Collision Rate
2.5. Validating Requirement 4 Experimentally
3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASIC | Application-specific integrated circuit |
| FPGA | Field-programmable gate array |
| GPU | Graphical processing unit |
| HTTPS | Hypertext tranfer protocol secure |
| MAC | Media access control |
| NTP | Network time protocol |
| PR | Probe request |
| PRNG | Pseudo random number generator |
| UUID | Universally unique identifier |
| RSSI | Received signal strength indicator |
| SA | Source address |
| TLS | Transport layer security |
Appendix A. Proofs
Appendix A.1. Proof of Theorem 1
Appendix A.2. Lemmas for Theorem 2
Appendix A.3. Proof of Theorem 2
References
- Martella, C.; Li, J.; Conrado, C.; Vermeeren, A. On current crowd management practices and the need for increased situation awareness, prediction, and intervention. Saf. Sci. 2017, 91, 381–393. [Google Scholar] [CrossRef]
- Uras, M.; Cossu, R.; Ferrara, E.; Liotta, A.; Atzori, L. PmA: A real-world system for people mobility monitoring and analysis based on Wi-Fi probes. J. Clean. Prod. 2020, 270, 122084. [Google Scholar] [CrossRef]
- Determe, J.F.; Singh, U.; Horlin, F.; De Doncker, P. Forecasting Crowd Counts With Wi-Fi Systems: Univariate, Non-Seasonal Models. IEEE Trans. Intell. Transp. Syst. 2020, 22, 6407–6419. [Google Scholar] [CrossRef]
- Singh, U.; Determe, J.F.; Horlin, F.; De Doncker, P. Crowd Forecasting based on WiFi Sensors and LSTM Neural Networks. IEEE Trans. Instrum. Meas. 2020, 69, 6121–6131. [Google Scholar] [CrossRef] [Green Version]
- Determe, J.F.; Azzagnuni, S.; Singh, U.; Horlin, F.; De Doncker, P. Monitoring Large Crowds With WiFi: A Privacy-Preserving Approach. IEEE Syst. J. 2022, 1–12. [Google Scholar] [CrossRef]
- Dodis, Y.; Pointcheval, D.; Ruhault, S.; Vergniaud, D.; Wichs, D. Security analysis of pseudo-random number generators with input: /dev/random is not robust. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; pp. 647–658. [Google Scholar]
- Stipčević, M.; Rogina, B.M. Quantum random number generator based on photonic emission in semiconductors. Rev. Sci. Instruments 2007, 78, 045104. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Zhang, Y.; Huang, W.; Yu, S.; Guo, H. 6 Gbps real-time optical quantum random number generator based on vacuum fluctuation. Rev. Sci. Instruments 2019, 90, 043105. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Demir, L.; Cunche, M.; Lauradoux, C. Analysing the privacy policies of Wi-Fi trackers. In Proceedings of the 2014 Workshop on Physical Analytics, Bretton Woods, NH, USA, 16 June 2014; pp. 39–44. [Google Scholar]
- Leach, P.; Mealling, M.; Salz, R. A Universally Unique Identifier (UUID) URN Namespace. 2005. Available online: https://www.rfc-editor.org/rfc/pdfrfc/rfc4122.txt.pdf (accessed on 18 April 2022).
- Demir, L.; Kumar, A.; Cunche, M.; Lauradoux, C. The pitfalls of hashing for privacy. IEEE Commun. Surv. Tutorials 2017, 20, 551–565. [Google Scholar] [CrossRef] [Green Version]
- Marx, M.; Zimmer, E.; Mueller, T.; Blochberger, M.; Federrath, H. Hashing of personally identifiable information is not sufficient. SICHERHEIT 2018 2018. [Google Scholar] [CrossRef]
- Fuxjaeger, P.; Ruehrup, S.; Paulin, T.; Rainer, B. Towards privacy-preserving Wi-Fi monitoring for road traffic analysis. IEEE Intell. Transp. Syst. Mag. 2016, 8, 63–74. [Google Scholar] [CrossRef]
- Ali, J.; Dyo, V. Practical Hash-based Anonymity for MAC Addresses. In Proceedings of the 17th International Joint Conference on e-Business and Telecommunications, ICETE 2020—Volume 2: SECRYPT, Lieusaint, Paris, France, 8–10 July 2020; Samarati, P., di Vimercati, S.D.C., Obaidat, M.S., Ben-Othman, J., Eds.; ScitePress: Setúbal, Portugal, 2020; pp. 572–579. [Google Scholar] [CrossRef]
- Hong, H.; De Silva, G.D.; Chan, M.C. Crowdprobe: Non-invasive crowd monitoring with Wi-Fi probe. Proc. ACM Interactive Mobile Wearable Ubiquitous Technol. 2018, 2, 1–23. [Google Scholar] [CrossRef]
- Potortì, F.; Crivello, A.; Girolami, M.; Barsocchi, P.; Traficante, E. Localising crowds through Wi-Fi probes. Ad Hoc Netw. 2018, 75, 87–97. [Google Scholar] [CrossRef]
- Nvidia RTX 2080 SUPER FE Hashcat Benchmarks. Available online: https://gist.github.com/epixoip/47098d25f171ec1808b519615be1b90d (accessed on 13 August 2020).
- Provos, N.; Mazieres, D. A Future-Adaptable Password Scheme. In Proceedings of the USENIX Annual Technical Conference, FREENIX Track, Monterey, CA, USA, 6–11 June 1999; pp. 81–91. [Google Scholar]
- Biryukov, A.; Dinu, D.; Khovratovich, D. Argon2: New generation of memory-hard functions for password hashing and other applications. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbruecken, Germany, 21–24 March 2016; pp. 292–302. [Google Scholar]
- Miškinis, R.; Jokubauskis, D.; Smirnov, D.; Urba, E.; Malyško, B.; Dzindzelėta, B.; Svirskas, K. Timing over a 4G (LTE) mobile network. In Proceedings of the 2014 European Frequency and Time Forum (EFTF), Neuchatel, Switzerland, 23–26 June 2014; pp. 491–493. [Google Scholar]
- Menezes, A.J.; Katz, J.; Van Oorschot, P.C.; Vanstone, S.A. Handbook of Applied Cryptography; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- Rudin, W. Principles of Mathematical Analysis; McGraw-hill: New York, NY, USA, 1964; Volume 3. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Determe, J.-F.; Azzagnuni, S.; Horlin, F.; De Doncker, P. MAC Address Anonymization for Crowd Counting. Algorithms 2022, 15, 135. https://doi.org/10.3390/a15050135
Determe J-F, Azzagnuni S, Horlin F, De Doncker P. MAC Address Anonymization for Crowd Counting. Algorithms. 2022; 15(5):135. https://doi.org/10.3390/a15050135
Chicago/Turabian StyleDeterme, Jean-François, Sophia Azzagnuni, François Horlin, and Philippe De Doncker. 2022. "MAC Address Anonymization for Crowd Counting" Algorithms 15, no. 5: 135. https://doi.org/10.3390/a15050135
APA StyleDeterme, J. -F., Azzagnuni, S., Horlin, F., & De Doncker, P. (2022). MAC Address Anonymization for Crowd Counting. Algorithms, 15(5), 135. https://doi.org/10.3390/a15050135