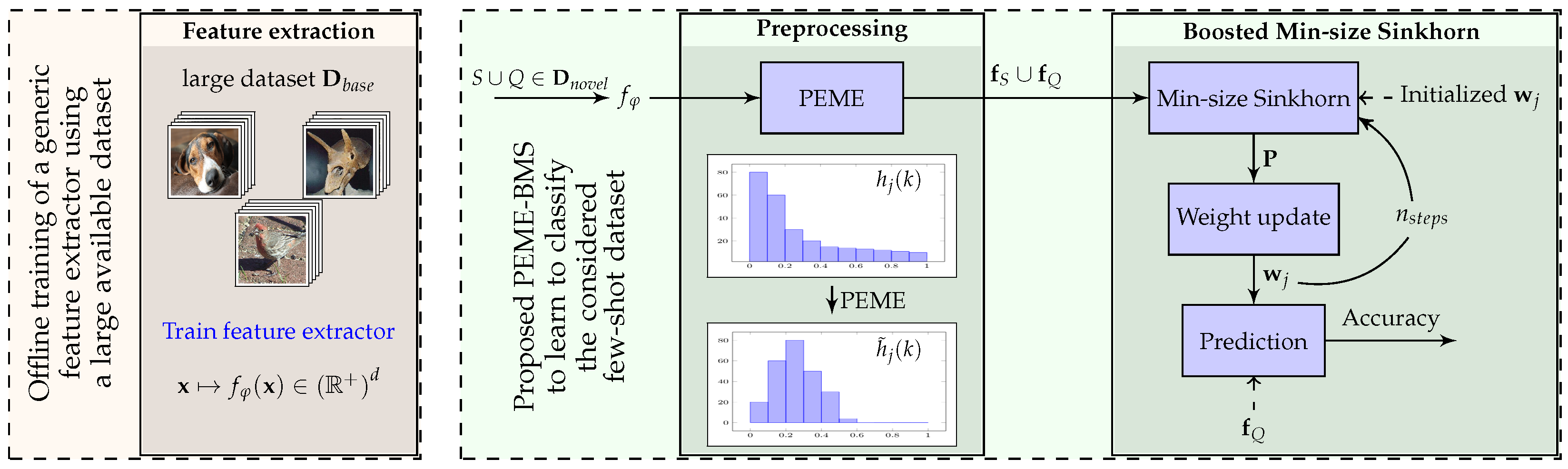
3.3. Feature Preprocessing
As mentioned in
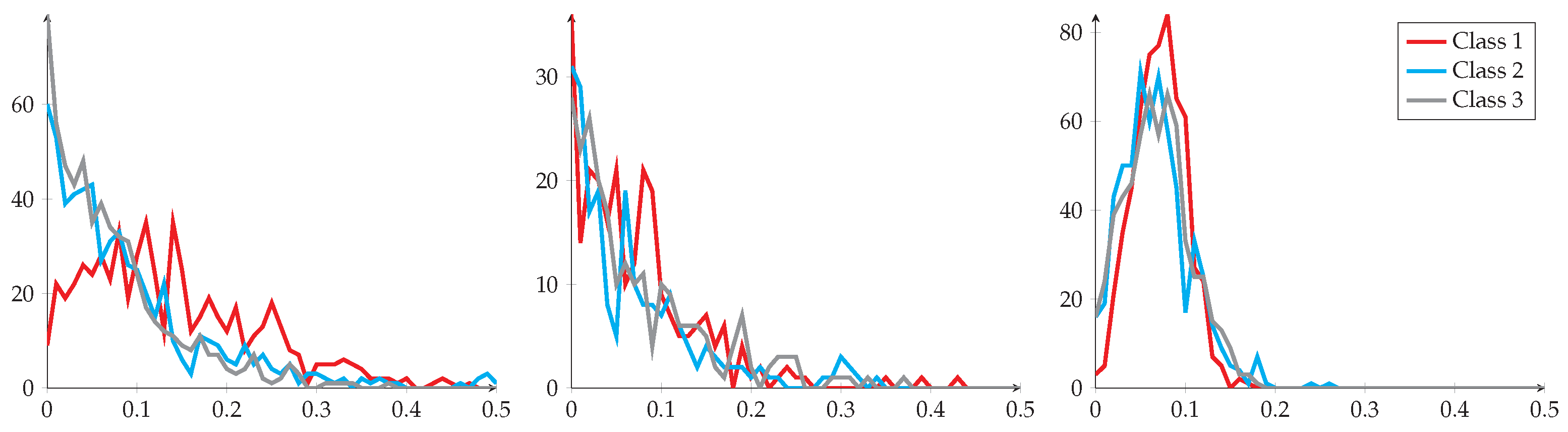
Section 2, many works hypothesize, explicitly or not, that the features from the same class are aligned with a specific distribution (often Gaussian-like). However, this aspect is rarely experimentally verified. In fact, it is very likely that features obtained using the backbone architecture are not Gaussian. Indeed, usually, the features are obtained after applying a ReLU function [
39] and exhibit a positive and yet skewed distribution mostly concentrated around 0 (more details can be found in the next section).
Multiple works in the domain [
20,
35] discuss the different statistical methods (e.g., batch normalization) to better fit the features into a model. Although these methods may have provable assets for some distributions, they could worsen the process if applied to an unexpected input distribution. This is why we propose to preprocess the obtained raw feature vectors so that they better align with typical distribution assumptions in the field. Denote
as the obtained features on
, and let
denote its value in the hth position. The preprocessing methods applied in our proposed algorithms are as follows:
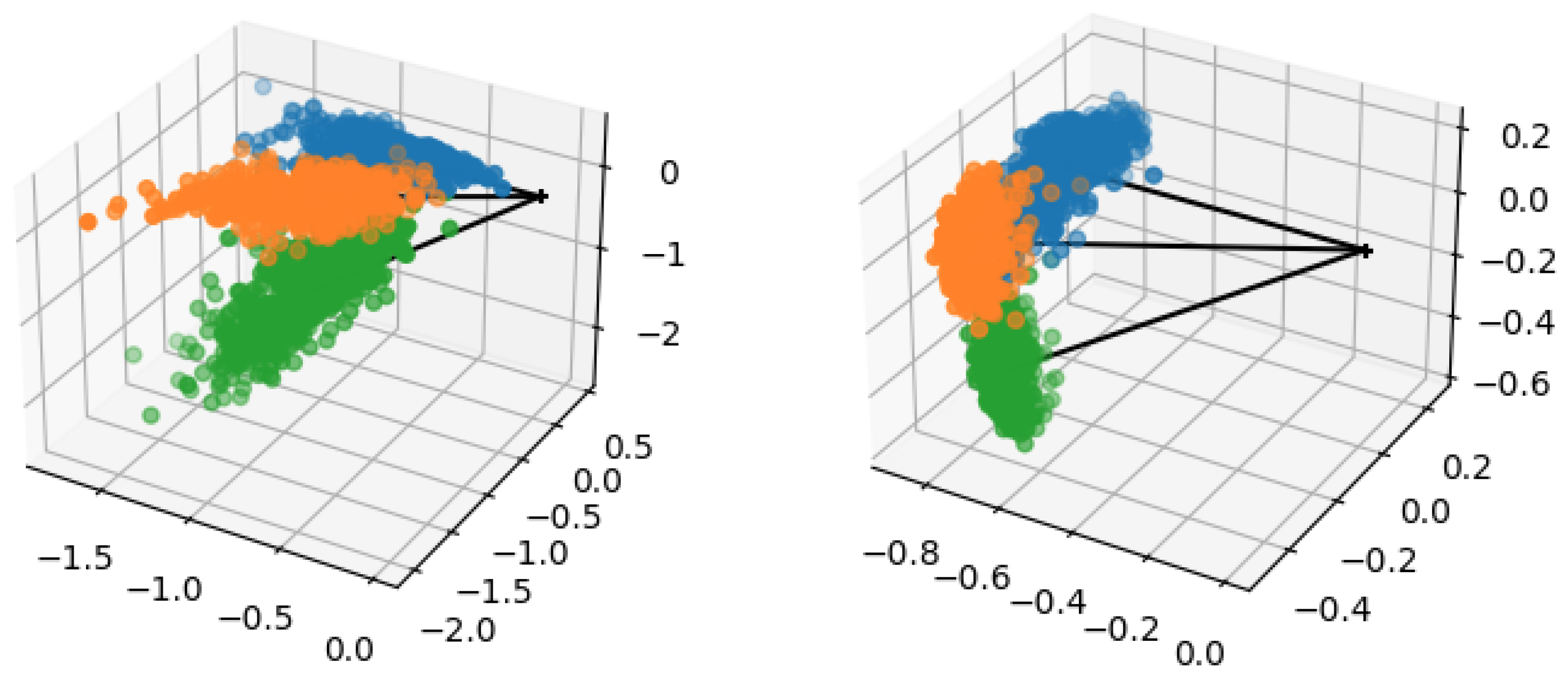
(E) Euclidean normalization. Also known as L2-normalization, which is widely used in many related works [
19,
35,
37], this step scales the features to the same area so that large variance feature vectors do not predominate the others. Euclidean normalization can be given by:
(P) Power transform. The power transform method [
1,
40] simply consists of taking the power of each feature vector coordinate. The formula is given by:
where
= 1 × 10
is used to make sure that
is strictly positive in every position, and
is a hyper-parameter. The rationale of the preprocessing above is that power transform, often used in combination with euclidean normalization, has the functionality of reducing the skew of the distribution and mapping it to a close-to-Gaussian distribution, adjusted by
. After experiments, we found that
gives the most consistent results for our considered experiments, which corresponds to a square-root function that has a wide range of usage on features [
41]. We will analyze this ability and the effect of power transform in more detail in
Section 4. Note that power transform can only be applied if considered feature vectors contain nonnegative entries, which will always be the case in the remainder of this work.
(M) Mean subtraction. With mean subtraction, each sample is translated using
, the projection center. This is often used in combination with euclidean normalization in order to reduce the task bias and better align the feature distributions [
20]. The formula is given by:
The projection center is often computed as the mean values of feature vectors related to the problem [
20,
35]. In this paper, we compute it either as the mean feature vector of the base dataset (denoted as
) or the mean vector of the novel dataset (denoted as
), depending on the few-shot settings. Of course, in both of these cases, the rationale is to consider a proxy to what would be the exact mean value of feature vectors on the considered task.
In our proposed method, we deploy these preprocessing steps in the following order: Power transform (P) on the raw features, followed by a Euclidean normalization (E). Then, we perform mean subtraction (M) followed by another Euclidean normalization at the end. The resulting abbreviation is PEME, in which M can be either or , as mentioned above. In our experiments, we found that using in the case of inductive few-shot learning and in the case of transductive few-shot learning consistently led to the most competitive results. More details on why we used this methodology are available in the experiment section.
When facing an inductive problem, a simple classifier such as a Nearest-Class-Mean classifier (NCM) can be used directly after this preprocessing step. The resulting methodology is denoted PEE-NCM. However, in the case of transductive settings, we also introduce an iterative procedure, denoted BMS for Boosted Min-size Sinkhorn, meant to leverage the joint distribution of unlabeled samples. The resulting methodology is denoted PEE-BMS. The details of the BMS procedure are presented thereafter.
3.4. Boosted Min-Size Sinkhorn
In the case of transductive few-shot, we introduce a method that consists of iteratively refining estimates for the probability each unlabeled sample belongs to any of the considered classes. This method is largely based on the one we introduced in [
1], except it does not require priors about sample distributions in each of the considered classes. Denoting
as the sample index in
and
as the class index, the goal is to maximize the following log post-posterior function:
Here,
denotes the class label for sample
,
denotes the marginal probability, and
represents the model parameters to estimate. Assuming a Gaussian distribution on the input features for each class, here we define
where
stand for the weight parameters for class
j. We observe that Equation (
4) can be related to the cost function utilized in optimal transport [
42], which is often considered to solve classification problems, with constraints on the sample distribution over classes. To that end, a well-known Sinkhorn [
43] mapping method is proposed. The algorithm aims at computing a class allocation matrix among novel class data for a minimum Wasserstein distance. Namely, an allocation matrix
is defined where
denotes the assigned portion for sample
i to class
j, and it is computed as follows:
where
is a set of positive matrices for which the rows sum to
and the columns sum to
,
denotes the distribution of the amount that each sample uses for class allocation, and
denotes the distribution of the amount of samples allocated to each class. Therefore,
contains all the possible ways of allocation. In the same equation,
can be viewed as a cost matrix that is of the same size as
, each element in
indicates the cost of its corresponding position in
. We will define the particular formula of the cost function for each position
in details later on in the section. As for the second term on the right of (
5), it stands for the entropy of
:
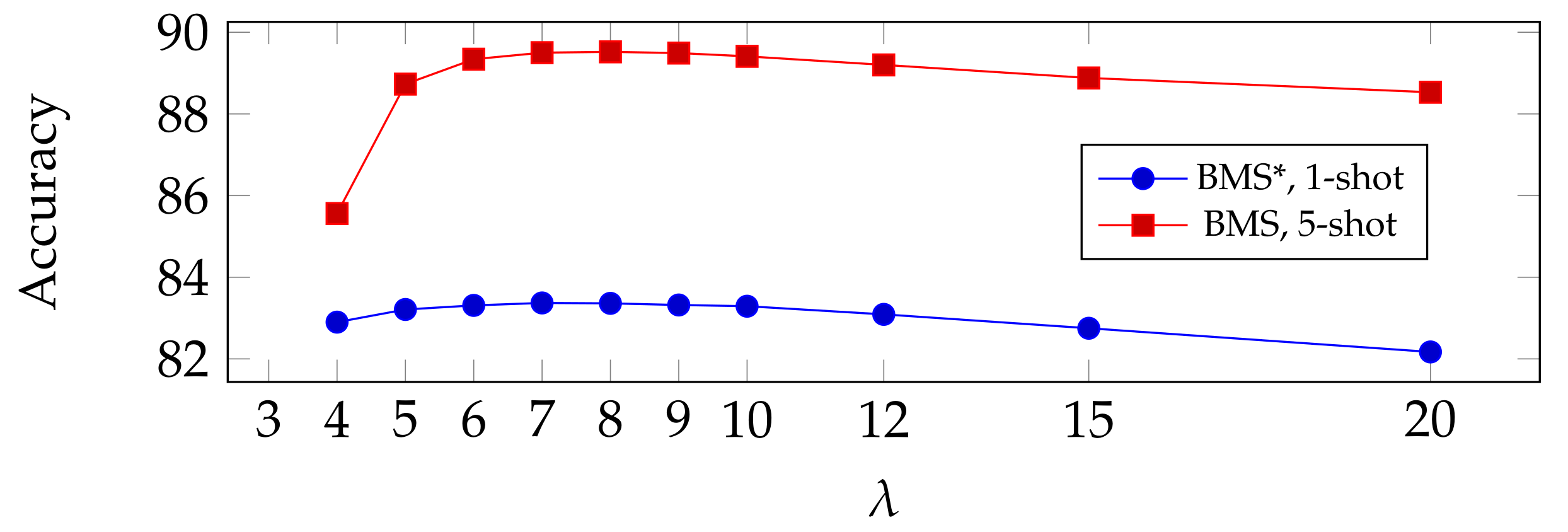
, regularized by a hyper-parameter
. Increasing
would force the entropy to become smaller, so that the mapping is less diluted. This term also makes the objective function strictly convex [
43,
44] and thus a practical and effective computation. From lemma 2 in [
43], the result of the Sinkhorn allocation has the typical form
. It is worth noting that here we assume a soft class allocation, meaning that each sample can be “sliced” into different classes. We will present our proposed method in detail in the following paragraphs.
Given all that is presented above, in this paper, we propose an Expectation–Maximization (
EM) [
45] based method, which alternates between updating the allocation matrix
and estimating the parameter
of the designed model, in order to minimize Equation (
5) and maximize Equation (
4). For a starter, we define a weight matrix
with
n columns (i.e., one per class) and
d rows (i.e., one per dimension of feature vectors), and for column
j in
, we denote it as the weight parameters
for class
j in correspondence with Equation (
4). It is initialized as follows:
where
We can see that contains the average of feature vectors in the support set for each class, followed by a L2-normalization on each column so that .
Then, we iterate multiple steps that we describe thereafter.
As previously stated, the proposed algorithm is an
EM-like one that iterately updates model parameters for optimal estimates. Therefore, this step, along with Min-size Sinkhorn presented in the next step, is considered as the
E-step of our proposed method. The goal is to find membership probabilities for the input samples; namely, we compute
that minimizes Equation (
5).
Here, we assume Gaussian distributions, and features in each class have the same variance and are independent from one another (covariance matrix
). We observe that, ignoring the marginal probability, Equation (
4) can be boiled down to negative L2 distances between extracted samples
and
, which is initialized in Equation (
6) in our proposed method. Therefore, based on the fact that
and
are both normalized to be unit length vectors (
being preprocessed using PEME introduced in the previous section), here we define the cost between sample
i and class
j to be the following equation:
which corresponds to the cosine distance.
In [
1], we proposed a Wasserstein distance-based method in which the Sinkhorn algorithm is applied at each iteration so that the class prototypes are updated iteratively in order to find their best estimates. Although the method showed promising results, it is established on the condition that the distribution of the query set is known, e.g., a uniform distribution among classes on the query set. This is not ideal, given the fact that any priors about
should be supposedly kept unknown when applying a method. The methodology introduced in this paper can be seen as a generalization of that introduced in [
1] that does not require priors about
.
In the classical settings, the Sinkhorn algorithm aims at finding the optimal matrix
, given the cost matrix
and regulation parameter
presented in Equation (
4). Typically, it initiates
from a softmax operation over the rows in
, then it iterates between normalizing columns and rows of
, until the resulting matrix becomes close to doubly stochastic according to
and
. However, in our case, we do not know the distribution of samples over classes. To address this, we firstly introduce the parameter
k, initialized so that
, meant to track an estimate of the cardinal of the class containing the least number of samples in the considered task. Then, we propose the following modification to be applied to the matrix
once initialized: we normalize each row as in the classical case but only normalize the columns of
for which the sum is less than the previously computed min-size
k [
20]. This ensures at least
k elements are allocated for each class, but not exactly
k samples as in the balanced case.
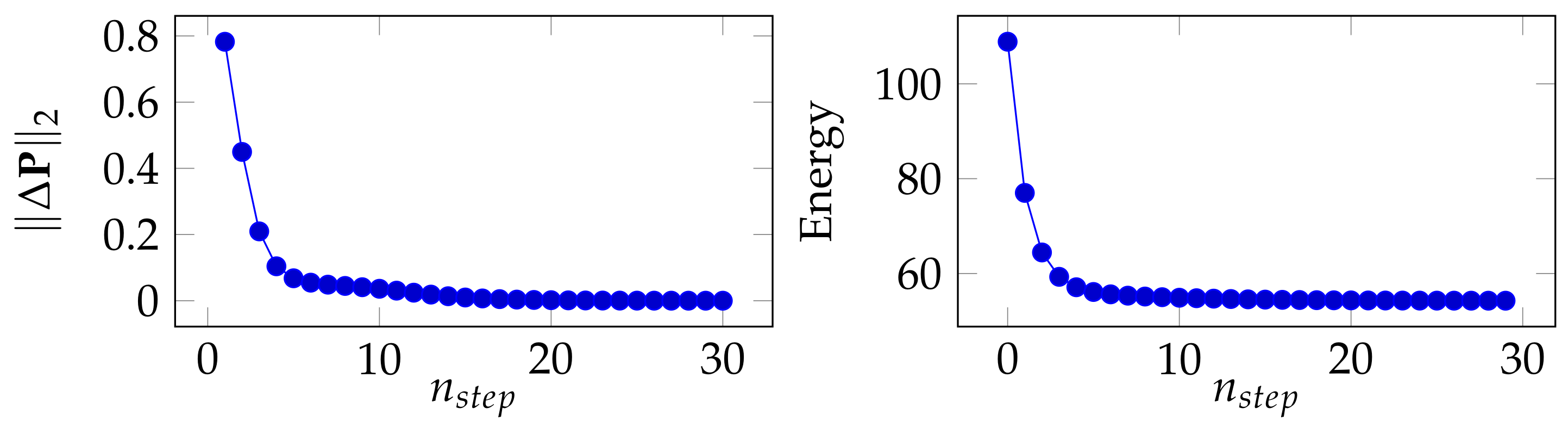
The principle of this modified Sinkhorn solution is presented in Algorithm 1.
| Algorithm 1 Min-size Sinkhorn |
Inputs:, Initializations:
forto 50 do end for return
|
This step is considered as the
M-step of the proposed algorithm, in which we use a variant of the logistic regression algorithm in order to find the model parameter
in the form of weight parameters
for each class. Note that
, if normalized, is equivalent to the prototype for class
j in this case. Given the fact that in Equation (
4), we also take into account the marginal probability, it can be further broken down as:
We observe that Equation (
4) corresponds to applying a softmax function on the negative logits computed through an L2-distance function between samples and class prototypes (normalized). This fits the formulation of a linear hypothesis between
and
for logit calculations, hence the rationale for utilizing logistic regression in our proposed method. Note that contrary to classical logistical regression, we implement here a form of self-distillation. Indeed, we use soft labels contained in
instead of one-hot class indicator targets, and these targets are refined iteratively.
The procedure of this step is as follows: now that we have a polished allocation matrix
, we firstly initialize the weights
as follows:
where
We can see that elements in
are used as coefficients for feature vectors to linearly adjust the class prototypes [
1]. Similar to Equation (
6), here
is the normalized newly-computed class prototype that is a vector of length 1.
Next, we further adjust weights by applying a logistic regression, and the optimization is performed by minimizing the following loss:
where
contains the logits, and each element is computed as:
Note that is a scaling parameter, it can also be seen as a temperature parameter that adjusts the confidence metric to be associated with each sample. It is learnt jointly with .
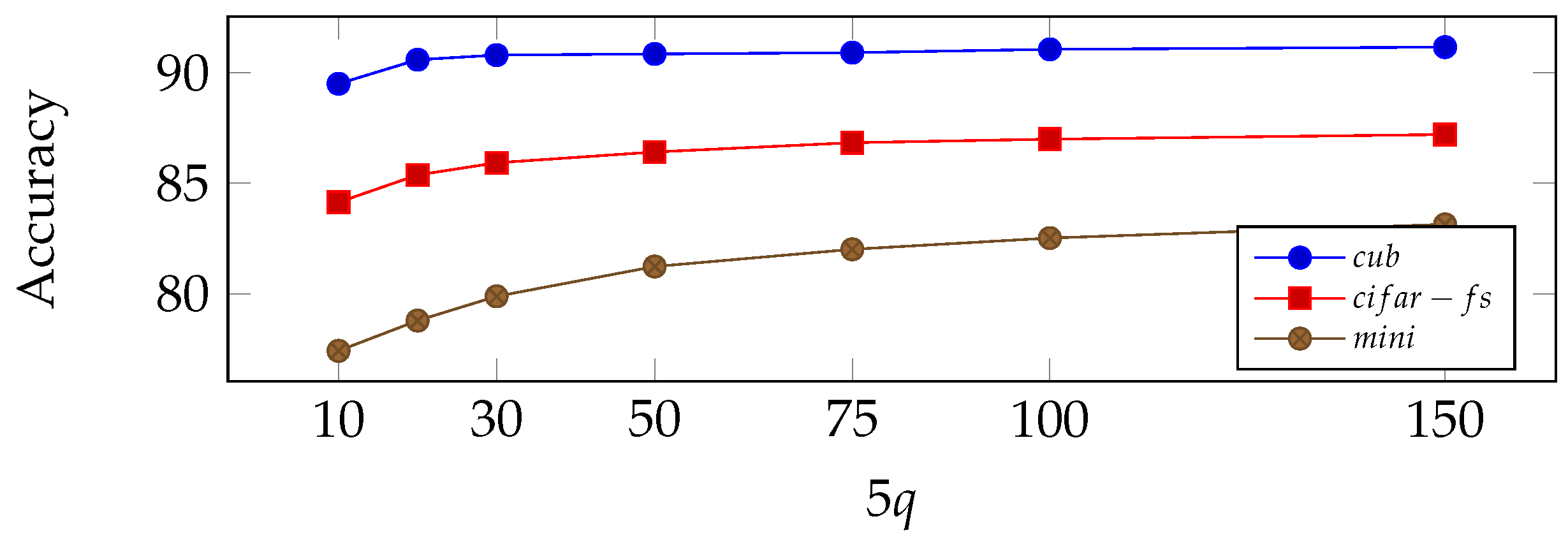
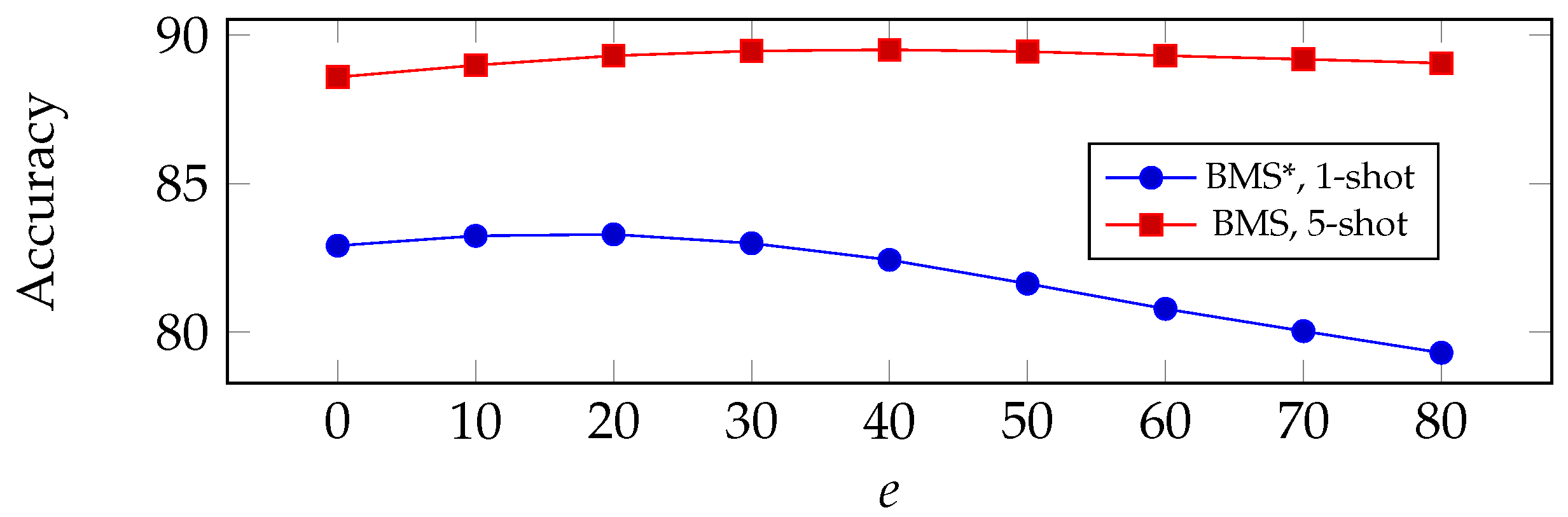
The deployed logistic regression comes with hyperparameters on its own. In our experiments, we use an SGD optimizer with a gradient step of
and
as the momentum parameter, and we train over
e epochs. Here, we point out that
is considered an influential hyperparameter in our proposed algorithm,
indicates a simple update of
as the normalized adjusted class prototypes (Equation (
10)) computed from
in Equation (
11), without further adjustment of logistic regression. In addition, note that when
, we project columns of
to the unit hypersphere at the end of each epoch.
- d
Estimating the class minimum size
We can now refine our estimate for the min-size
k for the next iteration. To this end, we firstly compute the predicted label of each sample as follows:
which can be seen as the current (temporary) class prediction.
Then, we compute:
where
,
representing the cardinal of a set.
Summary of the proposed method: all steps of the proposed method are summarized in Algorithm 2. In our experiments, we also report the results obtained when using a prior about
as in [
1]. In this case,
k does not have to be estimated throughout the iterations and can be replaced with the actual exact targets for the Sinkhorn. We denote this prior-dependent version PE
E-BMS* (with an added *).
| Algorithm 2 Boosted Min-size Sinkhorn (BMS) |
Parameters:
Inputs: Preprocessed , Initializations: as normalized mean vectors over the support set for each class (Equation ( 6)); Min-size . for to 20 do Compute cost matrix using (Equation ( 8)). # E-step Apply Min-size Sinkhorn to compute (Algorithm 1). # E-step Update weights using with logistic regression (Equations ( 10)–( 13)). # M-step Estimate class predictions and min-size k using (Equations ( 14) and ( 15)). end for return
|












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}